PERANCANGAN APLIKASI PENENTU KETERHUBUNGAN
ANTARA DATA MAHASISWA DAN MASA STUDI DENGAN
ALGORITMA REGRESI LINIER BERGANDA
(Studi Kasus Mahasiswa STT Harapan Medan)
TESIS
Oleh
ARIE SANTI SIREGAR
097038024/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
PERANCANGAN APLIKASI PENENTU KETERHUBUNGAN
ANTARA DATA MAHASISWA DAN MASA STUDI DENGAN
ALGORITMA REGRESI LINIER BERGANDA
(Studi Kasus Mahasiswa STT Harapan Medan)
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar
Magister Komputer dalam Program Studi Magister
Teknik Informatika pada Program Pascasarjana
Fakultas MIPA Universitas Sumatera Utara
Oleh
ARIE SANTI SIREGAR
097038024/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
PENGESAHAN TESIS
Judul Tesis : PERANCANGAN APLIKASI PENENTU
KETERHUBUNGAN ANTARA DATA
MAHASISWA DAN MASA STUDI DENGAN ALGORITMA REGRESI LINIER BERGANDA (Studi Kasus Mahasiswa STT Harapan Medan)
Nama Mahasiswa : ARIE SANTI SIREGAR
Nomor Induk Mahasiswa : 097038024
Program Studi : Magister Teknik Informatika
Fakultas : Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara
Menyetujui Komisi Pembimbing
Dian Rachmawati, S.Si, M.Kom
Anggota Ketua
Prof. Dr. Herman Mawengkang
Ketua Program Studi Dekan
Prof. Dr. Muhammad Zarlis
PERNYATAAN ORISINALITAS
PERANCANGAN APLIKASI PENENTU KETERHUBUNGAN
ANTARA DATA MAHASISWA DAN MASA STUDI DENGAN
ALGORITMA REGRESI LINIER BERGANDA
(Studi Kasus Mahasiswa STT Harapan Medan)
TESIS
Dengan ini penulis menyatakan bahwa penulis mengakui semua karya tesis ini
adalah hasil karya penulis sendiri kecuali kutipan dan ringkasan yang tiap bagiannya
telah dijelaskan sumbernya dengan benar.
Medan, 29 Juli 2011
ARIE SANTI SIREGAR
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini:
Nama Mahasiswa : ARIE SANTI SIREGAR
Nomor Induk Mahasiswa : 097038024
Program Studi : Magister (S2) Teknik Informatika
Jenis Karya Ilmiah : TESIS
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada
Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive
Royalty Free Right) atas tesis saya yang berjudul :
PERANCANGAN APLIKASI PENENTU KETERHUBUNGAN
ANTARA DATA MAHASISWA DAN MASA STUDI DENGAN
ALGORITMA REGRESI LINIER BERGANDA
(Studi Kasus Mahasiswa STT Harapan Medan)
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti
Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media,
memformat, mengelola dalam bentuk database, merawat, dan mempublikasikan tesis
saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai
penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.
Medan, 29 Juli 2011
Telah diuji pada
Tanggal : 29 Juli 2011
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Herman Mawengkang
Anggota : 1. Dian Rachmawati, S.Si, M.Kom
2. Prof. Dr. Muhammad Zarlis
3. M. Andri Budiman, ST, M.Comp. Sc, M.EM
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap : Arie Santi Siregar
Tempat dan Tanggal Lahir : Medan, 22 Maret 1975
Alamat Rumah : Jl. Selam V No. 32 Mandala By Pass
Medan 20226
Email :
Instansi Tempat Bekerja : Balai Pengembangan Pendidikan
Non Formal dan Informal (BP-PNFI)
Regional I Medan
Alamat Kantor : Jl. Kenanga Raya No. 64 Tj. Sari
Medan
DATA PENDIDIKAN
SD HARAPAN I MEDAN Tamat Tahun 1987
SMP HARAPAN I MEDAN Tamat Tahun 1990
SMA HARAPAN MEDAN Tamat Tahun 1993
D3 Statistika USU Tamat Tahun 1996
KATA PENGANTAR
Alhamdulillaahi Robbil ‘aalamiin, ungkapan tanda syukur penulis yang tiada
terhingga kepada Allah Azza wa Jalla atas segala kemudahan dan limpahan rahmat
serta hidayah-Nya penulis dapat menjalani masa perkuliahan hingga menyelesaikan
tesis dengan judul “Perancangan Aplikasi Penentu Keterhubungan Antara Data
Mahasiswa dan Masa Studi Dengan Algoritma Regresi Linier Berganda (Studi
Kasus Mahasiswa STT Harapan Medan)”.
Adapun maksud dari penyusunan tesis ini adalah untuk memenuhi salah satu
prasyarat untuk memperoleh gelar Magister Komputer (M.Kom) pada Program
Pascasarjana Magister Teknik Informatika FMIPA USU.
Dalam menyelesaikan tesis ini penulis banyak menemui kendala. Namun
berkat bantuan baik berupa bimbingan maupun arahan dari berbagai pihak kendala
tersebut dapat diatasi.
Oleh karena itu, pada kesempatan ini penulis menyampaikan rasa hormat dan
ucapkan terima kasih yang sebesar-besarnya, kepada :
1. Bapak Prof. Dr. Herman Mawengkang selaku ketua pembimbing yang dengan
penuh kesabaran membimbing, memotivasi, memberikan dukungan moril, kritik,
dan saran serta memberikan bahan-bahan yang berkaitan dengan penyusunan
tesis ini sehingga tesis ini dapat terselesaikan dengan baik.
2. Ibu Dian Rachmawati, S.Si, M.Kom selaku pembimbing anggota atas
bimbingan, arahan, dan waktu yang telah diluangkan kepada penulis serta
memberikan bahan-bahan yang berkaitan dengan penyusunan tesis ini sehingga
tesis ini dapat terselesaikan dengan baik.
3. Bapak Prof. Dr. Muhammad Zarlis, selaku pembanding dan Ketua Program
Studi Magister (S2) Teknik Informatika FMIPA USU yang telah memberikan
masukan dan saran pada saat kolokium dan seminar hasil serta dukungan moril
yang luar biasa, kritik dan saran sehingga tesis ini dapat selesai tepat waktu.
4. Bapak M. Andri Budiman, ST, M.Comp. Sc, M.EM, selaku pembanding dan
teman kecil penulis yang tetap baik hati untuk segala kebaikan yang luar biasa
selama penulis menjalani masa perkuliahan hingga menyelesaikan tesis ini.
5. Bapak Ade Candra, ST, M.Kom selaku pembanding yang telah memberikan
saran, masukan, dan arahan yang baik demi penyelesaian tesis ini.
6. Bapak Dr. Kastum, M.Pd selaku kepala BP-PNFI Regional I dan Bapak Drs.
Syamsir, M.Pd selaku kepala Seksi Informasi BP-PNFI Regional I yang telah
memberikan izin penulis untuk mengikuti perkuliahan di Program Studi
Magister (S2) Teknik Informatika FMIPA USU.
7. Teman-teman di seksi Informasi BP-PNFI Regional I Medan, Bang Syahril Edy
Putra, S.Sos, Romi, S.Pd, Andri Budiwan, Bambang S. Yulistiawan, M.Kom
yang dengan lapang dada telah membiarkan penulis untuk berkutat mengerjakan
tugas perkuliahan di sela-sela waktu mengerjakan tugas kantor. Teristimewa
untuk Haslinda Ritonga, S.Pd yang telah banyak membantu penulis mengerjakan
tugas kantor di tengah padatnya deadline tugas kuliah dan teman curhat yang
paling oke, Bang M. Ichwan Nst, M. Kom rekan seperjuangan di kuliah dan di
kantor untuk semua support yang luar biasa, dan tak ketinggalan Rani Raichani,
ST untuk semua kelelahan, bantuan, semangat, dan lain-lainnya (yang tak
sanggup penulis tuliskan satu persatu) dan Prima Dewi Gratia, M.Pd (untuk
koreksi tulisannya).
8. Sivitas akademika di STT Harapan Medan untuk segala bantuan, do’a dan
semangat selama penulis menjalani perkuliahan hingga menyelesaikan tesis ini.
9. Syurahbil Hadi, S.Si, M.Sc.Comp, untuk private lesnya, dukungan, motivasi,
dan tak ketinggalan bantuan programnya.
10.Riki Wanto, M.Kom (untuk bantuannya di detik-detik terakhir ujian tesis), Bang
Dedi Hartama, M.Kom (untuk private gratisnya), Mangku Mondroguno,
M.Kom, Kak Yuniar Andi Astuti, M.Kom, Amir Mahmud Husein, M.Kom, Kak
Hikmah Adwin Adam, M.Kom, Rosita Dalimunthe, S. Kom, Bang Husni Ilyas,
M.Kom, Sayed Fachrurrozy, M.Kom, Sundari Rento A, M.Kom, Poningsih,
M.Kom dan Rekan-rekan angkatan pertama S2 Teknik Informatika USU (untuk
Habibi Ramdhani Safitri, M.Kom (untuk semua perjuangan yang di lalui
bersama di tengah derasnya hujan dan listrik yang padam).
11.Seluruh Staf pengajar di Program Studi Magister (S2) Teknik Informatika
FMIPA USU yang telah membimbing penulis selama perkuliahan.
12.Staf administrasi S2 Teknik Informatika – USU, istimewa untuk Dwi Novika
Sari, S.Kom, dan Bang Jawaher untuk semua kebaikannya selama penulis
menjalani perkuliahan hingga menyelesaikan tesis ini.
Akhirnya kepada seluruh keluarga yang telah memacu penulis untuk
menyelesaikan tesis ini dan seluruh pihak yang tidak disebutkan semua. Semoga
segala perhatian, bantuan serta do’a yang telah diberikan kepada penulis mendapat
imbalan pahala yang berlipat ganda dari Allah SWT. Amiin Ya Robbal ‘Aalamiin
Dengan keterbatasan pengalaman, pengetahuan maupun pustaka yang
ditinjau, penulis menyadari bahwa tesis ini masih banyak kekurangan dan perlu
pengembangan lebih lanjut agar benar - benar bermanfaat. Oleh sebab itu, penulis
sangat mengharapkan kritik dan saran agar tesis ini lebih sempurna serta sebagai
masukan bagi penulis untuk penelitian dan penulisan karya ilmiah di masa yang akan
datang.
Akhir kata penulis berharap apa yang terkandung dalam tesis ini dapat
memberikan manfaat.
Medan, 29 Juli 2011
PERANCANGAN APLIKASI PENENTU KETERHUBUNGAN ANTARA
DATA MAHASISWA DAN MASA STUDI DENGAN ALGORITMA
REGRESI LINIER BERGANDA
(Studi Kasus Mahasiswa STT Harapan Medan)
ABSTRAK
Tesis ini membuat perancangan aplikasi dengan bahasa pemograman C++ untuk mencari atau menentukan solusi dari sistem persamaan linier (SPL) dalam menentukan keterhubungan antara data mahasiswa dan masa studi dengan menggunakan algoritma regresi linier berganda. Variabel yang digunakan adalah rata-rata nilai UN, IP Komulatif (IP Semester 1, 2, dan 3), jumlah sks mata kuliah yang diambil pada semester 4, dan pendidikan orang tua. Data diperoleh dari database pendidikan mahasiswa yang telah diwisuda pada periode I dan II Tahun 2010 serta periode II Tahun 2011 di Sekolah Tinggi Teknik Harapan (STTH) Medan. Maka, diperoleh hasil KD adalah sebesar 61%, ini menunjukkan bahwa variabel rata-rata nilai UN ( 1), IP komulatif (IP semester 1, 2 dan 3) ( 2), jumlah SKS mata kuliah yang diambil pada semester 4 ( 3), dan pendidikan orang tua ( 4) berpengaruh terhadap variabel masa studi ( ) sebesar 61% sedangkan sisanya sebesar 39% diterangkan oleh variabel lainnya yang tidak diteliti oleh penulis.
Kata kunci : model keterhubungan, database, regresi linier berganda, koefisien
THE APPLICATION DESIGN DETERMINANTS CONNECTEDNESS
BETWEEN STUDENTS AND DURATION OF STUDY DATA WITH
MULTIPLE LINEAR REGRESSION ALGORITHM
(Case Study Student STT Harapan Medan)
ABSTRACT
This thesis makes designing applications with C++ programming language to locate or determine the solution of systems of linear equations (SPL) in determining the connectedness between students and the study data using multiple linear regression algorithm. The variable used is the average value of the UN, cumulative IP (IP Semester 1, 2 and 3), the number of credits courses taken in semester 4, and parental education. Data obtained from the database of education students who have graduated in the period I, II year 2010 and period II in 2011 at the Sekolah Tinggi Teknik Harapan (STTH) Medan. KD is the result obtained by 61%, and this indicates that the variable average value of UN ( 1), cumulative IP (IP semesters 1, 2 and 3) ( 2), number of credit courses taken in semester 4 ( 3), and parent education ( 4) effect on the variable period of study ( ) by 61%. While the remaining 39% is explained by other variables that is not examined by the author.
DAFTAR ISI
KATA PENGANTAR ………... i
ABSTRAK……….. iv
ABSTRACT ………... v
DAFTAR ISI ……….… vi
DAFTAR TABEL ……….…. viii
DAFTAR GAMBAR ………... ix
DAFTAR LAMPIRAN ………... x
BAB I PENDAHULUAN ………... 1
1.1. Latar Belakang ……… 1
1.2. Perumusan Masalah ………. 3
1.3. Batasan Masalah ….………. 3
1.4. Tujuan Penelitian ………... 4
1.5. Manfaat Penelitian ………... 4
BAB II TINJAUAN PUSTAKA ………. 5
2.1. Penelitian Terdahulu ………. 5
2.2. Regresi ………….…..………... 6
2.3. Regresi Linier ……….……….. 9
2.3.1. Regresi Linier Sederhana ……….……….. 9
2.3.2. Regresi Linier Berganda ………..……….…. 10
2.4. Asumsi Regresi Linier ………. 11
2.5. Uji Keberartian Koefisien Regresi ………... 12
2.6. Pengujian Keberartian Regresi Ganda ..………... 16
2.7. Koefisien Determinasi ……….. 17
2.8. Ukuran Error ………. 18
2.9. UML ………. 19
2.9.1. Use Case Diagram ……….. 20
2.9.2. Activity Diagram ……… 20
BAB III METODOLOGI PENELITIAN ……… .. 22
3.1. Pendahuluan ……….. 22
3.2. Lokasi dan Waktu Penelitian ………. 22
3.3. Pelaksanaan Penelitian ……….. 22
3.3.1. Jenis dan Sumber Data.………… ………... 22
3.3.2. Teknik Pengumpulan Data …..……… 23
3.4. Perangkat Lunak yang Digunakan ………. 23
3.4.1. Bahasa Pemograman C++…..………... 23
3.4.2. Paket Statistik Untuk Ilmu Sosial (SPSS)………. 24
3.5. Perangkat Keras yang Digunakan ……….. 24
3.6. Use Case Diagram ……….. 25
3.7. Activity Diagram ……….... 25
3.8. Pseudo-Code……… 26
BAB IV HASIL DAN PEMBAHASAN ………. 34
4.1. Pendahuluan ………. 34
4.2. Hasil Percobaan ……… 34
4.2.1. Uji Asumsi Klasik ……….. 34
4.2.2. Analisis Regresi Linier Berganda Dengan Bahasa Pemograman C++………... 37
4.2.3. Menguji Keberartian Koefisien Regresi ………. 38
4.2.4. Koefisien Determinasi ……… 39
4.3. Ukuran Error ………. 40
4.4. Capture Program ………. 40
BAB V KESIMPULAN DAN SARAN ……… 45
5.1. Kesimpulan ……….. 45
5.2. Saran ……….… 47
DAFTAR PUSTAKA ………. 48
DAFTAR TABEL
Nomor Judul Halaman
2.1. Analisis Of Varians 15
4.1. Collinearity Statistic 35
4.2. Model Summary 36
4.3. Koefisien 37
4.4. Pengujian Hipotesis Secara Overall (Uji F) 39
DAFTAR GAMBAR
Nomor Judul Halaman
3.1. Use Case Diagram 25
3.2.
4.1.
4.2.
4.3.
4.4.
4.5.
4.6.
4.7.
Activity Diagram
Input Data
Tampilan Data
Jumlah Dari Masing-Masing Variabel
Jumlah Dari Masing-Masing Variabel
Persamaan Matematika
Koefisien Matriks
Nilai Variabel
25
41
41
42
42
43
43
DAFTAR LAMPIRAN
Nomor Judul Halaman
1 Data Mahasiswa STTH yang Diwisuda Periode I, II Tahun 2010 dan Periode II Tahun 2011
51
2 Cara Kerja Manual Dalam Menentukan Solusi
Dari Sistem Persamaan Linier (SPL) Dalam
Menentukan Keterhubungan Antara Data
Mahasiswa dan Masa Studi Dengan
Menggunakan Regresi Linier Berganda
64
3 Listing Program 69
PERANCANGAN APLIKASI PENENTU KETERHUBUNGAN ANTARA
DATA MAHASISWA DAN MASA STUDI DENGAN ALGORITMA
REGRESI LINIER BERGANDA
(Studi Kasus Mahasiswa STT Harapan Medan)
ABSTRAK
Tesis ini membuat perancangan aplikasi dengan bahasa pemograman C++ untuk mencari atau menentukan solusi dari sistem persamaan linier (SPL) dalam menentukan keterhubungan antara data mahasiswa dan masa studi dengan menggunakan algoritma regresi linier berganda. Variabel yang digunakan adalah rata-rata nilai UN, IP Komulatif (IP Semester 1, 2, dan 3), jumlah sks mata kuliah yang diambil pada semester 4, dan pendidikan orang tua. Data diperoleh dari database pendidikan mahasiswa yang telah diwisuda pada periode I dan II Tahun 2010 serta periode II Tahun 2011 di Sekolah Tinggi Teknik Harapan (STTH) Medan. Maka, diperoleh hasil KD adalah sebesar 61%, ini menunjukkan bahwa variabel rata-rata nilai UN ( 1), IP komulatif (IP semester 1, 2 dan 3) ( 2), jumlah SKS mata kuliah yang diambil pada semester 4 ( 3), dan pendidikan orang tua ( 4) berpengaruh terhadap variabel masa studi ( ) sebesar 61% sedangkan sisanya sebesar 39% diterangkan oleh variabel lainnya yang tidak diteliti oleh penulis.
Kata kunci : model keterhubungan, database, regresi linier berganda, koefisien
THE APPLICATION DESIGN DETERMINANTS CONNECTEDNESS
BETWEEN STUDENTS AND DURATION OF STUDY DATA WITH
MULTIPLE LINEAR REGRESSION ALGORITHM
(Case Study Student STT Harapan Medan)
ABSTRACT
This thesis makes designing applications with C++ programming language to locate or determine the solution of systems of linear equations (SPL) in determining the connectedness between students and the study data using multiple linear regression algorithm. The variable used is the average value of the UN, cumulative IP (IP Semester 1, 2 and 3), the number of credits courses taken in semester 4, and parental education. Data obtained from the database of education students who have graduated in the period I, II year 2010 and period II in 2011 at the Sekolah Tinggi Teknik Harapan (STTH) Medan. KD is the result obtained by 61%, and this indicates that the variable average value of UN ( 1), cumulative IP (IP semesters 1, 2 and 3) ( 2), number of credit courses taken in semester 4 ( 3), and parent education ( 4) effect on the variable period of study ( ) by 61%. While the remaining 39% is explained by other variables that is not examined by the author.
BAB I
PENDAHULUAN
1.1. Latar Belakang
Pesatnya perkembangan ilmu pengetahuan dan teknologi menyebabkan penggunaan
komputer semakin dominan dan universal. Dewasa ini komputer sangat membantu
dalam segala aspek kehidupan. Kemampuan komputer selain dapat menghitung data
juga untuk mengolah data sehingga menjadi informasi yang berguna dalam waktu
yang cepat dan akurat.
Hubungan antara suatu variabel dengan satu atau lebih variabel lain
seringkali dijumpai dalam kehidupan sehari-hari. Contohnya dalam bidang
pendidikan, ada kepandaian murid mungkin dipengaruhi oleh IQ-nya, namun juga
tidak lepas dari peranan guru, juga orang tua di rumah. Dalam bidang pertanian
sebagai contoh jumlah pakan yang diberikan pada ternak berhubungan dengan berat
badannya, dan sebagainya. Secara umum ada dua macam hubungan antara dua atau
lebih variabel, yaitu bentuk hubungan dan keeratan hubungan. Bila ingin mengetahui
bentuk hubungan dua variabel atau lebih digunakan analisis regresi. Bila ingin
melihat keeratan hubungan digunakan analisis korelasi.
Analisis regresi adalah teknik statistika yang berguna untuk memeriksa dan
memodelkan hubungan di antara variabel-variabel. Penerapannya dapat dijumpai
secara luas di banyak bidang seperti pendidikan, teknik, ekonomi, manajemen,
ilmu-ilmu biologi, ilmu-ilmu-ilmu-ilmu sosial, dan ilmu-ilmu-ilmu-ilmu pertanian. Pada saat ini, analisis regresi
berguna dalam menelaah hubungan dua variabel atau lebih terutama untuk
menelusuri pola hubungan yang modelnya belum diketahui dengan sempurna
sehingga dalam penerapannya lebih bersifat eksploratif.
Menurut Johnson dan Wichern, 1992 analisis regresi digunakan untuk
meramalkan sebuah variabel respon dari satu atau lebih variabel bebas , selain itu
juga digunakan untuk menaksir pengaruh-pengaruh variabel bebas terhadap
Analisis regresi merupakan salah satu tool yang paling banyak digunakan
dalam suatu penelitian karena ada beberapa keistimewaan di dalam analisis regresi,
diantaranya di dalam analisis regresi sudah termasuk analisis korelasi antara variabel
independen yang juga sering disebut faktor-faktor penyebab, dengan variabel
dependen . Selanjutnya dengan persamaan regresi yang didapat kita dapat membuat
peramalan apa yang akan terjadi dengan apabila terjadi perubahan pada ,
sebaliknya jika kita menginginkan nilai tertentu, kita dapat mengestimasi seberapa
besar faktor-faktor akan diubah untuk mewujudkan tujuan kita (Pratisto, 2009).
Perguruan tinggi merupakan salah satu bentuk jasa yang ditawarkan kepada
masyarakat yang ingin meningkatkan kualitas sumber daya manusianya. Semakin
ketatnya persaingan dalam mendapatkan lapangan pekerjaan menuntut perguruan
tinggi untuk menghasilkan sarjana yang berkualitas dan memiliki daya saing. Salah
satu upaya yang dapat dilakukan oleh perguruan tinggi adalah mahasiswa dapat
menyelesaikan studinya tepat waktu dengan nilai akademik yang memuaskan.
Walaupun telah banyak penelitian yang dilakukan berkaitan dengan masa
studi namun faktor-faktor yang mempengaruhi masa studi mahasiswa masih belum
dapat diketahui dengan pasti sehingga perlu dilakukan penelitian untuk melihat
keterhubungan data mahasiswa dengan masa studi.
Berdasarkan masalah yang telah diuraikan diatas maka penulis mengangkat
judul ”Perancangan Aplikasi Penentu Keterhubungan Antara Data Mahasiswa
dan Masa Studi Dengan Algoritma Regresi Linier Berganda (Studi Kasus
Mahasiswa STT Harapan Medan)”.
Tesis ini merancang penggunaan aplikasi bahasa pemograman C++ untuk
menentukan keterhubungan antara data mahasiswa dan masa studi dengan algoritma
regresi linier berganda.
1.2. Perumusan Masalah
Berdasarkan latar belakang di atas, maka dirumuskan permasalahan sebagai berikut
yaitu membuat perancangan aplikasi dengan bahasa pemograman C++ untuk mencari
keterhubungan antara data mahasiswa dan masa studi dengan menggunakan
algoritma regresi linier berganda.
1.3. Batasan Masalah
Penelitian ini perlu adanya batasan masalah agar tidak meluas kebahasan yang
lainnya. Adapun yang menjadi batasan masalah dalam penelitian ini adalah:
1. Penelitian ini terbatas hanya pada membuat perancangan aplikasi untuk
mencari atau menentukan solusi dari sistem persamaan linier (SPL)
dalam menentukan keterhubungan antara data mahasiswa dan masa studi
dengan menggunakan algoritma regresi linier berganda.
2. Data diperoleh dari database pendidikan mahasiswa yang telah diwisuda
pada periode I dan II Tahun 2010 serta periode II Tahun 2011 di Sekolah
Tinggi Teknik Harapan (STTH) Medan yang terdiri dari rata-rata nilai
UN, IP Komulatif (IP Semester 1, 2 dan 3), jumlah SKS mata kuliah
yang diambil pada semester 4, dan pendidikan orang tua.
3. Data yang dipergunakan harus di cek kembali dengan menggunakan
aplikasi SPSS untuk membuktikan apakah data tersebut linier atau tidak,
apabila data tersebut linier baru kemudian dibuat perancangan
aplikasinya.
4. Dalam membuat perancangan aplikasi untuk mencari atau menentukan
solusi dari sistem persamaan linier (SPL) dalam menentukan
keterhubungan antara data mahasiswa dan masa studi dengan algoritma
regresi linier berganda penulis menggunakan bahasa pemograman C++
dengan inputan data berextensi txt (*.txt).
1.4. Tujuan Penelitian
Tujuan yang ingin dicapai pada penelitian tesis ini yaitu :
1. Untuk mendapatkan sebuah rancangan aplikasi dengan bahasa
pemograman C++ untuk mencari atau menentukan solusi dari sistem
mahasiswa dan masa studi dengan menggunakan algoritma regresi linier
berganda.
2. Untuk membantu bagian manajemen pendidikan dalam mengambil
tindakan preventif bagi mahasiswa yang memiliki kecenderungan akan
lama menyelesaikan studi.
1.5. Manfaat Penelitian
Adapun manfaat yang diperoleh dari penelitian ini adalah :
1. Sebagai bahan masukan kepada Sekolah Tinggi Teknik Harapan (STTH)
Medan dan perguruan tinggi lain untuk memprediksi mahasiswa yang dapat
lulus tepat waktu sehingga beberapa faktor yang paling mempengaruhi untuk
masa studi dapat diperhatikan.
2. Menghasilkan suatu aplikasi perangkat lunak bahasa pemograman C++ untuk
mencari atau menentukan solusi dari sistem persamaan linier (SPL) dalam
menentukan keterhubungan antara data mahasiswa dan masa studi dengan
menggunakan algoritma regresi linier berganda.
3. Sebagai referensi bagi peneliti selanjutnya yang berkaitan dengan
BAB II
TINJAUAN PUSTAKA
2.1. Penelitian Terdahulu
Penelitian yang dilakukan oleh Kannan dan Nagarajan (2008) dengan judul “Factor
and Multiple Regression Analysis for Human Fertility in Kanyakumari District”
berfokus pada hubungan sebab dan efek pada kesuburan (fertility) manusia. Fertility
diistilahkan sebagai jumlah anak yang lahir dari seorang wanita. Seluruh set variabel
yang terkait dengan fertility diklasifikasikan ke dalam variabel alam (usia
perempuan, umur di pernikahan, agama, jenis keluarga), variabel pengetahuan
(pendidikan perempuan, pendidikan pasangan hidup) dan variabel ekonomi
(pekerjaan perempuan dan pasangan, penghasilan perempuan dan pasangan). Dengan
menggunakan analisis faktor dan analisis regresi linier berganda diketahui
keterhubungan dari masing-masing kelompok fertility yang dibahas secara terpisah
dan secara kolektif. Hasil analisis yang diperoleh dari penelitian ini adalah bahwa
kerja yang baik, pendapatan yang lebih tinggi, dan sistem keluarga nuklir dapat
membawa pengurangan tingkat fertility wanita di kabupaten Kanyakumari.
Penelitian yang dilakukan oleh Meinanda et al (2009) dengan judul
“Prediksi Masa Studi Sarjana dengan Artificial Neural Network”. Variabel yang
digunakan dalam penelitian ini adalah identitas mahasiswa, masa studi, kode mata
kuliah, nama mata kuliah, jumlah pengambilan mata kuliah, dan nilai mata kuliah.
Model analisis yang digunakan adalah artificial neural network dan multiple
regression. Hasil penelitiannya menunjukkan dalam melakukan prediksi masa studi,
model multiple regresi menghasilkan prediksi masa studi yang bias, sementara itu
artificial neural network dengan multilayer perceptron dalam penelitian ini
merupakan model terbaik untuk memprediksi masa studi.
Selanjutnya penelitian yang dilakukan oleh Suhartinah dan Ernastuti (2010)
Kelulusan Mahasiswa Universitas Gunadarma”. Variabel yang digunakan data NEM,
IP semester 1, IP semester 2, IPK semester 1-2, gaji orang tua, dan pekerjaan orang
tua. Model analisis yang dipergunakan adalah algoritma naive bayes dan algoritma
C4.5 yang merupakan algoritma dari metode teorema bayes dan decision tree. Hasil
penelitian menunjukkan bahwa dengan menggunakan algoritma C4.5 kesalahan yang
dihasilkan dalam proses prediksi lebih sedikit, untuk algoritma decision tree
memiliki kompleksitas yang lebih besar, sedangkan algoritma naive bayes bila
diimplementasikan menggunakan data yang digunakan dalam proses training akan
menghasilkan nilai kesalahan yang lebih besar karena pada naive bayes nilai suatu
atribut adalah independent terhadap nilai lainnya dalam satu atribut yang sama.
Namun memiliki akurasi yang lebih tinggi bila dimplementasikan ke data yang
berbeda dari data training dan ke dalam data yang jumlahnya lebih besar.
2.2. Regresi
Sir Francis Galton (1822 – 1911), memperkenalkan model peramalan, penaksiran,
atau pendugaan, yang selanjutnya dinamakan regresi, sehubungan dengan
penelitiannya terhadap tinggi badan manusia. Penelitian tersebut membandingkan
antara tinggi anak laki-laki dan tinggi badan ayahnya. Galton menunjukkan bahwa
tinggi badan anak laki-laki dari ayah yang tinggi setelah beberapa generasi
cenderung mundur (regressed) mendekati nilai tengah populasi. Dengan kata lain,
anak laki-laki dari ayah yang badannya sangat tinggi cederung lebih pendek dari
pada ayahnya, sedangkan anak laki-laki dari ayah yang badannya sangat pendek
cenderung lebih tinggi dari ayahnya. (Walpole, 1992).
Analisis regresi digunakan untuk menentukan bentuk (dari) hubungan antar
variabel. Tujuan utama dalam penggunaan analisis ini adalah untuk meramalkan atau
menduga nilai dari satu variabel dalam hubungannya dengan variabel yang lain yang
diketahui melalui persamaan garis regresinya. (Hasan, 2002).
Adakalanya, setelah kita memperoleh data berdasarkan sampel, kita ingin
menduga nilai dari suatu variabel yang bersesuaian dengan nilai tertentu dari
kita bentuk dari data sampel itu disebut kurva regresi terhadap , karena diduga
dari (Spiegel, 1988).
Dalam melakukan analisis regresi, sebagian besar mahasiswa biasanya tidak
melakukan pengamatan populasi secara langsung. Hal itu dilakukan selain
pertimbangan waktu, tenaga, juga berdasarkan pertimbangan biaya yang relatif besar
jika melakukan pengamatan terhadap populasi. Dalam hal ini, lazimnya digunakan
persamaan regresi linier sederhana sampel sebagai penduga persamaan regresi linier
sederhana populasi dengan bentuk persamaan seperti berikut :
dan atau . Dan karena antara dan memiliki hubungan, maka nilai
dapat digunakan untuk menduga atau meramal nilai . dinamakan variabel bebas
karena variabel ini nilai-nilainya tidak bergantung pada variabel lain. Dan disebut
variabel terikat juga karena variabel yang nilai-nilainya bergantung pada variabel
lain. Hubungan antar variabel yang akan dipelajari disini hanyalah hubungan linier
sederhana, yakni hubungan yang hanya melibatkan dua variabel ( dan ) dan
berpangkat satu. (Hasan, 2002).
Regresi sederhana, adalah bentuk regresi dengan model yang bertujuan untuk
mempelajari hubungan antara dua variabel, yakni variabel independen (bebas) dan
variabel dependen (terikat). Jika ditulis dalam bentuk persamaan, model regresi
sederhana adalah dan atau di mana, adalah
variabel tak bebas (terikat), adalah variabel bebas, dan atau a adalah penduga
bagi intercept (α), dan atau b adalah penduga bagi koefisien regresi (β) atau dengan kata lain α dan β adalah parameter yang nilainya tidak diketahui sehingga diduga melalui statistik sampel. (Sambas dan Maman, 2007).
Menurut kelaziman dalam ilmu statistika ada dua macam hubungan antara
dua variabel yang relatif sering digunakan, yakni bentuk hubungan dan keeratan
hubungan. Bentuk hubungan dapat diketahui melalui analisis regresi sedangkan
keeratan hubungan dapat diketahui dengan analisis korelasi. Analisis regresi
dipergunakan untuk menelaah hubungan antara dua variabel atau lebih terutama
untuk menelusuri pola hubungan yang modelnya belum diketahui dengan baik atau
mempengaruhi variabel dependen dalam suatu fenomena yang komplek. Jika ,
, , …, adalah variabel-variabel independen dan adalah variabel dependen,
maka terdapat hubungan fungsional antara dan , dimana variasi dari akan
diiringi pula oleh variasi dari . Jika dibuat secara matematis hubungan itu dapat
dijabarkan sebagai berikut: = f ( , , , …, , ), dimana adalah variabel
dependen (tak bebas), adalah variabel independen (bebas) dan adalah variabel
residu (disturbace term).
Berkaitan dengan analisis regresi ini, setidaknya ada empat kegiatan yang
lazim dilaksanakan yakni : (1) mengadakan estimasi terhadap parameter berdasarkan
data empiris, (2) menguji berapa besar variasi variabel dependen dapat diterangkan
oleh variasi independen, (3) menguji apakah estimasi parameter tersebut signifikan
atau tidak, dan (4) melihat apakah tanda magnitud dari estimasi parameter cocok
dengan teori. (Nazir, 2003).
Hubungan antar variabel dapat berupa hubungan linier ataupun hubungan
tidak linier. Misalnya, berat badan orang dewasa sampai pada tahap tertentu
bergantung pada tinggi badan, keliling lingkaran bergantung pada diameternya, dan
tekanan gas bergantung pada suhu dan volumenya. Jika dalam ilmu pemasaran, nilai
penjualan akan bergantung pada biaya promosi. Hubungan-hubungan itu bila
dinyatakan dalam bentuk matematis akan memberikan persamaan-persamaan
tertentu. Untuk dua variabel, hubungan liniernya dapat dinyatakan dalam bentuk
persamaan linier, yakni: dan atau . Hubungan antara
dua variabel pada persamaan linier jika digambarkan secara (scatter diagram), semua
nilai dan akan berada pada suatu garis lurus. Dan dalam ilmu ekonomi, garis itu
dinamakan garis regresi. (Hasan, 2002).
2.3.Regresi Linier
2.3.1. Regresi Linier Sederhana
Dalam regresi linier sederhana hanya ada satu variabel independen. Jika sampel
dan atau
di mana dan atau a, dan atau b adalah koefisien regresi dan adalah sisa
(residual) yaitu, selisih antara nilai yang diinginkan dengan nilai prediksi dari
variabel dependen . Metode yang paling umum untuk mengestimasi
garis regresi adalah dengan meminimalkan jumlah kuadrat residual (the sum of
squared residuals).
Dengan meminimalkan fungsi dari problem regresi yang di prediksi dengan slope
dan atau a sedangkan intercept dan atau b maka garis regresinya adalah
dan atau
dan atau
2.3.2. Regresi Linier Berganda
Regresi Linier Berganda memiliki lebih dari satu variabel independen
(Kleinbaum et al, 1998). Jika sampel observasi maka
model regresinya adalah
dan atau
Untuk mempermudah perhitungan yang mewakili satu persamaan (2.4) maka dibuat
notasi matriks sebagai berikut :
Koefisien matriks dihasilkan dengan memecahkan persamaan di bawah ini.
Kolom pertama digunakan untuk mewakili syarat intercept dan atau a.
2.4.Asumsi Regresi Linier
Sebelum melakukan analisis regresi linier tersebut, ada beberapa prasyarat yang
harus diperiksa (Abrams, 2007) sebagai berikut:
• Linearitas
Regresi linier mengasumsikan bahwa ada hubungan garis lurus antara
variabel independen dan variabel dependen yang kontiniu. Hal ini dapat
dilihat dari scatterplot bivariat, yaitu sebuah grafik dengan variabel
independen pada satu sumbu dan variabel dependen pada sumbu yang lain.
• Normalitas
Variabel dependen serta variabel independen harus terdistribusi secara
normal. Hal ini dapat diperiksa dengan beberapa cara, misalnya melihat
histogram untuk setiap variabel. Cara lain adalah dengan menghitung
skewness dan kurtosis untuk setiap variabel. Skewness adalah ukuran
kesimetrisan data. Ketika data itu miring, berarti data tidak berada di tengah
distribusi, dan data tidak terdistribusi secara normal. Sementara kurtosis
adalah ukuran bagaimana memuncak distribusinya, dan normalitas artinya
tidak terlalu memuncak dan tidak terlalu datar. Setiap nilai yang lebih besar
dari 3 atau kurang dari -3 haruss ditransformasikan terlebih dahulu sebelum
• Homoskedastis (Mendekati Sama Antara Satu Dengan Lainnya)
Regresi linier juga mengasumsikan bahwa hubungan antara variabel
dependen dan variabel biner independen adalah homoskedastis. Ini berarti
bahwa nilai residual kurang lebih sama untuk semua nilai variabel dependen
yang diprediksikan. Salah satu cara memeriksa homoskedastis dengan melihat
plot nilai residual, di mana sumbu-x merupakan nilai prediksi standar dan
sumbu y merupakan nilai residual standar. Data tersebut adalah
homoskedastis apabila plot nilai residual mempunyai lebar yang sama untuk
semua nilai variabel dependen yang diprediksi. Heteroskedastisitas biasanya
ditunjukkan oleh sekelompok nilai yang lebih luas sebagai nilai-nilai variabel
dependen yang diprediksi untuk mendapatkan nilai yang lebih besar.
• Multikolinearitas dan Singularitas
Multikolinearitas adalah suatu kondisi di mana variabel independen sangat
berkorelasi (0,90 atau lebih besar), dan singularitas adalah ketika
varibel-variabel independen sempurna berkorelasi, misalnya satu varibel-variabel independen
adalah kombinasi dari satu atau lebih variabel independen lainnya. Korelasi
bivariate tinggi dapat dilihat dengan menjalankan korelasi di antara variabel
independen. Jika ada korelasi bivariate tinggi, salah satu dari dua variabel
harus dihapus.
2.5.Uji Keberartian Koefisien Regresi
Pemeriksaan keberartian regresi dilakukan melalui pengujian hipotesis nol, bahwa
koefisien regresi dan atau b sama dengan nol (tidak berarti) melawan hipotesis
tandingan bahwa koefisien arah regresi tidak sama dengan nol.
Pengujian koefisien regresi dapat dilakukan dengan memperhatikan
langkah-langkah pengujian hipotesis berikut:
1. Menentukan rumusan hipotesis Ho dan H1
H
.
o :
H
ρ = 0 : Tidak ada pengaruh variabel X terhadap variabel Y.
2. Menentukan uji statistika yang sesuai. Uji statistika yang digunakan adalah
uji F. Untuk menentukan nilai uji F dapat mengikuti langkah-langkah berikut:
a. Menghitung jumlah kuadrat regresi (JK reg (wo)) dan atau (JK reg (a)
( )
n Y JKreg 2 ) (w0∑
= ) dengan rumus: (2.7) dan atau( )
n Y JKrega2
)
( =
∑
(2.7)b. Menghitung jumlah kuadrat regresi b|a (JK reg b|a
− =
∑
∑ ∑
n Y X XY w JKreg . . 1 ) w / (w1 0), dengan rumus:
(2.8) dan atau − =
∑
∑ ∑
n Y X XY bJKreg(b/a) . . (2.8)
c. Menghitung jumlah kuadrat residu (JK res
) ( Re ) w / (w Re 2 0 0
1 g w
g
res Y JK JK
JK =
∑
− −) dengan rumus:
dan atau (2.9) ) ( Re ) / ( Re 2 a g a b g
res Y JK JK
JK =
∑
− − (2.9)d. Menghitung rata-rata jumlah kuadrat regresi w0 (RJKreg(w0)) dan atau a (RJK reg (a)
) ( Re )
(w0 g w0
reg JK
RJK =
) dengan rumus:
(2.10) dan atau ) ( Re )
(a g a
reg JK
e. Menghitung rata-rata jumlah kuadrat regresi w1/w0 (RJK reg (w0)) dan atau regresi b/a (RJK reg (a)
) / ( Re ) /
(w1 w0 g w1 w0
reg JK
RJK =
) dengan rumus:
(2.11) dan atau ) / ( Re ) /
(b a gb a
reg JK
RJK = (2.11)
f. Menghitung rata-rata jumlah kuadrat residu (RJK res
2 Re − = n JK
RJKres s
) dengan rumus:
(2.12)
g. Mengitung F, dengan rumus:
s w w g RJK RJK F Re ) / (
Re 1 0
= (2.13) dan atau s a b g RJK RJK F Re ) / ( Re = (2.13)
3. Menentukan nilai kritis (α) atau nilai tabel F pada derajat bebas dw1 reg w1/w0 dan dw1reg = n – 2 dan atau dbreg b/a = 1 dan dbres
4. Membandingkan nilai uji F dengan nilai tabel F, dengan kriteria uji, Apabila
nilai hitung F
= n – 2.
lebih besar atau sama dengan (≥) nilai tabel F, maka H0
5. Membuat kesimpulan
ditolak.
Langkah-langkah uji keberartian regresi di atas dapat disederhanakan dalam
Tabel 2.1
Analisis of Varians
Keterangan:
JKT = ∑Y
( )
n Y Jkw 2 ) ( 0∑
= 2 (2.7) dan atauJk (a)
( )
nY 2
∑
= (2.7)
− =
∑
∑ ∑
n Y X XY wJk (w/w) 1. .
0 1
(2.8)
dan atau
Jk (b/a)
−
∑ ∑
∑
Xn YXY
b. .
= (2.8)
Jk Res Re ( / ) Re ( ) 2
0 0
1 w g w
w
g JK
JK
Y − −
∑
= (2.9)
dan atau
Jk Res Re ( / ) Re ( ) 2 a g a b g JK JK
Y − −
∑
= (2.9)
) / ( Re ) /
(w1 w0 Jk g w1 w0
dan atau
RJk (b/a) = Jk (b/a)
RJk (2.11) Res 2 Re − n JK s
= (2.12)
s g S S F Re 2 Re 2 = (2.13)
2.6.Pengujian Keberartian Regresi Ganda
Pemeriksaan keberartian pada analisis korelasi ganda dapat dilakukan dengan
mengikuti langkah-langkah berikut :
1. Menentukan rumusan hipotesis Ho dan H1 H
.
o :R = 0 : Tidak ada pengaruh variabel X1 dan X2 H
terhadap variabel Y.
1 : R ≠ 0 : Ada pengaruh variabel X1 dan X2
2. Menentukan uji statistika yang sesuai, yaitu :
terhadap variabel Y.
2 2 2 1 S S
F = (2.14)
Untuk menentukan nilai uji F di atas, adalah (Sudjana, 1996)
a. Menentukan Jumlah Kuadrat Regresi dengan rumus :
∑
∑
∑
+ + +=w x y w x y w x y
JK(Reg) 11 1 12 2 ... 1k k (2.15) dan atau
∑
∑
∑
+ + +=b x y b x y b x y
JK(Reg) 1 1 2 2 ... k k (2.15)
b. Menentukan Jumlah Kuadrat Residu dengan rumus :
( )
) (Re 2 2 )(Res JK g
n Y Y JK − − =
∑
∑
1 ) (Re ) (Re − − = k n JK k JK F s g hitung (2.17)
Dimana: k = banyaknya variabel bebas
3. Menentukan nilai kritis (α) atau nilai tabel F dengan derajat kebebasan untuk
dw11= k dan dw12 = n – k – 1 dan atau db1 = k dan db2
4. Membandingkan nilai uji F terhadap nilai tabel F dengan criteria pengujian:
Jika nilai uji F
= n – k – 1.
≥ nilai tabel F, maka tolak H
5. Membuat kesimpulan
0
2.7.Koefisien Determinasi
Koefisien ini dinyatakan dalam %, yang menyatakan kontribusi regresi, secara fisik
adalah akibat prediktor, terhadap variasi total variabel respon, yaitu Y. Makin besar
nilai R2, makin besar pula kontribusi atau peranan prediktor terhadap variasi respon.
Biasanya model regresi dengan nilai R2 sebesar 70% atau lebih dianggap cukup baik,
meskipun tidak selalu
∑
∑
= = − − = = n i i n i i Y Y Y Y R 1 2 1 2 Total Regresi 2 ) ( ) ˆ ( JK JK. Rumus koefisien determinasi adalah sebagai berikut :
(2.18)
Hubungan antara prediktor X dengan respon Y, selain dapat dinyatakan oleh
koefisien regresi, yaitu b1, dapat pula dinyatakan dengan koefisien korelasi, yang
dinotasikan rX,Y
Y X n i i n i i r X X Y Y w , 2 / 1 1 2 1 2 1 ) ( ) ( − − =
∑
∑
= =. Bedanya, koefisien regresi dapat digunakan untuk memprediksi
nilai respon, sedang pada koefisien korelasi tidak dapat. Persamaan yang menyatakan
hubungan ini adalah :
dan atau Y X n i i n i i r X X Y Y b , 2 / 1 1 2 1 2 1 ) ( ) ( − − =
∑
∑
== (2.19)
Rumus R2 ini juga menyatakan kuadrat koefisien korelasi antara Yˆdengan Y, sehingga bila dikaitkan dengan rX,Y
2 ˆ , 2 2
,Y YY
X R r
r = =
terdapat hubungan sebagai berikut :
2.8.Ukuran Error
Dalam regresi ada beberapa ukuran error yang sering dipakai untuk menilai
performansi suatu fungsi prediksi. Jika y menyatakan nilai prediksi untuk data ke-i i dan yˆ adalah nilai output aktual data ke-i dan m adalah banyaknya data, maka i beberapa ukuran error yang sering dipakai adalah:
1. Mean squared error (MSE)
(
)
∑
= − = m i i i y y m MSE 1 2 ˆ 1 (2.20)2. Mean absolute deviation (MAD)
m y y MAD m i i i
∑
= − = 1 ˆ (2.21)3. Mean absolute percentage error (MAPE)
m y y APE
m i
i i
∑
= − = 1ˆ
x100 (2.23)
Dengan melihat salah satu atau lebih ukuran error diatas, dapat diketahui
ukuran error untuk suatu set data. Semakin kecil nilai MSE, MAD atau MAPE
semakin bagus (Santosa, 2007).
2.9. UML
UML adalah singkatan dari Unified Modelling Language. Sesuai kata terakhir dari
kepanjangannya, UML itu adalah salah satu bentuk language atau bahasa. Menurut
(Adi Nugroho : 2005). “Unified Modeling Language (UML) adalah alat bantu
analisis serta perancangan perangkat lunak berbasis objek”.
Karena tergolong bahasa visual, UML lebih mengedepankan penggunaan
diagram untuk menggambarkan aspek dari sistem yang sedang dimodelkan.
Memahami UML itu sebagai bahasa visual itu
UML mendefinisikan diagram-diagram sebagai berikut: use case diagram,
class diagram, statechart diagram, activity diagram, sequence diagram, collaboration diagram, component diagram, deployment diagram.
penting, karena penekanan tersebut
membedakannya dengan bahasa pemrograman yang lebih dekat ke mesin. Bahasa
visual lebih dekat ke mental model pikiran kita, sehingga pemodelan menggunakan
bahasa visual bisa lebih mudah dan lebih cepat dipahami dibandingkan apabila
dituliskan dalam sebuah bahasa pemrograman.
Dalam tesis ini akan di dibuat use case diagram dan activity diagram untuk
memvisualisasikan alur kerja penelitian.
2.9.1. Use Case Diagram
Use case diagram menggambarkan fungsionalitas yang diharapkan dari sebuah
sistem. Yang ditekankan adalah “apa” yang diperbuat sistem, dan bukan
“bagaimana”. Sebuah use case merepresentasikan sebuah interaksi antara aktor
dengan sistem. Use case merupakan sebuah pekerjaan tertentu, misalnya login ke
adalah sebuah entitas manusia atau mesin yang berinteraksi dengan sistem untuk
melakukan pekerjaan-pekerjaan tertentu. Use case diagram dapat sangat membantu
bila kita sedang menyusun requirement sebuah sistem, mengkomunikasikan
rancangan dengan klien, dan merancang test case untuk semua feature yang ada pada
sistem.
2.9.2. Activity Diagram
Activity Diagram adalah sebuah cara untuk memodelkan aliran kerja dari suatu usecase bisnis dan aliran kejadian dalam use system dalam bentuk grafik. Diagram
ini menunjukkan langkah-langkah didalam aliran kerja, titik keputusan di dalam
aliran kerja, siapa yang bertanggung jawab menyelesaikan masing-masing aktivitas
dan objek-objek yang digunakan dalam aliran kerja.
Activity Diagram mengambarkan berbagai alir aktivitas dalam sistem yang
sedang dirancang, bagaimana masing-masing alir berawal, keputusan yang mungkin
terjadi dan bagaimana mereka berakhir. Activity Diagram juga dapat
menggambarkan proses parallel yang mungkin terjadi pada beberapa eksekusi.
2.10. Pseudo-Code
Pseudo-code adalah kode atau tanda yang menyerupai (pseudo) atau merupakan
penjelasan cara menyelesaikan suatu masalah. Pseudo-code sering digunakan
seseorang untuk menuliskan algoritma dari suatu permasalahan. Pseudo-code berisi
langkah-langkah untuk menyelesaikan suatu permasalahan dan hampir mirip dengan
logaritma hanya saja bentuknya sedikit berbeda dari algoritma. Pseudo-code
menggunakan bahasa yang hampir menyerupai bahasa pemograman. Selain itu,
biasanya pseudo-code menggunakan bahasa yang mudah dipahami secara universal
dan juga lebih ringkas dari pada algoritma.
Sebenarnya tidak ada aturan mengikat tentang penulisan algoritma dan
pseudo-code, karena kegunaan kedua hal ini adalah memudahkan seseorang untuk
menggambarkan urutan suatu kejadian. Biasanya untuk programmer, guna kedua hal
ini adalah sebagai dasar alur pembuatan program. Dimana dapat mempresentasikan
mudah dipahami. Jadi pseudo-code bisa dikatakan juga sebagai algoritma yang
BAB III
METODOLOGI PENELITIAN
3.1. Pendahuluan
Tujuan dari tesis ini untuk mendapatkan sebuah rancangan aplikasi penentu
keterhubungan antara data mahasiswa dan masa studi dengan menggunakan
algoritma regresi linier berganda.
Data dikumpulkan dari database pendidikan akademik mahasiswa yang yang
diwisuda periode I, II Tahun 2010 dan periode II Tahun 2011 di Sekolah Tinggi
Teknik Harapan (STTH) Medan. Penulis memberikan tinjauan singkat dari beberapa
analisis data yang digunakan pada penelitian ini.
3.2. Lokasi dan Waktu Penelitian
Penelitian dilakukan di Sekolah Tinggi Teknik Harapan Medan Kampus I Jl. Imam
Bonjol No. 35 Medan dan Kampus II Jl. H.M. Jhoni No. 70 Medan. Lamanya waktu
yang dibutuhkan untuk menyelesaikan penelitian ini selama 4 (empat) bulan yang
dimulai pada awal Februari 2011 sampai dengan akhir Juni 2011.
3.3. Pelaksanaan Penelitian
3.3.1. Jenis dan Sumber Data
Jenis data yang dikumpulkan dalam penelitian ini adalah bersumber dari data
sekunder yaitu data yang berasal dari jurnal, dokumen, dan peraturan yang ada di
Sekolah Tinggi Teknik Harapan (STTH) Medan jurusan Teknik Informatika yang
mendukung penelitian ini.
3.3.2. Teknik Pengumpulan Data
Teknik pengumpulan data yang digunakan dalam penelitian ini sebagai berikut :
1. Wawancara kepada pimpinan Sekolah Tinggi Teknik Harapan (STTH)
Medan dan para stafnya untuk mendapatkan keterangan data serta
2. Studi dokumentasi yaitu mengumpulkan database pendidikan mahasiswa
mengenai rata-rata nilai UN, IP Komulatif (IP Semester 1, 2 dan 3),
jumlah sks mata kuliah yang diambil pada semester 4, dan pendidikan
orang tua serta dokumentasi yang mendukung penelitian.
3. Untuk menghasilkan rancangan aplikasi penentu keterhubungan antara
data mahasiswa dan masa studi tesis ini menggunakan 500 data mahasiswa
(data mahasiswa dapat dilihat dalam lampiran1). Selanjutnya 100 data
mahasiswa (data mahasiswa dapat dilihat pada lampiran 2) digunakan
untuk menilai performansi prediksi masa studi mahasiswa.
3.4. Perangkat Lunak yang Digunakan
3.4.1. Bahasa Pemograman C++
Bahasa C dikembangkan di Bell lab pada tahun 1972 ditulis pertama kali oleh Brian
W. Kernighan dan Denies M. Ricthie merupakan bahasa turunan atau pengembangan
dari bahasa B yang ditulis oleh Ken Thompson pada tahun 1970 yang diturunkan
oleh bahasa sebelumnya, yaitu BCL. Bahasa C pada awalnya dirancang sebagai
bahasa pemograman yang dioperasikan pada sistem operasi UNIX.
Bahasa C merupakan bahasa pemograman tingkat menengah yaitu di antara
bahasa tingkat rendah dan tingkat tinggi yang biasa disebut dengan bahasa tingkat
menengah. Bahasa C mempunyai banyak kemampuan yang sering digunakan
diantaranya kemampuan untuk membuat perangkat lunak, misalnya dBase, Word
Star dan lain-lain.
Pada tahun 1980 seorang ahli yang bernama
mengembangkan beberapa hal dari bahasa C yang dinamakan “ C with Classes” yang
pada mulanya di sebut “ a better C” dan berganti nama pada tahun 1983 menjadi
C++ oleh Rick Mascitti, di buat di laboratorium Bell, AT&T.
Pada C++ ditambah konsep-konsep baru seperti class dengan sifat-sifatnya
yang disebut dengan Object Oriented Programming (OOP), yang mempunyai tujuan
Pada tesis ini penulis menggunakan bahasa pemograman C++ untuk mencari
atau menentukan solusi dari sistem persamaan linier (SPL) dalam menentukan
keterhubungan antara data mahasiswa dan masa studi dengan algoritma regresi linier
berganda.
3.4.2. Paket Statistik Untuk Ilmu Sosial (SPSS)
SPSS (Statistical Package for the Social Sciences) ini awalnya dirancang untuk
digunakan oleh ilmuwan sosial untuk menganalisa data. SPSS mengizinkan
pengguna untuk menarik data dan menampilkan operasi analisis statistik yang rumit,
seperti komputasi regresi dan menampilkan presentasi data grafis. Ini juga
menggunakan inferensial yang rumit dan prosedur statistik yang multi variasi, seperti
analisis varians (ANOVA), analisis faktor, analisis kluster, dan analisis data
katerogikal.
SPSS 18.00 digunakan pada tesis ini untuk melakukan uji asumsi klasik
regresi linier. Pengujian ini perlu dilakukan untuk mengetahui apakah koefisien
regresi yang kita dapatkan telah sahih (benar; dapat diterima).
3.5. Perangkat Keras yang Digunakan
Spesifikasinya perangkat keras yang digunakan dalam penelitian ini adalah sebagai
berikut:
1. Prosessor : Intel ® Celer
2. RAM : 1 GB.
3.6. Use Case Diagram
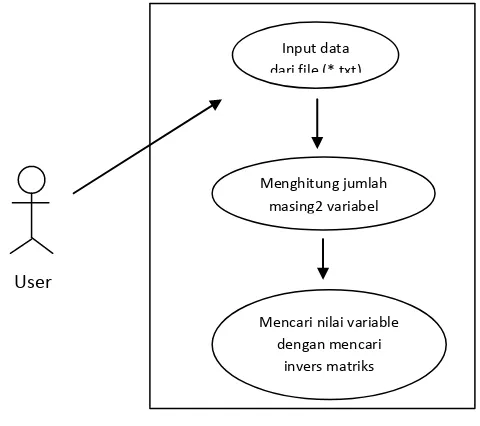
Berikut ini adalah gambar 3.1. yang merupakan use case diagram yang dilakukan
[image:43.595.157.397.172.385.2]pada penelitian ini.
Gambar 3.1. Use Case Diagram
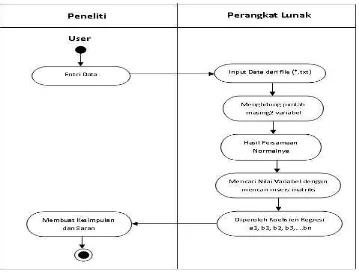
3.7. Activity Diagram
Berikut ini alur kerja yang dilakukan pada penelitian ini yang digambarkan dalam
activity diagram pada gambar 3.2. berikut: User
Input data dari file (* txt)
Menghitung jumlah masing2 variabel
Mencari nilai variable dengan mencari
Gambar 3.2. Activity Diagram
Dari gambar 3.2. di atas dapat dijelaskan bahwa yang pertama kali dilakukan peneliti
adalah mengidentifikasi masalah yang diteliti untuk diselesaikan yang tujuannya
untuk membuat perancangan aplikasi dengan menggunakan bahasa pemograman
C++ untuk mencari atau menentukan solusi dari sistem persamaan linier (SPL) dalam
menentukan keterhubungan data mahasiswa dengan masa studi dengan
menggunakan algoritma regresi linier berganda. Selanjutnya adalah input data dari
file yang berextenxi txt (*.txt). Selanjutnya menghitung jumlah dari masing-masing
variabel, kemudian diperoleh hasil persamaan normalnya. Langkah selanjutnya
mencari nilai variabel dengan cara mencari invers matriks menggunakan Eliminasi
Gauss Jordan. Langkah terakhir diperoleh koefisien regresi a, b1,b2,…, bn, yaitu
3.8. Pseudo-Code
Berikut ini adalah pseudocode bahasa pemograman C++ untuk mencari atau
menentukan solusi dari sistem persamaan linier (SPL) dalam menentukan
keterhubungan antara data mahasiswa dan masa studi adalah sebagai berikut :
1. Input data data dari file:
char *bacaFile (char *datafile){
char ch;
char token[40000];
char *tkn = token;
fflush(stdin);
fp = fopen(datafile,"r");
while((ch = getc(fp)) != EOF)
*(tkn++)=ch;
*tkn=0;
fclose(fp);
return (token);
}
double num (char *input) {
char numstring[20];
char *str;
int len=0;
str = input;
while ((strchr("0123456789-.", *str))==0)
str++;
if(strchr("0123456789-.", *str)) {
while ((isdigit(*str)) || (*str=='-') || (*str=='.'))
{ str++; len++; }
strncpy(numstring, str-len, len);
numstring[len] = 0;
mstr = str;
}
return((float)atof(numstring));
}
int row (char *tempmstr) {
int p=0;
while ((strchr("0123456789-.", *tempmstr))==0)
tempmstr++;
while (*tempmstr!='\0'){
if (*tempmstr == '\n') {
p++;
while ((strchr("0123456789-.", *tempmstr))==0)
tempmstr++;
}
tempmstr++;
}
--tempmstr;
if(isdigit(*tempmstr))
return p;
}
int column(char *tempmstr) {
int p=0;
while ((strchr("0123456789-.", *tempmstr))==0)
tempmstr++;
while (*tempmstr!='\n') {
if((*tempmstr=='\t')||(*tempmstr==' ') {
p++;
while ((*tempmstr=='\t')||(*tempmstr==' '))
tempmstr++;
}
else
tempmstr++;
}
--tempmstr;
if((*tempmstr==' ')||(*tempmstr=='\t'))
--p;
return ++p;
void Matrix::inputData(unsigned int m, unsigned int n) {
row=m; column=n;
for (i=1; i<=row; i++)
for (j=1; j<=column; j++)
element[i][j] = num(mstr);
}
int main () {
char place[200];
char choice;
cout<<"Input where is place of the data : \n";
cout<<"Example : c:\\data\\file1.txt \n\n";
cin>>place;
mstr = bacaFile(place);
cout<<"\n\n"<<mstr;
m=row(mstr);
n=column(mstr);
cout<<"\n\nThe number of rows = "<<m;
cout<<"\nThe number of column = "<<n;
data.inputData(m,n);
}
2. Menghitung jumlah dari masing-masing variabel :
Matrix Matrix::calculateMatrix (int comb) {
float sum;
Matrix temp(MAX,MAX);
for (i=1; i<=row+1; i++) {
j=1;
while (j<=column+comb+column-1) {
temp.element[i][j]=element[i][j];
if ((j>column) && (j<=column+comb))
for(k=1; k<=column-1; k++)
for(l=k; l<=column-1; l++) {
temp.element[i][j]=element[i][k]*element[i][l];
j++;
}
if ((j>column+comb) && (j<=column+comb+column-1))
for(k=1; k<=column-1; k++) {
j++;
}
j++;
}
if (i==row+1){
for(k=1; k<=column+comb+column-1; k++){
sum=0;
for(l=1; l<=row; l++)
sum+=temp.element[l][k];
temp.element[i][k]=sum;
}
}
}
temp.row=row+1;
temp.column=column+comb+column-1;
return temp;
}
int main () {
…
count+=i;
calculateData=data.calculateMatrix(count);
…
}
3. Hasil persamaan normalnya :
void Matrix::identifikasiVar (int columnData, int n, int count) {
int i,j,k;
char str[8], temp[8];
i=1;
while (i<=columnData) {
if(i<=n) {
strcpy(a[i],convertInt(i));
i++;
}
else if (i==n+1) {
strcpy(a[i],"y");
i++;
else if ((i>n+1) && (i<=n+1+count)) {
for(j=1; j<=n; j++)
for(k=j; k<=n; k++) {
strcpy(str,convertInt(j));
strcat(str,convertInt(k));
strcpy(a[i],str);
i++;
}
}
else {
for(j=1; j<=n; j++) {
strcpy(str,convertInt(j));
strcat(str,"y");
strcpy(a[i],str);
i++;
}
}
}
for(i=1; i<=n+1; i++) {
for(j=1; j<=n+1+1; j++) {
if (i==1) {
if (j==1)
persamaanMatrix.element[i][j]=row-1;
else
persamaanMatrix.element[i][j]=element[row][j-1];
}
else {
itoa(i-1, temp, 10);
while(strstr(a[k],temp)==0)
k++;
persamaanMatrix.element[i][j]=element[row][k];
k++;
}
}
}
persamaanMatrix.row=n+1;
persamaanMatrix.column=n+1+1;
}
Matrix temp(MAX,MAX);
for (i=1; i<=row; i++)
for (j=1; j<=column-1; j++)
coefisient.element[i][j]=element[i][j];
coefisient.row = row;
coefisient.column = column-1;
for(i=1; i<=row; i++)
ruasKanan.element[i][1]=element[i][column];
ruasKanan.row = row;
ruasKanan.column = 1;
}
int main () {
…
calculateData.identifikasiVar(n+count+n-1,n-1,count);
persamaanMatrix.parsingMatrix();
…
}
4. Mencari nilai variabel dengan mencari invers matrix menggunakan Eliminasi
Matrix Matrix::inversMatrix () {
foat kali, temp;
int i,j,k,sign,n=row;
Matrix identitas(MAX,MAX);
for(i=1;i<=n;i++)
for(j=1;j<=n;j++) {
if(i==j)
identitas.element[i][j]=1;
else
identitas.element[i][j]=0;
}
for(i=1; i<=n; i++) {
if (element[i][i]==0) {
sign=0;
j=i+1;
while (sign==0) {
if(element[j][i]!=0)
temp=element[i][k];
element[i][k]=element[j][k];
element[j][k]=temp;
temp=identitas.element[i][k];
identitas.element[i][k]=identitas.element[j][k];
identitas.element[j][k]=temp;
sign=1;
}
else
j++;
if(j>n) {
cout<<"\n\nMatrix has not Invers..!!!!";
getch();
exit(0);
}
}
}
kali=1/element[i][i];
for(j=1; j<=n; j++) {
identitas.element[i][j]=kali*identitas.element[i][j];
}
for(k=i+1;k<=n;k++)
if(element[k][i]!=0) {
kali=element[k][i];
for(j=1; j<=row; j++) {
element[k][j]=element[k][j]-(kali*element[i][j]);
identitas.element[k][j]=identitas.element[k][j]-(kali*identitas.element[i][j]);
}
}
}
for(i=n; i>1; i--) {
for(k=i-1;k>=1;k--)
if(element[k][i]!=0) {
kali=element[k][i];
for(j=1; j<=n; j++) {
element[k][j]=element[k][j]-(kali*element[i][j]);
identitas.element[k][j]=identitas.element[k][j]-(kali*identitas.element[i][j]);
}
}
identitas.row=identitas.column=n;
return identitas;
}
int main () {
…
invers=coefisient.inversMatrix();
persamaanMatrix.parsingMatrix();
…
}
5. Diperoleh koefisien regresi a, b1, b2, b3, …, bn, yaitu dengan mengalikan invers
matrix dengan persamaan matrix pada ruas kanan.
Matrix Matrix::operator*(const Matrix & M) {
unsigned int i, j, k;
Matrix R(row, M.column);
for (i = 1; i <= row; i++) {
R.element[i][j] = 0;
for (k = 1; k <= column; k++) {
R.element[i][j] += element[i][k] * M.element[k][j];
}
}
}
return R;
}
int main () {
…
variabel=invers*ruasKanan;
…
BAB IV
HASIL DAN PEMBAHASAN
4.1. Pendahuluan
Setelah bahan tersedia yaitu berupa data dan telah diketahui metode yang akan
digunakan maka tindakan selanjutnya adalah melakukan pengolahan data tersebut
dengan metode yang telah ada. Kemudian hasil pengolahan data tersebut dianalisis
sehingga dapat dibuat suatu kesimpulan yang berarti.
Bab ini menyajikan hasil penelitian yang diambil dari database mahasiswa
yang diwisuda pada periode I, II Tahun 2010 dan periode II Tahun 2011 di Sekolah
Tinggi Teknik Harapan (STTH) Medan. Data bersifat nominal yang terdiri dari
rata-rata nilai UN, IP Komulatif (IP Semester 1, 2 dan 3), jumlah sks mata kuliah yang
diambil pada semester 4, dan pendidikan orang tua.
Dari data yang sudah diperoleh dilakukan uji asumsi klasik dengan
menggunakan program dan pengolahan data SPSS (Statistical Package for the Social
Sciences). Selanjutnya dilakukan perancangan aplikasi penentu keterhubungan antara
data mahasiswa dan masa studi dengan algoritma regresi linier berganda
menggunakan bahasa pemograman C++
4.2. Hasil Percobaan
4.2.1. Uji Asumsi Klasik
Pengujian jenis ini digunakan untuk menguji asumsi, apakah model regresi yang
digunakan dalam penelitian ini memenuhi asumsi klasik layak uji atau tidak. Uji
asumsi klasik digunakan untuk memastikan bahwa multikorelasi, autokorelasi, dan
heteroskedastisitas tidak terdapat dalam model yang digunakan dan data yang
digunakan terdistribusi normal. Jika semua itu terpenuhi bahwa model analisis telah
• Multikolinieritas
Uji multikolinieritas bertujuan untuk menunjukkan apakah terdapat hubungan
(korelasi) yang sempurna atau mendekati sempurna antar variabel bebas yang
terdapat dalam model, yaitu koefisien korelasinya tinggi atau bahkan satu (Algifari,
2000).
Untuk mengetahui ada atau tidaknya gejala multikolinieritas dilakukan
dengan melihat harga VIF (Variance Inflation Factor) melalui aplikasi perangkat
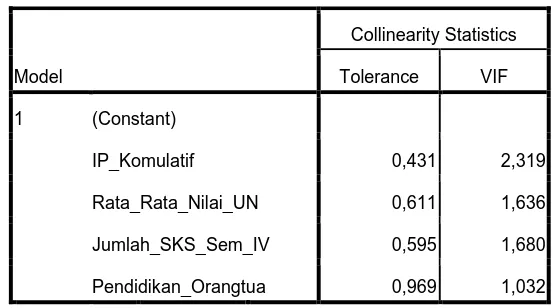
lunak SPSS Versi 18.00. Apabila nilai tolerance- nya diatas 0,1 dan VIF dibawah 10,
[image:61.595.177.454.323.477.2]maka model regresi bebas dari multikolinieritas (Ghozali, 2002).
Tabel 4.1. Collinearity Statistic
Model
Collinearity Statistics
Tolerance VIF
1 (Constant)
IP_Komulatif 0,431 2,319
Rata_Rata_Nilai_UN 0,611 1,636
Jumlah_SKS_Sem_IV 0,595 1,680
Pendidikan_Orangtua 0,969 1,032
Berdasarkan tabel 4.1. diatas dapat diketahui bahwa nilai VIF untuk rata-rata
nilai UN adalah 1,636. Nilai VIF untuk IP Komulatif (IP Semester 1, 2 dan 3) adalah
2,319. Nilai VIF untuk jumlah sks mata kuliah yang diambil pada semester 4 adalah
1,680. Nilai VIF untuk pendidikan orang tua adalah 1,032. Demikian juga untuk
nilai tolerance pada masing-masing vari