ABSTRACT
DEVI DIAN PRAMANA PUTRA. Extended Boolean Model on Retrieval Using P-Norm Model and Belief Revision. Supervised by JULIO ADISANTOSO.
Extended Boolean Model is introduced to intermediate between the Boolean system of query processing and the vector-processing model. The query structure inherent in the Boolean system is preserved, while at the same time weighted term may be incorporated into both queries and stored documents. The retrieved output can also be ranked in strict similarity order with the user queries. Belief Revision is a logical framework in which documents and queries are represented by propositional formulas. Disjunctive Normal Form (DNF) is used to represent documents and queries in the Belief Revision. The purpose of this research is to implement Extended Boolean Model using P-Norm Model and Belief Revision for documents in Bahasa Indonesia. This testing used 30 queries from a thousand agricultural documents and 13 queries from 93 medicinal plants documents. The test result shows that the use of medicinal plants documents is better than agricultural documents. This is due to agricultural documents which have a high similarity between documents. The performance of information retrieval with P-Norm Model and Belief Revision gave good result which is around 81% average precision for medicinal plants documents and 54% for agricultural documents.
1
PENDAHULUAN
Latar Belakang
Temu-kembali informasi model Boolean merupakan model yang paling sederhana. Model Boolean banyak digunakan karena mudah untuk diimplementasikan dan membutuhkan waktu yang relatif singkat untuk proses temu-kembali informasi. Model Boolean juga dapat memberikan hasil recall dan precision yang tinggi jika kueri diformulasikan dengan baik.
Dalam model Boolean kueri diekspresikan menggunakan ekspresi Boolean. Dokumen yang dikembalikan merupakan hasil pencocokan pasti dari kueri yang diberikan. Dokumen yang dikembalikan diprediksi relevan atau tidak relevan. Oleh karena itu dokumen yang dikembalikan bisa terlalu banyak atau sedikit.
Kondisi tersebut dapat membatasi informasi yang akan diterima oleh pengguna. Untuk itu diperlukan sebuah model yang mampu menangani pencocokan sebagian antara dokumen dengan kueri berbentuk Boolean. Salton et al. (1983) memperkenalkan Extended Boolean Model (EBM) yang dikenal juga sebagai P-Norm Model untuk mengatasi kelemahan dari model Boolean.
Lee dan Fox (1988) melakukan penelitian dengan membandingkan P-Norm Model dengan Mixed Min and Max Model (MMM) dan Paice Model. Penelitian tersebut menggunakan tiga koleksi dokumen yaitu: CISI, CACM, dan INSPEC. Hasil penelitian menunjukkan bahwa P-Norm Model mendapatkan nilai average precision yang paling baik. Namun P-Norm Model membutuhkan waktu polinomial dalam perhitungan ukuran kesamaan dengan semakin besarnya nilai p yang digunakan. Nilai p menunjukkan nilai keketatan pada operator Boolean.
Selanjutnya Losada dan Barreiro (1999) melakukan penelitian menggunakan Belief Revision (BR) untuk pemeringkatan dokumen dalam EBM. BR merupakan logical framework, dimana dokumen dan kueri direpresentasikan dengan formula proposisi. Pada penelitian tersebut didapatkan bahwa BR tidak membutuhkan waktu polinomial dalam perhitungan ukuran kesamaan. Penelitian tersebut membandingkan BR dengan P-Norm Model dengan nilai p=1 dengan bobot biner untuk dokumen dan kueri. Untuk itu, penelitian kali ini akan membandingkan Belief Revision
dengan P-Norm Model dengan nilai p=1, 2, 5 dan 9 untuk dokumen berbahasa Indonesia yaitu dokumen pertanian dan dokumen tanaman obat dengan struktur tag XML.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1.
Mengimplementasikan Belief Revision dan P-Norm Model untuk pemeringkatan dokumen Bahasa Indonesia.2.
Membandingkan kinerja Belief Revision dan P-Norm Model pada sistem temu-kembali.Ruang Lingkup
Dokumen yang digunakan dalam penelitian adalah dokumen XML berbahasa Indonesia.
Manfaat Penelitian
Manfaat dari penelitian ini adalah melakukan pemeringkatan dokumen berbahasa Indonesia (dokumen pertanian dan dokumen tanaman obat) dengan kueri berbentuk Boolean. P-Norm Model dan Belief Revision diharapkan dapat meningkatkan kinerja sistem dengan kueri berbentuk Boolean.
TINJAUAN PUSTAKA
Information Retrieval (Temu-Kembali Informasi)
Temu-kembali informasi berkaitan dengan merepresentasikan, menyimpan, mengorganisasikan, dan mengakses informasi. Merepresentasikan dan mengorganisasikan suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya. Akan tetapi, untuk mengetahui informasi yang diinginkan pengguna bukan merupakan suatu hal yang mudah. Untuk itu pengguna harus menransformasikan informasi yang dibutuhkan ke dalam suatu kueri yang akan diproses mesin pencari (IR system), sehingga kueri tersebut akan merepresentasikan informasi yang dibutuhkan oleh pengguna. Dengan kueri tersebut, IR system akan menemukembalikan informasi yang relevan dengan kueri (Baeza-Yates & Ribeiro-Neto 1999).
Inverted Index
1
PENDAHULUAN
Latar Belakang
Temu-kembali informasi model Boolean merupakan model yang paling sederhana. Model Boolean banyak digunakan karena mudah untuk diimplementasikan dan membutuhkan waktu yang relatif singkat untuk proses temu-kembali informasi. Model Boolean juga dapat memberikan hasil recall dan precision yang tinggi jika kueri diformulasikan dengan baik.
Dalam model Boolean kueri diekspresikan menggunakan ekspresi Boolean. Dokumen yang dikembalikan merupakan hasil pencocokan pasti dari kueri yang diberikan. Dokumen yang dikembalikan diprediksi relevan atau tidak relevan. Oleh karena itu dokumen yang dikembalikan bisa terlalu banyak atau sedikit.
Kondisi tersebut dapat membatasi informasi yang akan diterima oleh pengguna. Untuk itu diperlukan sebuah model yang mampu menangani pencocokan sebagian antara dokumen dengan kueri berbentuk Boolean. Salton et al. (1983) memperkenalkan Extended Boolean Model (EBM) yang dikenal juga sebagai P-Norm Model untuk mengatasi kelemahan dari model Boolean.
Lee dan Fox (1988) melakukan penelitian dengan membandingkan P-Norm Model dengan Mixed Min and Max Model (MMM) dan Paice Model. Penelitian tersebut menggunakan tiga koleksi dokumen yaitu: CISI, CACM, dan INSPEC. Hasil penelitian menunjukkan bahwa P-Norm Model mendapatkan nilai average precision yang paling baik. Namun P-Norm Model membutuhkan waktu polinomial dalam perhitungan ukuran kesamaan dengan semakin besarnya nilai p yang digunakan. Nilai p menunjukkan nilai keketatan pada operator Boolean.
Selanjutnya Losada dan Barreiro (1999) melakukan penelitian menggunakan Belief Revision (BR) untuk pemeringkatan dokumen dalam EBM. BR merupakan logical framework, dimana dokumen dan kueri direpresentasikan dengan formula proposisi. Pada penelitian tersebut didapatkan bahwa BR tidak membutuhkan waktu polinomial dalam perhitungan ukuran kesamaan. Penelitian tersebut membandingkan BR dengan P-Norm Model dengan nilai p=1 dengan bobot biner untuk dokumen dan kueri. Untuk itu, penelitian kali ini akan membandingkan Belief Revision
dengan P-Norm Model dengan nilai p=1, 2, 5 dan 9 untuk dokumen berbahasa Indonesia yaitu dokumen pertanian dan dokumen tanaman obat dengan struktur tag XML.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1.
Mengimplementasikan Belief Revision dan P-Norm Model untuk pemeringkatan dokumen Bahasa Indonesia.2.
Membandingkan kinerja Belief Revision dan P-Norm Model pada sistem temu-kembali.Ruang Lingkup
Dokumen yang digunakan dalam penelitian adalah dokumen XML berbahasa Indonesia.
Manfaat Penelitian
Manfaat dari penelitian ini adalah melakukan pemeringkatan dokumen berbahasa Indonesia (dokumen pertanian dan dokumen tanaman obat) dengan kueri berbentuk Boolean. P-Norm Model dan Belief Revision diharapkan dapat meningkatkan kinerja sistem dengan kueri berbentuk Boolean.
TINJAUAN PUSTAKA
Information Retrieval (Temu-Kembali Informasi)
Temu-kembali informasi berkaitan dengan merepresentasikan, menyimpan, mengorganisasikan, dan mengakses informasi. Merepresentasikan dan mengorganisasikan suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya. Akan tetapi, untuk mengetahui informasi yang diinginkan pengguna bukan merupakan suatu hal yang mudah. Untuk itu pengguna harus menransformasikan informasi yang dibutuhkan ke dalam suatu kueri yang akan diproses mesin pencari (IR system), sehingga kueri tersebut akan merepresentasikan informasi yang dibutuhkan oleh pengguna. Dengan kueri tersebut, IR system akan menemukembalikan informasi yang relevan dengan kueri (Baeza-Yates & Ribeiro-Neto 1999).
Inverted Index
2 dapat dilihat pada Gambar 1. Kumpulan dari
term yang unik disebut dictionary atau vocabulary. Untuk masing-masing term, terdapat kumpulan dokumen dimana term tersebut muncul yang disebut posting list. Setiap entry dalam posting list dapat pula berisi lokasi term di dalam dokumen seperti kata, kalimat dan paragraf. Lalu setiap entry dapat juga berisi bobot untuk term di dalam dokumen. Bobot tersebut digunakan dalam perhitungan ukuran kesamaan dari kueri yang dimasukkan.
Gambar 1 Struktur inverted index
Boolean Model
Boolean Model adalah model untuk temu-kembali informasi yang memungkinkan input kueri yang berbentuk ekspresi Boolean dari term yang merupakan kombinasi dari operator AND, OR, dan NOT (Manning et al 2008). Model Booelan mempertimbangkan bahwa index term muncul atau tidak di dalam dokumen, sehingga index term diasumsikan memiliki bobot biner. Kueri yang dimasukkan dapat direpresentasikan menggunakan Disjunctive Normal Form (DNF). Dimana klausa AND dihubungkan dengan penghubung OR. Pada model Boolean, kueri diproses sesuai dengan operator yang digunakan dan menampilkan dokumen berdasarkan urutan dokumen ditemukan. Dokumen yang dikembalikan tidak mencerminkan relevansi terhadap kueri yang diberikan, karena tidak ada pencocokan sebagian antara kueri dengan dokumen.
Extended Boolean Model
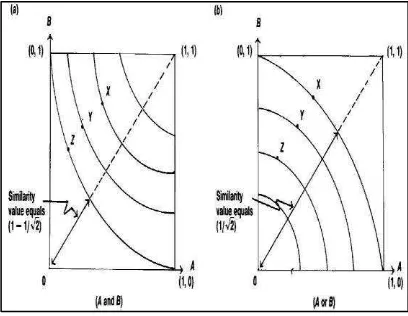
Extended Boolean Model (EBM) merupakan peningkatan dari model Boolean biasa. EBM menggabungkan karakateristik dari Vector Space Model dengan sifat-sifat aljabar Boolean dan peringkat kesamaan antara kueri dan dokumen (Salton et al 1983). Dengan cara ini dokumen mungkin sedikit relevan jika cocok dengan beberapa istilah kueri dan akan dikembalikan sebagai hasilnya. Ketika hanya dua term dalam kueri yang dimasukkan maka sebaran nilai kesamaan dapat dilihat pada Gambar 2. Pada Gambar 2 dapat dilihat bahwa setiap term digambarkan pada koordinat yang
berbeda. Untuk kueri AND titik (1,1) merepresentasikan dimana kedua term muncul dan merupakan titik yang paling diinginkan, sedangkan untuk kueri OR, titik (0,0) merepresentasikan dimana kedua term tidak muncul dan merupakan titik yang tidak diingikan. Jika hanya salah satu term yang muncul maka nilai ukuran kesamaan akan bernilai ⁄ untuk OR kueri dan ⁄ untuk AND kueri. Sehingga ukuran kesamaan akan berkisar dari 0 hingga 1. Perhitungan ukuran kesamaan dalam EBM menggunakan persamaan berikut (Salton et al 1983):
√
( ) √
dengan , merupakan bobot term A dan bobot term B pada dokumen.
Gambar 2 Sebaran ukuran kesamaan EBM
P-Norm Model
P-Norm Model memberikan gagasan untuk memasukkan nilai p, yaitu nilai yang menunjukkan keketatatan pada operator. Nilai p berkisar dari satu sampai tak-hingga. Untuk P-Norm Model ukuran kesamaan antara dokumen dan kueri didefinisikan sebagai berikut: ( ) [ ] ⁄ ( ) [ ] ⁄ dengan
merupakan kueri term berbobot
merupakan bobot term A dan term B pada dokumen
3
Belief Revision
Belief revision (BR) berkaitan dengan akomodasi sebuah informasi baru ke dalam knowledge base yang ada. Formalisasi logis dari BR telah diteliti dalam filsafat, database dan kecerdasan buatan untuk desain agen rasional. Dalam temu-kembali informasi BR direpresentasikan dalam logika proposisi. Dalam BR, model dibangun dari interpretasi. Himpuan dari model dapat dituliskan sebagai Mod( ) dimana adalah formula. Pseudocode dari Belief Revision yang digunakan dalam implementasi sistem dapat dilihat pada Gambar 3.
Gambar 3 Pseudocode Belief Revision
BR menggunakan Symmetric difference antara dua interpretasi yang berbeda yaitu I dan J. Ukuran dari jarak antar-interpretasi tersebut dapat ditulis sebagai dist(I,J). Lalu jarak antara Mod( ) dan I adalah:
Kita misalkan adalah kueri(q) dan I adalah model dokumen(md) dan k adalah jumlah term dalam kueri. Dokumen hanya mempunyai satu model(md), sedangkan kueri memiliki himpunan model(Mod(q)). Kita dapat menggunakan Dalal’s distance untuk model di atas.
Formula ini menggunakan jarak antara setiap model dari kueri (J) dan model dokumen (md), lalu dihitung kardinalitas dari masing-masing model kueri terhadap model dokumen. Langkah 1 sampai 10 pada Gambar 3 menunjukkan algoritme untuk formula di atas. Pertama akan ditetapkan nilai sama dengan nol. Lalu untuk masing-masing model dokumen ( ), ditetapkan nilai
sama dengan banyaknya kata unik dalam koleksi dokumen. Untuk masing-masing , dihitung nilai . Jarak dari klausa dokumen kepada kueri adalah jarak terdekat dari klausa dokumen ke klausa kueri. ( ) adalah kardinalitas dari { | } yaitu banyaknya term positif yang muncul dalam klausa satu dan negatif term pada klausa yang lain atau sebaliknya. | | merupakan banyaknya term dalam yang tidak termasuk dalam . Jika nilai maka nilai sama dengan nilai . Ulangi langkah 4 sampai tidak ada lagi yang tersisa. Update lalu ulangi langkah 2 sampai tidak ada lagi yang tersisa. Jarak rata-rata merupakan hasil bagi dengan banyaknya klausa . merupakan nilai terkecil untuk banyaknya term dalam klausa . Lalu dipilih kardinalitas terkecil sebagai jarak(distance).
Jarak (distance) dapat digunakan untuk menghitung ukuran kesamaan yang dinormalisasi dalam interval [0,1]. Langkah 11 menujukkan algoritme untuk formula di bawah.
Dari persamaan di atas diperoleh ukuran kesamaan (similarity measure) antara dokumen(d) dan kueri(q) dimana k adalah jumlah term yang muncul dalam kueri ( Losada and Barreiro 1999).
Pembobotan Tf-Idf
Term frequency (tf) merupakan frekuensi kemunculan suatu term t pada dokumen d. Document frequency (df) merupakan banyaknya dokumen di dalam korpus yang mengandung kata tertentu (Manning et al. 2008).
Pembobotan tf-idf memberikan bobot pada term t dalam dokumen d dengan nilai:
dengan
merupakan frekuensi term t pada dokumen d
merupakan jumlah dokumen dalam koleksi
4 Kesamaan antar kueri dan dokumen dapat
ditentukan dengan menghitung cosine similarity dari vektor istilah kueri ⃗ ) dan vektor istilah dokumen ( ⃗ ) (Manning et al. 2008):
⃗ ⃗ | ⃗ | | ⃗ |
dengan pembilang merupakan dot product (inner product) antara ⃗ dan ⃗ . Dot Product antara dua vektor didefinisikan sebagai ∑ , sedangkan penyebut merupakan perkalian panjang Euclidean. Panjang Euclidean didefinisikan sebagai
√∑ ⃗
Dalam EBM bobot term dalam dokumen harus dalam interval 0 sampai 1. Oleh karena itu bobot harus dinormalisasi (Salton et al 1983). Normalisasi bobot tf-idf didapatkan dari persamaan berikut:
dengan
merupakan bobot term i dalam dokumen j
merupakan frekuensi term i dalam dokumen j
merupakan frekuensi maksimum term i dalam dokumen j
merupakan nilai idf dari term i dalam koleksi
merupakan nilai maksimum idf term i dalam koleksi.
Evaluasi Temu-Kembali Informasi
Manning (2008) menyatakan, terdapat dua hal mendasar yang paling sering digunakan untuk mengukur kinerja temu-kembali secara efektif adalah recall dan precision (R-P). Perhitungan recall-precision diformulasikan sebagai berikut:
Relevant Not Relevant
Retrieved Tp fp
Not
Retrieved Fn tn
Precision = P = tp/(tp + fp)
Recall = R = tp/(tp+fn)
Menurut Baeza-Yates dan Ribeiro-Neto (1999), algoritma temu-kembali yang dievaluasi menggunakan beberapa kueri berbeda akan menghasilkan nilai R-P yang berbeda untuk masing-masing kueri. Average Precision (AVP) diperlukan untuk menghitung rata-rata tingkat precision pada berbagai tingkat recall, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Perhitungan AVP dapat diformulasikan sebagai berikut:
̅( ) ∑
dimana, ̅( )adalah AVP pada level recall r, Nq adalah jumlah kueri yang digunakan, dan Pi(r) adalah precision pada level recall r untuk kueri ke-i.
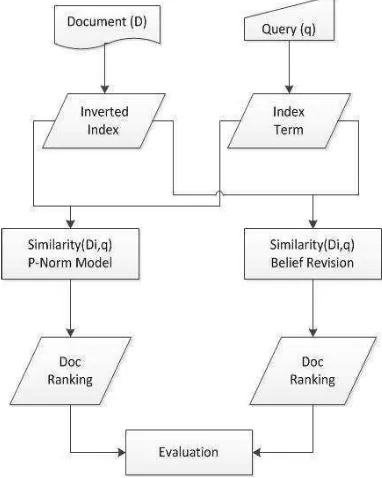
METODE PENELITIAN
Penelitian ini dilakukan dalam beberapa tahap, yaitu pengumpulan dokumen (korpus), pemrosesan dokumen, pemrosesan kueri, perhitungan ukuran kesamaan antara dokumen dengan kueri untuk P-Norm Model dan Belief Revision, pemeringkatan dokumen dari hasil perhitungan ukuran kesamaan dokumen-kueri dan evaluasi terhadap kinerja sistem. Secara umum gambaran sistem dapat dilihat pada Gambar 4.4 Kesamaan antar kueri dan dokumen dapat
ditentukan dengan menghitung cosine similarity dari vektor istilah kueri ⃗ ) dan vektor istilah dokumen ( ⃗ ) (Manning et al. 2008):
⃗ ⃗ | ⃗ | | ⃗ |
dengan pembilang merupakan dot product (inner product) antara ⃗ dan ⃗ . Dot Product antara dua vektor didefinisikan sebagai ∑ , sedangkan penyebut merupakan perkalian panjang Euclidean. Panjang Euclidean didefinisikan sebagai
√∑ ⃗
Dalam EBM bobot term dalam dokumen harus dalam interval 0 sampai 1. Oleh karena itu bobot harus dinormalisasi (Salton et al 1983). Normalisasi bobot tf-idf didapatkan dari persamaan berikut:
dengan
merupakan bobot term i dalam dokumen j
merupakan frekuensi term i dalam dokumen j
merupakan frekuensi maksimum term i dalam dokumen j
merupakan nilai idf dari term i dalam koleksi
merupakan nilai maksimum idf term i dalam koleksi.
Evaluasi Temu-Kembali Informasi
Manning (2008) menyatakan, terdapat dua hal mendasar yang paling sering digunakan untuk mengukur kinerja temu-kembali secara efektif adalah recall dan precision (R-P). Perhitungan recall-precision diformulasikan sebagai berikut:
Relevant Not Relevant
Retrieved Tp fp
Not
Retrieved Fn tn
Precision = P = tp/(tp + fp)
Recall = R = tp/(tp+fn)
Menurut Baeza-Yates dan Ribeiro-Neto (1999), algoritma temu-kembali yang dievaluasi menggunakan beberapa kueri berbeda akan menghasilkan nilai R-P yang berbeda untuk masing-masing kueri. Average Precision (AVP) diperlukan untuk menghitung rata-rata tingkat precision pada berbagai tingkat recall, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Perhitungan AVP dapat diformulasikan sebagai berikut:
̅( ) ∑
dimana, ̅( )adalah AVP pada level recall r, Nq adalah jumlah kueri yang digunakan, dan Pi(r) adalah precision pada level recall r untuk kueri ke-i.
METODE PENELITIAN
Penelitian ini dilakukan dalam beberapa tahap, yaitu pengumpulan dokumen (korpus), pemrosesan dokumen, pemrosesan kueri, perhitungan ukuran kesamaan antara dokumen dengan kueri untuk P-Norm Model dan Belief Revision, pemeringkatan dokumen dari hasil perhitungan ukuran kesamaan dokumen-kueri dan evaluasi terhadap kinerja sistem. Secara umum gambaran sistem dapat dilihat pada Gambar 4.5 Koleksi Dokumen
Dokumen yang digunakan sebagai dokumen pengujian adalah dokumen corpus yang berasal dari lab TKI hasil Penelitian Adisantoso & Ridha (2004). Dokumen yang berada di Lab TKI berjumlah 1000 dokumen pertanian dan 93 dokumen tanaman obat berasal dari Lab Computational Intelligence.
Pemrosesan Dokumen
Pada tahap ini dilakukan lowercasing terhadap dokumen, yaitu dengan mengubah semua huruf menjadi huruf non-capital agar menjadi case insensitive pada saat dilakukan pemrosesan teks dokumen. Selanjutnya dilakukan proses parsing yang merupakan proses memilah dokumen menjadi unit-unit yang lebih kecil misalnya berupa kata, frasa atau kalimat (Ridha 2002). Dalam penelitian ini unit terkecil yang digunakan adalah kata yang terdiri minimal tiga huruf. Selain itu, tanda baca yang terdapat dalam dokumen dihilangkan karena bukan merupakan penciri dari dokumen. Selanjutnya dilakukan pembuangan stopwords. Stopwords adalah kata umum yang biasanya muncul dalam jumlah yang besar dan dianggap tidak memiliki makna. Lalu dilakukan pembobotan pada term dengan pembobotan tf-idf dan tf-tf-idf yang sudah dinormalisasi.
Pemrosesan Kueri
Proses selanjutnya adalah melakukan pemrosesan terdapat kueri yang dimasukkan. Pemrosesan kueri sama halnya dengan pemrosesan dokumen. Kueri yang dimasukkan akan dilakukan lowercasing dan juga parsing. Pada pemrosesan kueri sedikit berbeda karena kueri yang dimasukkan mengandung operator Boolean, sehingga perlu dipisahkan antara term yang mengandung operator Boolean dengan term yang bukan operator Boolean. Pemisahan tersebut dilakukan untuk mengetahui jenis operator yang digunakan, sehingga memudahkan dalam perhitungan nilai ukuran kesamaan. Setelah pemrosesan kueri maka akan diperoleh array kueri yang dapat digunakan dalam proses perhitungan ukuran kesamaan.
Similarity Dokumen dengan Kueri
Pada perhitungan similarity antara dokumen dengan kueri untuk metode P-Norm Model, dilakukan pengecekan apakah jenis operator Boolean yang digunakan. Perhitungan ukuran kesamaan akan dilakukan sesuai dengan jenis operator yang dimasukkan, sedangkan
untuk Belief Revision, kueri direpresentasikan sebagai formula proposisi. Dalam formula proposisi dokumen dan kueri harus dalam bentuk Disjunctive Normal Form (DNF). DNF mempunyai bentuk: , dengan masing-masing adalah klausa yang dihubungkan dengan operator AND. Perhitungan nilai kesamaan Belief Revision dilakukan dengan membandingkan model kueri dengan model dokumen.
Pemeringkatan Dokumen
Pemeringkatan dokumen dilakukan setelah perhitungan nilai kesamaan antara dokumen dengan kueri untuk P-Norm Model dan Belief Revision. Pemeringkatan dokumen dilakukan dengan mengurutkan dokumen yang dikembalikan sesuai dengan bobot yang diperoleh. Semakin besar bobot yang diperoleh maka peringkat dokumen yang dikembalikan akan semakin tinggi.
Evaluasi Hasil Temu-Kembali
Pengujian sistem dilakukan dengan perhitungan terhadap recall dan precision. Recall adalah rasio dokumen relevan yang ditemukembalikan. Precision adalah dokumen yang ditemukembalikan, dokumen tersebut relevan. Dalam perhitungan recall, digunakan elevent standart recall yaitu 0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.7,0.8,0.9 dan 1.0. Perhitungan dilakukan untuk masing-masing metode.
Hasil perhitungan recall dan precision untunk masing-masing model akan dibandingkan dalam bentuk grafik recall-precision, selain itu juga akan dihitung average precision dari masing-masing model untuk memperoleh model yang baik untuk temu-kembali.
Asumsi
Asumsi-asumsi yang digunakan dalam pembangunan sistem ini adalah:
1. Tidak ada kesalahan dalam pengetikan kueri.
2. Setiap kata dalam kueri dipisahkan dengan operator AND dan OR.
6 Lingkungan Implementasi
Lingkungan implementasi yang akan digunakan adalah sebagai berikut:
Perangkat lunak:
Microsoft Windows 7 Profesional sebagai sistem operasi.
PHP sebagai bahasa pemrograman.
Netbeans IDE 6.9 sebagai IDE untuk pembangunan sistem.
Wamp Server Apache version 2.2.11 sebagai web server.
Notepad++.
Microsoft Office 2010 sebagai aplikasi yang digunakan untuk melakukan perhitungan dalam evaluasi sistem.
Perangkat keras:
Processor Intel Core 2 duo 2.2 GHz RAM 2 GB
Hardisk 320GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen PengujianPenelitian ini menggunakan 1000 dokumen pertanian dan 93 dokumen tanaman obat yang berasal dari Laboratorium Temu-Kembali Ilmu Komputer IPB. Deskripsi dari dokumen ini dapat dilihat pada Tabel 1.
Tabel 1 Deskripsi dokumen pengujian
Uraian Dokumen Pertanian Nilai (byte)
Ukuran keseluruhan dokumen 4.139.332
Ukuran rata-rata dokumen 4139
Ukuran dokumen terbesar 54.082
Ukuran dokumen terkecil 451
Uraian Dokumen Tanaman Obat
Nilai (byte)
Ukuran keseluruhan dokumen 297.796
Ukuran rata-rata dokumen 3202
Ukuran dokumen terbesar 13.628
Ukuran dokumen terkecil 928
Seluruh dokumen yang digunakan dalam penelitian ini berformat plain-text yang memiliki struktur XML. Struktur tulisan dokumen pertanian dapat dilihat pada Gambar
5, sedangkan struktur tulisan dokumen tanaman obat dapat dilihat pada Gambar 6.
Gambar 5 Contoh dokumen pertanian
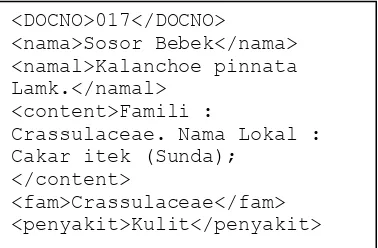
Gambar 6 Contoh dokumen tanaman obat
Dokumen dikelompokkan ke dalam tag-tag sebagai berikut:
<DOC></DOC>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag lain yang lebih spesifik.
<DOCNO></DOCNO>, tag ini menunjukkan ID dari dokumen.
<DATE></DATE>, menunjukkan tanggal dari berita.
<AUTHOR></AUTHOR>, menunjukkan penulis dari berita tersebut.
<TEXT></TEXT>, tag ini menunjukkan isi dari dokumen.
<nama></nama>, tag ini menunjukkan nama dari tanaman obat.
<namal></namal>, tag ini menunjukkan nama latin dari tanaman obat.
<DOC>
<DOCNO>balaipenelitian000000-001</DOCNO>
<TITLE>PRODUKTIVITAS SOM JAWA (Talinum paniculatum
Gaertn.)…
</TITLE>
<AUTHOR>Ireng DarwatiIreng Darwati, Mono Rahardjo, dan Rosita SMD </AUTHOR> <TEXT>
<P>Som Jawa merupakan tanaman yang menghasilkan umbi. Untuk menghasilkan umbi yang
optimaldiperlukan tanah yang
sifat-sifat fisik dan kesuburannya baik….</P> </TEXT> </DOC> <DOCNO>017</DOCNO> <nama>Sosor Bebek</nama> <namal>Kalanchoe pinnata Lamk.</namal> <content>Famili :
Crassulaceae. Nama Lokal : Cakar itek (Sunda);
</content>
6 Lingkungan Implementasi
Lingkungan implementasi yang akan digunakan adalah sebagai berikut:
Perangkat lunak:
Microsoft Windows 7 Profesional sebagai sistem operasi.
PHP sebagai bahasa pemrograman.
Netbeans IDE 6.9 sebagai IDE untuk pembangunan sistem.
Wamp Server Apache version 2.2.11 sebagai web server.
Notepad++.
Microsoft Office 2010 sebagai aplikasi yang digunakan untuk melakukan perhitungan dalam evaluasi sistem.
Perangkat keras:
Processor Intel Core 2 duo 2.2 GHz RAM 2 GB
Hardisk 320GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen PengujianPenelitian ini menggunakan 1000 dokumen pertanian dan 93 dokumen tanaman obat yang berasal dari Laboratorium Temu-Kembali Ilmu Komputer IPB. Deskripsi dari dokumen ini dapat dilihat pada Tabel 1.
Tabel 1 Deskripsi dokumen pengujian
Uraian Dokumen Pertanian Nilai (byte)
Ukuran keseluruhan dokumen 4.139.332
Ukuran rata-rata dokumen 4139
Ukuran dokumen terbesar 54.082
Ukuran dokumen terkecil 451
Uraian Dokumen Tanaman Obat
Nilai (byte)
Ukuran keseluruhan dokumen 297.796
Ukuran rata-rata dokumen 3202
Ukuran dokumen terbesar 13.628
Ukuran dokumen terkecil 928
Seluruh dokumen yang digunakan dalam penelitian ini berformat plain-text yang memiliki struktur XML. Struktur tulisan dokumen pertanian dapat dilihat pada Gambar
5, sedangkan struktur tulisan dokumen tanaman obat dapat dilihat pada Gambar 6.
Gambar 5 Contoh dokumen pertanian
Gambar 6 Contoh dokumen tanaman obat
Dokumen dikelompokkan ke dalam tag-tag sebagai berikut:
<DOC></DOC>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag lain yang lebih spesifik.
<DOCNO></DOCNO>, tag ini menunjukkan ID dari dokumen.
<DATE></DATE>, menunjukkan tanggal dari berita.
<AUTHOR></AUTHOR>, menunjukkan penulis dari berita tersebut.
<TEXT></TEXT>, tag ini menunjukkan isi dari dokumen.
<nama></nama>, tag ini menunjukkan nama dari tanaman obat.
<namal></namal>, tag ini menunjukkan nama latin dari tanaman obat.
<DOC>
<DOCNO>balaipenelitian000000-001</DOCNO>
<TITLE>PRODUKTIVITAS SOM JAWA (Talinum paniculatum
Gaertn.)…
</TITLE>
<AUTHOR>Ireng DarwatiIreng Darwati, Mono Rahardjo, dan Rosita SMD </AUTHOR> <TEXT>
<P>Som Jawa merupakan tanaman yang menghasilkan umbi. Untuk menghasilkan umbi yang
optimaldiperlukan tanah yang
sifat-sifat fisik dan kesuburannya baik….</P> </TEXT> </DOC> <DOCNO>017</DOCNO> <nama>Sosor Bebek</nama> <namal>Kalanchoe pinnata Lamk.</namal> <content>Famili :
Crassulaceae. Nama Lokal : Cakar itek (Sunda);
</content>
7 <content></content>, tag ini
mewakili isi dari dokumen meliputi deskripsi tanaman dan kegunaannya. <fam></fam>, tag ini menunjukkan
nama family dari tanaman obat.
<penyakit></penyakit>, tag ini menunjukkan penyakit yang berkaitan dengan tanaman obat.
Pemrosesan Dokumen
Sebelum dilakukan proses pengindeksan koleksi dokumen terlebih dahulu dilakukan pembuangan tagging. Pembuangan tagging ini dilakukan karena tagging bukan merupakan penciri dari suatu dokumen. Gambar 7 menunjukkan format dokumen setelah dilakukan pembungan tagging.
Setelah proses pembuangan tagging lalu dilakukan parsing terhadap dokumen, kemudian dilakukan proses pembuangan stopword, pembuangan tanda baca dan mengubah term ke lower case. Setelah itu dilakukan pembuatan inverted index dari masing-masing kata unik dan disimpan ke dalam file.
Pembobotan dilakukan untuk masing-masing dokumen dengan pembobotan Tf-Idf dan Tf-Idf yang sudah dinormalisasi. Hasil pembobotan juga disimpan ke dalam file.
Gambar 7 Format dokumen setelah dilakukan pembuangan tagging.
Pemrosesan Kueri
Kueri yang digunakan dalam penelitian ini berupa kueri yang berbentuk Boolean. Kata dalam kueri dipisahkan oleh operator AND dan OR.
Dalam pemrosesan kueri yang pertama dilakukan adalah melakukan proses case folding. Case folding adalah membuat huruf pada teks menjadi kecil. Lalu dilakukan pengecekan apakan dalam kueri terdapat operator Boolean, jika ada maka kata akan
dijadikan index dalam array dengan nama
‘i_root’ selainnya kata akan dijadikan index
dengan nama ‘i_term’ dan jika terdapat tanda
kurung maka kata akan dijadikan index dengan
nama ‘brackets’ dan akan dilakukan proses rekursif dalam memroses kueri tersebut. Contoh pemrosesan kueri, dengan kueri ‘gagal AND panen’ dapat dilihat pada Gambar 8.
Kueri ‘gagal AND panen’ sudah dalam DNF
sehingga dapat diproses untuk mendapatkan ukuran kesamaan.
Gambar 8 Contoh pemrosesan kueri
Temu-Kembali dengan Boolean Model
Pada temu-kembali menggunakan Boolean Model kueri yang dimasukkan mengandung operator Boolean. Kueri akan diproses secara rekursif sesuai dengan operator yang digunakan. Jika operator yang digunakan adalah AND maka akan dicari posting list dari index ‘i_term’ tersebut dan dilakukan proses intersection. Jika operator adalah OR maka akan dilakukan proses merge terhadap posting list ‘i_term’. Hasil yang dikembalikan dalam Boolean Model relevan atau tidak relevan dari kueri yang diberikan. Karena dalam Boolean Model tidak ada pencocokan sebagian antara dokumen dan kueri yang diberikan. Berikut adalah penggalan contoh hasil temu-kembali menggunakan Boolean Model dengan kueri
‘gagal AND panen’. balaipenelitian000000-001
PRODUKTIVITAS SOM JAWA Ireng Darwati
Som Jawa merupakan tanaman yang menghasilkan umbi. Untuk
menghasilkan umbi yang
optimal, diperlukan tanah
yang sifat-sifat fisik dan kesuburannya baik.
Array (
[i_term] => Array (
[0] => gagal [1] => panen )
[i_root] => Array (
[0] => and )
)
Array (
[0] => gatra070203.txt [1] => gatra161002.txt [2] => gatra190802.txt [3] => gatra210704.txt [4] => gatra260803.txt [5] => gatra301002.txt [6] => indosiar031203.txt [7] => indosiar040903.txt [8] => indosiar050704-002.txt [9] => indosiar130104.txt
8 Temu-Kembali dengan P-Norm Model
Pada temu-kembali menggunakan P-Norm Model akan ditentukan nilai p yang akan digunakan. Kueri akan diproses secara rekursif sesuai dengan operator yang digunakan. Jika operator adalah AND maka rumus yang digunakan adalah
( )
[
]
⁄
Jika operator yang digunakan adalah OR maka persamaan yang digunakan adalah
( )
[
]
⁄
dengan
merupakan kueri term berbobot
merupakan bobot term A dan term B pada dokumen
.
Pada P-Norm Model nilai p yang digunakan adalah 1, 2, 5 dan 9. Berikut adalah contoh 10 teratas hasil temu-kembali menggunakan P-Norm Model untuk nilai p=9 dengan kueri
‘gagal AND panen’.
Temu-Kembali dengan Belief Revision
Pada temu-kembali menggunakan Belief Revision kueri yang dimasukkan harus dalam bentuk DNF. Pada Gambar 9 dapat dilihat contoh perhitungan untuk algoritma Belief Revision.
Pada Gambar 9 literal merupakan himpunan kata unik dalam koleksi dokumen,
untuk model dokumen, untuk model kueri. Terdapat dua model dokumen dan dua model kueri. Hasil dari perhitungan similarity menghasilkan nilai 1, hal tersebut karena kueri yang dimasukkan dapat dipenuhi oleh model dokumen. Pada penelitian ini dokumen hanya mempunyai satu model sedangkan kueri memiliki satu atau lebih model. Berikut adalah contoh 10 teratas hasil temu-kembali menggunakan Belief Revision
pada dokumen pertanian dengan kueri ‘gagal AND panen’.
Gambar 9 Contoh perhitungan algoritma Belief Revision
Array (
[kompas030704.txt]=> 0.19519 [indosiar140204.txt]=> 0.12138 [republika060804-001.txt]=>0.09549 [situshijau280404-002.txt]
=>0.08724
[gatra301002.txt] => 0.08230 [indosiar040903.txt] => 0.08230 [gatra190902-02.txt] => 0.08055 [indosiar240703.txt] => 0.08055 [indosiar260803-001.txt] => 0.0776 [suarapembaruan260703-002.txt] => 0.07699
)
Array(
9 Evaluasi Sistem Temu-Kembali Informasi
Proses evaluasi dalam penelitian ini dilakukan pada dua koleksi dokumen dan kueri uji yang berbeda.
1.Pengujian pada Dokumen Pertanian
Proses evaluasi pada dokumen pertanian menggunakan 30 kueri uji yang telah ada sebelumnya berikut dokumen-dokumen yang relevan (Lampiran 2). Pencarian dengan kueri uji ini dilakukan dengan tujuan mendapatkan nilai recall dan precision dari sistem. Perhitungan AVP untuk Belief Revision dan P-Norm Model untuk dokumen pertanian terdapat pada Lampiran 4.
Perbandingan kinerja Belief Revision
dengan P-Norm Model
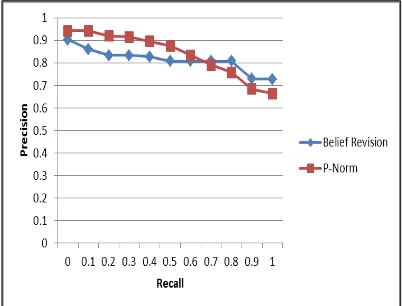
Perbandingan kinerja kinerja Belief Revision dengan P-Norm Model dapat dilihat pada Tabel 2. Lalu untuk ilustrasi perbandingan kinerja Belief Revision dengan P-Norm dapat dilihat pada Gambar 10.
Tabel 2 Nilai AVP BR dengan P-Norm Model pada dokumen pertanian
Metode AVP
Belief Revision 0.5490
P-Norm Model 0.5489
Pada Tabel 2 dapat dilihat bahwa Belief Revision mendapat nilai AVP sebesar 0.5490. Sedangkan P-Norm medapat nilai AVP sebesar 0.5489. Dapat dilihat bahwa Belief Revision mendapat nilai AVP yang lebih besar dari P-Norm yaitu dengan selisih sebesar 0.0001. Dengan menggunakan Belief Revision maka nilai AVP meningkat sebesar 0.01%. Kinerja sistem menggunakan Belief Revision secara umum dapat dikatakan lebih baik daripada P-Norm Model dengan average precision sekitar 54%. Hasil tersebut menunjukkan bahwa secara rata-rata pada tiap recall point, 54% hasil temu-kembali relevan terhadap kueri.
Gambar 10 Grafik R-P kinerja BR dengan P-Norm Model dokumen pertanian
2.Pengujian pada Dokumen Tanaman Obat
Proses evaluasi pada dokumen tanaman obat menggunakan 13 kueri uji berikut dokumen-dokumen yang relevan (Lampiran 3). Pengujian yang dilakukan sama seperti pengujian sebelumnya yaitu mendapatkan nilai recall dan precision dari sistem. Perhitungan AVP untuk Belief Revision dan P-Norm Model untuk dokumen pertanian terdapat pada Lampiran 5.
Perbandingan kinerja Belief Revision
dengan P-Norm Model
Perbandingan kinerja kinerja Belief Revision dengan P-Norm Model dapat dilihat pada Tabel 3. Pada Gambar 11 dapat dilihat perbandingan kinerja Belief Revision dengan P-Norm Model.
Tabel 3 Nilai AVP BR dengan P-Norm Model pada dokumen tanaman obat
Metode AVP
Belief Revision 0.8128
P-Norm Model 0.8378
Pada Tabel 3 dapat dilihat bahwa Belief Revision mendapat nilai AVP sebesar 81,28%. Sedangkan P-Norm Model mendapat nilai AVP sebesar 83.78%. Dari data di atas dapat dilihat bahwa Belief Revision memiliki nilai AVP yang lebih besar dari P-Norm Model yaitu dengan selisih sebesar 2.5%. Kinerja sistem menggunakan Belief Revision secara umum dapat dikatakan lebih baik daripada P-Norm Model dengan average precision sekitar 83%. Hasil tersebut menunjukkan bahwa secara rata-rata pada tiap recall point, 83% hasil temu-kembali relevan terhadap kueri.
10
KESIMPULAN DAN SARAN
Kesimpulan
Hasil penelitian ini menunjukkan bahwa:
1. Belief Revision akan optimal untuk dokumen yang homogen, sedangkan P-Norm Model akan optimal untuk dokumen yang kurang homogen.
2. Kinerja sistem yang didapatkan secara keseluruhan sudah cukup baik yaitu lebih dari 50%.
Saran
Terdapat beberapa hal yang dapat ditambahkan atau diperbaiki untuk penelitian ke depan seperti:
1. Menggunakan stemming untuk melihat pengaruh stemming terhadap kinerja Belief Revision dan P-Norm Model.
2. Menggunakan dokumen uji yang lebih banyak dan beragam.
3. Menggunakan pembobotan dalam Belief Revision.
Daftar Pustaka
Adisantoso J, Ridha A. 2004. Corpus Dokumen Teks Bahasa Indonesia untuk Pengujian Efektifitas Temu Kembali Informasi. Laporan Akhir Hibah Penelitian SP4, Departemen Ilmu Komputer FMIPA IPB, Bogor.
Baaeza-Yates R, Ribeiro B. 1999. Modern Information Retrieval. Addison-Wesley, New York.
Herdi H. 2010. Pembobotan dalam Proses Pengindeksan Dokumen Bahasa Indonesia menggunakan Framework Indri [skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor.
Lee W C, Fox E A. 1988. Experimental Comparation of Schemes for Interpreting Boolean Queries. TR-88-27, VPI&SU Comp. Science Dept., September 1988, Blacksburg, VA.
Losada D E, Barreiro A. 1999. Using a Belief Revision Operator for Document Ranking in Extended Boolean Models. In Proc. of SIGIR-99, the 22th ACM Conference on Research and Development in Information Retrieval, pages 66–73, Berkeley, California, August 1999.
Losada D E, Barreiro A. 2000. Implementing Document Ranking within a Logical Framework. SPIRE 2000: 188-198.
Losada D E, Barreiro A. 2001. A Logical Model for Information Retrieval Based on Propositional Logic and Belief Revision. Comput. J. 44(5): 410-424 (2001).
Manning C D, Raghavan P, Schutze H. 2009. Introduction to Information Retrieval. America, New York.
Ridha A. 2002. Pengindeksan Otomatis dengan Istilah Tunggal untuk Dokumen Berbahasa Indonesia. [skripsi]. Bogor: Departemen Ilmu Komputer, Institut Petanian Bogor.
TEMU-KEMBALI MODEL EXTENDED BOOLEAN MENGGUNAKAN
P-NORM MODEL DAN BELIEF REVISION
DEVI DIAN PRAMANA PUTRA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
TEMU-KEMBALI MODEL EXTENDED BOOLEAN MENGGUNAKAN
P-NORM MODEL DAN BELIEF REVISION
DEVI DIAN PRAMANA PUTRA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
DEVI DIAN PRAMANA PUTRA. Extended Boolean Model on Retrieval Using P-Norm Model and Belief Revision. Supervised by JULIO ADISANTOSO.
Extended Boolean Model is introduced to intermediate between the Boolean system of query processing and the vector-processing model. The query structure inherent in the Boolean system is preserved, while at the same time weighted term may be incorporated into both queries and stored documents. The retrieved output can also be ranked in strict similarity order with the user queries. Belief Revision is a logical framework in which documents and queries are represented by propositional formulas. Disjunctive Normal Form (DNF) is used to represent documents and queries in the Belief Revision. The purpose of this research is to implement Extended Boolean Model using P-Norm Model and Belief Revision for documents in Bahasa Indonesia. This testing used 30 queries from a thousand agricultural documents and 13 queries from 93 medicinal plants documents. The test result shows that the use of medicinal plants documents is better than agricultural documents. This is due to agricultural documents which have a high similarity between documents. The performance of information retrieval with P-Norm Model and Belief Revision gave good result which is around 81% average precision for medicinal plants documents and 54% for agricultural documents.
TEMU-KEMBALI MODEL EXTENDED BOOLEAN MENGGUNAKAN
P-NORM MODEL DAN BELIEF REVISION
DEVI DIAN PRAMANA PUTRA
Skripsi
Sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Temu-Kembali Model Extended Boolean Menggunakan P-Norm Model dan Belief Revision Nama : Devi Dian Pramana Putra
NRP : G64070059
Menyetujui:
Pembimbing
Ir. Julio Adisantoso, M.Kom NIP 19620714 198601 1 002
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP 19601126 198601 2 001
PRAKATA
Alhamdulilahirobbil’alamin, segala puji syukur penulis panjatkan kehadirat Allah SWT atas segala karunia-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul Temu-Kembali Model Extended Boolean Menggunakan P-Norm Model dan Belief Revision.
Penulis menyadari bahwa tugas akhir ini tidak akan terselesaikan tanpan bantuan dari berbagai pihak. Pada kesempatan ini penulis ingin mengucapkan terima kasih kepada:
1. Ibu dan Bapak serta adik yang selalu memberikan doa, nasihat, dukungan dan semangat kepada Penulis sehingga dapat menyelesaikan tugas akhir ini.
2. Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing tugas akhir. Terima kasih atas kesabaran, bimbingan serta dukungan dalam penyelesaian tugas akhir ini.
3. Bapak Ahmad Ridha, S.Kom, M.S dan Ibu Dr. Yeni Herdiyeni, S.Si, M.Kom selaku dosen penguji pada ujian skripsi.
4. Teman-teman satu bimbingan Nova Maulizar, Aprilia Ramadhina, Woro Indriyani, Fandi Rahmawan, Agus Umriadi, Isna Mariam, Nutri Rahayuni dan Ilkomerz 44 terima kasih atas kebersamaan dan semangatnya dalam menyelesaikan tugas akhir ini.
5. Seksi konsumsi seminar, Yuridhis Kurniawan dan Fandi Rahmawan.
6. Seluruh staf Departemen Ilmu Komputer IPB yang telah banyak membantu baik selama penelitian maupun selama perkuliahan.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Penulis berharap adanya masukan berupa saran atau kritik yang bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini. Semoga tugas akhir ini bermanfaat.
Bogor, Oktober 2011
RIWAYAT HIDUP
iv
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... v
DAFTAR TABEL ... v
DAFTAR LAMPIRAN... v
PENDAHULUAN ... 1 Latar Belakang ... 1 Tujuan Penelitian ... 1 Ruang Lingkup Penelitian ... 1 Manfaat Penelitian ... 1
TINJAUAN PUSTAKA ... 1 Information Retrieval (Temu-Kembali Informasi) ... 1 Inverted Index ... 1 Boolean Model ... 2 Extended Boolean Model ... 2 P-Norm Model ... 2 Belief Revision ... 3 Pembobotan Tf-Idf ... 3 Evaluasi Temu-Kembali Informasi ... 4
METODE PENELITIAN ... 4 Koleksi Dokumen ... 5 Pemrosesan Dokumen ... 5 Pemrosesan Kueri ... 5 Similarity Dokumen dengan Kueri ... 5 Pemeringkatan Dokumen ... 5 Evaluasi Hasil Temu-Kembali ... 5 Asumsi ... 5 Lingkungan Implementasi ... 6
HASIL DAN PEMBAHASAN ... 6 Koleksi Dokumen Pengujian ... 6 Pemrosesan Dokumen ... 7 Pemrosesan Kueri ... 7 Temu-Kembali dengan Boolean Model ... 7 Temu-Kembali dengan P-Norm Model ... 8 Temu-Kembali dengan Belief Revision ... 8 Evaluasi Sistem Temu-Kembali Informasi ... 9
KESIMPULAN DAN SARAN ... 10 Kesimpulan... 10 Saran ... 10
DAFTAR PUSTAKA ... 10
v
DAFTAR GAMBAR
Halaman
1 Struktur Inverted Index ... 2
2 Sebaran ukuran kesamaan EBM ... 2
3 Pseudocode Belief Revision ... 3
4 Gambaran umum sistem ... 4
5 Contoh dokumen pertanian ... 6
6 Contoh dokumen tanaman obat ... 6
7 Format dokumen setelah dilakukan pembuangan tagging ... 7
8 Contoh pemrosesan kueri ... 7
9 Contoh perhitungan algoritma Belief Revision ... 8
10 Grafik R-P kinerja BR dengan P-Norm Model pada dokumen pertanian ... 9
11 Grafik R-P kinerja BR dengan P-Norm Model pada dokumen tanaman obat ... .9
DAFTAR TABEL
Halaman
1 Deskripsi dokumen pengujian... 6
2 Nilai AVP BR dengan P-Norm Model pada dokumen pertanian ... 9
3 Nilai AVP BR dengan P-Norm Model pada dokumen tanaman obat ... 9
DAFTAR LAMPIRAN
Halaman
1 Antarmuka Implementasi ... 12
2 Gugus kueri dan jawaban untuk dokumen pertanian ... 13
3 Gugus kueri dan jawaban untuk dokumen tanaman obat ... 19
4 Hasil perhitungan precision pada elevent standart recall untuk dokumen pertanian ... 20
1
PENDAHULUAN
Latar Belakang
Temu-kembali informasi model Boolean merupakan model yang paling sederhana. Model Boolean banyak digunakan karena mudah untuk diimplementasikan dan membutuhkan waktu yang relatif singkat untuk proses temu-kembali informasi. Model Boolean juga dapat memberikan hasil recall dan precision yang tinggi jika kueri diformulasikan dengan baik.
Dalam model Boolean kueri diekspresikan menggunakan ekspresi Boolean. Dokumen yang dikembalikan merupakan hasil pencocokan pasti dari kueri yang diberikan. Dokumen yang dikembalikan diprediksi relevan atau tidak relevan. Oleh karena itu dokumen yang dikembalikan bisa terlalu banyak atau sedikit.
Kondisi tersebut dapat membatasi informasi yang akan diterima oleh pengguna. Untuk itu diperlukan sebuah model yang mampu menangani pencocokan sebagian antara dokumen dengan kueri berbentuk Boolean. Salton et al. (1983) memperkenalkan Extended Boolean Model (EBM) yang dikenal juga sebagai P-Norm Model untuk mengatasi kelemahan dari model Boolean.
Lee dan Fox (1988) melakukan penelitian dengan membandingkan P-Norm Model dengan Mixed Min and Max Model (MMM) dan Paice Model. Penelitian tersebut menggunakan tiga koleksi dokumen yaitu: CISI, CACM, dan INSPEC. Hasil penelitian menunjukkan bahwa P-Norm Model mendapatkan nilai average precision yang paling baik. Namun P-Norm Model membutuhkan waktu polinomial dalam perhitungan ukuran kesamaan dengan semakin besarnya nilai p yang digunakan. Nilai p menunjukkan nilai keketatan pada operator Boolean.
Selanjutnya Losada dan Barreiro (1999) melakukan penelitian menggunakan Belief Revision (BR) untuk pemeringkatan dokumen dalam EBM. BR merupakan logical framework, dimana dokumen dan kueri direpresentasikan dengan formula proposisi. Pada penelitian tersebut didapatkan bahwa BR tidak membutuhkan waktu polinomial dalam perhitungan ukuran kesamaan. Penelitian tersebut membandingkan BR dengan P-Norm Model dengan nilai p=1 dengan bobot biner untuk dokumen dan kueri. Untuk itu, penelitian kali ini akan membandingkan Belief Revision
dengan P-Norm Model dengan nilai p=1, 2, 5 dan 9 untuk dokumen berbahasa Indonesia yaitu dokumen pertanian dan dokumen tanaman obat dengan struktur tag XML.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1.
Mengimplementasikan Belief Revision dan P-Norm Model untuk pemeringkatan dokumen Bahasa Indonesia.2.
Membandingkan kinerja Belief Revision dan P-Norm Model pada sistem temu-kembali.Ruang Lingkup
Dokumen yang digunakan dalam penelitian adalah dokumen XML berbahasa Indonesia.
Manfaat Penelitian
Manfaat dari penelitian ini adalah melakukan pemeringkatan dokumen berbahasa Indonesia (dokumen pertanian dan dokumen tanaman obat) dengan kueri berbentuk Boolean. P-Norm Model dan Belief Revision diharapkan dapat meningkatkan kinerja sistem dengan kueri berbentuk Boolean.
TINJAUAN PUSTAKA
Information Retrieval (Temu-Kembali Informasi)
Temu-kembali informasi berkaitan dengan merepresentasikan, menyimpan, mengorganisasikan, dan mengakses informasi. Merepresentasikan dan mengorganisasikan suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya. Akan tetapi, untuk mengetahui informasi yang diinginkan pengguna bukan merupakan suatu hal yang mudah. Untuk itu pengguna harus menransformasikan informasi yang dibutuhkan ke dalam suatu kueri yang akan diproses mesin pencari (IR system), sehingga kueri tersebut akan merepresentasikan informasi yang dibutuhkan oleh pengguna. Dengan kueri tersebut, IR system akan menemukembalikan informasi yang relevan dengan kueri (Baeza-Yates & Ribeiro-Neto 1999).
Inverted Index
2 dapat dilihat pada Gambar 1. Kumpulan dari
term yang unik disebut dictionary atau vocabulary. Untuk masing-masing term, terdapat kumpulan dokumen dimana term tersebut muncul yang disebut posting list. Setiap entry dalam posting list dapat pula berisi lokasi term di dalam dokumen seperti kata, kalimat dan paragraf. Lalu setiap entry dapat juga berisi bobot untuk term di dalam dokumen. Bobot tersebut digunakan dalam perhitungan ukuran kesamaan dari kueri yang dimasukkan.
Gambar 1 Struktur inverted index
Boolean Model
Boolean Model adalah model untuk temu-kembali informasi yang memungkinkan input kueri yang berbentuk ekspresi Boolean dari term yang merupakan kombinasi dari operator AND, OR, dan NOT (Manning et al 2008). Model Booelan mempertimbangkan bahwa index term muncul atau tidak di dalam dokumen, sehingga index term diasumsikan memiliki bobot biner. Kueri yang dimasukkan dapat direpresentasikan menggunakan Disjunctive Normal Form (DNF). Dimana klausa AND dihubungkan dengan penghubung OR. Pada model Boolean, kueri diproses sesuai dengan operator yang digunakan dan menampilkan dokumen berdasarkan urutan dokumen ditemukan. Dokumen yang dikembalikan tidak mencerminkan relevansi terhadap kueri yang diberikan, karena tidak ada pencocokan sebagian antara kueri dengan dokumen.
Extended Boolean Model
Extended Boolean Model (EBM) merupakan peningkatan dari model Boolean biasa. EBM menggabungkan karakateristik dari Vector Space Model dengan sifat-sifat aljabar Boolean dan peringkat kesamaan antara kueri dan dokumen (Salton et al 1983). Dengan cara ini dokumen mungkin sedikit relevan jika cocok dengan beberapa istilah kueri dan akan dikembalikan sebagai hasilnya. Ketika hanya dua term dalam kueri yang dimasukkan maka sebaran nilai kesamaan dapat dilihat pada Gambar 2. Pada Gambar 2 dapat dilihat bahwa setiap term digambarkan pada koordinat yang
berbeda. Untuk kueri AND titik (1,1) merepresentasikan dimana kedua term muncul dan merupakan titik yang paling diinginkan, sedangkan untuk kueri OR, titik (0,0) merepresentasikan dimana kedua term tidak muncul dan merupakan titik yang tidak diingikan. Jika hanya salah satu term yang muncul maka nilai ukuran kesamaan akan bernilai ⁄ untuk OR kueri dan ⁄ untuk AND kueri. Sehingga ukuran kesamaan akan berkisar dari 0 hingga 1. Perhitungan ukuran kesamaan dalam EBM menggunakan persamaan berikut (Salton et al 1983):
√
( ) √
dengan , merupakan bobot term A dan bobot term B pada dokumen.
Gambar 2 Sebaran ukuran kesamaan EBM
P-Norm Model
P-Norm Model memberikan gagasan untuk memasukkan nilai p, yaitu nilai yang menunjukkan keketatatan pada operator. Nilai p berkisar dari satu sampai tak-hingga. Untuk P-Norm Model ukuran kesamaan antara dokumen dan kueri didefinisikan sebagai berikut: ( ) [ ] ⁄ ( ) [ ] ⁄ dengan
merupakan kueri term berbobot
merupakan bobot term A dan term B pada dokumen
3
Belief Revision
Belief revision (BR) berkaitan dengan akomodasi sebuah informasi baru ke dalam knowledge base yang ada. Formalisasi logis dari BR telah diteliti dalam filsafat, database dan kecerdasan buatan untuk desain agen rasional. Dalam temu-kembali informasi BR direpresentasikan dalam logika proposisi. Dalam BR, model dibangun dari interpretasi. Himpuan dari model dapat dituliskan sebagai Mod( ) dimana adalah formula. Pseudocode dari Belief Revision yang digunakan dalam implementasi sistem dapat dilihat pada Gambar 3.
Gambar 3 Pseudocode Belief Revision
BR menggunakan Symmetric difference antara dua interpretasi yang berbeda yaitu I dan J. Ukuran dari jarak antar-interpretasi tersebut dapat ditulis sebagai dist(I,J). Lalu jarak antara Mod( ) dan I adalah:
Kita misalkan adalah kueri(q) dan I adalah model dokumen(md) dan k adalah jumlah term dalam kueri. Dokumen hanya mempunyai satu model(md), sedangkan kueri memiliki himpunan model(Mod(q)). Kita dapat menggunakan Dalal’s distance untuk model di atas.
Formula ini menggunakan jarak antara setiap model dari kueri (J) dan model dokumen (md), lalu dihitung kardinalitas dari masing-masing model kueri terhadap model dokumen. Langkah 1 sampai 10 pada Gambar 3 menunjukkan algoritme untuk formula di atas. Pertama akan ditetapkan nilai sama dengan nol. Lalu untuk masing-masing model dokumen ( ), ditetapkan nilai
sama dengan banyaknya kata unik dalam koleksi dokumen. Untuk masing-masing , dihitung nilai . Jarak dari klausa dokumen kepada kueri adalah jarak terdekat dari klausa dokumen ke klausa kueri. ( ) adalah kardinalitas dari { | } yaitu banyaknya term positif yang muncul dalam klausa satu dan negatif term pada klausa yang lain atau sebaliknya. | | merupakan banyaknya term dalam yang tidak termasuk dalam . Jika nilai maka nilai sama dengan nilai . Ulangi langkah 4 sampai tidak ada lagi yang tersisa. Update lalu ulangi langkah 2 sampai tidak ada lagi yang tersisa. Jarak rata-rata merupakan hasil bagi dengan banyaknya klausa . merupakan nilai terkecil untuk banyaknya term dalam klausa . Lalu dipilih kardinalitas terkecil sebagai jarak(distance).
Jarak (distance) dapat digunakan untuk menghitung ukuran kesamaan yang dinormalisasi dalam interval [0,1]. Langkah 11 menujukkan algoritme untuk formula di bawah.
Dari persamaan di atas diperoleh ukuran kesamaan (similarity measure) antara dokumen(d) dan kueri(q) dimana k adalah jumlah term yang muncul dalam kueri ( Losada and Barreiro 1999).
Pembobotan Tf-Idf
Term frequency (tf) merupakan frekuensi kemunculan suatu term t pada dokumen d. Document frequency (df) merupakan banyaknya dokumen di dalam korpus yang mengandung kata tertentu (Manning et al. 2008).
Pembobotan tf-idf memberikan bobot pada term t dalam dokumen d dengan nilai:
dengan
merupakan frekuensi term t pada dokumen d
merupakan jumlah dokumen dalam koleksi
4 Kesamaan antar kueri dan dokumen dapat
ditentukan dengan menghitung cosine similarity dari vektor istilah kueri ⃗ ) dan vektor istilah dokumen ( ⃗ ) (Manning et al. 2008):
⃗ ⃗ | ⃗ | | ⃗ |
dengan pembilang merupakan dot product (inner product) antara ⃗ dan ⃗ . Dot Product antara dua vektor didefinisikan sebagai ∑ , sedangkan penyebut merupakan perkalian panjang Euclidean. Panjang Euclidean didefinisikan sebagai
√∑ ⃗
Dalam EBM bobot term dalam dokumen harus dalam interval 0 sampai 1. Oleh karena itu bobot harus dinormalisasi (Salton et al 1983). Normalisasi bobot tf-idf didapatkan dari persamaan berikut:
dengan
merupakan bobot term i dalam dokumen j
merupakan frekuensi term i dalam dokumen j
merupakan frekuensi maksimum term i dalam dokumen j
merupakan nilai idf dari term i dalam koleksi
merupakan nilai maksimum idf term i dalam koleksi.
Evaluasi Temu-Kembali Informasi
Manning (2008) menyatakan, terdapat dua hal mendasar yang paling sering digunakan untuk mengukur kinerja temu-kembali secara efektif adalah recall dan precision (R-P). Perhitungan recall-precision diformulasikan sebagai berikut:
Relevant Not Relevant
Retrieved Tp fp
Not
Retrieved Fn tn
Precision = P = tp/(tp + fp)
Recall = R = tp/(tp+fn)
Menurut Baeza-Yates dan Ribeiro-Neto (1999), algoritma temu-kembali yang dievaluasi menggunakan beberapa kueri berbeda akan menghasilkan nilai R-P yang berbeda untuk masing-masing kueri. Average Precision (AVP) diperlukan untuk menghitung rata-rata tingkat precision pada berbagai tingkat recall, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Perhitungan AVP dapat diformulasikan sebagai berikut:
̅( ) ∑
dimana, ̅( )adalah AVP pada level recall r, Nq adalah jumlah kueri yang digunakan, dan Pi(r) adalah precision pada level recall r untuk kueri ke-i.
METODE PENELITIAN
Penelitian ini dilakukan dalam beberapa tahap, yaitu pengumpulan dokumen (korpus), pemrosesan dokumen, pemrosesan kueri, perhitungan ukuran kesamaan antara dokumen dengan kueri untuk P-Norm Model dan Belief Revision, pemeringkatan dokumen dari hasil perhitungan ukuran kesamaan dokumen-kueri dan evaluasi terhadap kinerja sistem. Secara umum gambaran sistem dapat dilihat pada Gambar 4.5 Koleksi Dokumen
Dokumen yang digunakan sebagai dokumen pengujian adalah dokumen corpus yang berasal dari lab TKI hasil Penelitian Adisantoso & Ridha (2004). Dokumen yang berada di Lab TKI berjumlah 1000 dokumen pertanian dan 93 dokumen tanaman obat berasal dari Lab Computational Intelligence.
Pemrosesan Dokumen
Pada tahap ini dilakukan lowercasing terhadap dokumen, yaitu dengan mengubah semua huruf menjadi huruf non-capital agar menjadi case insensitive pada saat dilakukan pemrosesan teks dokumen. Selanjutnya dilakukan proses parsing yang merupakan proses memilah dokumen menjadi unit-unit yang lebih kecil misalnya berupa kata, frasa atau kalimat (Ridha 2002). Dalam penelitian ini unit terkecil yang digunakan adalah kata yang terdiri minimal tiga huruf. Selain itu, tanda baca yang terdapat dalam dokumen dihilangkan karena bukan merupakan penciri dari dokumen. Selanjutnya dilakukan pembuangan stopwords. Stopwords adalah kata umum yang biasanya muncul dalam jumlah yang besar dan dianggap tidak memiliki makna. Lalu dilakukan pembobotan pada term dengan pembobotan tf-idf dan tf-tf-idf yang sudah dinormalisasi.
Pemrosesan Kueri
Proses selanjutnya adalah melakukan pemrosesan terdapat kueri yang dimasukkan. Pemrosesan kueri sama halnya dengan pemrosesan dokumen. Kueri yang dimasukkan akan dilakukan lowercasing dan juga parsing. Pada pemrosesan kueri sedikit berbeda karena kueri yang dimasukkan mengandung operator Boolean, sehingga perlu dipisahkan antara term yang mengandung operator Boolean dengan term yang bukan operator Boolean. Pemisahan tersebut dilakukan untuk mengetahui jenis operator yang digunakan, sehingga memudahkan dalam perhitungan nilai ukuran kesamaan. Setelah pemrosesan kueri maka akan diperoleh array kueri yang dapat digunakan dalam proses perhitungan ukuran kesamaan.
Similarity Dokumen dengan Kueri
Pada perhitungan similarity antara dokumen dengan kueri untuk metode P-Norm Model, dilakukan pengecekan apakah jenis operator Boolean yang digunakan. Perhitungan ukuran kesamaan akan dilakukan sesuai dengan jenis operator yang dimasukkan, sedangkan
untuk Belief Revision, kueri direpresentasikan sebagai formula proposisi. Dalam formula proposisi dokumen dan kueri harus dalam bentuk Disjunctive Normal Form (DNF). DNF mempunyai bentuk: , dengan masing-masing adalah klausa yang dihubungkan dengan operator AND. Perhitungan nilai kesamaan Belief Revision dilakukan dengan membandingkan model kueri dengan model dokumen.
Pemeringkatan Dokumen
Pemeringkatan dokumen dilakukan setelah perhitungan nilai kesamaan antara dokumen dengan kueri untuk P-Norm Model dan Belief Revision. Pemeringkatan dokumen dilakukan dengan mengurutkan dokumen yang dikembalikan sesuai dengan bobot yang diperoleh. Semakin besar bobot yang diperoleh maka peringkat dokumen yang dikembalikan akan semakin tinggi.
Evaluasi Hasil Temu-Kembali
Pengujian sistem dilakukan dengan perhitungan terhadap recall dan precision. Recall adalah rasio dokumen relevan yang ditemukembalikan. Precision adalah dokumen yang ditemukembalikan, dokumen tersebut relevan. Dalam perhitungan recall, digunakan elevent standart recall yaitu 0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.7,0.8,0.9 dan 1.0. Perhitungan dilakukan untuk masing-masing metode.
Hasil perhitungan recall dan precision untunk masing-masing model akan dibandingkan dalam bentuk grafik recall-precision, selain itu juga akan dihitung average precision dari masing-masing model untuk memperoleh model yang baik untuk temu-kembali.
Asumsi
Asumsi-asumsi yang digunakan dalam pembangunan sistem ini adalah:
1. Tidak ada kesalahan dalam pengetikan kueri.
2. Setiap kata dalam kueri dipisahkan dengan operator AND dan OR.
6 Lingkungan Implementasi
Lingkungan implementasi yang akan digunakan adalah sebagai berikut:
Perangkat lunak:
Microsoft Windows 7 Profesional sebagai sistem operasi.
PHP sebagai bahasa pemrograman.
Netbeans IDE 6.9 sebagai IDE untuk pembangunan sistem.
Wamp Server Apache version 2.2.11 sebagai web server.
Notepad++.
Microsoft Office 2010 sebagai aplikasi yang digunakan untuk melakukan perhitungan dalam evaluasi sistem.
Perangkat keras:
Processor Intel Core 2 duo 2.2 GHz RAM 2 GB
Hardisk 320GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen PengujianPenelitian ini menggunakan 1000 dokumen pertanian dan 93 dokumen tanaman obat yang berasal dari Laboratorium Temu-Kembali Ilmu Komputer IPB. Deskripsi dari dokumen ini dapat dilihat pada Tabel 1.
Tabel 1 Deskripsi dokumen pengujian
Uraian Dokumen Pertanian Nilai (byte)
Ukuran keseluruhan dokumen 4.139.332
Ukuran rata-rata dokumen 4139
Ukuran dokumen terbesar 54.082
Ukuran dokumen terkecil 451
Uraian Dokumen Tanaman Obat
Nilai (byte)
Ukuran keseluruhan dokumen 297.796
Ukuran rata-rata dokumen 3202
Ukuran dokumen terbesar 13.628
Ukuran dokumen terkecil 928
Seluruh dokumen yang digunakan dalam penelitian ini berformat plain-text yang memiliki struktur XML. Struktur tulisan dokumen pertanian dapat dilihat pada Gambar
5, sedangkan struktur tulisan dokumen tanaman obat dapat dilihat pada Gambar 6.
Gambar 5 Contoh dokumen pertanian
Gambar 6 Contoh dokumen tanaman obat
Dokumen dikelompokkan ke dalam tag-tag sebagai berikut:
<DOC></DOC>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag lain yang lebih spesifik.
<DOCNO></DOCNO>, tag ini menunjukkan ID dari dokumen.
<