This thesis entitled "A prediction approach of being addicted to drugs using machine learning", submitted by Md. Tasnim Alam Fahim, ID of the Department of Software Engineering, Daffodil International University has been accepted as satisfactory for the partial fulfillment of the requirements for the degree of Bachelor of Science in Software Engineering and approval of its style and content. I hereby declare that this thesis has been done by me under the guidance of Asif Khan Shakir, Associate Professor, Department of Software Engineering, Daffodil International University.
We are grateful and deeply indebted to Asif Khan Shakir, Senior Lecturer, Department of SWE, Daffodil International University, Dhaka. In-depth knowledge and great interest of our supervisor in the field of “Machine Learning” to carry out this project. Imran Mahmud, Head of SWE Department, for his kind assistance in completing our project and also to other faculty members and staff of SWE Department of Daffodil International University.
We would like to thank our entire course mate at Daffodil International University, who participated in this discussion while completing the course work. In this paper, we will predict the risk of any individual for drug addiction using machine learning classification algorithms. Then we got a data set from Kaggle based on the risk of drug addiction, but there was not enough data to use in the study.
In addition, by using a feature selection technique called chi-square, we obtained the most influential causes of substance abuse.
- Background
- Motivation of the Research
- Problem Statement
- Research Questions
- Research Objectives
- Research Scope
- Thesis Outline
That is why we are interested in working with drug addiction and machine learning techniques. We wanted to establish a model through machine learning that could identify a person's vulnerability to drug addiction. Using machine learning techniques, we will identify and validate the primary risk factors of drug addiction.
We hope that our research will help society identify drug addicts based on their socio-economic behavior, thus facilitating prevention. We collected our data in a way that is useful and compatible with machine learning techniques. After collecting the data, we realized that the popular machine learning techniques are suitable for our research.
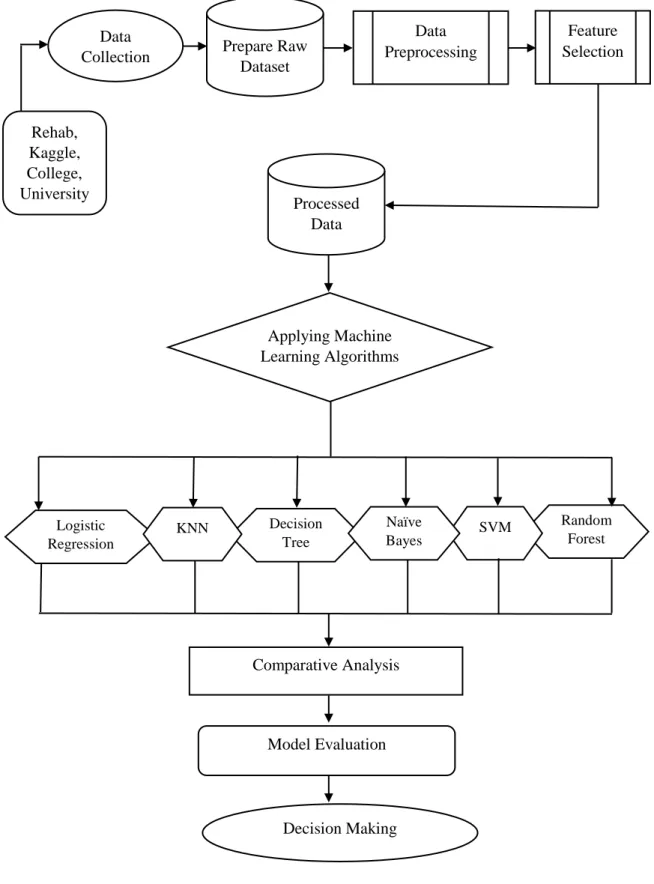
We also found out the most important factors of drug addiction that can tell us about a potential drug addict. Chapter-3 contains a detailed description of the data collection procedure, pre-processing of data, workflow of this research and statistical analysis.
Background
Related Works
They collected data from 6,511 participants through a survey based on their use of e-cigarettes or hookahs. In their research, the most essential predictor variables were identified by ReliefF, and the optimal number of predictors was estimated by Davies-Bouldin clustering for Random Forest. In their research, noble predictors such as 'household e-cigarette use' and 'perception of their tobacco use' were found. They were also found, 73%.
If other machine learning classifiers and feature selection methods were used, there may have been different predictor variables showing different reconciliation performance. 7] have developed fatality prediction models for drug poisoning and compared machine learning models with traditional logistic regression. And the Brier score was the lowest in the phases of training and validation for MLP.
To display the predictive power of the best performing machine learning algorithm, they also conducted a cross-cultural study scheme in the training, validation and testing process. The performance measurement was done based on those metrics: F1 prediction score, precision, accuracy, recall, negative predictive value and area under the curve. In their research, the elastic-net machine learning algorithm showed the best predictive performance in both included Canadian (AUC) and Australian (AUC) samples.
9] has proposed a model to predict daily smoking time based on decision tree machine learning algorithm. They used data that was collected by the Chinese Center for Disease Control and Prevention from information on smokers. In their research, they tested different machine learning algorithms and finally concluded that the performance of the prediction model based on the accuracy of XG Boost with feature extraction model is 84.11% which is better than other models .
10] proposed an approach of prediction of alcohol user based on artificial neural network (ANN). They used the regularization method to control overfitting and used least absolute shrinkage and selection operator (LASSO) for feature selection. 13] developed a model for predicting disease risk of cardiovascular on Biobank participants through machine learning.
Comparative Analysis & Summary
- Introduction
- Data Collection and Dataset
- Proposed Methodology
- Data Preprocessing
- Statistical Analysis
- Implementation Requirements
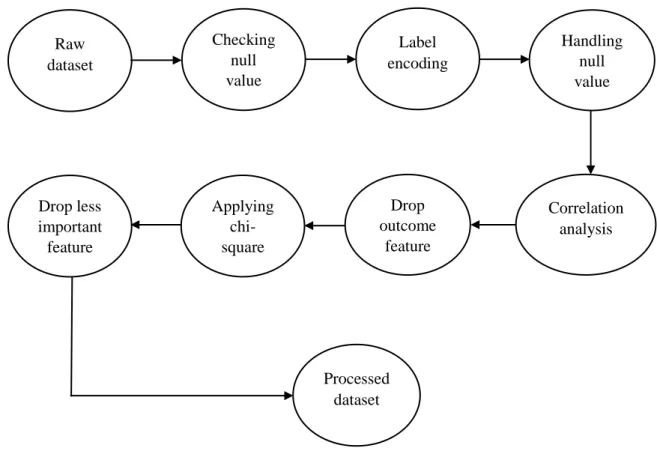
Since most of the data we collected was categorical, we converted our categorical data into numerical form by label coding. Next, we drop the outcome feature of our data set, which was “Addicted or Independent”. When we dropped the outcome function, we. 13 | Page ©Daffodil International University used a feature selection technique called chi-2 to learn about the most important and less important risk factors for drug addiction.
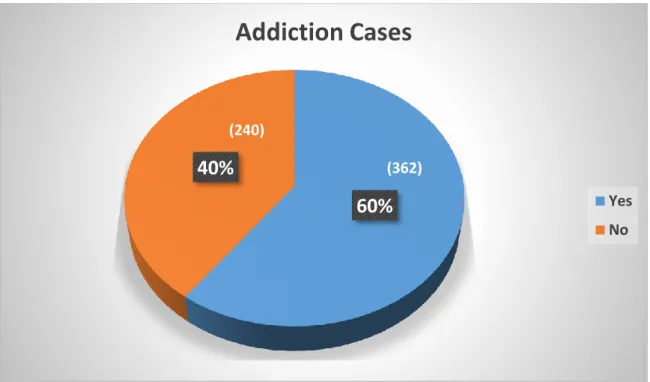
There were several classifications based on the final score of the two addiction rating scales. Using a feature selection technique called chi-square, we identified the most influential causes of drug addiction. The following figure 3.3 shows how many addicts and non-addicts were included in our research.
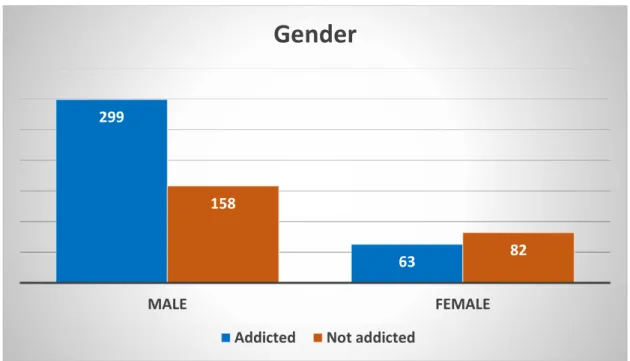
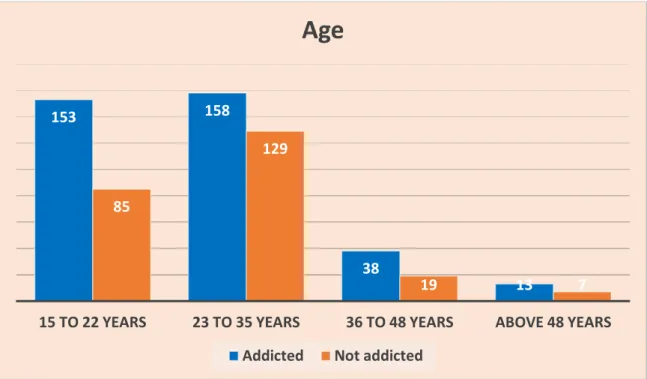
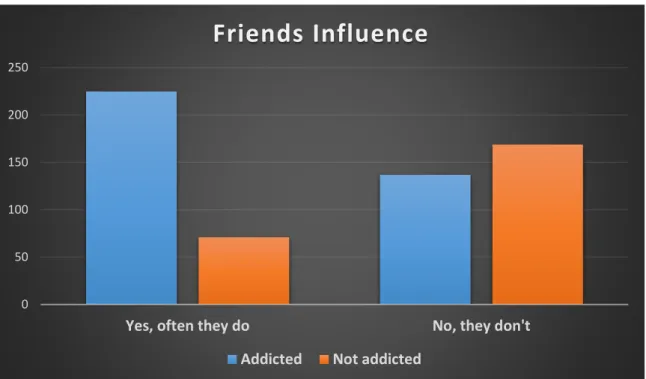
14 | Page ©Daffodil International University The following Figure 3.4 shows the age range of the data we collected for our study. From the following figure 3.5 we can see that men are more likely to be addicted than women. 16 | Page ©Daffodil International University Figure 3.8 shows that peer influence is one of the most important reasons for drug addiction.
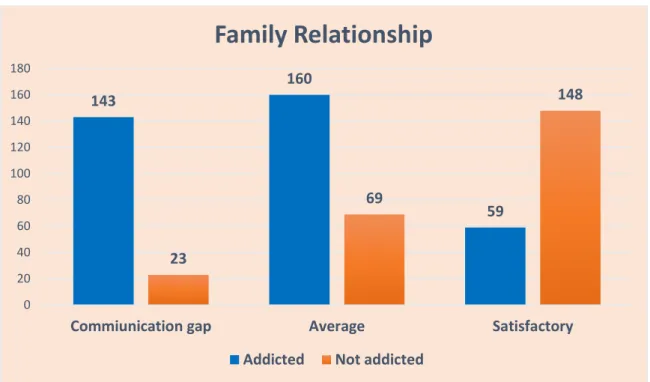
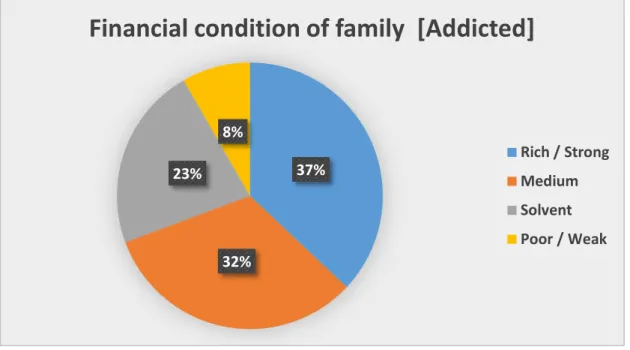
According to our research, the percentage of drug addicts is higher because of the influence of friends. In the figure below we see that the financial position of most families of drug addicts is strong. 18 | P a g e ©Daffodil International University Staying with a friend overnight is a major risk factor for drug addiction.
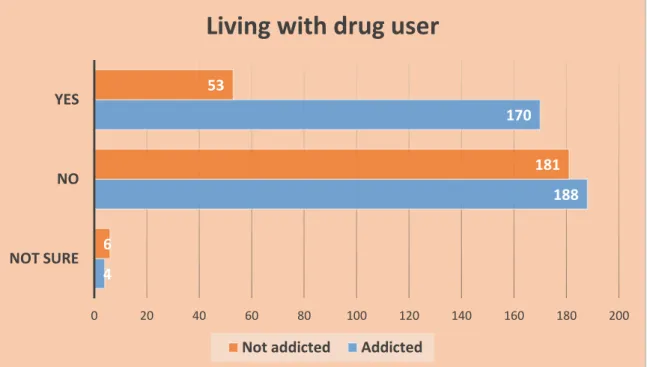
As Figure 3.12 shows, those who often and sometimes stay at a friend's house at night are the most addicted. Here we see that those who have an addict in the family are more likely to become addicted than non-addicts. 19 | P a g e © Daffodil International University Figure 3.14 shows the data of those who are not satisfied with their job or education.
20 | Page ©Daffodil International University Many people become addicted to drugs because of living with drug users and a habit of smoking. Those who use drugs once are more likely to become addicted, and those who are addicted are more likely to have withdrawal symptoms.
Introduction
Experimental Results and Analysis
- Experimental Evaluation
- Descriptive Analysis
It is best to use logistic regression when the nature of the target variable is dichotomous and need probability results, and also need to understand the impact of the function. The Decision Tree algorithm is used to establish classification models in the form of a tree-like structure, just like its name, and it belongs to supervised class learning. It is easier to understand as it follows the similar process that a human follows when they make any decision in real life [21].
The algorithm creates many decision trees and then obtains a prediction from each of them and finally makes a prediction by taking the average or median value of the output from the different trees. In other words, the assumption is that the existence of a property in a class is independent of the existence of any other property in the same class. Therefore, it is the preferred algorithm for smoothly scalable and traditionally real-world applications that need to respond quickly to user requests [21].
23 | P a g e ©Daffodil International University Support Vector Machine is a machine learning algorithm that is used in classification in most cases of the research field. The goal of the SVM algorithm is to construct optimal lines or decision boundaries that can divide the n-dimensional space into classes, so that in the future we can place new data points into the appropriate categories. It is used to reset missing values and data sets and is usually used for classification purposes.
In other words, the goal is to place all nearest neighbors around a new anonymous data point to determine which class it belongs to. It is a versatile algorithm that is very easy to interpret and can perform well with sufficient data [22]. Recall really counts how many actual positives our model captures by marking it as positive.
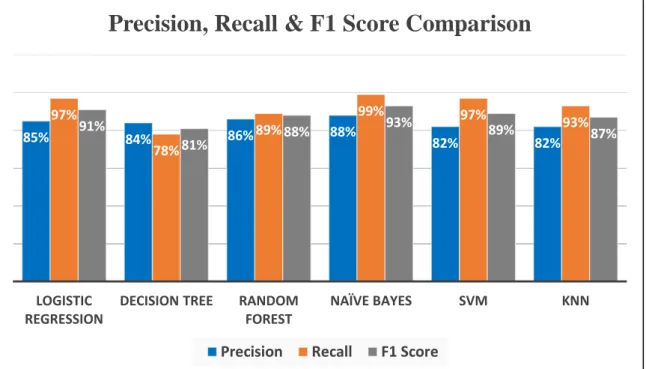
F1 is a good metric if we need to find a balance between precision and recall, as it is the weighted average of precision and recall. Calculating a confusion matrix is a much better way to give us a better result of what our classification model is doing right and what types of mistakes it is making. The following Table 4.2 presents the accuracy, precision, recall and F1 score for each of the algorithms for the sake of our research.
Discussion
26 | P a g e ©Daffodil International University Once we have built our model, the most important question that arises is how good our model is.
Findings and Contributions
Recommendations for Future Work
Comparing logistic regression models with alternative machine learning methods to predict the risk of death from drug intoxication,”. Huang, "Prediction of Daily Smoking Behavior Based on Decision Tree Machine Learning Algorithm IEEE 9th International Conference on Electronic Information and Emergency Communication (ICEIEC), Beijing, China, 2019, pp. Prediction of Risk for Alcohol Use Disorder Using Longitudinal Data with Multimodal Biomarkers and Family History:" a machine learning study”.
Meshram, "Designing Disease Prediction Model Using Machine Learning Approach rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 2019, pp Predicting cardiovascular disease risk using automated machine learning: a prospective study of 423,604 UK Biobank participants" , PLoS One Available: https://www.healthyplace.com/addictions/drug-addiction/causes-of-drug-addiction-what-causes-drug%20addiction.
Jiawei Han, Micheline Kamber, Jian Pei, Data Mining Concept and Technique, 3rd Edition, Morgan Kaufmann, 2012, pp. Stuart J. Russell, Peter Norvig, Artificial Intelligence a Modern Approach, 3rd ed., Upper Saddle River, NJ: Prentice Hall, 2010, pp.