1
Kartika Kosmetik merupakan toko penjualan produk kosmetik yang paling besar didaerah Rancaekek. Produk utama yang dijual di Kartika Kosmetik adalah produk-produk kebutuhan penunjang kecantikan dan kebutuhan salon, berbagai merk produk bisa ditemukan di toko ini. Jika konsumen akan membeli produk yang diinginkan, konsumen akan berkontak langsung dengan pelayan toko dan melakukan transaksi pembelian. Dalam melakukan strategi penjualannya, pihak kartika kosmetik juga seringkali membuat suatu paket penjualan produk pada kesempatan tertentu seperti hari-hari besar, yaitu hari raya Idul Fitri, hari raya Idul Adha, hari raya kemerdekaan, hari raya Natal, tahun baru dan hari besar lainnya. Paket produk tersebut berupa beberapa produk kosmetik yang dijual secara bersamaan dalam bentuk sebuah paket. Dengan adanya penjualan paket tersebut, kosumen mendapatkan keuntungan dari harga yang lebih murah dibandingkan jika membeli dengan harga satuan. Hal tersebut dapat menambahkan banyak konsumen dan meningkatkan penghasilan toko.
Ketersediaan data yang banyak dan juga kebutuhan perusahaan akan informasi merupakan kedua hal yang dapat dijadikan pertimbangan dalam penggunaan Data Mining. Data Mining memiliki banyak metode salahsatunya adalah Association Rules. Menurut "Data Preparationfor Data Mining" dalam Applied Artificial Intelligence (Zhang,Zhang, & Yang, 2003) Association Rule
merupakan salah satu metode yang bertujuan untuk mencari pola yang sering muncul pada banyak transaksi, dimana setiap transaksi terdiri dari beberapa item. Untuk permasalahan pada toko Kartika Kosmetik dapat diatasi dengan metode
Association Rule. Algoritma yang digunakan adalah algoritma CT-Pro. Algoritma
CT-Pro merupakan salah satu algoritma pengembangan dari FP-Growth. Perbedaannya terdapat pada langkah kedua dimana FP-Growth membuat FP-Tree
sedangkan CT-Pro membuat Compressed FP-Tree (CFP-Tree). Keunggulan struktur data CFP-Tree membuat penggunaan memori menjadi lebih hemat dan memungkinkan proses pencarian frequent itemset menjadi lebih cepat.
Dari pengimplementasian data mining dengan algoritma CT-Pro
diharapkan bisa menghasilkan aplikasi yang dapat membantu pihak Kartika Kosmetik dalam memberikan informasi yang bisa digunakan untuk mengambil keputusan menentukan produk apa saja yang bisa dijadikan sebuah paket penjualan produk yang nantinya akan ditawarkan ke konsumen.
1.2 Perumusan Masalah
1.3 Maksud dan Tujuan
Berdasarkan permasalahan yang diteliti, maka maksud dari penulisan tugas akhir ini adalah untuk membuat aplikasi Data Mining menggunakan metode
Association Rules dengan algoritma CT-Pro pada data transaksi penjualan untuk pembentukan paket penjualan produk di toko Kartika Kosmetik.
Sedangkan tujuan yang ingin dicapai dalam pembangunan aplikasi ini adalah :
1. Untuk menghasilkan informasi berupa pola pembelian konsumen dari data transaksi Kartika Kosmetik.
2. Untuk membantu pihak di Kartika Kosmetik dalam melakukan strategi bisnisnya dengan menentukan produk apa saja yang bisa dijadikan sebuah paket produk penjualan yang nantinya akan ditawarkan ke konsumen.
1.4 Batasan Masalah
Adapun batasan masalah yang dapat disimpulkan sebagai berikut :
1. Data yang dianalisa merupakan data transaksi penjualan di Kartika Kosmetik periode 1 bulan sebelum menjelang event yang diselenggarakan. Untuk sampel diambil event hari raya Idul Fitri, maka data yang dianalisa adalah data periode bulan Juni 2015.
2. Algoritma yang digunakan dalam Data Mining ini yaitu algoritma CT-Pro
untuk mencari frequent itemset (himpunan data yang paling sering muncul dalam sebuah kumpulan data), yang akan digunakan sebagai informasi untuk pihak Kartika Kosmetik sebagai rekomendasi dalam pembentukan paket produk kosmetiknya.
3. Informasi yang dihasilkan berupa penentuan paket produk kosmetik yang akan ditawarkan ke konsumen.
4. Metode analisis yang digunakanan dalam pembangunan perangkat lunak ini menggunakan pendekatan analisis Pemrograman Berorientasi Objek.
1.5 Metodologi Penelitian
Metodologi penelitian yang digunakan adalah metode penelitian deskriptif, yaitu metode penelitian yang bertujuan untuk memberikan gambaran atau deskripsi tentang suatu keadaan secara objektif [1]. Metodologi penelitian ini dibagi menjadi 2 tahap, yaitu metode pengumpulan data dan metode pembangunan perangkat lunak. Adapun metode pengumpulan data, penelitian
data mining dan pembangunan perangkat lunak sebagai berikut : 1.5.1 Metode Pengumpulan Data
Metode Metode pengumpulan data dapat diperoleh secara langsung dari objek penelitian dan referensi-referensi yang telah diperoleh. Cara-cara yang digunakan untuk mendapatkan data adalah sebagai berikut:
1. Studi Lapangan
Studi lapangan adalah metode pengumpulan data yang dilakukan dengan mengadakan penelitian ke Toko Kartika Kosmetik. Studi lapangan ini dilakukan dengan dua cara, yaitu:
a.Observasi
Observasi merupakan metode pengumpulan data dengan mengadakan penelitian dan peninjauan langsung ke Toko Kartika Kosmetik.
b.Wawancara
Wawancara merupakan metode pengumpulan data yang dilakukan dengan mengadakan tanya jawab secara langsung kepada area manager di Toko Kartika Kosmetik.
2. Studi Literatur
Studi Literatur merupakan metode pengumpulan data dengan cara mengumpulkan jurnal, paper dan bacaan-bacaan yang berkaitan dengan dengan topik yang sedang diteliti seperti Data Mining, Acossiation Rules
1.5.2 Metode Penelitian Data Mining
CRISP-DM (CRoss-Industry Standard Process for Data Mining) merupakan suatu konsorsium perusahaan yang didirikan oleh Komisi Eropa pada tahun 1996 dan telah ditetapkan sebagai proses standar dalam data mining yang dapat diaplikasikan di berbagai sektor industri[2]. Penjelasan tentang siklus hidup pengembangan data mining yang telah ditetapkan dalam CRISP-DM diacu pada gambar 1.1.
Gambar 1.1 Metode CRISP-DM [2]
Berikut ini adalah penjelasan mengenai enam tahap siklus hidup pengembangan data mining berdasarkan gambar di atas :
1. Business Understanding
2. Data Understanding
Pada tahap pemahaman data ini dimulai dengan pengumpulan data yang diperlukan yaitu data transaksi Kartika Kosmetik pada bulan Juni 2015.
3. Data Preparation
Pada tahap ini meliputi proses pengolahan data (yaitu data transaksi Kartika Kosmetik bulan Juni 2015) untuk membangun dataset akhir yang akan diproses pada tahap pemodelan. Pada tahap ini mencakup pemilihan tabel, record, dan atribut-atribut data, termasuk proses pembersihan dan transformasi data.
4. Modeling
Untuk tahapan pemodelan ini akan digunakan teknik Data Mining dengan metode Association Rule menggunakan algoritma CT-Pro, yang nantinya akan menghasilkan aturan asosiatif atau pola kombinasi produk kosmetik berdasarkan hasil dari data transaksi. Sehingga dapat diketahui informasi produk apa saja yang dapat dijadikan kombinasi dalam paket produk kosmeitk yang akan dijual.
5. Evaluation
Pada tahap ini dilakukan evaluasi terhadap keefektifan dan kualitas model yang digunakan, apakah dengan metode Association Rule dengan algoritma CT-Pro telah mencapai tujuan yang ditetapkan pada tahap awal.
6. Deployment
1.5.3 Metode Pembangunan Perangkat Lunak
Tahapan pembangunan perangkat lunak menggunakan metode waterfall, untuk tahapannya sebagai berikut :
1. Analisis dan definisi persyaratan.
Pada tahap ini merupakan pengumpulan kebutuhan-kebutuhn dalam pembuatan perangkat lunak seperti batasan dan tujuan sistem melalui konsultasi pada pihak terkait ditempat penelitian. Kebutuhan tersebut dianalisis kemudian didefinisikan secara rinci agar mendapatkan spesifikasi program yang dibutuhkan dengan baik.
2. Perancangan sistem dan perangkat lunak.
Setelah mengumpulkan kebutuhan dan syarat untuk sistem yang akan dibuat, perancangan sistem dan perancangan perangkat lunak dikerjakan. Kegiatan ini kemudian akan membangun arsitektur sistem secara keseluruhan.
3. Implementasi dan pengujian unit.
Pada tahap ini mulai dibuatnya perangkat lunak dari desain-desain yang sudah dirancang diatas.
4. Integrasi dan pengujian sistem.
Perangkat lunak yang telah dibuat kemudian diuji kelengkapannya untuk menjamin bahwa syarat kebutuhan sistem telah dipenuhi. Setelah pengujian selesai, kemudian perangkat lunak tersebut dikirim kepada pihak ditempat penelitian.
5. Operasi dan pemeliharaan.
Operasi dan pemeliharaan merupakan tahap menjalankan perangkat lunak yang sudah selesai dibangun.
1.6Sistematika Penulisan
Sistematika penulisan dalam tugas akhir ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut:
BAB 1 PENDAHULUAN
Bab ini membahas tentang latar belakang permasalahan, perumusan masalah, maksud dan tujuan, batasan masalah, metodologi penelitian dan sistematika penulisan.
BAB 2 TINJAUAN PUSTAKA
Bab ini membahas tentang profile umum toko Kartika Kosmetik, struktur organisasi toko Kartika Kosmetik, visi dan misi toko Kartika Kosmetik, struktur organisasi dan deskripsi jabatan serta berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Bab ini menganalisis masalah dari data hasil penelitian, kemudian dilakukan pula proses perancangan sistem yang akan dibangun sesuai dengan analisa yang telah dilakukan.
BAB 4 IMPLEMENTASI SISTEM DAN PENGUJIAN
Bab ini membahas tentang hasil implementasi dari hasil analisis dan perancangan sistem yang telah dibuat disertai juga hasil pengujian sistem yang dilakukan di toko Kartika Kosmetik untuk memperlihatkan sejauh mana system yang dibangun layak digunakan.
BAB 5 KESIMPULAN DAN SARAN
11
Kartika Kosmetik merupakan salah satu bidang usaha penjualan produk-produk kebutuhan kecantikan dan kebutuhan salon dari berbagai merk dalam negri maupun merk dari luar negri. Kartika Kosmetik berlokasi di Jln Raya Rancaekek Bandung-Garut KM 21.
2.1.1 Sejarah Toko Kartika Kosmetik
Toko Kartika Kosmetik didirikan oleh ibu Hj. Ratna Rosita pada tahun 1986. Nama Kartika diambil dari nama anak beliau yang bernama Reka Kartika. Ide untuk mendirikan toko Kartika Kosmetik ini berawal dari banyaknya konsumen wanita yang sudah membutuhkan kosmetik dan pada saat itu toko kosmetik masih dibilang jarang. Toko Kartika Kosmetik awalnya adalah sebuah kios kecil biasa yang menjual merk dagang dalam negri. Seiring berkembangnya waktu, kebutuhan akan penunjang kecantikan khususnya bagi kaum wanita semakin bertambah. Pada saat ini Kartika Kosmetik sudah banyak menjual produk dalam dan luar negri seperti : Rista, Wardah, Ponds, LaTulipe, Tloac Paris, Tull Jye, Tje Fuk, jade, Bless dan lain-lain. Hingga akhirnya sampai sekarang Toko Kartika Kosmetik merupakan toko kosmetik terbesar dan terkemuka diwilayahnya.
2.1.2 Logo
Gambar 2.1. Logo Toko Kartika Kosmetik
2.1.3 Visi dan Misi
Berikut adalah visi dan misi dari toko Kartika Kosmetik : 2.1.3.1 Visi
Visi dari toko Kartika Kosmetik adalah sebagai berikut:
1. Menjadi penyedia kosmetik yang aman, lengkap dan terpercaya, serta dapat memberikan pelayanan yang berkualitas
2.1.3.2 Misi
Misi dari toko Kartika Kosmetik adalah sebagai berikut:
1. Menyediakan produk kosmetik dari berbagai merk yang dibutuhkan oleh pelanggan
2. Menyediakan kosmetik yang aman yang memiliki label halal serta tercatat di Badan Pom
3. Memberikan pelayanan yang baik pada seluruh pelanggan
2.1.4 Struktur Organisasi
Struktur organisasi dari toko Kartika Kosmetik dapat dilihat dari gambar 2.2.
Pemimpin
Manager
Bag. Gudang Bag.
Keuangan
Karyawan Karyawan Karyawan
Deskripsi Jabatan : 1. Pemimpin
Pemimpin merupakan pemilik dari toko Kartika Kosmetik yang bertanggung jawab penuh terhadap segala sesuatu yang terjadi di toko Kartika Kosmetik.
2. Manager
Manager merupakan seseorang yang membantu pemimpin dalam mengontrol atau mengawasi segala kegiatan di toko Kartika Kosmetik. 3. Bag. Gudang
Bagian Gudang merupakan seseorang yang bertugas membantu pemilik dalam mengatur, mengelola, dan mencatat produk-produk yang ada digudang serta produk-produk yang akan dipesan untuk stok barang. 4. Bag. Keuangan
Bagian Keuangan merupakan seseorang yang bertugas untuk membantu pemilik dalam mencatat produk yang terjual dan transaksi yang telah terjadi.
5. Karyawan
2.2 Landasan Teori
Landasan teori menjelaskan apa saja yang berkaitan dengan materi atau teori yang digunakan sebagai acuan melakukan penenlitian. Landasan teori yang diuraikan merupakan hasil studi literatur, buku-buku, maupun situs internet.
2.2.1 Data
Data adalah representasi fakta dunia nyata yang mewakili suatu objek seperti manusia (pegawai, siswa, pembeli, pelanggan), barang, hewan, peristiwa, konsep, keadaan, dan sebagainya, yang direkam dalam bentuk angka, huruf, simbol, teks, gambar, bunyi, atau kombinasinya [4]. Dalam pendekatan basis data tidak hanya berisi basis data itu sendiri tetapi juga termasuk definisi atau deskripsi dari data yang disimpan. Definisi data disimpan dalam sistem katalog, yang berisi informasi tentang struktur tiap berkas, tipe dan format penyimpanan tiap item data, dan berbagai konstrin dari data. Semua informasi yang disimpan dalam katalog ini biasa disebut meta-data [5].
2.2.2 Basis Data
Basis Data terdiri atas 2 kata, yaitu Basis dan Data. Basis kurang lebih dapat diartikan sebagai markas atau gudang, tempat bersarang/berkumpul. Sedangkan Data adalah representasi fakta dunia nyata mewakili suau objek seperti manusia 9pegawai, siswa, pembeli, pelanggan), barang, hewan, peristiwa, konsep,keadaan, dan sebagainya, yang diwujudkan dalam bentuk angka, huruf, symbol, teks, gambar, bunyi, atau kombinasinya. Sebagai satu kesatuan istilah, Basis Data (Database) sendiri dapat didefenisikan dalam sejumlah sudut pandang seperti [6] :
a. Himpunan kelompok data 9arsip) yang saling berhubungan yang diorganisasi sedemikian rupa agar kelak dapat dimanfaatkan kembali dengan cepat dan mudah.
c. Kumpulan file/ tabel/ arsip yang saling berhubungan yang disimpan dalam media penyimpan elektroniks.
2.2.2.1Operasi Dasar Basis Data
Didalam sebuah disk, basis data dapat diciptakan dan dapat pula ditiadakan. Didalam sebuah disk, kita dapat pula menempatkan beberapa (lebih dari satu) basisdata. Sementara dalam sebuah basis data, kita dapat menempatkan satu atau lebih file/tabel. Pada file/tabel inilah sesungguhnya data disimpan/ditempatkan. Setiap basis data umumnya dibuat untuk mewakili sebuah semesta data yang spesifik. Misalnya, ada basis data kepegawaian, basis data akademik, basis data inventori (Pergudangan), dan sebagainya. Sementara dalam basis data akademik, misalnya, kita dapat menempatkan file mahasiswa, file mata_kuliah, file dosen, file jadwal, file kehadiran, file nilai, dan seterusnya. Karena itu, operasi-operasi dasar yang dapat kita lakukan berkenaan dengan basis data dapat meliputi [6] :
1. Pembuatan basis data baru (create database), yang identik dengan pembuatanlemari arsip yang baru.
2. Penghapusan basis data (drop database), yang identik dengan perusakan lemariarsip (sekaligus beserta isinya, jika ada).
3. Pembuatan file/tabel dari suatu basis data (create table), yang identik denganpenambahan map arsip baru ke sebuah lemari sarsip yang telah ada. 4. Penghapusan file/tabel dari suatu basis data (drop table), yang identik
denganperusakan map arsip lama yang ada di sebuah lemari arsip.
5. Penambahan/pengisian data baru ke sebuah file/tabel disebuah basis data (insert), yang identik dengna penambahan ke lemari arsip ke sebuah map arsip.
6. Pengambilan data dari sebuah file/tabel (retrieve/search) yang identik denganpencarian lembaran arsip dari sebuah map arsip.
8. Penghapusan data dari sebuah file/tabel (delete), yang identik denganpenghapusan sebuah lembaran arsip yang ada di sebuah map arsip.
Operasi yang berkenaan dengan pembuatan objek (basis data dan tabel) merupakan operasi awal yang hanya dilakukan sekali dan berlaku seterusnya. Sedang operasi-operasi yang berkaitan dengan isi tabel (data) merupakan operasi rutin yang akan berlangsung berulang-ulang dan karena itu operasi-operasi inilah yang lebih tepat mewakili aktivitas pengelolaan (management) dan pengolahan (processing) data dalam basis data [6].
2.2.2.2Objektif Basis Data
Telah disebutkan di awal bahwa tujuan awal dan utama dalam pengelolaan data dalam sebuah basis data adalah agar kita dapat memperoleh/menemukan kembali data (yang kita cari) dengan mudah dan cepat. Disamping itu, pemamfaatan basis data untuk pengelolaan data, juga memiliki tujuan-tujuan lain [6].
Secara lebih lengkap, pemanfaatan basis data dilakukan untuk memenuhi sejumlah tujuan (objektif) seperti buku ini [6] :
1. Kecepatan dan Kemudahan (Speed)
Pemanfaatan basis data memungkinkan kita untuk dapat menyimpan data atau melakukan perubahan/manipulasi terhadap data atau menampilkan kembali data tersebut dengan lebih cepat dan mudah, daripada jika kita menyimpan data secara manual (non elektronis) atau secara elektronis (tetapi tidak dalam bentuk penerapan basis data, misalnya dalam bentuk spread sheet atau dokumen teks biasa).
2. Efisiensi Ruang Penyimpanan (Space)
data, baik dengan menerapkan sejumlah pengkodean atau dengan membuat relasi-relasi (dalam bentuk file) antar kelompok data yang saling berhubungan.
3. Keakuratan (Accuracy)
Pemanfaatan pengkodean atau pembentukan relasi antar data bersama dengan penerapan aturan/batasan (constraint) tipe data, domain data, keunikan data, dan sebagainya, yang seara ketat dapat diterapkan dalam sebuah basis data, sangat berguna untuk menekan ketidakakuratan pemasukan/penyimpanan data.
4. Ketersediaan (Availability)
Pertumbuhan data (baik dari sisi jumlah maupun jenisnya) sejalan dengan waktu akan semakin membutuhkan ruang penyimpanan yang besar. Padahal tidak semua data itu selalu kita gunakan/butuhkan. Karena itu kita dapat memilah adanya data utama/master/referensi, data transaksi, data histori hingga data kadarluarsa. Data yang sudah jarang atau bahkan tidak pernah lagi kita gunakan, dapat kita atur untuk dilepaskan dari sistem basis data yang sedang aktif (menjadi off-line) baik dengan cara penghapusan atau dengan memindahkannya ke media penyimpanan off-line (seperti
removable disk atau tape). Di sisi lain, karena kepentingan pemakaian data, sebuah basis data dapat memiliki data yang disebar di banyak lokasi geografis. Data nasabah sebuah bank, misalnya, dipisah-pisah dan disimpan di lokasi yang sesuai dengan keberadaan nasabah. Dengan pemanfaatan teknologi jaringan komputer, data yang berada di suatu lokasi/cabang, dapat juga diakses (menjadi tersedia/available) bagi lokasi/cabang lain.
5. Kelengkapan (Completenes)
datang juga demikian. Dalam sebuah basis data, di samping data kita juga harus menyimpan struktur (baik yang mendefinisikan objek-objek dalam basis data maupun definisi dari tiap objek, seperti struktur file/tabel atau indeks). Untuk mengakomodasi kebutuhan kelengkapan data yang semakin berkembang, maka kita tidak hanya dapat menambah record-record data, tetapi juga dapat melakukan perubahan struktur dalam basis data, baik dalam bentuk penambahan objek baru (tabel) atau dengan penambahan field-field baru pada suatu tabel.
6. Keamanan (Security)
Memang ada sejumlah (aplikasi) pengelola basis data yang tidak menerapkan aspek keamanan dalam penggunaan basis data. Tetapi untuk sistem yang besar dan serius, aspek keamanan juga dapat diterapkan dengan ketat. Dengan begitu kita dapat menentukan siapa-siapa (pemakai) yang boleh menggunakan basis data beserta objek-objek di dalamnya dan menentukan jenis-jenis operasi apa saja yang boleh dilakukannya.
7. Kebersamaan Pemakaian (Sharability)
Pemakai basis data seringkali tidak terbatas pada satu pemakai saja, atau di satu lokasi saja atau oleh satu sistem/aplikasi saja. Data pegawai dalam basis data kepegawaian, misalnya, dapat digunakan oleh banyak pemakai, dari sejumlah departemen dalam perusahaan atau oleh banyak sistem (sistem penggajian, sistem akuntansi, sistem inventori, dan sebagainya). Basis data yang dikelola oleh sistem (aplikasi) yang mendukung lingkungan multiuser, akan dapat memenuhi kebutuhan ini, tetapi tetap dengan menjaga/menghindari (karena data yang sama diubah oleh banyak pemakai pada saat yang bersamaan) atau kondisi deadlock (karena ada banyak pemakai yang saling menunggu untuk menggunakan data).
2.2.3 Database Management Sytem
(utilitas) yang digunakan untuk mengakses dan memelihara database. Program-program tersebut menyediakan berbagai fasilitas operasi untuk memasukan, melacak, dan memodifikasi data kedalam database, mendefinisikan data baru, serta mengolah data menjadi informasi yang dibutuhkan (DBMS = Database + Program Utilitas) [4]. Perangkat lunak yang termasuk DBMS seperti dBase, FoxBase, Rbase, Microsoft-Access (sering juga disingkat Ms-Access) dan Borland Pradox (untuk DBMS yang sederhana) atau Borland-Interbase, MS-Sql, Sever, Oracle Database, IBM, DB2, Informix, Sybase, MySql, PostgreSQL (untuk DBMS yang lebih kompleks dan lengkap) [6].
2.2.4 Data Mining
Data mining, sering juga disebut knowledge discovery in database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan. Sehingga istilah pattern recognition sekarang jarang digunakan karena ia termasuk bagian dari data mining [7]. Data Mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan didalam database. Data Mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengektrasi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban, dkk. 2005) [8].
2.2.4.1Tahapan-Tahapan Data Mining
Gambar 2.3 Metode CRISP-DM [2]
Berikut ini adalah penjelasan mengenai enam tahap siklus hidup pengembangan data mining berdasarkan gambar di atas :
1. Business Understanding
Tahap pertama adalah memahami tujuan dan kebutuhan dari sudut pandang bisnis, kemudian menterjemakan pengetahuan ini ke dalam pendefinisian masalah dalam data mining. Selanjutnya akan ditentukan rencana dan strategi untuk mencapai tujuan tersebut.
2. Data Understanding
Tahap ini dimulai dengan pengumpulan data yang kemudian akan dilanjutkan dengan proses untuk mendapatkan pemahaman yang mendalam tentang data, mengidentifikasi masalah kualitas data, atau untuk mendeteksi adanya bagian yang menarik dari data yang dapat digunakan untuk hipotesa untuk informasi yang tersembunyi.
3. Data Preparation
pemilihan tabel, record, dan atribut-atribut data, termasuh proses pembersihan dan transformasi data untuk kemudian dijadikan masukan dalam tahap pemodelan (modeling).
4. Modeling
Dalam tahap ini akan dilakukan pemilihan dan penerapan berbagai teknik pemodelan dan beberapa parameternya akan disesuaikan untuk mendapatkan nilai yang optimal. Secara khusus, ada beberapa teknik berbeda yang dapat diterapkan untuk masalah data mining yang sama. Di pihak lain ada teknik pemodelan yang membutuhan format data khusus. Sehingga pada tahap ini masih memungkinan kembali ke tahap sebelumnya.
5. Evaluation
Pada tahap ini, model sudah terbentuk dan diharapkan memiliki kualitas baik jika dilihat dari sudut pandang analisa data. Pada tahap ini akan dilakukan evaluasi terhadap keefektifan dan kualitas model sebelum digunakan dan menentukan apakah model dapat mencapat tujuan yang ditetapkan pada fase awal (Business Understanding). Kunci dari tahap ini adalah menentukan apakah ada masalah bisnis yang belum dipertimbangkan. Di akhir dari tahap ini harus ditentukan penggunaan hasil proses data mining.
6. Deployment
2.2.4.2Metode Data Mining
Secara garis besar, Han dalam bukunya menjelaskan bahwa metode data mining dapat dilihat dari dua sudut pandang pendekatan yang berbeda, yaitu pendekatan deskriptif dan pendekatan prediktif [9].
Pendekatan deskriptif adalah pendekatan dengan cara mendeskripsikan data inputan. Metode yang termasuk kedalam pendekatan ini adalah :
1. Metode deskripsi konsep/kelas, yaitu data dapat diasosiasikan dengan kelas atau konsep. Ada tiga macam pendeskripsian yaitu (1) karakteristik data, dengan membuat summary karakter umum atau fitur data suatu kelas target, (2) diskriminasi data, dengan membandingkan class target dengan satu atau sekelompok kelas pembanding, (3) gabungkan antara karakterisasi dan diskriminasi.
2. Metode association rule, yaitu menemukan aturan asosiatif atau pola kombinasi dari suatu item yang sering terjadi dalam sebuah data.
Pendekatan kedua adalah pendekatan prediktif, yaitu pendekatan yang dapat digunakan untuk memprediksi, dengan hasil berupa kelas atau cluster. Metode yang termasuk dalam pendekatan ini adalah :
1. Metode klasifikasi dan prediksi, yaitu metode analisis data yang digunakan untuk membentuk model yang mendeskripsikan kelas data yang penting, atau model yang memprediksikan trend data. Klasifikasi digunakan untuk memprediksi kelas data yang bersifat kategorial, sedangkan prediksi untuk memodelkan fungsi yang mempunyai nilai kontinu.
2. Metode clustering, mengelompokan data untuk membentuk kelas-kelas baru atau sering disebut cluster. Metode clustering bertujuan untuk memaksimalkan persamaan dalam satu cluster dan meminimalkan perbedaan antar cluster.
2.2.5 Metode Association Rule
suatu minimarket adalah kita dapat mengetahui berapa besar kemungkinan seorang konsumen membeli suatu item bersamaan dengan item lainnya (membeli roti bersama dengan selai). Karena awalnya berasal dari studi tentang database transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama apa, maka association rule sering juga dinamakan market basket analysis [7].
Association Rule adalah bentuk jika “kejadian sebelumnya” kemudian
“konsekuensinya” (If antecedent, then consequent), yang diikuti dengan perhitungan aturan support dan confidence. Bentuk umum dari association rule
adalah Antecedent -> Consequent. Bila kita ambil contoh dalam sebuah transaksi pembelian barang di sebuah minimarket didapat bentuk association rule roti -> selai. Yang artinya bahwa pelanggan yang membeli roti ada kemungkinan pelanggan tersebut juga akan membeli selai, dimana tidak ada batasan dalam jumlah item-item pada bagian antecedent ataupun consequent dalam sebuah rule [10].
Association rule memiliki dua tahap pengerjaan, yaitu [11]: 1. Mencari kombinasi yang paling sering terjadi dari suatu itemset.
2. Mendefinisikan Condition dan Result (untuk conditional association rule). Dalam menentukan suatu association rule, terdapat suatu interestingness measure (ukuran kepercayaan) yang didapat dari hasil pengolahan data dengan perhitungan tertentu. Umumnya ada dua ukuran, yaitu :
1. Support : suatu ukuran yang menunjukkan seberapa besar tingkat dominasi suatu item/itemset dari keseluruhan transaksi. Ukuran ini menentukan apakah suatu item/itemset layak untuk dicari confidence-nya (misal, dari keseluruhan transaksi yang ada, seberapa besar tingkat dominasi suatu item yang menunjukkan bahwa item A dan item B dibeli bersamaan).
2. Confidence : suatu ukuran yang menunjukkan hubungan antara 2 item secara conditional (misal, menghitung kemungkinan seberapa sering item B dibeli oleh pelanggan jika pelanggan tersebut membeli sebuah item A).
kedua nilai minimum parameter yang sudah ditentukan sebelumnya, maka pola tersebut dapat disebut sebagai interesting rule atau strong rule [10].
2.2.5.1Metodologi Dasar Analisis Asosiasi
Metodologi dasar Association Rule terbagi menjadi dua tahap, yaitu [12]: a. Analisa pola frekuensi tinggi
Tahap ini mencari pola item yang memenuhi syarat minimum dari nilai support
dalam database. Menurut Larose, kita bebas menentukan nilai minimum support
(minsup) dan minimum confidence (mincof) sesuai kebutuhan [13]. Sebagai contoh, bila ingin menemukan data-data yang memiliki hubungan asosiasi yang kuat, minsup dan mincof-nya bisa diberi nilai yang tinggi. Sebaliknya, bila ingin melihat banyaknya variasi data tanpa terlalu mempedulikan kuat atau tidaknya hubungan asosiasi antara item-nya, nilai minsup dan mincofnya dapat diisi rendah [10]. Untuk rekomendasi dalam menentukan minimum support dapat diambil dari perhitungan rata-rata 1 jenis produk pada data yang digunakan, seperti rumus berikut :
Minimum support = (Persamaan 2-1)
Nilai support sebuah item diperoleh dengan rumus :
Support (A) = (Persamaan 2-2)
Persamaan 2 menjelaskan bahwa nilai support didapat dengan cara membagi jumlah transaksi yang mengandung item A (satu item) dengan jumlah total seluruh transaksi. Sedangkan untuk mencari nilai support dari 2 item menggunakan rumus berikut :
Support(A,B) = P(A ∩ B) =
(Persamaan 2-3)
b. Pembentukan Aturan Assosiatif
Setelah semua pola frekuensi tinggi ditemukan, kemudian mencari aturan asosiatif yang memenuhi syarat minimum untuk confidence dengan menghitung confidence
aturan assosiatif A -> B dari support pola frekuensi tinggi A dan B, menggunakan rumus :
Confidence = (A -> B) =
(Persamaan 2-4)
Persamaan 4 menjelaskan bahwa nilai confidence diperoleh dengan cara membagi jumlah transaksi yang mengandung item A dan item B (item pertama bersamaan dengan item yang lain) dengan jumlah transaksi yang mengandung item A (item
Pertama atau item yang ada disebelah kiri).
2.2.5.2Lift/Improvenment Ratio
Lift Ratio adalah parameter penting selain support dan confidence dalam
association rule. Lift ratio mengukur seberapa penting rule yang telah terbentuk berdasarkan nilai support dan confidence. Lift Ratio merupakan nilai yang menunjukkan kevalidan proses transaksi dan memberikan informasi apakah benar
item A dibeli bersamaan dengan item B [7].
Lift/Improvement Ratio dapat dihitung dengan rumus :
(Persamaan 2-5)
2.2.6 Algoritma CT-Pro
Algoritma ini merupakan pengembangan dari algoritma FP-GROWTH
dengan melakukan modifikasi pada tree yang digunakan. Algoritma ini menggunakan struktur Compressed FP-Tree (CFP-Tree) dimana informasi dari sebuah FP-Tree diringkas dengan struktur yang lebih kecil atau ringan, sehingga baik pembentukan tree maupun frequent itemset mining yang dilakukan menjadi lebih cepat. [14].
Langkah-langkah algoritma CT-PRO adalah sebagai berikut [15]: 1. Menemukan item-item yang frequent
a. Data-data yang telah dikumpulkan, diseleksi dan pilih data yang relevan (data yang lengkap).
b. Data-data yang ada, kemudian dilakukan transformasi data.
c. Kemudian masing masing data diseleksi berdasarkan minimum support
yang telah ditentukan, kemudian didapat Item Frequent Table.
d. Masing-masing item dihitung frekuensi kemunculannya sehingga dihasilkan
global item table.
e. Data kemudian dimapping berdasarkan index pada global item table.
2. Membuat CFP-Tree
Setelah ditemukan item-item yang frequent kemudian dilakukan pembangunan CFP-Tree. Frequent item yang ada diurutkan sesuai global item
dari nilai yang terbesar ke terkecil. CFP-Tree adalah tree dengan properti sebagai berikut :
a. CFP-Tree terdiri dari tree yang memiliki root yang mewakili index dari
item dengan tingkat kemunculan tertinggi dan kumpulan subtree sebagai anak dari root.
b. Jika I = {i1,i2, …, ik} adalah kumpulan dari frequent item dalam transaksi,
item dalam transaksi akan dimasukkan kedalam CFP-Tree dimulai dari
d. Setiap node dalam CFP-Tree memiliki empat field utama yakni item-id,
parentid, count yang merupakan jumlah item pada node tersebut, dan level yang menunjukkan struktur data tree pada node tersebut dimulai dari item
yang terdapat pada header table dengan level yang terdapat pada CFP-Tree [14].
Gambar 2.4 Struktur CFP-Tree
3. Melakukan penggalian frequent patterns
Setelah tahap pembangunan CFP-Tree dari sekumpulan data transaksi, akan diterapkan algoritma CT-Pro untuk mencari frequent itemset yang signifikan. Berikut adalah langkah-langkah dari algoritma CT-Pro :
a. Lakukan pencarian node yang berkaitan dengan item dimana pencarian dimulai dari global item dengan support count terkecil sampai global item
dengan support count terbesar karena CT-Pro bekerja Bottom-Up pada
Global CFP-Tree.
b. Dari semua node yang ditemukan untuk setiap item inilah yang disebut dengan Local Frequent item dan digunakan untuk membuat Local item tabel
yang pembuatannya dilakukan berdasarkan jumalah minimun support yang telah ditentukan.
c. Selanjutnya dibuat Local CFP-Tree berdasarkan Local Item Tabel yang terbentuk.
d. Dari Local CFP-Tree yang ada, kita dapat membuat frequent patternnya.
Dari hasil frequent pattern ini akan dilakukan mining dengan rumus
2.2.7 Unified Modelling Language (UML)
UML singkatan dari Unified Modeling Languages yang berarti bahasa pemodelan standar. Ketika kita membuat model menggunakan konsep UML ada aturan-aturan yang harus diikuti. Bagaimana elemen pada model-model yang kita buat berhubungan satu dengan yang lainnya harus mengikuti standar yang ada. UML bukan hanya sekedar diagram tetapi juga menceritakan konteksnya [16]. Berikut adalah beberapa model yang digunakan dalam perancangan Data Mining
pemaketan produk di toko Kartika Kosmetik untuk menggambarkan sistem dalam UML:
1. Diagram Use Case 2. Diagram Activity 3. Diagram Sequence 4. Diagram Class
2.2.7.1Use Case Diagram
Diagram Use Case menggambarkan apa saja aktifitas yang dilakukan oleh suatu sistem. Use Case menggambarkan fungsi tertentu dalam suatu sistem berupa komponen, kejadian atau kelas. Komponen Pembentuk Use Case Diagram adalah sebagai berikut :
1. Actor
Pada dasarnya actor bukanlah bagian dari use case diagram, namun untuk dapat terciptanya suatu use case diagram diperlukan beberapa actor. Actor
tersebut mempresentasikan seseorang atau sesuatu (seperti perangkat, sistem lain) yang berinteraksi dengan sistem. Sebuah actor mungkin hanya memberikan informasi inputan pada sistem, hanya menerima informasi dari sistem atau keduanya menerima, dan memberi informasi pada sistem. Actor hanya berinteraksi dengan use case, tetapi tidak memiliki kontrol atas use case. Actor
digambarkan dengan stick man . Actor dapat digambarkan secara secara umum atau spesifik, dimana untuk membedakannya kita dapat menggunakan
2. Use Case
Use case adalah gambaran fungsionalitas dari suatu sistem, sehingga
customer atau pengguna sistem paham dan mengerti mengenai kegunaan sistem yang akan dibangun.
Catatan : Use case diagram adalah penggambaran sistem dari sudut pandang pengguna sistem tersebut (user), sehingga pembuatan use case lebih dititikberatkan pada fungsionalitas yang ada pada sistem, bukan berdasarkan alur atau urutan kejadian.
Cara menentukan Use Case dalam suatu sistem: a. Pola perilaku perangkat lunak aplikasi.
b. Gambaran tugas dari sebuah actor.
c. Sistem atau “benda” yang memberikan sesuatu yang bernilai kepada actor. d. Apa yang dikerjakan oleh suatu perangkat lunak (*bukan bagaimana cara
mengerjakannya).
Ada beberapa relasi yang terdapat pada use case diagram: a. Association, menghubungkan link antar element.
b. Generalization, disebut juga inheritance (pewarisan), sebuah elemen dapat merupakan spesialisasi dari elemen lainnya.
c. Dependency, sebuah element bergantung dalam beberapa cara ke element lainnya.
d. Aggregation, bentuk assosiation dimana sebuah elemen berisi elemen lainnya.
Tipe relasi/ stereotype yang mungkin terjadi pada use case diagram: a. <<include>> , yaitu kelakuan yang harus terpenuhi agar sebuah event
dapat terjadi, dimana pada kondisi ini sebuah use case adalah bagian dari
use case lainnya.
b. <<extends>>, kelakuan yang hanya berjalan di bawah kondisi tertentu seperti menggerakkan alarm.
merupakan pilihan selama asosiasi hanya tipe relationship yang dibolehkan antara actor dan use case.
2.2.7.2Activity Diagram
Activity diagram memiliki pengertian yaitu lebih fokus kepada menggambarkan proses bisnis dan urutan aktivitas dalam sebuah proses. Dipakai pada business modeling untuk memperlihatkan urutan aktifitas proses bisnis. Memiliki struktur diagram yang mirip flowchart atau data flow diagram pada perancangan terstruktur. Memiliki pula manfaat yaitu apabila kita membuat diagram ini terlebih dahulu dalam memodelkan sebuah proses untuk membantu memahami proses secara keseluruhan. Dan activity dibuat berdasarkan sebuah atau beberapa use case pada use case diagram.
2.2.7.3Squence Diagram
Diagram sequen menggambarkan interaksi objek pada use case dengan mendeksripsikan waktu hidup objek dan pesan yang dikirimkan dan di terima antar objek. Oleh karena itu untuk menggambarkan diagram sequen maka harus diketahui objek-objek yang terlibat dalam sebuah use case beserta metode-metode sekuen juga di butuhkan untuk melihat skenario yang ada pada use case. Sequence diagram biasa digunakan untuk menggambarkan skenario atau rangkaian langkah-langkah yang dilakukan sebagai respons dari sebuah event untuk menghasilkan
output tertentu. Diawali dari apa yang men-trigger aktivitas tersebut, proses dan perubahan apa saja yang terjadi secara internal dan output apa yang dihasilkan. Masing-masing objek, termasuk aktor, memiliki lifeline vertikal. Message
digambarkan sebagai garis berpanah dari satu objek ke objek lainnya.
2.2.7.4Class Diagram
Diagram kelas atau class diagram menggambarkan struktur sistem dari segi pendefinisian kelas-kelas yang akan di buat untuk membangun sistem. Kelas memiliki apa yang disebut atribut dan metode atau oprasi.
33
Analisis sistem (System Analysis) dapat didefinisikan sebagai penguraian dari suatu sistem informasi yang utuh ke dalam bagian-bagian komponennya dengan maksud untuk mengidentifikasikan dan mengevaluasi permasalahan-permasalahan, kesempatan-kesempatan, hambatan-hambatan yang terjadi dan kebutuhan-kebutuhan yang diharapkan sehingga dapat diusulkan perbaikan-perbaikannya. Dalam analisa sistem ini meluputi beberapa bagian, yaitu :
1. Analisis Masalah
2. Analisis Prosedur Penentuan Paket 3. Analisis Crisp-DM
4. Analisis Non Fungsional dan Kebutuhan Non Fungsional 5. Analisis Kebutuhan Fungsional
3.1.1 Analisis Masalah
Berdasarkan hasil pengamatan, dapat disimpulkan bahwa permasalahan yang ada di toko Kartika Kosmetik yaitu belum adanya informasi penentuan paket produk kosmetik yang sesuai dengan minat konsumen yang akan ditawarkan menjelang hari-hari besar tertentu, seperti hari raya Idul Fitri, hari raya Idul Adha, hari raya kemerdekaan, hari raya Natal, tahun baru dan hari besar lainnya.
3.1.2 Prosedur Penentuan Paket Produk Kosmetik
Berdasarkan observasi ke toko Kartika Kosmetik bahwa prosedur atau alur pembentukan paket produk kosmetik adalah sebagai berikut:
1. Bagian keuangan membuat laporan penjualan selama 1 bulan periode sebelum hari raya, periode tersebut diambil karena pada saat itu biasanya konsumen berbelanja untuk kebutuhan hari raya.
3. Bagian gudang mengecek stok barang dan membuat laporan barang dari yang paling laku sampai yang tidak laku dan dari stok barang yang paling banyak hingga stok yang paling sedikit. Laporan stok tersebut diberikan pada pihak manager.
4. Manager kemudian membuat laporan paket produk secara manual dan acak, didasarkan dari laporan data stok. Produk yang paling laris akan dipasangkan dengan produk yang kurang laris dan produk yang stoknya masih banyak.
5. Laporan paket produk tersebut kemudian diberikan pada pemimpin untuk mendapatkan persetujuan.
6. Jika pemimpin tidak memberikan persetujuan, data dikembalikan pada pihak manager untuk diubah. Jika pemimpin memberikan persetujuan, data paket produk diberikan pada bagian gudang untuk dikemas.
7. Bagian gudang mengemas produk untuk dijadikan paket, jika sudah selesai paket tersebut akan diberikan pada karyawan untuk ditawarkan ke konsumen.
8. Bagian karyawan menawarkan produk pada konsumen selama 2 minggu sebelum lebaran sampai 2 minggu setelah lebaran.
3.1.3 Analisis Crisp-DM
Metode pembangunan perangkat data mining yang digunakan dalam penelitian ini adalah Cross-Industry Standard Process for Data Mining (CRISP-DM).
3.1.3.1Business Understanding
Pemahaman Bisnis atau disebut dengan Business Understanding
merupakan tahapan pertama yang dilakukan dalam kerangka kerja CRISP-DM. Dalam tahapan bisnis ini terbagi menjadi dua bagian, yaitu:
a. Identifikasi Tujuan Bisnis
Tujuan Bisnis dari toko Kartika Kosmetik yaitu memasarkan produk secara langsung untuk memenuhi permintaan konsumen.
b. Penentuan Sasaran Data Mining
Tujuan dari penerapan Data Mining ini adalah untuk mengetahui pasangan produk yang sering dibeli oleh konsumen atau pola pembelian konsumen yang sering terjadi yang akan dijadikan dasar oleh pihak Kartika Kosmetik dalam penentuan pembuatan paket produknya.
3.1.3.2Data Understanding
Sumber data yang didapat dalam penelitian ini merupakan data transaksi penjualan yang terjadi di toko Kartika Kosmetik periode 1 bulan sebelum menjelang hari raya Idul Fitri (contoh kasus diambil untuk hari raya Idul Fitri) yaitu periode bulan Juni 2015. Adapun detail informasi mengenai data transaksi penjualan yang digunakan dapat dilihat pada tabel 3.1 di bawah ini.
Tabel 3.1 Struktur Data Transaksi Penjualan
Dokumen Keterangan
Detail Data Transaksi
Deskripsi Data ini berisi mengenai data transaksi yang ada di toko Kartika Kosmetik
Format Microsoft Excel (.xlsx)
No Faktur Nomor struk
Tanggal Tanggal pencetakan struk Kode Barang Kode barang yang dibeli Nama Barang Nama barang yang dibeli Varian Jenis dari barang yang dibeli Harga Barang Harga barang yang dibeli Qty Jumlah barang yang dibeli
Jumlah Harga Barang dikalikan dengan Qty Total Harga Total harga dari barang yang dibeli
3.1.3.3Data Preparation
Persiapan Data merupakan tahap dimana akan dilakukan pemilihan tabel dan field yang akan digunakan dalam proses mining. Persiapan data dilakukan dengan sebutan Preprocessing Data. Preprocessing merupakan hal yang harus dilakukan dalam proses data mining, karena tidak semua data atau atribut data dalam data digunakan dalam proses data mining. Proses ini dilakukan agar data yang digunakan sesuai dengan kebutuhan. Adapun tahapan-tahapan preprocessing
data dalam penelitian ini adalah sebagai berikut: 1. Ekstrasi Data
2. Pemilihan Atribut
Proses pemilihan atribut atau selection data adalah proses dimana atribut data akan dipilih dan diproses sesuai dengan kebutuhan data mining. Sebelum melakukan proses cleaning atau pembersihan data akan lebih efisien jika melakukan proses selection atau pemilihan atribut ini terlebih dahulu. Karena dari data transaksi Kartika Kosmetik yang sebanyak ribuan record ini memiliki 10 atribut sedangkan yang dibutuhkan untuk
data mining hanya 2 atribut. Dengan menyeleksi atribut yang tidak dibutuhkan akan memudahkan pada proses pembersihan data nanti, sehingga pada saat pembersihan data tidak akan memperberat memori karena program harus membaca atribut yang tidak perlu. Dalam penelitian ini, 2 atribut yang akan digunakan adalah atribut No Faktur dan Nama Barang. Kedua atribut ini digunakan untuk memenuhi tujuan awal dimana akan dicari pola pembelian konsumen berdasarkan produk yang dibeli. Seperti atribut No Faktur digunakan untuk membedakan satu transaksi dengan transaksi lainnya, dan atribut Nama Barang digunakan untuk mengetahui barang apa saja yang dibeli dalam satu transaksi. No Faktur dengan tipe data varchar dirubah ke integer dengan di-trim
sehingga menjadi 6 angka dari belakang. Hasil pemilihan atribut dapat dilihat pada tabel D-2 pada lampiran D.
3. Pembersihan Data
menjadi 30 transaksi. Hasil pembersihan data dapat dilihat pada tabel D-3 pada lampiran D.
4. Penyiapan Data Awal
Setelah semua proses pembersihan data berhasil dilakukan dan data transaksi telah sesuai dengan kebutuhan yang diperlukan dalam proses
data mining, maka data transaksi sudah dapat digunakan untuk proses selanjutnya dalam sistem data mining. Data pada tabel D-3 pada lampiran D adalah data yang akan digunakan untuk proses mining.
3.1.3.4Modeling
Penelitian ini bertujuan untuk mendapatkan informasi mengenai pola pembelian konsumen yang nantinya akan digunakan oleh pihak Kartika Kosmetik sebagai dasar pengambilan keputusan untuk menentukan produk apa saja yang bisa dijadikan sebuah paket penjualan produk yang nantinya akan ditawarkan ke konsumen.
Dengan menerapkan Data Mining, data transaksi akan diolah dengan aturan asosiasi atau metode Association Rules untuk menemukan pola-pola pembelian produk yang sering dibeli oleh konsumen. Metodologi dasar
Association Rule terbagi menjadi dua tahap, yaitu Analisa pola frekuensi tinggi dan Pembentukan Aturan Assosiatif. Algoritma yang digunakan dalam penelitian ini adalah algoritma CT-Pro. Langkah-langkah algoritma CT-PRO adalah sebagai berikut:
1. Menghitung Frekuensi Kemunculan Tiap Item
Dengan menggunakan tabel D-3, masing-masing item dihitung frekuensi kemunculan berdasarkan itemnya. Hasil dari penghitungan kemunculan item
dapat dilihat pada tabel 3.2 dibawah ini.
Tabel 3.2 Hasi Perhitungan Kemunculan Produk
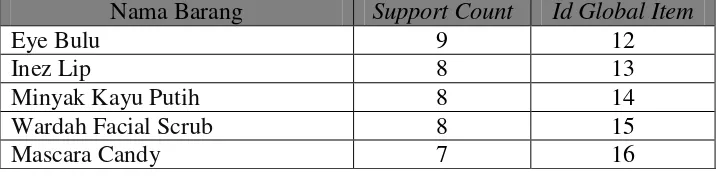
Nama Barang Support
Count Nama Barang
Support Count
Wardah Lig Day Cream Step 1 13 Minyak Kayu Putih 8
Nama Barang Support
Count Nama Barang
Support
2. Membangun Global Item Tabel
Berikut merupakan langkah-langkah untuk membuat global item tabel : a. Langkah pertama adalah menentukan minimum support untuk melihat
batasan terendah munculnya item. Untuk minimum support yang diambil pada penelitian ini adalah sebesar 7, maka batasan produk yang muncul harus sebanyak >= 7 kali.
b. Pada tabel 3.2, masing-masing item diseleksi berdasarkan minimum support count yang telah ditentukan sehingga terbentuk global item. Untuk setiap item diberikan id global item yaitu penomoran secara ascending dari frekuensi terbesar ke terkecil. Berikut adalah tabel global item yang dapat dilihat pada tabel 3.3.
Tabel 3.3 Global Item Tabel
Nama Barang Support Count Id Global Item
Nama Barang Support Count Id Global Item
minimum support dieleminasi dan hasilnya dapat dilihat pada tabel 3.4. Tabel 3.4 Item yang Frequent
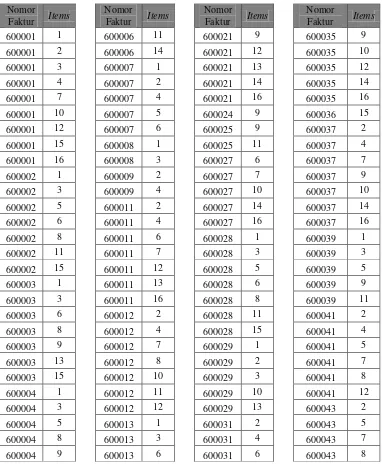
Nomor Faktur Nama Barang Nomor Faktur Nama Barang
600001 Casablanca Spray 600021 Eye Bulu
600001 Eye Bulu 600021 Inez Lip
600001 Mascara Candy 600021 Mascara Candy
600001 Ponds Fw Day Cream 600021 Minyak Kayu Putih
600001 Ponds Wb Ff 600021 Ponds Wb Ff
600001 Ponds Wb Lightenig Cream 600021 Ponds Wb Lightenig Cream
600001 Wardah Facial Scrub 600024 Elips Hair Mask
600001 Wardah Lig Day Cream Step 1 600025 Elips Hair Mask 600001 Wardah Lig Day Cream Step 2 600025 Natur E Hbl
600002 Inez Ppc 600027 Casablanca Spray
600002 Kapas Sariayu 600027 Kapas Sariayu
600002 Natur E Hbl 600027 Mascara Candy
600002 Rexona Wmn Roll On Power Dry 600027 Minyak Kayu Putih
600002 Wardah Facial Scrub 600027 Ponds Fw Day Cream
600002 Wardah Lig Day Cream Step 1 600028 Inez Ppc 600002 Wardah Lig Day Cream Step 2 600028 Kapas Sariayu
600003 Elips Hair Mask 600028 Natur E Hbl
600003 Inez Lip 600028 Rexona Wmn Roll On Power Dry
600003 Kapas Sariayu 600028 Wardah Facial Scrub
600003 Rexona Wmn Roll On Power Dry 600028 Wardah Lig Day Cream Step 1 600003 Wardah Facial Scrub 600028 Wardah Lig Day Cream Step 2 600003 Wardah Lig Day Cream Step 1 600029 Inez Lip
600003 Wardah Lig Day Cream Step 2 600029 Ponds Fw Day Cream
600004 Elips Hair Mask 600029 Ponds Wb Ff
600004 Inez Lip 600029 Wardah Lig Day Cream Step 1
600004 Inez Ppc 600029 Wardah Lig Day Cream Step 2
600004 Minyak Kayu Putih 600031 Eye Bulu
600004 Rexona Wmn Roll On Power Dry 600031 Kapas Sariayu
600004 Wardah Lig Day Cream Step 1 600031 Minyak Kayu Putih 600004 Wardah Lig Day Cream Step 2 600031 Natur E Hbl
600005 Casablanca Spray 600031 Ponds Wb Ff
600005 Kapas Sariayu 600031 Ponds Wb Lightenig Cream
600005 Mascara Candy 600033 Casablanca Spray
Nomor Faktur Nama Barang Nomor Faktur Nama Barang
600005 Wardah Lig Day Cream Step 1 600033 Inez Ppc
600005 Wardah Lig Day Cream Step 2 600033 Ponds Fw Day Cream
600006 Elips Hair Mask 600033 Ponds Wb Lightenig Cream
600006 Inez Ppc 600033 Rexona Wmn Roll On Power Dry
600006 Kapas Sariayu 600035 Elips Hair Mask
600006 Minyak Kayu Putih 600035 Eye Bulu
600006 Natur E Hbl 600035 Kapas Sariayu
600006 Rexona Wmn Roll On Power Dry 600035 Mascara Candy
600007 Inez Ppc 600035 Minyak Kayu Putih
600007 Kapas Sariayu 600035 Ponds Fw Day Cream
600007 Ponds Wb Ff 600035 Rexona Wmn Roll On Power Dry
600007 Ponds Wb Lightenig Cream 600036 Wardah Facial Scrub 600007 Wardah Lig Day Cream Step 1 600037 Casablanca Spray
600008 Wardah Lig Day Cream Step 1 600037 Elips Hair Mask 600008 Wardah Lig Day Cream Step 2 600037 Mascara Candy
600009 Ponds Wb Ff 600037 Minyak Kayu Putih
600009 Ponds Wb Lightenig Cream 600037 Ponds Fw Day Cream
600011 Casablanca Spray 600037 Ponds Wb Ff
600011 Eye Bulu 600037 Ponds Wb Lightenig Cream
600011 Inez Lip 600039 Elips Hair Mask
600011 Kapas Sariayu 600039 Inez Ppc
600011 Mascara Candy 600039 Natur E Hbl
600011 Ponds Wb Ff 600039 Wardah Lig Day Cream Step 1
600011 Ponds Wb Lightenig Cream 600039 Wardah Lig Day Cream Step 2
600012 Casablanca Spray 600041 Casablanca Spray
600012 Eye Bulu 600041 Eye Bulu
600012 Natur E Hbl 600041 Inez Ppc
600012 Ponds Fw Day Cream 600041 Ponds Wb Ff
600012 Ponds Wb Ff 600041 Ponds Wb Lightenig Cream
600012 Ponds Wb Lightenig Cream 600041 Rexona Wmn Roll On Power Dry 600012 Rexona Wmn Roll On Power Dry 600043 Casablanca Spray
600013 Elips Hair Mask 600043 Eye Bulu
600013 Kapas Sariayu 600043 Inez Ppc
600013 Wardah Lig Day Cream Step 1 600043 Natur E Hbl
600013 Wardah Lig Day Cream Step 2 600043 Ponds Fw Day Cream
600014 Wardah Facial Scrub 600043 Ponds Wb Ff
600014 Wardah Lig Day Cream Step 1 600043 Rexona Wmn Roll On Power Dry 600014 Wardah Lig Day Cream Step 2 600044 Eye Bulu
600016 Ponds Fw Day Cream 600044 Inez Lip
600016 Ponds Wb Ff 600044 Inez Ppc
600016 Ponds Wb Lightenig Cream 600044 Minyak Kayu Putih
600017 Inez Lip 600044 Natur E Hbl
600017 Inez Ppc 600044 Wardah Facial Scrub
600021 Casablanca Spray 600044 Wardah Lig Day Cream Step 1
3. Mapping Data
Mapping yaitu memetakan data transaksi dari tabel 3.4 terhadap id global item pada tabel 3.3, dimana nama barang pada tabel 3.4 digantikan oleh id global item sesuai denganyang ada pada tabel 3.3. Data transaksi kemudian diurutkan dari id global item terkecil ke terbesar dari setiap nomor fakturnya. Berikut adalah hasil mapping data transaksi tabel 3.4 yang dapat dilihat pada tabel 3.5 di bawah ini.
Tabel 3.5 Tabel Mapping
Nomor
Faktur Items
Nomor
Faktur Items
Nomor
Faktur Items
Nomor
Faktur Items
600004 13 600013 9 600031 11 600043 10
600004 14 600014 1 600031 12 600043 11
600005 1 600014 3 600031 14 600043 12
600005 3 600014 15 600033 4 600044 1
600005 6 600016 2 600033 5 600044 3
600005 7 600016 4 600033 7 600044 5
600005 15 600016 10 600033 8 600044 11
600005 16 600017 5 600033 10 600044 12
600006 5 600017 13 600033 13 600044 13
600006 6 600021 2 600035 6 600044 14
600006 8 600021 4 600035 8 600044 15
600006 9 600021 7
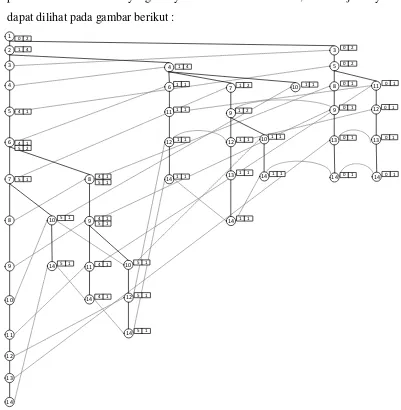
4. Membuat CFP-Tree
Setelah proses mapping kemudian proses pembentukan CFP-Tree. Untuk proses pembentukan CPF-Tree dapat dilihat pada lampiran D. Berikut adalah
1
5. Mencari Frequent Itemset
Setelah tahap pembangunan CFP-Tree dari sekumpulan data transaksi, akan diterapkan algoritma CT-Pro untuk mencari frequent itemset yang signifikan. Berikut adalah langkah-langkah dari algoritma CT-Pro :
1. Lakukan pencarian node yang berkaitan dengan item dimana pencarian dimulai dari global item dengan support count terkecil sampai global item dengan
support count terbesar karena CT-Pro bekerja Bottom-Up pada Global CFP-Tree. Dalam pencarian local Frequent Pattern Tree berisikan prefix path
(lintasan prefix) dan suffixpattern (pola akhiran). Untuk setiap pencarian suffix dilakukan dengan mencari lintasan prefix dari suffix yang dicari.
2. Dari semua node yang ditemukan untuk setiap item inilah yang disebut dengan
Local Frequent item dan digunakan untuk membuat Local item tabel yang pembuatannya dilakukan berdasarkan jumalah minimun support yang telah ditentukan.
3. Selanjutnya dibuat Local CFP-Tree berdasarkan Local Item Tabel yang terbentuk.
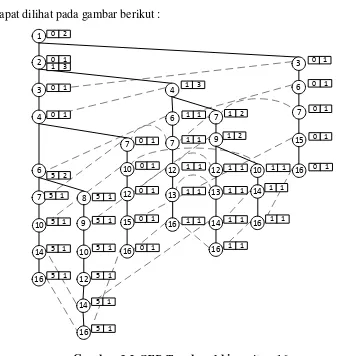
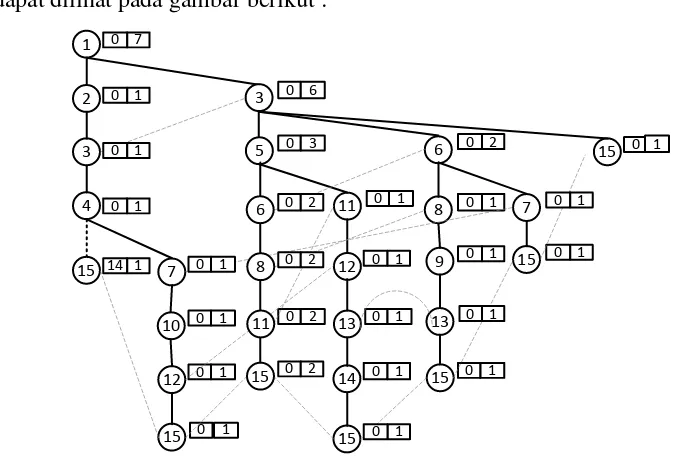
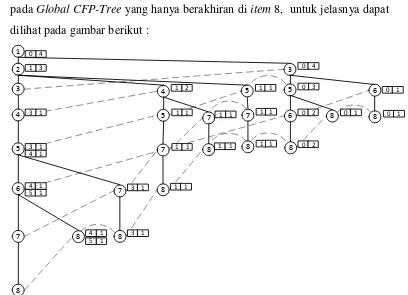
- Untuk pencarian localFrequentPatternTree untuk item 16. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 16, untuk jelasnya dapat dilihat pada gambar berikut :
9
Dari gambar 3.2 diatas didapat jumlah support count dari setiap node yaitu 1(2), 2(4), 3(2), 4(4), 6(4), 7(6), 8(1), 9(3), 10(4), 12(4), 13(2), 14(4) dan 15(2), karena minimum suportnya adalah 7, maka untuk node yang tidak memenuhi nilai
minmum support tidak dimasukan dalam local item tabel. Pada node diatas tidak ada yang memenuhi nilai minimum support, maka tidak terbentuk local item tabel
- Untuk pencarian localFrequentPatternTree untuk item 15. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 15, untuk jelasnya dapat dilihat pada gambar berikut :
1
Dari gambar 3.3 diatas didapat jumlah support count dari setiap node yaitu 1(7), 2(1), 3(7), 4(1), 5(3), 6(4), 7(2), 8(3), 9(1), 10(1), 11(3), 12(2), 13(2) dan 14(1). Karena minimum supportnya adalah 7, maka untuk node 2(1), 4(1), 5(3), 6(4), 7(2), 8(3), 9(1), 10(1), 11(3), 12(2), 13(2) dan 14(1) tidak memenuhi nilai
minmum support, maka tidak dimasukan dalam local item tabel. Berikut merupakan local item table yangterbentuk :
Tabel 3.6 Local item tabel Index Item Count
1 1 7
2 3 7
pembentukan tree-nya adalah Local Item tabel yang terbentuk dari Local Frequent item. Berikut adalah Local CFP-Tree dari item id 15 :
Index Item Count PST
1 1 7
2 3 7
Gambar 3.4 local CFP Tree untuk item 15
Kemudian membuat local CFP-tree projection untuk item 15, dapat dilihat pada gambar berikut :
15 Wardah Facial Scrub 8
3 Wardah Lig Day Cream Step 2 7 1 Wardah Lig Day Cream Step 1 7
1 Wardah Lig Day Cream Step 1 7
Gambar 3.5 local CFP-treeprojection 15
Dari local CFP-treeprojection maka didapatkan item frequent untuk index 15 dengan nama barang Wardah Facial Scrub adalah sebagai berikut: (15,1:7), (15,3:7), dan (15,3,1:7).
GlobalItemTable
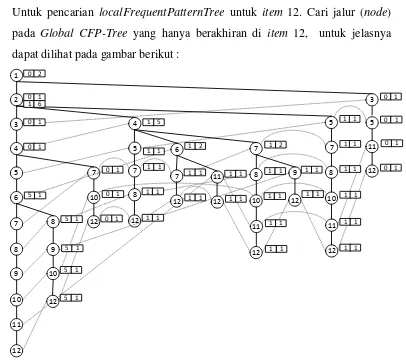
- Untuk pencarian localFrequentPatternTree untuk item 14. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 14, untuk jelasnya dapat dilihat pada gambar berikut :
1
Dari gambar 3.6 diatas didapat jumlah support count dari setiap node yaitu 1(2), 2(4), 3(2), 4(4), 5(6), 6(4), 7(3), 8(3), 9(5), 10(3), 11(3), 12(4) dan 13(3), karena minimum suportnya adalah 7, maka untuk node yang tidak memenuhi nilai
minmum support tidak dimasukan dalam local item tabel. Pada node diatas tidak ada yang memenuhi nilai minimum support, maka tidak terbentuk local item tabel
- Untuk pencarian localFrequentPatternTree untuk item 13. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 13, untuk jelasnya dapat dilihat pada gambar berikut :
1
minmum support tidak dimasukan dalam local item tabel. Pada node diatas tidak ada yang memenuhi nilai minimum support, maka tidak terbentuk local item tabel
- Untuk pencarian localFrequentPatternTree untuk item 12. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 12, untuk jelasnya dapat dilihat pada gambar berikut :
1
Dari gambar 3.8 diatas didapat jumlah support count dari setiap node yaitu 1(2), 2(7), 3(2), 4(6), 5(2), 6(3), 7(6), 8(4), 9(2), 10(4), dan 11(3) karena minimum suportnya adalah 7, maka untuk node yang tidak memenuhi nilai minmum support
tidak dimasukan dalam local item tabel. Berikut merupakan local item table yang terbentuk :
Tabel 3.7 Local item tabel Index Item Count
1 2 7
Item tabel data sedangkan pada Local CFP-Tree yang digunakan dalam pembentukan tree-nya adalah Local Item tabel yang terbentuk dari Local Frequent item. Berikut adalah Local CFP-Tree dari item id 12 :
Index Item Count PST
1 2 7
Gambar 3.9 local CFP Tree untuk item 12
Kemudian membuat local CFP-tree projection untuk item 12, dapat dilihat pada gambar berikut :
12 Eye Bulu 9
2 Ponds Wb Ff 7
Gambar 3.10 local CFP-treeprojection 12
Dari local CFP-treeprojection maka didapatkan item frequent untuk index 12 dengan nama barang Eye Bulu adalah sebagai berikut: (12,2:7).
2 Level 0 0 7
GlobalItemTable
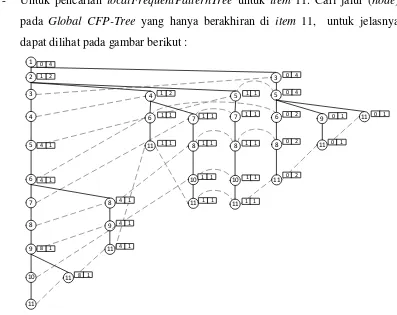
- Untuk pencarian localFrequentPatternTree untuk item 11. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 11, untuk jelasnya dapat dilihat pada gambar berikut :
1 suportnya adalah 7, maka untuk node yang tidak memenuhi nilai minmum support
- Untuk pencarian localFrequentPatternTree untuk item 10. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 10, untuk jelasnya dapat dilihat pada gambar berikut :
1
- Untuk pencarian localFrequentPatternTree untuk item 9. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 9, untuk jelasnya dapat dilihat pada gambar berikut :
1 yang memenuhi nilai minimum support, maka tidak terbentuk local item tabel
- Untuk pencarian localFrequentPatternTree untuk item 8. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 8, untuk jelasnya dapat dilihat pada gambar berikut :
1
yaitu 1(4), 2(2), 3(4), 4(3), 5(7), 6(5), dan 7(4) karena minimum suportnya adalah 7, maka untuk node yang tidak memenuhi nilai minmum support tidak dimasukan dalam local item tabel. Berikut merupakan local item table yangterbentuk :
Tabel 3.8 Local item tabel Index Item Count
1 5 7
Index Item Count PST
1 5 7
Gambar 3.15 local CFP Tree untuk item 12
Kemudian membuat local CFP-tree projection untuk item 12, dapat dilihat pada gambar berikut :
8 Rexona Wmn Roll On Power
Dry
10
5 Inez Ppc 7
Gambar 3.16 local CFP-treeprojection 8
Dari local CFP-treeprojection maka didapatkan item frequent untuk index 8 dengan nama barang Rexona Wmn Roll On Power Dry adalah sebagai berikut: (8,5:7).
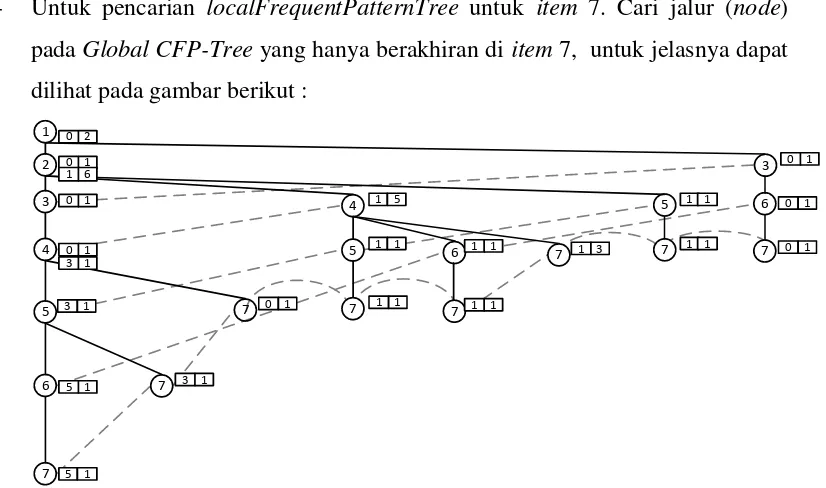
- Untuk pencarian localFrequentPatternTree untuk item 7. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 7, untuk jelasnya dapat dilihat pada gambar berikut :
Dari gambar 3.17 diatas didapat jumlah support count dari setiap node
yaitu 1(2), 2(7), 3(2), 4(7), 5(3), dan 6(3) karena minimum suportnya adalah 7, maka untuk node yang tidak memenuhi nilai minmum support tidak dimasukan dalam local item tabel. Berikut merupakan local item table yangterbentuk :
Tabel 3.9 Local item tabel Index Item Count
1 2 7
2 4 7
Dari Local Item tabel yang didapatkan pada tabel 3.9 dibuat Local CFP-Tree. Aturan pembentukan Local CFP-Tree sama dengan pembentukan Global CFP-Tree, yang membedakan adalah pada Global CFP-Tree yang digunakan dalam pembentukan tree-nya adalah Global Item tabel yang terbentuk dari Global Item tabel data sedangkan pada Local CFP-Tree yang digunakan dalam
Gambar 3.19 local CFP-treeprojection 7
- Untuk pencarian localFrequentPatternTree untuk item 6. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 6, untuk jelasnya dapat dilihat pada gambar berikut :
1
dan Frequent Patternnya juga tidak akan terbentuk.
- Untuk pencarian localFrequentPatternTree untuk item 5. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 5, untuk jelasnya dapat dilihat pada gambar berikut :
Dari gambar 3.21 diatas didapat jumlah support count dari setiap node yaitu 1(6), 2(3), 3(5), dan 4(4) karena minimum suportnya adalah 7, maka untuk node
yang tidak memenuhi nilai minmum support tidak dimasukan dalam local item tabel. Pada node diatas tidak ada yang memenuhi nilai minimum support, maka tidak terbentuk local item tabel sehingga untuk Local CFP-Tree dan Frequent Patternnya juga tidak akan terbentuk.
- Untuk pencarian localFrequentPatternTree untuk item 4. Cari jalur (node) pada Global CFP-Tree yang hanya berakhiran di item 4, untuk jelasnya dapat dilihat pada gambar berikut :
1
Gambar 3.22CFP-Tree berakhiran item 4
Dari gambar 3.22 diatas didapat jumlah support count dari setiap node
yaitu 1(2), 2(10), dan 3(1), karena minimum suportnya adalah 7, maka untuk
node yang tidak memenuhi nilai minmum support tidak dimasukan dalam local item tabel. Berikut merupakan node yang memenuhi nilai minimum support
yang diacu pada tabel 3.10.
Tabel 3.10 Local item tabel untuk item 4 Index Item Count
1 2 10