PERBANDINGAN KINERJA ALGORITME TEXTRANK DENGAN
ALGORITME LEXRANK PADA PERINGKASAN DOKUMEN
BAHASA INDONESIA
YUZAR MARSYAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa skripsi berjudul Perbandingan Kinerja Algoritme TextRank dengan Algoritme LexRank pada Peringkasan Dokumen bahasa Indonesia adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
YUZAR MARSYAH. Perbandingan Kinerja Algoritme TextRank dengan Algoritme LexRank pada Peringkasan Dokumen Bahasa Indonesia. Dibimbing oleh SONY HARTONO WIJAYA.
Peringkasan dokumen merupakan cara yang efektif untuk mendapatkan informasi dari suatu dokumen tanpa membaca keseluruhan dokumen. Peringkasan dokumen secara otomatis untuk bahasa Indonesia masih sedikit jumlahnya jika dibandingkan dengan perkembangan untuk bahasa lainnya. Penelitian ini mengembangkan peringkasan dokumen otomatis bahasa Indonesia menggunakan metode berbasis graf yaitu algoritme TextRank dan algoritme LexRank yang sudah terbukti baik kinerjanya untuk bahasa Inggris. Jumlah kalimat yang diekstraksi adalah 25% dari total kalimat dalam dokumen. Hasil ringkasan kedua algoritme dievaluasi dengan metode kappa measure. Hasil perhitungan kappa measure memperlihatkan algoritme TextRank lebih baik daripada algoritme LexRank.
Kata Kunci: Dokumen Bahasa Indonesia, LexRank, Peringkasan Dokumen Otomatis, TextRank.
ABSTRACT
YUZAR MARSYAH. Performance Comparison of LexRank Algorithm and TextRank Algorithm in Indonesian Text Summarization. Supervised by SONY HARTONO WIJAYA.
Text summarization is an effective way to obtain information from a document without reading the whole document. Currently the small number of automatic text summarizations for Indonesian are available compared to those for other languages. This study develops an Indonesian automatic text summarization using the graph-based methods, the TextRank algorithm and the LexRank algorithm. It has been proven that the methods and the algorithms have good performance in summarizing texts for English. This work extracts about 25% of the total of sentences in the document. The kappa measure method is applied to evaluate the results of the two algorithms. The result based measure kappa on shows that the TextRank algorithm has better performance than the LexRank algorithm.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada
Departemen Ilmu Komputer
PERBANDINGAN KINERJA ALGORITME TEXTRANK DENGAN
ALGORITME LEXRANK PADA PERINGKASAN DOKUMEN
BAHASA INDONESIA
YUZAR MARSYAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Perbandingan Kinerja Algoritme TextRank dengan Algoritme LexRank pada Peringkasan Dokumen Bahasa Indonesia Nama : Yuzar Marsyah
NIM : G64090038
Disetujui oleh
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
Tanggal Lulus:
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Desember 2012 ini ialah peringkasan dokumen, dengan judul Perbandingan Kinerja Algoritme TextRank dengan Algoritme LexRank pada Peringkasan Dokumen bahasa Indonesia.
Penulis menyadari bahwa dalam proses penyusunan skripsi ini terdapat banyak kekurangan karena keterbatasan pengetahuan dan kemampuan yang dimiliki. Namun, karya ini berhasil diselesaikan atas bantuan dari berbagai pihak. Oleh karena itu penulis ingin mengucapkan terima kasih kepada:
1 Allah subhanahu wa ta’ala atas nikmat dan karunia-Nya.
2 Ayah, ibu, adik, dan seluruh keluarga yang memberikan doa serta dukungan untuk menyelesaikan skripsi ini.
3 Bapak Sony Hartono Wijaya, SKom, MKom atas bimbingan dan pemberian saran dalam proses penyelesaian skripsi.
4 Bapak Ahmad Ridha, SKom, MS dan Ibu Imas S. Sitanggang, SSi, MKom sebagai penguji atas kritikan dan masukan yang positif untuk menyempurnakan skripsi ini.
5 Efta Lupikasari, Catur Wulandari, dan Fairus Muntazin yang telah membantu dalam pengujian sistem.
6 Seluruh rekan-rekan di Ilmu Komputer 46.
7 Teman-teman satu kontrakan Darmaga Regency: Fachri, Tama, Bias, Kuncoro, Syarif, Bayu, dan Ikhwan.
8 Semua pihak yang membantu secara langsung maupun tidak langsung yang tidak bisa penulis sebutkan satu per satu.
Semoga karya ini dapat bermanfaat bagi semua pihak.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Ruang Lingkup Penelitian 2
METODE 3
Bahan 3
Gambaran Umum Sistem 3
HASIL DAN PEMBAHASAN 6
SIMPULAN DAN SARAN 14
Simpulan 14
Saran 14
DAFTAR PUSTAKA 15
LAMPIRAN 16
DAFTAR TABEL
1 Hasil proses pemisahan kalimat 7
2 Nilai similarity dokumen gatra030203.txt dengan metode Content
Overlap 8
3 Nilai similarity dokumen gatra030203.txt dengan metode
Idf-modified-cosine 8
4 Hasil akhir proses pemeringkatan dokumen gatra030203.txt 9
5 Hasil pengujian ahli terhadap 30 dokumen 10
6 Komponen Kappa dan nilai Kappa tiap pasang ahli untuk algoritme
TextRank 10
7 Komponen Kappa dan nilai Kappa tiap pasang ahli untuk algoritme
LexRank 11
8 Komponen formula PABAK dan nilai PABAK algoritme TextRank 11 9 Komponen formula PABAK dan nilai PABAK algoritme LexRank 11
DAFTAR GAMBAR
1 Metodologi penelitian 3
2 Contoh bentuk dokumen 6
3 Tingkat relevansi hasil ringkasan 10
4 Perbandingan nilai PABAK algoritme TextRank dan algoritme
LexRank 12
5 Rata-rata waktu pengembalian hasil ringkasan 30 dokumen 12 6 Posisi kalimat yang diekstraksi algoritme TextRank pada dokumen
gatra040303.txt 13
7 Posisi kalimat yang diekstraksi algoritme LexRank pada dokumen
gatra040303.txt 13
DAFTAR LAMPIRAN
1 Data hasil penilaian ahli terhadap ringkasan algoritme TextRank 16 2 Data hasil penilaian ahli terhadap ringkasan algoritme LexRank 17 3 Penyebaran hasil penilaian ahli untuk perhitungan Kappa pada
algoritme TextRank 18
4 Penyebaran hasil penilaian ahli untuk perhitungan Kappa pada
PENDAHULUAN
Latar Belakang
Peringkasan suatu teks dokumen merupakan cara yang efektif untuk mendapatkan informasi dari suatu dokumen. Ringkasan membantu seseorang mendapatkan intisari dari dokumen tanpa harus membaca keseluruhan dokumen tersebut, sehingga waktu yang dibutuhkan untuk menyerap informasi menjadi lebih singkat. Peringkasan manual dilakukan dengan membaca keseluruhan dokumen kemudian diambil intisari dari dokumen tersebut, sedangkan peringkasan otomatis dilakukan oleh komputer tanpa harus membaca keseluruhan dokumen dan hasil ringkasan tergantung oleh algoritme yang digunakan pada sistem. Peringkasan manual membutuhkan waktu yang sangat lama untuk membuat ringkasan dari jumlah dokumen yang sangat banyak dan isi dokumen yang panjang. Oleh karena itu, peringkasan teks secara otomatis menjadi solusi yang bisa mempersingkat waktu peringkasan.
Peringkasan teks otomatis sangat berkembang belakangan ini. Hal ini disebabkan oleh adanya internet yang terus berkembang dari waktu ke waktu membuat jumlah dokumen yang ada semakin melimpah jumlahnya. Menurut Short et al. (2011), pada tahun 2008 server-server di dunia memproses informasi sebesar 9.57 ZB. Hasil peringkasan teks secara otomatis dapat mempermudah dan mempercepat pencarian suatu dokumen ataupun memahami suatu dokumen.
Penelitian tentang peringkasan teks otomatis sudah banyak dilakukan sejak tahun 1958. Akan tetapi, penelitian yang dilakukan hanya pada bahasa tertentu, seperti bahasa Inggris, Yunani, Cina, dan lain-lain (Zikra 2009). Sementara itu, untuk bahasa Indonesia masih sedikit penelitian yang dilakukan. Contoh nyata aplikasi peringkasan teks otomatis bahasa Indonesia adalah Sistem Ikhtisar Dokumen untuk Bahasa Indonesia (SIDOBI) yang dibuat oleh Badan Pengkajian dan Penerapan Teknologi (BPPT) pada tahun 2010.
Salah satu metode dalam peringkasan teks otomatis ialah peringkasan teks menggunakan pemeringkatan berbasis graf. Pada awalnya, metode pemeringkatan berbasis graf digunakan dalam pemeringkatan halaman web. Beberapa algoritme berbasis graf yang digunakan dalam pemeringkatan halaman web yaitu Kleinberg HITS (Kleinberg 1999 di dalam Mihalcea 2004) dan Google PageRank (Brin dan Page 1998 di dalam Mihalcea 2004). Seiring berjalannya waktu, metode berbasis graf mulai diimplementasikan untuk peringkasan dokumen. Algoritme peringkasan dokumen berbasis graf yang ada adalah algoritme LexRank dan algoritme TextRank. LexRank dan TextRank mengasumsikan graf yang fully-connected dan graf tidak berarah dengan unit teks (seperti kata atau kalimat) sebagai vertex dan similarity antarteks unit sebagai edge.
2
ringkasan berasal dari satu dokumen atau lebih dari satu dokumen. LexRank menggunakan pendekatan berbasis centroid dalam proses peringkasan. Menurut Erkan dan Radev (2004), pendekatan berbasis centroid cukup sukses dibandingkan dengan sistem peringkasan lainnya dalam peringkasan multi dokumen.
Berdasarkan latar belakang tersebut, dalam penelitian ini dikembangkan sistem peringkasan teks otomatis untuk bahasa Indonesia dengan menggunakan algoritme TextRank dan LexRank untuk peringkasan dokumen bahasa Indonesia. Alasan membandingkan kedua algoritme karena algoritme TextRank dan algoritme LexRank telah digunakan pada peringkasan untuk bahasa Inggris dan bahasa lainnya. Selain itu, kedua algoritme tersebut memiliki kelebihan masing-masing seperti yang sudah disebutkan sebelumnya sehingga perlu diteliti algoritme yang lebih efektif untuk dokumen bahasa Indonesia.
Perumusan Masalah
Peringkasan teks otomatis semakin diperlukan belakangan ini karena seseorang cenderung ingin mendapatkan informasi yang lengkap tanpa menghabiskan terlalu banyak waktu. Selain itu, peringkasan teks otomatis dapat mempercepat pencarian dan memahami suatu dokumen dari jumlah data yang sangat banyak. Peringkasan teks otomatis untuk bahasa Indonesia salah satunya menggunakan metode pemeringkatan berbasis graf. Metode pemeringkatan berbasis graf memiliki beberapa algoritme yang dikhususkan untuk peringkasan otomatis, yaitu algoritme TextRank dan algoritme LexRank. Kedua algoritme memiliki kelebihan masing-masing dan telah digunakan pada dokumen bahasa Inggris. Oleh karena itu, dibutuhkan suatu perbandingan kedua algoritme untuk menentukan algoritme yang efektif untuk dokumen bahasa Indonesia.
Tujuan Penelitian
Tujuan dari penelitian ini adalah membandingkan kinerja algoritme TextRank dengan algoritme LexRank dalam peringkasan dokumen bahasa Indonesia.
Ruang Lingkup Penelitian
3
METODE
Bahan
Pada penelitian ini jenis dokumen yang digunakan ialah dokumen berbahasa Indonesia. Semua dokumen menggunakan bahasa Indonesia semi-formal atau formal. Koleksi dokumen yang digunakan sebanyak 30 dokumen dan merupakan koleksi korpus pada penelitian Zikra (2009).
Gambaran Umum Sistem
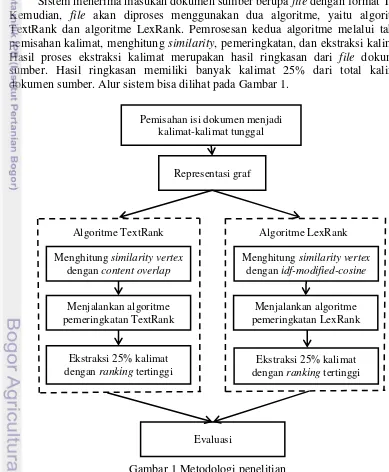
Sistem menerima masukan dokumen sumber berupa file dengan format TXT. Kemudian, file akan diproses menggunakan dua algoritme, yaitu algoritme TextRank dan algoritme LexRank. Pemrosesan kedua algoritme melalui tahap pemisahan kalimat, menghitung similarity, pemeringkatan, dan ekstraksi kalimat. Hasil proses ekstraksi kalimat merupakan hasil ringkasan dari file dokumen sumber. Hasil ringkasan memiliki banyak kalimat 25% dari total kalimat dokumen sumber. Alur sistem bisa dilihat pada Gambar 1.
Gambar 1 Metodologi penelitian
Pemisahan isi dokumen menjadi kalimat-kalimat tunggal
Representasi graf
Menghitung similarityvertex
dengan content overlap
Menghitung similarity vertex
dengan idf-modified-cosine
Menjalankan algoritme pemeringkatan TextRank
Menjalankan algoritme pemeringkatan LexRank
Ekstraksi 25% kalimat dengan ranking tertinggi
Ekstraksi 25% kalimat dengan ranking tertinggi
Algoritme TextRank Algoritme LexRank
4
Pemisahan Isi Dokumen Menjadi Kalimat-kalimat Tunggal
Dokumen yang terdiri atas beberapa kalimat dipecah menjadi kalimat-kalimat tunggal yang disimpan dalam suatu koleksi. Pemecahan dokumen dilakukan dengan menggunakan splitter berupa tanda baca seperti titik (“.”), tanda seru (“!”), tanda tanya (“?”), dan newline (Zikra 2009).
Representasi Graf
Pada peringkasan teks dengan metode pemeringkatan berbasis graf, vertex merepresentasikan kalimat-kalimat yang berada dalam dokumen sedangkan edge merepresentasikan similarity antara dua kalimat yang saling berelasi. Setiap kalimat tunggal yang diperoleh dari proses pemisahan kalimat dianggap sebagai vertex dalam graf.
Pada algortime Textrank formula yang digunakan untuk menghitung similarity adalah Content Overlap. Formula Content Overlap dituliskan sebagai berikut (Mihalcea dan Tarau 2004):
a t , | | | | ( ) ( )
dengan adalah jumlah kata yang sama antarkalimat dengan kalimat , log( dan log( ) adalah representasi panjang kalimat. Formula tersebut diberlakukan ke semua kalimat tunggal yang ada untuk mendapatkan bobot yang menghubungkan antarkalimat.
Berbeda dengan algoritme Textrank, pada algoritme Lexrank formula similarity yang digunakan ialah invers document frequency-modified-cosine (idf-modified-cosine). Formula idf-modified-cosine dituliskan sebagai berikut (Erkan dan Radev 2004): kalimat yang mengandung kata . Sama seperti algoritme Textrank, Formula idf-modified-cosine diberlakukan ke semua kalimat tunggal.
Proses Pemeringkatan
5 menggunakan formula untuk graf tidak berarah dan terboboti seperti yang dituliskan sebagai berikut (Mihalcea dan Tarau 2004):
d d ∑ ∑
Setiap kalimat tunggal diinisialisasi bobot awal 1 (Rogers 2002). Kemudian dilakukan iterasi dengan formula (4) sampai error rate di bawah threshold. Error rate adalah selisih skor vertex pada iterasi k dengan iterasi k+1. Setelah didapatkan bobot akhir setiap vertex, diurutkan mulai dari yang terbesar sampai yang terkecil.
Pada algoritme LexRank proses pemeringkatan dilakukan dengan menghitung degree centrality dari tiap vertex. Degree centrality adalah banyaknya edge yang terhubung ke suatu vertex. Kemudian nilai similarity diperbaharui dengan membagi nilai similarity lama dengan degree centrality. Nilai similarity yang baru dijadikan masukan untuk algoritme power method. Algoritme power method digunakan untuk mencari nilai eigen terbesar dari suatu matriks sehingga didapatkan eigenvector yang dominan dari nilai eigen tersebut. Hasil dari algoritme power method adalah matriks eigenvector yang merupakan bobot akhir dari setiap vertex. Kemudian bobot vertex diurutkan dari yang terbesar sampai yang terkecil.
Ekstraksi Kalimat
Proses ekstraksi kalimat dilakukan dengan mengambil 25% kalimat dari total kalimat yang ada di dokumen. Kalimat yang diekstraksi adalah kalimat yang memiliki peringkat paling tinggi. Menurut Kupiec et al. (1995), 25% hasil ekstraksi dari teks sumber memiliki 84% kalimat penting yang dipilih oleh para ahli untuk menjadi ringkasan. Hasil ekstraksi kalimat dijadikan sebagai hasil ringkasan.
Evaluasi
Pada penelitian ini evaluasi hasil dari algoritme TextRank dan LexRank akan dilakukan dengan menggunakan kappa measure. Kappa digunakan untuk mengukur tingkat kesesuaian dalam menilai klasifikasi data dari beberapa ahli (Manning et al. 2009). Relevansi klasifikasi data dalam penelitian ini dibagi dua kategori, yaitu relevan dan non-relevan. Kappa measure memiliki formula:
a a ( )
6
HASIL DAN PEMBAHASAN
Koleksi Dokumen Pengujian
Penelitian ini menggunakan dokumen berbahasa Indonesia yang diperoleh dari penelitian Zikra (2009). Dokumen yang digunakan sebanyak 30 dokumen dengan format TXT. Dokumen ini berisi tag-tag XML, namun hanya tag Text yang akan diproses oleh sistem karena tag ini merupakan isi dari dokumen. Gambar 2 memperlihatkan salah satu bentuk dokumen yang digunakan pada penelitian ini.
Gambar 2 Contoh bentuk dokumen Pemisahan Isi Dokumen Menjadi Kalimat-kalimat Tunggal
Proses ini memisahkan isi dokumen yang ingin diringkas menjadi kalimat-kalimat tunggal. Pemisahan ini menggunakan splitter b u a tanda ba a t t (“.”), tanda tan a (‘?”), tanda u (“!”), dan newline. Proses pemisahan ini dapat mengenali bentuk-bentuk gelar pada nama seseorang seperti “Prof. Dr. Budi, M.Sc”. Selain itu, proses ini bisa mengenali singkatan dari nama latin suatu spesies seperti E. Coli dan mengenal pemisah nominal ribuan seperti 2.350. Hasil proses ini menghasilkan rata-rata jumlah kalimat tiap dokumen sebanyak 29.97 kalimat dengan total kalimat dari 30 dokumen sebanyak 899 kalimat. Hasil lengkap dapat dilihat pada Tabel 1.
Representasi Graf Algoritme TextRank
Proses ini merepresentasikan isi dokumen ke dalam bentuk graf. Kalimat-kalimat tunggal dari proses sebelumnya dijadikan vertex. Nilai similarity setiap pasang kalimat dijadikan edge. Untuk mencari nilai similarity, algoritme TextRank menggunakan formula (1). Content overlap mengidentifikasi jumlah kata yang sama di setiap pasang kalimat yang ada pada dokumen. Similarity(Si, Sj)
adalah fungsi perhitungan similarity tiap pasang kalimat dalam dokumen. Banyaknya jumlah kata yang sama di kalimat Si dan Sj kemudian dibagi dengan
panjang kedua kalimat. Banyak kata yang sama dalam satu kalimat tidak mem n a uh h tun an. M a n a ata “ ad ” ada a at Sj muncul sebanyak
7 Tabel 1 Hasil proses pemisahan kalimat
Dokumen Kalimat Kata
8
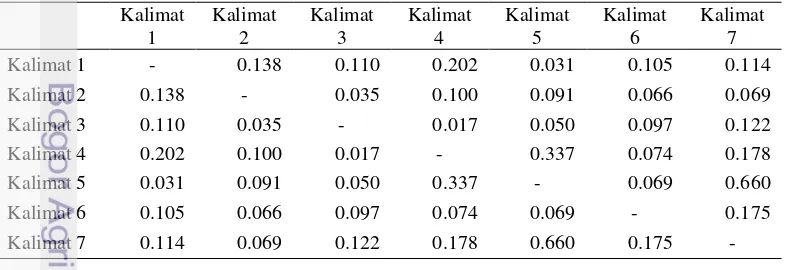
Tabel 2 Nilai similarity dokumen gatra030203.txt dengan metode Content Overlap
Proses ini sama seperti proses representasi graf algoritme TextRank. Akan tetapi, perbedaannya ada pada saat menghitung similarity. Pada proses ini perhitungan similarity dilakukan dengan menggunakan formula (2). Idf-modified-cosine menghitung bobot dari setiap term yang terdapat di setiap pasang kalimat dengan pembobotan tf-idf. Hasil dari pembobotan tf-idf untuk term yang terdapat di kedua kalimat kemudian dinormalisasi. Proses normalisasi dilakukan dengan membagi hasil tf-idf term yang terdapat di kedua kalimat dengan tf-idf setiap term pada masing-masing kalimat. Idf-modified-cosine memiliki nilai antara 0.0–18.95 pada percobaan 30 dokumen. Hal ini dipengaruhi oleh frekuensi kata yang muncul di setiap pasang kalimat dan frekuensi kemunculan kata tersebut di keseluruhan dokumen serta di kalimat itu sendiri. Jika tidak ada kata yang sama di setiap pasang kalimat maka nilai similarity idf-modified-cosine bernilai 0. Tabel 3 memperlihatkan nilai similarity salah satu dokumen uji dengan metode idf-modified-cosine. Sama seperti proses representasi graf algoritme TextRank, nilai similarity yang lebih dari 0 yang akan menjadi edge.
Tabel 3 Nilai similarity dokumen gatra030203.txt dengan metode Idf-modified-cosine
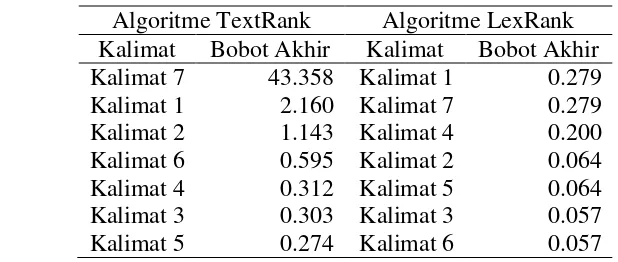
9 setelah proses pemeringkatan bernilai antara 0.1500–8.7155. Pada algoritme LexRank, proses pemeringkatan menghasilkan bobot akhir setiap vertex dari 30 dokumen antara 0.0000–0.2786. Hasil akhir proses pemeringkatan terhadap salah satu dokumen bisa dilihat pada Tabel 4.
Tabel 4 Hasil akhir proses pemeringkatan dokumen gatra030203.txt Algoritme TextRank Algoritme LexRank
Kalimat Bobot Akhir Kalimat Bobot Akhir Kalimat 7 43.358 Kalimat 1 0.279
Setelah diperoleh bobot akhir setiap vertex berdasarkan kedua algoritme, proses selanjutnya adalah proses ekstraksi kalimat. Proses ekstraksi kalimat merupakan proses memilih kalimat dari sebuah dokumen yang akan dijadikan ringkasan. Penelitian ini menggunakaan tingkat kompresi sebesar 25% dan kalimat yang dipilih adalah kalimat dengan peringkat paling tinggi. Misalkan suatu dokumen memiliki 20 kalimat, maka kalimat yang akan diekstraksi sebanyak 5 kalimat yang peringkatnya paling tinggi. Jika hasil perhitungan 25% dari total kalimat adalah bilangan desimal maka hasil perhitungan tersebut dibulatkan ke atas. Misalkan 25% kalimat yang diekstraksi adalah 5.5 maka banyak kalimat yang dijadikan ringkasan adalah 6 kalimat.
Evaluasi
Setelah didapatkan hasil ringkasan dari kedua algoritme, proses selanjutnya yaitu evaluasi hasil ringkasan dari kedua algoritme. Proses evaluasi menggunakan tiga orang ahli dan ringkasan yang dibuat oleh ketiga ahli tersebut serta perhitungannya menggunakan metode Kappa Measure. Para ahli merupakan lulusan Sastra Indonesia dan berprofesi sebagai pengajar bahasa Indonesia.
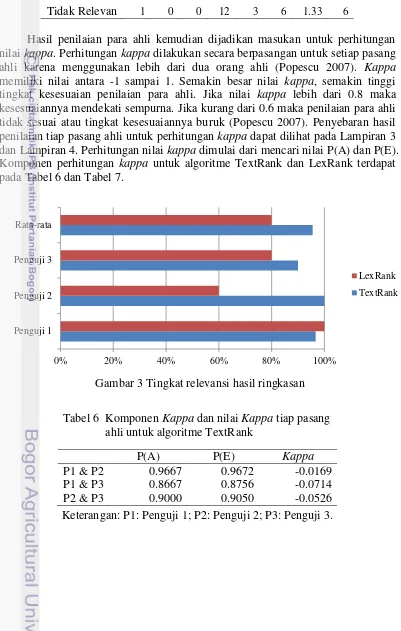
Para ahli menilai hasil ringkasan algoritme TextRank dan ringkasan algoritme LexRank dengan membandingkan hasil ringkasan kedua algoritme dengan ringkasan manual. Ringkasan manual adalah ringkasan yang dibuat oleh para ahli. Kategori penilaian dibagi dua, yaitu relevan dan non-relevan. Hasil penilaian ketiga ahli terdapat pada Tabel 5 dan untuk lebih lengkapnya dapat dilihat pada Lampiran 1 dan Lampiran 2.
10
0% 20% 40% 60% 80% 100%
Penguji 1 Penguji 2 Penguji 3 Rata-rata
LexRank
TextRank Tabel 5 Hasil pengujian ahli terhadap 30 dokumen
Relevansi Penguji 1 Penguji 2 Penguji 3 Rata-rata TR LR TR LR TR LR TR LR Relevan 29 30 30 18 27 24 28.67 24
Tidak Relevan 1 0 0 12 3 6 1.33 6
Hasil penilaian para ahli kemudian dijadikan masukan untuk perhitungan nilai kappa. Perhitungan kappa dilakukan secara berpasangan untuk setiap pasang ahli karena menggunakan lebih dari dua orang ahli (Popescu 2007). Kappa memiliki nilai antara -1 sampai 1. Semakin besar nilai kappa, semakin tinggi tingkat kesesuaian penilaian para ahli. Jika nilai kappa lebih dari 0.8 maka kesesuaiannya mendekati sempurna. Jika kurang dari 0.6 maka penilaian para ahli tidak sesuai atau tingkat kesesuaiannya buruk (Popescu 2007). Penyebaran hasil penilaian tiap pasang ahli untuk perhitungan kappa dapat dilihat pada Lampiran 3 dan Lampiran 4. Perhitungan nilai kappa dimulai dari mencari nilai P(A) dan P(E). Komponen perhitungan kappa untuk algoritme TextRank dan LexRank terdapat pada Tabel 6 dan Tabel 7.
Tabel 6 Komponen Kappa dan nilai Kappa tiap pasang ahli untuk algoritme TextRank
P(A) P(E) Kappa
P1 & P2 0.9667 0.9672 -0.0169 P1 & P3 0.8667 0.8756 -0.0714 P2 & P3 0.9000 0.9050 -0.0526 Keterangan: P1: Penguji 1; P2: Penguji 2; P3: Penguji 3.
11 Tabel 7 Komponen Kappa dan nilai Kappa tiap pasang
ahli untuk algoritme LexRank
P(A) P(E) Kappa
P1 & P2 0.6000 0.6800 -0.2500 P1 & P3 0.8000 0.8200 -0.1111 P2 & P3 0.5333 0.5800 -0.1111 Keterangan: P1: Penguji 1; P2: Penguji 2; P3: Penguji 3.
Algoritme TextRank memiliki nilai kappa rata-rata sebesar -0.0469 sedangkan nilai kappa rata-rata LexRank sebesar -0.15741. Jika nilai kappa kedua algoritme dibandingkan maka kedua algoritme memiliki nilai kappa yang sangat kecil dan bernilai negatif yang artinya tingkat kesesuaian para ahli sangat buruk. Akan tetapi metode kappa memiliki kekurangan yaitu pada saat nilai kesesuaian tinggi namun nilai kappa kecil (Feinstein dan Cicchetti 1990). Hal ini yang terjadi pada evaluasi peringkasan dokumen dengan algoritme TextRank dan LexRank. Pada algoritme TextRank dan LexRank nilai kesesuaian rata-rata tiap pasang ahli (P(A)) 0.9111 dan 0.6444. Akan tetapi nilai kappa yang dihasilkan bernilai negatif sehingga nilai kappa kedua algoritme tidak bisa langsung dibandingkan karena kekurangan metode kappa tersebut.
Menurut Bryt et al. (1993) di dalam Cunningham (2009), solusi untuk kekurangan kappa tersebut dengan menghitung nilai Prevelance-adjusted bias-adjusted kappa (PABAK). Semakin tinggi nilai PABAK semakin tinggi pula tingkat kesesuaian penilaian para ahli. Formula untuk menghitung PABAK sebagai berikut:
– ( )
Berdasarkan formula (6), nilai PABAK dari tiap pasang ahli terdapat pada Tabel 8 dan Tabel 9.
Tabel 8 Komponen formula PABAK dan nilai PABAK algoritme TextRank
P(A) PABAK
P1 & P2 0.9667 0.9334 P1 & P3 0.8667 0.7334 P2 & P3 0.9000 0.8000
Keterangan: P1: Penguji 1; P2: Penguji 2; P3: Penguji 3. Tabel 9 Komponen formula PABAK dan
nilai PABAK algoritme LexRank
P(A) PABAK
P1 & P2 0.6000 0.2000 P1 & P3 0.8000 0.6000 P2 & P3 0.5333 0.0666
12
Hasil perhitungan PABAK untuk algoritme TextRank memiliki rata-rata 0.8223 sedangkan untuk algoritme LexRank memiliki nilai PABAK rata-rata sebesar 0.2889. Algoritme TextRank memiliki nilai PABAK yang lebih tinggi dari algoritme LexRank. Tingkat relevansi algoritme TextRank terhadap isi dokumen juga tinggi. Hal ini memperlihatkan bahwa algoritme TextRank lebih baik dalam peringkasan dokumen bahasa Indonesia dibandingkan dengan algoritme LexRank. Perbandingan nilai PABAK bisa dilihat pada Gambar 4.
Gambar 4 Perbandingan nilai PABAK algoritme TextRank dan algoritme LexRank
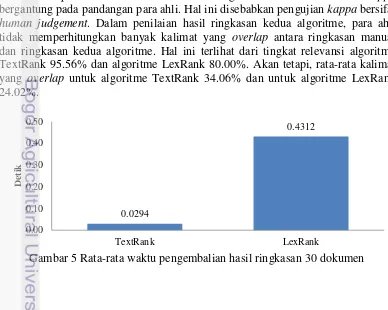
Algoritme TextRank dan Algoritme LexRank memiliki waktu yang berbeda dalam mengembalikan hasil ringkasan. Pada algoritme TextRank rata-rata waktu untuk mengembalikan hasil ringkasan adalah 0.0294 detik. Algoritme LexRank memiliki waktu rata-rata untuk mengembalikan hasil ringkasan 0.4312 detik. Rata-rata waktu pengembalian hasil ringkasan 30 dokumen terdapat pada Gambar 5.
Analisis Hasil Penilaian Para Ahli
Hasil penilaian untuk menentukan tingkat relevansi dan nilai kappa bergantung pada pandangan para ahli. Hal ini disebabkan pengujian kappa bersifat human judgement. Dalam penilaian hasil ringkasan kedua algoritme, para ahli tidak memperhitungkan banyak kalimat yang overlap antara ringkasan manual dan ringkasan kedua algoritme. Hal ini terlihat dari tingkat relevansi algoritme TextRank 95.56% dan algoritme LexRank 80.00%. Akan tetapi, rata-rata kalimat yang overlap untuk algoritme TextRank 34.06% dan untuk algoritme LexRank 24.02%.
13 Hasil ringkasan algoritme TextRank menurut para ahli mengandung kalimat-kalimat yang memiliki informasi lebih banyak dan lebih umum untuk mewakili dokumen sumber dibandingkan algoritme LexRank. Hal ini dilihat dari hasil ringkasan algoritme TextRank diekstraksi dari kalimat-kalimat awal dan akhir dokumen sumber. Sementara itu, algoritme LexRank mengekstraksi kalimat-kalimat yang posisinya di akhir dokumen sumber. Posisi kalimat yang diekstraksi pada salah satu dokumen oleh kedua algoritme terlihat pada Gambar 6 dan Gambar 7. Dokumen yang digunakan pada penelitian ini berupa artikel berita sehingga menurut para ahli kalimat-kalimat awal dari suatu artikel berita biasanya mengandung informasi inti dari suatu dokumen.
Gambar 6 Posisi kalimat yang diekstraksi algoritme TextRank pada dokumen gatra040303.txt
14
Para ahli menilai algoritme TextRank lebih cepat dalam mengeluarkan hasil ringkasan dibandingkan algoritme LexRank. Algoritme TextRank memiliki waktu rata-rata untuk mengembalikan hasil ringkasan tiap dokumen 0.0294 detik sedangkan algoritme LexRank 0.4312 detik. Pada algoritme TextRank, proses yang dilakukan dalam menghitung similarity dan pemeringkatan hanya operasi matematika biasa seperti penjumlahan, perkalian, pembagian, dan logaritma. Pada algoritme LexRank, selain operasi matematika biasa terdapat operasi perkalian matriks. Hal ini yang menyebabkan waktu pengembalian hasil ringkasan algoritme LexRank lebih lama dibandingkan algoritme TextRank.
SIMPULAN DAN SARAN
Simpulan
Pada penelitian ini telah berhasil dibuat dan dibandingkan kinerja algoritme TextRank dengan algoritme LexRank pada peringkasan dokumen bahasa Indonesia. Algoritme TextRank memperlihatkan kinerja yang lebih baik dalam meringkas dokumen bahasa Indonesia dibandingkan dengan algoritme LexRank. Hal ini terlihat dari tingkat relevansi rata-rata algoritme TextRank sebesar 95.56% dan nilai PABAK rata-rata 0.8223 lebih tinggi dari algoritme LexRank yang memiliki tingkat relevansi rata-rata 80.00% dan nilai PABAK rata-rata 0.2889. Jika dilihat dari waktu pengembalian hasil ringkasan, algoritme TextRank lebih cepat dalam mengembalikan hasil ringkasan dibandingkan dengan algoritme LexRank.
Saran
Pengembangan lebih lanjut perlu dilakukan untuk menghasilkan sistem peringkasan otomatis dokumen bahasa Indonesia yang lebih baik. Beberapa saran untuk pengembangan lebih lanjut sebagai berikut :
1 Melakukan proses stemming untuk menghilangkan imbuhan sehingga kata yang memiliki kata dasar yang sama dianggap sama dalam perhitungan similarity kedua algoritme, misalkan kata menyapu dengan kata sapu akan dianggap sama setelah proses stemming.
2 Melakukan proses menghilangkan stop word untuk menghilangkan kata-kata yang tidak memiliki makna seperti kata hubung sehingga tidak masuk dalam perhitungan nilai similarity.
3 Menggunakan metode pengujian yang lain seperti recall precision, F-measure atau Dice Coefficient.
15
DAFTAR PUSTAKA
Cunningham M. 2009. More than just the kappa coefficient: a program to fully characterize inter-rater reliability between two raters. Di dalam: SAS Global Forum 2009 Proceedings [Internet]; 2009 Mar 22-25; Washington DC, Amerika Serikat. Washington (US); [diunduh 2013 Jun 16]. Tersedia pada: http://support.sas.com/resources/papers/proceedings09/242-2009.pdf.
Erkan G, Radev DR. 2004. LexRank: graph-based lexical centrality as salience in text summarization. Journal of Artificial Intelligence Research. 22(2004): 457-479.
Feinstein AR, Cicchetti DV. 1990. High agreement but low kappa: I. The problems of two paradoxes. Journal of Clinical Epidemiology. 6(1990):543-549.
Kupiec J, Pedersen J, Chen F. 1995. A trainable document summarizer. Di dalam: Proceedings of the 18th annual international ACM SIGIR conference on Research and development in information retrieval; 1995 Jul 9-13; Seattle, Amerika Serikat. Seattle (US): ACM. hlm 68-73.
Manning C, Raghavan P, Schutze H. 2009. An Introduction to Information Retrieval. Cambridge (GB): Cambridge University Press.
Mihalcea R, Tarau P. 2004. TextRank : Bringing Order into Texts. Di dalam: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2004); 2004 Jul 25-26; Barcelona, Spanyol. Pennsylvania (US): Association for Computational Linguistics. hlm 404-411.
Popescu A. 2007. The kappa measure of inter-coder agreement on classification tasks. http://andreipb.free.fr/textes/apb-kappa-181207.pdf [3 Jun 2013]. Rogers I. 2002. The Google pagerank algorithm and how it works.
http://www.iprcom.com/papers/pagerank [16 Okt 2012].
Short JE, Bohn RE, Baru C. 2011. How much information? Report on enterprise server information. http://hmi.ucsd.edu/pdf/HMI_2010_EnterpriseReport_ Jan_2011.pdf [24 Jun 2013].
16
Lampiran 1 Data hasil penilaian ahli terhadap ringkasan algoritme TextRank No Penguji 1 Penguji 2 Penguji 3
1 R R R
2 R R R
3 R R R
4 R R TR
5 R R R
6 R R R
7 TR R R
8 R R R
9 R R TR
10 R R R
11 R R R
12 R R R
13 R R R
14 R R R
15 R R R
16 R R R
17 R R R
18 R R R
19 R R R
20 R R R
21 R R R
22 R R R
23 R R R
24 R R R
25 R R R
26 R R R
27 R R R
28 R R R
29 R R R
30 R R TR
17 Lampiran 2 Data hasil penilaian ahli terhadap ringkasan algoritme LexRank
No Penguji 1 Penguji 2 Penguji 3
1 R TR R
2 R TR R
3 R R R
4 R R TR
5 R TR R
6 R R R
7 R R R
8 R TR R
9 R R R
10 R R TR
11 R TR R
12 R R R
13 R R R
14 R R TR
15 R R R
16 R TR R
17 R TR R
18 R TR R
19 R TR TR
20 R R TR
21 R R R
22 R TR R
23 R TR R
24 R TR TR
25 R R R
26 R R R
27 R R R
28 R R R
29 R R R
30 R R R
18
Lampiran 3 Penyebaran hasil penilaian ahli untuk perhitungan Kappa pada algoritme TextRank
Penguji 2
Relevan Tidak Relevan
Penguji 1 Relevan 29 0
Tidak Relevan 1 0
Penguji 3
Relevan Tidak Relevan
Penguji 1 Relevan 26 3
Tidak Relevan 1 0
Penguji 3
Relevan Tidak Relevan
Penguji 2 Relevan 27 3
Tidak Relevan 0 0
Lampiran 4 Penyebaran hasil penilaian ahli untuk perhitungan Kappa pada algoritme LexRank
Penguji 2
Relevan Tidak Relevan
Penguji 1 Relevan 18 12
Tidak Relevan 0 0
Penguji 3
Relevan Tidak Relevan
Penguji 1 Relevan 24 6
Tidak Relevan 0 0
Penguji 3
Relevan Tidak Relevan
Penguji 2 Relevan 14 4
19
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 7 Mei 1992 dan merupakan anak pertama dari tiga bersaudara dari pasangan Drs. H. Muh. Firmansyah, MSi dan Hj. Susi Marlena, SE, MM.
Penulis mengawali pendidikan pada tahun 1997 sampai tahun 2003 di SD Negeri 03 Pagi Utan Kayu Utara. Selanjutnya, penulis meneruskan ke pendidikan lanjutan tingkat pertama dari tahun 2003 sampai tahun 2006 di SMP Negeri 7 Jakarta. Setelah itu, penulis melanjutkan pendidikan menengah atas di SMA Negeri 68 Jakarta dan lulus pada tahun 2009.
Pada tahun 2009, penulis diterima di Institut Pertanian Bogor (IPB) melalui jalur USMI kemudian terdaftar sebagai mahasiswa Fakultas Matematika dan IPA (FMIPA) pada Departemen Ilmu Komputer.