APLIKASI DATA MINING UNTUK MENAMPILKAN
INFORMASI HUBUNGAN KATEGORI KELULUSAN
DENGAN NILAI MAHASISWA MENGGUNAKAN
ALGORITMA APRIORI
(Studi Kasus di Jurusan Sistem Komputer Universitas Komputer Indonesia)
TUGAS AKHIR
Disusun Untuk Memenuhi Syarat Kelulusan Pada
Program Studi Strata Satu Sistem Komputer di Jurusan Sistem Komputer
Oleh
SRI ASTUTI PURBA 10209124
Pembimbing
Selvia Lorena Br Ginting, M.T Irfan Dwiguna Sumitra, M.Kom
JURUSAN SISTEM KOMPUTER
FAKULTAS TEKNIK DAN ILMU KOMPUTER UNIVERSITAS KOMPUTER INDONESIA
viii
1.4 Metode Pembuatan Aplikasi ... 3
1.5 Sistematika Penulisan ... 4
BAB II LANDASAN TEORI ... 5
2.1 Data mining ... 5
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 14
3.1 Analisis Masalah ... 14
3.2 Analisis Data ... 14
3.2.1 Sumber Data ... 15
3.2.2 Pembersihan Data ... 16
ix
3.3 Analisis Algoritma Apriori ... 19
3.3.1 Report dan Penyajian Hasil Proses ... 25
3.4 Analisis Kebutuhan Non Fungsional ... 26
3.5 Analisis Kebutuhan Pengguna (User) ... 26
3.6 Analisis Kebutuhan Perangkat Keras (Hardware) ... 27
3.7 Analisis Kebutuhan Perangkat Lunak (Software) ... 27
3.8 Analisis Kebutuhan Fungsional ... 28
3.8.1 Spesifikasi Kebutuhan Fungsional ... 28
3.8.2 Analisis Batasan Sistem ... 28
3.12 Perancangan Prosedural ... 37
3.12.1 Procedure Data Mining ... 37
3.12.2 Procedure Aturan Assosiatif untuk Menentukan Frequent Itemset . 38 3.13.3 Procedure Aturan Assosiatif untuk Menentukkan Nilai Support dan Confidence ... 39
BAB IV IMPLEMENTASI PROGRAM DAN PENGUJIAN ... 40
4.1 Implementasi ... 40
4.1.1 Lingkungan Implementasi ... 40
4.1.2 Implementasi Antarmuka ... 41
4.2 Pengujian ... 44
4.2.1 Pengujian Sistem ... 44
4.2.2 Skenario Pengujian ... 44
4.2.3 Hasil Pengujian Hubungan Kategori Kelulusan dengan Mata Kuliah ... 44
BAB V SIMPULAN DAN SARAN ... 58
5.1 Simpulan ... 58
5.2 Saran ... 59
60
Memprediksi Masa Studi Mahasiswa Menggunakan Algoritma K-Nearest
Neighborhood. Fakultas Teknik dan Ilmu Komputer, Universitas Komputer Indonesia
[2] Erwin. 2009. Analisis Market Basket dengan Algoritma Apriori dan FP-Growth. Jurnal Generik Vol.4 No2, Juli 2009
[3] Gunadi, G., & Sensuse, D. I. 2012. Penerapan metode data mining market basket Analysis terhadap data penjualan produk buku Dengan
menggunakan algoritma apriori dan Frequent pattern growth (fp-growth)
: Studi kasus percetakan pt. Gramedia. Jurnal Telematika M.Kom Vol.4 No.1, Maret 2012
[4] Han, J., & Kamber, M. 2006. Data Mining: Concept and Techniques.
Morgan Kaufman: San Fransisco
[5] Hermawati, F. A., 2013. Data Mining. Yogyakarta: Andi
[6] Huda, N. M., 2010. Aplikasi Data Mining Untuk Menampilkan Informasi Tingkat Kelulusan Mahasiswa]. Fakultas Mipa, Universitas Diponegoro. [7] Liao,Shu-Hsi., Chu Hui-Pei dan Hsia, Pei-Yuan. 2012. Data mining
techniques and applications – A decade review from 2000 to 2011. Department of Management Sciences, Tamkang University.
[8] Pramudiono, I., (2007). Pengantar Data Mining: Menambang Permata Pengetahuan di Gunung Data. Diakses tanggal 26 April 2014, dari
61
vi
segala rahmat dan kasih karunia-Nya yang tak terhingga, telah memberikan kesehatan, kemampuan serta kesempatan kepada Penulis sehingga dapat menyelesaikan Tugas Akhir yang berjudul “Aplikasi Data Mining Untuk Menampilkan Informasi Hubungan Kategori Kelulusan Dengan Nilai Mahasiswa Menggunakan Algoritma Apriori (Studi Kasus: Jurusan Sistem Komputer- UNIKOM)” ini dengan baik.
Dalam proses penyusunan Tugas Akhir ini banyak hal atau pihak yang telah memberikan dukungan sehingga Tugas Akhir ini dapat terselesaikan. Banyak pihak yang tak mungkin Penulis sebutkan satu persatu, namun dengan segala kerendahan hati, Penulis mengucapkan terima kasih kepada:
1. Keluarga terutama mama tersayang, abang, kakak, ipar dan semua keluarga besar tercinta yang senantiasa tidak henti-hentinya mencurahkan cinta, kasih sayang, perhatian, nasihat, dukungan secara moral maupun materil serta memberikan motivasi kepada penulis selama studi.
2. Bapak Wendi Zarman, M.Si., selaku Ketua Jurusan Sistem Komputer, Universitas Komputer Indonesia dan Dosen Wali kelas 09 TK-3.
3. Ibu Selvia Lorena Br. Ginting, M.T., selaku Pembimbing I yang telah banyak memberikan arahan, saran, nasihat, motivasi dan bimbingan kepada Penulis selama menempuh studi.
4. Bapak Irfan Dwiguna Sumitra, M.Kom., selaku Pembimbing yang juga telah memberikan arahan, bantuan, saran, nasihat, motivasi dan bimbingan kepada penulis.
vii
6. Keluarga besar Legioner Maria Ratu Pencinta Damai, dan sahabat-sahabat di KMK tempat penulis bercerita, terima kasih atas motivasi, saran, dan bantuannya selama ini.
7. Teman–teman angkatan 2009 dan khususnya kelas 09 TK-3, serta rekan-rekan seperjuangan Tugas Akhir yang telah banyak membantu selama studi maupun selama proses pengerjaan Tugas Akhir.
8. Semua pihak yang telah banyak membantu yang tidak dapat penulis sebutkan satu persatu, terima kasih banyak atas bantuan, dukungan dan motivasinya selama melaksanakan studi dan menyelesaikan Tugas Akhir ini.
Penulis menyadari bahwa Tugas Akhir ini masih jauh dari sempurna, baik dari pembahasan, pengkajian maupun cara penyusunan, hal tersebut terjadi karena keterbatasan dan kemampuan Penulis, oleh karena itu Penulis mengharapkan pendapat, kritik dan saran yang membangun untuk pengembangan Tugas Ahir ini agar lebih baik lagi di masa yang akan datang.
Akhirnya, Penulis berharap semoga penelitian ini menjadi sumbangsih yang bermanfaat bagi dunia sains dan teknologi di Indonesia, khususnya disiplin keilmuan yang Penulis dalami.
Bandung, Agustus 2014
Tempat, tanggal lahir : Hutapaung, 09 Mei 1990 Jenis kelamin : Perempuan
Agama : Katolik
Alamat Sementara : Jl. Kubang Selatan No. 10 Bandung Alamat Tetap : Simpang Tiga, Hutapaung
Kecamatan Pollung
Kabupaten Humbang Hasundutan No. Telepon : 0813 7553 3023
Email : [email protected]
Pendidikan Formal
2009 – 2014 : Universitas Komputer Indonesia, Bandung.
Fakultas Teknik dan Ilmu Komputer, Jurusan Sistem Komputer.
1 1.1 Latar Belakang
Informasi merupakan elemen penting yang sangat dibutuhkan oleh masyarakat. Hal ini tentu saja didukung oleh pertumbuhan teknologi dan media informasi yang sangat cepat. Tetapi perkembangan informasi yang demikian pesat, mengakibatkan terjadinya penumpukan data, tumpukan data ini jika tidak dikelola dengan benar akan menjadikan suatu informasi menjadi sulit dipahami, padahal data-data tersebut tentu saja sangat bermanfaat apabila disajikan dengan lebih sederhana dan memadai dengan cara penyajian yang akurat dari waktu ke waktu.
Perguruan tinggi tentu saja mengalami penumpukan data, hal ini terjadi karena jumlah mahasiswa yang bertambah setiap tahunnya. Data mahasiswa yang semakin bertambah, mengakibatkan data menumpuk dan menjadi sulit dianalisa. Pemanfaatan data dalam mengambil suatu keputusan, tidak cukup hanya mengandalkan data operasional saja, hal ini karena data operasional tidak cukup memadai untuk menampilkan informasi yang dibutuhkan, oleh karena itu diperlukan suatu analisis data untuk menggali potensi-potensi informasi yang ada. Untuk mengelola tumpukan data tersebut menjadi informasi yang bermanfaat, tentu dibutuhkan suatu teknik yaitu data mining. Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Penggunaan teknik data mining diharapkan dapat menampilkan data-data yang sebelumnya tersembunyi di dalam gudang data menjadi informasi yang berharga.
Komputer tingkat kelulusan mahasiswa masih terbilang rendah dengan Indeks Prestasi mahasiswa yang masih kurang dari 3,00 dengan masa studi lebih dari yang dijadwalkan, yaitu 8 semester. Oleh karena itu dengan memanfaatkan data akademik dan data kelulusan mahasiswa, penulis mengimplementasikan data mining untuk membuat suatu aplikasi, yaitu teknik asosiasi dengan algoritma apriori. Diharapkan dengan adanya aplikasi ini Jurusan Sistem Komputer baik sekretariat, dosen maupun mahasiswa dapat mengambil solusi atau kebijakan yang lebih baik dalam proses evaluasi pembelajaran, sehingga dapat meningkatkan tingkat kelulusan mahasiswa dan kualitas Jurusan Sistem Komputer
1.2 Maksud dan Tujuan
Maksud dari tugas akhir ini adalah dapat mengaplikasikan data mining
dengan menggunakan teknik asosiasi untuk menghasilkan suatu aplikasi yang dapat mengolah data yang menunjukkan perbandingan hubungan nilai mahasiswa terhadap kategori kelulusan mahasiswa di Jurusan Sistem Komputer.
Sedangkan tujuan yang ingin dicapai adalah, dengan adanya aplikasi ini diharapkan dapat membantu menyajikan informasi yang lebih baik sehingga dosen maupun sekretariat di jurusan Sistem Komputer dapat melakukan evaluasi pembelajaran, dan dapat membantu mahasiwa untuk mengambil keputusan-keputusan yang lebih strategis dalam proses belajar sehingga dapat meningkatkan tingkat kelulusan mahasiswa.
1.3 Batasan Masalah
Batasan masalah pada tugas akhir ini adalah:
1. Menggunakan data akademik dan data kelulusan jurusan Sistem Komputer 2. Data yang digunakan adalah data akademik mahasiswa angkatan 2001-2009 3. Data yang digunakan merupakan nilai empat mata kuliah yang ada di Jurusan
4. Algoritma yang digunakan adalah algoritma Apriori 5. Visual Basic 6.0 digunakan sebagai aplikasi antarmuka
6. Pengolahan basis data menggunakan databaseMicrosoft Access 2007
1.4 Metode Pembuatan Aplikasi
Metode yang dilakukan dalam Tugas Akhir ini adalah sebagai berikut: 1. Observasi
Pengumpulan data dengan metode pengamatan langsung 2. Interview
Pengumpulan data melalui wawancara dengan pihak-pihak yang berkaitan dengan tugas akhir ini, agar diperoleh gambaran dan informasi yang lebih jelas.
3. Studi Pustaka
Pengumpulan data melalui kajian pustaka yang bersumber baik dari buku, literatur, paper maupun teori-teori yang mendukung tugas akhir ini.
4. Perancangan Perangkat Lunak
Melakukan perancangan perangkat lunak yang akan digunakan yaitu dengan algoritma Apriori
5. Implementasi
Melakukan implementasi terhadap perangkat lunak yang akan dikembangkan berdasarkan hasil yang diperoleh dari perancangan
6. Pengujian
Menguji perangkat lunak dengan menggunakan studi kasus yang telah ditentukan.
7. Evaluasi
1.5 Sistematika Penulisan
Sistematika penulisan proposal penelitian ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB I PENDAHULUAN
Menguraikan tentang latar belakang masalah, menentukan tujuan dan kegunaan penelitian, yang kemudian diikuti dengan batasan masalah, asumsi, serta sistematika penulisan.
BAB II DASAR TEORI
Membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Pada bab ini berisi tentang analisis dan perancangan aplikasi data mining. BAB IV IMPLEMENTASI PROGRAM DAN PENGUJIAN
Pada bab ini berisi pengujian dan pembahasan tentang implementasi dari penerapan
teknik data mining serta validasi aplikasi.
BAB V SIMPULAN DAN SARAN
5
Bab ini menjelaskan tentang dasar teori yang digunakan dalam penyusunan tugas ahir ini, yaitu tentang pengertian data mining, pengelompokan
data mining, teknik Asosiasi dan juga algoritma Apriori
2.1 Data Mining
Data Mining merupakan suatu proses untuk menemukan informasi atau pengetahuan yang berguna dari suatu data yang berjumlah besar. Data mining
juga disebut sebagai serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data (Pramudiono, 2007).
Saat ini istilah data mining sudah berkembang jauh dalam mengadaptasi setiap bentuk analisa data. Pada dasarnya data mining berhubungan dengan analisa data dan
penggunaan teknik-teknik perangkat lunak untuk mencari pola dan keteraturan dalam
himpunan data yang sifatnya tersembunyi. Teknik-teknik ini tentu bervariasi dan
disesuaikan dengan kebutuhan analisis data.
2.1.1 Pengelompokan Data Mining
Terdapat tiga metode utama dalam data mining yaitu [9]: a. Supervised Learning (Pembelajaran dengan Guru)
Algoritma ini melakukan proses belajar berdasarkan nilai dari variabel target yang terasosiasi dengan nilai dari variabel prediktor, biasanya sebagian besar algoritma
data mining termasuk dalam metode ini antara lain estimation, prediction/forecasting, dan classification.
b. Unsupervised Learning (Pembelajaran tanpa Guru)
Algoritma ini mencari pola dari semua variable (atribut), algoritma data mining
c. Association Learning (Pembelajaran untuk Asosiasi Atribut)
Proses learning pada algoritma asosiasi (association rule) agak berbeda karena tujuannya adalah untuk mencari atribut yang muncul bersamaan dalam satu transaksi, biasanya metode ini banyak digunakan untuk analisa transaksi belanja. Algoritma data mining yang termasuk dalam metode ini adalah algoritma Apriori, Fp. Growth.
2.1.2 Tahap-tahap Data Mining
Terdapat 7 tahap utama data mining yaitu [6] : 1. Pembersihan Data (Data Cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak relevan dengan hipotesa data mining yang dimiliki. Data-data yang tidak relevan itu juga lebih baik dibuang. Pembersihan data juga akan mempengaruhi performasi dari teknik data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
2. Integrasi Data (Data Integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru. Tidak jarang data yang diperlukan untuk data mining
tidak hanya berasal dari satu database tetapi juga berasal dari beberapa database
3. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari
database. Sebagai contoh, sebuah kasus yang meneliti faktor kecenderungan orang membeli dalam kasus market basket analysis, tidak perlu mengambil nama pelanggan, cukup dengan id pelanggan saja.
4. Transformasi Data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining. Beberapa metode data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa metode standar seperti analisis asosiasi dan clustering hanya bisa menerima input data kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu dibagi-bagi menjadi beberapa interval. Proses ini sering disebut transformasi data. 5. Proses Mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi Pola (Pattern Evaluation)
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang ditemukan. Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai dengan hipotesa,
maka ada beberapa alternatif yang dapat diambil seperti menjadikannya umpan
balik untuk memperbaiki proses data mining, mencoba metode data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat.
7. Presentasi Pengetahuan (Knowledge Presentation)
atau aksi dari hasil analisis yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami data mining. Karenanya presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang diperlukan dalam proses data mining. Dalam presentasi ini, visualisasi juga bisa membantu mengkomunikasikan hasil data mining (Han, 2006).
2.2Metode Asosiasi
Aturan asosiasi atau sering disebut Association Rule, merupakan salah satu metode yang digunakan untuk menemukan hubungan diantara data atau bagaimana suatu kelompok data mempengaruhi suatu keberadaan data lain. Aturan asosiasi merupakan salah satu metode yang sering digunakan untuk mencari hubungan antara berbagai item. Sebagai contohnya, dari sebuah himpunan data transaksi mungkin akan ditemukan kejadian berikut, dimana seseorang yang membeli susu dalam transaksi yang sama akan membeli gula, atau seseorang yang membeli sikat gigi dalam yang transaksi yang sama juga akan membeli odol.
Ada beberapa algoritma yang sudah dikembangkan mengenai aturan asosiasi, Metode ini terbagi atas beberapa algoritma yaitu algoritma Apriori, algoritma FP-Growth dan algoritma CT-Pro. Apriori merupakan algoritma klasik yang sering dipakai. Ide dasar dari algoritma ini adalah dengan mengembangkan
frequent itemset, yaitu dengan cara menggunakan satu item dan kemudian secara rekursif mengembangkan frequent itemset tersebutdengan dua item, tiga item dan seterusnya hingga frequent itemset dengan semua ukuran. Untuk mengembangkan
frequent set dengan dua item, dapat menggunakan frequent set item. Alasannya adalah bila set satu item tidak melebihi support minimum, maka sembarang ukuran itemset yang lebih besar tidak akan melebihi support minimum tersebut. Secara umum, mengembangkan set dengan fc-item menggunakan frequent set dengan k – 1 item yang dikembangkan dalam langkah sebelumnya. Setiap langkah memerlukan sekali pemeriksaan ke seluruh isi database [6].
2.3 Algoritma Apriori
Algoritma Apriori termasuk jenis aturan asosiasi pada data mining. Selain apriori, yang termasuk pada golongan ini adalah metode generalized rule induction dan algoritma hash based. Aturan yang menyatakan asosiasi antara beberapa atribut sering disebut affinityanalysis atau market basketanalysis [10].
Metodologi dasar analisis asosiasi terbagi menjadi dua tahap yaitu[4]: 1. Analisa pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database.
2. Pembentukan aturan assosiatif
Ide dasar dari algoritma Apriori adalah mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam basis data. Nilai support
sebuah item diperoleh dengan menggunakan rumus berikut[3]:
= � � ℎ � � � � �� �
� � � � ...(i)
Nilai support dari 2 item diperoleh dengan menggunakan rumus[3] :
, =� ∩ ...(ii)
, = � � � � �� � �
� � � ...(iii)
Frequent itemset menunjukkan itemset yang memiliki frekuensi kemunculan lebih dari nilai minimum yang ditentukan (Φ). Misalkan Φ = 2, maka semua itemsets yang frekuensi kemunculannya lebih dari atau sama dengan 2 kali disebut frequent. Himpunan dari frequent k-itemset dilambangkan dengan Fk[3].
Bentuk algoritma dari Apriori dapat dituliskan sebagai berikut[3]: L1 = {frequent itemset with one element}
for (k=2; Lk-1≠⌀; k++) {
Ck = apriori-gen(Lk-1); //pembuatan kandidat
//baru for all transactions t {
C : himpunan kandidat itemset
c : kandidat itemset
t : transaksi
2.4Diagram Konteks
Diagram konteks bisa disebut dengan model sistem pokok (fundamental system model) mewakili keseluruhan elemen software dengan masukan (input) dan keluaran (output) yang diidentifikasi dengan anak panah masuk dan keluar memperlihatkan sumber data (Roger S Pressman, 1997). Diagram konteks adalah diagram yang terdiri dari suatu proses dan menggambarkan ruang lingkup suatu sistem. Diagram konteks merupakan level tertinggi dari DFD yang menggambarkan seluruh input ke sistem atau output dari sistem. Ia akan memberi gambaran tentang keseluruhan sistem. Sistem dibatasi oleh boundary (dapat digambarkan dengan garis putus). Dalam diagram konteks hanya ada satu proses. Tidak boleh ada store dalam diagram konteks.
2.4.1 DFD (Data Flow Diagram)
Data Flow Diagram (DFD) adalah suatu diagram yang menggunakan notasi-notasi untuk menggambarkan arus dari data sistem, yang penggunaannya sangat membantu untuk memahami sistem secara logika, tersruktur dan jelas. DFD merupakan alat bantu dalam menggambarkan atau menjelaskan proses kerja suatu sistem. Dalam DFD dijelaskan aliran masuk, aliran keluar, proses serta penyuntingan file yang digunakan
Ada empat komponen utama dalam DFD yaitu: Tabel 2.1 Komponen DFD
Simbol Keterangan
Simbol Keterangan
Aliran, Komponen ini dipresentasikan dengan menggunakan panah yang menuju ke atau dari proses. Digunakan untuk menggambarkan gerakan paket data atau informasi dari satu bagian ke bagian lain dari sistem dimana penyimpanan mewakili lokasi penyimpanan data
Nama Penyimpanan Penyimpanan, komponen ini digunakan untuk
memodelkan kumpulan data atau paket data.
Terminator, komponen berikut ini dipresentasikan menggunakan persegi panjang, yang mewakili entity luar dimana sistem berkomunikasi.
DFD ini merupakan alat perancangan sistem yang berorientasi pada alur data dengan konsep dekomposisi dapat digunakan untuk penggambaran analisa maupun rancangan sistem yang mudah dikomunikasikan oleh profesional sistem kepada pemakai maupun pembuat program.
Keuntungan menggunakan DFD adalah memudahkan pengguna yang kurang atau menguasai bidang komputer untuk mengerti sistem yang akan dikerjakan atau dikembangkan.
2.5Software Pendukung
Software pendukung merupakan alat yang yang digunakan untuk membangun sistem atau aplikasi yang akan digunakan. Software pendukung yang digunakan yaitu Visual Basic 6.0 dan Microsoft Access 2007
2.5 1 Visual Basic 6.0
Object Oriented Programming (OOP). Bahasa pemrograman VB ini dikembangkan oleh Microsoft sejak tahun 1991, merupakan pengembangan dari
pendahulunya yaitu bahasa pemrograman BASIC (Beginner’s All-purpose
Symbolic Instruction Code) yang dikembangkan pada era 1950-an. VB adalah salah suatu developement tools untuk membangun aplikasi dalam lingkungan Windows.
Pada pemrograman Visual, pengembangan aplikasi dimulai dengan pembentukkan user interface, kemudian mengatur properti dari objek-objek yang digunakan dalam user interface, dan baru dilakukan penulisan kode program untuk menangani kejadian-kejadian (event). Tahap pengembangan aplikasi demikian dikenal dengan istilah pengembangan aplikasi dengan pendekatan Bottom Up.
2.5.2 Microsoft Acces
Microsoft Access (atau Microsoft Office Access) adalah sebuah program aplikasi basis data komputer relasional yang ditujukan untuk kalangan rumahan dan perusahaan kecil hingga menengah. Aplikasi ini merupakan salah satu dari beberapa aplikasi Microsoft Office. Aplikasi ini menggunakan mesin basis data
14
Bab ini menjelaskan tentang analisis dan perancangan dalam membangun aplikasi data mining untuk mengetahui tingkat kelulusan mahasiswa di jurusan Sistem Komputer. Analisis meliputi analisis masalah, analisis data, analisis algoritma apriori, analisis fungsional, analisis non fungsiaonal serta perancangan aplikasinya.
3.1Analisis Masalah
UNIKOM merupakan salah satu perguruan tinggi swasta yang berada di kota bandung yang memiliki beberapa jurusan, salah satunya adalah jurusan Sistem Komputer. Di UNIKOM khususnya di Jurusan Sistem Komputer tingkat kelulusan mahasiswa masih terbilang rendah dengan Indeks Prestasi yang juga terbilang kecil, dengan masa studi lebih dari 5 tahun dari yang dijadwalkan yaitu 4 tahun. Oleh karena itu dengan memanfaatkan data akademik dan data kelulusan mahasiswa penulis mengimplementasikan data mining untuk menemukan informasi atau pengetahuan baru sehingga dapat digunakan untuk membantu evaluasi sistem pembelajaran di Sistem Komputer. Informasi yang dibutuhkan adalah nilai mahasiswa dan kategori kelulusan mahasiswa dengan atribut mata kuliah di jurusan Sistem Komputer.
3.2Analisis Data
Dalam penulisan tugas akhir ini akan dicari nilai support dan confidence
1. Hubungan Kategori Kelulusan dengan Mata Kuliah
Hasil dari proses mining ini dapat membantu untuk mengetahui bagaimana hubungan kategori kelulusan mahasiswa dengan nilai mata kuliah di jurusan sistem komputer dan dapat dimanfaatkan untuk dapat membantu evaluasi sistem pembelajaran di jurusan Sistem Komputer. Sehingga diharapkan dapat meningkatkan tingkat kelulusan mahasiswa.
3.2.1 Sumber Data
Data yang digunakan dalam penulisan tugas ahir ini merupakan data akademik mahasiswa angkatan 2001-2009. Hal ini didasarkan pada kebutuhan data, dengan asumsi bahwa mahasiswa angkatan 2001-2009 akan lulus dari rentang waktu tahun 2005-2013. Data tersebut diperoleh dari sekretariat Jurusan Sistem Komputer. Data yang diambil hanya dari data mahasiswa S1 di Jurusan Sistem Komputer. Adapun atribut dari data tersebut adalah
Tabel 3.1 Tabel Data Akademik Mahasiswa
ATRIBUT KETERANGAN
NIM (Nomor Induk
Mahasiswa)
Nomor Induk Mahasiswa atau yang disingkat NIM adalah kode yang dimiliki mahasiswa sebagai nomor unik identitas di Perguruan Tinggi.
Tahun Masuk/ Angkatan
ATRIBUT KETERANGAN
Lama Studi Merupakan lama studi, dihitung dimulai dari terdaftar sebagai mahasiswa sampai dinyatakan lulus.
IPK Indeks Prestasi Kumulatif (IPK) adalah ukuran kemampuan mahasiswa sampai pada waktu tertentu yang dapat dihitung berdasarkan jumlah (satuan kredit semester) SKS mata kuliah yang diambil sampai pada periode tertentu dikalikan dengan nilai bobot masing-masing mata kuliah dibagi dengan jumlah seluruh SKS mata kuliah (Anonim, 2009).
3.2.2 Pembersihan Data
Proses pembersihan data pada tugas akhir di sini adalah pembersihan data yang bersifat manual. Dimana proses pembersihan data dilakukan di luar aplikasi. Data dibersihkan dari data yang memilki missing value. Maksud dari missing value di sini contohnya adalah data yang tidak lengkap. Maksud dari data tidak lengkap contohnya ada field yang kosong. Dan apabila ada field yang kosong maka data tersebut akan dihilangkan secara manual. Atau contoh lain dari missing value adalah data yang isi dari fieldnya jauh dari data yang seharusnya, misalkan nilai mata kuliah kosong, maka data tersebut akan dihilangkan secara manual.
3.2.3 Transformasi Data
peraturan akademik yaitu untuk Program sarjana (S1) adalah 4 tahun (8 semester) dengan beban 144 -160 SKS, dan batas waktu studi paling lama adalah 14 semester terhitung sejak terdaftar sebagai mahasiswa semester I di UNIKOM. Sedangkan IPK dikategorikan berdasarkan predikat kelulusan yaitu:
Tabel 3.2 Predikat Kelulusan
IPK YUDISIUM LAMA STUDI
3,50 ≤ IPK ≤ 4,00 CUM LAUDE ≤ 4 TAHUN
2,75 ≤ IPK ≤ 3,49 SANGAT MEMUASKAN -
2,00 ≤ IPK ≤ 2,74 MEMUASKAN -
Dari Tabel 3.2 data kelulusan berdasarkan IPK dapat dikategorikan menjadi tiga yaitu :
1. IPK memuaskan dengan IPK 2,00 – 2,74 2. IPK sangat memuaskan dengan IPK 2,75 – 3,49 3. IPK tipe dengan pujian dengan IPK 3,50 – 4,00
Pengkategorian data kelulusan berdasarkan lama studi yaitu : 1. Sesuai jadwal, bila lama studi 4 tahun atau kurang dari 4 tahun 2. Tidak sesuai jadwal, bila lama studi lebih dari 4 tahun
Dari dua pengkategorian tersebut dapat dibuat kategori berdasarkan kombinasi keduanya, seperti yang dapat dilihat pada Tabel 3.3
Tabel 3.3 Transformasi Data
KATEGORI KETERANGAN
KATEGORI KETERANGAN
B2 Lama Studi lebih dari 4 tahun dan IPK 2,75 – 3,49 B3 Lama Studi lebih dari 4 tahun dan IPK 2,00 – 2,74
Dari kombinasi yang terdapat di Tabel 3.3 terdapat enam tingkatan untuk mengukur tingkat kelulusan mahasiswa.
Sedangkan untuk tabel indeks nilai dapat dilihat pada tabel di bawah ini: Tabel 3.4 Tabel Nilai
INDEKS PREDIKAT
A LULUS, Sangat Baik B LULUS, Baik
C LULUS, Cukup D LULUS, Kurang
E TIDAK LULUS
Tabel 3.4 digunakan untuk menunjukkan kategori kelulusan dalam mata kuliah yang diuji.
Tabel 3.5 Tabel Mata Kuliah
Kategori MATA KULIAH KETERANGAN
AP Algoritma Pemrograman I Singkatan untuk mata kuliah Algoritma Pemrograman I
BR Bahasa Rakitan Singkatan untuk mata kuliah Bahasa Rakitan
SD Sistem digital Singkatan untuk mata kuliah Sistem Digital
SM Sistem Mikroprosesor Singkatan untuk mata kuliah Sistem Mikroprosesor
3.3 Analisis Algoritma Apriori
Algoritma apriori adalah algoritma paling terkenal untuk menemukan pola frekuensi tinggi. Pola frekuensi tinggi adalah pola-pola item di dalam suatu
database yang memiliki frekuensi atau support di atas ambang batas tertentu yang disebut dengan istilah minimum support atau threshold. Threshold adalah batas minimum transaksi. Jika jumlah transaksi kurang dari threshold maka item atau kombinasi item tidak akan diikutkan perhitungan selanjutnya. Penggunaan
threshold dapat mempercepat perhitungan[6].
Algoritma aprioridibagi menjadi beberapa tahap yang disebut iterasi. Tiap iterasi menghasilkan pola frekuensi tinggi dengan panjang yang sama dimulai dari pass pertama yang menghasilkan pola frekuensi tinggi dengan panjang satu. Di iterasi pertama ini, support dari setiap item dihitung dengan men-scan database. Setelah support dari setiap item didapat, item yang memiliki support lebih besar dari minimum support dipilih sebagai pola frekuensi tinggi dengan panjang 1 atau sering disingkat 1-itemset. Singkatan k-itemset berarti satu set yang terdiri dari k item[6].
Iterasi kedua menghasilkan 2-itemset yang tiap set-nya memiliki dua item. Pertama dibuat kandidat 2-itemset dari kombinasi semua 1-itemset. Lalu untuk tiap kandidat 2-itemset ini dihitung support-nya dengan men-scan database.
Support artinya jumlah transaksi dalam database yang mengandung kedua item dalam kandidat 2-itemset. Setelah support dari semua kandidat 2-itemset didapatkan, kandidat 2-itemset yang memenuhi syarat minimum support dapat ditetapkan sebagai 2-itemset yang juga merupakan pola frekuensi tinggi dengan panjang 2[6].
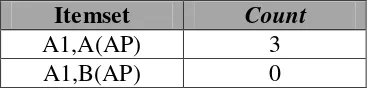
Tabel 3.6 Data Awal
NIM Kategori Kelulusan Nilai Algoritma Pemrograman I
1020xxx1 A2 B(AP)
Dari data awal tersebut didapat kandidat pertama (C1) seperti pada Tabel 3.7. Tabel 3.7 Kandidat Pertama (C1)
Itemset Count
Tabel 3.8 Hasil Setelah Threshold Ditetapkan (L1)
Dari Tabel 3.8 didapat kandidat kedua (C2) seperti pada Tabel 3.9 Tabel 3.9 Kandidat Kedua (C2)
Itemset Count
Setelah ditetapkan threshold menghasilkan data seperti Tabel 3.10 Tabel 3.10 Hasil Kedua (L2)
Itemset Count
A1, A(AP) 3
B2, E(AP) 4
Dari Tabel 3.10 dapat diambil hasil sebagai berikut:
Dapat dilihat bahwa proses mining hubungan tingkat kelulusan dengan nilai Algoritma Pemrograman mahasiswa dengan threshold 3 menghasilkan hubungan A1, A(AP) mempunyai nilai support 3/15 dan confidence 3/3 dan hubungan B2,E(AP) mempunyai nilai support 4/15 dan confidence 4/9. Dari contoh tersebut dapat disimpulkan bahwa mahasiswa yang mempunyai nilai A dalam mata kuliah Algoritma Pemrograman I, maka kategori kelulusannya adalah A1 yaitu lama Studi 4 tahun atau kurang dari 4 tahun dan IPK 3,50 - 4,00, dengan nilai keyakinan 100% dari 20 % seluruh proses dalam database. Sedangkan mahasiswa yang mendapat nilai E maka kategori kelulusannya adalah B2 yaitu Lama Studi lebih dari 4 tahun dan IPK 2,75 – 3,49 dengan nilai keyakinan 44,44% dari 26,27 % dari seluruh proses database.
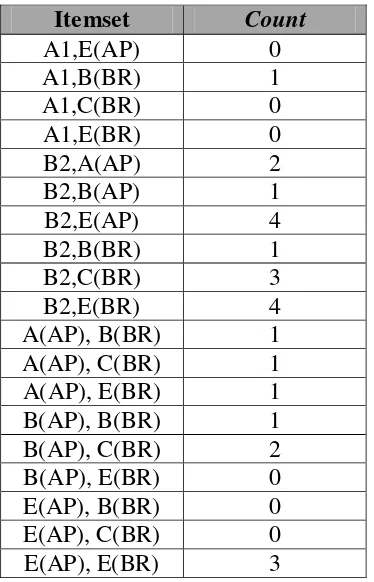
Contoh kedua dari proses mining untuk mengetahui hubungan tingkat kelulusan dengan nilai mata kuliah Bahasa Rakitan, dapat dilihat dalam contoh Tabel 3. 11 berikut:
Tabel 3.11 Data Awal Contoh Kedua
Dari data tersebut didapat kandidat pertama (C1) seperti pada Tabel 3.12 berikut Tabel 3.12 Kandidat Pertama (C1) contoh kedua
Itemset Count
Ditetapkan threshold = 3, maka kandidat yang nilainya kurang dari 3 akan dihapus, maka akan didapatkan hasil seperti pada Tabel 3.13
Tabel 3.13 Hasil Setelah Threshold Ditetapkan (L1) sebagai Contoh Kedua Itemset Count
Dari Tabel 3.13 didapat kandidat kedua (C2) seperti pada Tabel 3.14 Tabel 3.14 Kandidat Kedua (C2) contoh kedua
Itemset Count
A1,A(AP) 3
Itemset Count
Setelah diberikan threshold = 3 maka akan menghasilkan data seperti Tabel 3.15: Tabel 3.15 Hasil Kedua (L2) Contoh Kedua
Itemset Count
Dari Tabel 3.15 didapat kandidat ketiga (C3) seperti pada Tabel 3.16 Tabel 3.16 Kandidat Ketiga (C3)
Itemset Count
B2,E(AP),E(BR) 3
Dari data tersebut dapat diambil hasil sebagai berikut:
Confidence (B2, E(AP), E(BR)) = count (B2, E(AP), E(BR))/count (B2) = 3/9
Dalam proses tersebut ditetapkan minimum support atau threshold adalah 3. Pada iterasi pertama, item yang support-nya atau count-nya kurang dari 3 di eliminasi dari 1-itemset L1. Kemudian kandidat 2-itemset C2 dari iterasi kedua dibentuk dari cross product item-item yang ada di L1. Setelah kandidat 2-itemset itu dihitung dari database, ditetapkan 2-itemset L2. Proses serupa berulang di iterasi ketiga, tetapi selain (B2, E(AP), E(BR)) yang menjadi kandidat 3-itemset C3 sebenarnya ada juga itemset lain seperti (A1, A(AP), E(BR)), (B2, E(AP, C(BR) yang dapat diperoleh dari kombinasi L2, namun itemset tersebut dipangkas karena tidak memenuhi syarat minimum. Proses ini akan berulang sampai tidak ada lagi kandidat baru yang dapat dihasilkan dari minimum threshold. Jadi dari proses tabel kandidat ketiga dapat diketahui bahwa mahasiswa yang mendapatkan nilai E dalam Algoritma Pemrograman dan nilai E dalam Bahasa Rakitan akan lulus dalam kategori B2 dengan Lama Studi lebih dari 4 tahun dan IPK 2,75 – 3,49 dengan nilai keyakinan 33,33 % dengan support 20 % proses dalam
database.
Dari Tabel 3.11 bisa dilihat bahwa algoritma apriori dapat mengurangi jumlah kandidat yang harus dihitung support-nya dengan pemangkasan. Misalnya kandidat 3-itemset dapat dikurangi dari 3 menjadi 1 saja. Pengurangan jumlah kandidat ini merupakan sebab utama peningkatan performa algoritma apriori.
3.3.1 Report dan Penyajian Hasil Proses
Setelah proses mining akan disajikan hasil dari data mining berupa tabel hubungan kekuatan dengan nilai support dan confidence masing-masing atribut serta threshold yang digunakan. Semakin tinggi nilai confidence dan support
3.4 Analisis Kebutuhan Non Fungsional
Analisis merupakan penguraian dari suatu masalah atau objek yang akhirnya menghasilkan suatu kesimpulan. Hal ini dimaksud untuk mengidentifikasi dan mengevaluasi masalah atau objek.
Analisis non fungsional adalah sebuah langkah dimana seorang pembangun perangkat lunak menganalisis sumber daya yang akan menggunakan perangkat lunak yang dibangun.
Analisis non fungsional tidak hanya menganalisis siapa saja yang akan menggunakan aplikasi tetapi juga menganalisis perangkat keras dan perangkat lunak yang dimiliki oleh pemesan, sehingga dapat ditentukan kompabilitas aplikasi yang dibangun terhadap sumber daya yang ada. Setelah melakukan analisis non fungsional, maka dilanjutkan ke langkah berikutnya yaitu menentukan kebutuhan non fungsional sistem yang akan dibangun untuk disesuaikan dengan fakta yang ada.
Apabila terjadi ketidakcocokan antara fakta dan kebutuhan maka perlu adanya penyesuaian fakta terhadap kebutuhan yang ada. Apabila kebutuhan tidak dipenuhi maka system yang dibangun tidak akan berjalan baik sesuai yang diharapkan.
Analisis non fungsional dan kebutuhan non fungsional yang dilakukan dibagi dalam tiga tahapan, yaitu:
1. Kebutuhan pengguna (user)
2. Kebutuhan perangkat keras (hardware) 3. Kebutuhan perangkat lunak (software)
3.5 Analisis Kebutuhan Pengguna (User)
1. Terbiasa menggunakan aplikasi yang ada di sistem operasi Windows. 2. Memiliki pengetahuan tentang database.
3. Mengetahui atribut yang dianggap kuat untuk dilibatkan dalam proses Data mining
3.6 Analisis Kebutuhan Perangkat Keras (Hardware)
Kebutuhan hardware yang disarankan untuk menjalankan spesifikasi ini minimal memiliki spesifikasi sebagai berikut:
a. Processor 1,5 GHz b. Harddisk 20 GB c. RAM 512 MB
d. Monitor yang mendukung kualitas warna 16 bit dengan resolusi 800 x 600
pixels.
Berdasarkan spesifikasi yang telah ada, secara keseluruhan kebutuhan perangkat keras untuk aplikasi ini telah terpenuhi.
3.7 Analisis Kebutuhan Perangkat Lunak (Software)
Perangkat lunak merupakan sarana pendukung lainnya bagi pembangunan aplikasi tingkat kelulusan mahasiswa di jurusan Sistem Komputer ini. Perangkat lunak yang disarankan untuk menjalankan aplikasi ini adalah sebagai berikut: a. Sistem Operasi
Untuk sistem operasi windows disarankan, karena sistem operasi ini banyak dikenal oleh user awam dan lebih mudah dipelajari.
b. Database Management System
3.8 Analisis Kebutuhan Fungsional
Analisis merupakan penguraian dari suatu masalah atau objek yang akhirnya menghasilkan suatu kesimpulan. Hal ini dimaksud untuk mengidentifikasi dan mengevaluasi masalah atau objek. Dalam langkah ini akan dilakukan penentuan entitas-entitas baik entitas internal maupun entitas eksternal, data yang mengalir, serta prosedur-prosedur yang bisa dilakukan oleh masing-masing entitas.
3.8.1 Spesifikasi Kebutuhan Fungsional
Spesifikasi kebutuhan fungsional pada Aplikasi Data Mining ini merujuk pada kebutuhan akan perancangan data mining, seperti berikut ini :
Dapat menggabungkan data yang akan diproses mining dari data matakuliah dan data mahasiswa.
Dapat memilih data serta atribut yang akan diproses. Dapat mengubah data menjadi data yang siap diproses. Dapat memproses data untuk dimining.
Dapat menampilkan hasil proses mining dengan nilai support dan
confidence.
3.8.2 Analisis Batasan Sistem
Batasan dari sistem ini adalah :
1. Proses pengolahan data (penambahan, pengurangan dan hapus data) dilakukan oleh administrator.
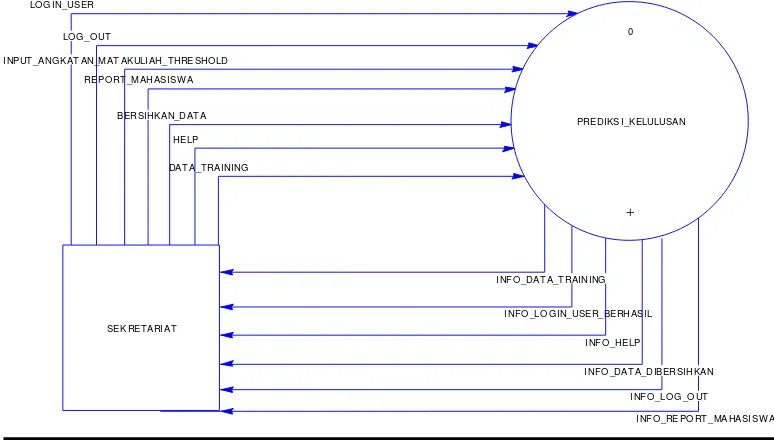
3.8.3 Diagram Konteks
digambarkan entitas eksternal yang merupakan brainware yang menghasilkan data yang akan diolah oleh sistem maupun tujuan dari informasi yang dihasilkan oleh sistem.
Gambar di bawah merupakan Diagram konteks pada aplikasi hubungan kategori kelulusan terhadap nilai mata kuliah mahasiswa di jurusan Sistem Komputer menggunakan algoritma apriori.
1. DCD/ DFD Level-0
Gambar 3.1 merupakan Diagram konteks pada Aplikasi Data mining
tingkat kelulusan mahasiswa menggunakan algoritma apriori.
Gambar 3.1 DFD Level-0
2. DFD Level-1
Diagram alir data merupakan sebuah representasi dari suatu sistem yang menggambarkan bagian-bagian dari sistem tersebut beserta keterkaitan antara bagian-bagian yang ada. Dari diagram alir data ini seseorang bisa mengetahui sumber dari informasi di dalam sistem, maupun tujuan dari masukan yang berasal
REP ORT_MAHASIS WA I NPUT_ANG KAT AN_MAT AKULI AH_THRE SHO LD
LO G _O UT 0
PRE DIKS I_KELULUSAN
+
dari entitas eksternal. Adapun diagram alir data level-1 dari aplikasi data mining
ditunjukan oleh gambar 3.2 berikut:
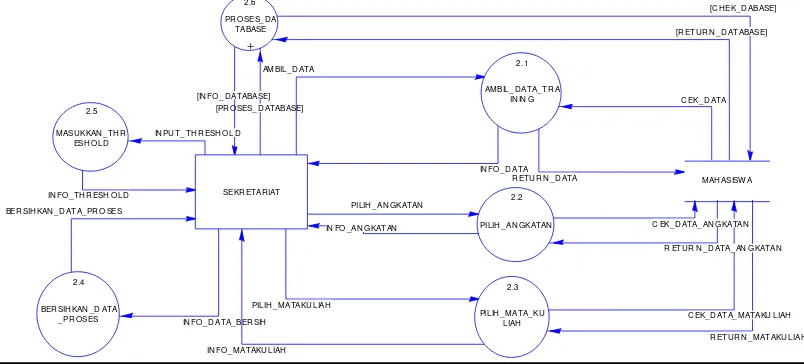
Gambar 3.2 DFD Level-1 3. DFD Level-2 untuk Proses 2
Gambar 3.3 DFD Level-2 untuk Proses 2
Gambar 3.3 menjelaskan tentang proses dari DFD level-2 proses 2. Dalam gambar tersebut pengolahan data training dipecah menjadi 3 bagian sub proses, dan spesifikasi prosesnya akan dijelaskan di Tabel 3.18.
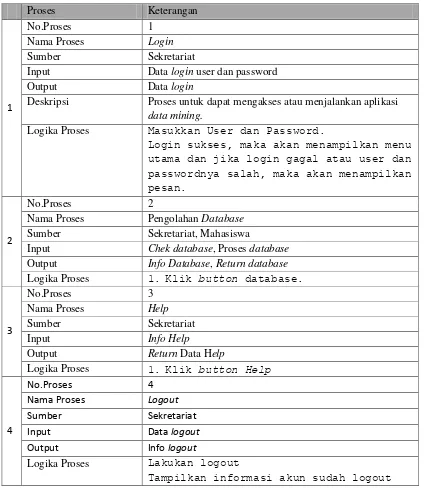
Tabel 3.17 Spesifikasi Proses DFD Level-1 Aplikasi Data Mining
Deskripsi Proses untuk dapat mengakses atau menjalankan aplikasi data mining.
Logika Proses Masukkan User dan Password.
Login sukses, maka akan menampilkan menu utama dan jika login gagal atau user dan passwordnya salah, maka akan menampilkan pesan.
2
No.Proses 2
Nama Proses Pengolahan Database Sumber Sekretariat, Mahasiswa
Input Chek database, Proses database Output Info Database, Return database Logika Proses 1. Klik button database.
3
Logika Proses 1. Klik button Help
4
Logika Proses Lakukan logout
Tabel 3.18 Spesifikasi Proses DFD Level-2 untuk Proses 2
Proses Keterangan
1
No.Proses 2.1
Nama Proses Ambil Data Training Sumber Mahasiswa, Sekretariat
Input Ambil data training, return data training Output Cek data training Info data
Logika Proses 1. Ambil data yang ingin diproses dari tabel mahasiswa
2. Tampilkan report data ke sekretariat
2
No.Proses 2.2
Nama Proses Pilih Angkatan
Sumber Mahasiswa, Sekretariat Input Pilih angkatan, Return data Output Cek Data Angkatan, info angkatan
Logika Proses 1. Pilih angkatan yang ingin diproses dari tabel mahasiswa
2. Tampilkan report angkatan ke
sekretariat
3
No.Proses 2.3
Nama Proses Pilih Mata Kuliah Sumber Sekretariat, Mahasiswa
Input Pilih mata kuliah, Return mata kuliah Output Cek data mata kuliah, Info data mata kuliah Logika Proses 1. Ubah data training
2. Simpan di tabel mahasiswa
4
No.Proses 2.4
Nama Proses Bersihkan Data Proses Sumber Sekretariat
Input Bersihkan Data
Output Data berhasil dibersihkan
Logika Proses 1. Bersihkan data proses yang sudah
ditampilkan, untuk memproses data
baru
5
No.Proses 2.5
Nama Proses Masukkan Threshold Sumber Sekretariat
Input Inputthreshold Output Info threshold
3.9 Perancangan Sistem
Perancangan merupakan bagian dari metodologi pembangunan suatu perangkat lunak yang harus dilakukan setelah tahapan analisis. Pada bagian ini akan dijelaskan perancangan sistem yang akan dibangun dan akan dijelaskan pada bab IV.
3.10 Perancangan Data
Perancangan data atau lebih dikenal dengan perancangan basis data yaitu menciptakan atau merancang data yang terhubung dan disimpan secara bersama-sama. Untuk menggambarkannya digunakanlah struktur file.
3.10.1 Struktur Tabel
Pada proses data mining tingkat kelulusan mahasiswa ini, dibutuhkan
database untuk menyimpan data hasil proses. Adapun struktur tabel digunakan untuk menggambar tabel-tabel beserta field-field yang digunakan secara lebih detail, dimana tipe data dan ukuran suatu field serta kunci-kunci (primary key atau
foreign key) disajikan.
Tabel di bawah ini merupakan tabel beserta field dan data type yang digunakan dalam database dengan menggunakan Microsoft Access 2007:
Proses Keterangan
6
No.Proses 2.6
Nama Proses Proses Database Sumber Sekretariat, Mahasiswa
Input Proses database, Returndatabase Output Chek Database, Info Proses Logika Proses 1. Tekan button proses
2. Tampilkan Report data yang sudah
Tabel 3.19 Data_Mahasiswa
Nama Field Tipe Panjang
Nim Number 8
Angkatan Number 4
IPK Number 4
Lama_Studi Number 2
Algoritma Text 4
Rakitan Text 4
Mikro Text 4
3.10.2 Arsitektur Antarmuka
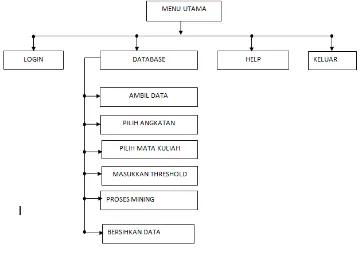
Berikut ini adalah perancangan struktur menu yang akan diterapkan pada program dan dirancang dengan efisien untuk mengurangi kompleksitas sistem yang akan ditunjukkan oleh Gambar 3.4 berikut.
3.11 Perancangan Antarmuka
Perancangan antarmuka merupakan suatu bentuk dari program yang akan dibuat untuk kebutuhan interface dengan pengguna. Spesifikasi antarmuka terdiri dari perancangan tampilan menu, tampilan form dan keluaran.
1. Form Login
Gambar 3.5 Perancangan Form Login
Tabel 3.20 Penjelasan Tentang Perancangan Form Login
No Keterangan
1 Jika berhasil, maka akan masuk ke Form Utama dan jika gagal maka akan diminta login ulang.
2 Merupakan button untuk membatalkan login.
2. Form Menu
3. Form Keseluruhan
Gambar 3.7 Perancangan Form Keseluruhan Data Mining
4. Form Report
3.12 Perancangan Prosedural
Perancangan prosedural akan menjelaskan tentang bagaimana perangkat lunak berjalan. Perancangan prosedural digambarkan dalam bentuk flowchart
sistem.
3.12.1 ProcedureData Mining
Berikut merupakan flowchart sistem Aplikasi Tingkat Kelulusan Mahasiswa yang akan dibangun
3.12.2 Procedure Aturan Assosiatif Untuk Menentukan Frequent Itemset
3.12.3 Procedure Aturan Assosiatif untuk Menentukkan Nilai Support dan Confidence.
40
Pada bab ini akan dibahas mengenai implementasi program. Hasil pembahasan ini bertujuan untuk menerapkan modul-modul yang telah dikerjakan pada tahap perancangan. Hasil perancangan pada tahap perancangan akan diimplemetasikan menjadi program atau aplikasi yang siap untuk digunakan.
4.1 Implementasi
Implementasi aplikasi data mining meliputi lingkungan implementasi perangkat
keras, perangkat lunak dan implementasi terhadap antarmuka. Implementasi dilakukan
dengan mentransformasikan fungsi program ke dalam kode-kode program. Pada tahap
implementasi, yang perlu diperhatikan adalah kesesuaian program yang dihasilkan
dengan perancangan yang telah dilakukan sekaligus memperhatikan lingkungan
pengembangan aplikasi seperti bahasa pemrograman yang dipakai untuk menghasilkan
program yang sesuai dengan perancangan yang telah dibuat dan tentunya sesuai dengan
spesifikasi kebutuhan.
4.1.1 Lingkungan Implementasi
Berikut ini adalah lingkungan implementasi perangkat lunak yang dibangun.
Implementasi terdiri dari dua lingkungan, yaitu lingkungan implementasi perangkat keras
dan lingkungan implementasi perangkat lunak. Spesifikasi yang digunakan dapat dilihat
pada Tabel 4.1
Tabel 4.1 Lingkungan Implementasi Lingkungan Perangkat Keras
Prosesor Intel ® CoreTM i3-2328M @ 2.2GHz
RAM 2GB
Harddisk 500GB
Lingkungan Perangkat Keras
Input Mouse dan Keyboard
Lingkungan Perangkat Lunak
Sistem Operasi Microsoft © Windows 7
Aplikasi Sistem Antarmuka Visual Basic 6.0
Pengolahan Database Microsoft Access 2007
4.1.2 Implementasi Antarmuka
Pada tampilan ini dilakukan penerapan hasil perancangan antarmuka ke dalam sistem yang dibangun dengan menggunakan perangkat lunak yang telah dipaparkan pada subbab lingkungan implementasi.
1. FormLogin
Form ini merupakan tampilan antarmuka yang muncul pertama kali. Form
ini merupakan kunci untuk menggunakan aplikasi ini. Jika login berhasil, maka akan masuk ke form selanjutnya yaitu form utama dan jika gagal login, maka pengguna diperintahkan untuk login ulang, yang dapat pada Gambar 4.1.
Gambar 4.1 Form Login
2. Form Utama
Form ini merupakan tampilan antarmuka setelah proses login berhasil,
Gambar 4.2 Menu Utama 3. Form Keseluruhan
Form ini merupakan antarmuka untuk menampilkan seluruh proses Asosiasi untuk menampilkan persentase hubungan kategori kelulusan terhadap nilai mahasiswa Sistem Komputer. Cara kerja form ini adalah dengan menginput data mahasiswa dari database yang akan ditampilkan dalam berupa tabel
griedview. Dalam proses ini akan dipilih mata kuliah dan juga threshold yang akan diuji yang kemudian akan ditampilkan dalam form report yang dapat dilihat pada Gambar 4.3
4. Form Report
Form ini merupakan report data mining yang sudah diproses. Form ini akan aktif dan tampil jika pengguna menekan tombol proses pada form asosiasi database mahasiswa, dalam form ini terdapat hasil dari proses mining berupa nilai masing-masing kategori yang mempunyai nilai confidence tertinggi. Selain itu terdapat tabel itemset dengan atribut itemset, cacah jumlah itemset atau count,
support, dan confidence dari itemset tersebut yang dapat dilihat pada Gambar 4.4
Gambar 4.4 Form Report
5. Form Help
Form ini berfungsi sebagai panduan manual untuk memproses data pada aplikasi yang dapat dilihat pada Gambar 4.5.
4.2 Pengujian
4.2.1 Pengujian Sistem
Pengujian sistem merupakan pengujian terhadap aplikasi yang dibuat, apakah aplikasi data mining ini berhasil atau tidak untuk menghitung persentase hubungan kategori kelulusan terhadap nilai mata kuliah mahasiswa di jurusan Sistem Komputer. Pengujian terjadi dalam dua proses yaitu
1. Pengujian database mahasiswa dengan menggunakan kombinasi mata kuliah sebagai bahan uji.
2. Pengujian database mahasiswa dengan menggunakan threshold yang berbeda dalam proses uji.
4.2.2 Skenario Pengujian
Program Aplikasi akan diujikan pada testing 1 database dengan ketentuan sebagai berikut pada Gambar 4.6:
Gambar 4. 6 Skenario Pengujian Algoritma
4.2.3 Hasil Pengujian Hubungan Kategori Kelulusan dengan Mata Kuliah
Dari kategori kelulusan dan atribut nilai tersebut maka langkah pertama yang dilakukan dalam proses asosiasi adalah menghitung setiap itemset yang terdapat dalam database, kemudian jumlah itemset tersebut akan diberikan nilai batasan minimum yang disebut dengan threshold, setelah itu akan dilakukan proses asosiasi dengan mengkombinasikan setiap data yang memenuhi threshold,
dan kemudian data yang sudah dikombinasikan akan dithreshold lagi, data yang jumlahnya sama atau lebih dari threshold akan dihitung kembali dan dikombinasikan. Proses tersebut akan terus berulang selama data tersebut masih bisa dikombinasikan dan masih memenuhi threshold.
Output yang dihasilkan dalam proses asosiasi ini berupa persentase
confidence (atau nilai keyakinan) dan persentase support (nilai pengunjung atau persentase kombinasi sebuah item dalam database ). Pengujian dilakukan dengan menggunakan threshold yang berbeda.
a. Pengujian Database Menggunakan Matakuliah Algoritma Pemrograman Angkatan 2001-2009
Pengujian ini dilakukan dengan cara menggunakan nilai satu mata kuliah yang diujikan dengan menggunakan threshold yang sama dengan tujuan dapat mengetahui nilai threshold dan hubungan kategori kelulusan dengan nilai mata kuliah yang terbaik. Tabel 4.2 merupakan hasil proses pengujian aplikasi menggunakan mata kuliah Algoritma Pemrograman dengan threshold =2, data yang digunakan merupakan database angkatan 2001-2009, dengan hasil sebagai berikut dapat dilihat pada Tabel 4.2.
Tabel 4.2 Hasil Proses Mining untuk Mata Kuliah Algoritma Pemrograman Menggunakan Threshold =2
ITEMSET Confidence % Support %
A1APA 58,50 22,00
A2APB 60,00 27,00
ITEMSET Confidence % Support %
Gambar 4.7 diatas merupakan grafik hubungan kategori kelulusan dengan nilai mata kuliah Algoritma Pemrograman, dari gambar tersebut dapat disimpulkan bahwa proses mining hubungan kategori kelulusan dengan nilai mata kuliah Algoritma Pemrograman dengan nilai C, mempunyai keyakinan 100 % lulus pada kategori A2 dengan nilai support pada database sebesar 17% , pada kategori B2 dengan nilai keyakinan 33,13% dengan nilai support 21,13% serta pada kategori B3 dengan nilai keyakinan sebesar 30% dari 7,50% support dalam
database. Dari gambar dapat diketahui bahwa dengan nilai C, maka peluang mahasiswa akan lulus pada kategori B2 akan lebih tinggi dengan nilai support
dalam database sebesar 21, 13%. Selain itu pada gambar dapat dilihat juga bahwa mahasiswa akan lulus pada kategori A1 hanya jika mendapatkan nilai A pada mata kuliah Algoritma Pemrograman dengan nilai keyakinan 58,50% dengan 22%
support dalam database.
b. Pengujian Database Menggunakan Matakuliah Bahasa Rakitan Angkatan 2001-2009
Pengujian ini dilakukan dengan cara menggunakan nilai satu mata kuliah yang diujikan dengan menggunakan threshold yang sama dengan tujuan dapat mengetahui nilai threshold dan hubungan kategori kelulusan dengan nilai mata kuliah yang terbaik. Tabel 4.3 merupakan hasil proses pengujian aplikasi menggunakan mata kuliah Bahasa Rakitan dengan threshold =2, data yang digunakan merupakan database angkatan 2001-2009, dengan hasil sebagai berikut dapat dilihat pada Tabel 4.3.
Tabel 4.3 Hasil Proses Mining untuk Mata Kuliah Bahasa Rakitan Menggunakan
Item Set Confidence % Support %
Gambar 4.8 Hasil Pengujian Menggunakan Mata Kuliah Bahasa Rakitan dengan
Threshold=2
Dari Gambar 4.8 dapat dilihat bahwa mahasiwa dapat lulus pada kategori kelulusan A1 dengan nilai mata kuliah Bahasa Rakitan A atau B dengan nilai keyakinan 100%, tetapi dapat dilihat bahwa nilai A mendapatkan support yang lebih besar dari nilai B yaitu sebesar 17% dari proses database. Selain itu dari gambar juga dapat dilihat pada kategori B2 mahasiswa dapat lulus dengan semua
0,00
Hasil Pengujian Matakuliah B. Rakitan
Menggunakan Threshold=2
Confidence %
nilai, tetapi nilai C mendapatkan support yang lebih besar dalam database yaitu sebesar 16%
c. Pengujian Database Menggunakan Matakuliah Sistem Digital Angkatan 2001-2009
Pengujian ini dilakukan dengan cara menggunakan nilai satu mata kuliah yang diujikan dengan menggunakan threshold yang sama dengan tujuan dapat mengetahui nilai threshold dan hubungan kategori kelulusan dengan nilai mata kuliah yang terbaik. Tabel 4.4 merupakan hasil proses pengujian aplikasi menggunakan mata kuliah Sistem Digital dengan threshold =2, data yang digunakan merupakan database angkatan 2001-2009, dengan hasil sebagai berikut dapat dilihat pada Tabel 4.4.
Tabel 4.4 Hasil Proses Mining untuk Mata Kuliah Sistem Digital Menggunakan
Gambar 4.9 Hasil Pengujian Menggunakan Mata Kuliah Sistem Digital dengan dengan keyakinan sebesar 100% pada nilai B dengan support sebesar 17% proses dalam database.
d. Pengujian Database Menggunakan Matakuliah Mikroprosessor Angkatan 2001-2009
Pengujian ini dilakukan dengan cara menggunakan nilai satu mata kuliah yang diujikan dengan menggunakan threshold yang sama dengan tujuan dapat
0,00
Hasil Pengujian Matakuliah S. Digital
Menggunakan Threshold=2
Confidence %
mengetahui nilai threshold dan hubungan kategori kelulusan dengan nilai mata kuliah yang terbaik. Tabel 4.5 merupakan hasil proses pengujian aplikasi menggunakan mata kuliah Mikroprosessor dengan threshold =2, data yang digunakan merupakan database angkatan 2001-2009, dengan hasil sebagai berikut dapat dilihat pada Tabel 4.5.
Tabel 4.5 Hasil Proses Mining untuk Mata Kuliah Mikroprosessor Menggunakan
Threshold =2
Item Set Confidence % Support %
A1SMA 83,50 17,50
A2SMA 40,00 18,00
A2SMB 33,00 6,00
A2SMC 50,00 9,00
B1SMA 40,00 6,00
B1SMB 60,00 10,00
B1SMC 60,00 6,00
B2SMA 23,00 13,00
B2SMB 28,67 16,33
B2SMC 39,29 23,43
B2SMD 39,80 20,20
B2SME 30,00 18,17
B3SMB 79,33 16,33
B3SMC 38,50 9,50
B3SMD 27 9
Gambar 4.10 Hasil Pengujian Menggunakan Mata Kuliah Sistem Mikroprosessor dengan Threshold=2
Dari Gambar 4.10 dapat dilihat bahwa untuk lulus pada kategori A1 pada mata kuliah Sistem Mikroprosessor harus lulus dengan nilai A dengan nilai keyakinan 83,50% dan didukung oleh nilai support sebesar 17,50% proses dalam
database. Selain itu dari gambar juga dapat dilihat bahwa mahasiswa lebih banyak lulus di kategori B2 yaitu dengan semua kategori nilai A-E dengan jumlah support
dalam database mencapai 91,13% proses dalam database. Hal ini bisa terjadi, karena masih ada faktor-faktor lain yang dapat mempengaruhi kategori kelulusan mahasiswa di jurusan Sistem Komputer.
e. Pengujian Database Menggunakan Satu Matakuliah Menggunakan Threshold=2 dengan Sampel Uji Satu Angkatan
Pengujian ini dilakukan dengan cara menggunakan nilai satu mata kuliah yang diujikan dengan menggunakan threshold yang sama dengan tujuan dapat mengetahui nilai threshold dan nilai mata kuliah yang terbaik. Tabel 4.6 merupakan hasil proses pengujian aplikasi menggunakan threshold =2, data yang digunakan merupakan database angkatan 2009, dengan hasil sebagai berikut:
0,00
Hasil Pengujian Matakuliah S. Mikroprosessor
Menggunakan Threshold=2
Confidence %
Tabel 4.6 Hasil Proses Mining Untuk Satu Mata Kuliah Menggunakan
Threshold=2
Angkatan 2009 dengan Satu Matakuliah
Mata Kuliah Item Set Count Confidence % Support %
Gambar 4.11 Hasil Pengujian Menggunakan Satu Mata Kuliah dengan
Threshold=2
Hasil Pengujian Menggunakan Satu Mata Kuliah
dengan Threshold = 2
Confidence
Dari Gambar 4.11 diatas dapat disimpulkan bahwa proses mining hubungan tingkat kelulusan dengan nilai A pada Algoritma Pemrograman mahasiswa dengan kategori A1 menggunakan threshold= 2 menghasilkan nilai confidence
atau keyakinan 100% dengan nilai support 27,27 % dari seluruh proses database. Dari hasil tabel diatas juga dapat dilihat bahwa nilai Algoritma Pemrograman mempunyai persentase yang lebih kuat untuk lulus di kategori A1 dibandingkan dengan mata kuliah lainnya.
f. Pengujian Database Menggunakan Satu Matakuliah dengan Threshold=3 dengan Sampel Uji Satu Angkatan
Pengujian ini dilakukan dengan cara menggunakan nilai satu mata kuliah yang diujikan dengan menggunakan threshold yang sama dengan tujuan dapat mengetahui nilai threshold dan nilai mata kuliah yang terbaik. Tabel 4.7 merupakan hasil proses pengujian aplikasi menggunakan threshold =3, data yang digunakan merupakan database angkatan 2009, dengan hasil sebagai berikut:
Tabel 4.7 Hasil Proses Mining Untuk Satu Mata Kuliah Menggunakan
Threshold=3
Angkatan 2009 dengan Satu Matakuliah
Mata Kuliah Item Set Count Confidence % Support % Algoritma
Pemrograman
A1(AP)A 3 100 27,27
A2(AP)B 3 60 27,27
Bahasa Rakitan - - - -
Sistem Digital A2(SD)E 3 60 27,27
Sistem
Gambar 4.12 Hasil Pengujian Menggunakan Satu Mata Kuliah dengan
Threshold=3
Dari Gambar 4.8 diatas dapat disimpulkan bahwa proses mining hubungan tingkat kelulusan dengan nilai A pada Algoritma Pemrograman mahasiswa dengan kategori A1 menggunakan threshold= 3 menghasilkan nilai confidence
atau keyakinan 100% dengan nilai support atau jumlah proses dari seluruh database sebanyak 27,27 %. Dari hasil tabel diatas juga dapat dilihat bahwa mahasiswa juga akan lulus pada kategori B2 atau Lebih dari 4 tahun jika nilai Sistem Mikroprossor adalah D dengan nilai keyakinan 100% dan nilai support
27,27 % jumlah proses dari seluruh database. Dalam Gambar 4.12, Nilai Bahasa Rakitan tidak memenuhi threshold, hal ini bisa terjadi karena nilai threshold yang terlalu tinggi atau data yang kurang memadai, sehingga kombinasi nilai dalam mata kuliah bahasa rakitan tidak memenuhi nilai threshold.
0 20 40 60 80 100 120
Hasil Pengujian Menggunakan Satu Mata
Kuliah dengan Threshold = 3
Confidence
g. Pengujian Database Menggunakan Kombinasi Matakuliah dengan Threshold=2 dengan Sampel Uji Satu Angkatan
Pengujian ini dilakukan dengan cara menggunakan kombinasi 1-4 matakuliah dengan tujuan dapat mengetahui kombinasi yang terbaik dan tingkat keberhasilan yang tinggi untuk mengetahui persentase nilai confidence dan
support dari kategori kelulusan dan nilai mahasiswa.
Pada Tabel 4.8 di bawah ini menunjukkan hasil pengujian aplikasi data mining dengan melakukan kombinasi mata kuliah dengan threshold = 2.
Tabel 4.8 Hasil Proses Mining Untuk Kombinasi Mata Kuliah Menggunakan
Threshold =2
Angkatan 2009 dengan Satu Matakuliah
Gambar 4.13 Hasil Proses Mining Untuk Kombinasi Mata Kuliah Menggunakan
Threshold =2
Dari Gambar 4. 13 dapat disimpulkan bahwa kombinasi dari 2-4 mata kuliah mempunyai hasil yang sama, hal ini bisa terjadi karena jumlah data yang kurang memadai, dan kurangnya variasi data sehingga kombinasi yang dilakukan tidak memenuhi threshold. Oleh karena itu untuk menguji algoritma apriori dengan kombinasi mata kuliah dibutuhkan data yang lebih besar.
Pada analisis Tabel e dan f di atas dapat dilihat bahwa dengan mengubah nilai threshold akan menghasilkan kombinasi yang bervariasi. Jadi, ukuran nilai
threshold yang besar belum tentu menjadi nilai threshold yang terbaik dengan tingkat keberhasilan yang tinggi, begitupun juga sebaliknya. Nilai threshold yang terbaik dipengaruhi oleh jumlah dan kombinasi data yang digunakan.
0 20 40 60 80 100 120
Hasil Proses Mining Pengujian Kombinasi Mata
Kuliah dengan Threshold=2
Conf