MENGGUNAKAN METODE CLUSTERING PADA PROGRAM
STUDI STRATA 1 ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA
SKRIPSI
NURUL MASITHAH GUCHI
071402059
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
PENGELOMPOKAN MAHASISWA POTENSIAL DROP OUT
MENGGUNAKAN METODE CLUSTERING PADA PROGRAM
STUDI STRATA 1 ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA
SKRIPSI
NURUL MASITHAH GUCHI
071402059
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
PENGELOMPOKAN MAHASISWA POTENSIAL DROP OUT
MENGGUNAKAN METODE CLUSTERING PADA PROGRAM
STUDI STRATA 1 ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA
SKRIPSI
Diajukan Untuk Melengkapi Tugas Dan Memenuhi Syarat Memperoleh Ijazah
Sarjana Teknologi Informasi
NURUL MASITHAH GUCHI
071402059
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Judul
:
PENGELOMPOKAN MAHASISWA POTENSIAL
DROP OUT MENGGUNAKAN METODE
CLUSTERING PADA PROGRAM STUDI
STRATA 1 ILMU KOMPUTER DAN
TEKNOLOGI INFORMASI UNIVERSITAS
SUMATERA UTARA
Kategori
:
SKRIPSI
Nama
:
NURUL MASITHAH GUCHI
Nomor Induk Mahasiswa :
071402059
Program Studi
:
SARJANA (S1) TEKNOLOGI INFORMASI
Departemen
:
TEKNOLOGI INFORMASI
Fakultas
:
ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI
Diluluskan di
Medan, 08 Mei 2013
Komisi Pembimbing :
Pembimbing 2
Pembimbing 1
Dra. Elly Rosmaini, M.Si
Syahril Efendi, S.Si, M.IT
NIP.196005 20198 503
NIP. 19671110 199602 100
Diketahui/Disetujui Oleh
Program Studi Teknologi Informasi
Ketua,
Prof. Dr. Opim Salim Sitompul, M.Sc
PENGELOMPOKAN MAHASISWA POTENSIAL DROP OUT
MENGGUNAKAN METODE CLUSTERING PADA PROGRAM
STUDI STRATA 1 ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya sendiri, kecuali kutipan dan
ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 08 Mei 2013
Puji dan syukur penulis panjatkan kehadirat Allah SWT yang telah melimpahkan
berkat dan rahmat-Nya sehingga penulis dapat menyelesaikan skripsi ini. Penulis sangat
menyadari bahwah Allah SWT lah yang sangat berperan membantu dan mengingatkan disaat
penulis jatuh ataupun terlena selama mengerjakan skripsi ini.
Dalam menyelesaikan skripsi ini penulis menyadari banyak mendapatkan bantuan
dari berbagai pihak baik bantuan secara materi maupun moril. Pada kesempatan ini dengan
segala kerendahan hati, penulis ingin mengucapkan terimakasih yang sedalam-dalamnya
kepada:
1.
Kedua orang tua penulis, yaitu Muhammad Bakti dan Junidar, karena berkat
dukungan dan kesabarannya baik secara moril maupun materil sehingga penulis dapat
menyelesaikan skripsi ini. Kepada Abang, Ramdhan Purnama Guchi dan Kakak, Rika
Ramadhana Guchi,Amd, Muharni Firdaus Guchi, Bapak Prof. Dr. Muhammad Zarlis
serta orang terkasih saya Jefriansyah, ST yang selalu memberikan dukungan kepada
penulis. Jazakallah Khoiron Katsir.
2.
Kepada Bapak Sahril Efendi, S.Si, MIT dan Ibu Dra. Elly Rosmaini, M.Si selaku
dosen pembimbing penulis yang telah memberikan saran dan masukan serta bersedia
meluangkan waktu, tenaga dan fikiran untuk menyelesaikan skripsi ini.
3.
Kepada dosen penguji saya Bapak Dedy Arisandi, ST, M.Kom dan Bapak Sajadin
Sembiring, S.Si, M.Sc yang banyak memberikan masukan.
4.
Kepada Ketua dan Sekretaris jurusan Prof. Dr. Opim Salim Sitompul, M.Sc dan Drs.
Syawaluddin, M.IT.
5.
Kepada Seluruh Dosen yang mengajar program studi Teknologi Informasi Universitas
Sumatera Utara.
6.
Teman-teman seangkatan di jurusan Teknologi Informasi 2007 : Boy Utomo Manalu,
Fanindya, Masyita Oktaviani, Khairunnisa, Agnes Margaretha, Ilham, seluruh
teman-teman sejawat yang tidak dapat saya sebutkan satu persatu. Terima kasih banyak atas
bantuan kalian.
7.
Teman-teman satu asrama putri USU, Sri Wulandari, Musfika Rati, Siti Hardianti,
Ardiansyah, Wendra, Fidel. Terima kasih atas dukungannya.
9.
Saudara-saudara dan Keluarga Terdekat.
Semoga Allah SWT membalas kebaikan dan jasa-jasa kalian.
Penulis menyadari bahwa hasil penulisan skripsi ini masih banyak kesalahan dan jauh
dari sempurna. Oleh karena itu, kritik dan saran dari pembaca sangatlah penulis harapkan
bagi perbaikan dan kesempurnaan di masa yang akan datang. Penulis memohon maaf apabila
terdapat kekurangan dan kesalahan dalam penulisan skripsi ini.
Akhir kata, penulis mengucapkan terima kasih kepada semua pihak terkait dalam
penyelesaian skripsi ini, yang tidak bisa di sebutkan satu persatu, biarlah Allah SWT yang
ABSTRAK
Kegiatan mengelompokkan jumlah mahasiswa potensial drop out merupakan hal
penting bagi institusi pendidikan khususnya perguruan tinggi. Untuk
menanggulangi kecendrungan mahasiswa-mahasiswa yang memiliki indeks
prestasi rendah sehingga memiliki kemungkinan mahasiswa untuk di drop out.
Pada penelitian ini teknik data mining dalam metode clustering akan di
implementasikan untuk mengelompokkan jumlah mahasiswa-mahasiswa yang di
potensial drop out untuk angkatan 2010/2011 pada program studi Strata 1
Teknologi Informasi dan Ilmu Komputer di Fakultas Ilmu Komputer dan
Teknologi Informasi Universitas Sumatera Utara.
GROUPING STUDENTS POTENTIAL DROP OUT USING CLUSTERING
METHODE AT DEGREE PROGRAM IN COMPUTER SCIENCE AND
INFORMATION TECHNOLOGY UNIVERSITY OF NORTH SUMATRA
ABSTRACT
Activities classified number of potential students drop out is important for
educational institutions especially universities. To overcome the tendency of
students who have a low GPA that has the possibility for students to drop out. In
this research, the data mining techniques such as clustering metohod used to
classify the number of students who is potential drop out at information
technology and Computer Science Program at Season 2010/2011 University of
North Sumatra.
DAFTAR ISI
ABSTRAK
1
ABSTRACT
2
DAFTAR ISI
3
DAFTAR TABEL
5
DAFTAR GAMBAR
6
BAB I
PENDAHULUAN
7
1.1.1
Latar Belakang
7
1.1.2
Perumusan Masalah
9
1.1.3
Batasan Masalah
9
1.1.4
Tujuan Penelitian
10
1.1.5
Manfaat Penelitian
10
1.1.5.1
Metodologi Penelitian
10
1.1.6
Sistematik Penulisan
12
BAB II LANDASAN TEORI
14
2.1Perangkat Lunak
14
2.2 Rekayasa Perangkat Lunak
16
2.3 Proses Rekayasa Perangkat Lunak
17
2.4 Kecerdasan Buatan
17
2.5 Penambangan Data (
Data Mining)
18
2.5.1 Tahapan Penambangan Data
(Data Mining)
23
2.5.2 Pengelompokan
Data Mining
24
2.6
Clustering
25
2.7
K-Means
25
2.8 Penelitian Terdahulu
31
2.9 Visual Basic.Net
38
BAB III ANALISA DAN PERANCANGAN
40
3.1 Analisis
40
3.1.1 Analisis Masalah
40
3.1.2 Analisis Data Sistem
41
3.1.3 Analisis Kebutuhan Fungsional
42
3.1.4 Analisis Kebutuhan Non Fungsional
42
3.2 Perancangan Sistem
43
3.2.1 Diagram Context
43
3.2.2 Data Flow Diagram Level 1
44
3.2.3 Flow Chart
45
3.3 Rancangan Antarmuka Pengguna
50
3.3.2 Rancangan Antarmuka Pembacaan Data IP Mahasiswa
51
3.3.3 Rancangan Antarmuka Iterasi-1
53
3.3.4 Rancangan AntarmukaIterasi
–
n
54
3.3.5 Rancangan Antarmuka Menu Pilihan Cetak Data
Pengelompokan
55
3.3.6 Ranacangan Antarmuka Cetak Data Prediksi
56
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
57
4.1 ImplementasiSistem
57
4.1.1 Lingkungn Implementasi
57
4.1.2 Tampilan Implementasi Program
58
4.2 Pengujian Sistem
59
BAB V KESIMPULAN DAN SARAN
69
5.1 Kesimpulan
69
5.2 Saran
70
DAFTAR PUSTAKA
72
DAFTAR TABEL
Tabel 2.1 Sampel Data
26
Tabel 2.2 Tabel Iterasi 1
27
Tabel 2.3 Tabel Iterasi 2
30
Tabel 2.4 Tabel Iterasi 3
31
DAFTAR GAMBAR
Gambar 2.1 Tahap-tahap Penambangan Data
23
Gambar 3.1 Diagram Context
43
Gambar 3.2 DFD Level 1
44
Gambar 3.3 Flow Chart
45
Gambar 3.4 Tabel Iterasi 1
48
Gambar 3.5 Rancangan Antarmuka Menu Aplikasi
50
Gambar 3.6 Rancangan Antarmuka Pembacaan Data IP Mahasiswa
51
Gambar 3.7 Tampilan Data Rancangan Antarmuka Pembacaan Data IP
Mahasiswa
52
Gambar 3.8 Rancangan Antarmuka Iterasi-1
53
Gambar 3.9 Rancangan AntarmukaIterasi-n
54
Gambar 3.10 Rancangan Antarmuka Menu Pilihan Cetak Data Pengelompokan
55
Gambar 3.11 Rancangan Antarmuka Cetak Data Pengelompokan
56
Gambar 4.1 Antarmuka Menu Utama Pengelompokan
58
Gambar 4.2 Antarmuka Pembacaan Data IP Mahasiswa
59
Gambar 4.3 Antarmuka Iterasi-1
60
Gambar 4.4 Antarmuka Iterasike-n
61
Gambar 4.5 Antarmuka Pilihan Cetak Data Pengelompokan
62
ABSTRAK
Kegiatan mengelompokkan jumlah mahasiswa potensial drop out merupakan hal
penting bagi institusi pendidikan khususnya perguruan tinggi. Untuk
menanggulangi kecendrungan mahasiswa-mahasiswa yang memiliki indeks
prestasi rendah sehingga memiliki kemungkinan mahasiswa untuk di drop out.
Pada penelitian ini teknik data mining dalam metode clustering akan di
implementasikan untuk mengelompokkan jumlah mahasiswa-mahasiswa yang di
potensial drop out untuk angkatan 2010/2011 pada program studi Strata 1
Teknologi Informasi dan Ilmu Komputer di Fakultas Ilmu Komputer dan
Teknologi Informasi Universitas Sumatera Utara.
GROUPING STUDENTS POTENTIAL DROP OUT USING CLUSTERING
METHODE AT DEGREE PROGRAM IN COMPUTER SCIENCE AND
INFORMATION TECHNOLOGY UNIVERSITY OF NORTH SUMATRA
ABSTRACT
Activities classified number of potential students drop out is important for
educational institutions especially universities. To overcome the tendency of
students who have a low GPA that has the possibility for students to drop out. In
this research, the data mining techniques such as clustering metohod used to
classify the number of students who is potential drop out at information
technology and Computer Science Program at Season 2010/2011 University of
North Sumatra.
BAB I
PENDAHULUAN
1.1
Latar Belakang
Beberapa institusi yang memanfaatkan sistem informasi berbasis komputer selama
bertahun-tahun sudah pasti memiliki jumlah data yang cukup besar pula. Data
yang dihasilkan dan disimpan dalam sistem komputer dirancang agar cepat dan
akurat baik dalam mengoperasikan maupun administrasinya. Data ini dirancang
untuk pelaporan dan analisa yang menggunakan data. Data tersedia secara luar
biasa melimpah. Sedemikian melimpahnya data, sehingga membuat kita semakin
tertantang
untuk bertanya “Pengetahuan apak
ah yang dapat dihasilkan dari data
tersebut
”.
Perguruan tinggi adalah salah satu institusi yang sudah pasti memiliki data
yang tidak kecil volumenya. Database perguruan tinggi menyimpan data
akademik, administrasi dan data mahasiswa. Data tersebut apabila digali dengan
tepat maka dapat diketahui pola atau pengetahuan untuk mengambil keputusan.
Salah satu data yang dapat digali adalah pemahaman informasi mahasiswa
yang potensial drop out. Hal ini penting untuk diketahui dan dipahami.
Pemahaman dapat dilakukan dengan mengungkapkan pengetahuan yang dimiliki
untuk memahami dan mengelompokkan. Pencegahan kegagalan adalah sangat
penting bagi managemen perguruan tinggi. Pengetahuan ini dapat digunakan
dalam membantu pihak perguruan tinggi untuk lebih mengenal situasi para
mahasiswanya dan dapat dijadikan sebagai pengetahuan dini dalam proses
pengambilan keputusan untuk tindakan preventif dalam hal mengantisipasi
mahasiswa
drop-out,
untuk
meningkatkan
prestasi
mahasiswa,
untuk
banyak lagi keuntungan lain yang bisa diperoleh dari hasil penambangan data
tersebut.
Ukuran keberhasilan atau prestasi mahasiswa dapat dilihat dari Indeks
Prestasi (IP) yang mencerminkan seluruh nilai yang diperoleh mahasiswa sampai
semester yang sedang berjalan. IP diperoleh dengan cara menjumlahkan seluruh
nilai mata kuliah yang telah diambil dan membaginya dengan total sks (satuan
kredit semester). Ada beberapa faktor yang menjadi penghalang bagi mahasiswa
mencapai dan mempertahankan IP tinggi yang mencerminkan usaha mereka
secara keseluruhan selama masa kuliah di perguruan tinggi. Faktor tersebut dapat
dijadikan target oleh pihak perguruan tinggi sebagai strategi untuk mengambil
tindakan dalam mengembangkan dan meningkatkan prestasi mahasiswa serta
meningkatkan kinerja akademik dengan cara memantau perkembangan kinerja
mereka.
Evaluasi kinerja merupakan salah satu dasar untuk memantau
perkembangan nilai prestasi akademik mahasiswa di dalam perguruan tinggi dan
pengelompokkan mahasiswa kedalam kategori yang berbeda sesuai dengan
prestasi mereka sudah menjadi kewajiban dalam tugas mereka. Dengan
pengelompokkan mahasiswa secara manual berdasarkan nilai rata-rata mereka,
maka tidak begitu mudah untuk memperoleh pandangan yang menyeluruh
mengenai keadaan nilai prestasi mahasiswa.
Dengan bantuan teknik
data mining
, seperti algoritma clustering, yang
memungkinkan untuk menemukan karakteristik-karakteristik dari nilai prestasi
mahasiswa dan menggunakan karakteristik mereka. Algoritma clustering yang
baik idealnya menghasilkan kelompok dengan batasan cluster yang berbeda,
meskipun dalam praktek pemisahan yang sempurna biasanya tidak bisa dicapai.
Berdasarkan uraian di atas, penulis terdorong untuk mengambil judul
Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara T.A.
2010/2011
.
”
1.2 Perumusan Masalah
Sebelumnya mahasiswa dan Instansi perguruan tinggi sering tidak menyadari
jumlah mahasiswa yang akan terkena dro out. Seringkali pihak instansi dan
mahasiswa mengetahui belakangan mahasiswa yang akan di drop out. Maka
dalam hal ini masalah yang dapat dirumuskan adalah : “
Bagaimana
mengelompokkan mahasiswa drop out akademik agar kecenderungan terhadap
mahasiswa drop out berkurang serta dapa mengantisipasi mahasiswa yang akan
terkena drop out.
1.3 Batasan Masalah
Mengingat akan keterbatasan waktu peulisan dan kemampuan, penulis membatasi
masalah yang akan dibahas pada skripsi ini. Batasan-batasan masalah yang akan
dibahas di dalam skripsi ini antara lain:
1.
Penelitian ini hanya mengelompokkan mahasiswa drop out di program studi
S1 Teknologi Informasi dan Ilmu Komputer Fakultas Ilmu Komputer dan
Teknologi Informasi Universitas Sumatera Utara, angkatan 2010 dan 2011.
2.
Objek yang dikelompokkan drop out adalah nilai Indeks Prestasi Mahasiswa.
3.
Data yang digunakan merupakan data IP mahasiswa dari semester awal
hingga IP semester yang sedang berlangsung.
4.
Algoritma yang digunakan dalam melakukan clusterring adalah algoritma
K-Means.
5.
Sistem yang dibangun hanya menghasilkan kelompok jumlah mahasiswa
1.4 Tujuan Penelitian
Adapun tujuan penelitian ini adalah untuk melakukan pengelompokan tentang
jumlah mahasiswa yang akan di drop out oleh suatu instansi pendidikan yang
bergerak di bidang perguruan tinggi.
1.5 Manfaat Penelitian
Adapun manfaat penelitian ini adalah:
1.
Bagi instansi pendidikan
Penelitian ini dilakukan agar instansi pendidikan dapat mengambil keputusan
yang dapat mengantisipasi dan memberi pemberitahuan mengenai mahasiswa
yang potensial untuk di drop out.
2.
Bagi penulis
Mengetahui bagaimana cara mengimplementasikan metode clusterig pada
sistem komputer serta mengetahui tingkat keakuratan metode tersebut
berdasarkan hasil perhitungannya pada penelitian ini.
3.
Bagi perkembangan ilmu pengetahuan
Penelitian ini digunakan sebagai bahan referensi dalam menambah
pengetahuan bagi peneliti lain yang ada relevansinya.
1.6 Metodologi Penelitian
Metodologi penelitian yang digunakan dalam pembuatan skripsi ini adalah:
Studi literatur yang dilakukan dalam penelitian ini adalah mengumpulkan
bahan referensi baik dari buku-buku, jurnal, makalah, internet dan beberapa
sumber lainnya.
2.
Pengumpulan Data
Pada tahap ini akan dilakukan pengumpulan data mahasiswa akademik
program studi S1 Teknologi Informasi dan Ilmu Komputer Fakultas Ilmu
Komputer dan Teknologi Informasi Universitas Sumatera Utara dari T.A.
2010
–
2011.
3.
Analisis Permasalahan
Pada tahap ini dilakukan analisis terhadap hasil studi literatur untuk
mengetahui dan mendapatkan pemahaman mengenai metode clustering untuk
menyelesaikan masalah pengelompokan mahasiswa yang potensial drop out
melalui suatu indeks prestasi mahasiswa akademik.
4.
Perancangan Sistem
Pada tahap perancangan sistem dilakukan perancangan sistem, pengumpulan
data dan merancang antarmuka. Proses perancangan dilakukan berdasarkan
hasil analisis studi literatur yang telah telah didapatkan.
5.
Implementasi Sistem
Pada tahapan implementasi sistem ini akan dilakukan pengkodean program
dalam sistem computer menngunakan bahasa pemrograman Visual Basic
2010 dan database MySQL 5.
6.
Pengujian
Pada tahap ini akan dipastikan apakah sistem pengelompokan mahasiswa
drop out pada program studi Imu Komputer dan Teknologi Informasi yang
telah dibuat
Sudah berjalan sesuai harapan.
7.
Dokumentasi dan Penyusunan laporan
Pada tahap ini dilakukan dokumentasi hasil analisis metode clutering untuk
menyelesaikan masalah pengelompokan mahasiswa potensial drop out
program sudi S1 Ilmu Komputer dan Teknologi Informasi angkatan
1.7.
Sistematika Penulisan
Sistematika pembahasan yang digunakan untuk menyelesaikan skripsi ini adalah
sebagai berikut:
BAB I
:
PENDAHULUAN
Menjelaskan mengenai latar belakang, perumusan masalah,
tujuan penelitian, manfaat penelitian, metodologi penelitian
dan sistematika penulisan.
BAB II
:
LANDASAN TEORI
Membahas beberapa teori penunjang berhubungan dengan
pokok pembahasan dalam skripsi ini yang secara garis besar
berisi tentang sistem pengelompokan mahasiswa potensial
drop out.
BAB III
:
ANALISA DAN PERANCANGAN
Pada bab ini akan dibahas analisis sistem, deskripsi sistem,
desain sistem yang digunakan dalam pembuatan sistem
pengelompokan mahasiswa potensial drop out pada program
studi S1 Ilmu Komputer dan Teknologi Informasi angkatan
2010/2011 menggunakan metode clustering.
BAB IV
:
IMPLEMENTASI DAN PENGUJIAN SISTEM
Pada bab ini akan dijelaskan mengenai implementasi dan
pengujian sistem berdasarkan hasil rancangan yang telah
BAB V
:
KESIMPULAN DAN SARAN
Bab ini memuat kesimpulan dari keseluruhan uraian bab-bab
sebelumnya
dan
saran-saran
yang
diajukan
untuk
BAB II
LANDASAN TEORI
Bab ini membahas teori penunjang yang berhubungan dengan penerapan metode
clustering
pada sistem pengelompokan mahasiswa potensial drop out.
2.1 Perangkat Lunak
Perangkat Lunak (
software
) adalah program komputer yang terasosiasi dengan
dokumentasi perangkat lunak seperti dokumentasi kebutuhan, model desain, dan
cara penggunaan (
user manual
). Sebuah program komputer tanpa terasosiasi
dengan dokumentasinya maka belum dapat dikatakan perangkat lunak (
software
).
Karakter perangkat lunak adalah sebagai berikut :
1.
Perangkat lunak dibangun dengan rekayasa (
software engineering
) bukan
diproduksi secara manufaktur atau pabrikan.
2.
Perangkat lunak tidak pernah usang (
wear out
) karena kecacatan dalam
perangkat lunak dapat diperbaiki.
3.
Barang produksi pabrikan biasanya komponen barunya akan terus diproduksi,
sedangkan perangkat lunak biasanya terus diperbaiki seiring bertambahnya
kebutuhan.
Aplikasi dari perangkat lunak adalah sebagai berikut :
Adalah kumpulan program dimana program yang satu ditulis untuk
memenuhi kebutuhan program lainnya.
2.
Perangkat lunak waktu nyata (
real time software
)
Merupakan perangkat lunak yang memonitor, menganalisis, mengontrol
sesuatu secara waktu nyata (
real time
).Reaksi yang dibutuhkan pada
perangkat lunak harus langsung menghasilkan respon yang diinginkan.
3.
Perangkat lunak bisnis (
business software
)
Merupakan perangkat lunak pengelola informasi bisnis (seperti akuntansi,
penjualan, pembayaran, dan penyimpanan (
inventory
)).
4.
Perangkat lunak untuk keperluan rekayasa dan keilmuan (
engineering and
scientific software
)
Merupakan perangkat lunak yang mengimplementasikan algoritma yang
terkait dengan keilmuan ataupun perangkat lunak yang membantu keilmuan,
misalkan perangkat lunak di bidang astronomi, di bidang matematika, dan
lain sebagainya.
5.
Perangkat lunak tambahan untuk membantu mengerjakan suatu fungsi dari
perangkat lunak yang lainnya (
embedded software
)
Misalnya perangkat lunak untuk mencetak dokumen ditambahkan agar
perangkat lunak yang memerlukan dapat mencetak laporan, maka perangkat
lunak untuk mencetak dokumen ini disebut
embedded software
.
6.
Perangkat lunak komputer personal (
personal computer software
)
Merupakan perangkat lunak untuk PC misalnya perangkat lunak pemroses
teks, pemroses grafik, dan lain sebagainya.
7.
Perangkat lunak berbasis web (
web based software
)
Merupakan perangkat lunak yang dapat diakses dengan menggunakan web
browser.
8.
Perangkat lunak intelijensia buatan (
artificial intelligence software
)
Merupakan perangkat lunak yang menggunakan algoritma tertentu untuk
mengelola data sehingga seakan-akan memiliki intelijensia seiring
Produk perangkat lunak yang dibuat oleh pengembang (
developer
)
perangkat lunak terdiri dari dua jenis :
1.
Produk Generik
Produk perangkat lunak yang dibuat oleh pengembang perangkat lunak untuk
dijual atau dipopulerkan (
open source
) tanpa ada yang memesan terlebih
dahulu, perangkat lunak yang termasuk dalam produk generik misalnya
perangkat lunak sistem operasi, perangkat lunak pendukung perkantoran
untuk membuat dokumen,
slide
presentasi, atau perhitungan dalam bentuk
papersheet
dan lain sebagainya.
2.
Produk Pemesanan
Produk perangkat lunak yang dibuat karena ada pelanggan yang melakukan
pemesanan, misalnya sebuah instansi memerlukan perangkat lunak untuk
memenuhi proses bisnis yang terjadi di instansinya, maka instansi itu akan
bekerja sama dengan pengembang untuk membuat perangkat lunak yang
diinginkan. (Rosa A.S, M. Shalahuddin; 2011: 2-4)
2.2 Rekayasa Perangkat Lunak
Rekayasa Perangkat Lunak (
software engineering
) merupakan pembangunan
dengan menggunakan prinsip atau konsep rekayasa dengan tujuan menghasilkan
perangkat lunak yang bernilai ekonomi yang dipercaya dan bekerja secara efisien
menggunakan mesin. Perangkat lunak banyak dibuat dan pada akhirnya sering
tidak digunakan karena tidak memenuhi kebutuhan pelanggan atau bahkan karena
masalah non-teknis seperti keengganan pemakai perangkat lunak (
user
) untuk
mengubaha cara kerja dari manual ke otomatis, atau ketidakmampuan
user
menggunakan komputer. Oleh karena itu, rekayasa perangkat lunak dibutuhkan
agar perangkat lunak yang dibuat tidak hanya menjadi perangkat lunak yang tidak
terpakai.
Rekayasa perangkat lunak lebih fokus pada bagaimana membuat
1.
Dapat terus dipelihara setelah perangkat lunak selesai dibuat seiring
berkembangnya teknologi dan lingkungan (
maintainability
).
2.
Dapat diandalkan dengan proses bisnis yang dijalankan dan perubahan yang
terjadi (
dependability
dan
robust
).
3.
Efisien dari segi sumber daya dan penggunaan.
4.
Kemampuan untuk dipakai sesuai denga kebutuhan (
usability
)
(Rosa A.S, M. Shalahuddin; 2011: 4-5).
2.3 Proses Rekayasa Perangkat Lunak
Proses perangkat lunak (
software process
) adalah sekumpulan aktivitas yang
memiliki tujuan mengembangkan atau mengubah perangkat lunak.
Secara umum proses perangkat lunak terdiri dari :
1.
Pengumpulan Spesifikasi (
Specification
), yaitu : mengetahui apa saja yang
harus dapat dikerjakan sistem perangkat lunak dan batasan pengembangan
perangkat lunak.
2.
Pengembangan (
Development
), yaitu : pengembangan perangkat lunak untuk
menghasilkan perangat lunak.
3.
Validasi (
Validation
) yaitu : memeriksa apakah perangkat lunak sudah
memenuhi kebutuhan pelanggan (
custumer
).
4.
Evolusi (
Evolution
) mengubah perangkat lunak untuk memenuhi perubahan
kebutuhan pelanggan (
custumer
). (Rosa A.S, M. Shalahuddin; 2011: 9).
2.4 Kecerdasan Buatan
Kecerdasan buatan berasal dari bahasa Inggris “
Artificial Intelligence
” disingkat
AI, yaitu
intelliegence
adalah kata sifat yang berarti cerdas, sedangkan
artificial
yang mampu berfikir, menimbang tindakan yang akan diambil, dan mampu
mengambil keputusan seperti yang dilakukan oleh manusia.
Berdasarkan defenisi ini, maka kecerdasan buatan menawarkan media
maupun uji teori tentang kecerdasan.Teori-teori ini nantinya dapat dinyatakan
dalam bahasa pemrograman dan eksekusinya dapat dibuktikan pada komputer
nyata.
Program konvensional hanya dapat menyelesaikan persoalan yang
diprogram secara spesifik.Jika ada informasi baru, sebuah program konvensional
harus diubah untuk menyesuaikan diri dengan informasi tersebut.Hal ini tidak
hanya menyebabkan boros waktu, namun juga dapat menyebabkan terjadinya
error. Sebaliknya, kecerdasan buatan memungkinkan komputer untuk berfikir atau
menalar dan menirukan proses belajar manusia sehingga informasi baru dapat
diserap sebagai pengetahuan, pengalaman, dan proses pembelajaran serta dapat
digunakan sebagai acuan di masa-masa yang akan datang. Dari sini dapat
dikatakan bahwa : cerdas adalah memiliki pengetahuan, pengalaman dan
penalaran untuk membuat keputusan dan mengambil tindakan. Jadi, agar mesin
bisa cerdas (bertidak seperti manusia) maka harus diberi bekal pengetahuan dan
diberi kemampuan untuk menalar (T. Sutojo, dkk; 2011: 1-3).
2.5 Penambangan Data (
Data Mining
)
Data mining
(penambangan data) adalah suatu proses untuk menemukan suatu
pengetahuan atau informasi yang berguna dari data berskala besar. Sering juga
disebut segabai bagian proses KDD (Knowledge Discovery in Databases).
(Santosa,2007).
Data mining adalah bagian dari proses KDD (Knowledge Discovery in
Database) yang terdiri dari beberapa tahapan seperti pemilihan data,
Data mining adalah suatu istilah yang digunakan untuk menguraikan
penemuan pengetahuan di dalam database. Data mining adalah proses yang
menggunankan teknik statistik, matematika, kecerdasan buatan dan machine
learning untukmengekstraksi dan mengindentifikasi informasi yang bermanfaat
dan pengetahuan yang terkait dari berbagai database besar`(Turban, dkk. 2005).
Menurut Gartner Group data mining adalah suatu proses menemukan
hubungan yang berarti, pola, dan kecendrungan dengan memeriksa dalam
sekumpulan besar data yang tersimpan dalam penyimanan dengan menggunakan
teknik pengenalan pola teknik statistik dan matematika.(Larose. 2005).
Selain defenisi diatas beberapa defenisi juga diberikan seperti tertera di
bawah ini : “data mining adalah serang
kaian proses untuk menggali nilai tambah
dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui
secara manual.” (Pramudiono, 2006).
“Data mining adalah analisis otomatis dari data berjumlahbesar atau
komplek dengan tujuan untuk menemukan pola atau kecendrungan yang penting
yang biasanya tidak disadari keberadaannya.”(Pramudiono, 2006).
“Data mining merupakan bidang dari beberapa bidang keilmuan yang
menyatukan teknik dari pembelajaran mesin, pengenalan pola, statistik, database,
dan visualisasi untuk penanganan permasalahan pengambilan informasi dari
database yang besar.” (Larose, 2005).
Data mining adalah mengenai pemecahan masalah dengan menganalisa
data yang ada di dalam database dan sering juga didefinisikan sebagai proses
menemukan pola dalam data, dimana proses tersebut harus otomatis atau
semi-otomatis dan pola yang ditemukan harus bermakna (Chakrabarti,
et al
., 2009).
Dari defenisi-defenisi yang telah disampaikan, hal penting yang terkait dengan
data mining adalah :
1.
Data mining merupakan suatu proses otomatis terhadap data yang sudah ada.
3.
Tujuan data mining adalah mendapatkan hubungan atau pola yang mungkin
memberikan indikasi yang bermanfaat.
Hubungan yang dicari dalam data mining dapat berupa hubungan antara
dua atau lebih dalam satu dimensi. Misalnya dalam dimensi produk kita dapat
melihat keterkaitan pembelian suatu produk dengan produk yang lain. Selain itu,
hubungan juga dapat dilihat antara dua atau lebih atribut dan dua atau lebih objek
(Ponniah, 2001).
Sementara itu, penemuan pola merupakan keluaran lain dari data mining.
Misalkan sebuah perusahaan yang akan meningkatkan fasilitas kartu kredit dari
pelanggan, maka perusahaan akan mencari pola dari pelanggan-pelanggan yang
ada untuk mengetahui pelanggan yang potensial dan pelanggan yang tidak
potensial.
Beberapa dari defenisi awal dari data mining mnyertakan fokus pada
proses otomatisasi. Bery dan Linoff dalam buku Data Mining Technique For
Marketing, Sales, and Cusstomers Support mendefenisikan data mining sebagai
proses ekplorasi dan analisis secara otomatis maupun semiotomatis terhadap data
dalam jumlah besar dengan tujuan menemukan pola atau aturan yang berarti
(Larose, 2005).
Istilah data mining dan knowledge discovery in database (KDD) sering
kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi
tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut
memiliki konsep berbeda, tetapi berkaitan satu sama lain. Dalam salah satu
tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara
garis besar dapat dijelaskan sebagai berikut (Fayyad, 1996).
1.
Data selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan
sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi
yang akan digunakan utuk proses data mining, disimpan dalam suatu berkas,
terpisah dari basis data operasional.
Sebelum proses data mining dapat dilaksakan, perlu dilakukan proses
cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup
antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan
memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga
dilakukan proses enrichment, yaitu pro
ses “memperkaya” data yang sudah
ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD,
seperti data atau informasi eksternal.
3.
Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data
tersebut sesuai dengan proses data mining. Proses coding dalam KDD
merupakan proses kreatif dan sangat tergantung pada jenis atau pola
informasi yang akan dicari dalam basis data.
4.
Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data
terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode
atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau
algoritma yang tepat sangat tergantung pada tujuan dan proses KDD secara
keseluruhan.
5.
Interpretation/Evaluation
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan
dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap
ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini
mencakup pemeriksaan apakah pola atau informasi yang ditemukan
bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
Cros-Industry Standart Process For Data Mining (CRISP-DM) yang
dikembangakan tahun 1996 oleh analisis dari beberapa industri seperti
DaimlerChrysler, SPSS dan NCR. CRISP DM menyediakan standar proses data
mining sebagai strategi pemecahan masalah secara umum dari bisnis atau unit
Dalam CRISP DM, sebuah proyek data mining memiliki siklus hidup yang
terbagi dalam enam fase. Keseluruhan fase berurutan yang ada tersebut bersifat
adaptif.Fase berikutnya dalam urutan bergantung pada keseluruhan dari fase
sebelumnya.Hubungan penting antarfase digambarkan dengan panah. Sebagai
contoh, jika proses berada pada fase modeling. Bedasarkan pada perilaku dan
karakteristik model, proses mungkin harus kembali kepada fase data preparation
untuk perbaikan lebih lanjut terhadap data atau perpindahan maju kepada fase
evaluation.
Enam fase CRISP DM (Larose, 2005)
1.
Fase Pemahaman Bisnis (Business Understanding Phase)
a.
Menentukan tujuan proyek dan kebutuhan secara detail dalam lingkuo
bisnis atau unit penelitian secara keseluruhan.
b.
Menerjemahkan
tujuan
dan
batasan
menjadi
formula
dari
permasalahan data mining.
c.
Menyiapkan strategi awal untuk mencapai tujuan.
2.
Fase Pemahaman Data (Data Understanding Phase)
a.
Mengumpulakan data.
b.
Menggunkan analisis penyelidikan data untuk mengenali lebih lanjut
data dan pencarian pengetahuan awal.
c.
Mengevaluasi kualitas data.
d.
Jika diinginkan, pilih sebagian grup data yang mungkin mengandung
pola dari permasalahan.
3.
Fase Pengolahan Data (Data Preperation Phase)
a.
Siapkan dari data awal, kumpulan data yang akan digunakan untuk
keseluruhan fase berikutnya. Fase ini merupakan pekerjaan berat yang
perlu dilaksakan secara intensif.
b.
Pilih kasus dari variabel yang ingin dianalisis dan yang sesuai dengann
analisis yang aka dilakukan.
c.
Lakukan perubahan pada beberapa variabel jika dibutuhkan.
4.
Fase Pemodelan (Modelling Phase)
a.
Pilih dan aplikasikan teknik pemodelan yang sesuai.
b.
Kalibrasi aturan model untuk menoptimalkan hasil.
c.
Perlu diperhatikan bahwa beberapa teknik mungkin untuk digunakan
pada permasalahan data mining yang sama.
d.
Jika diperlukan, proses dapat kembali ke fase pengolahan data untuk
menjadikan data ke dalam bentuk yang sesuai dengan spesifikasi
kebutuhan teknik data mining tertentu.
5.
Fase Evaluasi (Evaluation Phase)
a.
Mengevaluasi satu atau lebih model yang digunakan dalam fase
pemodelan untuk mendapatkan kualitas dan efektivitas sebelum
disebarkan untuk digunakan.
b.
Menetapkan apakah model yang memenuhi tujuan pada fase awal.
c.
Menetukan apakah permasalahan penting ari bisnis atau penelitian
yang tidak tertangani dengan baik.
d.
Mengambil keputusan berkaitan dengan penggunaan hasil dari data
mining.
6.
Fase Penyebaran ( Deployment Phase)
a.
Menggunakan model yang dihasilkan. Terbentuknya model tidak
menandakan telah terselesaikannya proyek.
b.
Contoh sederhana penyebaran : Pembuatan lapoaran.
c.
Contoh kompleks penyebaran : Penerapan proses data mining secara
paralel pada departemen lain.
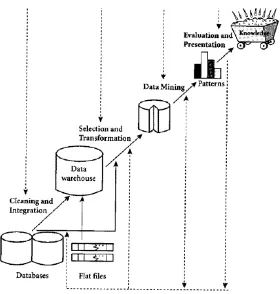
2.5.1 Tahapan Penambangan Data
(
Data mining
)
Penambangan data (
data mining
) dipahami sebagai suatu proses, yang memiliki
tahapan - tahapan tertentu yang bersifat interaktif dan juga ada umpan balik dari
Gambar 2.1.Tahap-tahap penambangan data.( Han, J.,
et al,2006
)
Tahap
–
tahap tersebut, bersifat interaktif dimana pemakai terlibat
langsung atau dengan perantaraan knowledge base.
1.
Pembersihan data
2.
Integrasi data
3.
Transformasi data
4.
Aplikasi teknik penambangan data (
data mining
)
5.
Evaluasi pola yang ditemukan
6.
Presentasi pengetahuan
2.5.2 Pengelompkan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat
dilakukan, yaitu (Larose, 2005).
Terkadang peneliti dan analis secara sederhana ingin mencoba mancari cara
untuk menggambarkan pola dan kecendrungan yang terdapat dalam data.
Deskripsi dari pola dan kecendrungan sering memberikan kemungkinan
penjelasan untuk suatu pola atau kecendrungan.
2.
Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi
lebih ke arah numerik dari pada ke arah kategori.
3.
Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam
prediksi nilai ari hasil akan ada di masa mendatang.
4.
Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori.
5.
Pengklusteran
Pengklusteran merupakan pengelompokkan record, pengamatan, atau
memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.
6.
Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul
dalam satu waktu.
2.6 Clustering
Clustering
adalah
suatu
metode
pengelompokan
berdasarkan
ukuran
kedekatan(kemiripan).Clustering berbeda dengan group, kalau group berarti
kelompok yang samakondisinya kalau tidak ya pasti bukan kelompoknya.Tetapi
kalau cluster tidak harus sama akan tetapi pengelompokannya berdasarkan pada
kedekatan dari suatu karakteristik sample yang ada, salah satunya dengan
karena hampir dalam mengidentifikasi permasalahan atau pengambilan keputusan
selalu tidak sama persis akan tetapi cenderung memiliki kemiripan saja. (Edi
satriyanto, M,Si)
Clustering
adalah suatu alat untuk analisa data, yangmemecahkan
permasalahan penggolongan.(http://www.bandmservices.com)
Clustering
berarti penyatuan sekelompok data yang mempunyai korelasi atau
karakteristik
sejenis
atau
dengan
kata
lain
mempunyai
kemiripan
(http:www//bestbuydoc.com).
2.7 K-Means
K-Means merupakan algoritma clustering yang berulang. Algoritma K-Means
dimulai dengan pemilihan secara acak K, K disini merupakan banyaknya cluster
yang ingin dibentuk kemudian tetapkan nilai-nilai K secara acak, untuk sementara
nilai tersebut menjadi pusat dari cluster atau biasa disebut dengan centroid, mean
atau “means” hitung jarak setiap data yang ada terhadap masing
-masing centroid
menggunakan rumus Euclidean hingga ditemukan jarak yang paling dekat dari
setiap data dengan centroid. Klasifikasikan setiap data berdasarkan kedekatannya
dengan
centroid.
Lakukan
langkah
tersebut
hingga
nilai
centroid
stabil.(Rismawan, 2008).
Sebagai gambaran, akan diambil contoh kasus berikut : anda diberi data
tentang 8 nasabah yang pernah memperoleh kredit dari Bank Bhatara Putra. Selain
itu, data mereka menyangkut jumlah rumah dan jumlah mobil yang mereka miliki
Tabel 2.1 Sampel Data
Nasabah
Jumlah Rumah
Jumlah Mobil
A
1
3
B
3
3
C
4
3
D
5
3
E
1
2
F
4
2
G
1
1
H
2
1
Kita akan menerapkan algoritma K-Means pada data di atas. Adapun
langkah-langkah pada algoritma K-Means adalah sebagai berikut :
1.
Tentukan K.
2.
Pilih K buah catatan dari sekian catatan yang ada sebagai pusat kelompok
awal (m
i)
3.
Untuk langkah ke
–
3 ini lakukan :
a.
Untuk setiap catatan, tentukan pusat kelompok terdekatnya dan
tetapkan catatan tersebut sebagai kelompok anggota dari kelompok
yang terdekat pusat kelompoknya.
b.
Hitung BCV ( Between Cluster Variation ) = Jarak Antar Cluster
c.
Hitung WCV( Within cluster Variation ) = Jarak antara anggota
dalam Cluster.
d.
rasio =
BCV
WCV
e.
Bandingkan rasio tersebut dengan rasio sebelumnya jika sudah ada,
jika rasio tersebut nilainya semakin besar maka lanjutkan ke
langkah ke -4, namun jika tidak hentikan prosesnya.
4.
Perbaharui pusat-pusat kelompok (bedasarkan kelompok yang di dapat
dari langkah ke
–
3) dan kembalilah ke langkah ke-3.
Implementasi dari algoritma k-means untuk kasus di atas adalah sebagai
berikut ini :
2)
B
m
1= (3,3)
E
m
2= (1,2)
F
m
3.= (4,2)
3)
Iterasi 1
A
C
1=
1−3 2+ 3−3 2= −2 2+ 0 2= 4 = 2C
2=
1−1 2+ 3−2 2= 0 2+ 1 2= 1 = 1C
3=
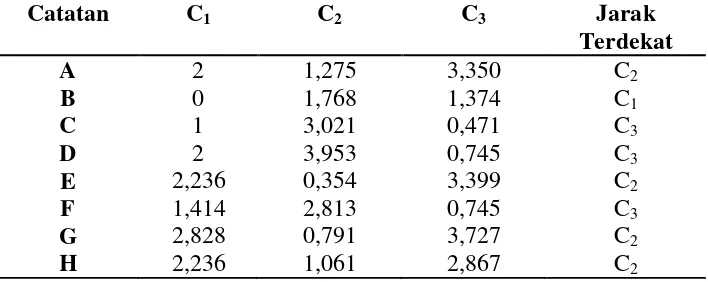
1−4 2+ 3−2 2= −3 2+ 1 2= 10 = 3,162 [image:37.595.133.442.112.255.2]Dari hasil tersebut diperoleh tabel iterasi 1 sebagai berikut :
Tabel 2.2 Tabel Iterasi 1
Catatan
C
1C
2C
3Jarak Terdekat
A
2
1
3,162
C
2B
0
2,236
1,414
C
1C
1
3,162
1
C
3D
2
4,123
1,414
C
3E
2,236
0
3
C
2F
1,414
3
0
C
3G
2,828
1
3,162
C
2H
2,236
1,414
2,236
C
2Dari tabel iterasi 1
C1 = B
(3,3)
C2 = A,E,G,H
= (1,3), (1,2), (1,1), (2,1)
= (4,3), (15,3), (4,2)
Hitung BCV
BCV = d (m1, m2) + d (m2, m3) + d (m1,m3)
=
3
−
1
2+
3
−
2
2+1
−
4
2+
2
−
2
2+3
−
4
2+
3
−
2
2=
2
2+
1
2+
−
3
2+
0
2+
−
1
2+
1
2=
5 +
9 +
2
= 2,263 + 3 + 1,414
= 6,650
Hitung WCV (diambil dari jarak terdekat)
A
C2 = 1
B
C1 = 0
C
C3 = 1
D
C3 = 1,414
E
C2 = 0
F
C3 = 0
G
C2 =1
H
C2 = 1,414
WCV = (1)
2+ (0)
2+ (1)
2+ (1,414)
2+(0)
2+ (0)
2+ (1)
2+ (1,414)
2= 1 + 0 + 1 + 1,999 + 0 + 0 + 1 +1,999 = 6,998
=
6,650
6,998
= 0,950
4)
m
1
rata-rata C
1(m
B) = (3,3)
m
2
rata-rata C
2(m
A, m
E, m
G, m
H)
(1,3) ; (1,2) ; (1,1) ; (2,1)
1+1+1+2
4
∶
3+2+1+1
4
5
4
:
7
4
(1,25 ; 1,75)
m
3
rata-rata C
3(m
C, m
D, m
F)
(4,3) ; (5,3) ; (4,2)
(4+5+4)
3
∶
(3+3+2)
3
13
3
:
8
3
(4,333 ; 2,666)
5)
A
C
1=
1
−
3
2+
3
−
3
2=
−
2
2+
0
2C
2=
1
−
1,25
2+
3
−
1,75
2=
0,25
2+
1,25
2=
0,062
2+
1,562
2=
1,624
= 1,274
C
3= dst…
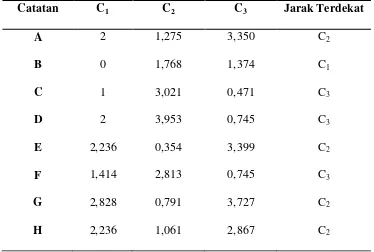
[image:40.595.143.497.343.484.2]Dari hasil tersebut diperoleh tabel iterasi 2 sebagai berikut :
Tabel 2.3 Tabel Iterasi 2
Catatan
C
1C
2C
3Jarak
Terdekat
A
2
1,275
3,350
C
2B
0
1,768
1,374
C
1C
1
3,021
0,471
C
3D
2
3,953
0,745
C
3E
2,236
0,354
3,399
C
2F
1,414
2,813
0,745
C
3G
2,828
0,791
3,727
C
2H
2,236
1,061
2,867
C
2Dari tabel iterasi 2
C
1= B
C
2= A,E,G,H
C
3=.C, D, F
= (4,3), (15,3), (4,2)
*Hitung BCV
=
(3
−
1,25)
2+ (3
−
1,75)
2+
(3
−
4,333)
2+ (3
−
2,666)
2+
(1,25
−
4,333)
2+ (1,75
−
2,666)
2=
(1,75)
2+ (1,25)
2+
(
−
1,333)
2+ (0,334)
2+
(
−
3,083)
2+ (
−
0,916)
2= 6,714
*Hitung WCV (diambil dari jarak terdekat)
WCV = sama
= 4,833
*Rasio =
BCV
WCV
= 1,394
* Rasio ke-2 (1,394) lebih besar dari rasio ke 1 (0,950) sehingga proses
dilanjutkan ke iterasi ke -3
6)
m
1
rata-rata (m
B) = (3,3)
m
2
rata-rata (m
A, m
E, m
G, m
H)
(1,25 ; 1,75)
m
3
rata-rata (m
C, m
D, m
F)
(4,333 ; 2,667)
Tabel 2.4 Tabel Iterasi 3
Catatan
C
1C
2C
3Jarak Terdekat
A
2
1,275
3,350
C
2B
0
1,768
1,374
C
1C
1
3,021
0,471
C
3D
2
3,953
0,745
C
3E
2,236
0,354
3,399
C
2F
1,414
2,813
0,745
C
3G
2,828
0,791
3,727
C
2H
2,236
1,061
2,867
C
2Dari tabel iterasi 3
C
1= B
C
2= A,E,G,H
C
3=.C, D, F
*Hitung BCV
BCV = 6,741
*Hitung WCV
WCV = 4,833
*Rasio =
BCV
Rasio 3 tidak lagi lebih besar nilainya dari rasio 2 sehingga algoritma
dihentikan (Susanto; 2010 : 81-92).
2.8 Penelitian Terdahulu
Pada penulisan skripsi ini digunakan beberapa penelitian terdahulu yang berkaitan
[image:43.595.99.523.391.745.2]dengan skripsi ini:
Tabel 2.5.Penelitian Terdahulu
No Pengarang
Judul
Keterangan
1
Gerben W.
Dekker, 2009
Predicting students drop
out: a case study
Menyebutkan bahwa monitoring
dan dukunganterhadap mahasiswa
di tahun pertama sangat penting
dilakukan.
Mahasiswa
jurusan
teknik
elektro
Universitas
Eindhovenyang
berhenti
studi
pada tahun pertama mencapai
hingga 40%. Kurikulum yang sulit
dianggap
sebagai
salah
satu
penyebab
tingginya
jumlah
mahasiswa
drop out
. Selain itu,
nilai, prestasi, kepribadian, latar
belakang sosial mempunyai peran
dalam
kesuksesan
akademik
mahasiswa. Dekker menggunakan
classifiers, logistic models,
rule-based learner
dan
random
forest.
Dalam penelitian ini, dilakukan
analisis
komparasi
empat
algoritma klasifikasi data mining
yaitu
logistic regression,decision
tree, naïve bayes
dan
neural
network
dengan
menggunakan
3681 data set mahasiswa yang
terdiri atas datademografi dan
akademik
mahasiswa
sehingga
dapat diketahui algoritma yang
paling akurat untuk memprediksi
mahasiswa non-aktif.
2
Md.
Hedayetul
Islam
Shovon,
Mahfuza
Haque, 2012
An Approach of
Improving Student’s
Academic Performance
by using K-means
clustering algorithm and
Decision tree
Dalam
penelitianini
mereka
menggunakan proses data mining
dalam
database
siswa
menggunakan algoritma k-means
clustering
dan
teknik
pohon
keputusan
untuk
memprediksi
kegiatan belajar siswa.
Mereka
berharap bahwa informasi yang
dihasilkan
setelah
penerapan
teknik
pertambangan
dan
pengelompokan data data dapat
membantu untuk instruktur serta
bagi siswa. Karya ini dapat
meningkatkan
kinerja
siswa,
mengambil langkah yang tepat
pada waktu yang tepat untuk
meningkatkan kualitas pendidikan.
Untuk pekerjaan di masa depan,
kami berharap dapat memperbaiki
teknik kam
iuntuk
mendapat
kanoutput lebih berharga dan
akurat, berguna untuk instruktur
untuk meningkatkan hasil belajar
siswa.
3
Bhise R.B.,
Thorat S.S.,
Supekar
A.K., 2013
Importance of Data
Mining in Higher
Education System
Dalam studi ini mereka membuat
penggunaan proses data mining
dalam
database
siswa
menggunakan K-means algoritma
untuk memprediksi hasil siswa.
Mereka berharap bahwa informasi
yang
dihasilkan
setelah
pelaksanaan
data
Teknik
pertambangan dapat membantu
untuk instruktur serta bagi siswa.
Untuk pekerjaan di masa depan
mereka
mendefinisikan
teknik
mereka untuk mendapatkan output
yang lebih berharga dan akurat
yang berguna instruktur untuk
meningkatkan hasil belajar siswa.
Beberapa perangkat lunak yang
berbeda
mungkin
akan
memanfaatkan
sementara pada
akan digunakan.
4
Eko
Nur
Wahyudi,
Arief Jananto
dan Narwati,
2011
Analisa Profil Data
Mahasiswa Baru
terhadap Program Studi
yang dipilih di
Perguruan Tinggi
Swasta Jawa Tengah
dengan Menggunakan
Teknik Data Mining
Berdasarkan analisa profil data
mahasiswa baru terhadap program
studi yang dipilih di perguruan
tinggi swasta jawa tengah dengan
menggunakan teknik data mining
maka dapat disimpulkan bahwa :
1.
Data mining dengan teknik
klustering pada data
mahasiswa baru pada PTS
di lingkungan Kopertis
Wilayah VI Jawa Tengah
berdasarkan jumlah
mahasiswa yang
melakukan registrasi
menghasilkan informasi
mengenai kelompok
bidang ilmu dan program
studi mulai dari jumlah
yang paling banyak hingga
jumlah yang paling sedikit
2.
Hasil
klastering
menunjukkan
bahwa
beberapa
bidang
ilmu
mempunyai dominasi yang
cukup
tinggi
terhadap
minat masuk mahasiswa
baru,
namun
demikian
tidak semua program studi
yang
dominan
meraih
jumlah mahasiswa yang
banyak, hanya beberapa
program studi saja yang
memiliki dominasi yang
cukup tinggi sesuai hasil
klaster pada bidang ilmu
3.
Trend minat mahasiswa
terhadap
bidang
ilmu
cukup signifikan terhadap
program
studi
yang
dipilihnya
5
Ahmad Yusuf,
Hari Ginardi
dan
Isye
Arieshanti,
2012
Pengembangan
Perangkat Lunak
Prediktor Nilai
Mahasiswa
Menggunakan Metode
Spectral Clustering dan
Bagging Regresi Linier
Berdasarkan hasil penelitian yang
telah dilakukan,terdapat beberapa
kesimpulan yang dapat diambil,
yaitu:
1.
Perangkat
lunak
yang
dikembangkan
dengan
algoritma
Spectral
Clustering
yang
mendukung
algoritma
Bootstrap
Aggregating
Regresi
Linier
terbukti
mampu
melakukan
prediksi nilai mahasiswa.
Hal ini terlihat dari nilai
kesalahan RMSE sekitar
0.05
–
0.08 dari dataset
yang digunakan.
dilakukan, perangkat lunak
yang
memanfaatkan
algoritma
Spectral
Clustering
yang
mendukung
Bootstrap
Aggregating Regresi Linier
memiliki performa yang
lebih
baik
jika
dibandingkan
dengan
perangkat
lunak
yang
menggunakan algoritma
K-Means Clustering.
3.
Parameter jumlah cluster
yang tidak tepat dapat
menyebabkan
kesalahan
hasil prediksi yang cukup
tinggi.
4.
Dari
uji
coba
yang
dilakukan, jumlah atribut
prediktor
yang
lebih
banyak dapat
menghasilkan
hasil prediksi menjadi lebih
baik.
2.9 Visual Basic.Net
Microsoft Visual Basic.Net
merupakan bagian dari kelompok bahasa
pemrograman
Visual Studio
yang dikembangkan oleh
Microsoft
.
Visual Studio
terdiri dari beberapa bahasa pemrograman diantaranya adalah
Microsoft Visual
Visual Studio
ini telah mengalami perubahan versi mulai dari
Visual
Studio 6.0
,
Visual Studio 2005
,
Visual Studio 2006
,
Visual Studio 2008
,
Visual
Studio 2010
.
Visual Studio 2011
, dan
Visual Studio 2012
.
Microsoft Visual Basic.Net
memiliki kelebihan-kelebihan yaitu suport
dengan bahasa
queryLanguange- Integreted Query
(
LINQ
) dan
suport
dengan
database Microsoft SQL Server
. Selain itu, kelebihan lain adalah memiliki
Object
Relation Designer
(
O/R Designer
) untuk membantu mengedit
LINQ
ke
SQL
dihubungkan dengan
database
dan
fiture
lain, seperti
WPF
(
Windows
Presentation Foundation
) dan
WCF
(
Windows Communication Foundation
).
Semua hal yang baru tersebut di atas menambah kelengkapan aplikasi
Microsoft
Visual Basic.Net
dalam membuat media dan dokumen. (Raharjo, Budi ; 2011)
Microsoft Visual Basic.Net
menggunakan teknologi
.Net
yang didasarkan
atas susunan berupa .
NetFramework
, sehingga setiap produk baru yang terkait
dengan teknologi
.Net
akan selalu berkembang mengikuti perkembangan
.Net
Framwork-
nya. Pada perkembangan nantinya, mungkin untuk membuat program
dengan teknologi
.Net
, dan memungkinkan para pengembang perangkat lunak
akan dapat menggunakan lintas sistem operasi, yaitu dapat dikembangkan di
sistem operasi
Windows
juga dapat dijalankan pada sistem operasi
Linux
, seperti
yang telah dilakukan pada pemrograman
Java
oleh
Sun Microsystem
. Pada saat ini
perusahaan-perusahaan sudah banyak meng-
update
aplikasi yang lama yang
dibuat dengan
Microsoft Visual Basic 6.0
ke teknologi
.Net
karena
kelebihan-kelebihan yang ditawarkan, terutama memungkinkan pengembang perangkat
lunak secara cepat mampu membuat program yang
robust
, serta berbasiskan
intergrasi ke
internet
yang dikenal dengan
XML Web Service
. (Ketut Darmayuda ;
Pemrograman Aplikasi Database dengan Microsoft Visual Basic .Net 2008 ; 2009
BAB III
ANALISIS DAN PERANCANGAN SISTEM
3.1. Analisis
Sub bab ini berisikan tentang analisis sistem yang akan dibangun. Sub bab ini
membahas teknik pemecahan masalah yang menguraikan sebuah sistem menjadi
bagian-bagian komponen dengan tujuan mempelajari seberapa baik bagian-bagian
komponen tersebut bekerja dan berinteraksi.
3.1.1 Analisis Masalah
Dari hasil analisis dijumpai masalah sebagai berikut :
1.
Perguruan tinggi adalah salah satu institusi yang sudah pasti memiliki data
akademik, administrasi dan data mahasiswa. Data tersebut apabila digali
dengan tepat maka dapat diketahui pola atau pengetahuan untuk mengambil
keputusan
2.
Pemahaman informasi mahasiswa yang potensial drop out penting untuk
diketahui, pemahaman dapat dilakukan dengan mengungkapkan pengetahuan
yang dimiliki untuk memahami, mengelompokkan, dan pencegahan
kegagalan adalah sangat penting bagi managemen perguruan tinggi.
Pengetahuan ini dapat digunakan dalam membantu pihak perguruan tinggi
untuk lebih mengenal situasi para mahasiswanya, dan dapat dijadikan sebagai
pengetahuan dini dalam proses pengambilan keputusan untuk tindakan
preventif dalam hal mengantisipasi mahasiswa-mahasiswa potensial drop-out,
untuk meningkatkan prestasi mahasiswa, untuk meningkatkan kurikulum,
meningkatkan proses kegiatan belajar dan mengajar dan banyak lagi
keuntungan lain yang bisa diperoleh dari hasil penambangan data.
3.
Evaluasi merupakan salah satu dasar untuk memantau perkembangan prestasi
akademik mahasiswa di dalam perguruan tinggi dan pengelompokkan
mahasiswa kedalam kategori yang berbeda sesuai dengan prestasi mereka
menjadi tugas yang rumit. Dengan pengelompokkan mahasiswa secara
tradisional berdasarkan nilai rata-rata mereka, maka sulit untuk memperoleh
pandangan yang menyeluruh mengenai keadaan prestasi mahasiswa. Dengan
bantuan teknik
data mining
, seperti algoritma clustering, memungkinkan
untuk menemukan karakteristik-karakteristik dari prestasi mahasiswa dan
menggunakan karakteristik mereka untuk memprediksi prestasi dimasa
depan.
3.1.2 Analisis Data Sistem
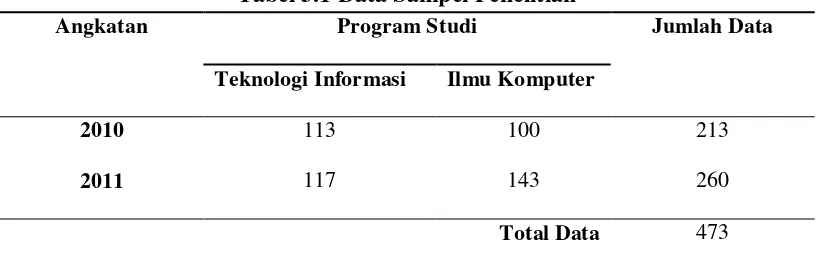
Data sampel yang digunakan dalam penelitian inidiperoleh dari administrasi
akademik Universitas Sumatera Utara Fakultas Ilmu Komputer dan Teknologi
Informasi. Adapun data yang dijadikan sampel dalam penelitian ini adalah data
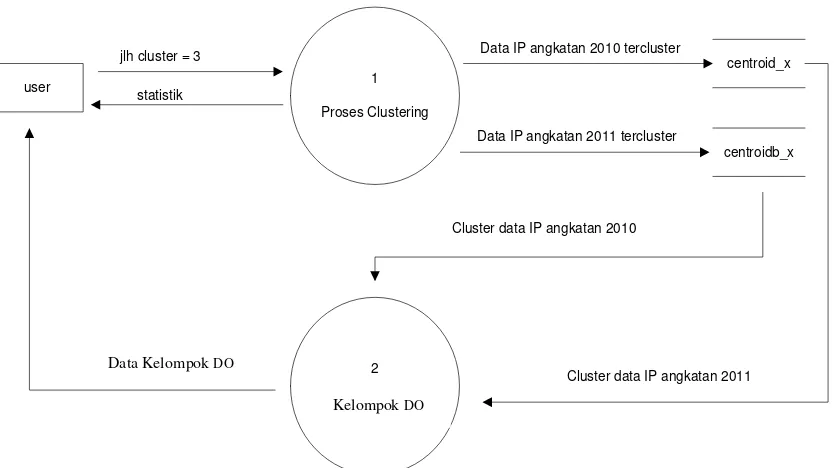
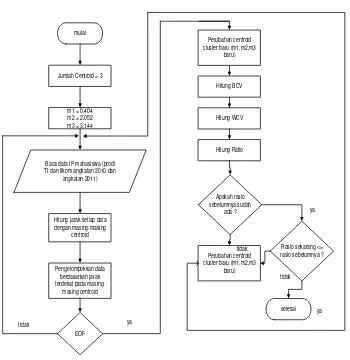
Gambar

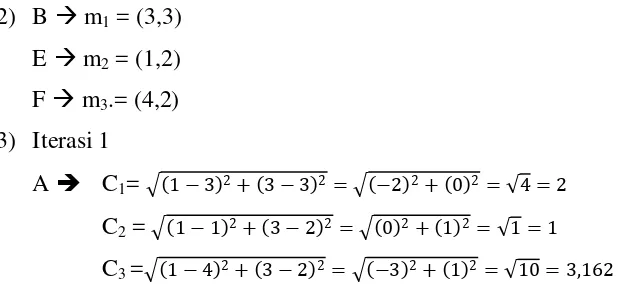

Dokumen terkait
Di Universitas Sumatera Utara, pada tahun 2015 jumlah calon mahasiswa baru yang.. diterima melalui jalur SNMPTN justru mengalami
Judul Skripsi : Pemanfaatan Teknologi Komunikasi oleh Mahasiswa (Studi Deskriptif Kuantitatif Pemanfaatan Line Today di Kalangan Mahasiswa Fakultas Ilmu Sosial dan Ilmu Politik
Skripsi ini berjudul Pemanfaatan Teknologi Komunikasi oleh Mahasiswa (Studi Deskriptif Kuantitatif Pemanfaatan Teknologi Komunikasi Line Today di Kalangan
Dari gambar di bawah menunjukkan alur penelitian prediksi mahasiswa drop out yaitu langkah pertama mencari data mahasiswa dengan observasi dan meminta data
dengan judul “Pengaruh Harga, Kualitas Produk, dan Citra Merek Terhadap Keputusan Pembelian Smartphone Merek Apple (iPhone) Pada Mahasiswa Ilmu Komputer dan Teknologi
