MODEL PROFIL MAHASISWA YANG POTENSIAL DROP OUT MENGGUNAKAN TEKNIK KERNEL K-MEAN CLUSTERING
DAN DECISION TREE
TESIS
Oleh
ZEFRI PAULANDA
107038004/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
MODEL PROFIL MAHASISWA YANG POTENSIAL DROP OUT MENGGUNAKAN TEKNIK KERNEL K-MEAN CLUSTERING
DAN DECISION TREE
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar Magister Komputer dalam Program Studi Magister (S2) Teknik Informatika pada
Program Pascasarjana Fasilkom-TI Universitas Sumatera Utara
Oleh
ZEFRI PAULANDA 107038004/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
MODEL PROFIL MAHASISWA YANG POTENSIAL DROP OUT MENGGUNAKAN TEKNIK KERNEL K-MEAN CLUSTERING
DAN DECISION TREE
PENGESAHAN TESIS
Judul Tesis : MODEL PROFIL MAHASISWA YANG
POTENSIAL DROP OUT
MENGGUNAKAN TEKNIK KERNEL K-MEAN CLUSTERING DAN DECISION TREE
Nama Mahasiswa : ZEFRI PAULANDA
Nomor Induk Mahasiwa : 107038004
Program Studi : Magister Teknik Informatika
Fakultas : Ilmu Komputer dan Teknologi Informasi
Universitas Sumatera Utara
Menyetujui Komisi Pembimbing
Dr. Marwan Ramli, M.Si
Anggota Ketua
Prof. Dr. Tulus
Ketua Program Studi, Dekan,
Prof. Dr. Muhammad Zarlis
NIP : 195707011986011003 NIP: 195707011986011003
PERNYATAAN ORISINALITAS
MODEL PROFIL MAHASISWA YANG POTENSIAL DROP OUT MENGGUNAKAN TEKNIK KERNEL K-MEAN CLUSTERING
DAN DECISION TREE
TESIS
Dengan ini saya menyatakan bahwa saya mengakui semua karya tesis ini adalah hasil kerja saya sendiri kecuali kutipan dan ringkasan yang tiap satunya telah dijelaskan sumbernya dengan benar.
Medan, Juni 2012
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini :
Nama : Zefri Paulanda
NIM : 107038004
Program Studi : Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak bebas Royalti Non-Eksklusif (non-Exlusive Royalty Free Right) atas tesis saya yang berjudul
MODEL PROFIL MAHASISWA YANG POTENSIAL DROP OUT MENGGUNAKAN TEKNIK KERNEL K-MEAN CLUSTERING
DAN DECISION TREE
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk data-base, merawat dan mempublikasikan Tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, Juni 2012
Telah diuji pada Tanggal : 19 Juni 2012
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Tulus
Anggota : 1. Dr. Marwan Ramli, M.Si
RIWAYAT HIDUP
DATA PRIBADI
Nama lengkap berikut gelar : Zefri Paulanda, ST Tempat dan Tanggal Lahir : Medan, 17 Juli 1977
Alamat Rumah : Jl. Sekip Gg. Agussalim No. 19 B Medan
Telepon / HP : 061- 4146243 / 08126455891
e-mail :
Instansi Tempat Bekerja : Guru SMP Negeri 5 Percut Sei Tuan
Alamat Kantor : Jl. Cucak Rawa II No. 3 Perumnas Mandala
Telepon : -
DATA PENDIDIKAN
SD : SD Negeri No. 060841 Medan Tamat : 1988
SMP : SMP Negeri 6 Medan Tamat : 1992
SMA : SMA Methodist I Medan Tamat : 1995
Strata-1 : Institut Sains Teknologi TD Pardede Tamat : 2005
KATA PENGANTAR
Pertama-tama kami panjatkan puji syukur kepada Tuhan Yang Maha Esa, atas segala limpahan rahmat dan karunia-Nya sehingga tesis ini dapat diselesaikan tepat pada waktunya. Dengan selesainya tesis ini, perkenankanlah kami mengucapkan terima kasih yang sebesar-besarnya kepada :
Rektor Universitas Sumatera Utara, Prof. Dr. dr. Syahril Pasaribu, DTM&H, M.Sc (CTM), Sp. A(K) atas kesempatan yang diberikan kepada saya untuk mengikuti dan menyelesaikan pendidikan Program Magister.
Dekan Fasilkom-TI (Fakultas Ilmu Komputer dan Teknologi Informasi) Universitas Sumatera Utara Prof. Dr. Muhammad Zarlis, atas kesempatan yang diberikan kepada saya menjadi mahasiswa Program Magister pada Program Pascasarjana Fasilkom-TI Universitas Sumatera Utara.
Ketua Program Studi Magister (S2) Teknik Informatika, Prof. Dr. Muhammad Zarlis dan Sekretaris Program Studi M. Andri Budiman, S.T, M.Comp, M.E.M beserta seluruh staff pengajar pada Program Studi Magister (S2) Teknik Informatika Program Pascasarjana Fasilkom-TI Universitas Sumatera Utara, yang telah bersedia membimbing penulis sehingga dapat menyelesaikan pendidikan tepat pada waktunya.
Terimakasih yang tak terhingga dan penghargaan setinggi-tingginya saya ucapkan kepada Prof. Dr. Tulus, selaku pembimbing utama dan kepada Dr. Marwan Ramli, M.Si, selaku pembimbing Anggota yang dengan penuh kesabaran menuntun serta membimbing saya hingga selesainya tesis ini dengan baik.
Terima kasih yang tak terhingga dan penghargaan setinggi-tingginya saya ucapkan kepada Prof. Dr. Muhammad Zarlis, Dr. Poltak Sihombing, M.Kom dan Prof. Dr Herman Mawengkang, sebagai pembanding yang telah memberikan saran dan masukan serta arahan yang baik demi penyelesaian tesis ini.
Kepada Ayahanda Alm. Drs. P. Gultom, Ibunda R. Hutabarat selaku orang tua, kepada A. Nainggolan dan M. Panjaitan selaku mertua, kepada Istri tersayang Eka Prasty Nainggolan, S.Pd, dan kepada kedua buah hatiku Slavina Mathilda Putrianda Br. Gultom dan Secilia Ananda Br. Gultom, kepada abangda dan kakanda, juga kepada adik ipar dan lae di Pakam, yang tidak dapat saya sebutkan satu persatu, terimakasih atas segala pengorbanannya, baik moril maupun materil budi baik ini tidak dapat dibalas hanya diserahkan kepada Yesus Kristus.
Rekan mahasiswa/i Angkatan kedua tahun 2010 pada Program Pascasarjana Fakultas Fasilkom-TI Universitas Sumatera Utara yang telah banyak membantu penulis baik berupa dorongan semangat dan doa selama mengikuti perkuliahan.
Semua pihak yang tidak dapat penulis sebutkan satu persatu dalam tesis ini, terimakasih atas segala bantuan dan doa yang diberikan. Dengan segala kekurangan dan kerendahan hati, sekali lagi penulis mengucapkan terima kasih. Semoga kiranya Tuhan yang membalas segala bantuan dan kebaikan yang telah kalian berikan.
Medan, Juni 2012
MODEL PROFIL MAHASISWA YANG POTENSIAL DROP OUT MENGGUNAKAN TEKNIK KERNEL K-MEAN CLUSTERING
DAN DECISION TREE
ABSTRAK
Tesis ini merepresentasikan suatu model profil mahasiswa yang potensial drop out. Model ini disusun dengan menggunakan kernel k-mean clustering dan Decision Tree. Ini dimotivasi oleh adanya ketidakseragaman penyebab mahasiswa yang drop out dalam program D3 Tehnik Informatika FMIPA USU Medan. Oleh karena itu perlu sebuah model profil mahasiswa yang kemungkinan drop out seorang mahasiswa. Sebagai contoh kasus diambil data mahasiswa D3 Tehnik Informatika FMIPA USU Medan untuk angkatan 2009/2010 dan 2010/2011. Data yang diperoleh terlebih dahulu dikelompokkan untuk mendapatkan informasi kondisi mahasiswa secara keseluruhan. Berdasarkan analisa model yang diperoleh ditemukan Mahasiswa yang potensial drop out disebabkan oleh karena tidak ada lagi minat belajar mahasiswa, kurangnya faktor dukungan orang tua, kurangnya kepercayaan diri juga kurangnya prilaku dan waktu belajar mahasiswa.
MODEL PROFILE OF POTENTIAL STUDENTS DROP OUT
TECHNIQUE USING KERNEL K-MEANS CLUSTERING
AND DECISION TREE
ABSTRACT
This thesis presents a model profile of potential students who drop out. The model was compiled using kernel k-means clustering and Decision Tree. This is motivated by the existence of unequal causes students who drop out in the program D3 Technical Information Faculty USU Medan. Therefore need a model profile of students who drop out the possibility of a student. For example take the case of student data D3 Technical Information Faculty USU Medan to force 2009/2010 and 2010/2011. The data obtained were grouped to obtain advance information of students overall condition. Based on the analysis of models obtained are found students who drop out due to potential because there is no interest in learning of students, lack of parental support factor, a lack of confidence is also a lack of time behavior and student learning.
DAFTAR ISI
2.1 Penambangan Data (Data Mining) 9
2.2 Penambangan Data Pada Pendidikan Tinggi 11
2.3 Algoritma Clustering (Clustering Algorithm) 15
2.3.1 Clustering Hirarkhi (Hierarchical Clustering) 19
2.3.2 Clustering Partisional (Partisional Clustering) 20
2.4 Analisis Cluster 22
2.5 Metode Kernel 23
2.6 Fungsi Kernel 24
2.7 Kernel K-Means Clustering 26
2.8 Decision Tree 31
2.9 Algoritma C 4.5 32
2.10 Persamaan dengan Riset-Riset Lain 37
2.11 Perbedaan dengan Riset-Riset Lain 38
2.12 Kontribusi Riset 39
BAB III METODOLOGI PENELITIAN 40
3.1 Lokasi dan Waktu Penelitian 40
3.2 Rancangan Penelitian 40
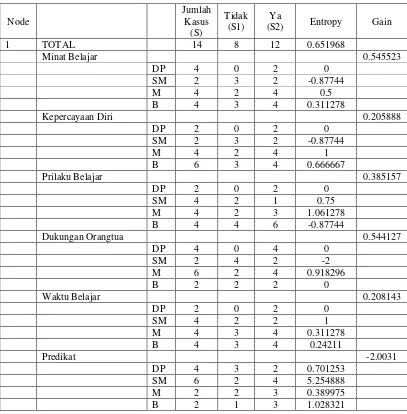
3.2.1 Perhitungan dengan menggunakan Gain dan Entropy 41
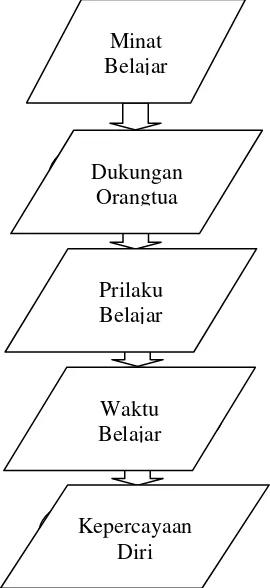
3.3 Diagram Aktivitas Penelitian 42
3.4 Teknik Pengumpulan Data 43
3.5 Pra Pemrosesan Data (Preprocessing Data) 44
3.7 Model Cluster 47
3.8 Interpretasi 48
BAB IV HASIL DAN PEMBAHASAN 53
4.1 Pendahuluan 53
4.2 Hasil Penelitian 53
4.3 Cluster Model 55
4.4 Cluster Data Berdasarkan Predikat Prestasi Akademik 57
4.5 Analisis Cluster 58
4.6 Analisis Percobaan Decision Tree 59
4.6.1. Cara untuk menghitung atribut pada
nilai Gain dan Entropy 65
BAB V KESIMPULAN DAN SARAN 70
5.1 Kesimpulan 70
5.2 Saran 70
DAFTAR PUSTAKA 71
DAFTAR GAMBAR
Nomor
Gambar Judul Halaman
2.1 Tahap-Tahap Menggali Pengetahuan Dari
Pangkalan Data
9
2.2 Proses Pemetaan Kernel 26
3.1 Diagram aktivitas Kerja Penelitian 54
4.1 Cluster Model 55
4.2
Distribusi data antara IPK dengan minat belajar, kepercayaan diri, prilaku belajar, dukungan orangtua dan waktu belajar
57
4.3 Anggota Cluster berdasarkan Predikat 58
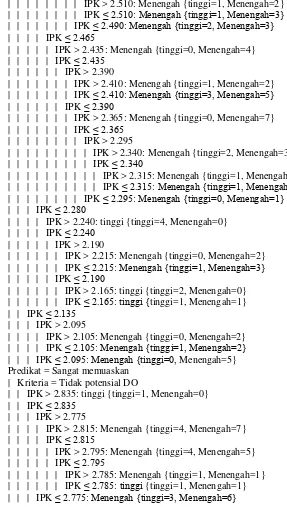
4.4 Grafik Decision Tree 59
4.5 Model Aturan Text Decision Tree 64
4.6 Profil Predikat Kelulusan 65
4.7 Pohon keputusan berdasarkan urutan gain
tertinggi
DAFTAR TABEL
Nomor
Tabel Judul Halaman
3.1 Tampilan Data Set 44
3.2 Tampilan Data 45
3.3 Kategorisasi IPK 46
3.4 Tampilan Kategorisasi Data 46
4.1 Data dalam bentuk XML 54
DAFTAR LAMPIRAN
Nomor
Lampiran Judul Halaman
A KUESIONER L-1
B Korelasi Penelitian 400 Data L-5
C Data percobaan pembuatan aturan decision tree L-10
MODEL PROFIL MAHASISWA YANG POTENSIAL DROP OUT MENGGUNAKAN TEKNIK KERNEL K-MEAN CLUSTERING
DAN DECISION TREE
ABSTRAK
Tesis ini merepresentasikan suatu model profil mahasiswa yang potensial drop out. Model ini disusun dengan menggunakan kernel k-mean clustering dan Decision Tree. Ini dimotivasi oleh adanya ketidakseragaman penyebab mahasiswa yang drop out dalam program D3 Tehnik Informatika FMIPA USU Medan. Oleh karena itu perlu sebuah model profil mahasiswa yang kemungkinan drop out seorang mahasiswa. Sebagai contoh kasus diambil data mahasiswa D3 Tehnik Informatika FMIPA USU Medan untuk angkatan 2009/2010 dan 2010/2011. Data yang diperoleh terlebih dahulu dikelompokkan untuk mendapatkan informasi kondisi mahasiswa secara keseluruhan. Berdasarkan analisa model yang diperoleh ditemukan Mahasiswa yang potensial drop out disebabkan oleh karena tidak ada lagi minat belajar mahasiswa, kurangnya faktor dukungan orang tua, kurangnya kepercayaan diri juga kurangnya prilaku dan waktu belajar mahasiswa.
MODEL PROFILE OF POTENTIAL STUDENTS DROP OUT
TECHNIQUE USING KERNEL K-MEANS CLUSTERING
AND DECISION TREE
ABSTRACT
This thesis presents a model profile of potential students who drop out. The model was compiled using kernel k-means clustering and Decision Tree. This is motivated by the existence of unequal causes students who drop out in the program D3 Technical Information Faculty USU Medan. Therefore need a model profile of students who drop out the possibility of a student. For example take the case of student data D3 Technical Information Faculty USU Medan to force 2009/2010 and 2010/2011. The data obtained were grouped to obtain advance information of students overall condition. Based on the analysis of models obtained are found students who drop out due to potential because there is no interest in learning of students, lack of parental support factor, a lack of confidence is also a lack of time behavior and student learning.
BAB I
PENDAHULUAN
1.1 Latar Belakang
Menurut Turban et al (2005), Aplikasi dari teknik penambangan data ini difokuskan untuk membangun metode-metode dalam mengungkapkan pengetahuan yang tersimpan di dalam data dan digunakan untuk membuka informasi yang tersembunyi di dalam data yang tidak nampak dipermukaan tetapi potensial untuk digunakan. Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan dan machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan
potensial dan berguna yang tersimpan di dalam database besar.
Konsep dari data mining adalah KDD (knowledge Discovery in Databases) yang terdiri dari beberapa tahapan seperti pemilihan data, pra
memberikan cara untuk mengeksplorasi karakteristik data yang diselidiki (Dunham. 2003).
Memiliki jumlah data yang sangat besar, misalnya data dosen, pegawai, sarana prasarana dalam Perguruan tinggi dapat melakukan analisa saat ini dituntut untuk memiliki kemampuan bersaing dengan memanfaatkan semua sumber daya yang dimiliki. Selain sumber daya sarana, prasarana dan manusia adalah salah satu sumber daya yang dapat digunakan untuk meningkatkan kemampuan bersaing. Sistem informasi dapat digunakan untuk mendapatkan, mengolah dan menyebarkan informasi untuk menunjang kegiatan operasional sehari-hari sekaligus menunjang kegiatan pengambilan keputusan strategis.
mengajar dan banyak lagi keuntungan lain yang bisa diperoleh dari hasil penambangan data.
Ukuran keberhasilan atau prestasi mahasiswa dapat dilihat dari Indeks Prestasi Kumulatif (IPK) mencerminkan seluruh nilai yang diperoleh mahasiswa sampai semester yang sedang berjalan, yang menunjukkan prestasi akademik mahasiswa bersangkutan sampai semester tersebut. IPK diperoleh dengan cara menjumlahkan seluruh nilai mutu semua mata kuliah yang telah diambil dan membaginya dengan total sks (satuan kredit semester).
Ada beberapa faktor yang menjadi penghalang bagi mahasiswa mencapai dan mempertahankan IPK tinggi yang mencerminkan usaha mereka secara keseluruhan selama masa kuliah di perguruan tinggi. Faktor tersebut dapat ditargetkan oleh pihak perguruan tinggi sebagai tindakan mengembangkan strategi untuk meningkatkan prestasi mahasiswa dan meningkatkan kinerja akademik dengan cara memantau perkembangan kinerja mereka. Menurut Oyelade (2010), evaluasi kinerja merupakan salah satu dasar untuk memantau perkembangan prestasi akademik mahasiswa di dalam perguruan tinggi dan pengelompokkan mahasiswa kedalam kategori yang berbeda sesuai dengan prestasi mereka menjadi tugas yang rumit. Dengan pengelompokkan mahasiswa secara tradisional berdasarkan nilai rata-rata mereka, maka sulit untuk memperoleh pandangan yang menyeluruh mengenai keadaan prestasi mahasiswa (Oyelade. 2010).
masa depan. Algoritma clustering yang baik idealnya menghasilkan kelompok dengan batasan cluster yang berbeda, meskipun dalam praktek pemisahan yang sempurna biasanya tidak bisa dicapai (Oyelade. 2010).
Pemahaman tentang profil mahasiswa merupakan pengetahuan yang sangat bermanfaat dalam proses pengambilan kebijakan oleh pimpinan perguruan tinggi. Namun masih sangat jarang penelitian yang berkaitan dengan bagaimana menggambarkan sebuah model profil mahasiswa yang dapat dijadikan sebagai basis pengetahuan dalam pengambilan keputusan. Profil Mahasiswa yang dimaksud dalam penelitian ini merupakan gambaran riil kondisi mahasiswa saat ini, berdasarkan informasi profil mahasiswa ini, akan dapat ditentukan tindakan yang semestinya diambil oleh pihak managemen perguruan tinggi untuk mengantisipasi kegagalan mahasiswa dalam menghadapi ujian akhir.
Dalam beberapa penelitian yang telah dilakukan oleh peneliti yang dituliskan dalam jurnal atau karya ilmiah tentang penggunaan data mining pada perguruan tinggi adalah : Romero dan Ventura (2007), telah melakukan survey menyimpulkan bahwa data mining yang berhubungan dengan pendidikan sangat baik untuk diteliti terutama di bidang e-learning, multimedia, artificial intelligent dan web database. Merceron dan Yacep (2005) melakukan penelitian menggunakan data mining untuk mengidentifikasi perilaku mahasiswa yang cenderung gagal pada prestasi akademikk sebelum ujian akhir. Waiyamai, (2003)
menggunakan data mining untuk membantu dalam pengembangan kurikulum
mengevaluasi kinerja mahasiswa. Sajadin, et al, (2009) menggunakan teknik data mining dalam pemantauan dan memprediksi peningkatan prestasi mahasiswa
berdasakan minat, prilaku belajar, pemanfaatan waktu dan dukungan orang tua di perguruan tinggi.
Kernel K-mean adalah pengembangan dari algoritma K-means yang menggunakan metode kernel untuk memetakan data yang berdimensi tinggi pada space yang baru sehingga dapat dipisahkan secara linier. Hal ini dilakukan untuk meningkatkan akurasi hasil klaster. Di dalam kernel K-mean diharapkan data bisa dipisahkan dengan lebih baik karena data yang overlap atau data outlier bisa menjadi linier di ruang dimensi baru (Santosa, 2007).
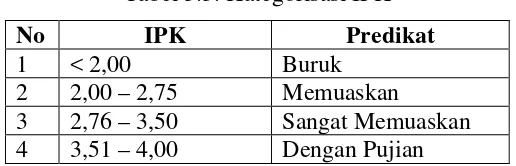
Menurut keputusan Rektor USU Nomor : 3128/J05/SK/AK/2004 Dalam Peraturan Akademik D3 Teknik Informatika FMIPA USU Medan, Mahasiswa dinyatakan lulus dengan ketentuan 2,00 < IPK < 2,75 dengan kriteria Memuaskan. Dengan mengetahui kategori karakteristik mahasiswa diharapkan dapat mendorong para mahasiswa untuk meningkatkan indeks prestasi akademiknya sebelum masa studi berakhir.
Dalam penelitian ini, akan digunakan teknik Kernel K-Means Clustering dan decision tree, untuk menganalisis dan membangun sebuah model profil mahasiswa. Metode ini dipergunakan berdasarkan berbagai laporan dalam literature bahwa teknik Kernel K-Mean Clustering merupakan salah satu metode klaster yang handal dan mampu mengklasterkan dataset campuran (Numerical and Categorical). Dari laporan metode ini memiliki hasil yang lebih baik jika
Tree merupakan metode dalam machine learning yang sangat dikenal dan handal dalam pattern classification. Sebagai asumsi awal penulis berkeyakinan bahwa metode ini akan cukup efektif digunakan untuk membangun model profil mahasiswa yang potensial mengalami kegagalan pada masa ujian akhir studinya.
Penelitian ini mengambil area pendidikan tinggi sebagai sebagai salah satu domain penelitian dalam bidang penambangan data dengan sumber data dari database akademik D3 Teknik Informatika FMIPA USU Medan hal ini dilakukan sebagai informasi yang diketahui bagian akademik D3 Teknik Informatika terdapat mahasiswa yang memiliki IP rendah dan cenderung DO dan data primer diperoleh dengan melakukan survei (menyebarkan kuesioner) terhadap mahasiswa D3 Teknik Informatika FMIPA USU Angkatan 2009/2010 dan 2010/2011, semester 3 dan 5 hal ini akan terdapat mahasiswa yang drop out.
1.2 Perumusan Masalah
Penelitian tesis ini memprediksi model profil mahasiswa yang cenderung drop out di D3 Teknik Informatika FMIPA USU Medan. Model ini dibangun dengan menggunakan k-mean clustering dan Decision tree.
1.3 Batasan Masalah
1. Sumber data untuk penelitian ini, diperoleh dari database akademik dan hasil digunakan bidang informatika dan komputer di D3 Teknik Informatika FMIPA USU Medan.
2. Model aturan prediksi dibentuk berdasarkan hasil pengolahan data
menggunakan teknik kernel k-mean clustering dan Decision Tree.
3. Untuk menganalisis data dalam penelitian ini akan menggunakan bantuan perangkat lunak data mining yang berbasis open source seperti Rapid Miner versi 5.2 dimana telah tersedia GUI untuk teknik Kernel K means clustering dan Decision Tree.
1.4 Tujuan Penelitian
Beranjak dari latar belakang permasalahan, tujuan penelitian ini adalah untuk Membangun model profil mahasiswa yang memiliki kecenderungan drop-out pada mahasiswa program diploma tiga dengan menggunakan teknik kernel
k-mean clustering dan Decision Tree.
1.5 Manfaat Penelitian
Secara praktis hasil penelitian ini juga dapat bermanfaat bagi institusi pendidikan tinggi sebagai referensi dan sebagai informasi pendukung dalam mengambil kebijakan strategis.
BAB II
TINJAUAN PUSTAKA
2.1 Penambangan Data (Data Mining)
Penambangan data (Data Mining) adalah serangkaian proses untuk menggali nilai tambah dari sekumpulan data berupa pengetahuan yang selama ini tersembunyi dibalik data atau tidak diketahui secara manual (Han, J dan Kamber, M, 2006). Proses untuk menggali nilai tambah dari sekumpulan data sering juga dikenal sebagai penemuan pengetahuan dari pangkalan data (Knowledge Discovery in Databases = KDD) yaitu tahap-tahap yang dilakukan dalam menggali
Gambar 2.1. Tahap-Tahap Menggali Pengetahuan Dari Pangkalan Data Sumber : Fayyad 1996
Tahap-tahap data mining seperti yang diilustrasikan pada Gambar 2.1 dapat dijelaskan sebagai berikut:
1. Pembersihan Data (Untuk membuang data yg tidak konsisten dan Noise) 2. Integrasi data ( Penggabungan data dari berbagai sumber)
3. Transformasi data (Data diubah menjadi bentuk yang sesuai untuk teknik data mining)
4. Aplikasi Teknik Data Mining
5. Evaluasi pola yang ditemukan (untuk menemukan informasi dan
pengetahuan yang menarik)
6. Presentasi pengetahuan (dengan menggunakan teknik visualisasi)
Berdasarkan beberapa pengertian tersebut dapat ditarik kesimpulan bahwa data mining adalah suatu teknik menggali informasi berharga yang terpendam
atau tersembunyi pada suatu koleksi data (database) yang sangat besar sehingga ditemukan suatu pola yang menaik yang sebelumnya tidak diketahui. Data mining sendiri berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Karena itu data mining sebenarnya memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent) machine learning, statistik dan database. Beberapa metode yang sering disebut dalam
Data mining sering digunakan untuk membangun model prediksi/inferensi
yang bertujuan untuk memprediksi tren masa depan atau prilaku berdasarkan analisis data terstruktur. Dalam konteks ini, prediksi adalah pembangunan dan penggunaan model untuk menilai kelas dari contoh tanpa label, atau untuk menilai jangkauan nilai atau contoh yang cenderung memiliki nilai atribut. Klasifikasi dan regresi adalah dua bagian utama dari masalah prediksi, dimana klasifikasi digunakan untuk memprediksi nilai diskrit atau nominal sedangkan regresi digunakan untuk memprediksi nilai terus-menerus atau nilai yang ditentukan (Larose, 2005).
Masalah-masalah yang sesuai untuk diselesaikan dengan teknik data mining dapat dicirikan dengan (Piatetsky dan Shapiro, 2006) :
- Memerlukan keputusan yang bersifat knowledge-based - Mempunyai lingkungan yang berubah
- Metode yang ada sekarang bersifat sub-optimal - Tersedia data yang bisa diakses, cukup dan relevan
- Memberikan keuntungan yang tinggi jika keputusan yang diambil tepat
2.2. Penambangan Data Pada Pendidikan Tinggi
mereka menyimpulkan bahwa pendidikan adalah wilayah penelitian yang sangat menjanjikan, dan cukup spesifik yang tidak dipresentasikan pada domain riset yang lain. Merceron. A dan Yacep.K (2005), memberikan sebuah studi kasus yang menggunakan data mining untuk mengidentifikasi prilaku mahasiswa yang gagal untuk memperingatkan mahasiswa sebelum ujian akhir. Data mining pada area pendidikan juga digunakan oleh Naeimeh D, et. al (2005), untuk mengidentifikasi dan kemudian meningkatkan proses pendidikan pada system pendidikan tinggi. Waiyamai K (2003), menggunakan data mining untuk membantu pengembangan kurikulum yang baru dan membantu mahasiswa teknik untuk menseleksi bidang utamanya. Sajadin S, et al (2009), menggunakan data mining untuk memonitor pencapaian dan meningkatkan prestasi akademik mahasiswa.
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Larose, 2005) :
1. Deskripsi (Description)
Terkadang penelitian analisis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menemukan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik daripada ke arah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai
prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya
3. Prediksi (Prediction)
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa datang. Contoh prediksi dalam bisnis dan penelitian adalah :
Prediksi harga beras dalam tiga bulan yang akan datang
Prediksi persentase kenaikan kecelakaan lalu lintas tahun depan jika batas
bawah kecepatan dinaikkan.
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi
4. Klasifikasi (Classification)
Contoh lain klasifikasi dalam bisnis dan penelitian adalah :
Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang
curang atau bukan
Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan
suatu kredit yang baik atau buruk
Mendiagnosis penyakit seorang pasien untuk mendapatkan kategori
penyakit apa.
5. Pengklusteran (Clustering)
Pengklusteran merupakan pengelompokkan record, pengamatan atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Cluster adalah kumpulan record yang memiliki kemiripan satu dengan yang
lainnya dan memiliki ketidakmiripan dengan record-record dalam cluster lain. Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam pengklusteran. Pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan record dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal.
Contoh pengklusteran dalam bisnis dan penelitian adalah :
Melakukan pengklusteran terhadap ekspresi dari gen, untuk mendapatkan
Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari
suatu produk bagi perusahaan yang tidak memiliki dana pemasaran yang besar.
Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap
perilaku finansial dalam keadaan baik atau mencurigakan.
6. Asosiasi (Assosiation)
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja
Contoh asosiasi dalam bisnis dan penelitian adalah :
Menemukan barang dalam supermarket yang dibeli secara bersamaan dan
barang yang tidak pernah dibeli secara bersamaan.
Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang
diharapkan untuk memberikan respons posistif terhadap penawaran upgrade layanan yang diberikan.
2.3 Algoritma Clustering (Clustering Algorithm)
Clustering (pengelompokkan data) mempertimbangkan sebuah pendekatan penting untuk mencari kesamaan dalam data dan menempatkan data yang sama ke
dalam kelompok-kelompok. Clustering membagi kumpulan data ke dalam
dan dekat dengan cara berpikir manusia, kapanpun kepada kita dipresentasikan jumlah data yang besar, kita biasanya cenderung merangkumkan jumlah data yang besat ini ke dalam sejumlah kecil kelompok-kelompok atau kategori-kategori untuk memfasilitasi analisanya lebih lanjut. Selain dari itu, sebagian besar data yang dikumpulkan dalam banyak masalah terlihat memiliki beberapa sifat yang melekat yang mengalami pengelompokkan-pengelompokkan natural (Hammuda dan Karay, 2003).
Algoritma-algoritma clustering digunakan secara ekstensif tidak hanya untuk mengorganisasikan dan mengkategorikan data, akan tetapi juga sangat bermanfaat untuk kompresi data dan konstruksi model. Melalui pencarian kesamaan dalam data, seseorang dapat mempresentasikan data yang sama dengan lebih sedikit simbol misalnya. Juga, jika kita dapat menemukan kelompok-kelompok data, kita dapat membangun sebuah model masalah berdasarkan pengelompokkan-pengelompokkan ini (Dubes dan Jain, 1988).
homogen secara relatif. Dimana kesamaan record dalam cluster dimaksimalkan dan kesamaan dengan record diluar cluster ini diminimalkan.
Clustering sering dilaksanakan sebagai langkah pendahuluan dalam proses
pengumpulan data, dengan cluster-cluster yang dihasilkan digunakan sebagai input lebih lanjut ke dalam sebuah teknik yang berbeda, seperti neural diatas dapat diperoleh sebagai jarak dari pembaharuan formula Lance-Williams (Lance & Williams, 1967).
D(C1.. C1, Ck = a(i) d (Ci, Ck)+ a(k) d (Cj, Ck)+ bd (Ci, Cj)+ cld (Ci, Ck)- d (Cj, Ck
Dimana, a,b,c, adalah koefisien-koefisien yang sesuai dengan hubungan tertentu. Formula ini menyatakan sebuah metrik hubungan antara kesatuan dari dua cluster dan cluster ketiga dalam bentuk komponen-komponen yang mendasari.
)
Clustering hirarki berdasarkan metrik hubungan mengalami kompleksitas
waktu. Dibawah asumsi-asumsi yang tepat, seperti kondisi daya reduksi (metode-metode grafik memenuhi kondisi ini), (metode-metode-(metode-metode metrik hubungan memiliki kompleksitas (N2
Dalam linguistik, pencarian informasi dan taksonomi biner aplikasi clustering dokumen adalah sangat membantu. Metode-metode aljabar linear, yang
didasarkan pada dekomposisi nilai singular (Singular Value Decomposition-SVD) digunakan untuk tujuan ini dalam filtering kolaboratif dan pencarian informasi (Berry & Browne, 1999). Aplikasi SVD terhadap clustering divisive hirarkhi dari kumpulan dokumen menghasilkan algroitma PDDP (Prinsipal Direction Divisive Partitioning) (Boley, 1998). Algoritma ini membagi dua data dalam ruang
orthogonal pada eigenvector dengan nilai singular yang besar. Pembagian cara
k (konstanta) juga memungkinkan jika k nilai singular yang besar. Pembagian cara k juga memungkinkan jika k nilai singular terbesar dipertimbangkan. Divisive hirarki yang membagi dua rata-rata k terbukti (Steinbach et al. 2000) dapat dipilih untuk clustering dokumen network. karena ukuran yang besar dari banyak database yang direpresentasikan saat ini, maka sering sangat membantu untuk menggunakan analisa clustering terlebih dahulu, untuk mengurangi ruang pencarian untuk algoritma-algoritma downstream. Aktivitas clustering pola khusus meliputi langkah-langkah berikut (Dubes dan Jain, 1988) :
(I) Representasi pola (secara opsional termasuk ekstraksi dan/atau seleksi sifat)
(II) Defenisi ukuran kedekatan pola yang tepat untuk domain data (III) Clustering pengelompokkan
(IV) Penarikan data (jika dibutuhkan) dan (V) Pengkajian output (jika dibutuhkan)
Pertimbangan dataset X yang terdiri dari point-point data (atau secara sinonim, objek-objek, hal-hal kasus-kasus, pola, tuple, transaksi) xi = (xi1, …, xid) Є A dalam ruang atribut A, dimana i = 1, N, dan setiap komponen adalah sebuah atribut A kategori numerik atau nominal. Sasaran akhir dari clustering adalah untuk menemukan point-point pada sebuah sistem terbatas dari subset k, cluster. Biasanya subset tidak berpotongan (asumsi ini terkadang dilanggar), dan
kesatuan mereka sama dengan dataset penuh dengan pengecualian yang memungkinkan outlier. Ci adalah sekelompok point data dalam dataset X, dimana X = Ci.. Ck.. Coutliers, Cjl.. Cj2 = 0.
2.3.1. Clustering Hirarkhi (Hierarchical Clustering)
Clustering hirarkhi membangun sebuah hirarkhi cluster atau dengan kata lain
sebuah pohon cluster, yang juga dikenal sebagai dendrogram. Setiap node cluster mengandung cluster anak; cluster-cluster saudara yang membagi point yang ditutupi oleh induk mereka. Metode-metode clustering hirarkhi dikategorikan ke dalam agglomerative (bawah-atas) dan idivisive (atas-bawah) (Jain & Dubes, 1988; Kaufman & Russeeuw, 1990). Clustering agglomerative dimulai dengan cluster satu point (singleton) dan secara berulang mengabungkan dua atau lebih cluster yang paling tepat. Cluster divisive dimulai dengan satu cluster dari semua
(I) Fleksibilitas yang tertanam mengenai level granularitas (II) Kemudahan menangani bentuk-bentuk kesamaan atau jarak (III) Pada akhirnya, daya pakai pada tipe-tipe atribut apapun
Kelemahan dari clustering hirarkhi berhubungan dengan : (I) Ketidakjelasan kriteria terminasi
(II) Terhadap perbaikan hasil clustering, sebagian besar algoritma hirarkhi tidak mengunjungi kembali cluster-clusternya yang telah dikonstruksi. Untuk clustering hirarkhi, menggabungkan atau memisahkan subset dari point-point dan bukan point-point individual, jarak antara pint-point individu harus digeneralisasikan terhadap jarak antara subset.
Ukuran kedekatan yang diperoleh disebut metrik hubungan. Tipe metrik hubungan yang digunakan secara signifikan mempengaruhi algortima hirarkhi, karena merefleksikan konsep tertentu dari kedekatan dan koneksitas. Metrik hubungan antar cluster utama (Murtagh 1985, Olson 1995) termasuk hubungan tunggal, hubungan rata-rata dan hubungan sempurna. Semua metrik hubungan
2.3.2. Clustering Partisional (Partitional Clustering)
Salah satu isu dengan algoritma-algoritma tersebut adalah kompleksitas tinggi, karena menyebutkan semua pengelompokkan yang memungkinkan dan berusaha mencari optimum global. Bahkan untuk jumlah objek yang kecil, jumlah partisi adalah besar. Itulah sebabnya mengapa solusi-solusi umum dimulai dengan sebuah partisi awal, biasanya acak, dan berlanjut dengan penyempurnaannya.
Praktek yang lebih baik akan berupa pelaksanaan algoritma partisional untuk kumpulan point-point awal yang berbeda (yang dianggap sebagai representative) dan meneliti apakah semua solusi menyebabkan partisi akhir yang sama atau tidak. Algoritma-algoritma clustering partisional berusaha memperbaiki secara local sebuah kriteria tertentu. Pertama, menghitung nilai-nilai kesamaan atau jarak, mengurutkan hasil, dan mengangkat nilai yang mengoptimalkan kriteria. Oleh karena itu, dapat dianggap sebagai algoritma seperti greedy.
algoritma-algoritma partitioning optimasi literative dibagi lagi ke dalam metode-metode K-medoids dan K-means.
2.4 Analisis Cluster
Analisis cluster adalah suatu analisis statitik yang bertujuan memisahkan obyek kedalam beberapa kelompok yang mempunyai sifat berbeda antar kelompok yang satu dengan yang lain. Dalam analisis ini tiap-tiap kelompok bersifat homogen antar anggota dalam kelompok atau variasi obyek dalam kelompok yang terbentuk sekecil mungkin (Prayudho, 2008).
Tujuan Analisis Cluster :
1. Untuk mengelompokkan objek-objek (individu-individu) menjadi kelompok-kelompok yang mempunyai sifat yang relatif sama (homogen)
2. Untuk membedakan dengan jelas antara satu kelompok (cluster) dengan kelompok lainnya.
Adapun manfaat Analisis Cluster sebagai berikut :
1. Untuk menerapkan dasar-dasar pengelompokkan dengan lebih konsisten
2. Untuk mengembangkan suatu metode generalisasi secara induktif, yaitu pengambilan kesimpulan secara umum dengan berdasarkan fakta-fakta khusus.
1. Merumuskan permasalahan
2. Memilih ukuran jarak atau kesamaan 3. Memilih prosedur pengklusteran 4. Menetapkan jumlah cluster 5. Interpretasi dan profil dari cluster 6. Menaksir reliabilitas dan validitas
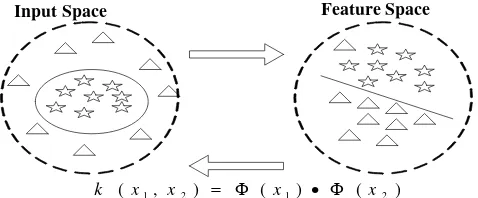
2.5 Metode Kernel
Machine learning untuk penelitian pengolah sinyal sangat dipengaruhi oleh
metode yang popular kernel Mercer (Christianini & Taylor, 2000). Point utama dalam metode kernel adalah apa yang disebut “kernel trick”, yang memungkinkan penghitungan dalam beberapa inner product, kemungkinan dengan dimensi yang tidak terbatas, ruang fitur Anggaplah xi dan xj
k (x
adalah dua point data ruang input. Jika fungsi kernel k(…) memenuhi kondisi Mercer maka :
i , xj) = Φ(xi).Φ(xj
Dimana, (x
) (2.1)
i,xj
1995). Metode-metode kernel yang sangat disupervisi telah dikembangkan untuk menyelesaikan masalah-masalah klasifikasi dan regresi.
K-means adalah algoritma unsupervised learning yang membagi kumpulan data ke dalam sejumlah cluster yang dipilih dibawah beberapa ukuran-ukuran optimisasi. Sebagai contoh, kita sering ingin meminimalkan jumlah kuadrat dari jarak Euclidean antara sampel dari centroid. Asumsi di belakang ukuran ini adalah keyakinan bahwa ruang data terdiri dari daerah elliptical yang terisolasi. Meskipun demikian, asumsi tersebut tidak selalu ada pada aplikasi spesifik. Untuk menyelesaikan masalah ini, sebuah gagasan meneliti ukuran-ukuran lain, misalnya kesamaan kosinus yang digunakan dalam pencarian informasi. Gagasan lain adalah memetakan data pada ruang baru yang memenuhi persyaratan untuk ukuran optimasi. Dalam hal ini, fungsi kernel merupakan pilihan yang baik.
2.6 Fungsi Kernel
Anggaplah kita diberikan sekumpulan sampel x1, x2, x3,…, xN, dimana xi ɛ RD, dan fungsi pemetaan Φ yang memetakan x1 dari ruang input RD
k (x
pada ruang baru Q. Fungsi kernel didefenisikan sebagai dot product dalam ruang baru Q :
i , xj) = Φ(xi).Φ(xj) (2.2)
Sebuah fakta penting mengenai fungsi kernel adalah bahwa fungsi ini dibangun tanpa mengetahui bentuk kongkrit dari Φ, yaitu transformasi yang didefinisikan secara implicit. Tiga fungsi kernel yang secara umum tercantum di bawah ini :
Polynomial k ( xi, xj) = (xi . xj + 1 )d Radial k ( x
(2.3)
i, xj) = exp (-r || xi – xj ||2 Neural k ( x
) (2.4)
i, xj) = tanh (axi . xj
Kelemahan utama dari fungsi Kernel meliputi, pertama beberapa sifat dari ruang baru hilang, misalnya, dimensionalitas dan tingkatan nilainya, sehingga kekurangan bentuk eksplisit untuk Φ. Kedua, penentuan bentuk kernel yang tepat untuk kumpulan data tertentu harus diwujudkan melalui eksperimen-eksperimen.
+ b) (2.5)
Gambar 2.2. Proses Pemetaan Kernel
2.7. KERNEL K-MEANS CLUSTERING
Clustering adalah salah satu metode yang terkenal dalam data mining, yang digunakan untuk mendapatkan kelompok-kelompok dari data, dimana setiap objek data akan dikelompokkan kedalam satu kelompok berdasarkan kemiripannya, dan yang lainnya akan dikelompokan pada kelompok yang lain.( Han,J. and Kamber,M, 2006)
K-Means Clustering merupakan teknik dalam klaster data yang sangat terkenal karena kecepatannya dalam mengklasterkan data. Akan tetapi K-Means Clustering memiliki kelemahan didalam memproses data yang berdimensi banyak. Khususnya untuk masukan yang bersifat non-linierly separable. K-Means clustering juga tidak mampu mengrupkan data yang bertipe kategorikal dan juga data campuran (numeric dan kategorikal). Kenyataan didunia nyata data yang tersedia atau yang diperoleh memiliki dimensi yang banyak dan juga bersifat campuran. Untuk mengatasi permasalahan ini, telah banyak diusulkan oleh para peneliti metode-metode yang dapat mengatasi kelemahan ini, salah satu diantaranya adalah Kernel K-Means Clustering (L.S Dhillon, et. al, 2005).
Input Space Feature Space
) ( ) ( ) ,
(x1 x2 x1 x2
Kernel K-Means Clustering, pada prinsipnya mirip dengan K-Means tradisional, letak perbedaan yang mendasar ada pada perubahan masukannya. Dalam Kernel K-Means data point akan dipetakan pada dimensi baru yang lebih tinggi menggunakan fungsi non-linier sebelum dilakukan proses clustering (Cristianini N, Taylor,J.S.2000) Kemudian Kernel K-Means akan mempartisi data menggunakan linier separator pada space yang baru.
Metode kernel pertama dan barangkali yang paling tepat adalah Support Vector Machine (SVM) (Burges, 1998), yang mengoptimalkan kriteria margin
maksimum dalam ruang fitur kernel. Algoritma k-means barangkali telah menjadi
teknik clustering popular sejak diperkenalkan dalam era 1960an. Ini
memaksimalkan jarak Euclidean kuadrat antara pusat-pusat cluster. Meskipun demikian, telah diketahui bahwa ini hanya optimal untuk (yang dapat dipisahkan secara linear) cluster terdistribusi Gaussian. Metode yang berbeda untuk melaksanakan algoritma ini dalam ruang kernel yakni kernel k-means telah diperoleh. Dalam (Zang dan Alexander, 2006) teknik optimasi stochastic dikembangkan dengan menggunakan kernel trick, sedangkan dalam (Girolami, 2002) pemetaan data actual diperkirakan melalui eigenvector dari apa yang disebut matriks kernel.
yang dapat dielakkan oleh kelas melalui pemetaan data yang diamati pada ruang data berdimensi yang lebih tinggi dengan cara nonlinear sehingga setiap cluster untuk setiap kelas membentang ke dalam bentuk sederhana”. Meskipun demikian, tidak jelas bagaimana kernel K-means berhubungan dengan sebuah operasi pada kumpulan data ruang input. Juga tidak jelas cara menghubungkan lebar kernel dengan sifat-sifat kumpulan data input. Beberapa pemikiran yang disebutkan pada point-point ini telah dibuat dalam (Girolami, 2002; Cristianini & Taylor, 2000).
Biasanya perluasan dari k-means ke kernel k-means direalisasi melalui pernyataan jarak dalam bentuk fungsi kernel (Girolami, 2002; Muller et al 2003). Meskipun demikian, implementasi tersebut mengalami masalah seris seperti biaya clustering tinggi karena kalkulasi yang berulang dari nilai-nilai kernel, atau
memori yang tidak cukup untuk menyimpan matriks kernel, yang membuatnya tidak dapat sesuai untuk corpora yang besar.
Anggaplah kumpulan data memiliki N sampel x1, x2,…xN. Algoritma K-means bertujuan untuk membagi sampel N ke dalam cluster K, C1, C2, …, CK, dan kemudian mengembalikan pusat dari setiap cluster, m1, m2,…,mk sebagai representative dari kumpulan data. Selanjutnya kumpulan data N-point dipadatkan ke dalam “code book” point K. Algoritma K-means clustering mode batch yang menggunakan jarak Euclidean bekerja sebagai berikut :
Algoritma 1
Langkah 1 Pilih awal pusat K : m1, m2, …. m Langkah 2 Menentukan setiap sampel x
K
terdekat, yang membentuk cluster K. yaitu menghitung
Langkah 3 Hitunglah pusat baru mk untuk setiap cluster C
M
Dimana Ck adalah jumlah sampel dalam Ck
k
C =
∑
n=i 1δ (xi,Ck)xi
Langkah 4 menghasilkan mk
Isu utama yang memperluas k-means tradisional ke kernel k-means adalah penghitungan jarak dalam ruang baru. Anggaplah u
(1 < k < K)
i = Φ (xi) menunjukkan transformasi x1. Jarak Euclidean antara ui dan uj
D
adalah pusat cluster dalam ruang yang ditransformasikan dimana,
= k (xi , xi) + f (xi , Ck) + g (Ck
Perbedaan utama antara kernel k-means dengan versi tradisional k-means ada di langkah 4, dalam algoritma Kernel K-means. Karena cluster dalam ruang yang ditransformasikan tidak dapat dinyatakan secara eksplisit, maka harus memilih pseudo centre. Dengan menggunakan Jarak Euclidean pada tradisional k-means, diperoleh kernel berdasarkan algoritma k-means sebagai berikut :
Algoritma 2 Langkah 3 Untuk setiap sampel latihan x
)
Dalam persamaan faktor k (xi, xj) diabaikan karena tidak berkontribusi untuk menentukan cluster terdekat. Perbedaan utama antara kernel k-means dan versi tradisionalnya ada dalam langkah 4.
2.8. DECISION TREE
Decision tree merupakan salah satu metode klasifikasi yang menggunakan
representasi struktur pohon (tree) dimana setiap node mempresentasikan atribut, cabangnya merepresentasikan nilai dari atribut, dan daun merepresentasikan kelas. Node yang paling atas dari decision tree disebut sebagai root
Decision tree merupakan metode klasifikasi yang paling popular
digunakan. Selain karena pembangunannya relatif cepat, hasil dari model yang dibangun mudah untuk dipahami.
Pada decision tree terdapat 3 jenis node, yaitu :
a. Root Node, merupakan node paling atas, pada node ini tidak ada input dan bisa tidak mempunyai output atau mempunyai output atau mempunyai output lebih dari satu.
b. Internal Node, merupakan node percabangan, pada node ini hanya terdapat satu input dan mempunyai output minimal dua.
2.9. ALGORITMA C 4.5
Algoritma C 4.5 adalah salah satu metode untuk membuat decision tree berdasarkan training data yang telah disediakan. Algoritma C 4.5 merupakan pengembangan dari ID3. Beberapa pengembangan yang dilakukan pada C 4.5 adalah sebagai antara lain bisa mengatasi missing value, bisa mengatasi continue data, dan praining.
Pohon keputusan merupakan metode klasifikasi dan prediksi yang sangat kuat dan terkenal. Metode pohon keputusan mengubah fakta yang sangat besar menjadi pohon keputusan yang merepresentasikan aturan. Aturan dapat dengan mudah dipahami dengan bahasa alami. Dan mereka juga dapat diekspresikan dalam bentuk bahasa basis data seperti Structured Query Language untuk mencari record pada kategori tertentu. pohon keputusan juga berguna untuk mengeksplorasi data, menemukan hubungan tersembunyi antara sejumlah calon variable input dengan sebuah variable target.
Karena pohon keputusan memadukan antara eksplorasi data dan pemodelan, pohon keputusan sangat bagus sebagai langkah awal dalam proses pemodelan bahkan ketika dijadikan sebagai model akhir dari beberapa teknik lain.
Variabel tujuan bisaanya dikelompokkan dengan pasti dan model pohon keputusan lebih mengarah pada perhitungan probability dari tiap-tiap record terhadap kategori-kategori tersebut atau untuk mengklasifikasi record dengan mengelompokkannya dalam satu kelas. Pohon keputusan juga dapat digunakan untuk mengestimasi nilai dari variabel continue meskipun ada beberapa teknik yang lebih sesuai untuk kasus ini.
Banyak algoritma yang dapat dipakai dalam pembentukan pohon keputusan, antara lain ID3, CART, dan C4.5 (Larose, 2006).
Data dalam pohon keputusan bisaanya dinyatakan dalam bentuk tabel dengan atribut dan record. Atribut menyatakan suatu parameter yang dibuat sebagai criteria dalam pembentukan pohon. Misalkan untuk menentukan main tenis, kriteria yang diperhatikan adalah cuaca, angin dan temperatur.
Salah satu atribut merupakan atribut yang menyatakan data solusi per item data yang disebut target atribut. Atribut memiliki nilai-nilai yang dinamakan dengan instance. Misalkan atribut cuaca mempunyai instance berupa cerah, berawan dan hujan (Basuki dan Syarif, 2003).
Proses pada pohon keputusan adalah mengubah bentuk data (tabel) menjadi model pohon, mengubah model pohon menjadi rule, dan menyederhanakan rule (Basuki dan Syarif, 2003).
Berikut ini algoritma dasar dari C 4.5 : Input : sampel training, label training, atribut
2. Jika semua sampel positif, berhenti dengan suatu pohon dengan satu simpul akar, beri tanda (+)
3. Jika semua sampel negatif, berhenti dengan suatu pohon dengan satu simpul akar, beri tanda (-)
4. Jika atribut kosong, berhenti dengan suatu bohon dengan suatu simpul akar, dengan label sesuai nilai yang terbanyak yang ada pada label training
5. Untuk yang lain, Mulai
a. A ---- atribut yang mengklasifikasikan sampel dengan hasil terbaik (berdasarkan Gain rasio)
b. Atribut keputusan untuk simpul akar ---- A c. Untuk setiap nilai, vi, yang mungkin untuk A
1) Tambahkan cabang di bawah akar yang berhubungan
dengan A = vi
2) Tentukan sampel Svi sebagai sbset dari sampel yang
mempunyai nilai vi untuk atribut A 3) Jika sampel Svi kosong
i. Di bawah cabang tambahkan simpul daun
dengan label = nilai yang terbanyak yang ada pada label training
ii. Yang lain tambah cabang baru di bawah cabang yang sekarang C 4.5 (sampel training, label training, atribut – [A].
d. Berhenti
Mengubah tree yang dihasilkan dalam beberapa rule. Jumlah rule sma dengan jumlah path yang mungkin dapat dibangun dari root sampai leaf node.
Tree Praining dilakukan untuk menyederhanakan tree sehingga akurasi dapat bertambah. Pruning ada dua pendekatan, yaitu :
b. Post-praining, yaitu menyederhanaan tree dengan cara membuang beberapa cabang subtree setelah tree selesai dibangun. Node yang jarang dipotong akan menjadi leaf (node akhir) dengan kelas yang paling sering muncul.
Secara umum algoritma C 4.5 untuk membangun pohon keputusan adalah sebagai berikut :
1. Pilih atribut sebagai akar
2. Buat cabang untuk masing-masing nilai 3. Bagi kasus dalam cabang
4. Ulangi proses untuk masing-masing cabang sampai semua kasus pada cabang memiliki kelas yang sama
Untuk memilih atribut sebagai akar, didasarkan pada nilai Gain tertinggi dari atribut-atribut yang ada. Untuk menghitung Gain digunakan rumus seperti tertera dalam Rumus I (Craw, 2005).
Gain(S,A) = Entropy(S) –
∑
=1 *Entropy(Si)S Si
n i
Dengan
S : Himpunan Kasus
A : Atribut
Sedangkan perhitungan nilai Entropy dapat dilihat pada rumus 2 berikut (Craw, 2005) :
Entropy(A) =
∑
ni=1−pi*log2 piDengan
S : Himpunan Kasus
A : Fitur
n : Jumlah partisi S
pi : Proporsi dari Si terhadap S
Riset-Riset Terkait
Terdapat beberapa riset yang telah dilakukn oleh banyak peneliti berkaitan dengan domain pendidikan, seperti yang akan dijelaskan di bawah ini.
Yu et al (2010) dalam risetnya menjelaskan mengenai sebuah pendekatan data mining dapat diaplikasikan untuk meneliti faktor-faktor yang mempengaruhi
tingkat daya ingat mahasiswa. Oyelade et al. (2010) dalam risetnya mengimplementasikan algoritma k-means clustering dikombinasikan dengan deterministik model untuk menganalisa hasil prestasi mahasiswa pada perguruan tinggi swasta
Nugroho, (2008) menjelaskan dalam risetnya mengenai Implementasi decision tree berbasis analisis teknikal untuk pembelian dan penjualan saham,
pergerakan trend ini bersifat spekulasi namun cukup mampu memberikan keuntungan.
Sunjana (2010b) menjelaskan dalam risetnya tentang klasifikasi data nasabah sebuah asuransi menggunakan algoritma C 4.5, berikut adalah kesimpulan yang dapat diambil dari data nasabah asuransi setelah dilakukan analisis menggumakan metode algoritma C 4.5 :
1. Aplikasi dapat menyimpulkan bahwa rata-rata nasabah memiliki status L dikarenakan pembayaran premi yang melebihi 10% dari penghasilam 2. Dengan persentase atribut premi dasar dan penghasilan, maka dapat
diketahui rata-rata status nasabah memiliki nilai P atau L
Bhargavi at al (2008) menjelaskan dalam risetnya tetang menguraikan pengetahuan menggunakan aturan dengan pendekatan decision tree.
Al-Radaideh et al (2006) menjelaskan dalam risetnya tentang pemanfaatan data mining terhadap data mahasiswa menggunakan decision tree.
Adeyemo dan Kuye (2006) menjelaskan dalam risetnya untuk memprediksi
kinerja mahasiswa di bidang akademik menggunakan algoritma decision tree. Dedy Hartama (2011) menjelaskan model aturan keterhubungan data mahasiswa menggunakan Algoritma C 4.5 untuk meningkatkan indeks prestasi. 2.10. Persamaan dengan Riset-Riset Lain
Ogor (2007) dalam penelitiannya menggunakan teknik data mining yang digunakan untuk membangun prototype Penilaian Kinerja Monitoring Sistem (PAMS) untuk mengevaluasi kinerja mahasiswa.
Sajadin et al (2009) menggunakan teknik data mining dalam pemantauan dan memprediksi peningkatan prestasi mahasiswa berdasarkan minat, prilaku belajar, pemanfaatan waktu dan dukungan orang tua di perguruan tinggi.
2.11. Perbedaan dengan Riset-Riset Lain
Dari beberapa riset yang dilakukan peneliti sebelumnya, terdapat beberapa titik perbedaan dengan riset yang akan dilakukan ini :
Analisa dalam proses pengambilan keputusan dalam melakukan tindakan preventif terhadap mahasiswa yang cenderung gagal kuliah atau drop-out, diperlukan sebuah model profil mahasiswa yang dapat menggambarkan situasi ril mahasiswa tersebut pada saat mengikuti perkuliahan, selanjutnya bagaimana model ini dapat dijadikan sebagai indikator untuk deteksi dini kondisi mahasiswa yang cenderung drop-out.
2.12. Kontribusi Riset
Penelitian ini memberikan kontribusi pada pemahaman kita tentang hubungan para dosen untuk lebih mengenal situasi para mahasiswanya, dan dapat dijadikan sebagai pengetahuan dini dalam proses pengambilan keputusan untuk tindakan preventif dalam hal mengantisipasi mahasiswa drop-out, untuk meningkatkan prestasi mahasiswa, untuk meningkatkan kurikulum, meningkatkan proses kegiatan belajar dan mengajar dan banyak lagi keuntungan lain yang bisa diperoleh dari hasil penambangan data yang telah ditentukan oleh perguruan tinggi.
Beberapa kemungkinan lain mungkin dianggap penting adalah dosen wali dapat menggunakan informasi yang diberikan dalam mengambil beberapa tindakan untuk meningkatkan kinerja mahasiswa dalam meningkatkan predikat kelulusan.
BAB III
METODOLOGI PENELITIAN
Dalam Bab ini akan digunakan dalam penelitian yang meliputi waktu dan tempat, rancangan penelitian, aktivitas penelitian dan teknik pengumpulan data serta analisis data
3.1. Lokasi dan Waktu Penelitian
Penelitian dilakukan di D3 Teknik Informatika FMIPA USU, Jl. Bioteknologi No. 1 Kampus USU Padang Bulan Medan. Lamanya waktu yang dibutuhkan untuk menyelesaikan penelitian ini selama 3 bulan yang dimulai pada Februari 2012 sampai dengan bulan April 2012
3.2. Rancangan Penelitian
Pada tahap awal penelitian dilakukan dengan cara menyebarkan kuesioner (angket) pada Mahasiswa D3 Teknik Informatika FMIPA USU Medan yang menjadi subjek penelitian. Kuesioner berisikan tentang Minat Belajar, Kepercayaan Diri, Prilaku Belajar, Dukungan Orang tua dan Waktu Belajar. Hasil kuesioner ini diolah dengan menggunakan software Rapidminer untuk mendapatkan pengelompokkan mahasiswa berdasarkan 4 kriteria yaitu Dengan Pujian (DP), Sangat memuaskan (SM), Memuaskan (M), Buruk (B).
3.2.1 Perhitungan Dengan Menggunakan Gain dan Entropy
Dari pengujian diperoleh cluster dari data yang telah diuji selanjutnya dilakukan analisis cluster dan diklasifikasi dalam decision tree untuk menganalisis dan mendapatkan model aturan Setelah itu data diuji dengan cara perhitungan sendiri. Cara untuk memilih atribut sebagai akar, didasarkan pada nilai Gain tertinggi dari atribut-atribut yang ada. Untuk menghitung Gain digunakan rumus seperti tertera dalam Rumus I (Craw, 2005).
Gain(S,A) = Entropy(S) –
∑
=1 *Entropy(Si) SSi n i
Dengan
S : Himpunan Kasus
A : Atribut
N : Jumlah Partisi atribut A |Si| : Jumlah kasus pada partisi ke i |S| : Jumlah kasus dalam S
Sedangkan perhitungan nilai Entropy dapat dilihat pada rumus 2 berikut (Craw, 2005) :
Entropy(A) =
∑
ni=1−pi*log2 piDengan
S : Himpunan Kasus
A : Fitur
n : Jumlah partisi S
3.3. Diagram Aktivitas Penelitian
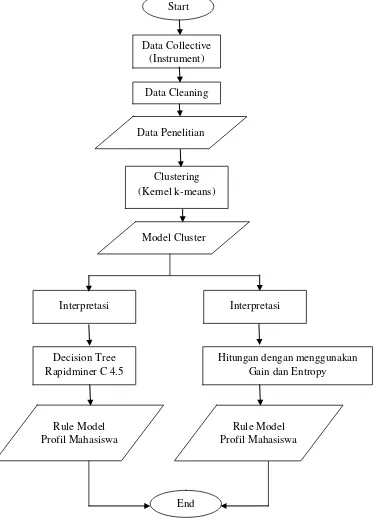
Berikut ini alur kerja yang akan dilakukan pada penelitian ini yang digambarkan dalam diagram aktivitas pada gambar 3.1 berikut :
Gambar 3.1. Diagram Aktivitas Kerja Penelitian
Start
Data Collective (Instrument)
Data Cleaning
Data Penelitian
Clustering (Kernel k-means)
Model Cluster
Interpretasi
Rule Model Profil Mahasiswa
End Decision Tree
Rapidminer C 4.5
Hitungan dengan menggunakan Gain dan Entropy Interpretasi
3.4. Teknik Pengumpulan Data
Untuk mendapatkan input yang baik dari teknik data mining, dilakukan
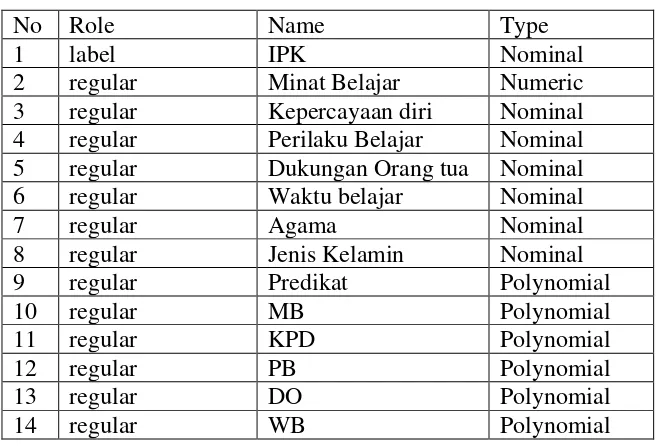
preprocessing terhadap data yang akan digunakan. Preprocessing data merupakan tahap prapemrosesan. Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning (pembersihan) pada data yang menjadi fokus atau target KDD. Dalam kasus ini, data yang diambil sebanyak 400 mahasiswa tahun ajaran 2009-2010 dan 2010-2011 dari D3 Teknik Informatika FMIPA USU Medan. Atribut yang digunakan pada penelitian ini berupa IPK, Minat Belajar, Kepercayaan diri, Prilaku Belajar, Dukungan Orang Tua, Jenis Kelamin, dan Predikat.
Data set kedua penulis mensurvei mahasiswa tentang prediksi prestasi akademik dengan menggunakan kuesioner tertulis. Penulis menciptakan instrument survey dan termasuk pertanyaan demografis secara umum. Jumlah mahasiswa sebanyak 400 orang, dan penulis mendapatkan data sampel sebanyak 400 orang dari 420 untuk data set pertama dan 400 orang untuk data kuisioner mahasiswa yang merupakan data set kedua. Sumber data yang dikumpulkan dari catatan kartu hasil studi akademik mahasiswa.
Tabel 3.1 Tampilan Data Set
No Role Name Type
1 label IPK Nominal
2 regular Minat Belajar Numeric
3 regular Kepercayaan diri Nominal
4 regular Perilaku Belajar Nominal
5 regular Dukungan Orang tua Nominal
6 regular Waktu belajar Nominal
7 regular Agama Nominal
8 regular Jenis Kelamin Nominal
9 regular Predikat Polynomial
10 regular MB Polynomial
11 regular KPD Polynomial
12 regular PB Polynomial
13 regular DO Polynomial
14 regular WB Polynomial
3.5. Pra Pemrosesan Data (Preprocessing Data)
Untuk mendapatkan input yang baik dari teknik data mining, dilakukan
preprocessing terhadap data yang akan digunakan. Preprocessing data merupakan tahap prapemrosesan. Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning (pembersihan) pada data yang menjadi fokus atau target KDD. Dalam kasus ini, data yang diambil sebanyak 400 mahasiswa tahun ajaran 2009-2010 dan 2010-2011 dari D3 Teknik Informatika FMIPA USU Medan. Atribut yang digunakan pada penelitian ini berupa IPK, Minat Belajar, Kepercayaan diri, Prilaku Belajar, Dukungan Orang tua, Waktu Belajar, Jenis Kelamin, Predikat.
400 orang, dan penulis mendapatkan data sampel sebanyak 400 orang untuk data kuesioner mahasiswa. Sumber data yang dikumpulkan dari catatan kartu hasil studi akademik mahasiswa.
Tabel 3.2. Tampilan data
Tabel 3.2 merupakan tampilan data yang diperoleh dari sistem file D3 Teknik Informatika FMIPA USU Medan Tahun Ajaran 2009-2010 dan 2010-2011 yang terdiri dari IPK, Minat Belajar, Kepercayaan diri, Prilaku Belajar, Dukungan Orang tua, Waktu Belajar, Jenis Kelamin, Predikat.
Tabel 3.3. Kategorisasi IPK
No IPK Predikat
1 < 2,00 Buruk
2 2,00 – 2,75 Memuaskan
3 2,76 – 3,50 Sangat Memuaskan
4 3,51 – 4,00 Dengan Pujian
Setelah dikategorisasi dihasilkan sebuah tabel data dengan format xls seperti pada tabel 3.4.
Tabel 3.4. Tampilan Kategorisasi Data
Hasil kategorisasi data akan digunakan untuk input data pada software open source Rapidminer. Setelah itu dilakukan transformasi data dari format xls
3.6. Clustering (Kernel k-Means )
Setelah dikategorisasi dalam input data pada software open source Rapidminer, maka dilakukan transformasi data dari format xls menjadi XML dengan cara membuka program Rapidminer, memilih lembar kerja baru lalu dipilih import dan data muncullah Read Excel lalu double klik di Read Excel, setelah itu pilih Import Configuration wizard untuk mengimport data dari Excel (xls) 2003 sehingga dihasilkan data pengujian dalam format XML
Dalam proses xls menjadi XML ada beberapa tahap proses pengujian untuk Data Import Wizard sehingga muncul tahap terakhir atau tahap keempat, terdapat pilihan kategori yang akan dipilih. IPK dikategorikan numeric, Minat Belajar, Kepercayaan Diri, Prilaku Belajar, Dukungan Orang Tua dan waktu belajar dikategrorikan integer. Predikat dikategorikan Polynomial, MB, KPD, PB, DO, WB dikategorikan binomial.
Clustering (kernel k-means) dipilih setelah memilih operator rapidminer Modelling dan clustering and Segmentation, lalu double klik di k-means (kernel). Setelah itu dapat dipilih 5 cluster dengan kernel type dot. Dapatlah diproses dengan memilih menu proses lalu pilih run, maka dihasilkanlah data clustering dengan 5 cluster yang berbeda cluster sesuai dengan rapidminer yang memproses data hasil kuesioner mahasiswa D3 Teknik Informatika FMIPA USU Medan.
3.7. Model Cluster
secara umum dengan berdasarkan hasil kuesioner yang diperoleh berdasarkan fakta-fakta khusus, menemukan tipologi yang cocok dengan karakter objek yang diteliti, dan mendeskripsikan sifat-sifat/karakteristik dari masing-masing cluster.
Dalam model ini tiap-tiap kelompok bersifat homogen antar anggota dalam kelompok atau variasi objek dalam kelompok yang terbentuk sekecil mungkin. Tujuan Model Cluster Untuk mengelompokkan objek-objek (individu-individu) menjadi kelompok-kelompok yang mempunyai sifat yang relatif sama (homogen) dan untuk membedakan dengan jelas antara satu kelompok (cluster) dengan kelompok lainnya.
3.8. Interpretasi
Hasil Interpretasi data menggunakan dataset nilai akademik yang diambil dari database D3 Teknik Informatika FMIPA USU Medan. Data set bersifat nominal yang terdiri dari IPK, Minat Belajar, Kepercayaan diri, Prilaku Belajar, Dukungan Orang tua, Waktu Belajar, Jenis Kelamin, dan Predikat, kemudian data ditransformasikan ke format data excel 2003. Kumpulan data yang diperoleh digunakan sebagai contoh sumber input untuk membuat model aturan menggunakan algoritma C.45 menggunakan software rapidminer.
Gain(S,A) = Entropy(S) –
∑
=1 *Entropy(Si)Sehingga diperoleh Rule Model profil mahasiswa dalam decision tree Rapidminer dan juga Hitungan dengan menggunakan Gain dan Entropy
Rule Model Profil Mahasiswa dalam Decision Tree Rapidminer
Rule Keterangan Rule Predikat
1. Jika rata-rata minat belajar = 2.3 Buruk
2 Jika rata-rata minat belajar = 2.3 dan rata-rata dukungan orang tua = 2.2
Buruk 3 Jika rata-rata minat belajar = 3.4 dan rata-rata
dukungan orang tua = 3.4
Memuaskan 4 Jika rata-rata minat belajar = 3.3 dan rata-rata
dukungan orangtua = 3.2
Memuaskan 7 Jika rata-rata minat belajar = 3.4 dan rata-rata
dukungan orang tua = 3.3 dan rata prilaku belajar = 3.3
Memuaskan
8 Jika rata-rata minat belajar = 3.5 dan rata-rata dukungan orang tua = 3.6 dan rata prilaku belajar = 3.3
Memuaskan
9 Jika rata-rata minat belajar = 3.8 dan rata-rata dukungan orang tua = 3.8 dan rata prilaku belajar = 3.5
10 Jika rata-rata minat belajar = 3.7 dan rata-rata dukungan orang tua = 3.6 dan rata prilaku belajar = 3.5
Sangat memuaskan
11 Jika rata-rata minat belajar = 3.9 dan rata-rata dukungan orang tua = 3.9 dan rata prilaku belajar = 3.8
Dengan pujian
BAB IV
HASIL DAN PEMBAHASAN
4.1. Pendahuluan
Bab ini menyajikan hasil penelitian yang sesuai dengan pertanyaan-pertanyaan yang diajukan pada permulaan. Penelitian dilaksanakan pada data set, untuk pertama, penulis menggunakan dataset nilai akademik yang diambil dari database D3 Teknik Informatika FMIPA USU Medan. Data set bersifat nominal yang terdiri dari IPK, Minat Belajar, Kepercayaan diri, Prilaku Belajar, Dukungan Orang tua, Waktu Belajar, Jenis Kelamin, dan Predikat, kemudian data ditransformasikan ke format data excel 2003.
Data set penulis menggunakan data set kuesioner yang terdiri dari data Minat Belajar, Kepercayaan diri, Prilaku Belajar, Dukungan Orang tua, Waktu Belajar, Jenis Kelamin mahasiswa. Kumpulan data yang diperoleh digunakan sebagai contoh sumber input untuk membuat model aturan menggunakan software rapidminer.
4.2. Hasil Penelitian
Tabel 4.1 Data dalam bentuk XML
Pada Tabel 4.1 Semua atribut ini merupakan data yang belum dikategorisasikan. Sedangkan atribut yang sudah dikategorisasikan adalah Predikat dengan tipe polynomial, MB (Minat Belajar) dengan tipe polynomial, KPD (kepercayaan diri) dengan tipe polynomial, PB (Prilaku Belajar) dengan tipe polynomial, DO (Dukungan Orang tua) degan tipe polynomial, WB (Waktu Belajar) dengan tipe polynomial.
4.3. Cluster Model
Cluster model yang diperoleh dari hasil pengujian terhadap data menggunakan metode Kernel K-means seperti yang terlihat pada Gambar 4.1
Gambar 4.1. Cluster Model
Dari gambar 4.1. dapat dilihat cluster model yang dihasilkan terdiri dari cluster 0 sebanyak 30 item, cluster 1 sebanyak 92 item, cluster 2 sebanyak 60 item, cluster 3 sebanyak 120 item dari total jumlah 400 item.
Cluster 0 adalah termasuk kategori buruk, cluster 1, 2, 3 dan 4 adalah termasuk kategori pujian, sangat memuaskan dan memuaskan. Dalam software Rapidminer setiap cluster bisa mempunyai jawaban yang sama (kuesioner pada mahasiswa) seperti yang terjadi dalam cluster 1, 2, 3, dan 4.
target dalam pengklusteran. Pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target
Cluster dapat juga dilihat dalam format tabel seperti yang dilihat pada tabel 4.2. berikut :
Tabel 4.2. Hasil Clustering dalam data View