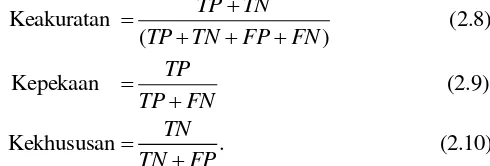PENERAPAN ALGORITME SMOTEBAGGING DALAM
PENYUSUNAN POHON KEPUTUSAN DAN REGRESI
LOGISTIK UNTUK KAJIAN KREDIT MACET
FITHRIA SITI HANIFAH
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis berjudul Penerapan Algoritme SMOTEBagging dalam Penyusunan Pohon Keputusan dan Regresi Logistik untuk Kajian Kredit Macet adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
RINGKASAN
FITHRIA SITI HANIFAH. Penerapan Algoritme SMOTEBagging dalam Penyusunan Pohon Keputusan dan Regresi Logistik untuk Kajian Kredit Macet. Dibimbing oleh HARI WIJAYANTO dan ANANG KURNIA.
Permasalahan yang sering ditemui dalam kasus klasifikasi adalah masalah data tidak seimbang yang merupakan kondisi dimana salah satu atau lebih kelas mendominasi kelas yang lain. Data tidak seimbang akan menghasilkan bias terhadap kelas dengan jumlah contoh yang lebih besar (mayor) karena pengklasifikasi akan cenderung memprediksi data kelas mayor, sedangkan kelas minor akan cenderung diabaikan (dianggap sebagai noise), sehingga data amatan pada kelas minor tidak dapat diklasifikasikan dengan benar. Untuk banyak kasus, kesalahan memprediksi objek dari kelas minor dapat memberikan resiko lebih besar dibanding dengan kesalahan memprediksi objek dari kelas mayor.
Penelitian ini mendiskusikan salah satu teknik penanganan masalah data tidak seimbang, yaitu SMOTEBagging. SMOTEBagging merupakan kombinasi dari metode SMOTE (Synthetic Minority Oversampling Technique) dan Bagging (Bootstrap Aggregating), dimana metode SMOTE akan dilibatkan dalam proses bagging, yaitu membangkitkan data buatan pada gugus data hasil proses bootsrap. Pohon Keputusan dengan algoritme CART (Classification and Regression Tree) dan regresi logistik merupakan pengklasifikasi yang akan digunakan pada setiap gugus data yang diperoleh.
Data yang digunakan pada penelitian ini merupakan data sekunder yang diambil dari salah satu Bank di Indonesia, Bank X, yaitu data nasabah kredit tanpa agunan. Peubah yang digunakan dalam penelitian ini merupakan karakteristik nasabah yang dinilai dalam credit scoring, yaitu sebanyak 17 peubah penjelas.
Berdasarkan hasil analisis, SMOTEBagging terbukti dapat meningkatkan kinerja klasifikasi pada data tidak seimbang pada pengklasifikasian data credit scoring pada kasus ini. Hal ini ditunjukkan dengan nilai AUC dan kepekaan yang lebih baik dibandingkan dengan model tanpa SMOTEBagging. Berdasarkan nilai AUC, pengklasifikasian credit scoring dengan menggunakan model regresi logistik lebih baik dibandingkan dengan model CART, baik dengan penerapan algoritme SMOTEBagging maupun tidak. Sedangkan berdasarkan nilai kepekaan, model CART lebih baik dibanding dengan regresi logistik untuk model tanpa SMOTEBagging, dan model regresi logistik lebih baik dibanding dengan CART untuk model dengan SMOTEBagging. Sementara itu, model dengan penerapan algoritme SMOTEBagging memiliki nilai AUC dan kepekaan yang lebih tinggi dibanding dengan model tanpa SMOTEBagging meskipun nilai kehususannya menurun. Oleh karena pada penelitian ini berfokus pada kelas minor (kredit macet), maka berdasarkan pada kepentingan dalam penelitian ini diambil kesimpulan bahwa SMOTEBagging dapat menaikkan tingkat akurasi model kelas minor.
SUMMARY
FITHRIA SITI HANIFAH. Application of SMOTEBagging Algorithm in Establishing Decision Tree and Logistic Regression Classifier in Study of Non-Performing Loan. Supervised by HARI WIJAYANTO and ANANG KURNIA.
The common problem in many cases of the classification is imbalanced data when there are one or more classes that dominate the overall dataset as majority classes and the other class which has rare occurrence as a minority class. The standard methods will produce a bias toward the classes with a greater number of instances (majority class) because the classifier will tend to predict to the majority class data. The minority class will be ignored (treated as noise), so the observation from the minority class cannot be classified correctly. In many cases, misclassifying the minority class objects could have a bigger risk than misclassifying the majority class.
This study will discuss one of handling methods for imbalanced dataset, SMOTEBagging. SMOTEBagging is a combination of SMOTE (Synthetic Minority Oversampling Technique) and Bagging (Bootstrap Aggregating), where the SMOTE will be involved in the process of Bagging, generating synthetic samples on data subset from bootstrap. Decision tree with CART (Classification and Regression Tree) algorithm and logistic regression are classifier used in each data subset.
The data used in this study is secondary data from one of banks in Indonesia, namely customer’s personal loan data of Bank X. This study used credit scoring customer characteristics data which is imbalanced data consisting of 17 explanatory variables.
Based on the result, SMOTEBagging algorithm increased performance of classification for imbalanced credit scoring dataset in this case. It was shown by area under curve (AUC) value and the accuracy of minority class (sensitivity) in model with SMOTEBagging is higher than model without SMOTEBagging. Based on AUC value, the classification of credit scoring by using logistic regression model was better than using CART model, either with the application of SMOTEBagging algorithm or without SMOTEBagging algorithm. In other hand, based on the sensitivity, the CART model better than logistic regression model without SMOTEBagging, and the logistic regression model is better than the CART model with SMOTEBagging. Meanwhile, the model with the application of SMOTEBagging algorithm, AUC value and sensitivity higher than model without SMOTEBagging, although the specificity value decreases. Therefore, because this study was focused on minority classes, based on the interest of this study we could conclude that SMOTEBagging could increase the level of accuracy of minority class prediction.
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika Terapan
PENERAPAN ALGORITME SMOTEBAGGING DALAM
PENYUSUNAN POHON KEPUTUSAN DAN REGRESI
LOGISTIK UNTUK KAJIAN KREDIT MACET
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2015
Judul Tesis : Penerapan Algoritme SMOTEBagging dalam Penyusunan Pohon Keputusan dan Regresi Logistik untuk Kajian Kredit Macet Nama : Fithria Siti Hanifah
NIM : G152130201
Disetujui oleh Komisi Pembimbing
Dr Ir Hari Wijayanto, MSi Ketua
Dr Anang Kurnia, SSi, MSi Anggota
Diketahui oleh
Ketua Program Studi Statistika Terapan
Dr Ir Indahwati, MSi
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur Penulis panjatkan kepada Allah Subhanahu wa ta’ala atas segala karunia-Nya sehingga penulis dapat menyelesaikan tesis dengan judul “Penerapan Algoritme SMOTEBagging dalam Penyusunan Pohon Keputusan dan Regresi Logistik untuk Kajian Kredit Macet”. Tesis ini juga dapat diselesaikan dengan bantuan dari berbagai pihak.
Terima kasih penulis ucapkan kepada Bapak Dr Ir Hari Wijayanto, MSi dan Bapak Dr Anang Kurnia, MSi selaku pembimbing yang telah memberikan bimbingan, arahan, dan saran kepada penulis, serta Bapak Prof. Dr. Ir. Khairil Anwar Notodiputro, MS selaku dosen panguji luar komisi yang memberikan arahan dan saran kepada penulis. Penulis juga mengucapkan terimakasih kepada Dirjen Dikti atas pemberian beasiswa BPPDN, Ayah dan Ibu atas dukungan, semangat dan do’anya, serta kakak dan adik-adikku yang selalu mendoakan dan memberi semangat. Terima kasih juga kepada seluruh staf program studi Statistiska, teman-teman S2 Statistika Terapan 2013, teman-teman S2 Statistika 2013, teman-teman S2 Statistika Terapan BPS yang telah membantu dan kebersamaannya. Dan terima kasih kepada semua pihak yang tidak dapat penulis sebutkan satu per satu yang telah membantu dalam penyelesaian tesis ini.
Semoga tesis ini dapat bermanfaat bagi semua pihak yang membutuhkan.
DAFTAR ISI
DAFTAR TABEL ii
DAFTAR GAMBAR ii
DAFTAR LAMPIRAN ii
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
2 TINJAUAN PUSTAKA 4
Data Tidak seimbang 4
SMOTE 4
Bagging 5
SMOTEBagging 6
Pohon Klasifikasi dan Regresi 7
Regresi Logistik 9
Kinerja Klasifikasi 11
3 METODE 12
Data 12
Metode Analisis 13
4 HASIL DAN PEMBAHASAN 16
Deskripsi Data 16
Model tanpa SMOTEBagging 19
Model dengan SMOTEBagging 22
Perbandingan Model 23
Karakteristik Peubah yang Mempengaruhi Kredit Macet 24
5 SIMPULAN 27
DAFTAR PUSTAKA 28
LAMPIRAN 29
DAFTAR TABEL
1 Confusion Matrix 11
2 Peubah Penyusun Model 12
3 Gambaran umum tentang data nasabah KTA Bank X 16
4 Kinerja klasifikasi model CART 19
5 Ketepatan klasifikasi model CART 20
6 Kinerja klasifikasi model regresi logistik 21
7 Ketepatan klasifikasi model regresi logistik 21
8 Kinerja klasifikasi model SMOTEBagging 22
9 Ketepatan klasifikasi model SMOTEBagging 22
10 Perbandingan kinerja klasifikasi 24
11 Peubah signifikan dalam Model 25
12 Peubah signifikan dalam Model 26
DAFTAR GAMBAR
1 Ilustrasi data tidak seimbang 4
2 Ilustrasi proses Bagging 6
3 Diagram Pohon 8
4 Kurva ROC perbandingan model CART dan regresi logistik 21 5 Kurva ROC model SMOTEBagging CART dan regresi logistik 23
6 Kurva ROC perbandingan model 24
DAFTAR LAMPIRAN
7 Deskripsi Peubah Penelitian 29
8 Bar Chart untuk persentase kredit macet 30
9 Pohon klasifikasi CART 32
10 Pendugaan parameter model regresi logistik dan backward stepwise 33 11 Grafik kinerja klasifikasi model SMOTEBagging CART berdasarkan
banyaknya Bootstrap 34
12 Grafik kinerja klasifikasi model SMOTEBagging regresi logistik
berdasarkan banyaknya Bootstrap 35
1
1
PENDAHULUAN
Latar Belakang
Dewasa ini, permintaan kredit melalui suatu bank mengalami perkembangan yang cukup pesat. Kredit bukan hanya digunakan bagi masyarakat golongan menengah ke bawah saja, tetapi juga oleh semua lapisan masyarakat untuk menunjang kegiatan perekonomiannya. Pemberian kredit kepada masyarakat ini tidak terlepas dari risiko. Dalam perbankan, risiko ini dikenal dengan risiko kredit yaitu risiko akibat kegagalan debitur dan/atau pihak lain dalam memenuhi kewajiban kepada bank. Risiko semacam ini (kredit macet) merupakan hal yang sangat dikhawatirkan oleh setiap bank, karena akan mengganggu kondisi keuangan bank, bahkan dapat mengakibatkan berhentinya kegiatan usaha bank. Oleh karena itu, diperlukan proses manajemen yang disebut dengan manajemen risiko agar dapat mengontrol risiko kredit dari suatu bank. Dalam Kodifikasi Peraturan Bank Indonesia tentang “Manajemen Risiko”, menyatakan bahwa manajemen risiko itu sendiri adalah serangkaian metodologi dan prosedur yang digunakan untuk mengidentifikasi, mengukur, memantau, dan mengendalikan risiko yang timbul dari seluruh kegiatan usaha bank.
Kebutuhan akan praktik tata kelola bank yang sehat dan penerapan manajemen risiko (dalam hal meminimalisasi risiko kemacetan pembayaran kredit) sangat perlu ditingkatkan agar semua kegiatan bank terkendali dan dapat memberikan keuntungan pada bank. Oleh karena itulah perlu adanya suatu pemodelan credit scoring yang dapat mengklasifikasikan calon debitur kedalam dua kategori yaitu kategori macet dan lancar dengan risiko salah pengklasifikasian seminimal mungkin. Sehingga bank dapat memutuskan apakah calon debitur dapat dikabulkan permohonan kreditnya atau tidak. Pada kasus ini, terdapat ketidakseimbangan antara data kelas macet dan data kelas lancar. Ada sebanyak 87,6% data yang berada di kelas kredit lancar, sedangkan kelas kredit macet hanya 12,4%. Dalam banyak kasus klasifikasi, permasalahan semacam ini memang sering terjadi. Data dikatakan tidak seimbang ketika ada satu atau lebih kelas yang mendominasi keseluruhan data sebagai kelas mayor dan kelas lain yang merupakan kejadian langka sebagai kelas minor. Masalah data tidak juga seimbang terjadi dalam berbagai kasus klasifikasi, seperti klasifikasi kemiskinan (Muttaqin et al. 2013), klasifikasi teks (Chawla et al. 2002), klasifikasi keberhasilan studi mahasiswa (Rahmah 2013), diagnosa medis (Yap et al. 2014), credit scoring (Brown dan Mues 2012), dan sebagainya.
2
(dianggap sebagai noise), sehingga data amatan pada kelas minor tidak dapat diklasifikasikan dengan benar (Galar et al. 2011).
Beberapa penelitian telah dilakukan dalam pengembangan teknik untuk kasus data tidak seimbang. He dan Garcia (2009) serta Galar et al. (2011) menjelaskan beberapa metode yang dapat digunakan untuk mengatasi masalah data tidak seimbang. Menurut Galar et al. (2011) pendekatan dapat dilakukan pada level algoritme, level data, dan cost-sensitive yang merupakan gabungan dari level algoritme dan level data.
Pendekatan paling sederhana adalah pendekatan pada level data yaitu menambahkan pre-processing step dengan menerapkan konsep sampling, yaitu undersampling dan oversampling. Pendekatan ini memodifikasi jumlah kelas data sehingga kedua kelas data dapat direpresentasikan dengan baik. Metode oversampling bekerja dengan menambah jumlah data, sedangkan undersampling dengan mengurangi jumlah data. Chawla et al. (2002) memperkenalkan SMOTE yang merupakan metode yang dikembangkan berdasarkan konsep oversampling. SMOTE bekerja dengan membangkitkan data buatan berdasarkan k-tetangga terdekat. Hal ini diharapkan dapat mengatasi kelemahan metode berbasis undersampling yang menghilangkan informasi penting dalam data yang dihilangkan.
Metode ensemble juga dapat digunakan untuk masalah data tidak seimbang dengan meningkatkan akurasi klasifikasi dari sebuah pengklasifikasi tunggal. Metode ini mengkombinasikan banyak pengklasifikasi tunggal yang kemudian hasil prediksi masing-masing pengklasifikasi digabungkan dengan proses voting. Salah satu metode ensemble adalah Bagging. Bagging merupakan metode yang menggunakan bootstrap dalam menghasilkan gugus data baru untuk membuat pengklasifikasi dalam banyak versi. Jika dibandingkan dengan pengklasifikasi tunggal, hasil prediksi bagging hampir selalu lebih akurat (Zhou 2012). Beberapa penelitian yang menggunakan Bagging untuk memperbaiki akurasi klasifikasi dari metode klasifikasi tunggal diantaranya Intansari et al. (2012) mengklasifikasikan pasien hasil pap test kanker serviks, dan Muttaqin et al. (2013) pada klasifikasi kemiskinan di Kabupaten Jombang.
Pada penelitian ini akan diterapkan metode SMOTEBagging pada metode pohon keputusan (decision tree) dengan algoritme CART, dan pada model regresi logistik. SMOTEBagging merupakan kombinasi dari metode SMOTE dan bagging, dimana metode SMOTE akan dilibatkan dalam proses bagging, yaitu membangkitkan data pada gugus data hasil proses bootstrap sehingga data menjadi seimbang sebelum dilakukan analisis. Dengan demikian diperoleh hasil kinerja klasifikasi yang lebih baik dalam memprediksi kredit macet.
Tujuan Penelitian
Berdasarkan latar belakang pada bagian sebelumnya, maka tujuan penelitian ini adalah:
1. Menerapkan metode klasifikasi dengan CART dan regresi logistik serta membandingkan hasil kinerja klasifikasinya.
3 data) pada data Kredit Tanpa Agunan (KTA) serta membandingkan hasil kinerja klasifikasinya.
4
2
TINJAUAN PUSTAKA
Data Tidak seimbang
Data tidak seimbang terjadi ketika ada satu atau lebih kelas yang mendominasi keseluruhan data sebagai kelas mayor dan kelas lainnya merupakan kejadian langka sebagai kelas minor. Data tidak seimbang akan menghasilkan suatu akurasi prediksi klasifikasi yang baik terhadap kelas mayor, sedangkan pada kelas minor akurasi yang dihasilkan jelek. Sulitnya mendapatkan model prediksi yang baik dan bermakna pada kelas minor karena adanya ketidakcukupan informasi (Yap et al. 2014).
Gambar 1 Ilustrasi data tidak seimbang
Terdapat beberapa pendekatan yang dapat dilakukan untuk mengatasi masalah data tidak seimbang. Pendekatan pertama yaitu pada level algoritme (internal), dengan membuat atau memodifikasi algoritme yang ada untuk memperhitungkan pentingnya contoh positif. Pendekatan kedua yaitu level data (eksternal), yang menambahkan preprocessing step. Serta pendekatan ketiga adalah cost-sensitive yang mengkombinasikan kedua pendekatan tersebut. Selain itu, metode ensemble juga dapat digunakan untuk mengatasi masalah data tidak seimbang dengan meningkatkan akurasi klasifikasi dari sebuah pengklasifikasi tunggal (Galar et al. 2011).
SMOTE
Synthetic Minority Oversampling Technique (SMOTE) adalah salah satu metode oversampling yang pertama kali diperkenalkan oleh Chawla et al. (2002). Metode oversampling adalah metode resampling yang mereplikasi/duplikasi data secara acak. Tujuan penambahan data ini agar jumlah data minor setara dengan data mayor. SMOTE merupakan metode oversampling yang bekerja dengan membuat “synthetic” data, yaitu membangkitkan data buatan.
5 menggunakan Value Distance Metric (VDM). Rumus jarak Euclidean didefinisikan sebagai berikut:
( , ) ( )'( )
x y xy xy (2.1)
Rumus Value Distance Metric (Cost dan Salzberg 1993) didefinisikan sebagai berikut:
1 2
1 ( , ) N r i i i v v
x y W Wx y
(2.2) Keterangan :
( , )
x y
: Jarak antara amatan X dan Y x y
W W : Bobot amatan (dapat di abaikan) N : Banyaknya peubah penjelas
r : Bernilai 1 (jarak Manhattan) atau 2 (jarak Euclidean)
v v1i 2i
: Jarak antar kategori pada setiap peubah, dengan rumus :
1 21 2
1 1 2
k S i i i c c v v c c
Keterangan :
v v1 2 : Jarak antara kategori ke-1 dan ke-2 yang termasuk pada kelas ke-i c1i : Banyaknya kategori ke-1 yang termasuk kelas ke-i
c2i : Banyaknya kategori ke-2 yang termasuk kelas ke-i
c1 : Banyaknya kategori ke-1 terjadi
c2 : Banyaknya kategori ke-2 terjadi
S : Banyaknya kategori pada peubah k : Konstanta (biasanya 1).
Berikut ini merupakan prosedur pembangkitan data buatan : 1. Data numerik
a. Hitung selisih antar vektor prediktor dengan k-tetangga terdekatnya. b. Kalikan selisih ini dengan angka acak antara 0 dan 1.
c. Tambahkan selisih dengan nilai asli prediktor tersebut kemudian buat data buatan.
2. Data kategorik
a. Pilih majority vote antara vektor utama yang dipertimbangkan dengan k-tetangga terdekatnya untuk nilai nominal. Jika terjadi nilai sama maka pilih secara acak.
b. Tetapkan nilai tersebut sebagai data buatan sampel baru.
Bagging
6
(training) sehingga diperoleh gugus data/data latih baru untuk membangkitkan pengklasifikasi dengan banyak versi, kemudian aggregating yaitu menggabungkan banyak nilai dugaan menjadi satu nilai dugaan.
Konsep aggregating pada bagging adalah voting untuk kasus klasifikasi dan rata-rata untuk kasus regresi. Penggunaan bagging ini berguna dalam mengatasi sifat ketidakstabilan dari metode klasifikasi tunggal. Tingkat ketepatan klasifikasi dari bagging tergantung pada jumlah replikasi bootstrap yang digunakan sehingga dapat dikatakan penentuan banyaknya replikasi bootstrap merupakan faktor yang mempengaruhi kebaikan bagging.
Menurut Sartono dan Syafitri (2010) dengan pengulangan bootstrap sebanyak 50 kali untuk kasus klasifikasi dan 25 kali untuk kasus regresi dapat memberikan hasil yang memuaskan.
Gambar 2 Ilustrasi proses Bagging
SMOTEBagging
SMOTEBagging adalah kombinasi dari SMOTE dan algoritme bagging yang melibatkan proses pembangkitan data buatan selama mengkonstruksi gugus data (Wang dan Yao 2009). Tujuan dari pengkombinasian ini adalah untuk menciptakan model yang kuat dalam mengklasifikasi data yang tidak seimbang tanpa mengorbankan akurasi keseluruhan.
7 sebanyak N. Jumlah oversampling dapat ditentukan hingga jumlah sampel kelas mayor dan minor berimbang.
Algoritme SMOTEBagging (Wang dan Yao 2009) : Data Latih
1. Menginisiasi data latih sebagai S.
2. Membangun gugus data Sk yang berisi contoh dari semua kelas dengan
jumlah yang sama.
a. Lakukan resampling pada kelas C dengan pengembalian dengan persentase 100%.
b. Untuk setiap kelas i ( 1, …, C-1)
Lakukan resampling dari contoh asli dengan pengembalian pada tingkat
( c) %.
i N
b N
Anggap ( c)(1 %) 100
i N
N b
N
Bangkitkan sampel baru dengan menggunakan SMOTE (k, N)
Dimana i merupakan kelas ke-i, Ni adalah jumlah contoh data latih kelas
ke-i, Nc adalah jumlah contoh data latih kelas mayor, N adalah jumlah
oversampling, b% merupakan nilai untuk mengontrol jumlah bangkitan data baru (range dari 10 sampai 100).
3. Menyusun pengklasifikasi dari data Sk
4. Mengubah persentase b%
5. Mengulang langkah 2 dan 3 sebanyak k kali. (k= 1, 2, …, M) Data Uji
1. Membangkitkan output dari masing-masing pengklasifikasi 2. Memperoleh prediksi kelas berdasarkan voting
Untuk gugus data yang terdiri dari dua kelas, yaitu satu kelas mayor dan satu kelas minor, jumlah oversampling yang dapat digunakan adalah 100, 200, 300, 400, dan 500 (Chawla et al. 2002).
Pohon Klasifikasi dan Regresi
CART (Classification and Regression Trees) merupakan salah satu metode atau algoritme dari salah satu teknik eksplorasi data decision tree yang dikembangkan oleh Leo Breiman, Jerome H. Friedman, Richard A. Olshen dan Charles J. Stone sekitar tahun 1980-an. CART adalah metode statistik non-parametrik yang digunakan untuk analisis klasifikasi, baik untuk peubah respon kategorik maupun kontinu dan peubah penjelas yang dapat terdiri dari peubah nominal, ordinal, maupun kontinu. Model pohon yang dihasilkan bergantung pada skala peubah respon, CART menghasilkan pohon klasifikasi jika peubah responnya kategorik dan menghasilkan pohon regresi jika peubah responnya kontinu (Breman et al. 1984).
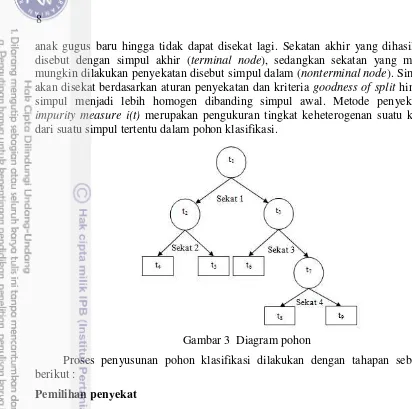
8
anak gugus baru hingga tidak dapat disekat lagi. Sekatan akhir yang dihasilkan disebut dengan simpul akhir (terminal node), sedangkan sekatan yang masih mungkin dilakukan penyekatan disebut simpul dalam (nonterminal node). Simpul akan disekat berdasarkan aturan penyekatan dan kriteria goodness of split hingga simpul menjadi lebih homogen dibanding simpul awal. Metode penyekatan impurity measure i(t) merupakan pengukuran tingkat keheterogenan suatu kelas dari suatu simpul tertentu dalam pohon klasifikasi.
Gambar 3 Diagram pohon
Proses penyusunan pohon klasifikasi dilakukan dengan tahapan sebagai berikut :
Pemilihan penyekat
Setiap penyekatan tergantung pada nilai yang hanya berasal dari satu peubah penjelas, dengan aturan sebagai berikut :
1. Untuk peubah kontinu Xj, penyekatan yang diperbolehkan adalah Xj ≤ c,
dimana c adalah nilai tengah antara dua nilai amatan peubah Xj berurutan
yang berbeda sebanyak n nilai tengah, sehingga akan terdapat n-1 penyekatan.
2. Untuk peubah kategorik, penyekatan yang terjadi berasal dari semua kemungkinan penyekatan berdasarkan terbentuknya dua anak gugus yang saling lepas (disjoint). Jika peubah Xj merupakan peubah kategorik nominal
dengan L kategori, maka akan ada 2L-1-1 penyekatan, sedangakan jika berupa peubah kategorik ordinal, maka akan ada L-1 penyekatan yang mungkin.
Metode penyekatan yang biasa digunakan adalah Indeks Gini yang diformulasikan sebagai berikut:
( ) ( | ) ( | ) i j
i t p j t p i t
dimana p(j|t) adalah proporsi kelas-j pada simpul t dan p(i|t) adalah proporsi kelas-i pada simpul t.
9
s t, i t( ) p i tL( )L p i tR( )R
dan penyekat terbaik adalah:
s t*, maxs
s t, (2.3)
dimana
i(t) = fungsi heterogenitas pada simpul t pL = proporsi pengamatan simpul kiri
pR = proporsi pengamatan menuju simpul kanan
i(tL) = fungsi heterogenitas pada simpul anak kiri
i(tR) = fungsi heterogenitas pada simpul anak kanan.
Penyekat yang menghasilkan φ(s,t) lebih tinggi merupakan penyekatan terbaik karena memungkinkan mereduksi keheterogenan lebih tinggi.
Penentuan simpul akhir
Simpul t dapat dijadikan simpul akhir jika tidak terdapat penurunan keheterogenan yang berarti pada penyekatan, artinya amatan dalam simpul sudah homogen. Salah satu penghenti dari proses penyekatan adalah kecilnya jumlah amatan dalam suatu simpul.
Penentuan dugaan respon pada setiap simpul akhir
Dugaan respon pada masing-masing simpul akhir yang dihasilkan berdasarkan jumlah terbanyak, yaitu :
0
( ) ( | ) max ( | ) max
( )
j
j j
N t
p j t p j t
N t
(2.4)
dengan p(j|t) adalah proporsi kelas j pada simpul t, Nj(t) adalah jumlah
pengamatan kelas j pada simpul t, dan N(t) adalah jumlah pengamatan pada simpul t. Dugaan respon tersebut memberikan nilai dugaan kesalahan klasifikasi paling kecil sebesar 1- p(j0|t).
Regresi Logistik
Regresi logistik adalah prosedur pemodelan yang diterapkan untuk memodelkan peubah respon Y yang bersifat kategori berdasarkan satu atau lebih peubah prediktor X, baik itu bersifat kategori maupun kontinu (Agresti 2002). Secara umum model peluang regresi logistik biner diformulasikan sebagai berikut:
0 1 1 2 2
0 1 1 2 2
exp( ... )
( | ) =
1 exp( ... )
p p
p p
x x x
E y x
x x x
atau
0 1 1 2 2
0 1 1 2 2
exp( ... )
( ) =
1 exp( ... )
p p
p p
x x x
x
x x x
10
0 1 1 2 2
( )
logit[ ] log = ... 1 ( )
i p p
x
x x x
x
(2.5)
yang merupakan fungsi penghubung (link function) terhadap prediktor (Agresti 2002).
Hosmer dan Lemeshow (1989) menyatakan bahwa metode umum pendugaan parameter regresi logistik adalah metode kemungkinan maksimum. Fungsi kemungkinan dari sebaran Bernoulli ditunjukkan dengan persamaan sebagai berikut:
1 1
( ) ( ) (1i ( )) i.
n
y y
i i
i
l
x xPrinsip dari metode ini adalah dengan memaksimumkan fungsi kemungkinan yang secara matematis lebih mudah dengan memaksimumkan logaritma fungsi kemungkinan berikut:
( ) i ij j ilog 1 exp j ij
j i i j
L y x n x
untuk mendapatkan nilai dugaan koefisien regresi logistik dilakukan dengan penurunan L( ) terhadap dan disamakan dengan nol. Persamaan hasil turunan masih nonlinier, maka dibutuhkan metode iterasi sebagai solusi (Agresti 2002).
Pengujian parameter secara simultan dilakukan dengan uji rasio kemungkinan. Hipotesis yang akan diuji adalah sebagai berikut:
1 2
: 0
o p
H
:
1
H paling tidak ada satu βi≠ 0.
Statistik uji yang digunakan dalam uji rasio kemungkinan (Agresti 2002), yaitu:
0
0 1
1
2 log l 2 log( ) log( )
G l l
l
(2.6)
dengan:
:
0
l Nilai maksimum dari fungsi kemungkinan untuk model di bawah hipotesis nol.
:
1
l Nilai maksimum dari fungsi kemungkinan untuk model di bawah hipotesis alternatif.
Nilai 2(L0L1) tersebut mengikuti sebaran khi-kuadrat dengan df p. Jika menggunakan taraf nyata sebesar , maka kriteria ujinya adalah tolak H0 jika
2
0 1 ( )
2(L L) p
atau nilai-p ≤ (Agresti 2002).
Pengujian parameter secara parsial dilakukan dengan menggunakan Uji Wald, dengan rumusan hipotesis sebagai berikut :
H0 : βi= 0
11 Statistik uji yang digunakan adalah Uji Wald (Agresti 2002), yaitu:
( )
i
i W
SE
(2.7) statistik W mengikuti sebaran normal baku.
Kinerja Klasifikasi
Kinerja suatu algoritme klasifikasi dapat dievaluasi dengan confusion matrix. Confusion matrix memuat informasi tentang hasil klasifikasi data aktual (keadaan sesungguhnya) dan hasil klasifikasi data hasil prediksi yang disajikan dalam Tabel 1 sebagai berikut:
Tabel 1. Confusion matrix
Hasil Prediksi
Positif Negatif
Keadaan sesungguhnya
Positif True Positive (TP) False Negative (FN) Negatif False Positive (FP) True Negative (TN) Keterangan:
TP adalah frekuensi contoh yang sesungguhnya positif dan di prediksi positif. FN adalah frekuensi contoh yang sesungguhnya positif dan di prediksi negatif. FP adalah frekuensi contoh yang sesungguhnya negatif dan di prediksi positif. TN adalah frekuensi contoh yang sesungguhnya negatif dan di prediksi negatif.
Cara untuk mengevaluasi hasil klasifikasi berdasarkan nilai pada confusion matrix adalah dengan menghitung nilai keakuratan (accuracy), kepekaan (sensitivity), dan kekhususan (specificity). Keakuratan menggambarkan tingkat ketepatan klasifikasi secara keseluruhan. Kepekaan menggambarkan keakuratan contoh pada kelas ke-i, sedangkan kekhususan menggambarkan keakuratan pada kelas ke-j. Formula evaluasi kinerja klasifikasi adalah:
Keakuratan (2.8)
( )
Kepekaan (2.9)
Kekhususan . (2.10) TP TN
TP TN FP FN TP
TP FN TN TN FP
Akurasi klasifikasi juga dapat diukur dengan menghitung luas di bawah kurva
Receiver Operating Characteristic (ROC), yaitu AUC (Area under Curve). Menurut
12
3
METODOLOGI
Data
Data yang digunakan pada penelitian ini adalah data sekunder, yaitu data nasabah Kredit Tanpa Agunan (KTA) pada salah satu Bank di Indonesia, Bank X. Kredit Tanpa Agunan adalah kredit dengan agunan hanya berupa objek yang dibiayai kredit. Fungsi agunan berupa objek yang dibiayai tersebut tidak hanya sebagai bukti penggunaan kredit, keseriusan atau kesungguhan calon debitur, tetapi juga sebagai faktor pengurang risiko kredit di kemudian hari jika fasilitas kredit yang diberikan tersebut mengalami macet/unpaid. Kredit ini diberikan kepada pegawai maupun pensiunan yang berpenghasilan tetap atau memiliki profesi tetap untuk membiayai berbagai macam kebutuhannya, dengan agunan hanya berupa objek yang dibiayai kredit. Limit kredit ini adalah sebesar 50 juta rupiah. Kriteria penerimaan kredit ini adalah sebagai berikut:
1. Warga Negara Indonesia yang berdomisili di Indonesia.
2. Telah diangkat menjadi pegawai tetap minimal 1 (satu) tahun dan berpenghasilan tetap.
3. Usia minimal 21 tahun atau sudah menikah dan pada saat kredit lunas sesuai usia pensiun (persyaratan ditentukan sesuai ketentuan yang berlaku).
4. Berdasarkan IDI – Bank Indonesia, calon debitur/debitur tidak memiliki kredit atau mempunyai kredit dengan kolektibilitas seluruhnya lancar dan tidak masuk Daftar Hitam Nasional Penarik Cek / Bilyet Giro Kosong. 5. Debt Service Ratio (DSR) maksimum 35%.
6. Penghasilan per bulan diatas Upah Minimum Provinsi (UMP) yang berlaku di daerah tersebut, minimal Rp. 1,5 juta.
Adapun peubah yang akan di gunakan pada penelitian ini adalah : Tabel 2. Peubah penyusun model
Peubah Nama Peubah Skala Y Status Kredit Nominal X1 Jenis Kelamin Nominal X2 Status Pernikahan Nominal X3 Kepemilikan Rumah Nominal
X4 Wilayah Nominal
X5 Pekerjaan Nominal
X6 Kepemilikan Kartu Kredit Nominal X7 Kepemilikan Akun Bank-X Nominal X8 Kepemilikan Akun Bank Lain Nominal X9 Pendidikan Ordinal
X10 Jabatan Ordinal
X11 Usia Rasio
X12 Banyak Tanggungan Rasio X13 Pendapatan Bersih Rasio X14 Rasio Utang Terhadap Pendapatan Rasio
X15 Masa Kerja Rasio
13
Metode Analisis
Tahapan analisis yang dilakukan adalah : Tahap Persiapan Data
1. Melakukan seleksi peubah, cleaning data dan pengkategorian data. Seleksi peubah dan cleaning data dilakukan dengan tujuan untuk mendapatkan data yang bersih dan siap digunakan dalam penelitian. Peubah-peubah yang digunakan merupakan peubah hasil penyeleksian berdasarkan literatur yang relevan, yang terdiri dari data numerik dan kategorik dimana untuk data kategorik yang memiliki kategori terlalu banyak dilakukan pengkategorian ulang berdasarkan kategori umum.
2. Melakukan eksplorasi data untuk mengetahui gambaran umum data yang di peroleh.
3. Membagi gugus data kedalam data latih dan data uji. Pada penelitian ini pembagian data dengan menggunakan simple random sampling, 80% untuk data latih dan 20% untuk data uji.
Tahap Pemodelan
4. Membangun model dengan data latih. a. Menggunakan metode CART.
1. Menentukan penyekat yang mungkin untuk setiap peubah penjelas berdasarkan aturan penyekatan.
2. Memilih penyekat yang terbaik dari masing-masing peubah penjelas sesuai dengan Persamaan (2.3).
3. Memilih penyekat terbaik dari kumpulan penyekat terbaik.
4. Lakukan iterasi pada langkah (4.a.1) - (4.a.3) sampai ditemukan satu dari beberapa hal berikut: (i) semua simpul sudah homogen, (ii) tidak terdapat lagi peubah penjelas yang digunakan, (iii) kecilnya jumlah amatan dalam simpul.
5. Menentuan simpul terminal.
6. Menentukan dugaan akhir setiap simpul terminal berdasarkan pada Persamaan (2.4).
b. Menggunakan metode regresi logistik.
1. Membuat model klasifikasi dengan regresi logistik pada data latih. Model umum regresi logistik ditunjukkan pada Persamaan (2.5) 2. Melakukan pengujian parameter baik secara simultan maupun parsial
berdasarkan pada Persamaan (2.6) dan Persamaan (2.7).
3. Mengeluarkan peubah yang tidak berbeda nyata dari dalam model (backward stepwise).
c. Menggunakan metode SMOTEBagging pada CART dan regresi logistik. 1. Membangun sebanyak k gugus data baru dari data latih dengan
metode bootstrap (pada penelitian ini menggunakan replikasi bootstrap sebanyak 10 hingga 1000 kali). Pada setiap data latih baru yang dibangun berisi contoh kelas mayor dan minor yang sama dengan data latih.
14
i. Menentukan k-tetangga terdekat (pada penelitian ini digunakan k=5) dan menghitung jarak antara contoh dan tetangga terdekatnya. Untuk peubah numerik digunakan jarak Euclidean pada Persamaan (2.1), sedangkan untuk peubah kategorik digunakan modus yang perhitungannya menggunakan Value Distance Metric (VDM) pada Persamaan (2.2).
ii. Membangkitkan data buatan (synthetic) dengan tahapan sebagai berikut :
Data numerik
- Berdasarkan 5 tetangga terdekat yang dihasilkan dari langkah sebelumnya, pilih satu secara acak.
- Hitung selisih antara data amatan dengan tetangga terdekat yang terpilih.
- Kalikan selisih yang diperoleh dari langkah sebelumnya dengan angka acak antara 0 dan 1.
- Nilai yang diperoleh di tambahkan dengan nilai data amatan asli. Hasil tersebut merupakan data buatan yang dibangkitkan.
- Lakukan sebanyak n kali sesuai dengan jumlah oversampling yang digunakan. Pada penelitian ini digunakan oversampling (%) sebanyak 100, 200, .., 500.
Data kategorik
- Berdasarkan 5 tetangga terdekat yang dihasilkan dari langkah sebelumnya, data buatan yang dihasilkan merupakan nilai modus dari kelima tetangga terdekatnya. Jika terdapat nilai modus yang sama maka pilih secara acak.
- Lakukan sebanyak n kali sesuai dengan jumlah oversampling yang digunakan. Pada penelitian ini digunakan oversampling (%) sebanyak 100, 200, .., 500.
3. Membangun model CART dan regresi logistik dari data yang dibangun dari langkah sebelumnya dengan tahapan yang sama dengan langkah 4.a dan 4.b, sehingga menghasilkan sebanyak k sub-model.
Tahap Evaluasi Model
5. Melakukan prediksi dengan data uji dengan model klasifikasi yang diperoleh dari langkah 4.a (CART) dan 4.b (regresi logistik).
6. Melakukan prediksi dengan data uji dengan model klasifikasi yang diperoleh dari langkah 4.c (SMOTEBagging), sebagai berikut:
a. Melakukan prediksi dari masing-masing sub-model pada model CART dan regresi logistik.
b. Menggabungkan k prediksi yang diperoleh dari hasil sebelumnya untuk memperoleh prediksi akhir berdasarkan majority voting, sebagai berikut:
1 1 1
1
( ) , ( ) ( )
2
T l T
j k
j i i
i k i
H x c if h x h x
15
j
c merupakan label kelas, j( )
i
h x merupakan prediksi kelas dari hiuntuk
label kelas cj, ( ) k i
h x merupakan prediksi kelas untuk semua label kelas. Prediksi akhir adalah cj jika vote lebih besar dari setengahnya.
7. Mengevaluasi model yang dibangun dengan model CART , regresi logistik, dan SMOTEBagging dengan menghitung nilai keakuratan, kepekaan, dan kekhususan pada Persamaan (2.8), Persamaan (2.9), dan Persamaan (2.10). 8. Membandingkan kebaikan hasil klasifikasi model CART, regresi logistik,
dan SMOTEBagging dengan melihat nilai Area Under Curve (AUC).
16
4
HASIL DAN PEMBAHASAN
Deskripsi Data
Kredit Tanpa Agunan (KTA) Bank X merupakan kredit perorangan tanpa agunan untuk berbagai kebutuhan seperti pendidikan, pernikahan, kesehatan, renovasi rumah dan kebutuhan keluarga lainnya. Gambaran umum tentang nasabah kredit KTA Bank X dapat dilihat dari Tabel 3 berikut :
Tabel 3 Gambaran umum tentang data nasabah KTA Bank X
Status Kredit Frekuensi Persentasi
Lancar 876 87,6%
Macet 124 12,4%
Jumlah 1000 100,0%
Berdasarkan Tabel 3, dari 1000 nasabah kredit KTA Bank X, sebanyak 124 (12,4%) nasabahnya mengalami gagal bayar. Artinya sebesar 12,4% nasabah yang awalnya memenuhi kualifikasi kredit atau diterima permohonan kreditnya pada akhirnya mengalami kredit macet.
Untuk mengetahui gambaran data nasabah yang mengalami kredit macet berdasarkan karakteristiknya, dapat dilihat pada Lampiran 2. Berdasarkan Lampiran 2, diketahui beberapa hal berikut:
1) Peubah Jenis Kelamin. Persentase kredit macet nasabah berjenis kelamin perempuan lebih kecil dibandingkan dengan nasabah berjenis kelamin laki-laki. Rasio odd dari kredit macet antara perempuan dan laki-laki adalah sebesar 0.838, artinya resiko terjadinya kredit macet pada perempuan 0.838 kali resiko terjadinya kredit macet pada laki-laki.
2) Peubah Status Pernikahan. Persentase kredit macet nasabah dengan status pernikahan menikah/pernah menikah lebih kecil dibandingkan dengan nasabah dengan status pernikahan tidak menikah. Rasio odd dari kredit macet antara nasabah dengan status pernikahan menikah/pernah menikah dan tidak menikah adalah sebesar 0.955, artinya resiko terjadinya kredit macet pada nasabah dengan status pernikahan menikah/pernah menikah 0.955 kali resiko terjadinya kredit macet pada nasabah yang tidak menikah. 3) Peubah Status Kepemilikan Rumah. Persentase kredit macet nasabah
dengan status kepemilikan rumah milik sendiri lebih besar dibandingkan dengan yang bukan milik sendiri. Rasio odd dari kredit macet antara nasabah dengan status kepemilikan rumah milik sendiri dan bukan milik sendiri adalah sebesar 1.137, artinya resiko terjadinya kredit macet pada nasabah dengan status kepemilikan rumah milik sendiri 1.137 kali resiko terjadinya kredit macet pada nasabah dengan status kepemilikan rumah bukan milik sendiri.
17 dan Bandung adalah sebesar 2.263, Jakarta dan Semarang adalah sebesar 3.467, Jakarta dan Surabaya adalah sebesar 1.478, Jakarta dan Banjarmasin adalah sebesar 3.097, Jakarta dan Makassar adalah sebesar 4.825, Jakarta dan Denpasar adalah sebesar 2.694, Jakarta dan Jayapura adalah sebesar 2.452. Artinya resiko terjadinya kredit macet pada nasabah yang berada di Jakarta 2.299 kali resiko terjadinya kredit macet pada nasabah yang berada di Medan, dan seterusnya.
5) Peubah Pekerjaan. Persentase kredit macet nasabah yang bekerja di lembaga pemerintah lebih besar dibandingkan dengan nasabah yang bekerja di lembaga non-pemerintah. Rasio odd dari kredit macet antara nasabah yang bekerja di lembaga pemerintah dan lembaga non-pemerintah adalah sebesar 1.075, artinya resiko terjadinya kredit macet pada nasabah yang bekerja di lembaga pemerintah 1.137 kali resiko terjadinya kredit macet pada nasabah yang bekerja di lembaga non-pemerintah.
6) Peubah Kepemilikan Kartu Kredit. Persentase kredit macet nasabah yang memiliki kartu kredit lebih hampir sama dibandingkan dengan nasabah yang tidak memiliki kartu kredit. Rasio odd dari kredit macet antara nasabah yang memiliki kartu kredit dan tidak memiliki kartu kredit adalah sebesar 0.990, artinya resiko terjadinya kredit macet pada nasabah yang memiliki kartu kredit 0.990 kali resiko terjadinya kredit macet pada nasabah yang tidak memiliki kartu kredit.
7) Peubah Kepemilikan Akun Bank X. Persentase kredit macet nasabah yang tidak memiliki akun Bank X lebih besar dibandingkan dengan nasabah dengan memiliki akun Bank X. Rasio odd dari kredit macet antara nasabah yang tidak memiliki akun Bank X dan memiliki akun Bank X adalah sebesar 3.210, artinya resiko terjadinya kredit macet pada nasabah yang tidak memiliki akun Bank X 3.210 kali resiko terjadinya kredit macet pada nasabah yang memiliki akun Bank X.
8) Peubah Kepemilikan Akun Bank Lain. Persentase kredit macet nasabah yang tidak memiliki akun Bank lain lebih besar dibandingkan dengan nasabah yang memiliki akun Bank lain. Rasio odd dari kredit macet antara nasabah yang tidak memiliki akun Bank lain dan memiliki akun Bank lain adalah sebesar 1.693, artinya resiko terjadinya kredit macet pada nasabah yang tidak memiliki akun Bank lain 1.693 kali resiko terjadinya kredit macet pada nasabah yang memiliki akun Bank lain.
9) Peubah Pendidikan. Persentase kredit macet nasabah dengan pendidikan tingkat sekolah lebih besar dibandingkan nasabah dengan pendidikan tingkat perguruan tinggi. Rasio odd dari kredit macet antara nasabah dengan pendidikan tingkat sekolah dan tingkat perguruan tinggi adalah sebesar 1.127, artinya resiko terjadinya kredit macet pada nasabah dengan pendidikan tingkat sekolah 1.127 kali resiko terjadinya kredit macet pada nasabah dengan pendidikan tingkat perguruan tinggi.
18
macet pada nasabah dengan jabatan puncak 2.963 kali resiko terjadinya kredit macet pada nasabah dengan jabatan lini pertama (bawah) dan 1.815 kali resiko terjadinya kredit macet pada nasabah dengan jabatan menengah. 11) Peubah Usia. Persentase kredit macet nasabah dengan usia pada selang <30
tahun paling besar dibandingkan dengan selang usia lainnya. Rasio odd dari kredit macet antara nasabah dengan usia pada selang <30 tahun dan pada selang 30-35 tahun adalah sebesar 1.161, usia pada selang <30 tahun dan pada selang 36-41 tahun adalah sebesar 1.607, dan usia pada selang <30 tahun dan pada selang >41 tahun adalah sebesar 1.008. Artinya, resiko terjadinya kredit macet pada nasabah dengan usia pada selang <30 tahun 1.161 kali resiko terjadinya kredit macet pada nasabah dengan usia pada selang 30-35 tahun, 1.607 kali resiko terjadinya kredit macet pada nasabah dengan usia pada selang 36-41 tahun, dan 1.008 kali resiko terjadinya kredit macet pada nasabah dengan usia pada selang >41 tahun.
12) Peubah Banyak Tanggungan. Persentase kredit macet nasabah dengan banyak tanggungan ≥2 lebih besar dibandingkan dengan banyak tanggungan <2. Rasio odd dari kredit macet antara nasabah dengan banyak tanggungan ≥2 dan banyak tanggungan <2 adalah sebesar 1.399, artinya resiko terjadinya kredit macet pada nasabah dengan banyak tanggungan ≥2 adalah 1.399 kali resiko terjadinya kredit macet pada nasabah dengan banyak tanggungan <2.
13) Peubah Pendapatan Bersih. Persentase kredit macet nasabah dengan pendapatan bersih pada selang <2.6 juta rupiah paling besar dibandingkan dengan pendapatan bersih pada selang lainnya. Rasio odd dari kredit macet antara nasabah dengan pendapatan bersih pada selang <2.60 juta dan pada selang 2.60-3.45 juta adalah sebesar 1.306, pendapatan bersih pada selang <2.60 juta dan pada selang 3.45-5.30 juta adalah sebesar 1.760, pendapatan bersih pada selang <2.60 juta dan pada selang >5.30 juta adalah sebesar 1.306. Artinya resiko terjadinya kredit macet pada nasabah dengan pendapatan bersih pada selang <2.60 juta adalah 1.306 kali resiko terjadinya kredit macet pada nasabah dengan pendapatan bersih pada selang 2.60-3.45 juta, 1.760 kali resiko terjadinya kredit macet pada nasabah dengan pendapatan bersih pada selang 3.45-5.30 juta, 1.306 kali resiko terjadinya kredit macet pada nasabah dengan pendapatan bersih pada selang >5.30 juta.
14) Peubah Rasio Utang terhadap Pendapatan. Persentase kredit macet nasabah dengan rasio utang pada selang >28.86% paling besar dibandingkan dengan rasio utang pada selang lainnya. Rasio odd dari kredit macet antara nasabah dengan rasio utang pada selang >28.86% dan pada selang <23.27% adalah sebesar 1.179, dan rasio utang pada selang >28.86% dan pada selang 23.27-28.86% adalah sebesar 1.227. Artinya resiko terjadinya kredit macet pada nasabah dengan rasio utang pada selang >28.86% adalah 1.179 kali resiko terjadinya kredit macet pada nasabah dengan rasio utang pada selang <23.27%, dan 1.227 kali resiko terjadinya kredit macet pada nasabah dengan rasio utang pada selang 23.27-28.86%.
19 1-2 tahun dan pada selang 3-5 tahun adalah sebesar 1.405, masa kerja pada selang 1-2 tahun dan pada selang 6-11 tahun adalah sebesar 2.249, masa kerja pada selang 1-2 tahun dan pada selang >11 tahun adalah sebesar 1.899. Artinya resiko terjadinya kredit macet pada nasabah dengan masa kerja pada selang 1-2 tahun adalah 1.405 kali resiko terjadinya kredit macet pada nasabah dengan masa kerja pada selang 3-5 tahun, 2.249 kali resiko terjadinya kredit macet pada nasabah dengan masa kerja pada selang 6-11 tahun, 1.899 kali resiko terjadinya kredit macet pada nasabah dengan masa kerja pada selang >11 tahun.
16) Peubah Lama Hubungan dengan Bank. Persentase kredit macet nasabah yang lama hubungan dengan bank 0-1 tahun merupakan persentase paling besar. Rasio odd dari kredit macet antara nasabah dengan lama hubungan pada selang 0-1 tahun dan pada selang 2-3 tahun adalah sebesar 1.936, lama hubungan pada selang 0-1 tahun dan pada selang 4-15 tahun adalah sebesar 2.687, lama hubungan pada selang 0-1 tahun dan >15 tahun adalah sebesar 7.884. Artinya resiko terjadinya kredit macet pada nasabah dengan lama hubungan pada selang 0-1 tahun 1.936 kali resiko terjadinya kredit macet pada nasabah dengan lama hubungan pada selang 2-3 tahun, 2.687 kali resiko terjadinya kredit macet pada nasabah dengan lama hubungan pada selang 4-15 tahun, dan 7.884 kali resiko terjadinya kredit macet pada nasabah dengan lama hubungan >15 tahun.
17) Peubah Tenor (Lama Pinjaman). Persentase kredit macet nasabah dengan tenor (lama peminjaman) selama <25 bulan merupakan persentase paling besar. Rasio odd dari kredit macet antara nasabah dengan tenor pada selang <25 bulan dan pada selang 25-36 bulan adalah sebesar 1.711, tenor pada selang <25 bulan dan pada selang >36 bulan adalah sebesar 2.378, artinya resiko terjadinya kredit macet pada nasabah dengan tenor pada selang <25 bulan 1.711 kali resiko terjadinya kredit macet pada nasabah dengan tenor pada selang 25-36 bulan dan 2.378 kali resiko terjadinya kredit macet pada nasabah dengan tenor pada selang >36 bulan.
Model tanpa SMOTEBagging CART
[image:31.595.165.451.677.756.2]Metode CART ini secara keseluruhan menghasilkan 21 simpul, dengan 11 buah simpul terminal yang dapat dilihat pada Lampiran 3. Hasil klasifikasi yang diperoleh dapat digunakan untuk memprediksi calon nasabah kredit tanpa agunan Bank X apakah masuk ke dalam nasabah yang baik (kredit lancar) atau tidak (kredit macet). Setelah diterapkan metode CART pada data KTA Bank X, diperoleh hasil yang ditunjukkan pada Tabel 4 berikut :
Tabel 4 Kinerja klasifikasi model CART (%) Data Latih Data Uji Keakuratan 89.75 87.00 Kepekaan 35.71 23.08 Kekhususan 97.29 96.55
20
Berdasarkan hasil pada Tabel 4, tingkat ketepatan pengklasifikasian amatan sebesar 89.75. Hasil validasi model dengan menggunakan data uji sebayak 200 nasabah kredit diperoleh tingkat ketepatan pengklasifikasian sebesar 87.00. Nilai AUC sebesar 77.79 untuk data latih dan 72.62 untuk data uji menunjukkan bahwa akurasi model cukup baik. Akan tetapi, kepekaan sangat kecil jika dibandingkan dengan kekhususannya, baik pada data latih maupun data uji. Hal ini menyebabkan prediksi model akan lebih mengarah pada kelas mayor, karena informasi dari kelas minor sangat sedikit sehingga cenderung diabaikan (dianggap sebagai noise). Oleh karena itu, calon nasabah yang mengajukan permohonan kredit akan cenderung diterima. Confusion matrix untuk ketepatan klasifikasi model CART dapat dilihat pada Tabel 5.
Tabel 5 Ketepatan klasifikasi model CART Keadaan
sesungguhnya
Prediksi
Data Latih Data Uji
Macet Lancar Macet Lancar Macet 35 63 6 20 Lancar 19 683 6 168
Regresi Logistik
Model regresi logistik pada penelitian ini menjelaskan hubungan antara status kredit dengan peubah penjelasnya. Model logit untuk kredit macet adalah sebagai berikut:
1 1.1 2.1 3.1 4.2 4.3 4.4
4.5 4.6 4.7 4.8 4.9 4.10 5.1
6.1 7.1 8.1 9.L 10.L
logit[ ] 1.288+0.116 0.367 -0.092 -1.432 0.742 0.005 -0.365 0.477 -0.132 -0.688 -0.403 -0.135 -0.341 -0.260 -1.242 0.868 -0.410 +1.221 0.
x x x x x x
x x x x x x x
x x x x x
10.Q 11
12 13 14 15 16 17
001 0.002 -0.032 -0.037 0.006 -0.047 -0.185 -0.029
x x
x x x x x x
Pendugaan parameter untuk model regresi logistik yang dihasilkan dengan memaksimumkan fungsi kemungkinan dapat dilihat pada Lampiran 4a. Untuk melihat apakah terdapat pengaruh dari setiap peubah terhadap model secara serentak (simultan) dilakukan uji rasio kemungkinan. Hasil yang diperoleh dari uji rasio kemungkinan (G2) sebesar 595.00 dan 2
(17,0.05) 8.67
, berarti 2 2
(17,0.05)
G
21 Tabel 6 Kinerja klasifikasi model regresi logistik (%)
Data Latih Data Uji Keakuratan 88.62 86.00 Kepekaan 8.16 0.0 Kekhususan 99.86 98.85
AUC 75.20 77.01
Berdasarkan hasil pada Tabel 6, tingkat ketepatan pengklasifikasian data pemodelan (latih) sebesar 88.62. Hasil validasi model dengan menggunakan data uji sebayak 200 nasabah KTA diperoleh tingkat ketepatan pengklasifikasian sebesar 86.00. Nilai AUC sebesar 75.20 untuk data latih dan 77.01 untuk data uji menunjukkan bahwa akurasi model cukup baik. Persentase ketepatan model dalam mengklasifikasikan nasabah kredit ini cukup tinggi. Akan tetapi, terdapat ketidakseimbangan dalam memprediksi nasabah kredit baik pada data pemodelan (latih) maupun data prediksi (uji). Hal ini terlihat pada nilai kepekaan yang sangat kecil. Ketidakseimbangan ini menyebabkan prediksi model akan lebih mengarah pada kelas mayor, yaitu status kredit lancar. Sehingga, calon nasabah yang mengajukan permohonan kredit akan cenderung diterima. Confusion matrix untuk ketepatan klasifikasi model regresi logistik dapat dilihat pada Tabel 7.
Tabel 7 Ketepatan klasifikasi model regresi logistik Keadaan
sesungguhnya
Prediksi
Data Latih Data Uji Macet Lancar Macet Lancar Macet 8 90 0 26 Lancar 1 701 2 172
[image:33.595.108.515.532.741.2]Gambar 5 menggambarkan kinerja ketepatan klasifikasi secara dua dimensi. Pada model regresi logistik, ketepatan klasifikasi pada data latih dan uji memberikan hasil yang hampir sama, sedangkan pada model CART data latih memiliki ketepatan klasifikasi lebih tinggi dibandingkan pada data uji. Artinya, pemodelan pada CART lebih bagus dibandingkan dengan goodness of fit-nya.
Gambar 4 Kurva ROC perbandingan model CART dan Regresi Logistik
ROC Curve Logistic Regression
False positive rate
T ru e p o si ti ve r a te
0.0 0.2 0.4 0.6 0.8 1.0
0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 Testing Training
ROC Curve CART
False positive rate
T ru e p o si ti ve r a te
0.0 0.2 0.4 0.6 0.8 1.0
22
Model dengan SMOTEBagging
Penerapan algoritme SMOTEBagging pada CART dan regresi logistik dilakukan dengan proses bootstrap pada data latih untuk menghasilkan beberapa himpunan data latih baru yang akan digunakan untuk membangun model klasifikasi. Pada himpunan data latih baru tersebut dilakukan proses SMOTE terlebih dahulu agar data latih seimbang sebelum dilakukan pemodelan. Grafik kinerja klasifikasi model SMOTEBagging dapat dilihat pada Lampiran 5 dan Lampiran 6. Kinerja klasifikasi model SMOTEBagging dengan jumlah oversampling 2 kali (200), 5 tetangga terdekat dan jumlah bootstrap sebanyak 50 kali, dapat dilihat pada Tabel 8 berikut:
Tabel 8 Kinerja klasifikasi model SMOTEBagging (%) Kinerja CART Regresi Logistik
Data Latih Data Uji Data Latih Data Uji Keakuratan 82.62 74.50 75.50 73.50 Kepekaan 75.51 50.00 61.22 76.92 Kekhususan 83.62 78.16 77.49 72.99 AUC 88.32 73.89 76.37 79.11
Nilai kepekaan pada validasi model CART dan regresi logistik setelah diterapkan algoritme SMOTEBagging meningkat menjadi 50.00 dan 76.92. Artinya, model dengan SMOTEBagging dapat memprediksi data yang masuk ke dalam kelas minor dengan lebih baik. Prediksi nasabah kredit pada data dengan model SMOTEBagging disajikan pada Tabel 9 sebagai berikut:
Tabel 9 Ketepatan klasifikasi model SMOTEBagging Keadaan
sesungguhnya
Prediksi
CART Regresi Logistik
Data Latih Data Uji Data Latih Data Uji Macet Lancar Macet Lancar Macet Lancar Macet Lancar Macet 74 24 13 13 60 38 20 6 Lancar 115 587 38 136 158 544 47 127
Berdasarkan Tabel 9, dapat dilihat bahwa pada data latih frekuensi contoh yang secara sesungguhnya macet dan di prediksi macet (TP) dan frekuensi contoh yang secara sesungguhnya lancar dan di prediksi lancar (TN) pada model CART lebih banyak dibandingkan dengan model regresi logistik, sebaliknya pada data uji. Hal ini menunjukkan bahwa hasil pemodelan model CART lebih bagus dibandingkan model regresi logistik, sedangkan goodness of fit model regresi logistik lebih bagus dibandingkan dengan model CART.
23
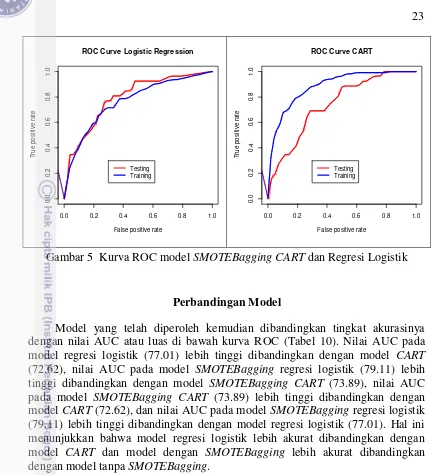
Gambar 5 Kurva ROC model SMOTEBagging CART dan Regresi Logistik
Perbandingan Model
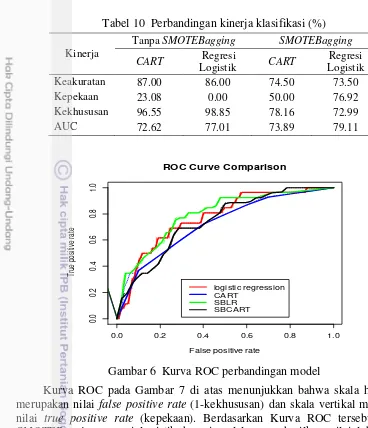
Model yang telah diperoleh kemudian dibandingkan tingkat akurasinya dengan nilai AUC atau luas di bawah kurva ROC (Tabel 10). Nilai AUC pada model regresi logistik (77.01) lebih tinggi dibandingkan dengan model CART (72.62), nilai AUC pada model SMOTEBagging regresi logistik (79.11) lebih tinggi dibandingkan dengan model SMOTEBagging CART (73.89), nilai AUC pada model SMOTEBagging CART (73.89) lebih tinggi dibandingkan dengan model CART (72.62), dan nilai AUC pada model SMOTEBagging regresi logistik (79.11) lebih tinggi dibandingkan dengan model regresi logistik (77.01). Hal ini menunjukkan bahwa model regresi logistik lebih akurat dibandingkan dengan model CART dan model dengan SMOTEBagging lebih akurat dibandingkan dengan model tanpa SMOTEBagging.
Selain membandingkan nilai AUC yang diperoleh, dapat pula mempertimbangkan kepekaan dan kekhususan dari masing-masing model. Nilai AUC sendiri disusun oleh kepekaan dan kekhususan. Pada penelitian ini lebih difokuskan pada nilai kepekaan, karena pada kasus ini menerima permohonan kredit macet akan lebih beresiko daripada menolak permohonan kredit lancar. Berdasarkan Tabel 24, model SMOTEBagging dapat meningkatkan kepekaan cukup besar meskipun kekhususan menurun. Kepekaan model SMOTEBagging CART (50.0) lebih tinggi dibandingkan dengan model CART (23.08). Begitu juga dengan model SMOTEBagging regresi logistik (76.92) lebih tinggi dibanding dengan model regresi logistik (0.0). Nilai kepekaan pada model regresi logistik (0.0) menunjukkan bahwa semua data di klasifikasikan pada kelas mayor (kelas kredit lancar). Dengan demikian, berdasarkan nilai kepekaan model dengan SMOTEBagging dapat memprediksi data kelas minor dengan jauh lebih baik.
ROC Curve Logistic Regression
False positive rate
T ru e p o si ti ve r a te
0.0 0.2 0.4 0.6 0.8 1.0
0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 Testing Training
ROC Curve CART
False positive rate
T ru e p o si ti ve r a te
0.0 0.2 0.4 0.6 0.8 1.0
24
Tabel 10 Perbandingan kinerja klasifikasi (%) Kinerja
Tanpa SMOTEBagging SMOTEBagging
CART Regresi
Logistik CART
Regresi Logistik Keakuratan 87.00 86.00 74.50 73.50 Kepekaan 23.08 0.00 50.00 76.92 Kekhususan 96.55 98.85 78.16 72.99 AUC 72.62 77.01 73.89 79.11
Gambar 6 Kurva ROC perbandingan model
Kurva ROC pada Gambar 7 di atas menunjukkan bahwa skala horizontal merupakan nilai false positive rate (1-kekhususan) dan skala vertikal merupakan nilai true positive rate (kepekaan). Berdasarkan Kurva ROC tersebut model SMOTEBagging regresi logistik hampir selalu menghasilkan nilai lebih besar dibandingkan dengan model lain. Hal ini menunjukkan bahwa model SMOTEBagging regresi logistik memberikan tingkat ketepatan yang lebih tinggi, sehingga model ini dapat dikatakan lebih baik daripada model yang lain.
Karakteristik Peubah yang Mempengaruhi Kredit Macet
CART
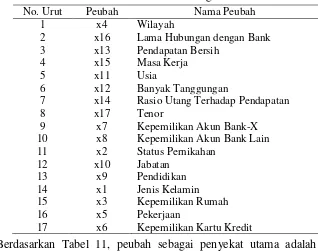
Berdasarkan pohon-pohon klasifikasi yang dihasilkan dari SMOTEBagging, secara subjektif dapat disimpukan bahwa peubah sebagai penyekat utama dari semua pohon yang dihasilkan yaitu penyekat yang mereduksi keheterogenan paling tinggi. Urutan peubah penting (variable importance) yang dihasilkan ditampilkan pada Tabel 11 berikut :
ROC Curve Comparison
False positive rate
Tr
ue
p
osi
tive
ra
te
0.0 0.2 0.4 0.6 0.8 1.0
0.
0
0.
2
0.
4
0.
6
0.
8
1.
0
logistic regression CART
25 Tabel 11 Urutan Peubah Penting dalam Model
No. Urut Peubah Nama Peubah 1 x4 Wilayah
2 x16 Lama Hubungan dengan Bank 3 x13 Pendapatan Bersih
4 x15 Masa Kerja 5 x11 Usia
6 x12 Banyak Tanggungan
7 x14 Rasio Utang Terhadap Pendapatan 8 x17 Tenor
9 x7 Kepemilikan Akun Bank-X 10 x8 Kepemilikan Akun Bank Lain 11 x2 Status Pernikahan
12 x10 Jabatan 13 x9 Pendidikan 14 x1 Jenis Kelamin 15 x3 Kepemilikan Rumah 16 x5 Pekerjaan
17 x6 Kepemilikan Kartu Kredit
Berdasarkan Tabel 11, peubah sebagai penyekat utama adalah wilayah, artinya peubah wilayah ini dapat mereduksi keheterogenan lebih tinggi dibandingkan dengan peubah lainnya, dan seterusnya.
Regresi Logistik
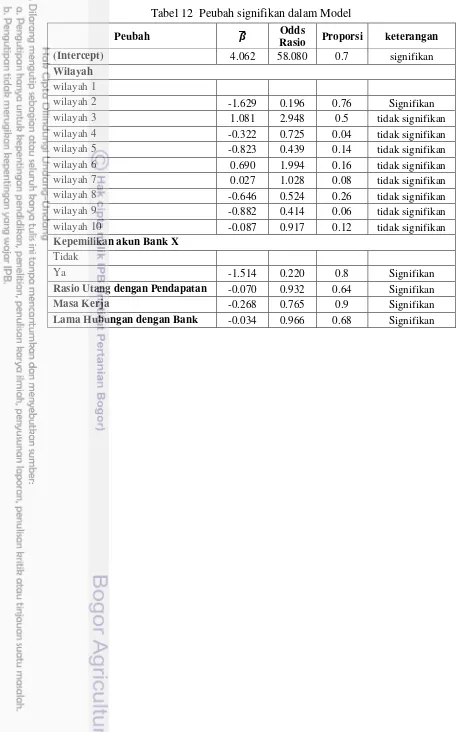
Berdasarkan model-model regresi logistik yang di hasilkan dari SMOTEBagging, secara subjektif dapat disimpukan bahwa peubah yang berpengaruh nyata dari semua model regresi logistik yang dihasilkan adalah seperti yang tercantum pada Tabel 12. Nilai pendugaan ̅merupakannilai rata-rata dari ̂ (dapat dilihat pada Lampiran 8).
Berdasarkan Tabel 12, maka dapat disimpulkan beberapa hal sebagai berikut:
1. Kecenderungan terjadinya kredit macet pada nasabah kredit di Wilayah 2 adalah sebesar 0.76 kali resiko terjadinya kredit macet pada pada nasabah kredit di Wilayah 1.
2. Kecenderungan terjadinya kredit macet pada nasabah kredit yang memiliki akun Bank X adalah sebesar 0.220 kali resiko terjadinya kredit macet pada pada nasabah kredit yang tidak memiliki akun Bank X.
3. Setiap kenaikan rasio utang dengan pendapatan sebesar satu persen (1), maka akan mengakibatkan perubahan resiko terjadinya kredit macet secara multiplikatif sebesar 0.932 kali, dengan syarat pengaruh lain konstan.
4. Setiap kenaikan masa kerja sebesar satu tahun, maka akan mengakibatkan perubahan resiko terjadinya kredit macet secara multiplikatif sebesar 0.765 kali, dengan syarat pengaruh lain konstan.
26
Tabel 12 Peubah signifikan dalam Model
Peubah ̅ Odds
Rasio Proporsi keterangan
(Intercept) 4.062 58.080 0.7 signifikan
Wilayah
wilayah 1
wilayah 2 -1.629 0.196 0.76 Signifikan wilayah 3 1.081 2.948 0.5 tidak signifikan wilayah 4 -0.322 0.725 0.04 tidak signifikan wilayah 5 -0.823 0.439 0.14 tidak signifikan wilayah 6 0.690 1.994 0.16 tidak signifikan wilayah 7 0.027 1.028 0.08 tidak signifikan wilayah 8 -0.646 0.524 0.26 tidak signifikan wilayah 9 -0.882 0.414 0.06 tidak signifikan wilayah 10 -0.087 0.917 0.12 tidak signifikan
Kepemilikan akun Bank X
Tidak
Ya -1.514 0.220 0.8 Signifikan
Rasio Utang dengan Pendapatan -0.070 0.932 0.64 Signifikan
Masa Kerja -0.268 0.765 0.9 Signifikan
27
5
SIMPULAN DAN SARAN
Simpulan
Berdasarkan nilai AUC, pengklasifikasian credit scoring dengan menggunakan model regresi logistik lebih baik dibandingkan dengan model CART, baik dengan penerapan algoritme SMOTEBagging maupun tidak. Sedangkan berdasarkan nilai kepekaan, model CART lebih baik dibanding dengan regresi logistik untuk model tanpa SMOTEBagging, dan model regresi logistik lebih baik dibanding dengan CART untuk model dengan SMOTEBagging. Sementara itu, model dengan penerapan algoritme SMOTEBagging memiliki nilai AUC dan kepekaan yang lebih tinggi dibanding dengan model tanpa SMOTEBagging meskipun nilai kehususannya menurun. Oleh karena pada penelitian ini berfokus pada kelas minor (kredit macet), maka berdasarkan pada kepentingan dalam penelitian ini diambil kesimpulan bahwa SMOTEBagging dapat menaikkan tingkat akurasi model kelas minor.
Salah satu kekurangan dari penggunaan metode SMOTEBagging adalah dari segi visualisasi hasil dan interpretasi, sehingga pada penelitian ini hanya dilakukan kesimpulan secara subjektif. Berdasarkan model SMOTEBagging CART, peubah penyekat utama adalah peubah wilayah, artinya peubah wilayah dapat mereduksi keheterogenan paling tinggi. Sedangkan pada model SMOTEBagging regresi logistik, peubah yang berpengaruh tehadap model diantaranya peubah wilayah, kepemilikan akun Bank X, rasio utang dengan pendapatan, masa kerja, dan lama hubungan dengan Bank.
Saran
28
DAFTAR PUSTAKA
Agresti A. 2002. Categorical Data Analysis. John Willey & Sons, Inc. New York. [BI] Bank Indonesia. 2013. Kodifikasi Peraturan Bank Indonesia: Manajemen
Risiko. Pusat Riset dan Edukasi Bank Sentral (PRES): Jakarta.
Breiman L, Friedman JH, Olshen RA, Stone CJ. 1984. Classification and Regression Trees. New York : Chapman & Hall/CRC.
Brown I, Mues C. 2012. An experimental comparison of classification algorithms for imbalanced credit scoring data sets. Expert Systems with Applications, 39(3), 3446-3453.
Chawla VN, Bowyer KW, Hall LO, Kegelmeyer WP. 2002. SMOTE: synthetic minority over-sampling technique. Journal of Artificial Intelligence Research. 16: 321-357.
FawcettT. 2006. An introduction to ROC analysis. Pattern Recognition Letters. 27: 861-874.
Galar M, Fernandez A, Barrenechea E, Bustince H, Herrera F. 2011. A review on ensembles for the class imbalance problem: bagging-, boosting-, and hybrid-based approaches. IEEE Transactions on Systems. 42: 463-484.
He H, Garcia EA. 2009. Learning from imbalanced data. IEEE Transaction on Knowledge and Data Engineering. 21: 1263-1284.
Hosmer DW, Lemeshow S. 1989. Applied Logistic Regression. John Willey and Sons, Inc: New York.
Intansari IAS, Purnami SW, Wulandari SP. 2012. Klasifikasi pasien hasil pap smear test sebagai pendeteksi awal upaya penanganan dini pada penyakit kanker serviks di RS. “x” surabaya dengan metode bagging logistic regression. Jurnal Sains dan Seni ITS Vol. 1 No. 1, D : 277-282.
Muttaqin MJ, Otok BW, Rahayu SP. 2013. Metode Ensemble pada CART untuk Perbaikan Klasifikasi Kemiskinan di Kabupaten Jombang. [Skripsi]. Surabaya. Institut Teknologi Sepuluh November.
Rahmah H. 2013. Penerapan Smote Pada Metode Cruise Untuk Penentuan Faktor Keberhasilan Studi Mahasiswa BUD. [Skripsi]. Bogor. Institut Pertanian Bog