PENGEMBANGAN SISTEM PENGECEKAN FORMAT
SKRIPSI DAN EJAAN BAHASA INDONESIA
OTRI DELVI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
OTRI DELVI. System Development for checking thesis format and Indonesian spelling. Supervised by MUSHTHOFA.
One of the requirements for an undergraduate degree at Bogor Agricultural University is that every student is required to write the thesis of in a form scientific paper using a predefined format. Currently, Bogor Agricultural University designed a new format of thesis writing. A system is needed to provide a thesis template and check the thesis according to the defined format to simplify the task of the student in writing the thesis and to ease the burden of the lecturers in examining the students writing. This research creates a Microsoft Office Word add-in that has three main functions: Generate New Thesis Template, Spell Checking, and Format Check. The Generate New Template function can give a new example of a thesis, user can add their need to write on the template’s file. The Spell Checking process uses Kamus Besar Bahasa Indonesia database to check the spelling of the thesis. The system marks any spelling or format error using the Microsoft Office Word comments. After that, the user can choose to correct or ignore the comments. This add-in application has two advantages, firstly it can simplify and shorten the student’s time for checking the format and spelling; secondly it can ease the burden of the lecturer in examining the students writing. The running time for the Spell Checking process is 20.08 seconds for 5000 words of thesis, and the Format Checking is 1.16 seconds for 20 pages of thesis.
PENGEMBANGAN SISTEM PENGECEKAN FORMAT
SKRIPSI DAN EJAAN BAHASA INDONESIA
OTRI DELVI
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul Skripsi : Pengembangan Sistem Pengecekan Format Skripsi dan Ejaan Bahasa Indonesia Nama : Otri Delvi
NIM : G64070086
Menyetujui: Pembimbing,
Mushthofa, S.Kom, M.Sc NIP. 19820325 300912 1 003
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Agus Buono, M.Si, M.Kom NIP. 19660702 199302 1 001
RIWAYAT HIDUP
Penulis dilahirkan di Lintau Buo, Sumatera Barat pada tanggal 12 Oktober 1989 dari pasangan Bapak Yufrizal dan Ibu Arnida. Penulis adalah putra pertama dari tiga bersaudara. Penulis lulus dari Sekolah Menengah Atas (SMA) Negeri 1 Padang Panjang pada tahun 2007 dan pada tahun yang sama diterima sebagai mahasiswa Institut Pertanian Bogor melalui jalur Seleksi Penerimaan Mahasiswa Baru (SPMB).
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhanahu wa-ta'ala atas segala karunia-Nya sehingga skripsi ini dapat diselesaikan. Skripsi yang berjudul Pengembangan Sistem Pengecekan Format Skripsi dan Ejaan Bahasa Indonesia ini merupakan penelitian yang dilakukan oleh penulis dari bulan September 2011 sampai bulan Juli 2012.
Penulis mengucapkan terima kasih kepada Bapak Mushthofa, S.Kom, M.Sc sebagai pembimbing yang telah memberi saran, masukan, dan ide-ide kepada penulis dalam menyusun skripsi ini. Penulis juga mengucapkan terima kasih kepada seluruh staf pengajar Departemen Ilmu Komputer atas ilmu yang telah diberikan, serta tidak lupa kepada staf tata usaha yang membantu administrasi selama kuliah di Institut Pertanian Bogor.
Ungkapan terima kasih juga disampaikan kepada ayah, ibu, serta seluruh keluarga atas doa dan kasih sayang dan semangat yang terus diberikan kepada penulis. Begitu juga kepada Rina yang selalu senantiasa memberi semangat kepada penulis dalam menyelesaikan skripsi ini, kemudian kepada Vai, Gamma, Mustafa, Yanta, Aco, Bangun, Rilan, Ridwan, Rifqi, Sayed, Kaka dan seluruh teman-teman Ilmu Komputer 44 atas bantuan, semangat, motivasi dan kebersamaannya selama penyusunan skripsi ini.
Semoga penelitian ini dapat memberikan manfaat kepada pembaca sebagai referensi penelitian lanjutan dan pengembangan ilmu pengetahuan.
Bogor, September 2012
v
DAFTAR ISI
Halaman
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
Manfaat Penelitian ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA Visual Studio Tools for Office (VSTO) ... 2
Model Objek Office ... 2
Model Objek Word ... 2
Regular Expression (RegEx) ... 2
Levenshtein Distance ... 3
Stemming ... 3
METODE PENELITIAN Studi Pustaka ... 4
Perancangan Template Skripsi ... 4
Perancangan Pengecekan Ejaan Penulisan Skripsi ... 4
Perancangan Pengecekan Format Penulisan Skripsi ... 5
Pengembangan ... 6
Pengujian dan Evaluasi ... 6
HASIL DAN PEMBAHASAN Analisis Kebutuhan dan Batasan Sistem ... 6
Lingkungan Pengembangan Sistem ... 6
Pengembangan Sistem... 7
Fungsi Generate Template Skripsi ... 7
Pemeriksaan Ejaan Bahasa Indonesia ... 7
Fungsi Pengecekan Format Skripsi ... 7
Implementasi Regular Expression dan Levenshtein Distance pada Sistem ... 8
Perancangan Antarmuka... 9
Pengujian dan Evaluasi ... 10
Persyaratan Minimum Sistem ... 11
Kekurangan Sistem ... 11
KESIMPULAN ... 12
SARAN ... 12
DAFTAR PUSTAKA ... 12
vi
DAFTAR TABEL
Halaman
1 Aturan section ... 5
2 Contoh pola string daftar pustaka ... 8
3 Indikator string peubah ... 9
4 Aturan string pattern daftar pustaka ... 9
5 Daftar pengujian black box pada sistem ... 10
6 Hasil pengecekan format dengan metode Black box testing ... 11
7 Hasil pengujian waktu pengecekan ejaan skripsi ... 11
8 Hasil pengujian tingkat keberhasilan sistem ... 11
DAFTAR GAMBAR
Halaman 1 Hierarki model objek. ... 22 Tahapan penelitian. ... 4
3 Flowchart pengecekan ejaan bahasa Indonesia. ... 4
4 Grafik waktu pengecekan ejaan bahasa Indonesia. ... 7
5 Grafik waktu pengecekan format skripsi. ... 8
6 Antarmuka add-in sistem pengecekan skripsi. ... 10
7 Form progress bar pada saat pengecekan ejaan. ... 10
8 Komentar kesalahan pada pengecekan ejaan bahasa Indonesia. ... 10
9 Komentar kesalahan pada pengecekan format skripsi. ... 10
10 Form masukan kata pada Ignore Words. ... 10
DAFTAR LAMPIRAN
Halaman 1 Rancangan ketentuan penulisan skripsi dengan format baru... 142 Datar pengecekan pada tiap section... 16
3 Hasil pengujian pengecekan ejaan... 21
4 Daftar string Regular Expression pengecekan daftar pustaka ... 20
5 Hasil pengujian pengecekan format ... 22
PENDAHULUAN
Latar Belakang
Skripsi atau tugas akhir merupakan salah satu kewajiban bagi setiap mahasiswa jenjang pendidikan sarjana sebagai persyaratan akademis untuk mendapatkan gelar sarjana (S1). Tugas akhir disusun dalam sebuah laporan berbentuk karya ilmiah. Institut Pertanian Bogor (IPB) memiliki format tertentu dalam penulisan skripsi.
Masalah kesalahan-kesalahan dalam penulisan format skripsi dan ejaan merupakan kendala yang sering terjadi selama proses penulisan skripsi. Dosen dan mahasiswa harus memeriksa ulang skripsi untuk mencari letak kesalahan format dan penulisan pada laporan tugas akhir secara manual. Proses pemeriksaan secara manual ini tentunya akan menyita banyak waktu, sehingga proses penulisan skripsi menjadi lama.
Salah satu aplikasi yang digunakan dalam menulis skripsi ialah Microsoft Office Word. Sebelumnya sudah dibangun sebuah sistem pengecekan format skripsi oleh Olimpiyanto (2011) dalam bentuk sebuah add-in pada Microsoft Office Word 2007 yang memiliki fungsi pemeriksaan format penulisan dan fungsi pemeriksaan ejaan pada dokumen skripsi.
Fungsi pengecekan ejaan pada sistem tersebut menggunakan fungsi spell checker Microsoft Office 2007 dengan tambahan kamus Bahasa Indonesia dari aplikasi StarDict. Tidak semua kata pada dokumen diperiksa, hanya kata-kata yang masuk dalam spelling error Microsoft Office Word saja. Dengan demikian kata-kata dalam bahasa asing yang tidak disalahkan dalam spelling error akan dianggap benar. Waktu pengecekan pada sistem ini juga masih lama.
Untuk pemeriksaan ejaan bahasa Indonesia yang baik diperlukan stemming pada kata-kata yang akan diperiksa. Nazief dan Andriani telah membuat sebuah algoritme stemming untuk pengecekan ejaan dalam bahasa Indonesia dengan hasil yang sangat baik (Asian 2007). Algoritme ini dapat digunakan sebagai langkah pendukung dalam memperbaiki metode pengecekan ejaan yang sebelumnya.
Fungsi pemeriksaan format skripsi pada sistem sebelumnya hanya terbatas pada format aturan penulisan Departemen Ilmu Komputer IPB. Pada saat ini telah dirancang sebuah
aturan format penulisan skripsi yang baru. Format penulisan ini akan dipakai secara menyeluruh di Institut Pertanian Bogor. Oleh karena itu fungsi pengecekan format yang dibangun oleh sistem sebelumnya tidak bisa digunakan lagi.
Oleh karena itu, perlu dikembangkan sebuah sistem pengecekan bahasa indonesia yang mampu mengatasi permasalahan di atas dan juga melakukan pengecekan format dan penulisan skripsi Institut Pertanian Bogor yang sesuai dengan aturan format yang baru (2012).
Tujuan
Tujuan penelitian ini yaitu:
1 Mengimplementasikan sebuah sistem pengecekan format skripsi sesuai dengan aturan format IPB yang baru (2012).
2 Memperbaiki metode pengecekan ejaan bahasa Indonesia yang telah diimplementasikan sebelumnya dengan menggunakan KBBI sebagai acuan kata-kata yang baku dan stemming menggunakan algoritme Nazief dan Andriani.
3 Mengukur efisiensi waktu pada sistem yang dibangun dalam melakukan proses pengecekan format dan ejaan.
Manfaat Penelitian
Penelitian ini diharapkan dapat bermanfaat bagi mahasiswa dalam memeriksa skripsi sesuai dengan format yang berlaku dan ejaan yang benar serta juga meringankan beban dosen dalam memeriksa tulisan mahasiswa Institut Pertanian Bogor.
Ruang Lingkup
Ruang lingkup penelitian ini yaitu:
1 Format penulisan skripsi yang digunakan merupakan format skripsi Institut Pertanian Bogor rancangan tahun 2012.
2 Sistem diimplementasikan dalam add-in Microsoft Office Word 2007 dan 2010.
3 Pengecekan ejaan hanya dilakukan untuk bahasa Indonesia.
TINJAUAN PUSTAKA
Visual Studio Tools for Office (VSTO)
Visual Studio Tools for Office (VSTO) merupakan sebuah fungsi tambahan pada Visual Studio yang digunakan untuk memanfaatkan kekuatan dan fungsionalitas teknologi Microsoft Office. Pada intinya, VSTO hanyalah sebuah platform yang memungkinkan dokumen Microsoft Office untuk mengeksekusi kode yang ada pada pemrograman .NET. Hal ini bukan berarti bahwa teknologi VSTO satu-satunya media yang tersedia untuk mengembangkan aplikasi berbasis Microsoft Office. VSTO telah dirancang untuk membuat aplikasi tersebut lebih mudah dan lebih handal daripada pendekatan yang tersedia (Bruney 2006).
VSTO menambahkan dukungan .NET untuk pemrograman Word, Excel, Outlook dan InfoPath untuk Visual Studio. VSTO mengubah dokumen Word atau Excel menjadi sebuah kelas .NET (.NET class) penuh dengan data pendukung yang mengikat, kontrol yang dapat dikodekan seperti Windows Forms Control, dan keistimewaan .NET lainnya. Hal ini memungkinkan pengembang untuk menempatkan kode .NET di dalam bentuk InfoPath. Pengembang bahkan dapat memprogram kunci objek Office tanpa harus melalui seluruh model objek Office (Carter & Lippert 2005).
Model Objek Office
Hampir semua program Office melibatkan penulisan kode yang menggunakan model objek dari aplikasi Office. Model Objek Office adalah sekumpulan objek yang disediakan aplikasi Office yang dapat digunakan untuk mengontrol aplikasi Office. Model objek memiliki tingkatan pengaksesan. Model objek yang disediakan bergantung dari jenis aplikasi Office yang digunakan.
Tiap model objek aplikasi Office terdiri atas banyak objek yang digunakan untuk mengontrol aplikasi Office. Word memiliki 248 objek yang berbeda, Excel 196 objek, dan Outlook sebanyak 67 objek. Objek yang paling penting dan paling sering digunakan dalam model objek adalah sesuatu yang sesuai dengan aplikasi itu sendiri, dokumen, dan elemen kunci dalam dokumen seperti berbagai teks di Word. Sebagai contoh, Gambar 1 merupakan hierarki sederhana model objek yang ada pada Word (Carter & Lippert 2005).
Model Objek Word
Langkah pertama dalam mempelajari model objek Word ialah dengan mendapatkan ide-ide dari struktur dasar hierarki model objek (Gambar 1). Objek Application digunakan untuk mengakses pengaturan dan opsi application-level. Application merupakan akar dari objek model dan menyediakan akses ke objek lain dalam model objek. Objek Document merupakan sebuah Word dokumen. Objek Paragraph memungkinkan pengembang untuk mengakses sebuah paragraf dalam dokumen Word. Objek Range merupakan sebuah barisan dari text yang berada pada dokumen. Objek Shape merupakan sebuah gambar, grafik atau objek lain yang ada pada dokumen Word (Carter & Lippert 2005).
Regular Expression (RegEx)
Regular Expression atau sering dikenal dengan istilah RegEx adalah sebuah fungsi yang menggambarkan pola-pola karakter dalam string, deskripsi karakter berulang, penggantian, dan pengelompokan karakter. RegEx dapat digunakan untuk mencari dan mengubah string (McMillan 2007).
RegEx sendiri merupakan pola string yang ingin dicari pada string lain. RegEx juga menggunakan pola karakter khusus atau dikenal dengan istilah metacharacters. Metacharacters digunakan untuk menandakan pengulangan, penggantian atau pengelompokan. RegEx juga didukung oleh pola substitusi, set karakter, quantifier, dan lainnya.
Regular Expression atau RegEx pada sistem ini digunakan pada proses stemming pada fungsi pengecekan ejaan bahasa Indonesia. Syntax yang digunakan dalam RegEx menggunakan syntax yang sederhana dari set karakter, pernyataan posisi, dan quantifier.
Gambar 1 Hierarki model objek.
1 2 3 4 5 6
T = m e - - r i
S = m e m o r i
Regex memiliki syntax yang terdiri dari delimiter, pattern, dan modifier. Delimiter digunakan untuk menentukan tempat pattern berawal dan berakhir. Pada Javascript, hanya bisa digunakan sebagai delimiter. Pattern adalah pola string yang ingin ditemukan atau dicocokkan. Modifier adalah mode RegEx meng-handle hasil pencarian string atau teks.
Levenshtein Distance
Levenshtein distance digunakan untuk mengukur kesamaan atau kemiripan antara dua buah kata. Jarak Levenshtein diperoleh dengan mencari cara termudah untuk mengubah suatu string. Secara umum, operasi yang diperbolehkan untuk keperluan ini ialah:
memasukkan karakter ke dalam string,
menghapus sebuah karakter dari suatu string,
mengganti karakter string dengan karakter lain (Manning et al. 2008).
Operasi perhitungan dua string meliputi tiga operasi string seperti di bawah ini. Untuk contoh yang digunakan, diasumsikan S adalah string sumber pencarian dan T adalah string yang ingin dicari.
1 Operasi penghapusan
Misalnya S = memori dan T = meri. Penghapusan dilakukan untuk karakter m pada lokasi ke-3 dan o pada lokasi ke-4. Dua operasi penghapusan tersebut menunjukkan transformasi S ke T yang diilustrasikan sebagai berikut.
2 Operasi penyisipan
Misalnya S = brian dan T = barisan. Operasi penyisipan dilakukan dengan menyisipkan a dan s pada posisi 2 dan 5 yang dapat ditunjukkan sebagai berikut.
3 Operasi Penggantian
Misalnya S = perasa dan T = pewara. String T ditransformasikan menjadi S dengan melakukan penggantian (substitusi) pada posisi ke-3 dan ke-5. Huruf r dan s pada S digantikan dengan w dan r pada T. Prosesnya
dapat ditunjukkan sebagai berikut.
Nilai jarak Levenshtein dapat dihitung dari jumlah operasi perhitungan string yang digunakan untuk menghitung jarak kedua string yang dibandingkan. Kemudian, untuk menghitung nilai kemiripan digunakan rumus:
Sim = 1 – ( Dis / MaxLegth)
Sim = Similarity atau nilai kemiripan Dis = jarak Levenshtein
MaxLength = nilai jarak terpanjang.
Rentang nilai similarity berkisar dari 0 sampai 1. Semakin besar nilai similarity, semakin tinggi juga kemiripan antara kedua string tersebut.
Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem Information Retrieval (IR) yang mentransformasikan kata-kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu. Sebagai contoh, kata bersama, kebersamaan, dan menyamai akan ditransformasikan ke akar katanya yaitu “sama”. Proses stemming pada teks berbahasa Indonesia berbeda dengan stemming pada teks berbahasa Inggris. Pada teks berbahasa Inggris, proses yang diperlukan hanya proses menghilangkan sufiks, sedangkan pada teks berbahasa Indonesia, selain sufiks, prefiks dan konfiks juga dihilangkan (Agusta 2009).
Prefiks (awalan) adalah afiks (imbuhan) yang ditempatkan di bagian muka dasar (mungkin kata dasar atau kata kompleks atau jadian), contohnya: ber-, di-, ke-, me-, meng-, mem-, meny-, pe-, pem-, peng-, peny-, per-, se-, dan ter-. Sufiks (akhiran) adalah morfem terikat yang digunakan di bagian belakang kata atau dilekatkan pada akhir dasar, contohnya: an, kan, i, pun, lah, kah, dan -nya. Konfiks adalah gabungan prefiks dan sufiks yang dilekatkan sekaligus pada awal dan akhir dasar, contoh : ke - an, ber - an, pe - an, peng - an, peny - an, pem - an, per - an, dan se - nya.
METODE PENELITIAN
Secara umum, metode penelitian yang dilakukan terdiri atas beberapa tahap. Tahapan-tahapan ini terlihat pada Gambar 2.
Studi Pustaka
Pada tahap ini dilakukan pembelajaran mengenai kasus atau permasalahan yang akan diselesaikan. Selain itu, studi pustaka juga dilakukan dengan mencari referensi-referensi yang mendukung dalam menyelesaikan masalah. Referensi yang digunakan dapat berupa buku, buku elektronik (e-book), maupun literatur-literatur yang ada di jaringan Internet dan lainnya.
Perancangan Template Skripsi
Tahap perancangan template akan menampilkan sebuah contoh skripsi yang sudah dilengkapi dengan format sesuai aturan yang baru (Lampiran 1). Contoh skripsi yang
ditampilkan juga telah disertai dengan petunjuk umum tentang isi tulisan.
Perancangan Pengecekan Ejaan Penulisan Skripsi
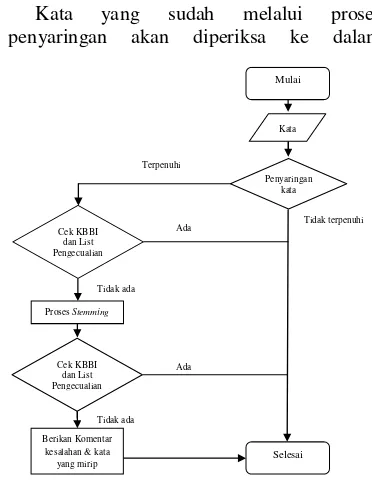
Tahap perancangan ini akan memeriksa semua kata pada dokumen skripsi ke dalam database KBBI dan list pengecualian. List pengecualian adalah daftar kata-kata yang benar tetapi tidak terdapat dalam database KBBI. Pada pemeriksaan ejaan bahasa Indonesia, digunakan database KBBI sebagai sumber kata-kata baku dan menggunakan satu list yang berisi kata-kata pengecualian. Kata pengecualian didapat dari masukan user. Database KBBI yang dipakai adalah database dari penelitian Iqbal (2010). Proses pemeriksaan ejaan dapat dilihat dari flowchart (Gambar 3).
Proses ini diawali dengan mengambil setiap kata pada dokumen, kemudian setiap kata disaring. Ada beberapa kata yang tidak akan diperiksa dalam proses ini, yaitu:
1 Kata yang ditulis memiliki huruf kapital, karena kata tersebut dianggap sebagai suatu nama objek.
2 Kata yang mengandung angka atau simbol-simbol.
3 Kata yang ditulis dengan huruf miring (italic), karena kata tersebut dianggap sebagai bahasa asing.
Kata yang sudah melalui proses penyaringan akan diperiksa ke dalam
Gambar 2 Tahapan penelitian. Mulai
Template Skripsi Pengecekan Ejaan Pengecekan Format
Database KBBI
List Pengecualian
Aturan Section - section
Gambar 3 Flowchart pengecekan ejaan bahasa Indonesia.
kesalahan & kata
database KBBI dan list pengecualian. Ketika kata-kata itu tidak ada di dalam database, selanjutnya dilakukan proses stemming.
Algoritme stemming yang digunakan ialah algoritme Nazief dan Adriani (Asian 2007). Setelah kata tersebut melewati proses stemming yang menghasilkan kata dasar, dilakukan pengecekan ulang ke dalam database. Ketika kata yang telah melewati proses stemming tidak ditemukan dalam database, diberikan komentar kesalahan ejaan pada kata tersebut dan diberikan beberapa saran kata mirip dengan kata tersebut.
Menurut Asian (2007), algoritme stemming yang digunakan Nazief dan Adriani memiliki tahapan-tahapan sebagai berikut:
1 Pencarian kata ke dalam kamus yang digunakan. Jika ditemukan maka diasumsikan bahwa kata tersebut adalah root word dan algoritme berhenti.
2 Inflection Suffixes (“-lah”, “-kah”, “-ku”,
3 Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di kamus, algoritme berhenti. Jika tidak, berlanjut ke langkah 3a
a Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-k”, “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus algoritme berhenti. Jika tidak ditemukan, lakukan langkah 3b.
b Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, kemudian dilanjutkan ke langkah 4.
4 Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus, dilanjutkan ke langkah 4a. Jika tidak ada, dilanjutkan ke langkah 4b.
a Periksa tabel kombinasi awalan-akhiran yang tidak diizinkan. Jika ditemukan, algoritme berhenti. Jika tidak, dilanjutkan ke langkah 4b.
b Untuk i = 1 sampai 3, tentukan tipe awalan kemudian hapus awalan. Jika root word belum juga ditemukan lakukan langkah 5. Jika sudah, algoritme berhenti. Catatan: jika
awalan kedua sama dengan awalan pertama, algoritme berhenti.
5 Melakukan Recoding.
6 Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal diasumsikan sebagai root word.
Tipe awalan ditentukan melalui langkah-langkah berikut:
1 Jika awalannya: “di-”, “ke-”, atau “se-”, tipe awalannya secara berturut-turut adalah “di-”, “ke-”, atau “se-”.
2 Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-”, dibutuhkan sebuah proses tambahan untuk menentukan tipe awalannya.
Perancangan Pengecekan Format Penulisan Skripsi
Tahap perancangan pemeriksaan format skripsi dengan menggunakan aturan section. Setiap section terdiri atas bagian-bagian dan aturan tertentu. Sistem ini bekerja pada section-section yang telah ditetapkan. Setiap section terdiri atas bagian-bagian tertentu dalam laporan tugas akhir. Jumlah section yang dipakai pada sistem sebanyak sebelas
Tabel 1 Aturan section
Section Aturan
Section 1 Bagian sampul
Section 2 Bagian abstrak
Section 3 Bagian halaman judul
Section 4 Bagian lembar pengesahan
Section 5 Bagian prakata
Section 6 Bagian riwayat hidup
Section 7 Bagian daftar isi
Section 8 Bagian daftar tabel, gambar dan lampiran
Section 9 Bagian isi
Section 10 Bagian daftar pustaka
section. Aturan-aturan section yang harus diperhatikan dapat dilihat pada Tabel 1.
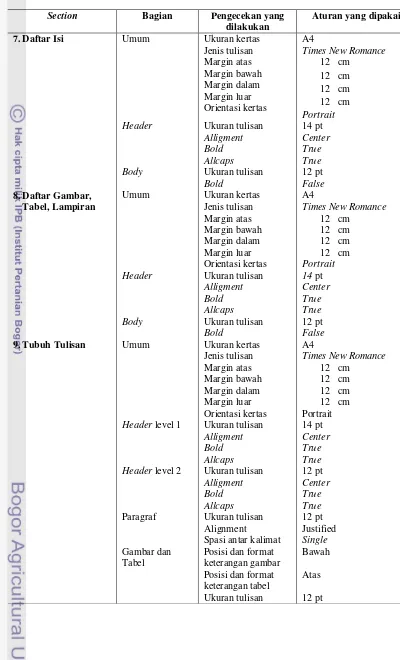
Fungsi lain pada sistem ini ialah pengecekan format penulisan skripsi. Pengecekan yang dilakukan pada sistem ini berbeda-beda pada setiap section-nya dan berdasarkan pada bagian-bagian yang menjadi aturan dari tiap section. Lampiran 2 merupakan daftar pengecekan yang dilakukan pada sistem tiap section. Secara garis besar, ada 3 pemeriksaan yang dilakukan pada setiap section, yaitu :
1 Format umum seperti ukuran kertas, jenis tulisan, margin halaman, dan orientasi.
2 Judul dan header yang diperiksa ialah ukuran tulisan, cetak tebal dan alignment tulisan.
3 Body tulisan atau paragraf yang diperiksa ialah ukuran tulisan, alignment, baris pertama paragraf, jarak antar baris.
Pengembangan
Pengembangan sistem merupakan tahap implementasi dari tahap perancangan sistem. Pada tahap ini dilakukan pembuatan antarmuka pengguna dan pengembangan kode program.
Pengujian dan Evaluasi
Pengujian dilakukan untuk mencari dan memperbaiki kesalahan-kesalahan yang terjadi pada sistem sehingga menyebabkan hasil yang dikeluarkan tidak sesuai dengan hasil yang diinginkan pengguna. Ada 2 kelas dasar dari pengujian perangkat lunak, yaitu:
1 Black Box Testing
Pengujian dilakukan menggunakan pada sistem menggunakan metode Black Box Testing. Black-Box Testing berfokus pada spesifikasi fungsional dari perangkat lunak.
2 White Box Testing
White box testing merupakan strategi pengujian yang diterapkan pada mekanisme internal suatu sistem atau komponen.
Basis path testing merupakan suatu metode yang digunakan dalam teknik white box testing. Metode basis path sangat
bermanfaat bagi seorang penguji perangkat lunak dalam menentukan:
1 Ukuran kompleksitas logika dari suatu struktur program, prosedur dan fungsi.
2 Menggunakan nilai kompleksitas untuk menentukan basis set (himpunan dasar) alur logika yang akan dieksekusi.
Metode basis path testing ini memerlukan masukan berupa source code atau algoritme dari suatu perangkat lunak.
HASIL DAN PEMBAHASAN
Analisis Kebutuhan dan Batasan Sistem
Add-in Microsoft Office Word (Ms Word) mengenai pengecekan format skripsi ini bertujuan memeriksa laporan tugas akhir mahasiswa. Masukan pada sistem ini adalah dokumen format Ms Word (*.doc atau *.docx) dengan keluaran berupa penandaan (highlight) dan pemberian komentar pada bagian yang terdapat kesalahan di dalam dokumen.
Fungsi-fungsi yang disediakan pada sistem ini terbagi menjadi 3 bagian, yaitu :
1 Fungsi untuk menampilkan suatu template contoh sebuah skripsi yang sudah menggunakan format yang benar. Template ini juga sudah dilengkapi dengan bagian masing-masing section dan ditampilkan dalam mode read only.
2 Fungsi untuk melakukan pemeriksaan terhadap ejaan. Fungsi ini menggunakan database KBBI dan sebuah list pengecualian dengan asumsi kata-kata pada kedua sumber database tersebut sudah baku dan benar. List Pengecualian adalah sebuah list sementara yang isinya dimasukkan sendiri oleh user ketika user menemukan sebuah kata yang benar, tetapi kata tersebut masih salah menurut KBBI. Fungsi pemeriksaan ejaan ini akan memberikan peringatan kepada user ketika dalam dokumen ada kata-kata yang tidak baku atau salah penulisan.
3 Fungsi untuk melakukan pemeriksaan terhadap format. Fungsi ini menggunakan aturan section untuk mempermudah pemeriksaan. Masing-masing section juga memiliki fungsi pengecekan yang berbeda.
Lingkungan Pengembangan Sistem
1 Perangkat keras
Intel Core i5 (@2.53 GHz), 2 GB RAM, hard disk berkapasitas 500 GB, mouse, keyboard, dan monitor.
2 Perangkat lunak
Sistem Operasi Windows 7 Professional, Visual Studio 2010 digunakan untuk membuat kode program (C#), dan Microsoft Office Word 2007 untuk melihat hasil program.
Pengembangan Sistem
Sistem ini menggunakan bahasa pemrogram C# (C-Sharp) dengan menggunakan Visual Studio Tools for Office sebagai salah satu bagian dari Visual Studio dalam mengembangkan dan meningkatkan fungsionalitas dari Microsoft Office.
Pembuatan kode program dibagi menjadi beberapa fungsi utama, yakni:
1 Fungsi pembuatan template skripsi yang berupa satu dokumen contoh laporan tugas akhir yang sudah benar format dan penulisannya.
2 Fungsi yang bertugas memeriksa ejaan bahasa Indonesia dalam penulisan laporan tugas akhir.
3 Fungsi pemeriksaan format penulisan dalam laporan tugas akhir.
Fungsi Generate Template Skripsi
Fungsi ini akan memanggil suatu dokumen contoh skripsi yang sudah benar formatnya dan dimunculkan dalam mode read only, sehingga user tidak bisa mengubah isi dan format dokumen yang asli. Dokumen yang sudah diubah akan disimpan seperti dokumen yang baru, tidak menimpa dokumen contoh yang dihasilkan fungsi.
Pemeriksaan Ejaan Bahasa Indonesia
Pengecekan ejaan bahasa Indonesia pada sistem ini menggunakan database KBBI sebagai acuan utama kata baku, dan list pengecualian untuk kata-kata pengecualian yang tidak ada dalam KBBI tetapi kata tersebut dipastikan benar penulisannya. Kata-kata yang dimasukkan dalam list pengecualian ini akan disimpan dalam metadata dokumen itu sendiri. Untuk kata-kata yang salah eja diberikan komentar kesalahan dan beberapa kata yang benar dan mirip dengan kata tersebut. Pemberian beberapa kata ini menggunakan database KBBI yang
dimasukkan ke dalam CUSTOM.DIC pada Microsoft Office. Waktu yang dibutuhkan pada pengecekan ejaan ini dipengaruhi oleh jumlah kata. Dari 10 kali pengujian, dapat dilihat perbandingan antara waktu yang dibutuhkan dengan jumlah kata yang diuji memperlihatkan fungsi linear. Gambar 4 menunjukkan grafik perbandingan kata dengan waktu yang dibutuhkan pada fungsi pengecekan ejaan.
Dengan menggunakan persamaan regresi linear sederhana dapat dilihat hubungan antara jumlah kata yang akan diperiksa (n) dan waktu yang diperlukan (t dalam satuan detik) dengan persamaan t = 0.0057 + 0.05148, dan nilai koefisien determinasi (R) = 0.9907.
Fungsi Pengecekan Format Skripsi
Fungsi ini memeriksa aturan-aturan pada setiap section dalam dokumen skripsi. Aturan yang digunakan dapat dilihat pada Lampiran 2. Ketidaksesuaian format dokumen dengan aturan yang telah ditentukan akan ditandai dengan pemberian komentar pada bagian yang salah.
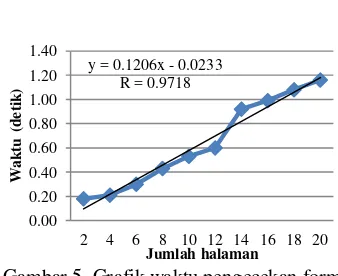
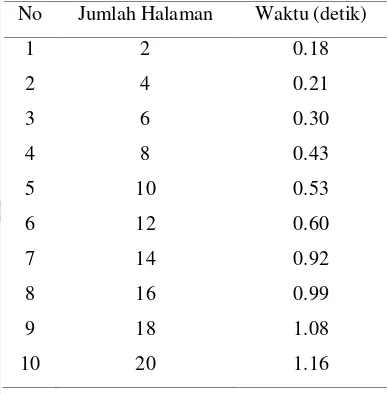
Waktu pengecekan format skripsi ini dipengaruhi oleh banyaknya halaman skripsi. Dari 10 kali pengujian dengan penambahan jumlah halaman pada gambar di atas (Gambar 5) dapat dilihat hubungan waktu yang diperlukan (t dalam satuan detik) dan jumlah halaman skripsi (n) yang akan diperiksa. Dengan menggunakan regresi linear sederhana, didapatkan persamaan antara waktu dan halaman yang diperiksa yaitu t = 0.1206n - 0.0233 dan nilai koefisien determinasi (R) = 0.9718.
Implementasi Regular Expression dan
Levenshtein Distance pada Sistem
RegEx juga digunakan dalam mendeteksi jenis-jenis string yang ada pada daftar pustaka. Misalkan dalam sebuah daftar pustaka terdiri atas nama, tahun, judul buku, dan penerbit, maka bagian-bagian tersebut akan dideteksi dengan RegEx sehingga diperoleh string pattern. String pattern dibangun dengan menggunakan karakter khusus tambahan yang ada pada RegEx.
Karakter khusus yang digunakan terdiri atas beberapa jenis fungsi seperti set karakter, pernyataan posisi, dan quantifier. Quantifier berguna untuk memberikan optional-optional tambahan untuk memberikan pernyataan dari sebuah string. Contoh beberapa pola-pola RegEx yang digunakan untuk membangun sebuah string pattern dapat dilihat pada Tabel 2, Daftar yang lebih lengkap dapat dilihat pada Lampiran 4.
Dalam pembentukan string pattern menggunakan RegEx pada daftar pustaka, setiap bagian dalam daftar pustaka diubah menjadi sebuah string untuk mewakili jenis
bagian tersebut. Daftar peubah string daftar pustaka dapat dilihat pada Tabel 3.
Pada Tabel 3, terdapat beberapa format string pattern yang dapat terjadi bersamaan, seperti nama penerbit (F) dengan tempat penerbit (L) dan nama jurnal (E) dengan halaman (D). Dengan demikian, ketika nama penerbit terdeteksi, maka langkah selanjutnya yang diperiksa ialah tempat terbit. Begitu pula jika nama jurnal telah dideteksi, halaman jurnal akan dicek terlebih dahulu.
Sebagai contoh, sebuah daftar pustaka yang diambil dari sebuah buku sebagai berikut:
Pada contoh ini, daftar pustaka memiliki 4 buah bagian, antara lain:
nama pengarang (Bruney A),
tahun terbit (2006),
judul buku (Professional VSTO 2005: Visual Studio 2005 Tools for Office), dan
tempat terbit dan nama penerbit (Indiana: Wiley Publishing, Inc).
Dengan demikian, dari keempat bagian tersebut dicari kemungkinan string yang dapat dibentuk. String pattern yang terbentuk yaitu, ABCFL, ABCIO, ABCO, ABCQ, ABCS. Setelah itu string yang terbentuk dicari kemiripannya dengan konstanta aturan string pattern setiap jenis daftar pustaka menggunakan algoritme Levenshtein.
Pada dasarnya, algoritme ini menghitung jumlah minimum transformasi suatu string menjadi string lain yang meliputi penggantian, penghapusan dan penyisipan. Dalam algoritme ini dilakukan penyeleksian panjang kedua string terlebih dahulu. Jika salah satu kedua string merupakan string kosong, jalannya algoritme ini berhenti dan memberikan hasil edit distance yang bernilai nol.
Konstanta string pattern daftar pustaka yang sesuai dengan Buku Panduan Karya Ilmiah IPB dapat dilihat pada Tabel 4. Jika string input daftar pustaka telah terbentuk, selanjutnya dilakukan penghitungan jarak terhadap setiap string pattern yang ada pada Tabel 4. Jika nilai kemiripannya 1, kedua string yang dibandingkan sama.
Bruney A. 2006. Professional VSTO 2005: Visual Studio 2005 Tools for Office. Indiana: Wiley Publishing, Inc.
Gambar 5 Grafik waktu pengecekan format skripsi.
Tabel 2 Contoh pola string daftar pustaka
Topik Pola string
Tahun "[0-9]{4}[-.$]"
Link/url @"http(s)?://([\w-]+\.)+ [\w-]+(/[\w- ./?%&=]*)?"
Nama "^[a-zA-Z','-'\\s]{1,100} [-.$]"
Judul "^[a-zA-Z+\\s(.$)] {1,1000}"
Perancangan Antarmuka
Antarmuka add-in berada pada tabulasi khusus add-in pada Microsoft Office Word 2007 (Gambar 6). Pembuatan tombol pada tabulasi add-in menggunakan ribbon buatan yang dapat dikembangkan pada Microsoft Visual Studio. Perancangan antarmuka pada sistem ini memiliki lima tombol, yaitu:
1 New Skripsi Template digunakan untuk menampilkan sebuah dokumen Microsoft Office Word contoh skripsi yang sudah dilengkapi dengan aturan dan format yang benar.
2 Spelling Check merupakan tombol untuk mengaktifkan fungsi pemeriksaan ejaan bahasa Indonesia pada Microsoft Office Word 2007. Fungsi pemeriksaan ejaan ini bisa dilakukan pada section tertentu saja atau keseluruhan dokumen. Selama proses pengecekan berjalan, muncul form Progress Bar sebagai keterangan proses sedang berjalan (Gambar 7) serta penandaan kesalahan dengan komentar ketika ditemukan kata yang salah (Gambar 8).
3 Format Check adalah tombol untuk mengaktifkan pemeriksaan format skripsi sesuai dengan aturan-aturan yang sudah ditentukan (Gambar 9). Tombol ini bisa diaktifkan ketika total section berjumlah 11. Apabila jumlah section kurang atau lebih dari 11 diberikan peringatan dan proses pengecekan format tidak akan dilakukan.
4 Delete Comment adalah tombol untuk menghapus hasil koreksi berupa komentar di samping halaman dokumen.
Tabel 4 Aturan string pattern daftar pustaka
Sumber pustaka String pattern
Jurnal ABCED
Buku ABCFL
Prosiding ABCGHIJFLD
Abstrak ABCGHIJFLDN
Skripsi, Tesis dan Disertasi
ABCKIO
Bibliografi ABCFL
Paten AOJCS
Surat Kabar AJCOTU
Peta VBCWFLM
Dokumen ABCIO
Kaset Audio /Video ABCPLFLMO
Situs web Elektronik ABCEDPRJ
Situs web Abstrak ABCEPRJ
Situs web Pertemuan ilmiah
ABCRJ Tabel 3 Indikator string peubah
String
pattern String yang diubah
A Nama
H Judul publikasi
I Lokasi
J Tanggal
K Jenis media pada (skripsi, tesis atau disertasi)
L Nama penerbit
M Deskripsi (peta atau sumber audio/video)
U Nomor kolom (media koran)
V Area (peta)
5 Ignore Words digunakan untuk memasukkan kata-kata oleh user yang dinilai sebagai kata benar. Kata yang dimasukan ke dalam list pengecualian ini
akan disimpan pada dokumen itu sendiri (Gambar 10).
Pengujian dan Evaluasi
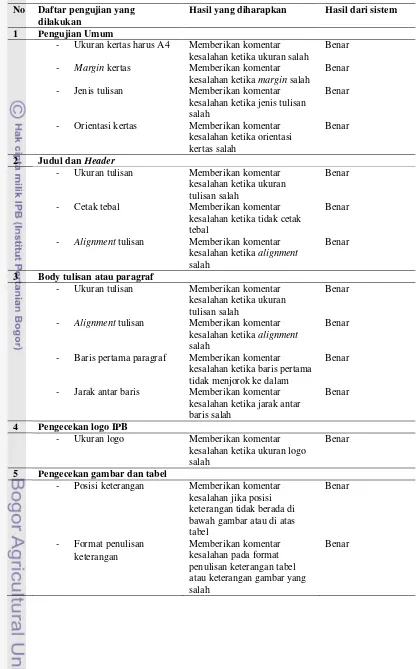
Pengujian yang telah dilakukan yaitu pengujian black box dan white box. Pengujian dengan metode black-box testing dilakukan pada setiap format yang dipakai. Pengujian black box dibagi menjadi dua bagian, yaitu pengujian fungsi-fungsi pada sistem yang dapat dilihat pada Tabel 5 dan pengujian efisiensi waktu yang digunakan sistem dalam menjalankan fungsinya. Daftar hasil pengujian dengan metode black box pada fungsi pengecekan ejaan Bahasa Indonesia pada sistem dapat dilihat pada Lampiran 4, dan daftar hasil pengujian pengecekan format pada sistem dapat dilihat pada Lampiran 5.
Dalam pengujian white box, fungsi-fungsi yang diujikan hanya fungsi-fungsi yang dianggap perlu mendapat perhatian. Hasil pengujian dengan metode white box dapat dilihat pada Lampiran 6.
Fungsi-fungsi yang diuji secara white box hanya fungsi penting dalam penelitian ini yaitu fungsi pemeriksaan ejaan, stemming dan pemeriksaan format skripsi. Hasil pengujian white box pada fungsi pemeriksaan ejaan dan stemming menghasilkan proses pengecekan ejaan yang benar dan memberikan komentar kesalahan pada kata yang salah eja. Baris program yang memiliki kesalahan mengakibatkan fungsi tidak berjalan dengan baik dan menimbulkan adanya kesalahan pada hasil proses pemeriksaan ejaan. Hasil pengujian white box pada fungsi pengecekan format akan menghasilkan pemeriksaan format yang sesuai dengan aturan format
Tabel 5 Daftar pengujian black box pada sistem
No Pengujian sistem
1 Pengujian tombol-tombol antarmuka pada sistem
2 Kata yang masuk dalam batasan sistem
3 Pengujian pengecekan kata ke dalam database
4 Pengujian stemming pada kata
5 Pengujian format umum
6 Pengujian format judul dan header
7 Pengujian format body atau paragraf Gambar 6 Antarmuka add-in sistem
pengecekan skripsi.
Gambar 7 Form progress bar pada saat pengecekan ejaan.
Gambar 8 Komentar kesalahan pada pengecekan ejaan.
Gambar 9 Komentar kesalahan pada pengecekan format skripsi.
penulisan. Baris program yang memiliki kesalahan akan mengakibatkan program tidak bisa berjalan dengan baik dan menimbulkan kesalahan pada hasil pemeriksaan format.
Pengujian efisiensi waktu yang digunakan sistem dapat dilihat dari hasil pengujian waktu dalam pengecekan format (Tabel 6) dan hasil pengujian waktu pengecekan ejaan (Tabel 7). Hasil pengujian waktu ini memperlihatkan sistem sudah mampu mengerjakan dengan waktu yang singkat. Waktu yang diperlukan sistem dalam melakukan pengecekan format dan ejaan berbanding lurus dengan banyaknya kata dan halaman yang ada pada dokumen.
Selain itu, dilakukan juga pengujian tingkat keberhasilan sistem. Pengujian ini dilakukan dengan cara menguji beberapa
dokumen yang sudah ditentukan kesalahan-kesalahan format maupun ejaan kemudian diperiksa oleh sistem. Hasil pengujian tingkat keberhasilan sistem ini dapat dilihat pada Tabel 8. Dari 5 kali pengujian dapat disimpulkan rata-rata tingkat keberhasilan sistem ini sebesar 96.5%.
Beberapa kesalahan sistem yang terjadi pada saat pengujian yaitu:
1 Ketidakmampuan sistem dalam membedakan imbuhan di- dengan awalan di-.
2 Kesalahan eja pada awal kalimat yang menggunakan huruf kapital.
3 Source code yang ditulis dengan font yang berbeda akan disalahkan.
4 Format yang salah ketika gambar atau tabel dibuat dalam text box.
Persyaratan Minimum Sistem
Spesifikasi perangkat lunak minimum untuk menjalankan aplikasi add-in ini yaitu:
1 Sistem Operasi Windows 7 x86.
2 Microsoft Office Word 2007 dan 2010.
3 .NET Framework 4 Client Profile.
4 Microsoft Visual Studio 2010 Tools for Office Runtime.
Kekurangan Sistem
Dari hasil pengujian masih terdapat berbagai kesalahan sistem. Kekurangan tersebut disebabkan sistem masih memiliki beberapa kekurangan dalam proses pengecekan. Kekurangan yang ada pada sistem antara lain:
1 sistem belum mampu membedakan imbuhan di- dengan awalan di-,
2 sistem tetap melakukan pengecekan untuk bagian skripsi yang menggunakan bahasa Tabel 7 Hasil pengujian waktu pengecekan
ejaan skripsi
Tabel 8 Pengujian tingkat keberhasilan sistem
No
Tabel 6 Hasil pengecekan format
No Jumlah Halaman Waktu (detik)
asing yang tidak dimiringkan penulisannya, dan
3 sistem belum bisa memeriksa gambar atau grafik yang ada di dalam Text Box,
KESIMPULAN
Dari penelitian yang telah dilakukan, dapat disimpulkan:
1 Telah dilakukan pengembangan sistem pengecekan format skripsi sesuai dengan format baru penulisan skripsi Institut Pertanian Bogor 2012.
2 Telah dilakukan perbaikan pengecekan ejaan bahasa Indonesia pada sistem.
3 Efisiensi waktu yang diperlukan dalam memeriksa dokumen skripsi sudah baik, waktu pemeriksaan dipengaruhi oleh jumlah kata atau jumlah halaman pada dokumen.
SARAN
Pada penelitian selanjutnya, disarankan agar program add-in ini:
1 Dikembangkan lebih lanjut mengenai pengecekan tata bahasa (grammar) pada dokumen berbahasa Indonesia sehingga sistem memiliki nilai fungsionalitas yang bertambah, dan
2 Adanya pengecualian pengecekan pada abstrak berbahasa Inggris dan source code program yang menggunakan font berbeda.
DAFTAR PUSTAKA
Agusta L. 2009. Perbandingan algoritme stemming Porter dengan algoritme Nazief & Adriani untuk stemming dokumen teks bahasa Indoneia. Di dalam: Konferensi Nasional Sistem dan Informatika; Bali, 14 November 2009. Bali: STIKOM KNS&I 2009. hlm 196-201.
Asian J. (2007). Effective techniques for Indonesian text [tesis]. Melbourne : School of Computer Science and Information Technology Science, Engineering, and Technology Portfolio, RMIT University
Bruney A. 2006. Professional VSTO 2005: Visual Studio 2005 Tools for Office. Indiana: Wiley.
Carter E, Lippert E. 2005. Visual Studio Tools for Office: Using C# with Excel, Word, Outlook, and InfoPath. Massachusetts: Addison-Wesley.
Iqbal R. 2010. Pengembangan stemmer berbasis Kamus Besar Bahasa Indonesia [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Manning CD, Raghavan P, Schütze H. 2008. Introduction to Information Retrieval. England: Cambridge University Press.
McMilan M. 2007. Data Structures and Algorithms Using C#. New York: Cambridge University Press.
Lampiran 1 Rancangan ketentuan penulisan skripsi dengan format baru
Bahan dan Ukuran Kertas Jenis kertas: HVS 80 gram;
Warna kertas: putih;
Ukuran kertas: A4 (21.0 cm 29.7 cm);
Peta, gambar, foto, diagram, sketsa, cetak biru (blue print), surat keputusan dan lainnya dapat menggunakan jenis, warna, dan ukuran berbeda sesuai dengan kebutuhan.
Ketentuan pengetikan
Pias (margin) kiri dari bidang tulisan adalah 4 cm, sedangkan batas kanan, atas, dan bawah masing-masing 3 cm.
Nomor halaman diketik di pojok atas kanan dengan batas kanan 3 cm dan batas atas 2 cm.
Naskah diketik pada halaman bolak-balik, termasuk bagian awal kecuali lembar pengesahan dan halaman penguji luar komisi harus saling berhadapan.
Jarak baris diketik 1 spasi.
Baris pertama dari paragraf menjorok 1 cm dari bidang tulisan sebelah kiri dan dibuat rata kanan (justified).
Paragraf yang bertingkat, bernomor atau merupakan uraian dari paragraf sebelumnya, ditulis dengan menjorok 0.5 cm dari paragraf di atasnya. Untuk paragraf bertingkat berikutnya, baris pertama lebih menjorok lagi 0.5 cm dari paragraf di atasnya.
Pemberian nomor pada paragraf bertingkat adalah dengan (1), (2), (3), dan seterusnya; tingkat kedua dengan a, b, c, dan seterusnya, tidak lebih dari 3 tingkatan.
Di tubuh tulisan, setiap bab baru tidak harus ditulis di halaman baru, termasuk penulisan Daftar Pustaka.
Jarak dari judul ke kalimat pertama sebesar 2 spasi, jarak kalimat terakhir di Bab terakhir ke Bab baru berikutnya sebesar 3 spasi.
Jenis huruf: Times New Romandengan ukuran 12 poin untuk teks, judul bab 14 poin. Ada pilihan jenis huruf lain untuk tampilan hasil komputer yaitu Courier New dengan ukuran 11 poin.
Nomor halaman dimulai dari Abstrak sampai Daftar Lampiran dinyatakan dengan i, ii, iii, iv, dan seterusnya.
Penomoran halaman dimulai dari bab Pendahuluan dengan menggunakan angka arab 1, 2, 3, 4, dan seterusnya.;
Judul bab diketik dengan menggunakan huruf kapital, dicetak tebal (bold), tidak ada titik, tidak digarisbawahi, boleh menggunakan angka arab tanpa titik, dan terletak di tengah-tengah (centered).
Judul subbab diketik dengan huruf kapital pada setiap awal kata, kecuali kata hubung (seperti: dan, serta, oleh, dengan, untuk) dan kata depan (seperti: di, ke, dari, pada). Judul subbab berjarak 2 spasi dari judul bab atau dari paragraf di atasnya dan 1 spasi dengan paragraf di bawahnya. Judul subbab diketik di tengah.
Judul bagian diketik dengan huruf kapital pada setiap awal kata. Judul bagian berjarak 2 spasi dari judul subbab atau paragraf di atasnya dan 1 spasi dengan paragraf di bawahnya, tidak diakhiri dengan titik, dan tidak digarisbawahi. Jika panjang judul bagian melebihi lebar bidang tulisan, jadikan 2 baris atau lebih dengan jarak 1 spasi.
Menempatkan Tabel atau Gambar di posisi paling atas atau paling bawah halaman.
Warna Sampul
Warna sampul (cover) untuk skripsi berbeda-beda, yakni untuk Faperta: hijau, FKH: ungu, FPIK: biru, Fapet: cokelat, Fahutan: abu-abu, Fateta: merah, FMIPA: putih, FEM: jingga, FEMA: hijau khas;
Sampul tesis: merah tua;
Lanjutan
Jumlah Maksimum Kata dan Halaman Skripsi tidak lebih dari 5000 kata;
Tesis tidak lebih dari 20 000 kata;
Disertasi sekurang-kurangnya 3 artikel atau publikasi;
Jumlah kata maksimum ini sudah mencakup lampiran;
Jika diperlukan, data mentah dimuat dalam CD untuk ditunjukkan kepada pembimbing dan penguji dan tidak disertakan dalam karya tugas akhir untuk menghindari penyalahgunaan data oleh pihak yang tidak bertanggung jawab.
Lembar Sampul
Jenis huruf Times New Roman dengan huruf kapital ukuran font 14;
Susunan kata pada judul membentuk segitiga terbalik dan tidak lebih dari 3 baris dengan jarak 1 spasi;
Panjang judul tidak lebih dari 15 kata;
Jarak antara judul karya tulis dengan nama lengkap mahasiswa, dengan logo dan nama departemen (atau Sekolah Pascasarjana) harus sesuai contoh lampiran;
Lampiran 2 Datar pengecekan pada tiap section
Section Bagian Pengecekan yang
dilakukan
Aturan yang dipakai
1.Halaman Sampul Umum Ukuran kertas
Jenis tulisan Margin atas Margin bawah Margin dalam Margin luar Orientasi kertas
A4
Times New Romance 12 cm
12 cm 12 cm 12 cm Portrait
Judul Ukuran tulisan
Alignment Nama penulis Ukuran tulisan
Alignment kota dan tahun
Ukuran tulisan
2.Halaman Abstrak Umum Ukuran kertas
Jenis tulisan Margin atas Margin bawah Margin dalam Margin luar Orientasi kertas
A4
Times New Romance 12 cm
12 cm 12 cm 12 cm Portrait Header Ukuran tulisan
Alligment Paragraf pertama Ukuran tulisan
Alignment
Indentation first line Spasi antar kalimat
12 pt
Indentation first line Spasi antar kalimat
12 pt Justifed 1 cm Single
3.Halaman judul Umum Ukuran kertas
Jenis tulisan Margin atas Margin bawah Margin dalam Margin luar Orientasi kertas
A4
Times New Romance 12 cm
12 cm 12 cm 12 cm Portrait
Judul Ukuran tulisan
Lanjutan
Section Bagian Pengecekan yang
dilakukan
Aturan yang dipakai
Nama penulis Ukuran tulisan Alignment “Skripsi… “ Ukuran tulisan
Alignment kota dan tahun
Ukuran tulisan
Umum Ukuran kertas
Jenis tulisan Margin atas Margin bawah Margin dalam Margin luar Orientasi kertas Ukuran tulisan Spasi antar kalimat
A4
Times New Romance 12 cm
5.Halaman Riwayat Hidup
Umum Ukuran kertas
Jenis tulisan Margin atas Margin bawah Margin dalam Margin luar Orientasi kertas
A4
Times New Romance 12 cm
12 cm 12 cm 12 cm Portrait Header Ukuran tulisan
Alligment Paragraf Ukuran tulisan
Alignment
Indentation first line Spasi antar kalimat
12 pt Justified 1 cm Single
6.Halaman Prakata Umum Ukuran kertas Jenis tulisan Margin atas Margin bawah Margin dalam Margin luar Orientasi kertas
A4
Times New Romance 12 cm
12 cm 12 cm 12 cm Portrait Header Ukuran tulisan
Alligment Paragraf Ukuran tulisan
Alignment
Indentation first line Spasi antar kalimat
Lanjutan
Section Bagian Pengecekan yang
dilakukan
Aturan yang dipakai
7.Daftar Isi Umum Ukuran kertas
Jenis tulisan Margin atas Margin bawah Margin dalam Margin luar Orientasi kertas
A4
Times New Romance 12 cm
12 cm 12 cm 12 cm Portrait Header Ukuran tulisan
Alligment Body Ukuran tulisan
Bold
12 pt False
8.Daftar Gambar, Tabel, Lampiran
Umum Ukuran kertas
Jenis tulisan Margin atas Margin bawah Margin dalam Margin luar Orientasi kertas
A4
Times New Romance 12 cm
12 cm 12 cm 12 cm Portrait Header Ukuran tulisan
Alligment Body Ukuran tulisan
Bold
12 pt False
9.Tubuh Tulisan Umum Ukuran kertas
Jenis tulisan Margin atas Margin bawah Margin dalam Margin luar Orientasi kertas
A4
Times New Romance 12 cm
12 cm 12 cm 12 cm Portrait Header level 1 Ukuran tulisan
Alligment Header level 2 Ukuran tulisan
Alligment Paragraf Ukuran tulisan
Alignment
Spasi antar kalimat
12 pt Justified Single Gambar dan
Tabel
Posisi dan format keterangan gambar Posisi dan format keterangan tabel Ukuran tulisan
Bawah
Atas
Lanjutan
Section Bagian Pengecekan yang
dilakukan
Aturan yang dipakai
10.Daftar Pustaka Umum Ukuran kertas
Jenis tulisan Margin atas Margin bawah Margin dalam Margin luar Orientasi kertas
A4
Times New Romance 13 cm
13 cm 13 cm 13 cm Portrait Header level 1 Ukuran tulisan
Alligment Bold Allcaps
14 pt
Center True True Daftar Pustaka Aturan-aturan
Lampiran 3 Daftar string Regular Expression pengecekan daftar pustaka
Pattern Keterangan Regular Expressions
A Nama "^[a-zA-Z','-'\\s]{1,100}[-.$]"
B Tahun "[0-9]{4}[-.$]"
C Judul "^[\\w\\W+\\s(.$)]{1,1000}"
E -D Nama jurnal & halaman
"^[\w\W\s]*[0-9\s]{1,4}[:\s][0-9-\s]{1,10}[\.$]"
F -L Tempat terbit & nama penerbit
"^[\\w\\W+\\s]{1,1000}[':'][\\w\\W+\\s]{1,1000} [-.$]"
G Nama editor
"^[a-zA-Z''-''{''}''('')'','';'':''\\/''\\'\\s]{0,400}[','? ] editor[-.$]"
H - I - J Judul publikasi, tempat, tanggal
"^[\\w\\W+\\s]{1,1000}[';'?]
[\\w\\W+\\s]{1,100}[','?][0-9'-'\\s]{1,7}[a-zA-Z\\s]{1,15}[0-9]{4}[-.$]"
I : O Tempat : nama institusi
"^[\\w\\W+\\s]{1,1000}[':'][\\w\\W+\\s]{1,1000} [-.$]"
J Tanggal "^[0-9'-'\\s]{1,7}[A-Za-z\\s]{1,17}[0-9]{4}[-.$]"
M Deskripsi "^[\\w\\W+\\s]{1,1000}[-.$]"
N Nomor abstrak "^[A-Za-z\\s]{1,20}[0-9]{1,5}[-.$]"
O Nama Institusi "^[\\w\\W+\\s]{1,500}[-.$]"
Q Keterangan "^[\\w\\W+\\s]{1,1000}[-.$]"
R Url "http(s)?://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?"
Lampiran 4 Hasil pengujian pengecekan ejaan
No Daftar pengujian Hasil yang diharapkan Keberhasilan
sistem 1 Pengecekan kata yang disaring
- Huruf kapital Tidak ada komentar Benar
- Angka Tidak ada komentar Benar
- Simbol Tidak ada komentar Benar
- Huruf miring Tidak ada komentar Benar
2 Pengecekan kata dalam KBBI dan
list Pengecualian
- Kata yang ada dalam KBBI Tidak ada komentar Benar - Kata yang ada dalam list
Pengecualian
Tidak ada komentar Benar
- Kata yang ada dalam KBBI tetapi tidak ada dalam list Pengecualian
Tidak ada komentar Benar
- Kata yang ada dalam list Pengecualian tetapi tidak ada dalam KBBI
Tidak ada komentar Benar
3 Pengecekan stemming
- me-, me- kan, me-i Menghasilkan kata dasar Benar - di-, di-kan, di-i Menghasilkan kata dasar Benar - diper-kan, diper-i Menghasilkan kata dasar Benar
- ke-an, ke-i Menghasilkan kata dasar Benar
- memper-kan, memper-i Menghasilkan kata dasar Benar
- se-, se-nya Menghasilkan kata dasar Benar
- ter-, ter-an Menghasilkan kata dasar Benar
- -nya, -ku, -mu, -an Menghasilkan kata dasar Benar
- -lah, -kah, -kan Menghasilkan kata dasar Benar
- Kata yang memiliki 2 akhiran Menghasilkan kata dasar Benar - Kata yang memiliki 2 awalan Menghasilkan kata dasar Benar - Dua kata yang digabung Tidak ada komentar Benar - Kata dasar yang meluruh ketika
diberi awalan
Lampiran 3 Hasil pengujian pengecekan format
No Daftar pengujian yang dilakukan
Hasil yang diharapkan Hasil dari sistem 1 Pengujian Umum
- Ukuran kertas harus A4 Memberikan komentar kesalahan ketika ukuran salah
Benar
- Margin kertas Memberikan komentar kesalahan ketika margin salah
Benar
- Jenis tulisan Memberikan komentar kesalahan ketika jenis tulisan salah
Benar
- Orientasi kertas Memberikan komentar kesalahan ketika orientasi kertas salah
Benar
2 Judul dan Header
- Ukuran tulisan Memberikan komentar kesalahan ketika ukuran tulisan salah
Benar
- Cetak tebal Memberikan komentar
kesalahan ketika tidak cetak tebal
Benar
- Alignment tulisan Memberikan komentar kesalahan ketika alignment salah
Benar
3 Body tulisan atau paragraf
- Ukuran tulisan Memberikan komentar kesalahan ketika ukuran tulisan salah
Benar
- Alignment tulisan Memberikan komentar kesalahan ketika alignment salah
Benar
- Baris pertama paragraf Memberikan komentar kesalahan ketika baris pertama tidak menjorok ke dalam
Benar
- Jarak antar baris Memberikan komentar kesalahan ketika jarak antar baris salah
Benar
4 Pengecekan logo IPB
- Ukuran logo Memberikan komentar
kesalahan ketika ukuran logo salah
Benar
5 Pengecekan gambar dan tabel
- Posisi keterangan Memberikan komentar kesalahan jika posisi keterangan tidak berada di bawah gambar atau di atas tabel
Benar
- Format penulisan keterangan
Memberikan komentar kesalahan pada format penulisan keterangan tabel atau keterangan gambar yang salah
Lampiran 4 Pengujian White Box pada Sistem
1. Tabel Pengujian white box fungsi SpellCheck
Flow Graph Source Code
internal void SpellCheckPerSection(Word.Range
ranget){
(1) ProcessBar UIProcess = new ProcessBar();
(1) StemmingWord stemming = new StemmingWord();
(1) object missing =
System.Reflection.Missing.Value;
(1) int count = ranget.Words.Count;
(1) readTextIgnore();
(1) readKBBIwordList();
(1) UIProcess.setMax(count);
(1) UIProcess.Visible = true;
(1) int NextWord = 0;
(2) foreach (Word.Range range in ranget.Words){
(3) if (range.Text != null){
(4) string kata = range.Text.Trim();
(4) NextWord++;
(4) UIProcess.progressBar(NextWord);
(4) UIProcess.messageBoxProses(range.Text);
(5) if (kata != "" && range.Font.Italic != -1 && wordCheck(kata) == 0 && kata.Length > 2){
(6) if (CheckToKBBIlistWord(kata) == 0) {
(7) if (CheckToIgnoreList(kata) != 1){
(8) kata = stemming.NAZIEF(kata);
(9) if (CheckToKBBIlistWord(kata) == 0) {
(10) Word.Comment komentar =
ranget.Comments.Add(range, ref missing);
(10) string[] suggestWord = { "tidak ada", "",
"" };
(10) suggestWord = SpellCheckSuggestWord(range);
(10)komentar.Range.Text = "Periksa kembali
ejaan ! " +suggestWord[0] + " "+ suggestWord [1] + " " +
suggestWord[2];}}}}}}
(11)UIProcess.Visible = false;}
Base path
1. 1-2-3-2-11 2. 1-2-3-4-5-2-11 3. 1-2-3-4-5-6-2-11 4. 1-2-3-4-5-6-7-2-11 5. 1-2-3-4-5-6-7-8-9-2-11 6. 1-2-3-4-5-6-7-8-9-10-2-11 7. 1-2-3-2-11
8. 1-2-3-4-5-2-11 9. 1-2-3-4-5-6-2-11 10. 1-2-3-4-5-6-7-2-11 11. 1-2-3-4-5-6-7-8-9-2-11
Lanjutan
2. Tabel Pengujian white box pada fungsi stemming Nazief
Flow Graph Source Code
public string NAZIEF(string kata){
(1) string kataAsal = kata;
(1) readKBBIwordList();
(2) kata = DelInflectionSuffixes(kata);
(3) kata = DelDerivationSuffixes(kata);
(4) kata = DelDerivationPrefix(kata);
(5) return kata;}
Base path
1. 1-2-3-4-5
3. Tabel pengujian white box pada fungsi DelInflectionSuffixes
Flow Graph Source Code
public string DelInflectionSuffixes(string kata){
(1) string kataAsal = kata;
(2) if (Regex.IsMatch(kata,
"([km]u|nya|[kl]ah|pun)$")) {
(3) string _kata = Regex.Replace(kata,
"([km]u|nya|[kl]ah|pun)$", "");
(4) if (Regex.IsMatch(kata, "([klt]ah|pun)$")) {
(5) if (Regex.IsMatch(_kata, "([km]u|nya)$")) {
(6) string _kata_ = Regex.Replace(_kata,
"([km]u|nya)$", "");
(7) return _kata_;}}
(8) return _kata;}
(9) return kataAsal;}
Base path
Lanjutan
4. Tabel Pengujian white box pada fungsi CekPrefixDissalowedSuffixes
Flow Graph Source Code
public bool CekPrefixDisallowedSuffixes(string kata){
(1) if (Regex.IsMatch(kata,
"^(be)[[:alpha:]]+(i)")) {
(5) return true;}
(2) if (Regex.IsMatch(kata,
"^(di)[[:alpha:]]+(an)")) {
(5) return true;}
(3) if (Regex.IsMatch(kata,
"^(ke)[[:alpha:]]+(i|kan)")) {
(5) return true;}
(4) if (Regex.IsMatch(kata,
"^(se)[[:alpha:]]+(i|kan)")) {
(5) return true;}
(6) return false;}
Base path
1. 1-6 2. 1-2-6 3. 1-2-3-6 4. 1-2-3-4-5 5. 1-2-3-4-6
5. Tabel Pengujian white box pada fungsi DelDerivationSuffixe
Flow Graph Source Code
public string DelDerivationSuffixes(string kata){
(1) string kataAsal = kata;
(2) if (Regex.IsMatch(kata, "(i|an)$")) {
(3) string _kata = Regex.Replace(kata, "(i|an)$", "");
(4) if (CheckToKBBIlistWord(_kata) != 0) {
(5) return _kata;}
(6) if (Regex.IsMatch(kata, "(kan)$")) {
(7) string _kata_ = Regex.Replace(kata, "(kan)$", "");
(8) if (CheckToKBBIlistWord(_kata_) != 0){
(9) return _kata_;}}
(10) if (CekPrefixDisallowedSuffixes(kata)){
(11) return kataAsal;}}
(12) return kataAsal;}
Base path
Lanjutan
6. Tabel Pengujian white box pada fungsi SectionCheck
Flow Graph
Source Code
public void CheckEachSection(){
(1) int totalSection =
Globals.ThisAddIn.Application.ActiveDocument.Sections.Count
;
(2) if (totalSection != 11){
(3) MessageBox.Show("Total section harus lengkap (11), Proses
dihentikan !");}
(4) else{
(4) object startIndex = 0;
(4) object endIndex = 0;
(4) int kesalahan = 0;
(4) object missingValue = System.Reflection.Missing.Value;
(4) Word.Document wordDocument =
Globals.ThisAddIn.Application.ActiveDocument;
(4) Word.Range Range =
Globals.ThisAddIn.Application.ActiveDocument.Range(ref
missingValue, ref missingValue);
(4) Word.Range Range2 =
Globals.ThisAddIn.Application.ActiveDocument.Range(ref
startIndex, ref endIndex);
(4) Range2.Select();
(4) Word.Range PageRange =
Globals.ThisAddIn.Application.ActiveDocument.Range(ref
Lanjutan
(4) Word.Bookmark PageBookmark;
(4) object EndOfPage = @"\page";
(4) object wdWhat = WdGoToItem.wdGoToPage;
(4) object wdWhich = Word.WdGoToDirection.wdGoToNext;
(4) int TotalPages =
Range.ComputeStatistics(WdStatistic.wdStatisticPages);
(4) int currentPage, NumberOfSection;
(5) for (currentPage = 1; currentPage <= TotalPages;
currentPage++){
(6) object count = (object)currentPage;
(6) Range = wordDocument.Bookmarks.get_Item(ref
EndOfPage).Range;
(6) PageBookmark = wordDocument.Bookmarks.get_Item(ref
EndOfPage);
(6) NumberOfSection =
(int)PageBookmark.Range.get_Information(WdInformation.wdActi
veEndSectionNumber);
(7) switch (NumberOfSection){
(8) case 1:
(8) SectionOneCheck sOneCheck = new SectionOneCheck();
(8) sOneCheck.SectionOne(PageBookmark, kesalahan, currentPage);
(8) kesalahan = sOneCheck.jumlahKesalahan();
(8) break;
(9) case 2:
(9) SectionTwoCheck sTwoCheck = new SectionTwoCheck();
(9) sTwoCheck.SectionTwo(PageBookmark, kesalahan, currentPage);
(9) kesalahan = sTwoCheck.jumlahKesalahan();
(9) break;
(10) case 3:
(10) SectionThreeCheck sThreeCheck = new SectionThreeCheck();
(10) sThreeCheck.SectionThree(PageBookmark, kesalahan,
currentPage);
(10) kesalahan = sThreeCheck.jumlahKesalahan();
(10) break;
(11) case 4:
(11) SectionFourCheck sFourCheck = new SectionFourCheck();
(11) sFourCheck.SectionFour(PageBookmark, kesalahan,
currentPage);
(11) kesalahan = sFourCheck.jumlahKesalahan();
(11) break;
(12) case 5:
(12) SectionFiveCheck sFiveCheck = new SectionFiveCheck();
(12) sFiveCheck.SectionFive(PageBookmark, kesalahan,
currentPage);
(12) kesalahan = sFiveCheck.jumlahKesalahan();
(12) break;
(13) case 6:
(13) SectionSixCheck sSixCheck = new SectionSixCheck();
(13) sSixCheck.SectionSix(PageBookmark, kesalahan, currentPage);
(13) kesalahan = sSixCheck.jumlahKesalahan();
(13) break;
(14) case 7:
(14) SectionSevenCheck sSevenCheck = new SectionSevenCheck();
(14) sSevenCheck.SectionSeven(PageBookmark, kesalahan,
currentPage);
(14) kesalahan = sSevenCheck.jumlahKesalahan();
Lanjutan
(15) case 8:
(16) SectionEightCheck sEightCheck = new SectionEightCheck();
(15) sEightCheck.SectionEight(PageBookmark, kesalahan,
currentPage);
(15) kesalahan = sEightCheck.jumlahKesalahan();
(15) break;
(16) case 9:
(16) SectionNineCheck sNineCheck = new SectionNineCheck();
(16) sNineCheck.SectionNine(PageBookmark, kesalahan,
currentPage);
(16) kesalahan = sNineCheck.jumlahKesalahan();
(16) break;
(17) case 10:
(17) SectionTenCheck sTenCheck = new SectionTenCheck();
(17) sTenCheck.SectionTen(PageBookmark, kesalahan, currentPage);
(17) break;}
(18) Range = PageRange.GoTo(ref wdWhat, ref wdWhich, ref count,
ref missingValue);
(18) Range.Select();}}}
Base Path:
1. 1-2-3