The author, whose copyright is declared on the title page of the work, has granted the British University in Dubai the right to loan his research work to users of its library and to make partial or single copies for teaching and research use. The author has also given the university permission to store or make a digital copy for similar use and for the purpose of digital preservation of the work. The complexity of the chemical and pharmacological properties forces the interaction between the drug molecule and all other entities in the biological system to follow specific rules.
The DDI network plays an important role in drug repurposing; it reveals the hidden features of the drug behavior.
INTRODUCTION
O VERVIEW
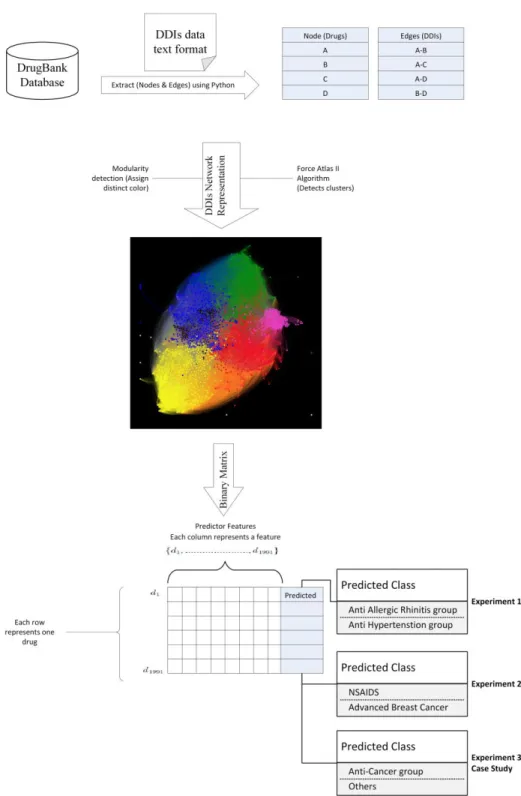
For example, (Huang et al. 2018) confirms that antipsychotic drugs have been modified for anticancer purposes. Machine learning classification models could be applied to a dataset of drug interactions (DDIs) to classify two different groups of drugs and predict new drug indications for drug repurposing. In the first step, the author used a community detection algorithm to identify the modularity-based structure in the DDI network.
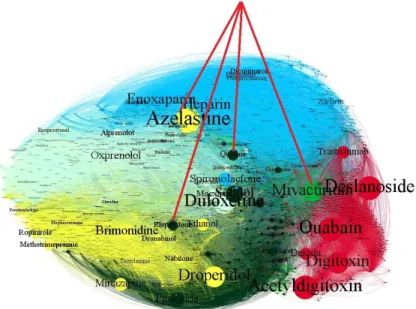
The author chose the Force Atlas II layout (Krzywinski et al. 2011) to illustrate the relationship between drugs (nodes) in the network. The distance (D) between any given nodes (in the geometric space) and the number of edges (E) each node have the main parameters in the equations. Azuaje 2012) emphasizes on the significant contribution of drug-target interactions (DTIs) network as well as drug-drug interactions (DDIs) network in the drug discovery process.
The drug interaction network was used as a measure of similarity between drugs to predict protein targets (Mei et al. 2012). In (Yoo et al. 2018), the author created a unique algorithm to predict drug interaction by investigating molecular and phenotypic drug networks. The author used triple cross-validation to evaluate the performance of the model. in order to avoid any biased assessment in prediction accuracy.
In the work of (Peng et al. 2017), the authors mentioned that only cases that were experimentally approved were recorded as positive cases in the DTI databases. Jamal et al., 2017) DrugBank, SIDER, PubChem CIDs Biological, Chemical, Phenotypic Predict Neurological Adverse Reactions Table 2.1 Review Summary Review summary with machine learning information in the related work. However, it indirectly correlates the benzphetamine content with the anti-cancer properties of the alkaloids tested.
The author said that Mebendazole boosted the immune system in the body, which may be related to its anti-cancer activity. In a recent work by (Jung et al. 2017), the author confirmed the anticancer properties of sirolimus. Figure (Figure 4.9 Cancer drugs) shows the clustering of cancer drugs in the DDI network.
P ROBLEM S TATEMENT
R ATIONALE AND M OTIVATION
R ESEARCH H YPOTHESES
D ISSERTATION S TRUCTURE AND O RGANIZATION
D EFINITIONS
O VERVIEW
The summary and conclusion of each article are demonstrated as well as the general limitations of the present work. Additionally, the second topic in this chapter presents the clinical evidence from the literature that supports the predicted anticancer properties of each drug candidate.
R EVIEW A RTICLES
The author identified three types of complex network topology (Poisson, Power-Law and Scale-free). The author proposed these drugs as promising candidates for drug repurposing based on the predicted novel properties. The author emphasized the important role of transcriptomics data represented by linkage map (CMap), side effect (SE) data, and gene-related data represented by genome-wide association study (GWAS).
In a similar work by (Setoain et al. 2015), the author used transcriptomic data (data related to gene expression) to construct a gene expression signature dataset. The author calculated a drug similarity score to build a model that predicts the relationship between drugs and diseases. In a related article by (Peng et al. 2015), the author used chemical similarity measures between drugs to provide the most promising drug prospect that may fit specific protein sites.
In his work, the author integrated network regulation together with the logistic function to predict the interactions between drugs and their targets such as (enzymes and receptors). The proposed model by the author is designed to predict new drug combinations and to avoid potential ADRs. In a recent work done by (Zhao & So 2018), the author conceded the significant role of machine learning in improving the drug reuse process.
The author used support vector machine and K-nearest neighbor to predict therapeutic protein targets based on topological properties. In the dataset studied by (Yamanishi et al. 2008), the author used a network of chemical and genetic drug information to predict drug-target interactions (DTI).
C LINICAL SUPPORT OF PREDICTED PROPERTIES
Tetracycline and doxycycline belong to the tetracycline group of drugs. Lokeshwar, Escatel & Zhu 2001) confirmed the activity of doxycycline as an important cellular anticancer agent. In addition, tetracycline has been investigated in clinical trials for its anticancer properties against lung and breast cancer. A recent review (Lian et al. 2018) concluded that all published work by researchers studying the anticancer properties of gemfibrozil provided evidence of its activity against cancer cells in humans.
However, the reason why histamine was classified as anticarcinogenic may be due to the fact that some anticancer drugs have carcinogenic activity, as reported in (Lien, E. J. and Ou, Xing-chang 1985). As mentioned in (Hanusova et al. 2015), metformin and pioglitazone are mainly indicated for the treatment of diabetes (a disease characterized by high blood glucose levels). Clinical and computational studies proved that the anticancer activity of the members belonging to this group.
Similar work by (Yde et al. 2009) noted that the anticancer effects of tamoxifen on breast cancer cells were enhanced by chlorpromazine when given in combinations. Barron et al. 2011) observed a reduced rate of breast cancer mortality and progression in patients receiving a nonspecific beta blocker (propranolol) compared to patients receiving a specific beta blocker (atenolol). However, (Peer & Margalit 2006) reported that fluoxetine could enhance the response of cancer cells to anticancer drugs through a possible mechanism of chemosensitization.
However, animal studies showed activity against liver and lung cancer as mentioned in (Hanusova et al. 2015). Zhang & Chu 2018) discussed the effectiveness results of leflunomide as well as the possible mechanisms of action of this drug to be an anticancer agent.
C URRENT L IMITATIONS
However, recent studies have recognized it as a powerful anti-cancer drug. Zhang & Chu 2018) discussed the effectiveness results of leflunomide as well as the possible mechanisms of action of this drug to be an anticancer agent.
O VERVIEW
D ATA A CQUISITION AND D ATASET C ONSTRUCTION
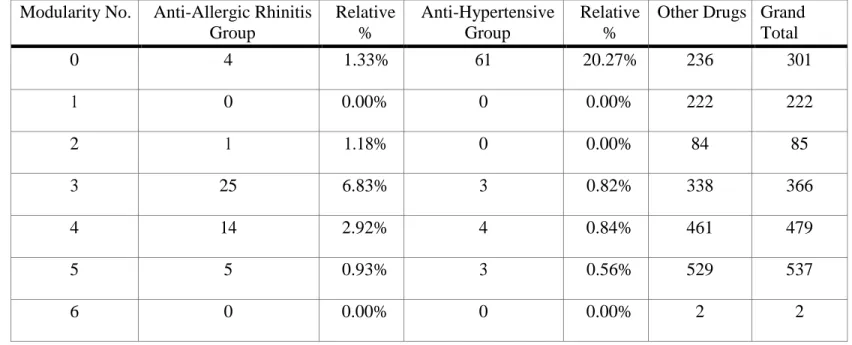
- Experiment (1): Anti-hypertensive drugs VS Anti Allergic rhinitis drugs
- Experiment (2): Advanced breast cancer drugs VS NSAIDs
- Case Study: Anti-Cancer Drug Prediction
The second step in constructing the data is to construct a binary matrix from the nodes and edges. A binary drug profile matrix is constructed with dimensions in which rows represent a list of drugs, columns represent a list of features. In this experiment, two groups of drugs were selected based on the largest number of affected populations and the maximum number of DDIs their members have with other drugs.
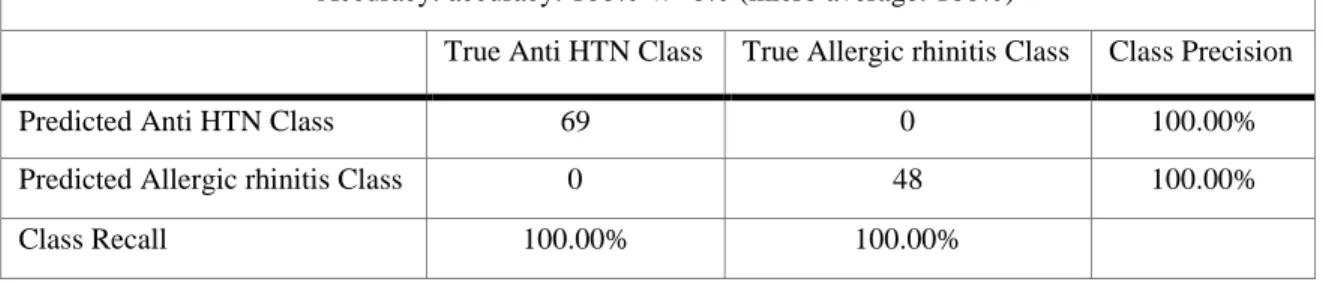
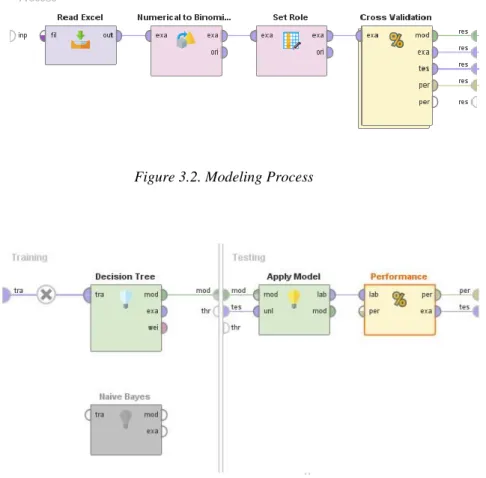
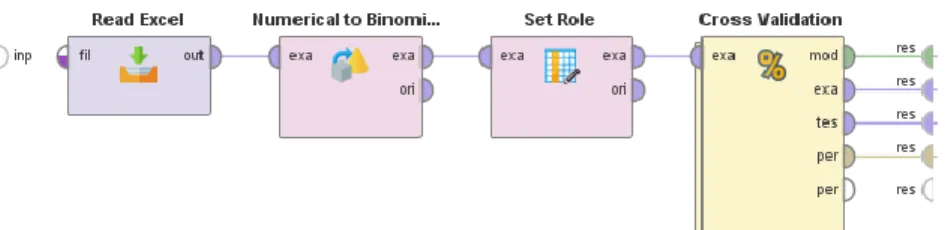
The first group is listed in table (Table 03.1 List of antihypertensive drugs), this group includes 69 drugs and is indicated for the treatment of hypertension. The second group includes 48 drugs and is listed in the table (Table 3.2 List of drugs for allergic rhinitis). Then the DDI data is used to build a binary matrix and apply classification algorithms (Decision Tree and Naive Bayes) to confirm the visual graph analysis with a measurable measure of performance.
The first group is listed in the table (Table 3.0.3 List of researched drugs for advanced breast cancer). This group contains 25 drugs that are indicated for the treatment of advanced stage breast cancer. The second group includes 40 drugs that belong to the group of drugs labeled (non-steroidal anti-inflammatory drugs), listed in the table (Table 3.0.4 List of investigated NSAID drugs.). Then, apply the classification technique on the DDI binary matrix using the appropriate predictable class attributes of the experiment (2).
This case study seeks to draw the classification boundary between groups of drugs showing anti-cancer properties against all other drugs using the DDIs binary matrix dataset. The trial selected 250 drugs listed in DrugBank v 5.1.1 and classified as an anti-cancer group according to the ATC system.

P REDICTION A LGORITHMS
- Decision Tree (DT)
- Naive Bayes (NB)
- Deep Learning (DL)
In this case study, we evaluate the classification performance of the model as well as the model predictions for retargeting. In other words, we need to identify the drugs that have the potential to be classified as an anti-cancer group. Recently, Deep Learning techniques have been designed for scientific domains that store and process large data, such as the area of bioinformatics (Bacciu et al. 2018).
The number of nodes in each hidden layer decreases towards the output layer (prediction layer).
M ODEL P ERFORMANCE E VALUATION M EASURES
O VERVIEW
- Experiment (1): Anti-Hypertensive Drugs VS Anti Allergic Rhinitis Drugs
- Experiment (2): NSAIDs VS Advanced Breast Cancer Drugs (ABCD)
- Case Study: Anti-Cancer Drug Prediction
The visual representation of DDI's complex network is illustrated in figure (Figure 4.1 Overall DDI's network visualization). Table (Table 4.1 DT performance measures (anti-hypertensive vs anti-allergic rhinitis)) reports the confusion matrix of the Decision Tree (DT) classification algorithm applied over the anti-hypertensive and anti-allergic rhinitis groups. The graph confirms the presence of connections between Amifostine with all members of the antihypertensive group (red nodes).
However, no association was observed between Amifostine and a member of the anti-allergic rhinitis group (blue nodes). Table (Table 4.3 NB Performance Metrics (Anti-Hypertensive VS Anti Allergic rhinitis)) shows the performance metrics for the Naive Bayes (NB) classifier. Figure (. Figure 4.6 Advanced drugs for breast cancer vs NSAIDs) illustrates the clustering pattern for the NSAID group (blue nodes) and the ABCD group (red nodes).
NB successfully identified 24 out of 25 nodes of Group ABCD (A), 1 node (Misoprostol) was predicted as a member of Group (A), while it belongs to Group (B). The table (Table 4.6 Node Distribution Experiment (2)) displays the distribution of the degree of the overall modularity groups of all nodes. Table (Table 4.8 Decision Tree Performance Metrics (NSAIDs VS Advanced Breast Cancer)) reports the results of the DT classifier.
A summary in (Table 4.9 and Table 4.10) presents the classification results of both NB and DT between NSAIDs and Advanced Breast Cancer Group. Lawson et al., 1994) cited clinical evidence from the literature confirming the anti-cancer properties of misoprostol. Table (Table 4.11 Anti-Cancer Node Distribution Case Study) shows the total number of nodes in each modularity and the component percentage within each modularity of each group. The confusion matrix of DT is presented in (Table 4.12 Performance Measures Decision Tree (Anti-Cancer vs. Others)).
DL shows a smaller improvement in precision and recall values of the anti-cancer group compared to DT.