ANALISIS QUERY PENCARIAN DATA MENGGUNAKAN
ALGORTIMA HASH JOIN DAN NESTED JOIN
TESIS
JUNUS SINURAYA
117038031
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
ANALISIS QUERY PENCARIAN DATA MENGGUNAKAN
ALGORITMA HASH JOIN DAN NESTED JOIN
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah
Magister Teknik Informatika
JUNUS SINURAYA
117038031
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
PERSETUJUAN
Judul tesis : ANALISIS QUERY PENCARIAN DATA MENGGUNAKAN ALGORITMA HASH JOIN
DAN NESTED JOIN
Kategori : -
Nama Mahasiswa : JUNUS SINURAYA Nomor Induk Mahasiswa : 117038031
Program Studi : S2 TEKNIK INFORMATIKA
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dr.Erna Budhiarti Nababan,M.IT Prof. Dr. Muhammad Zarlis
Diketahui/disetujui oleh
Program Studi S2 Teknik Informatika Ketua,
PERNYATAAN
ANALISIS QUERY PENCARIAN DATA MENGGUNAKAN ALGORITMA HASH JOIN DAN NESTED JOIN
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 28 Agustus 2013
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, Saya yang bertanda tangan di bawah ini :
Nama : JUNUS SINURAYA
NIM : 117038031
Program Studi : S2 TEKNIK INFORMATIKA Jenis Karya Ilmiah : TESIS
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty Free Right) atas tesis saya yang berjudul :
ANALISIS QUERY PENCARIAN DATA MENGGUNAKAN ALGORITMA HASH JOIN DAN NESTED JOIN
Beserta perangkat yang ada (jika diperlukan). Dengan hak Bebas Royalti Non-Eksklusif ini, Universitas Sumatera Utara Berhak menyimpan, mengalih media, menformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, Agustus 2013
Telah diuji pada
Tanggal : 28 Agustus 2013
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Muhammad Zarlis
Anggota : 1. Dr.Erna Budhiarti Nababan,M.IT
2. Dr. Poltak Sihombing,M.Kom
3. Dr. Sutarman, M.Sc
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap (berikut gelar) : Junus Sinuraya, ST
Tempat dan Tangal Lahir : Guru benua, 10 Maret 1981
Alamat Rumah : Jl.B.Katamso Gg Perbatasan Medan
Telepon/Fax/HP : 081370203112
Email : [email protected]
Instansi Tempat Bekerja : Politeknik LP3I Medan
Alamat Kantor : Jl.SM.Raja/Jl.Gajah Mada Medan
DATA PENDIDIKAN
SD : SD NEGERI GURU BENUA Tamat : 1991
SLTP : MTs NEGERI KABAN JAHE Tamat : 1994
SLTA : MA NEGERI 3 MEDAN Tamat : 2000
KATA PENGANTAR
Puji Syukur Penulis ucapkan kepada Tuhan Yang Maha Esa atas segala limpahan dan karunia-Nya sehingga penulis dapat menyelesaikan tesis ini dengan judul : ANALISIS QUERY PENCARIAN DATA MENGGUNAKAN ALGORITMA
HASH JOIN DAN NESTED JOIN.
Dengan selesainya tesis ini, penulis menyampaikan terimakasih sebesar-besarnya kepada :
1. Prof. Dr. dr. Syahril Pasaribu, D.T.M.&H., M.Sc. (C.T.M.), Sp.A.(K.) selaku Rektor Universitas Sumatera Utara yang telah memberikan kesempatan kepada penulis untuk mengikuti dan menyelesaikan pendidikan Program Magister.
2. Prof. Dr. Muhammad Zarlis selaku Dekan FASILKOM Dan TI Universitas Sumatera Utara.
3. M. Andri Budiman , ST., M.Comp Sc., M.E.M selaku Sekretaris Program Studi S2 Teknik Informatika.
4. Prof. Dr. Muhammad Zarlis, selaku Pembimbing Utama yang telah banyak memberikan bimbingan dan arahan serta motivasi kepada penulis.
5. Dr.Erna Budhiarti Nababan,M.IT, selaku Pembimbing Kedua yang telah banyak memberikan bimbingan dan arahan serta motivasi kepada penulis.
6. Dr. Poltak Sihombing,M.Kom, selaku Pembanding yang telah banyak memberikan kritikan serta saran kepada penulis.
7. Dr. Sutarman, M.Sc, selaku Pembanding yang telah banyak memberikan kritikan serta saran kepada penulis.
8. Dr. Zakarias Situmorang, MT, selaku Pembanding yang telah banyak memberikan kritikan serta saran kepada penulis..
9. Seluruh Staff Pengajar yang telah banyak memberikan ilmu pengetahuan selama masa perkuliahan serta Seluruh Staff Pegawai pada Program Studi S2 Teknik Informatika Universitas Sumatera Utara.
ketua, rekan-rekan dan seluruh staff pegawai Politeknik LP3I Medan yang telah memberikan semangat kepada penulis.
Akhir kata penulis hanya berdoa kepada Tuhan Yang Maha Esa semoga Tuhan memberikan limpahan karunia kepada semua pihak yang telah memberikan bantuan, perhatian, serta kerjasamanya kepada penulis dalam menyelesaikan tesis ini.
Medan, 28 Agustus 2013
Junus Sinuraya
ABSTRAK
Pengaksesan data atau pencarian data dengan menggunakan Query atau Join pada aplikasi yang terhubung dengan sebuah database perlu memperhatikan ketepatgunaan implementasi dari data itu sendiri serta waktu prosesnya. Ada banyak cara yang dapat dilakukan oleh database manajemen sistem dalam memproses dan menghasilkan jawaban sebuah query. Semua cara pada akhirnya akan menghasilkan jawaban (output) yang sama tetapi pasti mempunyai harga yang berbeda-beda, seperti misalnya kecepatan waktu untuk merespon data. Beberapa query yang sering digunakan untuk pemrosesan data yaitu Query Hash Join
dan Query Nested Join, kedua query memiliki algoritma yang berbeda tapi menghasilkan
output yang sama. Dengan menggunakan aplikasi yang dirancang menggunakan Microsoft Visual Studi 2010 dan Microsoft SQL Server 2008 berbasis jaringan untuk melakukan pengujian kedua algoritma atau query dengan paramter running time atau kecepatan waktu merespon data. Pengujian dilakukan dengan jumlah tabel yang dihubungkan dan jumlah baris/record. Hasil dari penelitian adalah kecepatan waktu query untuk merespon data untuk jumlah data yang kecil query hash join lebih baik sedangkan jumlah data yang besar query nested join lebih baik.
QUERY ANALISIS DATA SEARCH USING, ALGORITMA HASH
JOINAND NESTED JOIN
ABSTRACT
Data access or data retrieval using Query or Join in applications that connect to a database need to consider the efficiency of implementation of the data itself and the process time.There are many ways that can be done by the database management system to process and produce answers a query.All the way in the end will produce an answer (output) the same but certainly have different prices, such as the speed of time to respond to the data Some frequently used queries for data processing, namely Query Join and Hash Join Nested Queries, both have a query algorithms different but produces the same output. By using an application designed using Microsoft Visual Studies 2010 and Microsoft SQL Server 2008-based network to perform a second test or query algorithm with running time parameter or speed response time data. Testing is done with a number of tables are connected and the number of rows / records. Results of the study is to speed query response time data for the small amount of data that a better hash join query large amounts of data while the nested join query better
DAFTAR ISI
Halaman HALAMAN JUDUL
PENGESAHAN
PERNYATAAN ORISINALITAS PERSETUJUAN PUBLIKASI PANITIA PENGUJI
RIWAYAT HIDUP
KATA PENGANTAR i
ABSTRAK iii
ABSTRACT iv
DAFTAR ISI v
DAFTAR GAMBAR ix
DAFTAR TABEL x
BAB 1 PENDAHULUAN
1.1 Latar Belakang 1
1.2 Rumusan Masalah 2
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
BAB 2 LANDASAN TEORI
2.1 Pengertian DBMS 5
2.2 Sistem Basis Data 5
2.2.1 Konsep Basis Data Relasional 5
2.2.2 Konsep Model Relasional 6
2.2.3 Fungsi-Fungsi Basis Data Relasional 6
2.2.4 Istilah-istilah Basis data Relasional 7
2.3 Basis Data Terdistribusi 8
2.4.1 Data Manipulation 8
2.4.2 Konsep Query 12
2.5 Optimasi Query 13
2.6 Algoritma Hash Join 13
2.7 Algoritma Nested Join 14
2.7 RisetTerkait 15
2.8 Perbedaan dengan Riset lain 17
2.9 Kontribusi Riset 17
BAB 3 METODOLOGI PENELITIAN
3.1 Deskripsi Basis Data 19
3.1.1 Struktur Fisik Database 19
3.1.2 Relasi Antar Tabel 22
3.1.3 Skenario Pengujian Query 23
3.2 Query Algoritma 26
3.2.1 Query Algoritma Hash Join 26
3.2.2 Query Algoritma Nested Join 29
3.3 Parameter Pengujian 34
3.3.1 Rancangan Aplikasi 34
3.3.2 Alat Penelitian 35
BAB 4 HASIL DAN PEMBAHASAN
4.1 Hasil Penelitian 36
4.2 Hasil Pengujian Query 36
4.2.1 Hasil Pengujian 1 Relasi 37
4.2.2 Hasil Pengujian 2 Relasi 39
4.2.3 Hasil Pengujian 3 Relasi 41
4.2.4 Hasil Pengujian 4 Relasi 43
4.2.5 Hasil Pengujian 5 Relasi 44
4.3 Pembahasan Penelitian 46
4.3.1 Analisis Hasil Pengujian 1 Relasi 46
4.3.2 Analisis Hasil Pengujian 2 Relasi 49
4.3.3 Analisis Hasil Pengujian 3 Relasi 52
4.3.4 Analisis Hasil Pengujian 4 Relasi 55
BAB 5 KESIMPULAN DAN SARAN
5.1 Kesimpulan 60
5.2 Saran 60
DAFTAR GAMBAR
Nomor Gambar
Judul Halaman
3.1 Relasi Antar Tabel 23
3.2 Flowchart Skenario Pengujian Query 25
3.18 Rancangan Aplikasi 34
4.1 Perbandingan Running Time 1 Relasi 37
4.2 Grafik Perbandingan Running Time Query 1 Relasi 38
4.3 Perbandingan Running Time Query 2 Relasi 39
4.4 Grafik Perbandingan Running Time Query 2 Relasi 40
4.5 Perbandingan Running Time Query 3 Relasi 41
4.6 Grafik Perbandingan Query Pencarian Data 3 Relasi 42 4.7 Perbandingan Query PencarianData Relasi 3 Tabel 43 4.8 Grafik Perbandingan Query Pencarian Data Relasi 3
Tabel
44 4.9 Hasil Perbandingan Pengujian Running Time Query 5
Relasi
45 4.10 Grafik Perbandingan Pengujian Running Time Query 5
Relasi
46
4.11 Relasi antara 2 tabel 47
4.12 Display Estimated Execution Plan query hash join 1 relasi 47 4.13 Display Estimated Execution Plan query nested join 1
4.16 Display Estimated Execution Plan query hash join 1 relasi 50 4.17 Display Estimated Execution Plan query nested join
4.20 Display Estimated Execution Plan query hash join 3 relasi 53 4.21 Display Estimated Execution Plan query Nested join
Scalar 3 relasi
53 4.22 Display Estimated Execution Plan query Nested join
Correlated 3 relasi
54
4.23 Relasi antar 5 tabel 55
DAFTAR TABEL
Nomor Tabel
Judul Halaman
2.1 3.1
Tabel Riset Terkait Tabel TBMStruk
15 19
3.2 Tabel TBMKEl 20
3.3 Tabel TBMJen 20
3.4 Tabel TBMOby 21
3.5 Tabel TBMRoby 21
3.6 Tabel TBMSubRoby 22
3.7 Tahapan Relasi 24
ABSTRAK
Pengaksesan data atau pencarian data dengan menggunakan Query atau Join pada aplikasi yang terhubung dengan sebuah database perlu memperhatikan ketepatgunaan implementasi dari data itu sendiri serta waktu prosesnya. Ada banyak cara yang dapat dilakukan oleh database manajemen sistem dalam memproses dan menghasilkan jawaban sebuah query. Semua cara pada akhirnya akan menghasilkan jawaban (output) yang sama tetapi pasti mempunyai harga yang berbeda-beda, seperti misalnya kecepatan waktu untuk merespon data. Beberapa query yang sering digunakan untuk pemrosesan data yaitu Query Hash Join
dan Query Nested Join, kedua query memiliki algoritma yang berbeda tapi menghasilkan
output yang sama. Dengan menggunakan aplikasi yang dirancang menggunakan Microsoft Visual Studi 2010 dan Microsoft SQL Server 2008 berbasis jaringan untuk melakukan pengujian kedua algoritma atau query dengan paramter running time atau kecepatan waktu merespon data. Pengujian dilakukan dengan jumlah tabel yang dihubungkan dan jumlah baris/record. Hasil dari penelitian adalah kecepatan waktu query untuk merespon data untuk jumlah data yang kecil query hash join lebih baik sedangkan jumlah data yang besar query nested join lebih baik.
QUERY ANALISIS DATA SEARCH USING, ALGORITMA HASH
JOINAND NESTED JOIN
ABSTRACT
Data access or data retrieval using Query or Join in applications that connect to a database need to consider the efficiency of implementation of the data itself and the process time.There are many ways that can be done by the database management system to process and produce answers a query.All the way in the end will produce an answer (output) the same but certainly have different prices, such as the speed of time to respond to the data Some frequently used queries for data processing, namely Query Join and Hash Join Nested Queries, both have a query algorithms different but produces the same output. By using an application designed using Microsoft Visual Studies 2010 and Microsoft SQL Server 2008-based network to perform a second test or query algorithm with running time parameter or speed response time data. Testing is done with a number of tables are connected and the number of rows / records. Results of the study is to speed query response time data for the small amount of data that a better hash join query large amounts of data while the nested join query better
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Database Manajemen Sistem (DBMS) merupakan perantara bagi pemakai dengan basis data. Untuk berinteraksi dengan DBMS (basis data) menggunakan bahasa basis data yang telah ditentukan oleh perusahaan DBMS. Bahasa basis data biasanya terdiri atas perintah-perintah yang di formulasikan sehingga perintah-perintah tersebut akan diproses olah DBMS. Perintah-perintah biasanya ditentukan oleh user. Perintah user berinterakasi dengan Database Manajemen Sistem diantaranya yaitu memasukkan data, mengubah data, Menghapus dan menampilkan data atau disebut dengan Data Manipulation Language
(DML). Structure Query Language(SQL) adalah standar bahasa untuk berinteraksi dengan database dengan menggunakan operasi-operasi umum pada basis data.
Query adalah semacam kemampuan untuk menampilkan suatu data dari database dimana mengambil dari tabel-tabel yang didatabase, namun tabel tersebut tidak semua ditampilkan sesuai yang diinginkan atau data yang ingin ditampilkan.
Join table adalah penggabungan tabel-tabel menggunakan Query yang dilakukan melalui kolom/key tertentu yang memiliki nilai terkait untuk mendapatkan satu set data dengan informasi lengkap. Lengkap disini artinya kolom data didapatkan dari kolom-kolom hasil join antar tabel tersebut. Join diperlukan karena perancangan tabel pada sistem transaksional kebanyakan dinormalisasi, salah satu alasannya untuk mengurangi redundansi.
data atau pengolahan data tersebut dapat dilakukan dengan mengakses data yang terdapat dalam database. Pengaksesan data tersebut dilakukan dengan melakukan query-query pada basisdata- basisdata dengan database manajemen sistem. Kecepatan akses data dapat ditingkatkan dengan banyak cara, selain dari sisi perangkat kerasnya (hardware) dapat juga dilakukan dari sisi perangkat lunaknya (software) lebih khusus pada program aplikasinya.
Algoritma query melakukan join ada beberapa algoritma yang sering digunakan yaitu Algoritma Hash Join, Algoritma Nested Join. Masing-masing algoritma memilik kegunaan yang sama dalam menggabungkan beberapa tabel atau relasi tabel pada database manajemen sistem.
Algoritma Hash Join adalah sebuah algoritma join untuk menggabungkan data yang berjumlah besar. Cara kerja Hash Joins adalah Optimizer membuat sebuah Hash Table berdasarkan predikat Join. Setiap tabel di Inner maupun Outer masing-masing dijadikan sebuah kode dengan Hash Function kemudian setiap kode Hash dari
Inner akan dibandingkan dengan Hash Kode dari Outer. Apabila kode hash dari Inner
dan Outer sama maka akan dilakukan proses pengecekan nilai dari kolom yang pada akhirnya akan dimasukkan ke dalam hasil jika nilai kolomnya sama.
Algoritma Nested Join adalah sebuah Join yang efektif jika subset yang digabungkan berjumlah sedikit dan jika kondisi dalam perintah join efisien untuk menggabungkan 2(dua) tabel tersebut.
Beberapa penelititan di bidang optimasi query telah dilakukan oleh peneliti-peneliti. Antara lain Wahyu (2008) telah melakukan penelitian pengoptimasian query dengan algoritma Subset Query dalam sistem basis data. Dia mengatakan bahwa query optimasi dalam sistem data base sangat penting di evaluasi untuk menghasilkan hasil yang optimal dalam melakukan query.
Santiputri(2010) telah melakukan penelitian perbandingan Cross Product
dengan Subset Query pada multiple relasi dengan metode cost-based pada database non partisi cara mana yang lebih optimal sehingga pada akhirnya didapatkan query dengan waktu akses yang paling minimum tapi penelitian masih batas tabel partisi.
1.2. Rumusan Penelitian
akan semakin menurun unjuk kerjanya, ukuran unjuk kerja dalam hal ini kecepatan akses data dipengaruhi oleh banyak faktor salah satunya
Proses Join Query dalam pencarian data di database adalah salah satu sangat penting dan sulit untuk membuatnya, proses pencarian data menggunakan join query
mempunyai banyak metode-metode atau algoritma yang digunakan dan memiliki formula query yang berbeda menghasilkan Output yang sama.
Algoritma Join Query yang banyak digunakan dikalangan user adalah Algoritma
Nested Join dan Hash Join, kedua algoritma tersebut memiliki keunggulan dan kelemahan sehingga perlu diteliti bagaimana kerja/performance algoritma ini dalam pencarian data atau pengaksesan data dari segi kecepatan waktunya untuk merespon data.
1.3. Batasan Penelitian
Dalam penelitian ini akan dibatasi pada hal tertentu saja yaitu:
1. Mengukur kecepatan query menggunakan aplikasi dengan satuan detik.
2. Database management sistem yang digunakan adalah Ms.SQL Server 2008 dan aplikasi dirancang menggunakan Ms.Visual Basic.Net 2010.
3. Dijalankan pada struktur tabel yang sama, seperti jenis tipe data. 4. Struktur tabel tidak berindek atau cluster.
5. Data yang dihasilkan oleh query-query tersebut adalah sama. 6. Tabel yang diuji merupakan tabel non partisi.
7. Kecepatan running time berdasarkan jumlah banyaknya data. 8. Pengujian Client Server dengan jaringan Peer to Peer. 9. Tidak membahas struktur jaringan Client Server. 10.Pengujian dilakukan 6 tabel dan 5 Relasi.
1.3. Tujuan Penelitian
Tujuan dari penelitian ini adalah menganalisis perbandingan running time atau kecepatan query dari suatu aplikasi dengan menggunakan query Hash Join dan query Nested Join
1.4. Manfaat Penelitian
BAB 2
LANDASAN TEORI
2.1. Pengertian DBMS (Database Management System)
Database Management System atau DBMS adalah perangkat lunak yang didesain untuk membantu dalam memelihara dan menggunakan koleksi data dalam jumlah yang besar. Penggunaan DBMS adalah untuk menyimpan data dalam file dan menulis aplikasi dengan kode khusus untuk mengaturnya.
2.2. Sistem Basis Data
Basis data dan teknologinya telah memainkan peran penting seiring dengan pertumbuhan penggunaan komputer. Basis data telah digunakan pada hampir seluruh area dimana komputer digunakan, termasuk bisnis, teknik, kesehatan, hukum, pendidikan dan sebagainya. Kata basis data dapat didefinisikan sebagai kumpulan data yang saling berhubungan. Sedangkan kata data dapat didefinisikan sebagai fakta yang direkam atau dicatat. Sebagai contoh adalah nama, nomor telepon, dan alamat dari orang-orang yang anda kenal. Anda mungkin telah merekam data ini pada buku alamat, atau anda dapat menyimpannya dalam disket, menggunakan komputer personal dan perangkat lunak seperti dBASE IV.
Sistem Basis Data adalah suatu sistem menyusun dan mengelola record-record menggunakan komputer untuk menyimpan atau merekam serta memelihara data operasional lengkap sebuah organisasi/perusahaan sehingga mampu menyediakan informasi yang optimal yang diperlukan pemakai untuk proses mengambil keputusan. 2.2.1. Konsep Basis Data Relasional
Prinsip model relasional (relational model) pertama kali diperkenalkan oleh Dr. E.F
Codd, pada bulan Juni 1970 dalam sebuah tulisannya yang berjudul “ARelational Model of Data for Large Shared Data Banks.” Dalam tulisan tersebut, Dr. Codd menjelaskan
Model-model yang lebih populer digunakan pada saat itu adalah hierarchical dan network, atau bahkan simple flat file data stuctures. Relational Database Management Systems (RDBMS) segera menjadi sangat populer, terutama karena kemudahan penggunaannya dan fleksibilitas struktur datanya.
Selanjutnya, banyak vendor bermunculan untuk mendukung sistem ini diantaranya Oracle,Ms.SQL Server dimana mendukung RDBMS dengan paket untuk keperluan membangun aplikasi dan produk-produk siap pakai, sebagai total solusi bagi keperluan pengembangan teknologi informasi.
2.2.2. Konsep Model Relasional
Konsep basis data model relasional memiliki beberapa definisi penting sebagai berikut: Kumpulan objek atau relasi untuk menyimpan data
Kumpulan dari operator yang melakukan suatu aksi terhadap suatu relasi untuk menghasilkan relasi-relasi lain
Basis data relasional harus mendukung integritas data sehingga data tersebut harus akurat dan konsisten
Contoh dari relasi adalah tabel. Kita dapat menggunakan perintah-perintah SQL untuk menampilkan data dari tabel.
2.2.3. Fungsi-fungsi Basis Data Relasional
Basis data relasional memiliki fungsi-fungsi kegunaan sebagai berikut: Mengatur penyimpanan data
Mengontrol akses terhadap data
Mendukung proses menampilkan dan memanipulasi data
2.2.4. Istilah-istilah Basis Data Relasional
Beberapa istilah yang perlu kita pahami mengenai basis data relasional antara lain: Tabel : Merupakan struktur penyimpanan dasar dari basis data relasional, terdiri
Row (baris) : Baris merupakan kombinasi dari nilai-nilai kolom dalam tabel;
sebagai contoh, informasi tentang suatu departemen pada tabel Departmen. Baris
seringkali disebut dengan “record”.
Column (kolom) : Kolom menggambarkan jenis data pada tabel; sebagai contoh,
nama departemen dalam tabel Departmen. Kolom di definisikan dengan nama kolom dan tipe data beserta panjang data tertentu.
Field : Field merupakan pertemuan antara baris dan kolom. Sebuah field dapat berisi data. Jika pada suatu field tidak terdapat data, maka field tersebut dikatakan
memiliki nilai “null”.
Primary key : Primary key atau kunci utama merupakan kolom atau kumpulan kolom yang secara unik membedakan antara baris yang satu dengan lainnya; sebagai contoh adalah kode departemen. Kolom dengan kategori ini tidak boleh
mengandung nilai “null”, dan nilainya harus unique (berbeda antara baris satu dengan lainnya).
Foreign key: Foreign key atau kunci tamu merupakan kolom atau kumpulan kolom yang mengacu ke primary key pada tabel yang sama atau tabel lain. Foreign key ini dibuat untuk memaksakan aturan-aturan relasi pada basis data. Nilai data dari foreign key harus sesuai dengan nilai data pada kolom dari tabel yang diacunya atau bernilai “null”.
2.3. Basis Data Terdistribusi
Basis data terdistribusi adalah kumpulan data logic yang saling berhubungan secara fisik terdistribusi dalam jaringan komputer, yang tidak tergantung dari program aplikasi sekarang maupun masa yang akan datang.
satu bangunan atau terpisah oleh jarak yang jauh walaupun banyak bangunannya dan terhubung melalui jaringan internet. Dalam penggunaan basis data terdistribusi bisa dilakukan di server internet, ekstranet kantor atau intranet, maupun di jaringan perusahaan.
Pengguna atau disebut (user) dalam sebuah basis data terdistribusi bisa mengakses basis data melalui dua jenis aplikasi yaitu:
a. Aplikasi lokal adalah aplikasi yang tidak memerlukan data dari tempat lain. b. Aplikasi global adalah aplikasi dengan kebutuhan akan data dari tempat lain.
2.4. Konsep Structure Query Language(SQL)
Menurut Connoly dan Begg (2005, p113), pengertian SQL adalah transform- oriented language atau bahasa yang dirancang dengan penggunaan relasi untuk mengubah masukan menjadi keluaran yang ibutuhkan. Sebagai sebuah bahasa, standar internasional SQL menetapkan 2 komponen pokok, yaitu :
a. Data Definition Language (DDL) untuk mendefisinikan struktur basis data dan akses kontrol data.
b. Data Manipulation Language (DML) untuk mengembalikan dan memperbarui data.
2.4.1. Data Manipulation
Data manipulation di dalam SQL mencakup banyak hal mengenai query. Hal-hal yang akan dibahas disini adalah yang terkait dengan query secara umum, yaitu :
a. SELECT : untuk menampilkan hasil query data dalam basis data. b. INSERT : untuk memasukkan data ke dalam basis data.
c. UPDATE : untuk memperbarui data dalam basis data.
d. DELETE : untuk menghapus data dalam basis data.
Tujuan perintah SELECT adalah untuk mengembalikan nilai dan menampilkan data dari satu atau lebih tabel dalam basis data.
Perintah yang sangat baik kemampuannya dalam menampilkan relasi data adalah operasi Selection, Projection dan Join dalam perintah tunggal.
a. Selection
mencari gaji pegawai yang lebih dari 10000. Predikat dapat dihasilkan dari operasi logika AND, OR dan NOT.
b. Projection
Operasi projection bekerja pada relasi tunggal R dan mendefinisikan relasi yang berisi bagian secara vertikal dari R, mengambil nilai dari atribut yang ditentukan dan menghilangkan duplikasi.
c. Join
Operasi join sama halnya dengan operasi cross-product yang melakukan pencarian data yang sama pada kolom yang berkaitan antara 2 tabel dalam query. Dalam memenuhi kondisi query tertentu, penggunaan operasi join lebih baik daripada operasi
cross-product dalam efisiensi waktu dan pencarian yang dilakukan. Operasi
join akan mengkombinasikan dua relasi ke bentuk relasi yang baru, yang merupakan operasi dasar dalam relational algebra.
Menurut Ramakrishnan dan Gehrke (2005, p107), ada beberapa bentuk dari join, yaitu :
1. Condition Joins
Penggunaan join yang paling umum adalah bentuk condition join, yang melakukan kondisi seleksi pada cross-product antara 2 relasi (R dan S).
a. Equijoin
Operasi equijoin sama halnya ketika melakukan query dengan penggabungan relasi dengan mencari nilai data yang sama pada kolom yang berkaitan antara kedua relasi tersebut. Diilustrasikan dengan query : R.name1 = S.name2, dimana R dan S masing-masing adalah tabel untuk mencari nilai data yang sama pada kolom name1 pada tabel R dan kolom name2 pada tabel S.
b. Natural Join
Operasi natural join adalah operasi equijoin yang memiliki kesamaan dalam semua field yang memiliki nama yang sama dalam tabel R dan tabel S. Dalam hal ini, kita dapat menghilangkan kondisi dalam operasi join karena akan menghasilkan dua field dengan nama yang sama.
Dalam RDBMS, perintah SQL akan dianalisis oleh Optimizer, yang akan menentukan langkah-langkah yang paling optimal dalam menjalankan perintah SQL. Berikut ini ada beberapa cara JOIN yang ada pada basis data yaitu :
Nested Loop adalah sebuah JOIN yang efektif jika subset yang digabungkan berjumlah sedikit dan jika kondisi dalam perintah JOIN efisien untuk menggabungkan 2 tabel tersebut.Cara kerja Nested Loop adalah :
1. Optimizer menentukan sebuah tabel untuk dijadikan Outer
2. Tabel yang tersisa dijadikan Inner Table.
3. Pada setiap baris yang terdapat pada Outer Table, Optimizer akan mengakses semua baris yang terdapat pada Inner Table dengan kondisi yang di spesifikasikan di dalam JOIN.
b. Hash Joins
Hash Joins biasanya digunakan untuk mengabungkan data-data yang berjumlah besar. Cara kerja Hash Joins adalah Optimizer membuat sebuah Hash Table berdasarkan predikat JOIN. Setiap tabel di Inner maupun Outer masing-masing dijadikan sebuah kode dengan Hash Function kemudian setiap kode Hash dari Inner akan dibandingkan dengan Hash Kode dari Outer. Apabila kode hash dari Inner dan Outer
sama maka akan dilakukan proses pengecekan nilai dari kolom yang pada akhirnya akan dimasukkan ke dalam hasil jika nilai kolomnya sama.
c. Sort Merge Joins
Sort Merge Joins biasa digunakan untuk menggabungkan baris dari dua sumber yang tidak mempunyai hubungan. Biasanya Hash Joins mempunyai performa yang lebih baik dari pada Sort Merge Joins. Namun Sort Merge Joins akan bekerja lebih baik daripada Hash Join apabila terdapat kondisi sebagai Baris-baris sudah diurutkan.
d. Cartesian Joins
Sebuah Cartesian Joins digunakan ketika satu atau lebih tabel tidak mempunyai kondisi penggabungan terhadap tabel lainnya. Optimizer akan menggabungkan setiap baris di tabel pertama dengan setiap baris di tabel lainya untuk menghasilkan sebuah Cartesian Produk dari dua set tersebut.
e. Outer Joins
Outer Joins mempunyai proses dimana selain baris yang memenuhi kondisi JOIN yang dimasukkan ke dalam hasil. Outer Joins akan menambahkan baris yang tidak memenuhi kondisi JOIN namun digabung dengan nilai NULL. Terdapat 3 Jenis Outer Join yaitu :
b. Jika penggunaan Nested Loop Join tidaklah optimal karena jumlah data yang besar dan tidak adanya kondisi JOIN yang cukup efisien.
c. Jika Optimizer menemukan bahwa penggunaan Sort Merge akan meningkatkan performa daripada Hash Join karena
Berikut ini adalah cara-cara bagaimana Optimizer menganalisis perintah JOIN yang akan dijalankan dalam query : Untuk mengeksekusi sebuah perintah JOIN maka
Optimizer harus mengidentifikan beberapa hal, yaitu : 1. Cara akses perintah JOIN
Untuk perintah-perintah yang sederhana, Optimizer harus menentukan cara mengakses yang paling optimal untuk mendapatkan data dari setiap tabel yang di- JOIN.
2. Metode JOIN
Setiap ada perintah JOIN maka Optimizer akan menentukan metode JOIN mana yang paling tepat untuk digunakan, baik itu Nested Loop, Sort Merge, Cartesian atau Hash Joins.
2.4.2. Konsep Query
Query adalah semacam kemampuan untuk menampilkan suatu data dari database dimana mengambil dari table-tabel yang ada di database, namun tabel tersebut tidak semua ditampilkan sesuai dengan yang kita inginkan. data apa yang ingin kita tampilkan. misal : data peminjam dengan buku yang dipinjam, maka nanti akan mengambil data dari table peminjam dan tabel buku.
Bahasa query (query language) adalah bahasa khusus yang digunakan untuk melakukan query pada basis data. Contoh penggunaan bahasa query adalah: SELECT
ALL WHERE kota=”Yogyakarta” AND umur<40. Query tersebut meminta semua
record dari basis data yang sedang digunakan (misalkan basisdata konsumen) yang bertempat tinggal di Yogyakarta dan berumur lebih dari 40 tahun (kota dan umur adalah nama field yang telah didefinisikan). Standar bahasa query yang banyak digunakan adalah SQL (structured query language). Metode ini paling rumit tetapi paling fleksibel dibandingkan metode query yang lain, query dengan parameter yang telah tersedia dan query by example.
1. Untuk membuat/mendefinisikan obyek-obyek database seperti membuat tabel, relasi dan sebagainya. Biasanya disebut dengan Data Definition Language (DDL) 2. Untuk memanipulasi data, yang biasanya dikenal dengan Data Manipulation
Language (DML). Manipulasi data bisa berupa: a. Menambah, mengubah atau menghapus data.
b. Pengambilan informasi yang diperlukan dari database, yang mana datanya diambil dari tabel maupun dari query sebelumnya
2.5. Optimasi Query
Optimasi Query adalah suatu proses untuk menganalisa query untuk menentukan sumber-sumber apa saja yang digunakan oleh query tersebut dan apakah penggunaan dari sumber tersebut dapat dikurangi tanpa merubah output. Atau bisa juga dikatakan bahwa optimasi query adalah sebuah prosedur untuk meningkatkan strategi evaluasi dari suatu query untuk membuat evaluasi tersebut menjadi lebih efektif. Optimasi query mencakup beberapa teknik seperti transformasi query ke dalam bentuk logika yang sama, memilih jalan akses yang optimal dan mengoptimumkan penyimpanan data.
Tujuan dari optimasi query adalah menemukan jalan akses yang termurah untuk meminimumkan total waktu pada saat proses sebuah query. Untuk mencapai tujuan tersebut, maka diperlukan optimizer untuk melakukan analisa query dan untuk melakukan pencarian jalan akses.
2.6. Algoritma Hash Join
Hash join digunakan ketika men-join tabel-tabel yang berukuran besar atau dengan set data yang besar. Hash join memerlukan Equijoin predikat (predikat membandingkan nilai dari satu tabel dengan nilai-nilai dari tabel lain menggunakan operator yang sama
‘=’).
Optimizer menggunakan hash join untuk join dengan dua tabel jikajoin menggunakan Equijoin dan jika salah satu dari kondisi berikut benar:
a. Sejumlah data besar yang harus join.
Optimizer menggunakan lebih kecil dari dua tabel atau sumber data untuk membangun sebuah tabel hash dalam memori. Kemudian scan tabel yang lebih besar, menyelidiki tabel hash untuk menemukan baris join. Metode ini paling baik digunakan ketika tabel kecil cocok di memori yang tersedia. Biaya kemudian dibatasi untuk melewati single read untuk dua tabel. Hash join akan digunakan, jika tidak ada indeks yang memadai pada kolom join. Ini adalah situasi terburuk.
Query optimizer membuat hash join dalam dua tahap, yaitu :
a. Membangun (build) tabel hash di memori, yang lebih kecil dari dua tabel. b. Probe ini tabel hash dengan nilai hash untuk setiap tabel baris kedua.
Algoritma Hash Join : Fase Build
For each R1 begin
generate hash value of R1 join key
insert into build table to appropriate hash bucket end
Fase Probe for each R2 begin
generate hash value of R2 join key for each R1 in corresponding hash bucket if match R1 and R2
output (R1,R2) end
Jadi hash join memiliki dua input, yaitu masukan membangun dan masukan probe. Contoh query hash join :
select e.last_name, d.department_name, d.location_id from employees e, departments d, locations l where e.department_id = d.department_id;
2.7. Algoritma Nested Join
Nested query atau query bersarang adalah query yang memiliki query lain di dalamnya. Sub Query merupakan pernyataan Select yang merupakan bagian dari pernyataan
Insert,Select. Nested query digunakan untuk menangani masalah dalam query yang kompleks bahkan kita tidak tahu nilai berapa yang akan diSelect atau di Insert.
1. Subquery digunakan untuk menyelesaikan persoalan dimana suatu nilai yang tidak diketahui.
2. Meng-copy data dari satu tabel ke tabel lain. 3. Menerima data dari Inline View.
4. Mengambil data dari tabel lain untuk kemudian diupdate ke tabel yang dituju . 5. Menghapus baris dari satu tabel berdasarkan baris dari tabel lain.
Bentuk Umum dari Nested Query adalah:
select * from employees el where e.department_id in (Select d.department_id from department_name d)
2.8. Riset Terkait
Dalam melakukan penelitian, penulis menggunakan beberapa riset terkait yang dijadikan acuan yang membuat penelitian berjalan lancer. Adapun riset-riset terkait tersebut adalah :
Tabel 2.1 Riset terkait
No Judul Riset Nama Peneliti Dan Tahun dengan cross product, baik dalam 2 relasi yang dikondisi harus diindekskan
Tri Wahyu, 2008 Algoritma Subset Query
yang lebih kecil
dibanding dengan metode subset query. Sebaliknya untuk data lebih besar dari 5165
Query Rushmore Salah satu keuntungan optimisasi query Rushmore adalah bahwa mesin jet Query sekarang dapat
genetik, jika jumlah Pm diperkecil maka hasil optimum dapat dicapai.
3. Jumlah relasi kecil, harga pencarian tidakn berubah-ubah.
4. Dari hasil beberapa kali percobaan, bahwa semakin banyak jumlah yang digunakan maka waktu proses yang diperlukan algoritma genetic untuk menyelesaikan optimasi query akan semakin lama. 2.8 Perbedaan Dengan Riset Yang lain
Dalam penelitian ini yang memedakan antara peneliti sebelumnya adalah perbedaan algoritma, tahapan pengujian, Bahasa Pemrograman yang digunakan, Database Manajemen Sistem dan masukkan dari peneliti-peneliti sebelumnya yang mereka tuangkan dikesimpulan untuk melakukan penelitian selanjutnya.
2.9 Kontribusi Riset
Ada pun kontribusi penulis dalam melakukan penelitian ini adalah:
BAB 3
METODOLOGI PENELITIAN
3.1. Deskripsi Basis Data
Sumber data untuk menjadi studi kasus dalam penelitian ini adalah master basis data Anggaran mempunyai 6 tabel yang saling berhubungan. Semua tabel tidak memiliki indeks atau cluster yang digunakan dalam pencarian data.
3.1.1. Struktur Fisik Database
Pengujian query-query pencarian data menggunakan beberapa tabel yang saling berhubungan dari tabel satu dengan tabel yang lain. Berikut struktur fisik database yang akan diuji.
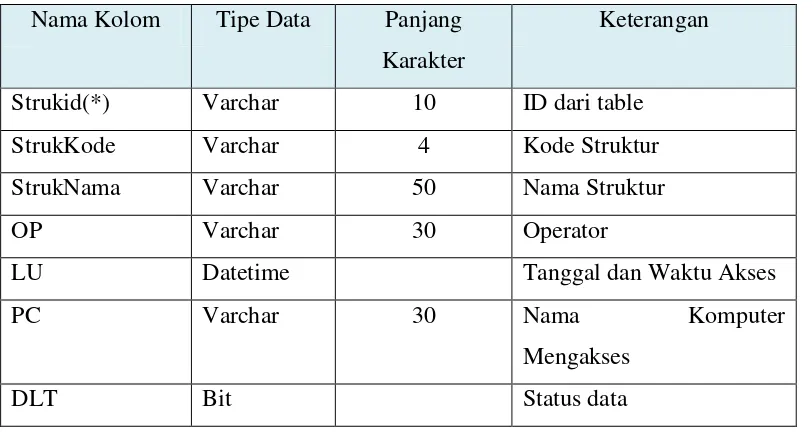
Tabel 3.1. TBMStruk
Nama Kolom Tipe Data Panjang Karakter
Keterangan
Strukid(*) Varchar 10 ID dari table
StrukKode Varchar 4 Kode Struktur
StrukNama Varchar 50 Nama Struktur
OP Varchar 30 Operator
LU Datetime Tanggal dan Waktu Akses
PC Varchar 30 Nama Komputer
Mengakses
DLT Bit Status data
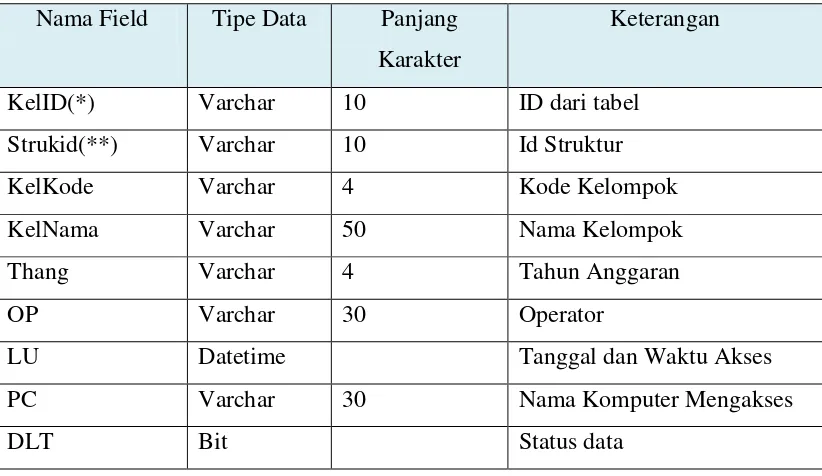
Tabel 3.2. TBMKel
Nama Field Tipe Data Panjang Karakter
Keterangan
KelID(*) Varchar 10 ID dari tabel
Strukid(**) Varchar 10 Id Struktur
KelKode Varchar 4 Kode Kelompok
KelNama Varchar 50 Nama Kelompok
Thang Varchar 4 Tahun Anggaran
OP Varchar 30 Operator
LU Datetime Tanggal dan Waktu Akses
PC Varchar 30 Nama Komputer Mengakses
DLT Bit Status data
Pada tabel TbmKel memilik 9 kolom yaitu Kelid, Strukid,Kelkode, KelNama, OP, LU, PC dan DLT serta semua kolom tersebut memiliki tipe data dan panjang karakter berbeda tergantung jenis data kolom tersebut. Sedangkan kunci unik dari tabel diatas adalah KelID dan kunci tamu adalah Strukid.
Tabel 3.3. TBMJen
Nama Field Tipe Data Panjang Karakter
Keterangan
JenID(*) Varchar 10 ID dari table
Kelid(**) Varchar 10 Id Kelompok
JenKode Varchar 4 Kode Jenis
JenNama Varchar 50 Nama Jenis
Thang Varchar 4 Tahun Anggaran
OP Varchar 30 Operator
LU Datetime Tanggal dan Waktu Akses
PC Varchar 30 Nama Komputer Mengakses
Pada tabel TbmJen memilik 9 kolom yaitu Jenid, Kelid, Jenkode, JenNama, OP, LU, PC dan DLT serta semua kolom tersebut memiliki tipe data dan panjang karakter berbeda tergantung jenis data kolom tersebut. Sedangkan kunci unik dari tabel diatas adalah JenID dan kunci tamu adalah Kelid.
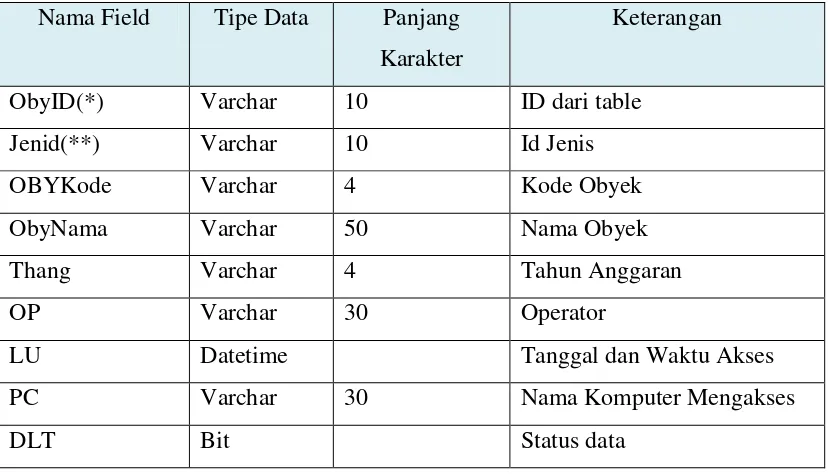
Tabel 3.4. TBMObyek
Nama Field Tipe Data Panjang Karakter
Keterangan
ObyID(*) Varchar 10 ID dari table
Jenid(**) Varchar 10 Id Jenis
OBYKode Varchar 4 Kode Obyek
ObyNama Varchar 50 Nama Obyek
Thang Varchar 4 Tahun Anggaran
OP Varchar 30 Operator
LU Datetime Tanggal dan Waktu Akses
PC Varchar 30 Nama Komputer Mengakses
DLT Bit Status data
Pada tabel TbmObyek memilik 9 kolom yaitu Obyid, Jenid, Obykode, ObyNama, OP, LU, PC dan DLT serta semua kolom tersebut memiliki tipe data dan panjang karakter berbeda tergantung jenis data kolom tersebut. Sedangkan kunci unik dari tabel diatas adalah ObyID dan kunci tamu adalah Jenid.
Tabel 3.5. TBMRoby
Nama Field Tipe Data Panjang Karakter
Keterangan
RObyID(*) Varchar 10 ID dari table
ObyID(**) Varchar 10 Id Obyek
ROBYKode Varchar 4 Kode Rincian Obyek
RObyNama Varchar 50 Nama Rincian Obyek
OP Varchar 30 Operator
LU Datetime Tanggal dan Waktu Akses
PC Varchar 30 Nama Komputer Mengakses
DLT Bit Status data
Pada tabel TbmRoby memilik 9 kolom yaitu Robyid, Obyid, Robykode, RobyNama, OP, LU, PC dan DLT serta semua kolom tersebut memiliki tipe data dan panjang karakter berbeda tergantung jenis data kolom tersebut. Sedangkan kunci unik dari tabel diatas adalah RobyID dan kunci tamu adalah Obyid.
Tabel 3.6. TBMSubRoby
Nama Field Tipe Data Panjang Karakter
Keterangan
SubRObyID(*) Varchar 10 ID dari table
RObyID(**) Varchar 10 Id Obyek
SubROBYKode Varchar 4 Kode Sub Rincian Obyek
SubRObyNama Varchar 50 Nama Sub Rincian Obyek
Thang Varchar 4 Tahun Anggaran
OP Varchar 30 Operator
LU Datetime Tanggal dan Waktu Akses
PC Varchar 30 Nama Komputer Mengakses
DLT Bit Status data
Pada tabel TbmSubRoby memilik 9 kolom yaitu SubRobyid, RObyid, SubRobykode, SubRobyNama, OP, LU, PC dan DLT serta semua kolom tersebut memiliki tipe data dan panjang karakter berbeda tergantung jenis data kolom tersebut. Sedangkan kunci unik dari tabel diatas adalah SubRobyID dan kunci tamu adalah RObyid.
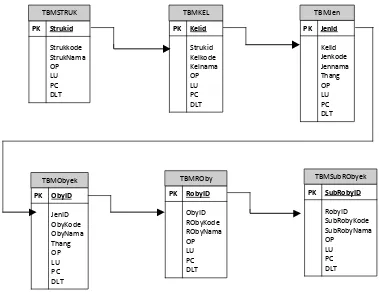
Untuk menunjukan hubungan keseluruhan tabel maka dibuat diagram relasi sebagai
Gambar 3.1. Relasi Antar Tabel
3.1.3 Skenario Pengujian Query
Pengujian pencarian data menggunakan query dua algoritma yaitu Query Hash Join dan Query Nested Join. Pengujian Query dalam hal pencarian data berdasarkan banyak jumlah data untuk melakukan pencarian data dibagi atas beberapa tahap relasi dan group data. Masing-masing group mempunyai jumlah data yang berbeda . berikut group data sebagai uji coba dan berdasarkan jumlah data yang berbeda untuk penelitian berikut tahap relasi dan tabel group data:
Tabel 3.7 Tahapan Relasi
Relasi 1 1 Relasi 2 2 Relasi 4 3 Relasi 5 4 Relasi 6 5 Relasi
Tabel 3.8 Tabel Group data Uji Penelitian
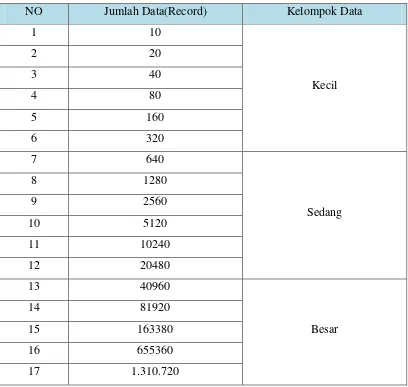
NO Jumlah Data(Record) Kelompok Data
1 10
Kecil
2 20
3 40
4 80
5 160
6 320
7 640
Sedang
8 1280
9 2560
10 5120
11 10240
12 20480
13 40960
Besar
14 81920
15 163380
16 655360
17 1.310.720
Start
Startime=0 EndTime=0 Durasi=0
Perintah Query Pencarian
Data
Startime
Eksekusi Query
Endtime
Durasi=Endti me-Startime
Stop
Gambar 3.2. Flowchart Skenario Pengujian Query
3.2. Query Algoritma
menggunakan Visual Basic.Net 2010 dan Microsoft SQL Server 2008 sebagai Database Manajemen Sistem.
3.2.1 QueryHash Join
Pengujian kinerja query Algoritma Hash Join dalam pencarian data dari sebuah aplikasi maka query dibagi berdasarkan jumlah tabel yang saling berhubungan.
1. Query 1 Relasi
Query 2 (dua) tabel yang saling berhubungan dengan menggunakan query algoritma Hash Join dimana menampikan informasi tabel TBMKEL secara penuh. Berikut query relasi 2 (dua) tabel menggunakan Algoritma Hash Join.
SELECT TBMKEL.* FROM TBMKEL, TBMSTRUK WHERE TBMKEL.STRUKID=TBMSTRUK.STRUKID
Query diatas menghubungkan TBMKEL dengan TBMSTRUK dengan menggunakan query hash join adapun kolom/field menghubungkan kedua tabel adalah STRUKID.
2. Query 2 Relasi
Query 3 (Tiga) tabel yang saling berhubungan dengan menggunakan Algoritma Hash Join untuk menampilkan informasi tabel TBMJEN secara penuh. Berikut query relasi 3 tabel:
SELECT TBMJEN.* FROM TBMJEN, TBMKEL, TBMSTRUK
WHERE TBMJEN.KELID = TBMKEL.KELID AND TBMKEL.STRUKID = TBMSTRUK.STRUKID
Query diatas menghubungkan TBMSTRUK, TBMKEL dan TBMJEN dengan menggunakan query hash join adapaun kolom/field yang menghubungkan ketiga tabel yaitu KELID antara tabel TBMJEN dengan TBMKEL dan STRUKID antara tabel TBMKEL dengan TBMSTRUK.
Query 4 (Empat) tabel yang saling berrelasi dengan menggunakan Query Hash Join
untuk menampilkan informasi table TBMOBY secara penuh. Berikut query relasi 4 tabel:
SELECT TBMOBY.* FROM TBMOBY, TBMJEN, TBMKEL, TBMSTRUK WHERE TBMOBY.JENID = TBMJEN.JENID AND TBMJEN.KELID = TBMKEL.KELID AND TBMKEL.STRUKID = TBMSTRUK.STRUKID
Query diatas menghubungkan TBMOBY, TBMJEN, TBMKEL, TBMSTRUK dengan menggunakan query hash join, adapun kolom/field yang menghubungkan keempat tabel yaitu Kolom/Field JENID yang menghubungkan tabel TBMOBY dengan TBMJEN, Kolom/Field KELID yang menghubungkan tabel TBMJEN dengan tabel
TBMKEL dan Kolom/Field STRUKID yang menghubungkan tabel TBMKEL dengan
tabel TBMSTRUK.
4. Query 4 Relasi
Query 5 (Lima) tabel yang saling berrelasi dengan menggunakan Query Hash Join untuk menampilkan informasi tabel TBMROBY secara penuh.. Berikut query relasi antar 5 tabel.
SELECT TBMROBY.* FROM TBMOBY, TBMJEN, TBMKEL, TBMSTRUK, TBMROBY WHERE TBMROBY.OBYID = TBMOBY.OBYID AND TBMOBY.JENID = TBMJEN.JENID AND TBMJEN.KELID = TBMKEL.KELID AND TBMKEL.STRUKID = TBMSTRUK.STRUKID
Query diatas menghubungkan tabel TBMROBY, TBMOBY, TBMJEN, TBMKEL, TBMSTRUK, TBMROBY. Adapun kolom/field yang menghubungkan
kelima tabel tersebut yaitu Kolom OBYID menghubungkan tabel TBMROBY dengan TBMOBY, Kolom JENID menghubungkan tabel TBMOBY dengan TBMJEN, kolom
KELID menghubungkan tabel TBMJEN dengan TBMKEL, dan kolom STRUKID
menghubungkan tabel TBMKEL dengan tabel TBMSTRUK. 5. Query 5 Relasi
SELECT TBMSUBROBY.* FROM TBMOBY, TBMJEN, TBMKEL, TBMSTRUK, TBMROBY, TBMSUBROBY
WHERE TBMSUBROBY.ROBYID = TBMROBY.ROBYID AND TBMROBY.OBYID = TBMOBY.OBYID AND TBMOBY.JENID = TBMJEN.JENID AND TBMJEN.KELID = TBMKEL.KELID
AND TBMKEL.STRUKID = TBMSTRUK.STRUKID
Query diatas menghubungkan tabel TBMSUBROBY, TBMROBY, TBMOBY, TBMJEN, TBMKEL, dan TBMSTRUK. Adapun kolom/field menghubungkan keenam
tabel yaitu kolom ROBYID menghubungkan tabel TBMSUBROBY dengan TBMROBY, kolom OBYID menghubungkan tabel TBMROBY dengan TBMOBY,
kolom JENID menghubungkan tabel TBMOBY dengan TBMJEN, kolom KELID menghubungkan tabel TBMJEN dengan TBMKEL dan kolom STRUKID menghubungkan tabel TBMKEL dengan tabel TBMSTRUK.
3.2.2 Query Nested Join
Pengujian membandingkan dua algoritma harus menghasilkan informasi yang sama tapi menggunakan metode yang berbeda. Pengujian pencarian data menggunakan Query Nested Join dibagi juga dibagi beberapa tahap berdasarkan jumlah tabel yang saling berrelasi. Berikut tahapan yang akan diuji:
1. Query 1 Relasi
Query 2 (dua) tabel saling berhubungan menggunakan query nested join ada dua cara yang akan diuji yaitu:
1. QueryScalar
Mengakses data atau menampilkan informasi 1 tabel secara penuh yaitu Tabel TBMKEL dimana satu kolom terpenuhi satu sub query. Berikut query scalar
SELECT * FROM TBMKEL WHERE TBMKEL.STRUKID IN(SELECT STRUKID FROM TBMSTRUK)
2. Query Correlated
Mengakses data atau menampilkan informasi 1 tabel secara penuh yaitu Tabel TBMKEL dimana satu kolom terpenuhi satu sub query. Berikut query nested join correlated tersebut:
SELECT * FROM TBMKEL WHERE TBMKEL.STRUKID IN(SELECT
STRUKID FROM TBMSTRUK WHERE
TBMKEL.STRUKID=TBMSTRUK.STRUKID)
Query diatas menghubungkan TBMKEL dengan TBMSTRUK dengan menggunakan query nested join scalar adapun kolom/field menghubungkan kedua tabel adalah STRUKID.
2. Query 2 Relasi
Query 3 (tiga) tabel saling berrelasi menggunakan query nested join ada dua cara yang akan diuji yaitu:
1. QueryScalar
SELECT * FROM TBMJEN WHERE TBMJEN.KELID IN(SELECT KELID FROM TBMKEL WHERE TBMKEL.STRUKID IN(SELECT STRUKID FROM TBMSTRUK))
2. Query Correlated
SELECT * FROM TBMJEN WHERE TBMJEN.KELID IN(SELECT KELID FROM TBMKEL WHERE TBMJEN.KELID=TBMKEL.KELID AND TBMKEL.STRUKID IN(SELECT STRUKID FROM TBMSTRUK WHERE TBMKEL.STRUKID=TBMSTRUK.STRUKID))
3. Query 3 Relasi
Query 4 (Empat) tabel saling berrelasi menggunakan query nested join ada dua cara yang akan diuji yaitu:
1. QueryScalar
SELECT * FROM TBMOBY WHERE TBMOBY.JENID IN (SELECT JENID FROM TBMJEN WHERE TBMJEN.KELID IN(SELECT KELID FROM TBMKEL WHERE TBMKEL.STRUKID IN(SELECT STRUKID FROM TBMSTRUK)))
2. Query Correlated
SELECT * FROM TBMOBY WHERE TBMOBY.JENID IN (SELECT JENID FROM TBMJEN WHERE TBMOBY.JENID=TBMJEN.JENID AND TBMJEN.KELID IN(SELECT KELID FROM TBMKEL WHERE TBMJEN.KELID=TBMKEL.KELID AND TBMKEL.STRUKID IN(SELECT
STRUKID FROM TBMSTRUK WHERE
TBMKEL.STRUKID=TBMSTRUK.STRUKID)))
Query diatas menghubungkan TBMOBY, TBMJEN, TBMKEL, TBMSTRUK dengan menggunakan query nested join baik secara scalar maupun correlated, adapun kolom/field yang menghubungkan keempat tabel yaitu Kolom/Field JENID yang menghubungkan tabel TBMOBY dengan TBMJEN, Kolom/Field KELID yang menghubungkan tabel TBMJEN dengan tabel TBMKEL dan Kolom/Field STRUKID yang menghubungkan tabel TBMKEL dengan tabel TBMSTRUK.
4. Query 4 Relasi
Query 5 (Lima) tabel saling berrelasi menggunakan Algoritma Nested Join ada dua cara yang akan diuji yaitu:
1. QueryScalar
SELECT * FROM TBMROBY WHERE TBMROBY.OBYID IN (SELECT OBYID FROM TBMOBY WHERE TBMOBY.JENID IN(SELECT JENID FROM TBMJEN WHERE TBMJEN.KELID IN(SELECT KELID FROM TBMKEL WHERE TBMKEL.STRUKID IN(SELECT STRUKID FROM TBMSTRUK))))
SELECT * FROM TBMROBY WHERE TBMROBY.OBYID IN (SELECT OBYID FROM TBMOBY WHERE TBMROBY.OBYID=TBMOBY.OBYID AND TBMOBY.JENID IN(SELECT JENID FROM TBMJEN WHERE TBMOBY.JENID=TBMJEN.JENID AND TBMJEN.KELID IN(SELECT KELID FROM TBMKEL WHERE TBMJEN.KELID=TBMKEL.KELID AND TBMKEL.STRUKID IN(SELECT STRUKID FROM TBMSTRUK WHERE TBMKEL.STRUKID=TBMSTRUK.STRUKID))))
Query diatas menghubungkan tabel TBMROBY, TBMOBY, TBMJEN, TBMKEL, TBMSTRUK, TBMROBY secara nested join baik secara scalar maupun
nested. Adapun kolom/field yang menghubungkan kelima tabel tersebut yaitu Kolom OBYID menghubungkan tabel TBMROBY dengan TBMOBY, Kolom JENID
menghubungkan tabel TBMOBY dengan TBMJEN, kolom KELID menghubungkan tabel TBMJEN dengan TBMKEL, dan kolom STRUKID menghubungkan tabel TBMKEL dengan tabel TBMSTRUK.
5. Query 5 Relasi
Query 6 (Enam) tabel saling berrelasi menggunakan algoritma Nested Join ada dua cara yang akan diuji yaitu:
1. QueryScalar
SELECT * FROM TBMSUBROBY WHERE TBMSUBROBY.ROBYID IN(SELECT ROBYID FROM TBMROBY WHERE TBMROBY.OBYID IN
(SELECT OBYID FROM TBMOBY WHERE
TBMROBY.OBYID=TBMOBY.OBYID AND TBMOBY.JENID IN(SELECT JENID FROM TBMJEN WHERE TBMOBY.JENID=TBMJEN.JENID AND TBMJEN.KELID IN(SELECT KELID FROM TBMKEL WHERE TBMJEN.KELID=TBMKEL.KELID AND TBMKEL.STRUKID IN(SELECT
STRUKID FROM TBMSTRUK WHERE
TBMKEL.STRUKID=TBMSTRUK.STRUKID)))))
2. Query Correlated
SELECT * FROM TBMSUBROBY WHERE TBMSUBROBY.ROBYID IN(SELECT ROBYID FROM TBMROBY WHERE TBMSUBROBY.ROBYID=TBMROBY.ROBYID AND TBMROBY.OBYID IN
(SELECT OBYID FROM TBMOBY WHERE
TBMJEN.KELID IN(SELECT KELID FROM TBMKEL WHERE TBMJEN.KELID=TBMKEL.KELID AND TBMKEL.STRUKID IN(SELECT
STRUKID FROM TBMSTRUK WHERE
TBMKEL.STRUKID=TBMSTRUK.STRUKID)))))
Query diatas menghubungkan tabel TBMSUBROBY, TBMROBY, TBMOBY, TBMJEN, TBMKEL, dan TBMSTRUK secara scalar maupun correlated. Adapun kolom/field menghubungkan keenam tabel yaitu kolom ROBYID menghubungkan tabel TBMSUBROBY dengan TBMROBY, kolom OBYID menghubungkan tabel
TBMROBY dengan TBMOBY, kolom JENID menghubungkan tabel TBMOBY
dengan TBMJEN, kolom KELID menghubungkan tabel TBMJEN dengan TBMKEL dan kolom STRUKID menghubungkan tabel TBMKEL dengan tabel TBMSTRUK.
Adapun hasil keluaran informasi pencarian data didapat dari query diatas relasi antar tabel sebagai berikut:
1. Relasi 2 Tabel
Query 1 (satu) relasi diatas menampilkan tabel TBMKEL secara penuh, adapun kolom/field yang ditampilkan yaitu KELID, STRUKID, KELKODE, KELNAMA, THANG, OP, LU, PC, dan DLT.
2. Relasi 3 Tabel
Query 2 relasi atau 3 tabel diatas menampilkan tabel TBMJEN secara penuh. Adapun kolom/field yang ditampilkan dari query diatas yaitu JENID, KELID, JENKODE, JENNAMA,THANG, OP, LU, PC dan DLT.
3. Relasi 4 Tabel
Query 3 relasi atau 4 tabel diatas menampilkan informasi tabel TBMOBY secara penuh. Adapun kolom/field yang ditampilkan informasi dari query diatas yaitu OBYID, JENID, OBYKODE, OBYNAMA, THANG, OP, LU, PC dan DLT.
4. Relasi 5 Tabel
Query 4 relasi atau 5 tabel diatas menampilkan informasi tabel TBMROBY secara penuh. Adapun kolom/field ditampilkan informasi dari query diatas yaitu ROBYID, OBYID, ROBYKODE, ROBYNAMA, THANG, OP,LU, PC dan
DLT.
Query 5 relasi atau 6 tabel diatas menampilkan informasi tabel TBMSUBROBY secara penuh. Adapun kolom/field ditampilkan informasi dari query diatas yaitu SUBROBYID, ROBYID, SUBROBYKODE, SUBROBYNAMA, THANG,
OP, LU, PC dan DLT.
3.3. Paramter Pengujian Query
Parameter yang digunakan untuk menguji query-query diatas dalam pencarian data adalah kecepatan waktu mengeksekusi dan menampilkan informasi daam pencarian data. Untuk menghitung waktu kecepatan yang diperlukan untuk mengakses data maka dibuat sebuah aplikasi. Satuan waktu untuk menghitung query-query diatas dalam satuan detik.
3.3.1. Rancangan Aplikasi
Rancangan Aplikasi untuk menguji query-query diatas sebagai berikut:
DataGrid View
Start
Gambar 3.3. Rancangan Aplikasi
3.4. Alat Penelitian
a. Perangkat keras
1. Processor Intel Pentium Core Duo. 2. RAM 2GB.
3. Harddisk 500 GB.
4. Monitor dengan resolusi 1024 x 768 pixel 32 bit color.
5. Mouse dan keyboard.
b. Perangkat lunak
1. Sistem Operasi Windows XP service pack 3. 2. Visual Basic.Net 2010.
BAB 4
HASIL PENELITIAN DAN PEMBAHASAN
4.1. Hasil Penelitian
Penulis melakukan percobaan pada jaringan peer to peer dengan spesifikasi hardware sebagai berikut:
1. Server
- Processor Intel Core I3 2.20 GHz - Hardisk 360 GB
- Memory 2 GB
- Sistem Operasi Windows 7 2. Client
- Processor Intel Core Duo 2.10 GHz - Harddisk 360 GB
- Memory 2 GB
- Sistem Operasi Windows XP - Microsfot Visual Basic.Net 2010 4.2. Hasil Pengujian Query
Agar memudahkan melihat perbandingan query hash join, nested join maka penulis mengelompokan data berdasarkan banyak jumlah data sebagai berikut:
- Kelompok data kecil berkisar antara 10-320 baris(Record)
- Kelompok data sedang berkisar antara 640-20480 baris(Record)
- Kelompok data besar berkisar antara 40960-1310720 baris(Record)
4.2.1. Hasil Pengujian Query 1 Relasi
Gambar 4.1. Perbandingan Running Time Query 1 Relasi
Dari data diatas diatas dapat dilihat bahwa kelompok data kecil atau record yang sedikit kecepatan waktu(detik) query dalam melakukan pencarian data ketiga query diatas memilik kecepatan waktu yang hampir sama walapun query hash join kadang agak lambat tetapi tidak terlalu besar sedangkan kelompok data menengah memilik waktu yang sama dan kelompok data besar waktu untuk mengakses data memiliki waktu yang berbeda dimana Query Nested Join Scalar menunjukan lebih baik dibanding query dua lainnya namun perbedaan waktu tidak begitu besar.
Gambar 4.2. Grafik Perbandingan Running TimeQuery 1 Relasi Dari grafik diatas dapat dianalisa sebagai berikut:
1. Query Hash Join mengakses data 1 tabel secara penuh dari aplikasi dengan jumlah data yang kecil waktu yang dibutuhkan hampir sama dengan ketiga query
dan jumlah data yang besar waktu yang dibutuhkan lebih baik dibanding query
lainnya.
3. Query Nested Join Correlated mengakses data 1 tabel secara penuh dari aplikasi jumlah data yang kecil waktu yang dibutuhkan untuk mengakses data sama dengan Query Nested Join Scalar tapi jumlah data yang besar lebih cepat dibanding Query Hash Join dan lebih lama dibanding Query Nested Join Scalar.
4.2.2. Hasil Pengujian 2 Relasi
Pengujian query dengan menghubungkan 3 (tiga) tabel menampilkan secara penuh 1 tabel untuk melakukan pencarian data atau mengakses data dari aplikasi dengan menggunakan 3 query yaitu Query Hash Join, Query Nested Join Scalar dan Query
Gambar 4.3. Perbandingan Running TimeQuery 2 Relasi
Dari hasil pengujian query berdasarkan data diatas bisa dijelaskan sebagai berikut:
1. Query kelompok data kecil Query Hash Join lebih lama dibanding query Nested Join dan query Nested Join scalar lebih baik dibanding Nested Join Correlated.
2. Query kelompok data sedang Query Hash Join lebih lama dibandingkan
query nested join, query nested join scalar lebih stabil dibanding yang lainnya.
3. Query kelompok data besar query nested join lebih baik dibanding query hash join sedangkan query nested join scalar lebih stabil dibanding query nested join correlated.
Gambar 4.4. Grafik Perbandingan Running TimeQuery 2 Relasi Dari grafik diatas dapat dianalisa sebagai berikut:
1. Query Hash Join mengakses data 1 tabel secara penuh dari aplikasi dengan jumlah data yang kecil waktu yang dibutuhkan hampir sama dengan ketiga query
dan jumlah data yang besar waktu yang dibutuhkan lebih baik dibanding query
lainnya.
3. Query Nested Join Correlated mengakses data 1 tabel secara penuh dari aplikasi jumlah data yang kecil waktu yang dibutuhkan untuk mengakses data sama dengan Query Nested Join Scalar tapi jumlah data yang besar lebih cepat dibanding Query Hash Join dan lebih lama dibanding Query Nested Join Scalar.
4.2.3. Hasil Pengujian Query 3 Relasi
Pengujian query yang dilakukan yang menghubungkan 4 tabel sekaligus dalam mengakses data satu tabel secara penuh. Berikut perbandingan waktu yang dibutuhkan query dalam mengakses data.
0
Gambar 4.5. Perbandingan Running Time Query 3 Relasi
Dari hasil pengujian query berdasarkan data diatas bisa dijelaskan sebagai berikut:
1. Query Kelompok data kecil query hash join dan nested join scalar lebih stabil dalam kecepatan mengakses data sedangkan query nested join correlated tidak berbeda jauh dengan 2 query lainnya tapi nested join correlated tidak stabil. 2. Query Kelompok data sedang query hash join lebih baik dibanding nested join
baik scalar maupun correlated.
3. Query Kelompok data besar memiliki waktu yang berbeda jauh dengan query hash join dengan query nested join dimana waktu selisih jauh lebih cepat query nested join dibanding query hash join.
Gambar 4.6. Grafik Perbandingan Query Pencarian Data Relasi 3 Tabel Dari grafik diatas dapat dianalisa sebagai berikut:
1. Query Hash Join mengakses data 1 tabel secara penuh dari aplikasi dengan jumlah data yang kecil waktu yang dibutuhkan hampir sama dengan ketiga query
dan jumlah data yang besar waktu yang dibutuhkan lebih baik dibanding query
lainnya.
3. Query Nested Join Correlated mengakses data 1 tabel secara penuh dari aplikasi jumlah data yang kecil waktu yang dibutuhkan untuk mengakses data sama dengan Query Nested Join Scalar tapi jumlah data yang besar lebih cepat dibanding Query Hash Join dan lebih lama dibanding Query Nested Join Scalar.
4.2.4. Hasil Pengujian Query 4 Relasi
Pengujian query yang dilakukan yang menghubungkan 5 tabel sekaligus dalam mengakses data satu tabel secara penuh. Berikut perbandingan waktu yang dibutuhkan query dalam mengakses data.
0
Gambar 4.7. Grafik Perbandingan Query Pencarian Data Relasi 3 Tabel
Hasil pengujian query diatas dapat dilihat bahwa untuk jumlah data yang kecil tidak ada perbedaan waktu yang dibutuhkan untuk mengakses data. Jumlah data yang besar terjadi perubahan yang signifikan dmana query hash join lebih besar waktu dibutuhkan untuk mengakses data dibandingkan Nested Join.
Gambar 4.8.Grafik Perbandingan Query Pencarian Data Relasi 5 Tabel
Dari grafik diatas dapat dilihat bahwa kelompok data kecil query hash join,
nestedjoin scalar dan correlated memiliki waktu yang sama, kelompok data sedang hash join lebih baik dibanding query lainnya dan kelompok data besar nested join correlated
lebih baik query lainnya.
4.2.5. Hasil Pengujian Query 5 Relasi 0
Hasil Pengujian query Hash Join, Nested Join yang dilakukan yang menghubungkan 6 (enam) tabel sekaligus dalam mengakses data satu tabel secara penuh. Berikut perbandingan running time query yang dibutuhkan dalam mengakses data.
Gambar 4.9. Hasil Perbandingan Pengujian Running TimeQuery 5 Relasi
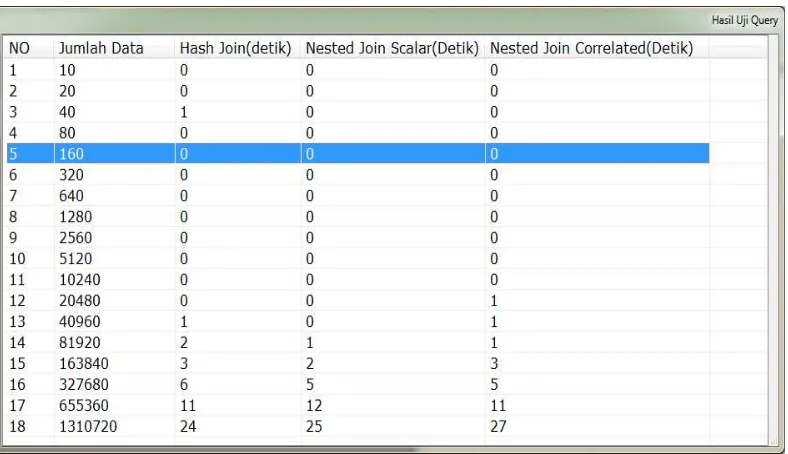
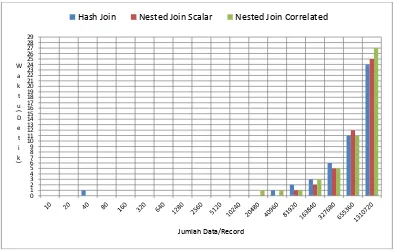
Pada gambar diatas hasil pengujian query Hash Join untuk jumlah data yang kecil waktu yang dibutuhkan mengakses data kecil dan jumlah data yang besar waktu yang dibutuhkan semakin tinggi. Hasil Pengujian Query Nested Join Scalar untuk jumlah data yang kecil waktu yang dibutuhkan kecil akan tetapi pada saat jumlah data yang sedang atau belum begitu besar hasil querynya cendrung naik dan waktu jumlah data yang besar juga semakin tinggi. Hasil Pengujian Query Nested Join Correlated untuk jumlah data yang kecil waktu yang dibutuhkan hampir sama dengan Query Hash Join tapi sedikit lebih baik dibanding Query Nested Join Scalar untuk data yang sedang dan jumlah data yang besar waktu yang dibutuhkan juga semakin tinggi.