1. package com.rickywijaya.kamusistilahpsikologi;
32. public class Psi_Arti extends Fragment implements View.OnClickListener 33. {
40. ArrayList<HashMap<String, String>> list_data; 41. HashMap<String, String> map;
42. ArrayAdapter<Kamus> adapter;
43. List<Kamus> listKamus;
44. SQLiteDatabase db; 45. Cursor cursor = null;
46. String arti = "", istilah = "", pat = ""; 47. int urutan = 0;
48. int algo;
49. public static int komparasi;
50. @Override
51. public void onCreate(Bundle savedInstanceState)
55. @Override
56. public View onCreateView(LayoutInflater inflater, ViewGroup container,
57. Bundle savedInstanceState) {
58. View rootView = inflater.inflate(R.layout.psi_arti, container, false); 59. text = (EditText) rootView.findViewById(R.id.editText);
60. lv = (ListView) rootView.findViewById(R.id.lv_data); 61. radio1 = (RadioButton) rootView.findViewById(R.id.radio1); 62. radio = (RadioGroup) rootView.findViewById(R.id.grup); 63. search = (Button) rootView.findViewById(R.id.search); 64. list_data = new ArrayList<HashMap<String, String>>();
65. algo = 1;
66. radio.setOnCheckedChangeListener(new RadioGroup.OnCheckedChangeListener()
67. {
68. public void onCheckedChanged(RadioGroup group, int checkedId) { 69. switch(checkedId){
80. text.setOnKeyListener(new View.OnKeyListener() {
81. @Override
82. public boolean onKey(View v, int keyCode, KeyEvent event) { 83. if ( text.getText().toString().length() == 0){
84. ambildata();
85. }
86. return false;
87. }
88. });
89. search.setOnClickListener(new View.OnClickListener() {
90. @Override
91. public void onClick(View v) {
92. search();
93. return;
94. }
95. });
96. ambildata();
97. lv.setOnItemClickListener(new OnItemClickListener() { 98. public void onItemClick(AdapterView<?> parent, View view, 99. int position, long id) {
100. TextView text = (TextView) view.findViewById(R.id.istilah); 101. TextView text1 = (TextView) view.findViewById(R.id.arti); 102. Bundle b = new Bundle();
103. b.putString("istilah", text.getText().toString().trim()); 104. b.putString("arti", text1.getText().toString().trim()); 105. Intent i = new Intent(getActivity(), ArtiActivity.class);
106. i.putExtras(b);
107. startActivity(i);
108. }
109. });
114. }
115. public void search() {
116. dbHelper = new DatabaseHelper(getActivity()); 117. db = dbHelper.getReadableDatabase();
118. pat = text.getText().toString(); 119. int ketemu = 0, i = 0;
120. urutan = 0; 121. komparasi = 0; 122. try {
123. list_data.clear();
124. long t = System.currentTimeMillis(); 125. if (cursor != null) {
126. cursor.moveToFirst();
127. do {
128. istilah = cursor.getString(0); 129. arti = cursor.getString(1);
130. if (pat.length() <= istilah.length()) {
131. if(algo == 1){
132. AlgoritmaNotSoNaive c = new AlgoritmaNotSoNaive();
133. ketemu = c.searching(pat.toUpperCase(), pat.length(), istilah.toUpperCase(), istilah.length());
134. }
135. else if (algo == 2){
136. AlgoritmaSkipSearch c = new AlgoritmaSkipSearch();
137. ketemu = c.searching(pat.toUpperCase(), pat.length(), istilah.toUpperCase(), istilah.length());
138. }
139. if (ketemu == 1) {
140. urutan++;
141. map = new HashMap<String, String>(); 142. map.put("urutan", Integer.toString(urutan));
150. } while (cursor.moveToNext());
151. }
152. long t2 = (System.currentTimeMillis() - t); 153. if (i == 0) {
154.Toast.makeText(getActivity().getBaseContext(), "Kata tidak ditemukan & Running Time : " + t2 + " ms & " + komparasi + " banyak komparasi", Toast.LENGTH_SHORT).show();
155. } else {
156.
157.ListAdapter adapt = new SimpleAdapter(getActivity(), list_data, R.layout.list_row, new String[]{"urutan", "istilah", "arti"},
158. new int[]{R.id.id, R.id.istilah, R.id.arti}); 159. lv.setAdapter(adapt);
160.Toast.makeText(getActivity().getBaseContext(), "Running Time : " + t2 + " ms & " + komparasi + "
banyak komparasi", Toast.LENGTH_SHORT).show();
161. }
162. }
166. }
167. public void ambildata() { 168. list_data.clear();
169. dbHelper = new DatabaseHelper(getActivity()); 170. db = dbHelper.getReadableDatabase();
171. cursor = db.query("tb_istilah", new String[]{"istilah", "arti"}, null, null, null, null, "istilah");
179. istilah = cursor.getString(0); 180. arti = cursor.getString(1);
181. map = new HashMap<String, String>();
182. map.put("urutan", Integer.toString(urutan) + "."); 183. map.put("istilah", istilah);
184. map.put("arti", arti); 185. list_data.add(map);
186. } while (cursor.moveToNext());
187. ListAdapter adapter = new SimpleAdapter(getActivity(), list_data, R.layout.list_row, new String[]{"urutan", "istilah", "arti"},
188. new int[]{R.id.id, R.id.istilah, R.id.arti}); 189. lv.setAdapter(adapter);
190. }
191. } catch (Exception e) {
20. import android.widget.ArrayAdapter;
31. public class Arti_Psi extends Fragment implements View.OnClickListener 32. {
38. ArrayList<HashMap<String, String>> list_data; 39. HashMap<String, String> map;
40. ArrayAdapter<Kamus> adapter;
41. List<Kamus> listKamus;
42. SQLiteDatabase db; 43. Cursor cursor = null;
44. String arti = "", istilah = "", pat = ""; 45. int urutan = 0;
46. int algo;
47. public static int komparasi;
48. @Override
49. public void onCreate(Bundle savedInstanceState)
50. {
51. super.onCreate(savedInstanceState);
52. }
53. @Override
54. public View onCreateView(LayoutInflater inflater, ViewGroup container,
55. Bundle savedInstanceState) {
56. View rootView = inflater.inflate(R.layout.psi_arti, container, false); 57. text = (EditText) rootView.findViewById(R.id.editText);
58. lv = (ListView) rootView.findViewById(R.id.lv_data); 59. radio = (RadioGroup) rootView.findViewById(R.id.grup); 60. search = (Button) rootView.findViewById(R.id.search); 61. list_data = new ArrayList<HashMap<String, String>>(); 62. algo = 1;
63. radio.setOnCheckedChangeListener(new RadioGroup.OnCheckedChangeListener()
64. {
65. public void onCheckedChanged(RadioGroup group, int checkedId) {
79. if ( text.getText().toString().length() == 0){
85. search.setOnClickListener(new View.OnClickListener() {
86. @Override
87. public void onClick(View v) {
88. search();
89. return;
90. }
91. });
92. ambildata();
93. lv.setOnItemClickListener(new OnItemClickListener() { 94. public void onItemClick(AdapterView<?> parent, View view, 95. int position, long id) {
96. TextView text = (TextView) view.findViewById(R.id.istilah); 97. TextView text1 = (TextView) view.findViewById(R.id.arti); 98. Bundle b = new Bundle();
99. b.putString("istilah", text.getText().toString().trim()); 100. b.putString("arti", text1.getText().toString().trim()); 101. Intent i = new Intent(getActivity(), IstilahActivity.class);
102. i.putExtras(b);
109. public void onClick(View v) {
110. }
111. public void search() {
112. dbHelper = new DatabaseHelper(getActivity()); 113. db = dbHelper.getReadableDatabase();
114. cursor = db.query("tb_istilah", new String[]{"istilah", "arti"}, null, null, null, null, "arti"); 115. pat = text.getText().toString();
116. int ketemu = 0, i = 0; 117. urutan = 0;
118. komparasi = 0; 119. try {
120. list_data.clear();
121. long t = System.currentTimeMillis(); 122. if (cursor != null) {
123. cursor.moveToFirst();
124. do {
125. istilah = cursor.getString(0); 126. arti = cursor.getString(1); 127. if (pat.length() <= arti.length()) {
128. if(algo == 1){
129. AlgoritmaNotSoNaive c = new AlgoritmaNotSoNaive();
130. ketemu = c.searching(pat.toUpperCase(), pat.length(), arti.toUpperCase(), arti.length());
131. }
132. else if (algo == 2){
136. if (ketemu == 1) {
137. urutan++;
138. map = new HashMap<String, String>(); 139. map.put("urutan", Integer.toString(urutan));
146. } while (cursor.moveToNext());
147. }
148. long t2 = (System.currentTimeMillis() - t); 149. if (i == 0) {
150. Toast.makeText(getActivity().getBaseContext(), "Kata tidak ditemukan & Running Time : " + t2 + " ms & " + komparasi + " banyak komparasi",
Toast.LENGTH_SHORT).show();
151. } else {
152. ListAdapter adapt = new SimpleAdapter(getActivity(), list_data, R.layout.list_arti, new String[]{"urutan", "arti", "istilah"},
153. new int[]{R.id.id, R.id.arti, R.id.istilah}); 154. lv.setAdapter(adapt);
155. Toast.makeText(getActivity().getBaseContext(), "Running Time : " + t2 + " ms & " + komparasi + " banyak komparasi", Toast.LENGTH_SHORT).show();
156. }
157. }
158. catch (Exception e) {
159. Toast.makeText(getActivity().getBaseContext(), e.toString(), Toast.LENGTH_SHORT).show();
160. }
161. }
162. public void ambildata() { 163. list_data.clear();
164. dbHelper = new DatabaseHelper(getActivity()); 165. db = dbHelper.getReadableDatabase();
166. cursor = db.query("tb_istilah", new String[]{"istilah", "arti"}, null, null, null, null, "istilah");
173. istilah = cursor.getString(0); 174. arti = cursor.getString(1);
175. map = new HashMap<String, String>();
176. map.put("urutan", Integer.toString(urutan) + "."); 177. map.put("arti", arti);
178. map.put("istilah", istilah); 179. list_data.add(map);
180. } while (cursor.moveToNext());
181. ListAdapter adapter = new SimpleAdapter(getActivity(), list_data, R.layout.list_arti, new String[]{"urutan", "arti", "istilah"},
182. new int[]{R.id.id, R.id.arti, R.id.istilah}); 183. lv.setAdapter(adapter);
187. } 5. public class AlgoritmaNotSoNaive { 6. int k,ell,a;
7. ArrayList<HashMap<String, String>> list_data; 8. public int searching(String pat, int m, String text, int n){
9. try{
10. Psi_Arti komp = new Psi_Arti(); 11. Arti_Psi komp1 = new Arti_Psi();
12. int j =0;
13. int hasil =0;
14. Boolean found = false; 15. char [] x = pat.toCharArray(); 16. char [] y = text.toCharArray(); 17. //preprocessing
29. if(x[1] != y[j+1] && komp.komparasi++>=0 && komp1.komparasi++>=0){
30. j += k;
36. for (int b=0;b<m;b++){
37. try{
38. if(x[b+1] == y[j+1+b] && x[0] == y[j] &&
komp.komparasi++>=0 && komp1.komparasi++>=0 ){
49. if(a == m){
62. catch (Exception e){
63. return 0;
4. public class AlgoritmaSkipSearch { 5.
6. public static int ASIZE = 256; 7.
8. public int searching(String pat, int m, String text, int n){
9. try{
10. Psi_Arti komp = new Psi_Arti();
11. Arti_Psi komp1 = new Arti_Psi();
12. char[] x = pat.toCharArray();
13. char[] y = text.toCharArray();
14. int i, j;
15. List1 ptr = null;
16. List1 z[] = new List1[ASIZE];
17. String sub_x, sub_y;
18. Boolean found = false;
19.
20. /*Prepocessing*/
21. for (int a=0; a<ASIZE; a++){
22. z[a] = null;
23. }
24.
25. for(i = 0; i < m; ++i){
26. ptr = new List1();
27. if (ptr==null) System.out.println("ERROR");
28. ptr.element = i;
29. ptr.next = z[x[i]];
30. z[x[i]] = ptr;
31. }
32.
33. /*Searching*/
37. for(ptr = z[y[j]]; ptr != null; ptr = ptr.next){
38. komp.komparasi++;
39. komp1.komparasi++;
40. int a=0;
41. for (int b=0;b<m;b++){
42. try{
43. if(x[b] == y[j-ptr.element+b] &&
komp.komparasi++>=0 && komp1.komparasi++>=0)
52. if(j-ptr.element<= n-m && a == m)
53. found = true;
71. class List1 {
DAFTAR RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap : Ricky Wijaya
Jenis Kelamin : Laki - Laki
Tempat, Tanggal Lahir : Medan, 16 September 1994
Alamat : Jl. Brijend Katamso gang : Persatuan no : 19 Medan
Agama : Buddha
Telp/Hp : 0857 6119 6782
E-mail : [email protected]
Pendidikan Terakhir : Universitas Sumatera Utara Medan, Fakultas Ilmu
Komputer dan Teknologi Informasi. Jurusan S1 Ilmu
Komputer
2012–2016 : S1 Ilmu Komputer Universitas Sumatera Utara, Medan
PENGALAMAN ORGANISASI
Anggota Kerohanian KMB-USU,2013 Anggota Komite KMB-USU, 2013-2014 Ketua Komite KMB-USU, 2015
Ketua Bidang Agama Buddha Pemerintahan Mahasiswa Fasilkom-TI USU, 2014-2015
PENGALAMAN KEPANITIAAN
Anggota Panitia Acara Dies Natalis Ilmu Komputer USU, 2013
Anggota Panitia Acara Seminar“What will you be?”IMILKOM USU, 2013 Anggota Panitia Acara Porseni Ilmu Komputer USU, 2014
Anggota Panitia Dana PMB Ilmu Komputer USU, 2014 Anggota Panitia Acara Waisak KMB-USU, 2013 Koordinator Panitia Acara PMB KMB-USU, 2013 Koordinator Panitia Keamanan Baksos KMB-USU, 2013 Koordinator Panitia Acara Waisak KMB-USU, 2014 Koordinator Panitia PTT Gathday KMB-USU, 2014 Ketua Panitia PPO KMB-USU, 2015
SEMINAR
Alapati, K. P. & Mannava. V. 2011. An GUI Based Implementation of Pattern
Matching Algorithms. International Journal of System And Technologies,
4(2): 207-215.
Bhandari, J. & Kumar, A. 2013. A Correlation Analysis of Suffix to Prefix rule,
Two Window Rule and Non-Tandem Rule of Exact String Matching
Algorithms.Proc. Of Int. Conf. On Advances in Computer Science, pp.
330-335
Cantone, D. & Faro, S. 2004. Searching for a subtring with constant extra space
complexity. In Ferragina, P. & Grossi, R (Eds.), Proceedings of The
International Conference on FUN with Algorithms (FUN 2004), pp.
181-131
Charas, C. & Lecroq, T, 2004. Handbook of Exact String-Matching Algorithms.
King's College London Publications.
Charras, C., Lecroq, T., & Pehoushek, J. D. 1998. A very fast string matching
algortihm for small alphabets and long patterns. Proceedings of the 9th
Annual Symposium on Combinatorial Pattern Matching,Piscataway, New
Jersey,pp. 55-64
Cormen, T.H, Leiserson, C.E, Rivest, R.L. & Stein, C. 2009.Introduction to
Algorithms. 3thEdition. The MIT Press:England.
Kamus Besar Bahasa Indonesia. (Online) http://www.kbbi.web.id (11 Maret 2016)
Naser, M. A. 2010. Parallel Quick-Skip Search Hybird Algorithm For The Exact
String Matching Problem. Master Thesis, Universiti Sains Malaysia, pp.
18-19.
Naser, M. A., Rashid, N. A., & Aboalmaaly, M.F. 2012. Quick-Skip Search Hybird
Algorithm for the Exact String Matching Problem.International Journal of
Computer Theory and Engineering, 4(2): 259-260.
National Institute of Standards and Technology. Dictionary of Algorithms and Data
Nugraha, D.W. 2012. Penerapan kompleksitas waktu AlgoritmaPrimuntuk menghitung kemampuan komputer dalam melaksanakan perintah.Jurnal
Ilmiah Foristek2(2):196-197.
Subandijo. 2011. Efisiensi Algoritma dan Notasi O-besar.Jurnal ComTech
2(2):850-858.
Syaroni, M. & Munir, R. 2005. Pencocokan String Berdasarkan Kemiripan Ucapan
(Phonetic String Matching) dalam Bahasa Inggris. Prosiding Seminar
Nasional: SNATI UII, Yogyakarta, 18 Juni 2005.pp. 1-6.
Whitten, J.L., Bentley, L.D. & Dittman, K.C. 2004. Metode Desain & Analisis
Sistem.Terjemahan TIM Penerjemah ANDI. ANDI : Yogyakarta.
Zarlis, M. & Handrizal. 2008.Algoritma & Pemrograman : Teori dan Pratik dalam
3.1 Analisis Sistem
Tahapan ini dilakukan untuk memaparkan pemahaman tentang sistem yang dibuat
secara keseluruhan. Baik kinerja sistem maupun proses perancangan aplikasi pada
sistem. pemahaman yang menyeluruh terhadap kebutuhan sistem sehingga
diperoleh tugas-tugas yang akan dikerjakan sistem. Tahapan ini dilakukan agar
pada saat proses perancangan aplikasi tidak terjadi kesalahan.
3.1.1 Analisis Masalah
Analisis masalah merupakan proses mengidentifikasi sebab dan akibat
dibangunnya sebuah sistem agar sistem yang akan dibangun tersebut dapat
berjalan sebagaimana mestinya sesuai dengan tujuan dari sistem itu. Selama ini
jika seseorang ingin mempelajari istilah dari sebuah cabang ilmu, pasti media
yang digunakan untuk memperlancar penguasaan istilahnya adalah melalui
kamus istilah. Seiring dengan berkembangnya teknologi, sekarang ini masyarakat
tidak lagi menggunakan kamus manual. Namun masyarakat lebih cenderung
memilih kamus digital atau yang lebih sering kita kenal yaitu kamus di
Smartphone. Aplikasi kamus didalam Smartphone tidaklah mencari kata secara
manual. Pencarian definisi / istilah kata yang telah tersimpan sebagai fieldnya
kemudian mendapat hasil yang mendetail adalah masalah yang akan diselesaikan
dengan menggunakan sistem ini.
Untuk mengidentifikasi masalah tersebut digunakan diagram Ishikawa
(fishbone diagram). Diagram Ishikawa berbentuk seperti ikan yang strukturnya
terdiri dari kepala ikan (fish’s head) dan tulang-tulang ikan (fish’s bones). Nama
atau judul dari masalah yang diidentifikasi terletak pada bagian kepala ikan.
tersebut (Whitten, J.L & Bentley, L.D. 2007). DiagramIshikawapada sistem ini
dapat dilihat padaGambar 3.1
Sistem Pencarian Kata pada Kamus Istilah Psikologi dengan AlgoritmaNot So Naivedan Algoritma
Skip Search
Belum ada aplikasi berbasis android yang membandingkan dua algoritmastring matching
yang dipilih
Gambar 3.1DiagramIshikawa
PadaGambar 3.1dapat dilihat bahwa terdapat empat kategori penyebab masalah pada penelitian Perbandingan Algoritma String Matching Not So NaivedanSkip
Search pada platform Andorid yang digambarkan dengan tanda panah yang
mengarah ke tulang utama, yaitu berkaitan dengan pengguna (users), bahan
(materials), metode (methods) dan media/alat yang terlibat (machine). Setiap
detail penyebab masalah tersebut digambarkan dengan tanda panah yang
mengarah ke masing-masing kategori.
3.1.2 Analisis Persyaratan
Untuk membangun sebuah sistem, perlu dilakukan sebuah tahap analisis
persyaratan. Terdapat dua bagian pada analisis persyaratan, yaitu persyaratan
fungsional dan persyaratan non-fungsional. Persyaratan fungsional
mendeskripsikan aktivitas yang disediakan suatu sistem. Sedangkan Persyaratan
nonfungsional mendeskripsikan fitur, karakteristik dan batasan lainnya.
3.1.2.1 Persyaratan Fungsional
Persyaratan fungsional disini mendeskripsikan tentang sistem yang disediakan.
Terdapat beberapa hal yang menjadi persyaratan fungsional pada Aplikasi Kamus
1. Sistem melakukan pencocokan string melalui kata yang dimasukkan oleh
pengguna.
2. Sistem dapat menghasilkan kata terjemahan dari inputan yang dicari dengan
menggunakan AlgoritmaNot So Naivedan AlgoritmaSkip Search.
3. Sistem melakukaninputanberupa kata ataupun berupa kalimat.
4. Sistem menampilkan hasil pencarian berupa bentuk kata ataupun berupa
kalimat.
3.1.2.2 Persyaratan Non-Fungsional
Persyaratan non-fungsional sistem merupakan karakteristik atau batasan yang
menentukan kepuasan pada sebuah sistem seperti kinerja, kemudahan pengguna,
biaya, dan kemampuan sistem bekerja tanpa mengganggu fungsionalitas sistem
lainnya. Terdapat beberapa persyaratan non-fungsional yang harus dipenuhi
diantaranya :
1. Performa
Sistem yang akan dibangun harus dapat menampilkan hasil pencarian yang
sesuai dengan apa yang dicari.
2. Mudah digunakan
Sistem yang akan dibangun harus mudah digunakan (user friendly), artinya
sistem ini akan mudah digunakan olehuserdengan tampilan yang sederhana
dan dapat dimengerti.
3. Hemat biaya
Sistem yang dibangun tidak memerlukan perangkat tambahan ataupun
perangkat pendukung lainnya yang dapat mengeluarkan biaya.
4. Manajemen Kualitas
Sistem yang akan dibangun harus memiliki kualitas yang baik yaitu tidak
mempersulituseruntuk melakukan pencarian kata.
3.1.3 Pemodelan
Pemodelan sistem dilakukan untuk memperoleh gambaran cara kerja sistem dan
tentang objek apa saja yang akan berinteraksi dengan sistem, serta hal-hal apa saja
yang harus dilakukan oleh sebuah sistem sehingga sistem dapat berfungsi dengan
Pada penelitian ini digunakanUML(Unified Modeling Language) sebagai
bahasa pemodelan untuk mendesain dan merancang aplikasi Kamus Istilah
Psikologi.Model UML yang digunakan antara lain Use Case Diagram, Activity
diagram,danSequence diagram.
3.1.3.1 Use Case Diagram
Use Case Diagram adalah sebuah diagram yang dapat merepresentasikan
interaksi yang terjadi antara user dengan sistem. Diagram use case ini
mendeskripsikan siapa saja yang menggunakan sistem dan bagaimana cara
mereka berinteraksi dengan sistem. Use Case Diagram dari sistem yang akan
dibangun dapat ditunjukkan padaGambar 3.2
Didalamuse casediagram digambarkan 1 orang aktor yang akan berperan yaitu
user. Untuk memperoleh definisi dari istilah psikologi maka user harus memilih
mode Istilah Psikologi – Definisi dan Definisi – Istilah Psikologi untuk memperoleh istilah psikologi dari definisi yang diinputkan. Definisi atau istilah
yang dicari akan diinputkan dalamsearch boxyang disediakan.
Selanjutnya user memilih Algoritma yang ingin digunakan antara
Algoritma Not So Naive dan Algoritma Skip Search. Setelah Algoritma dipilih
lalu sistem akan melakukan pencarian dan menampilkan hasil. Pada proses
memilih mode pengartian yang diinginkan, apakah Istilah Psikologi – Definisi atau Definisi–Istilah Psikologi, dapat dinyatakan dalamTabel 3.1
Tabel 3.1TabelUse CaseMemilihModeuntuk kata yang akan diartikan Name Memilih mode untuk kata yang akan diartikan
Actors User
Description Use Case ini mendeskripsikan proses mode, apakah Istilah
Psikologi–Definisi atau Definisi–Istilah Psikologi
Basic Flow Usermemilihmode
Alternate Flow User dapat dapat memilih mode dari Istilah Psikologi – Definisi atau Definisi–Istilah Psikologi
Pre Condition Useringin memilihmodeuntuk kata yang ingin diartikan
Pada ProsesInputkata, dapat dinyatakan dalamTabel 3.2
Tabel 3.2TabelUse CaseProsesInputkata
Pada Proses AlgoritmaNot So Naive, dapat dinyatakan dalamTabel 3.3 Tabel 3.3TabelUse CaseProses AlgoritmaNot So Naive
Name Algoritma Not So Naive
Actors User
Description Use Case ini mendeskripsikan proses pencarian kata
menggunakan AlgoritmaNot So Naive
Basic Flow Usermemilih Algoritma Not So Naive
Alternate Flow Usertidak memilih Algoritma
Pre Condition Useringin mencari kata
Post Condition Usermendapatkan hasil pencarian kata
Name Input kata
Actors User
Description Use Case ini mendeskripsikan penginputan kata yang ingin
diterjemahkan
Basic Flow Usermenginputkata
Alternate Flow
-Pre Condition Useringin menginputkata
Pada Proses AlgoritmaSkip Search, dapat dinyatakan dalamTabel 3.4 Tabel 3.4TabelUse CaseProses AlgoritmaSkip Search
Name Algoritma Skip Search
Actors User
Description Use Case ini mendeskripsikan proses pencarian kata
menggunakan AlgoritmaSkip Search
Basic Flow Usermemilih Algoritma Skip Search
Alternate Flow Usertidak memilih Algoritma
Pre Condition Useringin mencari kata
Post Condition Usermendapatkan hasil pencarian kata
3.1.3.2 Activity Diagram
Activity Diagram adalah teknik untuk menggambarkan logika procedural, jalur
kerja sistem. Diagram ini menggambarkan berbagai alur kerja dalam sistem yang
sedang dirancang, bagaimana masing-masing alur kerja berawal, decision yang
mungkin terjadi, dan bagaimana mereka aktifitas atau alur kerja berakhir.Activity
Gambar 3.3Activity DiagramSistem
Pada Gambar 3.3 ditujukan didalam Activity diagram dapat dijelaskan bahwa
user harus membuka program terlebih dahulu. Lalu user memilih mode
terjemahan apakah itu Istilah Psikologi–Definisi atau Definisi–Istilah Psikologi. Selanjutnyausermenginput kata yang ingin dicari. Laluusermemilih Algoritma
untuk melakukan pencarian kata. Maka sistem melakukan pemanggilan fungsi
pada Algoritma yang telah dipilih. Lalu sistem akan menampilkan hasil pencarian
3.2.3 Sequence Diagram
Sequence diagram adalah suatu diagram yang menggambarkan interaksi antar
objek pada sistem dalam sebuah urutan waktu atau rangkaian waktu. Sequence
diagramdari sistem yang akan dibangun dapat ditunjukkan padaGambar 3.4
Gambar 3.4Sequence DiagramSistem
Pada gambar 3.4 sequence diagram sistem memiliki empat objek yaitu
user, menu utama, database dan algoritma yang digambarkan dengan simbol
objek UML. Referensi pada use-case digambarkan denganlifeline–garisvertikal
putus – putus. Kotak persegi empat yang berada pada masing – masing objek merupakan behavior atau operasi yang perlu dilakukan oleh masing – masing
panah antara garis menggambarkan interaksi atau pesan yang telah dikirim ke
objek tertentu untuk menginvokasi salah satu operasinya untuk memenuhi
permintaan.
Pada tahap ini, yang dilakukan user adalah menentukan tipe terjemahan
terlebih dahulu,seperti Istilah Psikologi - Definisi atau Definisi–Istilah Psikologi di tampilan menu. Lalu tampilan menu menetapkan tipe terjemahan yang telah
dipilih dan mengambil seluruh kata yang ada dalam database untuk ditampilkan
dalam list view. Selanjutnya yang dilakukan user adalah menginput kata yang
ingin dicari dan memilih algoritma untuk melakukan pencarian, lalu sistem akan
mengambil seluruh kata dari database dan memanggil fungsi Algoritma yang
telah dipilih. Kemudian menampilkan hasil pencarian kata kepadauser.
3.2 Flowchart
Flowchartatau diagram alir merupakan gambar atau bagan yang memperlihatkan
urutan dan hubungan antar proses dengan pernyataannya (Zarlis, 2008).
Gambaran ini dinyatakan dengan simbol. Dengan demikian setiap simbol
menggambarkan proses tertentu. Sedangkan antara proses digambarkan dengan
3.2.1 Flowchart Gambaran Umum Sistem
Flowchartgambaran umum sistem dapat dilihat padaGambar 3.5dibawah ini.
Mulai
Gambar 3.5FlowchartGambaran Umum Sistem Kamus Istilah Psikologi Gambar 3.5 Menggambarkan alur sistem secara umum pada kamus Istilah Psikologi, dimana user memilih mode terjemahan seperti Istilah Psikologi
-Definisi atau -Definisi – Istilah Psikologi. Lalu user memilih Algoritma untuk pencarian kata. Selanjutnya user menginputkata yang ingin dicari. Maka sistem
akan mencocokkan kata sesuai dengan Algoritma yang telah dipilih lalu sistem
3.2.1 Flowchart Algoritma Not So Naive
FlowchartAlgoritmaNot So Naivedapat dilihat padaGambar 3.6dibawah ini.
MULAI
j += k Proses pencocokan
pola dengan teks
String
ditemukan? j += ell
Output Hasil
Gambar 3.6Flowchart AlgoritmaNot So Naive
Gambar 3.6Menggambarkan alur pada proses pencarian algoritmaNot So
Naive,dimana proses awal yang dilakukan adalah melihat apakah karakter urutan
0 dan 1 pada pola berupa karakter yang sama atau tidak. Jika sama, maka variabel
kakan diberi nilai 2 dan variabelelldiberi nilai 1 (nilaikdigunakan sebagai nilai
ketidakcocokan dan nilai ell digunakan sebagai nilai pergeseran jika saat fase
pencocokan karakter di urutan 1 mengalami kecocokan namun di urutan
selanjutnya mengalami ketidakcocokan). Lalu dilanjutkan ke fase pencocokan
dimana variabelxadalah panjang pola , variabel y adalah panjang teks, variabelj
adalah nilai untuk perulangan pencocokan, variabelmuntuk panjang pola, dann
untuk panjang teks, dari kiri ke kanan sampai string ditemukan atau posisi pola
bergeser sampai penghujung teks.
3.2.1 Flowchart Algoritma Skip Search
FlowchartAlgoritmaSkip Searchdapat dilihat padaGambar 3.7dibawah ini.
MULAI dengan rumus 2m-1 dan karakter di tengah teks yang akan digunakan untuk proses
pencocokan
Pergeseran posisi pola ke urutan teks dengan
Apakah terdapat karakter dalam pola yang sama 1 lagi dengan karakter untuk proses pencocokan?
Pola digeser
MULAI
Memasukan alphabet yang terkandung dalam pattern/ teks yang ingin dicari ke
dalam tabel/wadah
Memasukkan nilai posisi tiap alphabet yang terkandung dalam pattern/teks yang ingin
dicari ke dalam tabel/wadah
Selesai
Gambar 3.8Pre-processingAlgoritmaSkip Search
Gambar 3.7Menggambarkan alur pada proses pencarian Algoritma Skip Search, dimana proses awal yang dilakukan yaitu fase preprocessing. Di fase
preprocessingposisi karakter di teks akan disimpan dalam tempat penampungan
sementara yang kita istilahkan sebagai ember. Setelah itu, fase pencocokan akan
dimulai setelah batas jendela dan karakter yang menjadi acuan ditentukan. Jika
string tidak ditemukan, proses pencarian akan diulang dari fase penentuan batas
jendela, setelah posisi batas jendela digeser sebanyak panjang pola (tidak dari
urutan 0 lagi). Pencarian akan terus dilakukan sampai string ditemukan atau pola
mencapai penghujung teks.
3.3 Kamus Data
Kamus data merupakan sebuah daftar yang mengatur semua komponen data yang
berhubungan terhadap sistem dengan definisi singkat dan sejelas-jelasnya
masukan, keluaran, komponen penyimpanan, dan kalkulasi lanjutan. Kamus data
pada sistem dapat dilihat pada Tabel 3.5 berikut.
Tabel 3.5Kamus Data
Data Kolom Tipe Deskripsi
Data Id Integer Identifier
Istilah Text Teks berisi Istilah Psikologi
Arti Text Teks berisi Definisi dari
Istilah Psikologi
3.4 Perancangan Antarmuka Sistem (Interface)
Perancangan antarmuka bertujuan untuk memudahkan pengguna dalam
menggunakan atau berinteraksi dengan sistem. Sebuah antarmuka harus
dirancang dengan memperhatikan faktor pengguna sehingga sistem yang
dibangun dapat memberikan kenyamanan dan kemudahan untuk digunakan oleh
pengguna. Antarnuka yang dirancang diharapkan dapat menghasilkan aplikasi
yang ramah pengguna (user friendly).
3.4.1 Rancangan Halaman Splash Screen
HalamanSplash Screenmerupakan halaman yang pertama kali muncul pada saat
Gambar 3.9Rancangan TampilanSplash Screen
Keterangan :
1. Splash Screenuntuk menampilkan logo saat pertama kali membuka aplikasi.
3.4.2 Rancangan Navigation Drawer
Navigation Drawer terdiri dari Header, Beranda, Pencarian, Fitur, Bantuan,
Tentang, dan Keluar. Rancangan TampilanNavigation Drawerdapat dilihat pada
Gambar 3.10Rancangan TampilanNavigation Drawer
Keterangan :
1. MenuHomeberisi halaman utama dari program Kamus Istilah Psikolog.
2. MenuAboutberisi judul dan pembuat aplikasi.
3. MenuHelpuntuk panduanusermenggunakan aplikasi.
4. MenuExituntuk mengeluarkanuserdari aplikasi.
3.4.3 Rancangan Halaman Home
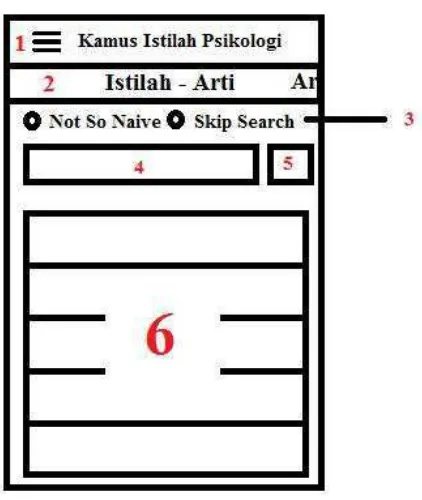
HalamanHometerdapatTab Swipe Gesture,Radio Button,Text Box,Buttondan
Gambar 3.11Rancangan Tampilan Home
Keterangan :
1. Navigation Drawer
2. Tab Swipe Gesture untuk memilih mode penerjemahan, apakah Istilah
Psikologi –Definisi atau Definisi–Istilah Psikologi
3. Radio Buttonuntuk memilih algoritma yang akan digunakan
4. Text Boxsebagai tempat untuk menampung kata yang ingin dicari
5. Buttonuntuk memulai pencarian
6. List View untuk menampilkan seluruh kata yang ada di dalam database dan
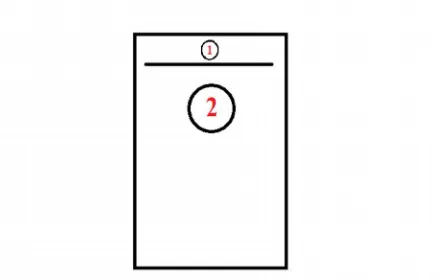
Gambar 3.12RancanganIntentdariList View ModeIstilah Psikologi– Definisi
Gambar 3.12merupakan hasil dari aksiuserjika memilih salah satuitemdarilist view. Yang dimana, sistem akan menampilkan halaman baru dengan nomor 1
merupakan Istilah Psikologi dan nomor 2 Definisi dari item yang dipilih.
Demikian juga untuk halamanmodeDefinisi - Istilah Psikologi. Sistem
akan menampilkan halaman yang sama dengan nomor 1 merupakan Definisi dari
3.4.4 Rancangan Halaman About
HalamanAboutterdapatNavigation Drawerdanimageyang menampilkan judul
aplikasi dan nama si pembuat. Rancangan Tampilan About dapat dilihat pada
Gambar 3.13
Gambar 3.13Rancangan HalamanAbout
Keterangan :
1. Navigation Drawer
2. Imageyang menampilkan judul dan nama pembuat program
3.4.5 Rancangan Halaman Help
Halaman Help terdapat Navigation Drawer dan image yang menampilkan
panduan cara untuk user menggunakan aplikasi. Rancangan TampilanHelpdapat
Gambar 3.14Rancangan HalamanHelp
Keterangan :
1. Navigation Drawer
IMPLEMENTASI DAN PENGUJIAN
4.1 Implementasi
Tahap implementasi sistem merupakan langkah lanjutan dari tahapan analisis dan
perancangan sistem yang dirangkum di bab tiga. Pada tahapan ini, segala yang
telah di bahas pada tahapan analisis dan perancangan akan diimplementasikan ke
dalam bahasa pemrograman Java dan menggunkan software Eclipse Mars 2. Pada
sistem ini terdapat 6 (delapan) tampilan halaman, yaitu Halaman Splash Screen,
Navigation Drawer, Halaman Home, Halaman About, Halaman Help, dan
Halaman Exit.
4.1.1 Tampilan Halaman Splash Screen
HalamanSplash Screenmerupakan halaman yang pertama kali muncul pada saat
Gambar 4.1Tampilan HalamanSplash Screen
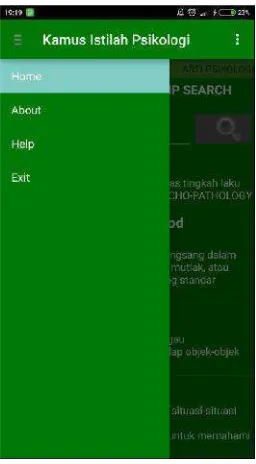
4.1.2 Tampilan Navigation Drawer
Navigation Drawerterdiri dariHome, About, Help,danExit. Tampilan Halaman
Navigation Drawerdapat dilihat padaGambar 4.2
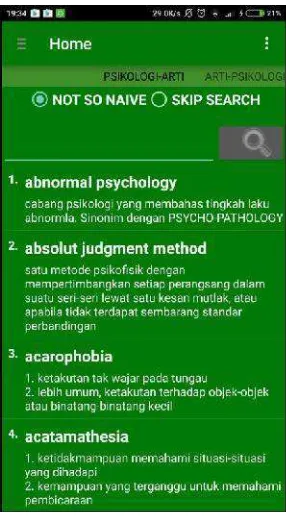
4.1.3 Tampilan Halaman Home
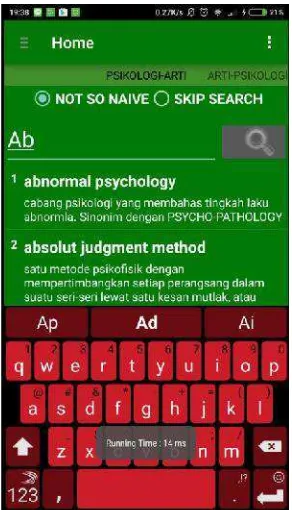
HalamanHome berfungsi melakukan pencarian kata pada kamus sesuai dengan
algoritma yang dipilih. Tampilan HalamanHomedapat dilihat padaGambar 4.3. Di bagian ini terdapatTab Swipe Gesture,Radio Buttonuntuk memilih algoritma,
Text Box untuk menginput kata yang ingin dicari, Button untuk memulai
pencarian dan List View yang berfungsi untuk menampilkan seluruh kata yang
ada di dalam database dan hasil pencarian algoritma. Terdapat Toast Message
yang akan menampilkanrunning timedari pencarian algoritma yang dapat dilihat
pada Gambar 4.3.1. Terdapat juga Halaman Intent jika salah satu kata di List View di klik dan akan menampilkan halaman baru yang berisi Istilah Psikologi
dan Definisi dari kata tersebut yang dapat dilihat padaGambar 4.3.2
Gambar 4.3.1TampilanToast Message
Gambar 4.3.2 Tampilan Halaman Intent Saat Salah Satu Kata di
List Viewdi Klik
4.1.4 Tampilan Halaman About
Halaman About berisi Judul Aplikasi dan Nama pembuat Aplikasi. Tampilan
Gambar 4.4Tampilan HalamanAbout
4.1.5 Tampilan Halaman Help
HalamanHelpmerupakan panduanuseruntuk menggunakan aplikasi. Tampilan
Halaman Bantuan dapat dilihat padaGambar 4.5.
4.1.5 Tampilan Halaman Exit
Halaman Exit berupa alert dialog ini berfungsi untuk mengeluarkan user dari
aplikasi . Tampilan Halaman Keluar dapat dilihat padaGambar 4.6
Gambar 4.6Tampilan HalamanExit
4. 2 Pengujian Sistem
Pengujian terhadap sistem dilakukan untuk membuktikan bahwa sistem yang
telah dibangun berjalan dengan baik serta sesuai dengan analisis dan perancangan
sistem yang telah dibuat sebelumnya. Dalam pengujian yang akan dicari adalah
string sebagai inputannya. Semua hasil pencarian ditampilkan sesuai dengan
inputan yangmatchpada pencarian.
4.2.1 Pengujian Pencarian kata pada Kamus Istilah Psikologi dengan Algoritma Not So Naive
Tabel 4.1Hasil Pencarian kata AlgoritmaNot So Naive
Pola Hasil
Pencarian
Gambar Hasil Pencocokan Running Time, Jumlah Kata
dan Banyak Komparasi
Da Match 24 ms, 8 kata
Xy Mismatch 20 ms, 0 kata dan 2924
banyak komparasi
Cult Match 21 ms, 3 kata
Imme Mismatch 20 ms, 0 kata dan 2315
banyak komparasi
Psycho Match 16 ms, 9 kata
Ba Match 63 ms, 145 kalimat dan 32996 banyak
komparasi
Yx Mismatch 59 ms, 0
kalimat, dan 39150 banyak
Bang Match 52 ms, 28 kalimat dan 32625 banyak
komparasi
Zoyo Mismatch 46 ms, 0
Tingkah Match 59 ms, 35 kalimat dan 35778 banyak
4.2.2 Pengujian Pencarian kata pada Kamus Istilah Psikologi dengan Algoritma Skip Search
PadaTabel 4.2dapat dilihat hasil pencarian kata pada Kamus Istilah Psikologi menggunakan AlgoritmaSkip Search.
Tabel 4.2Hasil Pencarian kata AlgoritmaSkip Search
Pola Hasil
Pencarian
Gambar Hasil Pencocokan Running Time dan Jumlah
Kata
Da Match 34 ms, 8 kata
Xy Mismatch 20 ms, 0 kata dan 1604
banyak komparasi
Cult Match 17 ms, 3 kata
Imme Mismatch 13 ms, 0 kata dan 977
banyak komparasi
Psycho Match 15 ms, 9 kata
Ba Match 65 ms, 145 kalimat dan 24096 banyak
komparasi
Yx Mismatch 51 ms, 0
kalimat dan 20249 banyak
Bang Match 42 ms, 28 kalimat dan 13329 banyak
komparasi
Zoyo Mismatch 38 ms, 0
kalimat dan 10263 banyak
Tingkah Match 35 ms, 35 kalimat dan 8850 banyak
komparasi
4.3. Hasil Pengujian
Hasil pengujian dari penelitian ini adalah Running time dari pencarian kata dan
jumlah kata yang ditemukan pada Algoritma Not So Naive dan AlgoritmaSkip
Search yang dilakukan terhadap string yang berbeda dimulai dari string dua
karakter, 4 karakter dan 6 karakter. Untuk pengujian string Istilah Psikologi
-Definisi dapat dilihat pada No. 1 sampai 5. Sedangkan pengujian string -Definisi
Tabel 4.3Hasil Pengujian AlgoritmaNot So Naive
2 Xy 20 ms 0 kata 2924 Mismatch
3 Cult 21 ms 3 kata 2320 Match
4 Imme 20 ms 0 kata 2315 Mismatch
5 Psycho 16 ms 9 kata 1757 Match
6 Ba 63 ms 145 kata 32996 Match
7 Yx 59 ms 0 kata 39150 Mismatch
8 Bang 52 ms 28 kata 32625 Match
9 Zoyo 46 ms 0 kata 37845 Mismatch
10 Tingkah 59 ms 35 kata 35778 Match
TOTAL 380 ms
RATA-RATA
Tabel 4.4Hasil Pengujian AlgoritmaSkip Search
2 Xy 20 ms 0 kata 1604 Mismatch
3 Cult 17 ms 3 kata 880 Match
4 Imme 13 ms 0 kata 977 Mismatch
5 Psycho 15 ms 9 kata 603 Match
6 Ba 65 ms 145 kata 24096 Match
7 Yx 51 ms 0 kata 20249 Mismatch
8 Bang 42 ms 28 kata 13329 Match
9 Zoyo 38 ms 0 kata 10263 Mismatch
10 Tingkah 35 ms 35 kata 8850 Match
TOTAL 330 ms
RATA-RATA
33 ms
Setelah mendapatkan Hasil Pengujian dariTabel 4.3danTabel 4.4maka dibuat grafik perbandingan hasil pengujian dari kedua Algoritma tersebut. Grafik dapat
Gambar 4.7Perbandingan HasilRunning TimeAlgoritmaNot So Naivedan AlgoritmaSkip Search
Dari grafik diatas dapat dijelaskan bahwa AlgoritmaNot So Naive mendapatkan
HasilRunning Timeyang sedikit lebih tinggi jika dibandingkan dengan Algoritma
Skip Search. Terutama saatteks yang dicari panjang (dimulai dari “Ba” sampai
“Tingkah” dimanapencarian string dilakukan pada Definisi –Istilah Psikologi), AlgoritmaNot So Naivememerlukanrunning timeyang lebih lama, tidak seperti
AlgoritmaSkip Searchyang lebih cepat dan akan lebih cepat saat pencarian teks
yang panjang. Total Hasil Perbandingan dari kedua Algoritma tersebut dapat
dijelaskan padaGambar 4.8
0 10 20 30 40 50 60 70
Da Xy Cult Imme Psycho Ba Yx Bang Zoyo Tingkah
Running Time
Gambar 4.8Perbandingan TotalRunning TimeAlgoritmaNot So Naivedan AlgoritmaSkip Search
Dari grafik diatas dapat dijelaskan bahwa untuk kasus yang sudah diujicobakan
secara total Algoritma Not So Naive memiliki nilai Total Running Time yang
sedikit lebih lama dibandingkan dengan Algoritma Skip Search. Artinya bahwa
AlgoritmaSkip Searchlebih cepat untuk pencocokan kata yang digunakan dalam
kamus dibandingkan dengan AlgoritmaNot So Naive.
4.4. Kompleksitas Algoritma
Kompleksitas algoritma yang akan diuji adalah kompleksitas Algoritma Not So
Naivedan AlgoritmaSkip Search.Seperti dijelaskan padaTabel 4.5, 4.6, 4.7, dan
4.8berikut:
4.4.1 Kompleksitas Algoritma Not So Naive
Tabel 4.5Kompleksitas fungsi preproses dari AlgoritmaNot So Naive
Code cost times cost.times
int k,ell; C1 1 C1
Total Waktu Yang Diperlukan
Running Time
FASE PRE-PROSES :
Tmax(n) = C1 + 4C2 + C3
= (C1 + 4C2 + C3)m0
= m0
= O(1)
Tabel 4.6Kompleksitas fungsi proses pencarian dari AlgoritmaNot So Naive
Code cost times cost.times
public int searching(String pat, int m, String text, int n){
Preproses(); C1 1 C1
int j =0; C2 1 C2
int hasil =0; C2 1 C2
while (j <= n-m){ C3 n C3n
if(x[1] != y[j+1] && komp.komparasi++>=0 &&
komp1.komparasi++>=0){
C4 n C4n
j += k;} C2 n C2n
else {
komp.komparasi++; C2 n C2n
Komp1.komparasi++; C2 n C2n
a=1; C2 n C1n
for (int b=0;b<m;b++){ C5 mn C5n
if(x[b+1] == y[j+1+b] && x[0] == y[j]
break; C6 mn C6mn
}}
if(a == m){ C4 n C4n
found = true;} C2 n C2n
j+= ell; C2 n C2n
}
if(found){ C4 N C4n
= O(mn)
Tabel 4.5 dan Tabel 4.6 menjelaskan tentang kompleksitas dari AlgoritmaNot
So Naive. Pada AlgoritmaNot So Naivefase preproses memiliki T(n) = O(1) dan
fase proses memiliki T(n) = O(mn). Maka kompleksitas AlgoritmaNot So Naive
adalah O(mn).
4.4.2 Kompleksitas Algoritma Skip Search
Tabel 4.7Kompleksitas fungsi preproses dari AlgoritmaSkip Search
Code cost times cost.times
public int preprocess(){
public static int ASIZE = 256; C1 1 C1
int i, j; C2 1 C2
List1 ptr = null; C1 1 C1
List1 z[] = new List1[ASIZE]; C1 1 C1
for (int a=0; a<ASIZE; a++){ C3 256 256C3
z[a] = null;} C1 256 256C1
for(i = 0; i < m; ++i){ C3 m C3m
ptr = new List1(); C1 m C1m
if (ptr==null) System.out.println("ERROR"); C4 m C4m
Tabel 4.8Kompleksitas fungsi proses pencarian dari AlgoritmaSkip Search
Code cost times cost.times
public int searching(String pat, int m, String text, int n){
Preprocess(); C1 1 C1
int i, j; C2 1 C2
char[] x = pat.toCharArray(); C3 1 C3
char[] y = text.toCharArray(); C3 1 C3
String sub_x, sub_y; C2 1 C2
Boolean found = false; C3 1 C3
for(j = m -1; j<n; j += m){ C4 n C4n
komp.komparasi++; C3 n C3n
komp1.komparasi++; C3 n C3n
for(ptr = z[y[j]]; ptr != null; ptr = ptr.next){
C4 n C4n
komp.komparasi++; C3 n C3n
Komp1.komparasi++; C3 n C3n
int a=0; C3 n C3n
for (int b=0;b<m;b++){ C4 mn C4mn
if(x[b] == y[j-ptr.element+b] && komp.komparasi++>=0 && komp1.komparasi++>=0)
if(j-ptr.element<= n-m && a == m) C5 mn C5mn
found = true;}}} C3 mn C3mn
if(found){ C5 1 C5
return 1;} C7 1 C7
Tabel 4.7danTabel 4.8menjelaskan tentang kompleksitas dari AlgoritmaSkip
Search. Pada AlgoritmaNot So Naive fase preproses memiliki T(n) = O(m) dan
fase proses memiliki T(n) = O(mn). Maka kompleksitas Algoritma Skip Search
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan pembahasan dan hasil dari penelitian, maka diperoleh beberapa
kesimpulan sebagai berikut:
1. AlgoritmaNot So Naivedan AlgoritmaSkip Searchdapat diimplementasikan pada
Aplikasi Kamus Istilah Psikologi.
2. Hasil running time menunjukkan bahwa Algoritma Not So Naive sedikit lebih
lambat dalam pencarian kata dibandingkan AlgoritmaSkip Searchdengan rata-rata
hasil running time adalah 38,0 ms. Sedangkan rata-rata hasil running time
AlgoritmaSkip Searchadalah 33ms.
3. Kelemahan AlgoritmaNot So Naivedalam penelitian ini adalah tidak bisa mencari
1 huruf saja. Karena pada pre-proses Algoritma Not So Naive, Algoritma ini
membutuhkan minimal 2 huruf awal yang dibandingkan untuk menentukan nilai
dari variabel kdan ellpada proses pencarian (variable k danell berfungsi sebagai
nilai pergeseran) dan AlgoritmaNot So Naivetidak terlalu efektif untuk pencarian
patternpanjang atau pencarian kalimat. Karena semakin panjangpatternatau teks,
pengecekan yang dilakukan Algoritma ini akan semakin banyak juga. Ini dapat
dilihat diTabel 4.3 dimana running time untuk 6 – 10 (teks yand dicari panjang, dimulai dari kata “Ba” sampai kata “Tingkah”) mengalami peningkatan yang sangat signifikan dari running time untuk 1-5 (teks yang dicari pendek, dimulai dari kata
“Da” sampai kata “Psycho”).
4. Kelemahan AlgoritmaSkip Searchdalam penelitian ini adalah sedikit lebih lambat
5. Skip Search, Algoritma ini membuat tabel dari teks yang akan dibandingkan dan
menyesuaikannya dengan kata yang dicari. Proses ini cukup memakan waktu,
ditambah dengan jika kata yang dicari pendek, maka pergeseran yang bisa dilakukan
Algoritma Skip Search juga pendek. Kelebihan Algoritma Skip Search adalah
unggul dalam pencarian kata yang panjang atau pencarian kalimat. Ini dikarenakan
makin panjang kata yang dicari, maka pergeseran yang dilakukan Algoritma Skip
Searchjuga panjang.
6. Hasil Kompleksitas AlgoritmaNot So Naiveadalah T(n) = O(mn). Sedangkan Hasil
Kompleksitas AlgoritmaSkip Searchjuga T(n) = O(mn).
5.2 Saran
Adapun saran-saran yang diperlukan untuk penelitian maupun pengembangan
berikutnya adalah:
1. Sistem ini sebaiknya ditambah menu pengolahan data seperti penambahan data,edit
data dan hapus data agar data dalam kamus semakin banyak untuk pencarian kata
pada kamus.
2. Untuk pengembangan selanjutnya, diharapkan aplikasi ini menyediakan menu
pilihan algoritma pencarianstringyang baru ditemukan agar terlihat perbedaan pada
pencarian string antara Algoritma yang lama dengan Algoritma yang sudah
LANDASAN TEORI
2.1. Algoritma
Algoritma adalah urutan langkah-langkah penyelesaian masalah yang disusun
secara matematis dan logis. Tanpa kita sadari, kebanyakan dari kegiatan yang kita
lakukan setiap harinya selalu berlandaskan algoritma.
Dalam beberapa konteks, algoritma adalah spesifikasi urutan langkah
untuk melakukan pekerjaan tertentu. Pertimbangan dalam pemilihan algoritma
adalah, pertama, algoritma haruslah benar. Artinya algoritma akan memberikan
keluaran yang dikehendaki dari sejumlah masukan yang diberikan. Tidak
peduli sebagus apapun algoritma, kalau memberikan keluaran yang salah,
pastilah algoritma tersebut bukanlah algoritma yang baik. (Zarlis & Handrizal,
2008).
2.1.1 Algoritma String Matching (pencocokan string)
Pengertian string menurut Dictionary of Algorithms and Data Structures,
National Institute of Standards and Technology (NIST) adalah susunan dari
karakter-karakter(angka,alfabet atau karakter yang lain) dan biasanya
direpresentasikan sebagai struktur dan array. Pencocokan string (string
matching) menurut Dictionary of Algorithms and Data Structures, National
Institute of Standards and Technology (NIST), diartikan sebagai sebuah
permasalahan untuk menemukan pola susunan karakterstringdi dalamstringlain
atau bagian dari isi teks.String Matchingmerupakan subjek yang sangat penting
di dalam domain yang sangat luas dalam pengolahan teks. (Charras & Lecroq.
Pencocokanstring(string matching) secara garis besar dapat dibedakan menjadi
dua yaitu :
1) Exact string matching, merupakan pencocokan 2 string secara tepat dengan
susunan karakter dalam string yang dicocokkan memiliki jumlah maupun
urutan karakter dalamstringyang sama. Contoh : katastepakan menunjukkan
kecocokan hanya dengan katastep.
2) Inexact string matchingatauFuzzy string matching, merupakan pencocokan
string secara samar, maksudnya pencocokan string dimana string yang
dicocokkan memiliki kemiripan dimana keduanya memiliki susunan karakter
yang berbeda (mungkin jumlah atau urutannya) tetapi string-string tersebut
memiliki kemiripan baik kemiripan tekstual/penulisan (approximate string
matching) atau kemiripan ucapan (phonetic string matching). Inexact string
matchingmasih dapat dibagi lagi menjadi dua yaitu :
a. Pencocokan string berdasarkan kemiripan penulisan (approximate string
matching) merupakan pencocokanstringdengan dasar kemiripan dari segi
penulisannya (jumlah karakter, susunan karakter dalam dokumen). Tingkat
kemiripan ditentukan dengan jauh tidaknya beda penulisan dua buahstring
yang dibandingkan tersebut dan nilai tingkat kemiripan ini ditentukan oleh
pemrogram (programmer). Contoh :c mpuler dengancompiler, memiliki
jumlah karakter yang sama tetapi ada dua karakter yang berbeda. Jika
perbedaan dua karakter ini dapat ditoleransi sebagai sebuah kesalahan
penulisan maka duastringtersebut dikatakan cocok.
b. Pencocokan string berdasarkan kemiripan ucapan (phonetic string
matching) merupakan pencocokanstringdengan dasar kemiripan dari segi
pengucapannya meskipun ada perbedaan penulisan dua string yang
dibandingkan tersebut. Contohstepdenganstebdari tulisan berbeda tetapi
dalam pengucapannya mirip sehingga duastring tersebut dianggap cocok.
Contoh yang lain adalahstep, dengansteppe,sttep,stepp, stepe. (Syaroni &
2.1.1.1 Algoritma Not So Naive
Algoritma Not So Naive pertama kali dipublikasikan oleh Christophe Hancart
tahun 1992. Algoritma Not So Naive merupakan variasi turunan dari algoritma
Naive atau yang sering disebut algoritma Brute Force. Cara kerja algoritma ini
adalah dengan memiliki fase pencarian mengecek teks dan pola dari kiri ke kanan.
Lalu, algoritma Not So Naive akan mengidentifikasi terlebih dahulu dua kasus
yang dimana di setiap akhir fase pencocokan pergeseran dapat dilakukan
sebanyak 2 posisi ke kanan, tidak seperti algoritmaNaiveyang dimana pergeseran
tetaplah sebanyak 1 posisi ke kanan.
Kita asumsikan bahwa P[0]≠ P[1]. Jika P[0] = T[s] dan P[1] = T[s+1],
maka di akhir fase pencocokan pergeseran s bisa dilakukan sebanyak 2 posisi,
karena P[0] ≠ P[1] = T[s+1]. Dan jika P[0] = P[1]. Jika P[0] = T[s] tapi P[1] ≠
T[s+1], maka sekali lagi pergesaransdapat dilakukan sebanyak 2 posisi (Cantone
& Faro, 2004) dimana P adalahPattern, T adalah Teks dansadalah nilai posisi.
2.1.1.1.1 Pencarian Algoritma Not So Naive
Saat fase pencarian dari AlgoritmaNot So Naiveperbandingan karakter dilakukan
dengan posisi pola mengikuti urutan 1, 2, ...,m-2,m-1, 0 dimanamadalah panjang
pattern.
Di setiap percobaan dimana “jendela” diposisikan di teks faktory[i..j +
m-1]. Jika x[0] = x[1] dan x[1] ≠ y[j+1] atau jikax[0] ≠ x[1] dan x[1] = y[j+1]
polanya akan digeser sebanyak 2 posisi di setiap akhir percobaan dan sebanyak 1
posisi jika kondisi di atas tidak terpenuhi (Alapati & Mannava, 2011) dimana y
adalah teks danxadalahpattern.
Berikut diberikan contoh untuk menunjukkan proses pencarian
Algoritma Not So Naive dengan pola WIJA yang akan dicari pada teks RICKYWIJAYA. Dimana karakter urutan 0 dan karakter urutan 1 pada pattern tidak mengalami kesamaan (x[0] !=x[1]) maka nilai variabelkakan diinisialisasi
dengan nilai 1 dan nilai variabel ell akan diinisialisasi dengan nilai 2 dimana
kedua variabel tersebut akan digunakan untuk nilai pergeseran pada proses
Tabel 2.1Proses Pencocokan Algoritma Not So Naive di Percobaan Pertama
Pada Tabel 2.1, perbandingan karakter pertama (x[1] == y[j+1]) mengalami kecocokan namun di perbandingan kedua mengalami ketidakcocokan, karena saat
perbandingan pertama telah terjadi kecocokan, namun di urutan selanjutnya tidak
terjadi kecocokan maka posisi pola akan digeser sebanyak 2 posisi sesuai dengan
nilai variabelell.
Tabel 2.2Proses Pencocokan AlgoritmaNot So Naivedi Percobaan Kedua
PadaTabel 2.2, perbandingan karakter pertama (x[1] !=y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola
digeser sebanyak 1 posisi sesuai dengan nilai variabelk.
Tabel 2.3Proses Pencocokan AlgoritmaNot So Naivedi Percobaan Ketiga
PadaTabel 2.3, perbandingan karakter pertama (x[1] !=y[j+1]) masih mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola
digeser sebanyak 1 posisi sesuai dengan nilai variabelk.
Tabel 2.4Proses Pencocokan AlgoritmaNot So Naivedi Percobaan Keempat
PadaTabel 2.4, perbandingan karakter pertama (x[1] !=y[j+1]) masih mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola
digeser sebanyak 1 posisi sesuai dengan nilai variabelk.
Tabel 2.5Proses Pencocokan AlgoritmaNot So Naivedi Percobaan Kelima
Pada Tabel 2.5, perbandingan karakter mengalami kecocokan (x[1] == y[j+1]) dimulai dari perbandingan karakter W, I, J, dan A semua mengalami kecocokan,
oleh sebab itu teks akan dikeluarkan. Namun, algoritma Not So Naive tidak
berhenti sampai disini. AlgoritmaNot So Naiveakan melakukan percobaan terus
sampai sisa teks lebih kecil daripada pola. Untuk percoabaan selanjutnya, posisi
pola akan digeser sebanyak 2 posisi sesuai dengan nilai variabelell.
Tabel 2.6Proses Pencocokan algoritmaNot So Naivedi Percobaan Keenam
PadaTabel 2.6, perbandingan karakter pertama mengalami ketidakcocokan (x[1] != y[j+1]). Maka akan dilakukan percobaan selanjutnya dengan posisi pola
digeser sebanyak 1 posisi sesuai dengan nilai variabelk. Namun dikarenakan sisa
teks telah lebih kecil daripada pola maka fase pencarian berhenti disini.
2.1.1.2 Algoritma Skip Search
AlgoritmaSkip Searchmerupakan salah satu algoritma pencocokanstring, yang
dipublikasikan secara luas oleh Charas, Cet al., (1998). Cara kerja algoritmaSkip
Search seperti algoritma Knuth Morris Pratt dengan mendeteksi jendela dari
karakter yang ada dari kiri ke kanan dan menyimpannya ke dalam sebuah wadah
untuk menentukan titik awal dari jendela karakter tersebut (Charas et al., Naser
Jadi, terdapat suatu pola yang ingin kita cari dan kita inisialkan x dan
memiliki panjang yang kita inisialkan dengan m. Teks yang ingin kita cari kita
inisialkan y dan memiliki panjang yang kita inisialkan dengan n. Untuk setiap
simbol alfabet, sebuah wadah akan menyimpan semua posisi simbol dari x. Saat
sebuah simbol berulang sebanyak k di dalam teks, maka akan ada sebanyak k
posisi yang sesuai dalam wadah simbol. Saat pola lebih pendek daripada alfabet
yang ada dalam teks, maka akan ada banyak tempat kosong dalam wadah.
Dalam perulangan utama dari fase pencarian terdapat proses memeriksa
setiap teks simbol ke m, Yj (yang nantinya iterasi utama n/m). Untuk Yj,
menggunakan setiap posisi yang ada di wadahz[Yj] untuk mendapatkan titik awal
yang memungkinkan (p) darixdi dalamy. Lalu dilakukan proses perbandinganx
denganydari posisip, simbol dengan simbol, sampai terjadi ketidakcocokan atau
seluruhnya cocok (Charraset al., 1998). AlgoritmaSkip Searchmemiliki efisiensi
dalam mencari huruf kecil dalam pola yang panjang (Naseret al., 2012).
2.1.1.2.1 Fase Preprocessing Algoritma Skip Search
Tahappreprocessing AlgoritmaSkip Searchterdiri dari tahap komputasi wadah
untuk menampung seluruh karakter alfabet untuk c∈ ∑
z[c] = { i; 0≤ i≤ m-1 and x[i] = c}.
Ruang dan waktu kompleksitas dari fasepreprocessingadalah O (m+ ) (Charras
& Lecroq, 2004). Berikut diberikan contoh pada Tabel 2.7 untuk menunjukkan proses pencarian AlgoritmaSkip Searchdengan polaWIJAyang akan dicari pada teksRICKYWIJAYA.
Tabel 2.7Tabel Teks dan Pola yang akan Dijadikan Contoh Kasus
Maka hasil dari fasepreprocessingAlgoritmaSkip Searchdapat dilihat diTabel 2.8
0 1 2 3 4 5 6 7 8 9 10
Teks R I C K Y W I J A Y A
Tabel 2.8Tabel Hasilpreprocessingdari AlgoritmaSkip Search
2.1.1.2.2 Fase Pencarian Algoritma Skip Search
Dalam Fase Pencarian, algoritma Skip Search menggunakan aturan The Two
Window Ruleuntuk menentukan batas sampai mana pola boleh digeser. Panjang
batasThe Two Window Rulemenggunakan rumus 2m-1 dimanamadalah panjang
dari pola (Bhandari & Kumar, 2013). Lalu panjang dari hasil aturan The Two
Window Rule akan bernilai ganjil dan karakter yang terdapat di tengah panjang
teks tersebutlah yang akan dilakukan proses pencocokan.
Gambar 2.1Penentuan Panjangwindowdan Karakter Tengah yang akan Digunakan dalam Proses Pencocokan 1
DariGambar 2.1didapatkan batas panjang untuk pola digeser adalah dari urutan 0 (huruf R) sampai urutan 6 (huruf I) dan karakter yang akan digunakan dalam
proses pencocokan adalah karakter K. Namun, berdasarkan tabel 8 karakter K
c z[c]
A (3)
C ∅
I (1)
J (2)
K ∅
R ∅
W (0)
bernilai nol (tidak ada dalam pola) maka percobaan akan dilanjutkan dengan
posisi jendela digeser sebanyak 4 posisi sesuai dengan panjang pola (m).
Gambar 2.2Penentuan Panjangwindowdan Karakter Tengah yang akan Digunakan dalam Proses Pencocokan 2
Dari Gambar 2.2 didapatkan batas panjang untuk pola digeser adalah dari urutan
4 (huruf W) sampai urutan 10 (huruf A) dan karakter yang akan digunakan dalam
proses pencocokan adalah karakter J. Berdasarkan tabel 8 karakter J terdapat di posisi 2 dalam pola, oleh karena itu pola akan langsung diposisikan menurut
posisi J, dan dilakukan proses pencocokan dari urutan 5, 6, 7 dan 8. Dalam
pencocokan 2 ini, pola yang berisi karakter W, I, J, dan A mengalami kecocokan
maka teks akan ditampilkan. Dan fase pencarian berhenti sampai disini. Ini
dikarenakan saat pola digeser sebanyak 4 posisi, panjang teks untuk dibandingkan
hanya bersisa 3 dimana panjang pola lebih banyak daripada panjang teks yang
akan dicocokan.
2.2. Kompleksitas Algoritma
Kebenaran suatu algoritma harus diuji dengan jumlah masukan tertentu untuk
melihat kinerja algoritma berupa waktu yang diperlukan untuk menjalankan
algoritmanya dan ruang memori yang diperlukan untuk struktur datanya.
Algoritma yang bagus adalah algoritma yang mangkus (efisien). Kemangkusan
algoritma diukur dari jumlah waktu dan ruang memori yang dibutuhkan untuk
menjalankan algoritma tersebut.
Ada dua macam kompleksitas algoritma, yaitu kompleksitas waktu dan
kompleksitas ruang. Kompleksitas waktu dari algoritma adalah mengukur jumlah
suatu masalah dengan menggunakan algoritma. Ukuran yang dimaksud mengacu
ke jumlah langkah-langkah perhitungan dan waktu tempuh pemrosesan.
Kompleksitas waktu merupakan hal penting untuk mengukur efisiensi suatu
algoritma.
Kompleksitas waktu dari suatu algoritma yang terukur sebagai suatu
fungsi ukuran masalah. Kompleksitas waktu dari algoritma berisi ekspresi
bilangan dan jumlah langkah yang dibutuhkan sebagai fungsi dari ukuran
permasalahan. Kompleksitas ruang berkaitan dengan sistem memori yang
dibutuhkan dalam eksekusi program.
Untuk mengukur kebutuhan waktu sebuah algoritma yaitu dengan
mengeksekusi langsung algoritma tersebut pada sebuah komputer, lalu dihitung
berapa lama durasi waktu yang dibutuhkan untuk menyelesaikan sebuah
persoalan dengan n yang berbeda-beda. Kemudian dibandingkan hasil komputasi
algoritma tersebut dengan notasi kompleksitas waktunya untuk mengetahui
efisiensi algoritmanya (Nugraha, D.W. 2012).
Kompleksitas algoritma diukur berdasarkan kinerjanya dengan
menghitung waktu eksekusi suatu algoritma. Menurut Cormenet al. (2009) waktu
eksekusi algoritma dapat diklasifikasikan menjadi tiga kelompok besar, yaitu
best-case (kasus terbaik), average-case (kasus rata-rata) dan worst-case (kasus
terjelek).
Pada pemrograman yang dimaksud dengan kasus terbaik, kasus terjelek
dan kasus rata-rata suatu algoritma adalah besar kecilnya atau banyak sedikitnya
sumber-sumber yang digunakan oleh suatu algoritma. Makin sedikit makin baik,
makin banyak makin jelek (Subandijo. 2011).
2.3. Kamus
Menurut Kamus Besar Bahasa Indonesia, pengertian kamus adalah buku acuan
yang memuat kata dan ungkapan yang biasanya disusun menurut abjad berikut
keterangan maknanya, pemakaiannya dan terjemahannya. Kamus juga dapat
digunakan sebagai buku rujukan yang menerangkan makna kata – kata yang