PE
ERBANDI
METO
D
IN
INGAN H
DE K-ME
DAN TWO
LATHIF
SEKOLAH NSTITUT P
HASIL PEN
EANS, FUZ
O STEP CL
FATURRAH
H PASCA S PERTANIA BOGOR
2010
NGGERO
ZZY K-ME
CLUSTER
HMAH
ARJANA AN BOGOR
OMBOLAN
EANS,
R
PERNYATAAN MENGENAI TUGAS AKHIR DAN SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis dengan judul “Perbandingan Hasil Penggerombolan Metode k-means, Fuzzy k-means, dan Two Step Cluster”
adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Januari 2010
Lathifaturrahmah
ABSTRACT
LATHIFATURRAHMAH. Comparison of k-means, fuzzy k-means, and two step
clustering methods. Under supervision of BUDI SUHARJO and I GUSTI PUTU PURNABA.
The main principle of cluster analysis is to classify objects into clusters based on similarity measures. K-means and fuzzy k-means can be classified as popular clustering methods, which are suitable for large data with continuous variables. However, a new method has been developed to be used for large data, that is the two step cluster method. This method allows processing data with different types of variables, which in this case are continuous and categorical. The aim of this research is to compare the clustering results of k-means, fuzzy k -means, and two step cluster method, in order to determine the ideal number of clusters for each method. This research uses hypotetical data taken from SPSS software, which fit the purpose to compare several methods. The results of this study show that in the case of two clusters, k-means and fuzzy k-means methods have more similarities with respect to the number objects in clusters, whereas the two step method gives unequal number of objects in clusters. All methods show that 2 clusters is an ideal number. It is influenced by the ratio between mean squares within clusters, which is smaller than the ratio in the case of 3 and 4 clusters.
RINGKASAN
LATHIFATURRAHMAH. Perbandingan Hasil Penggerombolan Metode k-means, Fuzzy k-means, dan Two step cluster. Dibimbing oleh BUDI SUHARJO dan I GUSTI PUTU PURNABA.
Masalah penggerombolan seringkali ditemui di kehidupan sehari-hari, baik itu terkait dengan bidang sosial, bidang kesehatan, bidang marketing maupun bidang akademik. Analisis gerombol adalah salah satu analisis peubah ganda yang digunakan untuk mengelompokkan objek-objek menjadi beberapa gerombol berdasarkan kemiripan peubah-peubah yang diamati, sehingga diperoleh kemiripan objek dalam gerombol yang sama dibandingkan antar objek dari gerombol yang berbeda.
Salah satu metode analisis gerombol adalah metode tak berhierarki (non hierarchical clustering methods). Contoh dari metode tak berhierarki yang sering digunakan adalah k-means dan fuzzy k-means, kedua metode ini cocok digunakan untuk data berukuran besar dan memiliki tipe peubah kontinu. Namun dewasa ini telah dikembangkan suatu metode untuk jenis data yang berukuran besar, yaitu metode two step cluster. Metode ini dikembangkan oleh Chiu et al. (2001) yang memungkinkan untuk mengolah data yang memiliki tipe peubah berbeda, yaitu kontinu dan kategorik.
Penelitian ini bertujuan untuk membandingkan hasil penggerombolan metode k-means, fuzzy k-means, dan two step cluster, sehingga dapat menentukan jumlah cluster yang ideal untuk masing-masing metode pada data Afifi.
Penelitian ini menggunakan data Afifi. Dari data yang sama ingin dibandingkan hasil penggerombolan dengan metode k-means, metode fuzzy k-means, dan metode two step cluster yang akan memberikan penggerombolan yang terbaik, yaitu yang mempunyai variansi di dalam yang lebih homogen dan variansi antar gerombol yang lebih heterogen.
Langkah-langkah yang digunakan dalam penelitian ini yaitu melakukan standarisasi data, menggerombolkan data dengan mencobakan berbagai nilai k
untuk metode k-means, fuzzy k-means, dan two step cluster, membandingkan hasil penggerombolan yang terbentuk. Hal yang dibandingkan meliputi distribusi jumlah gerombol, jumlah anggota identik, misclustering, variansi gerombol (variansi within cluster dan variansi between cluster), dan menyimpulkan cluster ideal pada masing-masing metode.
Hasil dari masing-masing gerombol metode k-means dan fuzzy k-means
lebih mirip pada penggerombolan 2 gerombol. Sedangkan metode two step cluster
dari awal penggerombolan jumlah anggota gerombol yang agak jauh berbeda dengan kedua metode lainnya.
© Hak Cipta milik IPB, tahun 2010 Hak Cipta dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tidak merugikan kepentingan yang wajar IPB
PERBANDINGAN HASIL PENGGEROMBOLAN
METODE K-MEANS, FUZZY K-MEANS
DAN TWO STEP CLUSTER
LATHIFATURRAHMAH
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Departemen Matematika
SEKOLAH PASCA SARJANA INSTITUT PERTANIAN BOGOR
Penguji Luar Komisi pada Ujian Tesis: Dr. Ir. Hadi Sumarno, MS.
Judul Tesis : Perbandingan Hasil Penggerombolan Metode K-Means, Fuzzy K-Means, dan Two Step Cluster
Nama : Lathifaturrahmah
NIM : G551070081
Disetujui Komisi Pembimbing
Dr. Ir. Budi Suharjo, MS Dr. Ir. I Gusti Putu Purnaba, DEA
Ketua Anggota
Diketahui
Ketua Progam Studi Dekan Sekolah Pascasarjana Matematika Terapan
Dr. Ir. Endar H. Nugrahani, MS Prof. Dr. Ir. Khairil A. Notodiputro, MS
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah SWT atas segala rahmat dan karuniaNya tugas akhir yang berjudul “Perbandingan Hasil Penggerombolan Metode k-means, Fuzzy k-means, dan Two Step Cluster” ini bisa terselesaikan sebagai salah satu syarat untuk menyelesaikan pendidikan pada Program Studi Matematika, Sekolah Pascasarjana Institut Pertanian Bogor.
Terimakasih yang mendalam penulis sampaikan kepada Bapa dan Mama atas segala doa dan kasih sayangnya. Terimakasih juga penulis sampaikan kepada Dr. Ir. Budi Suharjo, MS dan Dr. Ir. I Gusti Putu Purnaba, DEA selaku pembimbing yang telah membantu dan mengarahkan penulis selama penyusunan tugas akhir ini, serta Dr. Ir. Hadi Sumarno, selaku dosen penguji. Ucapan terima kasih juga juga penulis sampaikan kepada adik, kakak, sahabat dan teman-teman yang tidak dapat dituliskan namanya satu persatu atas segala do’a, dukungan, serta kasih sayangnya. Juga kepada semua pihak yang telah turut membantu dalam penulisan tesis ini, penulis berdo’a semoga Allah SWT membalas mereka dengan kebaikan.
Akhirnya penulis menyadari bahwa tugas akhir ini masih begitu banyak kekurangan. Dengan segala keterbatasan yang ada, semoga tugas akhir ini bermanfaat.
Bogor, Januari 2010
PE
ERBANDI
METO
D
IN
INGAN H
DE K-ME
DAN TWO
LATHIF
SEKOLAH NSTITUT P
HASIL PEN
EANS, FUZ
O STEP CL
FATURRAH
H PASCA S PERTANIA BOGOR
2010
NGGERO
ZZY K-ME
CLUSTER
HMAH
ARJANA AN BOGOR
OMBOLAN
EANS,
R
PERNYATAAN MENGENAI TUGAS AKHIR DAN SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis dengan judul “Perbandingan Hasil Penggerombolan Metode k-means, Fuzzy k-means, dan Two Step Cluster”
adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Januari 2010
Lathifaturrahmah
ABSTRACT
LATHIFATURRAHMAH. Comparison of k-means, fuzzy k-means, and two step
clustering methods. Under supervision of BUDI SUHARJO and I GUSTI PUTU PURNABA.
The main principle of cluster analysis is to classify objects into clusters based on similarity measures. K-means and fuzzy k-means can be classified as popular clustering methods, which are suitable for large data with continuous variables. However, a new method has been developed to be used for large data, that is the two step cluster method. This method allows processing data with different types of variables, which in this case are continuous and categorical. The aim of this research is to compare the clustering results of k-means, fuzzy k -means, and two step cluster method, in order to determine the ideal number of clusters for each method. This research uses hypotetical data taken from SPSS software, which fit the purpose to compare several methods. The results of this study show that in the case of two clusters, k-means and fuzzy k-means methods have more similarities with respect to the number objects in clusters, whereas the two step method gives unequal number of objects in clusters. All methods show that 2 clusters is an ideal number. It is influenced by the ratio between mean squares within clusters, which is smaller than the ratio in the case of 3 and 4 clusters.
RINGKASAN
LATHIFATURRAHMAH. Perbandingan Hasil Penggerombolan Metode k-means, Fuzzy k-means, dan Two step cluster. Dibimbing oleh BUDI SUHARJO dan I GUSTI PUTU PURNABA.
Masalah penggerombolan seringkali ditemui di kehidupan sehari-hari, baik itu terkait dengan bidang sosial, bidang kesehatan, bidang marketing maupun bidang akademik. Analisis gerombol adalah salah satu analisis peubah ganda yang digunakan untuk mengelompokkan objek-objek menjadi beberapa gerombol berdasarkan kemiripan peubah-peubah yang diamati, sehingga diperoleh kemiripan objek dalam gerombol yang sama dibandingkan antar objek dari gerombol yang berbeda.
Salah satu metode analisis gerombol adalah metode tak berhierarki (non hierarchical clustering methods). Contoh dari metode tak berhierarki yang sering digunakan adalah k-means dan fuzzy k-means, kedua metode ini cocok digunakan untuk data berukuran besar dan memiliki tipe peubah kontinu. Namun dewasa ini telah dikembangkan suatu metode untuk jenis data yang berukuran besar, yaitu metode two step cluster. Metode ini dikembangkan oleh Chiu et al. (2001) yang memungkinkan untuk mengolah data yang memiliki tipe peubah berbeda, yaitu kontinu dan kategorik.
Penelitian ini bertujuan untuk membandingkan hasil penggerombolan metode k-means, fuzzy k-means, dan two step cluster, sehingga dapat menentukan jumlah cluster yang ideal untuk masing-masing metode pada data Afifi.
Penelitian ini menggunakan data Afifi. Dari data yang sama ingin dibandingkan hasil penggerombolan dengan metode k-means, metode fuzzy k-means, dan metode two step cluster yang akan memberikan penggerombolan yang terbaik, yaitu yang mempunyai variansi di dalam yang lebih homogen dan variansi antar gerombol yang lebih heterogen.
Langkah-langkah yang digunakan dalam penelitian ini yaitu melakukan standarisasi data, menggerombolkan data dengan mencobakan berbagai nilai k
untuk metode k-means, fuzzy k-means, dan two step cluster, membandingkan hasil penggerombolan yang terbentuk. Hal yang dibandingkan meliputi distribusi jumlah gerombol, jumlah anggota identik, misclustering, variansi gerombol (variansi within cluster dan variansi between cluster), dan menyimpulkan cluster ideal pada masing-masing metode.
Hasil dari masing-masing gerombol metode k-means dan fuzzy k-means
lebih mirip pada penggerombolan 2 gerombol. Sedangkan metode two step cluster
dari awal penggerombolan jumlah anggota gerombol yang agak jauh berbeda dengan kedua metode lainnya.
© Hak Cipta milik IPB, tahun 2010 Hak Cipta dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tidak merugikan kepentingan yang wajar IPB
PERBANDINGAN HASIL PENGGEROMBOLAN
METODE K-MEANS, FUZZY K-MEANS
DAN TWO STEP CLUSTER
LATHIFATURRAHMAH
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Departemen Matematika
SEKOLAH PASCA SARJANA INSTITUT PERTANIAN BOGOR
Penguji Luar Komisi pada Ujian Tesis: Dr. Ir. Hadi Sumarno, MS.
Judul Tesis : Perbandingan Hasil Penggerombolan Metode K-Means, Fuzzy K-Means, dan Two Step Cluster
Nama : Lathifaturrahmah
NIM : G551070081
Disetujui Komisi Pembimbing
Dr. Ir. Budi Suharjo, MS Dr. Ir. I Gusti Putu Purnaba, DEA
Ketua Anggota
Diketahui
Ketua Progam Studi Dekan Sekolah Pascasarjana Matematika Terapan
Dr. Ir. Endar H. Nugrahani, MS Prof. Dr. Ir. Khairil A. Notodiputro, MS
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah SWT atas segala rahmat dan karuniaNya tugas akhir yang berjudul “Perbandingan Hasil Penggerombolan Metode k-means, Fuzzy k-means, dan Two Step Cluster” ini bisa terselesaikan sebagai salah satu syarat untuk menyelesaikan pendidikan pada Program Studi Matematika, Sekolah Pascasarjana Institut Pertanian Bogor.
Terimakasih yang mendalam penulis sampaikan kepada Bapa dan Mama atas segala doa dan kasih sayangnya. Terimakasih juga penulis sampaikan kepada Dr. Ir. Budi Suharjo, MS dan Dr. Ir. I Gusti Putu Purnaba, DEA selaku pembimbing yang telah membantu dan mengarahkan penulis selama penyusunan tugas akhir ini, serta Dr. Ir. Hadi Sumarno, selaku dosen penguji. Ucapan terima kasih juga juga penulis sampaikan kepada adik, kakak, sahabat dan teman-teman yang tidak dapat dituliskan namanya satu persatu atas segala do’a, dukungan, serta kasih sayangnya. Juga kepada semua pihak yang telah turut membantu dalam penulisan tesis ini, penulis berdo’a semoga Allah SWT membalas mereka dengan kebaikan.
Akhirnya penulis menyadari bahwa tugas akhir ini masih begitu banyak kekurangan. Dengan segala keterbatasan yang ada, semoga tugas akhir ini bermanfaat.
Bogor, Januari 2010
RIWAYAT HIDUP
Penulis dilahirkan di Karang Intan, Martapura pada tanggal 13 Maret 1984 dari ayah H. Husni Thamrin dan Hj. Jauhar Maknun. Penulis merupakan anak kedua dari tiga bersaudara.
DAFTAR ISI
Halaman
DAFTAR TABEL ... DAFTAR GAMBAR ... DAFTAR LAMPIRAN... 1 PENDAHULUAN
1.1 Latar Belakang ... 1.2 Tujuan Penelitian ... 1.3 Manfaat Penelitian ... 2 TINJAUAN PUSTAKA
2.1Skala Pengukuran Data ... 2.2Sebaran Objek ……... 2.3Analasis Gerombol... 2.4 Ukuran Jarak ... 2.5 K-means Clustering... 2.6 Fuzzy k-means Clustering ... 2.7 Two Step Clustering... 2.8 Variansi Gerombol…………... 3 METODE PENELITIAN
3.1 Bahan Penelitian... 3.2 Alur Penelitian …... 3.3 Langkah-Langkah Penelitian... 4 HASIL DAN PEMBAHASAN
4.1 Deskripsi Data... 4.2 Penggerombolan dengan 2 Gerombol ……….. 4.3 Penggerombolan dengan 3 Gerombol ……….. 4.4 Penggerombolan dengan 4 Gerombol ……….. 5 SIMPULAN DAN SARAN
5.1 Simpulan ... 5.2 Saran ... DAFTAR PUSTAKA ... LAMPIRAN ...
ix xi xii
1 2 3
4 6 8 9 12 14 15 18
21 22 23
25 32 35 39
45 45 46 47
DAFTAR TABEL
Halaman
1 Daftar peubah data Afifi………. 21
2 Deskripsi data Afifi………...
26
3 Anggota Analisis Komponen Utama 1 dan 2...
27
4
Akar ciri, proporsi keragaman, dan keragaman kumulatif ………
27
5
Distribusi anggota 2 gerombol …………...………
32
6 Persentasi misclustering 2 gerombol hasil antara k-means dengan
fuzzy k-means ………..………
33
7 Persentasi
misclustering 2 gerombol hasil antara k-means dengan
two step cluster ……….
33
8 Persentasi
misclustering 2 gerombol hasil antara fuzzy k-means
dengan two step cluster ………
33
9 Distribusi anggota 3 gerombol ……….
35
10 Persentasi
misclustering 3 gerombol hasil antara k-means dengan
fuzzy k-means ………
36
11 Persentasi
misclustering 3 gerombol hasil antara k-means dengan
two step cluster ……….
36
12 Persentasi
misclustering 2 gerombol hasil antara fuzzy k-means
dengan two step cluster ………
36
13 Distribusi anggota 4 gerombol ……….
39
14 Persentasi
misclustering 4 gerombol hasil antara k-means dengan
fuzzy k-means ………
40
15 Persentasi
misclustering 4 gerombol hasil antara k-means dengan
two step cluster ……….
40
16 Persentasi
misclustering 4 gerombol hasil antara fuzzy k-means
dengan two step cluster ………
40
18 Variansi 3 gerombol ……….
43
19 Variansi 4 gerombol ……….
43
20 Rata-rata jumlah kuadrat 2 gerombol……… 44
21 Rata-rata jumlah kuadrat 3 gerombol……… 44
22 Rata-rata jumlah kuadrat 4 gerombol……… 44
DAFTAR GAMBAR
Halaman
1 Contoh CF Tree ……….
16
2
Gambar alur rencana penelitian ...
21
3
Boxplot data Afifi ………….….…………...
25
4
Boxplot data Afifi standarisasi ……….…
26
5
Plot dua komponen utama pada data Afifi ………
28
6 Plot dua komponen utama 2 gerombol pada metode k-means ………….
34
7 Plot dua komponen utama 2 gerombol pada metode fuzzy k-means …...
34
8 Plot dua komponen utama 2 gerombol pada metode two step cluster….
35
9 Plot dua komponen utama 3 gerombol pada metode k-means …………..
37
10 Plot dua komponen utama 3 gerombol pada metode fuzzy k-means …...
38
11 Plot dua komponen utama 3 gerombol pada metode two step cluster….
38
12 Plot dua komponen utama 4 gerombol pada metode k-means …………..
41
13 Plot dua komponen utama 4 gerombol pada metode fuzzy k-means …...
42
14 Plot dua komponen utama 4 gerombol pada metode two step cluster….
42
DAFTAR LAMPIRAN
Halaman
1
BAB I PENDAHULUAN 1.1 Latar Belakang
Masalah penggerombolan seringkali ditemui di kehidupan sehari-hari, baik itu terkait dengan bidang sosial, bidang kesehatan, bidang marketing maupun bidang akademik. Mendeskripsikan dan memaparkan keunikan proses atau hasil pengelompokan merupakan hal yang menarik dan dapat memberikan ide-ide tertentu. Misalnya saja dalam membuat segmentasi pemasaran, dengan analisis gerombol dapat dikelompokkan pelanggan atau pembeli berdasarkan manfaat atau keuntungan yang diperoleh dari pembelian barang. Hasil dari penggerombolan ini selanjutnya dapat digunakan dalam pengambilan keputusan untuk strategi pemasaran selanjutnya. Namun jika pengelompokan ini tidak sesuai atau tidak representatif dengan apa yang diharapkan, apalagi menyangkut pengambilan keputusan yang cukup penting akibatnya akan cukup fatal. Oleh karena itu, perlu dilakukan review pada proses penggerombolan.
Analisis gerombol adalah salah satu analisis peubah ganda yang digunakan untuk mengelompokkan objek-objek menjadi beberapa gerombol berdasarkan pengukuran kemiripan peubah-peubah yang diamati, sehingga diperoleh kemiripan objek dalam gerombol yang sama dibandingkan antar objek dari gerombol yang berbeda.
Manfaat penggerombolan antara lain adalah untuk eksplorasi data, reduksi data, dan pelapisan data. Dengan eksplorasi data dapat diperoleh informasi yang ada dalam himpunan data, dengan reduksi data dimungkinkan mengambil suatu ringkasan gerombol yang dapat mewakili seluruh anggota tersebut. Penggerombolan dapat digunakan sebagai pelapisan data dalam penarikan contoh atau penggolongan tipe objek.
2
Pada umumnya metode pada analisis gerombol dibedakan menjadi metode berhierarki (hierarchical clustering methods) dan metode tak berhierarki (non hierarchical clustering methods). Metode berhierarki digunakan bila jumlah gerombol yang diinginkan tidak diketahui, sedangkan metode tak berhierarki digunakan bila jumlah kelompok yang diinginkan telah ditentukan sebelumnya. Contoh dari metode tak berhierarki yang sering digunakan adalah k-means dan
fuzzy k-means dan kedua metode ini cocok digunakan untuk data berukuran besar yang memiliki tipe peubah kontinu. Namun dewasa ini telah dikembangkan suatu metode untuk jenis data yang berukuran besar, yaitu metode two step cluster. Metode ini dikembangkan oleh Chiu et al. (2001) yang memungkinkan untuk mengolah data yang memiliki tipe peubah berbeda, yaitu kontinu dan kategorik.
Ketiga metode ini memiliki kelebihan maupun kelemahan. Menurut Serban dan Grigoreta (2006) dalam penelitiannya metode fuzzy k-means lebih baik dari pada k-means pada aspek mining. Kelebihan dari metode k-means adalahmampu mengelompokkan data besar dengan sangat cepat, sedangkan kekurangan dari metode k-means adalah banyaknya gerombol harus ditentukan sebelumnya (Teknomo 2007). Adapun kelebihan dari fuzzy k-means adalah mampu menempatkan suatu data yang terletak diantara dua atau lebih gerombolyang lain pada suatu gerombol, dan menurut Kusumadewi et al. (2006) kelemahannya adalah pada partisi fuzzy masih belum dapat membedakan apakah suatu data merupakan anggota beberapa gerombol atau merupakan data pencilan. Menurut Kusdiati (2006) dalam penelitiannya menyatakan bahwa persentasi salah klasifikasi dari metode two step cluster tidak berbeda nyata dengan yang dihasilkan dari metode k-means, jika peubahnya kontinu.
3
1.2Tujuan Penelitian
1 Membandingkan hasil penggerombolan metode k-means, fuzzy k-means, dan
two step cluster pada data Afifi.
2 Menentukan jumlah cluster yang ideal untuk masing-masing metode tersebut pada data Afifi.
1.3Manfaat Penelitian
1 Diharapkan dapat membantu peneliti dalam menentukan metode terbaik dari ketiga metode tersebut pada penggerombolan suatu data.
4
BAB II
TINJAUAN PUSTAKA 2.1 Skala Pengukuran Objek
Skala pengukuran objek sangat penting dalam analisis statistika.
Pengukuran yang diberikan sebagai pemberian angka-angka terhadap
benda-benda atau peristiwa-peristiwa diatur menurut kaidah-kaidah tertentu, dan
menunjukkan bahwa kaidah-kaidah yang berbeda menghendaki skala-skala serta
pengukuran-pengukuran yang berbeda pula. Skala pengukuran ini dibagi menjadi
empat macam, yaitu skala nominal, skala ordinal, skala interval dan skala rasio.
1 Skala Nominal
Skala nominal merupakan skala yang paling lemah/rendah di antara
keempat skala pengukuran. Skala nominal ini disebut juga sebagai skala
kategorik. Skala nominal merupakanskala pengukuran yang bersifat membedakan
benda atau peristiwa yang satu dengan yang lainnya berdasarkan nama (predikat).
Contoh skala pengukuran nominal adalah klasifikasi barang yang dihasilkan
pada suatu proses produksi dengan predikat cacat atau tidak cacat, maka nomor 1
untuk menyebut kelompok barang yang cacat dari suatu proses produksi dan
nomor 0 untuk menyebut kelompok barang yang tidak cacat dari suatu proses
produksi. Contoh lain, bayi yang baru lahir bisa laki-laki atau perempuan maka
dengan objek ini, peneliti harus menentukan angka untuk tiap kategori, sebagai
contoh : 1 untuk wanita dan 2 untuk laki-laki (angka ini hanya representasi dari
kategori atau kelas). Angka atau simbol yang diberikan tidak memiliki maksud
kuantitatif hanya menunjukkan ada atau tidak adanya atribut atau karakteristik
yang diteliti.
2 Skala Ordinal
Skala ordinal ini lebih tinggi daripada skala nominal. Skala pengukuran
yang sifatnya membedakan dan mengurutkan. Pada skala ini sudah dapat
membedakan benda atau peristiwa yang satu dengan yang lain, diukur dengan
skala ordinal berdasarkan jumlah relatif beberapa karakteristik tertentu pada
masing-masing benda atau peristiwa. Pengukuran ordinal memungkinkan segala
5
diminta untuk mengurutkan tiga buah produk berdasarkan tingkat kepuasan
terhadap produk, maka boleh ditetapkan nomor 1 untuk produk yang ciri
tertentunya tidak puas, nomor 2 untuk produk yang ciri tertentunya puas, dan
nomor 3 produk yang ciri tertentunya sangat puas.
3 Skala Interval
Skala interval ini lebih tinggi daripada skala ordinal. Apabila benda-benda
atau peristiwa-peristiwa yang diselidiki dapat dibedakan antara yang satu dan
lainnya kemudian diurutkan, dan jika perbedaan antara peringkat yang satu dan
lainnya mempunyai arti (yakni, bila satuan pengukurannya tetap), maka skala
interval dapat diterapkan. Skala interval tidak memiliki nol mutlak. Artinya
memiliki sebuah titik nol, tetapi titik nol ini bisa dipilih secara sembarang, artinya
bahwa titik nol tidak selalu bernilai nol. Contoh, pengukuran interval pada
pengukuran temperatur dalam derajat Fahrenheit titik nolnya pada 32, sedangkan
dalam derajat Celcius titik nolnya pada 0. Dengan demikian, jarak yang sama
antara anggota masing-masing pasangan nilai itu menunjukkan beda yang sama
dalam hal kadar ciri atau sifat yang diukur. Namun, skala interval tidak
menjadikan perbandingan/rasio antara dua buah nilai. Contoh, suhu 80 0F tidak
dapat dikatakan dua kali lebih panas dari suhu 400 F, karena diketahui bahwa suhu
80 0F sama artinya dengan suhu 26.7 0C, sedangkan suhu 40 0F sama dengan suhu
4.4 0 C.
4 Skala Rasio
Skala rasio ini lebih tinggi daripada skala interval. Skala pengukuran yang
sifatnya membedakan, mengurutkan dan mempunyai nilai nol mutlak. Karenanya
nilai-nilai dalam skala ini dapat dibandingkan dan dapat dilakukan operasi
matematis seperti penjumlahan, pengurangan, pembagian dan perkalian. Pada
skala rasio, antara masing-masing pengukuran sudah mempunyai nilai
perbandingan/rasio. Pengukuran dengan skala rasio yang sudah sering digunakan,
adalah pengukuran tinggi dan pengukuran berat. Dapat dikatakan bahwa
seseorang yang beratnya 90 kg memiliki kelebihan berat 45 kg dibanding yang
6
rasio, dapat dikatakan bahwa orang yang beratnya 90 kg mempunyai berat dua
kali lipat daripada orang yang beratnya 45 kg.
2.2 Sebaran Objek
Ada dua macam sebaran objek, yaitu:
1 Sebaran Diskrit
Apabila peubah yang diukur hanya mengambil nilai-nilai tertentu, seperti
bilangan bulat 0, 1, 2, 3, 4, … distribusi sebarannya disebut sebaran diskrit.
Beberapa contoh sebaran diskrit antara lain:
a. Sebaran Binomial
Dalam percobaan binomial percobaan dilakukan secara berulang sebanyak n
kali, dan masing-masing mempunyai dua kemungkinan, contohnya berhasil atau
gagal. Asumsi yang digunakan dalam sebaran ini adalah:
i) Percobaan dilakukan n kali.
ii) Masing-masing percobaan hanya memiliki dua hasil yang mungkin.
iii) Masing-masing percobaan independent dari percobaan-percobaan sebelumnya.
iv) p adalahprobabilitas memperoleh keberhasilan pada satu percobaan manapun
dan q = 1- p adalah probabilitas mendapat kegagalan pada satu percobaan.
Sebaran probabilitas binomial didefinisikan sebagai berikut:
; ; , untuk x = 0, 1, 2, …, n
b. Sebaran Poisson
Suatu peubah acak X disebut peubah acak Poisson dengan parameter
, , memiliki fungsi masa peluang yang didefinisikan sebagai berikut:
; ! , untuk x = 0, 1, 2, …
dengan:
= rata-rata kejadian dalam selang waktu tertentu
e = basis logaritma natural (≈2,7182882)
Contoh kejadian Poisson adalah banyaknya libur sekolah karena terjadi
banjir selama musim hujan, banyaknya pertandingan sepak bola yang dibatalkan
7
2 Sebaran Kontinu
Apabila peubah yang diukur dinyatakan dalam skala kontinu, sebaran
probabilitasnya dinamakan sebaran kontinu. Nilai sebaran kontinu dinyatakan
dalam bentuk fungsi matematis dan digambarkan dalam bentuk kurva. Beberapa
contoh sebaran kontinu antara lain:
a. Sebaran Normal
Sebaran normal adalah sebaran probabilitas kontinu yang bentuk visualnya
bersifat simetrik, mempunyai kurva berbentuk lonceng. Sebaran normal
sepenuhnya digambarkan hanya dengan dua parameter, yaitu mean atau nilai
harapan dan standar deviasi . Masing-masing nilai unik dari mean dan
standar deviasi menghasilkan kurva normal yang berbeda. Bila X adalah suatu
peubah acak normal dengan nilai tengan dan ragam , maka persamaan kurva
normalnya adalah
; , √ , untuk ∞ ∞,
sedangkan dalam hal ini 3.14159… dan e = 2.71828…
b. Sebaran Eksponensial
Biasanya merupakan suatu distribusi pelayanan kustomer pada suatu sistem
yang terjadi dalam interval yang konstan. Contohnya panjang waktu antara objek
dengan pelanggan ketika keluar dari supermarket, atau antar breakdown dari suatu
mesin. Sebaran probabilitasnya adalah
, , .
c. Sebaran Seragam (Uniform)
Sebaran seragam adalah sebaran yang sering digunakan dalam
membangkitkan sebaran lainnya dengan transformasi tertentu hasil bangkitan
sebaran seragam akan membentuk sebaran lainnya. Jika suatu peubah acak X,
dengan nilai x1,x2,…,xk memiliki peluang yang sama, maka sebaran seragamnya
diberikan oleh
8
d. Sebaran Gamma
Merupakan sebaran yang mempunyai peranan yang penting dalam teori
antrian dan teori reabilitas. Peubah acak X berdistribusi gamma, dengan
parameter dan maka
, , , untuk , ,
dengan
e.Sebaran Multinomial
Jika ada n percobaan dimana masing-masing percobaan dapat mempunyai k
hasil yang terjadi dengan kemungkinan p1,...,pk peubah acak X1,….,Xk
menghitung banyaknya kejadian dari tiap hasil maka dikatakan mempunyai
distribusi multinomial. Fungsi probabilitasnya adalah:
, , … , !… !! ) … )
2.3 Analisis Gerombol
Analisis gerombol adalah analisis statistik peubah ganda yang digunakan
terhadap n buah individu atau objek yang mempunyai p peubah, akan
dikelompokan ke dalam k kelompok. Objek yang terletak dalam satu gerombol
memiliki kemiripan sifat yang lebih besar dibandingkan dengan individu yang
terletak dalam gerombol lain (Dillon & Goldstein 1984).
Konsep dasar pengelompokan dua atau lebih objek ke dalam satu gerombol
adalah menggunakan ukuran kemiripan atau ketidakmiripan. Semakin tinggi sifat
kemiripan yang dimiliki suatu objek maka semakin besar pula peluang objek
tersebut untuk masuk dalam suatu gerombol tertentu.
Tujuan utama dari analisis gerombol adalah mengelompokkan objek-objek
seperti produk (barang dan jasa), benda (tumbuhan atau lainnya) dan orang
(responden, konsumen, atau lainnya) ke dalam kelompok-kelompok yang relatif
homogen. Analisis gerombol meneliti seluruh hubungan interdependensi dimana
9
and dependent variables). Analisis gerombol juga disebut analisis klasifikasi atau
taxonomi numerik (numerical taxonomi).
Menurut Anderberg (1973) terdapat dua metode dalam analisis gerombol
yaitu: metode berhierarki (hierarchical clustering methods) dan metode tak
berhierarki (non hierarchical clustering methods). Metode berhierarki digunakan
apabila belum ada informasi jumlah kelompok yang akan dipilih. Sedangkan
metode tak berhierarki bertujuan untuk mengelompokkan n objek ke dalam k
kelompok (k<n) dimana nilai k telah ditentukan sebelumnya. Pada dasarnya,
terdapat dua teknik penggerombolan pada metode berhierarki, yaitu teknik
penggabungan (agglomerative) dan teknik pembagian (divisive), sedangkan
metode tak berhierarki antara lain dengan teknik penyekatan (partitioning) dan
penggunaan grafik.
Gerombol yang baik adalah gerombol yang mempunyai sifat-sifat sebagai
berikut:
1 Kesamaan di dalam kelas (Intraclass similarity) yang tinggi antar anggotanya
dalam satu gerombol (within-cluster).
2 Kesamaan antar kelas (Interclass similarity) yang rendah antar satu gerombol
dengan gerombol lainnya (between cluster).
2.4 Ukuran Jarak
Menurut Andenberg (1973) ukuran jarak dibutuhkan untuk setiap pasang
objek yang akan dikelompokkan. Beberapa metode pengukuran jarak antar dua
objek, yaitu:
1 Jarak Euclidean
Jarak ini merupakan jarak yang umum digunakan, dan dapat digunakan
apabila semua peubahnya berskala kontinu. Jarak ini harus memenuhi asumsi
bahwa peubah-peubah yang diamati tidak berkorelasi dan antar peubah memiliki
satuan yang sama. Dalam metode ini, pengukuran jarak dilakukan dengan
menghitung akar kuadrat dari penjumlahan kuadrat selisih dari nilai
masing-masing peubah. Jarak Euclid dapat dirumuskan sebagai berikut:
10
dengan:
: jarak antara objek i dengan objek k
: nilai objek i pada peubah ke- k
: nilai objek j pada peubah ke- k
:banyaknya peubah yang diamati
2 Jarak Manhattan (City Block/Minkowski)
Jarak ini merupakan bentuk umum dari jarak Euclidean. Jarak Manhattan
digunakan jika peubah yang diamati berkorelasi atau tidak saling bebas. Dalam
metode ini, pengukuran jarak dilakukan dengan menghitung jumlah absolut
perbedaan untuk masing-masing peubah. Jarak Manhattan dapat dirumuskan
sebagai berikut:
| | .
dengan:
: jarak antara objek i dengan objek k
: nilai objek i pada peubah ke- k
: nilai objek j pada peubah ke- k
: banyaknya peubah yang diamati
3 Jarak Chebysev
Jarak Chebysev dilakukan dengan menghitung jumlah nilai maksimum
absolut perbedaan untuk beberapa peubah. Jarak Chebysev dapat dirumuskan
sebagai berikut:
Max | | (2.3) dengan:
: jarak antara objek i dengan objek k
: nilai objek i pada peubah ke- k
: nilai objek j pada peubah ke- k
4 Jarak Mahalonobis
Jarak ini sangat berguna dalam menghilangkan atau mengurangi perbedaan
skala pada masing-masing komponen. Jarak Mahalonobis dapat dirumuskan
sebagai berikut:
′ .4)
11
dengan:
: jarak antara objek i dengan objek k
: nilai objek i pada peubah ke- k : nilai objek j pada peubah ke- k S : matriks kovarian
5 Jarak Log-likelihood
Jarak ini digunakan untuk peubah berskala kontinu dan kategorik. Jarak
antara gerombol j dengan gerombol s dapat dirumuskan sebagai berikut:
, , (2.5)
dengan:
log log
log log
log log
dengan:
N : jumlah total observasi
Nj : jumlah observasi di dalam gerombol j
Njkl : jumlah objek di gerombol j untuk peubah kategorik ke k dengan kategori ke l
: ragam dugaan untuk peubah kontinu ke k untuk keseluruhan
observasi
: ragam dugaan untuk peubah kontinu ke k untuk keseluruhan
observasi dalam gerombol j KA :jumlah total peubah kontinu
KB :jumlah total peubah kategorik
12
2.5 k-means Clustering
Metode k-means pertama kali diperkenalkan oleh MacQueen JB pada tahun
1976. Metode ini adalah salah satu metode non hierarchi yang umum digunakan.
Metode ini termasuk dalam teknik penyekatan (partition) yang membagi atau
memisahkan objek ke k daerah bagian yang terpisah. Pada k-means, setiap objek
harus masuk dalam gerombol tertentu, tetapi dalam satu tahapan proses tertentu,
objek yang sudah masuk dalam satu gerombol, pada satu tahapan berikutnya
objek akan berpindah ke gerombol lain.
Pada dasarnya penggunaan algoritma dalam melakukan proses clustering
tergantung dari objek yang ada dan konklusi yang ingin dicapai. Ada beberapa
metode penggerombolan yang umum digunakan, antara lain adalah:
1 Metode berhierarchi
2 Metode tak berhierarchi
Untuk itu digunakan algoritma k-means yang di dalamnya memuat aturan
sebagai berikut:
1 Jumlah cluster yang diinginkan.
2 Hanya memiliki atribut bertipe numerik.
Metode k-means berawal dari penentuan jumlah gerombol yang ingin
dibentuk, kemudian menentukan objek sebagai centroid awal yang biasanya
dilakukan secara random, selanjutnya menghitung ukuran jarak dari
masing-masing objek ke centroid. Setelah objek masuk pada centroid terdekat dan
membentuk gerombol baru, centroid baru ditentukan kembali dengan menghitung
rata-rata objek pada centroid yang sama. Jika masih ada perbedaan dengan
centroid yang sudah dibentuk, maka dilakukan perhitungan kembali centroid
baru.
Hasil cluster dengan dengan metode k-means sangat bergantung pada nilai
pusat gerombol awal yang diberikan. Pemberian nilai awal yang berbeda bisa
menghasilkan gerombol yang berbeda. Ada beberapa cara memberi nilai awal
misalnya dengan mengambil sampel awal dari objek, lalu mencari nilai pusatnya,
memberi nilai awal secara random, menentukan nilai awalnya atau menggunakan
13
Dalam k-means objek dikelompokkan secara tegas ke gerombol yang
mempunyai centroid terdekat, suatu dapat di tentukan termasuk anggota
dan bukan anggota dari suatu kelas dapat didefinisikan sebagai fungsi
karakteristik yang dapat dirumuskan sebagai berikut:
µ , ; ; .
; .
Tujuan dari algoritma k-means adalah meminimumkan jarak antara objek
dengan centroid yang terdekat, yaitu dengan meminimumkan fungsi objektif J
yang dirumuskan sebagai fungsi dari U dan V sebagai berikut:
, , .
dengan:
U : matriks keanggotaan objek ke masing-masing gerombol
V : matriks centroid / rata masing-masing gerombol
: fungsi keanggotaan objek ke-k ke gerombol ke-i xk : objek ke-k
i
v
: nilai centroid gerombol ke-i
d : ukuran jarak
Kelebihan metode k-means diantaranya adalah mampu mengelompokan
objek besar dan pencilan objek dengan sangat cepat sehingga mempercepat proses
pengelompokan. Adapun kekurangan yang dimiliki oleh k-means diantaranya:
1 Sangat sensitif pada pembangkitan titik pusat awal secara random.
2 Memungkinkan suatu gerombol tidak mempunyai anggota.
3 Hasil pengelompokan bersifat tidak unik (selalu berubah-ubah) terkadang
bagus terkadang tidak.
4 Sangat sulit mencapai global optimum.
Selain itu kekurangan k-means adalah:
1 Menentukan banyaknya jumlah gerombol sebelum kita mengetahui jumlah
gerombol yang optimal.
2 Semua objek harus masuk kedalam satu cluster, dan sangat bergantung pada
14
2.6 Fuzzy k-means Clustering
Metode fuzzy k-means pertama kali diperkenalkan oleh Jim Bezdek pada
tahun 1981. Fuzzy k-means adalah suatu teknik pengelompokanobjek yang mana
keberadaan tiap-tiap objek dalam suatu cluster ditentukan oleh nilai keanggotaan.
(Kusumadewi et al. 2006).
Berbeda dengan k-means clustering, dimana suatu objek hanya akan menjadi
anggota satu cluster, dalam fuzzy k-means setiap objek bisa menjadi anggota dari
beberapa cluster, sesuai dengan namanya fuzzy yang berarti samar. Batas-batas
dalam k-means adalah tegas (hard) sedangkan dalam fuzzy k-means adalah soft
(Agusta 2007).
Konsep dasar fuzzy k-means pertama kali adalah menentukan pusat cluster
pada kondisi awal, pusat cluster ini masih belum akurat dan tiap objek memiliki
derajat keanggotaan untuk tiap-tiap cluster dengan cara memperbaiki pusat cluster
dan nilai keanggotaan tiap objek secara berulang maka akan dapat dilihat bahwa
pusat cluster akan bergerak menuju lokasi yang tepat.
Ketika gerombol-gerombol menjadi overlapping atau setiap objek
memungkinkan termasuk ke beberapa gerombol, maka dapat diinterpretasikan
sebagai fungsi keanggotaan yaitu , . Maka fungsi objektif J yang
dirumuskan sebagai fungsi dari U dan V sebagai berikut:
, , .
dengan:
U : matriks keanggotaan objek ke masing-masing gerombol
V : matriks centroid / rata-rata masing-masing gerombol
m : pembobot eksponen
μ
ik : fungsi keanggotaan objek ke-k ke gerombol ke-i xk : objek ke-kvi : nilai centroid ke-i d : ukuran jarak
Pada metode fuzzy k-means diperkenalkan suatu peubah m yang merupakan
fungsi pembobot (weighting exponent) dari membership function. Peubah m ini
disebut juga indeks fuzzy dan mempunyai nilai [1,4). Menurut penelitian yang
15
Untuk menghitung centroid (titik pusat)gerombol V, untuk setiap gerombol
digunakan rumus sebagai berikut:
∑
∑
= = = N k m ik N k kj m ik ij x v 1 1 ) ( ) ( μ μ dengan:m : pembobot eksponen
: fungsi keanggotaanobjek ke-k ke gerombol ke-i
xkj : objek ke-k gerombol ke-j
Sedangkan untuk menghitung fungsi keanggotaan objek ke-k ke gerombol ke-i
digunakan rumus sebagai berikut:
| |
∑
= c j1 dengan:: fungsi keanggotaan objek ke-k ke gerombol ke-i
xk : objek ke-k
vi : nilai centroid cluster ke-i vj : rata-rata centroid cluster ke-j
m : pembobot eksponen
2.7 Two Step Clustering
Metode two step cluster adalah metode yang didesain untuk menangani
jumlah objek yang besar, terutama pada masalah objek yang mempunyai peubah
kontinu dan kategorik. Prosedur penggerombolan dengan metode two step cluster
mempunyai dua tahapan yaitu tahap preclustering (penggerombolan awal) objek
ke dalam subcluster-subcluster kecil dan tahap penggerombolan akhir.
Langkah 1: Penggerombolan Awal(Preclustering)
Menurut Anonimous (2001) tahap penggerombolan awal dilakukan dengan
pendekatan sekuensial, yaitu objek diamati satu persatu berdasarkan ukuran jarak
yang kemudian ditentukan apakah objek tersebut masuk dalam gerombol yang
telah terbentuk atau harus membentuk gerombol baru. Pada langkah ini
f c D D V C r k k b c a ( a m p a m a t m
future itu se
cluster.
Definisi
Diberikan N
Vektor clu
CF=(N,M,V
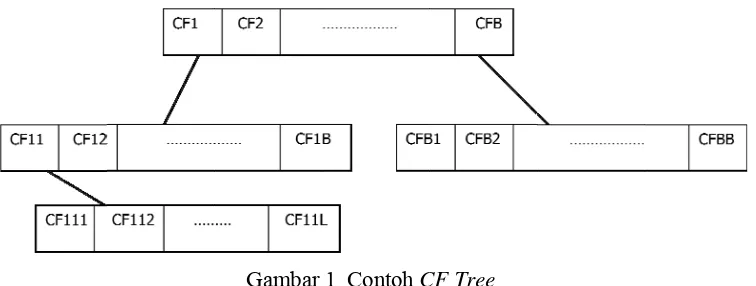
rata-rata dar kontinu pad kategorik. CF Tr branching fa CF Tre cabang beri
atau daun e
(subcluster-s awal secara menggunaka pada daerah anak geromb maka amata akan menjad tempat untu menjadi dua ndiri adalah
N titik objek
ustering fea
V,K) dimana
ri peubah ko
da N objek
ree adalah k
actor (B) dan
ee terdiri da
sikan indivi
entri yang t
subcluster).
acak yang a
an ukuran j
penerimaan
bol. Jika be
an tersebut a
di cikal baka
uk menamba
a. Proses in
kesimpulan
k d dimensi
ature dari
N adalah b
ontinu dari N
k, dan K a
keseimbanga
[image:42.612.134.512.310.453.2]n threshold (
Gambar
ari beberapa
idu objek (e
terdapat pad
Prosedur CF
akan diukur
arak yang t
n (threshold
esarnya jarak
akan masuk
al daun entr
h daun entri
ni akan ber
n dari inform
i pada suatu
cluster d
banyaknya o
N objek, V a
adalah bany
an tinggi po
(T).
1 Contoh C
tingkatan c
entries) dari
da cabang m
FTree dilak
jaraknya sa
telah ditentu
distance), m
k terletak di
ke dalam g
i yang baru.
i yang baru,
rlanjut samp
masi yang di
u cluster
didefinisikan
objek pada c
adalah varia
yaknya taraf
ohon dengan
CF Tree
abang (node
i gerombol
merepresenta
kukan denga
atu persatu d
ukan. Jika b
maka amatan
i luar wilaya
gerombol yan
. Jika suatu
, maka caba
pai semua a
kumpulkan
dimana i =
n sebagai
cluster, M m
ansi dari seti
f pada setia
n dua param
es) dan masi
awal. Tingk
asikan anak
an memilih s
dengan amat
besarnya jar
n akan menja
ah daerah p
ng telah dib
cabang tidak
ang daun ak
amatan tero
16
pada suatu
= 1,2,…,N.
17
lengkap. Jika CF Tree berkembang melewati batas ukuran maksimum yang telah
ditetapkan, maka CF Tree akan dibangun ulang dengan cara meningkatkan
kriteria batas penerimaan. Pemilihan kriteria batas penerimaan yang bagus dapat
mengurangi banyaknya CF Tree yang dibangun ulang.
Langkah 2: Penggerombolan akhir
Pada langkah ini, hasil dari CF Tree digerombolkan dengan analisis
gerombol hierarki dengan metode agglomerative, yaitu dimulai dengan n
gerombol yang masing-masing beranggotakan satu objek, kemudian dua
gerombol yang paling dekat digabung dan ditentukan kembali kedekatan antar
gerombol yang baru. Untuk menghitung banyaknya gerombol dapat dilakukan
dengan dua tahapan, yang pertama menghitung schwarz’s bayesian criterion
(BIC) atau akaike’s information criterion (AIC) untuk tiap gerombol. Rumus BIC
dan AIC untuk gerombol J adalah sebagai berikut:
log
dimana
log log
Solusi gerombol yang terbaik jika memiliki BIC terkecil, tetapi pada
beberapa kasus terdapat nilai BIC semakin meningkat jika jumlah gerombol
semakin meningkat. Jika terdapat kasus demikian maka diperlukan identifikasi
solusi gerombol terbaik oleh rasio perubahan BIC dan rasio peubahan jarak.
Tahap kedua digunakan kriteria perubahan rasio jarak untuk k buah
gerombol, R(k), yang didefinisikan sebagai:
R(k) = lv-1 / lv (2.14)
18
dimana:
lv = (mvlog n – BICv)/2 atau
lv = (2mvlog n – AICv)/2
v = k,k-1
dengan:
R(k) : rasio perubahan jarak
dk-1 : jarak jika k gerombol digabungkan dengan k-1 gerombol
2.8 Variansi Gerombol
Pada dasarnya variansi pada penggerombolan dapat dibedakan menjadi dua
yaitu: variansi didalam gerombol (variance within cluster) dan variansi antar
gerombol (variance between cluster).
Beberapa definisi variasi, yaitu:
1. Variansi Total
Jumlah total kuadrat selisih objek dengan rata-rata total seluruh objek, yaitu:
dimana
dengan:
xij : objek ke-i pada gerombol ke j k : banyaknya gerombol
: rata-rata total seluruh objek N : banyaknya objek
2 Variansi antar Kelompok
Jumlah total kuadrat selisih rata-rata tiap objek terhadap rata-rata total,
19
dengan:
xij : objek ke-i pada gerombol ke j
nj : banyaknya objek pada gerombol j : rata-rata total seluruh objek
3. Variansi dalam Kelompok
Jumlah total kuadrat selisih objek dengan rata-rata objek yang terkait, yaitu:
.
dengan:
xij : objek ke-i pada gerombol ke j
nj : banyaknya objek pada gerombol j . rata-rata objek pada gerombol j
Khusus untuk fuzzy, apabila terdapat objek xi dengan i = 1,2, … , n, dengan
derajat keanggotaan pada kelompok fuzzy B adalah , dan terdapat j
kelompok fuzzy dengan j= 1,2 , …, k, maka dapat didefinisikan:
dimana
Total variansi T, variansi antar fuzzy kelompok B, dan variansi dalam suatu
20
Seperti yang telah disebutkan di atas, hasil penggerombolan yang baik
adalah jika anggota setiap gerombol memiliki tingkat kemiripan yang tinggi satu
sama lain yang diukur dengan rata-rata jumlah kuadrat dalam gerombol (means
squares of within cluster) dan memiliki tingkat kemiripan yang rendah dengan
anggota dari gerombol lain yang diukur dengan rata-rata jumlah kuadrat antar
gerombol(means squares of between cluster).
Rata-rata jumlah kuadrat dalam gerombol (means squares of within cluster)
didefinisikan sebagai berikut :
. .
dengan:
xij :objek ke-i pada gerombol ke j
. rata-rata dari objek pada gerombol j
k : jumlah gerombol
n
: jumlah objek
Rata-rata jumlah kuadrat antar gerombol (means squares of between cluster)
didefinisikan sebagai berikut:
.
dengan:
xij :objek ke-i pada gerombol ke j
nj : banyaknya objek pada gerombol j . : rata-rata objek pada gerombol j : rata-rata total seluruh objek
Gerombol yang ideal mempunyai rata-rata jumlah kuadrat dalam gerombol
minimum yang merepresentasikan internal homogenity dan rata-rata jumlah
21
BAB III
METODE PENELITIAN
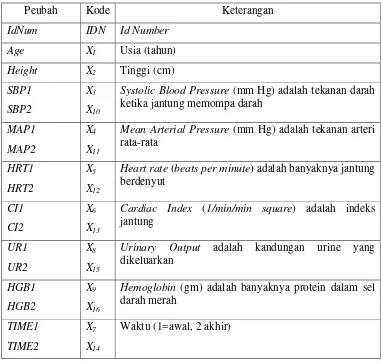
3.1 Bahan Penelitian [image:47.612.131.513.263.627.2]Penelitian ini menggunakan data Afifi dari paket SPSS. Data Afifi merupakan data yang dibuat oleh Afifi dan Azen (1972) pada Los Angeles Shock Unit. Data ini menggambarkan pengelompokkan pasien yang mengalami shock. Data ini memiliki 108 pasien dengan peubah-peubah sebagai berikut:
Tabel 1 Daftar peubah-peubah data Afifi
Peubah Kode Keterangan
IdNum IDN Id Number
Age X1 Usia (tahun)
Height X2 Tinggi (cm)
SBP1
SBP2
X3
X10
Systolic Blood Pressure (mm Hg) adalah tekanan darah ketika jantung memompa darah
MAP1
MAP2
X4
X11
Mean Arterial Pressure (mm Hg) adalah tekanan arteri rata-rata
HRT1
HRT2
X5
X12
Heart rate (beats per minute) adalah banyaknya jantung berdenyut
CI1
CI2
X6
X13
Cardiac Index (1/min/min square) adalah indeks jantung
UR1
UR2
X8
X15
Urinary Output adalah kandungan urine yang
dikeluarkan
HGB1
HGB2
X9
X16
Hemoglobin (gm) adalah banyaknya protein dalam sel darah merah
TIME1
TIME2
X7
X14
Waktu (1=awal, 2 akhir)
22
[image:48.612.125.500.81.703.2]
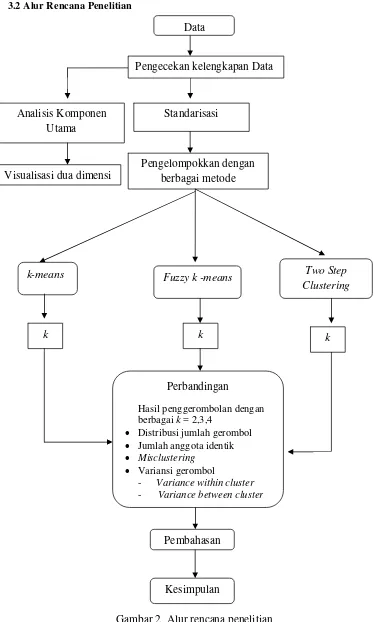
3.2 Alur Rencana Penelitian
Gambar 2 Alur rencana penelitian Pengelompokkan dengan
berbagai metode
Fuzzy k -means Two Step
Clustering k-means
k k k
Perbandingan
Hasil penggerombolan dengan berbagai k = 2,3,4
• Distribusi jumlah gerombol
• Jumlah anggota identik
• Misclustering
• Variansi gerombol
- Variance within cluster
- Variance between cluster
Pembahasan
Kesimpulan Standarisasi Analisis Komponen
Utama
Visualisasi dua dimensi
23
3.3 Langkah-Langkah Penelitian
Terkait dengan tujuan penelitian yang telah dikemukakan, maka beberapa tahapan diperlukan untuk dapat menjawab tujuan tersebut, yaitu :
1 Menentukan jenis variabel dari data.
2 Menggerombolkan data dengan mencobakan berbagai nilai k. Dalam penelitian ini dicobakan k = 2,3, dan 4.
3 Memilih ukuran jarak pada data tersebut.
4 Menerapkan metode k-means pada data dengan langkah-langkah sebagai berikut:
5 Menerapkan metode fuzzy k- means pada data dengan langkah-langkah sebagai berikut:
a Mentukan k sebagai jumlah gerombolyang ingin dibentuk. b Membangkitkan k titik pusat gerombol awal secara random. c Menghitung jarak setiap data ke masing-masing gerombol. d Memilih gerombolyang terdekat untuk setiap data.
e Menentukan posisi gerombolbaru dengan cara menghitung nilai rata-rata dari data yang terletak pada gerombolyang sama.
f Kembali ke langkah c jika posisi gerombol baru dengan gerombol lama tidak sama.
a Menentukan jumlah gerombol.
b Mengalokasikan data sesuai dengan jumlah gerombol yang ditentukan. c Menghitung nilai titik pusatdari masing-masing gerombol.
d Menghitung nilai fungsi keanggotaan masing-masing data ke masing- masing gerombol.
24
6 Menerapkan metode two step clustering pada data dengan langkah-langkah sebagai berikut:
7 Menghitung variansi gerombol pada masing-masing metode.
8 Membandingkan hasil penggerombolan yang terbentuk pada data dengan k- means, fuzzy k-means, dan two step clustering.
9 Menarik kesimpulan.
25
DAFTAR PUSTAKA
Agusta Y, 2007.K-Means-Penerapan, Permasalahan dan Metode Terkait. Jurnal Sistem dan Informatika Vol 3. STIMIK. Bali.
Anderberg MR. 1973. Cluster Analysis for Application. Academic Press, New York.
Anonimous. 2001. The SPSS TwoStep Cluster Component. A scalable component to segment your costumers more effectifely. White paper-technical report, SPSS Inc Chicago.
Anonimous. 2004. TwoStep Cluster Analysis. Technical Report, SPSS Inc. Chicago.
Bacher, J., K. Wenzig and M. Vogler. 2004. SPSS TwoStep Cluster : A First Evaluation. Friedrich-Alexander-Universitat Erlangen-Nunberg.
Dillon WR, & M. Goldstein. 1984. Multivariate Analysis Method and Applications. John Wiley & Sons. Canada.
Graham J Williams, 2008. Data Mining Algorithms Cluster Analysis. Adjunct Associate Professor, ANU.
Hong SL, 2006. Experiment With K-Means, Fuzzy C-Means And Approaches To Choose K And C. University of Central Florida. Orlando.
Johnson RA, DW Wichern. 1998. Applied Multivariate Statistical Analysis 4thed. Prantice- Hall Int.
Kusdiati. 2006. Pengkajian Keakuratan TwoStep Cluster dalam menentukan Banyaknya Gerombol Populasi. Tesis. Departemen Statistika Institut Pertanian Bogor: IPB.
Kusumadewi, dkk. 2006. Fuzzy Multi-Attribute Decision Making (FUZZY MADM). Yogyakarta. Graha Ilmu.
Santosa B, 2007. Data Mining. Teknik Pemanfaatan Data Untuk Keperluan Bisnis. Graha Ilmu. Yogyakarta.
Serban G, & Grigoreta SM. 2006. A Comparison of Clustering Teqniques In Aspect Mining. Studia Univ. Babes-Bolyai, Informatica, Volume L1.
26
25
BAB IV
HASIL DAN PEMBAHASAN
4.1 Deskripsi Data
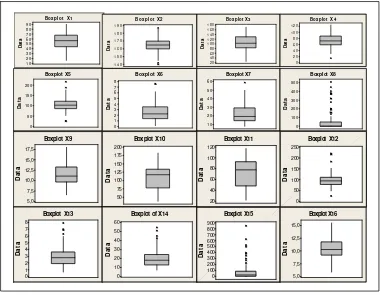
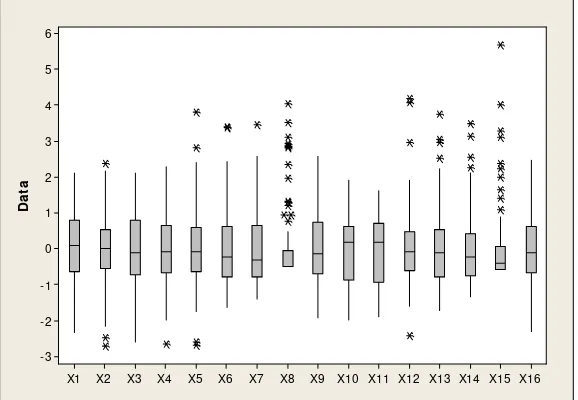
Setelah melalui proses pengecekan kelengkapan data, terdapat data hilang pada objek pengamatan untuk beberapa peubah. Objek pengamatan yang memiliki data hilang tersebut tidak diikutsertakan dalam analisis. Untuk memberikan gambaran data dari masing-masing peubah maka digunakanlah Boxplot, yang disajikan pada gambar dibawah ini:
9 0 8 0 7 0 6 0 5 0 4 0 3 0 2 0 1 0 D a ta
Box plot X1
[image:53.612.135.515.267.562.2]
Gambar 3 Boxplot data Afifi
Keterangan:
X1: Age X9 : Hemoglobin1
X2:Height X10 : Systolic Blood Pressure2
X3: Systolic Blood Pressure1 X11 : Mean Arterial Pressure 2
X4: Mean Arterial Pressure 1 X12 : Heart Rate 2
X5: Heart Rate1 X13 : Cardiac 2
X6: Cardiac1 X14 : CTime 2
X7:CTime2 X15 : Urine 2
X8:Urine 1 X16 : Hemoglobin 2
200 150 100 50 0 D a ta Boxplot X5
1 9 0 1 8 0 1 7 0 1 6 0 1 5 0 1 4 0
D
a
ta
Bo x p lo t X 2
1 8 0 1 6 0 1 4 0 1 2 0 1 0 0 8 0 6 0 4 0 2 0 D a ta
Boxplot X3
1 2 0 1 0 0 8 0 6 0 4 0 2 0 0 D a ta
Box plot X4
8 7 6 5 4 3 2 1 0 D a ta Boxplot X6 60 50 40 30 20 10 D a ta Boxplot X7 500 400 300 200 100 0 D a ta Boxplot X8 17,5 15,0 12,5 10,0 7,5 5,0 D a ta
Boxplot X9
200 175 150 125 100 75 50 D a ta Boxplot X10 120 100 80 60 40 20 D a ta
Boxplot X11
250 200 150 100 50 0 D a ta
Boxplot X12
8 7 6 5 4 3 2 1 0 D a ta
Boxplot X13
60 50 40 30 20 10 0 D a ta
Boxplot of X14
900 800 700 600 500 400 300 200 100 0 D a ta
Boxplot X15
26
Gambar 3 memperlihatkan bahwa sebaran data untuk masing-masing peubah tidak semuanya mempunyai pencilan. Gambar 3 juga memperlihatkan bahwa keragaman peubah X15 lebih besar dari keragaman peubah lainnya,
sedangkan peubah X13 mempunyai keragaman yang paling kecil dibandingkan
[image:54.612.159.455.209.403.2]peubah lainnya.
Tabel 2 Deskripsi data Afifi
Sedangkan untuk memberikan gambaran data yang sudah distandarisasi, dapat dilihat pada gambar berikut:
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12 X13 X14 X15 X16
[image:54.612.190.479.463.663.2]6 5 4 3 2 1 0 -1 -2 -3 D a ta
Gambar 4 Boxplot data Afifi standarisasi
Peubah Rata-Rata Standar Deviasi Min Max
27
Gambar 4 memperlihatkan bahwa data yang sudah distandarisasi ini mempunyai variansi yang semua peubahnya cenderung relatif lebih homogen.
[image:55.612.172.465.234.440.2]Karena dalam penggerombolan menggunakan konsep jarak Euclid, dimana konsep jarak ini mengharuskan tidak adanya korelasi antar peubah, maka terlebih dahulu dilakukan Analisis Komponen Utama (AKU), yang bertujuan untuk memperoleh peubah-peubah yang saling tidak berkorelasi. Hasil Analisis Komponen Utama disajikan pada tabel berikut:
Tabel 3 Koefisien Komponen Utama 1 dan 2
Peubah Komponen Utama 1 Komponen Utama 2
X1 -0.2055 0.1417
X2 0.2239 0.0050
X3 0.3371 0.1548
X4 0.3376 0.2173
X5 -0.0215 0.0765
X6 0.1763 -0.3690
X7 -0.2015 0.4052
X8 0.2015 -0.9954
X9 -0.0417 0.4142
X10 0.3468 0.2050
X11 0.3662 0.2304
X12 0.2278 0.1716
X13 0.3487 -0.2041
X14 -0.3005 0.2095
X15 0.1470 0.1334
X16 0.0623 0.4391
Tabel 4 Akar ciri, proporsi keragaman, dan keragaman kumulatif
KU Ke- Akar ciri Proporsi Keragaman (%) Keragaman Kumulatif (%)
1 4.1284 25.80 25.80
2 2.6764 16.73 42.53
3 1.5928 9.96 52.49
4 1.5928 8.05 60.54
5 1.2885 7.15 67.69
6 1.1445 6.78 74.48
7 1.0853 5.16 79.63
8 0.8249 4.57 84.20
9 0.7305 3.51 87.70
10 0.5608 3.11 90.81
11 0.4969 2.84 93.65
12 0.4543 2.42 96.07
13 0.3871 2.37 98.44
14 0.3787 0.85 99.2
15 0.0849 0.53 99.82
16 0.0287 0.18 100
[image:55.612.150.489.476.692.2]28
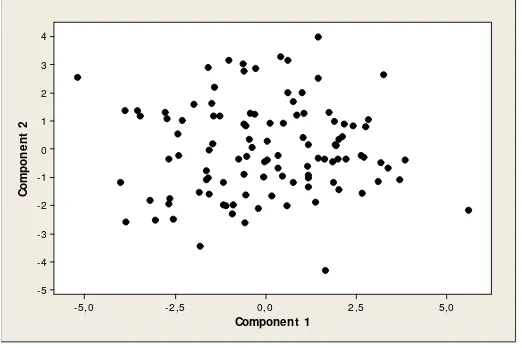
Sebagai hasil pendekatan yang dilakukan oleh Analisis Komponen Utama pada tabel di atas, dapat dilihat bahwa hanya terdapat 7 komponen utama yang memiliki akar ciri lebih dari 1, ini berarti bahwa ketujuh komponen utama tersebut memberikan kontribusi keragaman yang besar, dan komponen utama yang memiliki akar ciri kurang dari 1 dianggap memiliki kontribusi keragaman yang kurang. Dari tabel di atas, dapat dilihat juga bahwa akar ciri pertama yang memiliki nilai sebesar 4.1284 menjelaskan bahwa komponen utama ke-1 dapat menerangkan keragaman data sebesar 25.80%. Dengan cara yang sama untuk komponen utama selanjutnya sampai komponen ke 16 sebesar 2.87%. Komponen utama ke 1 dan ke 2 memberikan kontribusi keragaman sebesar 25.80% dan 16.73% . Sehingga jika digunakan kedua komponen tersebut, secara kumulatif akan didapatkan keragaman total yang mampu dijelaskan keduanya adalah sebesar 42.53%. Dan dari ketujuh komponen utama tersebut, secara kumulatif memiliki proporsi keragaman sebesar 79.63%, ini berarti bahwa sudah mewakili keragaman total dari seluruh data.
Jika digambarkan nilai kedua skor komponen utama di atas, akan didapatkan gambaran sebagai berikut:
5,0 2,5
0,0 - 2,5
- 5,0 4 3 2 1 0 - 1 - 2 - 3 - 4 - 5
Component 1
C
o
m
p
o
n
e
n
t
[image:56.612.190.451.412.586.2]2
Gambar 5 Plot dua komponen utama pada data Afifi
29
Metode k-means
Pembentukan pengelompokan pada metode k-means ini, diawali dengan menentukan jumlah gerombol yang diinginkan, dengan mengasumsikan inisial gerombol 1,…,k. Selanjutnya menentukan centroid awal secara random, yang kemudian menghitung ukuran jarak ke masing-masing objek ke centroid yang terdekat. Dengan meminimumkan fungsi objektifnya. Misalkan kasus ke i dari peubah ke j mempunyai nilai , , . Peubah-peubahnya diskalakan sehingga masalahnya dapat didekati dengan menggunakan jarak Euclid. Partisi P(M,K) dibuat dari cluster 1,2,…,K. Setiap kasus M dimasukkan ke
dalam cluster K. Rata-rata dari peubah ke j melebihi kasus pada cluster ke l yang didefinisikan oleh B(l,j). Banyaknya kasus pada l adalah N(l). Jarak antara kasus ke i dan cluster ke l adalah (Hartigan 1937):
,
,
/
Error partisi adalah
,
,
dimana l(i) adalah cluster yang mengandung kasus ke i. Prosedur umum untuk mencari partisi dengan e kecil oleh perubahan kasus dari satu cluster ke cluster yang lain. Pencarian berakhir ketika nilai e tidak berubah.
Langkah 1. Asumsikan inisial cluster 1,2,…, K. Hitung rata-rata cluster
, , dan inisialisasi error
,
,
dimana , ] didefinisikan jarak Euclid antara i dan rata-rata cluster yang mengandung i.
Langkah2. Untuk kasus pertama, hitung setiap cluster L
30
Pertambahan error pada pemindahan kasus pertama dari cluster akan termasuk ke cluster l. Jika minimum dari adalah negatif maka kasus pertama dari cluster l(1) dipindahkan ke l minimal, dan tambahkan peningkatan ini pada error (yang negatif) ke , .
Langkah 3. Ulangi Langkah 2 untuk kasus ke I ).
Langkah 4. Jika tidak ada perubahan dari satu cluster ke cluster lain, maka proses berhenti. Jika sebaliknya, kembali ke langkah 2.
Metode Fuzzy k-means
Pada penggerombolan dengan metode fuzzy k-means diawali dengan menentukan derajat keanggotaan secara acak setiap titik data terhadap cluster, yang kemudian menentukan titik pusat cluster yang berulang sampai berada pada wilayah penerimaan yang ditentukan. Algoritma fuzzy k-means ini bertujuan
meminimumkan fungsi objektif dari jarak data yang berbobot pada cluster, yaitu
, ,
dengan kendala
; untuk semua , …
dan
; untuk semua , …
µ , dengan:
µ fungsi keanggotaan dari data xk pada cluster i,
vi : centroid cluster ke I
d(vi,xk) : jarak antara centroid vi dan data xk .
Parameter m 1 disebut juga index fuzzy. Untuk m→ 1 cluster cenderung akan menjadi crisp. Sedangkan uik → 1 atau uik → 0 menghasilkan algoritma hard
c-means. Untuk m→ ∞, mempunyai uik → 1/c. Nilai m yang biasa digunakan
31
Sedangkan pada algoritma fuzzy k-means ini terdapat beberapa hal yang harus diperhatikan dalam proses penggerombolan diantaranya inisialisasi terhadap nilai centroid awal, nilai pemangkatan atau m, iterasi maksimal dan nilai error terkecil yang diinginkan.
Metode two step cluster
Pada metode two step cluster ini bisa digunakan untuk mengolah data yang kriteria peubahnya kontinu, kategorik maupun yang campuran antara kontinu dan kategorik. Jika dalam kasus data terdapat pencilan maka ketika dibentuk CF-tree diperiksa apakah dapat dimasukkan dalam gerombol yang sudah terbentuk tanpa harus membentuk CF-tree baru. Untuk mendeteksi ada tidaknya pencilan maka dil