WAVELET DAN LEARNING VECTOR QUANTIZATION
UNTUK PENGENALAN PEMBICARA
ASYUR ZALDI
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI
TESIS
DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis yang berjudul Wavelet dan
Learning Vector Quantization untuk Pengenalan Pembicara adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
RINGKASAN
ASYUR ZALDI. Wavelet dan Learning Vector Quantization untuk Pengenalan Pembicara. Di bawah bimbingan AGUS BUONO dan BIB PARUHUM SILALAHI
Noise pada sinyal suara merupakan factor utama yang mempengaruhi tingkat akurasi hasil pemrosesan sinyal, disadari pada kenyataan tidak ada sinyal yang tidak mengandung noise, yang dapat disebabkan suara latar belakang di tempat sumber berbicara, atau karena proses transmisi pada saat sinyal diterima. Salah satu metode yang populer dan sering digunakan untuk mengurangi noise
adalah transformasi wavelet, yang mengurangi noise (denoising) dari sinyal dengan memilah kemudian mengeleminir sinyal dengan kriteria tertentu, sebagai cara untuk menentukan bagian sinyal sesungguhnya atau bukan, yang kemudian disebut dengan wavelet thresholding. Wavelet digunakan untuk menganalisa sinyal berdasar penyekalaan, transformasi wavelet diperoleh dengan membagi sinyal menjadi beberapa ukuran sebagai perwakilan dari bidang frekuensi yang berbeda. Dengan kata lain, wavelet merupakan potongan gelombang (kecil) dan transformasi wavelet mengkonversi sinyal menjadi sederetan wavelet, dan kemudian dianalisa dalam batasan frekuensi dan durasinya.
White Gaussian noise digunakan untuk merepresentasikan noise yang sesungguhnya, dengan level Signal to Noise Ratio (SNR)yang digunakan sebesar 20dB, 10dB dan 0dB, yang ditambahkan pada setiap sinyal suara. Sinyal suara yang telah ditambahkan noise ini kemudian didenoising dengan proses wavelet thresholding sebelum digunakan pada proses pengenalan pembicara.
Dikarenakan sinyal yang diperoleh memiliki keragaman panjang gelombang serta karena perubahan karakteristik sumber suara yang relative kecil, maka Mel-frequency Cepstral Coefficient digunakan untuk mengekstrak ciri dari setiap sinyal suara menjadi sejumlah kecil koefisien dengan ukuran yang sama, selain alasan yang disebutkan diatas ekstraksi ciri berguna pula dalam menghadapi data ukuran besar, yaitu untuk mengurangi kebutuhan sumber daya yang diperlukan saat menganalisa data.
Learning Vector Quantization merupakan metode pengklasifikasian pola kedalam suatu kelas atau kategori tertentu yang didasarkan pada kompetisi. Jaringan LVQ adalah jaringan 2 lapis yang terdiri dari lapis masukan dan lapis keluaran, dengan lapis masukan mengandung neuron sebanyak dimensi masukan, dan lapis keluaran mengandung neuron sebanyak kelas yang ada. Kedua lapisan tersebut dihubungkan dengan penghubung yang memiliki bobot tertentu. Bobot dari neuron masukan yang menuju neuron keluaran berupa vektor yang mewakili kelasnya, yang kemudian disebut juga sebagai vector reference.
Sebagai hasilnya, proses pengenalan pembicara memberikan tingkat akurasi tertinggi untuk kelompok data pertama setelah dan sebelum denoising
relatif sama untuk data asli dan SNR 20dB yaitu sebesar 89.17% dan 58,33%, sedangkan untuk SNR 10dB dan 0 dB, hasil yang lebih baik diperlihatkan pada sinyal yang telah melalui denoising yaitu masing-masing sebesar 13,33% dan 9,17%. Untuk kelompok data kedua hasil dari data denoising lebih besar dari data sebelum denoising yaitu sebesar 95,00% untuk data asli, 72,50% untuk SNR 20dB, 20,00% untuk SNR 10dB dan 10,83% untuk SNR 0dB. Sedangkan untuk kelompok data ketiga, data asli menghasilkan akurasi yang relatif sama antara hasil denoising dan sebelum denoising yaitu sebesar 95,00%, sedangkan untuk SNR 20dB memberikan nilai 72,50%, 18,33% untuk SNR 10dB dan 10,83% untuk SNR 0dB.
SUMMARY
ASYUR ZALDI. Wavelet and Learning Vector Quantization in Speaker Recognition. Under direction of AGUS BUONO and BIB PARUHUM SILALAHI
Noise on the speech signal is a major factor that affects the accuracy of the results of signal processing, realized on the fact there is no signal that does not contain noise, which can be caused by background noise at the source of speaking, or because the transmission process when the signal is received. One method that is popular and is often used to reduce the noise is a wavelet transform, which reduces noise (denoising) of the signal with sorting and then eliminating the signals with certain criteria, as a way to determine which parts of the real signal or not, who then called wavelet thresholding. Wavelet used to analyze the signal based scaling, the wavelet transform is obtained by dividing the signal into multiple sizes as representatives from the fields of different frequencies. In other words, a wavelet is a wave pieces (small) and wavelet transformation to convert the signal into a series of wavelets and then analyzed the frequency and duration limits.
White Gaussian noise is used to represent the actual noise, the level of Signal to Noise Ratio (SNR) that is used by 20dB, 10dB and 0dB, is added to each voice signal. Sound signals that have been added noise is then denoising with wavelet thresholding process before being used in speaker recognition process.
Due to the signal obtained has a variety of wavelengths as well as changes in the characteristics of the speech source is relatively small, the Mel-frequency cepstral coefficient is used to extract the feature of each speech signal into a small number of coefficients of the same size, in addition to the reasons mentioned above feature extraction useful in facing the large size of data, to reduce the resource requirements necessary when analyzing the data.
Learning Vector Quantization is a pattern classification method into a class or a particular category based on competition. LVQ network is a network that consists of 2 layers of input and output layer, the input layer contains as many neurons dimensional input and output layers containing neurons as an existing class. Both layers are connected by a link that has a certain weight. The weights of the neuron input to the neuron output a vector that represents the class, which is then called a reference vector.
The aim of this study, to get a result from the speaker recognition by using the original speech signal and the speech signal denoising result of the process, with a speech signal source used as many as 20 sources that are stored in WAV format, with each source is recorded as many as 30 times. Then the voice signals are copied into three groups consisting of a complete signal, the signal is segmented into two parts and into five sections.
data denoising result is greater than the data before denoising that is equal to 95.00% of the original data, 72.50% for SNR 20dB, 10dB SNR 20.00% for and 10.83% for 0dB SNR. As for the third data group, the original data produces the same relative accuracy between the results of denoising and before denoising that is equal to 95.00%, while for the SNR 20dB provide value 72.50%, 18.33% to 10.83% and 10dB SNR for 0dB SNR.
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
WAVELET DAN LEARNING VECTOR QUANTIZATION
UNTUK PENGENALAN PEMBICARA
ASYUR ZALDI
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2015
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains
Pada
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia dan rahmat-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan April 2014 ini adalah pengenalan pembicara pada lingungan bernoise, dengan judul Wavelet dan
Learning Vector Quantization untuk Pengenalan Pembicara.
Terima kasih penulis ucapkan kepada Bapak Dr Ir Agus Buono, MSi MKom dan Bapak Dr Ir Bib Paruhum Silalahi, MKom selaku pembimbing yang telah banyak memberi ide dan saran. Ucapan terima kasih juga penulis sampaikan kepada istri tercinta Silvina Ansari, ananda Farhan Rabbaanii, Fahmi Akmal Zain serta Fikri Aufaa Zain dan keluarga besar Djunit atas segala doa dan kasih sayangnya.
Penghargaan penulis sampaikan kepada Bapak Olden Manabung selaku Technical Solutions Manager PT Coca-Cola Distribution Indonesia serta Bapak Agus Dwi Atmoko selaku Manager System Informasi PT Rekitt Benckiser Indonesia yang telah memberikan waktu luang dan izin bagi penulis, keluarga besar mahasiswa Ilmu Komputer IPB angkatan 14, seluruh staff tata usaha dan seluruh pihak yang belum disebutkan namanya yang telah banyak membantu hingga selesainya karya ilmiah ini.
Semoga karya ilmiah ini bermanfaat.
Bogor, Agustus 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
2 TINJAUAN PUSTAKA 3
Wavelet 3
Thresholding 4
Trasnformasi Paket Wavelet 6
Ekstraksi Ciri 7
Learning Vector Quantization 8
3 METODE 10
Tahapan Penelitian 10
Bahan dan Data 14
Alat 14
4 HASIL DAN PEMBAHASAN 14
Praproses 14
Denoising 16
Pembuatan Data Latih 17
Pengujian 18
5 SIMPULAN DAN SARAN 27
DAFTAR PUSTAKA 27
LAMPIRAN 29
DAFTAR TABEL
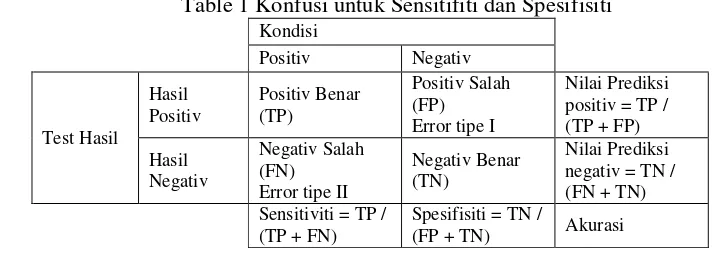
1 Konfusi untuk Sensitifiti dan Spesifisiti 13
2 Setup pembagian data pada proses pengujian 18
3 Tingkat akurasi pengenalan menggunakan data latih non denoising dengan data
uji non denoising dan denoising 18
4 Tingkat akurasi pengenalan menggunakan data latih denoising dengan data
uji non denoising dan denoising 19
5 Matriks konfusi untuk kelompok data pertama “ILMU KOMPUTER” 19 6 Tingkat akurasi pengenalan menggunakan data latih non denoising dengan data
uji non denoising dan denoising 20
7 Tingkat akurasi pengenalan menggunakan data latih denoising dengan data uji
non denoising dan denoising 21
8 Matriks konfusi untuk kelompok data kedua “ILMU” “ KOMPUTER” 21 9 Tingkat akurasi pengenalan menggunakan data latih non denoising dengan data
uji non denoising dan denoising 22
10 Tingkat akurasi pengenalan menggunakan data latih denoising dengan data uji
non denoising dan denoising 22
11 Matriks konfusi untuk kelompok data pertama “IL” “MU” “KOM” “PU” “TER” 22 12 Tingkat akurasi terbesar dari proses pengenalan untuk data latih nondenoising
dengan data uji non denoising dan denoising 23
13 Tingkat akurasi terbesar dari proses pengenalan untuk data latih denoising
dengan data uji non denoising dan denoising 23
DAFTAR GAMBAR
1 Sinyal non-stationer (suara) 3
2 Hard Threshold 5
3 Soft Threshold 5
4 White Gaussian Noise 6
5 Pohon dekomposisi tiga level transformasi paket wavelet 7
6 Learning Vector Quantization neural net 9
7 Blok Diagram aktifitas Pengenalan Pembicara 10
8 Penambahan WGN pada Sinyal suara 11
9 Coif4 11
10 Penghilangan jeda pada sinyal suara 14
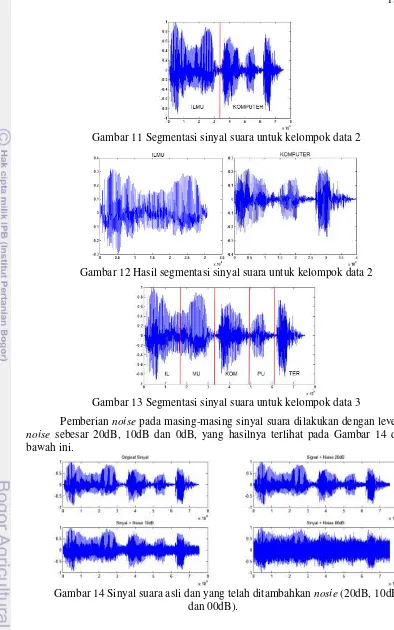
11 Segmentasi sinyal suara untuk kelompok data 2 15
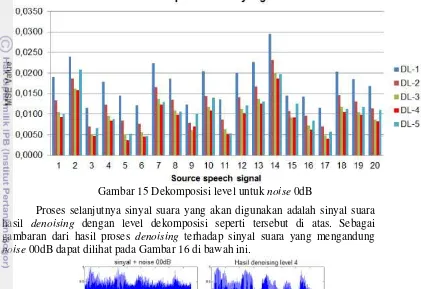
12 Hasil segmentasi sinyal suara untuk kelompok data 2 15
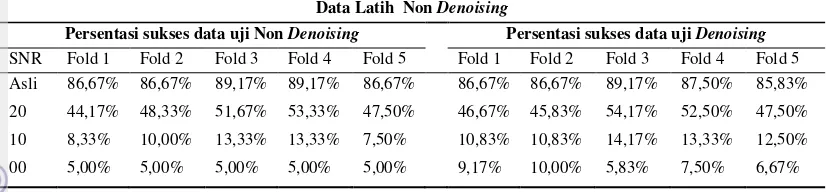
13 Segmentasi sinyal suara untuk kelompok data 3 15
14 Sinyal suara asli dan yang telah ditambahkan nosie (20dB, 10dB dan
00dB) 15
15 Dekomposisi level untuk noise 0dB 16
16 Sinyal bernoise 00dB dan hasil denoising pada LD = 4 16
17 MFCC sinyal asli dan sinyal bernoise 17
18 MFCC sinyal asli dan sinyal denoising 17
19 Tingkat pengenalan data latih nondenoising dengan data uji
20 Tingkat pengenalan data latih nondenoising dengan data uji denoising 24 21 Tingkat pengenalan data latih denoising dengan data uji nondenoising 24 22 Tingkat pengenalan data latih denoising dengan data uji denoising 24 23 Tingkat akurasi pengenalan pembicara untuk ketiga kelompok data 24
24 Sinyal suara asli dengan Spektrumnya 25
25 Sinyal suara dengan noise sebesar 0dB dengan spektrumnya 25 26 Sinyal suara hasil denoising dan spektrumnya 25 27 Spectogram dari sinyal yang ditampilkan pada gambar 23, 24 dan 25
diatas 26
DAFTAR LAMPIRAN
1 Metode Perekaman Suara 29
2 MSE hasil dekomposisi sinyal suara “ILMU KOMPUTER”, untuk
masing-masing noisenya 30
3 MSE hasil dekomposisi sinyal suara “ILMU”, untuk masing-masing
noise yang ada 31
4 MSE hasil dekomposisi sinyal suara “KOMPUTER”, untuk noise yang
ada 32
1
PENDAHULUAN
Latar Belakang
Suara adalah hal penting bagi manusia, yang digunakan sebagai alat komunikasi dan bertukar informasi. Juga berpotensi untuk digunakan sebagai alat berinteraksi dengan komputer (mesin), sehingga komputer dapat mengenali suara pembicara. Ini dimungkinkan bilamana sinyal suara yang dikirim tidak mengalami intervensi dari sinyal lain yang tidak diperlukan (noise) atau bersih dari noise, sehingga dapat diproses dengan benar.
Pada kenyataannya tidak ada sinyal yang tidak mengandung noise, keberadaan noise pada sinyal suara dapat mempengaruhi dan menurunkan performa dari proses yang akan menggunakannya oleh karenanya perlu dihilangkan (Verma & Verma, 2013), penyebab adanya noise mungkin saja dikarenakan suara latar belakang ditempat sumber berbicara, atau karena proses transmisi pada saat sinyal diterima (Kansara & Chapatwala, 2013), oleh karenanya diperlukan cara untuk menghilangkan/ mengurangi noise tersebut, atau dikenal kemudian sebagai denoising/ noise reduction. Pada dasarnya denoising
merupakan usaha untuk menghilangkan noise (mengurangi/ mereduksi) yang terkandung pada sinyal, dengan cara memilah dan mengeleminir sinyal yang tidak masuk kriteria tertentu. Metode yang digunakan untuk denoising disini adalah transformasi Wavelet, merupakan metode yang sering digunakan pada speech denoising (Aggarwal, et al., 2011) dan menjadi salah satu teknik yang sangat menjanjikan untuk memproses sinyal (Kansara & Chapatwala, 2013), caranya dengan membagi koefisien wavelet dan kemudian koefisien tersebut disusutkan (shrinkink) dalam domain wavelet (Goel & Jain, 2013). Pada dasarnya wavelet digunakan untuk menganalisa sinyal berdasar penyekalaan (scale), transformasi wavelet diperoleh dengan membagi sinyal menjadi beberapa ukuran sebagai perwakilan dari bidang frekuensi yang berbeda (Aggarwal, et al., 2011). Dengan kata lain, wavelet merupakan potongan gelombang (kecil) dan transformasi wavelet mengkonversi sinyal menjadi sederetan wavelet, dan kemudian dianalisa dalam batasan frekuensi dan durasinya.
Sebelum Learning Vector Quantization (LVQ) menggunakan sinyal suara yang ada untuk menghasilkan vector reference (vektor latih), terlebih dahulu dilakukan ekstraksi ciri untuk setiap sinyal suara dengan menggunakan Mel-frequency cepstral coefficients (MFCC), yang kemudian digunakan untuk proses pengenalan pembicara dengan cara menghitung jarak Euclidian antara sinyal suara (vektor masukan) dengan vektor ciri dari sinyal suara yang telah dibangun sebelumnya (Fausett, 1994).
Perumusan Masalah
2
mengurangi noise yang terkandung pada sinyal suara. Learning Vector Quantization digunakan untuk membuat model suara dari pembicara.
Tujuan Penelitian
Membangun model pengenalan suara menggunakan wavelet dan Learning Vector Quantization, dengan Mel-frequency cepstrum coefficients sebagi ekstraksi ciri.
Manfaat Penelitian
Menghasilkan data yang telah berkurang noisenya, dan meningkatkan tingkat akurasi dari proses pengenalan pembicara dengan metode LVQ. Menjadi bahan acuan penggunaan wavelet pada proses denoising, serta informasi aplikasi LVQ pada pemrosesan sinyal.
Ruang Lingkup
1 Identifikasi pembicara bersifat text dependent, dengan mengucapkan kata “ILMU KOMPUTER”. Proses perekaman suara dilakukan dengan menggunakan aplikasi Audacity 2.0.5 dengan tingkat frekuensi sebesar 44100 Hz dengan channel mono, banyaknya pembicara yang direkam sebanyak 20 orang (12 pria, dan 8 wanita).
2 White Gaussian noise digunakan sebagai simulasi dengan tingkatan noise
20dB, 10dB dan 0dB
3 Transformasi paket wavelet dengan Soft Thresholding digunakan sebagai aturan thresholdnya, dengan mother wavelet yang digunakan disini Coiflet orde 4.
4 Level dekomposisi diperoleh dari nilai Mean Square Error sinyal suara terkecil.
5 Mel-frequency cepstrum coefficients (MFCC) digunakan untuk mengkestrak ciri sinyal suara, bertujuan untuk memperkecil dimensi serta menyamakan panjang/ ukuran dari vektor sinyal suara
3
2
TINJAUAN PUSTAKA
Wavelet
Tidak seperti halnya Transformasi Fourier, Wavelet dapat digunakan untuk menganalisa sinyal yang non-stasioner dengan waktu yang beragam (Kansara & Chapatwala, 2013), ini sangat penting dikarenakan sinyal suara adalah sinyal non-stasioner dengan waktu yang berbeda-beda serta sinyal yang bersifat sementara (Dubey & Gupta, 2013), seperti terlihat pada Gambar 1. Sebagai alternative dari Short Time Fourier Transform (STFT) yang menggunakan jendela tunggal untuk seluruh sinyal yang ada, transformasi wavelet memiliki ide dasar penganalisaan berdasar pada penyekalaan, yaitu dengan menggunakan jendela yang kecil untuk frekuensi tinggi dan jendela yang lebar untuk frekuensi rendah (Kansara & Chapatwala, 2013).
Gambar 1 Sinyal non-stationer (suara)
Bila ( ) adalah induk wavelet (mother wavelet), maka bentuk Continue Wavelet Transform (CWT) diperoleh melalui multi-resolution (Stephane, 1989) dengan melakukan sejumlah proses dilatasi serta translasi dari fungsi wavelet masing-masing sebanyak a dan b (Aggarwal, et al., 2011), dengan kata lain CWT merupakan pergeseran dan penyekalaan sejumlah fungsi ( ), seperti tertulis pada persamaan (1)
, ( ) = 1 − … … … (1)
Dengan , ∈ , ≠ 0. Untuk fungsi ( ) CWT nya seperti pada persamaan (2)
( , ) = 1 − ( ) … … … (2)
dengan a merupakan nilai dilatasi (skala) yang berhubungan dengan frekuensi dan b nilai translasinya, yang berhubungan dengan posisi pergeseran dari fungsi wavelet sepanjang sinyal, yang berkorespondensi dengan waktu.
Pada prakteknya, transformasi yang digunakan adalah discrete wavelet transform (DWT), yang mentransformasikan sinyal diskrit menjadi koefisien diskrit dalam domain wavelet, yang berkerja pada a,b ∈R dengan a dan b bernilai sesuai persamaan (3). Untuk memfasilitasi komputer analisis dan proses, nilai dari
X(a,b) dihitung pada area diskrit seperti tertulis pada persamaan (4)
= 2#, = $. 2#, &'( ' ), $ ∈ * … … … (3)
4
( , ) = 2,-. / ( )
0 1
234
52 #' − $6 … … … (4)
Transformasi wavelet akan memecah sinyal menjadi sejumlah sinyal sebagai hasil penyekalaan dan pergeseran dari mother wavelet, oleh karenanya transformasi wavelet merupakan multi-resolution analysis yang sesuai untuk menganalisa sinyal non-stationer seperti sinyal audio.
Thresholding
Banyak metode thresholding ditawarkan berdasarkan pada teknik universal threshold dan adaptive (Sutha, et al., 2013), yang merupakan suatu cara untuk membuang noise atau me-rekonstruksi sinyal asli dari sinyal yang mengandung
noise dengan menggunakan koefisien wavelet dari hasil proses dekomposisi transformasi wavelet, yaitu dengan cara mengeleminir koefisien wavelet dari
noise sementara itu koefisien wavelet yang berguna akan dibiarkan (Huimin C et al.,2012). Pendekatannya adalah setiap koefisien wavelet dibandingkan dengan nilai threshold yang dipilih, sebagai cara untuk menentukan bagian dari sinyal sesungguhnya atau bukan, dan cara ini yang kemudian disebut dengan wavelet thresholding.
Thresholding pada koefisien wavelet biasanya digunakan pada detail koefisien #8 dari y, tidak pada koefisien aproksimasi 9#8, karena yang disebutkan terakhir mewakili bagian “low-frequency” yang memuat bagian terpenting dari sinyal, dan kurang terpengaruh oleh noise. Misal diberikan nilai threshold sebesar :, maka nilai koefisien dijadikan nol bila nilai absolutnya di bawah nilai threshold. Bila thresholdnya kecil, hasilnya akan mendekati sinyal input dan sinyal masih mengandung noise, sedangkan bila nilai threshold besar maka akan menghasilkan sinyal dengan sejumlah koefisien yang bernilai nol, hasilnya akan menghalusnya sinyal dari noise, sebagai akibatnya akan banyak kehilangan detail dari sinyal (Mupparaju & Satya Durga Jahnavi, 2013).
Donoho memperkenalkan metode menthreshold koefisien wavelet yaitu dengan aturan hard atau soft thresholding (Donoho, 1995), yang dituliskan pada persamaan (5) dan (6) di bawah ini.
1. Hard thresholding, pada threshold ini untuk nilai dari harga mutlak koefisien wavelet bila lebih kecil dengan nilai threshold yang diberikan akan di ganti menjadi 0 (nol) dan tidak untuk selainnya (Donoho & Johnstone , 1994), perhatikan Gambar 2.
;λ<( ) = =0 > > ≤λ
5
Gambar 2 Hard Threshold
2. Soft thresholding, pada threshold ini bila nilai harga mutlak dari koefisien wavelet lebih kecil dari nilai threshold, maka nilai koefisien akan diganti menjadi 0 (nol), selainnya hanya akan mengurangi ketinggian dari sinyal, perhatikan Gambar 3.
;λB( ) = =0 > > ≤ λ
CD('( )5> > −λ6> > >λ … … … (6)
Gambar 3 Soft Threshold 3. Universal threshold
Jika nilai threshold ditentukan terlalu besar, maka akan menyebabkan hilangnya sinyal yang asli dan jika nilainya terlalu kecil proses thresholding tidak akan menghasilkan seperti yang diharapkan. Salah satu metode untuk memilih nilai threshold dibuat oleh Donoho dan Johnstone seperti terlihat pada persamaan (7), dan di sebut sebagai Universal Threshold (Donoho & Johnstone , 1994).
ℎG = H I2log(L) … … … (7) dengan N merupakan banyaknya sample dari noise dan sigma merupakan standard deviasi dari noise, yang ditulis dalam persamaan (8) berikut ini.
6
MAD = Median Absolute Deviation, dengan c merupakan koefisien wavelet. 4. Noise
Noise digambarkan sebagai sinyal yang tidak diharapkan yang mempengaruhi suatu sinyal. Salah satunya adalah white gaussian noise (independent and identically distributed – iid) (Donoho, 1995) yang dinotasikan sebagai ST ∽TTVL(0,1), yang merupakan random sinyal dengan tingkat spektrum yang tetap seperti terlihat pada Gambar 4 di bawah ini
Gambar 4 Gaussian White Noise
Gaussian White Noise merupakan noise yang sudah umum dijadikan sebagai model untuk menirukan kejadian pada umumnya.
Jika (') adalah sinyal input yang bebas dari noise, W(') adalah white gaussian noise, maka sinyal bernoise secara matematis ditulis pada persamaan (9)
X(') = (') + W(') … … … (9)
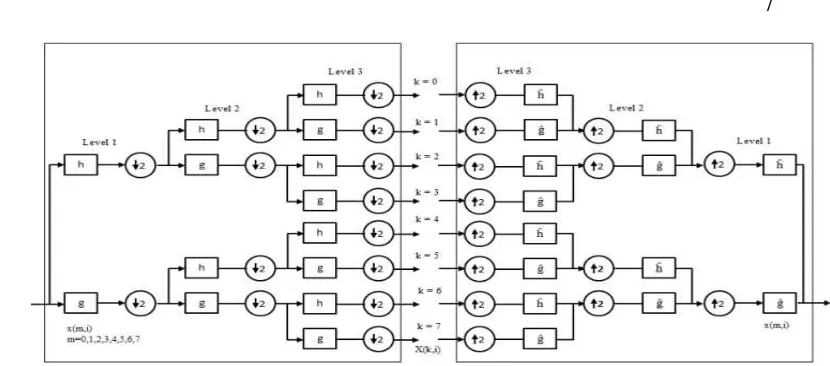
Transformasi Paket Wavelet
Transformasi paket wavelet merupakan pengembangan dari transformasi wavelet, yang memberikan penyelesaian untuk frekuensi rendah dan frekuensi tinggi. Pada Gambar 5 di bawah ini, terlihat dekomposisi dan rekonstruksi dari transformasi paket wavelet, dimana frekuensi rendah dan tinggi dibagi menjadi dua sub group. Dengan g-high pass filter, dan h-low pass filter, keluaran dari filter ini dibagi menjadi 2 dan diperoleh koefisien baru yaitu koefisien aproksimasi dan koefisien detil, proses ini dilakukan hingga level 3. Selanjutnya digunakan wavelet thresholding (hard atau soft thresholding) untuk mengurangi noise yang terkandung pada sinyal. Pada paket wavelet koefisien frekuensi tinggi dan rendah sama-sama didekomposisi, dimana untuk transformasi wavelet biasa hanya aproksimasi koefisien yang didekomposisi sementara detail koefisien dithreshold
7
Gambar 5 Pohon dekomposisi tiga level transformasi paket wavelet (Kansara & Chapatwala, 2013)
Ekstraksi Ciri
Sinyal suara memiliki beragam informasi tentang sumbernya seperti dialek, gaya bicara dan juga emosi, serta intensitas, frekuensi, bandwith dan lainnya yang dihasilkan pada saat sinyal suara dibuat. Jumlah data yang dihasilkan cukup besar sedangkan perubahan karakteristik dari suara relative lambat/ sedikit, sehingga data yang diperlukan relative kecil untuk mewakili karakteristik sumber suara. Oleh karenanya ekstraksi ciri digunakan untuk mengurangi ukuran data tanpa menghilangkan karakteristik sumber suara itu sendiri.
Selain yang disebutkan diatas ekstraksi ciri berguna dalam menghadapi data ukuran yang besar, yaitu untuk mengurangi kebutuhan sumber daya yang diperlukan. Saat menganalisa data, semakin banyak variable yang terlibat artinya akan membutuhkan memory yang cukup besar dan kemampuan perhitungan atau algoritme klasifikasi yang sesuai. Metode ekstraksi ciri yang digunakan disini adalah Mel-frequency Cepstral Coefficient (MFCC), merupakan metode yang sering digunakan untuk mengekstraksi ciri pada area pemrosesan sinyal suara (Abdalla, et al., 2013). Ada beberapa proses yang perlu dilalui untuk mendapatkan
coefficient pada proses MFCC ini yaitu; Frame Blocking, Windowing, Fast Fourier Transform, Mel-Frequency Wrapping, dan Cepstrum.
Frame Blocking, melakukan proses segmentasi pada sinyal suara dan menjadikannya beberapa frame yang saling tumpang tindih (overlap). Pada langkah ini sinyal di blok menjadi frame yang kecil sebanyak N sampel dengan frame selanjutnya dipisahkan dengan M sample (M<N), yang menyebabkan frame tumpang tindih sebanyak N-M sampel. Sudah menjadi standar para peneliti menggunakan nilai N = 256 dan M =100 dengan alasan pembagian ini sudah cukup untuk mendapatkan informasi, parameter ini sudah umum digunakan setiap proses menggunakan MFCC (Gupta, et al., 2013), proses ini membagi sinyal menjadi sejumlah frame hingga semua sinyal menjadi potongan sejumlah frame yang kecil.
Windowing, Sebagai hasil dari proses frame blocking sinyal dibaca per
8 Fast Fourier Transform sebagai algoritme yang digunakan untuk mengimplementasikan Discrete Fourier Transform, yang mengubah frame N sampel dari domain waktu ke domain frekuensi, dan hasilnya biasa disebut sebagai spectrum yang didefinsikan pada persamaan (12) berikut ini.
^= / 2
0 1
234 &
#_`82/0, $ = 0,1, … , L − 1 … … … (12)
Mel-Frequency Wrapping, mel-frequency merupakan skala frekuensi rendah yang bersifat linier di bawah 1000 Hz dan frekuensi tinggi lebih besar dari 1000 Hz, yang hubungan antara skala mel dan frekuensi dalam Hz ditulis pada persamaan (13) di bawah ini.
Q&b(c) = 2595 ∗ be(10 1 +700 … … … (13)c Cepstrum merupakan langkah untuk mengubah spectrum log mel menjadi domain waktu yang hasilnya kemudian disebut sebagai Mel-frequency Cepstrum Coefficient (MFCC). Koefisien mel spectrum berupa bilangan riil sehingga dapat dikonversi kedalam domain waktu dengan Discrete Cosine Transform (DCT), yang ditulis pada persamaan (14).
Learning Vector Quantization adalah metode pengklasifikasian pola kedalam suatu kelas atau kategori tertentu yang didasarkan pada kompetisi. Jaringan LVQ adalah jaringan 2 lapis yang terdiri dari lapis masukan dan lapis keluaran seperti terlihat pada Gambar 6, dengan lapis masukan mengandung
neuron sebanyak dimensi masukan, dan lapis keluaran mengandung neuron
sebanyak kelas yang ada. Kedua lapisan tersebut dihubungkan dengan penghubung yang memiliki bobot tertentu. Bobot dari neuron masukan yang menuju neuron keluaran berupa vektor yang mewakili kelasnya, yang kemudian disebut juga sebgai vector reference (Fausett, 1994).
9
Gambar 6 Learning Vector Quantization neural net (Fausett, 1994) Algoritme, tujuan dari LVQ adalah mencari unit keluaran yang mendekati vektor masukan. Selanjutnya jika x dan w dimiliki oleh kelas yang sama maka bobot diarahkan ke vektor inputan yang baru, sedangkan jika x dan w berasal dari kelas yang berbeda maka bobot diarahkan menjauh dari vektor masukan.
X : vektor latih ( 1, … , T, …, X)
T : Katagori yang benar atau kelas untuk vektor latih.
W# : faktor bobot untuk output unit yang ke j(W1#, … , WT#, … , W2#) f# : katagori/ kelas yang diwakili oleh unit output yang ke j
lX − n#l : jarak Euclidean antara vektor input dan (faktor bobot untuk) unit output yang ke j
Langkah 0. Menginisialisasi vektor referen, dan inisialisasi rate pelatihan (0) Langkah 1. Selama kondisi berhenti tidak terpenuhi, lakukan Langkah 2-6
Langkah 2. Untuk setiap vektor input x, lakukan Langkah 3-4 Langkah 3. Cari nilai j sehingga lX − n#l minimum Langkah 4. Ubah W# sebagai berikut
Jika T = f#, maka
W#('&W) = W#(eb ) + op − W#(eb )q
Jika T f#, maka
W#('&W) = W#(eb ) − op − W#(eb )q
Langkah 5. Kurangi rate pembelajaran
Langkah 6. Uji kondisi berhenti, kondisi ini bisa ditentukan dengan sejumlah iterasi (yaitu dieksekusinya Langkah 1.) atau nilai rate pembelajaran mencapai nilai tertentu yang cukup kecil.
10
3
METODE
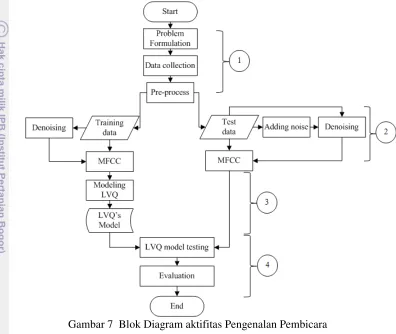
Tahapan Penelitian
Secara umum penelitian ini dapat dibagi menjadi 4 bagian besar, yang secara alur diagramnya terlihat pada Gambar 7, yang terdiri dari praproses, proses
denoising, dilanjutkan pembuatan vektor latih dengan LVQ, dan pengujian.
Gambar 7 Blok Diagram aktifitas Pengenalan Pembicara 1 Praproses
Pengambilan data/ perekaman suara asli diperoleh dari duapuluh sumber suara (12 pria, 8 wanita), direkam sebanyak tiga puluh kali dengan mengucapkan kata “ILMU KOMPUTER” dengan beberapa format seperti terlihat pada Lampiran 1, dengan frekuensi perekaman sebesar 44100Hz. Data yang didapat dari hasil perekaman diduplikat menjadi 3 kelompok, yang setiap kelompoknya digunakan sebagai data penelitian.
Data lengkap “ILMU KOMPUTER”
Data disegmentasi menjadi dua, “ILMU” dan “KOMPUTER” Data disegmentasi menjadi lima, “IL” “MU” “KOM” “PU” “TER”
Lakukan proses normalisasi dan pembuangan bagian silence pada ketiga kelompok data di atas, selanjutnya sinyal ditambahkan White Gaussian Noise
11 terstruktur sehingga cukup sulit untuk di dideteksi dan dihilangkan, karena terdapat pada setiap frekuensi (Change, et al., 2000).
Gambar 8 Penambahan WGN pada Sinyal suara 2 Denoising
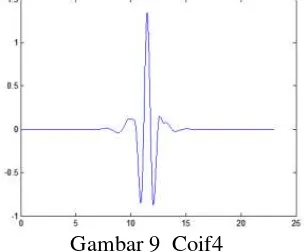
Pada prakteknya ada empat hal mendasar yang mempengaruhi Wavelet Threshold Denoising, yaitu pemilihan mother wavelet, pada penelitian ini Coiflet (Gambar 9) dipilih sebagai mother wavelet karena yang terbaik untuk proses sinyal suara (Huimin, et al., 2012).
Gambar 9 Coif4
12
2009) selanjutnya dipilih nilai MSE yang terkecil untuk setiap sinyal yang diproses, sementara estimasi nilai threshold menggunakan universal threshold dan aturan thresholding yang digunakan adalah softthreshold.
Mean Square Error (MSE) digunakan untuk mengukur perbedaan antara hasil proses yang dilakukan pada suatu sinyal dengan sinyal aslinya. Dengan mengandung noise, sedangkan persamaan (16) berikut merupakan MSE untuk sinyal sebagai hasil dari denoising.
Nhv = L w/( (')1 0
231
− y('))_x … … … (16)
Dengan z{(|) merupakan sinyal hasil denoising, dari kedua persamaan di atas (15) dan (16), denoising dikatakan berhasil bila MSE (16) hasilnya lebih kecil dari MSE (15) (Aggarwal, et al., 2011).
Ekstraksi ciri, Mel-frequency Cepstral Coefficient (MFCC) sebagai ekstraksi ciri yang telah banyak digunakan pada pemrosesan sinyal suara, dengan argument yang digunakan sampling rate 44100 Hz, time frame 25 ms, dan overlap
0,75 dengan coefficientcepstralnya 13.
3 Pembuatan vek tor la tih
Metode K-Fold Cross Validation digunakan sebagai cara untuk membagi dan menggunakan data untuk keperluan penelitian (cara membagi data latih dan data uji), dengan cara membagai data sample menjadi K subset. Jika satu subset sebagai data uji maka K-1 subset digunakan sebagai data latih, proses cross validation ini akan diulang hingga K-1 kali. Pada penelitian ini dipilih K=5, 5-fold cross validation yaitu data yang ada dijadikan 5 subset yaitu f1, . . . ,f5 dengan masing-masing subset memiliki ukuran yang sama (sebanyak 6). Pada proses pertama f2, … ,f5 menjadi data latih sementara f1 menjadi data uji, selanjutnya untuk yang kedua f1, f3, …, f5 menjadi data latih sementara f2 penjadi data uji,
proses dilanjutkan hingga f5 sebagai data uji. Yang datanya untuk fold pertama
diilustrasikan pada Table 1 di bawah ini.
Dengan metode pembagian data di atas, vektor ciri dari proses MFCC digunakan untuk membuat vektor latih dengan menggunakan LVQ dengan menggunakan data asli / yang belum ditambahkan noise, ada dua vektor latih yang dibuat pertama data asli yang tidak melalui proses denoising dan data asli yang dilakukan proses denoising. Dengan parameter LVQ yang digunakan seperti
13 4 Pengujian
Pengenalan pembicara dilakukan dengan menggunakan data latih hasil dari LVQ di atas. Yang kemudian dilakukan pengukuran jarak minimum antara sinyal suara masukan dengan data latih yang ada dengan menggunakan Euclidean Distance, seperti pada persamaan (17), mencari nilai j sehingga
l − W#l = }/( − W#)_ ⇒ minimum … … … (17)
dengan sebagai vektor input dan W#weight vector untuk yang ke j
5 Evaluasi
Pengenalan pembicara digunakan oleh mesin untuk mengenali seseorang dari kalimat yang diucapkan, pengenalan pembicara dapat menggunakan dua mode, yang pertama digunakan untuk mengidentifikasi seseorang dan kedua untuk memverifikasi identitas seseorang. Sebagai hasil dari proses pengklasifikasian di atas, kemudian dihitung tingkat akurasinya, untuk setiap data uji akan dilihat apakah data teridentifikasi dengan benar. Persentasi dari tingkat keakurasian dihitung dengan menggunakan rumus (18) di bawah ini.
rD'($ $‚G CD = ƒ h‚ G X '( &' G D$&' bDƒ h‚ G X '( D‚)D 100% … … … … (18)
Sensitifity dan spesifisity
Sensitivity – kemampuan untuk mengidentifikasi kondisi dengan benar, yang secara matematis ditulis pada rumus (19) di bawah ini.
C&'CD DcD D = ƒ …†‡ƒ ˆ0ƒ …† … … … (19) Specifisity - kemampuan menguji untuk mengeluarkan kondisi dengan benar, yang secara matematis ditulis pada persamaan (20) di bawah ini.
C‰&CDcDCD D = ƒ rL + ƒ Š‹ … … … (20)ƒ rL True Positive (TP) adalah data suatu kelas yang berhasil diidentifikasi dengan benar pada kelasnya. False Negative (FN) adalah data suatu kelas yang gagal teridentifikasi dikelasnya. True Negative (TN) adalah data yang bukan pada kelas yang diuji dan hasilnya tidak sama. False Positive (FP) adalah data yang bukan pada kelasnya memberikan hasil pada kelas yang diuji. Dengan table komfusinya diperlihatkan pada Tabel 1.
14
Bahan dan data
Sinyal suara diperoleh dengan merekam sebanyak 30 kali dari 12 sumber suara pria dan 8 sumber suara wanita, dengan hasil perekaman file berekstensi WAV dengan 44100Hz sampling rate dan pada mono-channel.
Alat
1 Perangkat Keras
Notebook Intel Core i3 CPU 1.33GHz Memory 4.00 GB
Harddisk 500GB 2 Perangkat Lunak
Sistem operasi Window 7 Professional 64 bit. Matlab R2014a
4
HASIL DAN PEMBAHASAN
Praproses
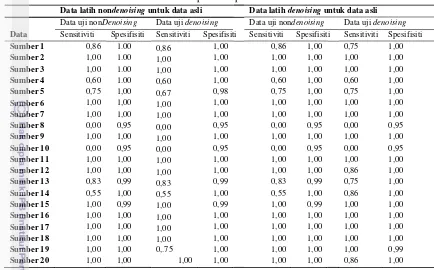
Penghilangan jeda pada awal dan akhir dari sinyal suara dilakukan seperti terlihat pada Gambar 10a, kemudian dilanjutkan dengan proses normalisasi dengan membagi setiap sinyal suara dengan absolut dari nilai maksimum sinyal suara itu sendiri, yang hasilnya terlihat pada Gambar 10b. Setiap sinyal suara dari hasil proses ini ditambahkan noise dengan tingkatan 20dB, 10dB dan 00dB seperti terlihat pada Gambar 14, yang akan digunakan pada proses denoising dan kemudian pada proses pengenalan pembicara, sementara Gambar 11, 12 dan 13 merupakan proses segmentasi dari sinyal suara.
15
Gambar 11 Segmentasi sinyal suara untuk kelompok data 2
Gambar 12 Hasil segmentasi sinyal suara untuk kelompok data 2
Gambar 13 Segmentasi sinyal suara untuk kelompok data 3
Pemberian noise pada masing-masing sinyal suara dilakukan dengan level
noise sebesar 20dB, 10dB dan 0dB, yang hasilnya terlihat pada Gambar 14 di bawah ini.
16
Denoising
Pada Gambar 15 di bawah ini diperlihatkan nilai terkecil dari hasil perhitungan MSE setelah sinyal suara melalui proses denoising untuk sinyal bernoise 0dB, yaitu pada level 4.
Gambar 15 Dekomposisi level untuk noise 0dB
Proses selanjutnya sinyal suara yang akan digunakan adalah sinyal suara hasil denoising dengan level dekomposisi seperti tersebut di atas. Sebagai gambaran dari hasil proses denoising terhadap sinyal suara yang mengandung
noise 00dB dapat dilihat pada Gambar 16 di bawah ini.
Gambar 16 Sinyal bernoise 00dB dan hasil denoising pada LD = 4
Mel-frequency cepstral coefficient
Mel-frequency cepstral coefficient (MFCC) digunakan untuk melakukan ekstraksi ciri pada setiap sinyal suara yang ada, dengan prosesnya diperoleh dari http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html , dengan parameter yang digunakan untuk frame duration = 25, frame shift = 10, preemphasis coefficient = 0.97, cepstral coefficient = 13.
Untuk perbandingan dari hasil proses MFCC diperlihatkan pada Gambar 17 merupakan MFCC sebelum proses denoising, dan Gambar 18 hasil dari
17
Hasil ekstraksi ciri dari data asli yang tidak ditambahkan noise, digunakan pada proses pengklasifikasian dengan mengunakan LVQ untuk menghasilkan vektor ciri, dengan nilai parameter learning rate yang digunakan sebesar 0,98, penurunan learning rate sebesar 0.006, bobot awal diambil dari salah satu anggota dari subset K-1 data dengan nilai epoch ditentukan sebanyak 160.
Dengan metode K-fold validation data dibagi sebanyak K subset dengan nilai K = 5, karena masing-masing sumber suara memiliki 30 data artinya untuk setiap K-Fold memiliki anggota sebanyak 6 data, maka untuk K = 1 data uji diambil dari data pertama sampai dengan data ke enam dengan data sisanya (24) menjadi data latih. Untuk K-Fold = 2, data uji yang digunakan adalah data yang ke tujuh hingga data dua belas sebagai data uji dengan sisanya menjadi data latih, dan seterusnya hingga mencapai K-Fold yang ke lima. Dengan demikian untuk setiap percobaan dilakukan sebanyak lima kali.
Proses dilakukan dengan membagi data uji menjadi 2 kelompok, yaitu data yang tidak didenoising dan data denoising. Demikian juga dengan data latih yang akan menjadi vektor ciri, memiliki 2 kelompok yang sama seperti terlihat pada Tabel 2, dengan masing-masing data tersebut memiliki lima proses (5 Fold).
Table 2 Setup pembagian data pada proses pengujian
Data Latih Data Uji
Data Asli Nondenoising Data lengkap Nondenoising
Data Asli Nondenosing Data lengkap Denoising
Data Asli Denoising Data lengkap Nondenoising
Data Asli Denoising Data lengkap Denoising
Data asli non denoising merupakan data latih yang dihasilkan dari data asli yang tidak melalui proses denoising, data ini kemudian dikombinasikan pengujiannya dengan data uji yang tidak didenoising dan yang didenoising. Begitu pula untuk Data asli denoising merupakan data latih yang diperoleh melalui proses denoising, dan kemudian diuji dengan menggunakan data uji
nondenoising dan data uji denoising, seperti tertulis pada tabel 6 di atas.
18
kelompok data tersebut. Proses pembagian data menjadi tiga kelompok yaitu dengan cara melakukan segmentasi terhadap sinyal suara seperti tertulis di bawah ini.
• Kelompok pertama data masih sama dengan saat perekaman suara “ILMU KOMPUTER”.
• Kelompok kedua, data dibagi menjadi dua bagian yaitu “ILMU” dan KOMPUTER”
• Kelompok ketiga, data dibagi menjadi 5 bagian yaitu “IL” “MU” “KOM” “PU” “TER”
Ketiga kelompok data tersebut akan digunakan pada setiap langkah dari proses yang telah dijabarkan di atas.
Pengujian
Secara umum proses verifikasi pembicara mengandung lima langkah: pembuatan data digital dari suara, ekstraksi ciri, penyesuaian pola, membuat keputusan menerima atau menolak dan pembuatan vektor referensi (CAMPBELL, JR, 1997), sebaik apapun algoritme yang digunakan pada pengenalan pembicara, kesalahan pada manusia seperti kesalahan pada pembacaan atau saat menyebutkan kata akan mengurangi performa. Proses melakukan pembadingan antara vektor ciri sebagai inputan dan vektor referensi yang ada berdasarkan pada jarak terdekat. 1 Kelompok data pertama “ILMU KOMPUTER”
Pada kelompok data pertama vektor ciri memiliki ukuran 13x1 sesuai dengan parameter yang diberikan pada proses MFCC di atas. Dengan matriks konfusinya dari sensitifiti dan spesifisiti proses pengenalan diperlihatkan oleh Tabel 5.
a. Data latih non denoising, perhatikan Table 3 di bawah ini, sisi kiri tabel menguji data latih dengan menggunakan data uji non denoising dan sisi kanan dengan menggunakan data uji denoising.
Untuk data uji non denoising nilai akurasi terbesar diberikan sinyal asli sebesar 89,17% yaitu pada Fold 3 dan Fold 4, untuk data dengan noise 20dB nilai akurasi terbesar diberikan Fold 4 sebesdar 53,33%, dan untuk data dengan noise 10dB nilai akurasi terbesarnya 13,33% diberikan oleh Fold 3 dan Fold 4, serta untuk data dengan noise 00dB memberikan nilai akurasi yang sama 5,00% untuk setiap Foldnya.
19 Table 3 Tingkat akurasi pengenalan menggunakan data latih non denoising
dengan data uji non denoising dan denoising
Data Latih Non Denoising
Persentasi sukses data uji Non Denoising Persentasi sukses data uji Denoising
SNR Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Fold 1 Fold 2 Fold 3 Fold 4 Fold 5
Asli 86,67% 86,67% 89,17% 89,17% 86,67% 86,67% 86,67% 89,17% 87,50% 85,83%
20 44,17% 48,33% 51,67% 53,33% 47,50% 46,67% 45,83% 54,17% 52,50% 47,50%
10 8,33% 10,00% 13,33% 13,33% 7,50% 10,83% 10,83% 14,17% 13,33% 12,50%
00 5,00% 5,00% 5,00% 5,00% 5,00% 9,17% 10,00% 5,83% 7,50% 6,67%
a. Data latih denoising, Table 4 di bawah ini adalah hasil dari proses uji dengan menggunakan data latih yang telah melalui proses denoising dengan data uji non denoising (sisi kiri tabel) dan data uji denoising (sisi kanan tabel).
Untuk data uji non denoising nilai akurasi terbesar diberikan sinyal asli sebesar 89,17% yaitu pada Fold 3 dan Fold 4, untuk data dengan noise 20dB nilai akurasi terbesar diberikan Fold 4 sebesdar 55,00%, dan untuk data dengan noise 10dB nilai akurasi terbesarnya 12,50% diberikan oleh Fold 3 dan 4, serta untuk data dengan noise 00dB memberikan nilai akurasi yang sama 5,00% untuk setiap Foldnya.
Untuk data uji denoising, untuk data asli nilai akurasi terbesar ada pada Fold 3 sebesar 89,17%, untuk data dengan noise 20dB memberikan nilai akurasi terbesar pada Fold 4 sebesar 55,83%, data dengan noise 10dB nilai akurasi terbesarnya diberikan oleh Fold 3 dengan nilai 13,33%, serta 10,00% diberikan oleh data dengan noise 00dB pada Fold 2.
Table 4 Tingkat akurasi pengenalan menggunakan data latih denoising
dengan data uji non denoising dan denoising
Data Latih Denoising
Persentasi sukses data uji Non Denoising Persentasi sukses data uji Denoising
SNR Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Fold 1 Fold 2 Fold 3 Fold 4 Fold 5
Asli 88,33% 88,33% 89,17% 89,17% 88,33% 88,33% 88,33% 89,17% 88,33% 88,33%
20 48,33% 44,17% 53,33% 55,00% 48,33% 46,67% 44,17% 53,33% 55,83% 47,50%
10 8,33% 9,17% 12,50% 12,50% 7,50% 10,83% 10,83% 13,33% 11,67% 10,83%
20
Table 5 Matriks konfusi untuk kelompok data pertama “ILMU KOMPUTER”
Data latih nondenoising untuk data asli Data latih denoising untuk data asli
Data uji nonDenoising Data uji denoising Data uji nondenoising Data uji denoising
Data Sensitiviti Spesifisiti Sensitiviti Spesifisiti Sensitiviti Spesifisiti Sensitiviti Spesifisiti
Sumber 1 0,86 1.00 0,86 1,00 0,86 1,00 0,75 1,00
2 Kelompok data ke dua “ILMU” “KOMPUTER”
Pada kelompok data kedua ini vektor cirinya memiliki ukuran 26x1 yang diperoleh dari hasil gabungan (ke bawah) data “ILMU” dengan ukuran 13x1 dan “KOMPUTER” dengan ukuran 13x1. Dengan matriks konfusinya dari sensitifiti dan spesifisiti proses pengenalan diperlihatkan oleh Tabel 8. a. Data latih non denoising, Tabel 6 berikut ini menunjukan hasil dari
pengujian data latih non denoising pada sisi kiri pengujian data latih dengan menggunakan data uji non denoising dan sisi kanan dengan menggunakan data uji denoising.
Untuk data uji non denoising nilai akurasi terbesar diberikan oleh data asli sebesar 94,17% oleh Fold 5, untuk data dengan noise 20dB nilai akurasi terbesar diberikan Fold 3 sebesdar 69,17%, dan untuk data dengan
21 Table 6 Tingkat akurasi pengenalan menggunakan data latih non denoising
dengan data uji non denoising dan denoising
Data Latih Non Denoising
Persentasi sukses data uji Non Denoising Persentasi sukses data uji Denoising
SNR Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Fold 1 Fold 2 Fold 3 Fold 4 Fold 5
Asli 90,83% 92,50% 91,67% 92,50% 94,17% 90,83% 92,50% 91,67% 92,50% 94,17%
20 57,50% 60,00% 69,17% 65,00% 68,33% 60,00% 60,83% 70,83% 63,33% 68,33%
10 11,67% 15,00% 17,50% 16,67% 14,17% 12,50% 11,67% 16,67% 17,50% 18,33%
00 5,00% 5,00% 5,00% 5,00% 5,00% 5,83% 10,83% 5,83% 5,83% 5,00%
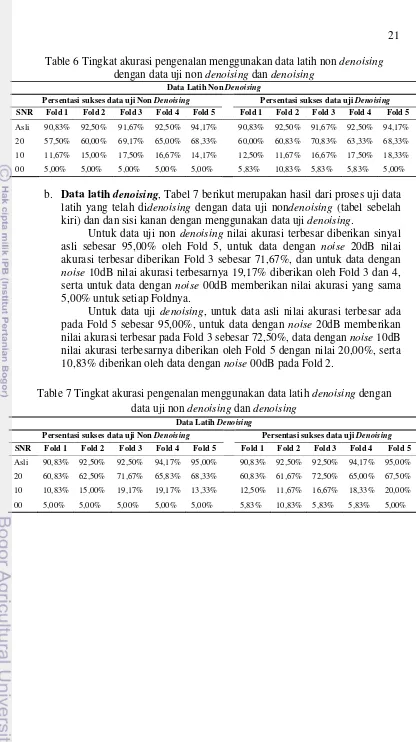
b. Data latih denoising, Tabel 7 berikut merupakan hasil dari proses uji data latih yang telah didenoising dengan data uji nondenoising (tabel sebelah kiri) dan dan sisi kanan dengan menggunakan data uji denoising.
Untuk data uji non denoising nilai akurasi terbesar diberikan sinyal asli sebesar 95,00% oleh Fold 5, untuk data dengan noise 20dB nilai akurasi terbesar diberikan Fold 3 sebesar 71,67%, dan untuk data dengan
noise 10dB nilai akurasi terbesarnya 19,17% diberikan oleh Fold 3 dan 4, serta untuk data dengan noise 00dB memberikan nilai akurasi yang sama 5,00% untuk setiap Foldnya.
Untuk data uji denoising, untuk data asli nilai akurasi terbesar ada pada Fold 5 sebesar 95,00%, untuk data dengan noise 20dB memberikan nilai akurasi terbesar pada Fold 3 sebesar 72,50%, data dengan noise 10dB nilai akurasi terbesarnya diberikan oleh Fold 5 dengan nilai 20,00%, serta 10,83% diberikan oleh data dengan noise 00dB pada Fold 2.
Table 7 Tingkat akurasi pengenalan menggunakan data latih denoising dengan data uji non denoising dan denoising
Data Latih Denoising
Persentasi sukses data uji Non Denoising Persentasi sukses data uji Denoising
SNR Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Fold 1 Fold 2 Fold 3 Fold 4 Fold 5
Asli 90,83% 92,50% 92,50% 94,17% 95,00% 90,83% 92,50% 92,50% 94,17% 95,00%
20 60,83% 62,50% 71,67% 65,83% 68,33% 60,83% 61,67% 72,50% 65,00% 67,50%
10 10,83% 15,00% 19,17% 19,17% 13,33% 12,50% 11,67% 16,67% 18,33% 20,00%
22
Table 8 Matriks konfusi untuk kelompok data kedua “ILMU” “ KOMPUTER”
Data latih nondenoising untuk data asli Data latih denoising untuk data asli
Data uji nondenoising Data uji denoising Data uji nondenoising Data uji denoising
Data Sensitiviti Spesifisiti Sensitiviti Spesifisiti Sensitiviti Spesifisiti Sensitiviti Spesifisiti
Sumber 1 0,46 1,00 0,86 1,00 1,00 1,00 1,00 1,00 dengan masing-masing berukuran 13x1. Dengan matriks konfusinya dari sensitifiti dan spesifisiti proses pengenalan diperlihatkan oleh Tabel 11.
a. Data latih non denoising, Tabel 9 berikut ini menunjukan hasil dari pengujian data latih dengan data uji nondenoising pada sisi kiri tabel dan pada sisi kanan tabel dengan menggunakan data uji denoising.
Untuk data uji non denoising nilai akurasi terbesar diberikan oleh data asli sebesar 95,00% oleh Fold 5, untuk data dengan noise 20dB nilai akurasi terbesar diberikan Fold 3 sebesar 70,83%, dan untuk data dengan noise 10dB nilai akurasi terbesarnya 17,50% diberikan oleh Fold 3 dan Fold 4, serta untuk data dengan noise 00dB memberikan nilai akurasi yang sama 5,00% untuk setiap Foldnya.
23 Table 9 Tingkat akurasi pengenalan menggunakan data latih non denoising
dengan data uji non denoising dan denoising
Data Latih Non Denoising
Persentasi sukses data uji Non Denoising Persentasi sukses data uji Denoising
SNR Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Fold 1 Fold 2 Fold 3 Fold 4 Fold 5
Asli 90,83% 92,50% 92,50% 94,17% 95,00% 90,83% 92,50% 92,50% 94,17% 95,00%
20 56,67% 62,50% 70,83% 63,33% 67,50% 59,17% 60,00% 71,67% 63,33% 68,33%
10 11,67% 15,00% 17,50% 17,50% 13,33% 12,50% 11,67% 16,67% 17,50% 17,50%
00 5,00% 5,00% 5,00% 5,00% 5,00% 5,83% 10,83% 5,83% 5,83% 5,00%
b. Data latih denoising, Table 10 berikut merupakan hasil dari proses pengujian data latih yang telah didenoising dengan data uji nondenoising (sisi kiri tabel) dan pada sisi kanan hasil uji dengan data denoising.
Untuk data uji non denoising nilai akurasi terbesar diberikan sinyal asli sebesar 95,00% oleh Fold 5, untuk data dengan noise 20dB nilai akurasi terbesar diberikan Fold 3 sebesar 70,83%, dan untuk data dengan noise 10dB nilai akurasi terbesarnya 17,50% diberikan oleh Fold 4, serta untuk data dengan noise 00dB memberikan nilai akurasi yang sama 5,00% untuk setiap Foldnya.
Untuk data uji denoising, untuk data asli nilai akurasi terbesar ada pada Fold 5 sebesar 95,00%, untuk data dengan noise 20dB memberikan nilai akurasi terbesar pada Fold 3 sebesar 72,50%, data dengan noise 10dB nilai akurasi terbesarnya diberikan oleh Fold 4 dan Fold 5 dengan nilai 18,33%, serta 10,83% diberikan oleh data dengan noise 00dB pada Fold 2.
Table 10 Tingkat akurasi pengenalan menggunakan data latih denoising dengan data uji non denoising dan denoising
Data Latih Denoising
Persentasi sukses data uji Non Denoising Persentasi sukses data uji Denoising
SNR Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Asli 90,83% 92,50% 93,33% 94,17% 95,00% 90,83% 92,50% 93,33% 94,17% 95,00%
20 60,00% 63,33% 70,83% 65,00% 69,17% 60,83% 63,33% 72,50% 65,00% 68,33%
10 10,83% 15,00% 16,67% 17,50% 13,33% 12,50% 11,67% 16,67% 17,50% 18,33%
24
Table 11 Matriks konfusi untuk kelompok data pertama “IL” “MU” “KOM” “PU” “TER”
Data Latih Non Denoising Untuk data Asli Data Latih Denoising Untuk data Asli
Data Uji Non Denoising Data Uji Denoising Data Uji Non Denoising Data Uji Denoising
Data Sensitiviti Spesifisiti Sensitiviti Spesifisiti Sensitiviti Spesifisiti Sensitiviti Spesifisiti
Sumber 1 1,00 1,00 1,00 1,00 1,00 1,00 1,00 1,00
Tingkat akurasi dari proses pembagian data penelitian seperti tertulis pada Tabel 2 diatas, hasilnya dapat dilihat pada Tabel 12 dan Tabel 13. Dengan bentuk histogramnya diperlihatkan masing-masing oleh Gambar 19, 20, 21, 22 dibawah ini.
Table 12 Tingkat akurasi terbesar dari proses pengenalan untuk data latih nondenoising dengan data uji non denoising dan denoising
Data latih non denoising
Data uji non denoising Data uji denoising
25 Table 13 Tingkat akurasi terbesar dari proses pengenalan untuk data latih
denoising dengan data uji non denoising dan denoising
Data latih denoising
Data uji non denoising Data uji denoising
SNR Kelompok
Yang secara histogram dapat sajikan seperti terlihat pada Gambar 19, 20. 21 dan Gambar 22 di bawah ini.
Gambar 19 Tingkat pengenalan data latih nondenoising dengan data uji
nondenoising
Gambar 20 Tingkat pengenalan data latih nondenoising dengan data uji
denoising
Gambar 21 Tingkat pengenalan data latih denoising dengan data uji
nondenoising
Gambar 22 Tingkat pengenalan data latih denoising dengan data uji
denoising
26
Gambar 23 Tingkat akurasi pengenalan pembicara untuk ketiga kelompok data Dari tabel dan histogram yang ditampilkan di atas terlihat proses denoising
tidak berhasil untuk meningkatkan kualitas sinyal suara mendekati sinyal aslinya, hal ini dapat dikatakan karena proses pengenalan pembicara terlihat berhasil untuk data asli dan seiring dengan besaran noise yang diberikan semakin turun kemampuan LVQ untuk mengenal sinyal suara yang dimasukan. Untuk menjelaskan ini, perhatikan Gambar 23, 24 dan Gambar 25 di bawah ini.
(a) (b)
Gambar 23 Sinyal suara asli dengan Spektrumnya
(a) (b)
27
(a) (b)
Gambar 25 Sinyal suara hasil denoising dan spektrumnya.
Dari gambar time domain dan frekuensi domain yang ditampilkan pada gambar 23, 24 dan 25 terlihat perbedaan antara sinyal asli pada gambar 23a dengan sinyal suara setelah diberikan noise sebesar 0dB gambar 24a, dan dapat dipastikan nilai MSEnya pastilah besar, lalu bandingkan dengan gambar 25a sinyal suara sebagai hasil denoising, bila dihitung nilai MSEnya jauh lebih kecil dari nilai MSE yang dihasilkan antara gambar 23a dan gambar 24a, dan secara visual terlihat sinyal hasil denoising pada gambar 25a mendekati bentuk dari sinyal asli yang terlihat pada gambar 23a. Akan tetapi bila dilihat spektrumnya yang ditampilkan pada gambar 23b dan gambar 25b terlihat sekali perbedaannya, banyak informasi/energi yang hilang/ terbuang dari gambar 25b yang merupakan sebagai hasil proses denoising yang berakibat pada proses pengenalan pembicara berkurang akurasinya, hal ini bisa saja terjadi dikarenakan pemilihan nilai
threshold atau mungkin pula aturan thresholding yag dipilih tidak tepat.
28
(c)
Gambar 26 Spectogram dari sinyal yang ditampilkan pada gambar 23, 24 dan 25 di atas
Gambar 26a merupakan spectrogram untuk sinyal suara asli dengan intensitas warna kuning (tempat suara berada) terlihat membentuk menyerupai sinyal asli pada domain waktu, sedangkan untuk gambar 26b WGN dengan tingkat 0dB telah mengisi setiap posisi dari frekkuensi yang ada sehingga bayangan warna kuning yang diperlihatkan pada gambar 26a mengalami penurunan kualitas, dilanjutkan dengan gambar 26c terlihat proses denoising
secara spectrogram tidak menghasilkan bayangan yang mendekati bentuk aslinya. Dari spectrogram pada gambar 26c dapat dikatakan penentuan nilai thresholding
beserta aturan threshold yang dipilih lebih berpengaruh terhadap hilangnya informasi dari sinyal suara.
5 SIMPULAN DAN SARAN
Proses denoising dengan parameter-parameternya tidak dapat membangkitkan sinyal yang telah ditambahkan noise kembali kekeadaannya semula, akan tetapi proses denoising masih memberikan hasil yang lebih baik bila dibandingkan dengan tanpa proses denoising. Perbaikan tingkat akurasi juga dipengaruhi oleh proses segmentasi sinyal suara, yang diperlihatkan oleh kelompok data kedua memberikan tingkat akurasi lebih baik dari kelompok data pertama, begitu pula dengan kelompok data ke tiga memberi hasil akurasi lebih baik dari kelompok sebelumnya, yang secara visual dan audio rekaman suara masih terdengar jelas dengan tingkat noise yang berkurang. Nilai akurasi dari proses pengklasifikasian yang dilakukan oleh LVQ diperoleh dengan nilai tertinggi 95,00%. Sementara nilai tertinggi untuk data dengan noise 20dB, 10dB dan 0dB masing-masing sebesar 72,50%, 20,00% dan 10,83%.
29
DAFTAR PUSTAKA
Abdalla MI, Abobakr HM, Gaafar TS. 2013. DWT and MFCCs based Feature Extraction Methods for Isolated Word Recognition. International Journal of Computer Applications, 69(20), p. 0975 – 8887.
Agbinya JI. 1996. Discrete Wavelet Transform Techniques in Speech Processing.
IEEE TENCON, pp. 514 - 519.
Aggarwal R, Singh JK, Gupta VK, Rathore S, Tiwari M, Khare Dr A, 2011. Noise Reduction of Speech Signal using Wavelet Transform with Modified Universal Threshold.. IJCA, 20(5), pp. 14-19.
Cai T, Wu X. 2008. Wavelet-Based De-Noising of Speech Using Adaptive Decomposition. Chengdu, Industrial Technology, 2008. ICIT 2008. IEEE International Conference on, pp. 1-5.
CAMPBELL JR JP. 1997. Speaker Recognition: A Tutorial. s.l., IEEE, pp. 1437-1462.
Change GS, Bin Y, Marin V. 2000. Adaptive Wavelet Thresholding for Image Denoising and Compression. IEEE TRANSACTIONS ON IMAGE PROCESSING, 9(9), pp. 1532-1542.
Donoho DL. 1995. De-Noising by Soft-Thresholding. IEEE, 41(3), pp. 613-627. Donoho DL, Johnstone IM. 1994. Thresholding Selection for Wavelet Shrinkage
of Noisy Data. Baltimore, Engineering in Medicine and Biology Society, 1994. Engineering Advances: New Opportunities for Biomedical Engineers. Proceedings of the 16th Annual International Conference of the IEEE, pp. A24-A25.
Dubey K, Gupta PV. 2013. Review on Speech Denoising Using Wavelet Techniques. International Journal of Engineering Trends and Technology (IJETT), 4(9), p. 3882.
Fausett L. 1994. Fundamentals of Neurak Networks: Architectures, Algorithms, and Applications. 6 ed. Boston: Prentice-hall International.
Goel R, Jain R. 2013. Speech Signal Noise Reduction by Wavelets. International Journal of Innovative Technology and Exploring Engineering, 2(4), pp. 191-193.
Gokhale MY, Khanduja DK. 2010. Time Domain Signal Analysis Using Wavelet Packet Decomposition Approach. Int. J. Communications, Network and System Sciences, Volume 3, p. 321–329.
Gupta S, Jaafar J, Wan Ahmad WF, Bansal A. 2013. FEATURE EXTRACTION USING MFCC. An International Journal (SIPIJ), 4(4), pp. 101 - 108. Huimin C, Ruimei Z, Yanli H. 2012. Improved Threshold Denoising Method
Based on Wavelet Transform. ELSEVIER, 33(2012), pp. 1354-1359.
Kansara M, Chapatwala PN. 2013. Noise Reduction from the Speech Signal using Wavelet Packet Transform. International Journal of Electronics and Computer Science Engineering, 2(2), pp. 745-751.
Matz V, Kreidl M, Smid R. 2004. Signal-to-Noise Ratio Improvement based on the Discrete Wavelet Transform in Ultrasonic Defectoscopy. Acta Polytechnica, 44(4), pp. 61-66.
30
Mupparaju S, Satya DJ, Venkata BN. 2013. Comparison of Various Thresholding Techniques of Image Denoising. International Journal of Engineering Research & Technology (IJERT), 2(9), p. 3294.
Pan Q, Zhang L, Dai G, Zhang H. 1999. Two Denoising Methods by Wavelet Transform. IEEE TRANSACTIONS ON SIGNAL PROCESSING, 47(12), pp. 3401-3406.
Sang YF, Wang D, Wu JC, 2010. Entropy-Based Method of Choosing the Decomposition Level in Wavelet Threshold De-noising. Entropy, 12(6), pp. 1499-1513.
Stephane MG. 1989. A Theory for Multiresolution Signal Decomposition:The Wavelet Representation. IEEE, 11(7), pp. 674-693.
Sutha S, Leavline EJ, Ghanana S, Antony DA
. 2013. A Comprehensive Study on Wavelet Based Shrinkage Methods for Denoising Natural Images. WSEAS TRANSACTIONS on SIGNAL PROCESSING, 9(4), pp. 203-215.
Verma N, Verma AK. 2013. Performance Analysis of Wavelet Thresholding Methods in Denoising of Audio Signalof Some Indian Musical Instruments.
31 Lampiran 1: Metode Perekaman Suara.
32
Lampiran 2: Nilai MSE hasil dekomposisi untuk sinyal suara “ILMU KOMPUTER”, untuk masing-masing noise yang ada.
Level Dekomposisi sinyal Asli Level Dekomposisi sinyal bernoise 20dB Level Dekomposisi sinyal bernoise 10dB Level Dekomposisi sinyal bernoise 00dB
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5