PENGEMBANGAN PROTOTIPE SPATIAL DATA MINING
UNTUK KARAKTERISASI DESA MISKIN DI JAWA BARAT
HARI AGUNG ADRIANTO
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
Dengan ini saya menyatakan bahwa tesis Pengembangan Prototipe Spatial Data Mining Untuk Karakterisasi Desa Miskin di Jawa Barat adalah karya saya sendiri dengan arahan Komisi Pembimbing dan belum diajukan dalam bentuk apapun kepada penguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Mei 2007
ABSTRAK
HARI AGUNG ADRIANTO. Pengembangan Prototipe Spatial Data Mining Untuk Karakterisasi Desa Miskin di Jawa Barat. Dibimbing oleh AGUS BUONO dan BABA BARUS.
Data mining, atau secara populer dirujuk sebagai Knowlegde discovery in databases (KDD) adalah teknik yang secara otomatis. melakukan ekstraksi pola yang merepresentasikan pengetahuan yang secara implisit tersimpan dalam basisdata besar, data warehouse, dan tempat penyimpanan yang masif lainnya. Spatial data mining berurusan dengan pencarian pengetahuan dalam basisdata spasial.Salah satu teknik dalam spatial data mining adalah karakterisasi spasial (spatial characterization). Karakterisasi spasial digunakan untuk mengungkap karakteristik atau deskripsi ringkas spasial dari sifat-sifat yang menarik pada sebuah komunitas (obyek target) tetapi tidak untuk keseluruhan basisdata. Dalam penelitian ini dilakukan pengembangan prototipe sistem yang dapat menerapkan teknik spatial data mining untuk mengungkap karakteristik spasial dari kondisi kemiskinan di Jawa Barat. Prototipe yang dihasilkan terdiri dari empat komponen yaitu modul pengolahan awal, modul spatial data mining, modul basisdata dan modul visualisasi. Modul spatial data mining tersusun atas neighbourhood graph, predicate filter, neighbourhood index dan algoritma karakterisasi spasial.
poor village characterization at West Java. Under the direction of AGUS BUONO and BABA BARUS
Data mining, also popularly referred to as Knowlegde discovery in databases (KDD), is the automated or convenient extraction of pattern representing knowledge implicitly stored in large databases, data warehouses, and other massive information repositories. Spatial data mining deal with knowledge discovery in spatial databases. One of spatial data mining task is characterization – to find a description of the spatial and non-spatial properties which are typical for the target objects but not for the whole database. In this research we developed a system prototype which can be implement spatial data mining technique to discover poor village characteristics at West Java. The prototype consist of four components : preprocessing module, spatial data mining module, database module and visualization module. Spatial data mining module consist of neighbourhood graph, predicate filter, neighbourhood index and spatial characterization algorithm.
PENGEMBANGAN PROTOTIPE SPATIAL DATA MINING
UNTUK KARAKTERISASI DESA MISKIN DI JAWA BARAT
HARI AGUNG ADRIANTO
Tesis
Sebagai salah satu syarat untuk memperoleh gelar
Magister Sains pada
Departemen Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Judul tesis : Pengembangan Prototipe Spatial Data Mining Untuk Karakterisasi Desa Miskin di Jawa Barat Nama : Hari Agung Adrianto
NRP : G651020034
Disetujui
Komisi Pembimbing
Ir. Agus Buono, M.Si, M.Kom. Dr. Baba Barus. Ketua Anggota
Mengetahui
Ketua Program Studi Ilmu Komputer Dekan sekolah pascasarjana
Dr. Sugi Guritman Prof. Dr.Ir. Khairil Anwar Notodiputro, M.Sc.
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian ini adalah pengembangan prototipe spatial data mining untuk karakterisasi desa miskin di Jawa Barat.
Terima kasih penulis sampaikan kepada Bapak Ir. Agus Buono, M.Si, M.Kom. dan Bapak Dr. Baba Barus selaku pembimbing. Di samping itu, penghargaan penulis sampaikan kepada Bapak Ir. Janawir, M.Si (BPS – Jakarta), Bapak Usman, S.Si, M.Si (LPEM UI) dan Bapak Ir. Diar Shiddiq yang telah membantu pengadaan data. Terima kasih pula penulis ucapkan kepada Ibu Dr. Sri Nurdiati, Ibu Imas S. Sitanggang, S.Si, M.Kom, Bapak Ir. Irmansyah, M.Si , Bapak Firman Ardiansyah, S.Si, M.Si dan Bapak Jatmiko yang telah meminjamkan / memberikan ijin penggunaan hardware yang diperlukan dalam penelitian ini. Ungkapan terima kasih juga disampaikan kepada istri tercinta Ade Irma Rufaidah serta anak tersayang Marwa Aliifah Muthmainnah dan Qonita Hafizha atas segala pengertiannya. Tak lupa terima kasih kepada ayah, ibu, mertua, serta seluruh keluarga dan sahabat atas segala doa dan dukungannya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Mei 2007
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 17 September 1976 dari ayah Amir Hidayat, S.H. dan ibu Muryati. Penulis merupakan anak kedua dari empat bersaudara.
DAFTAR ISI
Halaman
DAFTAR TABEL ... xi
DAFTAR GAMBAR ... xii
PENDAHULUAN Latar Belakang ... 1
Formulasi Permasalahan ... 3
Ruang Lingkup ... 3
Keaslian Penelitian ... 3
Manfaat Penelitian ... 4
Tujuan Penelitian ... 4
TINJAUAN PUSTAKA Konsep dan Definisi Kemiskinan ... 5
Susenas dan Podes ... 5
Prototyping ... 6
Basis data spasial ... 8
Spatial Data Mining ... 9
Teknik Spatial Data Mining ... 10
Karakterisasi Spasial ... 11
METODOLOGI PENELITIAN Penentuan Kebutuhan Sistem ... 19
Perancangan Cepat ... 19
Data Sumber ... 21
Modul Pengolahan Awal ... 22
Modul Spatial Data Mining ... 25
PENGEMBANGAN PROTOTIPE SPATIAL DATA MINING
UNTUK KARAKTERISASI DESA MISKIN DI JAWA BARAT
HARI AGUNG ADRIANTO
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
Dengan ini saya menyatakan bahwa tesis Pengembangan Prototipe Spatial Data Mining Untuk Karakterisasi Desa Miskin di Jawa Barat adalah karya saya sendiri dengan arahan Komisi Pembimbing dan belum diajukan dalam bentuk apapun kepada penguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Mei 2007
ABSTRAK
HARI AGUNG ADRIANTO. Pengembangan Prototipe Spatial Data Mining Untuk Karakterisasi Desa Miskin di Jawa Barat. Dibimbing oleh AGUS BUONO dan BABA BARUS.
Data mining, atau secara populer dirujuk sebagai Knowlegde discovery in databases (KDD) adalah teknik yang secara otomatis. melakukan ekstraksi pola yang merepresentasikan pengetahuan yang secara implisit tersimpan dalam basisdata besar, data warehouse, dan tempat penyimpanan yang masif lainnya. Spatial data mining berurusan dengan pencarian pengetahuan dalam basisdata spasial.Salah satu teknik dalam spatial data mining adalah karakterisasi spasial (spatial characterization). Karakterisasi spasial digunakan untuk mengungkap karakteristik atau deskripsi ringkas spasial dari sifat-sifat yang menarik pada sebuah komunitas (obyek target) tetapi tidak untuk keseluruhan basisdata. Dalam penelitian ini dilakukan pengembangan prototipe sistem yang dapat menerapkan teknik spatial data mining untuk mengungkap karakteristik spasial dari kondisi kemiskinan di Jawa Barat. Prototipe yang dihasilkan terdiri dari empat komponen yaitu modul pengolahan awal, modul spatial data mining, modul basisdata dan modul visualisasi. Modul spatial data mining tersusun atas neighbourhood graph, predicate filter, neighbourhood index dan algoritma karakterisasi spasial.
poor village characterization at West Java. Under the direction of AGUS BUONO and BABA BARUS
Data mining, also popularly referred to as Knowlegde discovery in databases (KDD), is the automated or convenient extraction of pattern representing knowledge implicitly stored in large databases, data warehouses, and other massive information repositories. Spatial data mining deal with knowledge discovery in spatial databases. One of spatial data mining task is characterization – to find a description of the spatial and non-spatial properties which are typical for the target objects but not for the whole database. In this research we developed a system prototype which can be implement spatial data mining technique to discover poor village characteristics at West Java. The prototype consist of four components : preprocessing module, spatial data mining module, database module and visualization module. Spatial data mining module consist of neighbourhood graph, predicate filter, neighbourhood index and spatial characterization algorithm.
PENGEMBANGAN PROTOTIPE SPATIAL DATA MINING
UNTUK KARAKTERISASI DESA MISKIN DI JAWA BARAT
HARI AGUNG ADRIANTO
Tesis
Sebagai salah satu syarat untuk memperoleh gelar
Magister Sains pada
Departemen Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Judul tesis : Pengembangan Prototipe Spatial Data Mining Untuk Karakterisasi Desa Miskin di Jawa Barat Nama : Hari Agung Adrianto
NRP : G651020034
Disetujui
Komisi Pembimbing
Ir. Agus Buono, M.Si, M.Kom. Dr. Baba Barus. Ketua Anggota
Mengetahui
Ketua Program Studi Ilmu Komputer Dekan sekolah pascasarjana
Dr. Sugi Guritman Prof. Dr.Ir. Khairil Anwar Notodiputro, M.Sc.
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian ini adalah pengembangan prototipe spatial data mining untuk karakterisasi desa miskin di Jawa Barat.
Terima kasih penulis sampaikan kepada Bapak Ir. Agus Buono, M.Si, M.Kom. dan Bapak Dr. Baba Barus selaku pembimbing. Di samping itu, penghargaan penulis sampaikan kepada Bapak Ir. Janawir, M.Si (BPS – Jakarta), Bapak Usman, S.Si, M.Si (LPEM UI) dan Bapak Ir. Diar Shiddiq yang telah membantu pengadaan data. Terima kasih pula penulis ucapkan kepada Ibu Dr. Sri Nurdiati, Ibu Imas S. Sitanggang, S.Si, M.Kom, Bapak Ir. Irmansyah, M.Si , Bapak Firman Ardiansyah, S.Si, M.Si dan Bapak Jatmiko yang telah meminjamkan / memberikan ijin penggunaan hardware yang diperlukan dalam penelitian ini. Ungkapan terima kasih juga disampaikan kepada istri tercinta Ade Irma Rufaidah serta anak tersayang Marwa Aliifah Muthmainnah dan Qonita Hafizha atas segala pengertiannya. Tak lupa terima kasih kepada ayah, ibu, mertua, serta seluruh keluarga dan sahabat atas segala doa dan dukungannya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Mei 2007
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 17 September 1976 dari ayah Amir Hidayat, S.H. dan ibu Muryati. Penulis merupakan anak kedua dari empat bersaudara.
DAFTAR ISI
Halaman
DAFTAR TABEL ... xi
DAFTAR GAMBAR ... xii
PENDAHULUAN Latar Belakang ... 1
Formulasi Permasalahan ... 3
Ruang Lingkup ... 3
Keaslian Penelitian ... 3
Manfaat Penelitian ... 4
Tujuan Penelitian ... 4
TINJAUAN PUSTAKA Konsep dan Definisi Kemiskinan ... 5
Susenas dan Podes ... 5
Prototyping ... 6
Basis data spasial ... 8
Spatial Data Mining ... 9
Teknik Spatial Data Mining ... 10
Karakterisasi Spasial ... 11
METODOLOGI PENELITIAN Penentuan Kebutuhan Sistem ... 19
Perancangan Cepat ... 19
Data Sumber ... 21
Modul Pengolahan Awal ... 22
Modul Spatial Data Mining ... 25
Modul Visualisasi ... 29
Pembangunan Prototipe ... 30
Pengujian Prototipe oleh Pengguna ... 30
Perbaikan Prototipe ... 30
HASIL DAN PEMBAHASAN Loading data peta ... 31
Membangun neighborhood graph ... 32
Cek MBR ... 33
Membangun List ... 34
Periksa Adjacency ... 35
Membangun neigborhood index ... 36
Hitung Jarak ... 37
Cari Arah ... 37
Pembentukan File Topologi ... 39
Loading ke SQL Server ... 39
Membentuk path ... 40
Penentuan Obyek Target ... 40
Membangun Path dengan k=2 ... 43
Membangun Filter Predikat ... 44
Membangun Path dengan k=n ... 46
Menghitung frequency factor ... 47
Membentuk aturan karakterisasi spasial ... 48
SIMPULAN DAN SARAN ... 50
DAFTAR PUSTAKA ... 52
DAFTAR TABEL
Halaman
1 Daftar kelompok/nama dan jenis peubah Podes (Santoso A, 2000) ... 23 2 Hubungan antara peubah dalam Santoso A. (2000) dengan peubah
dalam Podes 1996 ... 25 3 Transformasi peubah Podes 1996 ... 26 4 Nilai untuk masing-masing peubah ... 26 5 Desa Target ... 41 6 Frequency-Factor ... 48
DAFTAR GAMBAR
Halaman
15 Peta batas administrasi desa Propinsi Jawa Barat tahun 1996 ... 21 16 Histogram jarak desa ke rumah sakit ... 24 17 Proses dalam modul spasial ... 25 18 Minimum Bounding Rectangle (MBR) ... 26 19 Visualisasi neighbourhood graph ... 27 20 Visualisasi path dengan panjang 2 node ... 28 21 Visualisasi path dengan panjang 3 node ... 29 22 Alur loading data peta ... 31 23 Struktur Variabel S ... 31 24 Desa Miskin/Tidak Miskin di Pandeglang, Serang, Bogor, Bandung,
PENDAHULUAN
1.1. Latar Belakang
Banyak sekali data yang telah disimpan dalam basisdata, data warehouse, sistem informasi geografis, serta fasilitas penyimpanan informasi lainnya, dan data tersebut terus bertambah banyak dengan cepat. Dengan perkembangan teknologi penyimpnan data, kemampuan manusia untuk menyimpan data sangat jauh melampaui kemampuan untuk melakukan analisis dan ekstraksi informasi yang bermakna dari data yang tersimpan tersebut secara otomatis.
Knowledge Discovery in Databases (KDD) muncul sebagai bidang riset dan teknologi baru untuk melakukan pencarian pengetahuan yang menarik, implisit, dan belum diketahui sebelumnya dari basisdata yang besar. Menurut Frawley et al. (1991) yang diacu dalam Fayyad et al. (1996) KDD adalah non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data. Bagian dari KDD adalah data mining, yaitu kegiatan penyulingan data menjadi informasi atau fakta tentang kenyataan yang dijelaskan oleh basisdata. Dalam prosesnya data mining melibatkan beberapa bidang riset seperti sistem basisdata, machine learning, visualisasi data, statistika, dan information theory (Fayyad et al. 1996).
Data Susenas dan Podes memiliki referensi geografis dan waktu. Referensi geografis bisa dinyatakan dalam kode propinsi, kode kabupaten, kode kecamatan, kode desa, kode pos, atau kode wilayah tertentu. Saat ini telah tersedia peta batas wilayah administratif dalam bentuk digital yang memungkinkan analisis fenomena sosial-ekonomi dan kaitannya dengan lokasi geografis wilayah pencacahan. Hal ini menyebabkan meningkatnya kebutuhan akan teknik analisis data yang handal yang dapat mengkaitkan data sensus dengan distribusi geografisnya.
Perkembangan dalam struktur data spasial (Güting 1994), spatial reasoning (Egenhofer 1991) dan Computational Geometry telah merintis jalan bagi spatial data mining. Spatial data mining merupakan the extraction of implicit knowledge, spatial relations, or other patterns not explicitly stored in spatial databases (Koperski dan Han 1995 diacu dalam Koperski et al. 1996).
Spatial data mining telah digunakan oleh Ester et al. (1998) untuk menganalisis karakteristik spasial serta deteksi kecenderungan spasial pada data sensus penduduk daerah Bavaria, Jerman tahun 1987. Sedangkan Appice et al. (2003) menggunakan teknik spatial association rule untuk mendapatkan pengetahuan baru dari data sensus ekonomi UK.
Salah satu teknik dalam spatial data mining adalah karakterisasi spasial (spatial characterization). Karakterisasi spasial digunakan untuk mengungkap karakteristik atau deskripsi ringkas spasial dari properties yang menarik pada sebuah komunitas, misalnya bagaimana karakteristik daerah yang memiliki tingkat pertumbuhan ekonomi tinggi, atau bagaimana karakteristik daerah yang memiliki jumlah penduduk usia lanjut tinggi dan sebagainya.
3
1.2. Formulasi Permasalahan
Badan Pusat Spasial telah melakukan penghimpunan sejumlah besar data sosial ekonomi di Indonesia secara teratur, diantaranya melalui Susenas dan Podes. Dengan jumlah data yang besar tersebut dirasa perlu adanya sebuah sistem yang dapat melakukan analisis dan ekstraksi informasi yang bermakna dari data yang tersimpan tersebut secara otomatis. Karena data Susenas maupun Podes memiliki referensi geografis maka analisis yang dilakukan sebaiknya memperhatikan Hukum I Geografi yaitu “everything is related to everything else, but near things are more related than distant thing” (Tobler 1979). Agar proses analisis dapat dilakukan dengan lebih cepat dan akurat, maka sebaiknya menggunakan sistem manajemen basisdata yang mendukung data spasial dan non-spasial.
1.3. Ruang Lingkup
Teknik spatial data mining yang akan diterapkan pada prototipe adalah spatial characterization. Data spasial yang digunakan adalah batas administrasi desa Jawa Barat dan Banten tahun 2003. Data atribut desa diperoleh dari data Potensi Desa (Podes) tahun 2003. Karena atribut dalam data Podes sangat banyak, maka hanya beberapa atribut saja yang dilibatkan dalam pengembangan prototipe ini. Dalam memberikan sebuah label kepada sebuah objek berdasarkan nilai tertentu digunakan pendekatan crips (tidak fuzzy).
1.4. Keaslian Penelitian
1.5. Manfaat Penelitian
Dari penelitian ini diharapkan terbentuk prototipe sistem spatial data mining Prototipe tersebut diharapkan dengan mudah dan cepat mendapatkan pengetahuan implisit, hubungan spasial, atau pola-pola lainnya yang tidak secara eksplisit tersimpan dalam basisdata. Prototipe tersebut akan digunakan untuk mengungkap karakteristik spasial dari desa miskin di Jawa Barat.
1.6. Tujuan Penelitian
Penelitian ini memiliki tujuan yaitu:
1. Memahami konsep salah satu teknik dalam spatial data mining yaitu spatial characterization.
2. Membangun prototipe sistem spatial data mining yang mampu menjalankan teknik spatial characterization.
TINJAUAN PUSTAKA
2.1. Konsep dan Definisi Kemiskinan
Konsep kemiskinan yang digunakan dalam penelitian ini merujuk kepada
metode BPS, yaitu menggunakan pendekatan kemampuan dalam memenuhi
kebutuhan dasar (basic need) yang meliputi kebutuhan makanan dan kebutuhan bukan makanan. Selanjutnya dengan penetapan batas garis kemiskinan (proverty line), suatu rumah tangga dapat dikelompokkan ke dalam rumah tangga miskin atau tidak miskin.
Garis kemiskinan didefinisikan sebagai besarnya nilai rupiah yang harus
dikeluarkan oleh seseorang untuk memenuhi kebutuhan hidup minimumnya.
Kebutuhan hidup minimum terdiri dari kelompok makanan maupun kelompok
bukan makanan. Batas miskin untuk kebutuhan makanan dikonsepkan setara
2.100 kalori per hari. Batasan ini mengacu pada hasil Widyakarya Pangan dan
Gizi 1978. Pemenuhan energi setara 2.100 kalori diperoleh dari konsumsi
berbagai jenis kelompok makanan, yaitu : beras, umbi-umbian, ikan, daging dan
sebagainya.
Sedangkan batas miskin untuk kebutuhan bukan makanan tercermin dari
besarnya nilai rupiah yang harus dikeluarkan untuk memenuhi kebutuhan
minimum bukan makanan. Kebutuhan bukan makanan terdiri dari perumahan,
pendidikan, kesehatan, pakaian, serta aneka barang dan jasa lainnya (Sugiyono
2003).
2.2. Susenas dan Podes
Pengumpulan data Potensi Desa (Podes) adalah kegiatan rutin yang
dilaksanakan setiap sensus, baik sensus penduduk, sensus pertanian , maupun
sensus ekonomi. Sejak tahun 1994 Podes tidak hanya dilaksanakan pada
tahun-tahun kegiatan sensus saja tetapi dilaksanakan setiap tahun-tahun. Tujuan pengumpulan
data Podes antara lain untuk mendapatkan data tentang karakteristik desa secara
lebih rinci, yang meliputi data mengenai sarana dan prasarana desa, potensi
Survei Sosial Ekonomi Nasional (Susenas) merupakan survei rumah tangga
yang diselenggarakan setiap tahun. Susenas berfungsi sebagai wahana dalam
menghimpun data sosial ekonomi penduduk. Keterangan yang dihimpun antara
lain menyangkut aspek demografi, pendidikan, kesehatan/gizi,
perumahan/lingkungan, kriminalitas, kegiatan sosial budaya,
konsumsi/pengeluaran rumah tangga, perjalanan wisata dan kesejahteraan rumah
tangga.
Peubah Susenas yang dikumpulkan dibagi menjadi dua kategori, yaitu
peubah pokok (kor) dan peubah sasaran (modul). Peubah kor dikumpulkan setiap
tahun, sedangkan peubah modul dikumpulkan setiap tiga tahun. Setiap tahun salah
satu dari kelompok peubah modul ditetapkan, yaitu (1) konsumsi/pengeluaran
rumah tangga, (2) pendidikan, kesehatan, dan perumahan serta lingkungan, (3)
sosial budaya, kriminalitas, dan wisata nusantara dikumpulkan dari rumah tangga.
Pemilihan contoh Susenas umumnya dilakukan dalam 3 atau 4 tahap, yaitu
(1) pemilihan sejumlah kecamatan, (2) pemilihan sejumlah desa pada setiap
kecamatan terpilih, (3) pemilihan sejumlah wilayah pencacahan (wilcah) pada
setiap desa terpilih, dan (4) pemilihan sejumlah rumah tangga pada setiap wilcah
terpilih. Sejak tahun 1993 jumlah contoh Susenas sebanyak 202.000 rumah
tangga. Sebanyak 65.000 rumah tangga diberikan daftar pertanyaan modul,
sedangkan 137.000 rumah tangga diberikan pertanyaan modul saja. Santoso
(2000) menggunakan data Susenas 1996 untuk menghasilkan daftar desa miskin
di Jawa Barat.
2.3. Prototyping
Dalam pengembangan sebuah perangkat lunak, sering pengguna telah
mendefinisikan tujuan umum dari perangkat lunak yang diinginkan, tetapi tidak
melakukan identifikasi rinci dari kebutuhan masukan, pengolahan dan keluaran.
Dalam kasus lain, pengembang mungkin tidak yakin tentang efisiensi algoritma
yang digunakan, kemampuan adaptasi dari sistem operasi, atau bentuk interaksi
antara manusia dengan komputer yang digunakan. Dalam kasus-kasus seperti di
atas maka pendekatan pengembangan perangkat lunak yang paling sesuai adalah
7
Prototyping adalah proses yang memungkinkan pengembang perangkat lunak untuk membuat model dari perangkat lunak yang akan dibangun. Model
tersebut dapat dinyatakan dalam tiga bentuk: (1) prototipe berbentuk kertas atau
model berbasis PC yang menggambarkan bagaimana interaksi antara manusia dan
mesin terjadi, (2) workingprototype yang mengimplementasikan beberapa subset dari fungsionalitas yang diinginkan dari perangkat lunak, atau (3) program yang
telah ada saat ini yang mengerjakan sebagian atau seluruh fungsionalitas yang
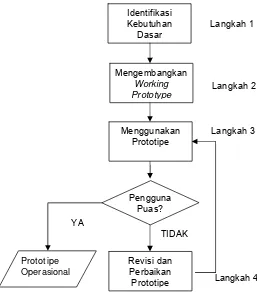
[image:31.612.213.470.280.574.2]diinginkan tetapi memiliki beberapa feature yang akan ditingkatkan dalam usaha pengembangan selanjutnya. Rangkaian kegiatan dalam prototyping digambarkan pada Gambar 1.
Gambar 1. Proses Prototyping (sumber: Laudon dan Laudon, 2005). Identifikasi
Kebutuhan Dasar
Langkah 1
Mengembangkan
Working
Prototype Langkah 2
Menggunakan Prototipe
Langkah 3
Pengguna Puas?
Prototipe Operasional
Revisi dan Perbaikan
Prototipe Langkah 4 TIDAK
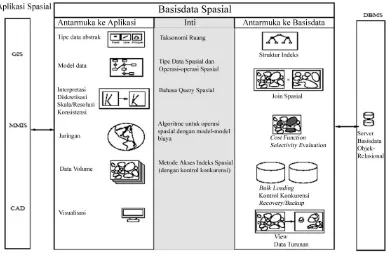
2.4. Basisdata Spasial
Shekhar dan Chawla (2003) mendefinisikan sistem manajemen basisdata
spasial (Spatial Database Management System - SDBMS) sebagai berikut:
1. SDBMS adalah modul perangkat lunak yang dapat bekerja dengan sistem
manajemen basisdata dasar, seperti Object-Relational Database Management System (OR-DBMS) atau Object-Oriented Database Management System (OO-DBMS)
2. SDBMS mendukung beberapa model data spasial, tipe data abstrak
(Abstract Data Type –ADT) dan bahasa query yang dapat memanggil ADT tersebut
3. SDBMS mendukung indeks spasial, algoritma yang efisien untuk
melaksanakan operasi spasial, serta aturan-aturan yang spesifik bagi domain
tertentu untuk optimasi query.
Gambar 2 menggambarkan arsitektur untuk membangun SDBMS
[image:32.612.140.528.396.650.2]berdasarkan OR-DBMS
9
2.5. Spatial Data Mining
Seperti berbagai bidang riset dan aplikasi lainnya, geografi telah berpindah
dari lingkungan miskin-data dan miskin-komputasi ke lingkungan kaya-data dan
kaya-komputasi. Bidang, cakupan, dan volume dataset geografik digital terus
berkembang dengan cepat. Agen di sektor publik dan swasta mengadakan,
memproses dan menyebarkan data digital tentang penggunaan lahan, peubah
sosial-ekonomi dan infrastruktur dengan resolusi geografis yang rinci. Berbagai
teknologi seperti penginderaan jarak jauh, global positioning sustem (GPS), perangkat yang peka lokasi – position aware devices (telepon selular, sistem navigasi kendaraan, wireless internet client) menyebabkan jumlah data geografik akan meningkat secara eksponensial dalam pertengahan abad ke-21 mendatang.
Metode analisis spasial tradisional dikembangkan pada saat biaya
pengumpulan data sangat mahal serta tenaga komputasi yang tersedia masih
lemah. Peningkatan jumlah data serta beragamnya sifat data geografik digital
menyebabkan teknik analisis spasial tradisional kewalahan. Teknik analisis spasial
tradisional berorientasi pada informasi sederhana yang berasal dari dataset yang
kecil dan seragam. Metode statistik tradisional, khususnya statistik spasial,
memiliki beban komputasi yang tinggi. Teknik-teknik tersebut memerlukan
penegasan dari pakar (corfirmatory) dan mensyaratkan peneliti untuk mempunyai dugaan sebelumnya (a priori hypotheses). Dengan demikian, teknik analisis spasial tradisional tidak dapat dengan mudah menemukan pola (pattern), kecenderungan (pattern) dan hubungan (relationship) yang baru dan tidak terduga, yang mungkin tersembunyi jauh di dalam dataset geografik yang sangat
besar dan beragam (Miller dan Han 2001). Penjelasan mendalam tentang analisis
spasial dapat ditemukan dalam Anselin (2004) dan ESRI (2005), sedangkan
penjelasan tentang statistik spasial dapat ditemukan dalam Cressie (1993).
Penggunaan sistem basisdata spasial yang makin meluas (Güting 1994,
Worboy 1995, Shekhar dan Chawla 2003) telah merintis peningkatan perhatian
Skema yang menggambarkan proses spatial data mining menurut Chawla et al. (2001) yang diilustrasikan pada Gambar 3.
Gambar 3. Proses Spatial Data Mining (sumber : Chawla et al. 2001).
2.6. Teknik Spatial Data Mining
Data mining merupakan area multidisiplin, dan terdapat banyak cara-cara baru untuk melakukan ekstraksi pola data. Ada tiga teknik data mining yang telah diterima secara umum, yaitu classification, clustering dan association rules (Shekhar & Chawla 2003).
Classification
Tujuan teknik klasifikasi adalah untuk menduga nilai sebuah atribut dari
relasi berdasarkan nilai atribut-atribut lainnya dari relasi tersebut. Definisi lainnya
menyatakan teknik klasifikasi memilih himpunan atribut dan nilai nilai atribut
yang relevan, yang digunakan untuk secara efektif memetakan obyek spasial ke
dalam kelas target yang telah didefinisikan sebelumnya.
Clustering
Teknik clustering merupakan contoh pembelajaran tak-terarahkan (unsupervised learning). Teknik ini berusaha mengelompokkan data tanpa memiliki pengetahuan awal tentang kluster atau jumlah kluster. Obyek spasial
dikelompokkan sehingga obyek dalam satu kluster adalah mirip, dan obyek dalam
11
kombinasi atribut non-spasial, atribut spasial, dan kedekatan obyek dalam ruang,
waktu dan ruang-waktu.
Association Rules
Teknik ini bertujuan menemukan hubungan diantara atribut-atribut dalam
sebuah relasi. Dalam konteks spasial, association rule melibatkan predikat spasial (topologi, jarak atau arah) dalam preseden atau anteseden-nya. Sebagai contoh
rules dinyatakan dalam bentuk is_close (house, beach) Æ is_expensive(house) yang bermakna rumah yang dekat dengan pantai mungkin harganya mahal.
Disamping teknik classification, clustering dan association rules di atas, Miller dan Han (2001) menyebutkan beberapa teknik lain yaitu :
• Outlier Detection, obyek spasial yang tidak masuk ke dalam kluster
manapun disebut pencilan (outlier). Jadi outlier detection adalah masalah kebalikan dari clustering.
• Spatial Trend Detection, teknik ini melibatkan pencarian pola perubahan
dengan memperhatikan tetangga dari beberapa obyek spasial.
• Geographic Characterization and Generalization, teknik ini menghasilkan deskripsi ringkas data berupa summary rules atau characteristics rule. Dalam data mining klasik (non-spasial), metode yang handal untuk
menghasilkan summary rules adalah metode induksi berorientasi atribut (attribute-oriented induction).
2.7. Karakterisasi Spasial
Spatial association rule dinyatakan dalam bentuk:
P1 ^ ……….^ Pm Æ Q1^……….^Qn (c%)
Dimana paling tidak satu dari predikat P1, …. , Pm, Q1, …., Qn adalah
predikat spasial dan c% adalah confidence yang mengindikasikan bahwa c% obyek yang memenuhi anteseden juga memenuhi konsekuen dari rule.
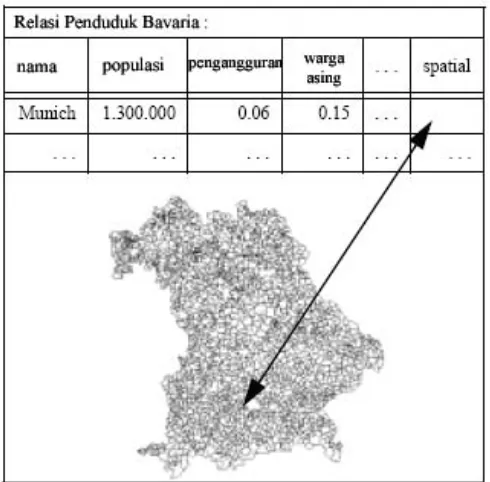
Untuk mengatasi keterbatasan tersebut, Ester et al. (2001) mendefinisikan karakterisasi spasial (spatial characterization) dari sekumpulan obyek target
terhadap basisdata tempat obyek tersebut tersimpan sebagai “deskripsi dari sifat
keseluruhan basisdata (a description of the spatial and non-spatial properties which are typical for the target objects, but not for the whole database)”. Sifat yang menjadi perhatian adalah frekuensi relatif nilai atribut non-spasial dan
frekuensi relatif tipe obyek yang berbeda. Perbedaan frekuensi relatif dalam
basisdata dengan frekuensi relatif dalam daerah target diperlihatkan pada
Gambar 4.
Gambar 4. Frekuensi sampel dan perbedaannya
[image:36.612.210.455.354.595.2]Atribut spasial dan non-spasial digambarkan dalam Gambar 5.
13
Berikut ini adalah beberapa batasan yang digunakan dalam teknik karakterisasi
spasial :
Definisi 1 : Hubungan Spasial
Untuk melakukan karakterisasi spasial, tidak hanya sifat dari obyek target
yang diperhatikan melainkan juga sifat obyek tetangga.Hubungan satu obyek
dengan obyek tetangganya dapat dinyatakan dalam tiga bentuk (Ester et al, 2001): 1. Hubungan Topologi : berdasarkan batas, interior atau komplemen dari dua
obyek. Contoh hubungan yang mungkin terjadi adalah (Gambar 6):
[image:37.612.148.494.234.542.2]
Gambar 6. Contoh hubungan topologi
(sumber : Egenhofer et al. 1989 dalam Shekhar dan Chawla, 2003).
2. Hubungan Jarak : membandingkan jarak dua obyek dengan sebuah
konstanta menggunakan operator pembanding aritmatik. Hubungan jarak
Ilustrasi hubungan jarak diperlihatkan pada Gambar 7.
Gambar 7. Contoh hubungan jarak (sumber :Ester et al, 2001)
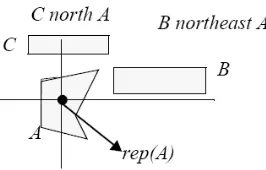
3. Hubungan Arah atau Orientasi : obyek pertama sebagai sistem koordinat
[image:38.612.304.437.235.320.2]virtual, quadrant dan half-plane menentukan arahnya (Gambar 8).
Gambar 8. Contoh hubungan arah (sumber :Ester et al, 2001)
Definisi 2 : (neighborhood graph and paths)
Ditetapkan neighborhood sebagai hubungan tetangga dan DB sebagai
basisdata obyek spasial. Sebuah neighborhood graph GneighborDB =
(
N,E)
adalah sebuah graph dengan node N=DB dan edge E ⊆NxN dimana sebuah edge e =(n1,n2) ada jika dan hanya jika terdapat neighbor(n1,n2). Hubunganneighbor(n1,n2) dapat berupa hubungan topologi, jarak atau arah. Gambar 9 memperlihatkan sebuah basisdata obyek spasial DB serta dua buah neighborhood graph dengan hubungan topologi meet dan hubungan arah north.
Gambar 9. Contoh Neighborhood Graph
15
Definisi 3 : Operasi pada neighborhood graph
Terdapat beberapa operasi yang dilakukan pada sebuah neighborhood graph (graf tetangga) yaitu (Ester et al, 2001):
1. Neighbours:
Graphs x Objects x Predicates Æ Sets_of_objects
Operasi Neighbours menghasilkan himpunan semua obyek (set of objects) yang terhubung dengan object pada graph yang memenuhi kondisi yang dinyatakan dalam predicates.
2. Path:
Sets_of_objects Æ set_of_path
Operasi path menghasilkan semua path dengan panjang l yang dibentuk oleh sebuah elemen tunggal dari obyek.
3. Extensions:
Graphs x Sets_of_path x integer x predicates Æ sets_of_path
Operasi Extensions menghasilkan himpunan semua path (set_of_all_path) dengan panjang tertentu integer pada graph yang merupakan perpanjangan sebuah elemen dari path.
Definisi 4 : Filter Predikat (Predicates Filter)
Ketika bergerak dari sebuah obyek menuju obyek lainnya dalam graf, dapat
digunakan beberapa filter yaitu (Ester et al, 2001): 1. Starlike Filter
Ketika memperpanjang sebuah path p = [n1,n2,….nk] dengan sebuah node nk+1, maka arah terakhir yang pasti (exact “final” direction) dari p tidak dapat digeneralisasi. Sebagai contoh, sebuah path dengan arah terakhir
tenggara maka hanya dapat diperpanjang dengan sebuah node dari sebuah
edge yang memiliki arah tenggara.
2. Variable Starlike Filter
Variable starlike filter memungkinkan path yang lebih halus, dengan hanya mensyaratkan ketika memperpanjang path p maka edge (nk, nk+1) paling tidak memenuhi arah awal yang pasti (exact “initial” direction) dari path p. Sebagai contoh, sebuah path dengan arah awal utara dapat diperpanjang
3. Vertical Starlike Filter
Filter ini merupakan bentuk khusus dari starlike filter dimana filter kurang ketat ke arah vertikal dibandingkan ke arah horizontal. Filter ini digunakan
jika memerlukan analisis lebih rinci ke arah vertikal.
Ilustrasi dari masing-masing filter dapat dilihat pada Gambar 10.
Gambar 10. Filter Predicates (sumber :Ester et al, 2001) Definisi 5 : Neighbourhood Index
Neighbourhood Index adalah sebuah tabel yang mencatat hubungan antarobyek dalam basisdata spasial. Neighbourhood index untuk DB dengan jarak maksimum max, dinyatakan sebagai berikut
(
)
{
1 2 1 2 1 2 2 1 1 2}
max O ,O ,dist,D,T |O ,O DB,O jarak O ^dist max^O DO^OTO
IDB = ∈ =dist ≤
dengan DB sebagai sebuah himpunan obyek spasial, max dan dist adalah bilangan real, D adalah hubungan arah (direction relation) dan T adalah hubungan topologi (topological relation). Ilustrasi Neighbourhood Index pada Gambar 11.
Gambar 11. Contoh Neighbourhood Index Definisi 6: Karakterisasi Spasial
Karakterisasi spasial adalah aturan yang menjelaskan sifat atribut untuk
sebuah wilayah dibandingkan dengan sifat atribut tersebut pada keseluruhan
basisdata. Ditetapkan DB neighbour
G adalah s neighbourhood graph dan target adalah subset dari basisdata spasial DB. Ditetapkan freqs(prop) yang menyatakan jumlah kemunculan sifat prop dalam himpunan s dan card(s) menyatakan kardinalitas dari s. Frequency factor dari prop terhadap targets dan DB dinyatakan dalam
17
Ditetapkan significance dan proportion sebagai bilangan real dan max-neighbours sebagai bilangan natural. Neighbours SGi (s)menyatakan himpunan dari seluruh obyek yang dapat dicapai dari satu elemen s dengan berjalan paling
banyak i edge dari graph tetangga G.
Kemudian, pekerjaan karakterisasi spasial adalah untuk menemukan setiap
sifat prop dan setiap bilangan natural n <= max-neighbours sehingga 1. himpunan objects = neighboursn(targets)
G dan
2. himpunan objects = neighboursGn({t}) untuk proportion paling kecil terdapat t∈target yang memenuhi kondisi,
Proses karakterisasi spasial menghasilkan aturan (rule) dalam bentuk
Aturan ini bermakna bahwa untuk himpunan dari seluruh target yang
diperluas oleh neighbours ni, sifat pi muncul dalam basisdata lebih banyak (atau lebih sedikit) dari freq-faci.. Contoh rule yang dihasilkan adalah sebagai berikut
Obyek dengan tingkat penduduk pensiun tinggi Î Apartemen per gedung = sangat rendah (0.91) ^ tingkat orang asing = sangat rendah (0.89) ^ tingkat akademisi = sedang (0.63) ^
Obyek target dan wilayah yang diperluas dengan tetangganya dapat dilihat
pada Gambar 12.
Gambar 12. Obyek target dan wilayah yang diperluas (sumber: Ester et al. 2001).
Sehingga secara umum algoritma spatial characterization adalah sebagai berikut
karakterisasi (graph GrDB; himpunan obyek target; real significance, proportion; integer
max-neighbors )
inisialisasi himpunan karakterisasi sebagai himpunan kosong; inisialisasi himpunan region menjadi target; inisialisasi n dengan 0; hitung frekuensiDB(prop)untuk semua sifat prop = (atribut, nilai);
while n ≤ max-neighbors do
for each atribut pada DB dan untuk atribut khusus tipe obyek do
for each nilai dari atribut do
hitung frekuensiregion(prop)untuk semua sifat prop = (atribut, nilai); if fregionDB (prop)≥significanceor fregionDB (prop)≤1/significancethen
tambahkan (prop, n, fDB (prop)
region ) ke dalam himpunan karakterisasi; if n < max-neighbors then
for each obyek dalam region do
tambahkan neighbors (GrDB, obyek, TRUE) ke dalam region; tambahkan nilai n dengan 1;
ekstrak semua tuple (prop, n, fregionDB (prop)) dari karakterisasi yang signifikan di dalam paling sedikit proportion region dengan n perluasan;
METODOLOGI PENELITIAN
Penelitian ini mengembangkan sistem spatial data mining untuk melakukan karakterisasi desa miskin di Propinsi Jawa Barat. Dengan sistem tersebut diharapkan dapat mengungkap hubungan antara data spasial dan non-spasial. Metode pengembangan sistem mengikuti model prototyping. Model prototyping mensyaratkan adanya interaksi antara pengembang dengan pengguna dalam beberapa iterasi, dan ini sejalan dengan proses pengembangan spatial data mining menurut Chawla et al. (2001). Hasil prototyping adalah working prototype yang mengimplementasikan beberapa subset dari fungsionalitas yang diinginkan sistem. Karena penelitian ini merupakan iterasi pertama dari pengembangan sistem, maka kegiatan yang akan dilakukan adalah: (1) penentuan kebutuhan sistem, (2) perancangan cepat, (3) pembangunan prototipe, (4) pengujian prototipe oleh pengguna dan (5) perbaikan prototipe. Kegiatan ke-enam dalam prototyping yaitu pengembangan produk belum dilakukan dalam penelitian ini.
3.1. Penentuan Kebutuhan Sistem
Prototyping dimulai dengan penentuan kebutuhan sistem. Sasaran yang ingin dicapai oleh sistem dalam penelitian ini adalah:
1. Sistem mendukung teknik karakterisasi spasial.
2. Sistem mampu menampung, mengolah dan menampilkan data spasial dan non-spasial.
3. Sistem bersifat modular, terbuka dan mudah dikembangkan.
3.2. Perancangan Cepat
Gambar 13. Diagram Konteks Prototipe Sistem Karakterisasi Spasial.
Sistem akan mengolah masukan yang diberikan dan memberikan keluaran berupa wilayah yang diperluas dan aturan karakterisasi (characteristic rule). Wilayah yang diperluas disajikan berupa peta sedangkan aturan karakterisasi disajikan dalam bentuk teks.
Prototipe sistem karakterisasi spasial terdiri dari beberapa komponen yaitu modul pengolahan awal (praproses), modul basisdata, modul spasial data mining serta modul visualisasi. Keterkaitan antar keempat komponen tersebut dapat dilihat pada Gambar 14.
Gambar 14. Arsitektur aplikasi. Sistem
Karakterisasi Spasial
Pengguna
Obyek target Wilayah yang diperluas dan aturan karakteristik Pengguna
Data Podes Jabar 1996
Peta Desa Jabar 2000
Modul Pengolahan
Awal
Modul Basisdata Modul
Spatial Data Mining • neighbourhood graph
• spatial filter
• neighbourhood index
• algoritme karakterisasi spasial
21
Data Sumber
Spatial data mining melibatkan data spasial dan data non-spatial (atribut). Data spasial yang digunakan dalam penelitian ini adalah peta batas administrasi desa Propinsi Jawa Barat tahun 2000, termasuk Banten yang sekarang menjadi propinsi tersendiri. Jumlah desa yang terlibat adalah 7327 desa (Gambar 15). Peta batas administrasi desa didapat dalam format ESRI shapefile (shp).
Gambar 15. Peta batas administrasi desa Propinsi Jawa Barat tahun 2000
Pada peta batas administrasi desa melekat beberapa atribut yaitu:
• ID2000 : nomor identitas desa yang ditetapkan BPS tahun 2000
• Propinsi : nama propinsi
• Kab_Kota : nama kabupaten atau kota
• Kecamatan : nama kecamatan
• Desa : nama desa
Data atribut yang digunakan adalah data Podes 2003 yang didapat dalam format SAS (SSD). Secara umum data Podes 2003 berisi:
• Karakteristik desa
• Populasi, perumahan dan lingkungan
• Fasilitas Sosial-budaya
• Fasilitas Rekreasi dan hiburan
• Fasilitas Kesehatan
• Fasilitas Transportasi
• Penggunaan Lahan
• Kondisi Ekonomi
• Unit Finansial Desa
• Karakteristik Kepala Desa
Modul Pengolahan Awal
Dalam pengolahan awal (pra-proses) terdapat kegiatan data cleaning, integrasi, seleksi dan transformasi.
a. Data cleaning dilakukan untuk menangani data yang hilang atau data yang tidak benar.
Jumlah poligon pada peta Jabar 2000 adalah 7327 sedangkan jumlah kode desa yang berbeda pada Podes 2003 adalah 7234 , untuk itu perlu dilakukan data cleaning.
b. Integrasi dilakukan untuk menggabungkan data dari berbagai sumber yang berbeda.
Penelitian menggunakan data atribut desa dan data spasial desa. Agar dapat menggabungkan data atribut desa dengan data spasial desa maka diperlukan atribut kunci yaitu kode desa. Untuk itu dilakukan pemeriksaan kode desa pada kedua data agar sesuai.
c. Seleksi digunakan untuk memilih data yang relevan untuk analisis. Santoso A pada tahun 2000. melakukan penelitian tentang kriteria desa miskin berdasarkan konsumsi kalori keluarga dan hubungannya dengan potensi desa. Data yang digunakan pada penelitian tersebut adalah Podes 196. Penelitian tersebut menghasilkan model regresi prediksi persentase keluarga miskin (Y) untuk desa di propinsi Jawa Barat sebagai berikut :
23
Daftar kelompok/nama dan jenis peubah yang terlibat dalam penelitian Santoso (2000) terdapat pada Tabel 1.
Tabel 1. Daftar kelompok/nama dan jenis peubah Podes (Santoso A, 2000) Kelompok
Peubah
Nama Peubah/Jenis Kode
1. Potensi / fasilitas sosial ekonomi desa
1. Tipe LKMD (1 = aktif, 0 = tidak aktif) X1 2. jalan utama desa (1 = aspal, 0 = non aspal) X2 3. Sumber penghasilan sebagian besar
penduduk (1 = pertanian, 0 = non-pertanian) X3
4. Jarak ke rumah sakit terdekat (km) X4 5. Fasilitas pendidikan (1 = lebih dari SD, 0 = SD)
X5
6.Fasilitas kesehatan (1 = ada, 0 = tidak ada) X6 7. Pasar (1= ada, 0 = tidak ada) X7 8. Kepadatan penduduk (km persegi) X8 9. Rasio banyaknya tempat ibadah per 1000 penduduk
X9
2. Fasilitas perumahan dan lingkungan
10. Sumber air minum buatan (1 = ada, 0 = tidak ada)
X10
11. Wabah penyakit (1 = ada, 0 = tidak ada) X11 12. Bahan bakar (1 = bahan bakar minyak dan gas, 0 = non BBMG)
X12
13. Pembuangan sampah (1= ada, 0 = tidak ada)
X13
14. Jamban (1 = jamban sendiri, 0 = jamban bersama)
X14
15. Keberadaan pelanggan koran/majalah (1= ada, 0 = tidak ada)
X15
3.
Kependudukan
16. Persentase rumah tangga tani X16 17. Persentase rumah tangga yang
menyekolahkan anak/famili ke perguruan tinggi
X17
18. Persentase rumah tangga yang menggunakan listrik
X18
19. Persentase rumah tangga yg memiliki TV X19 20.Persentase rumah tangga yang memiliki
telepon
X20
21. Persentase rumah tangga yang memiliki kendaraan roda 4
X21
22. Persentase rumah tangga yang memiliki kendaraan roda 2 atau 3
X22
Dari 17 atribut Podes yang digunakan dalam penelitian Santoso (2000), untuk pengembangan prototipe ini dicobakan lima atribut yaitu.
1. Tipe jalan utama desa
2. Jarak desa ke rumah sakit terdekat 3. Cara pembuangan sampah
4. Tempat buang air besar
5. Keberadaan pelanggan koran/majalah
Atribut lainnya dapat dilibatkan jika prototipe ini telah terbukti dapat bekerja dengan baik.
d. Transformasi dimana data dari beberapa sumber yang berbeda dikonversi ke dalam bentuk yang dapat diproses.
Algoritma karakterisasi spasial bekerja dengan atribut kategorik, sehingga atribut yang memiliki tipe numerik harus ditransformasi menjadi kategorik (diskretisasi). Dari lima atribut yang dipilih, hanya satu yang bertipe numerik yaitu jarak desa ke rumah sakit terdekat. Gambar 16 memperlihatkan histogram dari peubah ini. Dari histogram tersebut, jarak desa ke rumah sakit dibagi ke dalam tiga kelas yaitu dekat ( 0-30 km), sedang (30 – 60 km) dan jauh ( > 60 km)
100 80
60 40 20 0
X4 500
400
300
200
100
0
Fr
equency
Mean = 23.4 Std. Dev. = 22.755 N = 6,248
25
Modul Spatial Data Mining
Proses-proses dalam modul spasial diperlihatkan pada Gambar 17.
Gambar 17. Proses dalam modul spasial Menghitung
frequency factor
Loading
Data Peta Peta Jabar
Jabar
Membangun neighbourhood
graph
Adjacency
Membangun neighbourhood
index
Index
Membentuk path Obyek Target
path
Data Atribut Desa
Membentuk aturan karakterisasi
spasial
a. Loading Data Peta
Peta desa dimuat ke dalam lingkungan Matlab menggunakan fungsi shaperead yang terdapat dalam Mapping Toolbox. Fungsi shaperead akan
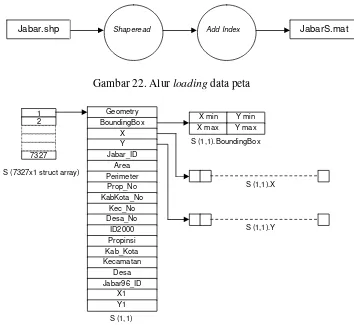
membaca file shapefile (shp) dan menyimpannya sebagai struc array dengan field sebagai berikut:
• Geometry : tipe obyek spasial (misal point, line atau polygon)
• BoundingBox : berisi koordinat dua titik MBR (Minimum Bounding Rectangle) yaitu (x-min, y-min) dan (x-max,y-max)
• X : merupakan array dari koordinat X titik-titik yang menyusun obyek
• Y : merupakan array dari koordinat Y titik-titik yang menyusun obyek
• X1 : merupakan koordinat X titik tengah obyek
• Y1 : merupakan koordinat Y titik tengah obyek
• Serta atribut yang melekat pada shapefile (misal kode_desa, nama_desa dan sebagainya)
b. Membangun neighbourhood graph
Neighbourhood graph disimpan dalam sebuah matriks NxN. Elemen pada baris i dan kolom j bernilai 1 jika obyek ke-i dan obyek ke-j merupakan tetangga dan bernilai 0 jika selainnya. Untuk membentuk neighbourhood graph dilakukan pekerjaan berikut ini
• Untuk semua obyek ke-i periksa apakah MBR obyek ke-i berpotongan dengan MBR obyek ke-k. Gambar 18(a) memperlihatkan sebuah obyek dengan MBR-nya, sedangkan Gambar 18(b) memperlihatkan tiga kemungkinan dimana MBR dua buah obyek berpotongan.
(a) (b)
27
• Untuk semua obyek ke-i dan obyek ke-k yang memenuhi syarat di atas, periksa apakah kedua obyek merupakan tetangga. Dalam penelitian ini didefinisikan dua buah desa merupakan tetangga jika dan hanya jika poligon batas kedua desa berpotongan di lebih satu titik. Gambar 19 merupakan visualisasi dari neighbourhood graph.
Gambar 19. Visualisasi neighbourhood graph.
c. Membangun neighbourhood index
Karena Neighbourhood graph berukuran N x N maka diperlukan sebuah indeks agar proses pembacaan hubungan antara dua obyek lebih cepat, tidak dihitung berkali-kali setiap diminta. Hubungan spasial yang disimpan dalam neighbourhood index dalam penelitian ini adalah hubungan jarak dan hubungan arah. Hubungan topologi tidak disimpan dalam indeks karena berdasarkan batasan yang diterapkan pada pembentukan neighbourhood graph maka hanya memiliki satu hubungan topologi yaitu berdampingan (adjacent).
d. Membentuk path
Proses pembentukan path dilakukan melalui tahapan berikut
• Tentukan obyek target.
: Pandeglang, Serang, Bogor, Bandung, Cirebon, Indramayu dan Garut. Pemilihan kabupaten tersebut didasarkan atas pertimbangan bahwa kabupaten yang dipilih merupkan kabupaten dengan persentase desa miskin (menurut kriteria BPS tahun 1995) dari desa yang terkena Susenas cukup besar yaitu sekitar 50 persen. Sehingga diperoleh jumlah desa miskin yang cukup mewakili untuk desa-desa di pulau Jawa. Disamping pertimbangan di atas ada pertimbangan lain, misalnya topografi dan kondisi geografis. Data desa miskin menurut Santoso A (2000) terdapat di Lampiran 1.
• Bentuk path dengan panjang 2 node
Gambar 20 merupakan visualisasi path dengan panjang 2 node untuk dua buah titik target.
Gambar 20. Visualisasi path dengan panjang 2 node
• Bentuk path perluasan dengan menerapkan filter spasial
29
Gambar 21. Visualisasi path dengan panjang 3 node
e. Menghitung frequency factor
Dalam menghitung frequency factor dari atribut akan diperhatikan pengaruh dari panjang path max-neighbours s dan nilai ambang significance
f. Membentuk aturan karakterisasi spasial
Selanjutkan dilakukan pembentukan aturan klasifikasi spasial dengan pola sebagai berikut
Modul Basisdata
Sistem manajemen basis data SQL Server 2000 akan digunakan untuk menyimpan neighbourhood indeks agar proses pencarian hubungan antar dua obyek lebih cepat.
Modul Visualisasi
3.3. Pembangunan Prototipe
Hasil dari perancangan cepat digunakan untuk pembangunan prototipe. Prototipe ini akan dievaluasi oleh pengguna dan digunakan untuk memperbaiki kebutuhan sistem dari perangkat lunak yang akan dikembangkan. Pengembang dapat menggunakan potongan program yang sudah ada atau perangkat lunak pembantu (tools) agar working prototype dihasilkan lebih cepat.
Perangkat lunak yang digunakan dalam pembangunan prototipe spatial data mining ini antara lain:
• Microsoft Windows 2000 sebagai sistem operasi
• Matlab dengan Mapping Toolbox sebagai lingkungan pemrograman
• SQL Server 2000 sebagai sistem manajemen basisdata
• SAS 6.1.2 dan SPSS 10 sebagai perangkat pengolahan data
• Weka sebagai perangkat data mining
• ArcGIS 9.2 sebagai perangkat pengolah data spasial (misal merge, dissolve peta)
Perangkat keras yang digunakan dalam pembangunan prototipe spatial data mining ini adalah personal komputer dengan spesifikasi Prosesor Intel Pentium IV 1.6 Ghz, RAM 2 Gb dan Harddisk 80 Gb.
3.4. Pengujian Prototipe oleh Pengguna
Tahap ini akan menguji kinerja prototipe. Faktor yang diamati dalam penelitian ini adalah hal yang mempengaruhi aturan karakterisasi yang dihasilkan prototipe, misalnya nilai konstanta significance dan jenis predicate filter
3.5 Perbaikan Prototipe
HASIL DAN PEMBAHASAN
3.1Loading data peta
[image:55.612.156.510.318.646.2]Peta digital desa di Jawa Barat dan Banten tahun 2000 didapat dalam format Mapinfo per masing-masing provinsi. Peta kedua peta kemudian dikonversi ke dalam format Shapefile dan digabung menjadi satu. Selanjutnya peta shapefile dimuat (loading) ke dalam lingkungan Matlab menggunakan fungsi shaperead yang tersedia di Matlab Mapping Toolbox. Dalam Matlab, peta desa disimpan sebagai variabel S (JabarS.mat) dengan tipe struct. Nomor indeks pada variabel S merepresentasikan urutan obyek bersangkutan dalam shapefile. Alur loading data peta disajikan pada Gambar 22, sedangkan ilustrasi struktur variabel S digambarkan sebagai berikut (Gambar 23).
Gambar 22. Alur loading data peta
Gambar 23. Struktur Variabel S
Shaperead Add Index JabarS.mat Jabar.shp
1
7327 2
S (7327x1 struct array)
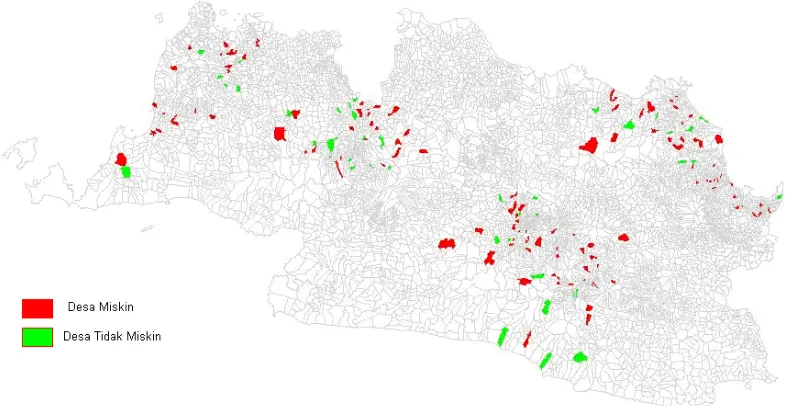
Gambar 24 memperlihatkan batas desa di Jawa Barat beserta lokasi ke-167 desa miskin/tidak miskin berdasarkan Santoso A(2000). Sumber data Santoso 2000 Jawa Barat meliputi 7 kabupaten yaitu : Pandeglang, Serang, Bogor, Bandung, Cirebon, Indramayu dan Garut. Pemilihan kabupaten tersebut didasarkan atas pertimbangan bahwa kabupaten yang dipilih merupakan kabupaten dengan persentase desa miskin (menurut kriteria BPS tahun 1995) dari desa yang terkena Susenas cukup besar yaitu sekitar 50 persen. Sehingga diperoleh jumlah desa miskin yang cukup mewakili untuk desa-desa di Jawa Barat.
Gambar 24. Desa Miskin/Tidak Miskin di Pandeglang, Serang, Bogor, Bandung, Cirebon, Indramayu dan Garut.
3.2Membangun neighborhood graph
33
Gambar 25. Sebagian desa di Jawa Barat
3.2.1 Cek MBR
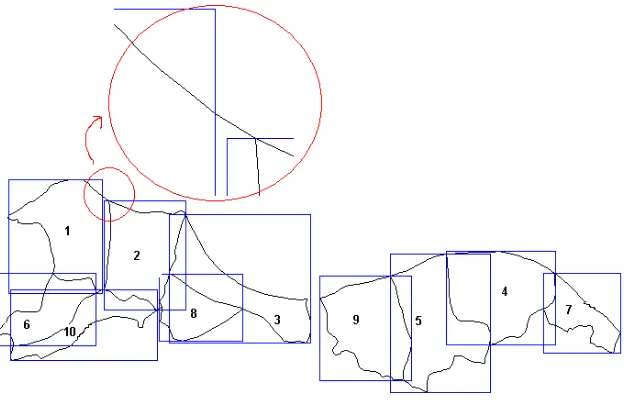
Neighbourhood graph disimpan dalam sebuah matriks N x N, sehingga membutuhkan waktu yang lama jika dilakukan pemeriksaan hubungan ketetanggaan untuk sebuah desa dengan seluruh desa selainnya. Untuk mempercepat maka dilakukan refinement melalui pemeriksaaan MBR desa yang berpotongan. Gambar 26 memperlihatkan sepuluh (10) desa pertama dalam S beserta MBR-nya masing-masing. Pada Gambar 26 terlihat adanya kesalahan dalam penentuan titik acuan MBR yang menyebabkan MBR desa 1 dianggap tidak berpotongan dengan MBR desa 2. Kesalahan ini diduga karena keterbatasan Matlab Mapping Toolbox. Pemeriksaan ulang terhadap kesalahan pengecekan MBR masih dilakukan secara manual (pengamatan visual) dan baru ditemukan satu kesalahan.
Berikut adalah pernyataan untuk pemeriksaaan MBR beserta hasilnya untuk sepuluh desa pertama di atas. Matriks not_separate sebagai hasil pemeriksaan MBR disajikan dalam Gambar 27.
Gambar 27. Matriks not_separate
3.2.2 Membangun List
Berdasarkan matriks not_separate kemudian dibentuk list desa yang MBR-nya tidak terpisah (not_separate_list). Variabel not_separate_list menggunakan struktur cell seperti digambarkan pada Gambar 28.
Gambar 28. Not_Separate_List if ( (maxX1 < minX2) ||... (minX1 > maxX2) ||... (maxY1 < minY2) ||... (minY1 > maxY2))
not_separate(poligon1,poligon2) = false; not_separate(poligon2,poligon1) = false;
Nomor Poligon N o m o r P o li g o n
1 : MBR Tidak terpisah 0 : MBR Terpisah
[image:58.612.232.395.528.654.2]35
3.2.3 Periksa Adjacency
Selanjutnya untuk semua desa yang MBR-nya berpotongan dilakukan pemeriksaan hubungan ketetanggaan. Dalam penelitian ini hubungan ketetanggaan didasarkan pada hubungan topologi Meet. Berikut statemen yang digunakan untuk memeriksa apakah dua buah poligon (batas desa) memenuhi hubungan spasial Meet:
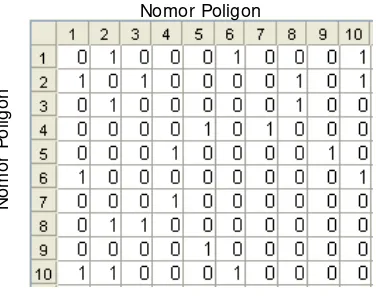
Berikut adalah matriks Adjacence (JabarA.mat) untuk sepuluh (10) desa pertama di Jawa Barat (Gambar 29).
[image:59.612.220.408.368.517.2]Gambar 29. Matriks Adjacence
Gambar 30 memperlihatkan desa contoh yang memenuhi hubungan Meet.
Gambar 30. Desa yang memenuhi hubungan Meet. poligon2= M{poligon1}(j);
poli1x = S(poligon1,1).X; poli1y = S(poligon1,1).Y; poli2x = S(poligon2,1).X; poli2y = S(poligon2,1).Y;
[xi,yi]=polyxpoly(poli1x,poli1y,poli2x,poli2y,'unique' );
adjacence = (size(xi,1)>1);
N
o
m
o
r
P
o
lig
o
n
Secara singkat alur pembentukan Neighbourhood Graph digambarkan pada Gambar 31.
Gambar 31. Alur pembentukan Neighbourhood Graph
3.3Membangun neigborhood index
[image:60.612.133.536.459.669.2]Algoritme karakterisasi spasial selain melibatkan nilai atribut setiap obyek juga memperhitungkan hubungan antarobyek. Dalam penelitian ini hubungan antarobyek yang digunakan adalah jarak dan arah. Untuk menghindari perhitungan jarak dan arah yang berulang-ulang, maka jarak dan arah sebuah desa terhadap desa lainnya disimpan dalam Neighbourhood Index. Neighbourhood Index direalisasikan sebagai sebuah tabel di dalam sistem manajemen basis data SQL Server. Gambar 32 menggambarkan alur pembangunan Neighbourhood Index.
Gambar 32. Alur pembangunan Neighbourhood Index JabarS.mat
Hitung Jarak
Cari Arah berdasarkan
MBR
Cari Arah berdasarkan
titik pusat
Cari Exact Direction
File Topologi T_1
s/d T_7327
Load ke SQL Server Neighbourhood
Index
JabarS.mat Cek MBR not_separate Membangun List
JabarM.mat Periksa
37
3.3.1. Hitung Jarak
Jarak antar dua desa didefinisikan sebagai jarak garis lurus antara titik pusat kedua desa (Gambar 33). Jarak antar dua desa dihitung berdasarkan jarak eucledian sebagai berikut:
distance = sqrt(((center(1,1)- center(2,1)).^2) +
((center(1,2)- center(2,2)).^2));
Gambar 33. Visualisasi jarak antardesa
3.3.2.Cari Arah
Arah antara dua desa didefinisikan sebagai posisi desa kedua secara relatif terhadap desa pertama yang dinyatakan dalam delapan arah mata angin. Gambar 34 merupakan visualisasi arah desa 4 relatif terhadap desa 1 dalam peta S menggunakan fungsi get_direction (S,1,4).
Gambar 34. Get_direction (S,1,4)
get_direction(S,1,4) ans =
Fungsi get_direction mengevaluasi arah berdasarkan posisi relatif MBR obyek kedua terhadap titik pusat obyek pertama yang menjadi acuan. Berikut adalah potongan programnya :
[image:62.612.137.490.326.588.2]Pada kondisi dimana MBR kedua desa berpotongan (Gambar 35) maka penentuan arah berdasarkan posisi relatif MBR tidak menghasilkan nilai valid. Untuk mengatasi hal tersebut maka fungsi get_direction dilanjutkan dengan pemeriksaan posisi relatif titik pusat obyek kedua terhadap titik pusat obyek pertama yang menjadi acuan. Berikut adalah potongan programnya :
Gambar 35. Get_direction (S,1,6)
Setelah arah dalam empat mata angin utama (utara, selatan, barat, timur) ditentukan selanjutkan menentukan arah sekunder (tenggara, baratdaya, baratlaut, timurlaut). Berikut potongan programnya :
if y >= originy, direction.utara =1;, tf= true;, end if y<= originy, direction.selatan=1;,tf= true;, end if x >= originx, direction.timur=1;, tf= true;, end if x<= originx, direction.barat=1;, tf= true;, end
get_direction(S,1,6)
39
3.3.3.Pembentukan File Topologi
Hasil perhitungan jarak dan penentuan arah sebuah desa terhadap seluruh desa lainnya dalam peta S disimpan dalam variabel T_X (file topologi T_X.mat), dimana X menunjukkan nomor desa. Pada tahap ini terbentuk 7327 file dan masing-masing berukuran sekitar 300 KB sehingga total berukuran 975 MB. Gambar 36 memperlihatkan struktur dari file topologi :
Gambar 36. Struktur file topologi
3.3.4.Loading ke SQL Server
Karena setiap file topologi jika dimuat ke lingkungan Matlab akan membutuhkan ruang memori sekitar 11 MB maka tidak mungkin memuat seluruh file topologi ke memori sekaligus (membutuhkan sekitar 80 GB memori). Agar data jarak dan arah dalam file topologi dapat disimpan dan diambil dengan cepat tanpa membutuhkan memori yang sangat besar maka file topologi tersebut di-loading ke dalam basis data. Dalam SQL Server 2000, file topologi dimuat ke dalam tabel NeighbourhoodIndex pada basis data sdm dengan struktur sebagai berikut (Gambar 37):
< 1x1 struct> < 1x1 struct> < 1x1 struct>
Node1 1 Node2 2 Distance 24775 Direction < 1x1 struct>
Timur 1 Tenggara 0 Selatan 0 Baratdaya 0 Barat 0 Baratlaut 0 Utara 0 Timurlaut 0 Undefined 0
if (direction.timur==1 & direction.selatan==1),direction.tenggara=1;, end
if (direction.barat==1 & direction.selatan==1),direction.baratdaya=1;, end
if (direction.barat==1 & direction.utara==1),direction.baratlaut=1;, end
Gambar 37. Struktur tabel NeighbourhoodIndex
Berikut potongan program yang digunakan untuk loading file topologi ke SQL Server :
Pada tahap ini terbentuk tabel NeighbourhoodIndex yang berisi 53.684.928 baris dan berukuran 1870 MB.
3.4Membentuk path
Alur proses pembentukan path digambarkan pada Gambar 38 dan terdiri dari beberapa tahap yaitu :
3.4.1.Penentuan Obyek Target
Obyek target merupakan subset dari desa yang termasuk kelas miskin. Dari 177 desa di 8 kabupaten yang dijadikan sampel oleh Santoso A(2000), 122 termasuk kelas miskin. Dari desa yang termasuk kelas miskin tersebut, dipilih 3 desa dari setiap kabupaten sebagai obyek target (Tabel 5). Gambar 39 memperlihatkan sebaran ke-24 desa obyek target (kuning) diantara desa miskin (merah) dan desa tidak miskin (hijau).
conn = database(dbTarget,'',''); dbTarget harus telah
terdaftar dalam ODBC connection
clear T
load(Tfile,'T') % load Tfile ke dalam variabel T
colnames = {'node1','node2','distance','exactdirection'}; for i=1:size(T,1);
% exdata = {T(i).node1, T(i).node2, T(i).distance,
T(i).direction.exactdirection};
exdata{i,1} = T(i).node1; exdata{i,2} = T(i).node2; exdata{i,3} = T(i).distance;
exdata{i,4} = T(i).direction.exactdirection;
end % end for i
41
Gambar 38. Alur proses pembentukan path
Tabel 5. Desa Target
Membentuk path k=2 Obyek Target
Path k=2 JabarA.mat
Membentuk path k=n Neighbourhood
Index
Filter Predikat
[image:65.612.136.505.390.645.2]43
3.4.2.Membangun Path dengan k=2
Path dengan panjang dua node (path k=2) menggambarkan tetangga langsung dari desa target. Karena desa tetangga adalah desa yang berdampingan dengan desa target maka pada tahap ini filter predikat yang memeriksa arah path belum diterapkan. Berikut potongan program dari fungsi sdm_pathk2 :
function pathk2 = sdm_pathk2(A,node) counter=0;
pathk2={};
for i=1:length(node)
tetangga=find(A(node(i),:)); for j=1:length(tetangga) counter=counter+1;
pathk2{counter,1}=[node(i) tetangga(j)]; end
end
[image:67.612.132.568.400.632.2]Dari 24 desa target, terbentuk 142 path k=2. Visualisasi path k=2 terdapat pada Gambar 40.
3.4.3.Membangun Filter Predikat
Filter predikat digunakan untuk menyaring arah perluasan path. Pada penelitian ini perluasan path dibatasi hingga memenuhi syarat umum sebuah node hanya muncul sekali dalam satu path. Sebuah path terdiri dari serangkaian node. Jika path terdiri dari dua node maka path tersebut hanya memiliki first_node dan last_node. Jika jumlah node dalam path lebih dari dua node maka dalam path tersebut terdapat sebuah node sebelum last node (before_last_node). Ketika sebuah path diperluas, maka filter predikat akan menyaring node baru mana yang akan ditambahkan ke dalam path. Ilustrasi proses perluasan path disajikan pada Gambar 41.
Gambar 41. Perluasan Path
Filter predikat yang dibangun pada penelitian ini adalah filter predikat arah (direction predicate filter) mencakup starlike dan variable_starlike filter. Filter vertical/horizontal variable starlike tidak dikembangkan karena diasumsikan bobot perluasan path memiliki kecenderungan yang sama ke seluruh arah. Dalam setiap filter predikat arah, arah path sebelum diperluas (exact_direction_previous) akan dibandingkan dengan arah path baru jika diperluas (exact_direction_new). Yang menjadi pembeda dari kedua filter predikat arah di atas adalah bagaimana menetapkan node acuan dalam mencari exact_direction_previous serta exact_direction_new. Filter predikat arah starlike menggunakan node terakhir (last_node dan before_last_node) sedangkan variable starlike menggunakan node pertama.
First Node Before Last Node Last Node
New Node ?
?
fi
lte
r
Path
45
Berikut potongan program filter predikat arah : switch filter
case ('starlike')
[jarak_new, exact_direction_new] =
sdm_read_topology_db(db,lastnode,newnode); [jarak_last, exact_direction_previous] =
sdm_read_topology_db(db,before_lastnode,lastnode);
% absolute exact direction
if strcmp( exact_direction_new , exact_direction_previous);, tf=1; else
if strcmp(exact_direction_previous,'timur') &
(strcmp(exact_direction_new,'tenggara') |
strcmp(exact_direction_new,'timurlaut')), tf=1;
elseif strcmp(exact_direction_previous,'barat') &
(strcmp(exact_direction_new,'baratdaya') |
strcmp(exact_direction_new,'baratlaut')), tf=1;
elseif strcmp(exact_direction_previous,'selatan') &
(strcmp(exact_direction_new,'tenggara') |
strcmp(exact_direction_new ,'baratdaya')), tf=1;
elseif strcmp(exact_direction_previous,'utara') &
(strcmp(exact_direction_new,'baratlaut') |
strcmp(exact_direction_new , 'timurlaut')), tf=1;
else tf=0;
end % end if
end %end if strcmp
case ('variable_starlike')
[jarak_new, exact_direction_new] =
sdm_read_topology_db(db,firstnode,newnode); [jarak_last, exact_direction_previous] =
sdm_read_topology_db(db,firstnode,lastnode);
if strcmp( exact_direction_new , exact_direction_previous);, tf=1; else % rel(i) is special relation of rel(1)
if strcmp(exact_direction_new , 'tenggara') &
( strcmp(exact_direction_previous,'timur')
|strcmp(exact_direction_previous,'selatan') ); tf=1;
elseif strcmp(exact_direction_new , 'baratdaya') &
( strcmp(exact_direction_previous,'barat')
|strcmp(exact_direction_previous,'selatan') ); tf=1;
elseif strcmp(exact_direction_new , 'baratlaut') &
( strcmp(exact_direction_previous,'barat')
|strcmp(exact_direction_previous,'utara') ); tf=1;
elseif strcmp(exact_direction_new , 'timurlaut') &
( strcmp(exact_direction_previous,'timur')
|strcmp(exact_direction_previous,'utara') ); tf=1;
else tf=0;
end % end special relation
end % end check direction predicate
end % end switch filter
if tf==1;
extendedpath = [path newnode]; % extending path
% extendedpath =[firstnode]...[before_lastnode][lastnode][newnode]
counter = counter +1;
pathkn{counter,1}= extendedpath;
3.4.4.Membangun Path dengan k=n
[image:70.612.130.551.254.668.2]Filter predikat yang terbentuk pada sub bab 3.4.3 digunakan untuk menyaring arah perluasan path. Visualisasi path dengan k=3 menggunakan filter starlike terdapat pada Gambar 42, sedangkan path dengan k=3 menggunakan filter variable starlike terdapat pada Gambar 43. Dari kedua gambar tersebut terlihat path dengan k=3 sudah banyak yang melintasi batas kecamatan.
[image:70.612.129.552.456.679.2]Gam