First, we would like to review the current state of research in the field of Arabic Sign Language recognition using deep learning and look for research gaps. In this dissertation, we want to investigate the application of deep learning to the task of Arabic Sign Language recognition.
Arabic Sign Language (ArSL)
In 2001, the Arab Federation of the Deaf formally introduced Arabic Sign Language as the official sign language for the speech and hearing impaired in Arab nations. In order to understand the issues related to sign language, we must first identify the role of the Arabic language as a spoken and written language and how it affects the Arabic sign language (Mustafa, 2021).
ArSL Recognition
In the case of sign language recognition, this means that the model is trained on different signs and gestures and learns from the extracted features. Meanwhile, the machine learning-based approach can learn its own rules from the data output and improves as more data is fed in to train the model.
Deep Learning
In supervised machine learning, the model takes in both labeled input and output training data to derive a function. While in unsupervised machine learning, only the input data is provided, and the model makes inferences (Adeyanju, Bello, & Adegboye, 2021).
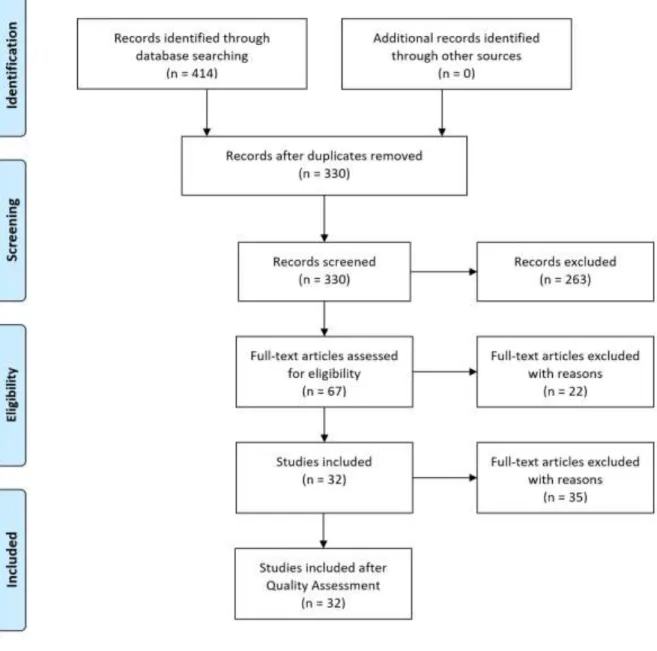
Methodology
- Search Strategy
- Identification of Research Questions
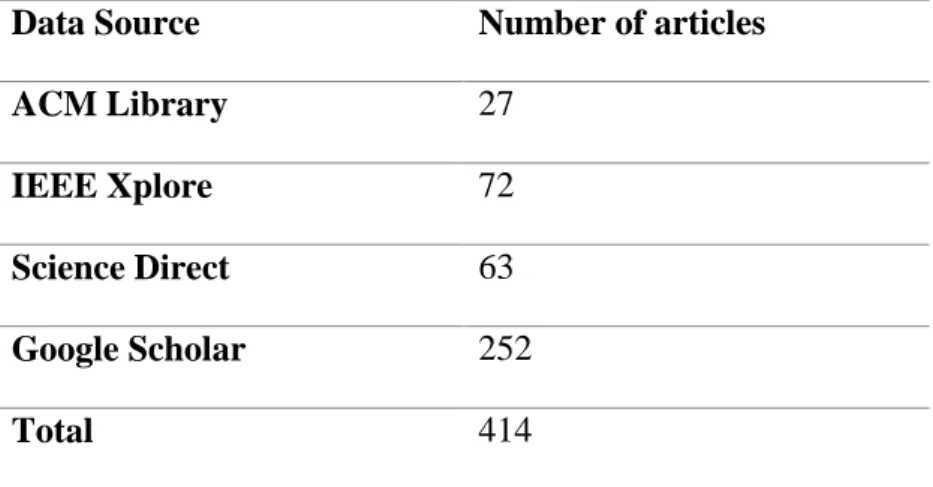
- Identification of Keywords and Data Sources
- Study Selection Criteria
- Study Selection Procedure
- Quality Assessment (Quality Criteria)
- Data Extraction
Preprocessing Feature Extraction Classifier Segmentation:. k-mean k-mediod ANN Signer Dependent Recognition Rate Real Time. Static/Dynamic with one/two hands. Jump motion sensor 44 signs (29 one-handed and 15 two-handed) performed by 5 signers.
Results
Synthesis of Data
Research Questions
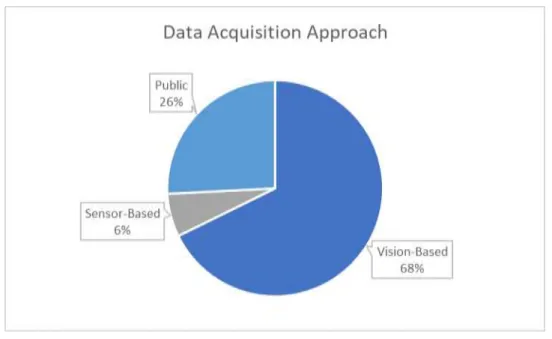
They find that the merger of the descriptors improves performance compared to other related works and allows for more flexibility and processing time. Another contribution of the paper is a segmentation approach that can be applied in real time to continuous sentences for ArSL recognition with promising results. Sensor-Based Recognition: Data such as the hand's movement, speed, and location are obtained from sensor devices.
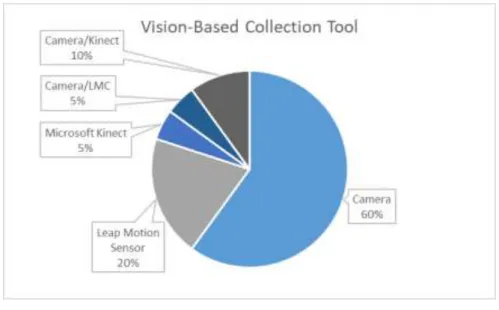
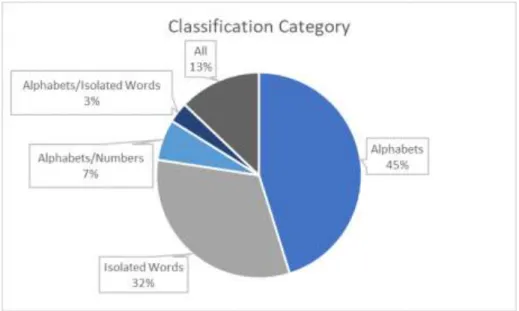
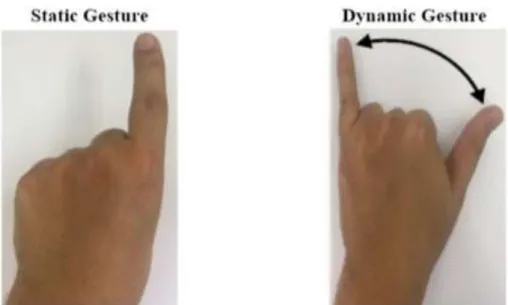
Classification category relates to the complexity of the signs that the system will be developed to recognize. The position of the hand and fingers is in motion in a given space and time. CNN: In the graph, we can see that Convolutional Neural Networks was the most used model, with some variations of the model.
In Figure 16, we can see that the majority of documents were tested in the signer-dependent mode, while an equal number of documents used the singer-independent mode or both testing modes.
Discussion
Implications for research
This is normally the case for deep learning models, as they are very powerful and can achieve state-of-the-art results, but require a huge amount of data to do so. Another point observed during the studies is the lack of real-world application in the ArSL recognition domain. This means that most of the research is focused on improving the classification accuracy of the deep learning models in the task of ArSL recognition, usually by improving data acquisition, feature extraction, or the classification techniques.
We also note that most of the papers were signer dependent, in that the data used for training and testing were collected from the same signers. Many research papers like (Boukdir et al., 2021) used the use of deep learning for feature extraction and not just classification.
Limitations
Even within the same data set (Hayani et al., 2019) note that changing the split of training-test data to include more training data achieves better results. Bencherif et al., 2021) note that the lack of a standardized data set makes the task of comparing recognition models even more difficult. Papers such as (Kamruzzaman, 2020) and (Latif et al., 2020) created artificial images from the original dataset to diversify their dataset, resulting in a remarkable increase in performance. Latif et al., 2020) state that increasing the number of data only has the effect of improving performance up to a certain point, after which model performance will not be affected.
However, considering that (Latif et al., 2020) uses a dataset of 50,000 compared to (Kamruzzaman, 2020) who uses a dataset of 100, we note that small datasets may benefit from augmentation. Another thing to consider is the increased time, computing power and memory required to train a model on more complex data, which in turn increases the cost as noted by (Latif et al., 2020) .
Proposed future work
As we mentioned at the beginning of this research paper, different countries have established their own sign language based on their own dialects. In everyday life, signers would use their own dialectal sign language rather than the official ArSL, much like dialects are used instead of the official Arabic language. To this end, researchers will need to consider expanding the scope of sign language recognition to include facial expressions and body language.
More research should be done on dialectical sign language if these systems are to be used in a real setting and truly benefit deaf people throughout the Arab world. Data collection: We will build a system that uses the MediaPipe framework to collect landmarks directly from the webcam without the use of additional devices.
Data
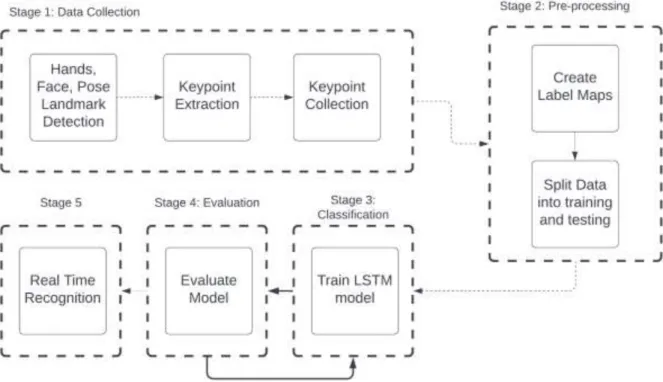
Data Collection
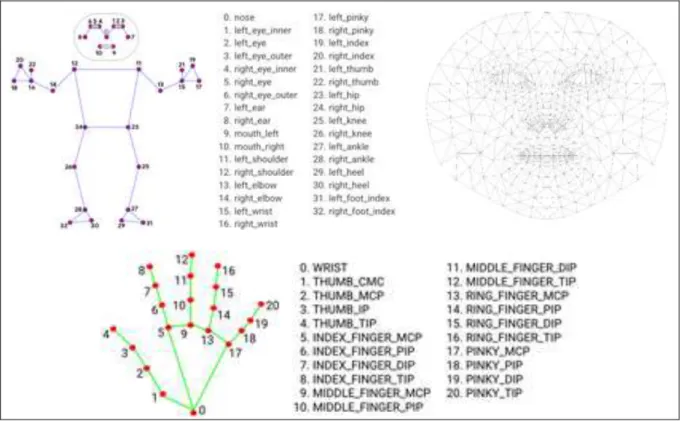
In Figure 21, we show the landmarks that can be detected by MediaPipe Holistic, which will be presented directly to the user as shown in Figure 20. These landmarks will be used to extract the key points on which the model will be trained. The data will be split 80-20 for training and testing: 24 video sequences for training and 6 for testing.
This data set will be kept out and not used at all to train the model. We choose six times as this will be the same number as the test data set.
Single vs Double Hands
Dataset
In (ALI, et al., 2014), one signer performs 5 characters with 200 samples each, noting that their approach is a traditional vision-based approach with static images, which creates the need for more samples than our approach. Mohandes, Aliyu, & Deriche, 2014) collects 12 hand features from 10 samples for each alphabet, with each sample containing 10 frames.
Pre-processing
Classification
Outcome with Softmax Activation function so the output will have the properties of a 0 to 1 probability distribution.
System Architecture
In this we will experiment with different values and hypermeters, more details are mentioned in the next section. We will also test in Signer Independent Mode using a separate data set collected from another signer. Once satisfied, we use both MediaPipe and our trained LSTM model to predict the tokens in real-time using video sequences.
Evaluation Metrics
Signer dependent mode: We will report the accuracy of the model on the training, validation and test datasets throughout our paper. Signer independent mode: once we have trained the model to a sufficient state, we will then apply it to the second data set we collected, which has a different signer performing the same tokens. The purpose of this is to investigate the feasibility of using our approach in a real environment.
For this part, we evaluate the feasibility of Building a real-time recognition system using MediaPipe and deep learning models.
Model training strategy
Epoch and batch size: We will use different epoch and batch size combinations and choose the combination that yields the highest accuracy. We must keep in mind that due to the stochastic nature of neural network models; results may differ even when the same model is trained on the same data set. Our approach can be further improved by repeating each hypermeter combination a number of times and averaging the accuracy.
Original Model
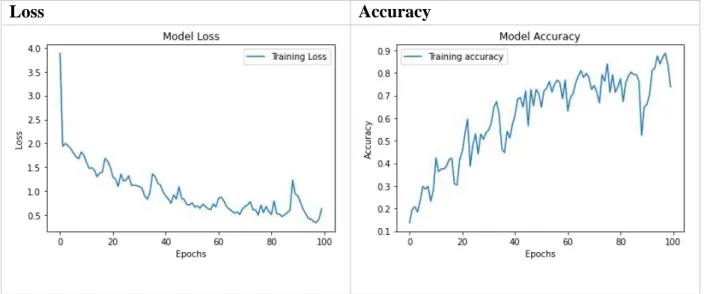
Very unusual, but the 2000 epochs prevent us from really seeing the model's changes in accuracy and loss, as it stabilizes and stops changing below 250 epochs. Therefore, we will train for 100 epochs to get a better estimate of model behavior and how to solve it. The model behaves normally as the loss is decreasing and the accuracy is increasing.
This means that the model is going in the right direction, but it is not achieving the desired results. While it was fine with precision and scaling, we can see that the log loss is behaving abnormally with a sudden spike in the middle.
Baseline Model
Batch Size and Epochs
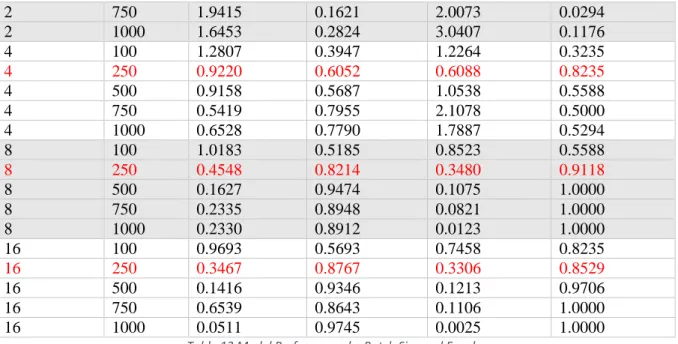
The results are shown in Table 13 where we report the training loss and accuracy as well as the validation loss and accuracy. Since models can fluctuate in results during training, we also plot the performance of the model to observe the behavior of the model and how stable it is. However, looking at our graphs and looking at our data, we realize that the model is actually overkill.
We decide on the batch size by the graphs in table 14, we can see that the model is the most stable at batch size 8. To conclude this part of the testing, we choose batch size 8 and epoch 250 moving forward.
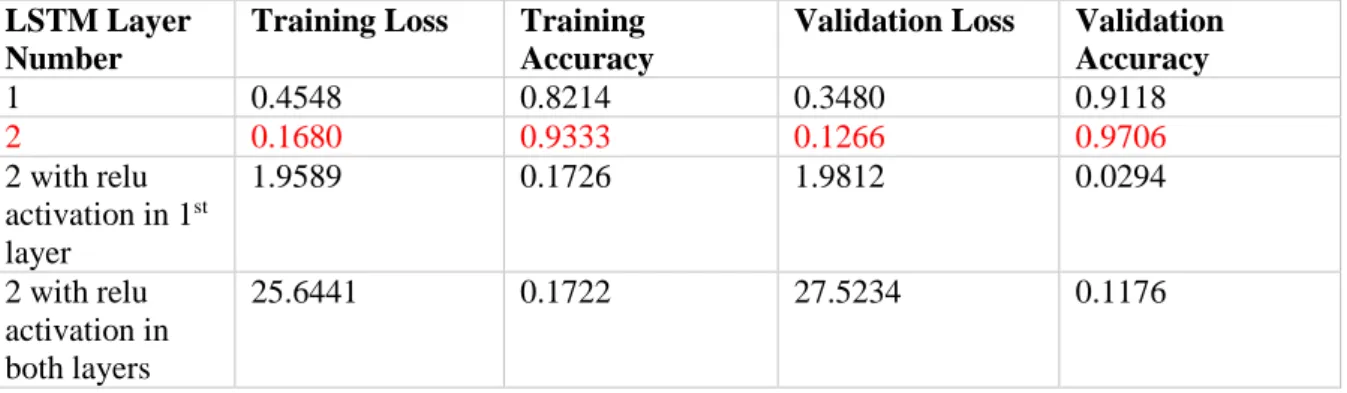
Different LSTM Layers
Thus, we experiment with adding the activation only to the first layer and then to both layers. The same can be seen in the graphs shown in table where the model fails with ReLU activation.
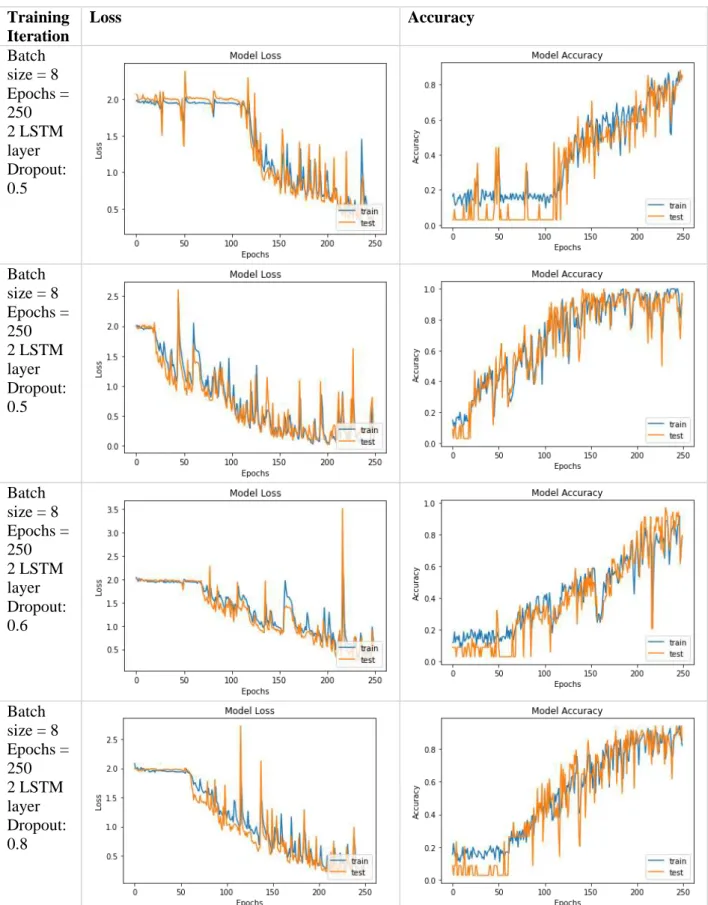
Different dropout rates
We notice that our model performs best at the default dropout rate of 0.5 that we choose. An examination of the graphs in Table 18 shows that the model is most stable even at this rate. To complete the testing for our base model, our established hypermeters are batch size 8, 250 epochs, 0.5 dropout rate, and 2 layers of LSTM.
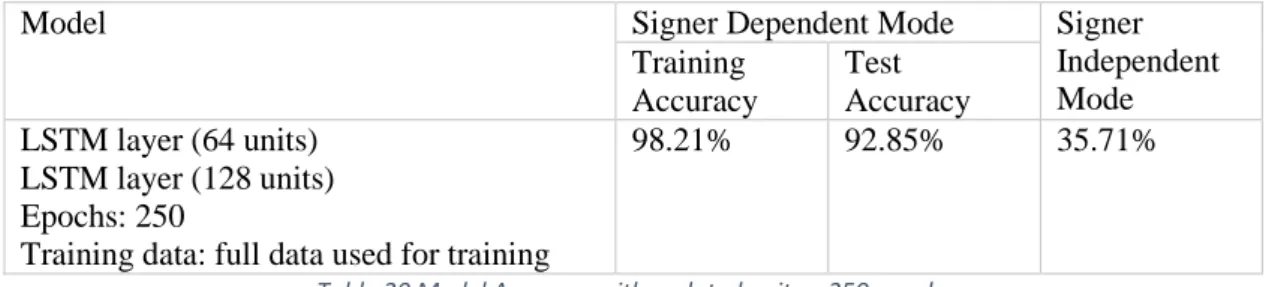
Signer Independent Testing
Improving performance (Signer Independent)
Just looking at the final results, we can see that the model performs even worse. However, while training, we notice that the model stabilizes at 200 epochs, after which the accuracy decreases. We therefore decide to try again to train the model for 200 periods and note the results in table 21.
To confirm this, we add a 20% validation split to the training data for more generalization and record the results in Table 22. Naturally, sign-dependent state accuracy is lower since we used less data to train the model.
Confusion matrix
Final Results
Real Time Recognition
Understand the current status of Arabic Sign Language recognition research using Deep Learning and find research gaps. Deaf people would also use their country's sign language instead of the official Arabic sign language. To our knowledge, we are the first paper to apply a sign language recognition system to Emirati Sign Language.
In addition to this, we were also able to achieve our goal of performing real-time sign language recognition using our system. We find that data collection is the main problem in the task of Arabic Sign Language recognition using deep learning.

Proposed Future Work
Improving Arabic Sign Language Recognition Using Deep Learning and Leap Motion Controller. A GPE implementation for real-time Arabic Sign Language recognition using multi-level multiplicative neural networks. An Automatic Arabic Sign Language Recognition System Based on Deep CNN: A Support System for the Deaf and Hard of Hearing.
Joint space representation and fingerspelling recognition of sign language using Gabor filter and convolutional neural network.