RELASIONAL PADA DAS DAN RAID
TESIS
JUANDA HAKIM LUBIS
117038067
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
JUANDA HAKIM LUBIS 117038067
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
Judul : ANALISA PERFORMANSI BASIS DATA
DITINJAU DARI ASPEK OPTIMASI QUERY DAN DESAIN MODEL DATA RELASIONAL PADA DAS DAN RAID
Kategori : Tesis
Nama : Juanda Hakim Lubis
Nomor Induk Mahasiswa : 117038067
Program Studi : Magister (S2) Teknik Informatika
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dr. Zakarias Situmorang Prof. Dr. Herman Mawengkang
Diketahui/disetujui oleh
Program Studi Magister (S2) Teknik Informatika
Ketua,
ANALISIS PERFORMANSI DATABASE DITINJAU DARI ASPEK OPTIMASI QUERY DAN DESAIN MODEL DATA
RELASIONAL PADA DAS DAN RAID
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 25 Oktober 2013
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan dibawah ini :
Nama : Juanda Hakim Lubis
NIM : 117038067
Program Studi : Magister (S2) Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty Free Right) atas tesis saya yang berjudul :
ANALISIS PERFORMANSI DATABASE DITINJAU DARI ASPEK OPTIMASI QUERY DAN DESAIN MODELDATA
RELASIONAL PADA DAS DAN RAID
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 25 Oktober 2013
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Herman Mawengkang
Anggota : 1. Dr. Zakarias Situmorang
2. Prof. Dr. Muhammad Zarlis
3. Prof. Dr. Tulus, Vor.Dipl.Math., M.Si
DATA PRIBADI
Nama Lengkap : Juanda Hakim Lubis, ST
Tempat dan Tanggal lahir : Lhokseumawe, 10 April 1987
Alamat Rumah : Jl. Bhakti Indah V no.60
Telepon : 085311116436
E-mail : [email protected]
Instansi Tempat Bekerja : Dinas Kependudukan dan Catatan Sipil
Alamat Kantor : JL. KH. Zainul Arifin No.17A, Stabat
DATA PENDIDIKAN
SD : SD 2 Tamansiswa TAMAT : 1999
SLTP : SLTP Yayasan Pendidikan Arun (YAPENA) TAMAT : 2002
SLTA : SMA Negeri 1 Medan TAMAT : 2005
S1 : Institut Teknologi Telkom TAMAT : 2010
Tiada sanjungan dan pujian yang berhak diucapkan, selain hanya kepada Allah SWT,
yang telah memberi kemampuan dan akal kepada hamba-Nya. Salawat dan salam
kepada teladan kebaikan Rasulullah SAW.Alhamdulillah, akhirnya penulis dapat
menyelesaikan Tesis ini dengan bimbingan, arahan kritik dan saran serta bantuan dari
pembimbing, pembanding, segenap dosen, rekan-rekan mahasiswa Program Studi
Magister (S2) Teknik Informatika Universitas Sumatera Utara.
Tesis ini diajukan sebagai salah satu syarat untuk memperoleh gelar Magister Fakultas
Komputer pada Program Studi Pascasarjana Magister Teknik Informatika pada
Fakultas Ilmu Komputer – Teknologi Informasi Universitas Sumatera Utara.Dengan
judul tesis “Analisis Performansi Database Ditinjau dari Aspek Optimasi Query dan
Desain Model Data Relational pada DAS dan RAID”. Pada proses penulisan sampai
dengan selesainya penulisan tesis ini, penulis mengucapkan terima kasih yang
sebesar-besarnya kepada :
1. Ayahanda dan Ibunda, terima kasih untuk semua curahan cinta dan kasih
sayangnya, perhatian dorongan dan do’a yang tidak henti-hentinya. Semoga
selalu dalam lindungan Allah SWT.
2. Keluarga besar: kak irma, kak efa, dan kak sari yang telah memberikan
nasehat, motivasi dan doa untuk adiknya tercinta.
3. Prof. Dr. Muhammad Zarlis selaku Dekan Fakultas Ilmu Komputer dan
Teknologi Informasi sekaligus Ketua Program Studi Magister (S2) Teknik
Informatika, dan M. Andri Budiman, ST, M.Comp.Sc, M.EM selaku sekretaris
Program Studi Magister (S2) Teknik Informatika.
4. Prof. Dr. Herman Mawengkang dan Dr. Zakarias Situmorang selaku
pembimbing yang telah membimbing penulis dengan penuh kesabaran hingga
selesainya tesis ini dengan baik.
5. Prof. Dr. Muhammad Zarlis, Prof. Dr. Tulus, Vor.Dipl.Math., M.Si, Dr. Erna
Budhiarti Nababan, M.IT selaku pembanding yang telah memberikan masukan
Informasi Universitas Sumatera Utara yang telah memberikan bantuan dan
pelayanan terbaik kepada penulis selama mengikuti perkuliahan hingga saat
ini.
7. Vicky Laily Qonita, untuk semangat, do’a, inspirasi, mimpi yang diberikan
untuk penulis. Terima kasih atas segala bentuk dukungannya selama ini.
8. Rekan mahasiswa/i angkatan ke 4 tahun 2011 pada Program Studi Magister
(S2) Teknik Informatika Program Pascasarjana Fakultas Ilmu Komputer dan
Teknologi Informasi Universitas Sumatera Utara yang telah bersama-sama
saling membantu selama mengikuti perkuliahan.
9. Semua pihak yang tidak dapat penulis sebutkan satu persatu, terima kasih atas
bantuan yang telah diberikan kepada penulis selama ini
Dengan segala kekurangan dan kerendahan hati, sekali lagi penulis mengucapkan
terimakasih.Semoga kiranya Allah SWT membalas segala bantuan dan kebaikan yang
telah diberikan.
Medan, 25 Oktober 2013
Penulis
Jumlah data yang disimpan di piringan magnetik (disket, harddisk, dll) meningkat 100% pertahun, perdepartemen,perperusahaan sehingga diperlukan suatu upaya untuk menjaga kinerja sistem basis data agar tetap optimal.Desain basis data merupakan langkah awal yang dilakukan untuk membuat suatu sistem agar kinerja basis data agar tetap optimal.Akan tetapi proses desain belum cukup untuk meningkatkan kinerja basis data. Salah satu cara adalah dengan meningkatkan kecepatan transaksi data yaitu dengan meningkatkan kecepatan pemrosesan query dan menggunakan hardisk yang dapat diakses secara paralel. Pada penelitian ini akan dilakukan pengujian berbagai model basis data relasional dengan menggunakan berbagai jumlah data, kemudian akan dilakukan pengujian pada DAS (Direct-Attached Storage) dan RAID menggunakan berbagai query dengan outputan yang sama, sehingga akan dianalisa cost query menggunakan metode Cost Base Optimizer dan waktu pengaksesan disk.Sehingga hasil dari penelitian ini bertujuan memberikan masukan kepada administrator sistem basis data agar dapat mendesain model basis data relational dengan tepat, penggunaan teknologi hardisk dengan bijak, dan menggunakan query yang benar dalam pengambilan data dengan tujuan agar kinerja basis data tetap optimal. Hasil dari pengujian ini adalah 1) desain model basis dataakan dapat berkerja lebih optimal dengan cara melakukan pemisahan entity yang berasal dari penggunaan spesialisasi, 2) RAID 0 memiliki performansi paling baikdibandingkan DAS dan RAID-1 dikarenakan saat komputer mengakses sebuah block data di satu harddiskkomputer juga dapat mengakses block data di harddisk yang lainnya, 3) jumlah record, ukuran atribut, jenis atau bentuk query, penggunaan kolom unique key atau primary key, penggunaan order by, urutan indeks, penggunaan fungsi SQLdapat mempengaruhi cost suatu query dalam performansi query.
ABSTRACT
The amount of data that is stored in magnetic disk (floppy disk, harddisk, etc) increases 100% each year for each department for each company so an effort to maintain a database system to be optimal is needed. Designing a database is the initial step when creating a system with an optimal database performance. However, just designing the database is not enough to increase the performance of the database.One of the ways is to increase the speed of data transaction by increaseing the speed of query processing and using harddisks that can be accessed parallely. In this reaseach, the testing of different relationship database model will be done by using multiple amount of data then DAS and RAID will be tested by using multiple query with the same amount of output. The cost query then is going to be analyzed by using Cost Base Optimizer method and the disk access time. The result of this research is to give input to database system administrator to design relationship database model appropriately, to use the harddisk technology wisely, and to use the right query on retrieving records resulting the database performance optimum. The results of this testing are 1) database design model will be optimum by doing entity separation from specialize usage, 2) RAID 0 have much better performance compared to DAS and RAID-1 because when computer accessed a data block from a harddisk, the computer also can access another data block from another harddisk, 3) the amount of record, the size of attribute, the type of query, the usage of unique key or primary key column, the usage of order by, the sequence of index, the usage of SQL function can affect the cost of query in query performance.
PENGESAHAN 1i
PERNYATAAN ORISINALITAS iii
PERSETUJUAN PUBLIKASI iv
PANITIA PENGUJI v
RIWAYAT HIDUP vi
KATA PENGANTAR vii
ABSTRAK ix
ABSTRACT x
DAFTAR ISI xi
DAFTAR TABEL xiii
DAFTAR GAMBAR xiv
BAB 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Perumusan Masalah 3
1.3 Batasan Masalah 4
1.4 Tujuan Penelitian 4
1.5 Manfaat Penelitian 5
BAB 2 TINJAUAN PUSTAKA 6
2.1 Model Data 6
2.1.1 Basis Data Relasional 6
2.2 Entity Relationship Model 6
2.2.1 Entitas dan Himpunan Entitas 7
2.2.2 Atribut 8
2.2.3 Relasi 8
2.2.4 Diagram ER 11
2.3 Konversi ER ke Tabel 12
2.3.1 Himpunan Entitas Lemah 12
2.3.2 Spesialisasi 13
2.4 Normalisasi 14
2.5 Optimasi Query 14
2.5.1 Konsep Dasar Optimasi Query 14
2.5.2 Metode Akses 17
2.5.3 Perhitungan Cost Operasi Query 17
2.5.4 Pemrosesan Querypada Oracle 10g 19
2.6.2 Standar Level 22
BAB 3 METODE PENELITIAN 27
3.1 Pendahuluan 27
3.2 Rancangan Penelitian 29
3.3 Perangkat Keras dan Perangkat LunakPengujian Sistem 39
BAB 4 HASIL DAN PEMBAHASAN PENELITIAN 40
4.1 Hasil Penelitian 40
4.1.1 Hasil Penelitian Response Time 40
4.1.2 Hasil Penelitian Cost Query 48
4.2 Analisis Hasil Penelitian 50
4.2.1 Analisis Hasil Penelitian Response Time 50 4.2.2 Analisis Hasil Penelitian Cost Query Pada 55
BAB 5 KESIMPULAN DAN SARAN 59
5.1 Kesimpulan 59
5.2 Saran 60
DAFTAR PUSTAKA 61
LAMPIRAN 1 62
LAMPIRAN 2 65
TABEL 3.1. Jumlah Record pada ER Model 1 30
TABEL 3.2. Jumlah Record pada ER Model 2 30
TABEL 3.3. Jumlah Record pada ER Model 3 33
TABEL 4.1. Perbandingan Response Time pada Simple Query 41 TABEL 4.2. Perbandingan Response Time pada Aggregate Query 42 TABEL 4.3. Perbandingan Response Time pada Inner Join Query 43 TABEL 4.4. Perbandingan Response Time pada Outer Join Query 44 TABEL 4.5. Perbandingan Response Time pada Subquery 45 TABEL 4.6. Perbandingan Response Time pada Correlated Query 46 TABEL 4.7. Perbandingan Response Time pada Kompleks Query 47
GAMBAR 2.1. Himpunan Entitas Mahasiswa 7
GAMBAR 2.2. Contoh Himpunan Entitas 8
GAMBAR 2.3. Gambaran Himpunan Entitas di Tabel 8
GAMBAR 2.4. Relasi digambarkan dengan belah ketupat 9
GAMBAR 2.5. Relasi dengan Kardinalitas 1 ke 1 9
GAMBAR 2.6. Relasi dengan Kardinalitas 1 ke Banyak 10 GAMBAR 2.7. Relasi dengan Kardinalitas Banyak ke 1 10 GAMBAR 2.8. Relasi dengan Kardinalitas Banyak ke Banyak 11
GAMBAR 2.9. Contoh Diagram ER 11
GAMBAR 2.10. Contoh Himpunan Entitas Lemah 12
GAMBAR 2.11. Contoh Spesialisasi 13
GAMBAR 2.12. Tahapan Pemrosesan Query 15
GAMBAR 2.13. RAID 0 23
GAMBAR 2.14. RAID 1 23
GAMBAR 2.15. RAID 2 24
GAMBAR 2.16. RAID 3 25
GAMBAR 2.17. RAID 4 25
GAMBAR 2.18. RAID 5 26
GAMBAR 3.1. Skenario Pengujian 28
GAMBAR 3.2. ER Model 1 29
GAMBAR 3.3. ER Model 2 31
GAMBAR 3.4. ER Model 3 32
Jumlah data yang disimpan di piringan magnetik (disket, harddisk, dll) meningkat 100% pertahun, perdepartemen,perperusahaan sehingga diperlukan suatu upaya untuk menjaga kinerja sistem basis data agar tetap optimal.Desain basis data merupakan langkah awal yang dilakukan untuk membuat suatu sistem agar kinerja basis data agar tetap optimal.Akan tetapi proses desain belum cukup untuk meningkatkan kinerja basis data. Salah satu cara adalah dengan meningkatkan kecepatan transaksi data yaitu dengan meningkatkan kecepatan pemrosesan query dan menggunakan hardisk yang dapat diakses secara paralel. Pada penelitian ini akan dilakukan pengujian berbagai model basis data relasional dengan menggunakan berbagai jumlah data, kemudian akan dilakukan pengujian pada DAS (Direct-Attached Storage) dan RAID menggunakan berbagai query dengan outputan yang sama, sehingga akan dianalisa cost query menggunakan metode Cost Base Optimizer dan waktu pengaksesan disk.Sehingga hasil dari penelitian ini bertujuan memberikan masukan kepada administrator sistem basis data agar dapat mendesain model basis data relational dengan tepat, penggunaan teknologi hardisk dengan bijak, dan menggunakan query yang benar dalam pengambilan data dengan tujuan agar kinerja basis data tetap optimal. Hasil dari pengujian ini adalah 1) desain model basis dataakan dapat berkerja lebih optimal dengan cara melakukan pemisahan entity yang berasal dari penggunaan spesialisasi, 2) RAID 0 memiliki performansi paling baikdibandingkan DAS dan RAID-1 dikarenakan saat komputer mengakses sebuah block data di satu harddiskkomputer juga dapat mengakses block data di harddisk yang lainnya, 3) jumlah record, ukuran atribut, jenis atau bentuk query, penggunaan kolom unique key atau primary key, penggunaan order by, urutan indeks, penggunaan fungsi SQLdapat mempengaruhi cost suatu query dalam performansi query.
ABSTRACT
The amount of data that is stored in magnetic disk (floppy disk, harddisk, etc) increases 100% each year for each department for each company so an effort to maintain a database system to be optimal is needed. Designing a database is the initial step when creating a system with an optimal database performance. However, just designing the database is not enough to increase the performance of the database.One of the ways is to increase the speed of data transaction by increaseing the speed of query processing and using harddisks that can be accessed parallely. In this reaseach, the testing of different relationship database model will be done by using multiple amount of data then DAS and RAID will be tested by using multiple query with the same amount of output. The cost query then is going to be analyzed by using Cost Base Optimizer method and the disk access time. The result of this research is to give input to database system administrator to design relationship database model appropriately, to use the harddisk technology wisely, and to use the right query on retrieving records resulting the database performance optimum. The results of this testing are 1) database design model will be optimum by doing entity separation from specialize usage, 2) RAID 0 have much better performance compared to DAS and RAID-1 because when computer accessed a data block from a harddisk, the computer also can access another data block from another harddisk, 3) the amount of record, the size of attribute, the type of query, the usage of unique key or primary key column, the usage of order by, the sequence of index, the usage of SQL function can affect the cost of query in query performance.
PENDAHULUAN
1.1 Latar Belakang
Kinerja (performance) sistem basis data merupakan isu yang semakin penting saat
sistem basis data terkomputerisasi beranjak semakin besar dan kompleks.Hal ini
dibuktikan dari hasil sebuah survey Universitas California di BerkeleyLightstone,
jumlah data yang disimpan di piringan magnetik (disket, harddisk, dll) meningkat
100% pertahun, perdepartemen, perperusahaan, artinya setiap perusahaan di dunia
yang menggunakan komputer data yang dimilikinya akan meningkat 2 kali lipat
pertahun. Oleh sebab itu perlu suatu upaya untuk menjaga kinerja sistem basis data
agar tetap optimal.
Strategi penilaian dan perbaikan kinerja bervariasi dalam hal efektivitasnya,
dan sistem-sistem yang dirancang untuk berbagai tujuan, misalnya sistem operasional
atau Sistem Pendukung Keputusan (DSS-Decission Support System), masing-masing
membutuhkan ketrampilan pengaturan kinerja yang berbeda-beda.Dalam hal ini,
kinerja sistem dirancang dan dikembangkan untuk suatu sistem
terkomputerisasi.Selain itu, permasalahan kinerja tentu saja juga sangat dipengaruhi
oleh hasil dari perkembangan teknologi komputer. Saat sistem menjadi usang,
bagaimanapun juga pintarnya seorang administrator database melakukan
perancangan-perancangan dan pengaturan-pengaturan tidak akan mampu mencapai
peringkat kinerja yang tinggi. Selain itu pula, tingkat kinerja yang tinggi juga sangat
dipengaruhi oleh perancanaan serta perancangan sistem basis data.
Upaya perancangan basis data dapat ditempuh dengan mendesain sebuah
model dari awal sama sekali sampai dilakukan perbaikan-perbaikan untuk
mendapatkan sebuah model data yang lebih permanen dan lebih mendekati pada
keadaan yang sebenarnya. Desain basis data merupakan langkah awal yang dilakukan
Dengan desain basis data seorang praktisi dapat mengurangi waktu proses untuk
operasi bisnis dalam beberapa kasus. Akan tetapi proses desain belum cukup untuk
meningkatkan kinerja basis data. Salah satu cara adalah dengan meningkatkan
kecepatan transaksi data yaitu dengan mentukan kecepatan pemrosesan query. Hal
tersebut dapat meningkatkan kinerja antara 25% dan 100%, kadang-kadang bisa lebih
(Powell, 2007).
Dari sudut perancangan basis data, tabel-tabel yang dirancang dengan baik
serta dilengkapi dengan indeks-indeks yang representatif sangat membantu
kinerja.Kadang juga proses normalisasi tabel yang dilakukan secara sangat seksama,
memberi efek yang setara dengan perbaikan perangkat keras. Hal yang sama juga
berlaku dengan menggunakan hardisk yang dapat diakses secara paralel (misalnya
RAID [Redundant Array of Inexpensive Disk]) yang merupakan trend perangkat keras
untuk sistem basis data yang berukuran besar), yang pada gilirannya akan sangat
mempengaruhi kinerja sisem basis data. RAID adalah salah satu cara dalam
meningkatkan kinerja dan performansi disk yaitu dengan membentuk suatu sistem dari
beberapa hardisk atau drive sehingga terbentuk satu partisi dari beberapa hardisk yang
bertujuan sebagai toleransi kesalahan.
Beberapa penelitian yang telah dilakukan tentang optimalisasi basis data antara
lain, Panus & Pirkl (2010), melakukan penelitian dengan melakukan pengujian
terhadap pengaruh penggunaan Oracle Optimizer Hints (SQL Hints) dan Clasic SQL
Query pada proses eksekusi. Optimalisasi tersebut diukur dengan menggunakan Cost
Query dan CPU dari Query. Hasil pengujian menunjukan bahwa penggunaan SQL
Hints lebih unggul daripada Clasic SQL Query, akan tetapi dari segi avarage time saat
proses eksekusi, Clasic SQL Query lebih cepat dibandingkan menggunakan SQL
Hints. Chandra, et al.(2007), menjelaskan tentang optimasi query pada oracle yang
bertujuan untuk menemukan strategi atau rencana evaluasi query terbaik pada
pemrosesan query, sehingga time proses dan total cost dari proses eksekusi menjadi
lebih efisien dan lebih murah. Kavita (2012), melakukan penelitian dengan membuat
sebuah model Materialized View untuk meningkat performansi query sehingga
membantu para database adminstrator untuk melakukan manajemen Materialized
View secara tepat sehingga akan membawa keuntungan bagi perusahaan dari segi
efisiensi operasional karena laporan dihasilkan lebih cepat. Salim (2011), mengkaji 2
yang bertujuan untuk memperoleh query plan yang paling optimal sehingga akan
diperoleh waktu yang paling optimal. Dari kajiannya tersebut diperoleh suatu
kesimpulan bahwa Rule Base Optimization merupakan urutan plan dari query tunggal
yang biasanya digambarkan sebagai query tree, dimana masing-masing plan lebih
efisien dari plan sebelumnya. Sedangkan Cost based optimization akan
memperkirakan dan membandingkan cost dari eksekusi sebuah query menggunakan
strategi-strategi eksekusi yang berbeda dan memilih strategi dengan perkiraan cost
terendah. Cost dari masing-masing plan adalah merupakan perkiraan, dengan memilih
yang paling efisien.
Walaupun banyak penelitian yang dilakukan berkaitan dengan optimalisasi
basis data yang bertujuan untuk memperbaiki kinerja sistem basis data, pada tesis ini
dilakukan penelitian terhadap beberapa model basis data relasional dengan
menggunakan berbagai jumlah data, kemudian akan dilakukan pengujian pada DAS
(Direct-Attached Storage) dan RAID menggunakan berbagai query dengan outputan
yang sama, sehingga akan dianalisa cost query menggunakan metode Cost Base
Optimizer dan waktu pengaksesan disk.
Penelitian tesis ini akanmengajukan cara memperoleh cost query dan waktu
pengaksesan disk. Sehingga administrator sistem basis data dapat mendesain model
basis data relational dengan tepat, penggunaan teknologi hardisk dengan bijak, dan
menggunakan query yang benar dalam pengambilan data dengan tujuan agar kinerja
basis data tetap optimal.
1.2 Perumusan Masalah
Berdasakan pada latar belakang yang telah dikemukan dapat dirumuskan beberapa
masalah yaitu,ketika jumlah data semakin lama semakin besar,
makadiperlukanpemilihan suatu desain modeldata relational yang dapatmempengaruhi
kinerja database dalam kecepatantransaksi data.Akan tetapi hal itu saja belum cukup
untuk meningkatkan kinerja database, sehingga perlu dilakukan analisis yang
mempengaruhi kinerja pemrosesan query dan seberapa pengaruh hardisk yang dapat
1.3 Batasan Masalah
Rumusan masalah diatas, dibatasi dengan beberapa hal sebagai berikut :
1. Menggunakan data Inventori
2. Menggunakan model Entity Relationshipdiagram (diagram ER)
3. Bekerja pada sistem terpusat (centralized)
4. Menggunakan DBMS Oracle pada proses optimasiquery.
5. Metode yang digunakan dalam proses optimasiquery berdasarkan proses Cost
based optimizer pada DBMS Oracle 10g.
6. Hanya menggunakan indexyang standar dan tidak ada penambahan index.
7. Parameter pengukuran yang dianalisis adalah cost (pengaksesan disk) dari
suatu query.
8. Menggunakan setting database standar (General purpose database)
9. Menggunakan RAID Level 0 (RAID-0), RAID Level 1 (RAID-1)
1.4 Tujuan Penelitian
Tujuan yang ingin dicapai pada penelitian tesis ini, yaitu :
1. Untukmengetahui perancangan desain model data yang dapat menghasilkan
proses pengambilan data lebih cepat, dengan melakukan perbaikan-perbaikan
desain model data dengan memiliki kebutuhan informasi yang sama untuk
mendapatkan sebuah model data yang lebih cepat dibandingakan dengan
desain sebelumnya.
2. Menganalisis cost query dan time proses dari berbagai query yang dijalankan
pada berbagai desain model data dengan output yang sama menggunakan
metode Cost Base Optimizer sehingga mengetahui langkah eksekusi yang
diambil oleh DBMS dan cost query yang dihasilkan untuk mengeksekusi query
tersebut.
3. Untuk mendapatkan hasil pengujianperformansi hardisk pada DAS, RAID-0,
1.5 Manfaat Penelitian
Manfaat dari penelitian tesis ini, yaitu :
1. Memberikan masukan kepada administrator sistem basis data agar dapat
mendesain model basis data relational dengan tepat, penggunaan teknologi
hardisk dengan bijak, dan menggunakan query yang benar dalam pengambilan
data dengan tujuan agar kinerja basis data tetap optimal.
2. Sebagai referensi bagi hasil studi dan peneliti selanjutnya yang diminati dan
TINJAUAN PUSTAKA
2.1 Model Data
Untuk membangun suatu sistem aplikasi, basis data merupakan pemodelan keadaan
dari “Real word” atau dunia nyata. Upaya perancangan basis data dapat ditempuh
dengan membuat sebuah model dari awal sama sekali sampai dilakukan
perbaikan-perbaikan untuk mendapatkan sebuah model data yang lebih permanen dan lebih
mendekati pada keadaan yang sebenarnya.
Menurut SilberSchatz et al. (2002), model data adalah kumpulan perangkat
konseptual untuk menggambarkan data, hubungan data, semantik (makna) data dan
batasan data.
Model basis data relasional merupakan salah satu model basis data disamping
ada model basis data hirarki dan model basis data jaringan (network). Model basis
data relasional adalah model yang menggunakan kumpulan table yang masing-masing
tabelnya terdiri dari kumpulan baris/record dan atribut/field.
2.1.1 Basis Data Relasional
Basis data relasional adalah basis data yang setiap entitasnya disimpan kedalam
tabel-tabel. Basis data akan dipilah-pilah kedalam berbagai tabel 2 dimensi. Setiap table
terdiri atas lajur mendatar yang disebut baris data (row atau record) dan jalur vertikal
yang biasa disebut kolom (columnatau field).
2.2 Entity Relationship Model
Dalam membuat sebuah Basis Data, hal pertama yang harus dilakukan adalah
mendesain tabel tabel yang akan digunakan untuk menyimpan data sesuai bisnis
tentang basis data. Pandangan
kedalam bentuk tabel, karena
ER adalah salah satu
basis data ke dalam bentuk
entitas yang ada(SilberSchatz,et
nyata yang bisa dibedakan
hubungan yang terjadi diantara satu
2.2.1 Entitas dan Himpunan
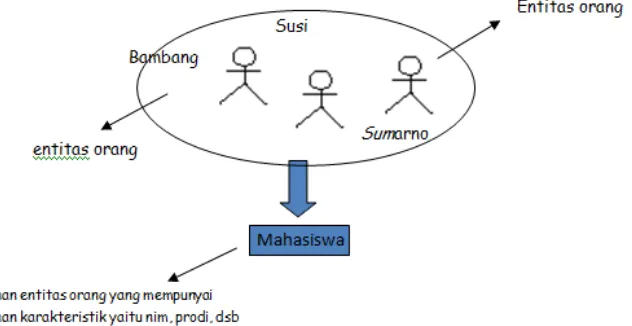
Definisi entitas adalah objek yang dirasa penting di sistem tersebut,
– Objek Konkrit
Contoh : Orang, Buku
– Objek Abstrak
Contoh : Jadwal, Pinjaman
Bambangadalah salah
sumarno merupakan him
Entitas (EntitySet) : Sekelompok
sama. Kumpulan entitas oran
dikatakan merupakan himpunan
individu suatu objek sedangkan
dari individu tersebut.
Gambar 2.
Pandangan konseptual ini tentunya harus bisa diimplementasikan
ntuk tabel, karena basis data relasional hanya mengenal tabel.
salah satu pemodelan basis data konseptual yang menggambarkan
dalam bentuk Entitas-Entitas dan Relasi yang terjadi di antara
SilberSchatz,et al. 2002). Entitas diartikan sebagai ‘objek
dibedakan dengan ‘objek’ yang lain. Relasi diartikan
hubungan yang terjadi diantara satu entitas dengan entitas yang lainnya.
Entitas dan Himpunan Entitas
ntitas adalah objek yang dirasa penting di sistem tersebut, yg bisa berupa :
Contoh : Orang, Buku
Contoh : Jadwal, Pinjaman, Tabungan
Bambangadalah salah satu contoh dari entitas. Sedangkan bambang,
n himpunan entitas orang. Dapat dikatakan bahwa
Sekelompok entitas yang sejenis dan berada dalam lingkup
entitas orang dengan karakteristik mempunyai nim, prodi,
merupakan himpunan entitas mahasiwa. Entitas menunjuk kepada
objek sedangkan himpunan entitas menunjuk pada rumpun
Gambar 2.1 Himpunan Entitas Mahasiswa
diimplementasikan
relasional hanya mengenal tabel.
yang menggambarkan
di di antara
entitas-objek’ didunia
diartikan sebagai
ersebut, yg bisa berupa :
Sedangkan bambang, susi,
bahwa Himpunan
dalam lingkup yang
nim, prodi, dsb bisa
menunjuk kepada pada
Sebuah entitas / himpunan
sebuah gambar persegi panjang.
dan pinjaman.
Gambar 2.
Setiap entitas mempunyai
gambaran konseptual basis
bentuk fisik dari basis data (* tabel dan kolom).
Gambar 2.
2.2.2 Atribut
Atribut merupakan gambaran
Contoh : atribut untuk himpunan
program studi, hobi, dsb.
batasan yg dibolehkan bagi suatu atribut.
2.2.3 Relasi
ER menggambarkan entitas
Relasimenggambarkan hubungan
dengan proses bisnisnya.
notasi belah ketupat.
Perhatikan contoh relasi antara mahasiswa dengan organisa
entitas / himpunan entitas dapat di gambarkan / di notasikan
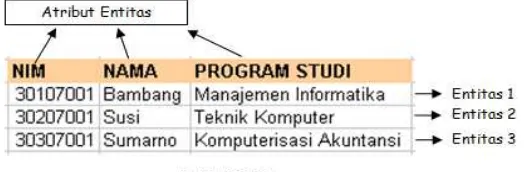
persegi panjang. Berikut merupakan contoh entitas mahasiwa,
Gambar 2.2 Contoh Himpunan Entitas
mempunyai atribut yang melekat pada entitas tersebut.
konseptual basis data (* entitas dan atribut) yang direfleksikan
k dari basis data (* tabel dan kolom).
Gambar 2.3 Gambaran Himpunan Entitas di Tabel
gambaran karakteristik dari sebuah entitas atau himpunan
untuk himpunan entitas mahasiswa adalah nim, nama,
, dsb.Setiap atribut mempunyai domain value set
yg dibolehkan bagi suatu atribut.
menggambarkan entitas-entitas dengan atributnya yang saling
menggambarkan hubungan antara entitas satu dengan entitas yang
bisnisnya. Notasi relasi didalam diagram ER digambarkan
Perhatikan contoh relasi antara mahasiswa dengan organisasi berikut.
di notasikan dengan
entitas mahasiwa, jadwal
entitas tersebut. Berikut
direfleksikan kedalam
atau himpunan entitas.
nama, alamat, ipk,
yaitu batasan
saling berelasi.
entitas yang lain sesuai
digambarkan dengan
Gambar 2.
Gambar di atas menunjukkan
organisasi. Relasi yang
mempunyai organisasi. Entitas
ipk, dsb. Sedangkan
nama_organisasi, jenis_org
2.2.3.1 Kardinalitas Relas
Kardinalias relasi menggambarkan
ber-relasi dengan entitas
biner, pemetaan kardinalitas relasi da Satu ke Satu
Gambar 2.
Relasi di atas
entitas A berpasangan
B. Asumsi
pj_cuci_piring.
maksimal 1
orang yang
maksimal 1,
itu relasi ini berkardi
Gambar 2.4 Relasi digambarkan dengan belah ketupat
atas menunjukkan hubungan antara entitas mahasiswa
yang terjadi adalah relasi mempunyai, dimana
organisasi. Entitas mahasiwa memiliki atribut nim, nama, alamat,
Sedangkan entitas organisasi memiliki atribut kd_organisasi,
sasi, jenis_organisasi (* olahraga/kesenian/jurusan dsb).
itas Relasi
asi menggambarkan banyaknya jumlah maksimum entitas
dengan entitas pada himpunann entitas yang lain. Pada himpunan
pemetaan kardinalitas relasi dapat berupa salah satu dari pilihan berikut :
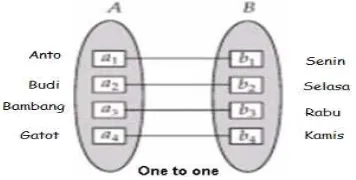
Satu ke Satu
Gambar 2.5 Relasi dengan Kardinalitas 1 ke 1
Relasi di atas menggambarkan bahwa untuk setiap entitas di
entitas A berpasangan dengan maksimal 1 entitas di himpunan
si penulis akan membuat sebuah tugas yaitu
pj_cuci_piring. 1 Orang di tugaskan untuk menjadi pj_cuci_piring
maksimal 1 hari. Begitupun juga jika di balik, pada 1 hari,
orang yang menjadi pj_cuci_piring. Dari A ke B kardinalitasnya
maksimal 1, dan dari B ke A kardinalitasnya maksimal 1.
u relasi ini berkardinalitas 1 ke 1.
mahasiswa dan entitas
dimana mahasiwa
nama, alamat, prodi,
atribut kd_organisasi,
maksimum entitas dapat
Pada himpunan relasi rupa salah satu dari pilihan berikut :
entitas di himpunan
di himpunan entitas
tugas yaitu menjadi
menjadi pj_cuci_piring di
1 hari, maksimal 1
B kardinalitasnya
Satu ke Banyak
Gambar 2.6 Relasi dengan Kardinalitas 1 ke Banyak
Relasi di atas menggambarkan bahwa untuk setiap entitas di himpunan
entitas A berpasangan dengan banyak entitas di himpunan entitas B.
Asumsi yang berbeda di pakai ketika memandang relasi ini, 1 orang
bisa memperoleh pj_cuci_piring untuk > 1 hari. Tetapi 1 hari hanya di
pj-kan hanya untuk maksimal 1 orang. Dari A ke B kardinalitasnya
maksimal adalah banyak, dan dari B ke A kardinalitasnya maksimal 1.
Oleh karena itu relasi ini berkardinalitas 1 ke banyak.
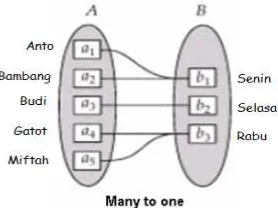
Banyak ke Satu
Gambar 2.7 Relasi dengan Kardinalitas Banyak ke 1
Relasi di atas menggambarkan bahwa untuk setiap entitas di himpunan
entitas A berpasangan dengan maksimal 1 entitas di himpunan entitas
B. Asumsikan bahwa untuk 1 hari pj_cuci_piring boleh di berikan pada
banyak orang, sedangkan 1 orang hanya di berikan tugas untuk menjadi
maksimal adalah
banyak. Oleh karena itu rel
Banyak ke Banyak
Gambar 2.
Relasi di atas
entitas A berpasangan
entitas B.
bebankan pada
menjadi pj_cuci_piring
maksimal adalah
adalah banyak.
banyak.
2.2.4 Diagram ER
Merupakan diagram model
basisdata berbasis grafis.
maksimal adalah 1, dan dari B ke A kardinalitasnya maksima
banyak. Oleh karena itu relasi ini berkardinalitas banyak ke 1.
Banyak ke Banyak
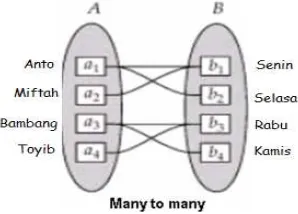
Gambar 2.8 Relasi dengan Kardinalitas Banyak ke Banyak
Relasi di atas menggambarkan bahwa untuk setiap entitas di
entitas A berpasangan dengan maksimal banyak entitas di
entitas B. Asumsikan bahwa dalam 1 hari pj_cuci_piring
bebankan pada banyak orang dan 1 orang bisa di bebankan
menjadi pj_cuci_piring lebih dari 1 hari. Dari A ke B kardinalitasnya
maksimal adalah banyak, dan dari B ke A kardinalitasnya
adalah banyak. Oleh karena itu relasi ini berkardinalitas
diagram model konseptual untuk menggambarkan struktur
Gambar 2.9 Contoh Diagram ER
alitasnya maksimal adalah
berkardinalitas banyak ke 1.
ke Banyak
entitas di himpunan
entitas di himpunan
pj_cuci_piring bisa di
di bebankan untuk
ke B kardinalitasnya
kardinalitasnya maksimal
berkardinalitas banyak ke
Notasi yang digunakan
o Garis
o Elips dobel
o Elips garis terputus
2.3 Konversi ER ke T
2.3.1 Himpunan Entitas Lem
Secara umum, Himpunan
bergantung pada entitas lain. Notasi
panjang, sedangkan relasi
diamond. Diskriminator /
entitas-entitas yang terdapat
dengan primary key. Konsep
lemah. Primary keypada Himpuna
kuat yg berelasi dan diskriminator /
Diskriminator di notas
Gambar 2.
Relasi di atas menggambarkan
tunjangan dari perusahaan
lemah. Tunjangan sebagai
bergantung pada entitas pegawai (* tidak akan ada t Notasi yang digunakan di Diagram ER adalah :
: Link yang menghubungkan atara Entitas
dengan atribut,dan entitas dengan
entitas
Elips dobel :Menunjukkan atribut yang multivalued
garis terputus :Menunjukkan atribut turunan
Tabel
ntitas Lemah
Himpunan Entitas Lemah tidak memiliki primary key
entitas lain. Notasi entitas lemah digambarkan dengan double
relasi untuk himpunan entitas lemah digambarkan deng
Diskriminator / key parsialadalah atribut-atribut yang dapat membedak
terdapat di himpunan entitas lemah. Diskriminator
. Konsep diskriminator hanya di pakai pada himpunan
pada Himpunan Entitas lemah ada 2 yaitu primary key
dan diskriminator / keyparsialnya.
Diskriminator di notasikan dengan garis bawah yang putus putus.
Gambar 2.10 Contoh Himpunan Entitas Lemah
atas menggambarkan bahwa seorang pegawai mendapatkan
perusahaan tempat dia bekerja. Tunjangan dalam hal ini adalah
sebagai entitas tidak bisa berdiri sendiri, tunjangan
as pegawai (* tidak akan ada tunjangan jika tidak ada pegawai). atara Entitas
dengan relasi atau
multivalued
key dan selalu
rkan dengan double persegi
digambarkan dengan double
t membedakan
Diskriminator tidak sama
pada himpunan entitas
primary keydari entitas
putus.
mendapatkan fasilitas
hal ini adalah entitas
tunjangan harus
Kardinalitas relasi
merupakan banyak ke 1
yang lebih kuat.
2.3.2 Spesialisasi
Spesialisasi merupakan proses
didalam didalam himpunan
spesialisasi adalah memberikan
dari himpunan entitas yang
pengelompokan.
Subgrouping di atas
memiliki atribut tersendiri
dan merupakan pembeda dar
gambar segitiga berlabelIS
Sifat dari spesialisasi
secara otomatis akan di turunkan pada level di bawahnya.
Contoh di atas menggambarkan
subgroupyaitu pegawai tetap
pegawai honorer sama sama
dari entitas pegawai. Perbedaa
atribut yang melekat pada
relasi yang terjadi pada himpunan entitas lemah
ke 1 atau 1 ke banyak dengan kardinalitas 1 di himpunan
merupakan proses desain top-down dengan mendesain
himpunan entitas yang berbeda dari himpunan entitas.
memberikan gambaran konseptual tentang perbedaan
itas yang hampir serupa dengan konsep sub
di atas menjadi himpunan entias yang levelnya lebih
tersendiri yang tidak dimiliki pada level di atasnya. Atribut
pembeda dari entitas di subgroupyang lain. IS A dinotasika
segitiga berlabelISA.
spesialisasi adalah inheritan atribut yaitu atribut pada
otomatis akan di turunkan pada level di bawahnya.
Gambar 2.11 Contoh Spesialisasi
atas menggambarkan bahwa entitas pegawai mempunya
pegawai tetap dan pegawai honorer. Kedua entitas pegawai
sama sama mempunyai atribut turunan yaitu nama dan
pegawai. Perbedaan dari pegawai tetap dan pegawai honorer
t pada subgroup-nya. Atribut besar tunjangan dan gaji
lemah biasanya
di himpunan entitas
mendesain subgrouping
entitas. Tujuan dari
perbedaan karakteristik
sub grouping /
levelnya lebih rendah dan
atasnya. Atribut ini khas
dinotasikan dengan
atribut pada level tinggi
pegawai mempunyai 2
pegawai tetap dan
nama dan id_pegawai
honorer terdapat di
hanya terdapat di himpunan entitas pegawai tetap, sedangkan atribut upah per jam dan
jumlah jam kerja terdapat di himpunan entitas pegawai honorer.
2.4 Normalisasi
Normalisasi merupakan cara pendekatan lain dalam membangun desain logik basis
data relasional yang tidak secara langsung berkaitan dengan model data, tetapi dengan
menerapkan sejumlah aturan dan criteria standar untuk menghasilkan stuktur tabel
yang normal.
Adapun bentuk normalisasi antara lain :
Bentuk normal tahap pertama (1st Normal Form/1NF)
Syaratnya jika sebuah tabel tidak memiliki atribut bernilai banyak
(multivalued attribut) atau dengan kata lain atribut yang atomik.
Bentuk normal tahap kedua (2nd Normal Form/2NF)
Syaratnya, memenuhi bentuk normal tingkat pertama, semua atribut yang
tidak termasuk dalam key primer memiliki ketergantungan fungsional
(KF) pada key primer yang utuh.
Bentuk normal tahap ketiga (3th Normal Form/3NF)
Syaratnya, memenuhi bentuk normal tingkat kedua. Tidak terdapat
ketergantungan fungsi transitif ( transitive functional dependency), yaitu
tidak terdapat ketergantungan fungsi antara atribut – atribut bukan kunci
ke atribut bukan kunci lainnya dalam tabel.
2.5 Optimasi Query
2.5.1 Konsep Dasar Optimasi Query
Menurut SilberSchatz et al. (2002) , query adalah sebuah pernyataan yang meminta
pengaksesan informasi. Query (permintaan) merupakan metode pengaksesan yang
paling sering digunakan. Dalam DBMS, query dinyatakan dalam SQL (Structured
Query Languange).
Dalam Database Management System (DBMS), query di proses melalui
Gambar 2.12 Tahapan Pemrosesan Query
Sebuah query yang diekspresikan dalam sebuah bahasa query tingkat tinggi
seperti SQL mula-mula harus dibaca, diuraikan dan disahkan (parser and translator).
Query tersebut kemudian dibentuk menjadi sebuah struktur data yang biasa disebut
dengan query tree. Dan kemudian DBMS (Database management system) harus
merencanakan sebuah strategi eksekusi untuk mendapatkan kembali hasil dari query
dari file-file database.
Query Optimizer memeriksa semua ekspresi-ekspresi aljabar yang sama untuk
query yang diberikan dan memilih salah satu dari ekspresi tersebut yang terbaik yang
memiliki perkiraan termurah. Dengan kata lain, tugas dari query optimizer adalah
menghasilkan sebuah rencana eksekusi. Proses ini disebut dengan optimisasi query.
Output dari Optimizer adalah evaluation plan, yaitu urutan rencana proses eksekusi
query oleh DBMS. Optimasi query merupakan sebuah proses untuk memilih
evaluation planyang terbaik untuk suatu query (Lewis, 2006). Query optimizeradalah
bagian dari DBMS yang melakukan fungsi optimasi query.
Ada beberapa tahapan dalam optimasi query, yaitu (Ramakrishnan, 1998) :
1. Membangkitkan plan-plan alternatif yang akan dipilih sebagai evaluation
plan.
2. Mengestimasi biaya eksekusi untuk setiap alternatif plan yang dihasilkan
pada tahap satu. Dari beberapa plan yang diperhitungkan, query optimizer
Optimasi query dapat dikategorikan menjadi 2 bagian, antara lain :
1. Cost Based Optimization
Pemilihan plan berdasarkan pada perkiraan biaya untuk setiap alternatif
plan. Optimizer akan memutuskan rencana eksekusi (execution plan )
mana yang terbaik dan paling efisien dengan mempertimbangkan pada
ketersediaan path aksesnya dan juga berdasar pada statistik informasi
untuk skema objek (tabel/indeks) yang di akses oleh sebuah sql statement.
Secara konsep, pendekatan cost-based terdiri atas 3 langkah berikut :
Optimizer membangkitkan seperangkat rencana eksekusi yang
potensial untuk SQL Statement berdasar pada ketersediaan path dan
petunjuk tentang sql statement tersebut.
Optimizer memperhitungkan cost pada tiap rencana eksekusi berdasarkan statistik pada kamus data untuk distribusi data dan
karakteristik maupun informasi tentang penyimpanan dari tabel, indeks,
dan partisi yang di akses oleh sebuah sql statement.
Optimizer membandingkan biaya setiap execution plan, dan kemudian memilih plan dengan biaya paling rendah
Adapun beberapa catatan mengenai hal ini, yaitu :
Cost dapat diartikan sebagai sebuah nilai resource yg dibutuhkan untuk eksekusi sql statement dari beberapa execution plannya
Optimizer menghitung cost dari tiap kemungkinan metode akses dan urutan pen-joinan berdasar estimasi resource seperti CPU time,
memori,I/O untuk ekseskusi statement sql menggunakan plan
Execution plan secara serial dengan cost besar butuh waktu eksekusi
lebih banyak daripada cost yg kecil
2. Rule Base Optimization
Pemilihan plan mengacu pada heuristic / petunjuk baku yang menentukan
prioritas eksekusi suatu operasi.
Pada dasarnya tujuan dari optimasi query menemukan jalan akses yang
termurah untuk meminimumkan total waktu pada saat proses sebuah query. Untuk
mencapai tujuan tersebut, maka diperlukan optimizeruntuk melakukan analisa query
dan untuk melakukan pencarian jalan akses.
2.5.2 Metode Akses
Metode akses /access method adalah metode-metode yang dapat dilakukan untuk
mengakses tuple dalam suatu relasi. Sebuah metode akses dapat berupa file scan
ataupun indeks dengan kondisi seleksi tertentu (Ramakrishnan, 1998).
Indeks adalah suatu metoda pengaksesan file data dari disk dengan menyimpan
alamat entri data file tersebut pada file lain yang berukuran lebih kecil dan lebih cepat
diakses. Indeks yang biasanya dipakai adalah indeks B+Tree dan Hash. Indeks
B+Tree dapat menjadi metode akses untuk seleksi operator <, <=, =, !=, >=, atau >.
Indeks hash dapat menjadi metode akses untuk seleksi dengan operator =.
Selektivitas sebuah metode akses adalah jumlah block yang diambil dengan
menggunakan metode akses tersebut. Metode akses yang paling selektif adalah
metode akses yang mengambil block paling sedikit. Penggunaan metode akses yang
paling selektif akan meminimalkan biaya pengambilan data.
2.5.3 Perhitungan Cost Operasi Query
Cost dari operasi query dapat dihitung dengan menjumlahkan beberapa parameter,
antara lain : biaya pengaksesan disk dan waktu proses CPU. Pengaksesan disk
merupakan faktor terpenting. Hal ini dikarenakan pengaksesan disk memakan biaya
lebih besar dibandingkan operasi dalam memori utama. Pada tugas akhir ini parameter
yang digunakan hanya biaya pengaksesan disk dimana merupakan jumlah
Sintaks umum SQL adalah sebagai berikut :
SELECT <daftar Attribute>
FROM <daftar Tabel>
WHERE <kondisi>
Dalam aljabar relasional, pernyataan SQL diatas terdiri atas beberapa operasi
yaitu projection, selection, dan join. Operasi select terdapat pada term-term klausa
WHERE. Operasi project terdapat pada daftar atribut list klausa SELECT. Operasi
join terdapat pada klausa FROM yang menyatakan daftar relasi lebih dari satu.
Kondisi join ditentukan dari term-term pada klausa WHERE.
1. Operasi Select
Operasi Select adalah operasi SQL yang digunakan untuk memilih sebuah
subset tuple-tuple dari sebuah relasi berdasarkan kondisi tertentu. Kondisi
tersebut terdapat dalam bentuk term-term pada klausa WHERE. Pada
umumnya, operasi select ditunjukkan oleh :
<kondisi pilihan>(R)
2. Operasi Project
Operasi Project adalah operasi SQL yang digunakan untuk memilih
atribut-atribut tertentu dari suatu relasi dan membuang atribut-atribut lainnya
yang tidak diperlukan. Pada umumnya operasi project ditunjukkan oleh :
π<daftar attribute>(R)
3. Operasi Join
Operasi Join adalah operasi SQL yang digunakan untuk
mengkombinasikan hubungan tuple-tuple dari dua relasi dengan suatu kondisi
penggabungan tertentu.Pada umumnya operasi project pada dua relasi
R(A1,A2,…An) dan S(B1,B2,…Bm) ditunjukkan oleh :
Dua relasi yang terlibat dibedakan menjadi relasi luar dan relasi dalam.
Untuk memudahkan, dalam left deep planterdapat konversi yaitu sub plan kiri
(L) dianggap sebagai relasi luar dan sub plan kanan (R) dianggap sebagai
relasi dalam.
2.5.4 Pemrosesan Querypada Oracle 10g
Pada saat sebuah query diproses, Oracle server prosesakan memeriksa apakah blok
data yang dibutuhkan ada di database buffer cache. Jika blok yang dibutuhkan tidak
terdapat di database buffer cache, maka server process akan melakukan pembacaan
untuk mencari blok yang dibutuhkan di data file untuk kemudian meletakkan
salinannya di database buffer cache. Jika saat pemrosesan query berikutnya
memerlukan blok yang sama dengan query sebelumnya, maka pemrosesan query
tersebut tidak memerlukan pembacaan data ke file fisik. Blok data yang berada di
memory dan tidak sering diakses akan dikeluarkan dari database buffer cache.
2.5.5 Explain Plan
Explain plan adalah suatu perintah yang digunakan untuk menampilkan perintah
eksekusi suatu query.
Dengan memanfaatkan explain plan kita bisa melihat langkah eksekusi yang
diambil oleh oracle, sehingga kita bisa meningkatkan performansi query kita.
Optimizer mengambil informasi tentang objek dan tipe dari query yang dijalankan,
kemudian memberikan keputusan bagaimana suatu query akan dieksekusi.
Contoh dari explain plan :
EXPLAIN PLAN SET statement_id = 'example_plan1' FOR
SELECT full_name FROM per_all_people_f
WHERE UPPER(full_name) LIKE 'Pe%' ;
Plan
---SELECT STATEMENT
Diatas menunjukan suatu contoh execution plan dari sebuah SELECT
statement. Tabel per_all_people_f diakses menggunakan full table scan.Seriap baris
dalam tabel per_all_people_f diakses, klausa WHERE clause dievaluasi untuk setiap
row.Kemudian SELECT statement mengembalikan row yang memenuhi klausa
where.
2.6 RAID
2.6.1 Konsep RAID
Dalam media penyimpanan data, disk rentan akan kerusakan yang akan
mengakibatkan hilangnya data dan turunnya kinerja disk. Salah satu cara dalam
meningkatkan kinerja dan performansi disk adalah RAID. RAID singkatan dari
Random Array of Inexpensive Disk. Metodenya dengan membentuk suatu sistem dari beberapa harddisk/drive sehingga terbentuk satu partisi dari beberapa harddisk,
dimana biasanya kita melakukan pembagian banyak partisi pada satu harddisk.
Kegunaan RAID adalah sebagai media perlindungan penyimpanan data sehingga
reliability data terjaga. RAID merupakan gabungan beberapa harddisk fisik ke dalam
sebuah unit logis penyimpanan, dengan menggunakan perangkat lunak atau perangkat
keras khusus.
Peningkatan Kehandalan dan Kinerja dari disk dapat dicapai melalui dua cara
(SilberSchatz,et al. 2002) :
1. Redudansi
Peningkatan kehandalan disk dapat dilakukan dengan redundansi, yaitu
menyimpan informasi tambahan yang dapat dipakai untuk membentuk kembali
informasi yang hilang jika suatu disk mengalami kegagalan.Salah satu teknik
untuk redundansi ini adalah dengan caramirroring atau shadowing, yaitu
dengan membuat duplikasi dari tiap - tiap disk. Jadi, sebuah disk logical terdiri
dari 2 disk physical, dan setiap penulisan dilakukan pada kedua disk, sehingga
jika salah satu disk gagal, data masih dapat diambil dari disk yang lainnya,
kecuali jika disk kedua gagal sebelum kegagalan pada disk pertama
diperbaiki.Pada cara ini, berarti diperlukan media penyimpanan yang dua kali
pengaksesan disk yang dilakukan untuk membaca dapat ditingkatkan dua kali
lipat dengan menggunakan RAID controller. Hal ini dikarenakan setengah dari
permintaan membaca dapat dikirim ke masing-masing disk.
2. Paralelisme
Peningkatan kinerja dapat dilakukan dengan mengakses banyak disk secara
paralel. Pada disk mirroring, di mana pengaksesan disk untuk membaca data
menjadi dua kali lipat karena permintaan dapat dilakukan pada kedua disk,
tetapi kecepatan transfer data pada setiap disk tetap sama. Kita dapat
meningkatkan kecepatan transfer ini dengan cara melakukan data striping ke
dalam beberapa disk. Data striping, yaitu menggunakan sekelompok disk
sebagai satu kesatuan unit penyimpanan, menyimpan bit data dari setiap byte
secara terpisah pada beberapa disk (paralel).
Adapun teknik-teknik yang digunakan dalam RAID sebagai berikut :
1. Teknik Stripping
Stripping merupakan teknik atau cara untuk pemecahan data ke beberapa disk.
Teknik ini meningkatkan performansi harddisk, dimana sekumpulan data dapat
dibaca dari beberapa harddisk pada satu waktu. Namun, apabila salah satu
harddisk mengalami kegagalan, maka harddisk lain pun tidak dapat berfungsi.
2. Teknik Mirroring
Mirroring merupakan teknik atau cara untuk penyalinan data ke lebih dari satu
harddisk. Teknik ini dapat meningkatkan proses pembacaan data, namun untuk
menulis kinerjanya lebih buruk karena data yang sama akan tertulis pada
2.6.2 Standar Level
Untuk skema level standard tersusun atas beberapa level. Beberapa variasi
dikembangkan untuk non nested level dan nested level.
Berikut ini jenis-jenis dari RAID non-nested level :
1. RAID 0
Dikenal dengan modus stripping.Membutuhkan minimal 2
harddisk.Sistemnya adalah menggabungkan kapasitas dari beberapa
harddisk.Sehingga secara logikal hanya "terlihat" sebuah harddisk dengan
kapasitas yang besar (jumlah kapasitas keseluruhan harddisk).
Pada awalnya, RAID 0, digunakan untuk membentuk sebuah partisi yang
sangat besar dari beberapa harddisk dengan biaya yang efisien.
Contoh: Peneliti membutuhkan suatu partisi dengan ukuran 2TB. Harga
sebuah harddisk berukuran 500GB adalah Rp.400.000,- sedangkan harga
harddisk berukuran 2TB adalah Rp.2.500.000,-. Maka peneliti dapat
membetuk suatu partisi berukuran 2TB dari 4 unit harddisk berukuran
500GB dengan menggunakan RAID 0. Tentunya skenario ini lebih murah
karena memakan biaya lebih murah: 4 x Rp.400.000,- = Rp.2.000.000,-.
Lebih murah daripada harus membeli harddisk yang berukuran 2TB.Oleh
sebab itu kenapa pada awalnya disebut redundant array of inexpensive
disk.
Data yang ditulis pada harddisk-harddisk tersebut terbagi-bagi menjadi
fragmen-fragmen.Dimana fragmen-fragmen tersebut disebar di seluruh
harddisk.Sehingga, jika salah satu harddisk mengalami kerusakan fisik,
maka data tidak dapat dibaca kembali.
Namun ada keuntungan dengan adanya fragmen-fragmen ini: kecepatan.
Data bisa diakses lebih cepat dengan RAID 0, karena saat komputer
membaca sebuah fragmen di satu harddisk, komputer juga dapat membaca
Gambar 2.13 RAID 0
2. RAID 1
Biasa disebut dengan modus mirroring.Membutuhkan minimal 2 harddisk.
Sistem ini memiliki kelebihan, yaitu menyalin isi sebuah harddisk ke
harddisk lain dengan tujuan: jika salah satu harddisk rusak secara fisik,
maka data tetap dapat diakses dari harddisk lainnya. Proses untuk
membaca data dapat dilakukan dengan setengah dari permintaan membaca
dikirim ke masing-masing disk (proses membaca data baik) atau membaca
data dilakukan dengan membaca dari kedua disk (proses membaca data
buruk). Hal ini tergantung kepada RAID Controllernya.
Contoh: Sebuah server memiliki 2 unit harddisk yang berkapasitas
masing-masing 500GB dan dikonfigurasi RAID 1. Setelah beberapa tahun,
salah satu harddisknya mengalami kerusakan fisik.Namun data pada
harddisk lainnya masih dapat dibaca, sehingga data masih dapat
diselamatkan selama bukan semua harddisk yang mengalami kerusakan
fisik secara bersamaan.
3. RAID 2
RAID 2, juga menggunakan sistem stripping. Namun ditambahkan tiga
harddisk lagi untuk pariti hamming, sehingga data menjadi lebih
handal.Karena itu, jumlah harddisk yang dibutuhkan adalah minimal 5
(n+3, n > 1).Ketiga harddisk terakhir digunakan untuk menyimpan
hamming code dari hasil perhitungan tiap bit-bit yang ada di harddisk
lainnya.
Contoh: Peneliti memiliki 5 buah harddisk (sebut saja harddisk A,B,C, D,
dan E) dengan ukuran yang sama, masing-masing 500GB. Jika
mengkonfigurasi keempat harddisk tersebut dengan RAID 2, maka
kapasitas yang didapat adalah: 2 x 500GB = 1TB (dari harddisk A dan B).
Sedangkan harddisk C, D, dan E tidak digunakan untuk penyimpanan
data, melainkan hanya untuk menyimpan informasi pariti hamming dari
dua harddisk lainnya: A dan B. Ketika terjadi kerusakan fisik pada salah
satu harddisk utama (A atau B), maka data tetap dapat dibaca dengan
memperhitungkan pariti kode hamming yang ada di harddisk C,D, E.
Gambar 2.15 RAID 2
4. RAID 3
RAID 3, juga menggunakan sistem stripping. Namun hanya ditambahkan
sebuah harddisk lagi untuk parity.. Karena itu, jumlah harddisk yang
dibutuhkan adalah minimal 3 (n+1 ; n > 1). Harddisk terakhir digunakan
untuk menyimpan parity dari hasil perhitungan tiap bit-bit yang ada di
harddisk lainnya.
Contoh: Peneliti memiliki 4 harddisk (sebut saja harddisk A,B,C, dan D)
keempat harddisk tersebut dengan RAID 3, maka kapasitas yang didapat
adalah: 3 x 500GB = 1,5TB. Sedangkan harddisk D tidak digunakan untuk
penyimpanan data, melainkan hanya untuk menyimpan informasi parity
dari ketiga harddisk lainnya: A, B, dan C. Ketika terjadi kerusakan fisik
pada salah satu harddisk utama (A, B, atau C), maka data tetap dapat
dibaca dengan memperhitungkan parity yang ada di harddisk D. Namun,
jika harddisk D yang mengalami kerusakan, maka data tetap dapat dibaca
dari ketiga harddisk lainnya.
Gambar 2.16 RAID 3
5. RAID 4
Sama dengan sistem RAID 3, namun menggunakan parity dari tiap block
harddisk, bukan bit. Kebutuhan harddisk minimalnya juga sama, 3 (n+1 ;
n >1). Kelebihannya yaitu pembacaan data transaksi dan tingkat
perpindahan saat penggabungan proses baca sangat tinggi. Akan tetapi
data sulit dibentuk ulang jika terjadi kegagalan disk,serta penulisan data
transaksi dan tingkat perpindahan saat penggabungan proses tulis sangat
buruk.
6. RAID 5
RAID 5 pada dasarnya sama dengan RAID 4, namun dengan pariti yang
terdistribusi. Yakni, tidak menggunakan harddisk khusus untuk
menyimpan paritinya, namun paritinya tersebut disebar ke seluruh
harddisk. Kebutuhan harddisk minimalnya juga sama, 3 (n+1 ; n >1). Hal
ini dilakukan untuk mempercepat akses dan menghindari bottleneck yang
terjadi karena akses harddisk tidak terfokus kepada kumpulan harddisk
yang berisi data saja. Kekurangan dari RAID 5 adalah sulit untuk
membentuk kembali jika terjadi kegagalan disk.
METODE PENELITIAN
3.1 Pendahuluan
Pembahasan dalam tesis ini akan menggunakan struktur data Inventori suatau
perusahaan tertentu. Aplikasi yang akan dibangun merupakan tools simulasi untuk
menganalisa performansi query yang dihasilkan dari tiap desain model data, sehingga
tidak terlalu memperhatikan faktor-faktor pendukung IMK (Interaksi Manusia
Komputer) seperti interface yang user friendly. Aplikasi ini akan meminta user untuk
memasukkan statement query dan kemudian menganalisis keluaran dari aplikasi
berupa hasil dari query, data statistik berupa cost query (disk I/O) serta
responstimenya.
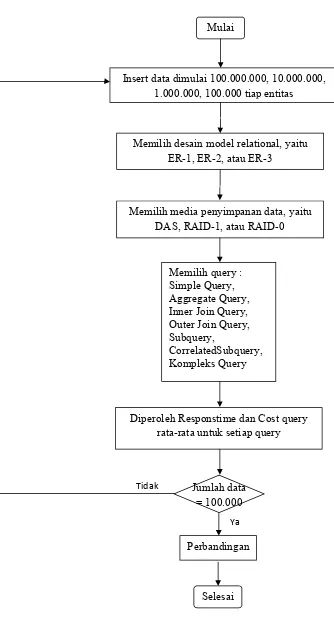
Dengan menggunakan perangkat lunak yang telah dibuat, akan dilakukan 3
skenario pengujian (gambar 3.1) dengan memasukan berbagai statement query dari 3
model data berdasarkan proses bisnis yang akan dianalisa. Skenario pertama, pegujian
akan dilakukan pada DAS . Skenario kedua, pengujian akan dilakukan pada RAID 1.
Skenario ketiga, pengujian akan dilakukan pada RAID 0. Untuk masing skenario,
pengujian akan dilakukan dengan menggunakan data yang berbeda-beda, yaitu
minimal jumlah data 100.000, 1.000.000, 10.000.000, dan 100.000.000 untuk setiap
entity yang dihasilkan pada desain model data pertama (desain ER-1).
Query yang dibuat dalam pengujian ini dibedakan menjadi 7 jenis yaituSimple
Query, Aggregate Query, Inner Join Query, Outer Join Query, Subquery, Correlated
Subquery, Kompleks Query yang digunakan baik untuk RAID maupun DAS.
Setiap pengujian terhadap statement query akan diperoleh waktu dan costnya.
Waktu yang diperoleh yaitu waktu time proses rata-rata untuk setiap query. Cost yang
diperoleh adalah total pengaksesan disk dimana merupakan jumlah pengambilan
Gambar 3.1Skenario Pengujian Mulai
Perbandingan
Memilih desain model relational, yaitu ER-1, ER-2, atau ER-3
Diperoleh Responstime dan Cost query rata-rata untuk setiap query
Selesai Memilih query : Simple Query, Aggregate Query, Inner Join Query, Outer Join Query, Subquery,
CorrelatedSubquery, Kompleks Query
Insert data dimulai 100.000.000, 10.000.000, 1.000.000, 100.000 tiap entitas
Memilih media penyimpanan data, yaitu DAS, RAID-1, atau RAID-0
Ya Jumlah data
3.2 Rancangan Penelitian
Rancangan penelitian ini pertama kali dilakukan adalah dengan merancang berbagai
desain model data dengan memiliki kebutuhan informasi yang sama. Selanjutnya akan
dilakukan pengujian dengan berbagai jenis query dan menggunakan jumlah data yang
berbeda-beda pada media penyimpanan data yang dipilih, yaitu DAS, RAID-1, atau
RAID-0.
Desain model yang digunakan untuk pengujian, yaitu :
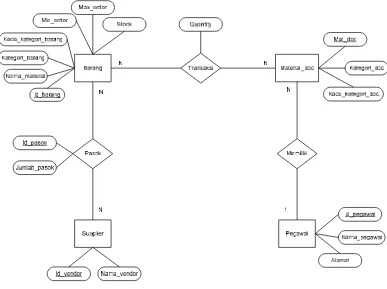
1. Diagram ER-1
Pada model ER-1 (gambar 3.2) , meggunakan desain yang sangat
sederhana dimana hanya menjelaskan tentang entity barang, supplier,
pegawai,material_doc, serta memiliki relasi transaksi dan pasok. Dengan
desain yang sederhana ini, sudah mampu mencakup informasi yang
dibutuhkan.
Berikut ini merupakan jumlah data untuk masing-masing pengujian pada desain
model ER-1. Data yang digunakan diperluas hingga 100.000.000 dari data
aslinya, yaitu :
Tabel 3.1 Jumlah Record Pada ER Model 1
Atribut
Jumlah Data Masing-Masing Pengujian
Pengujian 1 Pengujian 2 Pengujian 3 Pengujian 4
Barang 100.068.428 10.068.428 1.068.428 108.427
Karyawan 100.048.368 10.048.368 1.048.368 101.295
Material Doc 100.054.085 10.054.085 1.054.085 152.175
Pasok 100.022.952 10.022.952 1.022.952 102.952
Supplier 100.002.381 10.002.381 1.002.381 102.380
Transaksi 100.153.237 10.153.237 1.153.237 129.998
2. Diagram ER-2
Pada model ER-2 (gambar 3.3), meggunakan desain dengan sedikit
perubahan dari model ER-1, yaitu adanya variasi IS-A pada entity
material_doc untuk membedakan jenis barang dan jenis material_doc yang
sebelumnya tidak terdapat pada model ER-1, sehingga adanya penambahan
entity material_doc_terima dan material_doc_ambil.
Berikut ini merupakan jumlah data untuk masing-masing pengujian pada
desain model ER-2.Data yang digunakan berasal dari desain model ER-1,
yaitu :
Tabel 3.2 Jumlah Record Pada ER Model 2
Atribut
Jumlah Data Masing-Masing Pengujian
Pengujian 1 Pengujian 2 Pengujian 3 Pengujian 4
Barang 100.068.428 10.068.428 1.068.428 108.427
Karyawan 100.048.368 10.048.368 1.048.368 101.295
Tabel 3.2 Jumlah Record Pada ER Model 2 (Lanjutan)
Material Doc Ambil 50.041.660 5.041.660 541.660 90.521
Material Doc Terima 50.012.425 5.012.425 512.425 61.654
Pasok 100.022.952 10.022.952 1.022.952 102.952
Supplier 100.002.381 10.002.381 1.002.381 102.380
Transaksi 100.153.237 10.153.237 1.153.237 129.998
3. Diagram ER-3
Pada model ER-3 (gambar 3.4), sedikit berbeda dengan ER-2 yaitu tidak
adanya variasi IS-A pada material_doc untuk membedakan jenis
material_doc. Tetapi, pada model ER-3 ini jenis material_doc dipecah
menjadi 2 entity, yaitu entity material_doc_ambil dan material_doc_terima,
sehingga terjadi penambahan relasi transaksi-1 dan transaksi-2.
Berikut ini merupakan jumlah data untuk masing-masing pengujian pada desain
model ER-3. Data yang digunakan berasal dari desain model ER-2, yaitu :
Tabel 3.3 Jumlah Record Pada ER Model 3
Atribut
Jumlah Data Masing-Masing Pengujian
Pengujian 1 Pengujian 2 Pengujian 3 Pengujian 4
Barang 100.068.428 10.068.428 1.068.428 108.427
Karyawan 100.048.368 10.048.368 1.048.368 101.295
Material Doc Ambil 50.041.660 5.041.660 541.660 90.521
Material Doc Terima 50.012.425 5.012.425 512.425 61.654
Pasok 100.022.952 10.022.952 1.022.952 102.952
Supplier 100.002.381 10.002.381 1.002.381 102.380
Transaksi_1 25.589.439 2594181 294655 111.473
Transaksi_2 74.563.798 7559056 858582 18.525
Query yang dibuat dalam pengujian ini dibedakan menjadi 7 jenis yaitu Simple
Query, Aggregate Query, Inner Join Query, Outer Join Query, Subquery, Correlated
Subquery, Kompleks Query yang digunakan pada masing-masing desain model data
relational dengan output yang sama pada DAS, RAID 1, RAID 0 .
Setiap pengujian terhadap statement query akan diperoleh waktu dan costnya.
Waktu yang diperoleh yaitu waktu response time rata-rata untuk setiap query. Cost
yang diperoleh adalah total pengaksesan disk dimana merupakan jumlah pengambilan
page dari disk ke memori.
Statement query yang digunakan untuk pengujian yaitu :
1. Simple Query ER-1
select mat_doc,id_pegawai from material_doc
ER-2
select a.mat_doc mat_doc, a.id_pegawai id_pegawai
from material_doc_ambil a, material_doc b
where a.mat_doc = b.mat_doc and a.mat_doc = 4900005190
ER-3
select mat_doc_ambil mat_doc,id_pegawai from material_doc_ambil
where mat_doc_ambil = 4900005190
2. Aggregate Query ER-1
select count(*) Total from material_doc where kode_kategori_doc =113
ER-2
select Count(*) Total from material_doc_terima a, material_doc b
where a.mat_doc = b.mat_doc and a.kode_kategori_doc = 113
ER-3
select count(*) Total from material_doc_terima
3. Inner Join Query ER-1
select c.id_barang, a.nama_pegawai,c.quantity
from transaksi c inner
join material_doc b
on c.mat_doc = b.mat_doc inner
join karyawan a
on b.id_pegawai = a.id_pegawai