Peringkasan Teks Otomatis Berita Berbahasa
Indonesia Pada Multi-Document Menggunakan
Metode Support Vector Machines (SVM)
Deni Fitriaman#1, Masayu Leylia Khodra#2, Bambang Rianto Trilaksono*3#Teknik Informatika, Sekolah Teknik Elektro dan Informatika, Institut Teknologi Bandung Bandung, Jawa Barat, Indonesia
1 [email protected] 2 [email protected],
*Teknik Elektro, Sekolah Teknik Elektro dan Informatika, Institut Teknologi Bandung
Bandung, Jawa Barat, Indonesia 3 [email protected]
Abstrak — Banyaknya berita-berita online sering menarik
minat masyarakat untuk membacanya, tetapi kadang dengan terlalu banyaknya berita tersebut membuat orang susah mendapatkan informasi yang relevan. Ringkasan artikel berita dapat membantu pembaca untuk mendapatkan informasi penting dari berita. Pada penelitian ini sistem peringkasan teks
otomatis berita pada multi-document dibagi menjadi empat
tahap utama, yaitu: preprocessing, ekstraksi fitur, machine
learning, dan generate summarization dari beberapa artikel yang mempunyai topik sama. Fitur-fitur kalimat yang digunakan adalah panjang kalimat, posisi kalimat, adanya data
numeric, kata-kata thematic, similaritas kalimat dengan judul,
kemiripan kalimat dengan kumpulan kalimat lain, ikatan leksikal dengan kalimat sebelum dan sesudahnya. Pada
tahapan machine learning menggunakan metode support
vector machine (SVM) dengan algoritma LibSVM untuk
menghasilkan model. Sedangkan pada generate summarization
menggunakan metode maximal marginal relevance (MMR)
untuk menghilangkan redundancy data. Dengan menggunakan
metode LibSVM dihasilkan beberapa kandidat ringkasan yang selanjutnya diseleksi menggunakan metode MMR. Sehingga didapatkan hasil ringkasan ekstraksi yang efektif dan efisien.
Kata kunci — peringkasan teks, berita, multi-document, Support Vector Machine (SVM), Maximal Marginal Relevance (MMR).
I. PENDAHULUAN
Seiring dengan perkembangan zaman membuat kebutuhan manusia terhadap informasi semakin besar, hal ini membuat manusia mulai beralih dari pencarian berita tradisional (seperti koran, radio, televisi, dll) ke penggunaan aplikasi media online dan situs media sosial [1]. Perkembangan pesat layanan informasi online telah mengakibatkan ledakan informasi (information overloading) sehingga tidak ada waktu untuk membaca semua informasi berita online secara lengkap [2][3]. Informasi yang ada pada saat ini tidak hanya bersumber dari satu dokumen saja, melainkan dari beberapa dokumen (multi-document) [4]. Cara dalam mengatasi permasalahan itu adalah dengan membuat satu ringkasan dari beberapa artikel berita. Sebagai dampak dari besarnya kumpulan dokumen online dan meningkatnya kebutuhan bagi pembaca untuk mendapatkan informasi penting dari kumpulan dokumen tersebut, maka dikembangkannya penelitian mengenai metode peringkasan teks multi-document [2] [4].
Peringkasan teks (Text Summarization) adalah proses penyaringan informasi paling penting dari satu atau beberapa sumber untuk menghasilkan teks (ringkasan) dengan panjang tidak lebih dari setengah (kurang dari 50%) teks asli untuk pengguna [2] [5].
Metode peringkasan teks yang digunakan dalam penelitian ini adalah pendekatan pembelajaran mesin (machine
learning). Dengan menggunakan metode ini peringkasan
kalimat akan dipandang sebagai permasalahan klasifikasi kalimat. Kalimat dalam artikel akan dibagi menjadi dua kelas, yaitu kelas positif dan kelas negatif. Kalimat positif berisi kalimat yang termasuk ke dalam ringkasan, sedangkan kalimat negatif tidak termasuk ke dalam ringkasan [6]. Metode klasifikasi yang akan digunakan dalam penelitian kali ini adalah Support Vector Machine (SVM).
Tujuan dari penelitian ini adalah membangun SVM
Classifier untuk peringkasan teks berita online berbahasa
Indonesia pada multi-document, merumuskan kelompok fitur yang digunakan pada proses klasifikasi, serta menghasilkan ringkasan yang efektif dan efisien dengan menggunakan metode Maximal Marginal Relevance (MMR). Kumpulan dokumen yang digunakan sebagai dataset adalah kumpulan berita online yang diambil dalam satu topik dari sepuluh situs berita online (www.detik.com, www.liputan6.com, www.kompas.com, www.tribunnews.com, www.viva.co.id, www.okezone.com, www.tempo.co, www.antaranews.com, metrotvnews.com, dan www.mediaindonesia.com).
II. PERINGKASAN OTOMATIS BERITA ONLINE BERBAHASA INDONESIA PADA
MULTI-DOCUMENT
Peringkasan otomatis berita online berbahasa Indonesia pada multi-document adalah sistem peringkasan teks otomatis untuk kumpulan berita online yang diambil dari beberapa situs berita online yang memiliki topik yang sama (satu topik) dan menggunakan SVM Classifier. Masukan dari sistem adalah teks kumpulan berita yang diperoleh dari 10 situs berita online dalam satu topik. Output dari sistem adalah ringkasan ekstraksi dari teks input (compression rate). Sistem ini
memiliki dua proses utama, yaitu proses pelatihan (training) dan proses pengujian (testing). Pada proses pelatihan sistem akan mencari model klasifikasi untuk SVM Classifier, sedangkan pada proses pengujian dilakukan untuk mengetahui kinerja dari sistem. Arsitektur sistem Peringkasan Teks Otomatis multi-document ditunjukan oleh Gambar 1.
Preprocessing Kumpulan Dokumen Pelatihan Tokenization Stop-words / Stop-list Removal Inde xing Kumpulan Dokumen Masukan E k s t r a k s i F I t u r Vektor Fit ur Vektor Fit ur Pelatihan SVM SVM Classifier Model Klasifikasi Kandidat Kalimat Ringkasan Pembentukan Ringkasan (MMR) Hasil Ringkasan Gambar 1. Arsitektur Sistem Peringkasan Teks Berita Online
Berbahasa Indonesia pada Multi-Document
Langkah-langkah pada proses pelatihan adalah sebagai berikut:
a. Mempersiapkan dokumen pelatihan (training dataset). Training dataset yang digunakan adalah kumpulan teks berita online berbahasa Indonesia yang memiliki topic yang sama.
b. Membuat ringkasan manual dengan persentase pemampatan berkisar 25% sampai dengan 30% dari satu kumpulan topik yang sama. Yang digunakan oleh training dataset.
c. Melakukan preprocessing yang umum digunakan dalam metode temu-balik informasi (tokenizing, stop-word, case folding, dan indexing) pada setiap dokumen pelatihan.
d. Mengekstraksi dokumen pelatihan dengan cara mengubah seluruh kalimat ke dalam vektor fitur. e. Melatih SVM menggunakan vektor fitur untuk
mendapatkan model klasifikasi.
Sedangkan langkah-langkah pada proses pengujian adalah sebagai berikut:
a. Melakukan preprocessing dan ekstraksi fitur untuk mendapatkan vektor fitur.
b. Vektor fitur akan diklasifikasikan oleh SVM classifier dengan menggunakan model klasifikasi yang telah diperoleh pada proses pelatihan.
c. Setiap kalimat dalam dokumen akan diurutkan berdasarkan nilai α. N kalimat teratas diekstrak untuk disusun ke dalam ringkasan.
A. Support Vector Machines (SVM)
Support Vector Machines (SVM) merupakan salah satu
metode pembelajaran mesin (machine learning) yang memaksimumkan akurasi prediksi dengan mencari bidang pembatas (hyperplane) terbaik dari dua kelas dalam ruang fitur [7]. Gambar 2 memperlihatkan struktur konseptual dari SVM.
Gambar 2. Struktur Konseptual SVM
Salah satu bidang pemisah yang memberikan generalisasi paling baik adalah bidang pemisah yang dapat memaksimumkan margin. Margin adalah jarak antara bidang pembatas kelas-1 dengan kelas-2. Data yang berada paling dekat dengan bidang pemnatas disebut support vector [7].
Data pada ruang input (input space) berdimensi d dinotasikan dengan 𝑥𝑖∈ ℝ𝑑, sedangkan label kelas dinotasikan dengan 𝑦𝑖∈ {−1, 1} untuk I = 1,2, …, n, dimana
n adalah banyaknya data. Dengan asumsi kedua kelas dapat
dipisahkan secara linear bidang pembatas, maka persamaan bidang pembatasnya adalah:
𝑥𝑖. 𝑤 + 𝑏 = 0 (1)
Data 𝑥𝑖 yang terbagi ke dalam dua kelas didefinisikan sebagai vektor yang memenuhi pertidaksamaan:
𝑥𝑖. 𝑤 + 𝑏 ≤ −1 (2)
𝑥𝑖. 𝑤 + 𝑏 ≥ +1 (3)
Dimana w adalah normal bidang, dan b adalah posisi bidang relatif terhadap pusat koordinat.
Margin terbesar dapat dicari dengan cara memaksimalkan
jarak antar bidang pembatas kedua kelas, yaitu 2/|w|. Hal ini dirumuskan sebagai permasalahan quadratic programming [8], yaitu:
min τ(w) =1 2 |𝑤|
2 (4)
𝑆𝑢𝑏𝑗𝑒𝑐𝑡 𝑡𝑜: 𝑤. 𝑥 + 𝑏 ≥ 1, ∀𝑖
Permasalahan ini lebih mudah diselesaikan dengan mengubah persamaan (4) ke dalam fungsi Lagrangian berikut:
𝐿𝑝(𝑤, 𝑏, 𝛼) = 1
2|𝑤|2− ∑ 𝛼𝑖(𝑦𝑖(𝑥𝑖. 𝑤 + 𝑏) − 1) 𝑛
𝑖=1
𝛼𝑖 merupakan Lagrange multiplier yang bernilai tidak negatif (𝛼𝑖≥ 0). Nilai optimal dari persamaan 5 dapat dihitung dengan meminimalkan L terhadap w dan b, dan memaksimalkan L terhadap 𝛼𝑖. Dengan memperhatikan bahwa pada titik optimal gradient L adalah 0, persamaan 5 dapat diubah menjadi persamaan yang hanya mengandung 𝛼𝑖, yaitu:
max ∑ 𝛼𝑖 𝑛 𝑖=1 −1 2 ∑ 𝛼𝑖𝛼𝑗𝑥𝑖𝑥𝑗𝑦𝑖𝑦𝑗 𝑛 𝑖=1,𝑗=1
Permasalahan pada data yang tidak dapat dipisahkan secara linear oleh bidang pemisah, dapat diselesaikan dengan menggunakan teknik SVM soft margin hyperplane [9]. Dengan menggunakan teknik ini, persamaan 4 diubah dengan menambahkan slack variable 𝜉𝑖(𝜉𝑖 ≥ 0):
min 𝜏(𝑤, 𝜉) = 1 2|𝑤| 2+ 𝐶 ∑ 𝜉 𝑖 𝑛 𝑖=1 𝑆𝑢𝑏𝑗𝑒𝑐𝑡 𝑡𝑜: 𝑤. 𝑥 + 𝑏 ≥ 1 − 𝜉𝑖, ∀𝑖
Parameter C digunakan untuk mengontrol efek (tradeoff) antara margin dengan kesalahan (error) klasifikasi 𝜉. Nilai C yang semakin besar akan memberikan penalti yang lebih besar pada kesalahan klasifikasi. Nilai 𝛼𝑖 berada pada rentang 0 ≤ 𝛼𝑖 ≤ C.
Selain dengan menggunakan soft margin hyperplane permasalahan data yang tidak dapat dipisahkan secara linear, dapat diatasi dengan cara mengubah vektor fitur ke dalam dimensi yang lebih tinggi dengan menggunakan fungsi kernel. Fungsi kernel yang digunakan pada penelitan ini adalah
Radial Basis Function (RBF), karena kernel ini cocok untuk dataset yang besar [10]. Berikut ini persamaan fungsi kernel
RBF:
𝐾(𝑥𝑖, 𝑥) = exp(−𝛾|𝑥𝑖− 𝑥|2) , 𝛾 > 0 (8)
B. Ekstraksi Fitur
Pada teks berita online, kata kunci tidak diberikan oleh narasumber. Dalam penelitian ini kata kunci akan dicari dengan cara menghitung frekuensi.
Kata kunci digunakan dalam mengekstrak fitur. Fitur dalam penelitian ini merupakan hasil ekstraksi yang diasumsikan memberikan informasi mengenai kalimat. Berikut adalah fitur-fitur yang digunakan dalam mengekstraksi [9] [11]:
1. Fitur Panjang Kalimat
Kalimat yang paling pendek tidak akan dimasukkan ke dalam kandidat ringkasan. Fitur ini dihitung dengan membagi jumlah kata-kata dalam kalimat terhadap jumlah kata dari kalimat terpanjang.
2. Fitur Posisi Kalimat
Fitur ini mengasumsikan kalimat pertama pada setiap paragraf merupakan kalimat yang paling penting. Pada fitur ini akan diurutkan N kalimat pertama.
3. Fitur Data Numerik
Biasanya kalimat yang mengandung data numerik merupakan kalimat penting dan biasanya kalimat tersebut masuk ke dalam ringkasan.
4. Fitur Kata-Kata Thematic Dalam Kalimat
Fitur ini menghitung kemunculan relatif kata kunci pada suatu kalimat, biasanya kalimat yang memiliki relatif kata kunci yang baik, merupakan kalimat ringkasan. 5. Fitur Kalimat yang Menyerupai dengan Judul
Kalimat yang menyerupai judul adalah kalimat yang memiliki vocabulary overlap antara kalimat dengan judul.
6. Fitur Kemiripan Kalimat dengan Kumpulan Kalimat Lain
Kemiripan kalimat dapat dilihat dari vocabulary overlap antara kalimat dengan kalimat yang lain, untuk mempermudah maka kata yang dilihat hanya kata kunci. 7. Fitur Ikatan Leksikal dengan Kalimat Sebelumnya
Ikatan leksikal antara kalimat dengan kalimat sebelumnya didefinisikan sebagai kata (stem) yang muncul dalam kedua kalimat tersebut, nilai akan 1 apabila memiliki hubungan lexical, 0 jika tidak punya. 8. Fitur Ikatan Leksikal dengan Kalimat Sesudahnya
Ikatan leksikal antara kalimat dengan kalimat sesudahnya didefinisikan sebagai kata (stem) yang muncul dalam kedua kalimat tersebut, nilai akan 1 apabila memiliki hubungan lexical, 0 jika tidak punya.
C. Pembangunan Model
Untuk mendapatkan model klasifikasi yang dapat mengklasifikasikan kalimat dengan optimal, proses pembelajaran dilakukan dengan menggunakan parameter terbaik. Langkah-langkah untuk mencari parameter terbaik adalah sebagai berikut::
a. Berdasarakan dataset yang digunakan dalam penelitian ini, terjadi imbalanced dataset. Oleh karena itu perlu dilakukan perbaikan distribusi data dengan menggunakan metode Synthetic Minority Over-sampling
Technique (SMOTE). Pada proses pembelajaran
dilakukan dengan 10-fold cross validation.
b. Mencari parameter terbaik C dan 𝛾 dengan menggunakan tools yang sudah disediakan oleh Grid
Search dan LibSVM.
Setelah nilai C dan 𝛾 terbaik ditemukan, maka dilakukan proses pelatihan terhadap dataset yang sudah di-balance. Hasil dari proses pelatihan adalah sebuah model klasifikasi.
D. Pembentukan Ringkasan
Model klasifikasi yang digunakan oleh SVM Classifier akan memisahkan kalimat-kalimat dalam teks berita berdasarkan kelasnya. Kalimat-kalimat yang masuk ke dalam kelas positif akan diurutkan berdasarkan nilai relevansi, N jumlah kalimat dengan nilai relevansi tertinggi akan disusun dalam ringkasan [10]. Nilai relevansi dapat berupa nilai probabilitas kelas positif atau dengan menggunakan MMR.
III. EKSPERIMEN
A. Tools
Eksperimen pada penelitian ini menggunakan sistem peringkasan teks otomatis pada multi-document untuk berita berbahasa Indonesia. Aplikasi SVM menggunakan library LibSVM pada Weka 3.7.11.
B. Dataset
Dataset yang digunakan adalah kumpulan teks berita online
berbahasa Indonesia yang memiliki topik yang sama. Dataset (6)
ini diambil dari beberapa situs media berita online, diantaranya: detik.com, www.liputan6.com, kompas.com, www.tribunnews.com, www.viva.co.id, www.okezone.com, www.tempo.co, www.antaranews.com, metrotvnews.com, dan www.mediaindonesia.com. Proses pengumpulan dataset ini dilakukan secara manual, sedangkan domain berita yang digunakan adalah berita umum, politik, ekonomi, dan olahraga. Setiap kumpulan berita dalam satu topik dibuat sebuah ringkasan manual dengan pemampatan 25-30% dari rata-rata jumlah kalimat pada setiap artikelnya. Setiap kalimat dalam teks berita akan menjadi satu instance data. Pada Tabel 1 adalah dataset yang digunakan dalam penelitian ini.
Tabel 1 Kumpulan Dataset
Dataset Jumlah Artikel Jumlah Topik Kalimat Positif Kalimat Negatif Pelatihan 275 40 704 3047 Pengujian 88 10 272 1012 C. Balancing Dataset
Distribusi dataset pada data pelatihan menunjukkan adanya
imbalanced dataset, untuk mengatasi permasalahan tersebut
maka digunakan metode Synthetic Minority Oversampling
Technique (SMOTE). SMOTE merupakan metode
oversampling yang ide utamanya yaitu membuat class
minoritas baru dengan menginterpolasi beberapa instances class minoritas yang terletak berdekatan (dengan menggunakan teknik k nearest neighbors). Metode SMOTE ini bekerja dengan mencari k nearest neighbors (yaitu ketetanggaan data) untuk setiap data di kelas minor, setelah itu buat synthetic data sebanyak persentase duplikasi yang diinginkan Antara data minor.
D. Skenario Eksperimen
Pada penelitian ini akan dilakukan beberapa eksperimen untuk mendapatkan model terbaik, diantaranya pencarian parameter terbaik, fitur yang paling baik, dan kinerja SVM tanpa MMR dan dengan menggunakan MMR.
a. Eksperimen Penggunaan SMOTE untuk Imbalanced
dataset
Pada Eksperimen ini membandingkan hasil pelatihan sebelum menggunakan matode balancing dataset dan yang setelah menggunakan metode balancing dataset. Pada penelitian ini metode balancing dataset yang digunakan adalah Synthetic Minority Oversampling
Technique (SMOTE). Dari hasil tersebut didapatkan
bahwa hasil penelitian yang tanpa menggunakan
balancing dataset, tidak berhasil mengidentifikasi
kelas positif dan nilai f-measure pada kelas positifnya bernilai nol (0). Sedangkan hasil pelatihan yang menggunakan SMOTE untuk balancing dataset, berhasil mengidentifikasi kelas positif dan memiliki nilai f-measure pada kelas positif bernilai 0.810. b. Eksperimen Pencarian Parameter Terbaik
Pada Eksperimen ini akan menggunakan fungsi kernel RBF dimana kernel tersebut memerlukan parameter C &
𝛾 pada prosesnya. Untuk mendapatkan parameter terbaik, bisa di dapatkan dengan menggunakan tools Grid Search. Dari hasil pencarian menggunakan Grid Search, didapat sepasang parameter terbaik yaitu dengan nilai C = 4.0 dan nilai 𝛾 = 512.0. Nilai
f-measure yang diperoleh dari parameter terbaik tersebut
adalah 0.771.
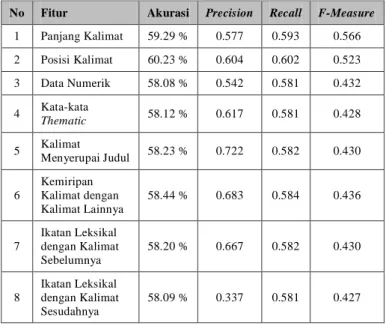
c. Eksperimen Fitur yang Paling Baik
Fitur yang dianggap paling baik adalah fitur yang memiliki nilai f-measure yang mendekati 1. Setiap fitur akan dibuat model klasifikasinya, lalu dilihat n fitur mana yang memiliki f-measure terbaik. Pada Tabel 2 adalah hasil pengukuran f-measure untuk setiap fitur.
Tabel 2 Hasil Eksperimen Setiap Fitur
No Fitur Akurasi Precision Recall F-Measure
1 Panjang Kalimat 59.29 % 0.577 0.593 0.566 2 Posisi Kalimat 60.23 % 0.604 0.602 0.523 3 Data Numerik 58.08 % 0.542 0.581 0.432 4 Kata-kata Thematic 58.12 % 0.617 0.581 0.428 5 Kalimat Menyerupai Judul 58.23 % 0.722 0.582 0.430 6 Kemiripan Kalimat dengan Kalimat Lainnya 58.44 % 0.683 0.584 0.436 7 Ikatan Leksikal dengan Kalimat Sebelumnya 58.20 % 0.667 0.582 0.430 8 Ikatan Leksikal dengan Kalimat Sesudahnya 58.09 % 0.337 0.581 0.427
d. Eksperimen Algoritma Klasifikasi Lainnya
Pada Eksperimen ini melakukan percobaan dengan menggunakan setting terbaik untuk SVM diaplikasikan juga ke algoritma klasifikasi naïve bayes, dan k-Nearest
Neighbor (kNN), yaitu: menggunakan SMOTE dan nilai
parameter terbaik (C = 4.0 dan nilai 𝛾 = 512.0) yang bertujuan untuk membandingkan akurasi (f-measure) dari hasil pelatihan algoritma tersebut dengan algoritma SVM yang digunakan dalam penelitian ini. Dari hasil eksperimen ini didapat hasil sebagai berikut:
Tabel 3 Hasil Perbandingan
Hasil SVM Naïve Bayes kNN
Akurasi 77.25% 59.29% 76.25%
Precision 0.771 0.576 0.761
Recall 0.773 0.593 0.762
f-measure 0.771 0.548 0.761
Pada Tabel 3 dapat dilihat hasil kedua pelatihan tersebut (naïve bayes, dan k-Nearest Neighbor) masih dibawah dari hasil pelatihan dengan menggunakan
Support Vector Machine (SVM). Sehingga dapat
disimpulkan bahwa kinerja dengan menggunakan SVM lebih baik dibandingkan dengan menggunakan klasifikasi naïve bayes, dan k-Nearest Neighbor (kNN).
e. Eksperimen Hasil Ringkasan tanpa MMR dan Hasil Ringkasan Menggunakan MMR
Gambar 3. Tampilan Hasil Ringkasan Tanpa MMR Pada Gambar 3 diatas dapat dilihat bahwa hasil ringkasan tanpa MMR memiliki susunan kalimat yang kurang baik, sehingga pembaca/pengguna akan sulit dalam memahami informasi penting yang akan disampaikan.
Gambar 4. Tampilan Hasil Ringkasan Dengan MMR Pada Gambar 4 diatas dapat dilihat bahwa hasil ringkasan SVM dengan menggunakan MMR memiliki susunan kalimat yang lebih baik dibandingkan dengan hasil tanpa MMR, sehingga pembaca/pengguna akan lebih mudah dalam memahami informasi penting yang akan disampaikan.
E. Survei Keterbacaan Ringkasan
Survei ini digunakan untuk mengukur apakah teks yang dihasilkan oleh sistem dapat dipahami oleh pembaca dan relevan dengan sumber berita aslinya. Survei ini dilakukan dengan cara mengirimkan kuisioner kepada 40 responden.
Ringkasan yang digunakan pada survei ini menggunakan model terbaik yang telah didapat pada proses training dengan parameter terbaik (C = 4.0 dan 𝛾 = 512.0) dari hasil eksperimen.
Survei ini bertujuan untuk mencari metode mana yang dapat menghasilkan ringkasan dengan tingkat keterbacaan yang lebih baik bagi pembaca.
Tabel 4 Scoring Board Hasil Ringkasan Tanpa MMR
Topik Kurang Cukup Baik Sangat Baik
1 15 25 0 0 2 10 30 0 0 3 20 20 0 0 4 10 30 0 0 5 25 15 0 0 6 12 28 0 0 7 9 31 0 0 8 16 24 0 0 9 5 25 10 0 10 2 28 10 0
Tabel 5 Scoring Board Hasil Ringkasan Dengan MMR
Topik Kurang Cukup Baik Sangat Baik
1 0 0 35 5 2 0 1 37 2 3 0 1 36 3 4 0 2 30 8 5 0 5 30 5 6 0 8 32 0 7 0 6 34 0 8 0 3 37 0 9 0 0 34 6 10 0 1 38 1
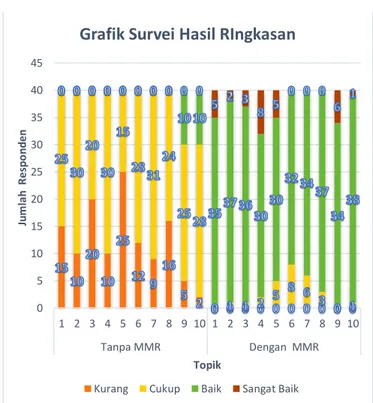
Dari hasil survei pada Tabel 4 dan Tabel 5 di atas, dapat dibuat sebuah grafik sebagai berikut:
Gambar 5. Grafik Survei Hasil Ringkasan
0 5 10 15 20 25 30 35 40 45 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10 Tanpa MMR Dengan MMR Ju m la h R esp o n d e n Topik
Grafik Survei Hasil RIngkasan
Hasil grafik pada Gambar 5 dapat dilihat bahwa responden memilih ringkasan yang dihasilkan oleh metode SVM menggunakan MMR lebih banyak daripada ringkasan SVM tanpa MMR. Sehingga dapat disimpulkan bahwa hasil ringkasan SVM dengan menggunakan MMR keterbacaannya lebih baik dibandingkan hasil ringkasan SVM tanpa MMR.
F. Evaluasi Hasil Ringkasan
Evaluasi hasil ringkasan ini untuk mengukur hasil ringkasan yang dilakukan oleh sistem apakah sudah baik, dan relevan dengan sumber berita aslinya. Pengevaluasian ini dilakukan dengan membandingkan dan memberi penilaian terhadap hasil ringkasan dimana penilaian itu diberikan oleh orang yang ahli dalam bidangnya atau dalam hal ini sering disebut human expert judgement. Pada pengevaluasian ini dilakukan oleh Dr. Dadang S. Anshori, M.Si (Dosen Bahasa Indonesia di UPI sekaligus Ketua Jurusan). Penilaian dari ringkasan akan dikelompokkan dalam empat kategori, yaitu kurang, cukup, baik dan sangat baik. Adapun hasil penilaiannya sebagai berikut.
Tabel 6 Scoring Board Hasil Ringkasan
Tipe
Ringkasan Kurang Cukup Baik
Sangat Baik Ringkasan Tanpa MMR 1 7 2 0 Ringkasan Dengan MMR 0 1 9 0
Gambar 6. Grafik Evaluasi Ringkasan oleh Human Expert Judgement
Dari Gambar 6 di atas dapat dilihat bahwa hasil ringkasan sistem dengan menggunakan MMR lebih baik dan relevan daripada hasil ringkasan sistem tanpa menggunakan MMR.
IV. KESIMPULAN
Pada sistem peringkasan teks otomatis berita berbahasa Indonesia pada multi-document dapat dilakukan secara efektif dengan cara mengklasifikasikan kalimat-kalimat dalam setiap artikel ke dalam kelas positif (termasuk ke dalam ringkasan) atau kelas negatif (tidak termasuk ke
dalam ringkasan) menggunakan SVM Classifier.
Selanjutnya dipilih n kalimat dari kelas positif berdasarkan nilai relevansinya. Nilai relevansi dapat berupa nilai probabilitas kemunculan kelas positif atau nilai MR yang dihasilkan melalui MMR.
Parameter klasifikasi SVM dengan kernel RBF terbaik yang digunakan sistem peringkasan teks otomatis pada
multi-document dalam Tesis ini yaitu, nilai C = 4.0 dan 𝛾 = 512.0. Nilai f-measure yang diperoleh dari parameter terbaik tersebut adalah 0.771.
Sistem peringkasan teks otomatis mengalami peningkatan kinerja jika permasalahan imbalanced dataset ditangani pada level data.
Empat fitur yang terbaik pada proses klasifikasi pada Tesis ini adalah panjang kalimat, posisi kalimat, kemiripan kalimat dengan kalimat lainnya, dan data numerik. Pembangunan model klasifikasi menggunakan empat fitur yang terbaik tidak meningkatkan kinerja proses klasifikasi.
REFERENSI
[1] An, J., Cha, M., Gummadi, K., dan Crowcroft, J. (2011).
Media Landscape in Twitter, A New World Convention
and Political Diversity, University of Cambridge. [2] Lioret, Elena. (2008). Text Summarization: An
Overview, Dept. Lenguajes y Sistemas Informaticos
Universidad de Alicante Alicante, Spain.
[3] Mani, Inderjeet, dan Marbury, T, Mark. (1999).
Advances in Automatic Text Summarization,
Massachusetts Institute of Technology, Massachusetts, Amerika.
[4] Wardhana, Wisnu L. (2008). Peringkas Multi-Dokumen
Untuk Bahasa Indonesia Menggunakan Teknik Centroid-Based Summarization Dan Teknik K-Means-Based Summarization. Skripsi pada Fakultas Ilmu
Komputer Universitas Indonesia. tidak diterbitkan. [5] S, Suneetha. (2011). Automatic Text Summarization: The
Current State of The Art, International Journal of Science
and Advance Technology, Vol.1 No.9, JNTU, Hyderabad.
[6] Kupiec, J., Pedersen, J., & Chen, F. (1995). A trainable
document summarizer. In Proceedings of the 18th annual
international ACM SIGIR conference on Research and development in information retrieval (pp. 68-73). ACM. [7] Joachims, Thorsten. (1999). Making Large-Scale SVM
Learning Practical. Universitait Dortmund, Jerman.
[8] Hovy, E., dan Lin, C. Y. (1998). Automated Text
Summarization and the SUMMARIST system,
Proceedings of a workshop on held at Baltimore, Maryland: October 13-15, 1998 (pp.197-214). Association for Computational Linguistics.
[9] Karamuftuoglu, Murat. (2002). An Approach to
Summarisation Based on Lexical Bonds. Document
Understanding Conferences.
[10] Ishikawa, Kai, 2004, Trainable Automatic Text
Summarization using Segementation of Sentence, NEC
Corporation.
[11] Fattah, Abdel, Mohamed dan Ren, Fuji. (2008).
Automatic Text Summarization, World Academy of
Science, Engineering and Technology 37. 0 2 4 6 8 10
Ringkasan Tanpa MMR Ringkasan Dengan MMR