This project/internship titled “Personalized Book Recommendation System Using Machine Learning Techniques” submitted by Shakil Ahmed, ID no. in the Department of Computer Science and Engineering, Daffodil International University, has been accepted as satisfactory in partial fulfillment of the requirements for the degree of B.Sc. Department of Computer Science and Engineering Faculty of Science and Information Technology Daffodil International University. We hereby declare that this project was carried out by us under the supervision of Dr.
Sheak Rashed Haider Noori, Associate Professor and Associate Head, Daffodil International University Department of CSE. We also declare that neither this project nor any part of this project has been submitted elsewhere for the award of any degree or diploma. Sheak Rashed Haider Noori, Associate Professor and Associate Head, Department of Daffodil International University CSE, Dhaka.
Deep knowledge and great interest from our supervisor in recommender system to carry out this project. His endless patience, scholarly guidance, constant encouragement, constant and energetic supervision, constructive criticism, valuable advice, reading many inferior drafts and correcting them at every stage have made it possible to complete this project. We would like to express our deepest gratitude to Head, Department of CSE for his kind help in completing our project and also to other faculty members and staff of CSE Department of Daffodil International University.
We would like to thank all our coursemates at Daffodil International University who participated in this discussion while completing the coursework.
Introduction
Motivation
Objective
Expected Outcome
Background
Research Summary
Third, we select the user neighbor according to the similarity ranking we got from previous steps. Finding the neighbor can be done using various algorithms and we have studied many of them in this work. Finally, we need to predict the rating for item recommendation after getting the result of previous steps.
Challenges
Related Works
- Item-Based Collaborative Filtering Recommendation Algorithms
- Collaborative Filtering for Implicit Feedback Datasets
- Collaborative Filtering via Euclidean Embedding
- Restricted Boltzmann Machines for Collaborative Filtering
Item-Based Collaborative Filtering Recommendation Algorithms” is done by Badrul Sarwar, George Karypis, Joseph Konstan and John Riedl. Since it is a challenge to produce high-volume real-time recommendation, this paper showed a way for efficient filtering. The techniques used in this work are called item-item collaborative filtering and later they also compare the result with the k-nearest neighbor approach.
This work was done by Yifan Hu, Chris Volinsky of AT&T Labs and Yehuda Koren of Yahoo Research. In this work, authors explained some mechanism of collaborative filtering when there is no explicit data from the user. For example, a study of an e-commerce website shows that only 15% - 20% of users rate an item after getting a product.
So in this scenario we have to depend on implicit data to recommend next content to the user. In this work, authors have shown the use of the Euclidean embedding method as an alternative to popular latent factor model. In this method, users and elements are embedded in a unified Eculidean space, where the distance between a user and an element is inversely proportional to the rating.
In this paper, Ruslan Salakhutdinov, Andriy Mnih, and Geoffrey Hinton of the University of Toronto have shown how a class of two-layer undirected graphical models can be used to predict user preferences.
Research Methodology
- Research Subject
- Data Collection
- Statistical Analysis
- Proposed Methodology
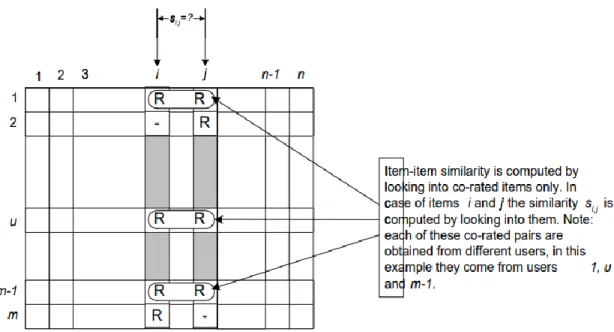
- Cosine-based Similarity
- Correlation-based Similarity
- Adjusted Cosine Similarity
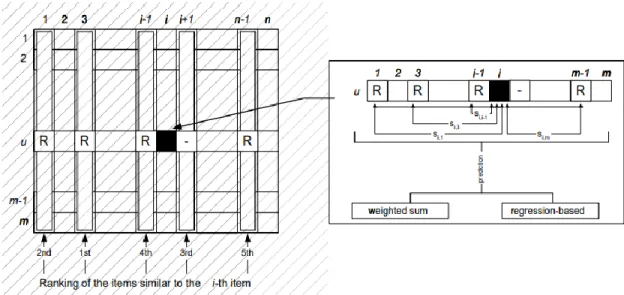
- Weighted Sum
- Regression
- Implementation Requirements
- Evaluation
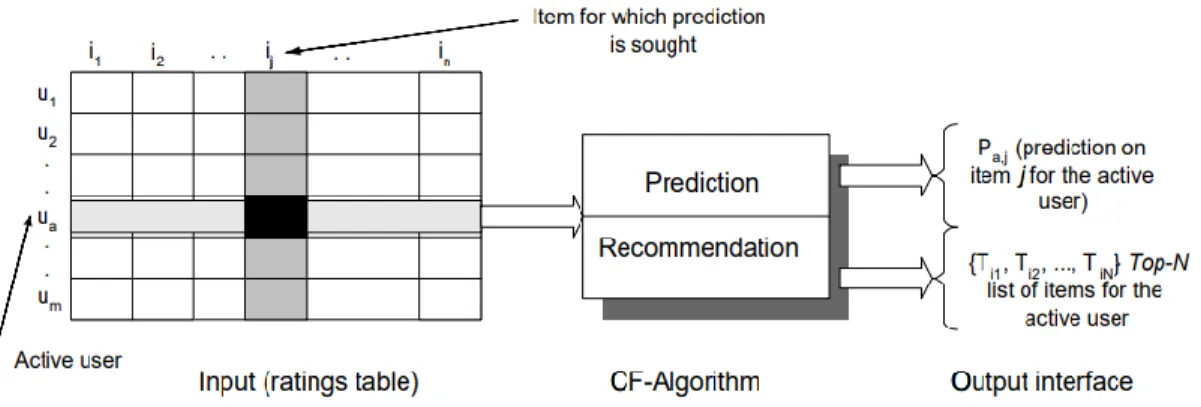
Collaborative filtering is the most interesting one to study about because it works with the buying pattern of all users in a system. In user-user collaborative filtering method, the system identifies similar users by buying pattern and groups them into a group. On the other hand, item-item collaborative filtering gives excellent results with less overhead since item information does not change frequently and it is possible to recommend books immediately.
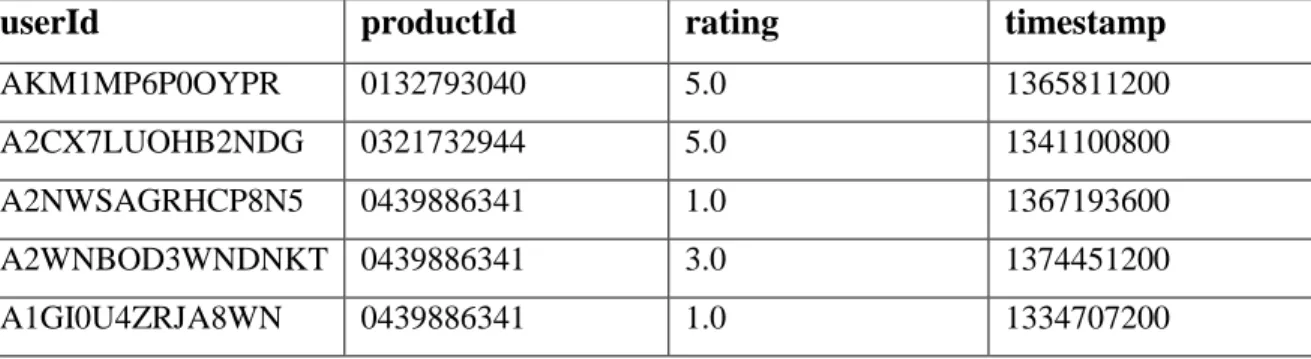
In this work, we used the Goodread book dataset which is open source and the reason for selecting this dataset is that it is a production dataset collected based on a real scenario. In the system of collaborative recommendations, the main point is to calculate the proximity between users. The first approach we took to measure the similarity between users is the Cosine Similarity method, where we need to find the cosine angle between two users.
If the cosine similarity between two users is closer, then we can cluster them into a similar neighbor. Another popular approach to measure similarity is to use SVM, which works well when the data is dense and continuous. In this work we have introduced the time-aware cosine similarity algorithm to calculate the similarity between users and find neighbors.
These preferences are relatively short-lived because these needs are no longer needed in the future, but we can identify the lifecycle loop as other users may have gone through this path. For these reasons, our neighbor should be updated from time to time and our algorithm should be aware of time. If our algorithm can figure out a user's work domain, it is more convenient to find neighbors.
After experimenting with various techniques, we have completed collaborative filtering for topic items for real-time capacity and scalability problem. Since it performs well in high-accuracy business scenarios, it is expected. Since a production system can have many users, but not everyone evaluates a large part of the product, it is less computationally demanding and time-efficient to find similarities between products.
In dataset, users are aligned by row and items are aligned by columns, so user-based collaborative filtering is done by computing along rows. It is also similar to the weighted sum method, but uses approximation of rating based on regression model.
MAE = ∑ |𝑃𝑖−𝑅𝑖|
Experimental Results
This section of the report regulates the internal and external definition of our applied framework. Until now, several researchers in the report have introduced several metrics to assess the exhibition of proposal frameworks. MAE is perhaps the most commonly used metric to assess proposal accuracy and is characterized as the normal of direct contrast between expectation ratings and real evaluations.
Conclusion and Future Scope 5.1 Conclusions
Scope of Further Study
So, “A new similarity function for neighbor selection for each target item in collaborative filtering” IEEE Transl. Bernabe-Moreno and Herrera-Viedma, "A model to represent user trust in recommender systems using ontologies and fuzzy linguistic modeling," Information Sciences, vol. Tuzhilin, "Towards the next generation of recommender systems; a survey of the state-of-the-art and possible extensions,” IEEE Transactions on Knowledge and Data Engineering , vol.
5] Badrul Sarwar, George Karypis, Joseph Konstan and John Riedl, "Item-Based Collaborative Filtering Recommendation Algorithms", vol. Wolf, J.L, "Horting Hatches an Egg: A New Graph-theoretic approach to Collaborative Filtering", Proceedings of the ACM KDD'99 Conference, p. 1] Amazon Science, available at https://www.amazon.science/the -history-of-amazons-recommendation algorithm was last accessed on February 18, 2021 at 21.00.