Informasi Dokumen
- Penulis:
- Mohamad Lukman Hakim Nugraha
- Pengajar:
- Ibu Ednawati Rainarli, S.Si., M.Si.
- Ibu Ken Kinanti Purnamasi, S.Kom., M.T.
- Ibu Kania Evita Devi, S.Pd., M.Si.
- Sekolah: Universitas Komputer Indonesia
- Mata Pelajaran: Teknik Informatika
- Topik: Implementasi K-Means Clustering Dan Learning Vector Quantization Untuk Optimasi Pengenalan Suara
- Tipe: skripsi
- Tahun: 2016
- Kota: Bandung
Ringkasan Dokumen
I. Pendahuluan
Bagian pendahuluan tesis ini membahas latar belakang masalah dalam optimasi pengenalan suara, yang menekankan keterbatasan akurasi metode sebelumnya seperti DTW. Penulis mengidentifikasi perlunya metode yang lebih efisien dan akurat, seperti implementasi K-Means Clustering dan Learning Vector Quantization (LVQ) untuk meningkatkan kinerja pengenalan suara. Rumusan masalah difokuskan pada penerapan kedua algoritma ini untuk optimasi akurasi. Tujuan penelitian adalah untuk mengukur peningkatan akurasi yang dihasilkan. Batasan masalah didefinisikan dengan jelas, mencakup aspek seperti jenis kata yang diucapkan, jumlah pembicara, lingkungan perekaman, dan spesifikasi teknis perekaman suara. Metodologi penelitian dijelaskan secara ringkas, meliputi studi literatur, analisis kebutuhan algoritma, perancangan perangkat lunak, implementasi, dan pengujian akurasi. Sistematika penulisan memberikan gambaran umum isi setiap bab.
1.1 Latar Belakang Masalah
Bagian ini menjelaskan konteks penelitian dengan memaparkan permasalahan dalam pengenalan suara, khususnya rendahnya akurasi metode-metode sebelumnya. Disebutkan bahwa penelitian ini termotivasi oleh kebutuhan untuk meningkatkan akurasi pengenalan suara melalui implementasi algoritma K-Means Clustering dan LVQ. Penulis juga menjelaskan keunggulan metode MFCC sebagai metode ekstraksi fitur dan kelemahan metode DTW dalam pencocokan suara. Latar belakang ini secara efektif membangun argumen untuk perlunya penelitian yang diusulkan, menunjukkan celah pengetahuan yang akan diatasi oleh tesis ini.
1.2 Rumusan Masalah
Bagian ini merumuskan pertanyaan penelitian secara spesifik dan terukur, berfokus pada bagaimana penerapan K-Means Clustering dan LVQ dapat mengoptimalkan akurasi pengenalan suara. Rumusan masalah ini memberikan kerangka kerja yang jelas bagi penelitian dan membantu membatasi ruang lingkup penelitian. Hal ini penting untuk memastikan bahwa penelitian tetap terfokus dan tujuannya dapat dicapai dengan efektif.
1.3 Maksud dan Tujuan
Bagian ini menjelaskan maksud dan tujuan penelitian dengan jelas. Maksudnya adalah untuk mengaplikasikan K-Means Clustering dan LVQ dalam optimasi pengenalan suara. Tujuannya adalah untuk mengukur tingkat akurasi yang dicapai dengan menggunakan kedua algoritma tersebut. Tujuan ini terukur dan dapat dievaluasi melalui pengujian yang dilakukan dalam penelitian. Kejelasan maksud dan tujuan penting untuk memberikan arah yang tepat bagi penelitian dan memudahkan pembaca dalam memahami kontribusi tesis.
1.4 Batasan Masalah
Bagian ini mendefinisikan batasan-batasan penelitian dengan rinci, yang meliputi jenis kata yang digunakan, jumlah pembicara, metode perekaman, lingkungan perekaman, spesifikasi teknis perekaman, format file audio, dan pendekatan pembangunan perangkat lunak. Batasan masalah ini penting untuk menghindari ruang lingkup penelitian yang terlalu luas dan memastikan bahwa penelitian dapat diselesaikan secara efektif dalam waktu dan sumber daya yang tersedia. Batasan ini juga meningkatkan validitas dan reliabilitas hasil penelitian.
1.5 Metodologi Penelitian
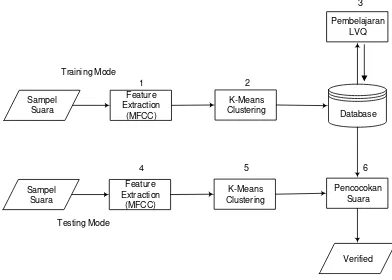
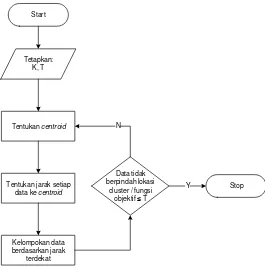
Bagian ini menjelaskan langkah-langkah penelitian secara sistematis, mulai dari studi literatur hingga pengujian akurasi. Penjelasan mencakup tahapan analisis kebutuhan algoritma (meliputi analisis masalah, proses, data masukan/keluaran, dan metode), perancangan perangkat lunak, implementasi, dan pengujian. Diagram alur penelitian memberikan gambaran visual dari langkah-langkah yang dilakukan. Metodologi yang jelas dan terstruktur menunjukkan validitas dan kredibilitas penelitian.
1.6 Sistematika Penulisan
Bagian ini memberikan gambaran umum tentang isi setiap bab dalam tesis. Ini membantu pembaca untuk memahami struktur dan alur argumen dalam tesis. Sistematika penulisan yang jelas dan terstruktur membuat tesis lebih mudah dibaca dan dipahami.
II. Landasan Teori
Bab ini memberikan landasan teori yang komprehensif terkait pengenalan suara, mencakup definisi, jenis-jenis pengenalan suara (speech recognition dan speaker recognition), teknik-teknik speech recognition, produksi suara manusia, klasifikasi sinyal eksitasi, konversi analog ke digital, dan detail algoritma MFCC, K-Means Clustering, LVQ, Euclidean Distance, K-Fold Cross Validation, dan Confusion Matrix. Penjelasan juga mencakup pemrograman berorientasi objek dan tools yang digunakan. Teori-teori yang dibahas berasal dari berbagai sumber, menunjukkan kajian literatur yang mendalam dan relevan.
2.1 Pengenalan Suara
Sub-bab ini memberikan definisi umum tentang pengenalan suara, membedakan speech recognition dan speaker recognition. Penjelasan tersebut mencakup perbedaan antara speaker verification dan speaker identification, menjelaskan proses verifikasi dan identifikasi pembicara. Penjelasan ini membangun fondasi pemahaman tentang bidang pengenalan suara dan memberikan konteks bagi pembahasan lebih lanjut tentang algoritma dan teknik yang digunakan dalam penelitian.
2.2 Jenis Pengenalan Suara
Sub-bab ini mengklasifikasikan sistem pengenalan suara berdasarkan jenis ucapan, meliputi isolated words, connected words, continuous speech, dan spontaneous speech. Penjelasan ini memberikan pemahaman yang lebih rinci tentang berbagai jenis data suara yang dapat diproses oleh sistem pengenalan suara. Pengelompokan ini penting untuk memahami kompleksitas dan tantangan dalam pengenalan suara.
2.3 Teknik-teknik Speech Recognition
Sub-bab ini membahas empat teknik utama dalam speech recognition: speech analysis, feature extraction, modeling, dan matching techniques. Penjelasan ini meliputi detail tentang setiap teknik, termasuk metode-metode yang digunakan dalam setiap tahap. Pemahaman yang mendalam tentang teknik ini penting untuk memahami bagaimana sistem pengenalan suara bekerja dan bagaimana metode yang digunakan dalam penelitian ini terkait dengan teknik yang ada.
2.4 Produksi Suara
Sub-bab ini membahas proses produksi suara pada manusia, meliputi organ-organ yang terlibat dan jenis-jenis suara (voiced, unvoiced, dan plosive sound). Penjelasan ini penting untuk memahami karakteristik suara dan bagaimana fitur-fitur suara diekstrak. Penjelasan ini memberikan landasan biologis untuk memahami data suara yang akan diproses dalam penelitian.
2.5 Klasifikasi Sinyal Eksitasi
Sub-bab ini mengklasifikasikan sinyal eksitasi dalam produksi suara menjadi sinyal silence, unvoiced, dan voiced. Klasifikasi ini penting untuk memahami variasi dalam sinyal suara dan bagaimana variasi ini memengaruhi proses pengenalan suara. Penjelasan ini menambah kedalaman pemahaman tentang data suara yang diproses.
2.6 Konversi Analog Menjadi Digital
Sub-bab ini menjelaskan proses konversi sinyal analog menjadi digital, meliputi sampling, kuantisasi, dan pengkodean. Penjelasan ini penting untuk memahami bagaimana sinyal suara direpresentasikan dalam bentuk digital yang dapat diproses oleh komputer. Pemahaman ini penting karena penelitian menggunakan data suara dalam bentuk digital.
2.7 Mel Frequency Cepstrum Coefficients (MFCC)
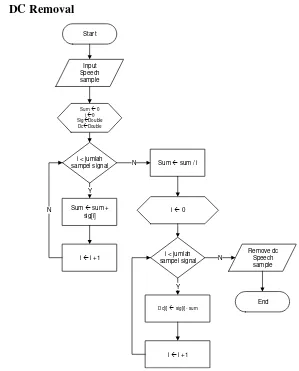
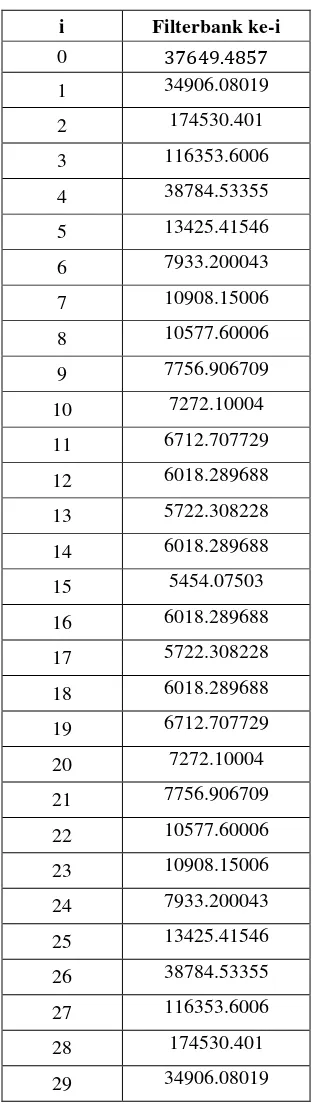
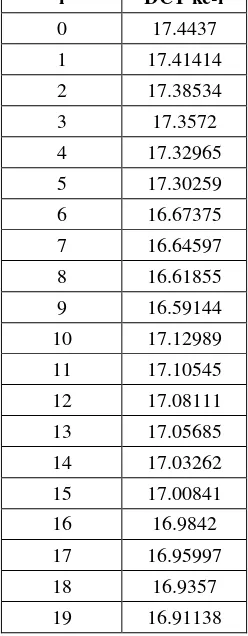
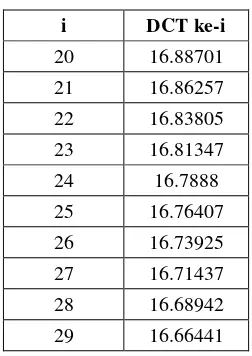
Sub-bab ini menjelaskan secara detail algoritma MFCC, meliputi DC removal, pre-emphasis, frame blocking, windowing, Fast Fourier Transform (FFT), Mel Frequency Warping, Discrete Cosine Transform (DCT), dan cepstral liftering. Penjelasan ini mencakup rumus-rumus matematika dan ilustrasi grafik yang membantu pembaca memahami prosesnya. Penjelasan yang komprehensif ini penting karena MFCC merupakan metode ekstraksi fitur utama dalam penelitian.
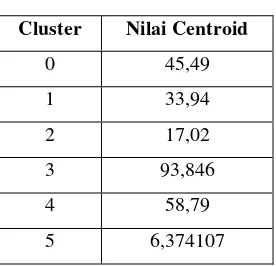
2.8 K-Means Clustering
Sub-bab ini menjelaskan algoritma K-Means Clustering, termasuk keunggulan dan kelemahannya dalam konteks pengenalan suara. Penjelasan ini mencakup langkah-langkah algoritma dan implikasinya untuk pengolahan data. Penjelasan ini penting karena K-Means Clustering merupakan algoritma inti dalam penelitian.
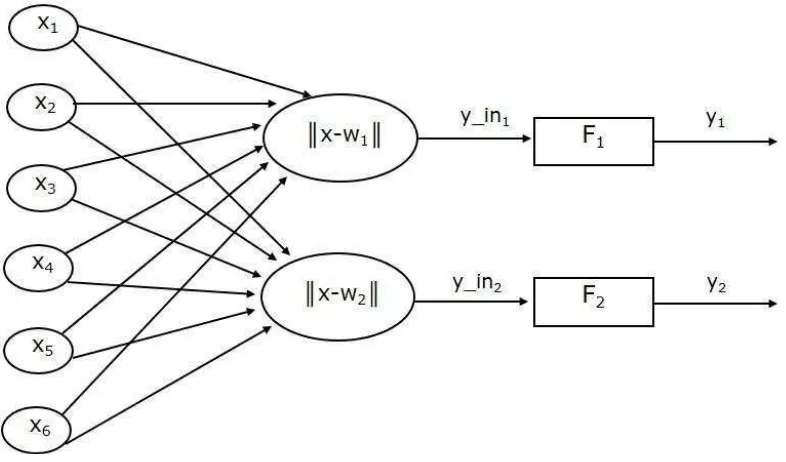
2.9 Learning Vector Quantization (LVQ)
Sub-bab ini menjelaskan algoritma LVQ, termasuk arsitektur dan langkah-langkah algoritmanya. Penjelasan ini mencakup detail tentang proses pembelajaran dan klasifikasi dalam LVQ. Penjelasan ini penting karena LVQ merupakan algoritma inti dalam penelitian.
2.10 Euclidean Distance
Sub-bab ini menjelaskan metode pengukuran jarak Euclidean Distance dan rumusnya. Penjelasan ini penting karena Euclidean Distance digunakan untuk mengukur kemiripan antara vektor fitur dalam penelitian.
2.11 K-Fold Cross Validation
Sub-bab ini menjelaskan teknik validasi silang K-Fold Cross Validation dan kegunaannya dalam mengevaluasi kinerja classifier. Penjelasan ini penting karena teknik ini digunakan dalam penelitian untuk mengevaluasi akurasi model.
2.12 Confusion Matrix
Sub-bab ini menjelaskan Confusion Matrix dan cara penggunaannya untuk mengevaluasi kinerja sistem klasifikasi. Penjelasan ini penting karena Confusion Matrix digunakan dalam penelitian untuk menganalisis hasil pengujian.
2.13 Pemrograman Berorientasi Objek
Sub-bab ini menjelaskan konsep-konsep dasar pemrograman berorientasi objek, seperti kelas, objek, metode, atribut, abstraksi, enkapsulasi, pewarisan, antarmuka, dan reusability. Penjelasan ini penting karena penelitian menggunakan pendekatan pemrograman berorientasi objek.
2.14 C#
Sub-bab ini (walaupun singkat dalam teks asli) menjelaskan penggunaan bahasa pemrograman C# dalam implementasi sistem pengenalan suara. Menunjukkan pilihan teknologi yang tepat dan relevan untuk tugas pemrograman.
2.15 Unified Modeling Language (UML)
Sub-bab ini (walaupun singkat dalam teks asli) menjelaskan penggunaan UML dalam perancangan sistem, meliputi Use Case Diagram, Class Diagram, Sequence Diagram, dan Activity Diagram. Menunjukkan penggunaan teknik perancangan sistem yang terstruktur dan standar.
2.16 Tools Pembangunan Perangkat Lunak
Sub-bab ini (walaupun singkat dalam teks asli) menjelaskan tools yang digunakan dalam pengembangan perangkat lunak, seperti Microsoft Visual Studio dan basis data. Menunjukkan alat-alat yang tepat dan mendukung proses pengembangan.
III. Analisis Kebutuhan Algoritma
Bab ini menganalisis kebutuhan algoritma untuk sistem pengenalan suara yang dikembangkan. Analisis ini meliputi analisis masalah, analisis proses, analisis data masukan dan keluaran untuk MFCC, K-Means Clustering, dan LVQ, analisis metode yang digunakan, analisis kebutuhan non-fungsional (perangkat keras, perangkat lunak, dan pengguna), dan analisis kebutuhan fungsional (menggunakan diagram UML seperti Use Case Diagram, Use Case Scenario, Activity Diagram, Class Diagram, dan Sequence Diagram). Bagian perancangan sistem membahas perancangan basis data, struktur menu, dan antarmuka pengguna.
3.1 Analisis Masalah
Bagian ini menganalisis permasalahan utama yang dihadapi dalam pengenalan suara dan bagaimana pendekatan yang diusulkan dalam penelitian ini akan mengatasi masalah tersebut. Analisis ini membantu dalam mengidentifikasi dan menjustifikasi penggunaan algoritma K-Means Clustering dan LVQ dalam sistem pengenalan suara.
3.2 Analisis Proses
Bagian ini menggambarkan tahapan proses pengenalan suara secara detail, mulai dari pengambilan data suara hingga menghasilkan output pengenalan. Analisis proses ini penting untuk memahami alur kerja sistem dan memastikan bahwa setiap tahapan diimplementasikan dengan benar.
3.3 Analisis Data Masukan dan Keluaran
Bagian ini menganalisis data masukan dan keluaran untuk setiap tahapan proses, khususnya untuk MFCC, K-Means Clustering, dan LVQ. Analisis ini menjelaskan jenis data yang dibutuhkan dan jenis data yang dihasilkan pada setiap tahapan. Analisis ini memastikan bahwa data yang diproses sesuai dengan kebutuhan algoritma yang digunakan.
3.4 Analisis Metode
Bagian ini memberikan penjelasan detail tentang metode yang digunakan, termasuk MFCC, K-Means Clustering, LVQ, dan Euclidean Distance. Penjelasan ini mencakup algoritma, parameter, dan implikasinya terhadap hasil pengenalan suara. Analisis ini memastikan bahwa metode yang dipilih tepat dan sesuai untuk memecahkan masalah yang dihadapi.
3.5 Analisis Kebutuhan Non-Fungsional
Bagian ini menganalisis kebutuhan non-fungsional sistem, termasuk kebutuhan perangkat keras, perangkat lunak, dan pengguna. Analisis ini penting untuk memastikan bahwa sistem dapat berjalan dengan baik dan memenuhi kebutuhan pengguna.
3.6 Analisis Kebutuhan Fungsional
Bagian ini menganalisis kebutuhan fungsional sistem menggunakan diagram UML, termasuk Use Case Diagram, Use Case Scenario, Activity Diagram, Class Diagram, dan Sequence Diagram. Analisis ini memberikan gambaran yang jelas tentang fungsi-fungsi sistem dan bagaimana fungsi-fungsi tersebut berinteraksi.
3.7 Perancangan Sistem
Bagian ini menjelaskan perancangan sistem secara keseluruhan, termasuk perancangan basis data, struktur menu, dan antarmuka pengguna. Perancangan ini memastikan bahwa sistem yang dibangun terstruktur dengan baik dan mudah digunakan.
IV. Implementasi dan Pengujian
Bab ini membahas implementasi dan pengujian sistem pengenalan suara. Implementasi meliputi implementasi perangkat keras, perangkat lunak, basis data, class, dan antarmuka. Pengujian meliputi skenario pengujian parameter LVQ, skenario pengujian K-Fold Cross Validation, dan hasil pengujian akurasi. Kesimpulan hasil pengujian membahas akurasi sistem yang telah diimplementasikan.
4.1 Implementasi
Bagian ini menjelaskan secara detail bagaimana sistem pengenalan suara diimplementasikan, meliputi implementasi perangkat keras, perangkat lunak, basis data, class, dan antarmuka pengguna. Penjelasan ini penting untuk menunjukkan bagaimana teori dan analisis yang telah dibahas di bab-bab sebelumnya diterjemahkan ke dalam sistem yang nyata.
4.2 Skenario Pengujian
Bagian ini menjelaskan skenario pengujian yang dilakukan, meliputi skenario pengujian parameter LVQ dan skenario pengujian K-Fold Cross Validation. Penjelasan ini memberikan informasi tentang bagaimana sistem diuji dan bagaimana data diproses selama pengujian. Penjelasan ini penting untuk memastikan validitas dan reliabilitas hasil pengujian.
4.3 Pengujian
Bagian ini menyajikan hasil pengujian sistem pengenalan suara, meliputi pengujian parameter LVQ dan pengujian K-Fold Cross Validation. Hasil pengujian ini memberikan bukti empiris untuk mendukung klaim-klaim yang dibuat dalam penelitian. Presentasi hasil yang terstruktur dan detail penting untuk menunjukkan kredibilitas penelitian.
4.4 Kesimpulan Hasil Pengujian
Bagian ini menyimpulkan temuan-temuan utama dari pengujian, terutama mengenai akurasi sistem pengenalan suara yang telah diimplementasikan. Kesimpulan ini menghubungkan hasil pengujian dengan tujuan penelitian dan memberikan penilaian terhadap keberhasilan penelitian.
V. Kesimpulan dan Saran
Bab ini menyimpulkan seluruh penelitian, membahas tingkat akurasi yang dicapai dengan penerapan K-Means Clustering dan LVQ dalam pengenalan suara. Saran untuk penelitian selanjutnya juga diberikan, misalnya mengenai perluasan dataset, penambahan fitur, atau peningkatan algoritma.
5.1 Kesimpulan
Bagian ini merangkum seluruh temuan penelitian dan menjawab rumusan masalah yang diajukan di awal. Kesimpulan ini menekankan kontribusi utama penelitian dan implikasinya untuk pengembangan sistem pengenalan suara yang lebih akurat.
5.2 Saran
Bagian ini memberikan saran untuk penelitian selanjutnya yang dapat dilakukan untuk meningkatkan sistem pengenalan suara yang dikembangkan. Saran ini dapat mencakup pengembangan algoritma, peningkatan kualitas data, atau eksplorasi metode yang berbeda.