PENERAPAN TEKNIK DATA MINING DENGAN METODE SMOOTH
SUPPORT VECTOR MACHINE (SSVM) UNTUK MEMPREDIKSI
MAHASISWA YANG BERPELUANG DROP OUT
(Studi Kasus Mahasiswa Politeknik Negeri Medan)
TESIS
Oleh
HABIBI RAMDANI SAFITRI
097038022 / TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
PENERAPAN TEKNIK DATA MINING DENGAN METODE SMOOTH SUPPORT VECTOR MACHINE (SSVM) UNTUK MEMPREDIKSI
MAHASISWA YANG BERPELUANG DROP OUT (Studi Kasus Mahasiswa Politeknik Negeri Medan)
TESIS
Diajukan Sebagai Salah Satu Syarat Untuk Memperoleh Gelar
Magister Komputer Dalam Program Studi Magister Teknik
Informatika Pada Program Pascasarjana Fakultas MIPA
Universitas Sumatera Utara
Oleh
HABIBI RAMDANI SAFITRI
097038022 / TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA MEDAN
PENGESAHAN TESIS
Menyetujui Komisi Pembimbing,
Ketua
Prof. Dr. Muhammad Zarlis
Ketua Program Studi Dekan
Prof. Dr. Muhammad Zarlis
NIP : 19570701 198601 1 003 NIP : 19631026 199103 1 001 Dr. Sutarman, M.Sc
Judul Tesis : PENERAPAN TEKNIK DATA MINING DENGAN METODE SMOOTH SUPPORT VECTOR MACHINE (SSVM) UNTUK MEMPREDIKSI MAHASISWA YANG BERPELUANG DROP OUT (Studi Kasus Mahasisawa Politeknik Negeri Medan)
Nama Mahasiswa : HABIBI RAMDANI SAFITRI Nomor Induk Mahasiswa : 097038022
Program Studi : TEKNIK INFORMATIKA
Fakultas : MATEMATIKA dan ILMU
PERNYATAAN ORISINALITAS
PENERAPAN TEKNIK DATA MINING DENGAN METODE SMOOTH SUPPORT VECTOR MACHINE (SSVM) UNTUK MEMPREDIKSI
MAHASISWA YANG BERPELUANG DROP OUT (Studi Kasus Mahasiswa Politeknik Negeri Medan)
TESIS
Dengan ini penulis nyatakan bahwa penulis mengakui semua karya tesis ini adalah hasil karya penulis sendiri kecuali kutipan dan ringkasan yang tiap bagiannya telah dijelaskan sumbernya dengan benar.
Medan, 29 Juli 2011
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertandatangan di bawah ini:
NamaMahasiswa : HABIBI RAMDANI SAFITRI
NomorIndukMahasiswa : 097038022
Program Studi : Magister (S2) Teknik Informatika JenisKaryaIlmiah : TESIS
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty Free Right) atas Tesis saya yang berjudul :
PENERAPAN TEKNIK DATA MINING DENGAN METODE SMOOTH SUPPORT VECTOR MACHINE (SSVM) UNTUK MEMPREDIKSI
MAHASISWA YANG BERPELUANG DROP OUT (Studi Kasus Mahasiswa Politeknik Negeri Medan)
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non-Eksklusifini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan Tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.
Medan, 29 Juli 2011
Telah diuji pada Tanggal : Juli 2011
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Muhammad Zarlis Anggota : 1. Prof. Dr. Herman Mawengkang
3. Prof. Dr. Tulus
DATA PRIBADI
RIWAYAT HIDUP
NamaLengkap Habibi Ramdani Safitri
TempatdanTanggalLahir Medan, 17 September 1976
AlamatRumah Jl. Pintu Air IV N0. 121 Komp. Polmed Padang Bulan Medan.
Email Politeknik Nege
InstansiTempatBekerja Politeknik Negeri Medan
DATA PENDIDIKAN
SD NEGERI 060853 Tamat Tahun 1989
SMP NEGERI 11 MEDAN SAMPALI Tamat Tahun 1992 SMA SWASTA PAB 1 MEDAN ESTATE Tamat Tahun 1995
D1 PTKK POLITEKNIK USU Tamat Tahun 1996
KATA PENGANTAR
Pertama-tama kami panjatkan puji syukur kehadirat Allah SWT atas segala limpahan rahmad dan karuniaNya sehingga Tesis ini dapat diselesaikan melalui bimbingan, arahan dan bantuan yang diberikan berbagai pihak khususnya pembimbing, pembanding, para dosen, teman mahasiswa, khususnya mahasiswa Program Studi Magister (S2) Teknik Informatika Universitas Sumatera Utara.
Tesis dengan judul : Penerapan Teknik Data Mining Dengan Metode Smooth Support Vector Machine (SSVM) Untuk Memprediksi Mahasiswa Yang Berpeluang Drop Out (Studi Kasus Mahasiswa Politeknik Negeri Medan) adalah merupakan syarat untuk memperoleh gelar Magister Komputer pada Program Pascasarjana Magister Teknik Informatika FMIPA USU.
Dengan selesainya tesis ini, perkenankanlah penulis mengucapkan terima kasih yang sebesar-besarnya kepada:
1. Ketua Program Studi Magister (S2) Teknik Informatika, Prof. Dr. Muhammad Zarlis. Sekretaris Program Studi Magister (S2) Teknik Informatika M. Andri Budiman, ST, M.Comp. Sc, M.EM,
2. Pembimbing Utama Prof. Dr. Muhammad Zarlis selaku pembimbing Utama yang dengan penuh kesabaran membimbing, memotivasi, memberikan dukungan moril, kritik dan saran serta memberikan bahan-bahan yang berkaitan dengan penyusunan tesis ini sehingga tesis ini dapat terselesaikan dengan baik.
3. Prof. Dr. Herman Mawengkang, M. Andri Budiman, ST, M.Comp. Sc, M.EM, dan Prof. Dr. Tulus, selaku pembanding yang telah memberikan saran, masukan dan arahan yang baik demi penyelesaian tesis ini
4. Direktur Politeknik Negeri Medan Ir. Zulkifli Lubis, M.I.Komp, Bambang Sugianto, MP selaku Pudir I, Ir. Sahruddin, MT Selaku Pudir II, Cipta Dharma, M.Si, Selaku Pudir III, Salamat Sibarani, MT, Selaku Pudir IV, yang telah memberikan izin penulis untuk mengikuti perkuliahan
5. Rekan-rekan di STT-Harapan untuk segala pengertiannya dan perhatiannya, khusus Dra. Herlina Harahap,M.Si, Ratna Simatupang, MT, Yetty Meutia, MT, Rahmawati, MT, terima kasih untuk semua bantuan dan dukungan yang diberikan.
6. Rekan-rekan angkatan pertama S2 Teknik Informatika USU, khususnya buat kak Arie Santi Siregar atas dukungannya selama ini dengan segala pengalaman yang telah dilewati. umumnya untuk semua bantuan, dukungan, dan kebahagian selama perkuliahan.
7. Staf dan karyawan S2 Teknik Informatika, yang sudah membantu dalam perkuliahan ini, terima kasih atas kebaikan, keramahan semoga sukses selalu. 8. Teristimewa seluruh keluarga besar yaitu Ibunda Hj. Mariani Oesman, Alm.
H. Ahmad Ridwan Nst, Bang Izul, Bang Fendi, Kak Lelan, Kak Adah, Kak Fatmah, Ponakan-ponakan atas dorongan moril dan materil yang telah diberikan selama perkuliahan sampai penulisan tesis ini.
Kepada semua pihak yang tidak dapat penulis sebutkan satu persatu dalam tesis ini, terima kasih atas segala bantuan yang diberikan.
Medan, Juli 2011
HABIBI RAMDANI SAFITRI NIM 097038022
PENERAPAN TEKNIK DATA MINING DENGAN METODE SMOOTH SUPPORT VECTOR MACHINE (SSVM) UNTUK MEMPREDIKSI
MAHASISWA YANG BERPELUANG DROP OUT (Studi Kasus Mahasiswa Politeknik Negeri Medan)
ABSTRAK
Support Vector Machines (SVM) adalah Algoritma baru dari Teknik data mining, meningkatnya popularitas dalam pembelajaran mesin dan statistic masyarakat. SVM telah diperkenalkan oleh Vapnik untuk memecahkan masalah pengenalan pola dan fungsi nonlinear estimasi. SVM telah menjadi alat pilihan untuk masalah klasifikasi dasar pembelajaran mesin dan data mining. Tidak seperti metode tradisional yang meminimalkan kesalahan pelatihan empiris, SVM bertujuan meminimalkan batas atas kesalahan generalisasi melalui memaksimalkan margin antara hyperplane memisahkan data. Hal ini dapat dianggap sebagai pelaksanaan perkiraan prinsip minimisasi risiko struktur, Metode smoothing, banyak digunakan untuk memecahkan masalah pemrograman matematis dan aplikasi penting, yang diterapkan disini untuk menghasilkan dan memecahkan sebuah reformulasi tak terbatas dari mesin vector dukungan untuk klasifikasi pola. Meskipun banyak varian SVM telah diusulkan, masih merupakan masalah penelitian aktif dalam rangka meningkatkan untuk klasifikasi yang lebih efektif. SSVM merupakan pengembangan dari SVM yang menggunakan teknik smoothing. Metode ini pertama kali diperkenalkan oleh Lee pad a tahun 2001. Ide dasar dari SSVM adalah untuk mengkonversi SVM primal formulasi untuk masalah minimisasi non mulus tanpa kendala. Penelitian Support Vector Machine (SSVM) adalah bidang aktif dalam data mining. Penulis mengembangkan metode untuk meningkatkan keakuratan hasil dari database masalah drop out mahasiswa Politeknik Negeri Medan khususnya jurusan Teknik Mesin dan Teknik Konversi Energi.
APPLICATION OF DATA MINING TECHNIQUE TO VECTOR
MACHINEMETHOD SMOOTH SUPPORT(SSVM) TO PREDICT
STUDENTS WHO DROP OUT CHANCE
(Case Study Mahasisawa Polytechnic Medan)
ABSTRACT
Support Vector Machines (SVM) is a new algorithm of data mining techniques, the increasing popularity in machine learning and statistics communities. SVM has been introduced by Vapnik to solve the problem of pattern recognition and nonlinear function estimation. SVM has become the tool of choice for the basic classification problem machine learning and data mining. Unlike traditional methods that minimize the empirical training error, SVM aims at minimizing the upper bound of generalization error through maximizing the margin between the hyperplane separating the data. This can be regarded as the implementation of the principle minimisasi risikostruktur estimates, smoothing method, widely used to solve mathematical programming problems and important applications, which are applied here to generate and solve an infinite reformulation of support vector machines for pattern classification. Although many variants of SVM have been proposed, is still an active research problem in order to improve for a more effective classification. SSVM is a development of the SVM that uses a smoothing technique. This method was first introduced by Leepad atahun 2001. The basic idea is to convert from SSVM SVM primal formulation for non-smooth minimization problem without constraint. Research Support Vector Machine (SSVM) is active in the field of data mining. The author developed a method to improve the accuracy of the results from the database drop-out problem Polytechnic students majoring in particular field of Mechanical Engineering and Energy Conversion Techniques.
DAFTAR ISI
Halaman LEMBAR PENGESAHAN ...
LEMBAR PERNYATAAN ORISINALITAS ... LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS...
KATA PENGANTAR ………. i
ABSTRAK ………... iii
ABSTRACT ………. iv
DAFTAR ISI ……… v
DAFTAR GAMBAR ……… vii
DAFTAR TABEL ………. viii
BAB I PENDAHULUAN ... 1
I.1 Latar Belakang ... 1
I.2 Perumusan Masalah ... 3
I.3 Batasan Masalah ... 3
I.4 Tujuan Penelitian ... 3
I.5 Manfaat Penelitian ... 4
I.6 Hipotesa ... 4
BAB II TINJAUAN PUSTAKA ... 5
II.1 Data Mining ... 5
II.2 Pengertian Teknik Data Mining ... 6
II.2.1 Teknik Data Mining ... 7
A.Classification ... 7
B.Association ... 8
C.Clustering ... 9
II.4 Tahapan Data Mining ... 10
II.5 Arsitektur Sistem Data mining ... 14
II.6 Tugas-tugas dalam Data mining ... 17
II.7 Pengertian SSVM (Smooth Support Vector Machine) .. 19
II.7.1 Karateristik SVM ………. 20
II.7.2 Kelebihan dan Kekurangan SVM ………. 20
BAB III METODOLOGI PENELITIAN ... 23
III.1 Tempat dan Waktu Penelitian ... 23
III.2 Pelaksanaan Penelitian ... 24
III.3 Variabel Yang Diamati ... 24
III.4 Prosedure Pengumpulan Data ... 24
III.5 Alat Analisis Data ... 23
III.6 Diagram Aktifitas Kerja Penelitian ... 28
BAB IV HASIL DAN PEMBAHASAN ... 30
IV.1 Pendahuluan ……… 30
IV.2 Hasil Percobaan Data Sample ………. 30
IV.3 Tampilan Hasil Program Prediksi Mahasiswa Drop Out 33
BAB V KESIMPULAN DAN SARAN ... 44
IV.1 Kesimpulan ... 44
IV.2 Saran ... 44
LAMPIRAN ...
DAFTAR GAMBAR
Halaman
1. Gambar 2.1. Contoh decision tree ... 8
2. Gambar 2.2 Contoh klasterisasi ... 10
3. Gambar 2.3 Tahap-Tahap Data Mining ... 11
DAFTAR TABEL
1. Tabel 3.1 Tabel Prodi Teknik Mesin Semester A T.A 2008/2009 ... 21
2. Tabel 3.2 Tabel Prodi Teknik Konversi Energi Semester A
T.A 2008/2009 ... 21
3. Tabel 3.3 Tabel Prodi Teknik Mesin Semester B T.A 2008/2009 ... 21
4. Tabel 3.4 Tabel Prodi Teknik Konversi Energi Semester B
T.A 2008/2009 ... 22
5. Tabel 3.5 Tabel Prodi Teknik Mesin Semester A T.A 2009/2010 ... 22
6. Tabel 3.6 Tabel Prodi Teknik Konversi Energi Semester A
T.A 2009/2010 ... 22
7. Tabel 3.7 Tabel Prodi Teknik Mesin Semester B T.A 2009/2010 ... 23
8. Tabel 3.8 Tabel Prodi Teknik Konversi Energi Semester A
PENERAPAN TEKNIK DATA MINING DENGAN METODE SMOOTH SUPPORT VECTOR MACHINE (SSVM) UNTUK MEMPREDIKSI
MAHASISWA YANG BERPELUANG DROP OUT (Studi Kasus Mahasiswa Politeknik Negeri Medan)
ABSTRAK
Support Vector Machines (SVM) adalah Algoritma baru dari Teknik data mining, meningkatnya popularitas dalam pembelajaran mesin dan statistic masyarakat. SVM telah diperkenalkan oleh Vapnik untuk memecahkan masalah pengenalan pola dan fungsi nonlinear estimasi. SVM telah menjadi alat pilihan untuk masalah klasifikasi dasar pembelajaran mesin dan data mining. Tidak seperti metode tradisional yang meminimalkan kesalahan pelatihan empiris, SVM bertujuan meminimalkan batas atas kesalahan generalisasi melalui memaksimalkan margin antara hyperplane memisahkan data. Hal ini dapat dianggap sebagai pelaksanaan perkiraan prinsip minimisasi risiko struktur, Metode smoothing, banyak digunakan untuk memecahkan masalah pemrograman matematis dan aplikasi penting, yang diterapkan disini untuk menghasilkan dan memecahkan sebuah reformulasi tak terbatas dari mesin vector dukungan untuk klasifikasi pola. Meskipun banyak varian SVM telah diusulkan, masih merupakan masalah penelitian aktif dalam rangka meningkatkan untuk klasifikasi yang lebih efektif. SSVM merupakan pengembangan dari SVM yang menggunakan teknik smoothing. Metode ini pertama kali diperkenalkan oleh Lee pad a tahun 2001. Ide dasar dari SSVM adalah untuk mengkonversi SVM primal formulasi untuk masalah minimisasi non mulus tanpa kendala. Penelitian Support Vector Machine (SSVM) adalah bidang aktif dalam data mining. Penulis mengembangkan metode untuk meningkatkan keakuratan hasil dari database masalah drop out mahasiswa Politeknik Negeri Medan khususnya jurusan Teknik Mesin dan Teknik Konversi Energi.
APPLICATION OF DATA MINING TECHNIQUE TO VECTOR
MACHINEMETHOD SMOOTH SUPPORT(SSVM) TO PREDICT
STUDENTS WHO DROP OUT CHANCE
(Case Study Mahasisawa Polytechnic Medan)
ABSTRACT
Support Vector Machines (SVM) is a new algorithm of data mining techniques, the increasing popularity in machine learning and statistics communities. SVM has been introduced by Vapnik to solve the problem of pattern recognition and nonlinear function estimation. SVM has become the tool of choice for the basic classification problem machine learning and data mining. Unlike traditional methods that minimize the empirical training error, SVM aims at minimizing the upper bound of generalization error through maximizing the margin between the hyperplane separating the data. This can be regarded as the implementation of the principle minimisasi risikostruktur estimates, smoothing method, widely used to solve mathematical programming problems and important applications, which are applied here to generate and solve an infinite reformulation of support vector machines for pattern classification. Although many variants of SVM have been proposed, is still an active research problem in order to improve for a more effective classification. SSVM is a development of the SVM that uses a smoothing technique. This method was first introduced by Leepad atahun 2001. The basic idea is to convert from SSVM SVM primal formulation for non-smooth minimization problem without constraint. Research Support Vector Machine (SSVM) is active in the field of data mining. The author developed a method to improve the accuracy of the results from the database drop-out problem Polytechnic students majoring in particular field of Mechanical Engineering and Energy Conversion Techniques.
BAB I
PENDAHULUAN
I.1 Latar Belakang.
Teknologi Informasi telah merambah ke seluruh sektor kehidupan, mulai dari digunakannya Teknologi Informasi ini hanya sebagai pengganti mesin ketik sampai dengan yang sudah mendukung dalam pengambilan keputusan manajemen. Teknologi Informasi telah berkembang begitu pesat. Hal ini tentu saja membawa dampak perubahan seluruh sektor kehidupan manusia. Pada dasarnya Teknologi informasi adalah perangkat yang berharga karena dapat memberikan berbagai manfaat baik langsung maupun tidak langsung. Pengetahuan tentang Teknologi informasi ini sangat penting, hal ini disebabkan karena teknologi informasi berada dimana-mana dan dapat membantu manusia menjadi lebih produktif sehingga menggairahkan dan dapat memberikan perubahan, mempertinggi karir, dan dapat memberikan kesempatan luas kepada manusia di dunia ini.
Politeknik Negeri Medan saat ini dituntut untuk memiliki keunggulan bersaing dengan memanfaatkan semua sumber daya yang dimiliki. Selain sumber daya sarana, prasarana, dan manusia, sistem informasi adalah salah satu sumber daya yang dapat digunakan untuk meningkatkan keunggulan bersaing. Saat ini Politeknik Negeri Medan belum mempunyai ketentuan yang akurat untuk memprediksi mahasiswa yang berpotensi drop out sehingga diperoleh sebuah model yang dapat memprediksi mahasiswa yang berpotensi drop out. Informasi yang diperoleh dengan sistem ini sangat bermanfaat atau berguna bagi manajemen untuk dapat melakukan tindakan-tindakan yang dianggap perlu untuk mencegah agar mahasiswa tersebut tidak sampai mengalami drop out.
diaplikasikan diberbagai bidang. Misalnya : Image Processing, Bio Informatik, Perbangkan, Pendidikan dan Industri.
SSVM merupakan pengembangan dari SVM yang menggunakan teknik smoothing. Metode inipertama kali diperkenalkan oleh Lee[3] pada tahun 2001. Ide dasar dari SSVM adalah untuk mengkonversi SVM primal formulasi untukmasalahminimisasinonmulustanpa kendala. Karenafungsi tujuandarimasalah optimisasi tidak dibatasi tidak dua kali differentiable, fungsi smoothing dapat diterapkan untuk halus masalah initidak dibatasi. Lee [3]
Support Vector Machine (SVM) pertama kali diperkenalkan oleh Vapnik pada tahun 1992 sebagai rangkaian harmonis konsep-konsep unggulan dalam bidang pattern recognition. Sebagai salah satu metode pattern recognition,usia SVM terbilang masih relatif muda. Walaupun demikian, evaluasi kemampuannya dalam berbagai aplikasinyamenempatkannya sebagai state of the art dalam pattern recognition, dan dewasa ini merupakan salah satu tema yangberkembang dengan pesat.
telah mengusulkan integral dari fungsi sigmoid untuk mendekati fungsi ditambah. Kemudian, Yuan telah mengusulkan fungsi polinom dan fungsi spline.
I.2 Perumusan Masalah
Dalam perumusan masalah ini mahasiswa yang berpotensi drop out merupakan salah satu informasi yang sangat penting bagi manajemen di Politeknik Negeri Medan dalam meminimalisasikan angka drop out mahasiswa sehingga diperlukan suatu cara atau metode yang dapat memprediksi mahasiswa yang cendrung drop out secara akurat.
Permasalahan dalam penelitian ini secara detail dirumuskan sbb :
1. Bagaimana membuat sebuah model untuk memprediksi mahasiswa yang cendrung atau berpotensi drop out khususnya Teknik Mesin Prodi Teknik mesin dan Teknik Konversi Energi
2. Bagaimana mengaplikasikan SSVM (SmoothSupport Vektor Machine) untuk memprediksi mahasiswa yang berpotensidrop out di politeknik Negeri Medan.
I.3 Batasan Masalah
Dalam penelitian ini penulis melakukan beberapa batasan permasalahan, mengingat waktu dalam penelitian sangat singkat. Maka disini penulis membatasi antara lain :
1. Penulis hanya memprediksi mahasiswa yang berpotensi drop out apa bila mahasiswa tersebut melanggar beberapa peraturan yang telah ditetapkan oleh Politeknik Negeri Medan, khususnya Teknik Mesin prodi Teknik Mesin dan Teknik Konversi Enegi.
2. Dalam penelitian ini penulis hanya menggunakan teknik data maining dengan metode SSVM (SmoothSupport Vektor Machine).
I.4 Tujuan Penelitian
I.5 Manfaat Penelitian
1. Dengan adanya informasi penting yang diterima oleh setiap mahasiswa baru, maka mahasiswa mampu mentaati peraturan-peraturan yang ada selama menjalankan perkulihan dipoliteknik negeri medan.
2. Membuat sistem prediksi terhadap mahasiswa yang bersifat potensial Droup Out yang ada pada Politeknik Negeri Medan.
I.6 Hipotesa
BAB II
TINJAUAN PUSTAKA
II.1 Data Mining
Data mining merupakan teknologi yang menggabungkan metoda analisis
tradisional dengan algoritma yang canggih untuk memproses data dengan volume besar. Data mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalamdatabase.Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasanbuatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang bermanfaat yang tersimpan di dalam database besar. (Turban et al, 2005 ).
Beberapa definisi awal dari data mining meyertakan focus pada proses otomatisasi. Berry danLinoff, (2004) dalam buku Data Mining Technique for Marketing, Sales, and Customer Support mendefinisikan data mining sebagai
suatu proses eksplorasi dan analisis secara otomatis maupun semi otomatis terhadap data dalam jumlah besar dengan tujuan menemukan pola atau aturan yang berarti (Larose, 2006).
Analisis yang diotomatisasi yang dilakukanoleh data mining melebihi yang dilakukan oleh sistem pendukung keputusan tradisional yang sudah banyak digunakan. Data Mining dapat menjawab pertanyaan-pertanyaan bisnis yang dengan caratradisional memerlukan banyak waktu dan cost tinggi. Data Mining mengeksplorasi basis datauntuk menemukan pola-pola yang tersembunyi, mencari informasi untuk memprediksi yangmungkin saja terlupakan oleh para pelaku bisnis karena terletak di luar ekspektasi mereka.
penyimpanan data berukuran besar. Istilah lain yang sering digunakan diantaranya knowledge discovery (mining) indatabases (KDD).
Istilah data mining dan Knowledge Discovery in Database (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining.
II.2 Pengertian Teknik Data Mining
Ada beberapa definisi dari data mining yang dikenal diiantaranya adalah :
1. Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual.
2. Data mining adalah analisa otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaannya
3. Data mining atau Knowledge Discovery in Databases (KDD) adalah pengambilan informasi
yang tersembunyi, dimana informasi tersebut sebelumnya tidak dikenal dan berpotensibermanfaat. Proses ini meliputi sejumlah pendekatan teknis yang berbeda, seperti clustering, data summarization, learning classification rules.
II.2.1 Teknik Data Mining
Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu
kumpulandata berupa pengetahuan yang selama ini tidak diketahui secara manual. Perlu diingat bahwa katamining sendiri berarti usaha untuk mendapatkan sedikit data berharga dari sejumlah besar datadasar. Karena itu data mining sebenarnya memiliki akar yang panjang dari bidang ilmu sepertikecerdasan buatan (artificial intelligent), machine learning, statistik dan basisdata. Beberapa teknikyang sering
disebut-sebut dalam literatur data mining antara lain yaitu association rule mining,clustering, klasifikasi, neural network, genetic algorithm dan lain-lain.
Model maupun hasil analisanya, salah satunya dengan kemampuan pembelajaran yang dimiliki beberapa teknik data mining seperti klasifikasi.Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu
kumpulandata berupa pengetahuan yang selama ini tidak diketahui secara manual. Perlu diingat bahwa katamining sendiri berarti usaha untuk mendapatkan sedikit data berharga dari sejumlah besar datadasar. Karena itu data mining sebenarnya memiliki akar yang panjang dari bidang ilmu sepertikecerdasan buatan (artificial intelligent), machine learning, statistik dan basisdata. Beberapa teknikyang sering
disebut-sebut dalam literatur data mining antara lain yaitu association rule mining,clustering, klasifikasi, neural network, genetic algorithm dan lain-lain.
A. Classification
Suatu teknik dengan melihat pada kelakuan dan atribut dari kelompok yang telahdidefinisikan.Teknik ini dapat memberikan klasifikasi pada data baru dengan memanipulasi datayang ada yang telah diklasifikasi dan dengan menggunakan hasilnya untuk memberikan sejumlahaturan. Aturan-aturan tersebut digunakan pada data-data baru untuk diklasifikasi. Teknik inimenggunkan supervised induction, yang memanfaatkan kumpulan pengujian dari record yangterklasifikasi
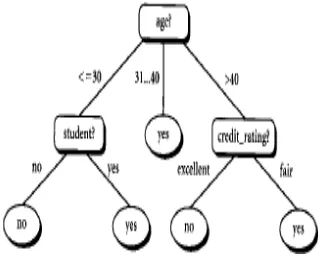
prediksi menggunakan struktur pohon atau strukturberhirarki.Decision tree adalah struktur flowchart yang menyerupai tree (pohon), dimana setiapsimpul internal menandakan suatu tes pada atribut, setiap cabang merepresentasikan hasil tes, dansimpul daun merepresentasikan kelas atau distribusi kelas. Alur pada decision tree di telusuri darisimpul akar ke simpul daun yang memegang prediksikelas
untuk contoh tersebut. Decision tree mudah untuk dikonversi ke aturan klasifikasi(classification rules)
Gambar 2.1 Contoh decision tree
B. Association
untukkombinasi barang tertentu.Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, supportyaitu prosentasi kombinasi atribut tersebut dalam basisdata dan confidence yaitu kuatnya hubunganantar atribut dalam aturan asosiatif.Motivasi awal pencarian association rule berasal dari keinginanuntuk menganalisa data transaksi supermarket, ditinjau dari perilaku customer dalam membeliproduk. Association rule ini menjelaskan seberapa sering suatu produk dibeli secara bersamaan.Sebagai contoh, association rule “beer =>diaper (80%)” menunjukkan bahwa empat dari limacustomer yang membeli
beer juga membeli diaper. Dalam suatu association rule X =>Y, X disebutdengan
antecedent dan Y disebut dengan consequent.Rule.
C. Clustering
Digunakan untuk menganalisis pengelompokkan berbeda terhadap data, mirip denganklasifikasi, namun pengelompokkan belum didefinisikan sebelum dijalankannya tool data mining. Biasanya menggunkan metode neural network atau statistik. Clustering membagi item menjadi kelompok-kelompok berdasarkan yang ditemukan tool data mining.Prinsip dari clustering adalah memaksimalkan kesamaan antar anggota satu kelas danmeminimumkan kesamaan antar cluster. Clustering dapat dilakukan pada data yang memilikibeberapa atribut yang
dipetakan sebagai ruang multidimensi.
Ilustrasi dari clustering dapat dilihatdi Gambar 3 dimana lokasi, dinyatakan dengan bidang dua dimensi, dari pelanggan suatu tokodapat dikelompokkan menjadi beberapa cluster dengan pusat cluster ditunjukkan oleh tanda positif(+).
Banyak algoritma clustering memerlukan fungsi jarak untuk mengukur kemiripan antar data,diperlukan juga metoda untuk normalisasi bermacam atribut yang dimiliki data.
II.3 Definisi Data Mining
Kemajuan dalam pengumpulan data dan teknologi penyimpanan yang cepatmemungkinkan organisasi menghimpun jumlah data yang sangat luas. Alat dan teknik analisis datayang tradisional tidak dapat digunakan untuk mengektrak informasi dari data yang sangat besar.Untuk itu diperlukan suatu metoda baru yang dapat menjawab kebutuhan tersebut. Data miningmerupakan teknologi yang menggabungkan metoda analisis tradisional dengan algoritma yangcanggih untuk memproses data dengan volume besar.
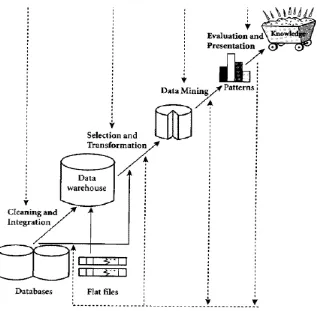
II.4 Tahapan Data Mining
Gambar 2.3. Tahap-Tahap Data Mining
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap yangdiilustrasikan di Gambar 1. Tahap-tahap tersebut. bersifat interaktif di mana pemakai terlibatlangsung atau dengan perantaraan knowledge base.
1. Pembersihan data, Digunakan untuk membuang data yang tidakkonsisten dan noise
3. Transformasi data,Transformasi dan pemilihan data ini untuk menentukan kualitas dari hasil data mining, sehinggadata diubah menjadi bentuk sesuai untuk di-Mining.
4. Aplikasi Teknik Data Mining,Aplikasi teknik data mining sendiri hanya merupakan salah satu bagian dari proses data mining Ada beberapa teknik data mining yang sudah umum dipakai.
5. Evaluasi pola yang ditemukan,Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksidievaluasi untuk menilai apakah hipotesa yang ada memang tercapai.
6. Presentasi Pengetahuan,Presentasi pola yang ditemukan untuk menghasilkan aksi tahap terakhir dari proses data miningadalah bagaimana memformulasikan keputusan atau aksi dari hasil analisa yang didapat.
Sesuai yang tercantum dalam buku “Advances in Knowledge Discovery danData mining” terdapat definisi sebagai berikut: Knowledge discovery (data mining) in databases (KDD) adalah keseluruhan proses non-trivial untuk mencari
dan mengidentifikasi pola (pattern) dalam data, dimana pola yang ditemukan bersifat sah (valid), baru (novel), dapat bermanfaat (potentially usefull), dapat dimengerti (ultimately understandable)[2].
1. Data Selection
Istilah data mining dan knowledge discovery in databases (KDD) sering kali digunakan secara bergantian untuk
menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbedaakan tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut[2]:
2. Pre-processing/ Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaningpada data yang menjadi focus KDD. Proses cleaning mencakup
antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal. 3. Transformation
Codinga dalah proses transformasipada data yang telah dipilih, sehingga
data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data
4. Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam
data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/ Evaluation
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut dengan interpretation.
contoh, pada saat coding atau data mining, analis menyadari proses cleaning belum dilakukan dengan sempurna, atau mungkin saja analis menemukan data atau informasi baru untuk “memperkaya” data yang sudah ada.
II.5 Arsitektur Sistem Data mining
Data mining merupakan proses pencarian pengetahuan yang menarik dari data
berukuran besar yang disimpan dalam basis data, data warehouse atau tempat penyimpanan informasi lainnya. Dengan demikian arsitektur sistem data mining memiliki komponen-komponen utama yaitu:
1. Basis data, data warehouse atau tempat penyimpanan informasi lainnya.
2. Basis data dan data warehouse server. Komponen ini bertanggung jawab dalam pengambilan relevant data, berdasarkan permintaan pengguna.
3. Basis pengetahuan. Komponen ini merupakan domain knowledge yang digunakan untuk memandu pencarian atau mengevaluasi pola-pola yang dihasilkan. Pengetahuan tersebut meliputi hirarki konsep yang digunakan untuk mengorganisasikan atribut atau nilai atribut ke dalam level abstraksi yang berbeda. Pengetahuan tersebut juga dapat berupa kepercayaan pengguna (user belief), yang dapat digunakan untuk menentukan kemenarikan pola yang diperoleh. Contoh lain dari domain knowledge adalah threshold dan metadata yang menjelaskan data dari berbagai sumber yang heterogen.
4. Data mining engine. Bagian ini merupakan komponen penting dalam arsitektur sistem data mining. Komponen ini terdiri modul-modul fungsional data mining seperti karakterisasi, asosiasi, klasifikasi, dan analisis cluster.
6. Antarmuka pengguna grafis. Modul ini berkomunikasi dengan pengguna dan sistem data mining. Melalui modul ini, pengguna berinteraksi dengan sistem mengan menentukan kueri atau task data mining. Antarmuka juga menyediakan informasi untuk memfokuskan pencarian dan melakukan eksplorasi data mining berdasarkan hasil data mining antara. Komponen ini juga memungkinkan pengguna untuk mencari (browse) basis data dan skema data warehouse atau struktur data, evaluasi pola yang diperoleh dan visualisasi pola dalam berbagai bentuk.
Data mining dapat diaplikasikan pada berbagai jenis penyimpanan data
seperti basis data relational, data warehouse, transactional database, object-oriented and object-relational databases, spatial databases, time-series data and temporal data, text databases and multimedia databases, heterogeneous and legacy databases dan WWW.
1. Basis data Relasional Basis data relasional merupakan koleksi dari table. Setiap table berisi atribut (field) dan biasanya menyimpan sejumlah besar tuple (record). Setiap tuple dalam table relasional merepesentasikan sebuah objek yang diidentifikasikan oleh kunci unik dan dideskripsikan oleh sekumpulan nilai atribut. Data relasional dapat diakses oleh kueri basis data yang ditulis dalam bahasa kueri relasional seperti SQL atau dengan bantuan antarmuka pengguna grafis.
2. Data warehouse Data warehouse merupakan tempat penyimpanan
informasi yang dikumpulkan dari berbagai sumber, disimpan dalam skema yang dipersatukan (unified schema) dan biasanya bertempat pada tempat penyimpanan tunggal. Data warehouse dikonstruksi melalui sebuah proses data cleaning, data transformation, data integration, data loading dan periodic data refreshing.
supplier atau aktivitas. Data disimpan untuk menyediakan informasi dari perspektif sejarah (seperti 5-10 tahun yang lalu) dan biasanya data tersebut diringkas (summarized). Sebagai contoh, daripada menyimpan data rinci dari transaksi penjualan, data warehouse dapat menyimpan ringkasan dari transaksi per tipe item untuk setiap toko atau diringkas dalam level yang lebih tinggi seperti daerah pemasaran.
Data warehouse biasanya dimodelkan oleh struktur basis data
multidimensional, dimana setiap dimensi berkaitan dengan sebuah atribut atau sekumpulan atribut dalam skema, dan setiap sel menyimpan nilai dari ukuran agregasi seperti count dan sales_amount. Struktur fisik dari data warehouse dapat berupa penyimpanan basis data relasional atau sebuah kubus data multidimensional.
Selain data warehouse, terdapat istilah penyimpanan data yang lain yaitu data mart. Sebuah data warehouse mengumpulkan informasi mengenai
subjek-subjek yang menjangkau seluruh organisasi, dengan demikian cakupannya enterprise-wide. Sedangkan data mart merupakan sub bagian dari data
warehouse. Fokus data mart adalah pada subjek yang dipilih dan dengan
demikian cakupannya adalah department-wide.
II.6 Tugas-tugas dalam Data mining
Tugas-tugas dalam data mining secara umum dibagi ke dalam dua kategori utama:
1. Prediktif. Tujuan dari tugas prediktif adalah untuk memprediksi nilai dari atribut tertentu berdasarkan pada nilai dari atribut-atribut lain. Atribut yang diprediksi umumnya dikenal sebagai target atau variabel tak bebas, sedangkan atribut-atribut yang digunakan untuk membuat prediksi dikenal sebagai explanatory atau variabel bebas.
2. Deskriptif. Tujuan dari tugas deskriptif adalah untuk menurunkan pola-pola (korelasi, trend, cluster, trayektori, dan anomali) yang meringkas hubungan yang pokok dalam data. Tugas data mining deskriptif sering merupakan penyelidikan dan seringkali memerlukan teknik postprocessing untuk validasi dan penjelasan hasil.
Berikut adalah tugas-tugas dalam data mining:
1. Analisis Asosiasi (Korelasi dan kausalitas)
Analisis asosiasi adalah pencarian aturan-aturan asosiasi yang menunjukkan kondisi-kondisi nilai atribut yang sering terjadi bersama-sama dalam sekumpulan data. Analisis asosiasi sering digunakan untuk menganalisa market basket dan data transaksi.
Aturan-aturan asosiasi memiliki bentuk X ⇒ Y, bahwa A1 ∧ A2 ∧ … ∧ Am → B1 ∧ B2 ∧ … ∧ Bn, dimana Ai (untuk i = 1, 2, …, m) dan Bj (untuk j = 1, 2, …,
n) adalah pasangan-pasangan nilai atribut. Aturan asosiasi X ⇒ Y diinterpretasikan sebagai tuple-tuple basis data yang memenuhi kondisi-kondisi dalam X juga mungkin memenuhi kondisi-kondisi dalam Y.
Contoh dari aturan asosiasi adalah age(X, “20..29”) ^ income(X, “20..29K”) ⇒ buys(X, “PC”) [support = 2%, confidence = 60%]
Klasifikasi dan Prediksi Klasifikasi adalah proses menemukan model (fungsi) yang menjelaskan dan membedakan kelas-kelas atau konsep, dengan tujuan agar model yang diperoleh dapat digunakan untuk memprediksikan kelas atau objek yang memiliki label kelas tidak diketahui. Model yang turunkan didasarkan pada analisis dari training data (yaitu objek data yang memiliki label kelas yang diketahui). Model yang diturunkan dapat direpresentasikan dalam berbagai bentuk seperti aturan IF-THEN klasifikasi, pohon keputusan, formula matematika atau jaringan syarf tiruan.
Dalam banyak kasus, pengguna ingin memprediksikan nilai-nilai data yang tidak tersedia atau hilang (bukan label dari kelas). Dalam kasus ini biasanya nilai data yang akan diprediksi merupakan data numeric. Kasus ini seringkali dirujuk sebagai prediksi. Di samping itu, prediksi lebih menekankan pada identifikasi trend dari distribusi berdasarkan pada data yang tersedia.
1. Analisis Cluster Tidak seperti klasifikasi dan prediksi, yang menganalisis objek data yang diberi label kelas, clustering menganalisis objek data dimana label kelas tidak diketahui. Clustering dapat digunakan untuk menentukan label kelas tidak diketahui dengan cara mengelompokkan data untuk membentuk kelas baru. Sebabai contoh clustering rumah untuk menemukan pola distribusinya. Prinsip dalam clustering adalah memaksimumkan kemiripan intra-class dan meminimumkan kemiripan interclass.
2. Analisis Outlier Outlier merupakan objek data yang tidak mengikuti perilaku umum dari data. Outlier dapat dianggap sebagai noise atau pengecualian. Analisis data outlier dinamakan outlier mining. Teknik ini berguna dalam fraud detection dan rare events analysis.
waktu. Teknik ini dapat meliputi karakterisasi, diskriminasi, asosiasi, klasifikasi, atau clustering dari data yang berkaitan dengan waktu.
Data mining merupakan bidang interdisplin. Disiplin ilmu ini banyak
dipengaruhi oleh disiplin sistem basis data, statistika, ilmu informasi, mesinpembelajaran, dan visualisasi. Sistem data mining dapat diklasifsikasikan berdasarkan beberapa kategori, yaitu :
1. Klasifikasi berdasarkan data yang akan di-mine seperti relational, transactional, object-oriented, object-relational, spatial, time-series, text,
multi-media dan www.
2. Klasifikasi berdasarkan pengetahuan yang akan di-mine, yaitu berdasarkan fungsionalitas data mining seperti karakterisasi, diskriminasi, asosiasi, klasifikasi, clustering, analisis outlier dan analisis evolusi. Sistem data mining yang komprehensif biasanya menyediakan beberapa fungsi-fungsi
data mining.
3. Klasifikasi berdasarkan teknik yang akan digunakan seperti database-oriented, data warehouse (OLAP), machine learning, Statistics,
Visualization dan neural network.
4. Klasifikasi berdasarkan aplikasi yang diadaptasi, sebagai contoh system data mining untuk keuangan, telekomunikasi, DNA, dan e-mail.
II.7 Pengertian SSVM (Smooth Support Vektor Machine).
Support Vector Machine (SVM) pertama kali diperkenalkan oleh Vapnik pada tahun 1992 sebagai rangkaianharmonis konsep-konsep unggulan dalam bidang pattern recognition. Sebagai salah satu metode pattern recognition,usia SVM terbilang masih relatif muda. Walaupun demikian, evaluasi kemampuannya dalam berbagai aplikasinyamenempatkannya sebagai state of the art dalam pattern recognition. SVM adalah metode learning machine yang bekerja atas prinsip
teori dasar SVM dan aplikasinya dalam bioinformatika, khususnya pada analisaekspresi gen yang diperoleh dari analisa microarray.Konsep SVM dapat dijelaskan secara sederhanasebagai usaha mencari hyperplaneterbaik yangberfungsi
sebagai pemisah dua buah class padainput space.
Konsep dasar SVMsebenarnya merupakan kombinasi harmonis dariteori-teori
komputasi yang telah ada puluhantahun sebelumnya, seperti margin hyperplane(Duda &
Hart tahun 1973, Cover tahun 1965,Vapnik 1964, dsb.), kernel diperkenalkan
olehAronszajn tahun 1950, dan demikian jugadengan konsep-konsep pendukung yang
lain.
Akan tetapi hingga tahun 1992, belum pernahada upaya merangkaikan
komponen-komponentersebut.
II.7.1 KARAKTERISTIK SVM
Karakteristik SVM sebagaimana telah dijelaskanpada bagian sebelumnya, dirangkumkan
sebagaiberikut:
1. Secara prinsip SVM adalah linear classifier
2. Pattern recognition dilakukan denganmentransformasikan data pada input
spaceke ruang yang berdimensi lebih tinggi, danoptimisasi dilakukan pada ruang
vector yangbaru tersebut. Hal ini membedakan SVMdari solusi pattern
recognition padaumumnya, yang melakukan optimisasiparameter pada ruang
hasil transformasiyang berdimensi lebih rendah daripadadimensi input space.
3. Menerapkan strategi Structural RiskMinimization (SRM)
4. Prinsip kerja SVM pada dasarnya hanyamampu menangani klasifikasi dua class.
II.7. 2 KELEBIHAN DAN KEKURANGAN SVM
Dalam memilih solusi untuk menyelesaikansuatu masalah, kelebihan dan
kelemahanmasing-masing metode harus diperhatikan.Selanjutnya metode yang tepat
dipilih denganmemperhatikan karakteristik data yang diolah.Dalam hal SVM, walaupun
berbagai studi telahmenunjukkan kelebihan metode SVMdibandingkan metode
konvensional lain, SVMjuga memiliki berbagai kelemahan. KelebihanSVM antara lain
1. Generalisasi
Generalisasi didefinisikan sebagaikemampuan suatu metode (SVM, neuralnetwork, dsb.) untuk mengklasifikasikansuatu pattern, yang tidak termasuk data yangdipakai dalam fase pembelajaran metode itu.Vapnik menjelaskan bahwa generalizationerror dipengaruhi oleh dua faktor: errorterhadap training set, dan satu faktor lagiyang dipengaruhi oleh dimensi VC(Vapnik-Chervokinensis). Strategipembelajaran pada neural network danumumnya metode learning machinedifokuskan pada usaha untukmeminimimalkan error pada training-set.Strategi ini disebut Empirical RiskMinimization (ERM). Adapun SVM selainmeminimalkan error pada
training-set, jugameminimalkan faktor kedua. Strategi inidisebut Structural Risk Minimization (SRM),dan dalam SVM diwujudkan denganmemilih
hyperplane dengan margin terbesar.Berbagai studi empiris menunjukkan bahwapendekatan SRM pada SVM memberikanerror generalisasi yang lebih kecil daripadayang diperoleh dari strategi ERM padaneural network maupun metode yang lain.
2. Curse of dimensionality.
bidang biomedicalengineering, karena biasanya data biologi yang tersedia sangat terbatas, dan penyediaannya memerlukan biaya tinggi.Vapnik membuktikan bahwa tingkat generalisasi yang diperoleh oleh SVM tidak dipengaruhi oleh dimensi dari input vector. Hal ini merupakan alasan mengapa SVM merupakan salah satu metode yang tepat dipakai untuk memecahkan masalah berdimensi tinggi, dalam keterbatasan sampel data yang ada.
BAB III
METODOLOGI PENELITIAN
Tujuan dari Tesis ini adalah untuk membuat model penerapan dalam memprediksi mahasiswa yang berpeluang drop out dengan keterhubungan data mahasiswa dengan jurusan untuk meningkatkan disiplin mahasiswa yang lebih baik dengan menyediakan data prestasi akademik mahasiswa berupa indeksprestasi yang dapat digunakan sebagai pedoman analisis dalam pembuatan keputusan.
Pada bagian ini kita mulai dengan menggambarkan studi kasus data mining pada system penilaian akademik di perguruan tinggi dan prosedur
bagaimana mengumpulkan data yang dapat digunakan pada penelitian ini.
Data dikumpulkan dari database pendidikan akademik dan mensurvei mahasiswa diploma yang telah menempuh semester 1sampaidengantahun 2011 di Politeknik Negeri Medan. Instrumen penelitian yang digunakan harus mempunyai ukuran yang akurat. Secara terperinci, bagaimana mendapatkan input yang lebih baik dalam proses data mining yang digambarkan pada bagian sebelum pemprosesan data. Penulis memberikan tinjauan singkat dari beberapa analysis data yang digunakan pada penelitian ini.
III.1 Tempat dan Waktu Penelitian
Penelitian ini diambil dilokasi Politeknik Negeri Medan Jln. Almamater No.1 Kampus USU Padang Bulan Medan. Penelitian ini dimulai pada bulan Pebruari - Juni 2010, dan penelitian ini membutuhkan waktu selama 5 bulan dalam menyelesaikan penelitian ini.
III.2 Pelaksanaan Penelitian
III.3 Variabel Yang Diamati
Berdasarkan pembahasan diatas dapat dikemukakan kerangka konsep penelitian sebagai berikut:
1. Daftar kehadiran mahasiswa
2. Ujian harian
3. Latihan
4. Laboratorium
5. UTS
6. UAS
III.4 Prosedur Pengumpulan Data
Rancangan penelitian ini dilakukan sesuai dengan pengamatan (observasi) untuk mempelajari tingkat kedisiplinan mahasiswa dalam mengikuti perkuliahan. Hasil pengamatan kemudian dibuat percobaan yang mendukung, selanjutnya dilakukan eksperimen data.
Dalam melakukan penelitian ini, dikumpulkan beberapa data atau daftar mahasiswa yang drop out (DO) pada jurusan Teknik Mesin pada Semester A Tahun Akademik 2008/2009 hingga 2009/ 2010. Berikut daftar mahasiswa sbb:
Tabel 3.1 Prodi Teknik Mesin.
N0 Nama NIM Kelas N0 Surat Tgl Surat Ket
9 Dedi Situmeang 0805011023 ME-1B 470/K2/AK/2009 14 April 2009 Nilai 10 Abdul Kodir Siregar 0805011001 ME-1C 471/K2/AK/2009 14 April 2009 Nilai 11 Sahat D. Sihombing 0805012198 ME-1H 472/K2/AK/2009 14 April 2009 Nilai 12 Jimmi Amse Ginting 062301061 ME-3B 473/K2/AK/2009 14 April 2009 Nilai
Tabel 3.2 Prodi Teknik Konversi Energi.
N0 Nama NIM Kelas N0 Surat Tgl Surat Ket
1 Tona Bontor Melki, S 0805052098 EN-1D 1549/K2/AK/2008 02 Desember 20008 Absen 2 Faridz Al Kindi 0705051019 EN-3B 1550/K2/AK/2008 02 Desember 20008 Absen 3 Ali Imran 0705051001 EN-3B 1551/K2/AK/2008 02 Desember 20008 Absen 4 Muhammad Abdul T 0805051027 EN-1B 89/K2/AK/2009 22 Januari 2009 Absen 5 Josia Sembiring 0805051018 EN-1A 476/K2/AK/2009 14 April 2009 Nilai 6 Ricky Satriaji 0705051088 EN-3A 477/K2/AK/2009 14 April 2009 Nilai
Daftar mahasiswa yang drop out pada Semester B Tahun Akademik 2008/2009 Tabel 3.3 Prodi Teknik Mesin
N0 Nama NIM Kelas N0 Surat Tgl Surat Ket
1 Yose Nainggolan 0805011102 ME-2B 1961/K2/AK/2009 22 Desember 2009 Nilai 2 Dwi Irawan 0705011026 ME-4A 1962/K2/AK/2009 23 Desember 2009 Nilai 3 Alfred Siallagan 0805012110 ME-2A 1963/K2/AK/2009 24 Desember 2009 Nilai 4 Yusdarlin 0805011104 ME-2G 1964/K2/AK/2009 25 Desember 2009 Nilai 5 M. Rizki Diapari S. 0805011060 ME-2D 1965/K2/AK/2009 26 Desember 2009 Nilai 6 Desmon Abdi J.G 0805011025 ME-2D 1966/K2/AK/2009 27 Desember 2009 Nilai 7 Ridho Saputra 0805012189 ME-2D 1967/K2/AK/2009 28 Desember 2009 Nilai 8 Suwardi Dwi Pramita 0805011089 ME-2C 1968/K2/AK/2009 29 Desember 2009 Nilai 9 Marcos Simorangkir 0805011065 ME-2C 1969/K2/AK/2009 30 Desember 2009 Nilai
Tabel 3.4 Prodi Teknik Konversi Energi
N0 Nama NIM Kelas N0 Surat Tgl Surat Ket
1 Syaiful Amri Sinaga 0805051047 EN-2A 1960/K2/AK/2009 22 Desember 2009 Nilai
III.5 AlatAnalisis Data
kasus linear yang dapat dikonversi ke masalah optimasi tanpa kendala., menganggap masalah mengklasifikasikan poin m n-dimensi ruang Rn nyata, diwakili oleh matriks m'n A, sesuai dengan keanggotaan dari masing-masing Ai titik dalam kelas 1 atau -1 sebagaimana ditentukan oleh matriks m 'm diberikan diagonal D dengan yang atau yang dikurangi di sepanjang diagonal. Untuk masalah ini SVM standar diberikan oleh program kuadrat berikut:
min
1Dalam pendekatan SSVM [3], masalah SVM dimodifikasi dihasilkan sebagai berikut:
)
Fungsiinidengan parameter pemulusan yang digunakan di siniuntukmenggantikanfungsi plus untukmendapatkan Vector Machine Dukunganhalus (SSVM)
Sama seperti sebelumnya, itu adalah memperoleh SSVM untuk masalah terpisahkan:
Beberapa Knot Spline-SSVM (MKS-SSVM):. Vector Machines halus Dukungan (SSVM) yang telah diusulkan oleh Lee dkk [3] adalah sangat penting dan Hasil yang signifikan untuk SVM karena banyak algoritma dapat digunakan untuk menyelesaikannya. Dalam SSVM, fungsi halus dalam fungsi tujuan (13) adalah integral dari sigmoid fungsi (9). Dalam studi ini, kami mengusulkan sebuah fungsi baru yang disebut mulus Beberapa Knot Spline (MKS) fungsi. Formulasi dan analisis kinerja kelancaran fungsi baru dan bagaimana membangun yang baru SSVM akan dijelaskan sebagai berikut:
m(x) =
III.6 Diagram Aktifitas Kerja Penelitian.
Berikut ini alur kerja yang akan dilakukan pada penelitian ini yang digambarkan dalam diagram aktivitas.
PENELITI PERANGKAT LUNAK
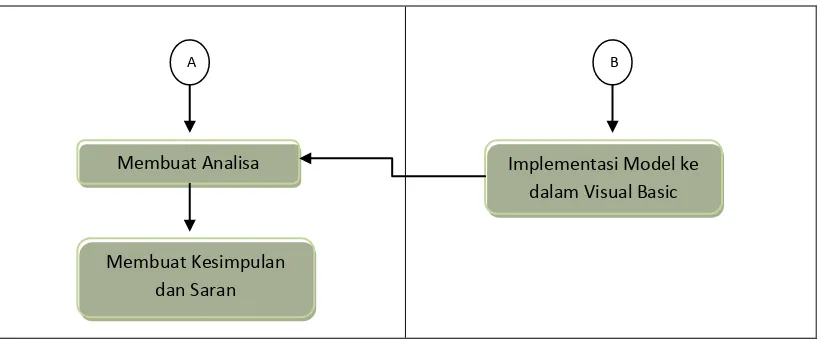
Gambar 3.1 Activity Diagram
Dari gambar 3.1 diatas dapat dijelaskan bahwa yang dilakukan pertama sekali oleh peneliti adalah mengidentifikasi masalah yang diteliti untuk diselesaikan yang mana tujuannya adalah menghasilkan prediksi potensial terhadap mahasiswa yang cendrung drop out, selanjutnya adalah mengumpulkan data mahasiswa yang diambil dari Akademin / jurusan. Data diambil dalam bentuk format xls, kemudian didapatkan hasil dalam bentuk program Visual Basic untuk dapat Kemudian dilakukan analisa dalam implementasi model kedalam Visual Basic. Setelah diperoleh hasil analisa maka di dapatlah kesimpulan dari hasil penelitian.
A B
Membuat Analisa
Membuat Kesimpulan dan Saran
BAB IV
HASIL DAN PEMBAHASAN
IV.1 Pendahuluan
Bab ini menyajikan hasil penelitian sesuai dengan pertanyaan-pertanyaan yang diajukan pada permulaan. Penelitian dilaksanakan untuk pertama, penulis menggunakan dataset nilai dan absensi mahasiswa diambil dari database Jurusan Teknik Mesin dan Teknik Konversi Energi
Teknik Mesin dan Teknik Konversi Energi. Data set bersifat nominal yang terdiri dari Absensi, Rata-rata Nialai Mata Kuliah kurikulum berbasis kompetensi dan semester. Kemudian data ditransformasikan keformat data Excel 2003.
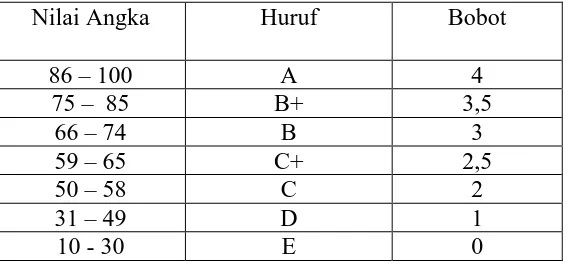
IV.2 Hasil Percobaan Data Sample
Prestasi Akademik mahasiswa untuk setiap matakuliah ditentukan oleh skala nilai berdasarkan tabel sebagai berikut:
Tabel 4.1 Skala Nilai
Nilai Angka Huruf Bobot
86 – 100 A 4
75 – 85 B+ 3,5
66 – 74 B 3
59 – 65 C+ 2,5
50 – 58 C 2
31 – 49 D 1
10 - 30 E 0
Dalam patokan angka tingkah laku (ATL) mahasiswa adalah :
Baik : 3
Dalam perhitungan nilai formula nilai akhir subyek mata kuliah yang baku ditetapkan oleh direktur dengan persetujuan senat, sebagai matakuliah sebagai berikut :
1. Nilai Matakuliah Teori
Keterangan :
NA : Nilai Akhir
NEK :Nilai Elemen Kompetensi ( Tugas-tugas, Latihan, Ujian
Formatif)
NUTS : Nilai Ujian Tengah Semester
NUAS : Nilai Ujian Akhir Semester
2. Nilai Matakuliah Praktek Laboratorium
Keterangan :
NA : Nilai Akhir
NPL : Nilai Praktek Laboratorium
NLP : Nilai Laporan Praktek Laboratorium
NUPL : Nilai Ujian Praktek Laboratorium
3. Nilai Matakuliah Praktek Bengkel
Keterangan :
NA : Nilai Akhir
NPB : Nilai Praktek Bengkel
NLPB : Nilai Laporan Praktek Bengkel
Indeks prestasi mahasiswa dalam semester dihitung dengan rumus :
N = Bobot nilai setiap matakuliah yang telah diselesaikan dalam satu
semester.
K = Nilai SKS setiap matakuliah yang telah diselesaikan dalam satu
semester.
Indeks prestasi kumulatif (IPK) merupakan ukuran keberhasilan studi mahasiswa untuk seluruh semester yang sudah diselesaikan dengan rumusan:
N = Bobot nilai setiap matakuliah yang telah diselesaikan selama
pendididkan.
K = Nilai SKS setiap matakuliah yang telah diselesaikan selama
pendidikan.
Excel. Dari sekumpulan data yang telah diperoleh maka dilakukan dengan menggunakan Program Visual Basic dalam melihat hasil akhir data mahasiswa, dihasilkan model keterhubungan data mahasiswa dengan masa studi.
Pengujian ini digunakan untuk menghasilkan model ssvm dalam memprediksi mahasiswa apakah mahasiswa tersebut drop out akhirnya atau tidak dapat disimpulkan hasil akhir program yang telah ada.
Pada Label NIM ditulis secara manual, NIM dibuat secara manual, setelah label NIM dibuat maka secara otomatis nama, program studi, stambuk dan no urut akan tampil.
Label yang akan diisi secara manual antara lain adalah NIM, Nomer Surat, Tanggal Surat, Nilai Ujian (Rata-rata) , Kelas dan SKS, hingga Akhirnya akan mendapatkan hasil secara keseluruhan, dan akan menghasilkan report untuk bahan pertimbangan, sehingga mendapatkan hasil IP apakah mahasiswa tersebut perlu dipertimbangkan atau tidak.
Dalam menentukan hasil nilai mahasiswa ditentukan dari rumus-rumus yang sudah dijabarkan.
Listing program
If KeyAscii = 13 Then TxtNilai.SetFocus End Sub
Private Sub CmdIP_Click() 'cari IP
TxtIP.Text = TxtTMutu.Text / TxtTSKS.Text
End Sub
Private Sub Command1_Click() End
End Sub
Private Sub Command2_Click()
MsgBox "KEMBALI?..", vbOKOnly, "PESAN" TxtMK.Text = ""
TxtNilai.Text = "" TxtNAngka.Text = "" TxtNHuruf.Text = "" TxtMUTU.Text = "" TxtKeterangan.Text = "" End Sub
Private Sub Command3_Click() TxtNilai.Text = " "
TxtNIM.Text = " " TxtNama.Text = " " TxtPRODI.Text = " " TxtNoUrut.Text = " " TxtNoUrut.Text = " " TxtSTAMBUK.Text = " " End Sub
Private Sub Form_Activate() TxtNIM.SetFocus
End Sub
Private Sub Form_Load() cboSKS.AddItem 10 cboSKS.AddItem 9 cboSKS.AddItem 8 cboSKS.AddItem 7 cboSKS.AddItem 6 cboSKS.AddItem 5 cboSKS.AddItem 4 cboSKS.AddItem 3 cboSKS.AddItem 2 cboSKS.AddItem 1 End Sub
Private Sub TxtMK_KeyPress(KeyAscii As Integer) If KeyAscii = 13 Then cboSKS.SetFocus
End Sub
'untuk mengisi listbox
LstMk.AddItem TxtMK.Text LstSKS.AddItem cboSKS.Text LstNhuruf.AddItem TxtNHuruf.Text LstNAngka.AddItem TxtNAngka.Text LstMutu.AddItem TxtMUTU.Text
'cari total sks
For y = 0 To LstSKS.ListCount - 1
totalsks = totalsks + Val(LstSKS.List(y)) Next y
TxtTSKS.Text = totalsks
'cari total mutu
For x = 0 To LstMutu.ListCount - 1
totalmutu = totalmutu + Val(LstMutu.List(x)) Next x
TxtTMutu.Text = totalmutu
End If End Sub
Private Sub TxtNilai_KeyPress(KeyAscii As Integer) If KeyAscii = 13 Then 'Jika Di Enter
If TxtNilai.Text >= 90 Then TxtNHuruf.Text = "A" TxtNAngka.Text = 4
ElseIf TxtNilai.Text >= 85 Then TxtNHuruf.Text = "A-"
TxtNAngka.Text = 3.5
TxtNHuruf.Text = "B+" TxtNAngka.Text = 3.25
ElseIf TxtNilai.Text >= 75 Then TxtNHuruf.Text = "B"
TxtNAngka.Text = 3
ElseIf TxtNilai.Text >= 70 Then TxtNHuruf.Text = "B-"
TxtNAngka.Text = 2.5
ElseIf TxtNilai.Text >= 65 Then TxtNHuruf.Text = "c+"
TxtNAngka.Text = 2.25
ElseIf TxtNilai.Text >= 60 Then TxtNHuruf.Text = "C"
TxtNAngka.Text = 2
ElseIf TxtNilai.Text >= 55 Then TxtNHuruf.Text = "C-"
TxtNAngka.Text = 1.5
ElseIf TxtNilai.Text >= 50 Then TxtNHuruf.Text = "D"
TxtNAngka.Text = 1 Else
TxtNHuruf.Text = "E" TxtNAngka.Text = 0
End If
'cari keterangan
If TxtNHuruf.Text = "D" Or TxtNHuruf.Text = "E" Then TxtKeterangan.Text = "Gagal"
Else
End If
'Cari Mutu
TxtMUTU.Text = Val(cboSKS.Text) + Val(TxtNAngka.Text)
TxtMUTU.SetFocus
End If
End Sub
Private Sub TxtNIM_KeyPress(KeyAscii As Integer) If KeyAscii = 13 Then 'Enter
TxtSTAMBUK.Text = Left(TxtNIM.Text, 2)
ElseIf Right(TxtNIM.Text, 3) = "089" Then TxtNama.Text = "SUWARDI DWI PRAMITA" ElseIf Right(TxtNIM.Text, 3) = "065" Then TxtNama.Text = "MARKOS SIMORANGKIR" ElseIf Right(TxtNIM.Text, 3) = "047" Then TxtNama.Text = "REYNALDO RAJAGUKGUK" ElseIf Right(TxtNIM.Text, 2) = "70" Then
TxtNama.Text = "REZEKI ADE PUTRA" TxtNama.Text = "DANIEL PANJAITAN" ElseIf Right(TxtNIM.Text, 3) = "038" Then TxtNama.Text = "REZA PRIMA KURNIAWAN" ElseIf Right(TxtNIM.Text, 3) = "060" Then
If Mid(TxtNIM.Text, 6, 1) = "5" Then
TxtPRODI.Text = "TEKNIK KONVERSI ENRGI" ElseIf Mid(TxtNIM.Text, 6, 1) = "1" Then
TxtPRODI.Text = "TEKNIK MESIN" ElseIf Mid(TxtNIM.Text, 6, 1) = "3" Then TxtPRODI.Text = "TEKNIK INDUSTRI" Else: TxtPRODI.Text = "TIDAK TERDAFTAR" End If
TxtNoUrut.Text = Right(TxtNIM.Text, 4) TxtMK.SetFocus
BAB V
KESIMPULAN DAN SARAN
V.1 Kesimpulan
Tesis ini menghasilkan beberapa kesimpulan sebagai berikut :
1. Diperoleh suatu model aturan yang dapat memperlihatkan aturan keterhubungan antara nilai rata-rata matakuliah dan kehadiran mahasiswa dalam mengikuti perkuliahaan.
2. Metode smoothing, banyak digunakan untuk memecahkan masalah pemrograman matematis dan aplikasi penting, diterapkan disini untuk menghasilkan dan memecahkan sebuah reformulasi mulus takterbatas dari mesin vector dukungan untuk klasifikasi pola menggunakan kernel benar-benar sewenang-wenang. Seperti reformulasi istilah vector dukungan mesin halus (SSVM).
3. Peraturan-peraturan yang telah ditetapkan oleh Politeknik Negeri Medan berlaku untuk seluruh Jurusan yang ada diPoliteknik Negeri Medan.
V.2 Saran
Adapun beberapa saran dalam perkembangan tesis ini dimana dengan menggunakan SSVM sebagai suatu pengujian dalam model pengaturan yang ada maka dengan ini ada beberapa saran untuk perkembangan tesis ini, antara lain :
1. Dalam penelitian lebih lanjut, pengujian model aturan dapat menggunakan metode SSVM (Smooth Support Vector Machine) sebagai alat pengujian akurasi kebenaran model aturan yang didapat. 2. Dari pendekatan model aturan yang didapat, perlu menjadi perhatian
DAFTAR PUSTAKA
1. Lee, Y.J.. And Mangasarian, O.L, 2001, A Smooth Support Vector
Machine for classification ,Journal of Computational Optimization and
Applications.20, , pp.5-22. Tgl. 08 Mei 2011, 10:00
2. Vapnik, V. 1998 Statistical Learning Theory, Wiley New York
3. Lee, Y.J. and Mangasarian, O.L., 2001. A smooth support vector machine. J. Comput. Optimiz. Appli., 20: 5-22. DOI: 10.1023/A:1011215321374. Tgl. 08 Mei 2011, 13.00
4. Embong. A, Purnami.W.S, and Zain.M.J. 2009, A New Smooth Support
Vector Machine And Its Applications in Diabetes Disease Diagnosis. Jurnal
of computer science 5(12): 1006-1011, Tgl. 16 Mei 2011, 13:00
5. Yuan, Y., W. Fan and Pu, D. 2007. Spline function smooth support vector
machine for classification. J. Ind. Manage. Optimiz., 3: 529-542.
2011, 13:00
6. Mangasarian, O.L.,2000. Generalized Support Vector Machines. In:
Advances in large Margin Classifiers, Smola, A., P. Bartlett, B. Scholkopf
and D. Schurrmans (Eds.). MIT Press, Cambridge, MA.,ISBN:
0-262-19448-1, pp: 35-146. Tgl. 01 Juli 2010-262-19448-1, 13:00
7. Yuh-Jye Lee and O. L. Mangasarian, SSVM: A Smooth Support Vector
Machine for Classification, University of Wisconsin 1210 West Dayton
Street Madison, WI 53706 [email protected]
Mei 2011, 10:00
8. M. N. Quadri1 Dr. N.V. Kalyankar, 2010 Drop Out Feature of Student Data for Academic Performance Using Decision Tree Techniques, 2 Vol. 10
Issue 2 (Ver 1.0), April Global Journal of Computer Science and Technology, Tgl. 15 Juni 2011
and Information Sciences, College of Science and Technology, Covenant University, Ota, Nigeri Department of Computer Science Lagos State University, Lagos, Nigeria. Application of k-Means Clustering
algorithm or prediction of Students’ Academic Performance. Tgl. 21 Juni