EKSTRAKSI CIRI DOKUMEN TUMBUHAN OBAT MENGGUNAKAN
CHI-KUADRAT
DENGAN KLASIFIKASI
NAIVE BAYES
YOGA HERAWAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
i
ABSTRACT
YOGA HERAWAN. Feature Extraction of Medicinal Plants using Chi-Square with Naïve Bayes Classifier. Supervised by YENI HERDIYENI.
This research presented a system for extracting terms and classifying medicinal plants documents using chi-square and naïve bayes classifier. Term extraction technique was used to make the classifier work efficiently and to increase classification accuracy. The criteria used in this research were the family of medicinal plants and utilization of medicinal plants for medication. The classification results were used to build an information retrieval system of Indonesian medicinal plants. This research used two significance levels for generating critical value, i.e 0.001 and 0.01. The experiment result showed that the critical value using significance level of 0.001 has better accuracy than the critical value using significance level 0.01. Accuracy of classification system using significance level of 0.001 were 97.44% for family and 89.74% for utilization of medicinal plants criteria. The information retrieval system tested using 29 queries about family and utilization of medicinal plants. The information retrieval system had an average value generated was 93.26%.
EKSTRAKSI CIRI DOKUMEN TUMBUHAN OBAT MENGGUNAKAN
CHI-KUADRAT
DENGAN KLASIFIKASI
NAIVE BAYES
YOGA HERAWAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Ekstraksi Ciri Dokumen Tumbuhan Obat Menggunakan Chi-Kuadrat dengan Klasifikasi Naive Bayes
Nama : Yoga Herawan NIM : G64070050
Menyetujui:
Pembimbing
Dr. Yeni Herdiyeni, S.Si., M.Kom. NIP. 19750923 200012 2 001
Mengetahui:
Ketua Departemen Ilmu Komputer Institut Pertanian Bogor
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
PRAKATA
Puji dan syukur penulis panjatkan kehadirat Allah SWT yang senantiasa memberikan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan tulisan ini dengan judul: Ekstraksi Ciri Dokumen Tumbuhan Obat Menggunakan Chi-Kuadrat dengan Klasifikasi Naive Bayes. Shalawat dan salam disampaikan kepada Nabi Muhammad SAW beserta keluarga, sahabat, dan pengikutnya yang tetap berada di jalan-Nya hingga akhir zaman.
Selama penelitian, penulis menyadari bahwa banyak pihak yang ikut membantu sehingga skripsi ini dapat diselesaikan, oleh karena itu penulis ingin menyampaikan ucapan terima kasih kepada:
1. Kedua orang tua tercinta serta kedua saudaraku tercinta, Herlina Pratiwi dan Prima Adi Pradana, atas doa dan semangat yang diberikan.
2. Ibu Dr. Yeni Herdiyeni, S.Si, M.Kom selaku pembimbing akademis yang telah memberikan banyak bantuan, kemudahan, saran dan ilmu kepada penulis.
3. Bapak Ir. Julio Adisantoso, M.Kom. dan Bapak Sony Hartono Wijaya, S.Kom., M.Kom. selaku dosen penguji atas kemudahan dan ilmu yang telah diberikan kepada penulis.
4. Sahabat sekaligus kakak bagi penulis, Febi Damiko, Bang Pram, Bang Khamsi, yang telah berbagi cerita suka dan duka, ilmu serta saran dan diskusi yang sangat membangun pola pikir penulis.
5. Sahabat-sahabat terbaik dari Ilkomerz44 Kristina Paskianti, Iyos Kusmana, Khamdan Amin, Danar Setya P, Mukhlis Said, Arizal Notyasa, Akbar “Jowo”, Akbar “masbero”, Imadudin “ijah” ayi, Agus “Alay” Umriadi dan Devi Dian Pramana Putra yang telah berbagi cerita suka dan duka bersama selama penulis menjadi mahasiswa.
6. Teman-teman J.Co Basketball FC, Amboro Rintoko, Bayu Chandra Winata, Akbar “jowo”, Mudho, atas jalinan persahabatan, semangat dan optimisme, serta keceriaan yang dilalui bersama penulis selama penulis menjadi mahasiswa.
7. Teman-teman satu bimbingan Kristina, Iyos, Fanni “Cicin”, Fanni “Culun”, Wido, Dimpy, Ella, Pak Rico, mbak Putri dan mbak Vira atas saran, masukan dan nasihat yang diberikan kepada penulis.
8. Irma Amalia Pratiwi yang selalu memberikan dorongan semangat dan doa kepada penulis. Penulis menyadari bahwa masih banyak kekurangan yang ditemukan dalam tugas akhir ini. Penulis berharap adanya saran dan kritik yang membangun dari semua pihak yang membaca tulisan ini. Semoga tulisan ini bermanfaat dan dapat menambah wawasan ilmu pengetahuan bagi penulis khususnya dan pembaca umumnya.
Bogor, September 2011
Yoga Herawan
iv
RIWAYAT HIDUP
Penulis dilahirkan di Wonogiri pada tanggal 30 Juli 1989 dari pasangan Ir. Slamet Sardjito dan Rahayu Dwi Hastuti. Penulis merupakan anak kedua dari tiga bersaudara.
Penulis menempuh pendidikan dasar di SD Negeri Wonogiri VII, SMP Negeri 1 Wonogiri. Tahun 2007 penulis lulus dari SMA Negeri 1 Wonogiri dan pada tahun yang sama penulis masuk Institut Pertanian Bogor (IPB) melalui jalur Ujian Saringan Masuk IPB (USMI). Penulis masuk Program S1 Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
v
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... vi
DAFTAR TABEL ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN ... 1
Latar belakang ... 1
Tujuan ... 1
Ruang lingkup ... 1
Manfaat ... 1
TINJAUAN PUSTAKA ... 1
Temu kembali informasi ... 1
Klasifikasi ... 2
Pemilihan fitur dokumen ... 2
Keputusan statistik dan hipotesis statistik ... 2
Chi-kuadrat ( )... 2
Document frequency thresholding (DF) ... 4
Naive Bayes classifier ... 4
Confusion matrix ... 5
Recallprecision ... 5
SphinxSearch ... 5
Pembobotan BM25 ... 6
METODE PENELITIAN ... 6
Dokumen tumbuhan obat ... 6
Praproses data ... 8
Pembagian data ... 8
Pemilihan fitur ... 8
Klasifikasi Naïve Bayes ... 8
Temu kembali informasi ... 9
Evaluasi model klasifikasi ... 9
Evaluasi sistem temu kembali ... 9
Lingkungan pengembangan sistem ... 9
HASIL DAN PEMBAHASAN ... 10
Praproses ... 10
Pemilihan fitur ... 10
Pengujian kinerja sistem... 11
KESIMPULAN DAN SARAN ... 12
Kesimpulan ... 12
Saran ... 12
vi
DAFTAR GAMBAR
Halaman
1. Distribusi chi-kuadrat………. 3
2. Tahapan penelitian……….. 7
3. Format koleksi dokumen……… 8
4. Rataan waktu proses klasifikasi pada setiap pemilihan nilai kritis (chi-kuadrat). ………… 10
5. Rataan waktu proses klasifikasi pada setiap pemilihan nilai threshold (df).……….. 11
6. Akurasi sistem klasifikasi……… 11
7. Grafik recall precision kueri uji ……….………..……….. 12
DAFTAR TABEL
Halaman 1. Tabel kontingensi antara kata terhadap kelas……… 32. Nilai kritis χ2 untuk tingkat signifikansi α ..………. 4
3. Confusion matrix untuk klasifikasi biner………... 5
4. Distribusi dokumen penyakit……… 7
5. Distribusi dokumen family……….. 7
6. Kumpulan kueri uji ……….. 9
DAFTAR LAMPIRAN
Halaman 1. Daftar 32 jenis tumbuhan obat Indonesia yang digunakan dalam penelitian……….. 152. Tabel distribusi chi-kuadrat pada berbagai tingkat signifikansi dan derajat bebas tertentu... 16
3. Confusion matrix untuk kelas family (berdasarkan pemilihan fitur chi-kuadrat pada nilai signifikansi 0,001)……….……… 17
1
PENDAHULUAN
Latar belakang
Indonesia merupakan negara
megabiodiversity yang memiliki kekayaan tumbuhan obat. Indonesia memiliki lebih dari 38.000 spesies tanaman (Bappenas 2003). Sampai tahun 2001 Laboratorium Konservasi Tumbuhan, Fakultas Kehutanan IPB telah mendata bahwa tidak kurang dari 2.039 spesies tumbuhan obat berasal dari hutan Indonesia (Zuhud 2009). Kandungan kimia yang terdapat dalam jenis tumbuhan obat tersebut mendorong peneliti untuk melakukan penelitian tentang penyakit yang dapat diobati dari suatu jenis tumbuhan obat tertentu. Melalui media cetak dan elektronik hasil penelitian tersebut didokumentasikan untuk diinformasikan kepada masyarakat. Internet membuat dokumentasi elektronik tersebar dengan mudah di dalam maupun luar negeri. Mesin pencari internet digunakan oleh pengguna di seluruh dunia untuk mencari informasi terkait tumbuhan obat yang dikehendaki. Banyaknya jumlah dokumentasi elektronik tersebut mempengaruhi kinerja mesin pencari dalam mengembalikan dokumen yang relevan terhadap keinginan pengguna. Untuk meningkatkan kinerja mesin pencari diperlukan sistem pengelolaan dokumen yang lebih baik dari sebelumnya.
Untuk itu diperlukan sistem klasifikasi dokumen secara otomatis. Salah satu teknik klasifikasi dokumen adalah Naïve Bayes. Naïve Bayes merupakan classifier sederhana yang didasarkan pada penerapan teorema Bayes. Kelebihan teknik ini adalah mampu mengklasifikasikan dokumen dengan tepat serta mudah dalam pengimplementasiannya (Thabtah 2009). Dalam jangka panjang, dokumen penelitian yang akan terindeks semakin bertambah seiring berjalannya waktu. Kerja yang lebih berat harus dilakukan oleh sistem classifier jika hanya mengandalkan teknik klasifikasi dokumen saja, hal tersebut dikarenakan sistem klasifikasi mengambil isi dari uraian setiap dokumen. Salah satu cara untuk meningkatkan kinerja dari sistem klasifikasi adalah dengan menerapkan teknik pemilihan fitur dokumen. Ada beberapa teknik yang digunakan untuk melakukan pemilihan fitur dokumen antara lain Document Frequency Thresholding (DF), Information Gain (IG),
Mutual Information (MI), Term strength (TS)
dan Chi-square testing (X2) (Yimming 2003).
Chi-square merupakan teknik pemilihan fitur
dokumen yang sangat efektif untuk memilih kata penciri suatu dokumen namun tidak menurunkan akurasi sistem klasifikasi (Yimming 1997). Document frequency thresholding merupakan teknik yang sederhana untuk mengurangi jumlah kata yang akan diproses. Teknik Document frequency thresholding mudah untuk diimplementasikan (Yimming 1997).
Penelitian ini akan membandingkan kinerja pemilihan fitur dokumen antara teknik chi-kuadrat dan teknik document thresholding frequency (df) yang kemudian dilakukan pembangunan sistem klasifikasi
Naïve Bayes untuk mengklasifikasikan dokumen tumbuhan obat Indonesia. Dalam penelitian ini, sistem klasifikasi akan mengklasifikasikan dokumen berdasarkan kategori family tumbuhan obat dan penyakit yang dapat disembuhkan oleh suatu jenis tumbuhan obat. Hasil klasifikasi tersebut kemudian akan digunakan untuk membangun sistem mesin pencari dokumen.
Tujuan
Tujuan penelitian ini adalah mengembangkan sistem temu kembali informasi tumbuhan obat yang bekerja berdasarkan hasil pemilihan fitur dokumen serta Naïve Bayes sebagai penglasifikasi dokumen.
Ruang lingkup
Ruang lingkup penelitian ini meliputi :
1. Dokumen terbatas pada 32 jenis tumbuhan obat Indonesia (Lampiran 1). 2. Dokumen yang digunakan berformat
XML.
3. Sistem menglasifikasikan dokumen berdasarkan penyakit yang dapat disembuhkan dan family dari suatu tumbuhan obat tertentu.
Manfaat
Manfaat dari penelitian ini adalah mempercepat dan mempermudah pengguna dalam mencari informasi tentang tumbuhan obat Indonesia.
TINJAUAN PUSTAKA
Temu kembali informasi
2 elektronik yang memenuhi kebutuhan
informasi tertentu (Manning et al. 2008). Sistem temu kembali informasi bertujuan untuk menjembatani kebutuhan informasi pengguna dengan sumber informasi.
Temu kembali informasi berkaitan dengan cara merepresentasikan, menyimpan, mengorganisasikan, dan mengakses informasi. Merepresentasikan dan mengorganisasikan suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya. Akan tetapi, untuk mengetahui informasi yang diinginkan pengguna bukan merupakan suatu hal yang mudah. Untuk itu pengguna harus menransformasikan informasi yang dibutuhkan ke dalam suatu kueri yang akan diproses mesin pencari (IR System), sehingga kueri tersebut merepresentasikan informasi yang dibutuhkan oleh pengguna. Dengan kueri tersebut, IR system akan menemukembalikan informasi yang relevan terhadap kueri (Baeza-Yates & Ribeiro-Neto 1999).
Klasifikasi
Klasifikasi adalah proses untuk menentukan kelas dari suatu objek tertentu. Pada klasifikasi dokumen, permasalahan yang muncul adalah sebagai berikut: diberikan sebuah deskripsi d X dari sebuah dokumen dimana X merupakan ruang dokumen. Sebuah himpunan tetap kelas
{ }, dengan menggunakan algoritme pembelajaran, dilakukan proses pembelajaran terhadap fungsi klasifikasi sehingga dapat memetakan dokumen pada kelas C.
Proses klasifikasi dibagi menjadi dua tahap, yaitu tahapan pembelajaran dan pengujian. Pada tahap pembelajaran, sebagian data yang telah diketahui kelasnya (data latih) digunakan untuk membuat model klasifikasi. Tahap pengujian menguji data uji dengan model klasifikasi untuk mengetahui akurasi model klasifikasi tersebut. Jika akurasi cukup maka model tersebut dapat digunakan untuk memprediksi kelas data yang belum diketahui (Han & Kamber 2006).
Pemilihan fitur dokumen
Pemilihan fitur dokumen merupakan suatu proses memilih sebanyak kata terbaik. Kata tersebut merupakan himpunan dari semua kata yang ada pada data latih.
Dalam penelitian ini, data dari himpunan tersebut akan digunakan sebagai penciri dokumen yang akan diklasifikasikan.
Pemilihan fitur dokumen memiliki dua tujuan utama yaitu membuat data latih yang diterapkan oleh sistem klasifikasi menjadi lebih sederhana serta untuk meningkatkan akurasi sistem klasifikasi. Peningkatan akurasi sistem klasifikasi disebabkan karena pada proses penghilangan fitur akan dihilangkan kata-kata yang bukan merupakan penciri dokumen (Manning et all 2008).
Keputusan statistik dan hipotesis statistik
Keputusan yang diambil berdasarkan informasi sampel yang didapatkan dari data disebut keputusan statistik. Sebagai contoh keputusan statistik adalah ketika akan memutuskan berdasarkan data sampel apakah suatu serum baru benar-benar efektif dalam menyembuhkan suatu penyakit, apakah suatu prosedur pendidikan lebih baik dari prosedur pendidikan lainnya.
Untuk mencapai suatu keputusan, diperlukan asumsi awal tentang populasi yang terlibat yang kemudian disebut sebagai hipotesis statistik. Hipotesis umumnya merupakan pernyataan umum yang berkaitan dengan distribusi probabilitas dari populasi. Hipotesis diperlukan untuk menentukan apakah hasil yang diduga cenderung untuk benar. Hipotesis nol (H0) menyatakan bahwa tidak ada perbedaan di dalam hasil yang sedang diperiksa atau disebut juga nol pengaruh (zero effect).
Chi-kuadrat ( )
Chi-kuadrat ( ) merupakan pengujian hipotesis mengenai perbandingan antara frekuensi sampel yang benar-benar terjadi (kemudian disebut frekuensi observasi) dengan frekuensi harapan yang didasarkan atas hipotesis tertentu pada setiap kasus atau data (selanjutnya disebut dengan frekuensi harapan .
Sampel berukuran N diambil dari suatu populasi normal berdeviasi standar σ. Untuk setiap sampel dihitung nilai sehingga diperoleh distribusi sampling untuk yang disebut distribusi chi-kuadrat.
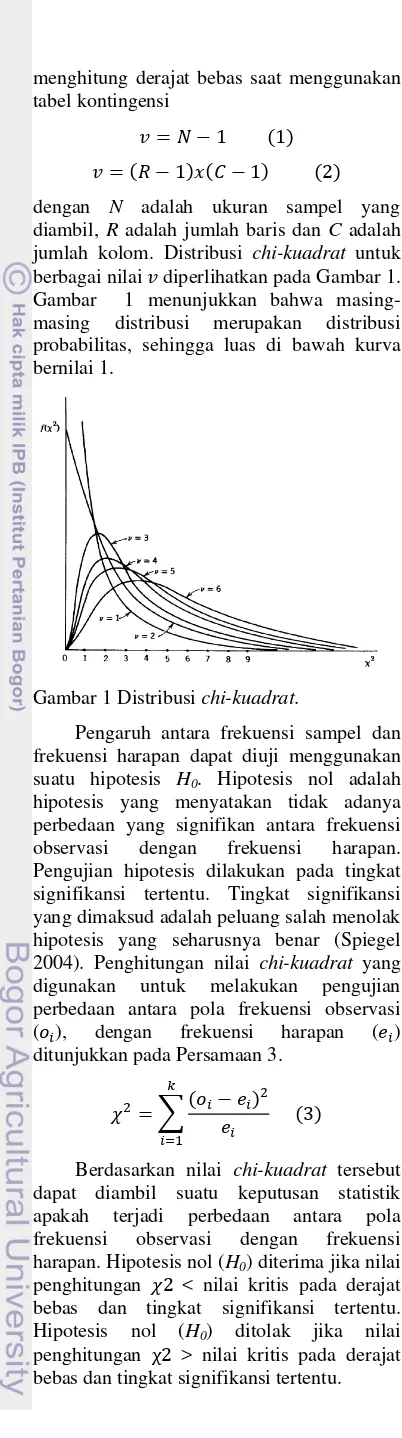
3 menghitung derajat bebas saat menggunakan
tabel kontingensi
dengan N adalah ukuran sampel yang diambil, R adalah jumlah baris dan C adalah jumlah kolom. Distribusi chi-kuadrat untuk berbagai nilai diperlihatkan pada Gambar 1. Gambar 1 menunjukkan bahwa masing-masing distribusi merupakan distribusi probabilitas, sehingga luas di bawah kurva bernilai 1.
Gambar 1 Distribusi chi-kuadrat.
Pengaruh antara frekuensi sampel dan frekuensi harapan dapat diuji menggunakan suatu hipotesis H0. Hipotesis nol adalah hipotesis yang menyatakan tidak adanya perbedaan yang signifikan antara frekuensi observasi dengan frekuensi harapan. Pengujian hipotesis dilakukan pada tingkat signifikansi tertentu. Tingkat signifikansi yang dimaksud adalah peluang salah menolak hipotesis yang seharusnya benar (Spiegel 2004). Penghitungan nilai chi-kuadrat yang digunakan untuk melakukan pengujian perbedaan antara pola frekuensi observasi ( ), dengan frekuensi harapan ( ) ditunjukkan pada Persamaan 3.
∑
Berdasarkan nilai chi-kuadrat tersebut dapat diambil suatu keputusan statistik apakah terjadi perbedaan antara pola frekuensi observasi dengan frekuensi harapan. Hipotesis nol (H0) diterima jika nilai penghitungan < nilai kritis pada derajat bebas dan tingkat signifikansi tertentu. Hipotesis nol (H0) ditolak jika nilai penghitungan > nilai kritis pada derajat bebas dan tingkat signifikansi tertentu.
Pada penelitian ini, mengukur derajat kebebasan antara kata penciri dengan kelas agar dapat dibandingkan dengan persebaran nilai (Mesleh 2007).
Chi-kuadrat mengevaluasi korelasi antara dua variabel dan kemudian menentukan apakah saling bebas atau berhubungan sesuai dengan nilai pada tabel chi.
Penghitungan nilai chi-kuadrat pada setiap kata yang muncul pada setiap kelas dapat dibantu dengan menggunakan tabel kontingensi. Nilai yang terdapat pada tabel kontingensi merupakan nilai frekuensi observasi dari suatu kata terhadap kelas. Tabel 1 menunjukkan tabel kontingensi antara kata terhadap kelas. Apabila frekuensi harapan pada kata dan kelas q adalah Epq, banyaknya frekuensi observasi dalam dokumen adalah , maka peluang
dan dapat digunakan untuk menghitung frekuensi harapan yang diperoleh dengan rumus pada Persamaan 4:
)
dengan nilai peluang kata dan peluang kelas:
Tabel 1 Tabel kontingensi antara kata terhadap kelas
Kelas
Kelas = 1 Kelas = 0
Kata
Kata = 1 A B
Kata = 0 C D
Penghitungan nilai chi-kuadrat
berdasarkan tabel kontingensi tersebut disederhanakan dalam Persamaan 5.
4 merupakan dokumen kelas dan tidak
memuat kata .
Pengambilan keputusan dilakukan berdasarkan nilai dari masing-masing kata. Kata yang memiliki nilai di atas nilai kritis pada tingkat signifikansi α adalah kata yang akan dipilih sebagai penciri dokumen. Kata yang dipilih sebagai penciri merupakan kata yang memiliki pengaruh terhadap kelas . Nilai kritis untuk tingkat signifikansi α ditunjukkan oleh Tabel 2. Tabel distribusi
chi-kuadrat pada berbagai tingkat signifikansi dan derajat bebas tertentu ditunjukkan dalam Lampiran 2.
Tabel 2 Nilai kritis untuk tingkat
Document frequency thresholding (DF)
Document frequency thresholding (df)
merupakan jumlah dokumen pada setiap kata unik yang muncul. Penghitungan df akan menghitung kemunculan kata unik dalam suatu kumpulan dokumen latih. Untuk menentukan bahwa kata tersebut berpengaruh terhadap suatu kumpulan dokumen, digunakan nilai threshold (Yimming 1997). Penentuan nilai threshold dilakukan dengan melihat sebaran kata dalam keseluruhan dokumen latih.
Kata yang memiliki nilai df di atas nilai
threshold yang telah ditentukan merupakan kata yang berpengaruh pada sekumpulan dokumen latih. Kata dengan nilai df yang rendah merupakan kata yang jarang muncul dalam koleksi dokumen latih. Dengan demikian, kata tersebut dianggap sebagai
noise dalam data latih.
Naive Bayes classifier
Metode klasifikasi Naïve Bayes adalah salah satu metode klasifikasi yang mengasumsikan seluruh atribut dari contoh yang bersifat independen satu sama lain pada
konteks kelas (McCallum & Nigam 1998). Meskipun secara umum asumsi tersebut merupakan asumsi yang buruk, pada praktiknya metode Naïve Bayes menunjukkan kinerja yang sangat baik (Rish 2001).
Menurut Manning (2008), peluang Bayes dapat digunakan untuk menghitung peluang bersyarat, yaitu peluang kejadian apabila suatu kejadian diketahui. Metode ini dapat memprediksi kemungkinan anggota suatu kelas berdasarkan sampel yang berasal dari anggota kelas tersebut. Klasifikasi Naïve Bayes termasuk dalam model multinomial yang mengambil jumlah kata yang muncul pada sebuah dokumen. Pada model ini sebuah dokumen terdiri atas beberapa kejadian kata. Berdasarkan asumsi Bayes, kemungkinan tiap kejadian kata dalam tiap dokumen adalah bebas, tidak terpengaruh dengan konteks kata dan posisi kata dalam dokumen.
Berdasarkan teori Bayes, peluang dokumen d untuk masuk ke dalam kelas c
atau P | ditunjukkan pada Persamaan 6:
| |
dengan P(d|c) adalah peluang kemunculan dokumen d di kelas c, adalah peluang awal suatu dokumen masuk ke dalam kelas c,
dan P(d) adalah peluang awal kemunculan dokumen d. Peluang awal kemunculan dokumen d dapat diabaikan karena memiliki nilai yang sama untuk seluruh kelas c,
sehingga Persamaan 6 dapat disederhanakan dalam Persamaan 7:
| |
Rumus untuk menghitung nilai peluang dokumen masuk ke dalam kelas c dan peluang kemunculan dokumen d berada pada kelas c adalah
|
∑
dengan Nc adalah banyaknya dokumen dalam kelas c, N adalah total dokumen, Tcd adalah banyaknya d dalamdokumen latih dari kelas
c.
Menurut Manning et al. (2008) kelas yang paling sesuai bagi dokumen d adalah kelas yang memiliki nilai | paling tinggi yaitu seperti ditunjukkan pada Persamaan 8:
5 Nilai peluang awal dapat
diestimasi dengan melihat jumlah dokumen yang dimiliki oleh kelas c relatif terhadap
Confusion matrix merupakan sebuah tabel yang terdiri atas banyaknya baris data uji yang diprediksi benar dan salah oleh model klasifikasi, yang digunakan untuk menentukan kinerja suatu model klasifikasi (Tan et al. 2005). Data uji diujikan untuk mendapatkan tingkat akurasi hasil prediksi yang berupa jumlah true positive, true negative, false positive, dan false negative
seperti yang dilihat pada Tabel 3 (Rachman
Keterangan untuk Tabel 3 dinyatakan sebagai berikut :
F11, yaitu jumlah dokumen dari kelas 1 yang benar diklasifikasikan sebagai kelas 1.
F00, yaitu jumlah dokumen dari kelas 0 yang benar diklasifikasikan sebagai kelas 0.
F01, yaitu jumlah dokumen dari kelas 0 yang salah diklasifikasikan sebagai kelas 1.
F10, yaitu jumlah dokumen dari kelas 1 yang salah diklasifikasikan sebagai kelas 0.
Perhitungan akurasi dinyatakan dalam Persamaan 9.
Recallprecision
Recall Precision adalah kriteria yang digunakan untuk mengevaluasi tingkat efektifitas kinerja sistem temu kembali informasi. Recall adalah rasio jumlah
dokumen relevan yang ditampilkan (retrieve)
terhadap jumlah seluruh dokumen yang relevan. Precision adalah rasio jumlah dokumen relevan yang ditampilkan terhadap jumlah seluruh dokumen yang ditampilkan (Manning 2008). Perhitungan recall-precision dijelaskan pada Persamaan 10 dan Persamaan 11 berikut. Neto (1999), algoritme temu-kembali yang dievaluasi menggunakan beberapa kueri berbeda, akan menghasilkan nilai R-P yang berbeda untuk masing-masing kueri.
Average Precision (AVP) diperlukan untuk menghitung rata-rata tingkat precision pada 11 tingkat recall, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Persamaan 12 merupakan formula untuk menghitung AVP.
Sphinx adalah platform search engine
yang didistribusikan pada GPL versi 2. Secara teknis, Sphinx merupakan perangkat lunak yang menyediakan fungsionalitas pencarian teks secara cepat dan relevan pada aplikasi yang berjalan di lingkungan klien. Sphinx telah dirancang khusus untuk berintegrasi dengan database SQL dan bahasa pemrograman tertentu (STI 2008).
Sphinx memiliki dua jenis fungsi pembobotan, yaitu phase rank dan statistical rank. Phase rank adalah fungsi pembobotan berdasarkan panjang kata antara tubuh dokumen dan frasa kueri. Statistical rank
6 C:\Sphinx\bin\indexer.exe --config
C:\Sphinx\sphinxDb.conf --all
C:\Sphinx\bin>
C:\Sphinx\bin\searchd –install – config
C:\Sphinx\sphinxDb.conf – servicename SphinxSkripsi
Pada tahap pembangunan sistem temu kembali informasi, terlebih dahulu dilakukan pemrosesan dokumen dengan menggunakan
SphinxSearch. Langkah yang dilakukan pertama kali yaitu melakukan pengindeksan ke semua koleksi dokumen. Proses pengeindeksan menghasilkan file hash. Perintah yang diberikan untuk melakukan pengindeksan koleksi dokumen adalah sebagai berikut:
Langkah selanjutnya yaitu pembuatan service
pada windows dengan nama SphinxSkripsi yang dapat dibuat dengan perintah sebagai berikut:
Service pada windows berguna untuk mencari hasil pengindeksan yang berupa file hash.
Pembobotan BM25
Metode BM25 merupakan metode pembobotan kata yang memeringkatkan setiap kumpulan dokumen yang didasarkan pada kata dalam kueri yang muncul pada setiap dokumen. Rumus dalam menghitung skor pada algoritme BM25 ditunjukkan pada Persamaan 13 berikut
Persamaan 13 menjelaskan bahwa
merupakan term frequency pada dokumen D, |D| merupakan banyaknya kata dalam dokumen D, dan avg dl merupakan rata-rata panjang dokumen dalam kumpulan teks dari dokumen tersimpan. k1 dan b merupakan parameter bebas dimana nilai yang biasa dipilih untuk k1=2,0 dan b=0,75. IDF(qi) merupakan bobot dari kata qi. Rumus untuk menghitung IDF ditunjukkan pada Persamaan 14 sebagai berikut
dimana N merupakan banyaknya koleksi dokumen, dan merupakan jumlah dokumen yang memuat kata qi.
METODE PENELITIAN
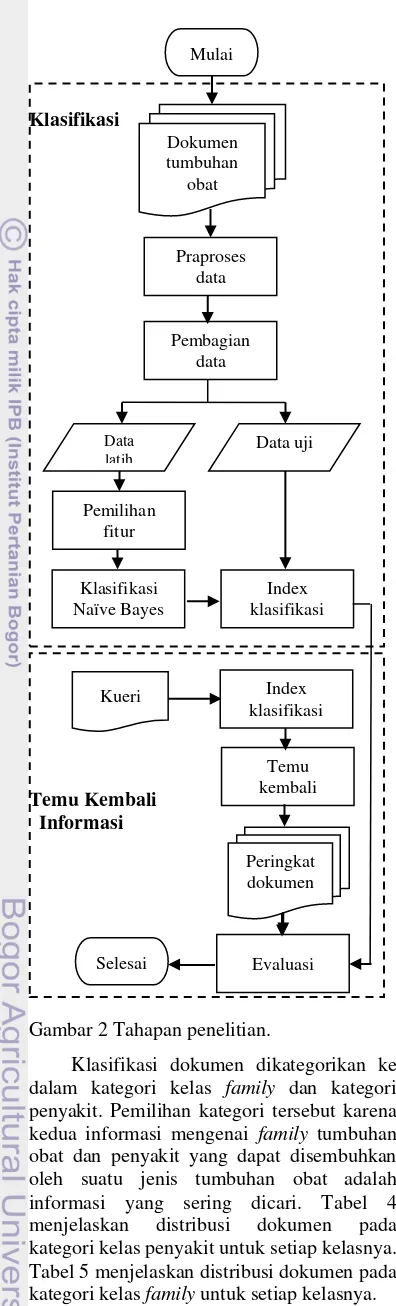
Penelitian ini dilaksanakan dalam beberapa tahapan yang diilustrasikan pada Gambar 2. Data yang diproses dalam sistem ini adalah koleksi dokumen. Input lain yang digunakan adalah stopwords yang merupakan daftar kata buang yang akan digunakan pada tahapan praproses. Tahap selanjutnya adalah dilakukan proses pemilihan fitur pada dokumen latih, kemudian hasilnya digunakan sebagai landasan dalam pembuatan vector space model. Vector space model digunakan untuk melakukan pembobotan terhadap kata sehingga akan merepresentasikan dokumen ke dalam bentuk vektor.
Tahapan berikutnya adalah melakukan klasifikasi Naïve Bayes pada dokumen uji yang belum diketahui kelasnya. Tahapan ini bertujuan untuk membangun model klasifikasi yang berupa indeks klasifikasi. Tahapan selanjutnya setelah model klasifikasi terbentuk yaitu pembangunan sistem temu kembali informasi yang akan mencari informasi berdasarkan hasil klasifikasi pada sistem. Pada tahap akhir, dilakukan evaluasi terhadap kinerja sistem klasifikasi dan kinerja sistem sistem temu kembali informasi yang dihasilkan.
Dokumen tumbuhan obat
Penelitian ini menggunakan koleksi dokumen tumbuhan obat sebagai korpus. Isi dari dokumen tidak diubah sehingga kesalahan ejaan dan tata bahasa tidak diperbaiki. Koleksi dokumen tumbuhan obat berjumlah 132 dokumen yang diperoleh dari buku-buku berikut:
1. Atlas Tumbuhan Obat Indonesia Jilid 1. Oleh dr. Setiawan Dalimartha
2. Atlas Tumbuhan Obat Indonesia Jilid 2. Oleh dr. Setiawan Dalimartha
3. Atlas Tumbuhan Obat Indonesia Jilid 3. Oleh dr. Setiawan Dalimartha
4. Obat Asli Indonesia Oleh Dr. Seno Sastroamidjojo
5. Ensiklopedi Millenium Jilid 1: Tumbuhan Berkhasiat Obat Indonesia.
7
Klasifikasi
Temu Kembali Informasi
Gambar 2 Tahapan penelitian.
Klasifikasi dokumen dikategorikan ke dalam kategori kelas family dan kategori penyakit. Pemilihan kategori tersebut karena kedua informasi mengenai family tumbuhan obat dan penyakit yang dapat disembuhkan oleh suatu jenis tumbuhan obat adalah informasi yang sering dicari. Tabel 4 menjelaskan distribusi dokumen pada kategori kelas penyakit untuk setiap kelasnya. Tabel 5 menjelaskan distribusi dokumen pada kategori kelas family untuk setiap kelasnya.
Koleksi dokumen bertipe file .txt dengan contoh format dokumen yang
terdapat pada Gambar 3. Dokumen dikelompokkan ke dalam tag sebagai berikut:
<DOK></DOK>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag lain yang lebih spesifik.
<ID></ID>, tag ini menunjukkan ID dari dokumen.
<NAMA></NAMA>, tag ini menunjukkan nama dari suatu jenis tanaman obat.
<NAMAL></NAMAL>, tag ini menunjukkan nama latin dari tanaman obat.
<DESKRIPSI></DESKRIPSI>, tag ini mewakili isi dari dokumen meliputi deskripsi tanaman dan kegunaannya.
<FAM></FAM>, tag ini menunjukkan nama family dari tanaman obat.
<PENYAKIT></PENYAKIT>, tag ini menunjukkan penyakit yang dapat disembuhkan dari jenis tumbuhan obat.
Tabel 4 Distribusi dokumen penyakit
No Kelas Jumlah
Tabel 5 Distribusi dokumen family
8 Gambar 3 Format koleksi dokumen.
Praproses data
Tahap praproses diawali dengan
lowercasing, tokenisasi, dan pembuangan
stopwords. Lowercasing adalah proses untuk mengubah semua huruf mejadi huruf non-capital agar menjadi case-insensitive pada saat dilakukan pemrosesan teks dokumen.
Tokenisasi adalah suatu tahap pemrosesan teks input yang dibagi menjadi unit-unit kecil yang disebut token atau term, yang dapat berupa suatu kata atau angka. Token yang dimaksud dalam penelitian ini adalah kata atau term. Proses tokenisasi dilakukan sesuai dengan aturan berikut :
Teks dipotong menjadi token. Karakter yang dianggap sebagai karakter pemisah token didefinisikan dengan ekspresi regular berikut :
/[\s\-+\/*0-9%,.\"\];()\':=`?\[!@><]+/
Token yang terdiri atas karakter numerik saja tidak diikutsertakan
Besar kecilnya karakter dari token dipertahankan atau tidak dilakukan penyeragaman.
Stopwords merupakan daftar kata-kata yang dianggap tidak memiliki makna. Kata yang tercantum dalam daftar ini dibuang dan tidak ikut diproses pada tahap selanjutnya. Kata-kata yang termasuk dalam stopwords
pada umumnya merupakan kata-kata yang sering muncul di setiap dokumen sehingga kata tersebut tidak dapat digunakan sebagai penciri suatu dokumen.
Pembagian data
Dokumen tumbuhan obat yang telah melewati tahap praproses data kemudian dibagi menjadi dua, yaitu data latih dan data uji dengan persentasi 70:30. Sebanyak 93 dokumen digunakan sebagai dokumen latih dan 39 dokumen sebagai dokumen uji. Tiap kelas dalam koleksi memiliki jumlah yang
relatif sama. Data latih digunakan sebagai
input pelatihan pengklasifikasi Naive Bayes, sedangkan data uji digunakan untuk menguji model hasil pelatihan Naive Bayes.
Pemilihan fitur
Hasil dari tahap praproses adalah vector term yang kemudian akan dilakukan pemilihan fitur. Pemilihan fitur memiliki dua tujuan, yaitu mengurangi jumlah kata yang digunakan dan meningkatkan akurasi hasil klasifikasi (Manning 2008). Fitur inilah yang kemudian digunakan pada tahap klasifikasi dokumen.
Pada penelitian ini, pemilihan fitur dilakukan dengan dua metode yaitu uji chi-kuadrat dan document thresholding frequency(df). Teknik pemilihan fitur yang terbaik di antara kedua teknik tersebut kemudian digunakan sebagai teknik yang digunakan pengembangan sistem.
Teknik chi-kuadrat memilih fitur berpengaruh dengan menghitung nilai antara kata dengan kelas yang dinyatakan dalam Persamaan 5. Pemilihan fitur dilakukan pada dua tingkat signifikansi , yaitu 0.01 dan 0.001. Kata yang terpilih pada tingkat signifikansi adalah kata yang memiliki nilai diatas nilai kritis 6.63, sedangkan kata yang terpilih pada tingkat signifikansi adalah kata yang memiliki nilai di atas nilai kritis 10.83.
Teknik df memilih fitur berpengaruh dengan cara menerapkan nilai threshold pada penghitungan jumlah kata yang muncul dalam koleksi dokumen latih. Nilai threshold
yang digunakan dalam penelitian ini adalah
threshold 3 dan 8. Kata yang terpilih dalam pemilihan fitur df, merupakan kata yang memiliki nilai penghitungan df diatas nilai
threshold yang sedang digunakan.
Fitur yang dihasilkan pada tahapan pemilihan fitur akan digunakan untuk membuat vector space model. Model terdiri atas beberapa dokumen yang direpresentasikan sebagai vektor dari frekuensi kemunculan fitur.
Klasifikasi Naïve Bayes
9 dokumen latih, dan penghitungan jumlah kata
yang terdapat pada dokumen yang berada dalam satu kelas yang sama.
Nilai peluang kata yang didapat kemudian digunakan untuk melakukan penghitungan Naïve Bayes pada dokumen uji untuk setiap kelasnya. Kemudian diambil nilai peluang yang terbesar pada nilai penghitungan Naïve Bayes. Nilai tersebut merupakan kelas dari dokumen uji tersebut.
Temu kembali informasi
Model klasifikasi yang telah terbentuk kemudian digunakan pada sistem temu kembali informasi untuk ditemukembalikan. Tujuan temu kembali ini adalah agar pengguna mendapatkan informasi dengan lebih mudah dan terstruktur. Sistem temu kembali informasi melakukan pengindeksan dokumen sumber (corpus) hanya pada kelas tertentu saja berdasarkan kuerinya. Pembobotan BM25 digunakan untuk menghitung bobot kedekatan kueri dengan dokumen koleksi. Penghitungan pembobotan BM25 telah dijelaskan seperti pada Persamaan 13 dan Persamaan 14.
Evaluasi model klasifikasi
Evalusi kinerja model penglasifikasi
Naive Bayes dilakukan dengan menghitung persentase ketepatan suatu dokumen tumbuhan obat masuk ke dalam kelas tertentu. Evaluasi untuk model penglasifikasi
Naive Bayes dinyatakan dalam bentuk
confusion matrix. Penghitungannilai akurasi terhadap model klasifikasi diperoleh melalui Persamaan 9.
Evaluasi sistem temu kembali
Evaluasi kinerja sistem temu kembali informasi dilakukan dengan menghitung nilai
recall dan precision dari 29 kueri yang diujikan pada sistem. Kueri uji ditentukan dengan cara memilih kata-kata yang mewakili isi setiap tumbuhan obat. Kata-kata tersebut menceritakan tentang penyakit yang dapat disembuhkan, kandungan kimia dalam suatu tumbuhan obat, karakteristik fisik tumbuhan obat tertentu, dan cara penggunaan suatu tumbuhan obat tertentu. Tabel 6 menunjukkan rincian kueri uji.
Penghitungan nilai recall precision yang dinyatakan dalam Persamaan 10 dan Persamaan 11 dilakukan untuk melihat tingkat efektifitas proses temu kembali
informasi terhadap suatu kueri. Penghitungan AVP dinyatakan dalam Persamaan 12.
Tabel 6 Kumpulan kueri uji
No Kueri
21 Tumbuhan Merambat 22 Tanaman Hias 23 Daun Elips 24 Buah Buni 25 Kalsium Oksalat 26 Zat Warna 27 Obat Diseduh 28 Obat Ditumbuk 29 Buah Diperas
Lingkungan pengembangan sistem
Penelitian ini menggunakan perangkat lunak dan perangkat keras dengan spesifikasi adalah sebagai berikut :
1. Perangkat Lunak :
Sistem operasi Microsoft Windows XP
Notepad++ sebagai code editor
Server XAMPP
Perangkat lunak MySQL untuk database
Web Browser (melalui Local Area Connection): Mozilla Firefox
2. Perangkat Keras :
10
Memory 2990MB RAM
Harddisk dengan kapasitas sisa 300GB
Monitor resolusi 1366 x 768 pixel Mouse dan keyboard
HASIL DAN PEMBAHASAN
Praproses
Pengindeksan dokumen latih yang keseluruhan berjumlah 93 dokumen menghasilkan 3.312 dan 10.346 kata yang berupa kata unik yang ditemui di setiap dokumen dalam keseluruhan dokumen latih.
Pemilihan fitur
Vektor kata unik yang telah dihasilkan dari tahapan praproses kemudian diproses pada tahap pemilihan fitur. Tahapan pemilihan fitur dokumen diujikan terhadap dua teknik berbeda. Teknik pemilihan fitur dokumen yang pertama adalah dengan teknik
chi-kuadrat. Pada teknik pemilihan fitur berikutnya adalah dengan menggunakan teknik document frequency thresholding (DF).
a. Chi-kuadrat (χ2)
Pemilihan fitur dengan teknik chi-kuadrat dilakukan pada dua nilai signifikansi (Tabel 2). Berdasarkan teori terpenuhinya hipotesis, nilai signifikansi 0,001 dapat diartikan bahwa kriteria kata yang dipilih adalah kata yang memiliki nilai χ2 diatas 10,83. Nilai signifikansi 0,01 diartikan sebagai kriteria kata yang dipilih adalah untuk setiap kata yang memiliki nilai χ2 diatas 6,63. Hasil dari tahapan ini adalah 2.942 kata unik pada pemilihan nilai signifikansi 0,01 dan 1.578 kata unik pada pemilihan nilai signifikansi 0,001. Kumpulan kata yang dihasilkan pada tahapan pemilihan fitur inilah yang kemudian hanya akan diolah pada sistem klasifikasi.
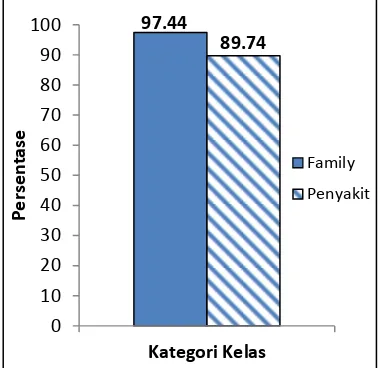
Klasifikasi dokumen pada nilai signifikansi 0,01 dan 0,001 memiliki akurasi yang sama besar yaitu 97,44% untuk kategori
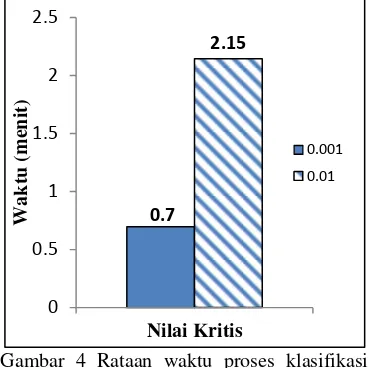
family dan 89,74% untuk kategori penyakit (Gambar 6). Pengaruh nyata yang diberikan oleh teknik pemilihan fitur dokumen terlihat pada lama waktu pemrosesan suatu dokumen uji hingga diklasifikasikan ke dalam kelas yang tepat. Gambar 4 menunjukkan waktu rata-rata yang diperlukan untuk menglasifikasikan dokumen uji pada setiap nilai signifikansi yang digunakan. Gambar 4
menjelaskan bahwa waktu rata-rata yang digunakan untuk memproses satu dokumen uji pada pemilihan nilai signifikansi 0,001 adalah selama 0,7 menit dan pada pemilihan nilai signifikansi 0,01 adalah selama 2,15 menit.
Gambar 4 Rataan waktu proses klasifikasi pada setiap pemilihan nilai kritis (chi-kuadrat).
Pemilihan nilai signifikansi 0,001 memberikan kinerja klasifikasi yang lebih baik daripada ketika pemilihan nilai signifikansi 0,01. Hal itu dikarenakan pada pemilihan nilai signifikansi 0,001 menghasilkan himpunan kata penciri yang berjumlah lebih sedikit daripada jumlah kata penciri yang dihasilkan pada pemilihan nilai signifikansi 0,01.
b. Documentfrequency thresholding (df).
Pemilihan fitur dokumen dengan teknik
document frequency thresholding (df)
dilakukan pada dua nilai threshold. Nilai
threshold yang digunakan adalah pada
threshold 3 dan 8. Hipotesis nol akan ditolak jika nilai threshold suatu kata lebih dari nilai
threshold yang digunakan. Nilai threshold 3 menghasilkan kata penciri dokumen latih sebanyak 935 kata. Nilai threshold 8 menghasilkan kata penciri dokumen latih sebanyak 417 kata. Kumpulan kata yang dihasilkan pada tahapan pemilihan fitur inilah yang kemudian hanya akan diolah pada sistem klasifikasi.
Klasifikasi dokumen pada nilai
11 digunakan untuk memproses satu dokumen
uji pada pemilihan nilai threshold 3 adalah selama 6,80 menit dan pada pemilihan nilai
threshold 8 adalah selama 5,36 menit.
Gambar 5 Rataan waktu proses klasifikasi pada setiap pemilihan nilai
threshold (df).
Berdasarkan hasil penelitian tersebut, sistem dikembangkan menggunakan pemilihan fitur dokumen chi-kuadrat pada nilai signifikansi 0,001. Pemilihan teknik chi-kuadrat dikarenakan pada teknik tersebut memiliki tingkat akurasi klasifikasi yang lebih baik dan membutuhkan waktu lebih cepat untuk menglasifikasikan dokumen uji daripada teknik document thresholding frequency(df).
Pengujian kinerja sistem
Proses evaluasi yang dilakukan terdiri atas dua proses evaluasi. Evaluasi pertama adalah pengujian tingkat akurasi sistem klasifikasi, dan evaluasi berikutnya adalah pengujian tingkat akurasi sistem temu kembali informasi. Evaluasi sistem dilakukan sesuai pada hasil pemilihan fitur dokumen pada tingkat signifikansi 0,001.
a. Akurasi sistem klasifikasi
Akurasi dari sistem klasifikasi dapat dihitung dengan menggunakan bantuan tabel
confussion matrix. Pada kategori kelas family
tabel confussion matrix ditunjukkan pada Lampiran 5 dan untuk kelas penyakit ditunjukkan pada Lampiran 6.
Akurasi sistem klasifikasi dapat dilihat pada Gambar 5. Akurasi sistem klasifikasi yang dikelaskan berdasarkan family
tumbuhan obat memiliki tingkat akurasi yang lebih tinggi daripada sistem yang dikelaskan
berdasarkan penyakit, yaitu masing-masing sebesar 97,44% dan 89,74%. Hal tersebut disebabkan oleh metode klasifikasi Naive Bayes bekerja dengan memperhitungkan peluang kemunculan suatu kata yang terdapat pada dokumen uji yang dihitung terhadap kemunculan kata dalam suatu kelas dokumen latih.
Gambar 6 Akurasi sistem klasifikasi.
Kata dalam dokumen uji pada dokumen yang salah penglasifikasian memiliki peluang kemunculan kata yang lebih besar untuk muncul pada kelas dokumen yang salah. Hal ini membuat keakurasian dalam penglasifikasian dokumen menjadi rendah. Untuk kategori family, rata-rata dokumen uji masuk ke dalam kelas yang tepat, karena kata penciri untuk suatu kelas family tertentu berbeda antar setiap kelasnya.
b. Akurasi sistem temu kembali informasi
Evaluasi sistem temu kembali informasi dilakukan menggunakan 29 kueri uji yang merepresentasikan isi dokumen. Kumpulan kata kueri yang digunakan dalam pengujian sistem temu kembali informasi dapat dilihat pada Tabel 6.
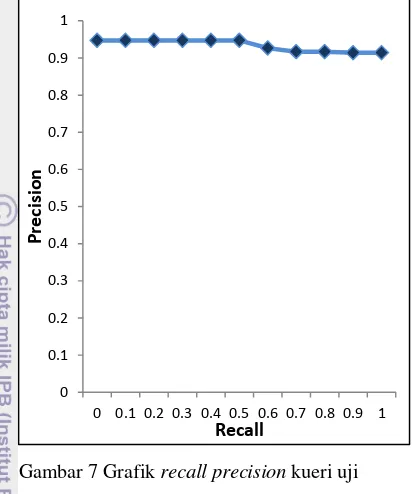
Pengujian sistem temu kembali informasi dilakukan menggunakan recall precision. Hasil penghitungan recall precision ditunjukkan pada Gambar 7.
12 Gambar 7 Grafik recall precision kueri uji
Gambar 7 menunjukkan nilai recall precision yang tinggi. Hal tersebut dibuktikan dengan melihat hasil dokumen yang dikembalikan kepada pengguna. Nilai
average precision adalah sebesar 93,26%. Dapat disimpulkan bahwa kinerja sistem temu kembali informasi memiliki tingkat keakuratan yang baik untuk setiap kueri uji yang diberikan.
Dokumen yang tidak relevan namun ikut ditemukembalikan hanya terjadi pada kueri uji „kalsium‟, „vitamin‟, „buah diperas‟, „gatal-gatal‟, dan „zat warna‟. Hal ini disebabkan karena kueri tersebut memiliki banyak arti penerjemahan antar setiap dokumen tumbuhan obat sehingga kueri tersebut tidak mampu mewakili informasi yang sebenarnya diinginkan oleh pengguna. Misalnya informasi yang diinginkan pengguna adalah informasi mengenai kandungan kalsium dalam tumbuhan obat (kueri „kalsium‟), namun sistem menemukembalikan informasi mengenai penyakit yang terjadi akibat kekurangan kalsium (kueri „kalsium‟). Kesalahan sistem dalam menemukembalikan dokumen disebabkan juga karena sistem melakukan pencarian dokumen untuk masing-masing kata kueri secara terpisah sehingga menyebabkan dokumen yang tidak relevan ikut terambil lebih banyak. Misalnya untuk kueri „zat warna‟, sistem akan melakukan pembobotan terhadap kata „zat‟ dan kata „warna‟. Hal ini sejalan dengan metode pembobotan BM25 yang hanya memperhatikan kemunculan satu kata tanpa
memperhatikan kedekatan kata yang digunakan pada kueri.
KESIMPULAN DAN SARAN
Kesimpulan
Penelitian ini menganalisis kinerja chi-kuadrat dibanding dengan kinerja document thresholding frequency (df) sebagai pengekstraksi fitur yang kemudian diterapkan ke dalam klasifikasi Naïve Bayes untuk membuat model klasifikasi sebagai dasar dari sistem temu kembali informasi. Dari hasil yang diperoleh dapat disimpulkan bahwa:
1. Penerapan teknik pemilihan fitur dokumen dapat meningkatkan kinerja sistem klasifikasi.
2. Kinerja pemilihan fitur dokumen dengan teknik chi-kuadrat lebih baik dibanding dengan document thresholding frequency(df).
3. Penggunaan nilai signifikansi 0,001 memberikan kinerja klasifikasi yang lebih baik daripada penggunaan nilai signifikansi 0,01 sehingga sistem dikembangkan pada nilai signifikansi 0,001 untuk pengekstraksi fiturnya. 4. Sistem klasifikasi memiliki tingkat
akurasi yang tinggi yaitu sebesar 97,44% untuk kategori klasifikasi berdasar family
dan 89,74% untuk klasifikasi berdasar penyakit.
5. Temu kembali informasi menggunakan Sphinx memberikan hasil yang sangat memuaskan. Ditunjukkan dengan nilai AVP sebesar 93,26%.
Saran
Beberapa hal yang perlu dikembangkan dalam penelitian ini:
1. Menggunakan dokumen corpus yang lebih beragam dan dalam jumlah yang lebih banyak.
2. Melakukan stemming pada proses pengindeksan awal.
3. Menggunakan kamus frase untuk memproses kata.
4. Penelitian ini menggunakan metode chi-kuadrat untuk memilih fitur dokumen. Disarankan untuk menggunakan metode pemilihan fitur yang lain, seperti
13 5. Penelitian ini menggunakan metode Naïve
Bayes sebagai sistem klasifikasi dokumen. Disarankan untuk menggunakan metode klasifikasi dokumen lainnya seperti SVM atau metode fuzzy.
DAFTAR PUSTAKA
Baeza-Yates R, Riberio-Neto B. 1999.
Modern Information Retrieval. England: Addison Wesley.
El-Kourdi, M., Bensaid, A., and Rachidi, T.
“Automatic Arabic Document
Categorixation Based on the Naïve Bayes Algorithm,” 20th
International Conference on Computational Linguistics, 2004, Geneva.
Forman G., M. “An Extensive Empirical Study of Feature Selection Metrics for Text Classification,” Journal of Machine Learning Research 3 (2003) 1289-1305.
Hadi W., Thabtah F., ALHawari S., Ababneh J.”Naive Bayesian and K-Nearest Neighbour to Categorize Arabic Text Data, “In Proceedings of the European Simulation and Modeling Conference, Le Havre, France, 2008
Han J, Kamber M. 2006. Data Mining : Concepts and Techniques. USA : Morgan Kaufman Publishers.
Hashimoto K., Yukawa T.,” Term Weighting Classification System Using the Chi-square Statistic for the Classification Subtask at NTCIR-6 Patent Retrieval Task, “In Proceedings of NTCIR-6 Workshop Meeting, Japan, 2007
Manning C D., Raghavan P., Schutze H., 2009. An Introduction to Information Retrieval. Cambridge, Cambridge University Press.
McCalum, A. & Nigam, K. 1998. A Comparison of Event Models for Naïve Bayes Text Classification.
Mesleh, A. A. “Chi Square Feature Extraction Based Svms Arabic Language Text Categorization Systems,” Journal of Computer Science (3:6), 2007,pp.430-435.
Metsis et al. 2006. Spam filtering with Naïve Bayes – Which Naïve Bayes?. Di dalam
CEAS 2006 –Third Conference on Email and AntiSpam.
Rish et al. 2001. An analysis of data characteristics that affect naïve Bayes performance. -.
Seddiqui M H., Aono M., 2000. Use of Ontology in Text Classification. Toyohashi University of Technology. Japan.
Spiegel M. 2004. Schaum’s Easy Outlines. Jakarta: Erlangga.
Steinbach M., Karypis G., Kumar V., 2000. A Comparison of Document Clustering Techniques. Department of Computer Science and Egineering. University of Minnesota. Minnesota.
Tan et al. 2006. Introduction to Data Mining.
USA: Addison Wesley.
Thabtah, Fadi. “Naïve Bayesian Based on Chi Square to Categorize Arabic Data,”Camunication of the IBIMA Vol. 10, 2009.
Yang Y, Pedersen J. 1997. A Comparative Study on Feature Selection in Text Categorization. International Conference on Machine Learning 1997.
Zuhud, E.A.M. 2009. Potensi Hutan Tropika Indonesia sebagai Penyangga Bahan Obat Alam untuk Kesehatan Bangsa.
Jurnal Bahan Alam Indonesia. Vol VI
15 Lampiran 1 Daftar 32 jenis tumbuhan obat Indonesia yang digunakan dalam penelitian
No Nama Nama Latin
1 Pandan wangi Pandanus amaryllifolius Roxb.
2 Jarak pagar Jatropha curcas Linn.
3 Dandang gendis Clinacanthus nutans Lindau
4 Akar kuning Arcangelisiaflava L.
5 Gadung cina Smilax china
6 Tabat barito Ficus deloidea L.
7 Kemuning Murraya paniculata [L..] Jack.
8 Pegagan Centella asiatica (L.) Urban
9 Krokot Portulaca oleracea L.
10 Zodia Evodia suaveolens
11 Iler Coleus scutellarioides, Linn,Benth
12 Jeruk nipis Citrus aurantifolia, Swingle.
13 Sambang darah Excoecaria cochinchinensis Lour.
14 Nanas kerang Rhoeo discolor (L.Her.) Hance
15 Sambang colok Aerva sanguinolenta Bl.
16 Remek daging Excecaria bicolor Hassk
17 Kumis kucing Orthosiphon aristatus (B1) Miq.
18 Sosor bebek Kalanchoe pinnata (Lam.) Per.
19 Landik Barleria lupulina Lindl.
20 Jambu biji Psidium guajava L.
21 Tapak dara Catharantus roseus (L.) G. Don.
22 Som jawa Talinum paniculatum (jacq.) Gaertn.
23 Jarong Achyranthes aspera Linn.
24 Mangkokan Nothopanax scutellarium Merr.
25 Andong Cordyline fruticosa (L) A. Cheval.
26 Kemangi Ocimum basilicum
27 Patah tulang Eupharbia tirucalli L.
28 Cincau hitam Cyclea peltata Miq.
29 Awar – awar Ficus septica Burm f.
30 Semanggi gunung Hydrocotyle sibthorpioides Lam.
31 Salam Syzygium polyanthum (Wight.) Walp.
16 Lampiran 2 Tabel distribusi chi-kuadrat pada berbagai tingkat signifikansi dan derajat bebas tertentu
d.f
1 1.32 2.71 3.84 5.02 6.63 7.88 10.8
2 2.77 4.61 5.99 7.38 9.21 10.6 13.8
3 4.11 6.25 7.81 9.35 11.3 12.8 16.3
4 5.39 7.78 9.49 11.1 13.3 14.9 18.5
5 6.63 9.24 11.1 12.8 15.1 16.7 20.5
6 7.84 10.6 12.6 14.5 16.8 18.5 22.5
7 9.04 12 14.1 16 18.5 20.3 24.3
8 10.2 13.4 15.5 17.5 20.1 22 26.1
9 11.4 14.7 16.9 19 21.7 23.6 27.9
10 12.5 16 18.3 20.5 23.2 25.2 29.6
11 13.7 17.3 19.7 21.9 24.7 26.8 31.3
12 14.8 18.5 21 23.3 26.2 28.3 32.9
13 16 19.8 22.4 24.7 27.7 29.8 34.5
14 17.1 21.1 23.7 26.1 29.1 31.3 36.1
15 18.2 22.3 25 27.5 30.6 32.8 37.7
16 19.4 23.5 26.3 28.8 32 34.3 39.3
17 20.5 24.8 27.6 30.2 33.4 35.7 40.8
18 21.6 26 28.9 31.5 34.8 37.2 42.3
19 22.7 27.2 30.1 32.9 36.2 38.6 32.8
20 23.8 28.4 31.4 34.2 37.6 40 45.3
21 24.9 29.6 32.7 35.5 38.9 41.4 46.8
22 26 30.8 33.9 36.8 40.3 42.8 48.3
23 27.1 32 35.2 38.1 41.6 44.2 49.7
24 28.2 33.2 36.4 39.4 32 45.6 51.2
25 29.3 34.4 37.7 40.6 44.3 46.9 52.6
26 30.4 35.6 38.9 42.9 45.6 48.3 54.1
27 31.5 36.7 40.1 43.2 47 49.6 55.5
28 32.6 37.9 41.3 44.5 48.3 51 56.9
29 33.7 39.1 42.6 45.7 49.6 52.3 58.3
30 34.8 40.3 43.8 47 50.9 53.7 59.7
40 45.6 51.8 55.8 59.3 63.7 66.8 73.4
50 56.3 63.2 67.5 71.4 76.2 79.5 86.7
60 67 74.4 79.1 83.3 88.4 92 99.6
70 77.6 85.5 90.5 95 100 104 112
80 88.1 96.6 102 107 112 116 125
80 98.6 108 113 118 124 128 137
100 109 118 124 130 136 140 149
Sumber: Ronald J. Wonnacolt and Thomas H. Wonnacot.
17 Lampiran 3 Confusion matrix untuk kelas family (berdasarkan pemilihan fitur chi-kuadrat pada nilai signifikansi 0,001)
Aktual Prediksi
Pan Men Smi Lam Eup Rut Bro Por Mor Apo Api Cra Myr Ach Ama Ara Aga Pan 2
Men 2
Smi 1
Lam 3
Eup 3
Rut 3
Bro 1
Por 2
Mor 2
Apo 1
Api 3
Cra 1
Myr 4
Ach 1 2
Ama 4
Ara 1
Aga 1
Keterangan :
18 Lampiran 4 Confusion matrix untuk kelas penyakit (berdasarkan pemilihan fitur chi-kuadrat pada nilai signifikansi 0,001)
Aktual Prediksi
PR K NRD KR PC SK PP
PR 7 1
K 3 1
NRD 1 7
KR 1
PC 1 10
SK 2
PP 4
Keterangan :
PR = Perawatan K = Kulit
NRD = Nyeri-Radang-Demam KR = Kronis
i
ABSTRACT
YOGA HERAWAN. Feature Extraction of Medicinal Plants using Chi-Square with Naïve Bayes Classifier. Supervised by YENI HERDIYENI.
This research presented a system for extracting terms and classifying medicinal plants documents using chi-square and naïve bayes classifier. Term extraction technique was used to make the classifier work efficiently and to increase classification accuracy. The criteria used in this research were the family of medicinal plants and utilization of medicinal plants for medication. The classification results were used to build an information retrieval system of Indonesian medicinal plants. This research used two significance levels for generating critical value, i.e 0.001 and 0.01. The experiment result showed that the critical value using significance level of 0.001 has better accuracy than the critical value using significance level 0.01. Accuracy of classification system using significance level of 0.001 were 97.44% for family and 89.74% for utilization of medicinal plants criteria. The information retrieval system tested using 29 queries about family and utilization of medicinal plants. The information retrieval system had an average value generated was 93.26%.
1
PENDAHULUAN
Latar belakang
Indonesia merupakan negara
megabiodiversity yang memiliki kekayaan tumbuhan obat. Indonesia memiliki lebih dari 38.000 spesies tanaman (Bappenas 2003). Sampai tahun 2001 Laboratorium Konservasi Tumbuhan, Fakultas Kehutanan IPB telah mendata bahwa tidak kurang dari 2.039 spesies tumbuhan obat berasal dari hutan Indonesia (Zuhud 2009). Kandungan kimia yang terdapat dalam jenis tumbuhan obat tersebut mendorong peneliti untuk melakukan penelitian tentang penyakit yang dapat diobati dari suatu jenis tumbuhan obat tertentu. Melalui media cetak dan elektronik hasil penelitian tersebut didokumentasikan untuk diinformasikan kepada masyarakat. Internet membuat dokumentasi elektronik tersebar dengan mudah di dalam maupun luar negeri. Mesin pencari internet digunakan oleh pengguna di seluruh dunia untuk mencari informasi terkait tumbuhan obat yang dikehendaki. Banyaknya jumlah dokumentasi elektronik tersebut mempengaruhi kinerja mesin pencari dalam mengembalikan dokumen yang relevan terhadap keinginan pengguna. Untuk meningkatkan kinerja mesin pencari diperlukan sistem pengelolaan dokumen yang lebih baik dari sebelumnya.
Untuk itu diperlukan sistem klasifikasi dokumen secara otomatis. Salah satu teknik klasifikasi dokumen adalah Naïve Bayes. Naïve Bayes merupakan classifier sederhana yang didasarkan pada penerapan teorema Bayes. Kelebihan teknik ini adalah mampu mengklasifikasikan dokumen dengan tepat serta mudah dalam pengimplementasiannya (Thabtah 2009). Dalam jangka panjang, dokumen penelitian yang akan terindeks semakin bertambah seiring berjalannya waktu. Kerja yang lebih berat harus dilakukan oleh sistem classifier jika hanya mengandalkan teknik klasifikasi dokumen saja, hal tersebut dikarenakan sistem klasifikasi mengambil isi dari uraian setiap dokumen. Salah satu cara untuk meningkatkan kinerja dari sistem klasifikasi adalah dengan menerapkan teknik pemilihan fitur dokumen. Ada beberapa teknik yang digunakan untuk melakukan pemilihan fitur dokumen antara lain Document Frequency Thresholding (DF), Information Gain (IG),
Mutual Information (MI), Term strength (TS)
dan Chi-square testing (X2) (Yimming 2003).
Chi-square merupakan teknik pemilihan fitur
dokumen yang sangat efektif untuk memilih kata penciri suatu dokumen namun tidak menurunkan akurasi sistem klasifikasi (Yimming 1997). Document frequency thresholding merupakan teknik yang sederhana untuk mengurangi jumlah kata yang akan diproses. Teknik Document frequency thresholding mudah untuk diimplementasikan (Yimming 1997).
Penelitian ini akan membandingkan kinerja pemilihan fitur dokumen antara teknik chi-kuadrat dan teknik document thresholding frequency (df) yang kemudian dilakukan pembangunan sistem klasifikasi
Naïve Bayes untuk mengklasifikasikan dokumen tumbuhan obat Indonesia. Dalam penelitian ini, sistem klasifikasi akan mengklasifikasikan dokumen berdasarkan kategori family tumbuhan obat dan penyakit yang dapat disembuhkan oleh suatu jenis tumbuhan obat. Hasil klasifikasi tersebut kemudian akan digunakan untuk membangun sistem mesin pencari dokumen.
Tujuan
Tujuan penelitian ini adalah mengembangkan sistem temu kembali informasi tumbuhan obat yang bekerja berdasarkan hasil pemilihan fitur dokumen serta Naïve Bayes sebagai penglasifikasi dokumen.
Ruang lingkup
Ruang lingkup penelitian ini meliputi :
1. Dokumen terbatas pada 32 jenis tumbuhan obat Indonesia (Lampiran 1). 2. Dokumen yang digunakan berformat
XML.
3. Sistem menglasifikasikan dokumen berdasarkan penyakit yang dapat disembuhkan dan family dari suatu tumbuhan obat tertentu.
Manfaat
Manfaat dari penelitian ini adalah mempercepat dan mempermudah pengguna dalam mencari informasi tentang tumbuhan obat Indonesia.
TINJAUAN PUSTAKA
Temu kembali informasi
1
PENDAHULUAN
Latar belakang
Indonesia merupakan negara
megabiodiversity yang memiliki kekayaan tumbuhan obat. Indonesia memiliki lebih dari 38.000 spesies tanaman (Bappenas 2003). Sampai tahun 2001 Laboratorium Konservasi Tumbuhan, Fakultas Kehutanan IPB telah mendata bahwa tidak kurang dari 2.039 spesies tumbuhan obat berasal dari hutan Indonesia (Zuhud 2009). Kandungan kimia yang terdapat dalam jenis tumbuhan obat tersebut mendorong peneliti untuk melakukan penelitian tentang penyakit yang dapat diobati dari suatu jenis tumbuhan obat tertentu. Melalui media cetak dan elektronik hasil penelitian tersebut didokumentasikan untuk diinformasikan kepada masyarakat. Internet membuat dokumentasi elektronik tersebar dengan mudah di dalam maupun luar negeri. Mesin pencari internet digunakan oleh pengguna di seluruh dunia untuk mencari informasi terkait tumbuhan obat yang dikehendaki. Banyaknya jumlah dokumentasi elektronik tersebut mempengaruhi kinerja mesin pencari dalam mengembalikan dokumen yang relevan terhadap keinginan pengguna. Untuk meningkatkan kinerja mesin pencari diperlukan sistem pengelolaan dokumen yang lebih baik dari sebelumnya.
Untuk itu diperlukan sistem klasifikasi dokumen secara otomatis. Salah satu teknik klasifikasi dokumen adalah Naïve Bayes. Naïve Bayes merupakan classifier sederhana yang didasarkan pada penerapan teorema Bayes. Kelebihan teknik ini adalah mampu mengklasifikasikan dokumen dengan tepat serta mudah dalam pengimplementasiannya (Thabtah 2009). Dalam jangka panjang, dokumen penelitian yang akan terindeks semakin bertambah seiring berjalannya waktu. Kerja yang lebih berat harus dilakukan oleh sistem classifier jika hanya mengandalkan teknik klasifikasi dokumen saja, hal tersebut dikarenakan sistem klasifikasi mengambil isi dari uraian setiap dokumen. Salah satu cara untuk meningkatkan kinerja dari sistem klasifikasi adalah dengan menerapkan teknik pemilihan fitur dokumen. Ada beberapa teknik yang digunakan untuk melakukan pemilihan fitur dokumen antara lain Document Frequency Thresholding (DF), Information Gain (IG),
Mutual Information (MI), Term strength (TS)
dan Chi-square testing (X2) (Yimming 2003).
Chi-square merupakan teknik pemilihan fitur
dokumen yang sangat efektif untuk memilih kata penciri suatu dokumen namun tidak menurunkan akurasi sistem klasifikasi (Yimming 1997). Document frequency thresholding merupakan teknik yang sederhana untuk mengurangi jumlah kata yang akan diproses. Teknik Document frequency thresholding mudah untuk diimplementasikan (Yimming 1997).
Penelitian ini akan membandingkan kinerja pemilihan fitur dokumen antara teknik chi-kuadrat dan teknik document thresholding frequency (df) yang kemudian dilakukan pembangunan sistem klasifikasi
Naïve Bayes untuk mengklasifikasikan dokumen tumbuhan obat Indonesia. Dalam penelitian ini, sistem klasifikasi akan mengklasifikasikan dokumen berdasarkan kategori family tumbuhan obat dan penyakit yang dapat disembuhkan oleh suatu jenis tumbuhan obat. Hasil klasifikasi tersebut kemudian akan digunakan untuk membangun sistem mesin pencari dokumen.
Tujuan
Tujuan penelitian ini adalah mengembangkan sistem temu kembali informasi tumbuhan obat yang bekerja berdasarkan hasil pemilihan fitur dokumen serta Naïve Bayes sebagai penglasifikasi dokumen.
Ruang lingkup
Ruang lingkup penelitian ini meliputi :
1. Dokumen terbatas pada 32 jenis tumbuhan obat Indonesia (Lampiran 1). 2. Dokumen yang digunakan berformat
XML.
3. Sistem menglasifikasikan dokumen berdasarkan penyakit yang dapat disembuhkan dan family dari suatu tumbuhan obat tertentu.
Manfaat
Manfaat dari penelitian ini adalah mempercepat dan mempermudah pengguna dalam mencari informasi tentang tumbuhan obat Indonesia.
TINJAUAN PUSTAKA
Temu kembali informasi
2 elektronik yang memenuhi kebutuhan
informasi tertentu (Manning et al. 2008). Sistem temu kembali informasi bertujuan untuk menjembatani kebutuhan informasi pengguna dengan sumber informasi.
Temu kembali informasi berkaitan dengan cara merepresentasikan, menyimpan, mengorganisasikan, dan mengakses informasi. Merepresentasikan dan mengorganisasikan suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya. Akan tetapi, untuk mengetahui informasi yang diinginkan pengguna bukan merupakan suatu hal yang mudah. Untuk itu pengguna harus menransformasikan informasi yang dibutuhkan ke dalam suatu kueri yang akan diproses mesin pencari (IR System), sehingga kueri tersebut merepresentasikan informasi yang dibutuhkan oleh pengguna. Dengan kueri tersebut, IR system akan menemukembalikan informasi yang relevan terhadap kueri (Baeza-Yates & Ribeiro-Neto 1999).
Klasifikasi
Klasifikasi adalah proses untuk menentukan kelas dari suatu objek tertentu. Pada klasifikasi dokumen, permasalahan yang muncul adalah sebagai berikut: diberikan sebuah deskripsi d X dari sebuah dokumen dimana X merupakan ruang dokumen. Sebuah himpunan tetap kelas
{ }, dengan menggunakan algoritme pembelajaran, dilakukan proses pembelajaran terhadap fungsi klasifikasi sehingga dapat memetakan dokumen pada kelas C.
Proses klasifikasi dibagi menjadi dua tahap, yaitu tahapan pembelajaran dan pengujian. Pada tahap pembelajaran, sebagian data yang telah diketahui kelasnya (data latih) digunakan untuk membuat model klasifikasi. Tahap pengujian menguji data uji dengan model klasifikasi untuk mengetahui akurasi model klasifikasi tersebut. Jika akurasi cukup maka model tersebut dapat digunakan untuk memprediksi kelas data yang belum diketahui (Han & Kamber 2006).
Pemilihan fitur dokumen
Pemilihan fitur dokumen merupakan suatu proses memilih sebanyak kata terbaik. Kata tersebut merupakan himpunan dari semua kata yang ada pada data latih.
Dalam penelitian ini, data dari himpunan tersebut akan digunakan sebagai penciri dokumen yang akan diklasifikasikan.
Pemilihan fitur dokumen memiliki dua tujuan utama yaitu membuat data latih yang diterapkan oleh sistem klasifikasi menjadi lebih sederhana serta untuk meningkatkan akurasi sistem klasifikasi. Peningkatan akurasi sistem klasifikasi disebabkan karena pada proses penghilangan fitur akan dihilangkan kata-kata yang bukan merupakan penciri dokumen (Manning et all 2008).
Keputusan statistik dan hipotesis statistik
Keputusan yang diambil berdasarkan informasi sampel yang didapatkan dari data disebut keputusan statistik. Sebagai contoh keputusan statistik adalah ketika akan memutuskan berdasarkan data sampel apakah suatu serum baru benar-benar efektif dalam menyembuhkan suatu penyakit, apakah suatu prosedur pendidikan lebih baik dari prosedur pendidikan lainnya.
Untuk mencapai suatu keputusan, diperlukan asumsi awal tentang populasi yang terlibat yang kemudian disebut sebagai hipotesis statistik. Hipotesis umumnya merupakan pernyataan umum yang berkaitan dengan distribusi probabilitas dari populasi. Hipotesis diperlukan untuk menentukan apakah hasil yang diduga cenderung untuk benar. Hipotesis nol (H0) menyatakan bahwa tidak ada perbedaan di dalam hasil yang sedang diperiksa atau disebut juga nol pengaruh (zero effect).
Chi-kuadrat ( )
Chi-kuadrat ( ) merupakan pengujian hipotesis mengenai perbandingan antara frekuensi sampel yang benar-benar terjadi (kemudian disebut frekuensi observasi) dengan frekuensi harapan yang didasarkan atas hipotesis tertentu pada setiap kasus atau data (selanjutnya disebut dengan frekuensi harapan .
Sampel berukuran N diambil dari suatu populasi normal berdeviasi standar σ. Untuk setiap sampel dihitung nilai sehingga diperoleh distribusi sampling untuk yang disebut distribusi chi-kuadrat.