TUGAS MANDIRI ANALISIS FAKTOR DAN ANALISIS
KORESPONDENSI DENGAN SPSS
Paper Disusun Untuk Memenuhi Tugas Mata Kuliah Komputasi Statistik
Dosen Pengampu : Getut Pramesti, S.Si., M.Si.
Oleh:
Istiqomah H
Nim :K1312042
FAKULTAS KEGURUAN DAN ILMU PENDIDIKAN
UNIVERSITAS SEBELAS MARET
SURAKARTA
TUGAS MANDIRI
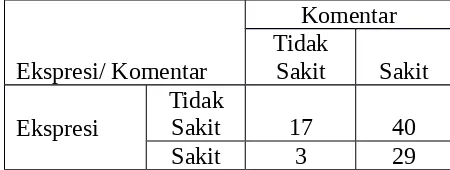
1. Suatu penelitian dilakukan untuk mengetahui ada tidaknya komentar pelanggan dengan ekspresi pelanggan ketika dilakukan tretmen facial pada wajahnya. Diketahui data seperti Tabel berikut:
Dari data diatas melalui analisis menggunakan SPSS diperoleh :
Chi-Square Tests
Pearson Chi-Square 4.919a 1 .027
Continuity Correctionb 3.816 1 .051
Likelihood Ratio 5.461 1 .019
Fisher's Exact Test .034 .022
Linear-by-Linear Association 4.864 1 .027
N of Valid Cases 89
a. 0 cells (0.0%) have expected count less than 5. The minimum expected count is 7.19. b. Computed only for a 2x2 table
Dari tabel Chi-Square test diperoleh nilai χ2 = 4.919 dengan derajat bebas (df) = 1 dan
Asymp.Sig.(2-sided) = 0.027
Jika α = 0.05 dan nilai 0.005 < 0.027 maka dapat dianalisis bahwa ekspresi pelanggan tidak berhubungan dengan komentar pelanggan. Dengan kata lain keterkaitan antara ekspresi pelangan dengan komentar dari pelanggan tidak signifikan.
Symmetric Measures
Value
Asymp. Std.
Errora Approx. Tb Approx. Sig.
Interval by Interval Pearson's R .235 .087 2.256 .027c
N of Valid Cases 89
a. Not assuming the null hypothesis.
Dari tabel symmetric Measures diatas diketahui nilai contingency Coefficient atau C = 0.235 dengan Aprox. Sig = 0.027. Menurut Iqbal Hasan (2003) untuk C= 0.235 dapat dikategorikan terdapat korelai yang lemah. Dengan demikian terdapat hubungan antara ekspresi pelanggan dengan komentar dari pelanggan namun hubungan tersebut lemah.
Dari hasil analisis tabel Chi-Square test sebelumnya, dapat dianalisis bahwa terdapat hubungan antara ekspresi pelanggan dengan kometar pelanggan namun hubungan tersebut bersifat lemah. Dengan tingkat signifikansi 5 % hubungan ini tidak signifikansi berpengaruh. Jadi sebenarnya terdapat keterkaitan antara ekspresi pelanggan dengan komentar pelanggan namun keterkaitan ini tidak signifikan berpengaruh terhadap komentar pelanggan.
a. Menurut saya, data di atas dapat dianalisis dengan menggunakan analisis korespondensi karena variabel data berskala nominal dan data memperagakan baris dan kolom secara serempak dari suatu table kontingensi dwi arah.
.
b. 1 Dengan nilai c=0.027 artinya terdapat keterkaitan antara ekspresi pelanggan dengan komentar pelanggan namun keterkaitan ini tidak signifikan berpengaruh terhadap komentar pelanggan. Jadi sebenarnya terdapat keterkaitan/ hubungan antara ekspresi pelanggan dengan komentar pelanggan namun keterkaitan ini tidak signifikan berpengaruh terhadap komentar pelanggan. Dengan demikian iya terdapat hubungan.
b.2 bagaimana profil ekspresi pelanggan dengan komentar? Apakah sudah sesuai?
Row Profiles
ekspresi
komentar
tidak sakit Sakit Active Margin
tidak sakit .298 .702 1.000
Mass .225 .775
Untuk row profile :
Tebel berisi frekuensi relatif dari variabel baris
Dari aplikasi ANKOR diatas variabel barisnya adalah komentar pelanggan. Dari tabel Row profiles nampak bahwa jumlah masing – masing dari tingkat baris adalah satu. Hal ini sudah sesuai dengan sifat fungsi densitas probabilitas.
Dari Tabel di atas diperoleh bahwa :
1. Probabilitas seseorang dengan ekspresi wajah tidak sakit dengan komentar pelanggan pada saat tidak sakit sebesar 0,298.
2. Probabilitas seseorang dengan ekspresi wajah tidak sakit dengan komentar pelanggan pada saat sakit sebesar 0,702.
3. Probabilitas seseorang dengan ekspresi wajah sakit dengan komentar pelanggan pada saat tidak sakit sebesar 0,094.
4. Probabilitas seseorang dengan ekspresi wajah sakit dengan komentar pelanggan pada saat sakit sebesar 0,775.
Column Profiles
ekspresi
Komentar
tidak sakit Sakit Mass
tidak sakit .850 .580 .640
sakit .150 .420 .360
Active Margin 1.000 1.000
Untuk coloumn profile:
Dalam aplikasi ANKOR diatas varibel kolomnya adalah nilai kecerdasan. Dari tebel column profiles nampak bahwa jumlah masing-masing dari tingkat kolom adalah satu hal ini sesuai dengan sifat fungsi densitas probabilitas.
Summary
Dimension Singular Value Inertia Chi Square Sig.
Proportion of Inertia
1 .235 .055 1.000 1.000 .087
Total .055 4.919 .027a 1.000 1.000
a. 1 degrees of freedom
Hasil analisis summary:
Dari tabel diatas nampak bahwa persentase proporsi kumulatif dua akar ciri utama sebesar 100 %, artinya dua vektor baris dan kolom mampu menjelaskan variabilitas data asal sebesar 100 % inersia total. Berarti gambar yang dihasilkan mampu menjelaskan sebesar 100 % variabilitas atau keanekaragaman data sebenarnya. Dari tabel yang sama dapat dianalisis bahwa :
Dimensi 1, menjelaskan variabilitas data sebesar 100%
Dimensi 2, menjelaskan variabilitas data sebesar 100%
Dari analisis diatas diperoleh bahwa profil ekspresi pelanggan dengan komentar sudah sesuai.
masing-masing dari tingkat kolom adalah satu. Dimana hal tersebut sudah sesuai dengan sifat dari fungsi densitas probabilitas.
2. Dilakukan penelitian untuk mengetahui pengaruh faktor X1 sampai X7 dan D terhadap Y.
Menurut Anda apakah semua faktor perlu dipertimbangkan dalam berat sapi (output, dalam kg)?
Dengan menggunakan aplikasi SPSS, akan dilakukan analisis Faktor dari data tersebut di atas. Dari hasil komputasi pada SPSS, berikut hasil output dan analisis
Descriptive Statistics
Mean Std. Deviation Analysis N Missing N
Beratbibit 1016.5294 466.40841 34 0
hijauan 29562.3529 12587.92087 34 0
jerami 12153.5294 5180.28131 34 0
dedak 757.6471 352.30031 34 0
suplemen 26.1503 14.05317 34 0
obat 3.7941 1.82208 34 0
tenagakerja 118.8676 27.40988 34 0
jeniskandang .1176 .32703 34 0
Correlation Matrixa
Beratbibit hijauan jerami dedak suplemen obat
tenaga
kerja jeniskandang
Correlation Beratbibit 1.000 .967 .769 .714 .774 .534 .503 -.373
hijauan .967 1.000 .799 .791 .845 .604 .606 -.208
jerami .769 .799 1.000 .894 .916 .799 .830 .212
dedak .714 .791 .894 1.000 .951 .815 .852 .339
suplemen .774 .845 .916 .951 1.000 .827 .834 .260
obat .534 .604 .799 .815 .827 1.000 .855 .449
tenagakerja .503 .606 .830 .852 .834 .855 1.000 .528
jeniskandang -.373 -.208 .212 .339 .260 .449 .528 1.000
Sig. (1-tailed)
Beratbibit .000 .000 .000 .000 .001 .001 .015
hijauan .000 .000 .000 .000 .000 .000 .119
jerami .000 .000 .000 .000 .000 .000 .114
dedak .000 .000 .000 .000 .000 .000 .025
suplemen .000 .000 .000 .000 .000 .000 .069
obat .001 .000 .000 .000 .000 .000 .004
tenagakerja .001 .000 .000 .000 .000 .000 .001
jeniskandang .015 .119 .114 .025 .069 .004 .001
a. Determinant = 2.343E-7
Indikasi adanya signifikansi korelasi akan dapat ditunjukkan dari nilai determinan =
Determinant = 2.343E-7. Karena 0,0000002343 lebih kecil dari 0,00001 maka mengindikasikan
bahwa multikolinier signifikan.
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .764
Bartlett's Test of Sphericity Approx. Chi-Square 450.362
Df 28
Sig. .000
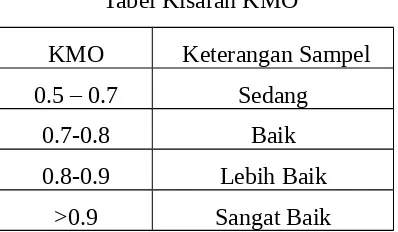
Tabel di atas merupakan nilai statistika KMO untuk indikasi kecukupan jumlah sampel. Berdasarkan pedoman dari Kaiser (1974) dan Hutcheson dan Sofroniou (1999) yaitu membuat kisaran nilai KMO minimum 0,5 dan kisaran lain seperti seperti tabel berikut.
KMO Keterangan Sampel
0.5 – 0.7 Sedang
0.7-0.8 Baik
0.8-0.9 Lebih Baik >0.9 Sangat Baik
Karena dari output diperoleh nilai Kaiser-Meyer-Olkin Measure of Sampling Adequacy
sebesar 0.764, maka dapat dikatakan bahwa indikasi kecukupan jumlah sampel adalah baik.
Uji bartlett dilakukan untuk mengetahui apakah matrik korelasi merupakan matrik identitas atau tidak. Karena 0.05 > sig=0 maka matrik R bukan merupakan matrik identitas sehingga dengan kata lain analisis faktor dapat digunakan pada data.
Inverse of Correlation Matrix
Beratbibit Hijauan jerami dedak suplemen obat tenagakerja Jeniskandang
Beratbibit
hijauan -60.600 40.745 11.393 7.775 -3.438 5.278 -1.373 -19.919
jerami -23.847 11.393 12.010 2.925 -2.069 1.413 -2.046 -9.076
Dedak -25.996 7.775 2.925 18.599 -5.123 2.576 .011 -14.832
suplemen
-10.867 -3.438 -2.069 -5.123 20.819
-1.249 1.759 -8.366
Obat -11.278 5.278 1.413 2.576 -1.249 5.547 -1.641 -5.577
tenagakerja
-3.171 -1.373 -2.046 .011 1.759
-1.641 7.565 -4.754
jeniskandang
61.287 -19.919 -9.076 -14.832 -8.366
-5.577 -4.754 33.845
Anti-image Matrices
Beratbibit hijauan jerami dedak suplemen obat tenagakerja jeniskandang
Anti-image Covariance
Beratbibit .007 -.011 -.015 -.010 -.004 -.015 -.003 .013
hijauan -.011 .025 .023 .010 -.004 .023 -.004 -.014
jerami -.015 .023 .083 .013 -.008 .021 -.023 -.022
dedak -.010 .010 .013 .054 -.013 .025 7.710E-5 -.024
suplemen -.004 -.004 -.008 -.013 .048 -.011 .011 -.012
obat -.015 .023 .021 .025 -.011 .180 -.039 -.030
tenagakerja
-.003 -.004 -.023
7.710E-5 .011 -.039 .132 -.019
jeniskandan
g .013 -.014 -.022 -.024 -.012 -.030 -.019 .030
Anti-image Correlation
hijauan -.816 .719a .515 .282 -.118 .351 -.078 -.536
jerami -.591 .515 .817a .196 -.131 .173 -.215 -.450
dedak -.518 .282 .196 .833a -.260 .254 .001 -.591
suplemen -.205 -.118 -.131 -.260 .943a -.116 .140 -.315
obat -.412 .351 .173 .254 -.116 .850a -.253 -.407
tenagakerja -.099 -.078 -.215 .001 .140 -.253 .941a -.297
jeniskandan
g .905 -.536 -.450 -.591 -.315 -.407 -.297 .307
a
a. Measures of Sampling Adequacy(MSA)
• Nilai KMO per-variabel juga dapat dilihat dari diagonal matrik anti-image correlation.
• Nilai KMO ini disarankan lebih dari 0,5 untuk setiap variabelnya.
• Dari tabel nampak terdapat satu variabel dengan nilai kurang dari 0,5 yaitu Variabel jenis kandang dengan nilai 0.307.
Karena dijumpai nilai KMO pada variable kandang kurang dari 0,5 maka disarankan untuk mengeluarkan variabel tersebut, kemudian melakukan analisis faktor tanpa variabel yang dimaksud.
Total Variance Explained
Component Initial Eigenvalues Extraction Sums of Squared Loadings
Total % of Variance
1 5.774 72.178 72.178 5.774 72.178 72.178 5.458 68.222 68.222
2 1.694 21.169 93.347 1.694 21.169 93.347 2.010 25.125 93.347
3 .202 2.522 95.869
Extraction Method: Principal Component Analysis.
• Tabel berisi tentang nilai eigen yang berasosiasi dengan setiap komponen linier (faktor) sebelum ekstraksi, setelah ekstraksi dan setelah rotasi.
• Sebelum ekstraksi, diidentifikasikan terdapat 8 komponen linier pada data.
Nilai eigen yang berasosiasi pada tiap faktor merepresentasikan variansi yang dijelaskan oleh faktor tersebut .
Jadi faktor 1 menjelaskan 72.178 % dari total variansi. Jika dibandingkan dengan nilai yang lain misal 21,169; 2.522; 1.666; 1.375; 0.609; 0.420; 0.062. Nampak bahwa faktor 1 lebih dominan dalam total variansi, disusul faktor ke 2 dengan menjelaskan 21,169% dari total variansi. Nilai eigen untuk faktor 1 dan 2 setelah ekstraksi tetap sama sebesar72.178 % dan 21.169 %. Sedangkan nilai eigen untuk factor 1 dan 2 setelah rotasi mengalami perubahan yaitu dengan nilai 68.222% dan 25.125 % hal ini dikarenakan terdapat factor yang terekstrasi > 1.
Initial Extraction
Extraction Method: Principal Component Analysis.
Untuk menentukan berapa faktor yang dapat diekstrak dapat dilihat dari nilai
communalities kolom extraction.
Karena semua nilainya lebih dari 0,7 atau variabelnya kurang dari 30 variabel maka pilihan faktor ekstraksi dapat dilakukan.
Selain itu , Dari tabel memuat nilai communalities sebelum dan setelah ekstraksi.
communalities merupakan proporsi variansi keseluruhan antar variabel.
communalities sebelum ekstraksi dilihat dari nilai initial sebesar 1 pada setiap variabel. setelah ekstraksi nilai communalities dapat dilihat dari nilai extraction.
Rata-rata communalities diperoleh dari :
´
communalities=0.996+0.961+0.906+0.930+0.952+0.845+0.907+0.971
8 =0.9335
Tanda panah pada Gambar mengindikasikan titik belok pada plot.Jadi factor ke 3 merupakan titik belok plot.
Untuk mengetahui kebaikan model dapat diperhatikan dari selisih korelasi observasi dengan korelasi model. Atau dari output tabel di atas sudah disajikan residual tiap korelasi.
Untuk model yang baik, diharapkan nilai residu yang kecil.
Untuk nilai yang dianjurkan adalah kurang dari 0,05. SPSS juga menampilkan ringkasan jumlah data yang mempunyai nilai lebih dari 0,05.
SETELAH VARIABEL JENIS KANDANG DIKELUARKAN
Tabel di atas merupakan nilai statistika KMO untuk indikasi kecukupan jumlah sampel. Berdasarkan pedoman dari Kaiser (1974) dan Hutcheson dan Sofroniou (1999), kisaran nilai KMO minimum 0,5 dan kisaran lain seperti tabel berikut.
Tabel Kisaran KMO
KMO Keterangan Sampel
0.5 – 0.7 Sedang
0.7-0.8 Baik
0.8-0.9 Lebih Baik
>0.9 Sangat Baik
Karena dari output diperoleh nilai Kaiser-Meyer-Olkin Measure of Sampling Adequacy
sebesar 0.834, maka dapat dikatakan bahwa indikasi kecukupan jumlah sampel adalah Lebih Baik.
Uji bartlett dilakukan untuk mengetahui apakah matrik korelasi merupakan matrik identitas atau tidak. Karena 0.05 > sig=0 maka matrik R bukan merupakan matrik identitas sehingga dengan kata lain analisis faktor dapat digunakan pada data.
Nilai KMO per-variabel juga dapat dilihat dari diagonal matrik anti-image correlation. Nilai KMO ini disarankan lebih dari 0,5 untuk setiap variabelnya. Dari Tabel tersebut ternyata dari tujuh sub-variabel pengukuran atau dimensi yang difaktorkan menunjukkan semua nilainya > 0,5 sehingga tidak perlu ada yang dikeluarkan.
Jadi, dari hasil pengerjaan SPSS diperoleh tidak semua faktor perlu dipertimbangkan dalam