SISTEM PENCARIAN TURUNAN KATA PADA AL-QURAN
MENGGUNAKAN
LIGHT STEMMING
DAN
CLUSTERING
UNTUK PEMBICARA BAHASA INDONESIA
GALIH KENANG AVIANTO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Sistem Pencarian Turunan Kata pada Al-Quran Menggunakan Light Stemming dan Clustering untuk Pembicara Bahasa Indonesia adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
GALIH KENANG AVIANTO. Sistem Pencarian Turunan Kata pada Al-Quran Menggunakan Light Stemming dan Clustering untuk Pembicara Bahasa Indonesia. Dibimbing oleh AHMAD RIDHA.
Pencarian topik pada Al-Quran dengan identifikasi akar kata sulit dilakukan bagi orang yang tidak memahami morfologi bahasa Arab. Light stemming merupakan metode ekstraksi stem yang dapat menggantikan posisi akar kata dalam pencarian topik. Namun, metode tersebut tidak mampu menghilangkan sisipan pada kata sehingga metode clustering diharapkan dapat menutupi kekurangan tersebut. Penelitian ini bertujuan membangun sistem pencarian turunan kata menggunakan light stemming dan clustering yang penulisan query -nya telah disesuaikan untuk pembicara bahasa Indonesia. Terdapat dua jenis query yang dapat diterima oleh sistem yang masing-masing berjumlah 30 yaitu, aksara Latin dan aksara Arab. Pengukuran kualitas pencarian menggunakan Average Precision (AVP), Mean Average Precision (MAP), dan Precision pada N menunjukkan bahwa light stemming lebih baik dibanding clustering dengan nilai AVP light stemming ialah 0.30, sedangkan clustering ialah 0.03 untuk jenis query aksara Latin. Adapun untuk waktu pencarian, light stemming lebih baik dibanding clustering pada jenis query aksara Arab.
Kata kunci: Al-Quran, clustering, light stemming, turunan kata
ABSTRACT
GALIH KENANG AVIANTO. Words Derivative Searching System in the Holy Quran Using Light Stemming and Clustering for Indonesian Speaker. Supervised by AHMAD RIDHA.
Topics searching in the Holy Quran using word derivative is difficult task without arabic word morphology knowledge. Light stemming is stem extraction method that can replaces word derivative plays in topics searching. However, this method fail to removes infix so clustering method can be better hopefully. This research aims to build word derivative searching system using light stemming and clustering that appropriate with Indonesian speaker’s query. There are two types of query that accepted by the system that have 30 queries in each: Latin and Arabic script. Searching quality evaluation using Average Precision (AVP), Mean Average Precision (MAP), and Precision at N shows that light stemming is better than clustering with 0.30 AVP in light stemming and 0.03 AVP in clustering. Whereas for running time, light stemming is four time faster than clustering at Arabic script.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
SISTEM PENCARIAN TURUNAN KATA PADA AL-QURAN
MENGGUNAKAN
LIGHT STEMMING
DAN
CLUSTERING
UNTUK PEMBICARA BAHASA INDONESIA
GALIH KENANG AVIANTO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Sistem Pencarian Turunan Kata pada Al-Quran Menggunakan Light Stemming dan Clustering untuk Pembicara Bahasa Indonesia Nama : Galih Kenang Avianto
NIM : G64090011
Disetujui oleh
Ahmad Ridha, SKom MS Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhanahu wata’ala atas limpahan karunia dan rahmat sehingga karya ilmiah ini bisa diselesaikan. Selawat dan salam semoga senantiasa tercurah kepada Nabi Muhammad Shallallahu’alaihiwasallam beserta keluarga, sahabat, dan pengikutnya hingga hari kiamat kelak. Penulis ingin menyampaikan ucapan terima kasih kepada pihak yang telah membantu dalam penulisan karya ilmiah ini, yaitu:
1 Ibu, Ayah, dan Adik tercinta yang senantiasa mendoakan dan memberi motivasi selama penulisan karya ilmiah.
2 Bapak Ahmad Ridha, SKom MS yang telah memberikan bimbingan, ide, dan saran dalam penulisan karya ilmiah.
3 Bapak Sony Hartono Wijaya, MKom dan Bapak Mushthofa, SKom MSc yang telah berkenan menjadi penguji.
4 Rekan satu bimbingan Ahmad Thoriq Abdul Aziz yang telah bersama-sama berjuang menyelesaikan penulisan karya ilmiah.
5 Muhammad Ginanjar Ramadhan, Aditya Erlangga, dan Sapariansyah yang telah bersedia meminjamkan komputer dan notebook. Semoga dapat menjadi pemberat timbangan amal kalian.
6 Masyarakat internet yang telah memberikan solusi ringkas dalam penulisan karya ilmiah ini.
Semoga karya ilmiah ini bermanfaat khususnya bagi umat Islam dan masyarakat pada umumnya.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
METODE 2
Gambaran Umum Sistem 2
Ekstraksi Stem 2
Pengelompokan Dokumen 4
Pemeringkatan Dokumen 4
Relevance Judgment 5
Pengukuran Kinerja 5
Implementasi 5
HASIL DAN PEMBAHASAN 5
Ekstraksi Stem Aksara Latin 5
Pembuatan Indeks 6
Pengelompokan Dokumen 7
Pemrosesan Query dan Pemeringkatan Dokumen 7
Pembentukan Koleksi Pengujian 9
Pengujian Sistem 9
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 13
DAFTAR PUSTAKA 14
RIWAYAT HIDUP 32
LAMPIRAN 15
DAFTAR TABEL
1 Nilai AVP, MAP, dan Precision pada Na untuk setiap metode 10 2 Perbandingan nilai AVP, MAP, dan Precision pada Na setiap query 12 3 Perbandingan waktu pencarian setiap jenis query setiap metodea 13
DAFTAR GAMBAR
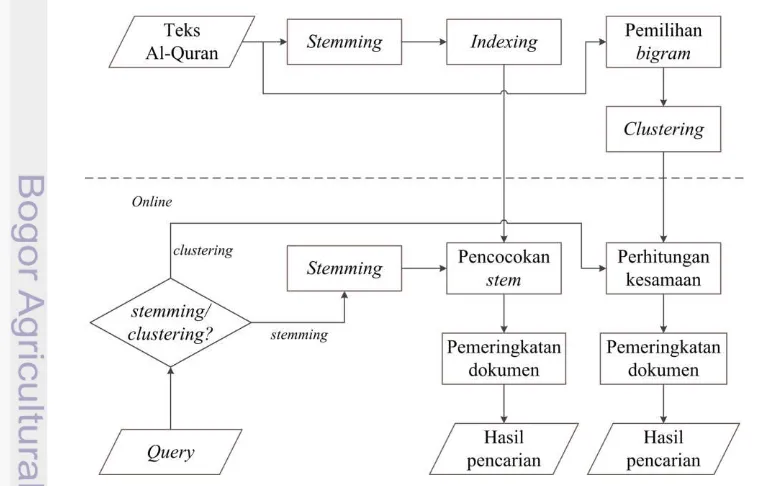
1 Diagram alir pada sistem 3
2 Skema indeks dalam aksara Latin 8
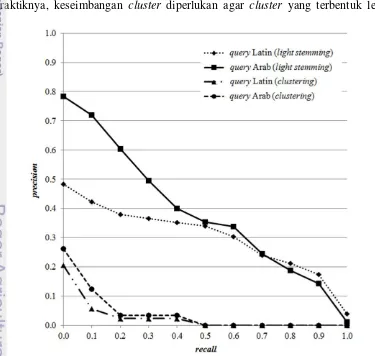
3 Kurva recall-precision setiap jenis query setiap metode 11
DAFTAR LAMPIRAN
1 Ilustrasi tahapan stemming pada aksara Arab 15
2 Ilustrasi tahapan stemming pada aksara Latin 16
3 Cuplikan fail matriks kesamaan 17
4 Cuplikan fail indeks dokumen dan indeks cluster 18
5 Fail indeks aksara Arab 19
6 Fail indeks aksara Latin 20
7 Daftar koleksi pengujian 21
8 Nilai AVP per metode per jenis query 28
9 Nilai MAP per metode per jenis query 29
10 Nilai Precision pada N per metode per jenis query 30
PENDAHULUAN
Latar Belakang
Al-Quran merupakan teks berbahasa Arab yang lebih dikenal oleh masyarakat, khususnya umat Islam, dibandingkan teks berbahasa Arab lainnya. Al-Quran merupakan rujukan utama umat Islam, namun belum banyak orang yang secara menyeluruh memahami isi dari kitab suci tersebut. Salah satu penyebabnya ialah pemahaman bahasa Arab yang kurang memadai.
Pencarian topik merupakan salah satu kegiatan yang menjadikan Al-Quran sebagai acuan. Hal ini dapat dilakukan dengan terlebih dahulu mencari akar kata bahasa Arab dari topik yang diinginkan pada konkordansi Al-Quran seperti Fath Al-Rahman (Al-Baqiy [tahun tidak diketahui]). Setelah akar kata ditemukan, barulah daftar surat dan ayat dari topik tersebut bisa didapatkan. Untuk mengetahui akar kata dari sebuah topik, diperlukan pemahaman mengenai morfologi kata bahasa Arab. Contohnya, kata مك ق خ yang merupakan terjemahan untuk topik penciptaan, akar katanya adalah ق خ. Jika akar kata tersebut diidentifikasi dengan benar, maka pencarian pada konkordansi dimulai dengan mencari akar kata yang diawali huruf , bukan huruf .
Stem merupakan turunan dari akar kata yang jika mendapatkan imbuhan akan menjadi kata. Kata-kata dalam bahasa Arab memiliki makna yang sama secara semantik jika dihasilkan dari akar kata yang sama (De Roeck dan Al-Fares 2000). Meskipun berbeda, stem bisa disetarakan dengan akar kata karena sifat turunannya. Light stemming merupakan salah satu metode ekstraksi stem dari kata beraksara Arab dengan menghilangkan awalan dan akhiran (Chen dan Gey 2002).
Kunci pencarian topik menggunakan konkordansi Fath Al-Rahman ialah menemukan akar kata atau dapat dikatakan bahwa topik merupakan turunan dari akar kata tersebut sehingga light stemming bisa digunakan sebagai pendekatan untuk pencarian topik. Namun, metode ini memiliki kekurangan yaitu tidak mampu menghilangkan sisipan pada sebuah kata sehingga kata akan dimasukkan pada kelompok stem yang berbeda dengan kata tanpa sisipan.
Berbekal kekurangan tersebut, De Roeck dan Al-Fares (2000) telah melakukan clustering pada dokumen berbahasa Arab dengan hasil yang cukup memuaskan. Metode clustering yang digunakan juga mampu mengatasi sisipan pada kata. Berdasarkan hal tersebut, diharapkan clustering akan lebih baik dibandingkan light stemming.
Sistem yang serupa telah dibuat oleh Istiadi (2012) dengan menggunakan kemiripan fonetis. Namun, sistem yang dibuat bukan ditujukan untuk pencarian kata, melainkan ayat yang memiliki lafal sesuai dengan query yang dimasukkan oleh pembicara bahasa Indonesia.
2
Perumusan Masalah
Adapun rumusan masalah dalam penelitian ini ialah menentukan metode yang lebih baik antara metode light stemming dan clustering dalam melakukan pencarian turunan kata berbahasa Arab pada Al-Quran.
Tujuan Penelitian
Tujuan penelitian ini, yaitu:
1 Membangun sistem pencarian turunan kata berbahasa Arab pada Al-Quran menggunakan light stemming dan clustering.
2 Mengembangkan metode light stemming untuk masukan aksara Latin.
3 Mengukur kinerja sistem pencarian turunan kata berbahasa Arab pada Al-Quran menggunakan light stemming dan clustering.
Manfaat Penelitian
Penelitian ini diharapkan dapat memudahkan pengguna untuk menemukan ayat-ayat terkait topik tertentu tanpa perlu mengidentifikasi akar kata dari topik yang dicari sehingga orang awam yang tidak bisa membaca buku Fath Al-Rahman bisa terbantu. Penelitian ini menggunakan teks Al-Quran sebagai corpus dan query yang dimasukkan menggunakan bahasa Arab.
METODE
Gambaran Umum Sistem
Sistem terdiri atas 2 proses utama, yaitu proses offline dan proses online. Proses offline meliputi stemming, pembuatan indeks, dan clustering dari teks Al-Quran. Keseluruhan proses offline hanya dilakukan sekali. Proses online dimulai dengan melakukan stemming pada query untuk metode light stemming atau perhitungan nilai kesamaan query-dokumen untuk metode clustering, kemudian dilakukan pemeringkatan pada hasil pencarian untuk setiap metode yang digunakan.Alur sistem secara umum dapat dilihat pada Gambar 1.
Data teks Al-Quran sebagai corpus didapatkan dari bahan penelitian Istiadi (2012) dengan format TXT yang diperoleh dari situs http://tanzil.net/download. Data tersusun per baris yang menunjukkan ayat Al-Quran serta dilengkapi dengan harakat, nomor surat, dan tanpa tanda berhenti di tengah ayat.
Ekstraksi Stem
3 pada teks Al-Quran dilakukan berdasarkan penelitian Chen dan Gey (2002) dengan menggunakan light stemming. Sebelum dilakukan ekstraksi stem, teks Al-Quran dilakukan praproses untuk meminimumkan data yang diolah (Chen dan Gey 2002). Tahapan praproses meliputi hal sebagai berikut:
menghilangkan harakat atau tanda baca,
normalisasi huruf alif madd ( آ ) dan huruf alif hamzah ( أ, إ ) menjadi huruf alif (ا ),
menghilangkan tasydid, dan
mengganti akhiran berupa huruf alif maqsura ( ) dan huruf ha ( ) berturut-turut dengan huruf ya ( ي ) dan huruf ta marbuthah ( ).
Setelah melalui tahap praproses, selanjutnya ialah menghilangkan awalan dan akhiran dengan urutan sebagai berikut:
1 Jika kata terdiri atas minimal 5 karakter, 3 karakter pertama dihilangkan jika 3 karakter tersebut merupakan salah satu dari: ا , ب, ف, ك, لل , م, اا, س, dan ا.
2 Jika kata terdiri atas minimal 4 karakter, 2 karakter pertama dihilangkan jika 2 karakter tersebut merupakan salah satu dari: ا, ا , ب, لل, , , , ا, يس, س , ي , , ك, dan ف.
3 Jika kata terdiri atas minimal 4 karakter dan diawali dengan , karakter awal tersebut dihilangkan.
4 Jika kata terdiri atas minimal 4 karakter dan diawali dengan atau , karakter atau tersebut dihilangkan hanya jika setelah penghilangan karakter tersebut stem yang dihasilkan terdapat dalam koleksi dokumen.
5 Secara rekursif akhiran yang terdiri atas 2 karakter dihilangkan dalam setiap kemunculan jika kata terdiri atas minimal 4 karakter sebelum akhiran berikut dihilangkan: ه, ي, مه, ن, م, ا , ي, ين, نه, مك, نك, مت, نت, ني, ا, ا, dan .
6 Secara rekursif akhiran yang terdiri atas 1 karakter dihilangkan ( , , ي, dan ) dalam setiap kemunculan jika kata terdiri atas minimal 3 karakter.
4
Ilustrasi tahapan di atas untuk query aksara Arab مك ق خ dapat dilihat pada Lampiran 1. Query tersebut terdiri atas akar kata ق خ dengan awalan (dan) serta akhiran ن (Kami) dan مك (kamu). Pada ilustrasi ini, tahapan light stemming berhasil menghasilkan stem yang sama dengan akar kata.
Tahapan ini diimplementasikan menggunakan bahasa pemrograman PHP serta menggunakan fungsi ekspresi reguler dan pemrosesan string. Dokumen atau ayat yang melalui tahapan light stemming berjumlah 6236 dokumen.
Pada query yang berupa aksara Latin, stem didapatkan dengan mengadopsi metode light stemming. Contohnya, pada query “fasiquun”, akan menghasilkan stem “fsq”. Hasil ekstraksi stem pada teks Al-Quran disimpan dalam fail TXT.
Indeks yang dibuat terdiri atas 2 bentuk, yaitu dalam aksara Arab dan aksara Latin. Indeks dalam aksara Arab dibuat dengan membuat inverted index dari teks Al-Quran hasil stemming. Informasi yang disimpan pada posting list berupa nomor surat, nomor ayat, frekuensi kemunculan stem, dan posisi kemunculan pertama stem pada dokumen.
Pembuatan indeks dalam aksara Latin serupa dengan indeks dalam aksara Arab, namun term yang disimpan merupakan hasil pengodean fonetis berdasarkan penelitian Istiadi (2012) dari term pada inverted index dalam aksara Arab. Untuk menanggulangi penulisan query yang beragam, indeks trigram dibuat dari bagian term pada inverted index.
Pengelompokan Dokumen
Kesamaan dokumen (ayat) dihitung berdasarkan algoritme Adamson (De Roeck dan Al-Fares 2000) yang menghitung jumlah substring yang sama antarkata. Algoritme ini menggeser “jendela” berukuran n karakter dengan overlap sebanyak 1 karakter. Pada penelitian ini digunakan jendela berukuran 2 (bigram) dan nilai kesamaan antara 2 dokumen dihitung dengan formula Jaccard. Unit terkecil dari gram yang digunakan pada penelitian ini adalah huruf. Hasil perhitungan kesamaan disimpan dalam fail TXT untuk kemudian dilakukan clustering menggunakan hierarchical agglomerative clustering (HAC). Adapun alasan digunakannya HAC adalah metode ini tidak perlu mengetahui jumlah cluster yang ingin dibentuk.
Pemeringkatan Dokumen
5 Relevance Judgment
Pasangan query-dokumen relevan didapatkan dari buku A Concordance of the Qur’an karya Kassis (1983). Daftar kata pada buku tersebut menggunakan transliterasi bahasa Inggris sehingga perlu diubah penulisannya yang disesuaikan dengan transliterasi bahasa Indonesia. Jumlah pasangan query-dokumen relevan yang diambil sebanyak 30 buah.
Pengukuran Kinerja
Kinerja sistem diukur untuk setiap metode pencarian yang digunakan. Kinerja yang diukur ialah waktu pencarian dan kualitas hasil pencarian berdasarkan query yang diujikan. Pengukuran kualitas pencarian dilakukan dengan menghitung nilai Average Precision (AVP), Mean Average Precision (MAP), dan Precision pada N dokumen teratas (dengan N adalah nilai minimum dari jumlah dokumen yang ditemukembalikan oleh kedua metode) (Manning et al. 2009). Alasan digunakannya ketiga ukuran nilai tersebut ialah melihat konsistensi setiap nilai dari kedua metode. Hasil pengukuran disajikan dalam bentuk kurva recall-precision untuk membandingkan kedua metode pencarian.
Implementasi
Implementasi sistem untuk pembuatan indeks, pengelompokan dokumen, dan pencarian dilakukan dengan bahasa pemrograman PHP. Spesifikasi perangkat keras dan perangkat lunak yang digunakan dalam implementasi ini, yaitu:
prosesor Intel Core 2 Duo 2.00 GHz,
memori 4 GB,
sistem operasi Windows 7 Professional,
web server Apache versi 1.7.7, dan
bahasa pemrograman PHP versi 5.3.8.
HASIL DAN PEMBAHASAN
Ekstraksi Stem Aksara Latin
Ekstraksi stem pada query aksara Latin mengadopsi tahapan dari metode ekstraksi stem menggunakan light stemming. Sebelum dilakukan stemming, teks akan melalui tahap praproses. Tahapan ini mengubah kata dengan pola W-lah menjadi W-lat dan pola W-loh menjadi W-lot, dengan W adalah sembarang string pada kata.
Fungsi penghitung jumlah karakter Arab pada aksara Latin dibuat untuk mendukung proses stemming. Rincian fungsinya, yaitu:
6
2 Jika kata diawali oleh karakter a, i, atau u dan diikuti oleh karakter selain a, i, u, e, o, atau l, nilai counter bertambah 1.
3 Jika kata diawali oleh karakter a, i, atau u dan diikuti oleh karakter l, nilai counter bertambah 1.
4 Jika kata diakhiri oleh substring ha, ih, na, ma, wa, ya, ni, kan, kin, kun, tam, tim, tum, tan, tin, tun, in, an, at,atau un, nilai counter bertambah 1.
5 Jika kata mengandung substring bb.., dd.., ff.., hh.., jj.., kk.., mm.., nn.., rr.., ss.., tt.., ww.., yy.., zz.., kh, gh, sy, th, dh, zh, atau ts, nilai counter bertambah 1, kemudian substring tersebut dihilangkan.
6 Hilangkan karakter vokal dari karakter yang tersisa.
7 Jumlah karakter merupakan total karakter sisa ditambah dengan nilai counter. Adapun tahapan stemming pada aksara Latin ialah sebagai berikut:
1 Jika jumlah karakter Arab terdiri atas minimal 5 karakter, substring yang terletak di awal kata dihilangkan jika substring tersebut merupakan salah satu dari: wal, bil, fal, kal, walil, mal, sal, lil, dan lal.
2 Jika jumlah karakter Arab terdiri atas minimal 4 karakter, substring yang terletak di awal kata dihilangkan jika substring tersebut merupakan salah satu dari: al, wa, bi, lal, lil, wama, wata, watu, wabi, la, saya, wasa, waya, wali, ka, dan fa.
3 Jika jumlah karakter Arab terdiri atas minimal 4 karakter, substring yang terletak di awal kata dihilangkan jika substring tersebut merupakan wa.
4 Jika jumlah karakter Arab terdiri atas minimal 4 karakter, substring yang terletak di awal kata dihilangkan jika substring tersebut merupakan salah satu dari: bi, la, dan li hanya jika setelah penghilangan tersebut stem yang dihasilkan terdapat dalam koleksi dokumen.
5 Jika jumlah karakter Arab terdiri atas minimal 4 karakter, secara rekursif substring yang terletak di akhir kata dihilangkan jika substring tersebut merupakan salah satu dari: ha, yah, him, hum, na, ma, wa, ya, ni, hun, hunna, kum, kun, tum, tun, in, an, on, at, dan un.
6 Aturan pengodean fonetis dilakukan.
Ilustrasi tahapan di atas untuk query aksara Latin “wakholaqnakum” bisa dilihat pada Lampiran 2. Pada ilustrasi ini, query yang diberikan terdiri atas akar kata “kholaq” dengan awalan “wa” serta akhiran “na” dan “kum”. Tahapan ini menghasilkan stem yang sesuai dengan hasil pengodean fonetis dari akar kata, yaitu HLK.
Pembuatan Indeks
7
Pengelompokan Dokumen
Dokumen yang dihitung kesamaannya menggunakan algoritme Adamson (De Roeck dan Al-Fares 2000) terdiri atas 2 jenis, yaitu teks Al-Quran dan teks dalam aksara Latin hasil pengodean fonetis teks Al-Quran. Pada teks Al-Quran dilakukan normalisasi (penggantian karakter tertentu dan penghilangan tanda baca) terlebih dahulu sebelum dihitung kesamaannya. Jumlah dokumen yang dihitung sebanyak 6236 dokumen. Untuk memperkecil ukuran matriks kesamaan, pasangan dokumen yang sudah dihitung tidak perlu dihitung ulang sehingga matriks yang mulanya berukuran menjadi . Matriks kesamaan kemudian ditulis ke dalam fail TXT sehingga terdapat 2 fail matriks kesamaan, yaitu matriks untuk teks Al-Quran dan teks hasil pengodean fonetis. Untuk memperkecil ukuran fail, pasangan dokumen dengan nilai kesamaan 0 tidak dituliskan. Cuplikan fail matriks kesamaan dapat dilihat di Lampiran 3.
Tahapan pembuatan cluster dimulai dengan membaca fail matriks kesamaan, kemudian diterapkan algoritme HAC. Pembuatan cluster akan berlangsung sampai nilai kesamaan dari cluster terakhir yang terbentuk mencapai nilai tertentu. Hal ini sama dengan melakukan pemotongan dendrogram pada titik tertentu setelah semua dokumen masuk ke dalam sebuah cluster. Adapun titik yang dipilih ialah 0.01 karena jumlah cluster yang dihasilkan lebih sedikit (jumlah komputasi lebih sedikit) dibandingkan titik lainnya pada rentang 0.00-1.00. Jumlah cluster yang terbentuk dari teks Al-Quran ialah 1170 cluster, sedangkan dari teks hasil pengodean fonetis ialah 2068 cluster.
Pemilihan centroid dilakukan setelah pembuatan cluster selesai. Untuk cluster dengan lebih dari 2 anggota, centroid merupakan dokumen yang memiliki rataan kesamaan terbesar dengan seluruh dokumen dalam cluster-nya. Untuk cluster dengan 2 anggota, centroid merupakan dokumen dengan jumlah karakter terbanyak.
Representasi cluster yang terbentuk dituliskan dalam 2 fail TXT yang berbeda. Fail pertama berisi indeks seluruh cluster beserta dokumen yang masuk dalam cluster tersebut, sedangkan fail kedua berisi indeks seluruh dokumen beserta cluster tempat dokumen tersebut dikelompokkan. Cuplikan kedua fail tersebut bisa dilihat di Lampiran 4.
Pemrosesan Query dan Pemeringkatan Dokumen
Light Stemming
Query yang masuk akan diolah berdasarkan jenisnya. Light stemming dilakukan terhadap query aksara Arab, sedangkan query aksara Latin diolah menggunakan algoritme stemming yang diadopsi dari light stemming. Query yang telah melalui proses stemming akan dipadankan dengan term dari indeks untuk mendapatkan dokumen yang dianggap relevan. Pembacaan inverted index untuk query aksara Arab dilakukan dengan langkah-langkah berikut.
1 Inisialisasi array V untuk term.
8
3 Untuk setiap token t pada query:
a Value dari key t pada V diambil sebagai offset f. b Posting list mulai byte f sampai akhir baris dibaca.
c Nilai TF-IDF dihitung, lalu disimpan sebagai value dari key t pada Vq. d Untuk setiap posting p dari posting list:
Nomor surat dan ayat dari p diambil sebagai key pada Vd.
Frekuensi dari p diambil dan dikalikan dengan IDF sebagai value dari key pada Vd.
p diambil dan dimasukkan dalam M. 4 Untuk setiap elemen dalam M:
a Nomor surat dan ayat diambil sebagai keyk dari D.
b Nilai cosine simmilarity dari Vq dan Vd dihitung dan diambil sebagai value dari key k.
5 D diurutkan secara menurun berdasarkan value. 6 D diberikan sebagai dokumen hasil pencarian.
Adapun untuk query aksara Latin pembacaan indeksnya sebagai berikut. 1 Inisialisasi arrayB untuk term dari indeks trigram.
2 Inisialisasi array V untuk term dari indeks hasil pengodean fonetis.
3 Inisialisasi array D (untuk dokumen yang ditemukan), array M (untuk posting list), array T (untuk term yang cocok dari indeks hasil pengodean fonetis), array Vq (untuk nilai vektor query), dan array Vd (untuk nilai vektor dokumen yang ditemukan).
4 Untuk setiap token t pada query:
a Setiap trigram m dari t diambil, array offset F diambil sebagai value dari key m pada B.
b Untuk setiap elemen e dari F:
Posting list dari indeks trigram dibaca mulai bytee sampai akhir baris.
Untuk setiap posting p dari posting list:
Term dari p diambil, trigram-nya diekstraksi, lalu jumlah trigram yang cocok dengan trigram t dihitung.
Jika jumlah trigram cocok ≥ 2, maka term dimasukkan ke dalam T.
Untuk setiap elemen l dari T:
Value dari keyl pada V diambil sebagai offsetg.
Posting list dari indeks kode fonetis dibaca mulai byteg sampai akhir baris.
Hasil pembacaan dengan posting list dari elemen T berikutnya digabung.
Nilai TF.IDF dari t dihitung dan disimpan sebagai value dari key t dalam Vq.
9
Untuk setiap posting q dari hasil penggabungan:
Nomor surat dan ayat dari q diambil sebagai key pada Vd.
Frekuensi dari q diambil dan dikalikan dengan IDF, lalu diambil sebagai value dari key pada Vd.
q diambil dan dimasukkan dalam M. 5 Untuk setiap elemen dalam M:
a Nomor surat dan ayat diambil sebagai key k dari D.
b Nilai cosine simmilarity dari Vq dan Vd dihitung dan diambil sebagai value dari key k.
6 D diurutkan secara menurun berdasarkan value. 7 D diberikan sebagai dokumen hasil pencarian.
Hasil pembacaan indeks untuk tiap jenis query akan mengembalikan dokumen yang dianggap relevan secara terurut bedasarkan skor pemeringkatan. Informasi yang disimpan pada setiap dokumen ialah identifier (berupa bilangan bulat), posisi kemunculan, dan skor pemeringkatan. Cuplikan indeks dalam aksara Arab dan Latin bisa dilihat secara berturut-turut pada Lampiran 5 dan Lampiran 6. Clustering
Semua jenis query (aksara Arab dan Latin) akan dilakukan ekstraksi bigram untuk kemudian dihitung nilai kesamaannya dengan semua centroid cluster. Query dalam aksara Arab dilakukan praproses terlebih dahulu seperti tahap praproses pada light stemming sebelum dilakukan ekstraksi bigram, sedangkan query dalam aksara Latin dilakukan pengodean fonetis. Cluster dengan nilai kesamaan centroid terbesar merupakan kumpulan dokumen yang dianggap relevan. Dokumen dari cluster terpilih kemudian dihitung kesamaannya dengan query untuk menentukan peringkat dokumen.
Ukuran cluster yang tidak seimbang menyebabkan jumlah dokumen yang ditemukembalikan terlampau sedikit. Oleh sebab itu, jika anggota dari cluster terpilih kurang dari 10, cluster berikutnya diambil berdasarkan urutan perhitungan kesamaan query-centroid sampai jumlah dokumen yang ditemukembalikan berjumlah minimal 10 dokumen.
Pembentukan Koleksi Pengujian
Koleksi pengujian didapatkan dengan mengambil 30 daftar kata dari buku A Concordance of the Qur’an. Pengambilan beberapa kata dari buku tersebut perlu disesuaikan dengan aturan transliterasi bahasa Indonesia. Sebagai contoh, kata “ADHAB” akan diubah menjadi “ADZAB”. Untuk setiap kata yang diambil, dibuat penulisan dalam aksara Arab sehingga query pengujian terdiri atas query dalam aksara Latin dan aksara Arab. Daftar koleksi pengujian bisa dilihat pada Lampiran 7.
Pengujian Sistem
10
dibandingkan metode clustering yang ditunjukkan dengan konsistensi nilai dari semua ukuran penilaian. Hasil temu kembali kedua metode menunjukkan jenis query aksara Arab lebih baik daripada aksara Latin. Rincian nilai AVP, MAP, dan Precision pada N untuk semua jenis query dapat dilihat pada Lampiran 8, 9, dan 10.
Hasil perhitungan waktu pencarian dari koleksi pengujian dapat dilihat pada Lampiran 11. Berdasarkan hasil tersebut, waktu pencarian untuk jenis query aksara Arab sekitar 3 kali lebih cepat dibandingkan jenis query aksara Latin pada metode light stemming, sedangkan pada metode clustering, jenis query aksara Latin lebih cepat daripada jenis query aksara Arab. Pada metode light stemming, rataan waktu pencarian untuk query aksara Latin ialah 0.20 detik dan untuk query aksara Arab ialah 0.07 detik. Sementara pada metode clustering, rataan waktu pencarian untuk query aksara Latin ialah 0.20 detik, dan untuk query aksara Arab ialah 0.33 detik.
Kurva recall-precision setiap metode disajikan dalam Gambar 3. Pada titik recall < 0.50, jenis query aksara Arab menunjukkan nilai precision yang lebih tinggi dibandingkan jenis query aksara Latin untuk metode light stemming, sedangkan pada titik recall ≥ 0.50 nilai precision kedua jenis query relatif sama. Untuk metode clustering, nilai precision kedua jenis query relatif sama di semua titik recall.
Pengaruh Sisipan pada Pengodean Fonetis
Konsekuensi dari kelemahan metode light stemming ialah huruf sisipan yang ikut terkodekan secara fonetis. Hal ini mengakibatkan pencarian yang seharusnya mengandung huruf sisipan ا, , dan ي menjadi tidak optimal. Contohnya, query “shiyam” kode fonetis: “SYM” yang seharusnya cocok dengan stem م يص, namun hasilnya tidak sesuai karena stem tersebut dikodekan menjadi “SYXM” sehingga jumlah trigram cocok < 2 yang merupakan syarat pengambilan term yang sesuai untuk query aksara Latin. Kondisi tersebut tidak berlaku jika kode fonetis dari stem dan query mengandung lebih banyak trigram cocok. Sebagai contoh, query “kawkab” kode fonetis: “KWKB” akan cocok dengan stem كاوك kode fonetis: “KWXKB” karena query trigram yang cocok ≥ 2.
Hal serupa juga terjadi pada metode light stemming untuk aksara Latin. Ekspresi query yang mengandung huruf sisipan ا, , dan ي tidak dapat diidentifikasi, terlebih jika query yang diberikan pendek, seperti “shiyam” م يص) dan “bashir” ريصب).
11
Analisis Hasil Clustering
Hasil temu kembali metode clustering sangat dipengaruhi oleh jumlah karakter (untuk jenis query Latin) atau jumlah term (untuk jenis query aksara Arab) dari koleksi dokumen. Dokumen berukuran kecil (jumlah karakter atau jumlah term sedikit) memiliki peluang temu kembali yang relatif tinggi dibandingkan dokumen berukuran besar untuk query yang sama. Hal ini disebabkan dokumen berukuran kecil akan memiliki nilai kesamaan dengan query yang relatif tinggi dibanding dokumen berukuran besar. Contohnya pada query “ma’wa”, dokumen relevan yang ditemukembalikan ialah dokumen dengan jumlah karakter 11, sedangkan dokumen relevan lain dengan jumlah karakter 50 tidak berhasil ditemukembalikan.
Nilai precision hasil temu kembali metode clustering menunjukkan hasil yang tidak optimal. Idealnya, centroid merupakan representasi dari cluster. Hasil evaluasi menunjukkan bahwa centroid tidak cukup mewakili anggota cluster. Pada dokumen 1724 (salah satu dokumen relevan untuk query “ma’wa”), dokumen 252 merupakan centroid dari cluster dokumen tersebut. Namun, dokumen 252 tidak mengandung kata kunci “ma’wa” yang merupakan pasangan query relevan untuk dokumen 1724 sehingga mengakibatkan dokumen 1724 tidak dapat ditemukembalikan oleh query“ma’wa”.
Faktor lain yang menyebabkan hasil pencarian dengan metode clustering tidak optimal ialah jumlah anggota antar-cluster yang tidak seimbang karena pada praktiknya, keseimbangan cluster diperlukan agar cluster yang terbentuk lebih
12
bermakna (Banerjee dan Ghosh 2006). Fluktuasi jumlah anggota cluster yang sangat tinggi ditunjukkan dengan perbedaan yang besar antara jumlah anggota cluster minimum dan maksimum. Jumlah minimum anggota cluster untuk teks Al-Quran dan teks hasil pengodean fonetis ialah 1, sedangkan jumlah maksimum untuk teks Al-Quran ialah 5067 dan teks hasil pengodean fonetis ialah 3953. Hal ini menyebabkan nilai precision akan bernilai ekstrim 0.00 atau 1.00.
Kualitas Pencarian
Berdasarkan semua ukuran nilai yang digunakan (AVP, MAP, dan Precision pada N), metode light stemming lebih baik dibandingkan metode clustering. Hal ini disebabkan kemungkinan temu kembali dokumen relevan dengan metode clustering relatif kecil karena centroid dari cluster yang terpilih tidak cukup mewakili anggota dari cluster tersebut. Selain itu, jumlah anggota cluster yang tidak seimbang menyebabkan metode clustering tidak efektif. Namun, terdapat pengecualian untuk query“kawkab”, “نيما”,“ma’wa”, dan “makara”.
Pada query “kawkab”, hasil temu kembali metode clustering mengembalikan 2 dokumen relevan pada 4 dokumen teratas, sedangkan metode light stemming hanya mengembalikan 1 dokumen. Hal ini menyebabkan ketiga ukuran penilaian metode clustering lebih tinggi daripada light stemming.
Pada query “نيما”dan “ma’wa”, hasil temu kembali metode light stemming tidak mengembalikan dokumen relevan pada 10 dokumen teratas sehingga ketiga ukuran penilaian bernilai 0. Sebaliknya, pada metode clustering, kedua query mengembalikan sebanyak 6 dan 3 dokumen relevan secara berturut-turut sehingga nilai AVP, MAP, dan Precision pada N metode clustering lebih baik daripada light stemming.
Pada query “makara”, nilai MAP metode clustering lebih baik daripada light stemming. Hal ini disebabkan hasil temu kembali metode clustering mengembalikan 1 dokumen relevan yang berada di urutan pertama, sedangkan pada light stemming, kemunculan dokumen relevan relatif tidak terurut pada urutan di atas 10. Rincian nilai AVP, MAP, dan Precision pada N dapat dilihat pada Tabel 2.
Secara umum hasil temu kembali jenis query aksara Arab lebih baik dibanding jenis query aksara Latin pada metode light stemming. Pada query aksara Arab, proses pencocokan query lebih bersifat exact matching. Hal ini berbeda dengan jenis query aksara Latin yang memperhatikan toleransi kesalahan dan variasi penulisan query. Akibatnya, nilai AVP, MAP, dan Precision pada N untuk jenis query aksara Arab lebih tinggi dibandingkan jenis query aksara Latin. Tabel 2 Perbandingan nilai AVP, MAP, dan Precision pada Na setiap query
Query
Light stemming Clustering
AVP MAP Precision
pada N AVP MAP
13
Waktu Pencarian
Secara umum waktu pencarian metode light stemming lebih cepat dibanding metode clustering dan salah satu faktor yang mempengaruhinya ialah jumlah iterasi perhitungan skor. Pada Tabel 3 terlihat bahwa jumlah iterasi metode clustering lebih banyak dibanding metode light stemming sehingga waktu pencarian pun lebih lama. Jenis query aksara Arab pada metode clustering memerlukan waktu pencarian lebih lama dibanding jenis query aksara Latin meskipun jumlah iterasi perhitungannya lebih sedikit. Hal ini disebabkan karakter pada jenis query Arab tidak dapat langsung diproses seperti pada jenis query aksara Latin dalam mengekstrak bigram sehingga untuk mengakses karakter pada posisi tertentu, perlu dilakukan pemisahan karakter Arab untuk kemudian diubah ke dalam struktur data array.
SIMPULAN DAN SARAN
Simpulan
Sistem pencarian turunan kata pada Al-Quran menggunakan metode light stemming dan clustering telah berhasil dibuat beserta penulisan query yang sesuai untuk pembicara bahasa Indonesia. Sistem memperlihatkan kinerja yang baik dengan metode light stemming dibanding metode clustering yang ditunjukkan oleh nilai AVP, MAP, dan Precision pada N yang tinggi dan waktu pencarian yang lebih singkat.
Secara umum, query dalam aksara Arab lebih baik direspons oleh sistem dilihat dari kualitas hasil pencarian dan waktu pencarian dibanding query dalam aksara Latin. Metode stemming yang dikembangkan untuk query dalam aksara Latin menunjukkan respon yang baik bila query yang dimasukkan relatif panjang.
Saran
Beberapa saran untuk penelitian selanjutnya ialah sebagai berikut:
1 Penggunaan metode stemming berbasis morfologi untuk mendeteksi sisipan pada kata dan penggunaan metode clustering dengan menggunakan balancing constraint untuk menyeimbangkan jumlah anggota cluster.
2 Pembentukan koleksi pengujian didampingi pakar bahasa Arab untuk mengetahui kedudukan kata dan skenario pencarian menggunakan bahasa Indonesia.
Tabel 3 Perbandingan waktu pencarian setiap jenis query setiap metodea
Metode Waktu pencarian (detik)
Latin Arab
light stemming 0.20 (c = 144) 0.07 (c = 80) clustering 0.20 (c = 2077) 0.33 (c = 1179)
a
14
DAFTAR PUSTAKA
Al-Baqiy. [tahun tidak diketahui]. Fathur-Rahman li Thalibi Ayat Al-Quran. [tempat tidak diketahui]: [penerbit tidak diketahui].
Banerjee A, Ghosh J. 2006. Scalable clustering algorithms with balancing constraints. Data Mining and Knowledge Discovery. 13(3):365-395.
Chen A, Gey F. 2002. Building an Arabic stemmer for information retrieval. Di dalam: Voorhees EM, Buckland LP, editor. The Eleventh Text Retrieval Conference (TREC 2002); 2002 Nop 19-22; Gaithersburg, Amerika Serikat. Gaithersburg (US): National Institute of Standards and Technology. hlm 631-639.
De Roeck AN, Al-Fares W. 2000. A morphologically sensitive clustering algorithm for identifying Arabic root. Proceedings of the 38th Annual Meeting on Association for Computational Linguistics; 2000 Okt 1-8; Hong Kong (CN). Stroudsburg (US): Association for Computational Linguistics. hlm 199-206. Istiadi MA. 2012. Sistem pencarian ayat Al-Quran berbasis kemiripan fonetis
untuk pembicara bahasa Indonesia [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Kassis HE. 1983. A Concordance of the Qur’an. Berkeley (US): University of California Press.
16
17 Lampiran 3 Cuplikan fail matriks kesamaan
18
19 Lampiran 5 Fail indeks aksara Arab
Term
7001 1:1:1:7;2:1:1:7;2:7:1:7;2:8:1:37;2:9:1...
|نمحر
40900 1:1:1:15;1:3:1:0;2:1:1:15;2:163:1:51;3...
|ميحر
41602 1:1:1:27;1:3:1:12;2:1:1:27;2:37:1:82;2...
| مح
49821 1:2:1:0;6:1:1:38;6:45:1:46;7:43:1:90;1...
|لل
20410 1:2:1:10;2:22:1:161;2:98:1:20;2:112:1:...
| ر
27040 1:2:1:18;2:5:1:27;2:21:1:32;2:26:1:145...
20
21 Lampiran 7 Daftar koleksi pengujian
22
Lampiran 7 Daftar koleksi pengujian (lanjutan)
23 Lampiran 7 Daftar koleksi pengujian (lanjutan)
24
Lampiran 7 Daftar koleksi pengujian (lanjutan)
25 Lampiran 7 Daftar koleksi pengujian (lanjutan)
26
Lampiran 7 Daftar koleksi pengujian (lanjutan)
27 Lampiran 7 Daftar koleksi pengujian (lanjutan)
Kode Query
Latin Kode
Query
Arab
Dokumen relevan (nomor surat:ayat)
Jumlah Relevan
Q29 MAKARA R29 ر م 3:54, 7:123, 13:42, 14:46, 16:26, 16:45, 27:50, 40:45, 71:22, 6:123, 6:124, 8:30, 10:21, 12:102, 16:127, 27:70, 35:10, 7:99, 7:123, 10:21, 12:31, 13:33, 13:42, 14:46, 27:50, 27:51, 34:33, 35:10, 35:43, 71:22, 3:54, 8:30
32
Q30 SULTHON R30 ط س 3:151, 4:91, 4:144, 4:153, 6:81, 7:33, 7:71, 10:68, 11:96, 12:40, 14:10, 14:11, 14:22, 15:42, 16:99, 16:100, 17:33, 17:65, 17:80, 18:15, 22:71, 23:45, 27:21, 28:35, 30:35, 34:21, 37:30, 37:156, 40:23, 40:35, 40:56, 44:19, 51:38, 52:38, 53:23, 55:33, 69:29
28
Lampiran 8 Nilai AVP per metode per jenis query
Kode
AVP
Light Stemming Clustering
Qi Ri Qi Ri
Q1 R1 0.00 0.27 0.00 0.00
Q2 R2 0.07 0.27 0.30 0.00
Q3 R3 0.50 0.44 0.02 0.00
Q4 R4 0.05 0.61 0.02 0.00
Q5 R5 0.52 0.71 0.00 0.01
Q6 R6 0.36 0.36 0.00 0.00
Q7 R7 0.00 0.00 0.00 0.45
Q8 R8 0.24 0.39 0.00 0.00
Q9 R9 0.77 0.91 0.09 0.18
Q10 R10 0.00 0.00 0.00 0.00
Q11 R11 0.02 0.18 0.18 0.05
Q12 R12 0.72 0.86 0.00 0.00
Q13 R13 0.53 0.51 0.00 0.00
Q14 R14 0.56 0.26 0.00 0.03
Q15 R15 0.07 0.14 0.00 0.00
Q16 R16 0.51 0.36 0.00 0.00
Q17 R17 0.30 0.75 0.00 0.00
Q18 R18 0.00 0.18 0.00 0.03
Q19 R19 0.00 0.01 0.00 0.00
Q20 R20 0.00 0.00 0.00 0.00
Q21 R21 0.00 0.00 0.00 0.00
Q22 R22 0.71 0.82 0.01 0.12
Q23 R23 0.00 0.64 0.00 0.00
Q24 R24 0.04 0.09 0.01 0.00
Q25 R25 0.07 0.28 0.00 0.00
Q26 R26 0.45 0.36 0.00 0.00
Q27 R27 0.91 0.91 0.09 0.09
Q28 R28 0.09 0.18 0.03 0.05
Q29 R29 0.60 0.45 0.09 0.09
Q30 R30 0.90 0.64 0.03 0.18
29 Lampiran 9 Nilai MAP per metode per jenis query
Kode
MAP
Light Stemming Clustering
Qi Ri Qi Ri
Q1 R1 0.00 1.00 0.00 0.00
Q2 R2 0.25 1.00 0.58 0.00
Q3 R3 0.46 0.48 0.17 0.00
Q4 R4 0.19 0.82 0.17 0.00
Q5 R5 0.57 0.95 0.00 0.11
Q6 R6 0.33 0.33 0.00 0.00
Q7 R7 0.04 0.05 0.00 1.00
Q8 R8 0.20 0.33 0.00 0.00
Q9 R9 0.82 1.00 0.83 1.00
Q10 R10 0.01 0.00 0.00 0.00
Q11 R11 0.04 1.00 1.00 0.50
Q12 R12 0.71 0.95 0.00 0.00
Q13 R13 0.79 0.73 0.00 0.00
Q14 R14 0.58 0.92 0.00 0.28
Q15 R15 0.05 0.21 0.00 0.00
Q16 R16 0.56 1.00 0.00 0.00
Q17 R17 0.26 0.70 0.00 0.00
Q18 R18 0.01 1.00 0.00 0.33
Q19 R19 0.00 0.01 0.00 0.00
Q20 R20 0.00 0.00 0.00 0.00
Q21 R21 0.00 0.00 0.00 0.00
Q22 R22 0.75 1.00 0.14 0.54
Q23 R23 0.00 1.00 0.00 0.00
Q24 R24 0.20 1.00 0.14 0.00
Q25 R25 0.15 0.67 0.00 0.00
Q26 R26 0.50 1.00 0.00 0.00
Q27 R27 1.00 1.00 1.00 0.63
Q28 R28 0.42 1.00 0.33 0.50
Q29 R29 0.90 1.00 1.00 1.00
Q30 R30 0.99 1.00 0.33 0.87
30
Lampiran 10 Nilai Precision pada N per metode per jenis query
Kode
Precision pada N
Light Stemming Clustering
Qi Ri Qi Ri
Q1 R1 0.00 1.00 0.00 0.00
Q2 R2 0.25 1.00 0.67 0.00
Q3 R3 0.50 0.50 0.10 0.00
Q4 R4 0.20 1.00 0.10 0.00
Q5 R5 0.50 0.90 0.00 0.10
Q6 R6 0.50 0.50 0.00 0.00
Q7 R7 0.00 0.00 0.00 0.60
Q8 R8 0.20 0.50 0.00 0.00
Q9 R9 0.80 1.00 0.20 0.40
Q10 R10 0.00 0.00 0.00 0.00
Q11 R11 0.00 1.00 0.10 0.10
Q12 R12 0.70 0.85 0.00 0.00
Q13 R13 0.70 0.60 0.00 0.00
Q14 R14 0.50 0.80 0.00 0.22
Q15 R15 0.00 0.10 0.00 0.00
Q16 R16 0.50 1.00 0.00 0.00
Q17 R17 0.20 0.60 0.00 0.00
Q18 R18 0.00 1.00 0.00 0.00
Q19 R19 0.10 0.00 0.00 0.00
Q20 R20 0.00 0.00 0.00 0.00
Q21 R21 0.00 0.00 0.00 0.00
Q22 R22 0.80 1.00 0.10 0.40
Q23 R23 0.00 1.00 0.00 0.00
Q24 R24 0.10 0.33 0.10 0.00
Q25 R25 0.10 0.60 0.00 0.00
Q26 R26 0.40 1.00 0.00 0.20
Q27 R27 1.00 1.00 0.10 0.20
Q28 R28 0.20 0.67 0.10 0.33
Q29 R29 1.00 1.00 0.10 0.10
Q30 R30 1.00 1.00 0.20 1.00
31 Lampiran 11 Waktu pencarian per metode per jenis query
Kode
Waktu Pencarian (detik)
Light Stemming Clustering
Qi Ri Qi Ri
Q1 R1 0.12 0.03 0.22 0.35
Q2 R2 0.12 0.03 0.20 0.33
Q3 R3 0.17 0.07 0.19 0.32
Q4 R4 0.18 0.04 0.19 0.33
Q5 R5 0.18 0.04 0.19 0.32
Q6 R6 0.29 0.12 0.19 0.32
Q7 R7 0.25 0.15 0.19 0.33
Q8 R8 0.23 0.10 0.20 0.32
Q9 R9 0.21 0.05 0.21 0.35
Q10 R10 0.33 0.07 0.19 0.32
Q11 R11 0.28 0.04 0.19 0.32
Q12 R12 0.16 0.04 0.19 0.32
Q13 R13 0.15 0.04 0.19 0.32
Q14 R14 0.16 0.04 0.19 0.32
Q15 R15 0.22 0.04 0.19 0.32
Q16 R16 0.19 0.04 0.20 0.33
Q17 R17 0.51 0.06 0.20 0.32
Q18 R18 0.28 0.04 0.20 0.32
Q19 R19 0.24 0.69 0.19 0.32
Q20 R20 0.25 0.04 0.19 0.32
Q21 R21 0.14 0.04 0.20 0.33
Q22 R22 0.12 0.05 0.19 0.34
Q23 R23 0.13 0.04 0.26 0.36
Q24 R24 0.15 0.04 0.19 0.32
Q25 R25 0.16 0.04 0.19 0.32
Q26 R26 0.17 0.04 0.19 0.32
Q27 R27 0.14 0.05 0.19 0.32
Q28 R28 0.13 0.04 0.19 0.32
Q29 R29 0.15 0.04 0.19 0.32
Q30 R30 0.14 0.03 0.20 0.33
32
RIWAYAT HIDUP
Penulis dilahirkan di Lumajang, Jawa Timur pada tanggal 1 Mei 1992. Penulis merupakan anak pertama dari pasangan Djoko Winarno dan Heri Yuni Indahwati. Pada tahun 2009, penulis menamatkan pendidikan di SMA Negeri 3 Kota Sukabumi, Jawa Barat. Penulis lulus jalur seleksi masuk Institut Pertanian Bogor (IPB) pada tahun yang sama melalui jalur Undangan Seleksi Masuk IPB dan diterima sebagai mahasiswa di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.