Fachhochschule Pölten, Österreich Tobias Kaefer Karlsruher Institut für Technologie (KIT), Deutschland LegalTech. Beetle Tobias Karlsruher Institut für Technologie (KIT), Deutschland Kaffee Lucie-Aimée University of Southampton, Vereinigtes Königreich.
Increasing Agility and Efficiency in Knowledge Extraction Workflows
1 Introduction
First, in Section 2, we summarize the two biggest challenges as a motivation for our work, followed by an overview of the release workflow described in Section 3. The implemented test methodology is described in Section 5 and the results of various experiments showing the impact, capabilities and the profit of the new release cycle are presented in Section 6.
2 Background and Motivation
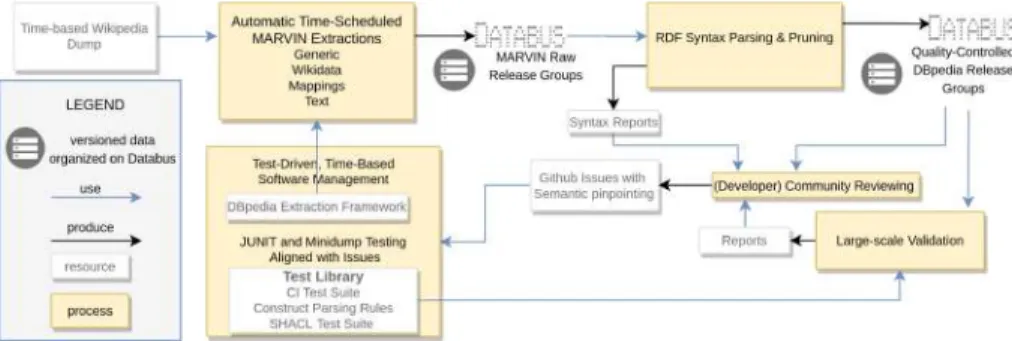
The DBpedia publishing workflow has been reengineered, its new primary focus on productivity and agility to address the challenges of size and complexity. Our release cycle counters the delay by introducing frequent, fixed time-based releases in combination with automated delivery of data to applications via the DBpedia Data Bus (cf. subsection.4.1).
3 DBpedia Release Cycle Overview
The process creates five core data groups, each generated by a different extraction process2: i) generic – information extracted by the generic extractors, ii) mappings – information extracted using user-specified mapping rules, iii) text-extracted content from Wikipedia articles eniv) ontology – .. the DBpedia ontology and v) wikidata – extracted and mapped structured data from Wikidata [6]. Cleaning, validation and reporting. The data (i.e. triples) published by the MARVIN agent is then picked up and parsed by the DBpedia agent to create strictly valid RDF triples without any violations (including warnings and errors) based on Apache Jena5.
4 Conceptual Design Principles
Traceability and Issue Management
Any data problem detected at the point of truth begins a costly process of forwarding the error in reverse order of the pipeline that delivered it. The vast majority of issues are related to i) a piece of data and ii) a procedure (ie code) that generated the data.
5 Testing Methodology
- Construct Validation
- Syntactical Validation
- Shape Validation
- Integration Validation
It is important to validate and clean up the DIEF results produced, as some of the methods used are bloated, outdated and wrong. Listing 3 shows an example of a query to obtain a completeness check of mapping group releases on the DBpedia Databus.18 There are other application-specific tests, e.g.
6 Experimental Evaluation
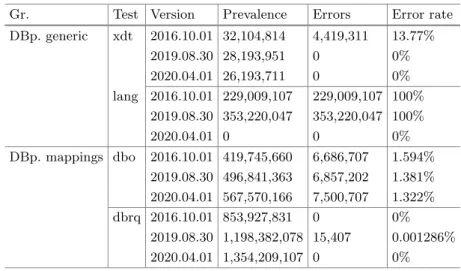
The new strict syntax cleanup was introduced on the mapping release version and later applied to the 'generic' release. For the DBpedia ontology, this test is assigned to the 'http://dbpedia.org/ontology/*' namespace and checks for correctly used IRIs from the DBpedia ontology.
7 Related Work
Including IRI test coverage and number of failed tests based on custom DBpediaConstruct Validation. These automated test cases mainly focus on the schema, whether the domain types, range values or data types are contained correctly.
8 Conclusion and Future Work
Next, we briefly mention two projects that attempt to assess the quality of linked data by applying alternative aspects. On the other hand, RDFUnit is a test-driven data debugging framework that can run both automatically generated and manually generated test cases (the predecessor of SHACL) against RDF datasets [7].
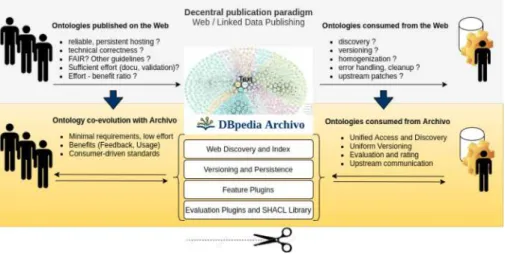
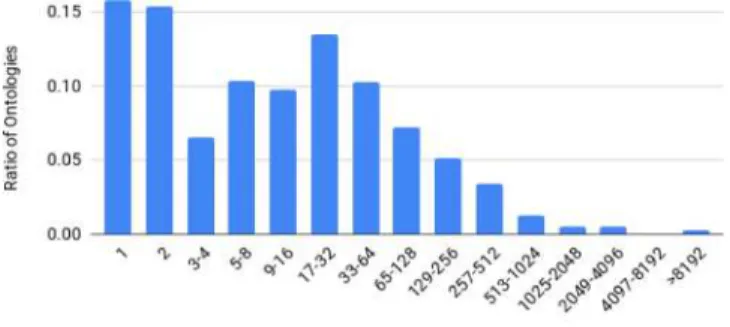
While there are thousands of ontologies on the web, a unified system for handling online ontologies has yet to emerge, and both publishers and users of ontologies face many uncertainties and challenges. The main discussion and efforts to date in the Semantic Web community are unbalanced and focused on authoring and publishing ontologies and related data in general with serious ones.
2 Related Work
Archiving and Versioning
It offers a structural and a form of semantic difference between two versions, achieved by performing structural differences on semantic closures (RDF(S) entailment). While some of the features (semantic difference and validation, documentation generation, custom tests for ontologies) are similar to Archivo, Vocol is designed for publishers and consumers to rely on to benefit from the system.
Ontology Repositories and Platforms
It provides storage for ontology submissions and archiving to registered users and performs indexing on the latest submission. It provides a search index on the terms defined in the vocabulary, a SPARQL query endpoint, and provides persistent access to vocabulary history.
Ontology Evaluation and Validation
In addition, it offers developer platform features such as user access rights and mappings between ontologies. It provides a homogeneous formal representation of ontology axioms using DOL, testing with HETS, and competency questions.
3 Archivo Platform Model
Versioning and Persistence on the Databus
Evaluation Plugins and SHACL Library
While similar (configure local needs, deploy locally), Archivo follows a more general approach (configure local needs, deploy globally). special-purpose test suites: 1) can encode generic validation rules (eg from OOPS and handle UC7), 2) can capture specific requirements needed by Archiva features, such as automatic generation of HTML documentation for LODE (UC8) (see next section), 3) can be specific to a subset or use cases of individual users' projects. While there are only a few SHACL test suites at the time of writing, we are allowing an online contribution and extension (Validation as a Platform) to the Archive in the hope of giving consumers a central place to code their requirements and also to discuss and agree on more universal ones.
Feature Plugins
4 Archivo Implementation
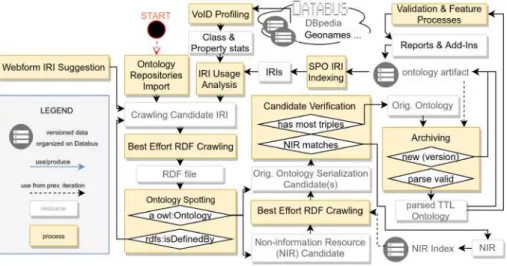
Ontology Discovery and Indexing
The goal of the discovery and indexing phase is to create a separate set (index) of non-information URIs/resource (NIR) ontologies for each iteration as input for further crawling and processing. The repository with the widest collection of highly popular linked open data cloud ontologies is Linked Open Vocabularies (LOVs) [20], which we used in this paper.
Analysis, Plugins and Release
Finally, the NIR is added to the index and the selected serialization is passed for release on the data bus. Release on the data bus: To deploy the ontology on the data bus, we use its non-informational URI as the basis for identifying the data bus.
Versioning and Persistence
The host information for the ontology URI serves as the group ID and the path serves as the name for the artifact ID. Archivo's lookup component14 with Linked Data interface enables the mapping from a non-informational URI to the stable and persistent Databus identifier to be resolved.
5 A Consumer-Oriented Ontology Star Rating
Two Star Baseline
Quality Stars
Logical Appropriateness: While logical requirements such as consistency are well defined in theory, from a consumer perspective this star is very implementation specific. We measure compatibility with currently available orators such as Pellet/Stardog (more to follow) and perform available tasks such as consistency checks (UC9), classification, etc.
Further Stars and Ratings
If a traceable Linked Data URI is used, we expect the URI to match the URI used in the Machine Readable License (UC7). In the future, we plan to tighten this criterion and expect a machine-readable license, which we will collect on the DBpedia Databus in a similar way to Archivo.
6 Evaluation
Archivo and Rating Statistics
System Comparison
Dash represents no, white/black filled circle represents partial/full support;TY: system type - (A)archive, (C)atalog, (I)ndex, (D)evelopment Platform;DO: ont. import - fully automated user ingestion requests/file submissions of new ontologies; DI: auto. update of ont.;UV:unified ont. semantic versioning of ont.;. Access to version/ontology system metadata for Archivo is designed to work via RDF and SPARQL, only a very basic REST API (and Linked Data interface) is available at the time of writing.
7 Future Work
Peroni, S., Shotton, D., Vitali, F.: The Live OWL documentation environment: a tool for automatic generation of ontology documentation. Ontologies have been used in many cognitive robotic systems that perform object identification capabilities detection (i.e., the functionality of an object) and for robotic platforms that act as caretakers for humans in a household environment [20,34].
3 Our Approach
Household Dataset
Instead, we implemented knowledge about object affordances and we represent knowledge, about objects by means of their affordances. Thus, to the best of our knowledge, we provide the largest ontology on object affordances, in a domestic environment.
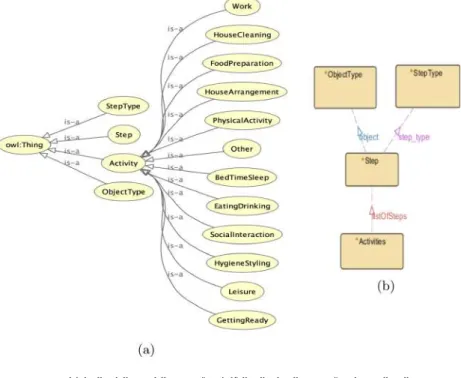
Ontology
IDn are the unique identity numbers between the objects that represent the same natural object. After constructing and populating the ontology, we developed a library in Python that constructs SPARQL queries directed at the ontology and retrieves responses.
Semantic Matching Algorithm
The input is provided by the user implicitly when he provides a keyword in a query that does not exist in the framework's KB. The comment field of the input entity is compared with each comment field of the returned entities from ConceptNet, using the TF-IDF algorithm to extract semantic similarity, line 21.
4 Evaluation
In our second evaluation, we asked 5 people who are not part of the first group to give us their answers in the queries Q1-Q7, excluding Q4 (we will denote this as Q1-Q7\Q4). Each had to give one answer for 5 queries from each of the queries (total Q1-Q7\Q answers) selected from the above mentioned data set.
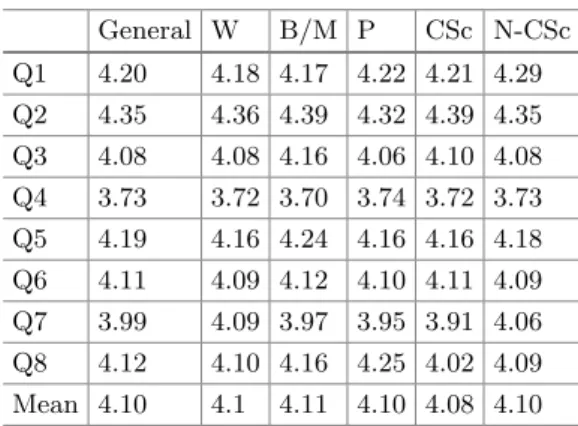
5 Discussion and Conclusion
As for the second part, 5 people who are not part of the first group were given the queries Q1-Q7\Q4 and had to give their answer from where we collected the gold standard data set. In: Proceedings of the 7th Workshop on Linked Data in Architecture and Construction (LDAC 2019), Lisbon, Portugal (2019).
Our approach is based on the concept ofness and aboutness of survey data introduced by [10]. First, we provide related work in Section 2 and construct the design of query functions and data model in Section 3.
3 Semantic Features of Survey Questions
Survey Questions
It is based on the Data Documentation Initiative (DDI) metadata standard, which is a recognized standard for describing survey data in the social sciences. In [5], the authors present an approach specialized for short text classification using external knowledge and deep neural networks.
A Taxonomy of Question Features
Describes the specificity of the knowledge required to answer the question according to the origin of that knowledge. Language tone characterizes the degree of formality or tone applied in the question.
Data Model and Vocabulary
Relative location indicates a location that is mentioned which is not described by a geographical name but by its meaning to the respondent. Arrows represent query features and groups, yellow boxes indicate the range of values for a query feature, orange boxes indicate a group.
4 Annotation and Enrichment
- Manual Annotation
- Automatic Prediction
- Evaluation Setup
- Results
Based on the annotations provided for the information type, we can extract this query feature automatically from the natural language text of the query and the article text, if applicable. For this second approach, we used the structure of the query texts as input to our models.
5 Conclusion
In addition, a user study is planned to test the relevance in terms of (a) the integrity of the aspect and its values, (b) the acceptance of the concept of information type, and (c) the confidence in the accuracy of the annotation. The design of the question feature may still need to be revised for user acceptance.
When users are satisfied with the retrieved results, they can move to the second step of our workflow, i.e. the table manipulation, to perform joins, filtering, sorting; Finally, they can represent knowledge through dynamic and actionable visualizations during the third and final step of our scaffolding approach. The main contributions of this article are: .. proposing a transitional approach to guide table manipulation experts in exploiting LOD by relying on their abilities in data manipulation and map creation; .. the implementation of the proposed approach in QueDI, a guided workflow consisting of 1) ELODIE, a SPARQL query builder provided on an FSI, enhanced by a NL query to query LOD without explicitly using SPARQL;.
3 QueDI: A Guided Approach to Query and Exploit LOD
- Linked Open Data Querying Challenges
- QueDI Overview
- Navigation Scenario on DBpedia
- Accuracy, Expressivity and Scalability over QALD-9
- Usability
When the user is satisfied with the results obtained, he/she can proceed to the second step, i.e., data manipulation (Fig.3.2). Sampling. The users involved in the testing phase are a total of 23: 11 with skills in computer science and data manipulation (we included students still studying and already graduated) and 12 lay users, without any technical skills in language research and heterogeneous background.

5 Conclusion and Future Work
Execution time. For each group we take into account the execution time compared to the time it takes for one expert in the field (aka QueDI) - hence called optimal value. In addition, we want to further simplify the exploratory search when requesting suggestions by also looking at synonyms and alternative forms of the searched keywords.
Targeting with Linked Data
Combining data from several local publishers can improve the profiling information and make their generated profiles - due to higher quality - competitive with global publishers. Local publishers and advertisers are not required to fully share their data, while improving ad targeting.
2 EcoDaLo
Our approach was demonstrated by multiple companies in Belgium (section 4), enabling federated integration of properties to improve targeting with local publishers. We functionally evaluate our solution (section 5), present related work (section 6), and conclude by discussing privacy and ethical considerations, as well as key features of our solution (section 7).
3 Federating Advertisement Targeting with Linked Data
High-Level Overview: Federated Querying with Common Identifier
Our solution consists of three main components (Figure 2, right): i) The EcoDaLo ad server – auxiliary to pre-existing ad servers used by individual publishers – targets and serves ads to visitors across publishers (Fig. 2, 3. This ad server only provides a common identifier; visitor properties remain under the control of individual publishers. ii) Each publisher provides a semantic layer that exposes captured visitor properties mapped to an interoperable unambiguous property model (Fig. 2, 1). iii).
Example of Federated Querying with Common Identifier
Design Considerations
The ad server only stores its own generated IDs, mapped to the individual publishers' IDs. When Alice later visits Publisher B, given her previously assigned EcoDaLo idE1, the ad server is updated and Publisher B's idB456 is added (Fig.3, 4.

4 Deployment
- EcoDaLo Ad Server
- Common Trait Model
- Mapping to the Common Trait Model
- Federated Querying Layer
- Developer-Friendly API
Each publisher is required to provide a mapping of the captured internal features to the common ones. This CSV file is then used to generate the RDF dataset that maps each publisher's internal features to the common property model.
5 Validation
Launched Campaign
This API is consumed (daily) by the EcoDaLo ad server to have an updated view of the consortium partners' captured properties. At an initial stage, the complexities of using RDF are hidden from the partners, which lowers the threshold for new partners to join the consortium: no prior knowledge of Semantic Web is required.
Functional Comparison
During federation, only common characteristics are shared with the EcoDaLo ad server, taking into account the visitor's privacy with respect to all data collected. maintainability. Attention has been paid to improving the maintainability of the federation approach, in particular the maintainability of common trait model generation and trait mapping description.
6 Related Work
Publishers join forces by introducing an integration component that makes it possible to collect all involved publishers' captured data [21]. This requires significant development efforts, tailored to existing publishers' data stores and detailed privacy compliance considerations.
7 Conclusion
Privacy and Ethical Considerations
The semantic classification is either created manually [28], or content and ads are automatically classified according to a common predefined knowledge graph [4]. Recent court decisions applied these rules to concrete cases [16] and emphasized explicit opt-in to give consent.
Key Features of Our Approach
Future Work
Verborgh, R., et al.: Triple Pattern Fragments: A Low-Cost Knowledge Graph Interface for the Web. The images or other third-party materials in this chapter are included in the chapter's Creative Commons license, unless otherwise indicated in a credit line for the material.
Mathematical Expressions Inside SPARQL Queries
To improve interoperability, we set and share MINDS: a translator to include Mathematical expressions INsiDe Sparql queries. In this section, we give an overview of the related work regarding mathematical formulas within SPARQL queries.
3 Motivating Example
This restriction implies the filtering of the records according to the year of their discovery. In the next section, we introduce MINDS: our solution to help query designers when dealing with mathematical expressions.
4 MINDS: From a Math Formula to SPARQL Bindings
However, these additional functions are not part of the standard and should only be expressed with allowed SPARQL operators: MINDS can then compute approximations to translate these functions into bindings. As expected, MINDS automatically converts the exponential part to an approximation using the classical series of the exponent (see Figure 2 for more).

5 Precision Results
Accuracy. First, we must remind that the number of terms used in the series has an impact on the quality of the approximation. Here we review the approximation of the natural logarithm ln in Fig.3, and of the cosine cos in Fig.4.

6 Use Cases
The three hypertext links above provide visualizations of the SPARQL queries and automatically calculate and display the results. Alethio15 models an Ethereum analytics platform that seeks to provide transparency across the transaction pool of the Ethereum network.
WarSampo KG is published as open data1 and is part of the international Linked Open Data Cloud. Since its opening in 2015, the WarSampo portal has been used by more than 710,000 end users, equivalent to more than 10% of the population of Finland.
2 Data: WarSampo Person Registers
The register contains 94,700 death records (DR) [8], which depict the status of the person at the time of his/her death. Most of the cells contain well-formed literal values, such as the municipality of birth, military rank, and date of return from exile.
3 Method: Linking Person Records
This is challenging due to heterogeneity of the metadata schemas, ambiguous metadata annotations, temporal changes and errors in the data. The RL solution5 is open source, and is used in the transformation processes of the DRs6 and the PRs7.
4 Results and Evaluation
The person registrations are modeled as instances of CIDOC CRM's document class, which is linked to the person instances in the actor ontology. Therefore, in many cases it is difficult to determine with certainty the true negative results, i.e. the cases where there is no match, which is crucial for the recall evaluation.
5 Discussion
Koho, M., Ikkala, E., Hyv¨onen, E.: Reassembling the Lives of Finnish WWII POWs on the Semantic Web. Koho, M., Ikkala, E., Leskinen, P., Tamper, M., Tuominen, J., Hyv¨onen, E.: WarSampo Knowledge Graph: Finland in World War II as Linked Open Data.