IMPLEMENTASI DATA MINING MENGGUNAKAN METODE ASSOCIATION
RULE UNTUK MEGOLAH DATA PERPUSTAKAAN
STT HARAPAN MEDAN
Rahmad Juhendra
1, Tulus
2, Habibi Ramdani Safitri
3 Program Studi Teknik Informatika - Sekolah Tinggi Teknik HarapanJl. HM Joni No 70 C Medan [email protected]
Abstrak
Perpustakaan Sekolah Tinggi Harapan Medan memiliki sistem informasi perpustakaan yang dapat memudahkan pengguna untuk meminjam buku. Namun data peminjaman buku yang tercatat pada database sistem masih belum mampu diolah kembali secara maksimal. Hal ini dikarenakan belum adanya modul pengolahan kembali data peminjaman sehingga hanya akan terakumulasi dan tertimbun didalam database sistem dan tidak menghasilkan kembali informasi dan pengetahuan yang bermanfaat untuk mendukung kemajuan manajemen perpustakaan. Teknik Data mining telah banyak digunakan untuk mengatasi permasalahan yang ada salah satunya dengan penerapan algoritma association rule untuk menemukan aturan asosiasi yang terbentuk dari dataset peminjaman buku. Dengan memanfaatkan data transaksi kunjungan perpustakaan akan dicari informasi tentang buku apa yang sering dipinjam oleh mahasiswa dan keterkaitan antara masing-masing peminjaman, sehingga pihak perpustakaan itu sendiri dapat melakukan penyusunan buku sesuai dengan tingkat nilai support dan confidence. Analisa mining data menggunakan tools Rapid Miner Studio, dimana dari hasil mining data transaksi dengan minimum support 3 dan confidence 50% diperoleh 21 aturan asosiasi. Salah satu aturan asosiasi yang terbentuk adalah jika meminjam buku Microsoft Office 2007 maka meminjam buku Belajar Visual Basic 2008 dengan nilai support 0.2 dan nilai confidence 100% yang merupakan aturan dengan nilai confidence tertinggi. Kemudian setelah itu dibuat suatu aplikasi yang dapat menunjukkan lokasi buku secara lebih spesifik sehinggan memudahkan pencarian bagi mahasiswa.
Kata Kunci : Data Mining, Aturan Asosiasi, Support, Confidence
Abstract
The library of STT Harapan Medan has a library information system that can allow users to borrow books. The Data of borrowing books recorded on the database system is still not able to be recycled to the maximum . This is due to the lack of data processing module back lending so it will only accumulate and accumulate within the database system and does not generate a return of information and useful knowledge to support the advancement of library management. Data mining techniques have been widely used to solve the existing problems either by the application of association rule algorithms for finding association rules formed by the dataset borrowing books. By utilizing transaction data visit the library to search for information about what books are often borrowed by students and the linkages between each borrowing, so that the library itself can undertake the preparation of a book in accordance with the level of support and confidence values. Analysis using data mining tools Rapid Miner Studio , where the results of the transaction data mining with minimum support 3 and 50 % confidence gained 21 association rules. One association rules formed is borrowing the book Microsoft Office 2007 then borrow books Learning Visual Basic 2008 for 0.2 support and confidence values 100 % which is the rule with the highest confidence score. Then after that created an application that can show the location of the book in a more specific sehinggan facilitate the search for students.
1. PENDAHULUAN
Dengan kemajuan teknologi informasi, kebutuhan akan informasi yang akurat sangat dibutuhkan dalam kehidupan sehari-hari, sehingga informasi menjadi suatu elemen penting dalam perkembangan masyarakat saat ini dan waktu mendatang. Namun kebutuhan informasi yang tinggi kadang tidak diimbangi dengan penyajian informasi yang memadai. Sering kali informasi tersebut masih harus digali ulang dari data yang jumlahnya sangat besar. Kemampuan teknologi informasi untuk mengumpulkan dan menyimpan berbagai tipe data jauh meninggalkan kemampuan untuk menganalisis, meringkas dan megekstrak pengetahuan dari data. Metode tradisional untuk menganalisis data yang ada tidak dapat menangani data dalam jumlah besar.
Data adalah representasi peristiwa dunia nyata yang mewakili suatu objek seperti manusia (pegawai, pelanggan, siswa, pembeli), barang, hewan, peristiwa, konsep, keadaan, dan sebagainya, yang diwujudkan dalam bentuk angka, huruf, symbol, teks, gambar, bunyi, atau kombinasinya [1]. Pemanfaatn data yang ada untuk menunjang kegiatan dalam pengambilan keputusan tidak cukup hanya dengan mengandalakan data operasional saja, diperlukan suatu analisis data untuk menggali potensi-potensi informasi yang ada. Para pengambil keputusan berusaha untuk memanfaatkan gudang data yang sudah dimiliki untuk menggali informasi yang berguna membantu dalam mengambil keputusan. Hal ini mendorong munculnya cabang ilmu baru untuk mengatasi masalah penggalian informasi atau pola yang penting atau menarik dari data dalam jumlah besar yang disebut dengan data mining. Penggunaan teknik data mining diharapkan dapat memberikan pengetahuan-pengetahuan yang sebelumnya tersembunyi di dalam gudang data sehingga menjadi informasi yang berharga.
Sekolah Tinggi Teknik Harapan adalah salah satu perguruan tinggi swasta di kota Medan Sumatera Utara. STT Harapan dilengkapi dengan berbagai fasilitas untuk menunjang kegiatan mahasiswanya, dimana salah satunya adalah fasilitas berupa perpustakaan. Perpustakaan STT Harapan memiliki koleksi buku yang cukup banyak dari berbagai cabang ilmu pengetahuan. Pengunjung perpustakaan cukup banyak, khususnya bagi mahasiswa yang sedang skripsi. Biasanya pengunjung perpustakaan akan meningkat karena mahasiswa tersebut membutuhkan referensi dari buku-buku untuk mendukung teori yang mereka pelajari.
1.1 Data Warehouse
Basis data adalah himpunan kelompok data yang saling berhubungan yang diorganisasi sedemikian rupa agar kelak dapat dimanfaatkan kembali dengan cepat dan mudah. Database merupakan bagian yang paling tinggi dari sistem data. Database adalah kumpulan beberapa file-file yang mempunyai kaitan antara satu file dengan file yang lain sehingga membentuk suatu data. Sedangkan sistem database adalah suatu landasan atau kerangka dasar yang terdiri dari sistem dan sub sistem yang digunakan untuk melayani aplikasi tertentu guna mencapai tujuan. Manajemen sebuah sistem database adalah suatu sistem perangkat lunak komputer [1].
Data warehouse adalah basis data yang menyimpan data sekarang dan data masa lalu yang berasal dari berbagai sistem operasional dan sumber yang lain (sumber eksternal) yang menjadi perhatian penting bagi manajemen dalam organisasi dan ditujukan untuk keperluan analisis dan pelaporan manajemen dalam rangka pengambilan keputusan [2].
Empat karakteristik dari data warehouse meliputi :
1. Subject Oriented
Sebuah data warehouse disusun dalam subjek utama, seperti pelanggan, suplier, produk, dan sales. Meskipun data warehouse terkonsentrasi pada operasi harian dan proses transaksi dalam perusahaan, data warehouse fokus pada pemodelan dan analisis data untuk pembuat keputusan. Oleh karena itu data warehouse mempunyai karakter menyediakan secara singkat dan sederhana gambaran seputar subjek lebih detail yang dibuat dari data luar yang tidak berguna dalam proses pendukung keputusan. 2. Integrated
Data warehouse biasanya dibangun dari bermacam-macam sumber yang berbeda, seperti database relasional, flat files, dan on-line transaction records. Pembersihan dan penyatuan data diterapkan untuk menjamin konsistensi dalam penamaan, struktur kode, ukuran atribut, dan yang lainnya.
3. Time Variant
Data disimpan untuk menyajikan informasi dari sudut pandang masa lampau (misal 5 – 10 tahun yang lalu). Setiap struktur kunci dalam data warehouse mempunyai elemen waktu baik secara implisit maupun eksplisit.
Sebuah data warehouse secara fisik selalu disimpan terpisah dari data aplikasi operasional. Penyimpanan yang terpisah ini, data warehouse tidak memerlukan proses transaksi, recovery dan mekanisme pengendalian konkurensi. Biasanya hanya membutuhkan dua operasi dalam akses data yaitu initial load of data dan access of data.
1.2 Data Mining
Data mining atau sering disebut sebagai knowledge discovery in database (KDD) adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam data berukuran besar. Keluaran data mining ini bisa dipakai untuk membantu pengambilan keputusan di masa depan. Pengembangan KDD ini menyebabkan penggunaan pattern recognition semakin berkurang karena telah menjadi bagian data mining [3]. Alasan utama mengapa data mining diperlukan adalah karena adanya sejumlah besar data yang dapat digunakan untuk menghasilkan informasi dan knowledge yang berguna. Informasi dan knowledge yang didapat tersebut dapat [4].
Data Mining adalah salah satu bidang yang berkembang pesat karena besarnya kebutuhan akan nilai tambah dari databaseskala besar yang makin banyak terakumulasi sejalan dengan pertumbuhan teknologi informasi. Definisi umum dari data mining itu sendiri adalah serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data [5]
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu:
1. Deskripsi (Description)
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menemukan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi (Estimation)
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih kearah numerik daripada kearah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai variabel dari target sebagai
nilai prediksi, selanjutnya pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi. 3. Prediksi (Prediction)
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada dimasa mendatang.
4. Klasifikasi (Clasification)
Dalam klasifikasi, terdapat target variabel kategori, sebagai contoh penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, sedang dan rendah.
5. Pengklusteran (Cluster)
Pengklusteran merupakan pengelompokan record, pengamatan atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan lainya dan memiliki ketidak miripan dengan record-record dalam kluster lain.
6. Asosiasi (Association)
Tugas Asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis disebut dengan analisis keranjang belanja.
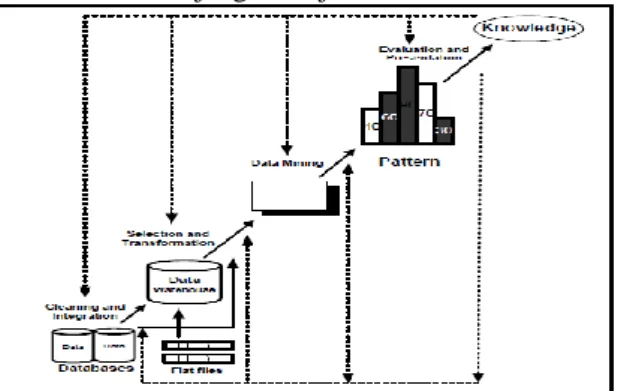
Gambar 1. Tahap-Tahap Data Mining 1.3 Association Rule
Analisis asosiasi atau association rule mining adalah teknik data mining untuk menemukan aturan assosiatif antara suatu kombinasi item. Algoritma aturan asosiasi akan menggunakan data latihan, sesuai dengan pengertian data mining, untuk menghasilkan pengetahuan. Pengetahuan apakah yang hendak dihasilkan dalam aturan asosiasi untuk mengetahuan item-item belanja yang sering dibeli secara bersamaan dalam suatu waktu. Aturan asosiasi yang berbentuk “if…then…” atau “jika…maka…” merupakan pengetahuan yang dihasilkan dari fungsi aturan asosiasi [6]. Association rule merupakan salah satu metode yang bertujuan mencari pola yang sering muncul di antara banyak transaksi, dimana setiap transaksi terdiri dari beberapa item [7].
Association rule merupakan salah satu metode yang bertujuan mencari pola yang sering muncul di antara banyak transaksi, dimana setiap transaksi terdiri dari beberapa item sehingga metode ini akan mendukung system rekomendasi melalui penemuan pola antar item dalam transaksi-transaksi yang terjadi. Analisis asosiasi dikenal juga sebagai salah satu metode data mining yang menjadi dasar dari berbagai metode data mining lainnya. Khususnya salah satu tahap dari analisis asosiasi yang disebut analisis pola frekuensi tinggi (frequent pattern mining) menarik perhatian banyak peneliti untuk menghasilkan algoritma yang efisien. Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support (nilai penunjang) yaitu presentase kombinasi item tersebut. dalam database dan confidence (nilai kepastian) yaitu kuatnya hubungan antar item dalam aturan assosiatif. Analisis asosiasi didefinisikan suatu proses untuk menemukan semua aturan assosiatif yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence (minimum confidence) [7].
1.4 Algoritma Apriori
Algoritma Apriori adalah algoritma analisis keranjang pasar yang digunakan untuk menghasilkan aturan asosiasi, dengan pola “if-then” [4]. Algoritma Apriori yang bertujuan untuk menemukan frequent itemsets dijalankan pada sekumpulan data. Analaisis Apriori didefenisikan suatu proses untuk menemukan semua aturan apriori yang memenuhi syarat minimum untuk support dan syarat minimum untuk confidence. Support adalah nilai penunjang, atau persentase kombinasi sebuah item dalam database, sedangkan confidence adalah nilai kepastian yaitu kuatnya hubungan antar item dalam sebuah apriori [7].
Algoritma Apriori termasuk jenis aturan asosiasi pada data mining. Selain Apriori, yang termasuk pada algoritma ini adalah metode Generalized Rule Induction dan algoritma Hash Based. Aturan yang menyatakan asosiasi antara beberapa atribut sering disebut affinity analisys atau market basket analysis [8].
Prinsip Algoritma Apriori adalah sebagai berikut :
1. Kumpulkan jumlah item tunggal, dapatkan item besar.
2. Dapatkan candidat pairs, hitung => large pairs dari item-item.
3. Dapatkan candidat triplets, hitung => large triplets dari itemitem dan seterusnya.
4. Sebagai petunjuk: setiap subnet dari sebuah frequent itemset harus menjadi frequent.
Metodologi dasar analisis asosiasi terbagi menjadi dua tahap :
1. Analisa pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus berikut:
Sedangkan nilai support dari dari 2 (dua) item diperoleh dari rumus:
2. Pembentukan aturan assosiatif
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan assosiatif yang memenuhi syarat minimum untuk confidence dengan menghitung confidence aturan assosiatif A _B. Nilai confidence dari aturan A _B diperoleh dari rumus berikut:
Prinsip algoritma Apriori dapat dijelaskan sebagai berikut :
1. Kumpulkan jumlah item tunggal, dapatkan item besar.
2. Dapatkan kandidat pairs => large pairs dari item-item.
3. Dapatkan kandidat triplets, hitung => large triplets dari item-item dan seterusnya.
4. Sebagai petunjuk : setiap subset dari sebuah frequent itemset harus menjadi frequent.
2. HASIL DAN PEMBAHASAN
Dalam penulisan tugas akhir ini akan dicari nilai support dan confidence dari pinjaman buku di perpustakaan Sekolah Tinggi Teknik Harapan (STT) Medan. Data transaksi pinjaman buku ini nantinya akan di mining dengan menerapkan association rule sehingga didapatkan aturan asosiasi baru yang berfungsi untuk memberikan informasi yang berguna bagi pengurus perpustakaan seperti mengetahui buku-buku apa saja yang biasanya dipinjam oleh mahasiswa, sehingga dapat dilakukan penyusunan buku dengan lebih baik guna mempermudah dalam pencarian buku.
2.1 Data Mining Association Rule
Data mining adalah proses analisis untuk mengekstraksi dan mengidentifikasi informasi yang
bermanfaat dan pengetahuan yang terkait dari database. Salah satu metodde yang digunakan dalam data mining yaitu metode Association Rule, dimana aturan asosiasi ingin memberikan informasi dalam bentuk hubungan if-then atau jika-maka.
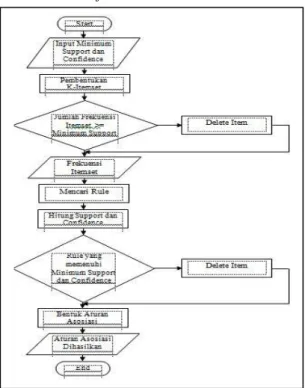
Langkah-langkah kerja dari algoritma Associaton Rule adalah sebagai berikut:
1. Tentukan besaran nilai minimum support dan confidence, dimana dalam penelitian ini jumlah besaran nilai minimum suppot = 3, sedangkan besaran minimum confidence = 50%.
2. Scan database transaksi peminjaman buku perpustakaan untuk mendapatkan 1-item set, kemudian ambil kandidat yang frekuensinya memenuhi minimum support count. Sedangkan yang tidak memenuhi minimum support dihilangkan atau dihapus.
3. Bangkitkan k+1 itemset dari itemset yang ada sebelumnya, kemudian buang atau bersihkan data kandidat yang subsetnya tidak memenuhi support count.
4. Hitung frekuensinya, ambil kandidat yang frekuesninya memenuhi dan selesai saat tidak ada kandidat yang memenuhi syarat.
5. Aturan asosiasi dihasilkan dengan menyeleksi yang memenuhi besaran minimum support dan minimum confidence.
Gambar 2. Flowchart Association Rule 2.2 Analisa Association Rule
Sebelum melakukan mining data dengan metode Association Rule, perlu disiapkan data yang akan di mining dimana data yang digunakan adalah data transaksi peminjaman buku dengan menggunakan data fiktif. Hal ini dimaksudkan
untuk memberikan gambaran bagaimana melakukan mining data sehingga menghasilkan aturan asosiasi (Association Rule).
Untuk melakukan penggalian dari data transaksi peminjaman buku, maka langkah-langkah yang harus dilakukan adalah:
1. Langkah pertama yaitu menetapkan besarnya besaran nilai minimum support dan confidence. Dimana dalam hal ini ditetapkan besaran support = 3 dan besaran confidence = 50 %. 2. Langkah kedua yaitu dengan menyususn semua
frequent itemset yaitu itemset yang memiliki nilai minimum support = 3 yang telah ditetapkan sebelumnya.
Untuk menganalisanya dimulai dengan membahas setiap frequent 1-itemset, kemudian diseleksi item apa saja yang memiliki minimum support = 3. Item-item yang memenuhi minimum support disebut frequent 1-itemset. Daftar frequent 1-itemset dapat dilihat pada tabel dibawah ini:
Tabel 1. Daftar Frequent 1-Itemset
No. Itemset Support
1. Algoritma dan
Pemrograman 4
2. Komunikasi Data 9 3. Belajar Visual Basic
2008 6
4. Konsep Basis Data 4 5. Cloud Computing 3 6. Microsoft Office 2007 4
7. Data Mining 7
8. Kriptografi 3
Dari daftar frequent 1-Itemset diatas, dibuat menjadi daftar calon frequent 2-Itemset. Maka akan didapat hasil seperti terlihat pada tabel 2 berikut:
Tabel 2. Daftar Calon Frequent 2-Itemset
No. Itemset Support
1. Algoritma dan Pemrograman,Komunikasi Data 1 2. Algoritma dan Pemrograman, Belajar Visual Basic 2008 1 3. Algoritma dan Pemrograman,Konsep Basis Data 0 4. Algoritma dan Pemrograman,Cloud Computing 2 5. Algoritma dan Pemrograman, Microsoft Office 2007 0 6. Algoritma dan Pemrograman,Data Mining 0 7. Algoritma dan Pemrograman,Kriptografi 1
8. Komunikasi Data, Belajar
Visual Basic 2008 1
9. Komunikasi Data, Konsep
Basis Data 3
10. Komunikasi Data,Cloud
Computing 0
11. Komunikasi Data, Microsoft
Office 2007 0
12. Komunikasi Data,Data
Mining 6
13. Komunikasi Data,Kriptografi 1 14. Belajar Visual Basic 2008,
Konsep Basis Data 0
15. Belajar Visual Basic 2008,
Cloud Computing 0
16. Belajar Visual Basic 2008, Microsoft Office 2007 4 17. Belajar Visual Basic
2008,Data Mining 0
18. Belajar Visual Basic
2008,Kriptografi 0
19. Konsep Basis Data, Cloud
Computing 1
20. Konsep Basis Data, Microsoft Office 2007 0 21. Konsep Basis Data, Data
Mining 4
22. Konsep Basis Data,
Kriptografi 1
23. Cloud Computing, Microsoft
Office 2007 1 24. Cloud Computing,Data Mining 1 25. Cloud Computing,Kriptografi 1 26. Microsoft Office 2007, Kriptografi 0
27. Microsoft Office 2007, Data
Mining 1
28. Data Mining, Kriptografi 0 Dari tabel diatas dapat dilihat bahwa yang memenuhi syarat minimum support atau yang berhak menjadi frequent 2-Itemset adalah seperti terlihat pada tabel 3 berikut ini:
Tabel 3. Daftar Frequent 2-Itemset
No. Itemset Support
1. Komunikasi Data,Konsep
Basis Data 3
2. Komunikasi Data,Data
Mining 6
3. Belajar Visual Basic 2008, Microsoft Office 2007
4
4. Konsep Basis Data, Data
Mining 4
Kemudian daftar frequent 1-Itemset diatas dibuat menjadi daftar calon frequent 3-Itemset yaitu seperti terlihat pada tabel 4 berikut ini:
Tabel 4. Daftar Frequent 3-Itemset
No. Itemset Support
1. Komunikasi Data, Konsep Basis Data, Data Mining 3
2.
Komunikasi Data, Konsep Basis Data, Belajar Visual Basic 2008
0
3.
Komunikasi Data, Konsep Basis Data, Microsoft Office 2007
0
4. Komunikasi Data, Data Mining, Belajar Visual Basic 2008
0
5. Komunikasi Data, Data Mining, Microsoft Office 2007
0
Dari tabel diatas dapat dilihat bahwa yang berhak menjadi frequent 3-Itemset adalah seperti terlihat pada tabel 5 dibawah ini:
Tabel 5. Daftar Frequent 3-Itemset
No. Itemset Support
1. Komunikasi Data, Konsep Basis Data, Data Mining 3
Setelah frequent 3-Itemset diperoleh, maka tahap selanjutnya menghitung nilai confidence dari masing-masing Frequent Itemset sehingga muncul calon aturan asosiasi. Aturan asosiasi ingin memberikan informasi dalam bentuk hubungan if-then atau jika-maka. Berikut contoh perhitungan untuk mencari nilai confidence dari masing-masing Frequent Itemset untuk menghasilkan calon aturan asosiasi.
Jika meminjam Komunikasi Data Maka meminjam Konsep Basis Data didapatkan nilai confidence = 3 / 9 = 0,33 = 33%.
Dari daftar calon aturan asosiasi diatas, maka akan dipilih aturan asosiasi yang memenuhi minimum support dan minimum confidence untuk menjadi aturan asosiasi. Dimana minimum support = 3 dan minimum confidence = 50% seperti yang sudah ditetapkan sebelumnya. Daftar aturan asosiasi dpat dilihat pada tabel 3.6 berikut ini:
2.3 Implementasi Dan Pengujian
Implementasi merupakan tahapan yang dilakukan untuk mengaplikasikan terhadap rancangan yang diperoleh sebelumnya. Pada penelitian ini akan mengimplementasikan data mining pengolahan data perpustakaan STT Harapan dengan menggunakan software Rapid Miner Studio. Dari hasil analisa data mining dengan Rapid Miner ini nantinya akan menghasilkan aturan asosiasi peminjaman buku, sehingga untuk mempermudah dalam pencarian buku dibuat aplikasi dengan alat bantu Visual Basic 2008 dengan program database MySQL. Adapun hasil yang diperoleh tberupa tampilan hasil dan hasil pengujian sistem.
2.3.1 Implementasi Komponen
Untuk mengimplementsaikan data mining pengolahan data perpustakaan ini dapat berjalan dengan baik, ada beberapa perangkat yang harus dipenuhi. Adapun perangkat-perangkat yang digunakan dapat diuraikan pada tabel berikut:
Tabel 7. Spesifikasi Kebutuhan Hardware No. Nama
Perangkat Keterangan 1. Processor AMD Dual Core atau
lebih rendah
2. Harddisk 320 GB atau lebih rendah
3. Memory 2 GB atau lebih rendah
4. Monitor 1366 x768
Tabel 8. Spesifikasi Kebutuhan Software No. Nama Perangkat Keterangan 1. Operating System Windows 7 2. Rapid Miner
Studio
Tools data mining
3. Microsoft Visual Basic 2008
Tools bahasa pemrograman
4. MySQL Database
5. .Net Framework Versi 3.5 atau lebih tinggi
6. Smadav Antivirus
2.3.2 Implementasi Data Mining
Untuk mengimplementasikan data mining peminjaman buku perpustakaan STT Harapan, menggunakan tools Rapid Miner studio.
Di bawah ini merupakan langkah-langkah kerja pengimplementasian data mining dengan menggunakan metode association rule pada Rapid Miner, yaitu sebagai berikut:
1. Langkah pertama pembuatan Format Tabular Tahap pertama yang dilakukan yaitu mempersiapkan data yang akan diolah, yaitu data transaksi peminjaman buku perpustakaan. Untuk pembuatan data format tabular menggunakan Microsoft Excel, dimana data yag digunakan dapat dilihat pada lampiran. Kemudian Lakukan importing data kedalam Repositori. Browse table Microsoft Excel yang telah dibuat, dan masukan kedalam Local Repository, seperti gambar dibawah ini:
Gambar 3. Importing Data Kedalam Repository 2. Drag dan Drop Tabel DataPerpustakaan tadi
kedalam Process. Sehingga Operator Database muncul dalam Main Proses. Operator Numerical to Binominal diperlukan untuk mengubah nilai atribut yang berada pada table TransaksiMakanan menjadi binominal. Kemudian hubungkan Tabel DataPerpustakaan dengan operator Numerical to Binominal. Proses ini akan membuat nilai dari Tabel Transaksi makan mejadi Binominal Attributes. Selanjutnya hubungkan operator Numerical to Binominal dengan operator FP-Growth dan isi Parameter FP-Growth dengan minimum support senilai 30% atau 0.3. Kemudian hubungkan operator FP-Growth dengan operator Association Rules dan isi Parameter Association Rules dengan minimum confidence 50% atau 0.5. Setelah itu hubungkan Association Rules pada result. Sehingga seluruhnya membentuk seperti gambar dibawah ini:
Gambar 4. Susunan Operator Association Rules 3. Setelah semua operator terhubung kemudia klik
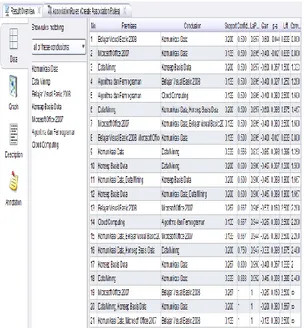
sebuah tab Association Rules yang baru, yang isinya adalah sebuah table berisi seluruh itemset yang memenuhi parameter FP-Growth dan Association Rules, seperti terlihat pada gambar berikut:
Gambar 5. Hasil Association Rules Dari hasil analisa data mining dengan Rapid Miner, yang mana jumlah rules yang dihasilkan yaitu 21 rules. Kita bisa mengambil beberapa dari rules ini untuk dijadikan sebuah pegangan dalam melakukan pengaturan ulang tata letak buku guna mempermudah pencarian buku. Tentunya yang memiliki nilai support dan confidence yang tinggi, yaitu salah satunya jika meminjam buku Microsoft Office 2007 maka meminjam buku Belajar Visual basic 2008 dengan nilai support 0.2 dan nilai confidence 100%.
Untuk melihat dalam bentuk grafik. kita dapat memilih opsi Graph View, sepeti yang ditunjukkan pada gambar berikut:
Gambar 6. Hasil Dalam Bentuk Graph View 2.3.3 Implementasi Pencarian Buku
Adapun program aplikasi pencarian buku menggunakan bahasa pemrograman Visual Basic.NET 2008 dan program Database menggunakan MySQL.
1. Form Login
Setelah program dijalankan, maka tampilan yang paling pertama muncul adalah Form Login, merupakan Form yang digunakan untuk login ke dalam sistem. Kita dapat login sebagai Admin atau user, perbedaanya jika login sebagai user ada beberapa form yang dibekukan atau tidak diakses.
Gambar 7. Hasil Pengujian Form Login 2. Form Menu Utama
Dalam tahap ini, dilakukan pengujian terhadap kemampuan sistem untuk menggunakan form menu utama di mana user akan berinteraksi langsung dengan sistem.
Gambar 8. Hasil Pengujian Form Utama 3. Form Data Petugas
Form Data Petugas adalah sebuah form yang dirancang untuk menampilkan data petugas, di mana dalam form ini dapat dilakukan Tambah, Simpan, Ubah, Hapus Data.
Gambar 9. Hasil Pengujian Form Petugas 4. Form Data Buku
Form Data Buku adalah sebuah form yang dirancang untuk menampilkan data buku, di mana dalam form ini dapat dilakukan Tambah, Simpan, Ubah, Hapus Data.
Gambar 10. Hasil Pengujian Form Data Buku 2.3.4 Pengujian Sistem
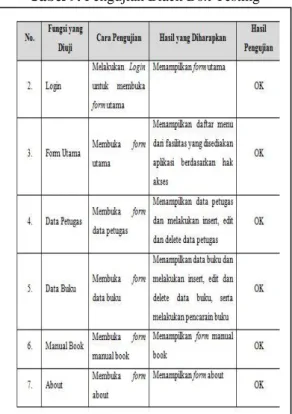
Setelah mendapatkan hasil tampilan perangkat lunak, tahap selanjutnya melakukan pengujian terhadap sistem tersebut. Adapun metode pengujian sistem yang dilakukan adalah metode Black Bos Testing. Metode black box testing merupakan metode testing pengujian yang dilakukan untuk mengamati hasil eksekusi melalui data uji dan memeriksa fungsional dari perangkat lunak. Adapun hasil pengujian fungsionalitas sistem yang telah dibuat dengan menggunakan metode pengujian Black Box testing, dapat dilihat pada tabel berikut:
Tabel 9. Pengujian Black Box Testing
3. PENUTUP 3.1 Kesimpulan
Kesimpulan yang dapat diambil dari penelitian data mining dengan metode association rule ini adalah sebagai berikut:
1. Proses mining data transaksi peminjaman buku perpustakaan mengunakan tools Rapid Miner Studio untuk menganalisa dan menghasilkan aturan asosiasi. Sedangkan untuk mempermudah proses pencarian buku di perpustakaan dibuat aplikasi dengan tools Microsoft Visual Basic.NET 2008.
2. Penerapan data mining peminjaman buku perpustakaan merupakan sebuah sistem pencarian aturan asosiasi melalui pengolahan data transaksi peminjaman buku dari setiap mahasiswa yang bertujuan untuk mencari hubungan antara buku yang sering dipinjam mahasiswa dengan menghitung besaran nilai support dan confidence. Sehingga informasi ini dapat memberikan pertimbangan tambahan bagi perpustakaan itu sendiri guna pengaturan buku-buku pada rak untuk mempermudah pencarian. 3. Dari hasil mining data kunjungan perpustakaan
STT Harapan didapatkan informasi buku yang sering dipinjam mahasiswa, sehingga dapat dilakukan rekomendasi pengaturan ulang tata letak buku guna mempermudah dalam pencarian buku.
4. Dari hasil mining data transaksi peminjaman buku perpustakaan dengan batasan minimum transaksi sebesar 3 transaksi dan minimum confidence sebesar 50% membentuk 21aturan asosiasi. Salah satu aturan asosiasi yang terbentuk adalah jika meminjam buku Microsoft Office 2007 maka meminjam buku Belajar Visual Basic 2008 dengan nilai support 0.2 dan nilai confidence 100% yang merupakan aturan dengan nilai confidence tertinggi.
3.2 Saran
Berdasarkan kesimpulan dari penelitian ini maka saran yang mungkin berguna untuk perkembangan lebih lanjut pada penelitian skripsi ini, yaitu sebagai berikut:
1. Penelitian selanjutnya dapat dikembangkan pada jenis data yang sama dengan menggunakan metode yang lebih baik seperti algoritma Generalized Sequential Pattern.
2. Jumlah buku yang dapat dianalisa ditingkatkan agar pola mining yang terbentuk semakin bervariasi dan banyak. Sehingga proses mining
lebih akurat dalam menentukan keterkaitan antara buku yang dipinjam.
3. Hasil aturan asosiasi yang terbentuk dapat dikembangkan menjadi basis pengetahuan untuk membuat aplikasi yang lebih bagus mengenai hubungan antara buku yang ada dalam perpustakaan.
4. DAFTAR PUSTAKA
[1]. Handojo, Andreas, dkk. 2008. Aplikasi Data Mining Untuk Meneliti Asosiasi Pembelian Item Barang di Supermaket dengan Metode Market Basket Analysis. Surabaya.
[2]. Arifin. 2010. Data Warehouse, Data Mart, OLAP, dan Data Mining. Sistem Informasi UDINUS.
[3]. Fadlina. 2014. Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule Metode Apriori. Volume III Nomor I, Padang, Informasi dan Teknologi Ilmiah (INTI).
[4]. Jananto, A. 2012. Penggunaan Market Basket Analysis untuk Menentukan Pola Kompetensi Mahasiswa. Jurnal Teknologi Informasi Dinamik Volume 17, No.2. Program Studi Sistem Informasi, Universitas Stikubank.
[5]. Aminulloh, S, G. 2016. Penerapan Data Mining Pada Penyewaan Film Di Atika
Menggunakan Metode Association Rules. Artikel Skripsi Universitas Nusantara PGRI Kediri.
[6]. Rian Pratama. 2008. Perancangan Data Warehouse Pemetaan Data Siswa Pada Disdikpora Kota Palembang. STMIK GI MDP.
[7]. Syaifullah, A, M. 2010. Implementasi Data Mining Algoritma Apriori Pada Sistem Penjualan. Naskah Publikasi AMIKOM Yogyakarta.
[8] Nurdin, Astika. D. Penerapan Data Mining Untuk Menganalisis Penjualan Barang Dengan Menggunakan Metode Apriori Pada Supermarket Sejahtera Lhokseumawe. Jurnal Techsi Vol. 6 No.1. Program Studi Teknik Informatika Universitas Malikussaleh.