KAJIAN PENDUGAAN AREA KECIL UNTUK MENDUGA
JUMLAH KEMATIAN BAYI DI JAWA BARAT
ARIE ANGGREYANI
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Kajian Pendugaan Area Kecil untuk Menduga Jumlah Kematian Bayi di Jawa Barat adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Februari 2016
Arie Anggreyani
RINGKASAN
ARIE ANGGREYANI. Kajian Pendugaan Area Kecil untuk Menduga Jumlah Kematian Bayi di Jawa Barat. Dibimbing oleh INDAHWATI dan ANANG KURNIA.
Survei Demografi dan Kesehatan Indonesia (SDKI) menyediakan sebagian besar informasi kesehatan di Indonesia. SDKI dilaksanakan setiap lima tahun sekali sejak tahun 1994. Pendugaan berdasarkan data SDKI hanya dilakukan untuk skala nasional atau provinsi sedangkan untuk level kabupaten, kecamatan dan kelurahan/desa masih kurang memadai. Metode pendugaan yang biasa digunakan adalah metode pendugaan langsung. Namun, pendugaan ini menghasilkan galat baku penduga besar. Hal ini disebabkan karena teknik pengambilan contoh yang kompleks dan ukuran contoh yang relatif kecil. Metode yang digunakan untuk mengatasi ketidakstabilan pendugaan langsung adalah pendugaan tidak langsung. Beberapa pendugaan tidak langsung adalah pendugaan tidak langsung berdasarkan model campuran dan pendugaan komposit. Pendugaan dengan model campuran adalah memodelkan dengan mengabungkan pengaruh dan pengaruh tetap sedangkan pendugaan komposit adalah pendugaan yang dilakukan dengan memboboti penduga berdasarkan desain dan model.
Peubah jumlah kejadian yang memiliki peluang yang sangat kecil biasanya diasumsikan memiliki sebaran Poisson. Sebaran Poisson memiliki asumsi equidispersi yaitu nilai harapan sama dengan ragam. Berdasarkan kondisi data, jika ragam amatan lebih besar daripada ragam sebarannya mengindikasikan adanya overdispersi dan sebaliknya disebut underdispersi. Beberapa metode untuk menangani overdispersi adalah dengan sebaran binomial negatif, pendekatan quasi-likelihood dan sebaran Tweedie.
Pada SDKI, terdapat beberapa area yang tidak tersurvei atau disebut nircontoh. Padahal, area nircontoh sangat penting untuk diduga. Sehingga diperlukan pendekatan untuk menduga area yang tidak tersurvei. Salah satu pendekatan yang digunakan adalah mengasumsikan bahwa suatu area memiliki pola kedekatan hubungan dengan area lain. Pendekatan yang digunakan untuk menganalisis pola hubungan antar area tersebut adalah dengan teknik pengerombolan (clustering).
Pada penelitian ini dilakukan pendugaan jumlah kematian bayi untuk kabupaten/kota di Provinsi Jawa Barat dengan membandingkan pendugaan langsung dan tidak langsung menggunakan data SDKI Provinsi Jawa Barat. Provinsi Jawa Barat terdiri dari 26 kabupaten/kota, dan diantaranya ada dua area yang tidak tersurvei yaitu Kota Banjar dan Kota Sukabumi. Hasil analisis pada kasus kematian bayi di Provinsi Jawa Barat diketahui terdapat masalah underdispersi pada model linier campuran Poisson. Berdasarkan plot sisaan dan rasio generalized chi-square dengan derajat bebasnya diketahui model linier
campuran pendekatan quasi-likelihood dan sebaran Tweedie dapat mengatasi masalah dispersi. Pendugaan model terbaik adalah model linier campuran pendekatan quasi-likelihood pada pendugaan komposit dilihat dari nilai MAPE, MSD dan MAD yang paling kecil.
SUMMARY
ARIE ANGGREYANI. The Study of Small Area Estimation for Estimating the Number of Infant Mortality in West Java, Indonesia. Supervised by INDAHWATI and ANANG KURNIA.
The Indonesian Demographic and Health Survey (IDHS) provides data related to the health subject. IDHS conducts every five years since 1994. The estimation of IDHS data only performs for a national or a provincial scale but not for a district, a sub-district and a village level. Estimation method for a district, subdistrict or village is usually done with the direct estimation. However, the drawback of the direct estimation is standard error estimation will be large. The reason is because the sampling technique is quite complex and the sample size is relatively small. A method to overcome the drawbacks of the direct estimation is a indirect estimation based prediction models of small area estimation (SAE). The two methods in indirect estimation are mixed model and composites estimation. The mixed model is model that contain both fixed and random effects while the composite estimation is an estimation in which combination design based and model based.
The number of occurences variable which has small probability is assumed to have a Poisson distribution. In the Poisson distribution, the expected of mean is equal to variance, namely is called equidispersion. In case, the variance of data is greater than the theoretical variance of Poisson distribution is overdispersion, otherwise it is called underdispersion. Some methods to deal with overdispersion are negative binomial distribution, quasi-likelihood approach and Tweedie distribution.
In IDHS, there are some area not as samples and they are needed to estimate. Those areas are assumed having a close relationship with other areas based on certain variables. One approach to cluster the areas based on the pattern of the relationship is a cluster analysis.
The goal of this study is comparing the direct and indirect estimation of the number of infant deaths for the districts/cities in West Java province. In total, there are 26 districts/cities; 24 districs/cities were surveyed and 2 cities were not surveyed. The two cities were Banjar city and Sukabumi city. The analysis of cases of infant mortality in West Java Province was known having problems of underdispersion on Poisson linear mixed model. Based on the residual plot and generalized chi-square, quasi-likelihood approach and Tweedie distribution can overcome the problem of dispersion. The best estimation method is based on quasi-likelihood approach. It can be seen from the smallest value of MAPE, MAD, and MAD.
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika
KAJIAN PENDUGAAN AREA KECIL UNTUK MENDUGA
JUMLAH KEMATIAN BAYI DI JAWA BARAT
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala
atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Maret 2015 ini ialah pendugaan area kecil, dengan judul Kajian Pendugaan Area Kecil untuk Menduga Jumlah Kematian Bayi di Jawa Barat.
Terima kasih penulis ucapkan kepada semua pihak yang telah turut berperan serta dalam penyusunan karya ilmiah ini, terutama kepada :
1. Ibu Dr Ir Indahwati, MSi dan Bapak Dr Anang Kurnia, SSi, MSi selaku pembimbing yang telah banyak memberi saran,
2. Bapak Dr. Kusman Sadik, SSi, MSi sebagai dosen penguji pada ujian sidang tesis,
3. Penghargaan penulis sampaikan kepada seluruh staf dan jajaran Pemerintah Kota Pagar Alam atas beasiswa yang telah diberikan,
4. Tim Hibah Penelitian Unggulan Sesuai Mandat dan Tim Bimbingan
Small Area Estimation (SAE) atas bantuan biaya penelitian dan segala
kerjasamanya.
5. Keluarga Besar Program Studi Statistika Sekolah Pascasarjana IPB yang telah banyak membantu baik secara moril maupun nonmoril, 6. Badan Pusat Statistik (BPS) atas segala informasi yang telah diberikan, 7. Ungkapan terima kasih juga disampaikan kepada mama, papa, serta
seluruh keluarga, atas segala doa dan kasih sayangnya.
8. Serta berbagai pihak lain yang tidak dapat penulis sebutkan seluruhnya satu persatu.
Semoga semua bantuan yang diberikan kepada penulis mendapatkan balasan dari Allah SWT. Penulis juga menyadari bahwa tesis ini masih jauh dari kesempurnaan. Namun demikian, penulis berharap semoga karya ilmiah ini dapat bermanfaat bagi semua pihak yang membutuhkan. Aamiin.
Bogor, Februari 2016
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
2 TINJAUAN PUSTAKA 3
Pendugaan Langsung (Direct Estimation) 3
Pendugaan Tidak Langsung (Indirect Estimation) 4
Dispersi 5
Quasi-Likelihood 5
Sebaran Tweedie 6
Generalized Linear Mixed Model (GLMM) 7
Empirical Best Prediction (EBP) 9
3 METODE 10
Data 10
Prosedur Analisis Data 10
4 HASIL DAN PEMBAHASAN 13
Penduga Langsung 13
Uji Korelasi antar Peubah Penyerta 14
Mendeteksi Masalah Dispersi 14
Penduga Tidak Langsung 16
Ukuran Kebaikan Model 18
Pendugaan Nircontoh 19
5 SIMPULAN DAN SARAN 21
Simpulan 21
Saran 21
DAFTAR PUSTAKA 22
LAMPIRAN 23
DAFTAR TABEL
1 Peubah respon dan peubah penjelas 10
2 Penduga langsung jumlah kematian bayi di Provinsi Jawa Barat 13 3 Hasil uji korelasi antar peubah penyerta 14 4 Ukuran kesesuaian pendugaan tidak langsung 16 5 Ukuran kebaikan dari pendugaan titik berdasarkan dugaan
langsung, dugaan berdasarkan model campuran, model komposit dengan modifikasi, dan model komposit dengan modifikasi 19 6 Penggerombolan kabupaten/kota di Provinsi Jawa Barat 19 7 Prediksi tingkat kematian bayi per 1000 jiwa untuk area contoh
dan nircontoh 20
DAFTAR GAMBAR
1 Plot sisaan terhadap nilai prediksi (a) model-1, (b) model-2, (c)
model-3, dan (d) model-4 15
2 Hasil prediksi terhadap nilai respon aktual dengan nilai dugaan tidak langsung model-1, model-2, model-3, dan model-4 16 3 Hasil prediksi komposit tanpa modifikasi model-1, model-2,
model-3, dan model-4 17
4 Hasil prediksi komposit dengan modifikasi model-1, model-2,
model-3, dan model-4 18
DAFTAR LAMPIRAN
1 Nilai komponen utama 25
2 Nilai dugaan langsung, dugaan berdasarkan model campuran, dan
dugaan komposit dengan modifikasi 26
3 Dendogram analisis gerombol kota dan kabupaten di Provinsi
1
1
PENDAHULUAN
Latar Belakang
Informasi kesehatan merupakan salah satu indikator untuk mengukur tingkat pembangunan dan kualitas hidup di suatu wilayah atau negara. Survei Demografi dan Kesehatan Indonesia (SDKI) menyediakan sebagian besar informasi kesehatan. SDKI dilakukan setiap lima tahun sekali sejak tahun 1994. Berdasarkan data SDKI, pendugaan yang dilakukan masih berskala nasional atau provinsi namun dengan adanya sistem desentralisasi diperlukan prediksi untuk area yang lebih kecil seperti level kabupaten, kecamatan maupun kelurahan/desa. Pendugaan untuk level kabupaten, kecamatan maupun kelurahan/desa terkadang masih sulit dilakukan karena memiliki ukuran contoh yang relatif kecil atau terdapat area yang tidak tersurvei. Sadik (2009) dan Kurnia (2009) telah mengaplikasikan suatu metode pendugaan untuk mengatasi hal tersebut yang dikenal dengan metode pendugaan area kecil (small area estimation, SAE).
SDKI didesain berdasarkan teknik penarikan contoh yang kompleks. Pendugaan yang biasa digunakan adalah model desain penarikan contoh ( design-based) disebut juga pendugaan langsung (direct estimation). Namun, metode
pendugaan langsung memiliki galat baku penduganya besar dan tidak dapat dilakukan jika nilai responnya bernilai nol. Untuk menangani masalah tersebut, Rao (2003) telah banyak mengembangkan penelitian pendugaan area kecil dengan meminjam kekuatan pada daerah sekitar untuk menghasilkan presisi yang lebih baik. Peminjaman kekuatan dalam pendugaan area kecil dapat diperoleh dari area yang berdekatan menurut ruang, waktu atau melalui informasi tambahan yang diperkirakan berkorelasi dengan peubah yang diamati (Hajarisman 2013). Pendugaan tersebut biasa disebut pendugaan tidak langsung (indirect estimation). Sadik (2009) menjelaskan bahwa dalam pendugaan tidak
langsung mengasumsikan bahwa keragaman didalam area kecil peubah respon dapat diterangkan oleh hubungan keragaman yang bersesuaian pada informasi penyerta (auxiliary) yang berupa pengaruh tetap, sedangkan keragaman specifik
area kecil diasumsikan dapat diterangkan oleh informasi tambahan yang berupa pengaruh acak area.
Peubah jumlah kejadian dengan peluang kejadian sangat kecil biasanya diasumsikan menyebar Poisson. Sebaran Poisson memiliki asumsi equidispersi yaitu nilai harapan sama dengan ragam. Jika ragam lebih besar dari rata-rata mengindikasikan adanya overdispersi dan sebaliknya disebut underdispersi. Overdispersi/underdispersi disebabkan oleh beberapa kemungkinan seperti adanya pencilan, korelasi antar amatan dalam peubah respon, dan kesalahan pendefinisian sebaran. Cameron & Trivadi (1998) dan Stroup (2013) menyatakan jika overdispersi terjadi menyebabkan nilai dugaan galat baku yang lebih kecil (underestimate) dan meningkatnya kesalahan jenis I. Beberapa metode untuk
2
hanya mengenai fungsi ragam. Dunn & Smith (2005) menjelaskan sebaran Tweedie adalah sebaran keluarga dua parameter dari keluarga eksponensial linier dengan penambahan parameter dispersi.
Pendugaan tidak langsung berbasis model adalah mengabungkan Pendugaan tidak langsung menghasilkan nilai yang tertuju pada garis dugaannya sehingga memungkinkan terjadi bias yang cukup besar. Pendekatan lain yang digunakan dalam pendugaan area kecil adalah pendugaan komposit. Pendugaan komposit adalah pendugaan yang dilakukan dengan memboboti penduga langsung berbasis desain dan pendugaan tidak langsung berbasis model. Pendugaan ini digunakan untuk menyeimbangkan bias dari penduga tak langsung dengan ketidakstabilan dari penduga langsung yaitu dengan memberikan rata-rata terboboti untuk kedua penduga tersebut. Bobot yang digunakan adalah rasio ragam pengaruh acak terhadap total ragam pengaruh acak dan ragam penarikan contoh. Namun, penduga komposit menghasilkan nilai yang sama dengan penduga langsung jika ragam penarikan contoh per area mendekati nol.
Desain dan ukuran contoh yang kecil pada SDKI menyebabkan munculnya juga masalah lain yaitu ketika dilakukan pendugaan untuk area yang tidak tersurvei (nircontoh). Salah satu pendekatan yang digunakan oleh Anisa (2014) untuk menduga area nircontoh adalah dengan mengasumsikan bahwa suatu area memiliki pola kedekatan hubungan dengan area lain. Pendekatan yang digunakan untuk menganalisis pola hubungan antar area tersebut dengan teknik pengerombolan (clustering).
Beberapa penelitian pendugaan jumlah kematian bayi dengan pendekatan area kecil telah banyak dilakukan, seperti Yadav & Ladusingh (2013) di India menduga angka kematian bayi dengan model sintetis, sedangkan Hajarisman (2013) menghitung angka kematian bayi dengan pemodelan area kecil melalui pendekatan model regresi Poisson Bayes berhirarki dua level. Pada penelitian ini dilakukan pendugaan jumlah kematian bayi untuk kabupaten/kota di Provinsi Jawa Barat dengan membandingkan pendugaan langsung, tidak langsung dan komposit menggunakan data SDKI Provinsi Jawa Barat.
Tujuan Penelitian
Tujuan yang ingin dicapai pada penelitian ini adalah:
1. Membangun model pendugaan area kecil terbaik untuk menduga jumlah kematian bayi tingkat kabupaten/kota di Provinsi Jawa Barat,
2. Membandingkan metode terbaik dalam mengatasi masalah dispersi dalam pemodelan, dan
3
2
TINJAUAN PUSTAKA
Pendugaan Langsung (Direct Estimation)
Pendekatan klasik untuk menduga parameter suatu area didasarkan pada desain penarikan contoh (design-based). Pendugaan tersebut disebut pendugaan
langsung (direct estimation). Metode pendugaan langsung menimbulkan dua
permasalahan penting. Pertama, penduga yang dihasilkan merupakan penduga tak bias tetapi memiliki galat baku yang besar karena diperoleh dari ukuran contoh yang kecil. Kedua, apabila pada suatu area kecil ke-i tidak terwakili di dalam survei, maka tidak memungkinkan dilakukan pendugaan secara langsung (Kurnia 2009).
Penelitian ini menduga jumlah kematian bayi pada tingkat Kabupaten/Kota di Jawa Barat menggunakan data SDKI 2012. Berdasarkan BPS (2012), metode penarikan contoh yang digunakan pada SDKI 2012 dengan metode penarikan contoh tiga tahap. Tahap 1, memilih sejumlah primary sampling unit (PSU) dari kerangka contoh PSU secara probability proportional to size (PPS). Tahap 2, memilih blok sensus secara secara PPS. Dan tahap 3,
memilih jumlah rumah tangga di setiap blok sensus secara sistematik. Teknik penarikan contoh survei tersebut sangat kompleks sehingga pendugaan total dan ragam menjadi sulit.
Metode pendugaan yang digunakan pada penelitian ini adalah metode linierisasi Taylor (Lee & Forthofer 2006). Linierisasi Taylor didesain untuk memperoleh hampiran nilai dan fungsi yang sulit dihitung. Bentuk dari deret
Linierisasi Taylor banyak digunakan untuk memperoleh hampiran beberapa fungsi nonlinier dan ragam dari fungsi tersebut. Dalam aplikasi statistika, pendugaan dengan metode linierisasi Taylor dievaluasi dari nilai rataan atau nilai harapan.
= [� ] + ′[� ] − [� ] + ′′[� ] −[�! ] + ⋯ (1)
Berdasarkan definisi ragam �[ ] = �[ ] − � [ ] , dan apabila digabungkan dengan persamaan (1), maka dapat diperoleh:
�[ ] = { ′[� ]} � + ⋯
Dalam kasus fungsi dua peubah, nilai ragamlinierisasi Taylor adalah
�[ , ] ≅ �� �� � � , (2)
Berdasarkan persamaan (2), Jika terdapat ni peubah acak, maka pendekatan ragam dari � = , , … , maka,
4
Jika persamaan (3) diaplikasikan dengan bobot penduga maka dihasilkan penduga metode Taylor sebagai berikut:
� = �̂ = ∑�
=
, = , , … ,
Pendugaan ragam bagi penduga total area ke-i didefinisikan sebagai berikut:
�[� ] ≅ � [∑ ∑ ]
Pada penelitian ini, adalah total bobot wanita usia subur pada area ke – i
rumah tangga ke-j dan = jumlah kematian bayi area ke – i rumah tangga ke – j.
Pendugaan Tidak Langsung (Indirect Estimation)
Kurnia (2009) dan Sadik (2009) menjelaskan ukuran contoh pada area terkadang berukuran kecil sehingga pendugaan langsung menghasilkan galat baku yang besar. Rao (2003) telah banyak mengembangkan suatu metode pendugaan tidak langsung (indirect estimation). Pendugaan tidak langsung digunakan untuk
meningkatkan keefektifan ukuran contoh dan menurunkan keragaman sehingga lebih akurat. Penduga tak langsung “meminjam informasi” dengan menggunakan nilai peubah dari contoh pada area lain yang diamati. Sadik (2009) menjelaskan salah satu model yang digunakan dalam pendugaan tidak langsung mengasumsikan bahwa keragaman didalam area kecil peubah respon dapat diterangkan oleh hubungan keragaman yang bersesuaian pada informasi penyerta (auxiliary) yang berupa pengaruh tetap, sedangkan keragaman specifik area kecil
diasumsikan dapat diterangkan oleh informasi tambahan yang berupa pengaruh acak area. Model pendugaan area kecil terdiri dari model level area (Tipe-A) dan model level unit (Tipe-B).
a. Model level area (Tipe-A)
Model level area digunakan ketika informasi peubah penyerta pada level satuan tidak diketahui sehingga diasumsikan � = �̅ atau � = ∑ � untuk g(.)
tertentu berhubungan dengan peubah penyerta pada area, yaitu ′ =
, … , � ′, dengan model liniernya : � = ′ + � , i = 1, …, m, dengan
� ~� , �� merupakan peubah acak pada area ke-i. Penduga langsung �̅̂
diasumsikan diketahui untuk menarik kesimpulan tentang nilai tengah area kecil �̅, yaitu : �̂ = �̅ = � + , i = 1, …, m, dengan adalah galat
penarikan contoh yang menyebar normal ~� , � dan �� diketahui. Kedua model tersebut digabungkan sehingga diperoleh model deterministik pada �
sebagai berikut:
�̂ = �̅ = ′ + � + , i = 1, …, m.
Pada pendugaan area kecil terdapat unit yang terambil (contoh) dan unit yang tidak terambil (nircontoh), sehingga model dapat diuraikan menjadi:
� = [y
5 b. Model level unit (Tipe-B)
Model level unit digunakan jika data peubah penyerta untuk setiap unit diketahu ′ = , … ,
� ′. Peubah yang diamati berhubungan dengan peubah penyerta melalui model regresi galat tersarang sebagai berikut:
= �̅ = ′ + � + , i = 1, …, m, j=1, …, Ni
Dispersi
Dispersi adalah ukuran penyebaran suatu kelompok data terhadap nilai tengah datanya. Sebaran Poisson memiliki asumsi nilai rataan sama dengan nilai ragam yang disebut equdispersi. Namun, kondisi yang sering terjadi adalah nilai ragam lebih besar dari rataan disebut overdispersi atau sebaliknya yang disebut underdispersi. Berdasarkan data, overdispersi dikatakan terjadi ketika ragam amatan lebih besar dari ragam secara teori dalam asumsi sebaran Poisson (Stroup 2013). Ketidak terpenuhinya asumsi Poisson memiliki kemiripan konsekuensi dengan ketidak terpenuhinya asumsi homoskedastisitas pada model linier regresi. Cameron & Trivadi (1998) dan Stroup (2013) menyatakan jika overdispersi terjadi menyebabkan nilai dugaan galat baku yang lebih kecil (underestimate) dan meningkatkan kesalahan jenis I, sehingga memberikan
kesimpulan yang keliru.
Beberapa penyebab yang menimbulkan overdispersi adalah ekstra keragaman di dalam peubah acak yang melebihi ragam peubah acak Poisson dan adanya pencilan pada data. Pada model campuran linier terampat, suatu kejadian Y yang mengikuti Poisson tetapi vektor acak v mengikuti suatu sebaran tertentu maka sebaran marginalnya menunjukkan perilaku overdispersi. Hinde & Demetrio (1998) menjelaskan penyebab lain terjadinya overdispersi adalah adamya keheterogenan antara amatan, korelasi antara respon amatan, dan teknik penarikan contohnya dengan gerombol.
Ada beberapa cara yang dapat digunakan untuk mendeteksi overdispersi yaitu nilai devians (deviance) dibagi dengan derajat bebasnya. Jika diperoleh nilai
lebih besar dari 1 maka menandakan adanya overdispersi, sedangkan jika nilai lebih kecil dari 1 maka menandakan adanya underdispersi. Stroup (2013) menjelaskan cara untuk mendeteksi overdispersi/underdispersi dapat dilihat plot sisaan baku, pearson dan studentized terhadap dugaan prediksi rata-rata. Kesimpulannya, dua diagnostik overdispersi yang dapat digunakan adalah plot sisaan dan nilai rasio khi-kuadrat dengan derajat bebas. McCullagh & Nelder (1989) dan Ver Hoef & Boveng (2007) menjelaskan cara yang umum digunakan untuk menangani overdispersi sebaran Poisson menggunakan pendekatan quasi-likelihood atau model binomial negatif.
Quasi-Likelihood
Sebaran data terkadang tidak jelas menyebabkan masalah pemodelan sehingga fungsi likelihood tidak selalu bisa diperoleh. Pendekatan yang dapat digunakan untuk mengatasi ketidakjelasan sebaran adalah melalui pendekatan quasi-likelihood. Quasi-likelihood merupakan suatu framework dalam pemodelan
6
Pendekatan quasi-likelihood mempunyai sifat-sifat yang penting (Hajarisman 2010) yaitu
1. Berbeda dengan pendekatan fungsi likelihood biasa, dalam fungsi quasi-likelihood tidak menentukan struktur peluang tertentu, tetapi hanya memerlukan asumsi mengenai dua buah momen pertama. Hal ini dapat disimpulkan bahwa fungsi quasi-likelihood mempunyai fleksibiltas tinggi. 2. Pemodelan terbatas, sehingga berbagai kemungkinan kesimpulan juga terbatas.
Pengujian dan selang kepercayaan mengandalkan pendugaan asimtotik.
McCullagh dan Nelder (1989) serta Pawitan (2001) menjelaskan mengenai konsep quasi-likelihood, dengan fungsinya sebagai berikut:
∑ �
=
� � − � − � =
dengan asumsi �[� ] = � dan �[� ] = �� � dengan � adalah parameter dispersi. Jika � > menunjukkan overdispersi pada model poisson. Quasi-likelihood dianggap mampu mengatasi masalah overdispersi maupun underdispersi, jika fungsi ragam yang diperoleh mampu mengambarkan ragam datanya.
Sebaran Tweedie
Model eksponensial dispersi (exponential dispersion model, EDM) adalah
sebaran keluarga dua parameter dari keluarga eksponensial linier dengan penambahan parameter dispersi (Jorgensen 1992; Dunn & Smyth 2005; Zhang 2013), dengan fungsi peluang sebagai berikut:
|�, � = , � exp ( � − � �� )
Beberapa EDM dapat dikarakteristikkan oleh fungsi ragam yang mengambarkan hubungan rataan dan ragam dari sebaran ketika dispersi dianggap konstan. Bentuk khusus dari EDM dengan kekuatan hubungan rataan dan ragam
� = ��) dengan nilai p indeks kekuatan fungsi ragam disebut dengan model Tweedie. Model Tweedie memuat beberapa sebaran yang penting seperti normal (p=0), Poisson (p=1), gamma (p=2), dan inverse Gaussian (p=3). Penelitian ini
menggunakan model eksponensial dispersi dengan nilai indeks kekuatan p berada pada selang 1 sampai 2 � = ��, 1<p<2). Sebaran Tweedie dengan indeks 1<p<2 merepresentasikan campuran sebaran Poisson gamma dan memiliki massa
peluang disertai dengan sebaran kontinu menjulur ke garis positif. Sebaran ini disebut juga sebaran Tweedie compound Poisson.
Dunn & Smith (2004) dan Zhang (2013) menjelaskan bahwa fungsi kepekatan peluang sebaran Tweedie dengan p=0, 1, 2, dan 3 dapat ditulis dalam
bentuk tertutup (closed form) sedangkan sebaran Tweedie compound Poisson
7 secara tertutup. Fungsi ragam dan indeks parameter p ditentukan terlebih dahulu
sebelum dilakukan inferensia. Dalam beberapa aplikasi, nilai indeks parameter p
ditentukan terlebih dahulu oleh penelitinya (Zhang 2013). Generalized Linear Mixed Model (GLMM)
Model linear seperti regresi linear memerlukan asumsi bahwa peubah respon menyebar normal. Namun, pada kenyataannya data yang digunakan tidak selalu menyebar normal. Solusi yang dikemukakan adalah model linear terampat (generalized linear model, GLM). Berdasarkan McCullagh & Nelder (1983),
model linier terampat dapat didefinisikan dalam beberapa komponen model: 1. Komponen acak yang menentukan sebaran peluang peubah respon. Komponen
acak terdiri dari pengamatan independen y dari distribusi di keluarga eksponensial, dengan fungsi sebagai berikut:
|� |�, , � = ( � − �� + , � )
dengan a(.), b(.), dan c(.) adalah fungsi spesifik, θ adalah parameter kanonik
dan ϕ adalah parameter dispersi.
2. Komponen sistematis, yang menentukan fungsi linear dari peubah penjelas yang digunakan sebagai prediktor,
3. Fungsi hubung yang berkaitan komponen sistematis dan nilai rata-rata dari komponen acak.
Model linear terampat digunakan untuk pengamatan tidak berkorelasi, sedangkan dalam beberapa penelitian didapatkan bahwa pengamatan-pengamatan berkorelasi satu sama lain. Model linear campuran terampat (generalized linear
mixed model, GLMM) mengembangkan model linear terampat dengan
memasukkan korelasi diantara respon, yaitu dengan meliputi pengaruh acak pada prediktor linear dan/atau memodelkan korelasi diantara data secara langsung. Model pendugaan area kecil merupakan bentuk khusus dari GLMM, dengan persamaan sebagai berikut:
� y|v = μ θ=g μ =Xβ+Zv
dengan y vektor N pengamatan, β vektor parameter pengaruh tetap, v vektor parameter pengaruh acak, X dan Z adalah matriks rancangan.
prediktor linear : θ = Xβ+Zv distribusi peubah acak : v ~ iid N ,G
distribusi peubah sisaan : ε ~ iid N ,G
Distribusi atau quasi-likelihood: � y|v = �|�, � � y|v = Vθ/ �Vθ/ , dengan
Vθ/ = [√� � ] = [√ � / � ] dan � = [ / � ].
Pendekatan pendugaan model linear campuran terampat umumnya berdasarkan prinsip kemungkinan (likelihood principle), dengan fungsi likelihood
sebagai berikut:
8
Bentuk fungsi likelihood pada persamaan (4) biasanya tidak dapat dievaluasi dalam bentuk tertutup dan memiliki integral dengan dimensi yang sama dengan jumlah level dari faktor acak v. Bentuk yang tidak tertutup (closed–form) menjadi
hambatan karena fungsi likelihood yang diperoleh menjadi tidak sederhana. Dua alternatif pendekatan yang dapat digunakan dalam pendugaan parameter adalah sebagai berikut:
- Linearisasi: secara khusus yaitu metode pseudo-likelihood.
- Pendekatan integral: Dua metode yang diterapkan oleh adalah pendekatan Laplace dan adaptif Gauss-Hermite quadrature.
Wolfinger & O’Connell (1993) mengembangkan prosedur pendugaan pseudo-likelihood. Prosedur ini diimplementasikan dengan ketepatan iterasi dari model linear campuran Gaussian terboboti (weighted gaussian linear mixed model) untuk memodifikasi peubah tak bebas. Metode pseudo-likelihood pada
model GLMM menggunakan prosedur sebagai berikut:
1. Hampiran analisis pertama adalah pendekatan deret Taylor. β̂ dan v̂ digunakan untuk menduga β dan v yang didefinisikan �̂ = − � = − (Xβ̂ + Zv̂). e̅ adalah pendekatan deret Taylor dengan formula sebagai berikut:
e̅ = − �̂ − − ′(Xβ̂ + Zv̂)(Xβ − Xβ̂ + Zv − Zv̂)
2. Hampiran peluang dan pendekatan distribusi bersyarat e̅ jika diberikan β dan v
dengan sebaran Gaussian memiliki momen pertama dan dua e̅ |β,v yang menganggap bersesuaian dengan e̅ |μ. e̅ |β, � adalah sebaran Gaussian dengan rataan 0 and ragam R�/ RR�/ .
3. Hampiran analisis selanjutnya adalah mensubtitusikan μ̂ ke μdalam matriks ragam:
dengan = diag[ � �|� / �]. Bentuk dari model linear campuran terboboti dengan diagonal matriks bobot adalah ̂ = ��− [ ′ �̂ ]− . Fungsi log likelihood Gaussian berkorespondensi dengan model linear campuran y* adalah sebagai berikut:
� �, �, �∗, �∗| ∗ = − log|� | − �− ∗− � � − ∗− � − log � dengan = − / �∗ − / + ��∗��, � adalah parameter dispersi, �∗ dan
�∗direparameterisasi dari matriks R dan D.
9 dengan � = ∗− � − − � − ∗.
4. Berdasarkan persamaan (5) dengan metode numerik, menduga �, v dan
� dihitung sebagai berikut:
�̂ = � − − � − ∗
�̂ = �̂∗ � − − �̂
�̂ = �̂��− �̂/ (6) Persamaan (6) dimaksimumkan dengan memperbaiki matriks D dan R setiap iterasinya.
Empirical Best Prediction (EBP)
Rao (2003) menjelaskan beberapa metode seperti metode Empirical Bayes
(EB) dan Hierarhical Bayes (HB) yang berlaku secara umum dalam menangani
model untuk biner dan data cacahan serta model linear campuran. Metode EB merupakan metode pendugaan parameter yang didasarkan pada metode Bayes dimana inferensia yang diperoleh berdasarkan pada pendugaan distribusi posterior dari peubah yang diamati. Rao (2003) menjelaskan beberapa pendekatan EB diringkas sebagai berikut: (1) mendapatkan fungsi kepekatan peluang (posterior) dari parameter area kecil yang menjadi perhatian, (2) menduga parameter model dari fungsi kepekatan peluang marginal, (3) menggunakan fungsi kepekatan peluang posterior dugaan untuk membuat inferensi parameter area kecil yang menjadi perhatian.
Penduga �̂ disebut Empirical Best Predictor (EBP) dari �̂ karena
diperoleh dari distribusi bersyarat dari �̂ diketahui yi tanpa mengasumsikan sebaran prior pada parameter model. EBP �̂ identik dengan Empirical Best Linear Unbiased Predictor (EBLUP) dengan asumsi normal. �̂���adalah sebagai
berikut : �̂��� = ̂ �̂ + − ̂ �̂
10
3
METODE
Data
SDKI adalah survei nasional yang dirancang untuk menyajikan informasi mengenai tingkat kelahiran, kematian, keluarga berencana dan kesehatan. Studi kasus yang digunakan pada penelitian ini menggunakan data profil kesehatan Jawa Barat tahun 2012 yang dikeluarkan oleh Dinas Kesehatan Provinsi Jawa Barat dan SDKI tahun 2012 yang dilakukan oleh BPS, BKKBN, KEMENKES, dan dibantu oleh United States Agency for International Development (USAID).
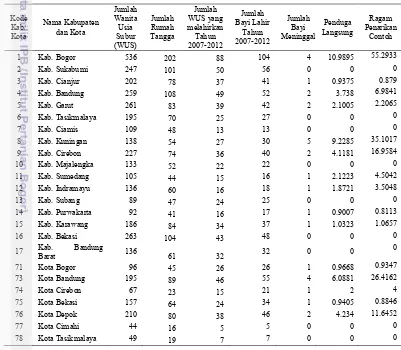
Peubah respon yang diamati pada penelitian ini adalah jumlah kematian bayi untuk setiap rumah tangga dalam 5 tahun sebelum survei, yang diambil dari data SDKI tahun 2012. Peubah tambahan diperoleh dari data profil kesehatan 2012 merupakan hasil registrasi yang dilakukan oleh Dinas Kesehatan di seluruh Kabupaten/Kota di Jawa Barat dengan rincian pada tabel 1.
Kabupaten didefinisikan sebagai level area, dan rumah tangga didefinisikan sebagai unit terkecil. Berdasarkan data SDKI Provinsi Jawa Barat, kabupaten/kota terbagi menjadi dua area, yaitu area contoh dan nircontoh. Pada tahun 2012 Provinsi Jawa Barat terdiri dari 26 kabupaten/kota dengan area contoh sebanyak 24 kabupaten/kota sedangkan 2 area nircontoh yaitu Kota Banjar dan Kota Sukabumi.
Tabel 1 Peubah respon dan peubah penjelas
Peubah Keterangan Satuan
Y Jumlah kematian bayi per kabupaten/kota Jiwa
X1 Jumlah dokter Per 100000 Jiwa
X2 Jumlah puskesmas Per 100000 Jiwa
X3 Jumlah rumah tangga berperilaku hidup
bersih dan sehat (PHBS) Per 10 Rumah Tangga X4 Jumlah bayi yang gizi buruk dan kurang
Pendugaan langsung adalah prediksi respon berupa rataan atau total berdasarkan teknik penarikan contoh atau disebut design-based.
Langkah-langkahnya adalah sebagai berikut:
1. Menghitung jumlah kematian bayi per rumah tangga untuk periode 2007-2012 untuk masing-masing kabupaten/kota di Provinsi Jawa Barat dan mengidentifikasi bobot setiap rumah tangga,
11 Pendugaan Tidak Langsung
Pendugaan tidak langsung adalah prediksi respon dengan memodelkan peubah respon dengan peubah tambahan yang berkaitan dengan menambah pengaruh acak. Pendugaan tidak langsung yang digunakan berbasis model campuran, dengan langkah-langkah sebagai berikut:
1. Menghitung jumlah kematian bayi untuk periode 2007-2012 untuk masing-masing kabupaten/kota di Provinsi Jawa Barat,
2. Menentukan nilai peubah-peubah penyerta yang diasumsikan terkait dengan jumlah kematian bayi,
3. Memilih peubah penyerta dengan mengidentifikasi terdapat multikolinier antar peubah. Jika terdapat multikolinier maka dilakukan komponen utama agar diperoleh peubah yang saling bebas,
4. Memodelkan peubah respon dan peubah penyerta hasil komponen utama dengan menggunakan model linier campuran terampat. Secara umum model linier campuran terampat dinyatakan dalam bentuk persamaan sebagai berikut:
̂ = − � = − (Xβ̂ + Zv̂)
� = Xβ̂ + Zv̂
dengan y merupakan vektor N pengamatan, � vektor pengaruh tetap, � vektor pengaruh acak, � vektor sisaan, X dan Z adalah matriks rancangan. Prediktor linier � dan g(.) sebagai fungsi penghubung.
Dalam penelitian ini menggunakan 4 model GLMM, yaitu:
Model-1: Model linier campuran Poisson adalah model linier campuran yang peubah respon diasumsikan menyebar Poisson (E(y )=Var(y)=µ ).
Model-2: Model linier campuran binomial negatif adalah model linier campuran yang peubah respon diasumsikan menyebar binomial negatif yang merupakan perluasan dari sebaran Poisson Gamma yang memuat parameter dispersi ϕ dengan Var(y)=µ(1+ ϕµ ).
Model-3: Model linier campuran pendekatan quasi-likelihood. Pendekatan quasi-likelihood memiliki keuntungan tidak memerlukan diketahuinya bentuk sebaran dari peubah respon. Fungsi quasi-likelihood didefinisikan sebagai (McCullagh & Nelder 1989):
Model-4: Model linier campuran pendekatan sebaran Tweedie. Sebaran Tweedie adalah keluarga eksponensial linier dengan menambahkan parameter dispersi dengan fungsi ragamnya
� = �� (Dunn & Smyth 2005).
12
6. Memeriksa dispersi dengan plot sisaan dan nilai devians dibagi derajat bebas setiap model,
7. Menduga jumlah kematian bayi berdasarkan keempat model tersebut. Pendugaan Komposit
Pendugaan komposit adalah pendugaan yang dilakukan dengan memboboti antara penduga berbasis desain dan berbasis model, dengan langkah-langkah sebagai berikut:
1. Mengunakan nilai penduga langsung �̂� dan ragam penarikan contoh��, 2. Mengunakan nilai penduga tidak langsung �̂�. dan ragam pengaruh acak ��, 3. Menghitung penduga komposit dengan pedekatan pendugaan empirical best
prediction (EBP) dengan rumus: �̂��� = ̂��̂�+ − ̂� �̂�.dengan �̂�. =
� � � + �� sebagai penduga tidak langsung, ̂� =���+�� � adalah bobot, dan
�̂�adalah penduga langsung,
4. Untuk beberapa area yang nilai responnya bernilai nol, menghasilkan ragam penarikan contohnya bernilai nol juga. Sehingga untuk mengatasi masalah tersebut dilakukan modifikasi dengan mengasumsikan bahwa suatu area memiliki hubungan kedekatan dengan area lain. Pendekatan ini menggunakan teknik pengerombolan. Penduga komposit modifikasi dihitung dengan rumus:
�̂���= ̂��̅̂� � + − ̂� �̂�.dengan �̂�. = � � � + �� sebagai penduga
Beberapa nilai statistik untuk menghitung ukuran kebaikan dengan menghitung nilai MAPE, MAD, dan MSD dengan formula sebagai berikut: - MAPE (Mean Absolute Percentage Error) = ∑ |� −�̂
1. Melakukan penggerombolan area berdasarkan peubah-peubah penjelas,
2. Mengindentifikasi area yang tidak tersurvei ke dalam gerombol yang terbentuk, 3. Menghitung nilai tengah pengaruh acak area yang segerombol, dengan formula
sebagai berikut:
�̅� = ��∑��=� �̂�,
4. Menduga jumlah kematian bayi untuk area yang tidak tersurvei, dengan model prediksi untuk area nircontoh sebagai berikut:
�̂�∗�= � � � + �̅�
13
4
HASIL DAN PEMBAHASAN
Penduga Langsung
Berdasarkan publikasi SDKI Tahun 2012, SDKI menggunakan empat macam kuesioner, yaitu rumah tangga, wanita usia subur, pria kawin, dan remaja pria. Pengukuran jumlah kematian bayi diperoleh dari kuesioner wanita usia subur (WUS) 15-49 tahun dengan bayi adalah anak berusia umur 0-12 bulan. Dalam SDKI 2012, jumlah WUS yang terambil menjadi contoh sebanyak 4132 jiwa dengan 1647 rumah tangga pada Tabel 2. Dari 4132 jiwa WUS, terdapat 727 jiwa WUS yang melahirkan pada tahun 2007-2012 dengan jumlah bayi lahir sebesar 814 jiwa. Jumlah kematian bayi (<12 bulan) sebanyak 29 jiwa dari 814 jiwa bayi lahir.
Tabel 2 Penduga langsung jumlah kematian bayi di Provinsi Jawa Barat
Kode
14
jumlah penduga yang cukup tinggi tidak sesuai jumlah penduduknya yang relatif kecil. Hal ini mengindikasikan kejadian kematian cukup tinggi di Kabupaten Kuningan. Jika dilihat berdasarkan ragam penarikan contohnya, Kabupaten Bogor, Kabupaten Kuningan, Kota Bandung, Kota Cirebon dan Kota Depok adalah lima teratas kabupaten/kota yang ragamnya besar. Ada beberapa area yang bernilai nol, hal ini disebabkan karena tidak ada kematian bayi dari contoh yang terambil.
Uji Korelasi antar Peubah Penyerta
Hasil pendugaan langsung pada Tabel 2 menunjukkan dugaan dan ragam penarikan contoh per kabupaten/kota yang masih cukup besar. Salah satu cara yang digunakan untuk mengatasi hal tersebut dilakukan pendugaan berbasis model dengan mencari peubah penyerta yang dianggap memiliki hubungan. Berdasarkan data profil kesehatan Provinsi Jawa Barat terpilih 5 buah peubah penyerta pada Tabel 1. Hasil uji korelasi dari kelima peubah tersebut yang tersaji pada Tabel 3. Tabel 3 menunjukkan terdapat beberapa peubah penyerta yang berkorelasi nyata yaitu jumlah dokter (X1) dengan jumlah puskesmas (X2), jumlah
puskesmas (X2) dengan jumlah PHBS (X3), dan jumlah puskesmas (X2) dengan
Jumlah BBLR (X5). Hal ini mengindikasikan adanya masalah multikolineritas
sehingga untuk mengatasi adanya korelasi antara peubah penyerta diterapkan komponen utama untuk mendapatkan peubah yang saling bebas. Semua komponen utama (Lampiran 1) digunakan tanpa mengurangi komponen agar informasi awal tidak hilang.
Tabel 3 Hasil uji korelasi antar peubah penyerta
15 2013). Pada kasus ini, diagnostik dispersi yang digunakan adalah plot sisaan dan rasio antara nilai devians dengan derajat bebasnya.
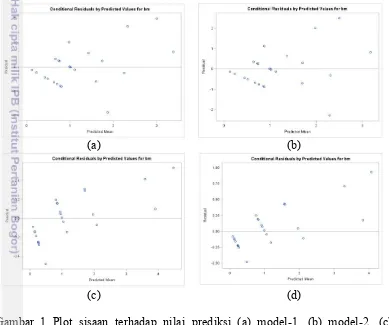
Gambar 1 menggambarkan pemeriksaan kelayakan keempat model dengan mendeteksi overdispersi dengan pola hubungan rata-rata prediksi (predicted mean) terhadap sisaan. Jika diidentifikasi lebih lanjut Gambar 1a dan 1b, nilai
rata-rata prediksi meningkat bersamaan dengan nilai sisaannya maka menunjukkan sisaan yang tidak homogen. Hal ini mengindikasikan masih adanya masalah dispersi. Pola hubungan rata-rata prediksi dengan sisaan yang cukup homogen terdapat pada Gambar 1c dan 1d. Hal ini berbeda pada Gambar 1a dan 1b, pada Gambar 1c dan 1d nilai sisaan cukup besar ketika rata-rata prediksi bernilai nol. Namun jika dilihat berdasarkan kebebasan sisaan, keempat model memiliki sisaan yang polanya tidak bebas.
\
Gambar 1 Plot sisaan terhadap nilai prediksi (a) model-1, (b) model-2, (c) model-3, dan (d) model-4
Cara lain untuk mendeteksi masalah overdispersi dapat dilihat berdasarkan nilai devians dibagi derajat bebas. Nilai generalized chi-square dibagi derajat
bebas model linier campuran poisson (model-1) pada Tabel 4 memiliki yang lebih kecil dari satu, sehingga menunjukkan adanya masalah underdispersi. Pada hakikatnya sebaran binomial negatif memiliki nilai ragam yang lebih besar dari sebaran Poisson dan bernilai sama ketika nilai ϕ = 0. Namun, model linier
campuran binomial negatif (model-2) memiliki nilai yang sama dengan model-1. Hal ini menunjukkan bahwa sebaran binomial negatif belum dapat menjelaskan keragaman datanya. Model-3 dengan fungsi ragam sebesar � � = . � dan
model-4 dengan fungsi ragam sebesar � � = . � . , nilai rasio antara
(a) (b)
16
generalized chi-square dan derajat bebas yang diperoleh sama dengan satu. Hal
ini mengambarkan karakteristik fungsi ragam dapat mengatasi masalah dispersi. Tabel 4 Ukuran kesesuaian pendugaan tidak langsung
Ukuran Kesesuaian Model-1 Model-2 Model-3 Model-4
-2 Res Log Pseudo-likelihood 69.17 69.05 77.23 78.64
Generalized Chi-Square 13.31 13.36 17.97 17.92
Gener. Chi-Square / df 0.74 0.74 1 1
Penduga Tidak Langsung
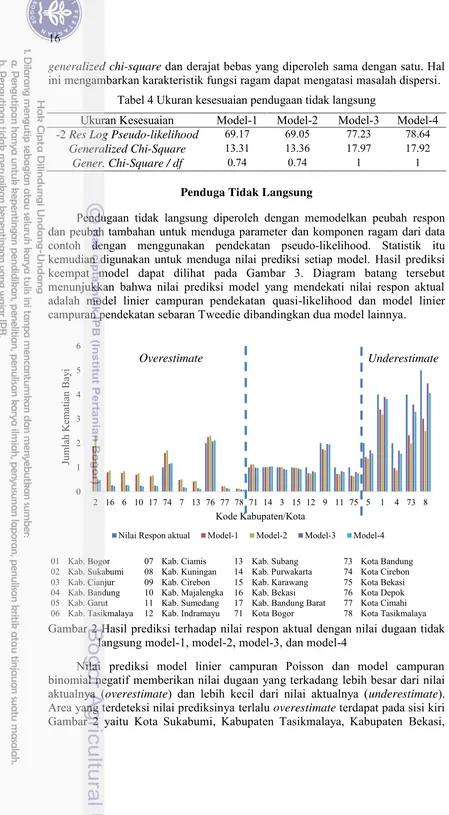
Pendugaan tidak langsung diperoleh dengan memodelkan peubah respon dan peubah tambahan untuk menduga parameter dan komponen ragam dari data contoh dengan menggunakan pendekatan pseudo-likelihood. Statistik itu kemudian digunakan untuk menduga nilai prediksi setiap model. Hasil prediksi keempat model dapat dilihat pada Gambar 3. Diagram batang tersebut menunjukkan bahwa nilai prediksi model yang mendekati nilai respon aktual adalah model linier campuran pendekatan quasi-likelihood dan model linier campuran pendekatan sebaran Tweedie dibandingkan dua model lainnya.
01 Kab. Bogor 07 Kab. Ciamis 13 Kab. Subang 73 Kota Bandung
Gambar 2 Hasil prediksi terhadap nilai respon aktual dengan nilai dugaan tidak langsung model-1, model-2, model-3, dan model-4
Nilai prediksi model linier campuran Poisson dan model campuran binomial negatif memberikan nilai dugaan yang terkadang lebih besar dari nilai aktualnya (overestimate) dan lebih kecil dari nilai aktualnya (underestimate).
Area yang terdeteksi nilai prediksinya terlalu overestimate terdapat pada sisi kiri
Gambar 2 yaitu Kota Sukabumi, Kabupaten Tasikmalaya, Kabupaten Bekasi,
0
Nilai Respon aktual Model-1 Model-2 Model-3 Model-4
17 Kabupaten Ciamis, Kabupaten Majalengka, Kabupaten Indramayu, Kabupaten Karawang, Kabupaten Bandung Barat, Kota Cirebon, Kota Cimahi dan Kota Tasikmalaya. Beberapa area yang terdeteksi yang terlalu underestimate terdapat
pada sisi kanan Gambar 2 adalah Kabupaten Bogor, Kabupaten Bandung, Kota Bandung, dan Kabupaten Kuningan.
Model dasar pendugaan area kecil mengunakan model level area yang dibangun dari Model Fay dan Herriot. Berdasarkan hasil estimasi berbasis desain dan berbasis model, dilakukan prediksi pendugaan area kecil untuk kabupaten dan kota dengan menggunakan model komposit yang setiap pendugaan memberikan bobot terhadap pendugaan pada Gambar 3. Jika diperbandingkan pendugaan tidak langsung dan pendugaan komposit, selisih nilai dugaan dengan nilai aktualnya yang memiliki nilai yang paling kecil adalah pendugaan komposit pendekatan quasi-likelihood. Hal ini mungkin didapatkan karena pemilihan fungsi ragam pada model quasi-likelihood yang lebih mengambarkan ragam data sebenarnya.
Nilai dugaan komposit untuk beberapa daerah masih bernilai nol terlihat pada Gambar 3. Kota dan kabupaten yang dugaannya masih bernilai nol adalah kabupaten Sukabumi, Kabupaten Tasikmalaya, Kabupaten Ciamis, Kabupaten Majalengka, Kabupaten Subang, Kabupaten Bekasi, Kota Cimahi dan Kota Tasikmalaya. Hal ini dikarenakan ragam penarikan contoh beberapa daerah bernilai nol yang menyebabkan bobotnya sama dengan satu sehingga diperoleh dugaan komposit sama dengan dugaan langsung.
01 Kab. Bogor 07 Kab. Ciamis 13 Kab. Subang 73 Kota Bandung
18
Salah satu pendekatan yang dapat digunakan untuk mengatasi masalah dugaan bernilai nol adalah mengasumsikan bahwa suatu area memiliki pola kedekatan hubungan dengan area lain dengan teknik pengerombolan. Bobot yang digunakan pada pendugaaan komposit adalah rasio ragam peubah acak terhadap total ragam peubah acak dan ragam penarikan contoh. Dugaan langsung dan ragam penarikan contohnya diperoleh dugaan langsung dan ragam penarikan contoh dari area yang segerombol. Hasil dugaan komposit dengan modifikasi tersaji pada Gambar 4.
Gambar 4 Hasil prediksi komposit dengan modifikasi 1, 2, model-3, dan model-4
Ukuran Kebaikan Model
19 Tabel 5 Ukuran kebaikan dari pendugaan titik berdasarkan dugaan langsung, dugaan berdasarkan model campuran, model komposit dengan modifikasi, dan model komposit dengan modifikasi
Ukuran
Campuran Dugaan Komposit tanpa Modifikasi Dugaan Komposit dengan Modifikasi Model
Pembentukan gerombol dilakukan dengan pendekatan analisis faktor dan gerombol berhirarki. Analisis faktor digunakan untuk melihat hubungan antar peubah-peubah yang diamati. Pengerombolan berdasarkan hasil skor faktor menggunakan metode analisis gerombol Berhirarki. Hasil analisis terasji pada Lampiran 3. Berdasarkan jarak antar gerombol yang paling jauh, jumlah gerombol yang terbentuk sebanyak 6 gerombol (Tabel 6). Daerah nircontoh yaitu Kota Banjar dan Kota Sukabumi segerombol dengan Kabupaten Subang, Kabupaten Ciamis, Kota Bandung, Kabupaten Garut dan Kab. Indramayu.
Tabel 6 Penggerombolan kabupaten/kota di Provinsi Jawa Barat Gerombol Jumlah Anggota Anggota Gerombol
1 6 Kab. Kuningan (8), Kab. Cirebon (9), Kab. Majalengka (10), Kab. Tasikmalaya (6), Kab. Sumedang (11), Kab. Sukabumi (2)
2 6 Kota Tasikmalaya (78), Kab. Bandung (4), Kab. Bandung Barat (17), Kab. Cianjur (3), Kab. Karawang (15), Kab. Bogor (1)
3 7 Kota Sukabumi (72), Kota Banjar (79), Kab. Subang (13), Kab. Ciamis (7), Kota Bandung (73), Kab. Garut (5), Kab. Indramayu (12)
4 3 Kota Depok (76), Kab. Purwakarta (14)
5 4 Kota Cimahi (77), Kota Bogor (71), Kota Bekasi (75), Kab. Bekasi (16)
6 1 Kota Cirebon (74)
Prediksi area nircontoh dilakukan dengan pendekatan menambahkan rata-rata pengaruh acak dalam satu gerombol. Hasil gerombol pada Tabel 6 menunjukkan bahwa Kota Banjar dan Kota Sukabumi segerombol dengan Kabupaten Subang, Kabupaten Ciamis, Kota Bandung, Kabupaten Garut dan Kabupaten Indramayu. Pengaruh acak untuk Kota Banjar dan Kota Sukabumi diperoleh dari rata-rata pengaruh acak Kabupaten Subang, Kabupaten Ciamis, Kota Bandung, Kabupaten Garut dan Kabupaten Indramayu.
20
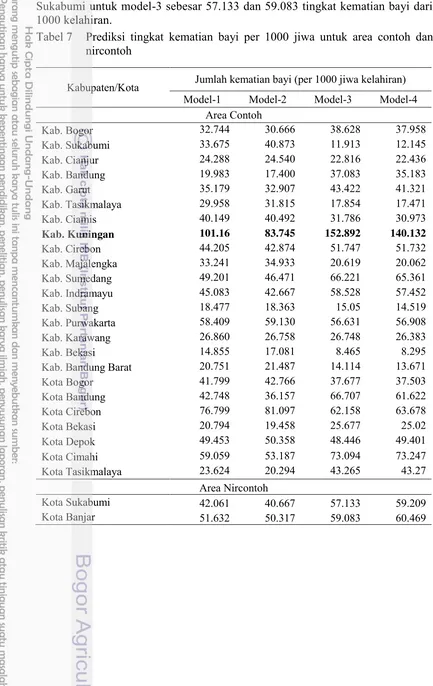
bayi per 1000 kelahiran untuk area nircontoh yaitu Kota Banjar dan Kota Sukabumi untuk model-3 sebesar 57.133 dan 59.083 tingkat kematian bayi dari 1000 kelahiran.
Tabel 7 Prediksi tingkat kematian bayi per 1000 jiwa untuk area contoh dan nircontoh
Kabupaten/Kota Jumlah kematian bayi (per 1000 jiwa kelahiran)
Model-1 Model-2 Model-3 Model-4
Area Contoh
Kab. Bogor 32.744 30.666 38.628 37.958
Kab. Sukabumi 33.675 40.873 11.913 12.145
Kab. Cianjur 24.288 24.540 22.816 22.436
Kab. Bandung 19.983 17.400 37.083 35.183
Kab. Garut 35.179 32.907 43.422 41.321
Kab. Tasikmalaya 29.958 31.815 17.854 17.471
Kab. Ciamis 40.149 40.492 31.786 30.973
Kab. Kuningan 101.16 83.745 152.892 140.132
Kab. Cirebon 44.205 42.874 51.747 51.732
Kab. Majalengka 33.241 34.933 20.619 20.062
Kab. Sumedang 49.201 46.471 66.221 65.361
Kab. Indramayu 45.083 42.667 58.528 57.452
Kab. Subang 18.477 18.363 15.05 14.519
Kab. Purwakarta 58.409 59.130 56.631 56.908
Kab. Karawang 26.860 26.758 26.748 26.383
Kab. Bekasi 14.855 17.081 8.465 8.295
Kab. Bandung Barat 20.751 21.487 14.114 13.671
Kota Bogor 41.799 42.766 37.677 37.503
Kota Bandung 42.748 36.157 66.707 61.622
Kota Cirebon 76.799 81.097 62.158 63.678
Kota Bekasi 20.794 19.458 25.677 25.02
Kota Depok 49.453 50.358 48.446 49.401
Kota Cimahi 59.059 53.187 73.094 73.247
Kota Tasikmalaya 23.624 20.294 43.265 43.27
Area Nircontoh
Kota Sukabumi 42.061 40.667 57.133 59.209
21
5
SIMPULAN DAN SARAN
Simpulan
Berdasarkan hasil analisis pada kasus kematian bayi di Provinsi Jawa Barat diketahui terdapat masalah underdispersi pada model linier campuran Poisson. Beberapa pendekatan digunakan untuk mengatasi masalah tersebut yaitu model linier campuran dengan sebaran binomial negatif, pendekatan quasi-likelihood dan sebaran Tweedie. Berdasarkan plot sisaan dan rasio generalized chi-square dengan derajat bebasnya diperoleh bahwa model linier campuran
pendekatan quasi-likelihood dan sebaran Tweedie dapat mengatasi masalah dispersi yang dihadapi. Pendugaan terbaik diperoleh berdasarkan pendugaan komposit dengan modifikasi pada model linier campuran pendekatan quasi-likelihood karena memberikan nilai MAPE, MAD, dan MSD lebih kecil dibandingkan pendekatan-pendekatan lainnya.
Saran
Overdispersi dalam data cacahan dapat disebabkan sejumlah alasan asumsi distribusi yang salah misalnya kesalahan asumsi sebaran, banyak respon bernilai nol atau ada pencilan. Berdasarkan keempat model GLMM yang dicobakan pada kasus jumlah kematian bayi di Provinsi Jawa Barat, model campuran pendekatan quasi-likelihood dan sebaran Tweedie dapat mengatasi overdispersi namun masih terindikasi pola sisaan yang tidak saling bebas. Analisis lebih lanjut yang disarankan pemodelan dengan peubah respon banyak bernilai nol yaitu zero inflated model serta dicobakan dengan menambah
22
DAFTAR PUSTAKA
Anisa R. 2014. Kajian Pengaruh Penambahan Informasi Gerombol terhadap Hasil Prediksi Area Nircontoh (Studi kasus pengeluaran per kapita kecamatan di Kota dan Kabupaten Bogor). [tesis]. Bogor (ID): Institut Pertanian Bogor. [BKKBN, BPS, KEMENKES, USAID] Badan Kependudukan dan Keluarga
Berencana Nasional, Badan Pusat Statistik, Kementerian Kesehatan, dan U.S. Agency for International Development. 2013. Laporan Pendahuluan Survei Demografi dan Kesehatan Indonesia 2012. [diunduh 2015 Sept 29]. Tersedia
pada :
http://www.bkkbn.go.id/litbang/pusdu/Hasil%20Penelitian/SDKI%202012/Lap oran%20Pendahuluan%20SDKI%202012.pdf.
[BPS] Badan Pusat Statistik. 2012. Profil Kesehatan Provinsi Jawa Barat 2012.
[diunduh 2015 Juli 2]. Tersedia pada :
http://www.depkes.go.id/resources/download/profil/PROFIL_KES_PROVINSI _2012/12_Profil_Kes.Prov.JawaBarat_2012.pdf.
Cameron AC, Trivedi PK. 1998. Regression Analysis of Count Data. New York:
Cambridge University Press.
Dunn PK, Smyth GK. 2005. Series Evaluation of Tweedie Dispersion Model Densities. J Stat Comp. 15:267-280.
Hadi AF, Notodiputro KA. 2009. Penduga Maksimum Likelihood untuk Parameter Dispersi Model Poisson–Gamma dalam Konteks Pendugaan Area Kecil. BIAStatistika. 3(1): 41-60.
Hajarisman N. 2013. Pemodelan Area Kecil untuk menduga angka kematian bayi melalui pendekatan model regresi Poisson bayes berhirarki dua-level. [disertasi]. Bogor (ID): Institut Pertanian Bogor.
Hinde J, Demetrio CGB. 2007. Overdispersion : Models and Estimation. [diunduh
2015 Desember 31]. Tersedia pada :
http://pointer.esalq.usp.br/departamentos/lce/arquivos/aulas/2011/LCE5868/Ov erdispersionBook.pdf
Jorgensen B. 1992. The Theory of Exponential Dispersion Models and Analysis of
Deviance. [diunduh 2015 Desember 31]. Tersedia pada :
http://www.impa.br/opencms/pt/biblioteca/mono/Mon_51.pdf
Kurnia A. 2009. Prediksi Terbaik Empirik untuk Model Transformasi Logaritma di dalam Pendugaan Area Kecil dengan Penerapan pada Data Susenas [disertasi]. Bogor (ID): Institut Pertanian Bogor.
Lee ES, Forthofer RN. 2006. Analyzing Complex Survey Data 2nd ed. USA :
SAGE Publication.
McCullagh P, Nelder JA. 1989. Generalized Linier Models. New York: Chapman
and Hall.
Pawitan Y. 2001. In All Likelihood: Statistical Modelling and Inference Using Likelihood. New York: Oxford science publications.
Rao JNK. 2003. Small Area Estimation. New York: John Wiley & Sons.
23 Stroup WW. 2013. Generalized Linear Mixed Models: Modern Concepts,
Methods and Applications. New York: Chapman and Hall.
Ver Hoef JM, Boveng PL. 2007. Quasi-Poisson VS. Negative Binomial Regression: How Should We Model Overdispersed Count Data?. Publications, Agencies, and Staff of the U.S. Departement of Commerce. Paper 142.
http://digitalcommons.unl.edu/usdeptcommercepub/142
Wedderburn RWM. 1974. Quasi-Likelihood Functions, Generalized Linear Models, and the Gauss-Newton Method. Biometrika. 61(3): 439-447.
Wolfinger R, O’connell. 2007. Generalized linear mixed models a pseudo-likelihood approach. J Stat Comput Sim. 48(3-4): 233-243.
doi:10.1080/00949659308811554.
Yadav A, Ladusingh L. 2013. District Level Infant Mortality Rate: an Exposition of Small Area Estimation. Population Association of America–Applied Demography Newsletter Vol. 26 No.1.
25 Lampiran 1 Nilai komponen utama
KU1 KU2 KU3 KU4 KU5
-0.5951 0.5869 -0.1921 0.7179 0.2277
0.1513 0.2907 1.5243 0.0647 -0.0130
-0.9722 1.0675 0.3522 0.3432 -0.1587
-1.6003 1.7286 -0.8985 0.3539 -0.1088
-0.3380 -0.4515 0.3591 -0.2417 -0.3278
-0.3456 0.8780 0.7335 -0.5272 0.0108
0.6427 -1.9565 0.0429 -0.0582 -0.4623
1.6268 -0.1829 1.8196 -1.3449 -0.0389
0.6788 2.1309 0.7741 0.8487 0.2049
0.0469 0.2935 0.7442 -0.5074 -0.1799
0.5838 0.5747 0.9347 0.4122 -0.0607
0.4279 -0.6978 0.5004 0.7273 -0.2874
-1.2372 -0.9670 -0.3342 -0.553 -0.9225
0.6049 -2.1058 0.0145 1.4593 0.5436
-0.5961 -0.1016 -0.5022 0.4735 -0.0147
-2.1274 -0.6290 -0.3177 -0.7759 -0.0591
-1.2328 0.5749 -0.0742 -0.0827 -0.1598
0.4197 -0.0783 -0.8448 -1.3495 0.9709
0.0815 -1.0963 -0.3401 0.0846 -0.3229
5.8627 0.5560 -1.6698 -0.2666 -0.2667
-2.0298 -0.3192 -1.3682 -0.8741 0.4268
-0.0985 -1.2659 0.2337 0.9972 0.6956
0.3735 0.2549 0.0943 -0.5467 0.7202
-0.3279 0.9147 -1.5859 0.6454 -0.4175
26
Lampiran 2 Nilai dugaan langsung, dugaan berdasarkan model campuran, dan dugaan komposit dengan modifikasi
Kode Kabupaten
/ Kota
Dugaan Langsung
Dugaan Berdasarkan Model
Campuran Dugaan Komposit dengan Modifikasi Model
27 Lampiran 3 Dendogram analisis gerombol kota dan kabupaten di Provinsi Jawa
28
RIWAYAT HIDUP
Penulis lahir di Bandar Lampung, pada tanggal 28 Mei 1988 dari pasangan Budiman dan Lili Suryani. Namun sejak kecil, penulis tinggal di Kota Pagar Alam, Sumatera Selatan. Pada tahun 2002, penulis melanjutkan pendidikan di SMA Negeri I Pagar alam dan lulus pada tahun 2005. Pada tahun yang sama, penulis diterima sebagai mahasiswa di Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB (USMI). Pada tahun kedua di IPB, penulis diterima di program studi Statistika sebagai mayor dengan minor Ekonomi Pertanian. Selama masa perkuliahan, penulis aktif dalam beberapa lembaga seperti Ikatan Mahasiswa Bumi Sriwijaya (IKAMUSI), himpunan keprofesian Gamma Sigma Beta (GSB), dan SERUM-G.