PENERAPAN DYNAMIC DENSITY BASED CLUSTERING
PADA DATA KEBAKARAN HUTAN
FANI WULANDARI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENERAPAN DYNAMIC DENSITY BASED CLUSTERING
PADA DATA KEBAKARAN HUTAN
FANI WULANDARI
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
FANI WULANDARI. Implementation of Dynamic Density Based Clustering on Forest Fire Data. Supervised by ANNISA.
Land and forest fire has become prominent issues in Indonesia. Possibilities of the occurrence of forest fire in Indonesia has increased from year to year. This makes early prevention very important for forest fire investigation. One of the efforts concerning the forest fire prevention is by knowing the distribution of hotspot clustering which have high potential for the occurrence of forest fire. This research has classified the hotspot data using Dynamic Density Based Clustering (DDBC) algorithm. The use of DDBC technique is capable of handling spatiotemporal aspects simultaneously by storing the position of each point. The storage of each point’s position is estimated using the strength of its relationship to other points that appear every year. The neighborhood concept of DDBC algorithm is a modified version of the neighborhood concept of the Density Based Spatial Clustering (DBSCAN) called Relationship Strength Threshold (RST). Cluster detection is performed on the points that fulfill the RST neighborhood value, so that only the point which was considered as a strong relationship will be grouped. The result of the clustering obtained through DDBC technique is the grouping of areas with high potential for forest fire occurrence. Visualization of the clustering results is presented based on a map that describe the distribution of hotspot so that the authorities can determine the prioritized areas for early forest fire prevention.
Menyetujui:
Pembimbing
Annisa, S.Kom, M.Kom NIP. 19790731 200501 2 002
Mengetahui:
Ketua Departemen Ilmu Komputer
Dr. Ir. Agus Buono, M.Si, M.Kom NIP. 19660702 199302 1 001
PRAKATA
Puji dan syukur penulis panjatkan kehadirat Allah subhanahu wa-ta’ala atas segala rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan tugas akhir dengan judul Penerapan Dynamic Density Based Clustering pada Data Kebakaran Hutan. Penelitian ini dilaksanakan mulai Mei 2011 sampai dengan Oktober 2011, bertempat di Departemen Ilmu Komputer Institut Pertanian Bogor.
Penulis menyampaikan terima kasih kepada pihak-pihak yang telah membantu dalam penyelesaian tugas akhir ini antara lain:
1 Papa, Mama, dan kakak tersayang Pandu Wicaksana yang tiada henti-hentinya memberikan doa, kasih sayang, nasihat dan dukungan kepada penulis.
2 Ibu Annisa, S.Kom., M.Kom. selaku dosen pembimbing yang telah banyak memberikan arahan dan bimbingan dengan sabar kepada penulis dalam menyelesaikan skripsi ini.
3 Bapak Hari Agung Adrianto, S.Kom., M.Si dan Bapak Toto Haryanto, S.Kom., M.Si selaku dosen penguji yang telah memberikan banyak masukan dan nasihat.
4 Yuridhis Kurniawan, M. Yoga Permana, Dhieka Avrilia Lantana, Dedek Apriyani, Ayi Imaduddin, Remarchtito Heyziputra, Muhammad Arif Fauzi dan Hidayat sebagai teman satu bimbingan yang selalu memberikan kritik, saran, dan semangat kepada penulis.
5 Agus Umriadi, Dika Satria, Fadly Hilman, Khamdan Amin, Aulia Retnoningtyas, Febriandini Harvina, dan Giovanni Anggra atas segala bantuan, ilmu, dan perhatian yang diberikan kepada penulis.
6 Woro Indriyani, Laras Mutiara Diva, Tri Setiowati, Ria Astriratma, Aprilia Ramadhina, Dipta Aditya, Fanny Risnuraini, Arif Nofyansyah, Fani Valerina, Isna Mariam, Ira Nurazizah, Sulma Mardiah, Windy Wahyu A.I, dan seluruh rekan-rekan Ilkomerz 44 atas doa, dukungan, suka, maupun duka yang senantiasa diberikan selama menjalani kehidupan sebagai mahasiswa. 7 Seluruh pihak yang terlibat secara langsung maupun tidak langsung atas segala bantuan, kerja
sama dan kenangan indah yang tidak akan pernah terlupakan.
Penulis menyadari bahwa masih terdapat kekurangan dalam penulisan skripsi ini. Semoga tulisan ini bermanfaat bagi pembacanya.
Bogor, Januari 2012
RIWAYAT HIDUP
Fani Wulandari dilahirkan di Depok pada tanggal 26 Maret 1990 dan merupakan anak kedua dari dua bersaudara dengan ayah bernama Hardono dan ibu bernama Rukmini.
Pada tahun 2007 lulus dari SMA Negeri 4 Depok dan diterima di Program Studi Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui jalur Seleksi Penerimaan Mahasiswa Baru (SPMB).
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... vi
DAFTAR TABEL ... vi
PENDAHULUAN Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup ... 1
Manfaat Penelitian ... 2
TINJAUAN PUSTAKA Data Mining ... 2
Hotspot (Titik Panas) ... 2
Clustering ... 2
Spatiotemporal Data ... 2
Density Based Clustering (DENCLUE) ... 3
Density Based Spatial Clustering (DBSCAN) ... 3
Dynamic Density Based Clustering (DDBC) ... 4
METODE PENELITIAN Pengolahan Data ... 6
Keterkaitan antar Titik ... 7
Cluster Detection ... 8
Performansi Hasil Cluster ... 9
Visualisasi Clustering ... 9
Implementasi ... 9
HASIL DAN PEMBAHASAN Praproses Data ... 9
Estimasi Hubungan Titik ... 10
Modifikasi Ketetanggan ... 11
Deteksi Cluster ... 12
Evaluasi Hasil Cluster ... 13
KESIMPULAN DAN SARAN Kesimpulan ... 14
Saran ... 14
DAFTAR PUSTAKA ... 14
DAFTAR GAMBAR
Halaman
1 Deskripsi data spatiotemporal (Rahim 2006). ... 2
2 Ilustrasi konsep directly density- reachable. ... 3
3 Ilustrasi konsep density-reachable. ... 3
4 Ilustrasi konsep density-connectivity. ... 3
5 Metodologi penelitian. ... 5
6 Langkah-langkah dalam tahap estimasi hubungan... 7
7 Mekanisme dalam deteksi cluster. ... 8
8 Langkah-langkah deteksi cluster dengan algoritme DDBC. ... 9
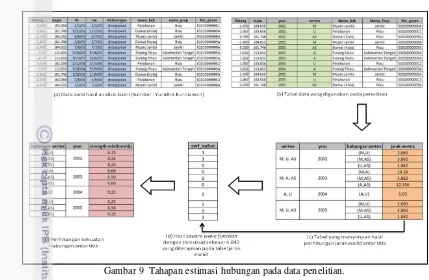
9 Tahapan estimasi hubungan pada data penelitian. ... 11
10 Perhitungan nilai RST. ... 11
11 Potongan fungsi ExpandCluster pada proses clustering. ... 12
12 Visualisasi hasil clustering data kebakaran hutan. ... 14
DAFTAR TABEL
Halaman 1 Representasi kemunculan objek ... 52 Hasil analisis kueri data hotspot tahun 2002 – 2005 (Kurniawan 2011) ... 6
3 Contoh data hotspot yang digunakan pada penelitian ... 10
4 Hasil clustering dari algoritme DDBC ... 12
5 Hasil perhitungan cluster variance ... 13
PENDAHULUAN
Latar Belakang
Kebakaran hutan dan lahan menjadi permasalahan yang kian mencolok di Indonesia. Peluang terjadinya kebakaran hutan di Indonesia meningkat dari tahun ke tahun. Hal tersebut menandakan perubahan titik api yang terjadi di suatu wilayah (spatial) bersifat dinamis seiring waktu yang berjalan. Mengingat faktor timbulnya kebakaran hutan yang tinggi di Indonesia, maka sangatlah penting untuk pembangunan sistem guna pencegahan kebakaran hutan sejak dini.
Salah satu upaya pencegahan kebakaran hutan tersebut yakni dengan mengetahui persebaran pengelompokan titik api yang berpotensi tinggi terhadap terjadinya kebakaran hutan. Konsep data mining sangat sesuai untuk diterapkan pada data hotspot tersebut. Salah satu penerapan metode data mining yang akan digunakan pada penelitian adalah clustering. Penelitian sebelumnya yang dilakukan oleh Fuad (2009) data titik-titik panas telah dikelompokkan sesuai sebarannya menggunakan clustering hasil operasi OLAP dan visualisasi hasil clustering dari data tersebut diimplementasikan dalam bentuk peta. Teknik clustering yang digunakan pada penelitian tersebut yakni K-Means. Algoritme K-Means membutuhkan penyimpanan posisi objek yang sifatnya terkait time stamp (valid time) disertai waktu dimulainya (start time) secara eksplisit. Tahap clustering dengan K-Means tersebut diterapkan menggunakan WEKA versi 3.5.7. Selain itu, atribut yang digunakan dalam clustering adalah atribut jumlah titik panas, sedangkan atribut wilayah dan waktu yang bertipe kategorik hanya digunakan sebagai keterangan.
Penelitian yang dilakukan akan mengimplementasikan algoritme dynamic density based clustering (DDBC) yang dikenal mampu menangani aspek spatial dan temporal secara bersamaan. Algoritme DDBC telah diperkenalkan pertama kali oleh Ghose dan Rosswog (2010). Penelitian tersebut mengevaluasi algoritme DDBC terhadap teknik Trajectory Mining dan Moving Cluster Mining menggunakan sejumlah data objek yang berpindah pada satuan waktu. Hasil penelitian menunjukkan bahwa algoritme DDBC mampu mendeteksi dan mencatat cluster yang heterogen secara simultan dari objek yang saling berpindah melalui persimpangan
terhadap cluster lain dalam time stamp terkait yang digunakan.
Posisi setiap titik pada data kebakaran hutan diperkirakan besar kekuatan hubungannya untuk setiap satuan tahun (temporal) kemunculannya dan diolah pada relationship graph. Penggunaan relationship graph akan mempermudah dalam membedakan hubungan antar titik yang kuat dan lemah. DDBC mengelompokan suatu populasi objek berdasarkan pada parameter kepadatannya (density) dengan fungsi ketetanggaan yang digunakan adalah Relationship Strength Threshold (RST) neighborhood. Data hotspot yang digunakan pada penelitian ini memiliki atribut seperti lintang dan bujur yang menyimpan aspek spatial serta atribut year yang menyimpan aspek temporal, sehingga algoritme DDBC yang mampu mengolah data spatiotemporal dapat diterapkan dengan baik melalui penelitian ini.
Hasil clustering yang diperoleh dengan penggunaan teknik DDBC menghasilkan pengelompokan terhadap daerah-daerah terkait yang rawan terhadap terjadinya kebakaran hutan. Daerah-daerah yang dikenali sebagai titik api tersebut memiliki frekuensi kemunculan yang tinggi sehingga dinilai rawan terhadap potensi terjadinya kebakaran hutan. Visualisasi hasil clustering disajikan dalam bentuk peta yang menggambarkan persebaran titik panas agar pihak yang berwenang dapat dengan mudah menentukan daerah yang diprioritaskan untuk dilakukan pencegahan kebakaran hutan.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Menerapkan teknik clustering dengan menggunakan algoritme Dynamic Density Based Clustering (DDBC) pada data kebakaran hutan.
2 Memvisualisasikan hasil clustering dalam bentuk sistem peta untuk memudahkan pengguna melihat lokasi persebaran titik-titik api.
Ruang Lingkup
Ruang lingkup dari penelitian ini adalah: 1 Data hotspot yang digunakan diperoleh dari
Direktorat Kebakaran Hutan (DPKH) Departemen Kehutanan RI.
3 Data hotspot yang digunakan adalah data titik api yang muncul berulang dalam rentang tahun 2002 sampai 2005.
Manfaat Penelitian
Hasil akhir dari clustering yang diperoleh pada penelitian ini diharapakan dapat mempermudah pihak yang berwenang terkait pengelolaan data hotspot untuk mengambil keputusan dalam upaya pencegahan kebakaran hutan sejak dini.
TINJAUAN PUSTAKA
Data Mining
Data mining adalah kegiatan penemuan pola-pola yang menarik dari data berukuran besar yang disimpan dalam basis data, data warehouse, atau sarana penyimpanan yang lain. Data mining dapat diklasifikasikan menjadi dua kategori yaitu descriptive data mining dan predictive data mining. Descriptive data mining menjelaskan himpunan data dengan memberikan banyak informasi secara jelas dalam kalimat yang singkat dan memberikan sifat-sifat umum yang menarik dari data. Predictive data mining menganalisis data yang bertujuan untuk membangun sebuah atau himpunan model, dan berusaha untuk meramalkan karakteristik dari himpunan data baru (Han & Kamber 2001).
Menurut (Han & Kamber 2001), fungsionalitas data mining adalah:
1 Deskripsi kelas/ deskripsi konsep dan diskriminasi,
2 Analisis asosiasi, 3 Klasifikasi dan prediksi, 4 Analisis cluster, 5 Analisis pencilan, dan 6 Analisis evolusi.
Hotspot (Titik Panas)
Data hotspot merupakan salah satu indikator kemungkinan terjadinya kebakaran hutan pada wilayah tertentu. Pemantauan hotspot dilakukan dengan penginderaan jauh (remote sensing) menggunakan satelit (Hayardisi 2008).
Satelit yang biasa digunakan adalah satelit National Ocean and Atmospheric Administration (NOAA) melalui sensor Advanced Very High Resolution Radiometer (AVHRR) karena sensor tersebut dapat membedakan suhu permukaan di darat dan laut. Satelit ini mendeteksi objek di permukaan bumi
yang memiliki suhu relatif lebih tinggi dibandingkan sekitarnya. Suhu yang dideteksi berkisar antara 210 K (37°C) untuk malam hari dan 315 K (42°C) untuk siang hari.
Penginderaan satelit tersebut tentunya akan membantu penanganan masalah kebakaran hutan, karena jika posisi lokasi hotspot telah diketahui maka bisa dilakukan penanganan lebih dini untuk mencegah terjadinya kebakaran hutan.
Clustering
Secara umum, clustering merupakan proses pengelompokan kumpulan objek ke dalam kelas-kelas atau clusters sehingga objek-objek dalam satu cluster memiliki kemiripan yang tinggi tetapi tidak mirip terhadap objek dari cluster lain (Han & Kamber 2001). Ukuran kemiripan dan ketidakmiripan dinilai berdasarkan nilai atribut yang mendeskripsikan objek.
Spatiotemporal Data
Data spatiotemporal adalah data spasial yang berubah seiring waktu (Rahim 2006). Jadi, data spatiotemporal adalah data spasial yang memiliki elemen temporal. Sedangkan data spasial adalah data yang memiliki referensi ruang kebumian (georeference) dimana berbagai data atribut terletak dalam berbagai unit spasial (tidak memiliki aspek temporal).
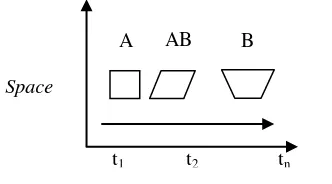
Gambar 1 menjelaskan deskripsi dari data spatiotemporal. Pada Gambar 1 dapat dilihat objek A pada waktu t1. Akibat sesuatu hal objek A tersebut berubah menjadi objek AB dalam waktu t2, kemudian objek AB berubah lagi menjadi objek B di waktu tn. Objek terus berubah tergantung pada situasi dan skenario. Data spatiotemporal adalah serangkaian data spasial yang telah berubah. Perubahan akan terjadi sampai waktu ke n, yaitu akhir dari proses perubahan (Rahim 2006).
Gambar 1 Deskripsi data spatiotemporal (Rahim 2006).
t1 t2 tn
Space
Density Based Clustering (DENCLUE)
Ide dasar dari DENCLUE adalah mengelompokan pemodelan seluruh data berdasarkan besarnya kepadatan (density) sebagai penjumlahan fungsi pengaruh (influence function) dari suatu titik. Konsep influence function adalah fungsi yang menjelaskan pengaruh suatu data di dalam ketetanggaannya. Contoh dari influence function yang telah banyak digunakan antara lain :
1 Square wave function
2 Gaussian function
Besarnya fungsi kepadatan dari data dapat dihitung dengan menjumlahkan seluruh influence function tertentu yang dipilih. Tahap clustering selanjutnya dapat ditentukan secara matematik dengan mengidentifikasi nilai lokal maksimum dari kepadatan (density-attractors) (Hinneburg A & Keim D 1998).
Density Based Spatial Clustering (DBSCAN)
DBSCAN memiliki cara kerja clustering yang hampir mirip dengan DENCLUE. Secara signifikan, DBSCAN bekerja dengan efisien dalam membentuk arbitrary-shaped cluster. Pengelompokan dilakukan terhadap titik dengan ketetanggaannya yang berada di dalam jarak (ɛ) tertentu yang harus memenuhi jumlah titik minimum (minPts). Pembentukan ketetanggaan dapat ditentukan melalui pemilihan fungsi jarak antara dua buah titik.
DBSCAN menggunakan konsep titik pusat (core point), titik batas (border point), dan noise. Titik yang memiliki sejumlah titik tetangga dan memenuhi jumlah titik minimum, serta berada dalam jarak tertentu disebut sebagai titik pusat, sedangkan titik batas memiliki jumlah titik tetangga namun tidak memenuhi jumlah titik minimum. Titik batas tersebut biasanya merupakan titik di dalam ketetanggaan dari titik pusat. Kriteria suatu titik dikatakan sebagai noise yaitu pada saat titik tersebut tidak termasuk titik pusat maupun titik batas, selain itu titik tersebut tidak memenuhi konsep directly density-reachable dari suatu titik pusat (Ester et al. 1996).
Beberapa konsep lain yang memiliki peranan penting dalam metode DBSCAN dijelaskan sebagai berikut.
1 Directly density-reachable
Konsep directly density-reachable akan dimisalkan dengan Gambar 2 di bawah berikut.
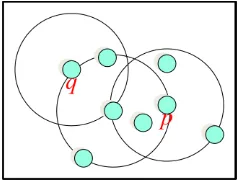
Gambar 2 Ilustrasi konsep directly density- reachable.
Titik q dikatakan directly density-reachable dari titik p, jika titik q berada di dalam ketetanggaan titik p dengan jarak tertentu (ɛ) dan titik p merupakan titik pusat. Konsep ini berlaku untuk sepasang titik pusat (simetris), namun tidak berlaku antara titik pusat dan titik batas.
2 Density-reachable
Titik p dikatakan density-reachable dari titik q (memenuhi syarat ɛ dan minPts) jika terdapat rantai yang menghubungkan titik p1,
…, pn dengan p1 = q, pn = p dan pi+1 directly density-reachable dari pi. Gambar 3 berikut memberikan ilustrasi mengenai konsep density-reachable.
Gambar 3 Ilustrasi konsep density-reachable. 3 Density-connectivity
Titik p density-connected terhadap titik q
(memenuhi syarat ɛ dan minPts) jika titik p dan q density-reachable dari titik r. Density-connectivity bersifat simetris terhadap suatu objek dengan objek lainnya. Berikut diberikan ilustrasi mengenai konsep density-connectivity.
Definisi terbentuknya suatu cluster C apabila memenuhi syarat berikut yaitu:
Jika titik p ϵ C dan jika q density-reachable dari titik p (memenuhi syarat ɛ dan minPts), maka titik q ϵ C (maximality).
Jika titik p density-connected ke titik q (memenuhi syarat ɛ dan minPts), maka titik q ϵ C (connectivity).
DBSCAN hanya mampu menghasilkan hasil clustering yang baik selama ukuran jarak yang digunakan tidak melebihi jumlah keseluruhan area dari data. Pada data yang berdimensi tinggi, ukuran matriks jarak dapat diperkecil guna efisiensi algoritme. Secara kontras dengan memperkecil matriks jarak, maka akan lebih sulit menentukan besarnya
jarak (ɛ) yang lebih tepat. Kelemahan utama pada DBSCAN yakni algoritme ini tidak dapat mengclusterkan data dengan adanya perbedaan jarak yang besar antar objek pada data.
Dynamic Density Based Clustering (DDBC)
Algoritme dynamic density based clustering bekerja berdasarkan area yang memiliki kepadatan tertentu dan mengkombinasikan objek-objek pada area tersebut ke dalam sebuah cluster. Algoritme ini bertujuan menentukan jumlah cluster yang ditampilkan pada data berdasarkan nilai kepadatannya dan mampu untuk menangani noise.
DDBC merupakan algoritme
penggabungan dari algoritme DBSCAN dan DENCLUE, yang keduanya merupakan algoritme clustering berdasarkan density. Dua tahapan besar pada algoritme DDBC yaitu tahap estimasi hubungan (relationship estimation) dan tahap deteksi cluster. Estimasi hubungan menjelaskan perkiraan kekuatan hubungan antara objek yang muncul, sementara deteksi cluster akan melakukan pengelompokan terhadap objek-objek tersebut yang memiliki hubungan yang kuat.
DDBC menggunakan konsep pada algoritme DENCLUE yakni influence function untuk menjelaskan adanya hubungan antar objek. Posisi suatu titik dihitung secara periodik. Pt merupakan posisi titik yang dihitung pada waktu t. Hubungan antar titik pada waktu t dihitung menggunakan fungsi jarak. Nilai dari fungsi jarak tersebut selanjutnya diestimasi menggunakan fungsi kernel untuk diketahui kekuatan hubungannya. Besarnya kekuatan hubungan ( ) antar titik dirumuskan sebagai berikut.
(1) Nilai h pada persamaan di atas menjelaskan history window yaitu periode waktu dimana perilaku titik mempengaruhi estimasi hubungan, dan nilai t merupakan satuan waktu saat tertentu, dan , merupakan posisi objek e dan g pada waktu c. Suatu relationship graph akan terbentuk untuk mengolah kekuatan hubungan antar titik yang terjadi di setiap tahun. Tahap berikutnya setelah terbentuk relationship graph adalah deteksi cluster. Teknik DDBC menggunakan algoritme DBSCAN yang telah dimodifikasi untuk mendeteksi cluster pada relationship graph. Perbedaan antara algoritme DBSCAN dengan yang telah dimodifikasi terletak pada penggunaan Relationship Strength Threshold (RST) dan penggunaan fungsi ketetanggaan (neighborhood function) (Rosswog & Ghose 2010).
RST memberikan penjelasan bahwa titik-titik yang dipertimbangkan pada deteksi cluster hanya hubungan antar titik pada relationship graph yang mempunyai bobot lebih besar dari RST. Hubungan yang bersifat lemah (bernilai kurang dari RST) didefinisikan sebagai noise. Besarnya nilai RST dapat diketahui melalui persamaan berikut.
Dimisalkan C merupakan cluster, dan titik x, y ϵ C, dan titik z ¬ϵ C. Titik y dan z berada di dalam ketetanggaan titik x pada waktu t dan h tertentu. Nilai p menjelaskan besarnya waktu yang diharapkan pada titik y akan muncul sebagai tetangga titik x, sedangkan nilai f menjelaskan besarnya waktu yang diharapkan pada titik z akan muncul sebagai tetangga titik x.
kombinasinya satu dengan lainnya yang menandakan adanya hubungan antar objek tersebut.
Tabel 1 Representasi kemunculan objek berdasarkan time stamp
Objek Hubungan Objek
Time Stamp
X, Y, Z (X, Y) (X, Z)
(Y, Z) 1
W, X, Y, Z
(W, X) (W, Y) (W, Z) X, Y) (X, Z) (Y, Z)
2
X, Y, Z (X, Y) (X, Z)
(Y, Z) 3
A, B, C (A, B) (A, C)
(B, C) 4
Berdasarkan Tabel 1 di atas dapat disimpulkan bahwa objek W yang hanya muncul pada time stamp 2 dan objek A, B, dan C pernah memiliki hubungan terkait dengan seluruh objek-objek data clustering sebanyak satu kali. Objek lainnya seperti X, Y, dan Z pernah memiliki hubungan dengan objek data clustering dengan kemunculan sebanyak tiga kali. Konsep RST pada hubungan ketetanggaan (neighborhood) dari vertex v ϵ V (G) dirumuskan sebagai NRST(v) yang dijelaskan pada persamaan di bawah ini. Dengan menggunakan rumus RST neighborhood di bawah, maka selanjutnya cluster akan dibentuk sesuai konsep yang terdapat pada algoritme DBSCAN. Kelebihan lain pada DBSCAN yang telah dimodifikasi yaitu pengelompokan objek akan lebih sederhana karena hanya objek yang terhubung oleh edge yang akan diutamakan.
(3)
Analisis Cluster
Analisis cluster dapat diperoleh dari kepadatan cluster yang dibentuk (cluster density). Penyebaran hasil suatu cluster dapat ditentukan dengan variance within cluster (Vw) dan variance between cluster (Vb). Varian untuk setiap tahap pembentukan cluster dihitung menggunakan persamaan di bawah berikut.
dengan adalah varian pada cluster C, c
bernilai 1, …, k dimana k merupakan jumlah cluster. Nilai adalah jumlah data pada
cluster C, adalah data ke-i pada suatu cluster, dan merupakan nilai rata-rata dari data pada cluster C. Selanjutnya dari nilai varian tersebut dihitung nilai variance within cluster (Vw) dan variance between cluster (Vb) sesuai dengan persamaan di bawah ini.
(5)
(6) dengan N adalah jumlah semua data, adalah jumlah data pada cluster ke-i, nilai merupakan varian pada cluster ke-i, dan merupakan rata-rata dari .
Salah satu metode yang digunakan untuk menentukan cluster yang ideal adalah batasan varian, yaitu dengan menghitung kepadatan cluster berupa variance within cluster (Vw) dan nilai variance between cluster (Vb) (Man L et al. 2009). Cluster yang ideal mempunyai Vw minimum yang merepresentasikan internal homogenity dan maksimum Vb yang menyatakan external homogenity.
METODE PENELITIAN
Penelitian ini menggunakan teknik clustering dengan algoritme DDBC pada data kebakaran hutan. Tahap-tahap yang akan dilakukan pada penelitian dijelaskan secara jelas pada Gambar 5.Gambar 5 Metodologi penelitian. (4)
Mulai
Analisis Data Hotspot
Praposes Data
Estimasi Hubungan antartitik
Pendeteksian clustering
Output Cluster
Analisis varian hasil cluster
Visualisasi clustering
Pengolahan Data
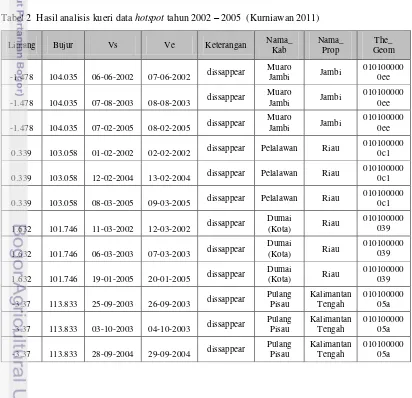
Data yang digunakan pada penelitian ini adalah data titik api yang memiliki kemunculan paling banyak yakni tiga kali pada tahun 2002 hingga tahun 2005. Pengambilan data untuk kemunculan titik api yang berulang tersebut didasarkan pada kemampuan algoritme DDBC melakukan pengolahan aspek temporal dengan baik untuk setiap hubungan titik yang terjadi. Data tersebut diperoleh dari Direktorat Pengendalian Kebakaran Hutan (DPKH) Departemen Kehutanan RI. Data yang digunakan merupakan hasil analisis kueri yang telah diujikan (Kurniawan 2011). Hasil analisis kueri data hotspot yang muncul pada tahun 2002 sampai 2005 menghasilkan sebanyak 151 data. Tabel 2 berikut menunjukkan contoh data awal dari hasil analisis kueri data hotspot yang muncul pada tahun 2002-2005.
Mengingat kebutuhan data terhadap cara kerja algoritme DDBC maka diperlukan beberapa penghapusan atribut serta penambahan
atribut. Atribut yang dihapus yaitu atribut keterangan yang berdasarkan analisis kueri tersebut menjelaskan bahwa titik tersebut disappear (menghilang). Atribut yang menyimpan nilai aspek temporal pada Tabel 2 adalah atribut Vs dan Ve. Kedua atribut tersebut memiliki tipe data berupa date yang mengandung komponen tanggal, bulan, dan tahun. Pada tahap pengolahan data dalam penelitian ini, kedua atribut tersebut disimpan dalam atribut year. Atribut year hanya menyimpan komponen tahun kemunculan hotspot tersebut.
Penambahan atribut yang diterapkan yaitu atribut vertex. Atribut vertex merepresentasikan posisi lintang dan bujur suatu titik api. Penamaan dari atribut vertex tersebut diperoleh secara alphabet sehingga setiap nilai vertex mempunyai nilai lintang dan bujur yang berbeda, namun mempunyai Kabupaten dan Propinsi yang sama. Hasil pengolahan data yang digunakan dalam penelitian dapat dilihat secara detail pada Lampiran 1.
Tabel 2 Hasil analisis kueri data hotspot tahun 2002 – 2005 (Kurniawan 2011) Lintang Bujur Vs Ve Keterangan Nama_
Kab
Nama_ Prop
The_ Geom
-1.478 104.035 06-06-2002 07-06-2002 dissappear
Muaro
Jambi Jambi
010100000 0ee
-1.478 104.035 07-08-2003 08-08-2003 dissappear
Muaro
Jambi Jambi
010100000 0ee
-1.478 104.035 07-02-2005 08-02-2005 dissappear
Muaro
Jambi Jambi
010100000 0ee
0.339 103.058 01-02-2002 02-02-2002 dissappear Pelalawan Riau
010100000 0c1
0.339 103.058 12-02-2004 13-02-2004 dissappear Pelalawan Riau
010100000 0c1
0.339 103.058 08-03-2005 09-03-2005 dissappear Pelalawan Riau
010100000 0c1
1.632 101.746 11-03-2002 12-03-2002 dissappear
Dumai
(Kota) Riau
010100000 039
1.632 101.746 06-03-2003 07-03-2003 dissappear
Dumai
(Kota) Riau
010100000 039
1.632 101.746 19-01-2005 20-01-2005 dissappear
Dumai
(Kota) Riau
010100000 039
-3.37 113.833 25-09-2003 26-09-2003 dissappear
Pulang Pisau Kalimantan Tengah 010100000 05a
-3.37 113.833 03-10-2003 04-10-2003 dissappear
Pulang Pisau Kalimantan Tengah 010100000 05a
-3.37 113.833 28-09-2004 29-09-2004 dissappear
Keterkaitan antar Titik
Data yang telah diperoleh melalui tahap sebelumnya, kemudian diolah dalam tahap estimasi hubungan. Titik api akan dilihat keterkaitannya satu sama lain melalui tahap estimasi ini. Berikut diberikan Gambar 6 untuk penjelasan lebih detail mengenai estimasi hubungan.
Langkah-langkah yang digunakan pada tahap estimasi hubungan dijelaskan sebagai berikut:
1 Hubungan antar objek yang terjadi terkait time stampnya dicari nilai jaraknya seperti pada Gambar 6a menggunakan Euclidian distance.
2 Hasil jarak antar titik tersebut kemudian diolah kembali dengan penggunaan influence function. Pada penelitian ini, influence function dikenal pula sebagai kernel function. Kernel function yang digunakan adalah square wave function yang akan memberikan hasil berupa nilai boolean. Penggunaan square wave function menjelaskan titik-titik yang besar pengaruhnya dalam radius dan waktu tertentu. Pada Gambar 6b diperoleh hubungan titik yang berpengaruh setelah
dterapkan square wave function. Pada perumusan kernel function didefinisikan bahwa jarak Euclid antar titik yang nilainya lebih besar dari threshold ( ) akan diberi representasi nilai 0, dan diberi nilai 1 apabila berlaku sebaliknya. Hubungan titik yang bernilai 0 tersebut tidak akan berpengaruh besar pada tahap selanjutnya yaitu perhitungan kekuatan hubungannya (strength relationship). 3 Nilai boolean yang merepresentasikan
hubungan antar titik digunakan dalam perhitungan kekuatan hubungan (strength relationship) antar titik. Strength relationship menjelaskan bobot dari edge yang menghubungkan titik-titik pada representasi relationship graph. Bobot tahun awal kemunculan suatu titik akan digunakan sebagai nilai standar pertambahan bobot untuk tahun kemunculan berikutnya. Pada tahun terakhir terkait data, maka akan terbentuk relationship graph yang memiliki edge berupa nilai kekuatan hubungan final. Representasi relationship graph disajikan melalui Gambar 6c.
Cluster Detection
Dalam tahap deteksi cluster, titik hasil relationship graph diolah kembali. Konsep ketetanggaan yang digunakan pada DDBC adalah RST neighborhood. Titik yang akan digunakan pada tahap cluster detection hanya titik yang terhubung oleh edge yang memiliki bobot lebih besar dari RST. Titik-titik tersebut merupakan titik yang memiliki hubungan yang kuat dan selanjutnya akan digunakan teknik clustering yang memiliki tahapan yang sama seperti teknik DBSCAN. Gambar 7 berikut menjelaskan langkah-langkah yang dilakukan pada deteksi cluster.
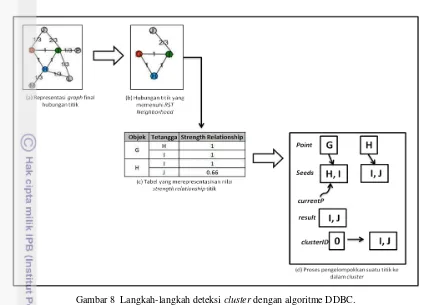
Gambar 7 Mekanisme dalam deteksi cluster. Berikut ini diilustrasikan tahapan pada deteksi cluster. Jika diberikan hasil relationship graph final seperti Gambar 8a, diambil contoh hubungan titik yang terjadi pada time stamp akhir yakni 3. Pada time stamp 3 terdapat titik yaitu G, H, I, J, L, M, dan P. Titik yang memiliki hubungan yaitu (G, H), (G, J), (H, I), (H, L), (H, M), (I, J), (I, L), dan (I,P). Relationship graph yang terbentuk sesuai dengan data seperti pada Gambar 8a akan dideteksi cluster sesuai dengan mekanisme pada
Gambar 7. Berikut ini merupakan langkah-langkah deteksi clustering dengan algoritme DDBC yang akan dilakukan sebagai berikut: 1 Hubungan titik yang terjadi pada Gambar 8a
akan diperiksa apakah nilai strength relationship atau direpresentasikan sebagai bobot yang menghubungkan titik tersebut memenuhi konsep RST neighborhood. Apabila nilai strength relationshipnya lebih kecil dari nilai RST, maka titik tersebut tidak diikutsertakan pada tahap selanjutnya. Pada contoh Gambar 8 tersebut digunakan nilai RST yakni sebesar 0.6 sehingga diperoleh hubungan titik yang bernilai lebih dari 0.6 seperti pada Gambar 8b. Representasi tabel untuk menyimpan hubungan titik beserta nilai strength relationship dapat dilihat pada Gambar 8c.
2 Ambil salah satu titik sebagai inisialisasi point awal seperti pada Gambar 8d yaitu titik G. Periksa titik G apakah memiliki jumlah titik tetangga yang lebih besar dari jumlah tetangga minimum (minPts), hal yang sama dilakukan pada algoritme DBSCAN. Apabila jumlah tetangganya memenuhi jumlah titik tetangga minimum, maka simpan tetangganya sebagai seeds. 3 Gunakan titik pertama pada seeds sebagai
currentP. Pada contoh Gambar 8d dijelaskan bahwa titik H disimpan sebagai currentP. Periksa kembali apakah titik H memiliki jumlah tetangga yang lebih besar dari jumlah tetangga minimum, apabila memenuhi maka simpan titik tetangga dari titik H sebagai result. Lakukan perulangan pada result untuk memeriksa apakah setiap titik tersebut termasuk ke dalam noise atau titik tersebut pernah diclusterkan. Pengelompokkan dilakukan terhadap result yang tidak termasuk ke dalam noise dan titik yang belum pernah dikelompokkan. Pada contoh Gambar 8d, titik I dan J yang disimpan sebagai result dikelompokkan ke dalam cluster 0.
4 Setelah perulangan terhadap result selesai dilakukan, maka nilai currentP akan berubah yakni titik selanjutnya di dalam seeds. Langkah perulangan untuk nilai currentP dilakukan sesuai langkah 3 di atas. Cluster akan bertambah ketika seeds telah kosong, maka dilakukan tahap pengambilan titik sebagai point seperti pada langkah 2.
Directly Density-Reachable
Data yang diperoleh dari relationship graph dicari ketetanggaannya menggunakan konsep RST neighborhood dan banyaknya jumlah tetangga harus bernilai lebih besar/sama dengan jumlah titik minimum.
Gunakan salah satu titik yang memenuhi konsep directly density-reachable sebagai inisialisasi awal, dan cari ketetanggaan dari titik tersebut disimpan sebagai seeds. Titik yang tidak memenuhi directly density-reachable dikenali sebagai noise. Berdasarkan hasil ketetanggaan seeds, ambil titik pertama tetangganya dan simpan sebagai currentP.
CurrentP dicari kembali ketetanggaannya dan diperiksa apakah tetangganya memenuhi jumlah titik minimum dan titik tetangganya disimpan sebagai result. Lakukan perulangan pada result untuk diperiksa apakah titik tersebut berada di dalam noise atau pernah diclusterkan, apabila tidak memenuhi maka titik tersebut dimasukkan pada cluster.
Gambar 8 Langkah-langkah deteksi cluster dengan algoritme DDBC.
Performansi Hasil Cluster
Pada tahap ini dilakukan analisis terhadap hasil cluster. Analisis yang digunakan adalah analisis cluster variance. Besarnya variance within cluster (Vw) dan variance between cluster (Vb) akan dihitung untuk mengukur besarnya penyebaran dari data hasil clustering.
Visualisasi Clustering
Hasil akhir clustering diimplementasikan dalam bentuk visual berupa map based. Tampilan peta akan menunjukkan hasil pengelompokan wilayah hotspot berdasarkan tingkat kerawanan terjadinya kebakaran hutan. Perbedaan warna pada node menandakan pengelompokkan suatu titik ke dalam cluster yang berbeda.
Implementasi
Pada tahap ini akan diimplementasikan hasil clustering data hotspot beserta visualisasi. Implementasi dilakukan menggunakan bahasa pemrograman PHP. Berikut merupakan perangkat lunak dan perangkat keras yang digunakan untuk mengembangkan sistem adalah sebagai berikut:
Perangkat lunak:
Sistem operasi : Windows 7 Ultimate
XAMPP 1.7
DBMS PostgreSQL
Bahasa Pemrograman PHP 4.49
Web browser Mozilla Firefox 4
Notepad++
GeoServer
Adobe Dreamwaver CS3 Perangkat keras:
Prosesor: Intel® Core(TM)2 Duo CPU T6600 @ 2.20 GHz
Memory 2 GB
Monitor dengan resolusi 1024x768 px
Mouse dan keyboard
HASIL DAN PEMBAHASAN
Praproses Data
Data yang diperoleh dalam penelitian ini merupakan data hasil analisis kueri yang telah diujikan pada penelitian Kurniawan (2011). Data hotspot yang digunakan adalah titik-titik yang muncul berulang kali di rentang tahun 2002 hingga 2005. Banyaknya data yang diperoleh dari hasil analisis kueri sebanyak 151 data. Kemunculan titik api pada suatu daerah bervariasi. Kemunculan paling banyak yakni tiga kali dalam rentang tahun tersebut, namun terdapat pula titik yang hanya muncul di satu tahun tertentu.
Sumatera Utara, Sumatera Barat, Kalimantan Barat, Kalimantan Tengah, dan Sulawesi Selatan. Tampilan contoh data yang digunakan pada penelitian dapat dilihat secara detail pada Lampiran 1. Keseluruhan data tersebut akan diolah melalui beberapa tahap di dalam algoritme DDBC. Pada proses akhir dari tahap estimasi hubungan antar titik masih digunakan keseluruhan data, namun untuk tahap berikutnya yakni tahap deteksi clustering terjadi proses pencarian ketetanggaan menggunakan konsep RST (Relationship Strength Threshold).
Pada penelitian ini besarnya RST yang digunakan adalah 0.5, sehingga perolehan nilai bobot final dari tahap akhir estimasi hubungan antar titik akan diperiksa apakah bernilai lebih kecil dari RST. Hubungan antar titik yang kuat dinilai lebih besar atau sama dengan besarnya RST. Banyaknya data yang memenuhi konsep hubungan yang kuat tersebut, untuk selanjutnya diolah pada tahap clustering adalah sebanyak 15 titik. Pencocokan kebutuhan data dengan teknik algoritme DDBC membutuhkan penghapusan beberapa atribut dari data hasil analisis kueri. Atribut yang dihapus yaitu Vs, Ve, dan keterangan, selain penghapusan beberapa atribut yang tidak banyak berpengaruh, ditambahkan pula atribut yang penting dalam teknik DDBC yaitu atribut vertex.
Atribut vertex diperoleh berdasarkan nilai lintang dan bujur yang mewakili suatu titik api. Penambahan atribut vertex bertujuan mempermudah pembentukan relationship graph. Penerapan aspek temporal dimasukkan ke dalam atribut year yang menyimpan komponen tahun kemunculan titik api. Frekuensi kemunculan setiap hotspot berbeda-beda, sebagai contoh terdapat data hotspot yang hanya muncul sekali pada tahun 2002. Namun terdapat pula titik api yang muncul sebanyak tiga kali yaitu pada tahun 2002, tahun 2003, dan tahun 2005. Keseluruhan data hotspot tetap
digunakan untuk perhitungan pada tahap selanjutnya. Tabel 3 merupakan contoh data hotspot yang digunakan pada penelitian.
Estimasi Hubungan Titik
Data hotspot yang telah diolah pada tahap praproses selanjutnya akan dicari hubungannya menggunakan fungsi jarak euclid. Secara garis besar proses estimasi hubungan antar titik pada penelitian ini dapat dilihat pada Gambar 9. Perhitungan jarak dilakukan pada titik yang muncul setiap tahunnya. Hasil jarak euclid tersebut selanjutnya diolah dengan menggunakan persamaan influence function. Jenis influence function yang digunakan pada penelitian adalah square wave function. Penggunaan square wave function bertujuan pula sebagai fungsi kernel function yang akan memberikan keluaran berupa nilai Boolean. Nilai jarak antar titik seperti diperoleh pada Gambar 9c diproses menggunakan square wave function yang mempunyai nilai threshold ( sebesar 4.842. Nilai threshold tersebut merupakan hasil standar deviasi dari perolehan jarak euclid dari keseluruhan data (Kang 2008). Besarnya jarak antar titik yang bernilai lebih besar dari threshold diberi nilai 0 yang artinya hubungan antar titik tersebut tidak berpengaruh terhadap keseluruhan data clustering dan hubungan titik tersebut dikatakan lemah.
Hasil akhir dari fungsi kernel tersebut akan memberikan nilai keluaran boolean yaitu 0 dan 1, dapat dilihat pada Gambar 9d. Nilai-nilai hubungan antar titik yang telah diperoleh, maka selanjutnya akan dilakukan perhitungan kekuatan hubungan. Besarnya kekuatan hubungan ( merepresentasikan bobot yang menghubungkan dua buah titik dengan memasukkan nilai boolean yang telah diperoleh sebelumnya ke dalam persamaan strength relationship, maka didapat nilai = 0.25.
Tabel 3 Contoh data hotspot yang digunakan pada penelitian
Lintang Bujur Time Vertex Nama_kab Nama_prop The_geom
-1.478 104.035 2002 M Muaro Jambi Jambi 01010000000A
-1.478 104.035 2003 M Muaro Jambi Jambi 01010000000A
-1.478 104.035 2005 M Muaro Jambi Jambi 01010000000A
0.339 103.058 2002 U Pelalawan Riau 0101000000C1
0.339 103.058 2004 U Pelalawan Riau 0101000000C2
0.339 103.058 2005 U Pelalawan Riau 0101000000C3
RST = = 0.5 Gambar 9 Tahapan estimasi hubungan pada data penelitian. Pada penelitian ini, besarnya nilai strength
relationship untuk setiap hubungan antar titik yang berpengaruh memiliki nilai yang sama yaitu 0.25, hal tersebut terjadi berdasarkan perolehan nilai boolean melalui perumusan square wave function adalah sama yakni sebesar 1. Kasus yang lain terjadi pada hubungan antar titik yang menghasilkan nilai 0 dalam perhitungan square wave function, maka hubungan titik tersebut pun akan memperoleh bobot sebesar 0. Gambar 9e memberikan representasi sederhana untuk proses perolehan nilai strength relationship hubungan antar titik setiap tahun kemunculannya.
Pembobotan akan bertambah terhadap suatu hubungan titik apabila hubungannya muncul berulang di tahun berikutnya. Perulangan pembobotan tersebut diinisialisasi menggunakan nilai awal sebesar 0.25 pada tahun 2002. Hubungan titik yang muncul kembali di tahun berikutnya akan bertambah menjadi 0.5, sedangkan hubungan titik yang tidak muncul di tahun berikutnya berkurang menjadi 0. Banyaknya perulangan dilakukan hingga tahun 2005 dan selanjutnya akan diperoleh bobot final dari relationship graph.
Modifikasi Ketetanggan
Bobot yang merepresentasikan kekuatan hubungan antar titik kembali diolah guna kebutuhan clustering. Teknik DDBC menggunakan konsep RST neighborhood, besarnya nilai RST dapat dihitung melalui
persamaan yang telah diberikan sebelumnya. Gambar 10 berikut menjelaskan perhitungan nilai RST yang digunakan di dalam penelitian.
Gambar 10 Perhitungan nilai RST. Penggunaan nilai f adalah sebesar 1 yakni merepresentasikan waktu kemunculan suatu objek sebagai ketetanggaan dari objek lain yang merupakan bagian cluster. Kemunculan objek tersebut sebagai tetangga objek cluster adalah paling banyak satu kali dalam rentang empat tahun berdasarkan penggunaan data.
Besarnya history window (h) yang digunakan adalah 4. Penggunaan nilai history window tersebut merujuk berdasarkan time stamp yang digunakan pada penelitian yaitu disimpan di dalam atribut year. Atribut year yang digunakan yaitu tahun 2002, 2003, 2004, dan 2005. Penggunaan nilai p sebesar 3 yakni merepresentasikan waktu kemunculan objek yang merupakan bagian cluster sebagai ketetanggaan dari objek lain di cluster tersebut.
01 functionExpandCluster($SetofPoint, $Point,$clID, $Min){
02 global $classified; 03 global $cluster_NOISE; 04 global $cluster;
05 $seeds = $SetofPoint[$Point]; 06
07 if(count($seeds) < $Min){
08 array_push($cluster_NOISE, $Point);
09 return 0; } 10 else{ 11
12 foreach($seeds as
$point_seed => $value_seed){
13 $result_currentP =
$SetofPoint[$point_seed];}
tahap clustering berikutnya karena hubungan vertex tersebut didefinisikan lemah. Titik yang bernilai lebih dari RST digunakan dalam konsep RST Neighborhood dan akan diproses selanjutnya dalam tahap clustering.
Deteksi Cluster
Banyaknya jumlah titik yang memenuhi RST Neighborhood sebanyak 15 titik. Tampilan data untuk daerah-daerah yang memenuhi syarat hubungan ketetanggan yang dinilai kuat dapat dilihat pada Lampiran 2. Hubungan titik tersebut memiliki nilai strength relationship yang lebih besar dari RST. Berdasarkan data yang diperoleh titik-titik tersebut merepresentasikan daerah yang berada pada Provinsi Riau dan Sumatera Utara. Titik tersebut selanjutnya dikelompokkan sesuai dengan konsep clustering pada konsep DBSCAN.
Banyaknya titik yang berada dalam ketetanggaan RST harus memenuhi salah satu syarat DBSCAN yaitu mempunyai titik tetangga yang lebih besar jumlahnya dari jumlah titik minimum (minPts). Besarnya nilai minPts yang digunakan pada penelitian ini adalah 4. Ukuran standar besarnya nilai minPts sebesar 4 telah cukup mewakili jumlah ketetanggan suatu point (Ester et al. 1996). Berdasarkan penggunaan nilai minPts yang berubah-ubah pada penelitian dapat disimpulkan adanya hubungan antara minPts dan pembentukan cluster. Semakin kecil nilai minPts, maka semakin kecil kemunculan noise, dan sebaliknya semakin besar minPts, maka semakin sedikit jumlah cluster yang terbentuk.
Teknik DDBC yang diterapkan untuk mengelompokan titik-titik api menggunakan konsep yang sama seperti pada DBSCAN, yaitu penggunaan konsep reachable, density-connectivity, dan cluster. Titik yang mempunyai ketetanggaan dengan jumlah yang lebih dari minPts akan diproses untuk dikelompokkan menggunakan fungsi ExpandCluster.
Berikut diberikan potongan fungsi
ExpandCluster menggunakan bahasa
pemrograman PHP pada Gambar 11.
Fungsi ExpandCluster seperti yang dapat dilihat pada Gambar 11 akan memberikan hasil akhir berupa clusters dan noise. Apabila suatu titik tidak mempunyai jumlah tetangga yang lebih besar dari nilai minPts sebesar 4, maka titik tersebut akan dikelompokkan ke dalam noise.
Gambar 11 Potongan fungsi ExpandCluster pada proses clustering.
Berdasarkan penggunaan data yang akan dikelompokkan yakni sebanyak 15 titik, data yang berhasil dideteksi dalam cluster adalah sebanyak 8 titik. Hasil clustering yang diperoleh dari algoritme DDBC yakni sebanyak 3 cluster dan banyaknya noise adalah 3 titik. Pembagian cluster yang dihasilkan berikut dapat dilihat pada Tabel 4, selain itu daerah yang dikelompokkan ke dalam noise adalah Kabupaten Dumai dan Indragiri Hilir.
Tabel 4 Hasil clustering dari algoritme DDBC sebanyak 3 cluster
Clusters Vertex
Cluster 0
Tapanuli Selatan,
Pelalawan, Dumai (Kota), Bengkalis
Cluster 1 Pelalawan Cluster 2 Bengkalis
Pada cluster 0 terdapat 4 kabupaten, cluster 1 dan cluster 2 hanya memiliki masing-masing satu kabupaten. Kabupaten Pelalawan yang dikelompokkan ke dalam cluster 1 dapat didefinisikan sebagai pencilan (outlier), hal yang sama pun berlaku pada daerah Bengkalis yang dikelompokkan dalam cluster 2. Hal ini disebabkan persebaran pola dari kedua titik tersebut tidak mengikuti sebaran yang terbentuk, selain itu berdasarkan hasil clustering dapat dilihat bahwa kedua kabupaten yaitu Pelalawan dan Bengkalis telah dikelompokkan sebelumnya ke dalam cluster 0.
1, dikarenakan pada penelitian ini informasi yang disimpan oleh suatu daerah hanya terbatas pada level Kabupaten.
Penggunaan dari data awal sebanyak 15 titik terdapat 4 titik yang tidak terdeteksi ke dalam cluster maupun noise yaitu Kabupaten Muaro Jambi, Mandailing Natal, dan Rokan Hulu. Pada penerapan algoritme DDBC ini, hal tersebut dapat terjadi disebabkan daerah-daerah tersebut tidak pernah muncul sebagai tetangga dari titik lain dan jumlah tetangga yang dimiliki daerah tersebut tidak memenuhi banyaknya jumlah titik minimum ketetanggaan (minPts).
Evaluasi Hasil Cluster
Hasil clustering yang telah diperoleh pada Tabel 4 akan dilihat nilai persebarannya menggunakan analisis varian. Suatu cluster dikatakan baik apabila anggota di dalam cluster mempunyai tingkat kemiripan yang tinggi antar satu dengan lainnya (internal homogeneity) dan sama sekali berbeda terhadap anggota cluster lainnya (external homogeneity).
Hasil perhitungan nilai cluster variance untuk cluster yang telah terbentuk disajikan dalam Tabel 5. Besarnya cluster variance ( ) pada cluster 1 dan cluster 2 yang masing-masing hanya memiliki satu anggota cluster akan bernilai lebih besar jika dibandingkan dengan cluster variance dari cluster 0.
Tabel 5 Hasil perhitungan cluster variance
Cluster Cluster variances ( )
Cluster 0 1.676
Cluster 1 10622.094 Cluster 2 10292.851
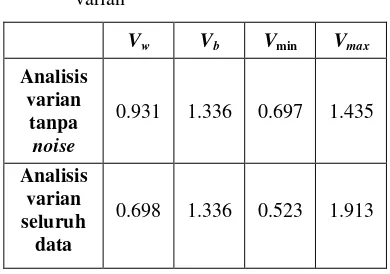
Analisis varian yang digunakan pada penelitian ini menggunakan dua perhitungan yakni analisis cluster seluruh data dan analisis cluster tanpa penggunaan noise. Jumlah seluruh data yang akan dikelompokkan sebanyak 15 titik. Hasil perhitungan analisis varian tersebut disajikan dalam Tabel 6.
Hasil perhitungan analisis varian seluruh data termasuk data noise menghasilkan nilai Vw yang kecil apabila dibandingkan dengan nilai Vw dari perhitungan analisis varian tanpa menyertakan noise. Hal tersebut terjadi pada penelitian dikarenakan pada perhitungan variances within cluster tersebut mengikutsertakan kabupaten yang dikenali sebagai unclassified. Berdasarkan hasil tersebut, maka dapat disimpulkan bahwa besarnya
keragaman dari hasil clustering tanpa noise memiliki kesamaan internal di dalam cluster yang lebih kecil dibandingkan hubungan antar cluster yang sama sekali berbeda. Secara umum hasil perhitungan dengan noise maupun dengan keseluruhan data menghasilkan analisis varian terhadap seluruh cluster telah mampu memenuhi kriteria cluster yang baik.
Tabel 6 Hasil perhitungan keseluruhan analisis varian
Vw Vb Vmin Vmax
Analisis varian
tanpa noise
0.931 1.336 0.697 1.435
Analisis varian seluruh
data
0.698 1.336 0.523 1.913
Clustering menggunakan teknik DDBC telah mengelompokan titik api ke dalam tiga cluster yaitu kabupaten yang dikelompokkan ke dalam cluster 0 yaitu Tapanuli Selatan, Pelalawan, Dumai, dan Bengkalis Pada cluster 1 yaitu daerah Pelalawan dan pada cluster 2 yaitu daerah Bengkalis. Daerah-daerah yang dikelompokkan ke dalam cluster 0 menjelaskan bahwa kabupaten tersebut seringkali muncul dalam rentang tahun 2002 sampai 2005, sehingga daerah tersebut akan lebih sering muncul sebagai ketetanggaan suatu daerah lain. Kabupaten yang terdapat dalam cluster 0 termasuk ke dalam kelompok titip api yang berpotensi tinggi terhadap terjadinya kebakaran hutan. Kabupaten yang dikelompokkan ke dalam cluster 1 dan 2 dikenali sebagai outlier, sedangkan Kabupaten Dumai dan Indragiri Hilir pada penelitian ini dideteksi sebagai noise. Daerah-daerah tersebut memiliki jumlah tetangga yang kurang dari titik minimum ketetanggaan yakni sebanyak 4 daerah.
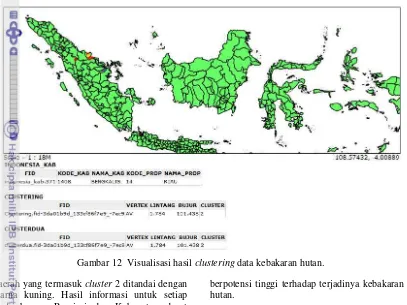
Gambar 12 Visualisasi hasil clustering data kebakaran hutan. daerah yang termasuk cluster 2 ditandai dengan
warna kuning. Hasil informasi untuk setiap node berupa Propinsi dan Kabupaten dapat diperoleh dengan melakukan klik pada node yang diinginkan.
KESIMPULAN DAN SARAN
Kesimpulan
Penggunaan teknik dynamic density based clustering (DDBC) mengelompokan data titik api berdasarkan kepadatannya terhadap satu dengan yang lainnya. Berdasarkan hasil penelitian yang diperoleh teknik DDBC telah mampu mengenali noise dari data hotspot. Hasil clustering yang diperoleh menjelaskan titik-titik api yang frekuensi kemunculannya cukup tinggi, dalam kasus ini paling banyak yakni sebanyak tiga kali kemunculan pada rentang tahun 2002 sampai tahun 2005.
Pengelompokkan titik-titik api berdasarkan hasil cluster termasuk ke dalam titik api yang berada dalam kondisi rawan terhadap kebakaran hutan. Pada cluster 0 mengelompokan daerah Tapanuli Selatan, Pelalawan, Dumai, dan Bengkalis. Pada cluster 1 dan 2 masing-masing hanya mengelompokan daerah Pelalawan dan Bengkalis. Visualisasi hasil clustering menggunakan peta akan mempermudah pengambilan informasi guna mengetahui kabupaten maupun provinsi tertentu yang merepresentasikan keberadaan titik api yang
berpotensi tinggi terhadap terjadinya kebakaran hutan.
Saran
Pada penelitian ini masih terdapat beberapa ketidaksempurnaan sehingga diharapkan pengembangan menggunakan algoritme DDBC dapat diperluas menggunakan data yang cocok sehingga memberikan hasil pengelompokan data yang lebih baik.
DAFTAR PUSTAKA
Ester M, Kriegel HP, Sander J, Xu X. 1996. A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of 2nd International Conference on Knowledge Discovery and Data Mining.
Fuad T. 2009. Clustering hasil operasi olap untuk data warehouse hotspot menggunakan algoritme k-means [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Han J, Kamber M. 2001. Data Mining: Concept And Techniques. USA: Morgan Kaufman Publisher.
[skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Hinneburg A, Keim D. 1998. An efficient approach to clustering in large multimedia databases with noise. Knowledge Discovery and Data Mining, 5865.
Kurniawan Y. 2011. Pembangunan spatiotemporal data model pada data hotspot dengan konsep Event-based Spatiotemporal Data Model (ESTDM) [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Kang L, Liu Y, Zeng S. 2007. Advances in computation and intelligence. Proceedings of 3rd International Symposium ISICA 16-17.
Man L, Chew LT, Jian S, Yue L. 2009. Supervised and traditional term weighting methods for automatic text categorization. IEEE Pattern Analysis and Machine Intelligence 31(4): 721-735.
Rahim MS. 2006. The development of spatiotemporal data model for dynamic visualization of virtual geographical information system [tesis]. Johor: Fakultas Sains Komputer dan Sistem Maklumat, Universitas Teknologi Malaysia.
Lampiran 1 Data hotspot yang muncul berulang pada tahun 2002 - 2005
lintang bujur year vertex nama_kab nama_prop the_geom
1.169 100.178 2004 Z Rokan Hulu Riau 010100000008
1.169 100.178 2005 Z Rokan Hulu Riau 010100000008
1.169 100.178 2005 Z Rokan Hulu Riau 010100000008
-1.478 104.035 2002 M Muaro Jambi Jambi 01010000000A
-1.478 104.035 2003 M Muaro Jambi Jambi 01010000000A
-1.478 104.035 2005 M Muaro Jambi Jambi 01010000000A
1.067 98.963 2003 Y Mandailing
Natal
Sumatera
Utara 010100000012
1.067 98.963 2004 Y Mandailing
Natal
Sumatera
Utara 010100000012
1.067 98.963 2005 Y Mandailing
Natal
Sumatera
Utara 010100000012
1.627 101.64 2002 AQ Dumai (Kota) Riau 010100000029
1.627 101.64 2002 AQ Dumai (Kota) Riau 010100000029
1.627 101.64 2002 AQ Dumai (Kota) Riau 010100000029
1.627 101.64 2005 AQ Dumai (Kota) Riau 010100000029
0.622 111.943 2004 W Kapuas Hulu Kalimantan
Barat 010100000031
0.622 111.943 2004 W Kapuas Hulu Kalimantan
Barat 010100000031
0.622 111.943 2004 W Kapuas Hulu Kalimantan
Barat 010100000031
-2.574 121.38 2003 G Luwu Timur Sulawesi
Selatan 0101000000B8
-2.574 121.38 2003 G Luwu Timur Sulawesi
Selatan 0101000000B8
-2.574 121.38 2004 G Luwu Timur Sulawesi
Selatan 0101000000B8
-1.917 113.388 2004 J Katingan Kalimantan
Tengah 010100000046
-1.917 113.388 2004 J Katingan Kalimantan
Tengah 010100000046
-1.917 113.388 2004 J Katingan Kalimantan
Lampiran 2 Data hotspot yang memenuhi RST neighborhood
lintang bujur vertex nama_kab nama_prop the_geom
-1.478 104.035 M Muaro Jambi Jambi 01010000000A
1.632 101.746 AS Dumai (Kota) Riau 010100000039
-0.689 102.708 N Indragiri Hilir Riau 01010000005A
-0.586 103.003 P Indragiri Hilir Riau 0101000000D5
-1.488 104.037 L Muaro Jambi Jambi 0101000000EE
1.784 101.438 AV Bengkalis Riau 010100000079
0.32 102.99 S Pelalawan Riau 01010000008F
1.397 100.148 AE Tapanuli Selatan Sumatera
Utara 0101000000B6
0.339 103.058 U Pelalawan Riau 0101000000C1
1.588 101.518 AN Dumai (Kota) Riau 0101000000FE
0.334 103.063 T Pelalawan Riau 010100000079
1.936 101.399 AW Bengkalis Riau 0101000000A8
1.569 101.823 AL Dumai (Kota) Riau 0101000000E9
1.067 98.963 Y Mandailing Natal Sumatera
Utara 010100000012
ABSTRACT
FANI WULANDARI. Implementation of Dynamic Density Based Clustering on Forest Fire Data. Supervised by ANNISA.
Land and forest fire has become prominent issues in Indonesia. Possibilities of the occurrence of forest fire in Indonesia has increased from year to year. This makes early prevention very important for forest fire investigation. One of the efforts concerning the forest fire prevention is by knowing the distribution of hotspot clustering which have high potential for the occurrence of forest fire. This research has classified the hotspot data using Dynamic Density Based Clustering (DDBC) algorithm. The use of DDBC technique is capable of handling spatiotemporal aspects simultaneously by storing the position of each point. The storage of each point’s position is estimated using the strength of its relationship to other points that appear every year. The neighborhood concept of DDBC algorithm is a modified version of the neighborhood concept of the Density Based Spatial Clustering (DBSCAN) called Relationship Strength Threshold (RST). Cluster detection is performed on the points that fulfill the RST neighborhood value, so that only the point which was considered as a strong relationship will be grouped. The result of the clustering obtained through DDBC technique is the grouping of areas with high potential for forest fire occurrence. Visualization of the clustering results is presented based on a map that describe the distribution of hotspot so that the authorities can determine the prioritized areas for early forest fire prevention.
PENDAHULUAN
Latar Belakang
Kebakaran hutan dan lahan menjadi permasalahan yang kian mencolok di Indonesia. Peluang terjadinya kebakaran hutan di Indonesia meningkat dari tahun ke tahun. Hal tersebut menandakan perubahan titik api yang terjadi di suatu wilayah (spatial) bersifat dinamis seiring waktu yang berjalan. Mengingat faktor timbulnya kebakaran hutan yang tinggi di Indonesia, maka sangatlah penting untuk pembangunan sistem guna pencegahan kebakaran hutan sejak dini.
Salah satu upaya pencegahan kebakaran hutan tersebut yakni dengan mengetahui persebaran pengelompokan titik api yang berpotensi tinggi terhadap terjadinya kebakaran hutan. Konsep data mining sangat sesuai untuk diterapkan pada data hotspot tersebut. Salah satu penerapan metode data mining yang akan digunakan pada penelitian adalah clustering. Penelitian sebelumnya yang dilakukan oleh Fuad (2009) data titik-titik panas telah dikelompokkan sesuai sebarannya menggunakan clustering hasil operasi OLAP dan visualisasi hasil clustering dari data tersebut diimplementasikan dalam bentuk peta. Teknik clustering yang digunakan pada penelitian tersebut yakni K-Means. Algoritme K-Means membutuhkan penyimpanan posisi objek yang sifatnya terkait time stamp (valid time) disertai waktu dimulainya (start time) secara eksplisit. Tahap clustering dengan K-Means tersebut diterapkan menggunakan WEKA versi 3.5.7. Selain itu, atribut yang digunakan dalam clustering adalah atribut jumlah titik panas, sedangkan atribut wilayah dan waktu yang bertipe kategorik hanya digunakan sebagai keterangan.
Penelitian yang dilakukan akan mengimplementasikan algoritme dynamic density based clustering (DDBC) yang dikenal mampu menangani aspek spatial dan temporal secara bersamaan. Algoritme DDBC telah diperkenalkan pertama kali oleh Ghose dan Rosswog (2010). Penelitian tersebut mengevaluasi algoritme DDBC terhadap teknik Trajectory Mining dan Moving Cluster Mining menggunakan sejumlah data objek yang berpindah pada satuan waktu. Hasil penelitian menunjukkan bahwa algoritme DDBC mampu mendeteksi dan mencatat cluster yang heterogen secara simultan dari objek yang saling berpindah melalui persimpangan
terhadap cluster lain dalam time stamp terkait yang digunakan.
Posisi setiap titik pada data kebakaran hutan diperkirakan besar kekuatan hubungannya untuk setiap satuan tahun (temporal) kemunculannya dan diolah pada relationship graph. Penggunaan relationship graph akan mempermudah dalam membedakan hubungan antar titik yang kuat dan lemah. DDBC mengelompokan suatu populasi objek berdasarkan pada parameter kepadatannya (density) dengan fungsi ketetanggaan yang digunakan adalah Relationship Strength Threshold (RST) neighborhood. Data hotspot yang digunakan pada penelitian ini memiliki atribut seperti lintang dan bujur yang menyimpan aspek spatial serta atribut year yang menyimpan aspek temporal, sehingga algoritme DDBC yang mampu mengolah data spatiotemporal dapat diterapkan dengan baik melalui penelitian ini.
Hasil clustering yang diperoleh dengan penggunaan teknik DDBC menghasilkan pengelompokan terhadap daerah-daerah terkait yang rawan terhadap terjadinya kebakaran hutan. Daerah-daerah yang dikenali sebagai titik api tersebut memiliki frekuensi kemunculan yang tinggi sehingga dinilai rawan terhadap potensi terjadinya kebakaran hutan. Visualisasi hasil clustering disajikan dalam bentuk peta yang menggambarkan persebaran titik panas agar pihak yang berwenang dapat dengan mudah menentukan daerah yang diprioritaskan untuk dilakukan pencegahan kebakaran hutan.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Menerapkan teknik clustering dengan menggunakan algoritme Dynamic Density Based Clustering (DDBC) pada data kebakaran hutan.
2 Memvisualisasikan hasil clustering dalam bentuk sistem peta untuk memudahkan pengguna melihat lokasi persebaran titik-titik api.
Ruang Lingkup
Ruang lingkup dari penelitian ini adalah: 1 Data hotspot yang digunakan diperoleh dari
Direktorat Kebakaran Hutan (DPKH) Departemen Kehutanan RI.
3 Data hotspot yang digunakan adalah data titik api yang muncul berulang dalam rentang tahun 2002 sampai 2005.
Manfaat Penelitian
Hasil akhir dari clustering yang diperoleh pada penelitian ini diharapakan dapat mempermudah pihak yang berwenang terkait pengelolaan data hotspot untuk mengambil keputusan dalam upaya pencegahan kebakaran hutan sejak dini.
TINJAUAN PUSTAKA
Data Mining
Data mining adalah kegiatan penemuan pola-pola yang menarik dari data berukuran besar yang disimpan dalam basis data, data warehouse, atau sarana penyimpanan yang lain. Data mining dapat diklasifikasikan menjadi dua kategori yaitu descriptive data mining dan predictive data mining. Descriptive data mining menjelaskan himpunan data dengan memberikan banyak informasi secara jelas dalam kalimat yang singkat dan memberikan sifat-sifat umum yang menarik dari data. Predictive data mining menganalisis data yang bertujuan untuk membangun sebuah atau himpunan model, dan berusaha untuk meramalkan karakteristik dari himpunan data baru (Han & Kamber 2001).
Menurut (Han & Kamber 2001), fungsionalitas data mining adalah:
1 Deskripsi kelas/ deskripsi konsep dan diskriminasi,
2 Analisis asosiasi, 3 Klasifikasi dan prediksi, 4 Analisis cluster, 5 Analisis pencilan, dan 6 Analisis evolusi.
Hotspot (Titik Panas)
Data hotspot merupakan salah satu indikator kemungkinan terjadinya kebakaran hutan pada wilayah tertentu. Pemantauan hotspot dilakukan dengan penginderaan jauh (remote sensing) menggunakan satelit (Hayardisi 2008).
Satelit yang biasa digunakan adalah satelit National Ocean and Atmospheric Administration (NOAA) melalui sensor Advanced Very High Resolution Radiometer (AVHRR) karena sensor tersebut dapat membedakan suhu permukaan di darat dan laut. Satelit ini mendeteksi objek di permukaan bumi
yang memiliki suhu relatif lebih tinggi dibandingkan sekitarnya. Suhu yang dideteksi berkisar antara 210 K (37°C) untuk malam hari dan 315 K (42°C) untuk siang hari.
Penginderaan satelit tersebut tentunya akan membantu penanganan masalah kebakaran hutan, karena jika posisi lokasi hotspot telah diketahui maka bisa dilakukan penanganan lebih dini untuk mencegah terjadinya kebakaran hutan.
Clustering
Secara umum, clustering merupakan proses pengelompokan kumpulan objek ke dalam kelas-kelas atau clusters sehingga objek-objek dalam satu cluster memiliki kemiripan yang tinggi tetapi tidak mirip terhadap objek dari cluster lain (Han & Kamber 2001). Ukuran kemiripan dan ketidakmiripan dinilai berdasarkan nilai atribut yang mendeskripsikan objek.
Spatiotemporal Data
Data spatiotemporal adalah data spasial yang berubah seiring waktu (Rahim 2006). Jadi, data spatiotemporal adalah data spasial yang memiliki elemen temporal. Sedangkan data spasial adalah data yang memiliki referensi ruang kebumian (georeference) dimana berbagai data atribut terletak dalam berbagai unit spasial (tidak memiliki aspek temporal).
[image:30.595.321.487.598.690.2]Gambar 1 menjelaskan deskripsi dari data spatiotemporal. Pada Gambar 1 dapat dilihat objek A pada waktu t1. Akibat sesuatu hal objek A tersebut berubah menjadi objek AB dalam waktu t2, kemudian objek AB berubah lagi menjadi objek B di waktu tn. Objek terus berubah tergantung pada situasi dan skenario. Data spatiotemporal adalah serangkaian data spasial yang telah berubah. Perubahan akan terjadi sampai waktu ke n, yaitu akhir dari proses perubahan (Rahim 2006).
Gambar 1 Deskripsi data spatiotemporal (Rahim 2006).
t1 t2 tn
Space
Density Based Clustering (DENCLUE)
Ide dasar dari DENCLUE adalah mengelompokan pemodelan seluruh data berdasarkan besarnya kepadatan (density) sebagai penjumlahan fungsi pengaruh (influence function) dari suatu titik. Konsep influence function adalah fungsi yang menjelaskan pengaruh suatu data di dalam ketetanggaannya. Contoh dari influence function yang telah banyak digunakan antara lain :
1 Square wave function
2 Gaussian function
Besarnya fungsi kepadatan dari data dapat dihitung dengan menjumlahkan seluruh influence function tertentu yang dipilih. Tahap clustering selanjutnya dapat ditentukan secara matematik dengan mengidentifikasi nilai lokal maksimum dari kepadatan (density-attractors) (Hinneburg A & Keim D 1998).
Density Based Spatial Clustering (DBSCAN)
DBSCAN memiliki cara kerja clustering yang hampir mirip dengan DENCLUE. Secara signifikan, DBSCAN bekerja dengan efisien dalam membentuk arbitrary-shaped cluster. Pengelompokan dilakukan terhadap titik dengan ketetanggaannya yang berada di dalam jarak (ɛ) t