to the Department of Computer Science and Engineering, Daffodil International University has been accepted as satisfactory in partial fulfillment of the requirements for the degree of B.Sc. Department of Computer Science and Engineering Faculty of Natural Sciences and Information Technology Påskelilje International University. We hereby declare that this project has been carried out by us under the supervision of Abu Kaisar Mohammad Masum, Associate Professor, Department of CSE Daffodil International University.
Speech recognition has been a very popular topic for computer science and engineering students. To check the performance of our system, we have used the local accent of Chittagong people as a reference. Automatic speech recognition (ASR) system is used in natural language processing (NLP) for the purpose of speech recognition.
Speech recognition has been around for a while and has seen a lot of technical progress over the years. Daffodil International University 2 the world has started using a variety of deep learning approaches in developing and deploying their own speech recognition systems. One of the most debated topics in the field of NLP is accent identification.
Chittagong (sagia or siaiga), spoken in the Chittagong division of Bangladesh, is an Indo-Aryan language.
Motivation
The Indo-European language family includes Chittagong, which belongs to the Bengali-Assamese sub-branch of the Eastern group of Indo-Aryan languages. It is a descendant of Proto-Indo-European and Old Indo-Aryan through an Eastern Middle Indo-Aryan. According to Chatterji (1926), Chittagong belongs to the Vangiya group of Magadhi Prakrit and all Bengali dialects developed separately from the literary Bengali known as sadhu bhasha.
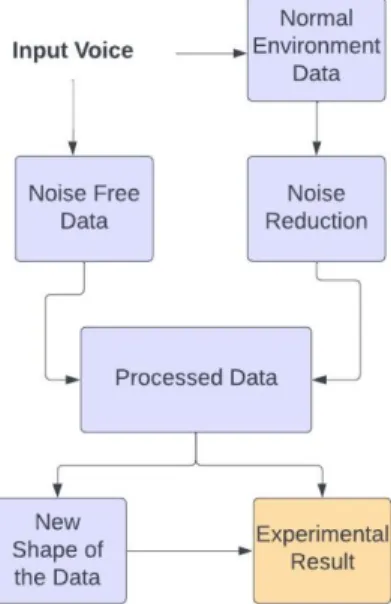
This study provides an application that can estimate the geographical location of a person based on the frequency of his voice waves using both the standard Bangla language and the regional Bengali dialect used in the Chittagong area. In this particular case, MFCC was used for feature extraction, and a number of techniques were used to achieve the highest possible level of system accuracy. Those who live in rural areas and do not speak standard Bangla well would find it difficult to access the services offered by these networks.
For this reason, we decided to develop a system that could identify the different dialects spoken in Bengal based on their spectral characteristics. The main objective of the study is to use a robust data set to develop a system that facilitates human-computer interaction for the benefit of those living in rural areas with the highest possible level of accuracy.
Rationale of the Study
Expected Outcome
Report Layout
Daffodil International University 6 In Chapter 4, this chapter presents the results of the previous chapters as well as comparisons and best practices.
Background
- Related Works
- Comparative Analysis and Summary
- Challenges
- Data Collection
- Ensuring that language is compatible with the system
- Model Selection
- Workflow
In [9], a new feature extraction method for sound event classification based on a visual signature obtained from a time-frequency representation of sound is presented. Many researches have been done on the classification of accented languages, some have used MFCC, LSTM or other feature extractor, or some research have used an image approach using spectrograms. Although the data quality of the two surveys was not the same, their pre-processing produced almost the same result.
Because most of the data was used for training purposes and less for testing purposes. In some cases, the identification of the perpetrators or the location of the most dangerous area of the crime can be useful. One of the main problems we faced was gathering the necessary data for our project. Specifically, we found it challenging to obtain organized datasets for the Bangla language.
Moreover, it was difficult to find a sufficient number of sources of data on Chittagong accents of the language. To overcome this problem we had to go to Chittagong and collect some data and plant a representative there for the further collection of more necessary data. Earlier we mentioned that one of the main challenges for this project was to obtain the necessary data.
So, for the authentic Chittagong accent, we had to go to Chittagong and collect the exact accented voice. Parsing and structuring Bangla text has been a major challenge due to the complexity of the grammar, which is more complicated than that of English. However, we persevered and through our efforts we were able to gain a deeper understanding of the language.
Despite the considerable amount of research done on accent classification, it remains a challenging area of study for the Bangla language. Much of the research on this topic has been conducted using the English language, which has led to the development of numerous models for accent classification. However, it was difficult to identify the most suitable model for the Bangla language that would provide the highest level of accuracy.
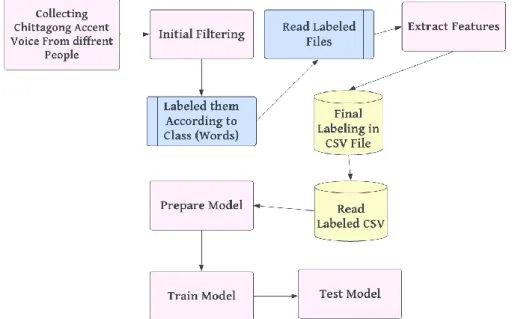
Research Methodology
- Research subject and instrument
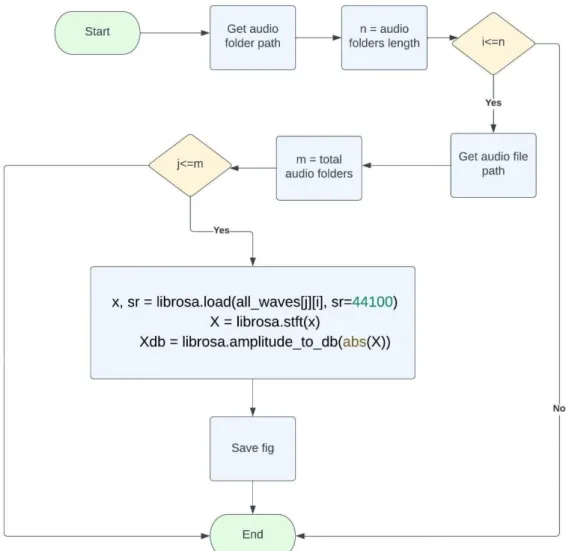
- Normalization: We converted all the audio file into WAV format and the same sample rate using a software called Audacity. The used audio sample rate was
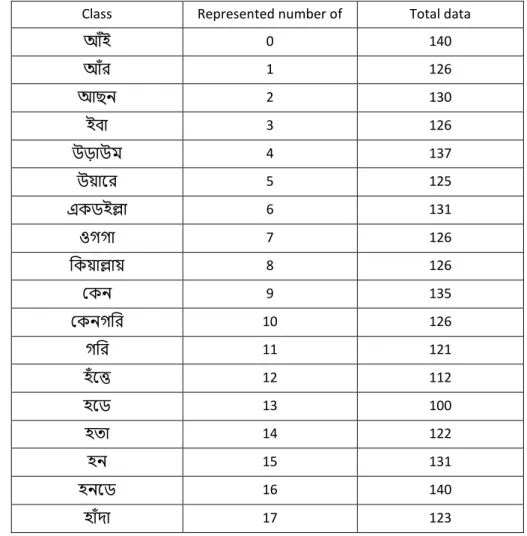
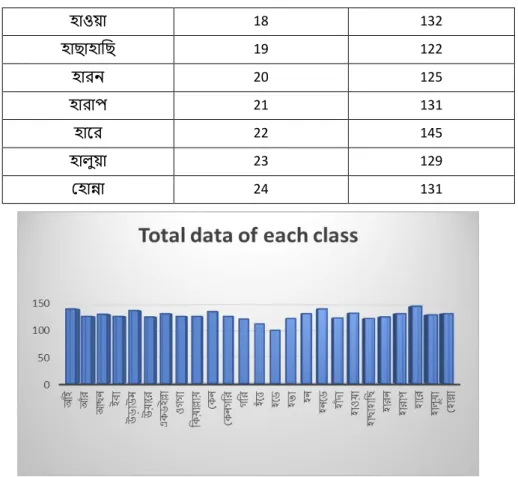
- Segmentation: Each audio file consists of a speaker saying each words 5 times of total 25 words. We segmented each words audio separately and stored them
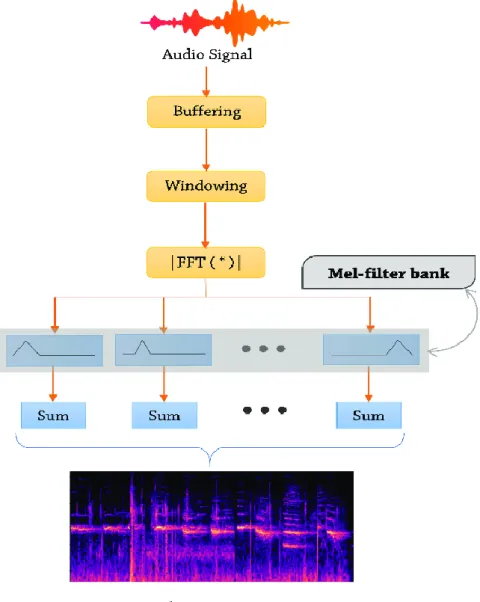
- Conversion: One of our research methods needed audio Spectrograms of training Neural network model. That's why we needed to convert the audio files
- Dataset utilized
- Use of a feature extractor ex. Mfcc
- Image approach ex. Converting audio to Mel spectrograms
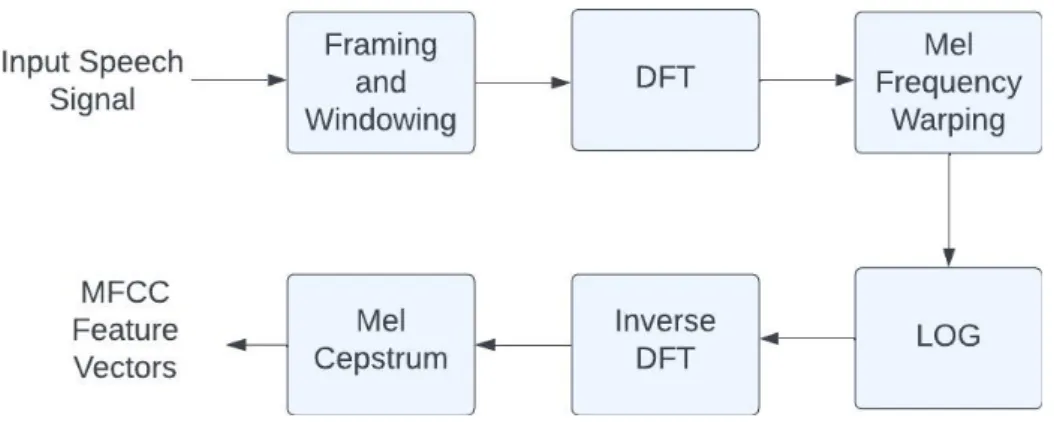
- MFCC feature extractor: Mfccs are commonly used to extract features from audio signal so that a speech detection system can be trained and tested with it
- Statistical Analysis
- Methodology
- Implementation Requirements Python 3.11.0
- Experimental setup
- Experimental Result and analysis
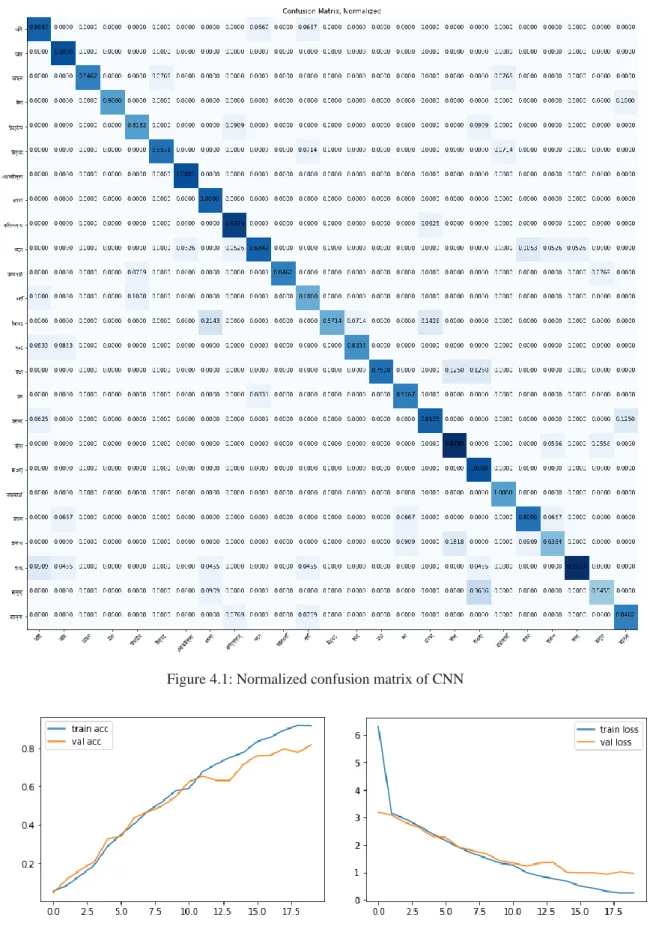
We do this because applying Fourier transform is not very informative about the change nature of the audio. We used 80% data for training the CNN model and 20% data for testing and validating the model. If we test the model with 20% of the test data, we get the result shown in the below confusion matrix and train accuracy versus validation accuracy and train error and validation error curve.
When both the train accuracy and validation accuracy increase as the number of epochs increases, the model likely learns and becomes more accurate. Daffodil International University 25 Figure 4.6: Train accuracy vs Validation accuracy curve Figure 4.7: Train loss and Validation loss. Daffodil International University 26 Figure 4.9: Train accuracy vs. Validation accuracy Figure 4.10: Train loss and Validation loss curve.
This indicates that the model is able to maintain its performance on both the training and validation sets and does not overfit the training data. The confusion matrix analyzing the performance of the model using 20% test data is shown below. In certain circumstances, continuing to train the model after this stage can lead to overfitting, when the model begins to remember the training data and performs poorly on new, unforeseen data (validation set).
In other cases, the model may simply have learned all it can from the data, and more training will not increase accuracy. In either scenario, the model may benefit from additional refinement of the model architecture or from the collection of more diverse and representative training data. To increase performance, we made the model architecture more complex, added more hidden layers and cluster normalization.
Although it gave higher accuracy, but as we can see in figure 4.9 there is a big gap between train loss and validation loss curve. Without adequate training data, the model may not be able to learn well or generalize to new samples. Poor data quality: It can be challenging for the model to extract usable features from audio data that is distorted or of poor quality.
Insufficient training: The model may not converge to a good solution if it is not trained for a sufficient number of epochs or if the learning rate is not set correctly. You may need to try several methods, such as collecting more, higher-quality data, experimenting with different model architectures, or changing the training hyperparameters to increase model accuracy.
Impact on Society, Environment and Sustainability
- Impact on Society
- Impact on Environment
- Ethical Aspects
- Sustainability Plan
We are sensitive to the need to protect the personal information of persons whose data we collect. Our application will be designed for end-to-end users, and we will continue to improve it to provide our customers with access to the most recent features as they become available.
Summary, Conclusion, Recommendation and Implication for Future Research
Summary of the Study
Conclusion
This is also applicable in the context of this work, as there are likely many aspects that could be improved. In Bangla language, there are a large number of accents that we have worked with only a small part of them. By increasing the number of accents we use, we have the opportunity to expand our language skills and better understand the diversity and complexity of the Bangla language.
To make our model stronger, we need to include more diversity in our speaker selection. A variety of perspectives and experiences can enrich discussions and presentations, leading to a more complete and robust model. By including a range of speakers from different backgrounds, we can ensure that all views are represented and that our model is stronger as a result.
It is important to recognize the value of diversity and to actively seek out and include a variety of speakers in our model. We experiment with different classifiers to find the most effective one for our needs. This involves testing several options and comparing their performance to determine which one best suits our specific situation.
By testing different classifiers and comparing them, we hope to find the one that will most accurately classify the data we are working with. We believe that this process of testing multiple options and comparing their results is important to ensure that we are using the most appropriate classifier for our purposes.