DENGAN KOMPUTASI MENGGUNAKAN
PENDEKATAN BAYES
GUSTI NGURAH ADHI WIBAWA
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Dengan ini saya menyatakan bahwa disertasi “Pendugaan Parameter Model AMMI dengan Komputasi Menggunakan Pendekatan Bayes” adalah karya saya sendiri dan belum pernah diajukan dalam bentuk apapun kepada perguruan tinggi manapun.
Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan atau tidak
diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar
Pustaka di bagian akhir disertasi ini.
Bogor, Agustus 2012
GUSTI NGURAH ADHI WIBAWA. Parameter Estimation of AMMI Models with Computation using Bayesian Approach. Supervised by AUNUDDIN, AHMAD ANSORI MATTJIK, and I MADE SUMERTAJAYA.
Statistics on the application of plant breeding research has long used primarily in quantitative genetics. Modeling requirements for selection is needed to support efforts to obtain improved varieties. In modeling, there are two main paradigms used to estimate model parameters as the frequentist and Bayesian.
Standard AMMI is a classical method has been used extensively for modeling and analysis genotype and environmental interactions. Homogeneity variance error is one of assumptions that must be satisfied in this method. Heterogeneity of variance error can lead to errors in conclusions regarding treatment effect. This study focuses attention on the computational efficiency of Bayesian in AMMI model parameters assumed in the data with heterogeneous variance error and evaluate the suitability of the configuration of genotype and environment interactions in Biplot AMMI.
In the data with heterogeneous variance error, there are various differences between the treatment which is likely to cause a reduction in the efficiency of variance estimators in suspected treatment effect. Data transformation is usually used to overcome the problem of heterogeneity variance error. However, it is often quite difficult to obtain a suitable transformation and interpretations of treatment effect obtained from the transformation of data. Therefore we need another approach that can overcome the problem of heterogeneity variance error.
The continued development of computerization, the Bayesian approach is a method that has been used to estimate parameters of linier-bilinier model. Bayesian approach is utilizing prior information about parameters to be expected and information from the sample that will be combined to get a posterior distribution.
In this paper was evaluated the use of Bayesian approach to estimate model parameters and configuration AMMI biplot. There are two types of data used in this study, the simulated data and real data results of multilocation trials. Each type of data has homogeneous and heterogeneous variance. Prior distribution was a conjugate prior and values for posterior distribution were estimated by Gibbs sampling algorithm.
The analysis showed that the Bayesian approach was quite efficient to estimate genotype and environment interaction effect. In fact, AMMI-BS using the BIC to determine the number of principal components of the interaction has a higher efficiency than AMMI-B. Bayesian approach to efficient enough in assuming an interaction effect can be seen from the variance that are smaller than standard AMMI.
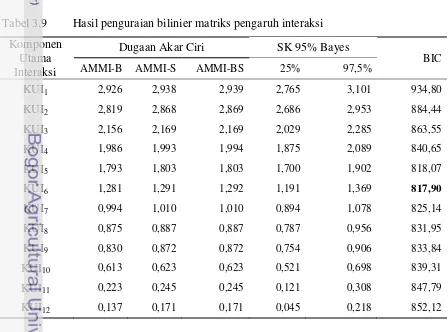
If the estimation of bilinier components of each method is used to construct the AMMI biplot to know the configuration of interaction structure, there are relatively similar in configuration among the three methods.
GUSTI NGURAH ADHI WIBAWA. Pendugaan Parameter Model AMMI dengan Komputasi Menggunakan Pendekatan Bayes. Dibimbing oleh AUNUDDIN, AHMAD ANSORI MATTJIK, dan I MADE SUMERTAJAYA.
Penerapan Statistika sudah cukup lama digunakan pada penelitian pemuliaan tanaman terutama dalam genetika kuantitatif. Kebutuhan pemodelan pada proses seleksi diperlukan untuk mendukung upaya memperoleh varietas unggul. Dalam pemodelan, terdapat dua paradigma utama yang digunakan untuk pendugaan parameter model yaitu frequentist dan Bayes.
Metode AMMI standar merupakan metode klasik yang telah digunakan secara luas untuk pemodelan dan analisis interaksi genotipe dan lingkungan (IGL). Kehomogenan ragam galat percobaan merupakan salah satu asumsi yang harus dipenuhi pada metode ini. Ketidakhomogenan ragam galat dapat menyebabkan terjadinya kesalahan dalam pengambilan kesimpulan mengenai pengaruh perlakuan. Penelitian ini memfokuskan perhatian pada efisiensi komputasi Bayes dalam menduga parameter model AMMI pada data dengan ragam heterogen dan mengevaluasi kesesuaian konfigurasi interaksi genotipe dan lingkungan pada Biplot AMMI.
Pada data dengan ragam galat heterogen, terdapat perbedaan ragam antar perlakukan yang kemungkinan akan menyebabkan berkurangnya efisiensi penduga ragam dalam menduga pengaruh perlakuan. Transformasi data biasanya digunakan untuk mengatasi masalah keheterogenan ragam galat. Namun, seringkali cukup sulit untuk memperoleh transformasi yang cocok dan melakukan interpretasi pengaruh perlakuan yang diperoleh dari data hasil transformasi. Oleh karena itu diperlukan pendekatan lain yang relatif mampu mengatasi masalah keheterogenan galat.
Semakin berkembangnya komputerisasi, pendekatan Bayes merupakan suatu metode yang dapat digunakan untuk menduga parameter model linier-bilinier. Pendekatan Bayes memanfaatkan informasi awal (prior information) tentang parameter yang akan diduga dan informasi dari contoh yang akan dikombinasikan membentuk suatu sebaran posterior. Pada penelitian ini digunakan dua pendekatan Bayes yaitu AMMI Bayes (AMMI-B) dan AMMI Bayes SVD (AMMI-BS). Pada AMMI-B, semua parameter model diduga mengunakan komputasi Bayes. Sedangkan pada AMMI-BS, hanya nilai tengah dan pengaruh utama serta pengaruh interaksi yang diduga dengan komputasi Bayes, sementara komponen bilinier diduga dengan SVD (Singular Value Decomposition).
Terdapat dua jenis data yang digunakan pada penelitian ini, yaitu data simulasi dan data riil hasil percobaan lokasi ganda. Sebaran prior yang digunakan pada pendekatan Bayes adalah conjugate prior dengan nilai ragam prior merupakan non informatif prior. Nilai dari sebaran posterior diduga menggunakan algoritma Gibbs sampling. Sedangkan dugaan parameter model diperoleh dari nilai rata-rata posterior.
Kemiripan Biplot AMMI diperoleh karena nilai dugaan akar ciri dan vektor ciri yang dihasilkan oleh ketiga metode dan besarnya keragaman interaksi yang digambarkan melalui Biplot AMMI hampir sama.
@Hak Cipta Milik Institut Pertanian Bogor (IPB), tahun 2012
Hak Cipta Dilindungi Undang-undang
1. Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumber:
a. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik atau tinjauan suatu masalah
b. Pengutipan tidak merugikan kepentingan yang wajar
Oleh:
GUSTI NGURAH ADHI WIBAWA
G161070041/STK
Disertasi
Sebagai salah satu syarat untuk memperoleh gelar Doktor
pada
Program Studi Statistika
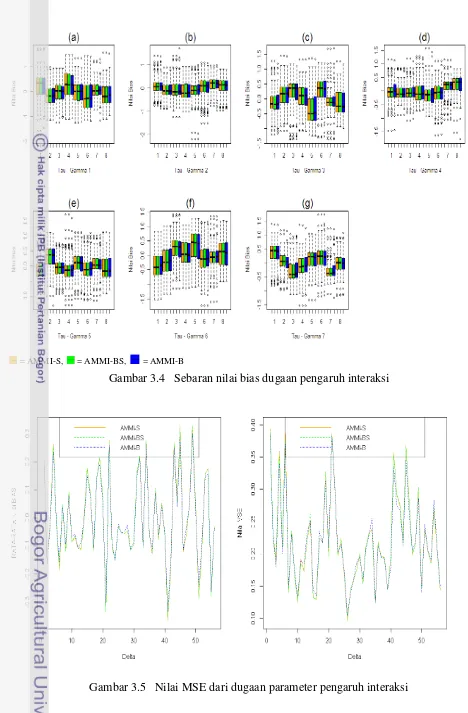
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Penguji pada Ujian Tertutup
: Dr. Ir. Hari Wijayanto, MS.
Dr. Ir. I Wayan Mangku, MSc.
Penguji pada Ujian Terbuka
: Dr. Ir. M. Syukur, MS.
Dr. Ir. Budi Susetyo, MS.
Nama Mahasiswa : Gusti Ngurah Adhi Wibawa
Nomor Pokok : G161070041
Program Studi : Statistika
Menyetujui
Komisi Pembimbing,
Prof. Dr. Ir. Aunuddin, M.Sc Ketua
Prof. Dr. Ir. A. A. Mattjik, M.Sc Dr. Ir. I Made Sumertajaya, M.Si
Anggota Anggota
Mengetahui,
Ketua Program Studi Dekan Sekolah Pascasarjana
Dr.Ir. Aji Hamim Wigena, M.Sc. Dr. Ir. Dahrul Syah, M.Sc.Agr
Tanggal Ujian Terbuka : 31 Juli 2012
xv
Puji syukur penulis panjatkan kehadapan Ida Sang Hyang Widi Wasa, Tuhan
Yang Maha Esa, atas berkat rahmatnya sehingga Disertasi ini dapat terselesaikan.
Disertasi ini merupakan salah satu syarat untuk memperoleh gelar Doktor pada
Program Studi Statistika di Institut Pertanian Bogor.
Dalam penyelesaian tulisan ini, Penulis banyak mendapat bantuan dan
dukungan dari berbagai pihak. Untuk itu penulis mengucapkan terimakasih dan
penghargaan yang sebesar-besarnya kepada:
1. Rektor Universitas Haluoleo dan Dekan Fakultas MIPA Universitas Haluoleo
yang telah mengijinkan Penulis untuk melanjutkan studi ke IPB.
2. Direktorat Jenderal pendidikan Tinggi Kementerian Pendidikan dan
Kebudayaan, yang telah memberikan bantuan biaya pendidikan melalui program
BPPS.
3. Bapak Prof. Dr. Aunuddin, MSc, Prof. Dr. A.A. Mattjik, MSc, dan Dr. Ir. I
Made Sumertajaya, MSi selaku pembimbing yang telah banyak memberikan
arahan, saran, bimbingan, nasehat dan dorongan moral kepada penulis. Ucapan
terimakasih juga penulis haturkan kepada penguji atas masukan dan saran untuk
perbaikan disertasi ini.
4. Bapak Dr. Aan Andang Daradjat dari Balai Besar Penelitian Tanaman Padi (BB
Padi) di Sukamandi, Subang Jawa Barat yang telah mengijinkan menggunakan
data hasil penelitian BB Padi untuk dijadikan sebagai bahan kajian dalam
disertasi ini.
5. Staf pengajar Departemen Statistika IPB atas saran, bimbingan, nasehat dan
dorongan moral kepada penulis, khususnya kepada Bapak Dr. Hari Wijayanto
dan Dr. Anang Kurnia atas bantuan akses jurnal dan diskusinya.
6. Rekan-rekan mahasiswa S2 dan S3 Statistika IPB atas kebersamaan selama
menempuh studi, terutama Tim Hibah Pascasarjana di bawah asuhan Prof. Dr.
A.A. Mattjik, MSc.
7. Seluruh anggota keluarga Penulis yang telah banyak memberikan dorongan
moral dan spiritual.
xvi ini bermanfaat.
Bogor, Agustus 2012
xvii
Penulis adalah anak ketiga dari pasangan I Gusti Made Mastra dan Ni Gusti
Ayu Nyoman Budi, lahir pada tanggal 16 Juni 1972 di Kendari, Sulawesi Tenggara.
Penulis mengenyam pendidikan sarjana di Jurusan Statistika, Fakultas
Matematika dan Ilmu pengetahuan Alam, Institut Pertanian Bogor pada tahun
1992-1997. Setahun setelah lulus pendidikan sarjana, penulis bekerja sebagai staf
pengajar honorer di Jurusan Matematika FMIPA Universitas Haluoleo dan pada
tahun 1999 diangkat sebagai pengajar tetap.
Pada tahun 2004, penulis memperoleh gelar Magister Sains pada Program
Studi Statistika di universitas yang sama di bawah bimbingan Prof. Dr. Barizi, MES
dan Prof. Dr. Ir. Latifah K. Darusman, MS. Sejak tahun 2007 Penulis menempuh
program Doktor dengan Beasiswa Program Pascasarjana (BPPS) dari Direktorat
Jenderal Pendidikan Tinggi (DIKTI) Kementerian Pendidikan dan Kebudayaan
Republik Indonesia.
Sejak tahun 2008 Penulis diberi kesempatan untuk ikut bergabung dalam
Hibah Pascasarjana di bawah asuhan Prof. Dr. Ir. A.A. Mattjik, MSc yang
memfokuskan perhatian pada pemodelan statistika pada bidang pemuliaan tanaman.
Untuk menunjang keilmuan pada bidang pemuliaan tanaman, Penulis menempuh
beberapa matakuliah penunjang pada bidang tersebut, antara lain: Pemuliaan
Tanaman, Genetika Kuantitatif, dan Metode Penelitian Pemuliaan Tanaman.
Selama mengikuti pendidikan Program Doktor, beberapa karya ilmiah penulis
bersama pembimbing akan dipublikasikan dalam jurnal ilmiah dan sebagian telah
dibukukan. Karya ilmiah tersebut antara lain:
1. Wibawa GNA, Aunuddin, Mattjik AA, dan Sumertajaya IM. 2012. Pendugaan
Parameter Model AMMI dengan Komputasi Bayesian. Akan diterbitkan pada
Jurnal Math-Info Vol. 6/ No. 1/ Januari 2013.
2. Wibawa GNA, Aunuddin, Mattjik AA, dan Sumertajaya IM. 2012. Komputasi
Bayesian untuk Menduga Parameter Model AMMI dengan Ragam Galat
Heterogen. Akan diterbitkan pada Jurnal BIAStatistics Vol. 6/No. 2/September
xix
DAFTAR ISI ... XIX DAFTAR TABEL ... XXI DAFTAR GAMBAR ... XXIII DAFTAR LAMPIRAN ... XXV
BAB I. PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Tujuan dan Manfaat Penelitian ... 6
1.3. Kerangka Pikir ... 6
1.4. Kebaharuan ... 8
BAB II. TINJAUAN PUSTAKA ... 9
2.1. Percobaan Lokasi ganda... 9
2.2. Analisis AMMI (Additive Main Effect Multiplicative Interaction) ... 9
2.3. Metode Bayes ... 10
2.4. Bayes AMMI ... 11
2.4.1. Sebaran Prior ... 11
2.4.2.Sebaran Posterior ... 14
2.5. Markov Chain Monte Carlo ... 18
2.6. Pemilihan Model AMMI ... 21
2.7. Evaluasi Kesesuaian Konfigurasi... 21
BAB III. PENDUGAAN PARAMETER MODEL AMMI PADA DATA DENGAN RAGAM HOMOGEN ... 23
3.1. Pendahuluan ... 23
3.2. Tujuan ... 23
3.3. Data dan Metode Analisis ... 24
3.3.1. Data ... 24
3.3.2. Metode Analisis ... 26
3.4. Hasil dan Pembahasan ... 33
3.4.1. Data Hasil Simulasi ... 33
3.4.2. Data Riil ... 39
3.5. Kesimpulan ... 46
BAB IV. PENDUGAAN PARAMETER MODEL AMMI PADA DATA DENGAN RAGAM HETEROGEN ... 47
4.1. Pendahuluan ... 47
4.2. Tujuan ... 47
4.3. Data dan Metode Analisis ... 47
4.3.1. Data ... 47
4.3.2. Metode Analisis ... 49
4.4. Hasil dan Pembahasan ... 49
xx
5.1. Dugaan Parameter ... 74
5.2. Konfigurasi Struktur Interaksi Genotipe dan Lingkungan ... 76
BAB VI. KESIMPULAN DAN SARAN ... 77
6.1. Kesimpulan ... 77
6.2. Saran ... 77
DAFTAR PUSTAKA ... 79
xxi
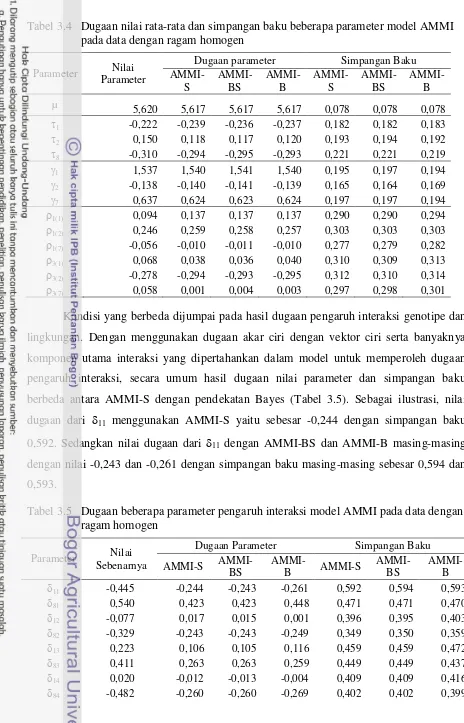
Tabel 3.1 Nilai setiap parameter model untuk membangkitkan data ... 24 Tabel 3.2 Daftar uji lokasi ganda galur-galur padi sawah ... 25 Tabel 3.3 Daftar lokasi percobaan ... 26 Tabel 3.4 Dugaan nilai rata-rata dan simpangan baku beberapa parameter
model AMMI pada data dengan ragam homogen ... 34 Tabel 3.5 Dugaan beberapa parameter pengaruh interaksi model AMMI
pada data dengan ragam homogen ... 34 Tabel 3.6 Rata-rata bias mutlak dan MSE ... 38 Tabel 3.7 Tabel analisis ragam data riil dengan ragam galat homogen ... 41 Tabel 3.8 Dugaan nilai rata-rata dan beberapa parameter pengaruh utama
model AMMI ... 42 Tabel 3.9 Hasil penguraian bilinier matriks pengaruh interaksi ... 43 Tabel 4.1 Nilai setiap parameter model untuk membangkitkan data ... 48 Tabel 4.2 Dugaan nilai rata-rata dan simpangan baku beberapa parameter
model AMMI pada data dengan dua ulangan ... 50 Tabel 4.3 Dugaan beberapa parameter pengaruh interaksi model AMMI
pada data dengan dua ulangan ... 51 Tabel 4.4 Rata-rata bias mutlak dan rata-rata MSE pada data dengan dua
ulangan ... 54 Tabel 4.5 Dugaan nilai rata-rata dan simpangan baku beberepa parameter
model AMMI pada data dengan tiga ulangan ... 55 Tabel 4.6 Dugaan pengaruh interaksi model AMMI pada data dengan tiga
ulangan ... 55 Tabel 4.7 Rata-rata bias mutlak dan rata-rata MSE pada data dengan tiga
ulangan ... 58 Tabel 4.8 Dugaan nilai rata-rata dan simpangan baku parameter model
AMMI pada data dengan empat ulangan ... 59 Tabel 4.9 Dugaan beberapa parameter pengaruh interaksi model AMMI
pada data dengan empat ulangan ... 60 Tabel 4.10 Rata-rata bias mutlak dan rata-rata MSE pada data dengan empat
ulangan ... 63 Tabel 4.11 Tabel Analisis Ragam Data Percobaan Padi ... 67 Tabel 4.12 Dugaan nilai rata-rata dan beberapa parameter pengaruh utama
xxiii
Gambar 1.1 Kerangka pikir penelitian ... 8 Gambar 3.1 Tahapan memperoleh data simulasi dengan ragam galat
homogen ... 25 Gambar 3.2 Sebaran nilai bias dugaan rata-rata, pengaruh genotipe dan
pengaruh lingkungan ... 35 Gambar 3.3 Sebaran nilai bias dari dugaan parameter pengaruh utama
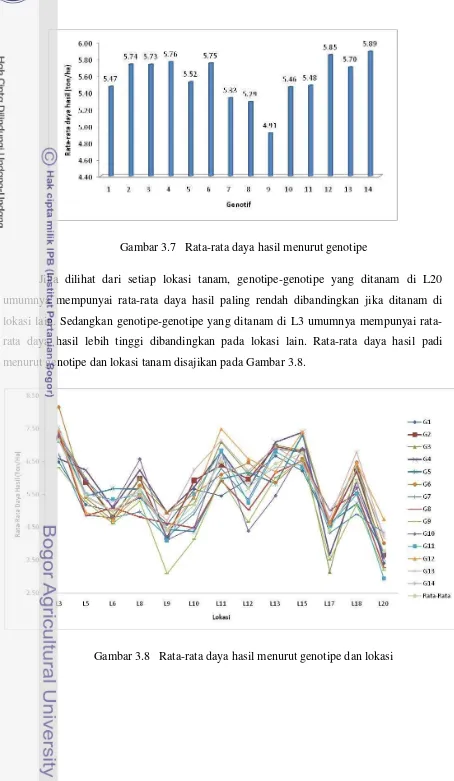
kelompok tersarang pada lingkungan ... 36 Gambar 3.4 Sebaran nilai bias dugaan pengaruh interaksi ... 37 Gambar 3.5 Nilai MSE dari dugaan parameter pengaruh interaksi ... 37 Gambar 3.6 Nilai R2 procrustes ... 39 Gambar 3.7 Rata-rata daya hasil menurut genotipe ... 40 Gambar 3.8 Rata-rata daya hasil menurut genotipe dan lokasi ... 40 Gambar 3.9 Dugaan pengaruh utama berdasarkan data riil ... 43 Gambar 3.10 Dugaan nilai akar ciri ... 44 Gambar 3.11 Dugaan pengaruh interaksi ... 45 Gambar 3.12 Biplot AMMI menurut pendekatan yang digunakan ... 46 Gambar 4.1 Tahapan memperoleh data simulasi dengan ragam galat
heterogen ... 49 Gambar 4.2 Sebaran banyaknya komponen utama interaksi yang
dipertahankan pada model ... 52 Gambar 4.3 Sebaran nilai bias dugaan pengaruh interaksi ... 53 Gambar 4.4 Nilai rata-rata bias dan MSE dari dugaan parameter pengaruh
interaksi pada data dengan ragam heterogen ... 53 Gambar 4.5 Sebaran banyaknya komponen utama interaksi yang
dipertahankan pada model ... 56 Gambar 4.6 Sebaran nilai bias dugaan pengaruh interaksi pada data dengan
4 ulangan ... 57 Gambar 4.7 Nilai rata-rata bias dan MSE dari dugaan parameter pengaruh
interaksi pada data dengan ragam heterogen ... 58 Gambar 4.8 Sebaran banyaknya komponen utama interaksi yang
dipertahankan pada model ... 61 Gambar 4.9 Sebaran nilai bias dugaan pengaruh interaksi pada data dengan
3 ulangan ... 62 Gambar 4.10 Nilai rata-rata bias dan MSE dari dugaan parameter pengaruh
xxiv
Gambar 4.17 Dugaan pengaruh interaksi ... 70 Gambar 4.18 Biplot AMMI menurut pendekatan yang digunakan ... 71 Gambar 5.1 Hubungan banyaknya ulangan dengan nilai MSE ... 75 Gambar 5.2 Hubungan banyaknya ulangan dengan banyaknya komponen
xxv
Lampiran 1 Hasil uji kehomogenan ragam ... 83 Lampiran 2 Plot CUSUM akar ciri yang dihasilkan menggunakan AMMI-B
pada data riil padi (ragam homogen) ... 84 Lampiran 3 Plot CUSUM nilai tengah yang dihasilkan menggunakan
AMMI-B pada data riil padi (ragam heterogen) ... 85 Lampiran 4 Plot CUSUM dugaan pengaruh genotipe yang dihasilkan
menggunakan AMMI-B pada data riil padi (ragam heterogen) ... 85 Lampiran 5 Plot CUSUM dugaan pengaruh lingkungan yang dihasilkan
menggunakan AMMI-B pada data riil padi (ragam heterogen) ... 86 Lampiran 6 Plot CUSUM pengaruh kelompok tersarang pada lokasi yang
dihasilkan menggunakan AMMI-B pada data riil padi (ragam
heterogen) ... 86 Lampiran 7 Plot CUSUM akar ciri yang dihasilkan menggunakan AMMI-B
pada data riil padi (ragam heterogen) ... 87 Lampiran 8 Dugaan nilai rata-rata dan simpangan baku parameter model
AMMI pada data dengan ragam homogen ... 88 Lampiran 9 Dugaan pengaruh interaksi model AMMI pada data dengan
ragam homogen ... 89 Lampiran 10 Dugaan nilai rata-rata dan simpangan baku parameter model
AMMI pada data dengan dua ulangan (kasus ragam galat
heterogen) ... 90 Lampiran 11 Dugaan pengaruh interaksi model AMMI pada data dengan dua
ulangan (kasus ragam galat heterogen) ... 91 Lampiran 12 Dugaan nilai rata-rata dan simpangan baku parameter model
AMMI pada data dengan tiga ulangan (kasus ragam galat
heterogen) ... 93 Lampiran 13 Dugaan pengaruh interaksi model AMMI pada data dengan
tiga ulangan (kasus ragam galat heterogen) ... 94 Lampiran 14 Dugaan nilai rata-rata dan simpangan baku parameter model
AMMI pada data dengan empat ulangan (kasus ragam galat
heterogen) ... 95 Lampiran 15 Dugaan pengaruh interaksi model AMMI pada data dengan
empat ulangan (kasus ragam galat heterogen) ... 97 Lampiran 16 Dugaan pengaruh utama dan interaksi serta ragam berdasarkan
data riil uji lokasi ganda (kasus ragam galat homogen) ... 99 Lampiran 17 Dugaan pengaruh utama dan interaksi serta ragam berdasarkan
1.
BAB I. PENDAHULUAN
1.1. Latar Belakang
Percobaan yang melibatkan dua faktor telah umum digunakan pada
penelitian pemuliaan tanaman seperti uji daya hasil tanaman padi dan jagung. Dua
faktor utama yang biasanya dilibatkan dalam uji daya hasil (uji lokasi ganda) yakni
genotipe tanaman dan kondisi lingkungan (lingkungan: tempat (site), musim,
perlakuan agronomis (agronomy treatment). Percobaan ini bertujuan untuk
meningkatkan keakuratan pendugaan daya hasil, melihat kestabilan hasil dan pola
respon genotipe antar lingkungan, serta membantu pemulia menentukan
genotipe-genotipe terbaik untuk direkomendasikan sebagai varietas baru.
Dari uji lokasi ganda diharapkan mampu memilah pengaruh utama
(genotipe dan lingkungan) dan pengaruh Interaksi antara Genotipe dengan
Lingkungan (IGL). Dari pengaruh interaksi tersebut dapat dipilah
genotipe-genotipe yang mampu beradaptasi pada berbagai kondisi lingkungan (genotipe-genotipe
stabil) dan genotipe-genotipe yang hanya sesuai pada lingkungan tertentu (genotipe
spesifik). Untuk mampu memilah kedua pengaruh ini dengan baik dibutuhkan
pendekatan analisis yang tepat.
Pendekatan analisis yang berkembang sampai saat ini untuk percobaan
lokasi ganda antara lain analisis kestabilan Eberhat and Russel, analisis regresi
linier terhadap pengaruh lingkungan dan Additive Main effect and Multiplicative
Interaction (AMMI). Dari beberapa penelitian yang telah dilakukan diketahui
bahwa pendekatan AMMI lebih baik dalam mengkaji struktur interaksi antara
genotipe dengan lingkungan. Model AMMI mampu menjelaskan interaksi dengan
baik melalui model interaksi lengkap atau dikenal sebagai suku
multiplikatif/bilinier (Sumertajaya 1998). Groenen & Koning (2004) menunjukkan
penggunaan biplot pada model bilinear sebagai cara baru menggambarkan interaksi
pada model aditif (ANOVA model). Struktur interaksi diuraikan dari matriks sisaan
(singular value decomposition, SVD). SVD merupakan pendekatan kuadrat
terkecil dengan reduksi dimensi (pangkat matriks) data yang terbaik dan
menyediakan penyajian secara grafis yang dikenal secara luas dengan nama Biplot.
Seiring dengan permasalahan riil pada pemuliaan tanaman pangan,
beberapa hal dari pendekatan AMMI yang dibangun dengan landasan teori
pemodelan pada data yang berdistribusi Normal, teknik komputasi yang sederhana
dan telah secara luas digunakan perlu dikembangkan untuk memperluas cakupan
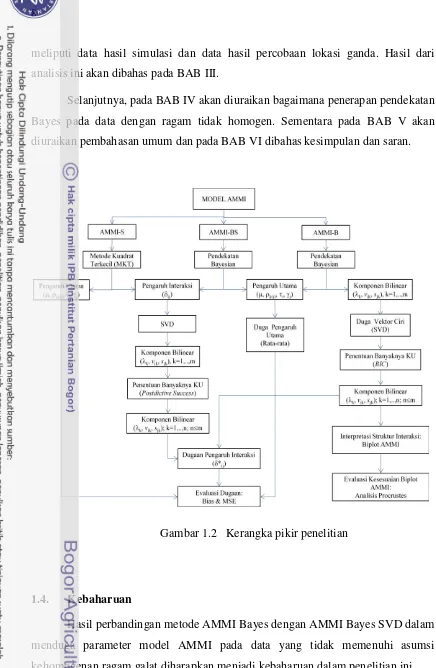
analisis. Gambar 1.1 menyajikan roadmap dari pengembangan pendekatan AMMI
(Mattjik et al 2011). Beberapa hal terkait pengembangan model AMMI antara lain:
1. Pengujian subhipotesis pada IGL melalui aproksimasi menggunakan
resampling data dengan pengembalian untuk menguji kontribusi yang
diberikan oleh genotipe dan lingkungan terhadap pengaruh interaksi (Yulianti
2009).
2. Pengembangan metode secara inferensia untuk interpretasi hasil biplot AMMI
melalui penggunaan resampling bootsrap yang dikembangkan karena biplot
AMMI hanyalah suatu analisis eksplorasi dan tidak menyediakan pengujian
hipotesis (Novianti 2010).
3. Pengembangan model AMMI untuk mengatasi masalah data tidak lengkap
(incomplete data) melalui EM-AMMI (Sumertajaya 2005).
4. Pengembangan model AMMI pada data dengan respons ganda dengan tujuan
agar mampu menarik kesimpulan secara komprehensif dari berbagai respons
yang diamati (Sumertajaya 2005).
5. Pengembangan model SEM-AMMI (Structural Equation Modeling-AMMI)
untuk mengatasi keterbatasan model AMMI dalam menjelaskan pengaruh dari
kovariat genotipe dan lingkungan terhadap nyatanya pengaruh IGL (Jaya
2008).
6. Pengembangan model robust-AMMI melalui penggunaan algoritma
alternating regression pada model faktor analisis dengan pendekatan robust
factorization matrix untuk mengatasi masalah munculnya pengamatan
2011).
7. Pengembangan model G-AMMI untuk menangani data kualitatif misalnya
data cacahan yang berdistribusi Poisson (Hadi 2012).
8. Pengembangan model AMMI dengan pendekatan Bayes untuk mengatasi
kemungkinan diperolehnya nilai dugaan komponen ragam yang negatif yang
dapat saja terjadi pada model analisis ragam. Pendekatan Bayes yang sudah
dikembangkan yaitu model Bayes pada stabilitas genotipe (Silvianti 2009).
Gambar 1.1 Pengembangan model AMMI
Berdasarkan beberapa pendekatan analisis yang berkembang untuk
percobaan lokasi ganda menunjukkan bahwa penerapan Statistika sudah cukup
lama digunakan pada penelitian pemuliaan tanaman terutama dalam genetika
kuantitatif. Kebutuhan pemodelan untuk seleksi pada uji lokasi ganda diperlukan
untuk mendukung upaya memperoleh varietas unggul.
Dalam pemodelan, terdapat dua paradigma utama yang digunakan untuk
pendugaan parameter model yaitu frequentist dan Bayes. Perbedaan utama dari
pendugaan parameter. Pada paradigma frequentist, parameter diasumsikan bernilai
tetap dan pendugaan parameternya hanya didasarkan pada informasi yang dibawa
oleh contoh, sedangkan pada paradigma Bayes parameter model yang akan diduga
memiliki sebaran yang bersifat acak dan dalam pendugaan parameter tidak hanya
menggunakan informasi yang dibawa oleh contoh, tetapi juga menggunakan
informasi awal (prior information).
Jika dibandingkan dengan pendekatan frequentist, pendekatan Bayes dapat
memberikan dugaan yang memiliki ketepatan (presisi) lebih tinggi. Informasi ini
diperkuat dalam literatur Berger (1985) dan Gill (2008). Pendekatan Bayes juga
dapat mengatasi kemungkinan diperolehnya nilai dugaan komponen ragam yang
negatif yang dapat saja terjadi pada model analisis ragam.
Pada pendekatan frequentist, metode AMMI (Additive Main effect and
Multiplicative Interaction), selanjutnya disebut sebagai AMMI-S (AMMI Standar),
merupakan suatu metode yang telah umum digunakan untuk menganalisis data
hasil percobaan uji daya hasil terutama untuk mengkaji struktur interaksinya
(Gauch 2006). Metode ini menggabungkan analisis ragam aditif bagi pengaruh
utama perlakuan dengan analisis komponen utama pada pengaruh interaksi.
Metode ini sudah secara luas digunakan karena teknik komputasinya yang relatif
sederhana.
Salah satu asumsi yang harus dipenuhi pada metode AMMI-S yaitu
kehomogenan ragam dari galat percobaan. Ragam galat percobaan disyaratkan
homogen untuk memperoleh ragam galat gabungan yang digunakan dalam
pengujian pengaruh dari faktor/perlakuan yang dicobakan.
Namun, seringkali asumsi kehomogenan ragam galat percobaan dari suatu
data hasil percobaan tidak terpenuhi (Myers et al 2010). Adanya perbedaan ragam
antar perlakukan akan mengakibatkan berkurangnya efisiensi dari penduga ragam
dalam menduga pengaruh-pengaruh perlakuan. Jika perbedaan ragam antar
perlakuan besar, maka sensitivitasnya semakin kecil sehingga uji F yang digunakan
untuk mengetahui perbedaan pengaruh perlakuan pada analisis ragam menjadi tidak
homogen dapat menyebabkan terjadinya kesalahan dalam pengambilan kesimpulan
mengenai pengaruh perlakuan. Sebagai ilustrasi, dari hasil uji F disimpulkan ada
pengaruh perlakuan terhadap respon padahal dapat saja perbedaan tersebut
diakibatkan oleh tidak terpenuhinya asumsi kehomogenan ragam galat.
Transformasi data biasanya digunakan untuk mengatasi masalah
keheterogenan ragam galat percobaan dari data yang akan dianalisis. Beberapa jenis
transformasi yang umum digunakan antara lain: transformasi logaritma, akar
kuadrat dan arcsin. Namun, transformasi yang cocok dalam arti berhasil
memperbaiki perilaku data dan memberikan pengertian yang logis memerlukan
pertimbangan yang lebih luas (Aunuddin 1989). Disamping itu, terdapat kesulitan
dalam melakukan interpretasi pengaruh perlakuan yang diperoleh dari data hasil
transformasi (Myers et al 2010).
Untuk mengatasi masalah keheterogenan ragam galat percobaan dalam
melakukan analisis AMMI, Viele & Srinivasan (1999) menggunakan komputasi
Bayes untuk menduga parameter model AMMI dengan tehnik Markov Chain
Monte Carlo (MCMC) melalui Gibbs sampling dengan memasukkan langkah acak
(random walk) Metropolis-Hastings. Metropolis-Hastings digunakan untuk
memperbaiki nilai dugaan parameter bilinier.
Liu (2001) mengembangkan komputasi menggunakan pendekatan Bayes,
yang selanjutnya disebut AMMI-B, dalam menduga parameter model AMMI
menggunakan tehnik MCMC melalui Gibbs sampling untuk menduga semua
parameter model dan mengecek kekonvergenan sebaran serta kekonsistenan
pemilihan model. Hasil penelitiannya menunjukkan bahwa dengan pendekatan
Bayes, dugaan parameter model lebih efisien daripada metode klasik (AMMI-S).
Liu juga menunjukkan bahwa untuk model AMMI-B, output yang dihasilkan
melalui Gibbs sampling tidak dipengaruhi oleh nilai awal dari parameter yang
digunakan pada proses simulasi karena hasilnya selalu konvergen ke sebaran
posterior target.
Komputasi menggunakan pendekatan Bayes juga digunakan oleh Silvianti
AMMI-BS (AMMI Bayes dan SVD). Namun, Silvianti menerapkan komputasi
Bayes hanya untuk menduga parameter pengaruh utama dan pengaruh interaksi,
sedangkan pendugaan parameter bilinier seperti akar ciri dan vektor ciri tetap
dihitung dengan SVD (Singular Value Decomposition).
Adanya dua pendekatan Bayes yang digunakan untuk menduga parameter
model AMMI, penelitian ini membandingkan efisiensi penggunaan pendekatan
AMMI-B dengan pendekatan AMMI-BS.
1.2. Tujuan dan Manfaat Penelitian
Penelitian ini bertujuan untuk:
1. Mengkaji penerapan komputasi Bayes untuk menduga parameter model AMMI
pada data dengan ragam galat heterogen.
2. Mengevaluasi kesesuaian konfigurasi interaksi dari genotipe dan lingkungan
antara metode standar dengan komputasi Bayes.
Sedangkan manfaat dari penelitian ini adalah komputasi Bayes dapat
digunakan sebagai salah satu alternatif metode untuk menduga parameter model
AMMI pada data dengan ragam galat heterogen.
1.3. Kerangka Pikir
Data yang diperoleh dari hasil percobaan lapangan kadang-kadang tidak
sesuai dengan rancangan yang sudah ditetapkan pada tahap perencanaan. Salah satu
permasalahan tersebut adalah diperolehnya data dengan ragam galat tidak
homogen.
Keheterogenan ragam galat percobaan dapat terjadi karena munculnya satu
atau dua ulangan dengan pemberian penanganan yang kurang homogen atau kurang
kehati-hatian dari peneliti dalam mengontrol kondisi lingkungan, apalagi pada uji
lokasi ganda perlakuan yang dilibatkan cukup banyak.
Pendekatan Bayes merupakan salah satu alternatif metode yang digunakan
untuk menduga parameter model AMMI pada kasus data dengan ragam tidak
homogen. Beberapa hal yang diperhatikan dalam menduga parameter model AMMI
Dalam pendekatan Bayes diperlukan sebaran awal dari parameter model yang
sering disebut sebagai sebaran prior. Dalam menentukan sebaran prior
seringkali mempertimbangkan kemudahan dalam membuat sebaran posterior.
2. Penentuan sebaran posterior
Sebaran posterior diperoleh dari hasil kombinasi antara informasi awal tentang
parameter dengan informasi tentang parameter tersebut yang dibawa oleh data
observasi.
3. Pendugaan parameter dari sebaran posterior
Masalah utama dalam penerapan pendekatan Bayes terletak pada cara
mendapatkan sebaran posterior yang sering memerlukan proses pengintegralan
fungsi yang berdimensi tinggi sehingga perhitungan menjadi sulit. MCMC
(Markov Chain Monte Carlo) adalah suatu metode yang dapat digunakan untuk
tujuan tersebut.
4. Pendugaan parameter model AMMI
Berdasarkan hasil komputasi melalui MCMC selanjutnya diduga parameter
model AMMI.
5. Interpretasi struktur interaksi
Dengan Bayes AMMI akan diperoleh dugaan dari parameter bilinier. Struktur
interaksi antara genotipe dan lingkungan digambarkan dalam bentuk biplot
AMMI.
6. Evaluasi kesesuaian konfigurasi.
Hasil penanganan data dengan ragam tidak homogen terkait kinerja hasil
dugaan parameter model AMMI dengan komputasi Bayes ditunjukkan melalui
perbandingan konfigurasi Biplot menggunakan Analisis Procrustes.
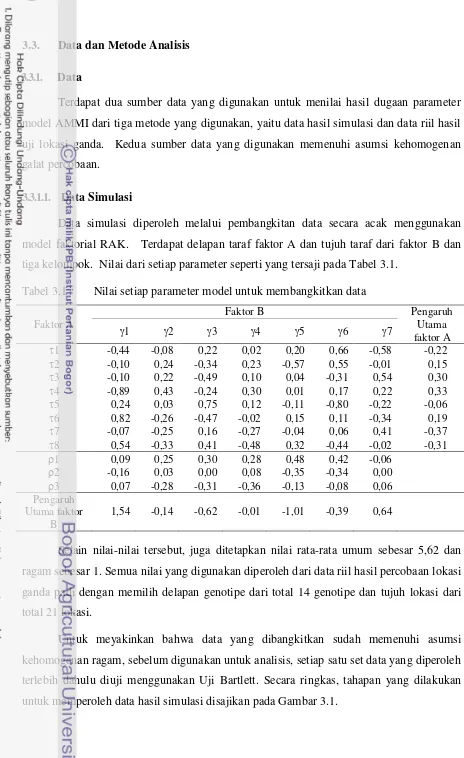
Secara ringkas, kerangka pikir yang digunakan dalam mengkaji penerapan
komputasi Bayes dalam menangani data dengan ragam tidak homogen terkait hasil
dugaan parameter model AMMI dapat dilihat pada Gambar 1.2.
Pembahasan mengenai penerapan pendekatan Bayes pada model AMMI
akan diawali dengan melihat hasil dugaan ketiga metode (AMMI-S, AMMI-BS,
meliputi data hasil simulasi dan data hasil percobaan lokasi ganda. Hasil dari
analisis ini akan dibahas pada BAB III.
Selanjutnya, pada BAB IV akan diuraikan bagaimana penerapan pendekatan
Bayes pada data dengan ragam tidak homogen. Sementara pada BAB V akan
[image:34.595.47.483.41.709.2]diuraikan pembahasan umum dan pada BAB VI dibahas kesimpulan dan saran.
Gambar 1.2 Kerangka pikir penelitian
1.4. Kebaharuan
Hasil perbandingan metode AMMI Bayes dengan AMMI Bayes SVD dalam
menduga parameter model AMMI pada data yang tidak memenuhi asumsi
2.
BAB II. TINJAUAN PUSTAKA
2.1. Percobaan Lokasi ganda
Istilah uji daya hasil seringkali disebut sebagai uji lokasi ganda karena uji ini
dilakukan pada beberapa lokasi dengan kondisi lingkungan yang berbeda. Uji lokasi ganda
ini dilakukan untuk mengkaji pengaruh genotipe pada berbagai kondisi lingkungan yang
meliputi tempat, tahun tanam dan perlakuan agronomi lainnya. Model rancangan dari uji
ini hampir sama dengan model rancangan percobaan biasa, hanya saja blok disarangkan ke
dalam lingkungan. Model linier untuk uji lokasi ganda dengan genotipe sebagai perlakuan
adalah sebagai berikut:
ijk ij j i k(j)
ijk μ ε
y dengan:
ijk
y = respon dari genotipe ke-i pada lingkungan ke-j dalam kelompok ke-k
μ = nilai rata-rata umum
i
= pengaruh genotipe ke-i, i=1,2,….a
k(j)
= pengaruh kelompok ke-k tersarang pada lingkungan ke-j, k=1,2….r
j
= pengaruh lingkungan ke-j, j=1,2…b
ij
= pengaruh interaksi genotipe ke-i dengan lingkungan ke-j
ijk
ε = pengaruh sisaan dari genotipe ke-i dalam kelompok ke-k yang dilakukan di
lingkungan ke-j
Model di atas merupakan model dua faktor, yaitu genotipe dan lingkungan.
2.2. Analisis AMMI (Additive Main Effect Multiplicative Interaction)
Metode AMMI merupakan metode yang telah umum digunakan untuk analisis data
lokasi ganda. Metode AMMI sangat efektif menjelaskan interaksi genotipe dengan
lingkungan. Metode ini merupakan gabungan antara analisis ragam pada pengaruh aditif
dengan analisis komponen utama pada pengaruh multiplikatif. Pengaruh multiplikatif
diperoleh dari penguraian interaksi genotipe dengan lingkungan menjadi komponen utama
Jika menggunakan metode MKT dengan iterasi untuk pendugaan parameter model
AMMI, tahapan analisis diawali dengan melihat pengaruh aditif dari genotipe dan
lingkungan menggunakan analisis ragam, kemudian dilanjutkan dengan melakukan
penguraian nilai singular untuk komponen multiplikatif interaksi genotipe x lingkungan.
Bentuk multiplikatif diperoleh dari penguraian interaksi genotipe dengan lingkungan
menjadi komponen utama interaksi (KUI). Dengan melakukan tahapan tersebut, maka
model AMMI dapat dituliskan dalam bentuk persamaan sebagai berikut:
dengan:
ijk
y = respon dari genotipe ke-i pada lingkungan ke-j dalam kelompok ke-k
μ = nilai rata-rata umum
i
= pengaruh genotipe ke-i, i=1,2,….a
k(j)
= pengaruh kelompok ke-k tersarang pada lingkungan ke-j, k=1,2….r
j
= pengaruh lingkungan ke-j, j=1,2…b
= nilai singular untuk komponen bilinier ke-l, λ1λ2...λm
= pengaruh ganda genotipe ke-i melalui komponen bilinier ke-l
= pengaruh ganda lingkungan ke-j melalui komponen bilinier ke- l
ij
= sisaan dari komponen bilinier
ijk
ε = pengaruh sisaan dari genotipe ke-i dalam kelompok ke-k yang dilakukan di
lingkungan ke-j
M = banyaknya KUI yang dipertahankan dalam model
2.3. Metode Bayes
Metode Bayes merupakan salah satu metode pendugaan parameter yang
memanfaatkan informasi awal/informasi prior tentang parameter yang akan diduga () dan
informasi dari contoh (x) yang akan dikombinasikan membentuk suatu sebaran yang
disebut sebagai sebaran posterior. Sebaran posterior ini merupakan sebaran dasar pengujian
Di dalam kerangka metode Bayes, dipandang sebagai suatu peubah acak yang
mempunyai fungsi sebaran dengan ruang parameter sebagai daerah fungsi. Fungsi
sebaran dari informasi awal disebut sebagai fungsi kepekatan awal (sebaran prior) dari
(π(θ)). Sedangkan fungsi kepekatan peubah acak X dipandang sebagai fungsi kepekatan bersyarat X| yang ditulis sebagai f(x|). Sementara f(x,) digunakan untuk menyatakan
fungsi kepekatan bersama X dan , dan f(x,)= f(x|) π(θ) dan X memiliki kepekatan marginal:
dF x f x
m
| , untuk peubah acak kontinumaka untuk m(x) > 0 dapat diperoleh sebaran posterior sebagai berikut:
|
, .x m
x f
x
Fungsi π(θ|x) dinamakan sebagai sebaran posterior yang didefinisikan sebagai sebaran bersyarat θ jika data contoh x diketahui.
2.4. Bayes AMMI
Komputasi Bayes telah digunakan oleh Viele & Srinivasan (1999) untuk menduga
parameter model AMMI pada data dengan ukuran contoh tidak sama dan ragam heterogen.
Liu (2001) mengembangkan pendekatan ini untuk menduga semua parameter model
AMMI dan mengecek kekonvergenan sebaran serta kekonsistenan pemilihan model.
2.4.1. Sebaran Prior
Sebaran prior merefleksikan pengetahuan atau keyakinan peneliti tentang
parameter. Dalam menentukan sebaran prior seringkali mempertimbangkan kemudahan
dalam membuat sebaran posterior, karena secara umum tidak mudah menghitung m(x) dan π(θ|x) (Berger 1985). Kelas sebaran prior yang membuat sebaran posterior dapat ditentukan dengan mudah karena posterior memiliki keluarga sebaran yang sama dengan keluarga
sebaran prior disebut sebagai conjugate prior.
Untuk memperoleh dugaan Bayes dari parameter, perlu ditentukan terlebih dahulu
sebaran prior dari setiap parameter model AMMI (, , , , , ,2 jk ik k j
Srinivasan (1999) dan Liu (2001) mengasumsikan bahwa , i, dan j menyebar Normal, 2
menyebar Invers Gamma, sementara k menyebar Normal Positif, sedangkan vik dan sjk
masing-masing menyebar menurut sebaran von-Mises Fisher.
Misalkan X N(, 2), suatu peubah acak Y dikatakan menyebar normal positif
(N+) jika sebaran dari Y proporsional terhadap sebaran X untuk y≥0, dan 0 untuk y lainnya. Suatu vektor satuan acak x (||x||=1) berdimensi p dikatakan menyebar menurut
sebaran von-Mises Fisher, Mp(, k), jika memiliki fungsi kepekatan peluang (Mardia dan
Jupp 2000; Dillon dan Sra 2003):
dengan ||||=1, k≥ 0, Sp-1 adalah unit hypersphere berdimensi p, dan cp(k) adalah
Ip(k) merupakan fungsi Bassel yang dimodifikasi pada ordo ke-p
dengan (.) merupakan fungsi Gamma.
Parameter menunjukkan rata-rata arah dan k menunjukkan consentration
parameter. Jika k=0, maka x menyebar menurut sebaran seragam sperikal (Mardia dan
Jupp 2000).
Sebaran von-Mises Fisher merupakan sebaran keluarga eksponensial (Mardia dan
El-Atoum 1976; Nuñez-antonio dan Gutiérrez-peña 2005). Conjugate prior dari sebaran ini
juga merupakan sebaran von-Mises Fisher.
Prior yang digunakan untuk menduga parameter model AMMI dengan komputasi
Bayes adalah conjugate prior yaitu (Viele & Srinivasan1999; Liu 2001):
2
, ~
T
a aK
K N , 2 ~ μτ
τ ;
T
b bK K
N , 2
~ μγ
γ ;
2 ~ IG ,
2
, ~
N
n
vinU(v,0)
sinU(s,0)
symbol N, IG, N+, dan U berturut-turut melambangkan sebaran normal, invers gamma,
sebaran normal positif, dan sebaran seragam sperikal (sebaran von-Mises Fisher dengan
k=0). Km merupakan suatu matriks sembarang yang berukuran mx(m-1) dan memenuhi
sifat dan , dengan Jm merupakan matriks berukuran
mxm yang semua unsurnya bernilai satu.
Cara membangkitkan peubah yang menyebar secara seragam sperikal adalah (Liu
2001):
1. Bangkitkan x U(Vm) dengan tahapan:
- Bangkitkan m-vektor acak, v=(v1,…, vm)T, dari N(0, Im)
- Normalisasi vector v:
m j j ii v v
x
1 2
untuk i=1,…,m
maka x = (x1,…,xm)TU(Vm)
2. Bangkitkan ~ ( m s)
m
v U
x dengan vms ˆ{h:hm,hTh1}
m t, h orthogonal pada vector
independen s(s>0) dan v1,v2,…,vs ada pada . Untuk model AMMI, vn dan sn harus
diasumsikan hanya mempunyai sebaran ( m s)
m
v
U untuk m=g atau m=l dan s=m, karena
vn dan snorthogonal pada vector 1m dan dengan yang lainnya. Ambil Cs=(v1,v2,..,vs) dan
diasumsikan v1,v2,..,vs sebuah gugus dari vector ortonormal sehingga CsTCs=Is.
- Bangkitkan (m-s)-vektor acak, v=(v1,…, vm-s)T, dari N(0, Im-s)
- Normalisasi vector v:
m s
j j i
i v v
k
1 2
untuk i=1,2,…,m-s
maka k = (k1, k2,…,km-s)TU(Vm-s)
Ambil B=(Cs|es+1,…,em), dengan el adalah satu dari vector elementer, contoh el=(0,
0, …, 0, 1, 0, …,0), dengan unsur ke-l adalah satu, dan yang lainnya bernilai nol. Ambil C=(cs,cs+1, …, cm) yang diturunkan dari ortonormalisasi B. Jika Cr=(cs+1, …, cm) dan x = Crk, maka x ~ U(Vm) yang orthogonal padaCs.
Adapun cara membangkitkan data yang menyebar menurut sebaran von-Mises
Fisher, misalnya y ~ Mp(v, k), dapat dilakukan dengan tahapan sebagai berikut:
1.
Bangkitkan vektor x ~ Mp(, k) dengan =(0, 0,…,1)T menggunakan algoritma fungsi
vsamp (Dhillon & Sra 2003).
2. Hitung nilai y = Px dengan Px ~ Mp(P, k). P merupakan matriks simetrik yang
bersifat ortogonal. Matriks P dapat diperoleh melalui transformasi Householder (Noble
& Daniel 1988).
2.4.2. Sebaran Posterior
Sebaran posterior merupakan refleksi dari perbaikan nilai parameter setelah
dilakukan observasi contoh. Atau dengan perkataan lain, sebaran posterior merupakan
kombinasi antara informasi awal tentang parameter dengan informasi tentang parameter
tersebut yang dibawa oleh data observasi. Sebaran posterior merangkum informasi tentang
semua nilai yang tidak pasti (termasuk parameter yang tidak terobservasi, hilang, latent,
maupun data yang tidak terobservasi) dalam analisis Bayes (Gelman 2002). Data yang
dibentuk sebagai likelihood digunakan sebagai bahan untuk memperbaharui informasi
prior menjadi sebuah informasi posterior yang siap untuk digunakan sebagai bahan
inferensia. Secara analitik, fungsi kepekatan posterior diperoleh dari perkalian antara prior
dengan likelihood.
. prior likelihood
posterior
Sebaran untuk (Yijk |θ) adalah:
yijk |
~N
ijk,2
dengan ijk k(j)ij dan
m
k
jk ik k j i
ij v s
1
serta θ didefinisikan sebagai
2
)
( , , , , , ,
,
k j i j k vik sjk .
ijk ijk ijk a b rijk ijk ijk y y L 2 2 2 2 2 2 2 1 2 2 1 exp 2 2 1 exp 2 .
Sebaran posterior bersama adalah:
|
( )
( ) ( ) ( )
2
2 .
k k s k v k j j n s v L y k k k jSebaran posterior dari masing-masing parameter diperoleh dari perkalian antara prior dari
parameter dengan likelihood.
Sebaran posterior untuk μ (Liu 2001)
. , ~ | 2 exp 2 1 exp 2 exp 2 1 exp 2 exp | 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 . 2 2 2 2 . 2
rab rab y rab N lainnya rab y rab rab y r y r lainnya ij ij ij ij ij Sebaran posterior untuk τ
Karena adanya kendala τT1a=0, maka τ diasumsikan diperoleh melalui sebaran
prior norma ganda. Untuk memperoleh sebaran posteriornya dilakukan transformasi
satu-satu dari τ ke vektor yang berpangkat penuh τ*, τ*=( τ1*, …, τa-1*)T =KaTτ, cari sebaran posterior dari τ* dan ditransformasi kembali ke τ dengan τ=Krτ*.
) ) 2 exp
| 2 2
2 2 * τ * τ (τ* μ μ * (τ τ* T i i rb lainnya
dengan μ K τ2* 2K μτ .
T a 2 T a 2 τ* rb rb Jadi, . , μ ~ |
τ* 2 2 1
2 2 τ*
Ia
Dengan demikian, sebaran posterior dari yaitu T a aK K rb rb rb N
lainnya 2 2
2 2 2 2 2 2 , ˆ ~ | τ μτ τ
adalah sembarang matriks berukuran m x (m-1) dengan dan , dimana adalah matriks berukuran m x m yang semua unsurnya bernilai satu.
Sebaran posterior untuk γ
Sebaran posterior dari γ diperoleh melalui cara yang sama seperti mencari sebaran
posterior dari yaitu:
. , μ γˆ ~ |
γ 2 2
2 2 2 2 γ 2 2 T b bK K ra ra ra N lainnya
Sebaran posterior untuk
Sebaran posterior dari diperoleh melalui cara yang sama seperti mencari sebaran
posterior dari , hanya saja akan dicari untuk setiap . Sebaran posteriornya
yakni:
.
,
μ
~
|
2 22 2 2 2 2 2
T r r jj
K
K
a
a
a
N
lainnya
j j j j j
Sebaran posterior untuk k
2 2 22 22 . 2 , | r r y s v r N
lainnya ij ik jk ij
k
untuk k-1≥ k≥ k+1 dan diasumsikan 0= dan m+1=0.
Sebaran posterior untuk vk dengan k=1, 2, …, m
dengan
.. jij jk
k s y
v
Untuk model AMMI, karena vn harus orthogonal terhadap vector 1a dan v yang lain,
A-vk, ada matriks Hk berukuran a x (a-m) dimana kolom dari Hk adalah suatu gugus
vektor ortonormal dan orthogonal terhadap 1a dan A-vk. Jika didefinisikan
k T k
k H v
v* yang merupakan transformasi linier satu-satu, sebaran posterior dari v*k
dengan vk*Vam adalah:
k T k k k k T k k T k k k v v rc v H H v r lainnya v ~ exp exp | * 2 2 *
dengan T k
k k
k c H v
v 1
~ dan .
k T k k T k
k v H H v
c
Selanjutnya diperoleh | ~ ( , ,~ )
2 * k k k k v rc m a FM lainnya v
, dengan FM adalah
sebaran von Mises Fisher.
Sebaran posterior untuk sk dengan k=1, 2, …, m
k T k k i j ij jk ik k k s s r y s v r lainnya s 2 . 2 exp exp | dengan
..i ij ik
k v y
s
Dengan cara yang hampir sama seperti dalam menentukan sebaran posterior untuk
vk, sebaran dari * | ~ ( , 2 ,~k) k k k s rd m b FM lainnya s
, dimana T k
k k
k d R s
s 1
~ dan
k T k k T k
k s R R s
d serta Rk berukuran b x (b-m) dimana kolom dari Rk adalah suatu
gugus vector ortonormal dan orthogonal terhadap 1b dan S-sk.
ijk ijk ijk abr ijk ijk ijk abr y y L lainnya 2 2 ) 1 2 / ( 2 2 ) 1 ( 2 2 2 2 2 2 2 2 1 1 exp ) ( exp ) ( 2 1 exp 2 , | ) ( | 2
.
2
1
,
2
~
|
2 2
ijk ijk ijky
abr
IG
lainnya
2.4.3. Dugaan Parameter Model AMMI
Nilai dugaan dari parameter model diperoleh melalui proses komputasi dengan
simulasi menggunakan Gibbs sampling menggunakan sebaran posterior bersyarat dari
setiap parameter. Misalkan θl untuk l= 1,…,m adalah contoh yang dibangkitkan dengan Gibbs sampling, maka nilai dugaan untuk parameter θ selain parameter vektor ciri (v dan s) adalah (Liu 2001):
. ~ 1 1
m l l m Sedangkan parameter v dan s diduga melalui tahapan sebagai berikut:
1. Buat matriks B yang berukuran pxq dengan pq dimana kolom dari B dibentuk dari
vektor vk atau sk.
2. Hitung
m l l m B B 1 1 .
3. Lakukan penguraian nilai singular untuk matriksBsehingga diperoleh B LDRT
.
4. Hitung T
LR
Bˆ yaitu matriks yang unsur-unsur kolomnya merupakan dugaan dari parameter vk atau sk.
2.5. Markov Chain Monte Carlo
Masalah utama dalam penerapan pendekatan Bayes terletak pada cara mendapatkan
sebaran posterior yang sering memerlukan proses pengintegralan fungsi yang berdimensi
tinggi. Hal ini dapat menyebabkan perhitungan menjadi sulit. MCMC (Markov Chain
Monte Carlo) adalah suatu metode yang dapat digunakan untuk tujuan tersebut. Dasar
dan bergerak melalui semua bagian dari suatu sebaran posterior. Ada dua bagian pengertian dari MCMC yaitu “Monte Carlo” yang berhubungan dengan proses simulasi secara acak dan “Markov Chain” yang berhubungan dengan proses sampling suatu nilai
baru dengan syarat nilai sebelumnya dari sebaran posterior (Lynch 2007). Algoritma
MCMC diimplementasikan dengan cara mengambil contoh berulang-ulang dari p sebaran
posterior bersyarat [θ1|θ2, ..., θp], ..., [θp|θ1, ..., θp−1] (Albert 2007).
2.6.1 Markov Chain
Suatu Rantai Markov (Markov Chain) {Xn, n≥0} merupakan suatu proses stokastik yang memenuhi sifat (Neal 2010):
,
Dengan Xn melambangkan state dari proses setelah n kejadian. Pada dasarnya, kejadian
saat ini hanya dipengaruhi oleh kejadian yang langsung mendahuluinya dan tidak
bergantung pada rangkaian kejadian sebelum-sebelumnya yang lain.
2.6.2 Monte Carlo
Monte Carlo dikembangkan untuk membangkitkan bilangan acak untuk
menghitung integral (Walsh 2004). Misalkan ingin dihitung integral dari suatu fungsi
kompleks
Jika h(x) merupakan hasil kali antara fungsi f(x) dengan fungsi kepekatan peluang p(x)
yang didefinisikan pada selang (a, b) maka
.
Jadi integral dapat diekspresikan sebagai nilai harapan dari f(x) yang berhubungan dengan
fungsi peluang p(x), jadi
Hal ini disebut sebagai integrasi Monte Carlo (Gilks et al 1996).
Integrasi Monte Carlo dapat digunakan untuk menduga sebaran posterior yang
dibutuhkan pada analisis Bayes. Misalkan
,
maka I(y) diduga oleh dengan xi dibangkitkan dari fungsi peluang
p(x). Galat baku Monte Carlo diduga dengan
.
2.6.3 Gibbs Sampling
Gibbs sampling merupakan salah satu metode untuk membangun algoritma Markov
Chain Monte Carlo (MCMC). Gibbs sampling adalah suatu teknik untuk membangkitkan
peubah acak dari sebaran (marjinal) secara tidak langsung, tanpa perlu menghitung fungsi
kepekatannya (Casella & George 1992).
Gibbs Sampling dapat diterapkan apabila sebaran peluang bersama (joint probability
distribution) tidak diketahui secara eksplisit, tetapi sebaran bersyarat (conditional
distribution) dari tiap-tiap variabel diketahui (Hoff 2009). Misalkan diketahui suatu vector
dari parameter = {1, 2, …, p}, dan informasi mengenai ukuran peluang adalah
p()=p(1, 2, …, p). Dengan memberi nilai awal (0) = {1(0), 2(0), …, p(0) }, Gibbs sampling akan membangkitkan (l) dari (l-1) seperti berikut.
a. Untuk l=1, 2, …, m, dibangkitkan:
1. contoh 1(l)~p(1|2(l-1), …, p(l-1)) 2. contoh 2(l)~p(2|1(l), 3(l-1),…, p(l-1))
:
:
3. contoh p(l)~p(p|1(1),2(l), …, p-1(l))
Fungsi kepekatan p,,p2,…,pp disebut sebaran bersyarat penuh yang digunakan untuk
simulasi. Walaupun dalam dimensi tinggi semua simulasi adalah univariate. Dalam Gibbs
sampling tidak ada mekanisme penerimaan dan penolakan semua contoh hasil simulasi
diterima.
2.6. Pemilihan Model AMMI
Untuk menentukan banyaknya komponen utama yang dipertahankan pada model
AMMI, Liu (2001) merekomendasikan metode BIC (Bayes Information Criteria) sebagai
metode yang efektif untuk pemilihan model. Model terbaik yang akan dipilih adalah model
dengan BIC minimum. Formula dari BIC adalah:
) log( )
ˆ ( log 2 )
(m L q N
BIC t
dengan L(ˆ) adalah fungsi kemungkinan maksimum dengan m komponen interaksi dan
qt = a+b-1+b(r-1)+m(a+b-m-2) yaitu banyaknya parameter bebas pada model serta N
adalah ukuran contoh efektif dari data yang digunakan untuk menduga 2 yang merupakan
rata-rata ukuran contoh efektif dari semua parameter bebas yang lain pada model
berpangkat penuh (rab untuk menduga , rb untuk menduga i, ra untuk menduga j, dan r
untuk menduga k, vik, atau sjk), dimana untuk model AMMI, N=4r (Liu 2001).
2.7. Evaluasi Kesesuaian Konfigurasi
Dalam analisis AMMI, Biplot AMMI merupakan alat analisis untuk menguraikan
struktur interaksi berdasarkan komponen utama interaksi yang diperoleh. Untuk
mengevaluasi kesesuaian konfigurasi biplot yang dihasilkan digunakan Metode Procrustes.
Metode Procrustes merupakan suatu metode yang dapat digunakan untuk melihat
kesamaan bentuk dan ukuran dari dua konfigurasi, salah satu konfigurasi dibuat tetap,
sementara konfigurasi yang lain ditransformasi sehingga cocok dengan konfigurasi yang
pertama (Digby & Kempton, 1987). Sumertajaya (2005) menggunakan metode ini untuk
3.
BAB III.
PENDUGAAN PARAMETER MODEL AMMI PADA DATA
DENGAN RAGAM HOMOGEN
3.1. Pendahuluan
Analisis AMMI-S merupakan analisis yang umum digunakan untuk menganalisis
data percobaan yang melibatkan dua faktor dengan interaksi dalam pendugaan parameter
model dan interpretasi faktor interaksi melalui biplot AMMI. Metode ini cukup populer
digunakan untuk menduga daya hasil tanaman dan interpretasi kestabilan pada percobaan
lokasi ganda.
Perkembangan komputer yang semakin maju sangat membantu mengatasi kesulitan
perhitungan dalam menduga parameter suatu model yang rumit, mendorong semakin
berkembangnya penggunaan metode Bayes untuk menduga parameter suatu model, salah
satunya untuk pendugaan parameter model AMMI.
Pada penelitian ini, metode standar (AMMI-S) dan pendekatan Bayes (AMMI-BS
dan AMMI-B) digunakan untuk menduga parameter model menggunakan data yang
memenuhi asumsi kehomogenan ragam galat percobaan.
Selain digunakan untuk menduga parameter model, analisis AMMI juga digunakan
untuk mengkaji struktur interaksinya. Alat analisis yang digunakan untuk tujuan ini yaitu
Biplot AMMI. Pada penelitian ini dievaluasi Biplot AMMI yang dihasilkan terkait
kesesuaian konfigurasi interaksi dari ketiga metode menggunakan analisis Procrustes.
3.2. Tujuan
Tujuan dari penelitian ini yaitu:
1. Menduga parameter model AMMI men1ggunakan metode AMMI-S, AMMI-BS dan
AMMI-B.
2. Mengevaluasi kesesuaian konfigurasi interaksi dari AMMI antara ketiga metode yang
3.3. Data dan Metode Analisis
3.3.1. Data
Terdapat dua sumber data yang digunakan untuk menilai hasil dugaan parameter
model AMMI dari tiga metode yang digunakan, yaitu data hasil simulasi dan data riil hasil
uji lokasi ganda. Kedua sumber data yang digunakan memenuhi asumsi kehomogenan
galat percobaan.
3.3.1.1. Data Simulasi
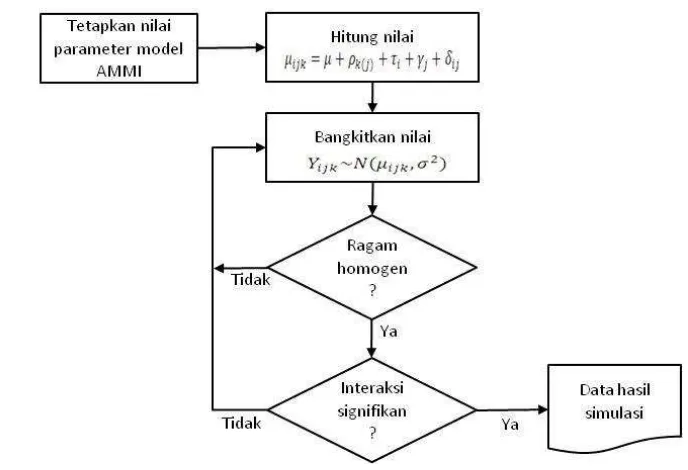
Data simulasi diperoleh melalui pembangkitan data secara acak menggunakan
model faktorial RAK. Terdapat delapan taraf faktor A dan tujuh taraf dari faktor B dan
[image:50.595.49.513.59.817.2]tiga kelompok. Nilai dari setiap parameter seperti yang tersaji pada Tabel 3.1.
Tabel 3.1 Nilai setiap parameter model untuk membangkitkan data
Faktor A
Faktor B Pengaruh
Utama faktor A
1 2 3 4 5 6 7
1 -0,44 -0,08 0,22 0,02 0,20 0,66 -0,58 -0,22
2 -0,10 0,24 -0,34 0,23 -0,57 0,55 -0,01 0,15
3 -0,10 0,22 -0,49 0,10 0,04 -0,31 0,54 0,30
4 -0,89 0,43 -0,24 0,30 0,01 0,17 0,22 0,33
5 0,24 0,03 0,75 0,12 -0,11 -0,80 -0,22 -0,06
6 0,82 -0,26 -0,47 -0,02 0,15 0,11 -0,34 0,19
7 -0,07 -0,25 0,16 -0,27 -0,04 0,06 0,41 -0,37
8 0,54 -0,33 0,41 -0,48 0,32 -0,44 -0,02 -0,31
1 0,09 0,25 0,30 0,28 0,48 0,42 -0,06
2 -0,16 0,03 0,00 0,08 -0,35 -0,34 0,00
3 0,07 -0,28 -0,31 -0,36 -0,13 -0,08 0,06
Pengaruh Utama faktor
B
1,54 -0,14 -0,62 -0,01 -1,01 -0,39 0,64
Selain nilai-nilai tersebut, juga ditetapkan nilai rata-rata umum sebesar 5,62 dan
ragam sebesar 1. Semua nilai yang digunakan diperoleh dari data riil hasil percobaan lokasi
ganda padi dengan memilih delapan genotipe dari total 14 genotipe dan tujuh lokasi dari
total 21 lokasi.
Untuk meyakinkan bahwa data yang dibangkitkan sudah memenuhi asumsi
kehomogenan ragam, sebelum digunakan untuk analisis, setiap satu set data yang diperoleh
terlebih dahulu diuji menggunakan Uji Bartlett. Secara ringkas, tahapan yang dilakukan
Gambar 3.1 Tahapan memperoleh data simulasi dengan ragam galat homogen
3.3.1.2. Data Riil
Data riil yang digunakan merupakan hasil percobaan lokasi ganda yang melibatkan
14 galur padi yang ditanam pada 21 lokasi. Dari 14 galur yang digunakan, 3 diantaranya
merupakan varietas pembanding (Gilirang, INPARI1, dan Ciherang) dan 11 galur lainnya
merupakan galur baru (1 galur berasal dari BATAN, 5 galur dari BB Padi, 1 galur dari
Biogen, dan 4 galur dari IPB). Nama-nama galur dan lokasi disajikan pada Tabel 3.2 dan
Tabel 3.3. Deskripsi data yang digunakan disajikan pada Lampiran 16.
Tabel 3.2 Daftar uji lokasi ganda galur-galur padi sawah
KODE GALUR ASAL KETERANGAN
G1 IPB-3 (IPB97-F-20-2-1) IPB PTB, WCK,HDB
G2 BIO-1-AC-BLB/BLAS-05 BIOGEN HDB,BLAS
G3 B10531E-KN-14-3-0-LR-B376-1 BB-PADI WCK,BLB, GENJAH
G4 OBS 1735/PSJ BATAN GENJAH, WCK, BLB
G5 BP11252-2-PN-12-2-2-2-1-7-MR-6 BB-PADI PTB, WCK,HDB, GENJAH
G6 BIO-8-AC-BLB-05 BIOGEN HDB,BLAS
G7 OBS 1740/PSJ BATAN GENJAH, WCK, BLB
G8 IPB-6 (IPB107-F-8-3) IPB PTB, WCK,HDB
G9 BP3300-2C-2-3 BB-PADI WCK,BLB
G10 OBS 1739/PSJ BATAN GENJAH, WCK, BLB
KODE GALUR ASAL KETERANGAN
G12 CIHERANG CHECK
G13 INPARI 1 CHECK
G14 CIMELATI CHECK
Percobaan dilaksanakan dengan menggunakan rancangan acak kelompok dengan 3
ulangan. Setiap galur ditanam pada petak berukuran 4 m x 5 m. Tanam dilakukan pada
saat umur bibit 21 hari, sebanyak 1 bibit per rumpun, dengan jarak tanam 25 cm x 25 cm.
Peubah yang digunakan dalam analisis yakni hasil gabah (kg/ha).
Data yang digunakan merupakan data hasil percobaan yang dilakukan oleh
Konsorsium Padi Nasional yang berpusat di Balai Besar Padi Sukamandi. Percobaan
dilakukan pada musim tanam 2008-2009.
Tabel 3.3 Daftar lokasi percobaan
No Lingkungan No Lingkungan No Lingkungan
1 Asahan1* 8 Ngawi2 15 Pusakanagara2
2 Bali1* 9 NTB1 16 Pesawaran2*
3 Bali2 10 NTB2 17 Purworejo1
4 Bantul2* 11 Probolinggo2 18 Rangkasbitung2
5 Bantaeng1 12 Pasar miring1 19 Tabanan1*
6 Marmada2 13 Purworejo2 20 Takalar2
7 Ngawi1* 14 Pusakanagara1* 21 Taman Bogo2*
Keterangan: 1= musim tanam pertama; 2 = musim tanam kedua *= lokasi tidak diikutkan dalam analisis
Agar asumsi kehomogenan ragam galat