RIWAYAT HIDUP PENULIS
DATA PRIBADI
Nama : Juwita Permata Sari
NIM : 10111651
Tempat, Tgl Lahir : Garut, 21 Januari 1994 Jenis Kelamin : Perempuan
Agama : Islam
Alamat : Kp. Cikantong RT 01 RW 04 Desa Sukmukti Kec Sukawening Kab.Garut 44184
No. Telp : 085793158271
E-Mail : [email protected]
PENDIDIKAN
Tahun 2011-2016 : Universitas Komputer Indonesia, Fakultas Teknik dan Ilmu Komputer, Jurusan Teknik Informatika, Jenjang Strata1.
Tahun 2008– 2011 : SMK YPPT GARUT Tahun 2005– 2008 : SMP Negeri 1 Sukawening Tahun 1999– 2005 : SD Negeri Sukamukti IV
PENERAPAN DATA MINING MENGGUNAKAN METODE
ASSOCIATION RULES PADA DATA TRANSAKSI MAKMUR JAYA
KOSMETIK
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
JUWITA PERMATA SARI
10111651
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
penyusunan skripsi yang berjudul “PENERAPAN DATA MINING MENGGUNAKAN METODE ASSOCIATION RULES PADA DATA TRANSAKSI MAKMUR JAYA KOSMETIK” ini dengan baik.
Adapun tujuan dari penyusunan skripsi ini adalah untuk memenuhi salah satu syarat dalam menyelesaikan studi jenjang strata satu (S1) di Program Studi Teknik Informatika Universitas Komputer Indonesia.
Penulis menyadari bahwa dalam proses penulisan skripsi ini banyak mengalami kendala, namun berkat bantuan, bimbingan, kerjasama dari berbagai pihak dan berkah dari Allah SWT sehingga kendala-kendala yang dihadapi dapat diatasi. Untuk itu penulis menyampaikan rasa hormat dan terima kasih sebesar-besarnya kepada :
1. Allah Subhannahu wa Ta’ala yang telah mencurahkan rahmat dan karunia-Nya hingga saat ini.
2. Bapak Alif Finandhita, S.Kom., M.T. selaku dosen pembimbing yang telah meluangkan waktu, pikiran, memberikan motivasi, arahan, dan saran serta ilmu pengetahuannya kepada penulis dalam penyusunan skripsi ini.
3. Bapak Adam Mukharil Bachtiar, S.Kom., M.T. selaku dosen reviewer yang telah memberikan saran serta kritiknya dalam penyusunan skripsi ini.
4. Ibu Gentisya Tri Mardiani, S.Kom., M.Kom. selaku dosen wali yang telah memberikan banyak masukan dan kritikannya terhadap penyusunan tugas akhir ini.
iv
6. Ibu Ai Sumiarsih selaku manager di Makmur Jaya Kosmetik yang telah bersedia memberikan kesempatan kepada penulis untuk melakukan penelitian tugas akhir ini.
7. Ibunda Iis Liswati, Ayahanda Asep Saepudin, Mamah Hj Hasanah, Abah H.Memed (Alm), Apa Iya Juhriya(Alm) tercinta yang selalu memberi
dukungan, do’a dan semangat tanpa hentinya, terimakasih atas kasih sayang
yang tiada ada duanya.
8. Adik tersayang Sansan dan Wildan yang selalu memberi motivasi serta dukungan kepada penulis agar cepat menyelesaikan kuliah.
9. Teman - teman IF-14 angkatan 2011.
10. Teman – teman satu bimbingan Pak Alif Finandhita, S.Kom., M.T dan teman
– teman satu angkatan TA .
11. Sahabat yang tak terlupakan Idam, Tono, Rizal atas dukungan dan kebersamaanya selama ini, penulis tidak akan pernah melupakan masa-masa indah bersama kalian.
12. Teman – teman seperjuangan Keling, Lukman, Eza, Egi, Sisil yang rela bertukar pendapat dan berjuang bersama hingga akhir dalam mentuntaskan tugas akhir ini.
13. Sahabat tercinta Anti, Anna, Rifni, Farida, Gilang, Hesti, Iis, barudak Re’damz,
barudak A’TKJ 11, semua sahabat yang tidak bisa disebutkan satu persatu atas
dukungan, semangat dan motivasi serta selalu mendengarkan curhatan dikala galau melanda
14. Semua pihak yang tidak dapat penulis sebut satu persatu yang telah membantu dalam penyelesaian penulisan skripsi ini.
v
Bandung, 30 Juli 2016
vi
Contents
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... iv
DAFTAR GAMBAR ... vii
DAFTAR TABEL ... xii
DAFTAR SIMBOL ... xv
DAFTAR LAMPIRAN ... xx
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Perumusan Masalah ... 2
1.3 Maksud dan Tujuan ... 2
1.4 Batasan Masalah... 2
1.5 Metodologi Penelitian ... 3
1.5.1 Metode Pengumpulan Data ... 3
1.5.2 Metode Pembangunan Data mining ... 3
1.6 Sistematika Penulisan ... 5
BAB 2 TINJAUAN PUSTAKA ... 7
2.1 Profil Institusi ... 7
2.1.1 Sejarah Toko ... 7
vii
2.2.1 Data ... 9
2.2.2 Basis Data ... 10
2.2.3 Database Mangement System ... 11
2.2.4 Data Mining ... 11
2.2.5 Cross-Industry Standard Process for Data Mining (CRISP-DM) ... 14
2.2.6 Association Rule ... 17
2.2.7 Algoritma FP-Growth ... 19
2.2.8 FP – Tree ... 23
2.2.9 Unified Modeling Language (UML) ... 24
2.2.10 MySQL ... 26
BAB 3 ANALISIS DAN PERANCANGAN ... 27
3.1 Analisis Sistem ... 27
3.1.1 Analisis Masalah ... 27
3.1.2 Analisis Penerapan Metode Crisp-DM ... 27
3.1.3 Analisis Spesifikasi Kebutuhan Perangkat Lunak ... 93
3.1.3.1 Analisis Pengguna ... 93
3.1.3 Analisis Spesifikasi Kebutuhan Perangkat Lunak ... 93
3.2 Perancangan Sistem ... 112
3.2.1 Perancangan Class ... 112
3.2.2 Perancangan Basis data ... 116
3.2.6 Perancangan Struktur Menu ... 118
3.2.7 Perancangan Antar Muka ... 119
3.2.5 Perancangan Pesan ... 122
viii
4.1 Implementasi Sistem ... 124
4.1.1 Perangkat Keras yang Digunakan ... 124
4.1.2 Perangkat lunak yang digunakan ... 124
4.1.3 Implementasi Basis Data ... 125
4.1.4 Implementasi Antarmuka ... 126
4.2 Pengujian Sistem ... 127
4.2.1 Rencana Pengujian ... 127
4.2.2 Pengujian Fungsional ... 127
4.2.2 Kesimpulan Pengujian Fungsional ... 130
4.2.3 Pengujian Wawancara ... 130
4.2.4 Kesimpulan Pengujian Wawancara ... 131
4.2.5 Pengujian Hasil ... 131
4.2.7 Kesimpulan Pengujian Hasil ... 135
BAB 5 KESIMPULAN DAN SARAN ... 136
5.1 Kesimpulan ... 136
5.2 Saran ... 136
140
[2] P. Chapman, J. Clinton, R. Keber, T. Khabaza, T. Reinartz, C. Shearer and R. Wirth, CRISP-DM 1.0, Step-by-step data mining guide, 2000
[3] H.A.Fajar, Data Mining. Andi, 2013.
[4] Kusrini, Strategi Perancangan dan Pengolahan Basis Data, Andi, 2007. [5] B. Santoso, Data Mining: Teknik Pemanfaatan Data Untuk Keperluan
Bisnis, Yogyakarta: Graha Ilmu, 2007.
[6] Yuhefizard, Database Management Menggunakan Microsoft Access 2003, Jakarta : PT. Elex Media Komputindo, 2008.
[7] Prasetyo Eko, Data Mining, Andi, 2012.
[8] J. Han and M. Kamber, Data Mining : Concept and Techniques, 2nd ed. San Fransisco: Morgan Kauffman, 2006.
[9] Kusrini and E. T. Lutfi, Algoritma Data Mining, Andi, 2009.
[10] J. Santoni, “Implementasi Data Mining Dengan Metode Market Basket
Analysis,” Teknologi Informasi dan Pendidikan, vol. 5, p.2, Sep.2012 [11] D.T. Larose, DISCOVERING KNOWLEDGE IN DATA : An Introduction to
DATA MINING, Hoboken, New Jersey: John Wiley & Sons, Inc., 2005.
1
PENDAHULUAN
1.1 Latar Belakang Masalah
Makmur Jaya Kosmetik merupakan toko produk kosmetik yang paling besar di daerah Garut, berdiri sejak tahun 1996. Produk utama yang dijual di adalah produk-produk kebutuhan penunjang kecantikan, berbagai merk produk-produk bisa ditemukan di toko ini. Untuk mendapatkan produk yang diinginkan, konsumen akan berkontak langsung dengan pelayan toko dan melakukan transaksi pembelian. juga menawarkan paket produk kosmetik.
Dari hasil pengamatan, toko Makmur Jaya Kosmetik mengalami permasalah dalam pembentukan paket. Dari sekian banyak produk paket yang ditawarkan hanya sedikit paket yang dibeli oleh pelanggan, karena pasangan produk yang dijual dalam satu paket merupakan produk yang kurang dibutuhkan oleh pelanggan. Hal ini terjadi karena kurangnya pertimbangan dari pemilik toko terhadap pola pembelian konsumen dalam pembentukan paket, sehingga mengakibatkan melesetnya informasi dalam pembentukan paket penjualan produk kosmetik dan mengakibatkan terjadinya penumpukan barang di gudang sehingga barang tersebut menjadi kadaluarsa dan tidak bisa dijual lagi.
Data Mining memiliki banyak metode salah satunya adalah Association Rules.
Menurut "Data Preparationfor Data Mining" dalam Applied Artificial Intelligence (Zhang,Zhang, & Yang, 2003) Association Rule merupakan salah satu metode yang bertujuan untuk mencari pola yang sering muncul pada banyak transaksi, dimana setiap transaksi terdiri dari beberapa item. Untuk permasalahan pada toko dapat diatasi dengan metode Association Rule. Salah satu pengaplikasian dari Association Rule
himpunan data yang paling sering muncul (frequent itemset) dalam sebuah kumpulan data yang besar Pola pembelian yang didapat merupakan pola pembelian konsumen yang sering terjadi pada pembelian.
Berdasarkan masalah yang dihadapi di , maka perlu dilakukan suatu “
PENERAPAN DATA MINING MENGGUNAKAN METODE ASSOCIATION RULES PADA DATA TRANSAKSI MAKMUR JAYA KOSMETIK” Agar dapat mengetahui pola pembelian dari pelanggan dan memberikan informasi yang berguna kepada pihak untuk mengambil keputusan dalam membentuk paket penjualan produk kosmetiknya.
1.2 Perumusan Masalah
Berdasarkan uraian latar belakang masalah di atas maka rumusan masalahdalam penelitian ini adalah bagaimana menerapkan Data Mining
menggunakan metode Association Rules dengan algoritma FP-Growthuntuk rekomendasi pembentukan paket penjualan produk di toko .
1.3 Maksud dan Tujuan
Berdasarkan permasalahan yang diteliti, maka maksud dari penulisan tugas akhir ini adalah untuk membuat aplikasi Data Mining menggunakan metode
Association Rules dengan algoritma FP-Growth pada data transaksi penjualan untuk
rekomendasi pembentukan paket penjualan produk di toko .
Sedangkan tujuan yang ingin dicapai dalam pembangunan aplikasi ini adalah untuk menghasilkan informasi berupa rekomendasi paket penjualan produk kosmetik pada pihak .
1.4 Batasan Masalah
1. Data yang dianalisa merupakan data transaksi penjualan di periode Januari 2016.
2. Jenis item yang dicakup merupakan produk yang dijual, yaitu berupa jenis kosmetik berbagai merk.
4. Informasi yang dihasilkan berupa pola pembelian konsumen yang akan menjadi dasar sebagai pembentukan paket yang akan ditawarkan kepada konsumen.
1.5 Metodologi Penelitian
Metodologi penelitian merupakan suatu proses yang digunakan untuk memecahkan suatu masalah yang logis, dimana memerlukan data untuk mendukung terlaksananya suatu penelitian. Metodologi penelitian yang digunakan adalah metode deskriptif, yaitu metode yang menggambarkan fakta-fakta dan informasi dalam situasi atau kejadian dimasa sekarang secara sistematis, faktual dan akurat. Metodologi penelitian ini memiliki dua metode, yaitu metode pengumpulan data dan metode pembangunan perangkat lunak.
1.5.1 Metode Pengumpulan Data
Metode Metod epengumpulan data dapat diperoleh secara langsung dari objek penelitian dan referensi-referensi yang telah diperoleh. Cara-cara yang digunakan untuk mendapatkan data adalah sebagai berikut:
1. StudiLapangan
Studi lapangan adalah metode pengumpulan data yang dilakukan dengan mengadakan penelitian ke Toko . Studi lapangan ini dilakuka dengan dua cara, yaitu: a. Observasi
Observasi merupakan metode pengumpulan data dengan mengadakan penelitian dan peninjauan langsung ke Toko .
b. Wawancara
Wawancara merupakan metode pengumpulan data yang dilakukan dengan mengadakan tanya jawab secara langsung kepada area manager di Toko .
2. StudiLiteratur
1.5.2 Metode Pembangunan Data mining
Dalam penelitian ini mengikuti standar dari Cross-Industry Standard for Data
mining (CRISP-DM) merupakan suatu standar yang telah dikembangkan pada tahun
1996 yang ditunjukkan untuk melakukan proses analisis dari suatu industri sebagai strategi pemecahan masalah dari bisnis satu unit penelitian [3]. Untuk data yang dapat di proses dengan CRSP-DM ini, tidak ada ketentuan atau karakteristik tertentu, karena data tersebut akan diproses kembali pada fase-fase di dalamnya.
Gambar 1. 1 Cross Industri Standard for Data Mining(CRISP-DM)[4]
Berikut ini adalah tahapan-tahapan yang akan dilakukan dalam penelitian ini sesuai dengan CRISP-DM :
1. Business understanding
2. Data understanding
Pada tahap pemahaman data ini terlebih dahulu akan mengumpulkan semua data yang diperlukan dari hasil data-data transaksi penjualan di Makmur Jaya Kosmetik dari bulan Januari 2016. Dilanjutkan dengan proses pemahaman tentang data yang akan digunakan sebagai hipotesa untuk menemukan informasi yang tersembunyi.
3. Data preparation
Tahap ini meliputi semua kegiatan untuk membangun dataset akhir (data yang akan diproses pada tahap pemodelan/modeling) mengacu dari data transaksi penjualan Makmur Jaya Kosmetik dengan periode januari 2016. Pada tahap ini juga mencakup pemilihan tabel, record, dan atribut-atribut data, termasuk proses pembersihan untuk kemudian dijadikan masukan dalam tahap pemodelan (modeling).
4. Modeling
Dalam tahapan pemodelan ini akan menggunakan teknik metode data mining
dengan metode association rule dengan cara menemukan aturan asosiatif atau pola kombinasi produk berdasarkan hasil data transaksi, sehingga dapat diketahui item produk mana saja yang sering dibeli oleh konsumen secara bersamaan.
5. Evaluation
Pada tahap evaluasi ini akan dibandingkan hasil Fp-growth dilakukan oleh sistem dengan perhitungan manual, dengan mengambil beberapa sampel acak. Evaluasi ini ditujukan untuk mengukur apakah pemodelan yang dilakukan sesuai dengan tujuan pengimplementasian data mining pada sistem ini.
6. Deployment
1.6 Sistematika Penulisan
Sistematika penulisan yang digunakan dalam penyusunan laporan tugas akhir ini adalah sebagai berikut :
BAB 1. PENDAHULUAN
Bab ini membahas mengenai Latar Belakang Masalah, Rumusan Masalah, Maksud dan Tujuan, Batasan Masalah, Metodologi Penelitian, dan Sistematika Penulisan yang digunakan.
BAB 2. TINJAUAN PUSTAKA
Bab ini membahas tentang sejarah, logo, visi, misi, struktur organisasi dari Makmur Jaya Kosmetik dan berbagai konsep dasar dan teori-teori yang berhubungan dengan judul penelitian, seperti pengertian data, data mining, associaiton rule algoritma Fp-growth , UML, kamus data dan spesifikasi proses.
BAB 3. ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi tentang analisis dan perancangan sistem yang akan dibangun berdasarkan data penjualan yang diperoleh dari Makmur Jaya Kosmetik dengan menggunakan data mining dengan metode associaiton rule menggunakan algoritma
Fp-growth
BAB 4. IMPLEMENTASI DAN PENGUJIAN
Bab ini menjelaskan tentang implementasi dan pengujian terhadap tingkat kekuatan dan keakuratan aturan-aturan asosiasi yang telah didapatkan berdasarkan pola pembelian yang telah diterapkan sesuai dengan algoritma Fp-growth .
BAB 5. KESIMPULAN DAN SARAN
7
TINJAUAN PUSTAKA
2.1 Profil Institusi
Makmur Jaya Kosmetik merupakan salah satu bidang usaha penjualan produk-produk kebutuhan kecantikan dan kebutuhan salon dari berbagai merk dalam negeri maupun merk dari luar negeri. Makmur Jaya Kosmetik berlokasi di Jln. Jend. A. Yani No.62 Garut
2.1.1 Sejarah Toko
Toko Makmur Jaya Kosmetik didirikan oleh ibu Hj. Ratna Rosita pada tahun 1986. Nama Makmur Jaya diambil dari nama anak beliau yang bernama Reka Makmur Jaya. Ide untuk mendirikan toko Makmur Jaya Kosmetik ini berawal dari banyaknya konsumen wanita yang sudah membutuhkan kosmetik dan pada saat itu toko kosmetik masih dibilang jarang. Toko Makmur Jaya Kosmetik awalnya adalah sebuah kios kecil biasa yang menjual merk dagang dalam negri. Seiring berkembangnya waktu, kebutuhan akan penunjang kecantikan khususnya bagi kaum wanita semakin bertambah. Pada saat ini Makmur Jaya Kosmetik sudah banyak menjual produk dalam dan luar negri seperti : Rista, Wardah, Ponds, LaTulipe, Tloac Paris, Tull Jye, Tje Fuk, jade, Bless dan lain-lain. Hingga akhirnya sampai sekarang Toko Makmur Jaya Kosmetik merupakan toko kosmetik terbesar dan terkemuka diwilayahnya.
2.1.2 Logo
Gambar 2. 1 Logo Toko
2.1.3 Visi dan Misi
Berikut adalah visi dan misi dari toko :
2.1.3.1 Visi
Visi dari toko adalah sebagai berikut:
1. Menjadi penyedia kosmetik yang aman, lengkap dan terpercaya, serta dapat memberikan pelayanan yang berkualitas
2.1.3.2 Misi
Misi dari toko adalah sebagai berikut:
1. Menyediakan produk kosmetik dari berbagai merk yang dibutuhkan oleh pelanggan
2. Menyediakan kosmetik yang aman yang memiliki label halal serta tercatat di Badan Pom
3. Memberikan pelayanan yang baik pada seluruh pelanggan
2.1.4 Struktur Organisasi
Struktur organisasi dari toko dapat dilihat dari gambar 2.2.
Pemimpin
Manager
Bag. Gudang Bag.
Keuangan
Karyawan Karyawan Karyawan
Deskripsi Jabatan :
1. Pemimpin
Pemimpin merupakan pemilik dari toko yang bertanggung jawab penuh terhadap segala sesuatu yang terjadi di toko .
2. Manager
Manager merupakan seseorang yang membantu pemimpin dalam mengontrol atau mengawasi segala kegiatan di toko .
3. Bag. Gudang
Bagian Gudang merupakan seseorang yang bertugas membantu pemilik dalam mengatur, mengelola, dan mencatat produk-produk yang ada digudang serta produk-produk yang akan dipesan untuk stok barang.
4. Bag. Keuangan
Bagian Keuangan merupakan seseorang yang bertugas untuk membantu pemilik dalam mencatat produk yang terjual dan transaksi yang telah terjadi.
5. Karyawan
Karyawan merupakan seseorang yang bertugas untuk melayani konsumen dalam melakukan pembelian dan transaksi pembayaran.
2.2 Landasan teori
Landasan teori yang berkaitan dengan materi atau teori yang digunakan sebagai acuan melakukan penenlitian. Landasan teori yang diuraikan merupakan hasil studi literatur, buku-buku, maupun situs internet.
2.2.1 Data
Data adalah segala fakta, angka atau teks yang dapat diproses oleh komputer. Data
dapat digunakan sebagai input dan menghasilkan sebuah informasi. Data adalah sesuatu yang belum memiliki arti dan masih membutuhkan suatu pengolahan. Dalam data terdapat
himpunan data yang merupakan kumpulan dari objek dan atributnya. Atribut merupakan
dari sekumpulan record, yang masing-masing terdiri dari satu set atribut yang tetap. Salah satu yang termasuk dalam tipe data record yaitu data transaksi. Data transaksi merupakan sebuah tipe khusus dari record data, dimana tiap record (transaksi) meliputi satu set item
[3].
2.2.2 Basis Data
Basis data adalah kumpulan data yang saling berelasi. Data sendiri merupakan fakta mengenai obyek, orang, dan lain – lain. Data dinyatakan dengan nilai (angka, deretan karakter, atau symbol) [4].
Basis Data sendiri dapat didefinisikan dalam sejumlah sudut pandang seperti[4] : 1. Himpunan kelompok data (arsip) yang saling berhubungan yang diorganisasi
sedemikian rupa agar kelak dapat dimanfaatkan kembali dengan cepat dan mudah.
2. Kumpulan data yang saling berhubungan yang disimpan secara bersama sedemikian rupa dan tanpa pengulangan (redudansi) yang tidak perlu, untuk memenuhi berbagai kebutuhan.
3. Kumpulan file/ tabel/ arsip yang saling berhubungan yang disimpan dalam media penyimpanan elektronis.
2.2.2.1 Data pada Basis Data dan Hubungannya
Ada 3 jenis data pada sistem database, yaitu [5] :
1. Data operasional dari suatu organisasi, berupa data yang tersimpan dalam basis data
2. Data masukan (input data), data dari luar sistem yang dimasukan melalui peralatan input (keyboard), yang dapat merubah data operasional.
3. Data kelauran (output data), berupa laporan melalui peralatan output sebagai hasil dari dalam sistem yang mengakses data operasional.
2.2.2.2 Keuntungan dan Kerugian Pemakaian Sistem Database
Keuntungan [5] :
2. Data dapat dipakai secara bersama-sama.
3. Memudahkan penerapan standarisaasi dan batas-batas pengamanan. 4. Terpeliharanya keseimbangan atas perbedaan kebutuhan data dari setiap aplikasi.
5. Program /data independent. Kerugian :
1. Mahal dalam implementasinya. 2. Rumit
3. Penanganan proses recoverybackup sulit.
4. Kerusakan pada sistem basis data dapat mempengaruhi.
2.2.3 Database Mangement System
Database Management System atau disingkat DBMS adalah perangkat lunak
(software) yang berfungsi untuk mengelola database. Mulai dari membuat database itu sendiri, sampai dengan prosesyang berlaku dalam database tersebut, baik berupa entry, edit, hapus, query terhadap data, membuat laporan dan lain sebagainya secara efektif dan efesien. Salah satu jenis DBMS yang sangat terkenal saat ini adalah Relational DBMS (RDBMS), RDBMS mempresentasikan data dalam bentuk tabel – tabel yang saling berhubugan. Sebuah tabel disususn dalam bentuk baris (record) dan kolom (field) [6].
2.2.4 Data Mining
Data mining adalah proses untuk mendapatkan informasi yang berguna dari gedung basis data yang besar. Data mining juga dapat diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan keputusan. Istilah
data mining kadang disebut juga knowledge discovery. Salah satu teknik yang dibuat dalam data mining adalah bagaimana menelusuri data yang ada untuk membangun sebuah model, kemudian menggunakan model tersebut agar dapat mengenali pola data yang lain yang tidak berada dalam
basis data yang tersimpan. Dalam data mining, pengelompokan data juga bisa dilakukan. Tujuannya adalah agar kita dapat megetahui pola universal data-data yang ada [7].
1. Proses penemuan pola yang menarik dari data yang tersimpan dalam jumlah besar.
2. Ekstrasi dari suatu informasi yang berguna atau menarik (non-trivial, implisit, sebelumnya belum diketahui potensi kegunaannya) pola atau pengetahuan dari data yang di simpan dalam jumlah besar.
3. Eksplorasi dari analisa secara otomatis atau semiotomatis terhadap data data dalam jumlah besar untuk mencari pola dan aturan yang berarti.
2.2.4.1 Metode Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang
dapat dilakukan, yaitu [9] : 1. Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat mengumpulkan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelesan untuk suatu pola atau kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih kearah numerik daripada ke arah kategori. Model dibangun dengan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada dimasa mendatang. Contoh prediksi dalam bisnis dan penelitian adalah :
1. Prediksi harga beras dalam tiga bulan yang akan datang.
2. Prediksi persentase kenaikan kecelakaan lalu lintas tahun depan jika batas bawah dinaikan.
4. Klasifikasi
Dalam klasifikasi, terdapat terget variabel kategori. sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori yaitu: pendapatan tinggi, pendapatan sedang, dan pendapatan rendah. Contoh lain klasifikasi dalam bisnis dan penelitian adalah :
1. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau bukan.
2. Mendiagnosis penyakit seorang pasien untuk mendapatkan termasuk kategori penyakit apa.
5. Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk class objek-objek yang memiliki kemiripan.
Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan tidak memiliki kemiripan dengan record-record dalam kluster lain. Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam pengklusteran. pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi,
algoritma pengklusteran mencoba untuk melakukan pembagian terhadap
1. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produk sebuah perusahaan yang tidak memiliki dana pemasaran yang besar.
2. Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilaku finansial dalam baik maupun mencurigakan.
3. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang pasar. Contoh asosiasi dalam bisnis dan penelitian adalah : 1. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler
yang diharapkan untuk memberikan respon positif terhadap penawaran upgrade layanan yang diberikan.
2. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli secara bersamaan.
2.2.5 Cross-Industry Standard Process for Data Mining (CRISP-DM)
Cross-Indutry Standard Prosess for Data Mining (CRISP-DM) yang
Fase-fase dari CRISP-DM [11] : 1. Business understanding
a. Penentuan tujuan objek dan kebutuhan secara detail dalam lingkup bisnis atau unit penelitian secara keseluruhan.
b. Menilai situasi objek untuk mengetahui sumber daya yang tersedia.
c. Menerjemahkan tujuan dan batasan menjadi formula dari permasalahan data mining.
2. Data understanding
a. Mengumpulkan data.
b. Menggunakan analisis penyelidikan data untuk mengenali lebih lanjut data dan pencarian pengetahuan awal.
c. Mengevaluasi kualitas data.
d. Jika diinginkan, pilih sebagian kecil grup data yang mungkin mengandung pola dari permasalahan.
3. Data preparation
a. Siapkan dari data awal, kumpulan data yang akan digunakan untuk
keseluruhan fase berikutnya. Fase ini merupakan pekerjaan berat yang perlu dilaksanakan secara intensif.
b. Pilih kasus dan variabel yang ingin dianalisis dan yang sesuai dengan analisis yang akan dilakukan.
c. Lakukan perubahan pada beberapa variabel jika dibutuhkan.
d. Sipakan data awal sehingga siap untuk perangkat pemodelan.
4. Modelling
a. Pilihan dan aplikasikan teknik pemodelan yang sesuai.
b. Membangun model yang digunakan.
c. Menilai model yang digunakan.
d. Jika diperlukan, proses dapat kembali ke fase pengolahan data untuk
menjadikan data ke dalam bentuk yang sesuai dengan spesifikasi kebutuhan teknik data mining tertentu.
e. Aturan bisnis pembentukan paket
5. Evaluation
a. Mengevaluasi satu atau lebih model yang digunakan dalam fase pemodelan untuk mendapatkan kualitas dan efektivitas sebelum disebarkan untuk
digunakan.
b. Menetapkan apakah terdapat model yang memenuhi tujuan pada fase awal.
d. Mengambil keputusan berkaitan dengan penggunaan hasil dari data mining.
6. Deployment
a. Menggunakan model yang dihasilkan. Terbentuknya model tidak menandakan telah terselesaikannya proyek.
b. Contoh sederhana penyebaran : pembuataan laporan.
c. Contoh kompleks penyebaran : penerapan proses data mining secara paralel pada departemen lain.
2.2.6 Association Rule
Aturan asosiasi (Association rule) adalah salah satu teknik tentang ‘apa
bersama apa’. Ini bisa berupa transaksi di supermarket, misalnya seseorang yang
membeli susu bayi juga membeli sabun mandi. Di sini berarti susu bayi bersama sabun mandi. Karena awalnya berasal dari studi tentang database transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama produk apa, maka aturan asosiasi juga sering dinamakan Market Basket [10].
Untuk mencari association ruledari suatu kumpulan data, tahap pertama yang harus dilakukan adalah mencari frequent itemset terlebih dahulu. Frequent itemset
adalah sekumpulan item yang sering muncul secara bersamaan. Setelah semua pola
frequent itemset ditemukan, barulah mencari aturan asosiatif atau aturan keterkaitan yang memenuhui syarat yang telah ditentukan.
Jika diasumsikan bahwa barang yang dijual di swalayan adalah semesta, maka setiap barang akan memiliki Booleanvariable yang akan menunjukan keberadaannya atau tidak barang tersebut dalam satu transaksi atau satu keranjang belanja. Pola
Boolean yang didapat digunakan untuk menganalisa barang yang dibeli secara
bersamaan. Pola tersebut dirumuskan dalam sebuah association rule. Sebagai contoh konsumen biasanya akan membeli kopi dan susu yang ditujukan sebagai berikut :
Nilai support 2% menunjukan bahwa keseluruhan dari total transaksi konsumen membeli kopi dan susu secara bersamaan yaitu sebanyak 2%. Sedangkan confidence
60% yaitu menunjukan bila konsumen membeli kopi dan pasti membeli susu sebesar 60%.
Penting tidaknya suatu aturan asosiatif dapat diketahui dengan dua parameter, yaitu support dan confidence. Support (nilai penunjang) adalah presentase kombinasi
item tersebut dalam database, sedangkan confidence (nilai kepastian) adalah kuatnya hubungan antar-item dalam aturan asosiasi.
Dalam menentukan suatu association rule, terdapat suatu ukuran kepercayaan yang didapat dari hasil pengelolahan data dengan perhitungan tertentu. Umumnya ada dua ukuran, yaitu:
1) Support : suatu ukuran yang menunjukan seberapa besar tingkat dominasi suatu
itemset dari keseluruhan transaksi. Ukuran ini menentukan apakah suatu itemset
layak untuk dicari confidence-nya ( misal, dari keseluruhan transaksi yang ada, seberapa besar tingkat dominasi suatu item yang menunjukan bahwa item A dan
item B dibeli bersamaan).
2) Confidence : suatu ukuran yang menunjukan hubungan antara 2 item secara
conditional (misal, menghitung kemungkinan seberapa sering item B dibeli oleh
pelanggan jika pelanggan tersebut membeli sebuah item A).
Kedua ukuran ini nantinya berguna dalam menentukan kekuatan suatu pola dengan membandingkan pola tersebut dengan nilai minimum kedua parameter tersebut yang ditentukan oleh pengguna. Analisis asosiasi didefinisikan suatu proses untuk menemukan semua aturan asosiasi yang memenuhi syarat minimum untuk support
(minimum support) dan syarat minimum untuk confidence (minimum confidence).
Nilai support sebuah item diperoleh dengan rumus sebagai berikut[11] :
� � A =� �ℎ � � � � � � � � ��� � �x100%….. Persamaan (2.1)
Sementara itu, nilai support dari 2 item diperoleh dari rumus berikut:
Sedangkan nilai confidence dapat dicari setelah pola frekuensi munculnya sebuah item
ditemukan. Rumus untuk menghitung confidence adalah sebagai berikut:
� � =J Ja a aa a a ya ya a a a x100%…..Persamaan(2.3)
2.2.7 Algoritma FP-Growth
Algoritma fp-growth merupakan salah satu alternatif algoritma yang cukup efektif untuk mencari himpunan data yang paling sering muncul (frequent itemset) dalam sebuah kumpulan data yang besar. Algoritma fp-growth merupakan algoritma
association rules yang cukup sering dipakai. Algoritma fp-growth ini dikembangkan
dari algoritma apriori. Algoritma apriori menghasilkan kombinasi yang sangat banyak sehingga sangat tidak efisien.
Algoritma fp-growth ini merupakan salah satu solusi dari algoritma apriori yang memakan waktu yang sangat lama karena harus melakukan pattern matching yang secara berulang-ulang. Sedangkan dalam proses algoritma fp-growth terdapat banyak kelebihan yang terbukti sangat efisien karena hanya dilakukan pemetaan data atau scan
database sebanyak 2 kali untuk membangun struktur ”tree”. Maka dari itu, algoritma
fp-growth dikenal juga dengan sebutan algoritma FP-Tree . Dengan menggunakan
struktur FP-Tree , algoritma fp-growth dapat langsung mengekstrak frequent itemset
dari susunan FP-Tree yang telah terbentuk. Metode fp-grwth dapat dibagi menjadi 3 tahapan utama yaitu sebagai :
1) Tahap Pembangkitan conditional pattern base.
Conditional Pattern Base merupakan sub database yang berisi prefix path dan
suffix pattern. Pembangkitan conditinal pattern base didapatkan melalui
FP-Tree yang telah dibangun sebelumnya.
2) Tahap Pembangkitan Conditional FP-Tree
Pada tahap ini, support count dari setiap item pada setiap conditional pattern base dijumlahkan, lalu setiap item yang memiliki jumlah support count
3) Tahap Pencarian frequent itemset
Apabila conditional FP-Tree merupakan lintasan tunggal (single path), maka didapatkan frequent itemset dnegan melakukan kombinasi item untuk setiap
conditional FP-Tree . Jika bukan lintasan tunggal, maka dilakukan
pembangkitan FP-Growth secara rekursif.
Ketiga tahap tersebut merupakan langkah yang akan dilakukan untuk mendapat
frequent itemset,yang dapat dilihat pada algoritma berikut :
Contoh kasus penerapan Algoritma FP-Growth
Input : FP-Tree Tree
Output : Rt Sekumpulan lengkap pola frequent Method : FP-Ggrowth ( Tree, null )
Procedure : FP-Growth ( Tree, _ ) {
01 : if Tree mengandung single path P;
02 : then untuk tiap kombinasi ( dinotasikan _ ) dari node node dalam path do 03 : bangkitkan pola _ _ dengan support daro node-node dalam _;
04 : else untuk tiap a1 dalam header dari Tree do
{
05 : bangkitkan pola
06 : bangun _ = a1 _ dengan support = a1. Support
07 : if Tree _ = _
-Misalkan didapat hasil dari tabel pembangkitan conditional pattern base
sebagai berikut, diketahui sebelumnya nilai minimum support 5%.
a. Tahap Pembangkitan Conditional Pattern Base
Tabel 2. 1 Conditional Pattern Base
Item Conditional Pattern Base
1 2,3, 1:6
b. Tahap Pembangkitan Conditional FP-Tree
Pada tahap ini, support count dari setiap item dijumlahkan, lalu setiapdan dibandingkan dengan conditional fp - tree
- Conditional fp – tree 1: { 2,4,3 }
Karena support count 1 adalah 6, maka memenuhi minimum support yaitu 4. Berikut adalah tahap-tahap pembangkitan conditional FP-Tree 1.
- Pada lintasan yang berakhiran {1} dengan support count 1 atau lebih yang dimilikinya akan dihilangkan dan support count yang melewati
lintasan pertama atau lintasan lainnya yang berakhiran {1}, akn disamain sesuai dengan support count yang dimilikinya.
- Proses selanjutnya adalah apabila dalam suatu lintasan, melintasi dua atau lebih, maka support count akan selalu bertambah 1
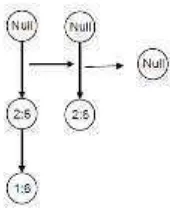
Setelah proses pembangkitan, proses terakhir adalah mencari frequent itemset yang keluar. 2:6 dan 3:6 adalah item yang keluar
Gambar 2. 6 Conditional FP-Tree 1,2:6 Hasil Frequent Itemset
Gambar 2. 7 Conditional FP-Tree 1,3:6 Hasil Frequent Itemset
c. Tahap Pencarian frequent itemset
- Akumulasiakn count setiap item
- Buat conditional FP-Tree
Gambar 2. 8 Conditional FP-Tree Untuk Item Frequenset 1, 2:6
2.2.8 FP – Tree
FP-Tree merupakan struktur penyimpanan data yang dimampatkan. FP-Tree
dibangun dengan memetakan setiap data transaksi ke dalam setiap lintasan tertentu dalam FP-Tree . Karena dalam setiap transaksi yang dipetakan, mungkin ada transaksi yang memiliki item yang sama, maka lintasannya memungkinkan untuk saling menimpa. Semakin banyak data transaksi yang memiliki item yang sama, maka proses pemampatan dengan struktur data FP-Tree semakin efektif. Kelebihan dari FP-Tree
adalah hanya memerlukan dua kali pemindaian data transaksi yang terbukti sangat efisien. Adapun FP-Tree adalah sebuah pohon dengan definisi sebagai berikut :
1. FP-Tree dibentuk oleh sebuah akar yang diberi label null, sekumpulan pohon yang beranggotakan item-item tertentu, dan sebuah tabel frequent header.
2. Setiap simpul dalam FP-Tree mengandung tiga informasi penting, yaitu
label item, menginformasikan jenis item yang dipresentasikan simpul
tersebut, support count merepresentasikan jumlah lintasan transaksi yang melalui simpul tersebut, dan pointer penghubung yang menghubungkan simpul-simpul dengan label item sama antar lintasan, ditandai dengan garis putus-putus.
2.2.9 Unified Modeling Language (UML)
Unified Modeling Language (UML) adalah himpunan struktur dan teknik untuk
pemodelan desain program berorientasi objek serta aplikasinya. Berikut adalah beberapa model yang digunakan dalam perancangan Data Mining Pemaketan Produk untuk menggambarkan sistem dalam UML:
1. Diagram Use Case
2. Diagram Class 3. Diagram Aktivitas 4. Diagram Objek
2.2.9.1. Diagram Use Case
Diagram use case adalah model fungsional sebuah sistem yang menggunakan aktor dan use case. Use case adalah layanan (services) atau fungsi–fungsi yang disediakan oleh sistem untuk penggunanya.
Deskripsi Diagram Use Case:
1. Sebuah use case adalah dimana sistem digunakan untuk memenuhi satu atau lebih kebutuhan pemakai.
2. Use case merupakan awal yang sangat baik untuk setiap fase
pengembangan berbasis objek, design testing, dan dokumentasi.
3. Use case menggambarkan kebutuhan sistem dari sudut pandang di luar
sistem.
4. Use case menentukan nilai yang diberikan sistem kepada pemakainya.
5. Use case hanya menetapkan apa yang seharusnya dikerjakan oleh
6. Use case tidak untuk menentukan kebutuhan nonfungsional, misal: sasaran kerja, bahasa pemrograman.
2.2.9.2 Diagram Class
Diagram class adalah Diagram UML yang menggambarkan class
-class dalam sebuah sistem dan hubungannya antara satu dengan yang lain, serta dimasukkan pula atribut dan operasi. Tahapan dari Diagram class adalah sebagai berikut:
1. Mengidentifikasi objek dan mendapatkan class-classnya. 2. Mengidentifikasi atribut class-class.
3. Mulai mengkonstruksikan kamus data. 4. Mengidentifikasi operasi pada class-class.
5. Mengidentifikasikan hubungan antar class dengan menggunakan
asosiasi, agregasi, dan inheritance (pewarisan).
2.2.9.3 Diagram Aktifitas
Diagram aktivitas adalah representasi grafis dari seluruh tahapan alur kerja. Diagram ini mengandung aktivitas, pilihan tindakan, perulangan dan hasil dari aktivitas tersebut. Diagram ini dapat digunakan untuk menjelaskan proses bisnis dan alur kerja operasional secara langkah demi langkah dari komponen suatu sistem.
2.2.9.4 Diagram Objek
Diagram objek adalah suatu Diagram yang berfungsi untuk mengatur
Diagram objek, dapat berguna. Sebuah Diagram objek dasarnya instansiasi semua atau bagian dari Diagram class
2.2.10 MySQL
MySQL adalah multiuser database yang menggunakan bahasa structured
Query Language (SQL). MySQL dalam operasi client server melibatkan server
daemon MySQL di sisi server dan berbagai macam program serta library yang berjalan di sisi client. MySQL mampu menangani data yang cukup besar. Perusahaan yang mengembangkan MySQL yaitu TcX, mengaku bahwa MySQL yang mampu menyimpan data lebih dari 40 database, 10.000 tabel dan sekitar 7 juta baris, totalnya kurang lebih 100 Gigabyte data [12].
27
ANALISIS DAN PERANCANGAN
3.1 Analisis Sistem
Analisis sistem (System Analysis) dapat didefinisikan sebagai penguraian dari suatu sistem informasi yang utuh ke dalam bagian-bagian komponennya dengan maksud untuk mengidentifikasikan dan mengevaluasi permasalahan-permasalahan, kesempatan-kesempatan, hambatan-hambatan yang terjadi dan kebutuhan-kebutuhan yang diharapkan sehingga dapat diusulkan perbaikan-perbaikannya. Dalam analisa sistem ini meluputi beberapa bagian, yaitu :
1. Analisis Masalah
2. Analisis Penerapan Metode Crisp-DM
3. Analisis Prosedur Penentuan Paket Produk Kosmetik 4. Analisis Spesifikasi Kebutuhan Perangkat Lunak
3.1.1 Analisis Masalah
Berdasarkan hasil pengamatan, dapat disimpulkan bahwa permasalahan yang ada di toko yaitu belum adanya informasi penentuan paket produk kosmetik yang sesuai dengan minat konsumen yang akan ditawarkan.
3.1.2 Analisis Penerapan Metode Crisp-DM 3.1.2.1Pemahaman Bisnis
Pemahaman Bisnis atau disebut dengan Business Understanding merupakan tahapan pertama yang dilakukan dalam kerangka kerja CRISP-DM. Dalam tahapan bisnis ini terbagi menjadi dua bagian, yaitu:
1. Penentuan Tujuan Bisnis
Menjual produk dalam bentuk paket untuk memenuhi permintaan konsumen dan menghasilkan keuntungan untuk perusahaan.
Menilai situasi merupakan tahapan untuk menjelaskan sumber daya yang tersedia di Makmur Jaya Kosmetik. Berikut Merupakan sumber daya yang ada pada Makmur Jaya Kosmetik
1. Sumber Daya Perangkat Keras
1.1Terdapat Alat penunjang transaksi yaitu, printer thermal dan cashdrawer (laci Kasir)
1.2Komputer 2. Sumber daya data
2.1Sumber daya data yang di Makmur Jaya Kosmetik yaitu data transaksi penjualan.
2.2Sumber daya data ini bersifat internal yaitu tersimpan di database Makmur Jaya Kosmetik
3. Sumber data personil
3.1Pegawai kasir yang bertugas melakukan transaksi pembeli , mencetak nota dan membuat laporan penjualan yang akan di serahkan ke manager.
4. Kebutuhan
4.1Data yang digunakan dalam penelitian ini adalah data transaksi penjualan.
5. Asumsi
5.1Data transaksi yang digunakan merupakan hasil import dari aplikasi kasir di Makmur Jaya Kosmetik dengan format database (.sql) 5.2Data transaksi yang digunakan periode bulan Januari 2016 6. Batasan
3. Penentuan Sasaran Data Mining
Mengetahui keterkaitan produk yang sering dibeli oleh kosumen sehingga bisa dijadikan acuan dalam penentuan paket produk.
3.1.2.2Pemahaman Data
Tahapan pemahaman data dimulai dengan pengumpulan data awal dan hasil kegiatan untuk mengidentifikasi masalah data, untuk mendetekdi subset menarik untuk membetuk hipotesis untuk informasi yang tersembunyi.
1. Mengumpulkan Data Awal
Sumber yang didapat adalah data transaksi di Makmur Jaya Kosmetik. Yang dapat dilihat di Gambar 3.1.
Data yang ada saat ini merupakan bentuk tidak normal, untuk memudahkan proses analisis dalam data miningmaka dilakukan proses normalisasi. Berikut adalah tahapan proses normalisasi:
a. Tahap 1: Bentuk unnormalize
Tabel 3. 1 Bentuk Unnormalize Data Transaksi
b. Tahap 2: Bentuk Normal Ke-1
Tabel 3. 2 Bentuk Norma ke-1
Nama toko Alamat
toko
Tlp toko
No Faktur Tang
gal
Kode Nama Produk Qty Harga Jumla
h
Total Harga
Makmur
16010001 01/01
/2016
01/01/2016 WFS60 Wardah Facial Scrub 60 ml
1 3900 0
39000 5541500
1601000
22500 5541500
1601000 1
01/01/2016 CHPWGU V40
CITRA HAZ
SPOTLES WHITE GLOW UV 40 G
1 1050 0
10500 5541500
1601000
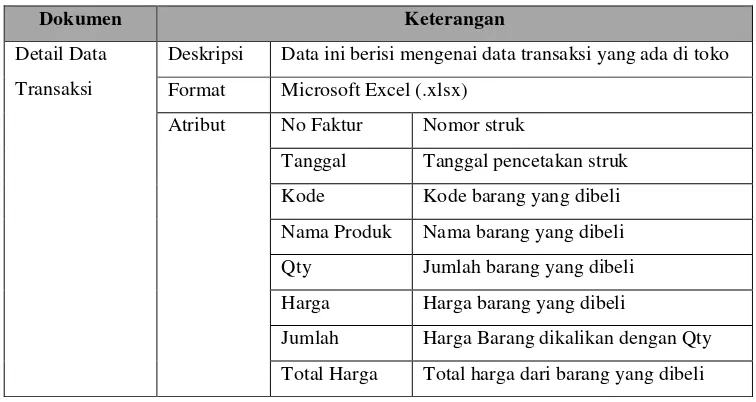
2. Mendeskripsikan Data
Tahap kedua dalam pemahaman data adalah mendeskripsikan data dengan tujuan untuk memahami data yang didapat dari hasil pengumpulan data awal. Berikut merupakan penjelasan dari masing-masing atribut yang terdapat pada tabel transaksi yang dapat dilihat pada tabel 3.1 dibawah ini :
Tabel 3. 3Struktur Data Transaksi Penjualan
Dokumen Keterangan
Detail Data
Transaksi
Deskripsi Data ini berisi mengenai data transaksi yang ada di toko
Format Microsoft Excel (.xlsx)
Atribut No Faktur Nomor struk
Tanggal Tanggal pencetakan struk
Kode Kode barang yang dibeli
Nama Produk Nama barang yang dibeli
Qty Jumlah barang yang dibeli
Harga Harga barang yang dibeli
Jumlah Harga Barang dikalikan dengan Qty
Total Harga Total harga dari barang yang dibeli
3.1.2.2.3 Verify Data Quality (Verifikasi Kualitas Data)
Dari data transaksi yang didapat terdapat noise, noise yaitu data transaksi yang hanya memiliki 1 barang dalam sekali transaksi sehingga data tersebut perlu dihilangkan dikarenakan data tersebut akan mempengaruhi proses mining kedepanya. Maka dari itu data – data yang memiliki noise akan dilakukan pembersihan data pada tahap berikutnya.
1601000 1
01/01/2016 KS35 KAPAS SARIAYU 35
01/01/2016 PSHPAD17 0
22000 5541500
1601000 1
01/01/2016 WLDCS30 S1
Wardah Lig Day Cream Step 1 30 gr
1 2400 0
3.1.2.3Data Preparation
Persiapan Data merupakan tahap dimana akan dilakukan pemilihan tabel dan
field yang akan digunakan dalam proses mining. Persiapan data dilakukan dengan sebutan Preprocessing Data. Preprocessing merupakan hal yang harus dilakukan dalam proses data mining, karena tidak semua data atau atribut data dalam data digunakan dalam proses data mining. Proses ini dilakukan agar data yang digunakan sesuai dengan kebutuhan. Adapun tahapan-tahapan preprocessing data dalam penelitian ini adalah sebagai berikut:
1. Ekstrasi Data
Ekstraksi data dapat diartikan sebagai proses pengambilan data dari sumber data dalam rangka untuk melanjutkan proses pengolahan data ke tingkat selanjutnya ataupun untuk menyimpan data hasil ekstrak tersebut. Dalam penelitian ini, data yang berasal dari flat file berformat microsoft excel (.xlsx) di ekstrak kedalam format sql, kemudian disimpan kedalam sebuah database agar memudahkan dalam proses pengolahan data. Berikut merupakan contoh sampel data transaksi 1 bulan periode bulan Januari sebanyak 30 transaksi yang terdapat di toko , dimana atribut-atribut yang terdapat dalam data tersebut antara lain No, No Faktur, Tanggal, Kode Barang, Nama Barang, Varian, Harga Barang, Qty, Jumlah, dan Total Harga.
2. Pemilihan Atribut ( Select Data)
Proses pemilihan atribut atau selection data adalah proses dimana atribut data akan dipilih dan diproses sesuai dengan kebutuhan data mining. Sebelum melakukan proses cleaning atau pembersihan data akan lebih efisien jika melakukan proses
selection atau pemilihan atribut ini terlebih dahulu. Karena dari data transaksi yang sebanyak ribuan record ini memiliki 10 atribut sedangkan yang dibutuhkan untuk data
mining hanya 2 atribut. Dengan menyeleksi atribut yang tidak dibutuhkan akan
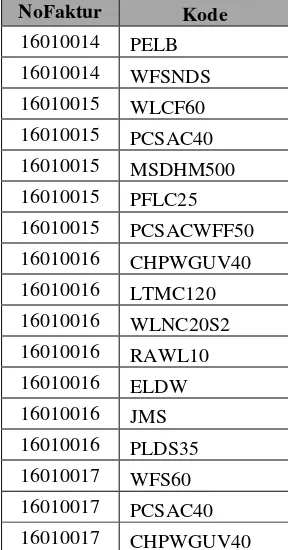
tidak perlu. Dalam penelitian ini, 2 atribut yang akan digunakan adalah atribut No Faktur dan Kode. K edua atribut ini digunakan untuk memenuhi tujuan awal dimana akan dicari pola pembelian konsumen berdasarkan produk yang dibeli. Seperti atribut No Faktur digunakan untuk membedakan satu transaksi dengan transaksi lainnya, dan atribut Kode digunakan untuk mengetahui produk apa saja yang dibeli dalam satu transaksi.
Tabel 3. 4 Pemilihan Atriburt
NoFaktur Kode NoFaktur Kode
16010001 WFS60 16010014 PELB
16010001 PCSAC40 16010014 WFSNDS
16010001 CHPWGUV40 16010015 WLCF60
16010001 LTMC120 16010015 PCSAC40
16010001 KS35 16010015 MSDHM500
16010001 PAR 16010015 PFLC25
16010001 PSHPAD170 16010015 PCSACWFF50
16010001 WLDCS30S1 16010016 CHPWGUV40
16010002 WFS60 16010016 LTMC120
16010002 PCSAC40 16010016 WLNC20S2
16010002 CHPWGUV40 16010016 RAWL10
16010002 MSDHM500 16010016 ELDW
16010002 PFLC25 16010016 JMS
16010002 KS35 16010016 PLDS35
16010002 PELB 16010017 WFS60
16010002 PSHPAD170 16010017 PCSAC40
16010003 WLCF60 16010017 PCSACWFF50
16010003 CHPWGUV40 16010017 PAR
16010003 MSDHM500 16010017 WLBBCL15
16010003 KS35 16010017 SSHP170
16010003 PELB 16010018 WFS60
16010003 WLDCS30S1 16010018 MSDHM500
16010003 WLNC20S2 16010018 LTMC120
16010003 WFSNDS 16010018 PFLC25
16010003 WELFSP20 16010018 MKP120
16010004 WLCF60 16010018 ELDW
16010004 PCSAC40 16010019 WLCF60
16010004 CHPWGUV40 16010019 PCSACWFF50
16010004 PELB 16010019 RAWL10
16010004 PSHPAD170 16010019 HICAT60
16010005 WFS60 16010020 WFS60
16010005 PCSAC40 16010020 WLCF60
16010005 MSDHM500 16010020 PFLC25
16010005 LTMC120 16010020 PAR
16010005 PAR 16010020 EHVITR
16010005 PELB 16010021 WLCF60
16010005 WLDCS30S1 16010021 SSHP170
16010006 WLCF60 16010022 HICAT60
16010007 PCSAC40 16010023 WFS60
16010008 WFS60 16010023 PCSAC40
16010008 CHPWGUV40 16010023 MSDHM500
16010008 MSDHM500 16010023 LTMC120
16010008 KS35 16010023 PFLC25
16010008 PELB 16010024 WFS60
16010008 PSHPAD170 16010024 PCSACWFF50
16010009 WLCF60 16010024 PAR
16010009 CHPWGUV40 16010024 WLBBCL15
16010009 KS35 16010024 EHVITR
16010009 PAR 16010025 WLCF60
16010009 PELB 16010025 CHPWGUV40
16010009 WLDCS30S1 16010025 PFLC25
16010009 WFSNDS 16010025 RAWL10
16010009 SSHP170 16010025 HICAT60
16010010 WFS60 16010026 WFS60
16010010 PCSAC40 16010026 PCSAC40
16010010 CHPWGUV40 16010026 MSDHM500
16010010 MSDHM500 16010026 PCSACWFF50
16010010 LTMC120 16010026 WLNC20S2
16010010 KS35 16010026 WLBBCL15
16010010 PELB 16010026 SSHP170
16010010 PSHPAD170 16010026 EHVITR
16010011 WLCF60 16010027 WFS60
16010011 LTMC120 16010027 PCSAC40
16010011 KS35 16010027 LTMC120
16010011 PSHPAD170 16010027 PFLC25
16010011 WLDCS30S1 16010027 PCSACWFF50
16010011 WLNC20S2 16010027 WLBBCL15
16010011 WFSNDS 16010027 WELFSP20
16010011 SSHP170 16010028 WFS60
16010012 WFS60 16010028 WLCF60
16010012 WLCF60 16010028 PFLC25
16010012 CHPWGUV40 16010028 PCSACWFF50
16010012 LTMC120 16010028 RAWL10
16010012 PAR 16010028 WELFSP20
16010012 WLDCS30S1 16010029 WLCF60
16010013 WLCF60 16010029 PCSAC40
16010013 MSDHM500 16010029 MSDHM500
16010013 KS35 16010029 PFLC25
16010013 PSHPAD170 16010029 PCSACWFF50
16010013 WLNC20S2 16010029 EHVITR
16010013 WFSNDS 16010030 WLCF60
16010013 HICAT60 16010030 PCSAC40
16010014 WFS60 16010030 CHPWGUV40
16010014 PCSAC40 16010030 MSDHM500
16010014 CHPWGUV40 16010030 PFLC25
16010014 LTMC120 16010030 PCSACWFF50
16010014 KS35 16010030 WLNC20S2
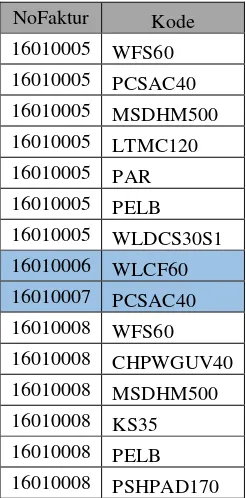
3. Pembersihan Data
Proses pembersihan data atau cleaning data adalah proses menghilangkan data tidak relevan atau inkosisten dan proses menghilangkan noise. Noise disini yaitu data transaksi yang hanya memiliki 1 produk dalam sekali pembelian. Dalam data transaksi ini akan dilakukan pengeleminasian terhadap transaksi yang memiliki jumlah produk kurang dari 2 produk dalam satu kali transaksinya, karena syarat ini diperlukan dalam
Association Rules untuk melihat keterhubungan antar 2 produk atau lebih. Setelah melakukan proses pembersihan data, dari data transaksi yang awalnya sebanyak 33 transaksi di cleaning menjadi 27 transaksi.
Sebelum Pembersihan Data Setelah Pembersihan Dara
NoFaktur Kode NoFaktur Kode
16010005 WFS60 16010005 WFS60
16010005 PCSAC40 16010005 PCSAC40
16010005 MSDHM500 16010005 MSDHM500
16010005 LTMC120 16010005 LTMC120
16010005 PAR 16010005 PAR
16010005 PELB 16010005 PELB
16010005 WLDCS30S1 16010005 WLDCS30S1
16010006 WLCF60 16010008 WFS60
16010007 PCSAC40 16010008 CHPWGUV40
16010008 WFS60 16010008 MSDHM500
16010008 CHPWGUV40 16010008 KS35
16010008 MSDHM500 16010008 PELB
16010008 KS35 16010008 PSHPAD170
16010008 PELB 16010008 PSHPAD170
Tabel 3. 5 Hasil Pembersihan Data
NoFaktur Kode NoFaktur Kode
16010001 WFS60 16010014 WFSNDS
16010001 PCSAC40 16010015 WLCF60
16010001 CHPWGUV40 16010015 PCSAC40
16010001 LTMC120 16010015 MSDHM500
16010001 PAR 16010015 PCSACWFF50
16010001 PSHPAD170 16010016 CHPWGUV40
16010001 WLDCS30S1 16010016 LTMC120
16010002 WFS60 16010016 WLNC20S2
16010002 PCSAC40 16010016 RAWL10
16010002 CHPWGUV40 16010016 ELDW
16010002 MSDHM500 16010016 JMS
16010002 PFLC25 16010016 PLDS35
16010002 KS35 16010017 WFS60
16010002 PELB 16010017 PCSAC40
16010002 PSHPAD170 16010017 CHPWGUV40
16010003 WFS60 16010017 PCSACWFF50
16010003 WLCF60 16010017 PAR
16010003 CHPWGUV40 16010017 WLBBCL15
16010003 MSDHM500 16010017 SSHP170
16010003 KS35 16010018 WFS60
16010003 PELB 16010018 MSDHM500
16010003 WLDCS30S1 16010018 LTMC120
16010003 WLNC20S2 16010018 PFLC25
16010003 WFSNDS 16010018 MKP120
16010003 WELFSP20 16010018 ELDW
16010004 WLCF60 16010019 WLCF60
16010004 PCSAC40 16010019 PCSACWFF50
16010004 CHPWGUV40 16010019 RAWL10
16010004 PELB 16010019 HICAT60
16010004 PSHPAD170 16010020 WFS60
16010005 WFS60 16010020 WLCF60
16010005 PCSAC40 16010020 PFLC25
16010005 MSDHM500 16010020 PAR
16010005 LTMC120 16010020 EHVITR
16010005 PAR 16010021 WLCF60
16010005 PELB 16010021 SSHP170
16010005 WLDCS30S1 16010023 WFS60
16010008 WFS60 16010023 PCSAC40
16010008 CHPWGUV40 16010023 MSDHM500
16010008 MSDHM500 16010023 LTMC120
16010008 KS35 16010023 PFLC25
16010008 PSHPAD170 16010024 PCSACWFF50
16010009 WLCF60 16010024 PAR
16010009 CHPWGUV40 16010024 WLBBCL15
16010009 KS35 16010024 EHVITR
16010009 PAR 16010025 WLCF60
16010009 PELB 16010025 CHPWGUV40
16010009 WLDCS30S1 16010025 PFLC25
16010009 WFSNDS 16010025 RAWL10
16010009 SSHP170 16010025 HICAT60
16010009 MKP120 16010025 MKP120
16010010 WFS60 16010026 WFS60
16010010 PCSAC40 16010026 PCSAC40
16010010 CHPWGUV40 16010026 MSDHM500
16010010 MSDHM500 16010026 PCSACWFF50
16010010 LTMC120 16010026 WLNC20S2
16010010 KS35 16010026 WLBBCL15
16010010 PELB 16010026 SSHP170
16010010 PSHPAD170 16010026 EHVITR
16010011 WLCF60 16010027 WFS60
16010011 LTMC120 16010027 PCSAC40
16010011 KS35 16010027 LTMC120
16010011 PSHPAD170 16010027 PFLC25
16010011 WLDCS30S1 16010027 PCSACWFF50
16010011 WLNC20S2 16010027 WLBBCL15
16010011 WFSNDS 16010027 WELFSP20
16010011 SSHP170 16010028 WFS60
16010012 WFS60 16010028 WLCF60
16010012 WLCF60 16010028 PFLC25
16010012 CHPWGUV40 16010028 PCSACWFF50
16010012 LTMC120 16010028 RAWL10
16010012 PAR 16010028 WELFSP20
16010012 WLDCS30S1 16010029 WLCF60
16010013 WLCF60 16010029 PCSAC40
16010013 MSDHM500 16010029 MSDHM500
16010013 KS35 16010029 PFLC25
16010013 PSHPAD170 16010029 PCSACWFF50
16010013 WLNC20S2 16010029 EHVITR
16010013 HICAT60 16010030 PCSAC40
16010014 WFS60 16010030 CHPWGUV40
16010014 PCSAC40 16010030 MSDHM500
16010014 CHPWGUV40 16010030 PFLC25
16010014 LTMC120 16010030 PCSACWFF50
16010014 KS35 16010030 WLNC20S2
16010014 PAR 16010030 WLBBCL15
16010014 PELB
3.1.2.4Modeling
Pemodelan merupakan tahap untuk mebuat model atau desain sistem yang akan dibangun. Data yang digunakan untuk pengolahan data adalah data yang tertera pada tabel 3.3
1. Select Modeling Technique ( Memilih Teknik Pemodelan)
Dengan menggunakan metode Data Mining, data transaksi akan diolah dengan aturan asosiasi untuk menemukan pola-pola pembelian barang yang sering dibeli oleh konsumen. Didalam tahap ini metode yang digunakan adalah Assosiacion Rule.
Penelitian ini bertujuan menemukan pola assosiasi pembelian konsumen. Teknik pemodelan yang digunakan dalam penelitian ini adalah metode Association
Rules sedangkan algoritma yang digunakan dalam penelitian ini adalah algoritma
FP-Growth Dengan menerapkan Data Mining, data transaksi akan diolah dengan aturan
asosiasi atau metode Association Rules untuk menemukan pola-pola pembelian produk yang sering dibeli oleh konsumen.
2. Build Model ( Membangun Model)
Algoritma yang digunakan dalam penelitian ini adalah algoritma
FP-Growth. Algoritma ini akan mencari himpunan menu yang sering dibeli dengan melihat
FP-Tree yang sudah dibuat terlebih dahulu sehingga proses pencarian himpunan produk dapat lebih cepat dilakukan daripada algoritma apriori. Berikut ini adalah langkah-langkah proses pengerjaan algoritma FP-Growth :
Dengan menggunakan tabel 3.3, masing-masing item dihitung frekuensi kemunculan berdasarkan itemnya. Hasil dari penghitungan kemunculan item dapat dilihat pada tabel 3.4 dibawah ini.
Tabel 3. 6 Hasi Perhitungan Kemunculan Produk
Nama Produk Support
Count
Wardah Facial Scrub 60 ml 16
PONDS CS ACNE C 40 13
PONDS CS ACNE C 40 13
CITRA HAZ SPOTLES WHITE GLOW UV 40 G 13 MAKARIZO SALON DAILY HAIR MASK 500gr NEW 12
La Tulip Milk Cleanser 120 ml New 10
PONDS FAIR LOVELY CREAM 25 G 10
KAPAS SARIAYU 35 9
PONDS CS ACNE CLEAR WHITE FF50 G 9
Pensil Alis Revlon 8
Pixy Eye Liner Black 8
PANTENE SHP ANTI DANRUFF 170 ML ATLAS 7
Wardah Lig Day Cream Step 1 30 gr 6
Wardah LIG NIGHT CREAM 20 step 2 6
WARDAH FACIAL SERUM NORMAL DRY SKIN 5
SUNSILK SHP SOFT 170 ML 5
WARDAH LIGHT BB CREAM LIGHT 15ML 5
REXONA ADVANCED WHITENING LOT 10G 4
ELIPS Hair Vit Repair 4
Wardah Excl. Liq Found. 02 Sheer Pink 20 ml 3
MINYAK KAYU PUTIH 120 3
HOT IN CREAM A.THERAPY 60 G 3
Eye LINER DAVIS WARNA 2
Just Miss Serut 1
Purbasari lips Daily Series 35 1
Awal mula ditentukan minimum support dan juga confidence dari keinginan pengguna untuk melihat batasan terendah munculnya menu. Penentuan minimum
support terlalu besar maka hasil yang didapatkan terlalu sedikit bahkan tidak ada, sedangkan apabila nilai minimum support nya terlalu kecil, hasil yang didapatkan terlalu banyak. Untuk kasus ini dimisalkan ditentukan minimum support : 4 dan
confidence : 60%.. Hal ini dilakukan dengan memproses data yang ada pada tabel 3.6
yang dapat dilihat pada tabel 3.7.
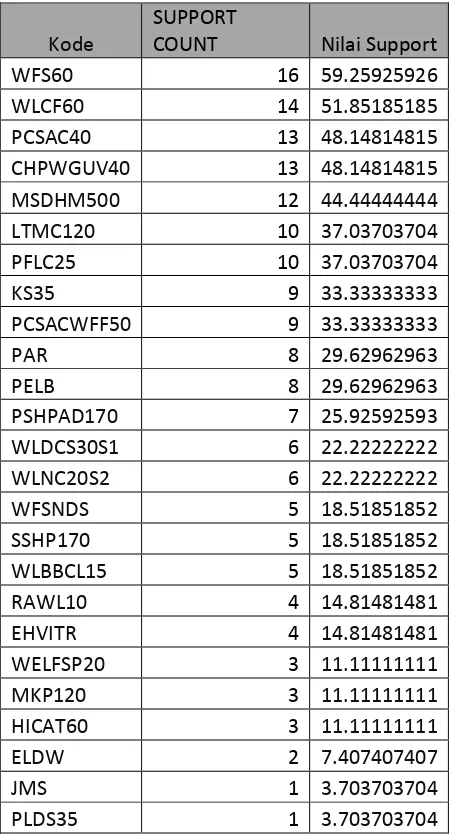
Tabel 3. 7 Hasil Perhitungan Support Item
Kode
SUPPORT
COUNT Nilai Support
WFS60 16 59.25925926
WLCF60 14 51.85185185
PCSAC40 13 48.14814815
CHPWGUV40 13 48.14814815
MSDHM500 12 44.44444444
LTMC120 10 37.03703704
PFLC25 10 37.03703704
KS35 9 33.33333333
PCSACWFF50 9 33.33333333
PAR 8 29.62962963
PELB 8 29.62962963
PSHPAD170 7 25.92592593
WLDCS30S1 6 22.22222222
WLNC20S2 6 22.22222222
WFSNDS 5 18.51851852
SSHP170 5 18.51851852
WLBBCL15 5 18.51851852
RAWL10 4 14.81481481
EHVITR 4 14.81481481
WELFSP20 3 11.11111111
MKP120 3 11.11111111
HICAT60 3 11.11111111
ELDW 2 7.407407407
JMS 1 3.703703704
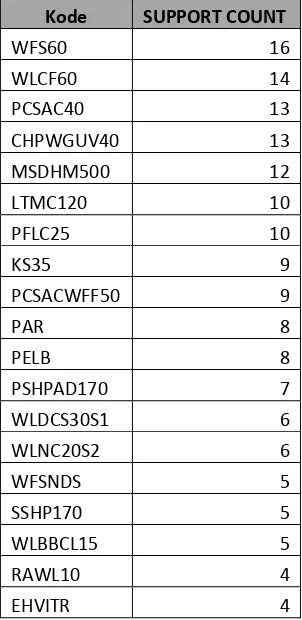
Langkah ke dua yaitu mengeleminasi menu yang tidak memenuhi minimum support 15%. Hasil Pengeleminasian menu dapat dilihat pada tabel 3.8.
Tabel 3. 8 Hasil Eleminasi Minimum Support
Kode SUPPORT COUNT
WFS60 16
WLCF60 14
PCSAC40 13
CHPWGUV40 13
MSDHM500 12
LTMC120 10
PFLC25 10
KS35 9
PCSACWFF50 9
PAR 8
PELB 8
PSHPAD170 7
WLDCS30S1 6
WLNC20S2 6
WFSNDS 5
SSHP170 5
WLBBCL15 5
RAWL10 4
EHVITR 4
Langkah ketiga yaitu mengurutkan kembali frequent berdasarkan banyaknya kemunculan menu yang disebut dengan Frequency of occurrence yang dapat dilihat pada tabel 3.9.
Tabel 3. 9 Priority
Kode
SUPPORT
COUNT Priority
WFS60 16 1
WLCF60 14 2
PCSAC40 13 3
CHPWGUV40 13 4
MSDHM500 12 5
PFLC25 10 7
KS35 9 8
PCSACWFF50 9 9
PAR 8 10
PELB 8 11
PSHPAD170 7 12
WLDCS30S1 6 13
WLNC20S2 6 14
WFSNDS 5 15
SSHP170 5 16
WLBBCL15 5 17
RAWL10 4 18
EHVITR 4 19
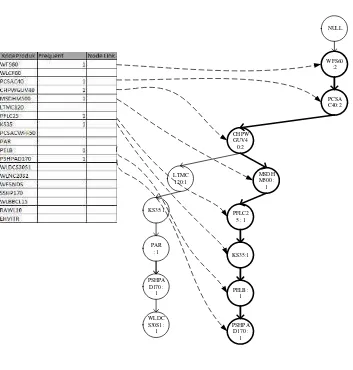
Langkah keempat adalah membuat fp-tree. Berikut proses pembentukan FP-Tree
dibawah ini :
1) Transaksi 16010001 : WFS60, PCSAC40, CHPWGUV40, LTMC120, KS35, PAR, PSHPAD170, WLDCS30S1
2) Lakukan pembacaan pada data transaksi pertama yang akan diproses.
3) Lakukan pengecekan pada rootyang diinisialisasikan dengan Null, jika root belum mempunyai anak (child), maka data yang dibaca tadi menjadi anak pertama dari root. Dan support count
WFS60 :1
NULL
PCSA C40:1
CHPW GUV4 0:1
LTMC 120:1
KS35:1
PAR :1
PSHPA D170 : 1
WLDC S30S1 : 1
Gambar 3. 2 Tree Transaksi 16010001
1) Transaksi 16010002 : WFS60, PCSAC40, CHPWGUV40, MSDHM500, PFLC25, KS35, PELB, PSHPAD170
1) Lakukan pembacaan pada data transaksi kedua yang akan diproses.
2) Jika data yang keluar berikutnya sama dengan data yang pertama, maka itu bukan anak kedua dari root, tetapi tetap anak dari root yang sebelumnya keluar, yang berubah adalah
WFS60 :2 NULL
PCSA C40:2
CHPW GUV4 0:2
LTMC 120:1
KS35:1
PAR :1
PSHPA D170 : 1
WLDC S30S1 :
1
MSDH M500 : 1
PFLC2 5 : 1
KS35:1
PELB : 1
PSHPA D170 : 1
Gambar 3. 3 Tree Transaksi 16010002
2) Transaksi 16010003 : WFS60, WLCF60, CHPWGUV40, MSDHM500, KS35, PELB, WLDCS30S1, WLNC20S2, WFSNDS, WELFSP20
1) Lakukan pembacaan pada data transaksi ketiga yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda
lintasanmaka node pada laintasan yang lain tidak bertambah
support count-nya, hanya data yang dibaca sama saja yang
WFS60
3) Setelah pembacaan sampai ke transaksi 16010030 : WLCF60, PCSAC40, CHPWGUV40, MSDHM500, PFLC25, PCSACWFF50, WLNC20S2, WLBBCL15 akan membentuk FP-tree di Gambar 3.5
WFS60