ANALISIS ALGORITME FAKTORISASI PENYARING
KUADRIK BESERTA IMPLEMENTASINYA
SECARA PARALEL
RADEN BAGUS DIMAS PUTRA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ANALISIS ALGORITME FAKTORISASI PENYARING
KUADRIK BESERTA IMPLEMENTASINYA
SECARA PARALEL
RADEN BAGUS DIMAS PUTRA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
R BAGUS DIMAS PUTRA. Analysis of Quadratic Sieve Algorithm with Parallel Implementation supervised by SUGI GURITMAN and HENDRA RAHMAWAN.
Algorithm for finding the prime factors of large composite numbers are importance because of the widespread use of public key cryptosystems whose security depends on the presumed difficulty of the factorization problem. This research uses quadratic sieve algorithm for factoring big composite numbers. Quadratic sieve is the best algorithm for factoring composite numbers bellow 100 decimal digits. The quadratic sieve is analyzed and implemented using C programming language and parallelized by functional decomposition and domain decomposition. This research uses additional libraries for parallel implementation and for computing big integer numbers, which are MPI and GMP. The implementation result is tested in a computer with four processors. The factorized composite numbers are 25, 30, and 35 digits. The objectives of this research is to measure and analyze the performance of parallel quadratic sieve algorithm using performance metrics and the complexity of the implemented quadratic sieve.
This research uses two ways for parallelizing method: functional decomposition toward sieving stage and domain decomposition on sieving stage. The best result of parallel quadratic sieve is the domain decomposition on sieving stage which has an average efficiency of 91.6%. The result is not good enough because there are an additional task for changing GMP data type to MPI data type on parallel implementation. The complexity of the communication is e^((ln N ln ln N)^(1/2) 10log
N + 4 (P-1))/B which means it becomes worse the higher the composite numbers are. Performance metrics also become worse because of the additional task and the communication.
Judul Penelitian : Analisis Algoritme Faktorisasi Penyaring Kuadrik Beserta Implementasinya Secara Paralel
Nama : Raden Bagus Dimas Putra
NIM : G64080039
Menyetujui:
Mengetahui: Ketua Departemen,
Dr. Ir. Agus Buono, M.Si, M.Kom
NIP. 19660702 199302 1 001
Tanggal Lulus:
Pembimbing 1, Pembimbing 2,
Dr. Sugi Guritman NIP. 19620927 199203 1 004
PRAKATA
Alhamdulillah, segala puji dan syukur penulis panjatkan ke hadirat Allah subhanahu wata'ala
yang telah memberikan rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan penulisan
skripsi yang berjudul “Analisis Algoritme Faktorisasi Penyaring Kuadrik Beserta Implementasinya Secara Paralel” yang merupakan salah satu syarat untuk menyelesaikan pendidikan program sarjana pada Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam di Institut Pertanian Bogor. Shalawat dan salam tak lupa penulis sampaikan kepada Nabi Muhammad
shallallahu 'alaihi wasallam serta kepada keluarganya, sahabatnya, dan kepada para pengikutnya. Dalam menyelesaikan tulisan ini penulis mendapat bantuan dari banyak pihak. Oleh karena itu, penulis ingin menyampaikan rasa terima kasih kepada:
Bapak Dr. Sugi Guritman selaku dosen pembimbing pertama dan Bapak Hendra Rahmawan, S.Kom, M.T selaku dosen pembimbing kedua. Terima kasih atas segala pengetahuan dan bantuan serta nasehat-nasehat yang diberikan kepada penulis.
Ibunda Sahani, Ayahanda Haryanto, serta adik R Bagus Agung W K dan Rr Aprilia Putri C yang telah memberikan doa, kasih sayang, dukungan, serta motivasi untuk menyelesaikan penelitian ini.
Bapak Endang Purnama Giri, S.Kom, M.Kom selaku dosen penguji. Terima kasih atas segala bantuan yang diberikan kepada penulis.
Bapak Sony Hartono Wijaya, S.Kom, M.Kom selaku dosen pembimbing akademik serta staf pengajar dan tata usaha yang telah memberikan bantuan dan kerjasamanya selama penulis menjadi mahasiswa Ilmu Komputer angkatan 45.
Fitri Karlinda yang senantiasa memberikan doa, bantuan, dukungan, dan motivasi.
Teman-teman Ilkomerz 45 khususnya Jaka Ahmad Juliarta dan Anggi Putrantio yang telah membantu pelaksanaan seminar dan senantiasa memberikan bantuan, dukungan serta motivasi kepada penulis.
Seluruh mahasiswa Ilkom 44, 45, 46, dan 47 atas persahabatan yang luar biasa.
Semoga karya ini bisa memberikan manfaat untuk perkembangan dunia kriptografi dan teknologi informasi di Indonesia.
Bogor, Desember 2012
RIWAYAT HIDUP
Penulis bernama R Bagus Dimas Putra lahir di Jakarta pada tanggal 4 Agustus 1990. Penulis merupakan anak pertama dari tiga bersaudara yang terlahir dari pasangan Haryanto dan Sahani. Pada tahun 2008, penulis menamatkan pendidikan di SMA Negeri 2 Bogor, Jawa Barat. Pada tahun yang sama penulis menempuh pendidikan ke jenjang yang lebih tinggi yaitu Institut Pertanian Bogor (IPB). Penulis masuk IPB melalui jalur Undangan Seleksi Masuk IPB (USMI) dan diterima sebagai mahasiswa mayor Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
DAFTAR ISI
Halaman
DAFTAR TABEL ... vii
DAFTAR GAMBAR ... vii
DAFTAR LAMPIRAN ... vii
PENDAHULUAN Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup Penelitian ... 1
TINJAUAN PUSTAKA Prima dan Bilangan Komposit ... 1
Teorema Dasar Aritmatika (TDA) ... 1
Subeksponensial ... 1
Faktorisasi Fermat ... 1
Metode Kraitchik dan Dixon ... 2
Faktor Basis ... 2
Least Absolute Residue ... 2
B-smooth ... 2
Prima Relatif ... 2
Residu Kuadrik ... 2
Bergantung Linear ... 2
Penyaring Kuadrik (QS) ... 2
Penyaring Kuadrik Dasar (Basic QS) ... 2
Pemrograman Paralel ... 3
Arsitektur Komputer Paralel ... 3
Distributed Memory ... 3
Metode Foster ... 4
GMP ... 4
Message Passing Interface (MPI) ... 4
Blocking dan Nonblocking Communication ... 4
Communicator ... 5
Performance Metric ... 5
METODE PENELITIAN Studi Pustaka ... 5
Analisis Algoritme Sekuensial QS ... 5
Implementasi Algoritme Sekuensial QS ... 6
Penerapan Metode Foster pada Algoritme QS ... 6
Analisis Algoritme Paralel QS... 6
Implementasi Algoritme Paralel QS ... 6
Perancangan Percobaan ... 6
Percobaan ... 6
Analisis Kinerja ... 6
HASIL DAN PEMBAHASAN Studi Pustaka ... 6
Analisis Algoritme Sekuensial QS ... 7
Implementasi Algoritme Sekuensial QS ... 7
Penerapan Metode Foster pada Algoritme QS ... 7
Analisis Algoritme Paralel QS... 8
Implementasi Algoritme Paralel QS ... 8
Percobaan ... 9 Analisis Kinerja ... 9 KESIMPULAN DAN SARAN
DAFTAR TABEL
Halaman
1 Hasil Pencarian Residu Kuadrik... 15
2 Hasil Pencarian si Positif. ... 15
3 Hasil Pencarian si Negatif. ... 15
4 Hasil Faktorisasi si... 16
5 Bentuk Biner dari Pangkat Faktor si. ... 17
DAFTAR GAMBAR
Halaman 1 Arsitektur distributed memory, multiple-CPU computer... 32 Ilustrasi Metode Foster (Quinn 2004) ... 4
3 Metode penelitian ... 5
4 Hasil metode Foster ... 8
5 Waktu eksekusi percobaan 1 ... 9
6 Waktu eksekusi percobaan 2 ... 9
7 Waktu eksekusi 25 digit ... 9
8 Waktu eksekusi 30 digit ... 10
9 Waktu eksekusi 35 digit ... 10
10 Speed up 25 digit ... 10
11 Speed up 30 digit ... 10
12 Speed up 35 digit ... 10
13 Efisiensi 25 digit ... 10
14 Efisiensi 30 digit ... 11
15 Efisiensi 35 digit ... 11
16 Efisiensi rata-rata ... 11
17 Cost dan overhead 25 digit ... 11
18 Cost dan overhead 30 digit ... 11
19 Cost dan overhead 35 digit ... 11
20 Cost dan overhead rata-rata ... 12
DAFTAR LAMPIRAN
Halaman 1 Langkah-langkah penyelesaian kasus dan analisis algoritme QS. ... 152 Penurunan fungsi waktu eksekusi algoritme QS ... 20
PENDAHULUAN
Latar Belakang
Masalah dalam memfaktorisasi bilangan komposit telah membingungkan para ahli matematika selama lebih dari dua milenium (West 2007). Selain membutuhkan ketelitian yang tinggi hal tersebut juga membutuhkan waktu yang sangat lama bila memfaktorisasi bilangan komposit berdigit banyak. Pada masa kini faktorisasi bilangan komposit berdigit banyak dijadikan ajang kompetisi dengan hadiah utama sebesar $200,000. Kompetisi ini diselenggarakan oleh RSA Laboratories dan terus berlangsung hingga sekarang.
Salah satu algoritme untuk memfaktorisasi bilangan komposit adalah algoritme penyaring kuadrik atau lebih sering dikenal dengan
quadratic sieve (QS). Algoritme ini
diperkenalkan oleh Carl Pomerance pada tahun 1982.
Algoritme QS sangat tepat jika digunakan untuk memfaktorisasi bilangan komposit yang berukuran lebih sedikit dari 100 digit desimal (Pomerance 1996). Menurut hasil pembandingan Pomerance pada tahun 1996 dan beberapa penelitian lainnya algoritme ini adalah yang tercepat dalam memfaktorisasi bilangan komposit yang berukuran lebih kecil dari 100 digit desimal. Meskipun tercepat menurut hasil penelitian West pada tahun 2007 dalam tesisnya menyebutkan bahwa untuk memfaktorisasi bilangan komposit berukuran 70 digit saja membutuhkan waktu lebih dari 31.000 detik atau sekitar 9 jam jika dilakukan secara sekuensial.
Salah satu metode untuk mempercepat waktu eksekusi adalah dengan menggunakan pemrosesan paralel yang bisa diterapkan secara
distributed memory (tiap prosesor memiliki memorinya masing-masing), shared memory
(tiap prosesor menggunakan sebuah memori secara bersama-sama), dan hybrid (distributed shared memory). Pada penelitian ini diterapkan pemrosesan paralel terhadap proses memfaktorisasi bilangan komposit menggunakan algoritme QS dengan distributed memory. Pemrosesan paralel yang digunakan adalah dengan cara domain decomposition dan
functional decomposition. Tujuan Penelitian
Tujuan dari penelitian ini adalah :
1. Menganalisis kompleksitas algoritme QS secara sekuensial maupun paralel.
2. Mengimplementasikan algoritme QS secara sekuensial dan paralel pada komputer
menggunakan bahasa C dengan library MPI dan GMP.
3. Menganalisis kinerja algoritme QS secara sekuensial dan paralel dengan menghitung waktu eksekusi, speed up, efisiensi, cost, dan overhead.
Ruang Lingkup Penelitian
Analisis teori, analisis algoritme, analisis uji perbandingan, dan implementasi algoritme penyaring kuadrik dibatasi untuk panjang bilangan komposit yang difaktorisasi adalah 25, 30, dan 35 serta jumlah proses yang dibangkitkan adalah 1, 2, 3, dan 4. Analisis
performance metrics dibatasi pada waktu eksekusi, speed up, efisiensi, cost, dan
overhead. Bahasa pemrograman yang
digunakan adalah C dengan library tambahan MPI dan GMP.
TINJAUAN PUSTAKA
Prima dan Bilangan Komposit
Prima adalah suatu bilangan Intejer p≥ 2 jika bilangan tersebut hanya dapat dibagi oleh 1 dan p. Intejer positif yang bukan prima disebut bilangan komposit (Crandall & Pomerance 2005).
Teorema Dasar Aritmatika (TDA)
Teorema dasar aritmatika berbunyi, "Setiap intejer N > 1 dapat dituliskan sebagai hasil kali beberapa bilangan prima. N = p1a1p
Subeksponensial yaitu suatu algoritme eksponensial yang memiliki kompleksitas no(1) atau pertumbuhannya seolah-olah seperti pertumbuhan polinomial berderajat tinggi serta kompleksitas ini adalah yang terkecil dalam algoritme faktorisasi (Crandall & Pomerance 2005).
Faktorisasi Fermat
Ide dasar algoritme Fermat untuk faktorisasi
Metode Kraitchik dan Dixon
Metode Kraitchik dan Dixon adalah perkembangan dari metode Fermat namun metode ini telah melakukan penyaringan sehingga pencarian menjadi lebih singkat (Guritman 2010).
Proses yang dilakukan pada metode ini sama dengan metode penyaring kuadrik dasar, tetapi terdapat beberapa perbedaan yang di antaranya adalah: ketika membuat barisan prima batas nilai prima terbesar B didefinisikan sendiri, prima yang dibangkitkan tidaklah harus residu kuadrik, serta total penyaringan tidak ditetapkan sehingga pencarian dilakukan sejumlah yang diharapkan. Oleh karena itu algoritme penyaring kuadrik menyelesaikan kekurangan algoritme ini.
Faktor Basis
Faktor basis adalah suatu himpunan bilangan prima yang berbeda yang lebih kecil atau sama dengan dari suatu nilai basis B atau
dapat dinotasikan sebagai
F={p|p prima dan p≤B} (Guritman 2010).
2 (Crandall & Pomerance 2005).
B-smooth
Suatu nilai b dikatakan smooth apabila pada
b2≡t (mod n) bilangan t merupakan least keduanya prima atau salah satunya. Contoh: 22 dan 15 adalah prima relatif namun 19 dan 57 serta 7 dan -7 bukan prima relatif karena hasil GCD(a,b) ≠ 1.
Residu Kuadrik
Untuk bilangan prima relatif a dan m dengan
m positif, bilangan a adalah residu kuadrik (mod m) jika dan hanya jika x2≡a(mod m) memiliki penyelesaian untuk bilangan bulat x (Crandall & Pomerance 2005). Jika tidak memiliki penyelesaian maka a adalah residu nonkuadrik (mod m). Contoh: 30 adalah residu
kuadrik terhadap 7 karena memiliki penyelesain yaitu 3 dan 4 sehingga 32≡30(mod 7) atau 42≡30(mod 7). Selain itu setiap bilangan ganjil adalah residu kuadrik terhadap 2 karena pasti memiliki solusi yaitu 1.
Bergantung Linear
Vektor-vektor v1,v2,… ,vn dalam ruang
vektor V adalah bergantung linear jika terdapat skalar-skalar c1,c2,… ,cn yang tidak semuanya
Penyaring kuadrik adalah algoritme faktorisasi bilangan komposit modern yang memiliki kecepatan subeksponensial. Algoritme ini memungkinkan untuk memfaktorisasi lebih dari 50 digit yang algoritme sebelumnya hanya mampu memfaktorisasi hingga 20 digit.
Penyaringan kuadrik memiliki beberapa variasi di antaranya adalah :
1. Basic QS
2. Fast matrix methods 3. Large prime variation 4. Multiple polynomials 5. Self initialization
6. Zhang’s special QS (Crandall & Pomerance
2005).
Penyaring Kuadrik Dasar (Basic QS)
Ide dasar metode ini sama dengan metode Kraitchik dan Dixon yang merupakan pengembangan dari metode Fermat, yang akan menjadi penekanan di sini adalah pengoptimalan pada metode penyaringan. Hal ini terkait dengan:
1. Memilih nilai B yang cukup optimal. 2. Memilih barisan prima p1<p2<…< pk≤B
yang bisa mempercepat proses penyaringan.
3. Menentukan barisan pelacakan x1,x2,…,xn sehingga memperbesar probabilitas bahwa semua faktor prima dari si=xi2mod N berada dalam F = p1<p2<…< pk . Dalam hal ini si disebut B-smooth.
1. Inisialisasi
a. Tentukan nilai B
B~ L(N) dengan formulasi vektor binernya. b. Dapatkan sebanyak (F+c) hasil mengantisipasi terjadinya kegagalan faktorisasi pada langkah terakhir. 3. Kalkulasi Aljabar Linear
a. Untuk setiap x,s ∈ S, nyatakan s biner definisikan matrik A berukuran
S× F.
d. Dari matriks A, dengan metode aljabar linear, pilih r vektor yang bergantung linear dan himpunan anggota-anggota
S yang terkait yaitu H =
xi1,si1 , xi2,si2 ,…, xir,sir . 4. Faktorisasi
a. Dari himpunan H, hitung
X = rk=1xik mod N dan faktorisasi gagal. Catatan bahwa dalam kasus gagal, bisa kembali ke Langkah-3 untuk mencari r vektor bergantung linear yang lain. Jika A tidak memuat himpunan vektor yang bergantung linear, maka nilai B atau c harus
diperbesar (Crandall & Pomerance 2005).
Contoh penyelesaian suatu kasus menggunakan algoritme penyaring kuadrik dasar (QS) dipaparkan dalam Lampiran 1 beserta analisis kompleksitasnya.
Pemrograman Paralel
Pemrograman paralel adalah teknik pemrograman komputer yang memungkinkan eksekusi perintah atau operasi secara bersamaan (Jordan & Alaghband 2006).
Algoritme paralel adalah sebuah urutan yang memberi tahu bagaimana cara untuk memecahkan suatu masalah menggunakan beberapa prosesor. Algoritme ini mencakup identifikasi bagian dari pekerjaan bersama ke dalam proses yang berjalan secara paralel, pengaturan akses data yang dibagi ke beberapa prosesor, pendistribusian input, output, dan data yang terkait dengan program serta koordinasi proses di berbagai tahapan pelaksanaan program paralel (Grama et al. 2003).
Arsitektur Komputer Paralel
Arsitektur komputer multiprocessors secara umum terbagi menjadi dua berdasarkan pemakaian memori utamanya, yaitu centralized multiprocessors atau biasa disebut juga shared memory dan distributed multicomputer atau
distributed memory (Quinn 2004). Dari sebuah pandangan pemrograman, pada zaman sekarang setiap komputer pribadi memiliki lebih dari satu memori sehingga memori dan prosesor dikelompokkan bersama dan melahirkan suatu pendekatan terhadap arsitektur komputer paralel, pendekatan ini dikenal sebagai
distributed shared memory (Wilkinson & Allen 2010).
Distributed Memory
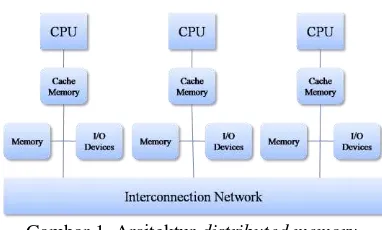
Gambar 1 Arsitektur distributed memory, multiple-CPU computer
utama terdistribusi ke semua prosesor dan tiap prosesor memisahkan ruang alamat lokalnya (Quinn 2004). Ilustrasi arsitektur distributed memory dapat dilihat pada Gambar 1.
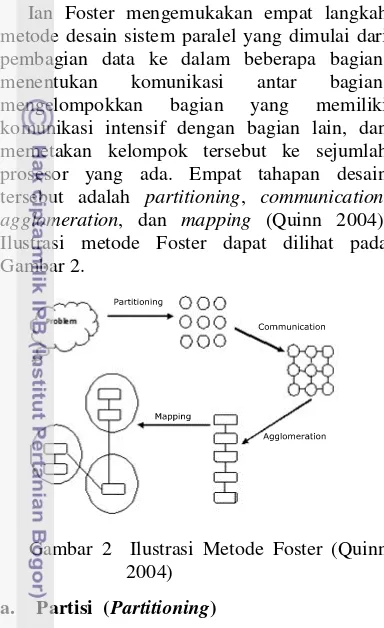
Metode Foster
Ian Foster mengemukakan empat langkah metode desain sistem paralel yang dimulai dari pembagian data ke dalam beberapa bagian, menentukan komunikasi antar bagian, mengelompokkan bagian yang memiliki komunikasi intensif dengan bagian lain, dan memetakan kelompok tersebut ke sejumlah prosesor yang ada. Empat tahapan desain tersebut adalah partitioning, communication,
agglomeration, dan mapping (Quinn 2004). Ilustrasi metode Foster dapat dilihat pada Gambar 2.
Gambar 2 Ilustrasi Metode Foster (Quinn 2004)
a. Partisi (Partitioning)
Partisi adalah suatu proses pembagian komputasi dan data ke dalam beberapa bagian. Ada dua cara untuk melakukan partisi, yaitu
domain decomposition dan functional
decomposition. Domain decomposition adalah pendekatan model algoritme paralel yang melakukan pembagian data menjadi beberapa bagian terlebih dahulu, kemudian menentukan bagaimana mengasosiasikan komputasi dengan data tersebut. Sedangkan functional
decomposition melakukan pembagian
komputasi terlebih dahulu (Quinn 2004). b. Komunikasi (Communication)
Setelah melakukan partisi maka yang harus dilakukan adalah membuat suatu skema komunikasi antar bagian tersebut. Ada dua jenis komunikasi yang digunakan yaitu local communication dan global communication.
Local communication adalah membuat saluran antar task ketika ada task yang membutuhkan nilai dari task lainnya. Global communication
terjadi ketika ada primitif task dengan jumlah
yang signifikan menyumbangkan data untuk menunjukkan proses komputasi (Quinn 2004). c. Aglomerasi (Agglomeration)
Aglomerasi adalah proses pengelompokkan
task ke dalam task yang lebih besar guna meningkatkan kinerja program maupun menyederhanakan program (Quinn 2004). d. Pemetaan (Mapping)
Pemetaan adalah proses penugasan task ke prosesor. Tujuan dari pemetaan adalah memaksimalkan kemampuan prosesor dan meminimalkan komunikasi antar prosesor (Quinn 2004).
GMP
GMP adalah library gratis untuk presisi aritmatika, operasi pada bilangan bulat bertanda, bilangan rasional, dan bilangan pecahan. Tidak ada batasan praktis untuk presisi kecuali memori yang tersedia pada mesin yang menjalankan GMP. GMP memiliki sangat banyak kumpulan fungsi, dan fungsi tersebut memiliki antarmuka yang sederhana.
Message Passing Interface (MPI)
MPI adalah sebuah standar library
pengenalan dasar pemrograman sistem paralel. MPI dapat digunakan dengan berbagai bahasa pemrograman seperti bahasa C dan Fortran. Operasi utama yang dilakukan oleh standar MPI yaitu:
a. Point-to-point Communication
MPI point-to-point communication adalah komunikasi antar dua proses. Satu proses bertugas mengirim data atau operasi dan proses lainnya bertugas menerima data atau operasi tersebut.
b. Collective Communication
MPI collective communication adalah komunikasi dipanggil oleh semua proses dalam communicator dan melibatkan seluruh proses tersebut (Quinn 2004). Blocking dan Nonblocking Communication
Pada umumnya setiap fungsi komunikasi pada MPI bersifat blocking communication
yang artinya setiap memanggil fungsi komunikasi proses tersebut akan menunggu hingga proses-proses yang melakukan komunikasi selesai berkomunikasi baru bisa melakukan aktivitas lainnya.
menyelesaikan komunikasinya untuk melakukan kegiatan yang lain. Untuk menyelesaikan komunikasi nonblocking, MPI menyediakan fungsi penyelesaian yang bersifat
blocking dan nonblocking (Quinn 2004). Communicator
Communicator adalah suatu tempat yang merupakan kumpulan proses-proses yang berhubungan dalam suatu komunikasi (Quinn 2004).
Performance Metric
Performance metrics adalah salah satu cara untuk menganalisis kinerja algoritme paralel (Grama et al. 2003). Beberapa persamaan
performance metric yaitu: a. Waktu Eksekusi
Waktu eksekusi serial adalah waktu yang dihitung dari awal sampai akhir eksekusi pada komputer sekuensial, dilambangkan dengan Ts. Waktu eksekusi paralel adalah waktu yang dihitung ketika komputasi paralel dimulai sampai elemen proses terakhir selesai dieksekusi, dilambangkan dengan Tp.
b. Speed up
Speed up (S) adalah rasio dari waktu yang digunakan untuk menyelesaikan masalah dalam program sekuensial (Ts) terhadap waktu yang diperlukan untuk menyelesaikan masalah yang sama dengan program paralel (Tp). Speed up dirumuskan pada persamaaan berikut:
S = Ts Tp. c. Efisiensi
Efisiensi (E) adalah rasio antara speed up
dengan banyaknya prosesor yang digunakan (p). Efisiensi dirumuskan pada persamaan berikut: perkalian waktu eksekusi paralel dengan jumlah prosesor yang digunakan. Fungsi
cost dirumuskan pada persamaan berikut:
C = pTp.
e. Overhead
Overhead adalah kelebihan dari total waktu yang dibutuhkan oleh semua proses paralel dibandingkan proses sekuensial pada masalah yang sama. Fungsi overhead
dirumuskan pada persamaan berikut:
To = pTp - Ts.
METODE PENELITIAN
Penelitian ini akan dikerjakan dalam beberapa tahap. Implementasi algoritme paralel penyaring kuadrik akan menggunakan metode Foster. Tahapan tersebut disesuaikan dengan metode penelitian yang dapat dilihat pada Gambar 3.
Gambar 3 Metode penelitian Studi Pustaka
Pada tahap ini, kegiatan yang dilakukan adalah mengumpulkan semua informasi yang terkait dengan penelitian. Informasi tersebut didapat dari jurnal, buku, internet, dan artikel yang membahas algoritme QS dan pemrosesan paralel.
Analisis Algoritme Sekuensial QS
penyelesaian suatu kasus beserta kompleksitas algoritme QS secara sekuensial.
Implementasi Algoritme Sekuensial QS
Pada tahap ini algoritme sekuensial QS diimplementasikan dengan menggunakan bahasa C dan library tambahan GMP versi 5.0.4.
Fungsi-fungsi utama yang akan dibuat dalam algoritme ini adalah:
1. “Inisialisasi” sebagai fungsi pembentukan nilai B, barisan prima yang merupakan kuadratik residual dari nilai N.
2. “Penyaringan” merupakan fungsi untuk menentukan pasangan barisan yang merupakan nilai smooth dari B.
3. “Kalkulasi aljabar linear” yaitu untuk menentukan pasangan vektor bergantung linear.
4. “Faktorisasi” yaitu menentukan apakah hasil dari kalkulasi aljabar linear tersebut memiliki faktor prima dari nilai yang difaktorisasi.
Penerapan Metode Foster pada Algoritme QS
Pada tahap ini dirancang algoritme QS secara paralel menggunakan metode Foster dengan tahapan partisi, komunikasi, aglomerasi, dan pemetaan.
Analisis Algoritme Paralel QS
Tahapan ini bertujuan mengetahui kompleksitas algoritme paralel beserta kompleksitas komunikasi dari algoritme QS. Implementasi Algoritme Paralel QS
Pada tahap ini algoritme paralel QS diimplementasikan dengan menggunakan bahasa C menggunakan library MPICH2. Implementasi paralel akan dilakukan dengan dua cara yaitu domain decomposition dan
functional decomposition. Perancangan Percobaan
Tahapan ini menentukan parameter-parameter yang dibutuhkan untuk percobaan. Parameter-parameter tersebut antara lain: 1. Perangkat keras dan perangkat lunak. 2. Jumlah digit yang difaktorisasi. 3. Jumlah proses.
4. Performance Metric. Percobaan
Dalam percobaan akan dicatat waktu eksekusi proses faktorisasi bilangan komposit
dari implementasi algoritme QS secara sekuensial dan paralel.
Analisis Kinerja
Pada tahap analisis, hasil percobaan sekuensial QS akan ditentukan waktu eksekusinya dan algoritme paralel QS akan ditentukan waktu eksekusi, speed up, cost, efisiensi, dan overhead.
HASIL DAN PEMBAHASAN
Studi Pustaka
Hasil pengumpulan informasi mengenai algoritme QS dan pemrosesan paralel yang terkait tulisan ini telah dicantumkan dalam bab tinjauan pustaka dan beberapa akan dibahas di bab lainnya.
Sebelum beranjak pada algoritme QS terlebih dahulu akan dijelaskan mengenai sejarah terbentuknya algoritme QS. Pada awalnya pendahulu algoritme ini adalah Metode Fermat yang memperbaiki algoritme brute force
atau yang lebih dikenal dengan trial division.
Fermat memiliki pemikiran yaitu pencarian faktorisasi dari perkalian dua buah bilangan prima akan lebih cepat jika dicari dari tengah karena pada umumnya hasil pencarian akan lebih dekat dengan akar nilai tersebut dibandingkan dengan awal nilai. Contoh: 7x11=77. Hasil faktorisasi 77 akan lebih cepat dicari dari akar 77 yaitu 8 dibandingkan dengan mencari dari 1. Jika mencari dari 8 proses pencarian hanya butuh dua kali yaitu 8 dan 7 sedangkan jika dari 1 akan dibutuhkan tujuh kali pencarian. Kompleksitas algoritme ini sama dengan pendahulunya namun bestcase pada algoritme ini adalah worstcase pada algoritme sebelumnya dan sebaliknya.
Analisis Algoritme Sekuensial QS
Pada dasarnya algoritme basic QS memiliki harapan waktu eksekusi L(N)1+o(N), dimana L(N) =e lnNln lnN. Persamaan tersebut didapatkan dari hasil turunan kecepatan ketika memilih B
saat proses inisialisasi. Kompleksitas dari algoritme ini yaitu no(1) dimana kompleksitas tersebut adalah turunan dari hasil waktu eksekusi tersebut. Adapun proses penurunan waktu eksekusi tertera pada Lampiran 2.
Secara rinci penjelasan kompleksitas algoritme sekuensial QS yang dibuat pada tulisan ini dilampirkan pada Lampiran 1 bersamaan dengan langkah-langkah penyelesaian menggunakan algoritme QS. Adapun hasil pemaparan dari kompleksitas algoritme penyaring kuadrik dasar (QS) adalah O(e lnNln lnN) yang artinya sebanyak-banyaknya pencarian pada algoritme QS adalah sebesar
e lnNln lnN.
Implementasi Algoritme Sekuensial QS
Implementasi dari algoritme QS tahapannya dilakukan indentik dengan langkah-langkah penyelesaian yang ada pada tulisan ini. Terdapat sedikit perbedaan yang bertujuan memperkecil kompleksitas dari tahapan tersebut. Perbedaan pada setiap tahapannya akan dijelaskan bersamaan dengan kompleksitas dari tahapan-tahapan tersebut dalam implementasinya. Catatan kompleksitas pada setiap tahapan sama secara big O. Adapun perbedaan tersebut adalah
1. Inisialisasi
Perbedaan pertama yaitu fungsi ini dibagi menjadi 2 bagian dengan nama inisialisasi untuk segala perhitungan yang bersifat konstan dan compute_fb untuk membentuk faktor basis. Perbedaan kedua yaitu tidak ada perhitungan B sebagai batas namun langsung menghitung jumlah residu kuadrik yang lebih kecil dari B yaitu B mempengaruhi kompleksitas sebelumnya karena fungsi yang dibuat pada akhirnya seolah-olah tetap mecari anggota faktor basis yang besarannya kurang dari B. Perbedaan lainnya yaitu setiap anggota faktor basis langsung dikalikan pada tahap inisialisasi. Sehingga kompleksitas tahap ini menjadi
Dalam implementasinya fungsi ini diberi nama saring. Perbedaannya adalah nilai z yang dipakai adalah 4. Proses pengalian anggota faktor basis telah dilakukan pada tahap inisialisasi. Proses pembuatan matriks pangkat yang seharusnya terjadi pada tahap 3 dipindahkan ke tahap ini yang bertujuan untuk optimasi pengerjaan secara paralel sehingga kompleksitasnya menjadi
k+15e lnNln lnN+64e
1 2lnNln lnN
lnNln lnN . 3. Kalkulasi aljabar linear
Fungsi ini diberi nama alin_biner. Perbedaan dalam implementasinya yaitu pada tahap ini hanya melakukan operasi biner untuk mendapatkan vektor-vektor yang bergantung linear sehingga komplesitasnya adalah k+4elnNln lnN
lnNln lnN. 4. Fakorisasi
Secara garis besar, fungsi ini tidak mengalami perubahan sehingga kompleksitasnya adalah k + 4e
1 2 lnNln lnN
lnNln lnN. Jadi kompleksitas keseluruhan program sekuensial yang dibuat adalah
K+70e
Penerapan Metode Foster pada Algoritme QS
Dalam algoritme QS proses harus dilakukan secara bertahap sehingga partisi yang optimal dilakukan adalah domain decomposition. Tahap yang paling optimal untuk dipartisi yaitu tahap penyaringan karena memiliki kompleksitas paling besar. Pada tulisan ini tidak dimungkinkan melakukan partisi secara domain decomposition pada tahap lainnya karena menggunakan fungsi-fungsi standar dari library
GMP sehingga tahap lain selain penyaringan harus dilakukan secara utuh.
Pada tulisan ini karena partisi domain decomposition hanya bisa dilakukan pada tahap penyaringan maka akan dilakukan juga
functional decomposition terhadap tahap
penyaringan. Ilustrasi pembagian pekerjaan pada setiap proses dapat dilihat pada Gambar 4.
Gambar 4 Hasil metode Foster Analisis Algoritme Paralel QS
Dari hasil penerapan metode Foster kompleksitas akan mengecil jika proses yang dibentuk lebih dari dua. Karena jika proses yang dibentuk hanya dua yang terjadi hanyalah perpindahan data dari proses dua ke proses satu sehingga hanya menambah kompleksitas yaitu komunikasi. Jadi kompleksitas algoritme QS secara paralel yang ideal adalah
K+70e
Komunikasi yang digunakan dalam tulisan ini adalah pengiriman suatu nilai dari setiap proses ke proses 1. Adapun biaya saat melakukan komunikasi data adalah y
B dimana y adalah jumlah data dalam byte dan B adalah
bandwidth atau kecepatan pengiriman data antar proses yang dinotasikan dalam byte/detik. Perhitungan bandwidth berbeda-beda bergantung pada arsitektur paralel yang digunakan. Jika menggunakan arsitektur 1 komputer dengan banyak prosesor maka
bandwidth adalah kecepatan pengiriman data antar prosesor melalui RAM. Jika menggunakan arsitektur banyak komputer maka bandwidth
adalah kecepatan pengiriman data antar komputer yang bisa berupa kecepatan kabel LAN, wireless, atau internet.
Pada tulisan ini jumlah data yang dikirimkan adalah log10Nbyte karena data yang dikirimkan merupakan sebuah string dengan panjang log10N. Proses pengiriman dilakukan sebanyak
e lnNln lnN kali karena pengiriman dilakukan hanya ketika nilai smooth ditemukan.
Komunikasi lain yang dilakukan adalah pengiriman sebuah bilangan bulat dari proses 1 ke proses lainnya sebagai bentuk bahwa pencarian telah selesai sehingga proses lain dapat menghentikan pekerjaannya. Komunikasi ini dilakukan sebanyak P-1 pengulangan. Dalam implementasi yang dilakukan, sebuah bilangan bulat berukuran 4 byte sehingga total kompleksitas komunikasi dari algoritme ini adalah c = e ln
Nln lnNlog
10N+4(P-1)
B .
Implementasi Algoritme Paralel QS
Dalam implementasinya domain decomposition yang dilakukan bersifat round robin yang artinya setiap data dibagikan secara bergantian pada setiap proses. Contoh: jika ada 5 data {d1,d2,d3,d4,d5} dan 2 proses {p1,p2} secara round robin data akan dibagi menjadi {d1,d3,d5} untuk p1 dan {d2,d4} untuk p2. Terdapat pekerjaan tambahan saat terjadi komunikasi yaitu proses perubahan tipe data dari bilangan besar ke string dan dari string ke bilangan besar serta pengecekan pengiriman. Terjadi pengurangan pekerjaan yaitu pada saat pembentukan matriks pangkat karena dibuat bersamaan dengan pencarian nilai smooth. Karena proses mencari nilai smooth lebih lama dibandingkan pembentukan matriks pangkat maka nilai kompleksitas mencari matriks pangkat terbuang. Sehingga kompleksitas implementasi algoritme QS secara paralel adalah
dalam kompleksitas tersebut dapat ditafsirkan bahwa waktu eksekusi program paralel akan naik jika hanya menggunakan dua proses dibandingkan dengan implementasi secara sekuensial.
Perancangan Percobaan
Percobaan penelitian akan dilakukan dalam lingkungan sebagai berikut:
a. Satu komputer quad core. b. Prosesor Intel Core i7-3610QM.
d. RAM 8192 MBytes. e. Kecepatan RAM 667 MHz.
f. Sistem operasi Windows 7 64bit Professional Edition.
g. Aplikasi yang dibutuhkan untuk menjalankan program: MPICH2, compiler
bahasa pemrograman C dengan library
tambahan MPI dan GMP.
Proses percobaan akan dibagi menjadi dua bagian yaitu percobaan sistem secara keseluruhan yang kemudian akan dibandingkan antara sekuensial dengan paralel dan percobaan sistem pada tahap penyaringan yang dilakukan dengan cara domain decomposition.
Pada percobaan pertama parameter-parameter yang digunakan adalah
1. Jumlah digit yang difaktorisasi adalah 25, 30, dan 35 digit.
2. Jumlah proses yang dibangkitkan adalah 1, 2, 3 dan 4.
3. Performance metric yang dihitung adalah waktu eksekusi, speed up, cost, efisiensi, dan overhead.
Pada percobaan kedua parameter-parameter yang digunakan adalah
1. Jumlah digit yang difaktorisasi adalah 25, 30, dan 35 digit.
2. Jumlah proses yang digunakan saat melakukan penyaringan adalah 1, 2, dan 3. 3. Performance metric yang dihitung adalah
waktu eksekusi, speed up, cost, efisiensi, dan overhead.
Percobaan
Data yang digunakan dalam penelitian ini adalah bilangan bulat positif berukuran besar yang dibentuk dari suatu aplikasi matematika untuk membentuk bilangan bulat prima berukuran besar secara acak. Data-data tersebut adalah 7299149961857474937873353 sebagai data 25 digit yang merupakan bentuk perkalian dari 2570207923343 x 2839906412071, 831688082926290986707736279471 sebagai data 30 digit yang merupakan bentuk perkalian dari 1007259158096473 x 825694237913927, dan data yang berukuran 35 digit adalah 80293214381737181784027059366179183 sebagai bentuk dari hasil perkalian 279869390409959723 x 286895305928675021.
Percobaan dibagi menjadi 2 jenis. Jenis percobaan 1 yaitu waktu eksekusi keseluruhan tahap sampai mendapatkan hasil yang dilakukan dengan cara functional decomposition serta
domain decomposition. Percobaan 2 yaitu waktu eksekusi pada tahap penyaringan yang dilakukan dengan cara domain decomposition. Data hasil percobaan dapat dilihat pada Lampiran 3.
Analisis Kinerja
Hasil dari percobaan adalah waktu eksekusi,
speed up, efisiensi, cost, dan overhead yang dipaparkan sebagai berikut.
Waktu Eksekusi
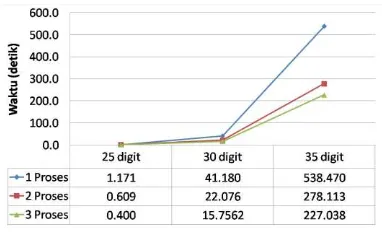
Hasil dari waktu eksekusi percobaan 1 dan 2 dapat dilihat pada Gambar 5 dan 6 serta perbandingan waktu eksekusi 25, 30, dan 35 digit dapat dilihat pada Gambar 7, 8, dan 9.
Gambar 5 Waktu eksekusi percobaan 1
Gambar 6 Waktu eksekusi percobaan 2 Dari Gambar 5 dan 6 dapat disimpulkan bahwa semakin tinggi jumlah digitnya maka waktu eksekusi akan semakin bertambah dan juga sebaliknya semakin banyak proses yang di bentuk maka waktu eksekusi akan semakin berkurang.
Gambar 8 Waktu eksekusi 30 digit
Gambar 9 Waktu eksekusi 35 digit Pada percobaan 1 terlihat bahwa waktu eksekusi menggunakan 2 proses lebih lambat dibandingkan dengan 1 proses atau sekuensial. Hal ini dikarenakan jika menggunakan 2 proses, yang terjadi adalah paralelisasi dengan cara
functional decomposition yang kompleksitasnya lebih tinggi dibandingkan dengan sekuensial. Pangkat tertinggi dari kompleksitas sekuensial adalah 15e lnNln lnN sedangkan pada implementasi paralel adalah 17e lnNln lnN
P-1 dan jika
jumlah proses = 2 menjadi 17e lnNln lnN. Walaupun demikian kenaikan waktu eksekusi tidak begitu signifikan karena terjadi pengurangan waktu eksekusi yaitu ketika membuat matriks pangkat dari nilai smooth.
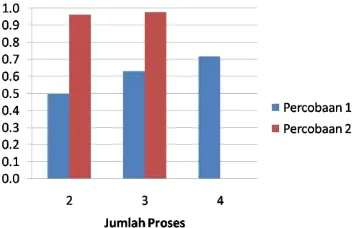
Speed Up
Speed up merupakan percepatan yang terjadi ketika ada penambahan proses. Hal ini dapat dihitung dari perbandingan waktu sekuensial dan paralel. Hasil speed up dari eksekusi data 25, 30, dan 35 digit dapat dilihat pada Gambar 10, 11, dan 12.
Dari Gambar 10, 11, dan 12 dapat disimpulkan bahwa speed up yang terjadi pada percobaan 2 sudah baik karena sudah mendekati sejumlah proses yang dibentuk namun pada percobaan 1 kurang baik karena terdapat
functional decomposition sehingga 1 proses menganggur dan mengakibatkan penurunan kecepatan yang signifikan.
Gambar 10 Speed up 25 digit
Gambar 11 Speed up 30 digit
Gambar 12 Speed up 35 digit Efisiensi
Efisiensi merupakan dasar penilaian terhadap kelayakan suatu pekerjaan dilakukan secara paralel. Hasil perhitungan efisiensi dari eksekusi data 25, 30, dan 35 digit dapat dilihat pada Gambar 13, 14, 15, dan 16.
Gambar 14 Efisiensi 30 digit
Gambar 15 Efisiensi 35 digit Dari Gambar 13 ,14, dan 15 terlihat bahwa efisiensi dari percobaan 1 kurang baik hal ini dikarenakan algoritme QS harus dilakukan dengan cara bertahap. Karena percobaan 1 mengandung functional decomposition maka akan terjadi pengangguran pada sebuah proses. Sehingga dapat disimpulkan bahwa algoritme QS kurang baik jika dilakukan dengan cara
functional decomposition.
Gambar 16 Efisiensi rata-rata Dari Gambar 16 dapat terlihat bahwa efisiensi rata-rata percobaan 2 sudah baik karena berada di atas 87% sehingga dapat disimpulkan bahwa algoritme QS baik jika dilakukan domain decomposition dalam tahap penyaringan. Selain itu dapat disimpulkan juga bahwa pada algoritme QS efisiensi akan semakin berkurang seiring bertambahnya suatu nilai. Hal ini dikarenakan semakin besar data yang dieksekusi maka akan semakin banyak komunikasi yang terjadi sehingga mengurangi
efisiensi. Rata-rata dari keseluruhan efisiensi adalah 91.6%. Dengan kata lain proses domain
decomposition pada tahap penyaringan
algoritme QS 91.6% efisien untuk memfaktorisasi data sampai dengan 35 digit.
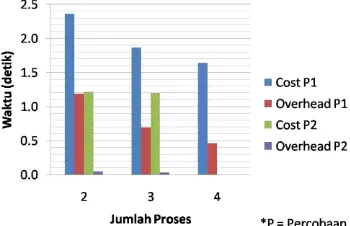
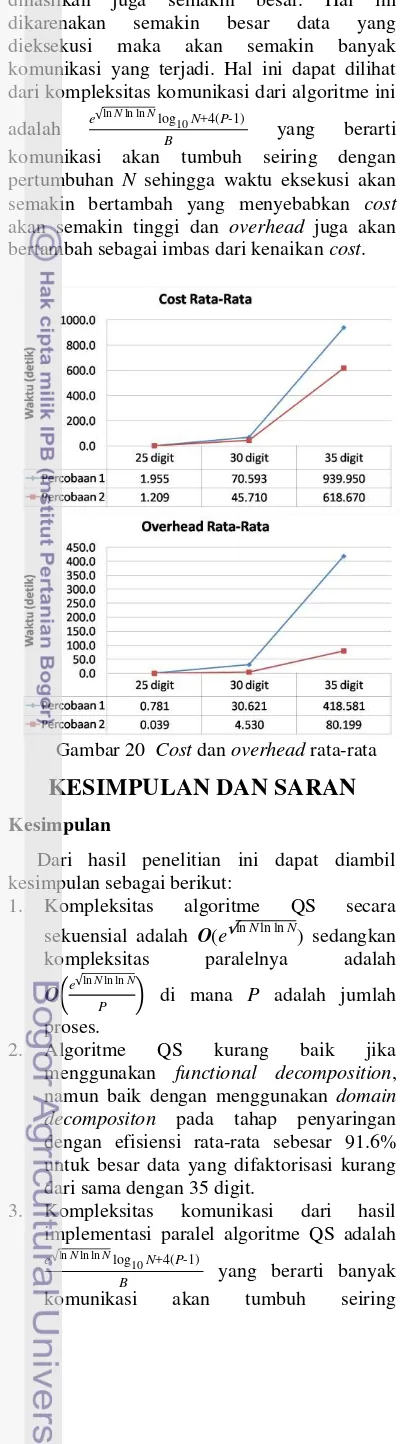
Cost dan Overhead
Hasil perhitungan cost dan overhead dari eksekusi data 25, 30, dan 35 digit dapat dilihat pada Gambar 17, 18, 19, dan 20.
Gambar 17 Cost dan overhead 25 digit
Gambar 18 Cost dan overhead 30 digit
Gambar 19 Cost dan overhead 35 digit
Cost adalah total keseluruhan waktu pada seluruh proses. Nilai cost yang baik adalah sama dengan waktu sekuensial. Sedangkan
overhead adalah selisih nilai cost dengan waktu sekuensial. Overhead merupakan bentuk kelebihan waktu total keseluruhan proses dalam paralel terhadap waktu sekuensialnya.
dihasilkan juga semakin besar. Hal ini dikarenakan semakin besar data yang dieksekusi maka akan semakin banyak komunikasi yang terjadi. Hal ini dapat dilihat dari kompleksitas komunikasi dari algoritme ini adalah e ln
Nln lnNlog
10N+4(P-1)
B yang berarti
komunikasi akan tumbuh seiring dengan pertumbuhan N sehingga waktu eksekusi akan semakin bertambah yang menyebabkan cost
akan semakin tinggi dan overhead juga akan bertambah sebagai imbas dari kenaikan cost.
Gambar 20 Cost dan overhead rata-rata
KESIMPULAN DAN SARAN
Kesimpulan
Dari hasil penelitian ini dapat diambil kesimpulan sebagai berikut:
1. Kompleksitas algoritme QS secara sekuensial adalah O(e lnNln lnN) sedangkan kompleksitas paralelnya adalah O e lnNln lnN
P di mana P adalah jumlah proses.
2. Algoritme QS kurang baik jika menggunakan functional decomposition, namun baik dengan menggunakan domain decompositon pada tahap penyaringan dengan efisiensi rata-rata sebesar 91.6% untuk besar data yang difaktorisasi kurang dari sama dengan 35 digit.
3. Kompleksitas komunikasi dari hasil implementasi paralel algoritme QS adalah e lnNln lnNlog10N+4(P-1)
B yang berarti banyak komunikasi akan tumbuh seiring
bertambahnya N sehingga menyebabkan nilai cost dan overhead akan semakin besar jika data semakin besar.
Saran
Saran untuk penelitian lebih lanjut:
1. Pada penelitian selanjutnya dapat dikembangkan menggunakan varian lain dari algoritme QS dalam memfaktorisasi bilangan besar yang memiliki waktu eksekusi jauh lebih cepat dibandingkan
basic QS seperti: MP-QS, large prime variation QS, dan lain sebagainya.
2. Pada penelitian selanjutnya dapat menggunakan library lain gabungan antara MPI dan GMP sehingga proses pengiriman data tidak perlu mengubah tipe data terlebih dahulu sehingga kompleksitasnya akan menurun dan waktu eksekusi menjadi lebih cepat.
3. Pada penelitian selanjutnya dapat dikembangkan pemrograman paralel pada algoritme QS menggunakan shared memory atau gabungan MPI dan shared memory.
DAFTAR PUSTAKA
Crandall R, Pemorance C. 2005. Prime Number a Computational Perspective. Ed ke-2. New York: Springer.
Grama A, Gupta A, Karypis G, Kumar V. 2003.
Introduction to Parallel Computing. Harlow: Addison-Wesley.
Guritman S. 2010. Faktorisasi dan Logaritme Diskret. Bogor: IPB Press.
Jordan H, Alaghband G. 2006. Fundamentals of Parallel Processing. New Jersey: Prentice Hall.
Junaedi F. 1997. Analisa algoritma Monte Carlo dalam rancangan kokoh [tesis].
Semarang: Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Diponegoro.
Leon SJ. 2001. Aljabar Linear dan Aplikasinya. Bondan A, penerjemah; Hardani HW, editor. Jakarta: Erlangga. Terjemahan dari:
Linear Algebra with Applications.
Quinn MJ. 2004. Parallel Programming in C with MPI and OpenMP. San Francisco: McGraw-Hill.
West AG. 2007. Bound optimization for parallel quadratic sieving using large prime variation [tesis]. Virginia: The Faculty of the Departement of Computer Science, Washington and Lee University.
Wilkinson B, Allen M. 2010. Parallel
Programming Teknik dan Aplikasi
Menggunakan Jaringan Workstation dan Komputer Paralel. Hidayat S, Santosa YB, Hery A, Himamunanto R, penerjemah. Yogyakarta: ANDI. Terjemahan dari:
Lampiran 1 Langkah-langkah penyelesaian kasus dan analisis algoritme QS.
Secara rinci kompleksitas algoritme sekuensial QS yang dibuat pada tulisan ini akan dijelaskan bersamaan dengan contoh menyelesaikan permasalahan dengan algoritme QS. Contoh: misalkan p = 47 dan q = 103 sehingga N = p x q yaitu 4841. Adapun langkah-langkah penyelesaian algoritme QS yaitu:
1. Inisialisasi.
Tetapkan B sebagai batas faktor basis dan menentukan barisan prima p sehingga N residu kuadrik terhadap p. �=
1
2 ln�ln ln� yaitu 8.4 lalu cari bilangan prima sesuai ketentuan yaitu seperti yang tertera pada Tabel 1.
p N (mod p) Residu Kuadrik
2 1 YA
3 2 TIDAK
5 1 YA
7 4 YA
Tabel 1 Hasil Pencarian Residu Kuadrik.
Sehingga faktor basis yang terbentuk adalah F={2,3,7}. Kompleksitas dari proses inisialisasi yaitu konstan pada menghitung B dan 3
1
2 ln�ln ln� untuk pencarian faktor basis. Pada tulisan ini kompleksitas yang dicantumkan adalah kompleksitas perkiraan sesuai yang terlihat oleh kasat mata. Pada kenyataannya kompleksitas mencari p, N (mod p), dan residu kuadrik berbeda-beda sesuai algoritme yang digunakan. Pada tulisan ini perkiraan kompleksitas inisialisasi yaitu k + 3
1
2 ln�ln ln� dimana k adalah konstan. 2. Penyaringan.
Saring barisan � =��2− � untuk �0= � sebanyak � + dimana c adalah konstan. Pada tulisan ini = 2. Pemilihan nilai 2 akan dijelaskan pada tahap selanjutnya. Sebenarnya nilai c dapat ditentukan sesuai kebutuhan, namun agar mempermudah pengertian terhadap algoritme ini nilai c dipilih 2, sehingga jumlah nilai � yang harus disaring adalah 5. Setelah ditemukan sejumlah yang ditentukan, pasangkan xi dengan �. Nilai � harus merupakan
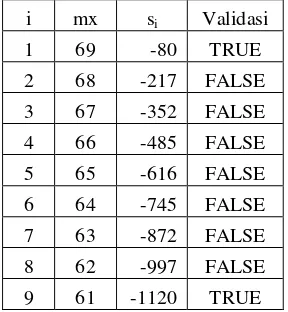
B-smooth yaitu faktor-faktor pembentuk � harus berada pada faktor basis. Contoh: 200 merupakan B-smooth karena faktor pembentuk 200 yaitu 23 x 52. Bilangan 2 dan 5 berada dalam faktor basis sehingga 200 termasuk B-smooth. Contoh berikutnya 488 bukan merupakan B-smooth karena faktor pembentuk 488 yaitu 23 x 61. Karena 61 bukan anggota dari faktor basis maka 488 bukan B-smooth. Adapun hasil dari penyaringan yaitu seperti yang tertera pada Tabel 2 dan Tabel 3.
i x si Validasi
1 70 59 FALSE
2 71 200 TRUE
3 72 343 TRUE
4 73 488 FALSE
5 74 635 FALSE
6 75 784 TRUE
Tabel 2 Hasil Pencarian si Positif.
i mx si Validasi
1 69 -80 TRUE
2 68 -217 FALSE
3 67 -352 FALSE
4 66 -485 FALSE
5 65 -616 FALSE
6 64 -745 FALSE
7 63 -872 FALSE
8 62 -997 FALSE
9 61 -1120 TRUE
Lampiran 1 Lanjutan
Pada tulisan ini cara mencari � yang B-smooth yaitu mencari 1 yang positif lalu 1 yang negatif. Karena hanya membutuhkan 5 buah � maka jumlah � yang dihasilkan yaitu 3 buah positif dan 2 buah negatif. Catatan pencarian � dapat dilakukan hanya dengan mencari yang positif saja atau negatif saja. Karena algoritme pendahulunya yaitu Metode Fermat hanya mencari ke satu arah dikarenakan jika mencari ke dua arah akan membuat pencarian lebih lama. Berbeda dengan Metode Fermat proses penyaringan ke satu arah pada algoritme QS akan membuat proses penyaringan lebih lama, karena semakin menjauhi � nilai � yang merupakan B-smooth akan semakin sulit ditemukan. Oleh sebab itu alangkah lebih baik proses penyaringan dilakukan ke dua arah. Pada kasus ini kita hanya perlu mencari 15 kali pencarian. Pada kasus terburuknya menurut Pomerance dan penelitian lainnya kita harus mencari sebanyak ln�ln ln� yaitu sebanyak 70 kali pencarian. Dalam kasus ini terlihat
ln�ln ln� seperti � namun sebenarnya pertumbuhan ln�ln ln� lebih lambat dibandingkan dengan �. Menurut hasil penurunan perhitungan jumlah dari � adalah sebanyak �
ln�. Proses validasi untuk mengecek � yang merupakan B-smooth menggunakan algoritme sebagai berikut:
a. Kalikan semua bilangan prima yang berada pada faktor basis dan simpan dalam suatu variabel misalkan T.
b. Untuk setiap � lakukan modulasi T (mod �) lalu kuadratkan. Lakukan sebanyak z kali. Jika menghasilkan 0 maka � adalah B-smooth dan sebaliknya (Crandall & Pomerance 2005).
Bilangan z adalah bilangan kecil yang merupakan turunan dari B. Bilangan z paling optimal saat ini jika menggunakan penyaringan kuadrik dasar adalah 6 untuk bilangan tertinggi yang layak difaktorisasi. Pada tulisan ini bilangan z yang dipakai adalah 4 karena N tertinggi yang difaktorisasi adalah berjumlah 35 digit. Akan tetapi untuk menghitung kompleksitas akan digunakan z = 6 sebagai bentuk kasus terburuk. Catatan untuk algoritme penyaring kuadrik yang lain z bisa lebih besar dari 6 karena nilai N yang difaktorisasi bisa jauh lebih besar dibandingkan dengan algoritme penyaring kuadrik dasar. Pada kenyataannya z tumbuh sesuai pertumbuhan N namun pertumbuhannya sangatlah lambat. Dengan demikian dapat disimpulkan kompleksitas penyaringan pada algoritme QS adalah
+2
1
2 ln�ln ln�
ln�ln ln�+ 3
ln�ln ln�+ 18 ln�ln ln�
= +2 1
2 ln�ln ln� ln�ln ln� + 21
ln�ln ln�
dimana k adalah segala bentuk perhitungan yang bersifat konstan atau tidak terpengaruh oleh pertumbuhan N.
3. Kalkulasi Aljabar Linear.
Dari hasil saringan pasangan xi dan � faktorkan � terhadap faktor basis dan buat matriks
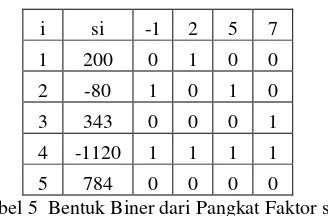
pangkat dari si. Pangkat dibutuhkan untuk untuk mencari bentuk kuadrat karena � =��2− � kongruen terhadap �=��2− � yang artinya N akan bisa diselesaikan jika � berbentuk kuadrat. Pada tahap ini akan dilakukan operasi perhitungan terhadap pangkat � sehingga mendapatkan � yang berbentuk kuadrat. Adapun hasil faktorisasi seperti yang tertera pada Tabel 4.
i si -1 2 5 7
1 200 0 3 2 0
2 -80 1 4 1 0
3 343 0 0 0 3
4 -1120 1 5 1 1
5 784 0 4 0 2
Lampiran 1 Lanjutan
Untuk mendapatkan bentuk kuadrat, setiap faktor � haruslah berpangkat genap. Dalam proses mengalikan 2 buah � yang terjadi adalah proses penjumlahan pangkat dari setiap faktor � tersebut. Pada proses penjumlahan terdapat tiga kondisi yaitu: pertama ganjil ditambah ganjil = genap, kedua ganjil ditambah genap adalah ganjil, dan terakhir genap ditambah genap adalah genap. Jika diperhatikan secara seksama proses penjumlahan pangkat ini sama dengan proses XOR pada bilangan biner dimana ganjil = 1 dan genap = 0. Dalam tahap ini yang dibutuhkan adalah � berbentuk kuadrat dan tidak memerhatikan pangkat dari � tersebut. Oleh karena itu untuk memudahkan proses pembentukan � yang kuadrat alangkah lebih mudah pangkat dari faktor-faktor � tersebut diubah ke dalam bentuk biner. Adapun bentuk biner dari pangkat faktor-faktor � dapat dilihat pada Tabel 5. Setelah mendapatkan matriks biner lakukan kalkulasi aljabar linear biner untuk mendapatkan vektor-vektor yang bergantung linear. Vektor bergantung linear seperti definisinya pada tinjauan pustaka yaitu vektor yang memiliki pengali konstanta tak 0 dan menghasilkan vektor 0. Vektor 0 dalam biner yaitu suatu vektor yang semua anggotanya 0. Jika vektor 0 diibaratkan sebagai pangkat dari faktor-faktor
�, vektor 0 adalah bentuk pangkat kuadrat dari �.
i si -1 2 5 7
1 200 0 1 0 0
2 -80 1 0 1 0
3 343 0 0 0 1
4 -1120 1 1 1 1
5 784 0 0 0 0
Tabel 5 Bentuk Biner dari Pangkat Faktor si.
Mungkin akan timbul pertanyaan "mengapa harus yang bergantung linear?" Seperti definisinya bergantung linear yaitu ada pengali tak 0 terhadap suatu vektor sehingga menghasilkan vektor 0. Dalam biner tak 0 berarti 1 yang artinya vektor bersangkutan adalah vektor yang membentuk vektor 0. Untuk lebih jelasnya mengenai bergantung linear akan dibahas dalam hasil operasi aljabar linear biner. Operasi aljabar linear biner yang dilakukan dalam tulisan ini dipaparkan dalam algoritme sebagai berikut
a. Pasangkan matriks pangkat dengan matriks identitas sejumlah i. b. Lakukan operasi baris dasar sebagai berikut:
1. Pilih satu paling kiri dari matriks pangkat.
2. Pindahkan baris tersebut bersama dengan baris matriks identitas kebarisan paling atas.
3. Lakukan operasi XOR pada matriks pangkat dan identitas pada baris yang memiliki kedudukan 1 yang sama dengan yang dipilih langkah 1.
4. Ulangi langkah pertama dengan matriks baru yaitu matriks dibawah baris yang terpilih.
5. Lakukan hingga 1 yang paling kanan.
Adapun ilustrasi langkah-langkah operasi baris dasar pada matriks biner adalah sebagai berikut:
1. Pasangkan matriks biner dan identitas sebagai berikut identitas i1 i2 i3 i4 i5
0 1 0 0 1 0 0 0 0
1 0 1 0 0 1 0 0 0
0 0 0 1 0 0 1 0 0
1 1 1 1 0 0 0 1 0
Lampiran 1 Lanjutan
2. Lakukan operasi baris dasar sebagai berikut pilih baris ke 2, pindahkan ke baris pertama, lalu lakukan operasi XOR pada baris ke 4 menggunakan baris tersebut. Sehingga hasilnya adalah
identitas i1 i2 i3 i4 i5
1 0 1 0 0 1 0 0 0
0 1 0 0 1 0 0 0 0
0 0 0 1 0 0 1 0 0
0 1 0 1 0 1 0 1 0
0 0 0 0 0 0 0 0 1
3. Selanjutnya pilih baris ke 2 dan lakukan operasi XOR pada baris ke 4 menggunakan baris tersebut. Hasil dari operasi baris dasar tersebut adalah
identitas i1 i2 i3 i4 i5
1 0 1 0 0 1 0 0 0
0 1 0 0 1 0 0 0 0
0 0 0 1 0 0 1 0 0
0 0 0 1 1 1 0 1 0
0 0 0 0 0 0 0 0 1
4. Selanjutnya pilih baris ke 3 dan lakukan operasi XOR pada baris ke 4 menggunakan baris tersebut. Hasil dari operasi baris dasar tersebut adalah
identitas i1 i2 i3 i4 i5
1 0 1 0 0 1 0 0 0
0 1 0 0 1 0 0 0 0
0 0 0 1 0 0 1 0 0
0 0 0 0 1 1 1 1 0
0 0 0 0 0 0 0 0 1
5. Karena sudah mencapai 1 yang paling kanan hentikan operasi baris dasar.
Dari hasil aljabar tersebut yang dimaksud vektor 0 adalah 2 baris terakhir pada matriks pangkat pada hasil akhir operasi baris dasar pada matriks biner. Sedangkan konstanta tak 0 pembentuk vektor 0 adalah 2 baris terakhir pada matriks identitas. Vektor-vektor bergantung linear yang dimaksud yaitu vektor-vektor pembentuk vektor 0 yang memiliki nilai 1. Contoh: pada baris ke 4 1 1+ 1 2+ 1 3+ 1 4+ 0 5=� yang artinya 1, 2, 3, dan 4 saling bergantung linear dimana c1=1, c2=1, c3=1, c4=1, dan c5=0. Disini terjawab mengapa c=2 saat
penyaringan yaitu untuk mendapatkan minimal 1 pasang vektor yang bergantung linear sehingga setidaknya ada 1 vektor 0 sebagai bentuk kuadrat dari �. Kompleksitas dari setiap faktorisasi � pada kasus terburuknya adalah 2x+1 dimana x terburuk pada algoritme ini adalah 6. Pada kasus terburuknya setiap faktorisasi � adalah 128 kali pembagian. Proses perubahan ke biner tidak memiliki kompleksitas karena pada kenyataannya pangkat langsung diubah ke biner saat perhitungan agar lebih cepat. Kompleksitas aljabar linear biner adalah + 2 � ( � −1)/2 + � = k + |�|2 sehingga secara keseluruhan kompleksitas dari tahap kalkulasi aljabar linear adalah
+256 1
2 ln�ln ln� ln�ln ln� +
Lampiran 1 Lanjutan 4. Faktorisasi.
Ambil salah satu pasang vektor yang bergantung linear. Kalikan semua xi yang merupakan
pembentuk vektor 0 atau yang memiliki ci=1 dan simpan dalam variabel X. Lakukan hal yang
sama terhadap � namun sebelum disimpan dalam suatu variable akarkan hasil perkalian tersebut dan simpan dalam variabel Y. Lakukan operasi p=GCD(X-Y,N). Jika 1< p < N, p adalah faktor dari N. Jika p = 1 atau p = N berarti faktorisasi gagal dan cari pasangan yang lain. GCD adalah fungsi mencari faktor persekutuan terbesar atau yang lebih dikenal dengan FPB. Adapun langkah algoritme GCD(A,B) yang dimaksud adalah
a. A = A (mod B) b. Tukar A dan B
c. Ulangi dari langkah a hingga nilai B bernilai 0 yang berarti A adalah hasil GCD(A,B). Catatan kegagalan pada tahap faktorisasi sering kali terjadi karena lupa mengakarkan hasil perkalian � sebelum disimpan dalam variabel Y. Pada contoh kasus dalam tulisan ini jika diambil baris ke-empat dari hasil akhir operasi baris dasar pada matriks biner hasilnya adalah p = GCD(21516408-78400,4841) = 103 untuk mencari faktor lainnya cukup dengan membagi N dengan p yaitu 47. Jika yang diambil adalah baris ke-lima dari hasil akhir operasi baris dasar pada matriks biner hasilnya adalah p = GCD(75-28,4841) = 47 yang hasilnya kebetulan berlawanan dengan baris ke-empat. Adapun kompleksitas dari tahap ini adalah 2 � yaitu proses pembentukan Y dan X. Untuk proses GCD dan lainnya dianggap konstan karena hanya melakukan sedikit perhitungan. Sehingga kompleksitas tahap ini adalah
+4
1
2 ln�ln ln� ln�ln ln� .
Dengan demikian dapat disimpulkan kompleksitas total dari algoritme penyaring kuadrik dasar dalam tulisan ini adalah
+ 3 1
2 ln�ln ln�+2 1
2 ln�ln ln� ln�ln ln� + 21
ln�ln ln�+256 1
2 ln�ln ln� ln�ln ln� +
4 ln�ln ln� ln�ln ln� +
4 1
2 ln�ln ln� ln�ln ln� .
= +262 1
2 ln�ln ln� ln�ln ln� + 3
1
2 ln�ln ln�+4
ln�ln ln�
ln�ln ln� + 21
ln�ln ln�.
Lampiran 2 Penurunan fungsi waktu eksekusi algoritme QS
Dalam memilih B yang optimal sehingga waktu eksekusi akan minimum, fakta pertama yang cukup relevan adalah probabilitas sukses bahwa suatu anggota dalam ℤ� merupakan B-smooth adalah sekitar
�−� dengan �=ln�
ln�
Sebagai ilutrasi, jika N = 600377819 dan B = 100, maka peluang intejer acak dalam ℤ� merupakan B-smooth sekitar 1.5159 x 10-3. Jika penentuan barisan pelacakan megunakan Metode Fermat (�1= � ), maka peluang sukses bahwa s adalah B-smooth menjadi lebih baik, yaitu sekitar
�−� dengan �=12ln� ln�
Perlu diingat pula bahwa dengan pelacakaan ini, penghitung s cukup dengan = �2− � dan positif.
Sekarang, jika diberikan suatu nilai B, seberapa cepat waktu yang diperlukan untuk menguji bahwa satu adalah B-smooth untuk suatu nilai x? Pertanyaan ini perlu mendapat perhatian karena peluang sukses bahwa adalah B-smooth cukup kecil sehingga uji tersebut akan dilakukan berulang-ulang. Metode termudah yang terkait dengan pertanyaan tersebut adalah trial division
(dengan representasi TDA). Metode tercepat adalah dengan Penyaringan Eratosthenes yang hanya melibatkan (ln ln�) operasi, namun metode ini memerlukan memori besar.
Dalam penyaringan Kraitchik dan Dixon dipilih F adalah himpunan semua prima ≤ �, berarti � = � (�) merupakan banyaknya semua prima kurang atau sama dengan �. Sebagaimana dinyatakan sebelumnya bahwa nilai � terkait banyaknya vektor biner bergantung linear yang diperlukan. Jadi nilai � yang kecil akan mempercepat proses penyaringan. Berikut ini diberikan suatu ide dasar untuk memperkecil nilai � . Jika p adalah prima yang membagi
= �2− �, maka
�2≡ � ( )
Ini berarti � merupakan residu kuadratik modulo (Bilangan Legendre � = 1). Dengan demikan, prima ≤ � yang menyebabkan � bukan residu kuadratik modulo tidak layak untuk dijadikan anggota �. Jadi, � selayaknya didefinisikan sebagai
�= / � �, ≤ �, � = 1
Maka berdasarkan suatu proposisi yang berbunyi "Misalkan prima ganjil, maka sebanyak −1 2 (separuh) anggota ℤ adalah residu kuadratik dan separuh sisanya −1
2 adalah nonresidu kuadratik." Sekarang � ~�( )
2 ~
�
ln� (berkurang setengahnya).
Akhirnya, bagaimana menentukan nilai B yang terbaik? Perhatikan bahwa karena probabilitas untuk satu s merupakan B-smooth adalah �−�, harapan sukses untuk mendapat satu s yang B -smooth adalah ��. Dengan demikian, harapan sukses untuk mendapatkan s yang B-smooth sebanyak ( � + 1) adalah melibatkan langkah (operasi) sebanyak
�� � + 1 =�� �( )
2 + 1
Jika pengujian s adalah B-smooth diasumsikan menggunakan Metode Penyaringan
Eratosthenes dan pelacakanya menggunakan Metode Fermat, maka total langkah yang diperlukan bisa dinyatakan sebagai fungsi
(�) =�� �
2 + 1 (ln ln�), dengan �= ln� 2 ln�
~�� �
ln�+ 1 (ln ln�), dengan �=
Lampiran 2 Lanjutan
Dari pendefinisian fungsi ini, akan dicari (dengan pendekatan) nilai B sebagai fungsi dari N
yang meminimalkan (�). Untuk penyederhanaan didefinisikan
� = � ~ � � + ln�
sehingga
�=�
1
� � � +
� �ln� +
1
�
= �
� 1 + ln� +
1
�
Kemudian, dicari bilangan kritisnya diperoleh dari persamaan
�= 0⇔
�
� 1 + ln� +
1
�= 0
Karena
�
�= �
1
2ln� ln�
−1= −ln� 2� ln� 2
dan
ln�= ln ln�
2 ln� = ln ln� −ln ln� −ln 2 maka persamaannya menjadi
ln�
2� ln� 2 ln ln� −ln ln� −ln 2 + 1 = 1
�
2 ln� 2= ln ln� −ln ln� −ln 2 + 1
Dengan pendekatan selanjutnya diperoleh ln�~1
2 ln�ln ln�
sehingga
�~ ln�ln ln� 1 2
⇔ �2~ ln�ln ln�
Dari hasil ini menunjukan bahwa estimasi running time adalah (�)~ ln�ln ln�
ketika dipilih nilai B adalah
�~ (�)
Hasil tersebut mengabaikan proses aljabar linearnya. Dengan asumsi validitas dari semua lompatan heuristik dibuat, kita telah menggambarkan suatu algoritme deterministik untuk pemfaktoran komposit ganjil bukan berpangkat dengan waktu eksekusi
(�)1+ (�)
Lampiran 3 Hasil percobaan Jenis Percobaan
Jumlah Digit
Waktu Eksekusi Program (detik) 1 proses 2 proses 3 proses 4 proses
1 25
1.170 1.192 0.614 0.416
1.156 1.157 0.640 0.403
1.164 1.203 0.633 0.410
1.158 1.162 0.621 0.407
1.221 1.188 0.601 0.412
waktu rata-rata 1.174 1.180 0.622 0.410
speed up 0.994 1.888 2.866
efisiensi 0.497 0.629 0.716
cost 2.361 1.865 1.638
overhead 1.187 0.692 0.465
Jenis Percobaan
Jumlah Digit
Waktu Eksekusi Program (detik) 1 proses 2 proses 3 proses 4 proses
1 30
39.995 41.369 21.843 15.868 39.975 41.436 22.248 15.760 39.951 41.030 22.068 15.930 39.949 41.101 22.222 15.671 39.987 41.057 22.091 15.643 waktu rata-rata 39.971 41.199 22.094 15.774
speed up 0.970 1.809 2.534
efisiensi 0.485 0.603 0.633
cost 82.397 66.283 63.098
overhead 42.426 26.312 23.126
Jenis Percobaan
Jumlah Digit
Waktu Eksekusi Program (detik) 1 proses 2 proses 3 proses 4 proses
1 35
521.248 536.037 278.788 226.518 521.176 538.656 277.951 228.246 520.931 540.544 278.804 226.060 522.243 539.277 278.296 226.977 521.245 538.013 276.916 227.681 waktu rata-rata 521.369 538.505 278.151 227.096
speed up 0.968 1.874 2.296
efisiensi 0.484 0.625 0.574
cost 1077.011 834.453 908.386
Lampiran 3 Lanjutan Jenis Percobaan
Jumlah Digit
Waktu Eksekusi Program (detik) 1 proses 2 proses 3 proses
2 25
1.178 0.602 0.407
1.148 0.625 0.395
1.195 0.624 0.400
1.153 0.607 0.398
1.179 0.586 0.401
waktu rata-rata 1.171 0.609 0.400
speed up 1.923 2.925
efisiensi 0.961 0.975
cost 1.218 1.201
overhead 0.047 0.030
Jenis Percobaan
Jumlah Digit
Waktu Eksekusi Program (detik) 1 proses 2 proses 3 proses
2 30
41.352 21.827 15.852 41.410 22.232 15.743 41.014 22.052 15.905 41.084 22.206 15.655 41.042 22.062 15.626 waktu rata-rata 41.180 22.076 15.756
speed up 1.865 2.614
efisiensi 0.933 0.871
cost 44.152 47.269
overhead 2.971 6.088
Jenis Percobaan
Jumlah Digit
Waktu Eksekusi Program (detik) 1 proses 2 proses 3 proses
2 35
535.984 278.726 226.490 538.627 277.924 228.212 540.515 278.777 225.923 539.242 278.248 226.949 537.984 276.888 227.616 waktu rata-rata 538.470 278.113 227.038
speed up 1.936 2.372
efisiensi 0.968 0.791
cost 556.225 681.114
overhead 17.755 142.644
Keterangan