B1-139
SISTEM TTS DALAM BAHASA INDONESIA MENGGUNAKAN
METODE FSA DAN DATABASE DIPHONE
Ely Setyo Astuti, ST, MT 1) , DR. Eng. Agus Naba, MT2), Ir.Wahyu Adi Prijono, MT.3)
1)
Staf pengajar STT STIKMA Internasional Malang.
2) 3)
Staf Pengajar Magister Teknik Elektro Pasca Sarjana Universitas Brawijaya Malang.
ABSTRAK Pemenggalan suku kata adalah salah satu bagian dari mata pelajaran Bahasa Indonesia. Salah satu cara agar lebih mudah mempelajari pemenggalan suku kata dan mengetahui bagaimana pengucapan suatu kata dalam Bahasa Indonesia dengan menggunakan teknologi TTS (Text to Speech). TTS merupakan suatu sistem yang melakukan dua konversi yaitu konversi dari teks ke fonem dan konversi dari fonem ke ucapan. Penelitian ini bertujuan untuk merancang dan membuat perangkat lunak sistem TTS. Sistem dibangun dengan metode FSA (Finite State Automata) untuk pemenggalan suku kata Bahasa Indonesia sesuai dengan Ejaan Yang Disempurnakan. Metode FSA dua tingkat - yang merupakan perbaikan dari metode FSA tiga tingkat dari penelitian Anung (2000) - untuk pemenggalan suku kata. Proses penggabungan suku kata dan konversinya menjadi ucapan dalam sistem TTS menggunakan teknik Diphone Concatenation. Teknik ini bekerja dengan cara menggabung-gabungkan segmen-segmen bunyi suku kata yang telah direkam sebelumnya berupa file suara berekstensi *.wav. Hasil ujicoba membuktikan bahwa metode FSA dua tingkat bisa mengenali suku kata Bahasa Indonesia dengan tingkat keberhasilan 96%, kesalahan 3,94% untuk kata dasar, sedangkan untuk kata berimbuhan dengan tingkat keberhasilan 69%, kesalahan 30,88%. Semua pasangan vokal ‘au’, ‘ai’ dan ‘oi’ akan dikenali sebagai diftong.Teknik diphone concatenation dapat menggabung-gabungkan file suara diphone menjadi ucapan suatu kata/kalimat. Sistem TTS ini hanya bisa memilih satu diphone.
Kata kunci: Text to speech, Suku kata, Bahasa Indonesia, Finite-State Automata, Database Diphone
1. Pendahuluan
Bahasa Indonesia adalah bahasa resmi
Republik Indonesia sebagaimana disebutkan dalam Undang-Undang Dasar RI 1945, Pasal 36. Ia juga merupakan bahasa persatuan bangsa Indonesia seperti disiratkan dalam Sumpah Pemuda 28 Oktober 1928. Bahasa Indonesia adalah sebuah dialek bahasa Melayu yang dinamis dan terus
menghasilkan kata-kata baru, baik melalui
penciptaan maupun penyerapan dari bahasa daerah dan asing (Wikipedia Ensiklopedia Indonesia, Ejaan Yang disempurnakan).
Salah satu bagian dalam mata pelajaran bahasa Indonesia adalah pemenggalan suku kata. Menurut Anung (2000), setidaknya ada dua kegunaan pemenggalan suku kata, yaitu : a) Jika kita melihat peranan suku kata dalam bahasa tulisan, maka pemenggalan suku kata perlu dilakukan ketika kata yang kita tulis panjangnya melebihi batas kanan kertas, b)Jika kita melihat peranan suku kata dalam bahasa lisan, maka
pemenggalan suku kata diperlukan untuk
mengetahui bagaimana cara mengucapkan suatu kata.
Agar lebih mudah mempelajari
pemenggalan suku kata dan mengetahui bagaimana pengucapan suatu kata dalam Bahasa Indonesia
dapat menggunakan teknologi Text to Speech
(TTS). TTS merupakan suatu sistem yang
melakukan dua konversi yaitu konversi dari teks ke fonem dan konversi dari fonem ke ucapan yang dilakukan secara berurutan dengan input teks dan
menghasilkan output ucapan.
Para pengembang teknologi sudah
membangun sistem TTS pada sistem komputer. Akan tetapi, penggunaan TTS masih terbatas pada Bahasa Inggris atau bahasa asing lainnya. Bladon dan Carlson (1987), melakukan penelitian sistem TTS dengan gaya dan dialek bahasa Inggris. Emorine dan Martin (1988) dalam bahasa Perancis. Borkar (2004) melakukan penelitian TTS synthesizer
dengan sistem berbasis komputer dalam bahasa Konkani (Goan). Rao et.al (2005) melakukan penelitian TTS synthesis menggunakan unit-unit daftar suku kata dalam bahasa India. Jayavardhana et.al (2001) mengembangkan penelitian sistem TTS
synthesis untuk membaca input berupa teks (novel) ke dalam bentuk ucapan dalam bahasa Tamil. Khishore dan Alan (2005) mengembangkan sistem TTS pada Universal Digital Library yang bertujuan untuk menjadikan sistem baca perpustakaan dalam format digital dengan menggunakan bahasa India.
Pada tahun 2000 Anung melakukan
penelitian yang mengenali suku kata Bahasa Indonesia menggunakan Finite-State automata tiga
tingkat. Secara khusus penelitian tersebut
membahas tentang cara pemenggalan suku kata Bahasa Indonesia sesuai dengan aturan persukuan menurut Kamus Besar Bahasa Indonesia. Penelitian sistem TTS bahasa Indonesia sudah dilakukan Arman pada tahun 2000 dengan nama IndoTTS.
Rommel (2005) mengimplementasikan sistem
FSA adalah salah suatu sistem pemodelan matematika yang khusus mempelajari tentang bahasa, yaitu Teori Bahasa Formal (TBF). Bahasa yang dibahas pada TBF adalah bahasa tulisan dengan masukan dan keluaran berupa diskrit. FSA dapat berfungsi sebagai pengenal (recognizer) suatu bahasa dengan melakukan pengelolaan dari masukan-masukan yang berupa string dan mengeluarkan suatu keputusan YA jika string masukan termasuk dalam bahasa dan TIDAK jika string masukan tidak termasuk dalam bahasa (Hariyanto, 2004).
Synthesizer yang menggunakan teknik
diphone concatenation bekerja dengan cara menggabung beberapa segmen bunyi yang telah direkam sebelumnya. Setiap segmen berupa
diphone (gabungan dua buah fonem) yang disimpan dalam diphone database. (Arman, 2002).
Dalam penelitian ini, penulis mengembangkan dari penelitian sebelumnya (Anung, 2000) yaitu pengenalan suku kata Bahasa Indonesia dengan Algoritma FSA tiga tingkat menjadi sistem TTS Bahasa Indonesia dengan algoritma FSA dua tingkat dan database diphone. Metode FSA dua tingkat digunakan untuk pemenggalan suku kata dalam bahasa Indonesia. Proses penggabungan suku kata dan konversinya menjadi ucapan dalam
sistem TTS ini menggunakan teknik diphone
concatenation. Teknik ini bekerja dengan cara menggabungkan segmen-segmen bunyi suku kata yang telah diidentifikasi dan direkam sebelumnya. Setiap segmen berupa suku kata (diphone) disimpan dalam Database Diphone.
Penelitian “Sistem TTS dalam Bahasa
Indonesia menggunakan metode Finite State Automata dan database diphone” diharapkan bisa membantu anak-anak dalam mempelajari suku kata dalam Bahasa Indonesia dan cara pengucapannya, membantu orang buta dalam mempelajari cara pengucapan kata yang ditulis dengan huruf alfabet (braille) dalam bahasa Indonesia, membantu orang asing dalam mempelajari bahasa Indonesia secara otodidak, dan membantu komunikasi orang tuna wicara dan orang yang tidak diperbolehkan berbicara karena sakit.
2. Tinjauan Pustaka
Bahasa formal adalah kumpulan kalimat. Dalam pembicaraan selanjutnya ‘bahasa formal’ akan disebut ‘bahasa’ saja. Bahasa dalam bentuk tulisan sebenarnya terdiri atas simbol-simbol yang bisa digunakan dalam sebuah bahasa membentuk sebuah himpunan dan disebut sebagai abjad.
Deretan karakter membentuk string. Bahasa
didefinisikan sebagai himpunan semua string yang dapat dibentuk dari suatu abjad. Kaidah/aturan pembentukan kata/kalimat disebut grammar (tata bahasa).
Otomata berasal dari bahasa Yunani automatos, yang berarti sesuatu yang bekerja secara otomatis (mesin). Otomata merupakan suatu sistem yang terdiri atas sejumlah berhingga state, dimana state menyatakan informasi mengenai input yang lalu,
dan dapat pula dianggap sebagai memori mesin. Input pada mesin otomata adalah bahasa yang harus dikenali oleh mesin. Selanjutnya mesin otomata membuat keputusan yang mengindikasikan apakah input ini diterima atau tidak.
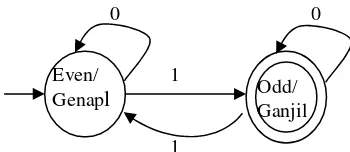
Gambar 2.1. Mesin otomata sederhana
Contoh sebuah mesin otomata sederhana diberikan dalam Gambar 2.1. Bila mesin mendapat untai/ string input: Ada, adu, add maka keputusan mesin adalah diterima, diterima, ditolak.
Gambar 2.2. Diagram State untuk FSA
Keterangan Gambar 2.2:
• Lingkaran menyatakan state/kedudukan
• Label pada lingkaran adalah nama state
tersebut
• Busur menyatakan transisi yaitu perpindahan kedudukan/state
• Lingkaran didahului sebuah busur tanpa label menyatakan state awal
• Lingkaran ganda menyatakan state akhir/final
Menurut Arman (2000), sistem TTS pada
prinsipnya terdiri dari dua sub sistem, yaitu :
1) Bagian Konverter Teks ke Fonem (Text to Phoneme), serta
2) Bagian Konverter Fonem to Ucapan
(Phoneme to Speech).
Gambar 2.3 Blok Diagram sistem TTS
Gambar 2.3 menunjukkan blok diagram sistem TTS. Bagian Konverter Teks ke Fonem berfungsi untuk mengubah kalimat masukan dalam suatu bahasa tertentu yang berbentuk teks menjadi
rangkaian kode-kode bunyi. Konverter Fonem ke Ucapan akan menghasilkan bunyi atau sinyal ucapan yang sesuai dengan kalimat yang ingin diucapkan. Dua teknik yang banyak digunakan
adalah formant synthesizer serta diphone
concatenation. Konversi dari teks ke fonem sangat dipengaruhi oleh aturan-aturan yang berlaku dalam suatu bahasa.
Bahasa Indonesia mengenal bahasa tulisan maupun bahasa lisan. Dalam bahasa lisan, dikenal istilah fonem, yang merupakan kesatuan bahasa terkecil yang dapat membedakan arti. Dalam bahasa tulisan, fonem dilambangkan dengan huruf. Dengan kata lain, huruf adalah tulisan dari fonem. Seringkali istilah fonem disamakan dengan huruf, padahal tidak selamanya berlaku demikian. Fonem dibagi menjadi vokal dan konsonan. Bahasa Indonesia mengenal 5 vokal yaitu : a, e, i ,o, u, dan 25 konsonan yaitu : b, c, d ,f , g , h, j , k, kh, l, m, n, ng, ny, p, q, r, s, sy, t, v, w, x, y, z. Konsonan kh, ng, ny dan sy adalah contoh fonem yang terdiri atas dua huruf. Selain itu dikenal pula istilah diftong, yaitu gabungan 2 vokal yang membentuk kesatuan bunyi, yaitu : au, ai, oi. Pada beberapa buku referensi, diftong digolongkan sebagai vokal pula.
Aturan pemenggalan kata pada kata dasar dilakukan sebagai berikut. a).Jika di tengah kata ada vokal yang berurutan, pemenggalan itu dilakukan di antara kedua huruf vokal itu. Misalnya: ma-in, sa-at, bu-ah. Huruf diftong ai, au, dan oi tidak pernah diceraikan sehingga pemenggalan kata tidak dilakukan di antara kedua huruf itu. Misalnya: au-la bukan a-u-la. b). Jika di tengah kata ada huruf konsonan, termasuk gabungan-huruf konsonan, di antara dua buah huruf vokal, pemenggalan dilakukan sebelum huruf konsonan. Misalnya: ba-pak, ba-rang, su-lit. c). Jika di tengah kata ada dua huruf konsonan yang berurutan, pemenggalan dilakukan di antara kedua huruf konsonan itu. Gabungan huruf konsonan tidak pernah diceraikan. Misalnya: man-di, ap-ril, swas-ta, d). Jika di tengah kata ada tiga buah huruf konsonan atau lebih, pemenggalan dilakukan di antara huruf konsonan yang pertama dan huruf konsonan yang kedua. Misalnya: in-stru-men ul-tra
Menurut Tofani & Nugroho, (1995) Bahasa Indonesia mengenal beberapa pola umum suku kata, yaitu :
Gambar 3.1. Diagram alur TTS dalam Bahasa Indonesia
3.2 Algoritma Finite State Automata (FSA)
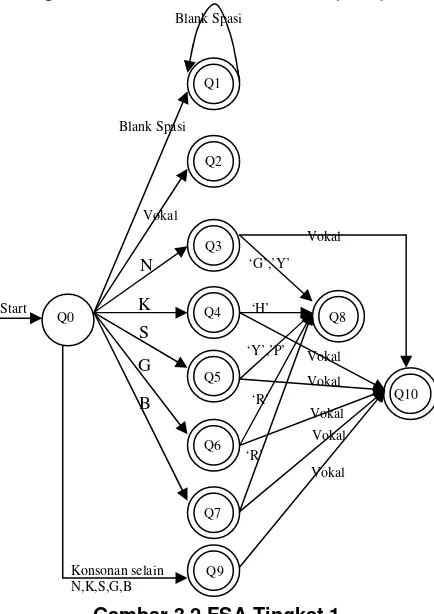
Gambar 3.2 FSA Tingkat 1. Normalisasi teks
Kenali Suku kata BI dengan Algoritma FSA,
Algoritma FSA yang digunakan untuk pengenalan suku kata bahasa Indonesia dirancang dalam dua tingkat. Perancangan ini merupakan pengembangan dari algoritma FSA yang telah dibuat sebelumnya oleh Anung dengan FSA tiga tingkat. Dalam algoritma FSA Anung, tingkat pertama mengenali pola suku kata V, K dan KV. Pada tingkat 2 FSA mengenali suku kata dengan pola V, VK, VKK, KV, KVK, KKV, KKVK, KKKV, KKKVK. Sedangkan pada tingkat ketiga pola suku kata yang dapat dikenali adalah VK, VKK, KVK, KVKK, KKVK, KKVKK, V, KV, KVV, KKV, KKVV
Gambar 3.3 FSA Tingkat 2
FSA tingkat 2 juga dapat mengenali diftong (au, ai dan oi), namun kemunculan dua vokal tersebut secara berurutan belum tentu berupa diftong. Semua pasangan vokal ‘au’, ‘ai’ dan ‘oi’ akan dikenali sebagai diftong.
3.3 Perekaman suara
Synthesizer yang menggunakan teknik diphone concatenation bekerja dengan cara menggabung-gabungkan segmen-segmen bunyi yang telah direkam sebelumnya. Setiap segmen berupa
diphone (gabungan dua buah fonem). Sebelum melakukan perekaman suara untuk menghasilkan diphone database dilakukan persiapan:
1. Identifikasikan jumlah suku kata (diphone) dari Bahasa Indonesia.
2. Membuat daftar kombinasi lengkap diphone.
jumlah diphone dikurangi dengan
menghilangkan kombinasi diphone tertentu yang anda anggap tidak pernah terjadi, misalnya urutan dua fonem konsonan yang sama, seperti b-b, c-c, dan sebagainya.
3. Membuat daftar contoh kata yang mengandung setiap diphone
Pada saat perekaman diphone, terdapat beberapa hal yang harus diperhatikan, yaitu :
Menyiapkan ruangan, yang mempunyai
karakteristik : bebas noise(noise rendah), tidak ada pantulan suara.
1. Siapkan perangkat perekaman yang berkualitas tinggi dan tempat nyaman.
2. Perekaman serangkaian diphone, lalu disimpan pada file yang berbeda.
3. Memeriksa seluruh kualitas suara hasil
rekaman. Jika ada suara yang kurang
memuaskan, lakukan perekaman ulang.
Dalam satu kali perekaman akan merekam beberapa suku kata sekaligus. Maka dari itu hasil rekaman masih berupa serangkaian diphone. Rangkaian tersebut akan dipotong-potong menjadi per satu suku kata dengan menggunakan software adhope audition 1.0. Hasil perekaman berupa file suara berekstensi *.wav.
4. Hasil Dan Pembahasan 4.1 Pengenalan suku kata
Untuk mengenali suku kata Bahasa
Indonesia menggunakan pemodelan FSA bertingkat yang berfungsi untuk mempermudah pemisahan suku kata. Sebagai contoh pada saat kita membaca dua huruf pertama pada kata anak (VKVK) dan kata anda (VKKV) kita belum bisa memutuskan apakah pemisahan suku kata akan dilakukan diantara kedua huruf tersebut atau tidak. Setelah membaca huruf ketiga, barulah bisa diputuskan di mana harus dilakukan pemisahan suku kata. Jika huruf ketiga
berupa sebuah konsonan maka pemisahan
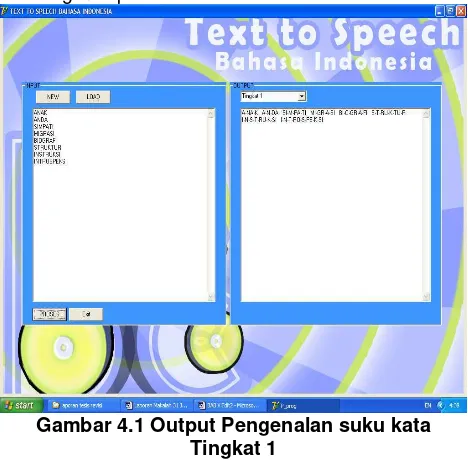
dilakukan setelah huruf kedua (kata anda akan menjadi an-da). Sedangkan jika huruf ketiga adalah sebuah vokal, maka harus ditelusuri mundur dan memisahkan suku kata setelah huruf pertama (kata anak akan menjadi a-nak). FSA tingkat pertama yang mengenali pola V, K, . KV. Hasil eksekusi algoritma FSA Tingkat 1 ditunjukkan dalam gambar 4.1. Hasil-hasil pengujian lain dari algoritma Tingkat 1 terangkum pada tabel 4.1
Gambar 4.1 Output Pengenalan suku kata Tingkat 1
Pada tingkatan pertama kata anak akan dipisahkan menjadi a-na-k (V-KV-K). Algoritma FSA Tingkat 1 (lihat gambar 3.2)
q
q
q
q
q
q
q K
V K STAR
T
q K
K
q
K KV
K
K V
K
q
q V spas
i
V K
Tabel 4.1 Hasil pengujian pengenalan suku kata tingkat 1
INPUT (teks)
OUTPUT Tingkat 1 Tingkat 2
Anak a-na-k -
Anda A-n-da -
Buah Bu-a-h -
Kenyang Ke-nya-ng -
Ultra u-l-t-ra -
Simpati Si-m-pa-ti -
Migrasi mi-gra-si -
Biografi Bi-o-gra-fi
Struktur s-t-ru-k-tu-r -
Pantai Pa-n-ta-i -
Eks e-k-s -
Kemudian pada tingkat kedua FSA akan mengenali suku kata dengan pola VK, VKK, KVK, KVKK, KKVK, KKVKK, V, KV, KVV, KKV, KKVV (Gambar 3.3). Gambar 4.2 menunjukkan hasil eksekusi algoritma Tingkat 2.
Gambar 4.2 Output Pengenalan suku kata Tingkat 2
Kata anak pada Tingkat 1 menghasilkan output a-na-k yang selanjutnya akan menjadi input pada Tingkat 2. Output pada tingkat 2 akan menjadi a-nak (V-KVK). Pemisahan sesudah huruf pertama ini terjadi karena tidak dikenal suku kata berpola VKV. Sedangkan kata anda pada tingkat pertama akan
dipisahkan menjadi a-n-da (V-K-KV), yang
selanjutnya masuk ke tingkat kedua akan dipisahkan menjadi an-da. Hal ini sesuai dengan aturan pemisahan suku kata Bahasa Indonesia. Contoh hasil pengujian lain terangkum pada tabel 4.2
Tabel 4.2 Hasil pengujian pengenalan suku kata tingkat 2
INPUT (teks)
OUTPUT Tingkat 1 Tingkat 2
Anak a-na-k a-nak
anda A-n-da an-da
Buah Bu-a-h Bu-ah
Kenyang Ke-nya-ng Ke-nyang
Ultra u-l-t-ra Ul-tra
Simpati Si-m-pa-ti Sim-pa-ti
Migrasi mi-gra-si mi-gra-si
Biografi Bi-o-gra-fi Bi-o-gra-fi struktur s-t-ru-k-tu-r struk-tur
Pantai Pa-n-ta-i pan-tai
Eks e-k-s Eks
Selain itu FSA pada Tingkat 2 juga dapat mengenali diftong. Dalam penelitian ini semua vokal ‘au’, ‘ai’, ‘oi’ akan dianggap sebagai diftong.
Untuk input yang berupa angka akan
dinormalisasi terlebih dahulu dalam bentuk teks yang lengkap. Misalnya input teks: 17 agustus 1945 akan dinormalisasi menjadi tujuh belas agustus seribu sembilan ratus empat puluh lima. Selanjutnya akan mengikuti proses yang sama dengan input teks lainnya, berupa pengenalan suku katanya. Hasil pengenalan suku kata akan menjadi: tu-juh be-las a-gus-tus se-ri-bu sem-bi-lan ra-tus em-pat pu-luh li-ma.
4.2 Pengolahan Hasil Rekaman
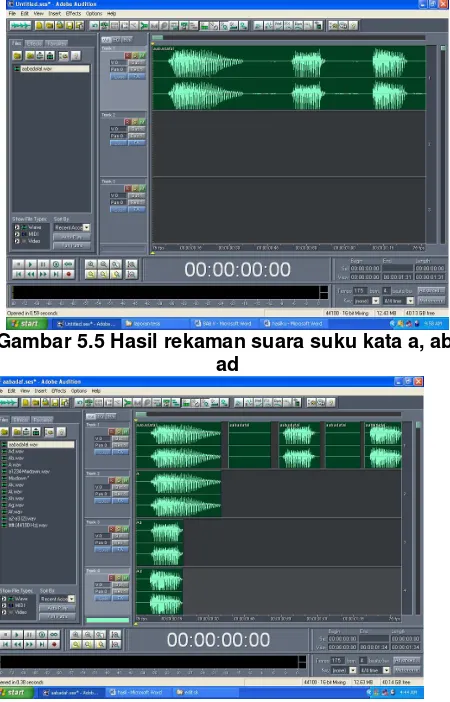
Hasil perekaman suku kata masih berupa serangkaian diphone (suku kata) dalam bentuk file suara berekstensi *.wav. Misalnya suku kata yang huruf depan a, ab, ad, direkam dalam satu kali rekaman suara. Serangkaian suku kata tersebut
akan dipotong-potong, diolah menggunakan
software menjadi per satu suku kata. Gambar 5.5 menunjukkan hasil rekaman suku kata a, ab, ad. Hasil rekaman tersebut letakan pada track1. Selanjutnya masing-masing suku kata a di pindah ke
track2 dan ab ke track3, ad di track4 (gambar 4.6)
Gambar 5.5 Hasil rekaman suara suku kata a, ab, ad
Gambar 5.8 Hasil pemisahan suku kata
teridentifikasi di rekam dan di simpan sebagai database diphone.
4.3 Konversi ke ucapan
Proses terakhir adalah dari hasil pemisahan suku kata dicocokkan dengan database diphone untuk menge-load diphone tersebut sehingga menjadi output pengucapan suatu kata/ kalimat.
Pada penelitian ini untuk pengkonversian dari suku kata ke ucapan masih terbatas untuk 1 pilihan diphone. Misalnya suku kata me mempunyai dua macam pengucapan diphone seperti mê pada kata merah dan më pada kata melati. Program ini belum bisa memilih kapan menggunakan diphone mê dan kapan më. Dengan sistem database suku kata mempunyai kelebihan kapasitas database lebih sedikit daripada database kata sehingga proses lebih cepat, akan tetapi hasil suara yang diperoleh masih patah-patah.
5. Kesimpulan Dan Saran 5.1 Kesimpulan
• metode FSA dua tingkat bisa mengenali suku
kata Bahasa Indonesia dengan tingkat
keberhasilan 96%, kesalahan 3,94% untuk kata dasar, sedangkan untuk kata berimbuhan dengan tingkat keberhasilan 69%, kesalahan 30,88%.
• Metode FSA belum bisa membedakan
gabungan dua vokal au, ai, oi yang diftong dan bukan diftong. Semua gabungan dua vokal au, ai, oi dianggap diftong.
• Untuk pengkonversian dari suku kata ke ucapan
masih terbatas untuk 1 pilihan 1 diphone. Misalnya untuk suku kata me pada kata merah dan melati.
• Dengan sistem database suku kata mempunyai
kelebihan kapasitas database lebih sedikit daripada database kata sehingga proses lebih cepat, akan tetapi hasil suara yang diperoleh masih patah-patah.
5.2 Saran
Dari kesimpulan hasil penelitian iharapkan pada penelitian berikutnya :
Mengembangkan pada kata berimbuhan. Membedakan gabungan dua vokal au, ai, oi
yang diftong dan bukan diftong Bisa mempunyai lebih dari 2 diphone.
Untuk hasil suara yang lebih halus dan natural
diperlukan suatu algoritma untuk
menggabungkan diphone dengan diphone lainnya, serta algoritma untuk memanipulasi diphone, khususnya untuk mengubah durasi serta pitch diphone. Ada berbagai teknik yang dapat digunakan untuk mendukung pensintesa jenis ini diantaranya adalah autoregressive (AR), Glottal AR, hybrid harmonic/stocastic, time
domain PSOLA (TD-PSOLA), multiband
resynthesis-PSOLA (MBR-PSOLA), serta Linear
Prediction-PSOLA (LP-PSOLA) [Dut97].
Diharapkan dengan penambahan salah satu metode di atas akan dihasilkan suara yang lebih halus dan natural.
DAFTAR PUSTAKA
Alam, 2001. Borland Delphi 6.0. PT. Elex Media Komputindo kelompok Gramedia. Jakarta Arman, 2002. Konversi dari Text ke Ucapan.
Departement Teknik Elektro, ITB, Bandung. Arman, 2002. Perkembangan Teknologi TTS dari
Masa ke Masa. Departement Teknik Elektro, ITB, Bandung.
Basuki, 2000. Pengenalan Suku Kata Bahasa
Indonesia Menggunakan Finite-State Automata. Jurusan Ilmu Komputer, Universitas Katolik Parahyangan, Bandung. Borkar, . Text to Speech System for Konkani
(GOAN) Language. Electronics Department
Rajarambapu Institute of Technology
Sakharale, Islampur, Maharashtra, India. Dutoit, Thierry. 1997. An Introduction to
Text-to-Speech Synthesis. Kluwer Academic, Publisher Dordrecht (Text, Speech, and Language Series, edited by Nancy Ide and Jean Veronis, volume 3). State University. USA.
G. L. Jayavardhana, A. G. Ramakrishnan, M vijay Venkatesh, R. Murali Shankar. Thirukkural, A Text to Speech Synthesis System.
Department of Electrical Engineering, Indian Institute of Science, Bangalore, India. Hariyanto Bambang. 2004. Teori Bahasa, Otomata,
dan Komputasi serta terapannya.
Informatika Bandung, Bandung. HOPCROFT, J.E. dan J.D. ULLMAN. 1979.
Introduction to Automata Theory, anguages and Computation.Addison-Wesley
Publishing Company, Reading, Massachusetts.
Kelley Dean.1999. Otomata dan Bahasa-bahasa Formal : Suatu Pengantar. PT. Prehallindo, Jakarta.
Nageshwara Rao, Thomas Samuel, Nagarajan T, Murthy Hema A. Text to Speech Synthesis Using Syllable-like Units. Department of Computer Science and Engineering, Indian Institute of Technology, Madras, India.
Parson, Thomas W. 1986. Voice and Speech
Processing. McGraw Hill, New York.
Romel, Edwin. 2005. Aplikasi SMS dengan Text to Speech Bahasa Indonesia pada sistem Operasi Symbian. Departemen Teknik Elektro, ITB, Bandung.
Sojka Petr, Kopecek Ivan, Pala Karel. 2004. Text, Speech and Dialogue: 7th International Conference. TSD 2004, Brno, Czech Republic.
www.Wikipedia Indonesia, ensiklopedia bebas