Massive amounts of content are uploaded to social media platforms every second by online users. In contrast, social media platforms are becoming the basis for allowing toxic behavior, online harassment, personal attacks and hate speech.
Online Hate Speech
The type of hate speech we consider in this thesis is online hate speech, where the hateful content appears online on any of the user-generated social media platforms. This indicates that no hateful content may be displayed regardless of the language used or the place where it is presented.
Research Problem of Arabic Hate-Speech Detection
Modern Standard Arabic (MSA) is the official language of the Arab countries (Middle East) and is the main language of education, media and culture. Arabic dialect varies based on the geographical location of the Arabic speakers (Habash, 2010; Diab and Habash, 2012).
Scope of the Work
In this thesis, we address the problem of detecting Arabic hate speech for one of the most dominant dialects in social media, which are Egyptian and Gulf Saudi dialects. The complexity of the definition of hate speech in the Arab region with a high degree of subjectivity in what counts as hate speech. Natural Language Processing (NLP): Here, the system must perform a more sophisticated analysis of linguistic morphology to extract certain semantic features to identify hostile speech.
We leave the study of this part of the system to future research and directions in this task.
Research Questions
We investigate the use of dialect machine translation to navigate the problem of the linguistic complexity of the Arabic dialects. A typical text classification system for detecting hate speech might include modules of dialects and have three modules as follows. Research Question 2: Which feature engineering is the most effective Arabic text classification in detecting online hate speech for Arabic.
Research question 3 : Which feature engineering is most effective for Cross-Lingual Text Classification in detecting Arabic hate speech online.
Thesis Structure
In particular, text classification uses machine learning (ML) and natural language processing (NLP) techniques to discover patterns and classify from different types of available text Sebastiani (2005). In the following sections, we provide a brief overview of related work on online hate speech and cross-linguistic text classification. Research Question 1: Can cross-language text classification from English to Arabic be useful in detecting online hate speech.
Research Question 1: Can English-to-Arabic cross-language text classification be useful in detecting online hate speech.
Machine Learning
Supervised Machine Learning: An algorithm has been developed to use labeled data to learn the relationships between inputs and outputs, and apply this learning to predict future inputs. Unsupervised Machine Learning: The algorithm only gets input data and the goal is to find a hidden structure from unlabeled data. Semi-supervised machine learning: This approach is midway between unsupervised and supervised learning, labeled and unlabeled data are used for training, usually a huge amount of labeled data and a small amount of labeled data, semi-assisted learning used when the labeled data needs relevant resources to learn from and train on.
Reinforcement Learning (RL): is another emerging ML technique, where learning is performed through interaction with the environment.
Text processing for Text Classification
- Text Pre-processing
- Stop Word Removal
- Document Indexing and Term Weighting
This is done on the basis of language-dependent linguistic knowledge of the words that appear in the text. The weight is usually linked to the term frequency of occurrence in the document and the sum of documents containing that term. The frequency is usually calculated by how often the term appears in the document and in the collection.
Inverse document frequency (id f) While t f indicates the frequency of the term in the collection, id f represents the uniqueness of the term in the collection.
Text Classification Methods
- Rule-Based Systems
- Machine learning Based Systems
Both TF and IDF metrics are considered one of the most important features in text classification modeling, which are often combined and multiplied together with one of the TF-IDF formulas (Allan et al., 1995; He and Ounis, 2006). Another advantage of the rule-based technique is that it is human-readable and can be easily upgraded or updated over time for small systems. Rule-based systems are difficult to maintain, and if not adapted, the accuracy of existing ones will decrease (Monkey Learn, 2019).
One of the most widely used feature extraction approaches to text classification is the bag-of-words (POW) approach, where the frequency of a term in a specific index of terms is extracted from the entire training corpus represented by a vector become
Machine Learning Algorithms
- Naive Bayes Methods
- Support Vector Machine Methods
- Random Forest
- Deep Learning Methods
Although it may be considered less accurate compared to other approaches, many researchers have found it to be effective enough for text classification in multiple domains, as it requires a relatively small amount of training data to estimate the parameters needed for classification (Ting et al., 2011). Increasing the random forest and maintaining accuracy for small and large data sets, the process of averaging the results in the random forest of different decision trees supports the model to overcome the known problem of overfitting, which is one of the advantages of the random forest, it can be used without preparing the input data (prepossessing). The disadvantage of random forest is the time-consuming and complex nature of the model (Statnikov et al., 2008). During the training and validation process, a back-propagation algorithm is used to go back through the network and adjust the model parameters according to the training data for a better fit Yu et al.
The use of these word embedding approaches in text classification enables the inclusion of various linguistic annotations and external knowledge much better than previous classification models based on machine learning (Mikolov et al., 2013; LeCun et al., 2015; Khan et al., 2010). ).
Text Classification Evaluation
Summary
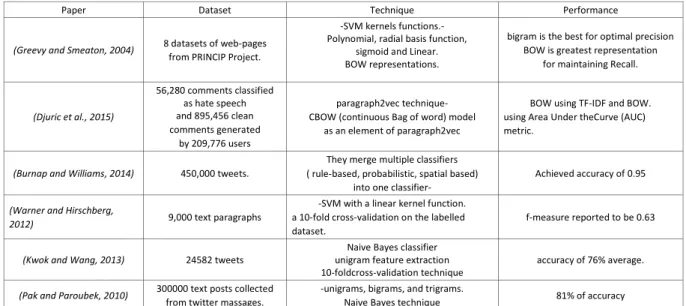
Greevy and Smeaton (2004) proposed a methodology that uses bigram and bag-of-word technique feature selection to train Support Vector Machines (SVM) models to classify this web content that can be identified as hate speech or racist for specific people or sweat. The research presented in (Burnap and Williams, 2014) implemented a controlled text rating system that can identify hate speech in tweets. They discussed various types of hate speech and the current problems they are causing for online businesses.
In terms of f-measure reported to be 0.63), than bigram, trigram patterns for classifying hate speech in online comments and news sections.
Cross-Lingual Text Classification
Xu and Yang (2017) present an innovative method for CLTC based on model distillation, which adjusts and covers a framework originally designed for model compression. Using lightweight probabilistic predictions for the online documents in a label-rich language as the supervisory labels in a similar corpus of documents, Xu and Yang (2017) successfully train a classifier for various languages where labeled training data does not exist. A confronting feature matching technique is also used in Xu and Yang (2017) through the model training to reduce distribution differences.
The approach proposed in Xu and Yang (2017) had the favorable or equivalent performance of the other state-of-art approaches.
Summary of previous work
The approach proposed in Xu and Yang (2017) had the favorable or equivalent performance of the other state-of-art approaches. Greevy and Smeaton, 2004) 8 datasets from PRINCIP Project web pages. Research question 3: Which feature processing is most effective for Cross-Lingual Text classification in detecting Arabic hate speech online. We had about 1000 comments, after filtering out the non word based comments (emoji, flags etc) we had about 750 comments ready for analysis in our hate speech.
This could be against the organizers of the event or those who appear in the videos.
Egyptian Tweets Data Collection
Hate label: For any comment containing abusive or threatening speech or writing that expresses prejudice against someone.
Arabic Data Pr-Processing
- Representation
- Tokenisation, Stemming, lemmatisation and stop words
- Text Cleaning and error correction
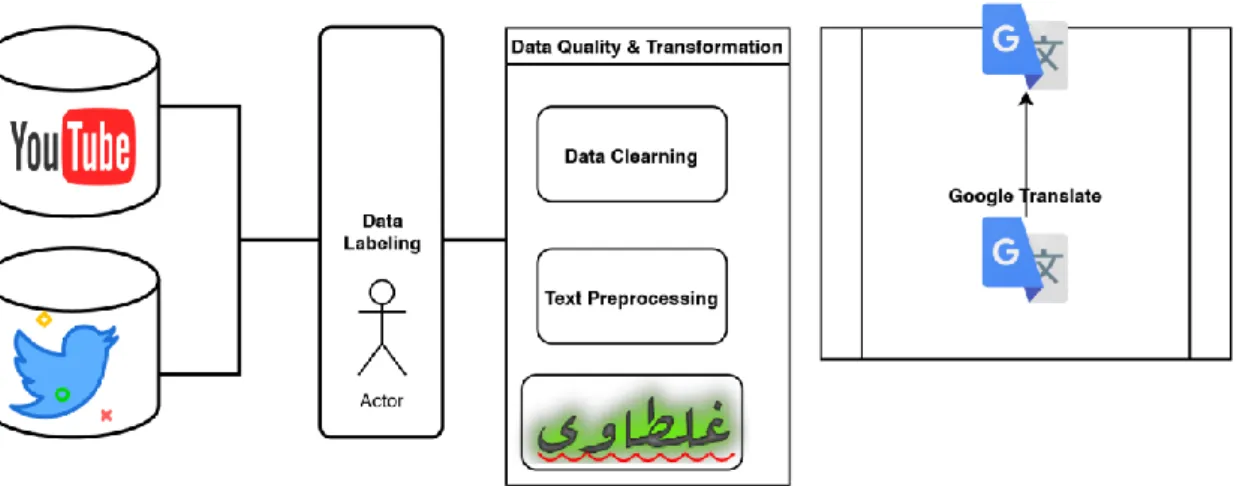
Both Youtube comments and tweets were tokenized into words using the standard pyarabic library version of tokenization (Zerrouki). To simplify the text for classification, we also used the same library to remove Harakat, Shadda and tatweel from the text9. We performed error correction, since this is informal social text and contains many spelling errors, we used Ghalatawi, an Arabic AutoCorrect library known to be very effective for spelling errors (Zerrouki et al., 2014).
Ghalatawi uses a rule-based method for error correction that works on two manually implemented methods, a word list and regular expressions.
Translated Data Pr-Processing
Google Translate is a nonprofit multilingual statistical machine translation system implemented by Google. The main reason for choosing this translation tool over others is that it has proven to be the most effective tool for translating social content in Arabic (Khwileh et al., 2017). Note that it is known to be very difficult to translate, previous research such as (Khwileh et al., 2016; Khwileh and Jones, 2016) showed that Arabic translation quality in particular is more likely to be hampered by translation errors compared to other languages such as. English, French and Italian.
Examples of poor and good translations from both datasets are shown in Figure 4.3 and Figure 4.4.
Proposed Methodology for Text Classification
- Feature Engineering for Hate-Speech Detection
- Machine Learning Methods for Hate-Speech Detection
For Arabic text on Tasks 1 and 2, we use the methods explained in Section 4.3 for data preprocessing, including tokenization, text cleaning, and error correction. WordLevel TF-IDF Vectors: represent the TF-IDF scores of every single term in different documents of the datasets. CharLevel TF-IDF Vectors: calculates the Tf-idf scores of character level n-grams in the corpus.
All bidding processing methods are based on calculation of both term frequency calculation and TF-IDF representation explained in Chapter 2, Section 2.
Investigating Text Classification for Hate Speech Detection
- Cross-Lingual Arabic Text Classification Results
- Arabic Text Classification
To display the most frequent terms in both datasets sorted by tags, we use the calculation of the average TF-IDF scores for each phrase in the datasets. We used the TF-IDF vectorizer implemented by scikit learn to learn the results of TF-IDF ngrams. Regarding the feature representation, the results from Tables 4.3 and Tables 4.4 show that the character-level representation is more effective for Arabic text classification in this task.
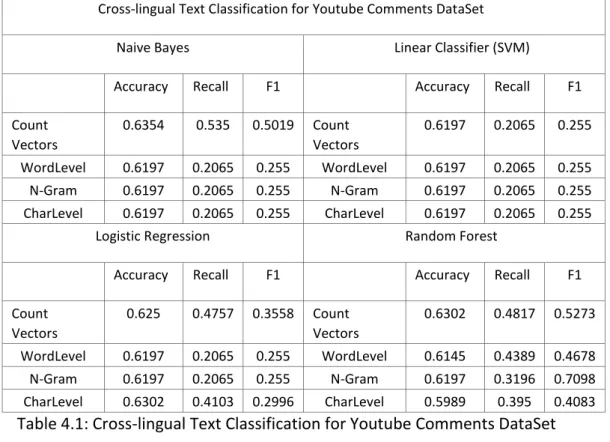
Finally, comparing the cross-language classification results shown in the previous section in Tables 4.1 and 4.2 with the Arabic classification results shown in Tables 4.3, 4.4, we can see that across all tasks, using all methods, cross-language classification achieves better results or mostly similar performance to Arabic classification.
Summary and Conclusions
- Future Directions
Research Question 3: Which feature engineering is most effective for cross-language text classification in Arabic online hate speech detection. We believe that cross-language text classification would greatly benefit from scalable machine learning approaches such as logistic regression, support vector machines, and deep neural networks. In Proceedings of the 27th Annual ACM SIGIR International Conference on Research and Development in Information Retrieval, pages 468–469.
In Proceedings of the 2013 Conference of the North American Chapter of the Society for Computational Linguistics: Human Language Technologies, pages 746–.
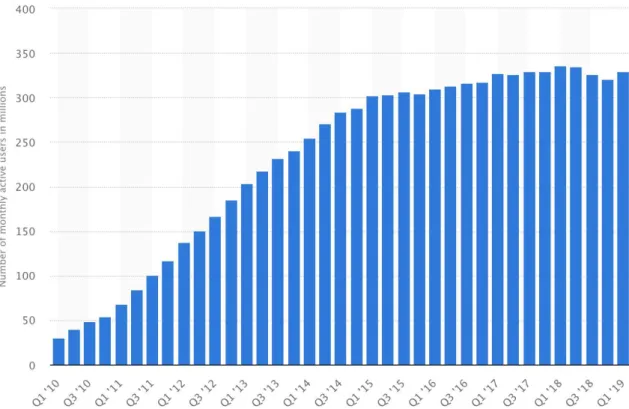
Twitter growth in monthly active users for the past decade
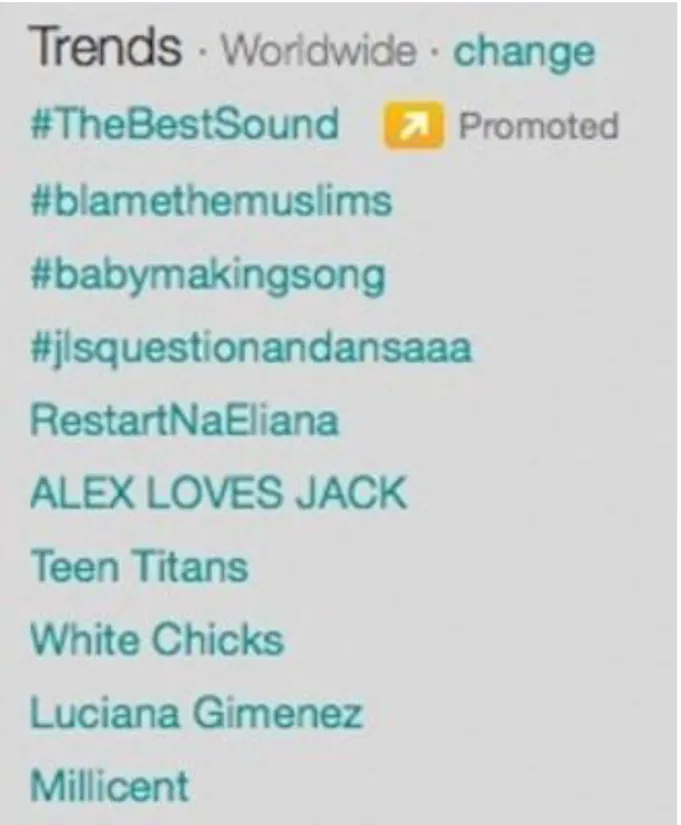
Twitter Trends demonstrating hateful hashtag attacking the Muslim protect group
Example of Reported hateful content in Twitter
An Overview Text Classification process
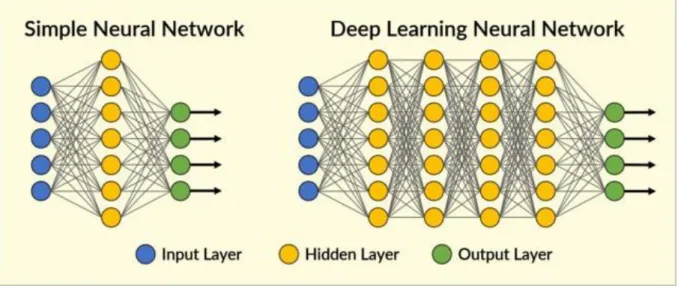
Deep Neural Networks
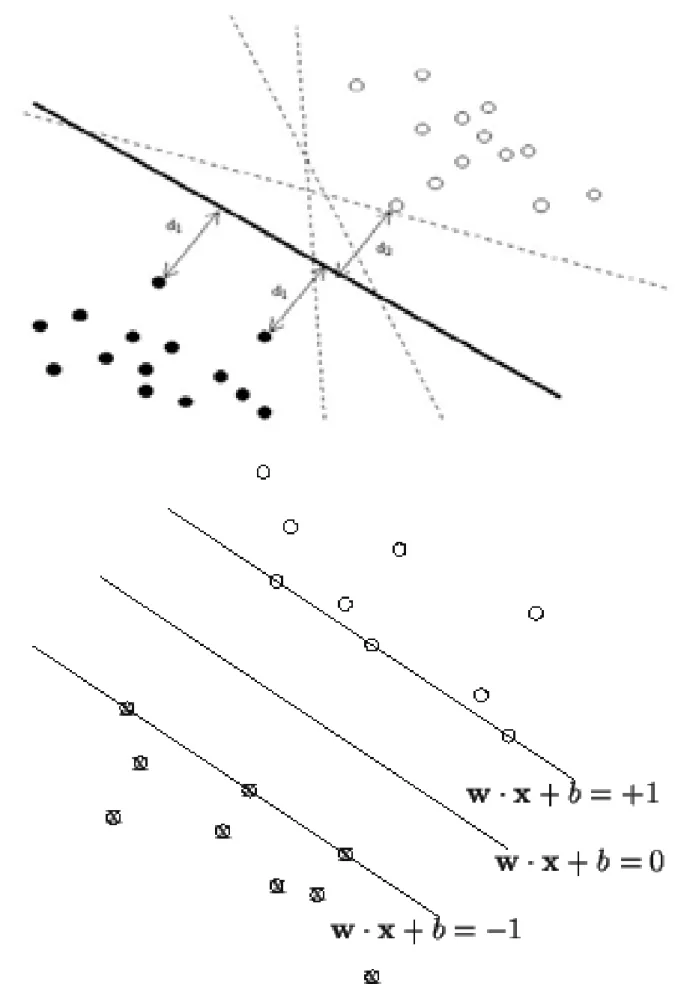
An illustration of optimal separating hyperplane in SVM classification. Top
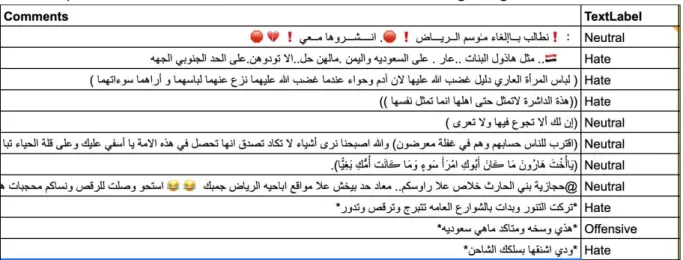
Selected examples of annotated comments with labels from our Youtube com-
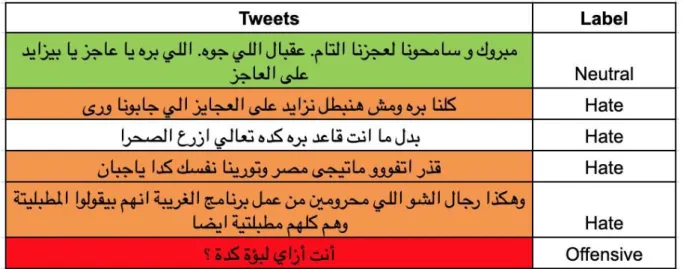
Selected examples of annotated tweets with labels from Mubarak et al. (2017)
Sample of Bad Google Translations
Sample of Good Google Translation
Summary of the proposed methodology for Investigating Hate speech Detection
Labels distribution count for the tweets dataset
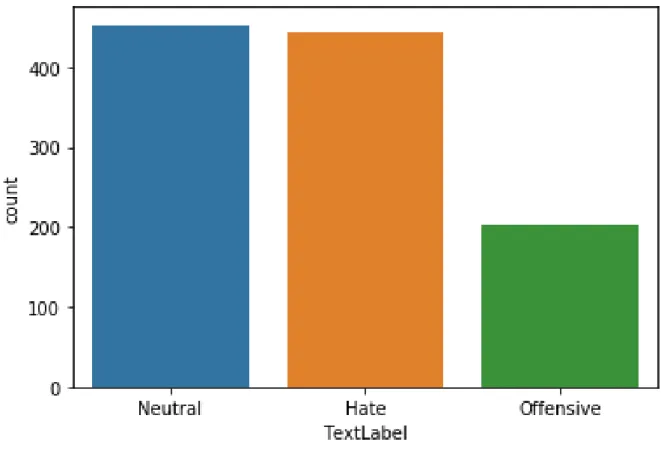
Labels distribution count for the YouTube dataset
Top ngram appearing in each label of the Youtube dataset ranked by the mean
Top ngram appearing in each label of the tweets dataset ranked by the mean TF-IDF