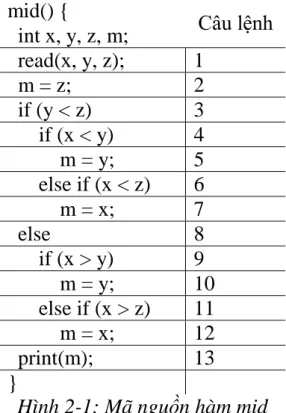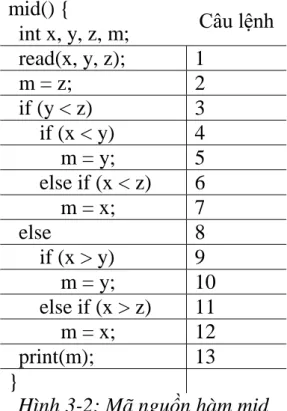ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
Nguyễn Văn Hiệp
Xây dựng công cụ định vị lỗi cho ứng dụng C/C++
LUẬN VĂN THẠC SĨ
Ngành: Kỹ thuật phần mềm
HÀ NỘI – 2022
TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
Nguyễn Văn Hiệp
Xây dựng công cụ định vị lỗi cho ứng dụng C/C++
Ngành: Kỹ thuật phần mềm
Chuyên ngành: Kỹ thuật phần mềm Mã số: 8480103.01
LUẬN VĂN THẠC SĨ
Ngành: Kỹ thuật phần mềm
NGƯỜI HƯỚNG DẪN KHOA HỌC: TS. Võ Đình Hiếu
HÀ NỘI – 2022
Tôi xin cam đoan rằng luận văn của tôi chưa từng được nộp như một báo cáo luận văn tại trường Đại học Công nghệ - ĐHQGHN hoặc bất kỳ trường đại học khác. Những gì tôi viết ra không sao chép từ các tài liệu, không sử dụng các kết quả nghiên cứu của người khác mà không trích dẫn cụ thể. Nếu sai tôi hoàn toàn chịu trách nhiệm theo quy định của trường Đại học Công nghệ - ĐHQGHN.
Hà Nội, ngày 8 tháng 8 năm 2022 Học viên cao học
Nguyễn Văn Hiệp
Đầu tiên, tôi xin gửi lời cảm ơn trân trọng và sâu sắc tới TS. Võ Đình Hiếu, người thầy đã trực tiếp hướng dẫn tận tình và đưa ra những lời khuyên trong quá trình học tập và nghiên cứu của tôi trong quá trình học tập và làm luận văn. Tôi cũng xin gửi lời cảm ơn các thầy cô trong trường Đại học Công nghệ - ĐHQGHN đã tận tâm truyền đạt kiến thức bổ ích giúp tôi phát triển. Cuối cùng tôi xin cảm ơn gia đình, người thân và bạn bè đã hỗ trợ, tạo động lực giúp tôi hoàn thiện bản thân.
Luận văn này được hỗ trợ từ đề tài KHCN cấp ĐHQGHN, Mã số: QG.20.59.
Chương 1 Giới thiệu ... 1
Chương 2 Kiến thức nền tảng ... 3
2.1 Khái niệm lỗi: Fault, Error, Failure... 3
2.2 Kiểm thử phần mềm ... 3
2.3 Gỡ lỗi ... 6
2.4 Các nghiên cứu về định vị lỗi ... 7
2.5 Các kỹ thuật định vị lỗi ... 7
2.5.1 Các kỹ thuật định vị truyền thống ... 7
2.5.2 Kỹ thuật định vị lỗi dựa trên lát cắt ... 8
2.5.3 Kỹ thuật định vị lỗi dựa phổ ... 10
2.5.4 Kỹ thuật định vị lỗi dựa trên xác suất ... 13
2.5.5 Kỹ thuật định vị lỗi dựa trên trạng thái ... 15
2.5.6 Kỹ thuật định vị lỗi dựa trên học máy ... 16
2.5.7 Kỹ thuật định vị lỗi dựa trên khai phá dữ liệu... 17
Chương 3 Công cụ định vị lỗi HiFa cho các ứng dụng C/C++ ... 19
3.1 Kỹ thuật định vị lỗi cho ứng dụng C/C++ ... 19
3.1.1 Tổng quan kỹ thuật ... 19
3.1.2 Ví dụ minh họa ... 21
3.2 Kiến trúc tổng quan công cụ HiFa ... 25
3.3 Quá trình điều chỉnh mã nguồn ... 26
3.3.1 Tổng quan về LLVM ... 27
3.3.2 Quá trình điều chỉnh mã của công cụ HiFa ... 30
3.4 Quá trình xử lý dữ liệu phổ ... 33
4.1 Thử nghiệm ... 36
4.1.1 Dữ liệu thử nghiệm ... 36
4.1.2 Chỉ số đánh giá ... 37
4.2 Kết quả và đánh giá ... 38
Chương 5 Kết luận ... 45
Hình 2-1: Mã nguồn hàm mid ... 4
Hình 2-2: Đồ thị dòng điều khiển tương ứng độ đo C2 của hàm mid ... 5
Hình 2-3: Đồ thị dòng dữ liệu của chương trình mid ... 6
Hình 2-4: Số lượng nghiên cứu về định vị lỗi từ 2003 - 2021 ... 7
Hình 2-5: Tổng quan thuật toán của predicate switching ... 16
Hình 2-6: Thuật toán Định vị lỗi sử dụng phân tích N-gram ... 18
Hình 3-1: Tổng quan kỹ thuật sửa lỗi dựa trên phổ ... 19
Hình 3-2: Mã nguồn hàm mid ... 21
Hình 3-3: Kiến trúc công cụ HiFa ... 26
Hình 3-4: LLVM Framework ... 28
Hình 3-5: Kiến trúc trình biên dịch LLVM ... 29
Hình 3-6: Các LLVM pass ... 30
Hình 3-7: Quá trình điều chỉnh mã nguồn ... 31
Hình 3-8: Bảng xếp hạng nghi ngờ được tạo ra khi sử dụng HiFa ở giao diện dòng lệnh ... 34
Hình 3-9: Giao diện đồ hoạ người dùng của công cụ HiFa ... 34
Hình 4-1: Điểm Expense của Barinel và DRT ... 38
Hình 4-2: Điểm Expense của Dstar và Jaccard ... 39
Hình 4-3: Điểm Expense của Kulczynski2 và Mccon ... 39
Hình 4-4: Điểm Expense của Minus và Ochiai... 40
Hình 4-5: Điểm Expense của Op và Tarantula ... 40
Hình 4-6: Điểm Expense của Wong3 và Zoltar ... 41
Hình 4-7: Hiệu quả định vị lỗi của các kỹ thuật với phổ ESHS ... 42
Hình 4-8: Hiệu quả định vị lỗi của các kỹ thuật với phổ DHS ... 42
Hình 4-9: Hiệu quả định vị lỗi của các kỹ thuật với phổ DHS-def ... 43
Hình 4-10: Hiệu quả định vị lỗi của các kỹ thuật với phổ DHS-use ... 43
Bảng 2.1. Ví dụ về phương pháp dựa trên lát cắt chương trình ... 10
Bảng 2.2: Các chỉ số xếp hạng của các kỹ thuật SFL ... 12
Bảng 3.1: Bộ kiểm thử của hàm mid ... 22
Bảng 3.2: Phổ ESHS của hàm mid... 22
Bảng 3.3: Phổ DHS của hàm mid ... 23
Bảng 3.4: Độ nghi ngờ và thứ hạng của từng câu lệnh phiên bản lỗi 1 ... 24
Bảng 3.5: Độ nghi ngờ và thứ hạng của từng câu lệnh phiên bản lỗi 2 ... 25
Bảng 3.6: Dữ liệu về các câu lệnh được điều chỉnh ... 33
Bảng 4.1: Chi tiết về các chương trình trong dữ liệu thử nghiệm ... 36
Bảng 4.2: Kích thước tệp thực thi của từng chương trình ... 44
BHS Branch Hit Spectrum
BiS Bidirectional Dynamic Slice BP Back Propagation
BwS Backward Dynamic Slice CFG Data Flow Graph
CPS Complete Path Spectrum DFG Control Flow Graph
DHS Data-dependence Hit Spectrum ESHS Executable Statement Hit Spectrum FwS Forward Dynamic Slice
IR Intermediate Representation IVMP Interesting Value Mapping Pairs SFL Spectrum-based Fault localization
Chương 1 Giới thiệu
Trong quá trình phát triển phần mềm, việc gỡ lỗi phần mềm là một quá trình tốn kém và hầu như thủ công. Chương trình phần mềm sẽ được chạy kiểm thử với bộ kiểm thử nhất định. Nếu có xuất hiện lỗi trong các bài kiểm thử, lập trình viên sẽ phải thực hiện kiểm tra lại chương trình để xác định các câu lệnh gây lỗi. Sau đó, họ sẽ sửa các lỗi này. Trong các hoạt động của gỡ lỗi phần mềm này, hoạt động định vị lỗi hay xác định vị trí lỗi là hoạt động tốn kém nhất. Quá trình xác định lỗi trong thực tế thường được thực hiện một cách thủ công và tuần tự. Sau khi hoàn thành quá trình phát triển, các lập trình viên thực hiện chạy kiểm thử với chương trình và quan sát kết quả của chương trình. Nếu có một ca kiểm thử có lỗi, các lập trình viên thực hiện đặt các điểm ngắt tại các vị trí mà họ nghi ngờ có khả năng gây lỗi. Sau đó, họ chạy lại chương trình với ca kiểm thử đã gây lỗi trước đó và quan sát trạng thái của chương trình để xác định lỗi. Lập trình viên sẽ thực hiện lặp đi lặp lại quá trình này cho đến khi ca kiểm thử không cho lỗi nữa.
Quá trình trình này gây tốn thời gian và công sức.
Do đó, việc áp dụng kỹ thuật và công cụ định vị lỗi có thể giảm đáng kể chi phí gỡ lỗi. Kỹ thuật định vị lỗi tự động đưa ra các đề xuất, gợi ý về vị trí có thể gây lỗi cho các lập trình viên. Từ đó, họ có thể chỉ cần tập trung vào vị trí được đề xuất để kiểm tra, giúp giảm thời gian và công sức để sửa lỗi. Các nhà nghiên cứu đã đưa ra rất nhiều kỹ thuật để thực hiện định vị lỗi. Các kỹ thuật định vị lỗi truyền thống như: hệ thống nhật ký (logging), lệnh khẳng định (assertions), điểm ngắt (breakpoints) và phân tích hồ sơ (profiling). Các kỹ thuật định vị lỗi nâng cao như: dựa trên lát cắt (slide-based), dựa trên phổ (spectrum-based), dựa trên xác suất (statistics-based), dựa trên trạng thái (state-based), dựa trên học máy
(machine learning-based), dựa trên khai phá dữ liệu (data mining-based), dựa trên mô hình (model-based), …
Kỹ thuật định vị lỗi dựa trên phổ (spectrum-based) là kỹ thuật được sử dụng và nghiên cứu phổ biến nhất. Tuy nhiên, các nghiên cứu không cung cấp công khai công cụ kèm theo hoặc các công cụ chưa hoàn chỉnh, khó tiếp cận và cải tiến cho việc định vị lỗi cho các chương trình C/C++. Mục tiêu của luận văn là nghiên cứu các kỹ thuật định vị lỗi hiện nay, từ đó đã lựa chọn ra kỹ thuật định vị lỗi dựa trên phổ phù hợp với các chương trình C/C++. Dựa trên kỹ thuật này, luận văn xây dựng công cụ hoàn chỉnh, có tên HiFa, định vị lỗi tự động cho các ứng dụng C/C++. HiFa được tích hợp nhiều kỹ thuật SFL để định vị lỗi như: Tarantula, Ochiai, Op2, Dstar, … Bên cạnh phổ theo câu lệnh cơ bản ESHS được sử dụng phổ biến trong các nghiên cứu, luận văn đề xuất thêm các phổ theo cặp def-use DHS cho kỹ thuật định vị lỗi dựa theo phổ. Công cụ HiFa được thử nghiệm với các tập dữ liệu thử nghiệm: dữ liệu lỗi chế tác: bộ Siemens (7 chương trình), chương trình Grep và chương trình Sed; và dữ liệu lỗi thật: chương trình Space.
Các phần còn lại của luận văn có nội dung như sau. Chương 2 cung cấp các kiến thức nền tảng về lỗi, kiểm thử phần mềm và các kỹ thuật định vị lỗi. Chương 3 mô tả phương pháp định vị lỗi đề xuất và kiến trúc của công cụ định vị lỗi.
Chương 4 trình bày các thử nghiệm, kết quả và đánh giá về khả năng định vị lỗi của công cụ. Cuối cùng, Chương 5 là kết luận luận văn và các công việc cải tiến công cụ trong tương lai.
Chương 2 Kiến thức nền tảng
Chương này cung cấp các kiến thức nền tảng cho luận văn. Khái niệm lỗi, gỡ lỗi và kiểm thử được giới thiệu tổng quan. Sau đó, hiện trạng nghiên cứu các kỹ thuật định vị lỗi hiện này. Luận văn cung cấp các nguyên tắc cơ bản của các kỹ thuật định vị lỗi, hiệu suất và hiệu quả của chúng.
2.1 Khái niệm lỗi: Fault, Error, Failure
IEEE Standard [1] định nghĩa fault, error, failure như sau: Fault là một bước, một quá trình hay một định nghĩa dữ liệu sai trong chương trình máy tính. Một fault được tạo ra khi một nhà phát triển viết chương trình. Error là một trạng thái sai của chương trình khi thực thi có thể gây ra failure. Failure mô tả một chương trình đưa ra kết quả sai lệch so với kết quả mong muốn.
Luận văn thực hiện nghiên cứu các phương pháp định vị lỗi khi chương trình có ca kiểm thử thất bại trong quá trình kiểm thử. Nên lỗi được định vị sẽ là loại lỗi Failure. Khi luận văn sử dụng thuật ngữ "Định vị lỗi" tức là định vị câu lệnh hay thành phần chương trình gây ra failure.
2.2 Kiểm thử phần mềm
Kiểm thử phần mềm là một bước cơ bản trong quá trình phát triển phần mềm.
Thông qua kiểm thử ta có thể biết được phần mềm có hoạt động đúng với yêu cầu đặc tả. Kiểm thử giúp cải thiện chất lượng của phần mềm. Một ca kiểm thử (testcase) gồm tập các giá trị đầu vào và kết quả đầu ra mong đợi của chương trình. Một ca kiểm thử thành công khi chương trình hoạt động thỏa mãn hành vi mong đợi, kết quả đầu ra thực tế giống với kết quả đầu ra mong đợi của ca kiểm thử. Ngược lại, một ca kiểm thử thất bại khi chương trình hoạt động không thỏa mãn hành vi mong đợi của ca kiểm thử.
Các chiến lược kiểm thử hay việc xây dựng các ca kiểm thử đảm bảo kiểm tra phần mềm dưới các góc độ khác nhau. Xây dựng bộ kiểm thử có thể theo các cách tiếp cận khác nhau như: kiểm thử hộp đen (kiểm thử chức năng), kiểm thử hộp trắng (kiểm thử cấu trúc).
Kiểm thử chức năng tạo ra các ca kiểm thử thông qua đặc tả của phần mềm.
Quá trình xây dựng ca kiểm thử chỉ sử dụng các giá trị đầu vào và các giá trị đầu
ra mong đợi. Cách tiếp cận này có thể xác định được chương trình hoạt động đúng với hành vi mong muốn trong đặc tả. Kiểm thử chức năng có ba phương pháp phổ biến gồm phương pháp phân tích giá trị biên, phân lớp tương đương và bảng quyết định [2].
Ngược lại, kiểm thử cấu trúc có cách tiếp cận khác để xây dựng ca kiểm thử.
Kiểm thử cấu trúc tập trung vào mã nguồn của chương trình làm cơ sở để xác định ca kiểm thử. Cách tiếp cận này đảm bảo cấu trúc mã nguồn được kiểm tra, cho phép phát hiện các lỗi tiềm ẩn của chương trình. Hai phương pháp được sử dụng trong kiểm thử cấu trúc là kiểm thử dòng điều khiển (control flow testing) và kiểm thử dòng dữ liệu (data flow testing). Độ đo kiểm thử xác định mức độ bao phủ chương trình của một bộ kiểm thử (tập các ca kiểm thử). Mức độ bao phủ của một bộ kiểm thử là tỷ lệ các thành phần được kiểm thử bởi các ca kiểm thử so với tổng thể chương trình. Các thành phần có thể là câu lệnh, các khối lệnh, nhánh điều khiển, điểm quyết định, biến, hàm, … Độ bao phủ càng lớn thì độ tin cậy của bộ kiểm thử càng cao. Mục tiêu của chiến lược kiểm thử là xây dựng bộ kiểm thử với số ca kiểm thử tối thiểu nhưng đạt được độ bao phủ tối đa.
mid() { Câu lệnh
int x, y, z, m;
read(x, y, z); 1
m = z; 2
if (y < z) 3 if (x < y) 4 m = y; 5 else if (x < z) 6 m = x; 7
else 8
if (x > y) 9 m = y; 10 else if (x > z) 11 m = x; 12
print(m); 13
}
Hình 2-1: Mã nguồn hàm mid
Kiểm thử dòng điều khiển dựa trên khái niệm đồ thị dòng điều khiển (CFG).
Một CFG là một đồ thị có hướng gốm các đỉnh là các câu lệnh/khối lệnh và các cạnh là các dòng điều khiển giữa các câu lệnh/khối lệnh. Kiểm thử dòng điều
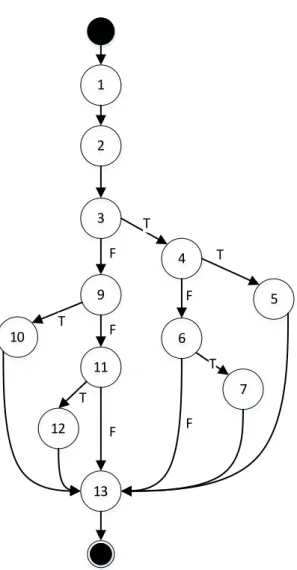
khiển gồm độ đo C1, độ đo C2 và độ đo C3. Độ đo C1: mỗi câu lệnh của chương trình được thực thi ít nhất một lần khi chạy bộ kiểm thử. Độ đo C2: mỗi nhánh điều kiện được thực hiện khi thực hiện kiểm thử. Độ đo 3: các điều kiện con của điều kiện phức tạp được thực hiện ít nhất một lần cả hai nhanh đúng và sai. Hình 2-2 thể hiện đồ thị dòng điều khiển đạt độ đo C2 của hàm mid [3] (Hình 2-1). Đồ thị dòng điều khiển này có 5 điểm quyết định (đỉnh 3, 4, 6, 9, 11) và bốn đường thực thi.
Hình 2-2: Đồ thị dòng điều khiển tương ứng độ đo C2 của hàm mid Kiểm thử dòng dữ liệu dựa trên đồ thị dòng dữ liệu (DFG). Đồ thị dòng dữ liệu là một CFG được mở rộng để bao gồm thông tin luồng dữ liệu. Kiểm thử dòng dữ liệu kiểm tra các hoạt động liên quan tới gán và sử dụng các biến trong chương trình. Một đồ thị dòng dữ liệu chỉ ra các định nghĩa và cách sử dụng của một biến trong chương trình. Một định nghĩa (definition) là câu lệnh thực hiện
1
10
9
4 3
13 11 F
F
F T
T 2
5 6
7 12
T
F T
F T
gán giá trị cho một biến. Một sử dụng (use) là một câu lệnh sử dụng một biến.
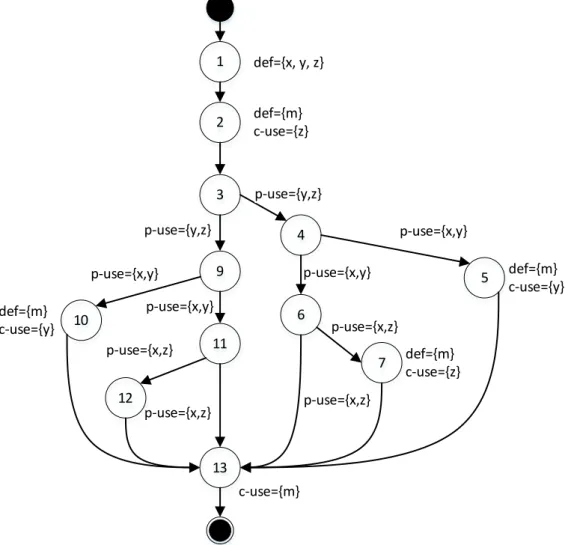
Biến có thể dùng để tính toán tương ứng với c-use hoặc kiểm tra điều kiện tương ứng với p-use. Hình 2-3 thể hiện đồ thị dòng dữ liệu của hàm mid.
Hình 2-3: Đồ thị dòng dữ liệu của chương trình mid
2.3 Gỡ lỗi
Lỗi chương trình là một hệ quả tất yếu trong quá trình viết chương trình. Lỗi có thể xảy ra với nhiều lý do: lỗi đánh máy, hiểu sai yêu cầu phần mềm, gán sai giá trị cho biến, … Việc sử dụng từ lỗi (bug) bắt đầu từ thế kỷ 20, nó được sử dụng để chỉ ra những sai sót trong hệ thống kỹ thuật. Thuật ngữ gỡ lỗi (debug) sau đó được liên kết tới các hoạt động tìm kiếm và sửa các lỗi chương trình.
Trong quá trình kiểm thử hay triển khai, một lỗi được phát hiện khi chương trình thể hiện một hành vi không mong muốn. Sau khi xảy ra lỗi, quá trình gỡ lỗi được thực hiện. Nhà phát triển thực hiện kiểm tra mã nguồn trước tiên để tìm ra
1
10
9
4 3
13 11 p-use={y,z}
p-use={x,y}
p-use={x,z}
p-use={y,z}
p-use={x,y}
2
5 6
7 12
p-use={x,z}
p-use={x,y}
p-use={x,y}
p-use={x,z}
p-use={x,z}
def={x, y, z}
def={m}
c-use={z}
def={m}
c-use={z}
def={m}
c-use={y}
def={m}
c-use={y}
c-use={m}
nguyên nhân gây lỗi. Sau đó họ sửa lỗi này. Gỡ lỗi là quá trình giải quyết vấn đề yêu cầu hiểu biết và kỹ năng lập luận để hiểu về chương trình và xác định, sửa lỗi.
2.4 Các nghiên cứu về định vị lỗi
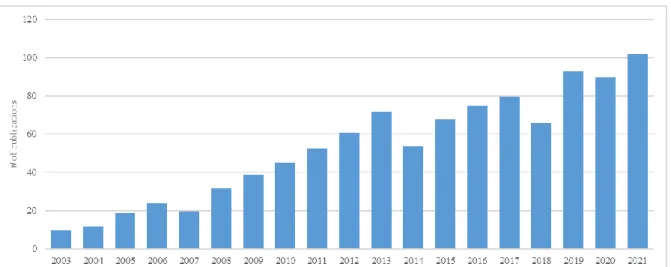
Từ những năm 1970 đã có rất nhiều nghiên cứu được thực hiện để đưa ra các phương pháp, kỹ thuật định vị lỗi phần mềm. Kể từ khi James A.Jones và cộng sự đề xuất kỹ thuật Tarantula năm 2005 [3], nghiên cứu về kỹ thuật định vị lỗi đã phát triển mạnh mẽ. Điều này dễ dàng được nhận thấy ở biểu đồ thống kê số lượng nghiên cứu, báo cáo về định vị lỗi trong giai đoạn 2003 – 2021 [4] trong Hình 2-4.
Số lượng các công bố nghiên cứu về định vị lỗi trước những năm 2005 là dưới 10 nghiên cứu, sau năm 2005 số lượng nghiên cứu tăng mạnh không ngừng. Những năm gần đây 2020, 2021 số lượng nghiên cứu đạt xấp xỉ 100 nghiên cứu.
Hình 2-4: Số lượng nghiên cứu về định vị lỗi từ 2003 - 2021
2.5 Các kỹ thuật định vị lỗi
2.5.1 Các kỹ thuật định vị truyền thống
Các kỹ thuật định vị lỗi truyền thống rất trực quan và đơn giản, bất cứ nhà phát triển nào cũng có thể sử dụng được. Kỹ thuật định vị lỗi truyền thống [5]
gồm 4 phương pháp sau: hệ thống nhật ký (Logging), khẳng định (Assertions), điểm ngắt (Breakpoints) và phân tích hồ sơ (Profiling). Phương pháp Logging sử dụng các câu lệnh để in các thông tin trong chương trình (ví dụ: lệnh printf() trong ngôn ngữ C). Đây là một cách cực kỳ đơn giản và hiệu quả để theo dõi thông tin về trạng thái, bộ nhớ của chương trình. Khi chương trình thực thi gặp lỗi, nhà phát triển thực hiện kiểm tra dữ liệu log của chương trình để tìm ra các điểm sai khác về trạng thái hay dữ liệu từ đấy tìm ra được vị trí câu lệnh lỗi. Assertions là các
câu lệnh do nhà phát triển thêm vào để đảm bảo các giá trị trạng thái của chương trình đúng với mong muốn. Chương trình sẽ dừng lại khi một trong cách câu lệnh assertion đánh giá sai. Bằng phương pháp dùng các câu lệnh Assertions, nhà phát triển có thể đánh giá được phạm vi các câu lệnh chứa câu lệnh gây lỗi. Phương pháp Breakpoints cho phép nhà phát triển đặt các breakpoint để dừng chương trình. Tại các điểm dừng này, nhà phát triển có thể lấy được thông tin trạng thái, nội dung bộ nhớ của chương trình. Thậm chí nhà phát triển có thể thay đổi được giá trị của bộ nhớ, thêm các câu lệnh mới ngay sau breakpoint để điều chỉnh, thu thập thêm thông tin về lỗi. Từ các thông tin này, nhà phát triển có thể xác định được vị trí của câu lệnh lỗi. Phương pháp Profiling là một phương pháp phân tích các chỉ số của chương trình khi thực thi như: thời gian thực thi, sử dụng bộ nhớ để đánh giá và tối ưu chương trình. Phương pháp này có thể sử dụng để xác định các loại lỗi như: lỗi rò rỉ bộ nhớ, lỗi hàm thực thi với số lần không mong muốn.
2.5.2 Kỹ thuật định vị lỗi dựa trên lát cắt
Lát cắt chương trình là một kỹ thuật để trừu tượng hóa một chương trình thành một dạng rút gọn bằng cách xóa các phần không liên quan sao cho lát cắt kết quả sẽ vẫn hoạt động giống như chương trình ban đầu đối với các yêu cầu nhất định. Hàng trăm bài báo về chủ đề này đã được xuất bản kể từ khi Weiser lần đầu tiên đề xuất phương pháp cắt lát tĩnh vào năm 1979 [6]. Một trong những ứng dụng quan trọng của phương pháp cắt tĩnh là giảm miền tìm kiếm khi lập trình viên định vị lỗi trong chương trình của họ. Điều này dựa trên ý tưởng rằng nếu một ca kiểm thử không thành công do giá trị biến không chính xác trong một câu lệnh, thì lỗi sẽ được tìm thấy trong lát cắt tĩnh được liên kết với biến đó, cho phép chúng ta giới hạn tìm kiếm lỗi trong lát cắt thay thế thay vì tìm kiếm toàn bộ chương trình. Cách tiếp cận trên được mở rộng bằng cách xây dựng một xúc xắc chương trình (programe dice) [7] với các mặt xúc xắc là các lát cắt. Các lát cắt này không có sự phụ thuộc lẫn nhau. Do giữa hai lát cắt không có sự phụ thuộc lẫn nhau nên vị trí lỗi chỉ thuộc một lát cắt nhất định. Cách tiếp cận này giúp giảm thêm miền tìm kiếm cho vị trí lỗi.
Một nhược điểm của phương pháp cắt lát tĩnh là lát cắt cho một biến nhất định tại một câu lệnh nhất định chứa tất cả các câu lệnh thực thi có thể ảnh hưởng đến giá trị của biến này. Do đó, nó có thể tạo ra một lát cắt với một số câu lệnh không nên đưa vào. Điều này là do chúng ta không thể dự đoán giá trị của biến trong thời gian chạy thông qua phân tích tĩnh. Để loại trừ các câu lệnh như vậy
khỏi một mặt xúc xắc (một lát cắt), chúng ta cần sử dụng phương pháp lát cắt động (dynamic slicing) [8] thay thay thế phương pháp lát cắt tĩnh. Một lát cắt động chứa tất cả các câu lệnh ảnh hưởng đến giá trị của một biến cho một lần thực thi chương trình cụ thể. Zhang và cộng sự đã đề xuất kỹ thuật cắt lát động nhiều điểm [9], bao gồm ba kỹ thuật: Lát động lùi (Backward Dynamic Slice - BwS), Lát động chuyển tiếp (Forward Dynamic Slice - FwS) và Lát động hai chiều (Bidirectional Dynamic Slice - BiS). Kỹ thuật BwS nắm bắt bất kỳ câu lệnh nào được thực thi ảnh hưởng đến giá trị đầu ra của một biến bị lỗi, trong khi kỹ thuật FwS tính toán dựa trên sự khác biệt đầu vào tối thiểu giữa ca kiểm thử không thành công và thành công, cô lập các phần của đầu vào gây ra lỗi. Kỹ thuật BiS lật các giá trị của một số câu lệnh điều kiện nhất định khi thực hiện một ca kiểm thử không thành công để chương trình tạo ra một đầu ra chính xác.
Các kỹ thuật mới thay thế kỹ thuật lát cắt tĩnh và lát cắt động là việc sử dụng lát cắt thực thi (execution slicing) [10]. Một lát cắt thực thi đối với một ca kiểm thử luồng dữ liệu nhất định chứa tập hợp các câu lệnh được thực thi trong ca kiểm thử này. Lý do để lựa chọn lát cắt thực thi thay thế cắt lát tĩnh là một lát tĩnh tập trung vào việc tìm kiếm các câu lệnh có thể có tác động đến các biến liên quan đối với bất kỳ đầu vào nào, trong khi đó lát cắt thực thi tìm kiếm các câu lệnh được thực thi bởi một đầu vào cụ thể.
Bảng 2.1 mô tả ví dụ [5] các loại lát cắt của chương trình. Cột 1 thể hiện danh sách các câu lệnh của chương trình. Cột 2 của bảng là mã nguồn của chương trình ví dụ. Chương trình có một lỗi tại dòng lệnh S7. Lát cắt tĩnh cho biến đầu ra product chứa tất cả các câu lệnh có thể có thể ảnh hưởng đến giá trị của product:
S1, S2, S5, S5, S7, S5, S10 và S13, như trong cột thứ 3. Lát cắt động cho biến product có chứa các câu lệnh có ảnh hưởng đến giá trị của product đối với ca kiểm thử có giá trị đầu vào a = 2, bao gồm các câu lệnh S1, S2, S5, S7 và S13 (như trong cột thứ tư). Lát cắt thực thi đối với ca kiểm thử có giá trị đầu vào a = 2 chứa tất cả các câu lệnh được thực hiện bởi ca kiểm thử này. Do đó, lát cắt thực thi cho ca kiểm thử có giá trị đầu vào a = 2 bao gồm các câu lệnh S1, S2, S4, S5, S5, S6, S12, S13 như thể hiện trong cột thứ 5 của Bảng 2.1.
Bảng 2.1. Ví dụ về phương pháp dựa trên lát cắt chương trình
Mã nguồn Lát cắt tĩnh Lát cắt động Lát cắt thực thi
S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13
input(a) i = 1;
sum = 0;
product = 1;
if (i<a){
sum=sum+i;
product=product+i;
}else{
sum=sum-i;
product=product/i;
}
print (sum);
print (product);
input(a) i = 1;
product = 1;
if (i<a){
product=product+i;
}else{
product=product/i;
}
print (product);
input(a) i = 1;
if (i<a){
product=product+i;
print (product);
input(a) i = 1;
sum = 0;
product = 1;
if (i<a){
sum=sum+i;
product=product+i;
print (sum);
print (product);
Các công cụ gỡ lỗi dựa trên lát cắt chương trình đã được phát triển và sử dụng trong thực tế như Xsuds tại Telcordia [11] và eXVantage tại Avaya [12].
2.5.3 Kỹ thuật định vị lỗi dựa phổ
Phổ chương trình cung cấp các thông tin thực thi của chương trình theo một số khía cạnh nhất định như: thông tin thực thi của các nhánh điều kiện hay các đường thực thi không có vòng lặp. Phổ chương trình có thể dùng để theo dõi hành vi của chương trình, do đó nó có ích cho việc xác định vị trí gây lỗi. Khi việc thực thi chương trình không thành công, thông tin phổ có thể được sử dụng để xác định mã đáng ngờ gây ra lỗi. Thông tin về độ phủ mã (code coverage) hoặc ESHS (Executable Statement Hit Spectrum) có thể cho ta biết những câu lệnh, thành phần nào được thực thi trong quá trình thực thi chương trình thất bại hay thành công. Với thông tin này, ta có thể xác định được thành phần nào liên quan tới lỗi, thu hẹp phạm vi tìm kiếm thành phần gây lỗi.
Nhiều kỹ thuật định vị lỗi dựa trên phổ chương trình đã được đề xuất (chủ yếu dựa trên ESHS). Trong đó kỹ thuật Tarantula [3] là kỹ thuật nổi tiếng nhất.
Kỹ thuật này sử dụng thông tin về độ phủ các câu lệnh và kết quả của các lần thực thi bộ kiểm thử để xác định độ nghi ngờ của từng câu lệnh. Độ nghi ngờ của câu lệnh được kỹ thuật Tarantula xác định bằng công thức:
𝑇𝑎𝑟𝑎𝑛𝑡𝑢𝑙𝑎(𝑠) =
𝑓𝑎𝑖𝑙𝑒𝑑(𝑠) 𝑡𝑜𝑡𝑜𝑙𝑓𝑎𝑖𝑙𝑒𝑑 𝑓𝑎𝑖𝑙𝑒𝑑(𝑠)
𝑡𝑜𝑡𝑎𝑙𝑓𝑎𝑖𝑙𝑒𝑑+ 𝑝𝑎𝑠𝑠𝑒𝑑(𝑠) 𝑡𝑜𝑡𝑎𝑙𝑝𝑎𝑠𝑠𝑒𝑑
(1)
Trong đó: s là câu lệnh được tính độ nghi ngờ
Failed(s) là số lượng ca kiểm thử thất bại mà s được thực thi Passed(s) là số lượng ca kiểm thử thành công mà s được thực thi Totalfailed là tổng số ca kiểm thử thất bại của bộ kiểm thử
Totalpassed là tổng số ca kiểm thử thành công của bộ kiểm thử Chỉ số xếp hạng nghi ngờ là vấn đề then chốt của các kỹ thuật định vị lỗi dựa trên phổ. Chúng được sử dụng để tính toán khả năng các câu lệnh của chương trình sẽ gây lỗi. Các nghiên cứu về SFL sử dụng thuật ngữ khác nhau để chỉ các chỉ số xếp hạng: kỹ thuật (technique), công thức đánh giá rủi ro (risk evaluation formula), chỉ số (metric), hệ số (coefficient), hệ số tương tự (similarity coefficient). Các chỉ số xếp hạng hiệu quả được đặc trưng bởi việc xác định các câu mã lệnh đáng ngờ từ tần suất của các câu lệnh được thực hiện trong các ca kiểm thử thành công và thất bại. Các câu lệnh được thực thi nhiều hơn trong các ca kiểm thử thất bại có nhiều khả năng gây lỗi hơn. Nếu không, các câu lệnh ít được thực thi hơn trong các ca kiểm thử thất bại và hiện diện nhiều hơn trong các ca kiểm thử thành công ít có khả năng bị lỗi hơn.
Bảng 2.2 liệt kê một số chỉ số xếp hạng nghi ngờ được sử dụng trong kỹ thuật định vị lỗi dựa trên phổ. Các tham số Nef, Nnf, Nep, Nnp đại diện cho bốn trạng thái có thể có của câu lệnh chương trình trong quá trình thực thi kiểm thử: Nef cho biết số lượng ca kiểm thử thất bại mà câu lệnh được thực thi; Nnf là số lượng ca kiểm thử thất bại mà câu lệnh không được thực thi; Nep là số lượng ca kiểm thử thành công mà câu lệnh được thực thi; và Nnp là số lượng ca kiểm thử thành công mà câu lệnh không được thực thi. Tarantula [3] là hệ số đầu tiên được đề xuất cho định vị lỗi. Thông tin phổ được lưu trữ trong ma trận phủ (coverage matrix) chứa tất cả các câu được thực thi bởi bộ kiểm thử và kết quả thực thi của các ca kiểm thử này. Do đó, Tarantula sử dụng ma trận phủ để tính toán tần số mà mỗi câu lệnh được thực thi trong các ca kiểm thử không thành công và chia nó cho tần số mà các câu lệnh được thực thi trong các ca kiểm thử thất bại và các ca kiểm thử thành công.
Bảng 2.2: Các chỉ số xếp hạng của các kỹ thuật SFL
Hệ số Công thức tính
Tarantula
𝑁𝑒𝑓 𝑁𝑒𝑓 + 𝑁𝑛𝑓 𝑁𝑒𝑓
𝑁𝑒𝑓 + 𝑁𝑛𝑓 + 𝑁𝑒𝑝 𝑁𝑒𝑝+ 𝑁𝑛𝑝
Jaccard 𝑁 𝑁𝑒𝑓
𝑒𝑓 + 𝑁𝑛𝑓 + 𝑁𝑒𝑝
Op 𝑁𝑒𝑓 − 𝑁𝑒𝑝
𝑁𝑒𝑝+ 𝑁𝑛𝑝 + 1
Barinel 1 − 𝑁𝑒𝑝
𝑁𝑒𝑝+ 𝑁𝑒𝑓
Dstar 𝑁𝑒𝑓
𝑁𝑒𝑝+ 𝑁𝑛𝑓
Kulczynski2 1
2 ( 𝑁𝑒𝑓
𝑁𝑒𝑓 + 𝑁𝑛𝑓+ 𝑁𝑒𝑓 𝑁𝑒𝑓 + 𝑁𝑒𝑝)
McCon 𝑁
2𝑒𝑓 − 𝑁𝑛𝑓𝑁𝑒𝑝 (𝑁𝑒𝑓 + 𝑁𝑛𝑓)(𝑁𝑒𝑓+ 𝑁𝑒𝑝) Zoltar
𝑁𝑒𝑓
𝑁𝑒𝑓 + 𝑁𝑛𝑓 + 𝑁𝑒𝑝+10000𝑁𝑛𝑓𝑁𝑒𝑝 𝑁𝑒𝑓 Wong3 𝑁𝑒𝑓 + 𝑝, 𝑤ℎ𝑒𝑟𝑒 𝑝 = {
𝑁𝑒𝑝 𝑖𝑓 𝑁𝑒𝑝 ≤ 2
2 + 0.1(𝑁𝑒𝑝− 2) 𝑖𝑓 2 < 𝑁𝑒𝑝 ≤ 10 2.8 + 0.001(𝑁𝑒𝑝− 10) 𝑖𝑓 𝑁𝑒𝑝 > 10 DRT
𝑁𝑒𝑓
1 + 𝑁𝑒𝑝
𝑁𝑒𝑓 + 𝑁𝑛𝑓 + 𝑁𝑒𝑝+ 𝑁𝑛𝑝
Minus 𝑁𝑒𝑓
𝑁𝑒𝑓+ 𝑁𝑛𝑓 𝑁𝑒𝑓
𝑁𝑒𝑓 + 𝑁𝑛𝑓+ 𝑁𝑒𝑝 𝑁𝑒𝑝+ 𝑁𝑛𝑝
−
1 − 𝑁𝑒𝑓 𝑁𝑒𝑓 + 𝑁𝑛𝑓 1 − 𝑁𝑒𝑓
𝑁𝑒𝑓 + 𝑁𝑛𝑓 + 1 − 𝑁𝑒𝑝 𝑁𝑒𝑝 + 𝑁𝑛𝑝
Ochiai 𝑁𝑒𝑓
√(𝑁𝑒𝑓 + 𝑁𝑛𝑓)(𝑁𝑒𝑓 + 𝑁𝑒𝑝)
Ochiai2 𝑁𝑒𝑓𝑁𝑛𝑝
√(𝑁𝑒𝑓 + 𝑁𝑒𝑝)(𝑁𝑛𝑝+ 𝑁𝑛𝑓)(𝑁𝑒𝑓 + 𝑁𝑛𝑓)(𝑁𝑒𝑝+ 𝑁𝑛𝑝)
Hệ số Ochiai ban đầu được áp dụng cho sinh học phân tử, sau đó đã được sử dụng trong một số nghiên cứu SFL [13]. Ochiai không tính đến các câu lệnh không
được thực hiện trong các ca kiểm thử thành công (Nep). Căn bậc hai cũng làm giảm trọng số của Nnf và Nep trong điểm khả nghi. Hệ số Jaccard [14] được sử dụng bởi Chen để chỉ ra các thành phần bị lỗi trong các ứng dụng phân tán. Hệ số Zoltar [15] là một biến thể của Jaccard. Công thức của nó tăng lên, nhiều hơn Jaccard, sự đáng ngờ của các thành phần chương trình thường xuyên được thực thi trong các ca kiểm thử thất bại. Zoltar được phát triển để phát hiện lỗi trong các hệ thống nhúng sử dụng các chương trình bất biến. Hệ số Op [16] là một số liệu xếp hạng được tối ưu hóa cho các chương trình lỗi đơn. Giả sử có một lỗi duy nhất trong chương trình, chỉ những câu lệnh được thực thi trong tất cả các trường hợp kiểm thử không thành công mới bị nghi ngờ. Wong3 [17] giảm dần tầm quan trọng của việc thành công của các ca kiểm thử. Ý tưởng là các ca kiểm thử thành công đầu tiên đóng góp nhiều hơn vào việc định vị lỗi hơn là các ca kiểm thử thành công tiếp theo. Kulczynski2 đến từ lĩnh vực Trí tuệ nhân tạo (Artificial Intelligence) và McCon ban đầu được sử dụng trong các nghiên cứu về các cộng đồng sinh vật phù du. Hai hệ số này đã cho kết quả tốt hơn đối với các chương trình có hai lỗi đồng thời [18]. Minus [19] là chỉ số xếp hạng giống Tarantula trừ đi phần trăm mà một thành phần không được thực thi trong các ca kiểm thử không thành công và chia cho phần trăm mà thành phần này không được thực thi cho tất cả các lần thực thi. Tần số bổ sung này được gọi là nhiễu, nó làm giảm tầm quan trọng của việc không thực thi trong phân tích. Các hệ số khác như Barinel [20], Dstar [21], DRT [30], … cũng được sử dụng để xác định độ nghi ngờ.
2.5.4 Kỹ thuật định vị lỗi dựa trên xác suất
Kỹ thuật gỡ lỗi dựa trên xác suất Liblit05 [20] có thể cô lập các lỗi trong chương trình với các biểu thức điều kiện (predicates) tại các điểm cụ thể. Đối với mỗi biểu thức điều kiện P, Liblit05 tính xác suất mà P là true khi ca kiểm thử thất bại Failure(P) và xác suất mà việc thực thi P true khi ca kiểm thử thất bại, Context(P). Các dự đoán có Failure(P) - Context(P) ≤ 0 bị loại bỏ. Các biểu thức điều kiện còn lại được ưu tiên dựa trên điểm quan trọng. Điểm quan trọng cho biết mối quan hệ giữa các biểu thức điều kiện và lỗi chương trình. Các biểu thức điều kiện có điểm cao hơn nên được kiểm tra trước. Việc thay thế các biểu thức điều kiện bằng các hồ sơ đường dẫn (path profiles) có thể cải thiện hiệu quả của Liblit05. Hồ sơ đường dẫn được thu thập trong quá trình thực thi và được tổng hợp trong quá trình thực hiện bộ kiểm thử thông qua báo cáo phản hồi. Điểm quan
trọng được tính cho mỗi đường dẫn và các kết quả đầu tiên được lựa chọn và trình bày dưới dạng nguyên nhân gốc.
Kỹ thuật SOBER [21] được đề xuất để xếp hạng các biểu thức điều kiện đáng ngờ. Một biểu thức điều kiện P có thể được đánh giá là đúng nhiều lần khi thực hiện một ca kiểm thử. Công thức 𝜋(𝑃) = n(t)
n(t)+𝑛(𝑓) là xác suất mà P được đánh giá là đúng trong mỗi lần thực hiện một ca kiểm thử, trong đó n(t) là số lần P được đánh giá là đúng và n(f) là số lần P được đánh giá là sai. Nếu phân phối của π(P) trong các lần thực thi không thành công khác đáng kể với phân phối trong các lần thực thi thành công, thì P có liên quan đến một lỗi. Một heuristic tương tự được sử dụng để xếp hạng tất cả các biểu thức điều kiện. Ngoài ra, thử nghiệm giả thuyết phi tham số được áp dụng để xác định mức độ khác biệt giữa phổ của các biểu thức điều kiện cho các ca kiểm thử thành công và thất bại. Cải tiến mới này đã được đánh giá theo thử nghiệm là có hiệu quả [22].
Một kỹ thuật dựa khác dựa trên phân tích bảng chéo (Crosstab) [23] để tính toán mức độ đáng ngờ của các các câu lệnh. Bảng chéo được xây dựng cho mỗi câu lệnh với hai danh mục dọc (được bao phủ / không được bao phủ) và hai danh mục ngang (thực thi thành công / thực thi không thành công). Kiểm tra giả thuyết được sử dụng để cung cấp tham chiếu về sự phụ thuộc / độc lập giữa các kết quả thực thi và phạm vi của mỗi câu lệnh. Mức độ đáng ngờ của mỗi câu lệnh phụ thuộc vào mức độ kết hợp giữa mức độ bao phủ của nó và kết quả thực thi.
Sự khác biệt chính giữa Crosstab, SOBER và Liblit05 là Crosstab thường có thể được áp dụng để xếp hạng các phần tử chương trình đáng ngờ (tức là câu lệnh, biểu thức điều kiện, hàm hay phương thức, …), trong khi hai kỹ thuật còn lại chỉ xếp hạng các biểu thức điều kiện đáng ngờ cho định vị lỗi. Đối với Liblit05 và SOBER, các câu lệnh tương ứng của k biểu thức điều kiện đầu được coi là tập hợp ban đầu được kiểm tra để xác định vị trí lỗi. Liblit05 không cung cấp cách nào để định lượng xếp hạng cho tất cả các câu lệnh. Một thứ tự của các biểu thức điều kiện được xác định, nhưng phương pháp này không nêu chi tiết cách sắp xếp các câu lệnh liên quan đến bất kỳ lỗi nào nằm ngoài một biểu thức điều kiện. Đối với SOBER, nếu lỗi không nằm trong tập hợp các câu lệnh ban đầu, các câu lệnh bổ sung phải được đưa vào bằng cách thực hiện tìm kiếm theo chiều rộng trên biểu đồ phụ thuộc chương trình tương ứng, điều này có thể tốn thời gian. Tuy nhiên, việc tìm kiếm như vậy là không bắt buộc đối với Crosstab, vì tất cả các câu
lệnh của chương trình đều được xếp hạng dựa trên mức độ đáng ngờ của chúng.
Các kết quả được báo cáo cho thấy rằng Crosstab hầu như luôn luôn hiệu quả hơn trong việc xác định lỗi trong bộ Siemens so với Liblit05 và SOBER [23].
2.5.5 Kỹ thuật định vị lỗi dựa trên trạng thái
Trạng thái chương trình bao gồm các biến và giá trị của chúng tại một điểm cụ thể trong quá trình thực thi chương trình. Zeller đề xuất kỹ thuật gỡ lỗi delta [24], bằng cách đối chiếu các trạng thái chương trình giữa các lần thực hiện một ca kiểm thử thành công và một ca kiểm thử thất bại thông qua đồ thị bộ nhớ của chúng. Các biến được kiểm tra mức độ đáng ngờ bằng cách thay thế các giá trị của chúng từ một ca kiểm thử thành công bằng các giá trị tương ứng của chúng từ cùng một điểm trong một ca kiểm thử không thành công và lặp lại việc thực thi chương trình. Nếu quan sát thấy lỗi giống hệt nhau, biến đó không được coi là đáng ngờ. Công cụ delta đã được sử dụng rộng rãi trong công nghiệp để gỡ lỗi tự động.
Chuyển mạch biểu thức điều kiện (predicate switching) [25] là một kỹ thuật định vị lỗi dựa trên trạng thái chương trình khác, trong đó các trạng thái chương trình được thay đổi để thay đổi mạnh mẽ các nhánh được thực thi trong một lần thực thi không thành công. Một biểu thức điều kiện được chuyển đổi có thể làm cho chương trình thực thi thành công được gắn nhãn là một biểu thức điều kiện quan trọng. Kỹ thuật này bắt đầu bằng cách tìm giá trị sai sót đầu tiên trong các biến. Kỹ thuật có các chiến lược tìm kiếm khác nhau, chẳng hạn như thứ tự được thực hiện lần đầu tiên được chuyển đổi (LEFS) và thứ tự dựa trên mức độ ưu tiên (PRIOR), có thể giúp xác định các ứng cử viên tiếp theo cho các biểu thức điều kiện quan trọng. Hình 2-5 [25] thể hiện thuật toán của kỹ thuật chuyển mạch biểu thức điều kiện.
Step 1: Find Erroneous Value
Examine failed run to identify the first erroneous value – erroneous output or value that crashes the program.
Step 2: Find Predicates for Switching Run the program again for the following:
(a) Generate Predicate Trace (P T ) identifying all instances of branch predicates executed and their execution order.
(b) Perform Predicate Ordering of predicates in PT using LEFS or PRIOR.
Step 3: Find Critical Predicate
for each pred. instance P in ordered P T do
Generate instrumented program to switch P ’s outcome;
Execute above program; if program run succeeds, report P and terminate search.
endfor
Hình 2-5: Tổng quan thuật toán của predicate switching
2.5.6 Kỹ thuật định vị lỗi dựa trên học máy
Học máy là nghiên cứu các thuật toán máy tính được cải thiện thông qua trải nghiệm. Các kỹ thuật học máy có khả năng thích ứng, mạnh mẽ và có thể tạo ra các mô hình dựa trên dữ liệu, với sự tương tác hạn chế của con người. Điều này đã dẫn đến việc các kỹ thuật học máy được sử dụng trong nhiều lĩnh vực như tin sinh học, xử lý ngôn ngữ tự nhiên, mật mã, thị giác máy tính, v.v. Các kỹ thuật định vị lỗi dựa trên học máy cố gắng học hoặc suy ra vị trí của lỗi dựa trên trên dữ liệu đầu vào như phủ câu lệnh và kết quả thực thi (thành công hay thất bại) của mỗi ca kiểm thử.
Wong và Qi đề xuất kỹ thuật định vị lỗi dựa trên mạng nơ-ron truyền ngược (Back Propagation - BP) [26], một trong những mô hình mạng nơ-ron phổ biến trong thực tế. Mạng nơron BP có cấu trúc đơn giản, giúp dễ dàng triển khai bằng các chương trình máy tính. Đầu tiên, dữ liệu về phủ của mỗi ca kiểm thử và kết quả thực thi tương ứng được thu thập. Dữ liệu này được sử dụng cùng nhau để đào tạo mạng nơ-ron BP để mạng có thể tìm hiểu mối quan hệ giữa chúng. Sau đó, phủ của một bộ các ca kiểm thử ảo mà mỗi trường hợp chỉ bao gồm một câu lệnh trong chương trình được đưa vào mạng BP được đào tạo và kết quả đầu ra có thể được coi là khả năng mỗi câu lệnh chứa lỗi.
Briand và cộng sự sử dụng thuật toán cây quyết định (decision tree) C4.5 [27] để xây dựng các quy tắc phân loại các ca kiểm thử thành các phân vùng khác
nhau sao cho các ca kiểm thử không thành công trong cùng một phân vùng có thể bị lỗi do cùng một lỗi nguyên nhân. Tiền đề cơ bản là các điều kiện lỗi riêng biệt cho các ca kiểm thử có thể được xác định tùy thuộc vào các đầu vào và đầu ra của ca kiểm thử. Mỗi đường dẫn trong cây quyết định đại diện cho một quy tắc mô hình hóa các điều kiện thất bại riêng biệt, có thể bắt nguồn từ các lỗi khác nhau và dẫn đến một dự đoán xác suất thất bại riêng biệt. Phạm vi báo cáo của cả ca kiểm thử thất bại và thành công trong mỗi phân vùng được sử dụng để xếp hạng các câu lệnh bằng cách sử dụng phương pháp heuristic tương tự như Tarantula để tạo thành một bảng xếp hạng. Các bảng xếp hạng riêng này sau đó được hợp nhất để tạo thành bảng xếp hạng báo cáo cuối cùng có thể được kiểm tra để xác định lỗi.
2.5.7 Kỹ thuật định vị lỗi dựa trên khai phá dữ liệu
Cùng với kỹ thuật dựa trên học máy máy học, khai phá dữ liệu cũng tìm cách tạo ra một mô hình sử dụng thông tin thích hợp được trích xuất từ dữ liệu. Khai phá dữ liệu có thể phát hiện ra các mẫu ẩn trong các mẫu dữ liệu có thể không được phát hiện bằng phân tích thủ công riêng lẻ, đặc biệt khi khối lượng thông tin lớn. Ví dụ như có thể áp dụng khai phá dữ liệu trong định vị lỗi để xác định kiểu thực thi câu lệnh dẫn đến lỗi. Ngoài ra, mặc dù dấu vết thực thi (execution traces) hoàn chỉnh của một chương trình là một tài nguyên có giá trị để định vị lỗi, nhưng khối lượng dữ liệu khổng lồ khiến nó khó sử dụng trong thực tế. Do đó, một số nghiên cứu đã áp dụng một cách sáng tạo các kỹ thuật khai phá dữ liệu vào các dấu vết thực thi.
Nessa và cộng sự [28] đã đề xuất thuật toán định vị lỗi sử dụng phân tích N- gram. Hình 2-6 [28] thể hiện thuật toán được đề xuất. Các chuỗi con của câu lệnh N-gram có độ dài N được tạo ra từ dữ liệu dấu vết. Các dấu vết thực hiện thất bại sau đó được kiểm tra để tìm ra các N-gram có tỷ lệ xuất hiện cao hơn một ngưỡng nhất định. Một phân tích thống kê được tiến hành để xác định xác suất có điều kiện mà một N-gam nhất định xuất hiện trong một dấu vết thực hiện không thành công đã cho, xác suất này được gọi là độ tin cậy cho N-gam đó. N-gam được sắp xếp theo thứ tự tin cậy giảm dần và các câu lệnh tương ứng trong chương trình được hiển thị dựa trên lần xuất hiện đầu tiên của chúng trong danh sách. Các nghiên cứu điển hình về bộ thử nghiệm Siemens cũng như chương trình space và grep đã chỉ ra rằng kỹ thuật này có hiệu quả hơn trong việc xác định lỗi so với Tarantula.
1: procedure LocalizeFaults(Y,YF,K,MINSUP) 2: for all Yi ∈Y do
3: Convert Yi to block trace 4: end for
5: NG←
6: for N=1 to NMAX do
7: NG←NG ∪ GenerateNGrams(Y,N) 8: end for
9: Lrel←{n|n∈NG and |n| =1}
10: for all n ∈ Lrel do
11: if Support(n) ≠ |YF| then
12: Remove n from NG and Lrel
13: end if 14: end for
15: NG1←{n|n∈NG and for all s ∈ Lrel, sn}
16: NG←NG−NG1
17: for all n ∈ NG do
18: if Support(n) < MINSUP then
19: Remove n from NG
20: end if 21: end for
22: for all n ∈ NG do
23: NF←|{Yk|Yk∈YF and n∈Yk}|
24: NT←|{Yk|Yk∈Y and n∈Yk}|
25: n.confidence←NF÷NT 26: end for
27: SortNGin descending order of confidence
28: Convert the block numbers in the N-grams in NG to line numbers 29: Report the line numbers in the order of their first appearance in NG 30: end procedure
Hình 2-6: Thuật toán Định vị lỗi sử dụng phân tích N-gram
Chương 3 Công cụ định vị lỗi HiFa cho các ứng dụng C/C++
Chương này trình bày phương pháp định được luận văn đề xuất để định vị lỗi cho các ứng dụng C/C++. Luận văn cung cấp kiến trúc tổng quan của công cụ HiFa đã phát triển. Các kiến thức cơ bản về framework LLVM và các phương pháp tạo phổ của chương trình cũng được mô tả chi tiết.
3.1 Kỹ thuật định vị lỗi cho ứng dụng C/C++
3.1.1 Tổng quan kỹ thuật
Như đã trình bày trong Chương 2, hiện nay có rất nhiều phương pháp định vị lỗi, luận văn lựa chọn phương pháp định vị lỗi dựa trên phổ để giải quyết bài toán tìm lỗi cho các ứng dụng C/C++ vì tính hiệu quả và phù hợp của nó. Phương pháp dựa trên phổ chiếm 35% các bài báo nghiên cứu về định vị lỗi [5]. Phương pháp này có cách tiếp cận đơn giản khi chỉ cần có thông tin phổ thực thi của chương trình và áp dụng công thức tính độ nghi ngờ.
Hình 3-1: Tổng quan kỹ thuật sửa lỗi dựa trên phổ
Hình 3-1 mô tả tổng quan về kỹ thuật định vị lỗi dựa trên phổ chương trình.
Mã nguồn chương trình được điều chỉnh (instrument) thành chương trình có thể thực thi. Khi chương trình này được thực thi ta thu được số lần thực thi của từng thành phần trong chương trình. Thực hiện thực thi chương trình với bộ kiểm thử ta thu được thông tin phổ của chương trình. Thông tin phổ của chương trình bao gồm: biết số lượng ca kiểm thử thất bại mà thành phần được thực thi Nef; số lượng ca kiểm thử thất bại mà thành phần không được thực thi Nnf; số lượng ca kiểm thử thành công mà thành phần được thực thi Nep; số lượng ca kiểm thử thành
công mà thành phần không được thực thi Nnp. Từ thông tin phố này, áp dụng công thức tính độ nghi ngờ của kỹ thuật định vị lỗi dựa trên phổ, ta tính được độ nghi ngờ cho từng thành phần và xếp loại thành bảng xếp hạng nghi ngờ. Dựa bảng xếp hạng nghi ngờ này, nhà phát triển sẽ kiểm tra và xác định được thành phần gây lỗi.
Tùy thuộc vào việc lựa chọn thành phần chương trình là gì mà ta có các loại phổ khác nhau. Thành phần của chương trình có thể là câu lệnh (statement), hàm (function), nhánh điều khiển (branch), đường thực thi (path), đường hoàn thành (complete path), đường dữ liệu (data path), … Tương ứng ta có được các loại phổ [29] như ESHS, BHS, CPS, DHS, …
Phổ ESHS (Executable Statement Hit Spectrum) ghi lại các câu lệnh được thực thi khi chạy ca kiểm thử. Hầu hết các nghiên cứu từ trước đến nay [3] [13] - [18] [30] [31] đều sử dụng phổ ESHS để định vị lỗi. Từ phổ ESHS, ta có thể xác định luôn được độ nghi ngờ của từng câu lệnh bằng cách áp dụng công thức tính độ nghi ngờ cho câu lệnh này. Ví dụ, ta có 1 câu lệnh được thực thi trong 2 ca kiểm thử thành công, 1 ca kiểm thử thất bại. Câu lệnh này không được thực thi trong 3 ca kiểm thử thành công và 2 ca kiểm thử thất bại. Giá trị nghi ngờ của câu lệnh này theo kỹ thuật Dstar sẽ là 1/(2 + 2) = 0.25.
Để cải tiến các kỹ thuật định vị lỗi dựa trên phổ đã được đề xuất trước đây sử dụng phổ ESHS, luận văn đề xuất sử dụng phổ DHS để đánh giá mức độ hiệu quả của kỹ thuật định vị lỗi dựa trên phổ. Phổ DHS (Data-dependence Hit Spectrum) ghi lại các cặp def-use được thực thi khi chương trình được thực thi.
Một cặp def-use chứa 1 câu lệnh định nghĩa biến def và 1 câu lệnh sử dụng biến use. Câu lệnh use có thể là câu lệnh dùng biến để tính toán c-use hoặc là câu lệnh sử dụng biến trong biểu thức điều kiện p-use. Đường đi từ câu lệnh def đến câu lệnh use là một def-clear path. Đường đi từ một def đến một use được gọi là def- clear path của một biến nếu biến này không được định nghĩa lại trong đường đi [2]. Khi thực hiện kiểm thử, cả hai câu lệnh def và use phải được thực thi thì phổ DHS của cặp def-use này được nghi lại. Độ nghi ngờ của cặp def-use cũng được xác định tương tự như với 1 câu lệnh. Lỗi của chương trình do 1 câu lệnh gây ra nên ta thực hiện ánh xác độ nghi ngờ của cặp def-use sang các câu lệnh liên quan.
Độ nghi ngờ của một câu lệnh là giá trị nghi ngờ cao nhất trong các cặp def-use chứa câu lệnh này. Giá trị nghi ngờ của câu lệnh s là S(s) = maxs du(s)M(s), với
du(s) là tập các cặp def-use chứa câu lệnh s, M(s) là tập giá trị nghi ngờ của tập du.
Từ giá trị nghi ngờ của phổ ESHS và DHS, luận văn đề xuất thêm 2 giá trị nghi ngờ là DHS-def và DHS-use (từ đây trở đi sẽ gọi là phổ DHS-def và DHS- use). Phổ DHS-def sẽ sử dụng độ nghi ngờ của DHS chỉ với câu lệnh def, câu lệnh use vẫn sử dụng phổ ESHS. Phổ DHS-use sẽ sử dụng độ nghi ngờ của DHS cho câu lệnh use, câu lệnh def sử dụng phổ ESHS.
3.1.2 Ví dụ minh họa
Để hiểu rõ hơn về kỹ thuật định vị lỗi dựa trên phổ, phần này miêu tả một ví dụ minh họa về quá trình thực hiện của kỹ thuật SFL. Xem xét hàm ví dụ mid [3]
có mã nguồn như trong Hình 3-2. Hàm mid() nhận 3 giá trị nguyên đầu vào và trả về giá trị trung vị của 3 giá trị đầu vào. Hàm mid có 2 phiên bản lỗi sau: phiên bản 1: thay đổi câu lệnh 7 (m = x) thành m = y; phiên bản lỗi 2: thay đổi câu lệnh 2 (m = z) thành m = x.
mid() { Câu lệnh
int x, y, z, m;
read(x, y, z); 1
m = z; 2
if (y < z) 3 if (x < y) 4 m = y; 5 else if (x < z) 6 m = x; 7
else 8
if (x > y) 9 m = y; 10 else if (x > z) 11 m = x; 12
print(m); 13
}
Hình 3-2: Mã nguồn hàm mid
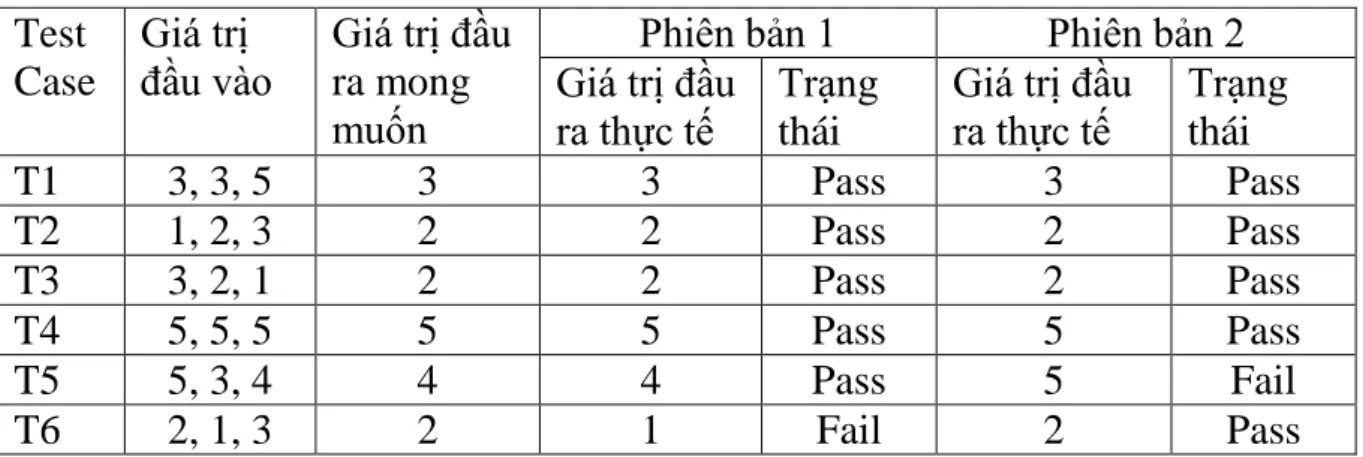
Để kiểm thử hàm mid(), ta sử dụng bộ kiểm thử với 6 ca kiểm thử với các giá trị đầu vào được thể hiện ở Bảng 3.1. Phiên bản lỗi 1 có 5 ca kiểm thử thành công là T1, T2, T3, T4, T5; và 1 ca kiểm thử thất bại là T6. Phiên bản lỗi 2 cũng có số lượng ca kiểm thử thất bại là 1 nhưng là ca kiểm thử T5.
Bảng 3.1: Bộ kiểm thử của hàm mid Test
Case
Giá trị đầu vào
Giá trị đầu ra mong muốn
Phiên bản 1 Phiên bản 2 Giá trị đầu
ra thực tế
Trạng thái
Giá trị đầu ra thực tế
Trạng thái
T1 3, 3, 5 3 3 Pass 3 Pass
T2 1, 2, 3 2 2 Pass 2 Pass
T3 3, 2, 1 2 2 Pass 2 Pass
T4 5, 5, 5 5 5 Pass 5 Pass
T5 5, 3, 4 4 4 Pass 5 Fail
T6 2, 1, 3 2 1 Fail 2 Pass
Bảng 3.2 thể hiện ma trận phổ thực thi của mỗi câu lệnh ESHS (câu lệnh được thực thi) được thể hiện bằng dấu chấm đen.
Bảng 3.2: Phổ ESHS của hàm mid
Dòng Phiên bản 1 Phiên bản 2
T1 T2 T3 T4 T5 T6 Độ nghi
ngờ
T1 T2 T3 T4 T5 T6 Độ nghi
ngờ
1 ● ● ● ● ● ● 0.41 ● ● ● ● ● ● 0.41
2 ● ● ● ● ● ● 0.41 ● ● ● ● ● ● 0.41
3 ● ● ● ● ● ● 0.41 ● ● ● ● ● ● 0.41
4 ● ● ● ● 0.5 ● ● ● ● 0.5
5 ● 0.0 ● 0.0
6 ● ● ● 0.58 ● ● ● 0.58
7 ● ● 0.71 ● ● 0.0
8 ● ● 0.0 ● ● 0.0
9 ● ● 0.0 ● ● 0.0
10 ● 0.0 ● 0.0
11 ● 0.0 ● 0.0
12 0.0 0.0
13 ● ● ● ● ● ● 0.41 ● ● ● ● ● ● 0.41 Xem xét phiên bản lỗi 1 trong Bảng 3.2, câu lệnh 1 thực thi trong cả 6 ca kiểm thử bao gồm cả ca kiểm thử thành công và thất bại. Kỹ thuật Ochiai gán độ nghi ngờ của câu lệnh 1 theo như công thức như sau:
𝑠𝑢𝑠𝑝𝑖𝑐𝑖𝑜𝑢𝑠𝑛𝑒𝑠𝑠(1) = 1
√1 ∗ (1 + 5) = 0.41
Như vậy, độ nghi ngờ của câu lệnh 1 là 0.41. Sau khi thực hiện tính độ nghi ngờ của tất cả các câu lệnh của chương trình, ta được bộ giá trị độ nghi ngờ của chương trình mid(). Thực hiện sắp xếp độ nghi ngờ của các câu lệnh từ lớn tới bé ta được xếp hạng của câu lệnh. Câu lệnh 7 có độ nghi ngờ cao nhất nên câu lệnh này có xếp hạng 1 là xếp hạng cao nhất. Nhà phát triển sẽ kiểm tra các câu lệnh từ xếp hạng cao nhất tới thấp nhất. Câu lệnh 7 sẽ là câu lệnh đầu tiên được kiểm tra. Nếu lỗi không phải là câu lệnh 7, nhà phát triển tiếp tục kiểm tra câu lệnh có xếp hạng tiếp theo. Do có 4 câu lệnh có cùng độ nghi ngờ là 5 nên cả 4 câu lệnh này xếp hạng 7. Do câu lệnh 7 có xếp hạng đầu tiên nên nhà phát triển tìm được lỗi tại câu lệnh đầu tiên được kiểm tra.
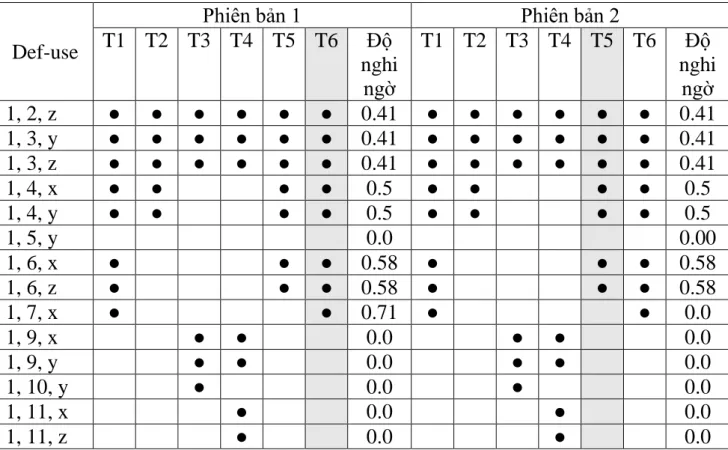
Bảng 3.3 thể hiện phổ thực thi DHS của mỗi cặp Def-use. Xem xét phiên bản lỗi 2 trong Bảng 3.3, cặp def-use (2, 13) của biến m được thực thi trong 1 ca kiểm thử thành công T4 và 1 ca kiểm thử thất bại T5. Độ nghi ngờ của cặp def-use (2, 13, m) là 0.71. Cặp def-use này có độ nghi ngờ cao nhất nên câu lệnh 2 có xếp hạng nghi ngờ là 1.
Bảng 3.3: Phổ DHS của hàm mid
Def-use
Phiên bản 1 Phiên bản 2
T1 T2 T3 T4 T5 T6 Độ nghi
ngờ
T1 T2 T3 T4 T5 T6 Độ nghi
ngờ 1, 2, z ● ● ● ● ● ● 0.41 ● ● ● ● ● ● 0.41 1, 3, y ● ● ● ● ● ● 0.41 ● ● ● ● ● ● 0.41 1, 3, z ● ● ● ● ● ● 0.41 ● ● ● ● ● ● 0.41
1, 4, x ● ● ● ● 0.5 ● ● ● ● 0.5
1, 4, y ● ● ● ● 0.5 ● ● ● ● 0.5
1, 5, y 0.0 0.00
1, 6, x ● ● ● 0.58 ● ● ● 0.58
1, 6, z ● ● ● 0.58 ● ● ● 0.58
1, 7, x ● ● 0.71 ● ● 0.0
1, 9, x ● ● 0.0 ● ● 0.0
1, 9, y ● ● 0.0 ● ● 0.0
1, 10, y ● 0.0 ● 0.0
1, 11, x ● 0.0 ● 0.0
1, 11, z ● 0.0 ● 0.0
1, 12, x 0.0 0.0
2, 13, m ● ● 0.0 ● ● 0.71
5, 13, m ● 0.0 ● 0.0
7, 13, m ● ● 0.71 ● ● 0.0
10, 13, m ● 0.0 ● 0.0
12, 13, m 0.0 0.0
Từ mức độ nghi ngờ trong Bảng 3.2 và Bảng 3.3, ta thu được thứ hạng nghi ngờ của các câu lệnh của phiên bản lỗi 1 như Bảng 3.4. Cả 4 phổ đều đưa ra độ nghi ngờ cho câu lệnh 7 là 0.71. Phổ ESHS và DHS-def xếp hạng câu lệnh 7 có mức độ nghi ngờ cao nhất (xếp hang 1) do chỉ có duy nhất câu lệnh này có độ nghi ngờ là 0.71. DHS xếp hạng câu lệnh 7 thứ hạng nghi ngờ thứ 3 do có 2 câu lệnh 1 và 13 cùng có mức nghi ngờ là 0.71. Câu lệnh 7 được DHS-use xếp hạng nghi ngờ thứ 2 do có cùng mức độ nghi ngờ với câu lệnh 13.
Bảng 3.4: Độ nghi ngờ và thứ hạng của từng câu lệnh phiên bản lỗi 1 Câu lệnh
Độ nghi ngờ Xếp hạng
ESHS DHS DHS- def
DHS-
use ESHS DHS DHS- def
DHS- use
1 0.41 0.71 0.41 0.41 7 3 7 8
2 0.41 0.00 0.41 0.41 7 13 7 8
3 0.41 0.41 0.41 0.41 7 7 7 8
4 0.50 0.50 0.50 0.50 3 6 3 5
5 0.00 0.00 0.00 0.00 13 13 13 13
6 0.58 0.58 0.58 0.58 2 5 2 3
7 0.71 0.71 0.71 0.71 1 3 1 2
8 0.00 0.00 0.00 0.00 13 13 13 13
9 0.00 0.00 0.00 0.00 13 13 13 13
10 0.00 0.00 0.00 0.00 13 13 13 13
11 0.00 0.00 0.00 0.00 13 13 13 13
12 0.00 0.00 0.00 0.00 13 13 13 13
13 0.41 0.71 0.41 0.71 7 3 7 2
Bảng 3.5 thể hiện độ nghi ngờ và thứ hạng của từng câu lệnh phiên bản lỗi 2. Ba phổ DHS đều đưa ra độ nghi ngờ cho câu lệnh 2 là 0.71. Phổ ESHS lại có