The guardianship in partial fulfillment of the requirements for the degree of Bachelor of Science in Computer Science has been reviewed and recommended for admission. Accepted and approved in partial fulfillment of the requirements for the degree of Bachelor of Science in Computer Science. Tes2Speech is an Android mobile app for recognizing handwritten text and optionally converting it to speech.
Background of the Study
An example of this app is a Handwriting Android Text-to-Speech app, in which you type words on the device's screen and turn it into speech. A specific example of speech impairment is Aphasia – a communication disorder resulting from damage to the parts of the brain that contain language [7]. According to the latest report by US-based industry tracker Strategy Analytics, nearly 2.5 billion people or 35% of the global population are expected to own smartphones by the end of 2015 [9].
Statement of the Problem
Another problem is that preschoolers sometimes do not know how to pronounce the words they have written. Another existing problem is that mobile ICRs such as HandySpeech are not relearnable, meaning that the user cannot retrain their application once deployed. It is also non-customizable, which means that the user's handwriting may not be recognized by the application.
Objectives of the Study
Significance of the Project
Tess2Speech can also be useful in teaching preschool students, because sometimes preschool students can write but cannot say the words they have written. Using this app, students can just write words on the screen or take pictures of the words they have written and let this app speak the words. Students can also check if their spelling is correct as this application also informs the user if the converted text exists in the English dictionary.
Scope and Limitations
The accuracy of the Tesseract will depend on the quality of the handwriting and the quality of the image itself. The quality of the converted speech depends on the text-to-speech engine installed by the user. The performance of Tess2Speech's writable canvas depends on the phone's hardware (touchscreen capability).
Assumptions
Review of Related Literature 12
Because this application can be divided into two – optical character recognition and text-to-speech – some studies exist only for OCRs/ICRs and others only for TTS. Another research paper entitled Intelligent Character Recognition (ICR): A Novel Algorithm to Extract Text from a Scanned Form Based Image [2] proposed a system that performs a series of image preprocessing to support the OCR. The paper titled Optical Character Recognition by Open Source OCR Tool Tesseract: A Case Study [22] proved that using grayscale images improves the accuracy of Tesseract (see Table 1).
![Figure 2: Consonants of Odia Alphabet. [21]](https://thumb-ap.123doks.com/thumbv2/filepdforg/10735162.0/25.892.295.657.415.814/figure-2-consonants-of-odia-alphabet-21.webp)
Text-to-Speech
Image-to-Speech
HandySpeech
Theoretical Framework 19
OCR involves analyzing the captured or scanned images and then translating character images into character codes, so that they can be edited, searched, stored more efficiently, displayed online and used in machine processes [27]. This step refers to extracting the most relevant information from the text image that helps to recognize the characters in the text. The editable text extracted from the input image is displayed in the output text.
![Figure 5: Most OCR Tool’s Process would look like this. [27]](https://thumb-ap.123doks.com/thumbv2/filepdforg/10735162.0/31.892.238.708.548.823/figure-5-ocr-tool-process-look-like-27.webp)
Intelligent Character Recognition, Learning Classifier Systems,
LCS is a combination of an evolutionary algorithm from the field of biology and reinforcement learning and supervised learning from the field of machine learning [28] (see Figure 6). The Learning Classifier System algorithm optimizes the payoff or reward based on exposure to stimuli from a problem-specific environment, managing the allocation of credit for those rules that prove useful, and finding new rules and variations of existing rules using an evolutionary process [29] . An enhanced component, also called a credit allocation component, that distributes the reward received from the environment to the classifier.
![Figure 6: Field tree – foundation of the LCS Community. [28]](https://thumb-ap.123doks.com/thumbv2/filepdforg/10735162.0/34.892.195.741.524.934/figure-6-field-tree-foundation-lcs-community-28.webp)
Image Processing/Preprocessing
Tesseract
Text-to-Speech
Design and Implementation 44
Because it needs to be user-friendly, Tesseract training is abstracted from the user, but its sub-exploded block diagram is shown in Figure 19. After the user finishes editing the box files, the Tess2Speech trainer will automatically train the Tesseract and automatically output .traineddata with the name they specified the user. This .traineddata file can now be used in the Tess2Speech mobile application by copying the .traineddata into the Tess2Speech Tessdata folder (see section B.5 to find the Tess2Speech tessdata folder).
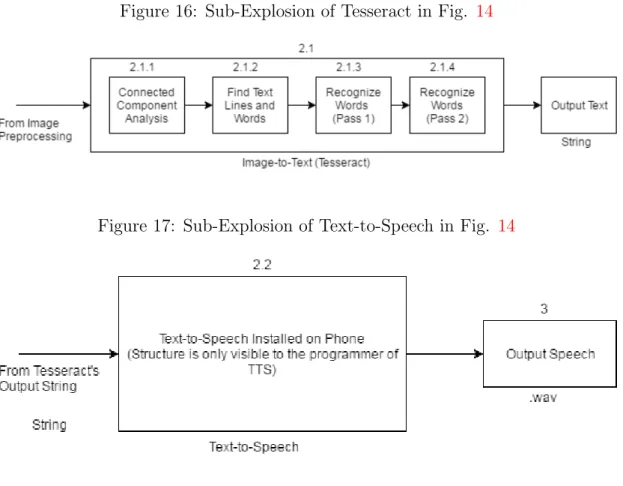
System Architecture
To be able to use the training data in Tess2Speech, it must be located in the Tess2Speech 'tessdata' folder. This means that the operation of Tess2Speech TTS is based on the TTS used on the phone. As we stated in the Background of the study, stylus-based applications are mostly proprietary and expensive.
In the canvas part of Tess2Speech, I created a Canvas object on the phone screen, similar to how MS Paint works, and then convert the contents of that canvas to an image every time I want to convert that handwriting to text or speech. The functionality of this canvas depends on the phone's hardware (touch screen capability). Almost all smartphones have a camera and it is accessible through all the applications installed on the phone.
Since Tess2Speech relies heavily on the quality of the images, an image captured by a high-resolution camera will most likely give better accuracy. It is stated in Scope and Limitations no.7 that the paper border should not be seen as it adds noise to the image and can be interpreted as a character such as 'l' (small L) or '1' (one) . As a solution, I implemented a selection for the user to crop the image and select only which part of the image is relevant.
Since Image De-Skewing is difficult to implement without using large libraries, I also provided an alternative solution by allowing the user to manually rotate the image allowing them to correctly align the texts in the image.
Technical Architecture
120 MB free space (50+ MB for the application itself and 50+ MB for built-in trained data and other files). Tesseract and jTessBoxEditor do not need to be installed as they are already included in the Tess2Speech trainer.
Training Methodology
Results 63
This allows the user to use the phone's camera to take pictures of the desired input image displayed on the screen (see Figure 28a). After pressing the 'Browse Image' button, a Chooser dialog box will appear (Figure 27b) offering the user choices from available applications installed on the phone that can open images. The user can now choose the desired input image and it will be displayed on the phone's screen (see Figure 28a).
The Rotate' button allows the user to rotate the image to any angle by adjusting the search bar below the image (Figure 28b). The first item in the overflow menu is "Browse input PDF.." which allows the user to use a PDF as an input image. Here the user can choose which part or chapter of the epub they want to view.
The user is also asked which pages are being saved to, just like in Figure 31e. All trained data files in the 'tessdata' folder are shown here (Figure 35b). The user can choose more than one trained data. The next item is 'TTS Settings' which redirects the user to the phone's TTS settings (Figure 35c).
The next item is "Spell Check Settings" in which the user will be redirected to the "Language and input" settings of their phone (figure 35d).

Tess2Speech Trainer
Discussions 80
Using the training methodology discussed in Chapter 4 D., I used a 6-user model training dataset for developing my experimental trained data. After training Tesseract using these training datasets, I tested the performance of the resulting experimental trained data using the test datasets in figure 40. The summary of the test results of the experimentally trained data is shown in table 6.
I compared the experimental training data I created with Tesseract's default training data (table 5 shows the summary of the default Tesseract). On Test Data 1, there is a 45.5% improvement in character recognition accuracy and a 69.9% improvement in word recognition accuracy. On Test Data 3, there is a 45.68% improvement in character recognition accuracy and a 54.97% improvement in word recognition accuracy.
The average character and word accuracies of the pre-trained Tesseract dataset are 54.45% and 33.61%, respectively. On the other hand, the average character and word accuracy of the experimental trained data is 99.18%. Another solution is to increase the frequencies of these frequently misclassified characters in the training images.
Although the average character and word accuracies I got are 99.18% and 97.58% respectively, there is still no conclusion that the trained data really reached this accuracy FOR ALL handwritings, since only 6 are used for the training images manuscripts.

Developing Tess2Speech Trainer
The user can upload an image containing handwriting (can also be computer printed texts) or just write the handwritten text on the mobile phone screen through the canvas and convert it to text or speech. The user can also customize Tess2Speech by training their handwriting with the Tess2Speech Trainer and using the .traineddata output files for their application. As a solution, I used tess-two [35], which contains Tesseract and Leptonica translation tools for use on the Android platform.
As a workaround, if a paragraph is more than 4000 characters long, I split the paragraph into strings of length 4000 and stored them in an ArrayList. As a workaround, I used the PDFViewer library by Joan Zapata [38] to view PDFs for APIs below 21. Image quality depends on the phone's camera (unless scanned and then sent to the phone).
As a solution, I implemented in Tess2Spech the ability to perform image preprocessing on an image before converting the image to text or speech. As a solution, I implemented the ability to rescale the image to a smaller dimension before converting the image to text or speech. I also implemented the cropping feature so that users can remove unnecessary parts of the image that could produce junk text.
As a workaround, since Tesseract can use multiple trained data simultaneously, the user can choose any combination of .traineddata files, including 'eng.traineddata' in Tesseract's language settings in Tess2Speech.

Significance of Tess2Speech
Conclusions 90
Patel, “Optical Character Recognition by Open Source OCR Tool Tesseract: A Case Study,” International Journal of Computer Applications, vol. Supriya Indalkar, “Optical Character Recognition”, International Journal of Recent Technology and Engineering (IJRTE)), vol. Helland, “Seven grayscale conversion.” http://www.tannerhelland.com/. Cigan, “Java image binarization using Otsu's algorithm.” http:. developer.bostjan-cigan.com/java-image-binarization/, December 2012.
32] VietOCR, “jTessBoxEditor.” http://vietocr.sourceforge.net/. 33] Wutka, “Directed Acyclic Word Graphs.” http://www.wutka.com/dawg. Path = Tess2Speech/tess2Speech/src/main/java/anteraaron/tess2speech/. Path = Tess2Speech/tess2Speech/src/main/java/anteraaron/tess2speech/. WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND.
![Table 1: Tesseract OCR Result Analysis after Grayscaling images. [22]](https://thumb-ap.123doks.com/thumbv2/filepdforg/10735162.0/27.892.164.786.137.721/table-tesseract-ocr-result-analysis-after-grayscaling-images.webp)
![Figure 3: Screen Capture of HandySpeech Interface. [15].](https://thumb-ap.123doks.com/thumbv2/filepdforg/10735162.0/29.892.183.768.670.1008/figure-3-screen-capture-of-handyspeech-interface-15.webp)
![Figure 4: Areas of Character Recognition. [26]](https://thumb-ap.123doks.com/thumbv2/filepdforg/10735162.0/30.892.176.873.194.765/figure-4-areas-of-character-recognition-26.webp)
![Figure 7: Tesseract-OCR Architecture. [18]](https://thumb-ap.123doks.com/thumbv2/filepdforg/10735162.0/40.892.232.825.174.544/figure-7-tesseract-ocr-architecture-18.webp)
![Figure 8: Tesseract-OCR Architecture in Recognizing a word. [18]](https://thumb-ap.123doks.com/thumbv2/filepdforg/10735162.0/41.892.173.836.653.1100/figure-8-tesseract-ocr-architecture-recognizing-word-18.webp)
![Figure 11: Static Character Classifier way of identifying the character using the training prototype data [18]](https://thumb-ap.123doks.com/thumbv2/filepdforg/10735162.0/43.892.170.868.662.852/figure-static-character-classifier-identifying-character-training-prototype.webp)
