LISTING PROGRAM
public class MainActivity extends AppCompatActivity {
int SPLASH_TIME_OUT = 3000;
@Override
protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
new Handler().postDelayed(new Runnable() {
public class MenuActivity extends AppCompatActivity {
private Button startButton; private Button aboutButton;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) { super.onCreate(savedInstanceState);
startButton = (Button) findViewById(R.id.start_button); aboutButton = (Button) findViewById(R.id.about_button);
startButton.setOnClickListener(startClickListener);
aboutButton.setOnClickListener(aboutClickListener);
}
View.OnClickListener startClickListener = new View.OnClickListener() {
View.OnClickListener aboutClickListener = new View.OnClickListener() {
public class AboutActivity extends AppCompatActivity {
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) { super.onCreate(savedInstanceState);
setContentView(R.layout.activity_about); }
4. BoyerMoore.class
endMillis = System.currentTimeMillis();
// apakah hash sesuai?
}
public class MenuActivity extends AppCompatActivity {
private Button startButton; private Button aboutButton;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) { super.onCreate(savedInstanceState);
setContentView(R.layout.activity_menu);
startButton = (Button) findViewById(R.id.start_button); aboutButton = (Button) findViewById(R.id.about_button);
startButton.setOnClickListener(startClickListener); aboutButton.setOnClickListener(aboutClickListener);
}
View.OnClickListener startClickListener = new View.OnClickListener() {
View.OnClickListener aboutClickListener = new View.OnClickListener() {
@Override
public void onClick(View view) {
startActivity(i);
public class UUAdapter extends ArrayAdapter<UUModel> {
public UUAdapter(Context context, int resource, List<UUModel> objects) {
super(context, resource, objects); }
@Override
public View getView(int position, View convertView, ViewGroup parent) {
}
public class SearchActivity extends AppCompatActivity {
private ArrayList<UUModel> uuModels; private UUAdapter uuAdapter;
private int MAX_CHAPTER = 14;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_search);
// initialisasi view
listView = (ListView) findViewById(R.id.item_list_view); statusTextView = (TextView) boyerMoreButton.setOnClickListener(new
String pattern = isi kata yang dicari.", Toast.LENGTH_SHORT).show();
} "BAB " + i, pattern, contentLines, pos);
//tambah kan ke list UUModels uuModels.size() + " bab, "+banyak_kata+" kata dengan durasi " + formatter.format((endMillis-startMillis)) + "ms");
rabinKarpButton.setOnClickListener(new View.OnClickListener() { isi kata yang dicari.", Toast.LENGTH_SHORT).show();
} else {
long startMillis = System.currentTimeMillis();
for (int i = 1; i <= MAX_CHAPTER; i++) { "BAB " + i, pattern, contentLines, pos);
} }); }
private String readTextFile(InputStream inputStream) { ByteArrayOutputStream outputStream = new
public class ContentActivity extends AppCompatActivity {
private LinearLayout contentLinearLayout;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) { super.onCreate(savedInstanceState);
Intent intent = getIntent();
contentLinearLayout = (LinearLayout) findViewById(R.id.content_linear_layout);
for(int i = 0; i < contentLines.length; i++){ TextView lineTextView = new TextView(this);
lineTextView.setLayoutParams(new ActionBar.LayoutParams( ActionBar.LayoutParams.MATCH_PARENT,
ActionBar.LayoutParams.WRAP_CONTENT));
if(pos[i] >= 0){
Spannable spanText =
Spannable.Factory.getInstance().newSpannable(contentLines[i]); spanText.setSpan(new
BackgroundColorSpan(0xFFFFFF00), pos[i], (pos[i] + pattern.length()), Spannable.SPAN_EXCLUSIVE_EXCLUSIVE); lineTextView.setText(spanText);
}else{
lineTextView.setText(contentLines[i]); }
contentLinearLayout.addView(lineTextView); }
CURRICULUM VITAE
Data Pribadi
Nama : Pradita Oktaviani
Tempat/Tanggal Lahir : PekanBaru/ 21 Oktober 1994
Tinggi/Berat Badan : 165 cm / 45 kg
Agama : Islam
Kewarganegaraan : Indonesia
Alamat Sekarang : Jl. Stasiun Gg TriKarya No.10 Medan
Alamat Orang Tua : Jl. Stasiun Gg TriKarya No.10 Medan
Telp/ Hp : 085361420720
Email : [email protected]
--- Riwayat Pendidikan
[2010 – 2014] : S1 Ilmu Komputer Universitas Sumatera Utara, Medan
[2007 – 2010] : SMA KARTIKA I-1 Medan
[2004 – 2007] : SMP KARTIKA I-2 Medan
Keahlian/Kursus
Keahlian Komputer :
Pemrograman : PHP,
Database : Microsoft Access,MySQL
Desain : Adobe Photoshop, Coreldraw
Multimedia : Adobe Flash
Perkantoran : Microsoft Office
--- Pengalaman Organisasi
[2007 – 2009] Pramuka SMP KARTIKA I-2 MEDAN
[2010 – 2012] Palang Merah Indonesia SMA KARTIKA I-1 MEDAN
--- Pengalaman Kepanitiaan
-
--- Seminar
[2014] Seminar Nasional Literasi I for asi SENARAI Prestasi
DAFTAR PUSTAKA
Abdullah, N. 2010. Kekerasan Terhadap Anak “Bom Waktu” Masa Depan.Jurnal Psikoligis. 1(5): 6
Andres, N., Christopher. & Saloko, H. 2010. Penelaahan Algoritma Rabin-Karp dan Perbandingan Prosesnya dengan Algoritma Knut-Morris-Pratt. Jurnal Informatika. 2(1): 4.
Atmopawiro, A. 2014. Pengkajian dan Analsis Tiga Algoritma Efisien Rabin-Karp, Knuth-Morris-Pratt, dan Boyer-Moore dalam Pencarian Pola dalam Suatu Teks. Jurnal Komputer dan Informatika. 5(3):10.
Barakbah, A.R., Karlita, T. & Ahsan, A.S. 2013. Logika dan Algoritma. Jurnal UNIKOM. 4(2): 1-2.
Charras, C., & Thierry L. 2004. Handbook of Exact String-Matching Algorithms. College Publication.
Efendi, D., Hartono, T. & Kurniadi, A. 2013. Penerapan String Matching Menggunakan Boyer-Moore Pada Translator Bahasa Pascal Ke C. JurnalInformatika. 11(2): 271.
Mona. ( Editor ). 2015. Undang-Undang Republik Indonesia Nomor 35 Tahun 2014 Tentang Perubahan Atas Undang-Undang Republik Indonesia Nomor 23 Tahun 2002 Tentang Perlindungan Anak. Pustaka Gramedia : Yogyakarta.
Rahman, Astriyani. 2010. Eksploitasi Orang Tua Terhadap Anak Dengan Memperkerjakan Sebagai Buruh. Skripsi. Universitas Gunadharma.
Safaat, N. 2015. Android: Pemrograman Aplikasi Smartphone dan Tablet PC berbasis Android. 2nd. Informatika : Bandung.
BAB III
ANALISIS DAN PERANCANGAN
3.1 Analisis Sistem
Tahapan ini dilakukan untuk memaparkan pemahaman tentang sistem yang dibuat secara
keseluruhan. Baik kinerja sistem maupun proses perancangan aplikasi pada sistem.
pemahaman yang menyeluruh terhadap kebutuhan sistem sehingga diperoleh tugas-tugas
yang akan dikerjakan sistem. Tahapan ini dilakukan agar pada saat proses perancangan
aplikasi tidak terjadi kesalahan.
3.1.1 Analisis Masalah
Seringnya terjadi tindak kekerasan baik secara fisik, mental maupun sosial kepada anak yang
dilakukan oleh orang-orang terdekat serta lingkungan sekitar mereka, membuat anak-anak
merasa tidak aman untuk bisa bersosialisasi secara optimal. Kurangnya pemahaman anak
Indonesia tentang hak-hak dan perlindungan yang sepantasnya mereka dapatkan oleh Negara
menjadi masalah yang akan diselesaikan. Pencarian kata dalam menemukan pola string yang
sama, menampilkan pada bab, pasal berapa saja yang mengandung string yang dicari dan
mencari algoritma mana yang lebih baik dalam pencarian string, menjadi masalah yang akan
diselesaikan.
Untuk membantu mengidentifikasi masalah di atas, maka di gunakan diagram
Ishikawa (fishbone diagram). Diagram Ishikawa adalah sebuah alat grafis yang digunakan
untuk menampilkan pendapat tentang komponen inti suatu kondisi di dalam organisasi.
diagram Ishikawa juga dapat menemukan dan mengatasi masalah-masalah yang akan di
Sulit Mencari Kata Yang Diinginkan User Metode String Matching
Apa Yang Baik Digunakan
Mesin Yang Dapat Meng- Materi Yang Mudah Compile Di Android Diakses
Gambar 3.1 Diagram Ishikawa
3.1.2 Analisis Persyaratan
Pada tahap analisis persyaratan ini dapat terbagi menjadi dua, yaitu : fungsional dan
non-fungsional. Persyaratan fungsional dapat diartikan sebagai penyedia aktivitas-aktivitas yang
ada dalam suatu sistem tersebut. Sedangkan, persyaratan non-fungsional dapat diartikan
sebagai mendeskripsikan fitur, performa fitur, karakteristik dari fitur, dan batasan lainnya.
3.1.2.1 Kebutuhan Fungsional
Kebutuhan fungsional yang terdapat pada aplikasi pencarian teks undang-undang
perlindungan anak terdiri atas :
METODE MANUSIA
MESIN MATERI
Tabel 3.1 Kebutuhan Fungsional
SRS ID Fungsi
F-01 Sistem dapat menjalankan algoritma yang akan digunakan untuk mencari string (Boyer-Moore atau Rabin-Karp)
F-02 Menemukan string dengan algoritma yang sudah dipilih F-03 Mencari string dalam teks.txt
F-04 Masukkan string terdiri dari satu kosa kata atau lebih
F-05 Sistem dapat menampilkan hasil pencrian string dengan menggunakan algoritma yang sudah dipilih sebelumnya
3.1.2.2 Kebutuhan Non-Fungsional
Kebutuhan fungsional yang terdapat pada aplikasi pencarian teks undang-undang
perlindungan anak terdiri atas :
Tabel 3.2 Kebutuhan Non-Fungsional
SRS ID Fungsi
NF-01 Menggunakan Interface yang mudah sehingga user cepat memahami aplikasi
NF-02 Menggunakan desain yang minimalis
NF-03 Menggunakan software Android Studio dalam pembuatannya
NF-04 Aplikasi ini hemat biaya karena tidak memerlukan perangkat tambahan dalam peng-operasiannya
3.1.3 Pemodelan
Pekerjaan-pekerjaan pemodelan spesifikasi kebutuhan pada dasarnya akan menghasilkan
beberapa jenis model-model berikut :
o Model berbasis skenario, yang menggambar spesifikasi kebutuhan perangkat lunak
dari berbagai sudut pandang “aktor” sistem/perangkat lunak. Contoh : Use Case.
o Model data, yang menjelaskan ranah informasi untuk permasalahan yang akan
diselesaikan.
o Model berorientasi kelas, yang memperhatikan kelas-kelas dalam konteks
bekerjasama untuk mencapai sasaran-sasaran spesifikasi kebutuhan perangkat lunak.
Contoh : diagram kelas.
o Model berorientasi aliran, yang menggambarkan elemen-elemen fungsional
sistem/perangkat lunak dan yang akan menggambarkan bagaimana caranya mereka
melakukan transformasi terhadap data saat data yang bersangkutan melintasi sistem.
o Model perilaku, yang menggambarkan bagaimana perangkat lunak berperilaku
terhadap event-event yang datang dari luar sistem
Pada penelitian ini digunakan UML (Unified Modeling Language) sebagai bahasa
pemodelan untuk mendesain dan merancang aplikasi pencarian teks undang-undang
perlindungan anak. Model UML yang digunakan antara lain Use case diagram, Activity
diagram, dan Sequence diagram.
3.1.3.1 Preprocessing
Preprocessing adalah tahapan awal dalam mengolah data yang di-input sebelum benar-benar
memasuki proses tahapan utama pada suatu sistem.
3.1.3.1.1 Case Folding
Case Folding merupakan tahapan yang mengubah huruf kapital menjadi huruf kecil dalam
tahap pencarian string pada database. Mengubah huruf “A” sampai dengan “Z” menjadi
Gambar 3.2 Preprocessing-Case Folding UpperCase to
LowerCase
(function)
Sistem memproses string yang di-input user dan mencari pada teks .txt sebanyak 14 bab.
Sistem mencari string menggunakan
algoritma Rabin-Karp Sistem mencari string
menggunakan algoritma Boyer-Moore
Inputstring oleh user
Input teks undang-undang
perlindungan anaksebanyak 14 bab dengan format
Sistem
3.1.3.2 Use Case Diagram
Use case diagram adalah gambaran yang dapat merepresentasikan interaksi antara aktor dan
sistem itu sendiri. Use case diagram sangat membantu dalam memahami kebutuhan
fungsional dalam suatu sistem yang dibangun. Use case diagram yang akan dibangung dapat
digambarkan pada gambar 3.2 sebagai berikut.
Gambar 3.3 Use Case Diagram
Tabel 3.3 Use Case Memasukkan String
Name Memasukkan String
Actors User
Description Use case mendeskrisikan untuk meng-input string yang akan dicari di dalam teks undang-undang perlindungan anak
Basic Flow User meng-inputstring
Alternate Flow
-Pre Condition User dapat melihat tampilan menu utama
Post Conditon User dapat mengetahui string yang dicari pada teks undang-undang perlindungan anak
Pada proses memilih algoritma, dapat dinyatakan dalam tabel 3.4.
Tabel 3.4 Use Case Memilih Algoritma
Name Memasukkan String
Actors User
Description Use Case ini mendeskripsikan pemilihan algoritma yang akan dipakai dalam pencarian teks undang-undang perlindungan anak
Basic Flow User memilih algoritma yang ingin digunakan
Alternate Flow
User dapat mengganti algoritma yang ingin digunakan
Pre Condition User dapat melihat tampilan button pemilihan algoritma
Post Conditon User sudah memilih algoritma
3.1.3.3 Activity Diagram
Activity diagram menggambarkan berbagai alir aktivitas dalam sistem yang akan dibangun,
bagaimana sistem itu berawal, kemungkinan decision yang akan terjadi, dan bagaimana
sebuah sistem akan berakhir. Manfaat dari activity diagram ialah untuk membantu memahami
Activity diagram dibuat berdasarkan sebuah atau beberapa use case diagram. Proses
pencarian dengan Algoritma Boyer-Moore dan algoritma Rabin-Karp, dapat dilihat Activity
Diagrampada Gambar 3.3 berikut:
Gambar 3.4 Activity Diagram 3.1.3.4 Sequence Diagram
Sequence Diagram merupakan diagram yang berfungsi untuk menampilkan perilaku
sistem/aplikasi tersebut. Diagram ini menunjukkan bagaiman pesan dikirim dan diterima
diantara objek, dan diurutan yang mana. Sequence Diagram dapat membantu dalam
menggambarkan data yang masuk dan keluar dari sistem. Sequence diagram untuk proses
pencarian teks undang-undag perlindungan anak menggunakan algoritma Boyer-Moore dan
Gambar 3.5 Sequence Diagram
Pada tahap ini, user membuka aplikasi, sistem mengembalikan feedback berupa intro sistem.
Setelah itu, user masuk ke dalam menu utama sistem. User dapat melihat keseluruhan isi bab
dan pasal yang terdapat pada sistem tersebut, sistem akan mengembalikan hasil ke user. User
meng-input string dan memilih algoritma mana yang akan di pakai, sistem memproses
algoritma tersebut dengan mencari file.txt yang terdapat undang-undang perlindungan anak,
lalu sistem mengembalikan hasil pencarian untuk ditampilkan ke user.
3.1.3.5 Flowchart Sistem
Flowchart merupakan bagan yang memperlihatkan urutan maupun hubungan antar proses
beserta keterangannya yang dinyatakan dengan simbol. Dengan demikian setiap simbol
menggambarkan proses tertentu. Sedangkan antara proses digambarkan dengan garis
penghubung. Untuk melihat Flowchart dari sistem yang akan dibangun perhatikan gambar
Gambar 3.6 Flowchart Sistem MULAI
Input kata yang dicari
Input algoritma yang digunakan
Melakukan pencocokan
Tidak
Ya
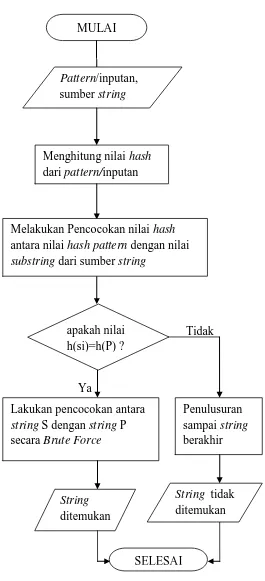
Gambar 3.8 Flowchart Rabin-Karp MULAI
Pattern/inputan, sumber string
Menghitung nilai hash dari pattern/inputan
apakah nilai h(si)=h(P) ?
Lakukan pencocokan antara string S dengan string P secara Brute Force
Penulusuran sampai string berakhir
SELESAI Melakukan Pencocokan nilai hash antara nilai hash pattern dengan nilai substring dari sumber string
String ditemukan
3.2 Perancangan Sistem
Proses perancangan antarmuka (interface) sebuah sistem adalah proses yang cukup penting
dalam membuat aplikasi. Sebuah antarmuka harus dirancang dengan memperhatikan faktor
pengguna sehingga sistem yang dibangun dapat memberikan kenyamanan dan kemudahan
untuk digunakan oleh pengguna.
3.2.1 Menu Intro
Gambar 3.9 Rancangan Interface Menu Intro
Tabel 3.5 Keterangan Gambar Rancangan Interface Menu Intro
No Keterangan
1. Image View 1 untuk menampilkan intro pada aplikasi sebelum benar-benar masuk
ke menu utama aplikasi.
Image View 1
Undang-undang perlindungan
Gambar 3.10 Rancangan Interface Menu Pemilihan
Tabel 3.6 Keterangan Gambar Rancangan Interface Menu Pemilihan
No Keterangan
1. Button 1 mulai untuk memulai aplikasi pencarian string 2. Button 2 tentang untuk menampilkan biodata diri
3.3.3 Menu Tentang
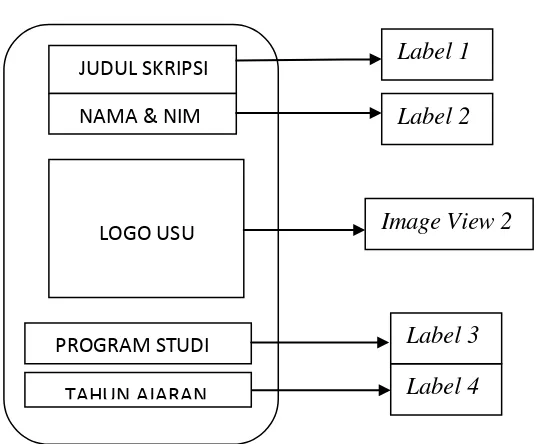
Gambar 3.11 Rancangan Interface Menu Tentang Button 1 Button 2
Label 1
Label 2
Image View 2
Label 3
Label 4 MULAI
TENTANG
JUDUL SKRIPSI
NAMA & NIM
LOGO USU
PROGRAM STUDI
Tabel 3.7 Keterangan Gamber Interface Menu Tentang
No Keterangan
1. Label 1 untuk menampilkan judul skripsi
2. Label 2 untuk menampilkan nama dan nim
3. Image View 2 untuk menampilkan logo Universitas Sumatra Utara 4. Label 3 untuk menampilak program studi
5. Label 4 untuk menampilkan tahun ajaran dan tempat
3.3.4 Menu Utama
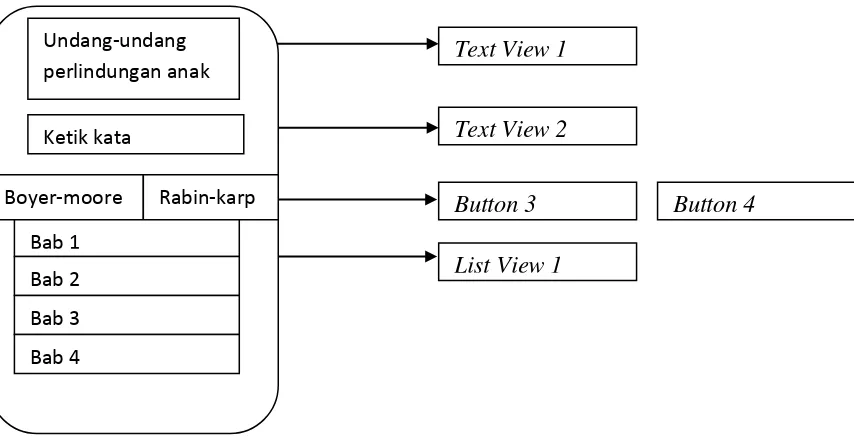
Gambar 3.12 Rancangan Interface Menu Utama
Tabel 3.8 Keterangan Rancangan Gambar Interface Menu Utama
No Keterangan
1. Text View 1 untuk menampilkan judul Undang-UndangPerlindungan anak
2. Text View 2 untuk menampilkan teks isi string
3. Button 3 untuk tombol algotima Boyer-Moore
4. Button 4 untuk tombol algortima Rabin-Karp
5. Text View 3 untuk menampilkan kata yang dicari
6. List Vuew 1 untuk menampilkan hasil pencarian string Text View 1
Text View 2
Button 3 Button 4
List View 1 Undang-undang
perlindungan anak
Ketik kata
Boyer-moore Rabin-karp
Bab 1
Bab 2
Bab 3
BAB 4
IMPLEMENTASI DAN PENGUJIAN
4.1 Implementasi
Implementasi sistem merupakan tahapan yang harus dilalui dalam proses pengembangan
perangkat lunak dari suatu sistem. Tahap ini dilakukan setelah melalui tahap Analisis dan
Perancangan sistem yang telah diuraikan pada bab sebelumnya.Sistem ini dibangun dengan
menggunakanBasic4Android.Pada sistem initerdapat 5 menu, yaitu: Menu Intro,Menu
Pemilihan, Menu Tentang, dan Menu Utama.
4.1.1 Implementasi Algoritma Boyer-Moore dan Rabin-Karp
Penerapan algoritma Boyer-Moore dan algoritma Rabin-Karp dalam sistem yang dibuat
adalah pada proses pencarian string dengan algoritma Boyer-Moore dan algoritma
Rabin-Karp dalam mencari teks undang-undang perlindungan anak .
Adapun langkah pertama yang dilakukan adalah melakukan peng-inputan .txt teks
undang-undang perlindungan anak dengan jumlah 14 bab. Lalu, User akan memasukkan string yang
nantinya akan melakukan proses pencarian string dengan algoritma Boyer-Moore dan
algoritma Rabin-Karp. Kata yang sesuai dengan string akan di tampilkan ke user. Jika tidak
ada string yang sama pada saat proses pencarian string maka string tidak ditemukan.
Algoritma Boyer-Moore bekerja dengan cara memeriksa string dari kanan ke kiri teks
dengan pola perlonjakan kata yang besar sesuai dengan tabel BmBc dan BmGs yang
terbentuk. Algoritma Rabin-Karp melakukan pencocokan string dengan cara melakukan
pencocokan nilai hash yang didapatkan dengan mendaftarkan semua string ke tabel ASCII
4.2 Antarmuka Sistem
Pada Aplikasi pencarian teks dalam undang-undang perlindungan anak menggunakan
algoritma Boyer-Moore dan Rabin-Karp ini terdapat lima menu, yaitu :
1. Menu Intro
2. Menu Pemilihan
3. Menu Tentang
4. Menu Utama
4.2.1 Menu Intro
Menu intro merupakan menu atau form yang pertama kali akan muncul ketika user membuka
aplikasi pencarian teks undang-undang perlindungan anak.
Gambar 4.1 Menu Intro 4.2.2 Menu Pemilihan
Form ini berisikan button tentang dan button mulai, sehingga user dapat memilih akan
Gambar 4.2 Menu Pemilihan 4.2.3 Menu Tentang
Form ini berisi tentang identitas dari penulis
4.2.4 Menu Utama
Form ini merupakan menu utama pada aplikasi pencarian teks dalam undang-undang
perlindungan anak. Dalam form ini akan melakukan pencarian string dengan menggunakan
algoritma Boyer-Moore dan algoritma Rabin-Karp dalam menemukan string yang tepat.
User akan meng-input string, lalu user akan memilih algoritma mana yang akan
digunakan (algoritma Boyer-Moore atau algoritma Rabin-Karp). Lalu sistem akan melakukan
pencarian string dengan algoritma yang telah dipilih. Sistem akan menampilkan hasil
pencarian string.
Contoh string : “perlindungan”
Gambar 4.4 Hasil Pencarian Algoritma Boyer-Moore (a)
Pada gambar di atas terdapat 9 bab dari 14 bab, 48 kata dengan durasi 80 ms dalam
undang-undang perlindungan anak yang terdapat string “perlindungan” dengan menggunakan
Gambar 4.5 Hasil Pencarian Algoritma Boyer-Moore (b)
Gambar 4.6 Hasil Pencarian Algoritma Rabin-Karp (a)
Pada gambar di atas terdapat 9 bab dari 14, 48 kata denngan durasi 300 ms dalam
undang-undang perlindungan anak yang terdapat string “perlindungan” dengan menggunakan
Gambar 4.7 Hasil Pencarian Algoritma Rabin-Karp (b)
Pada gambar di atas dapat dilihat teks yang berwarna kuning yang mengandung string “perlindungan” dengan menggunakan algoritma Rabin-Karp.
4.3 Hasil Pengujian
Hasil pengujian pada dari peneletian ini adalah kompleksitas dari kedua algoritma (
4.3.1 Kompleksitas Algoritma Big θ
public BoyerMoore(String pattern, String text) { this.pattern = pattern;
}
T(n) = 6C1+3C2+C3+C4m+2C2m+C4m
= (6C1+3C2+C3)݉0+ (C4+2C2+C4)݉1
= ݉0+ ݉1= θ(m)
Tabel 4.1 adalah tabel kompleksitas algoritma Boyer-Moore , dimana proses pencarian
kompleksitasnya menggunakan bahasa Java, C sebagai konstanta, # sebagai ukuran masukan,
dan C. # (C kali #) adalah untuk mencari Theoritical Running Time (T(n)) atau kompleksitas
waktu, sehingga dapat dijumlahkan hasil dari perkalian C kali #, maka diperoleh hasil θ(m)
untuk pembentukan bad character-nya.
Tabel 4.2 Kompleksitas Boyer-Moore Suffixes
Code C # C.#
private static int[] suffixes(char[] x, int m) {
C1 1 C1
int f=0, g, i; C3 1 C3
int suff[] = new int[m]; C2 1 C2
suff[m - 1] = m; C2 m C2m
g = m - 1; C2 m C2m
for (i = m - 2; i >= 0; --i) { C4 m C4m
if (i > g && suff[i + m - 1 - f] < i - g)
C5 m C5m
suff[i] = suff[i + m - 1 - f];
C2 m C2m
else { C6 m C6m
if (i < g) C6 m C6m
f = i; C2 m C2m
while (g >= 0 && x[g] == x[g + m - 1 - f])
C7 m C7m
--g; C8 m C8m
suff[i] = f - g; }
}
C2 m C2m
return suff; }
C9 m C9m
T(n) = C1+C2+C3+2C2m+C4m+4C2m+C5m+2C6m+C7m+C8m+C9m
= (C1+C2+C3)݉0+ (2C2+C4+4C2+C5+2C6+C7+C8+C9)݉1
= ݉0+ ݉1= θ(m)
Tabel 4.2 adalah tabel kompleksitas algoritma Boyer-Moore , dimana proses pencarian
kompleksitasnya menggunakan bahasa Java, C sebagai konstanta, # sebagai ukuran masukan,
dan C. # (C kali #) adalah untuk mencari Theoritical Running Time (T(n)) atau kompleksitas
waktu, sehingga dapat dijumlahkan hasil dari perkalian C kali #, maka diperoleh hasil θ(m)
untuk pembentukan suffixes-nya.
Tabel 4.3 Kompleksitas Boyer-Moore BmGs
Code C # C.#
private static void preBmGs(char[] x, int m) {
C1 1 C1
int i, j; C3 1 C3
int suff[] = suffixes(x, m); C2 1 C2
for (i = 0; i < m; ++i) C4 m C4m
bmGs[i] = m C2 m C2m
if (suff[i] == i + 1) C5 m C5m
for ( j < m - 1 - i; ++j) C4 m C4m
if (bmGs[j] == m) C5 m C5m
bmGs[j] = m - 1 - i; C2 m C2m
for (i = 0; i <= m - 2; ++i) C4 m C4m
bmGs[m - 1 - suff[i]] = m - 1 - i; C2 m C2m
}
static int[] bmGs; static int[] bmBc;
C3 m C3m
T(n) = C1+C2+C3+C4m+4C2m+ C3m+3C4m+2C5m
= (C1+C2+C3)݉0+ (C4+4C2+C3+3C4+2C5)݉1
= ݉0+ ݉1= θ(m)
Tabel 4.3 adalah tabel kompleksitas algoritma Boyer-Moore , dimana proses pencarian
kompleksitasnya menggunakan bahasa Java, C sebagai konstanta, # sebagai ukuran masukan,
dan C. # (C kali #) adalah untuk mencari Theoritical Running Time (T(n)) atau kompleksitas
waktu, sehingga dapat dijumlahkan hasil dari perkalian C kali #, maka diperoleh hasil θ(m)
untuk pembentukan Good Suffix-nya
Tabel 4.4 Kompleksitas Boyer-Moore Check
Code C # C.#
public boolean check2() { C1 1 C1
long startMillis =
System.currentTimeMillis();
C2 1 C2
return result;
Tabel 4.4 adalah tabel kompleksitas algoritma Boyer-Moore , dimana proses pencarian
kompleksitasnya menggunakan bahasa Java, C sebagai konstanta, # sebagai ukuran masukan,
dan C. # (C kali #) adalah untuk mencari Theoritical Running Time (T(n)) atau kompleksitas waktu, sehingga dapat dijumlahkan hasil dari perkalian C kali #, maka diperoleh hasil θmn.
Maka untuk θ keseluruhan algoritma Boyer-Moore adalah sebagai berikut :
return duration;
double patternHash = getHash(pattern); C2 1 C2
int patternLength = pattern.length(); C2 1 C2
T(n) = 7C1+19C2+2C3+C3mn+C4m+C5m+C6m+C7m
= (7C1+19C2+2C3+C7)݉0+(C4+C5+C6+C7)݉1+(C3mn)
= ݉0+ ݉1+ m.n = θ(mn)
Tabel 4.5 adalah tabel kompleksitas algoritma Rabin-Karp , dimana proses pencarian
kompleksitasnya menggunakan bahasa Java, C sebagai konstanta, # sebagai ukuran masukan,
dan C. # (C kali #) adalah untuk mencari Theoritical Running Time (T(n)) atau kompleksitas
waktu, sehingga dapat dijumlahkan hasil dari perkalian C kali #, maka diperoleh hasil θ(mn).
T(n) = C1+2C2+5C2n+C6n+C7n+C8n
= (C1+2C2)݉0+(5C2+C6+C7+C8)݊1
= ݉0+ n = θm+n
= θ(mn)+ θ(m+n) = θ(mn)
Tabel 4.6 adalah tabel kompleksitas algoritma Rabin-Karp , dimana proses pencarian
kompleksitas nya menggunakan bahasa Java, C sebagai konstanta, # sebagai ukuran masukan,
dan C. # (C kali #) adalah untuk mencari Theoritical Running Time (T(n)) atau kompleksitas
waktu, sehingga dapat dijumlahkan hasil dari perkalian C kali #. Maka, diperoleh hasil θmn. Maka untuk θ keseluruhan algoritma Boyer-Moore adalah sebagai berikut :
θ(mn)(Rabin-Karp) + θ(mn)(Rabin-Karp(a)) = θmn. Maka, hasil kompleksitas algoritma Rabin-Karpadalah θ(mn).
Maka kompleksitas algoritma Boyer-Moore dan kompleksitas algoritma Rabin-Karp bernilai sama, yaitu : θ(mn).
4.3.2 Real-Running-Time
Tabel 4.7 Running-Time Boyer-Moore
n String Boyer-moore(s)
5 Peril 0,070 s
10 Perlindung 0,060 s
20 perlindungan khusus 0,080 s
30 perlindungan khusus adalah perl 0,100 s
40 perlindungan khusus adalah perlindungan y
0,100 s
50 perlindungan khusus adalah perlindungan yang diberik
0,090 s
60 perlindungan khusus adalah perlindungan yang diberikan kepada
perlindungan yang diberikan kepada anak dalam situasi darurat, anak yang
be
0,120 s
rata-rata 0,09181818181818 s
Pada tabel 4.7 n merupakan banyaknya string yang di ujicoba untuk menentukan hasil
real-running-time dalam penemuan string-nya. n(5) artinya panjang string yang diuji sebanyak 5
karakter, dan real-running-time yang dibutuhkan untuk penemuan 5 karakter adalah: 0,070 s.
n(10) artinya panjang string yang diuji sebanyak 10 karakter, dan real-running-time yang
dibutuhkan untuk penemuan 10 karakter adalah: 0,060 s. n(20) artinya panjang string yang
diuji sebanyak 20 karakter, dan real-running-time yang dibutuhkan untuk penemuan 20
karakter adalah: 0,080 s. n(30) artinya panjang string yang diuji sebanyak 30 karakter, dan
real-running-time yang dibutuhkan untuk penemuan 30 karakter adalah: 0,100 s. n(40)
artinya panjang string yang diuji sebanyak 40 karakter, dan real-running-time yang
dibutuhkan untuk penemuan 40 karakter adalah: 0,100 s. n(50) artinya panjang string yang
diuji sebanyak 50 karakter, dan real-running-time yang dibutuhkan untuk penemuan 50
karakter adalah: 0,080 s. n(60) artinya panjang string yang diuji sebanyak 60 karakter, dan
real-running-time yang dibutuhkan untuk penemuan 60 karakter adalah: 0,090 s. n(70)
artinya panjang string yang diuji sebanyak 70 karakter, dan real-running-time yang
dibutuhkan untuk penemuan 70 karakter adalah: 0,100 s. n(80) artinya panjang string yang
diuji sebanyak 80 karakter, dan real-running-time yang dibutuhkan untuk penemuan 5
karakter adalah: 0,090 s. n(90) artinya panjang string yang diuji sebanyak 90 karakter, dan
real-running-time yang dibutuhkan untuk penemuan 90 karakter adalah: 0,110 s. n(100)
artinya panjang string yang diuji sebanyak 100 karakter, dan real-running-time yang
Gambar 4.8 Grafik Running-Time Boyer-Moore
Pada gambar 4.8 sumbu X merupakan waktu real-running-time untuk mencari string dimulai
dari panjang sebanyak 5 karakter sampai dengan 100 karakter. Sumbu Y merupakan
banyaknya karakter yang diuji, n merupakan banyak karakter.
Disimpulkan bahwa waktu running-time dalam mencari string n(5) = 0,070 s, dan
menurun pada n(10) = 0,060 s, waktu running-time dalam mencari string n(100) = 0,530 s,
dengan rata-rata pencarian setiap string 0,09181818181818 s. Nilai rata-rata didapat dari
menjumlahkan semua waktu running-time dan membagi sebanyak berapa kali percobaan
yang diuji. Grafik yang terbentuk berbentuk linear yang artinya kompleksitas yang terbentuk adalah θ(mn).
0 0.1 0.2 0.3 0.4 0.5
n(5) n(10) n(20) n(30) n(40) n(50) n(60) n(70) n(80) n(90) n(100)
Boyer-Moore
Tabel 4.8 Running-Time Rabin-Karp
n String Rabin-Karp(s)
5 peril 0,180 s
10 perlindung 0,240 s
20 perlindungan khusus 0,410 s
30 perlindungan khusus adalah perl 0,590 s
40 perlindungan khusus adalah anak dalam situasi darurat, anak yang
be
0,840 s
rata-rata 0,618181818282 s
Pada tabel 4.8 n merupakan banyaknya string yang di ujicoba untuk menentukan hasil
real-running-time dalam penemuan string-nya. n(5) artinya panjang string yang diuji sebanyak 5
karakter, dan real-running-time yang dibutuhkan untuk penemuan 5 karakter adalah: 0,180 s.
n(10) artinya panjang string yang diuji sebanyak 10 karakter, dan real-running-time yang
dibutuhkan untuk penemuan 10 karakter adalah: 0,240 s. n(20) artinya panjang string yang
diuji sebanyak 20 karakter, dan real-running-time yang dibutuhkan untuk penemuan 20
karakter adalah: 0,410 s. n(30) artinya panjang string yang diuji sebanyak 30 karakter, dan
dibutuhkan untuk penemuan 40 karakter adalah: 0,670 s. n(50) artinya panjang string yang
diuji sebanyak 50 karakter, dan real-running-time yang dibutuhkan untuk penemuan 50
karakter adalah: 0,570 s. n(60) artinya panjang string yang diuji sebanyak 60 karakter, dan
real-running-time yang dibutuhkan untuk penemuan 60 karakter adalah: 0,770 s. n(70)
artinya panjang string yang diuji sebanyak 70 karakter, dan real-running-time yang
dibutuhkan untuk penemuan 70 karakter adalah: 0,810 s. n(80) artinya panjang string yang
diuji sebanyak 80 karakter, dan real-running-time yang dibutuhkan untuk penemuan 5
karakter adalah: 0,850 s. n(90) artinya panjang string yang diuji sebanyak 90 karakter, dan
real-running-time yang dibutuhkan untuk penemuan 90 karakter adalah: 0,870 s. n(100)
artinya panjang string yang diuji sebanyak 100 karakter, dan real-running-time yang
dibutuhkan untuk penemuan 100 karakter adalah: 0,840 s.
Gambar 4.9 Grafik Running-Time Rabin-Karp
Pada gambar 4.9 sumbu X merupakan waktu real-running-time untuk mencari string dimulai
dari panjang sebanyak 5 karakter sampai dengan 100 karakter. Sumbu Y merupakan
banyaknya karakter yang diuji, n merupakan banyak karakter.
Disimpulkan bahwa waktu running-time dalam mencari string n(5) = 0,840 s, dan
menurun pada n(50) = 0,570 s, running-time dalam mencari string n(100) = 0,840 s, dengan
rata-rata pencarian setiap string 0,618181818282 s. Nilai rata-rata didapat dari menjumlahkan
semua waktu running-time dan membagi sebanyak berapa kali percobaan yang diuji. Grafik 0
n(5) n(10) n(20) n(30) n(40) n(50) n(60) n(70) n(80) n(90) n(100)
Rabin-Karp
namun, pada saat running-time algoritma Rabin-Karp mempunyai kompleksitas θ(m+n).
Gambar 4.8 dan 4.9 dapat digabungkan untuk memudahkan perbandingkan waktu
running-time kedua algoritma tersebut, dapat dilihat pada gambar 4.10.
Tabel 4.9 Running-Time Boyer-Moore dan Rabin-Karp
n String Boyer-Moore (s) Rabin-Karp (s)
5 Peril 0,070 s 0,180 s
10 Perlindung 0,060 s 0,240 s
20 perlindungan khusus 0,080 s 0,410 s
30 perlindungan khusus adalah perl 0,100 s 0,590 s
40 perlindungan khusus adalah anak dalam situasi darurat, anak yang
be
Pada tabel 4.9 n merupakan banyaknya string yang di ujicoba untuk menentukan hasil
real-running-time dalam penemuan string-nya. n(5) artinya panjang string yang diuji sebanyak 5
karakter, dan real-running-time yang dibutuhkan untuk penemuan 5 karakter adalah: 0,070 s
dan 0,180 s. n(10) artinya panjang string yang diuji sebanyak 10 karakter, dan
real-running-time yang dibutuhkan untuk penemuan 10 karakter adalah: 0,060 s dan 0,240 s. n(20) artinya
panjang string yang diuji sebanyak 20 karakter, dan real-running-time yang dibutuhkan untuk
penemuan 20 karakter adalah: 0,080 s dan 0,410 s. n(30) artinya panjang string yang diuji
sebanyak 30 karakter, dan real-running-time yang dibutuhkan untuk penemuan 30 karakter
adalah: 0,100 s dan 0,590 s. n(40) artinya panjang string yang diuji sebanyak 40 karakter, dan
real-running-time yang dibutuhkan untuk penemuan 40 karakter adalah: 0,100 s dan 0,670 s.
n(50) artinya panjang string yang diuji sebanyak 50 karakter, dan real-running-time yang
dibutuhkan untuk penemuan 50 karakter adalah: 0,080 s dan 0,570 s. n(60) artinya panjang
string yang diuji sebanyak 60 karakter, dan real-running-time yang dibutuhkan untuk
penemuan 60 karakter adalah: 0,090 s dan 0,770 s. n(70) artinya panjang string yang diuji
sebanyak 70 karakter, dan real-running-time yang dibutuhkan untuk penemuan 70 karakter
adalah: 0,100 s dan 0,810 s. n(80) artinya panjang string yang diuji sebanyak 80 karakter, dan
real-running-time yang dibutuhkan untuk penemuan 5 karakter adalah: 0,090 s dan 0,850 s.
n(90) artinya panjang string yang diuji sebanyak 90 karakter, dan real-running-time yang
dibutuhkan untuk penemuan 90 karakter adalah: 0,110 s dan 0,870 s. n(100) artinya panjang
string yang diuji sebanyak 100 karakter, dan real-running-time yang dibutuhkan untuk
Gambar 4.10 Grafik Running-Time Boyer-Moore dan Rabin-Karp
Pada gambar 4.9 sumbu X merupakan waktu real-running-time untuk mencari string dimulai
dari panjang sebanyak 5 karakter sampai dengan 100 karakter. Sumbu Y merupakan
banyaknya karakter yang diuji, n merupakan banyak karakter.
Dapat diambil kesimpulan bahwa algoritma Rabin-Karp memerlukan waktu yang
lebih lama dalam penemuan string yang berukuran panjang n(5) – n(100). Sedangkan,
rata-rata waktu yang dibutuhkan dalam penemuan string untuk Boyer-Moore : 0,091818181818s,
Rabin-Karp : 0,618181818282s. Nilai rata-rata didapat dari menjumlahkan semua waktu running-time dan membagi sebanyak berapa kali percobaan yang diuji. Grafik yang terbentuk merupakan kompleksitas θ(mn).
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
n(5) n(10) n(20) n(30) n(40) n(50) n(60) n(70) n(80) n(90) n(100)
Rabin-Karp
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan hasil dari perbandingan algoritma Boyer-Moore dan algoritma Rabin-Karp
dalam pencarian string pada teks undang-undang perlindungan anak berbasis android, maka
dapat disimpulkan bahwa :
1. Sistem ini mengimplementasikan algoritma Boyer-Moore dan algoritma Rabin-Karp
dalam pencarian teks undang-undang perlindungan anak.
2. Dalam Algoritma Boyer-Moore pemeriksaan teks dilakukan dari kanan ke kiri teks,
dengan nilai lompatan string berdasarkan perbandingan table BmGs dan BmBc yang
terbentuk.
3. Dalam Algoritma Rabin-Karp pemeriksaan teks dilakukan dengan mencocokan nilai hash
pada teks, yang didapat dari tabel ASCII.
4. Real-Running-Time untuk algoritma Boyer-Moore memiliki rata-rata penemuan string :
0,091818181818 s dan algortima Rabin-Karp memiliki rata-rata penemuan string :
0,618181818282 s.
5.2 Saran
Adapun saran yang dapat diberikan untuk mengembangkan penelitian ini adalah sebagai
berikut:
1. Untuk pengembangan selanjutnya,diharapkan dapat menambahkan undang-undang IT
atau pun undang-undang lainnya.
2. Untuk pengembangan selanjutnya, diharapkan aplikasi ini menyediakan button view
untuk dapat melihat isi undang-undang perlindungan anak.
3. Untuk pengembangan selanjutnya, diharapkanaplikasi ini menyediakan menu pilihan
algoritma pencarian string dalam proses pencarian seperti Turbo, Knuth-Morris-Pratt,
BAB II
LANDASAN TEORI
2.1 Anak
Anak adalah seseorang yang belum berusia 18 (delapan belas) tahun, termasuk anak yang
masih dalam kandungan (Mona, 2015). Anak merupakan tunas sebuah bangsa. Kemajuan
sebuah banngsa bergantung pada kualitas anak-anak pada bangsa itu sendiri. Agar anak kelak
mampu memikul tanggung jawab tersebut, maka perlu mendapat kesempatan yang
seluas-luasnya untuk tumbuh dan berkembang secara optimal, baik fisik, mental maupun sosial.
2.2 Android
Android adalah sistem operasi untuk perangkat mobile berbasis linux yang mencakup sistem
operasi, middleware dan aplikasi. Android menyediakan platform terbuka bagi para
pengembang untuk menciptakan aplikasi mereka (Safaat, 2015).
2.3 Sejarah Android
Pada awal mula sejarah android, Google Inc. membeli Android Inc. yang merupakan
pendatang baru yang membuat piranti lunak untuk ponsel/smartphone. Kemudian untuk
mengembangkan Android, dibentuklah Open Handset Alliance, konsorsium dari 34
perusahaan piranti keras, piranti lunak, dan telekomunikasi, termasuk Google, HTC, Intel,
Motorola, Qualcomm, T-Mobile, dan Nvidia.
Pada saat perilisan perdana android, 5 November 2007, Android bersama Open
Handset Alliance menyatakan mendukung pengembangan open source pada perangkat
mobile. Di lain pihak, Google merilis kode-kode Android di bawah lisensi Apache, sebuah
lisensi perangkat lunak dan open platform perangkat seluler.
Sekitar September 2007 Google mengenalkan Nexus One, salah satu jenis
smartphone yang menggunakan Android sebagain sistem operasinya. Telepon seluler ini
diproduksi oleh HTC Corporation dan tersedia dipasaran pada 5 Januari 2010. Pada 9
Desember 2008, diumumkan anggota baru yang bergabung dalam program kerja Android
Ltd, Softbank, Sony Ericsson, Toshiba Corp, dan Vodafone Group Plc. Seiring pembentukan
Open Handset Alliance, OHA mengumumkan produk perdana mereka, Android, perangkat mobile yang merupakan modifikasi kernel Linux 2.6. Sejak Android dirilis telah dilakukan
berbagai pembaruan berupa perbaikan bug dan penambahan fitur baru.
Tidak hanya menjadi sistem operasi di smartphone, saat ini Android menjadi pesaing
utama dari Apple pada sistem operasi Tablet PC. Pesatnya pertumbuhan Andoroid selain
faktor yang disebutkan di atas adalah karena Android itu sendiri adalah platform yang sangat
lengkap baik itu sistem operasinya, Aplikasi dan Tools Pengembangan, Market aplikasi
Android serta dukungan yang sangat tinggi dari komunitas Open Handset Alliance di dunia,
sehingga Android terus berkembang pesat baik dari segi teknologi maupun dari segi jumlah
device yang ada di dunia (Safaat, 2015).
2.4 Fitur Android
Sebagai platform aplikasi-netral, Android memberikan kesempatan untuk membuat aplikasi
bawaan Handphone/Smartphone. Beberapa fitur-fitur Android yang sangat penting adalah
sebagai berikut :
o Fremework aplikasi yang mendukung penggantian komponen dan reusable.
o Mesin Virtual Dalvik dioptimalkan untuk perangkat mobile
o Intregrated browser berdasarkan angine open source WebKit
o Grafis yang dioptimalkan dan didukung oleh libraries grafis 2D, grafis 3D,
berdasarkan spesifikasi opengl ES 1,0 (opsional akselerasi hardware)
o SQLite untuk penyimpanan data
o Media support yang mendukung audio, video, dan gambar (MPEG4, H.264, MP3,
AAC, AMR, JPG, PNG, GIF), GSM Telephony (tergantung hardware)
o Bluetooth, EDGE, 3G, dan WiFi (tergantung hardware)
o Kamera, GPS, kompas, dan accelerometer (tergantung hardware)
o Lingkungan Development yang lengkap dan kaya termasuk perangkat emulator, tools
2.5 Versi Android
o Android versi 1.1
Pada 9 Maret 2009, Google merilisi Android versi 1.1 Android versi ini dilengkapi
dengan pembaruan estetis pada aplikasi, jam, alarm, voice search (pencarian suara),
pengiriman pesan dengan Gmail, dan pemberitahuan email.
o Android versi 1.5 (Cupcake)
Pada pertengahan Mei 2009, Google kembali merilis telepon seluler dengan
menggunakan Android dan SDK (Software Development Kit) dengan versi 1.5
(Cupcake). Terdapat beberapa pembaruan termasuk juga penambahan beberapa fitur
dalam seluler versi ini yakni kemampuan merekam dan menonton video dengan
modus kamera, mengupload video ke Youtube dan gambar ke Picasa langsung dari
telepon, dukungan bluetooth A2DP, kemampuan terhubung secara otomatis ke
headset bluetooth, animasi layar, dan keyboard pada layar yang dapat disesuikan
dengan sistem.
o Android versi 2.0/2.1 (Eclair)
Pada 3 Desember 2009 diluncurkan ponsel Android dengan versi 2.0/2.1 (Éclair),
perubahan yang dilakukan adalah pengoptimalan hardware, peningkatan Google
Maps 3.1.2, perubahang UI dengan browser baru dan dukungan HTML5, daftar
kontak yang baru, dukungan flash untuk kamera 3,2 Mp, digital Zoom, dan bluetooth
2.1.
o Android versi 2.2 (Froyo)
Pada bulan Mei 2010 Android versi 2.2 diluncurkan. Android inilah yang sekarang
sangat banyak beredar di pasaran, salah satunya adalah dipakai di Samsung FX tab
yang sudah ada dipasaran. Fitur yang tersedia pada versi ini sudah kompleks.
o Android versi 2.3 (Gingerbread)
Android versi 2.3 ini diluncurkan pada Desember 2010.
o Android versi 3.0 ( Honeycomb)
Dirilis Februari 2011 sebagain android revisi 1 serta android revisi 2 versi 3.0 telah
dirilis pada Juli 2011.
o Android versi 4.0 (Jelly Bean)
Android Jelly Bean diluncurkan pertama kali pada Juli 2012, dengan berbasis Linux
Level 18. Penamaan mengadaptasi nama sejenis permen dalam beraneka macam rasa
buah. Ukurannya sebesar kacang merah. Permen ini keras di luar tapi lunak di dalam
serta lengket bila di gigit.
o Android versi 4.4 (KitKat)
Android 4.4 Kitkat API level 19.Google mengumumkan Android KitKat (dinamai
dengan izin Nestle dan Hershey) pada 3 september 2013. Dengan tanggal rilis 31
Oktober 2013. KitKat merupakan merk sebuah coklat yang dikeluarkan oleh Nestle.
Rilis berikutnya setelah nama KitKat diperkirakan banyak pengamat akan diberi
nomor 5.0 dan dinamai „Pie’ (Safaat, 2015).
2.6 Query
Query adalah satu atau beberapa kata atau frase / kalimat yang di masukan / di ketikan oleh
pengguna saat melakukan pencarian pada search engine (google atau search engine lainnya).
2.7 Search Engine
Mesin pencari (search engine) adalah salah satu program komputer yang di rancang khusus
untuk membantu seseorang menemukan file-file yang disimpan dalam komputer, misalnya
dalam sebuah web server umum di web atau komputer sendiri. Mesin pencari memungkinkan
kita untuk meminta content media dengan kriteria yang spesifik ( biasanya berisikan frase
atau kata yang kita inginkan) dan memperoleh daftar file yang memenuhi kriteria tersebut.
Mesin pencari biasanya menggunakan indeks untuk mencari file setelah pengguna
memasukan kriteria pencarian. Mesin pencari yang akan dibahas adalah mesin pencari khusus
yang digunakan untuk mencari informasi di dalam database lokal. Untuk memudahkan dan
mempercepat pencarian, mesin pencari mempunyai metode pencarian tertentu yang sering
disebut algoritma. Adapun struktur umum sebuah mesin pencari adalah sebagai berikut :
1. Kotak teks pencari
Kotak ini digunakan sebagai tempat memasukan kata kunci yang akan dijadikan acuan
dilakukan pencarian.
2. Tombol pencari
2.8 Algoritma
Algoritma adalah merupakan jantung ilmu komputer atau informatika. Banyak cabang ilmu
komputer yang diacu dalam terminologi algoritma. Namun jangan beranggapan algoritma
selalu identik dengan ilmu komputer saja. Cara membuat kue atau masakan dalam resep
masakan, itu juga merupakan algoritma (Saniman & Fathoni 2008). Logika berasal dari dari
bahasa Yunani yaitu LOGOS yang berarti ilmu.
Logika dapat diartikan ilmu yang mengajarkan cara berpikir untuk melakukan
kegiatan dengan tujuan tertentu. Algoritma berasal dari nama seorang Ilmuwan Arab yang
bernama Abu Jafar Muhammad Ibnu Musa Al Khuwarizmi penulis buku berjudul Al Jabar
Wal Muqabala. 2 Kata Al Khuwarizmi dibaca orang barat menjadi Algorism yang kemudian
lambat laun menjadi Algorithm diserap dalam bahasa Indonesia menjadi Algoritma.
Algoritma dapat diartikan urutan penyelesaian masalah yang disusun secara sistematis
menggunakan bahasa yang logis untuk memecahkan suatu permasalahan (Barakbah & Ahsan
2013).
Algoritma adalah suatu himpunan berhingga dari instruksi-instruksi yang secara jelas
memperinci langkah-langkah proses pelaksanaan, dalam pemecahan suatu masalah tertentu,
atau suatu kelas masalah tertentu, dengan dituntut pula bahwa himpunan instruksi tersebut
dapat dilaksanakan secara mekanik (Barakbah & Ahsan 2013).
2.8.1 Algoritma String Matching
Pengertian string menurut Dictionary of Algorithms and Data Structures, National Institute
of Standards and Technology (NIST) adalah susunan dari karakter-karakter (angka, alfabet
atau karakter yang lain) dan biasanya direpresentasikan sebagai struktur data array. String
dapat berupa kata, frase, atau kalimat. Pencocokan string (string matching) menurut
Dictionary of Algorithms and Data Structures, National Institute of Standards and Technology (NIST), diartikan sebagai sebuah permasalahan untuk menemukan pola susunan
karakter string di dalam string lain atau bagian dari isi teks. Algoritma pencarian string
(String Matching) salah satu bagian terpenting dalam berbagai proses yang berkaitan dengan
data dengan tipe teks.
2.8.2 Klasifikasi Pencocokan String
Pencocokan string (string matching) secara garis besar dapat dibedakan menjadi dua yaitu (...
o Exact string matching, merupakan pencocokan string secara tepat dengan susunan
karakter dalam string yang dicocokkan memiliki jumlah maupun urutan karakter dalam
string yang sama. Contoh: kata step akan menunjukkan kecocokan hanya dengan kata step.
2. Inexact string matching atau Fuzzy string matching, merupakan pencocokan string secara
samar, maksudnya pencocokan string dimana string yang dicocokkan memiliki kemiripan
dimana keduanya memiliki susunan karakter yang berbeda (mungkin jumlah atau
urutannya) tetapi string-string tersebut memiliki kemiripan baik kemiripan
tekstual/penulisan (approximate string matching) atau kemiripan ucapan (phonetic string
matching). Inexact string matching masih dapat dibagi lagi menjadi dua yaitu :
a. Pencocokan string berdasarkan kemiripan penulisan (approximate string matching)
merupakan pencocokan string dengan dasar kemiripan dari segi penulisannya (jumlah
karakter, susunan karakter dalam dokumen). Tingkat kemiripan ditentukan dengan
jauh tidaknya beda penulisan dua buah string yang dibandingkan tersebut dan nilai
tingkat kemiripan ini ditentukan oleh pemrogram (programmer). Contoh: cimpuler
dengan compiler, memiliki jumlah karakter yang sama tetapi ada dua karakter yang
berbeda. Jika perbedaan dua karakter ini dapat ditoleransi sebagai sebuah kesalahan
penulisan maka dua string tersebut dikatakan cocok.
b. Pencocokan string berdasarkan kemiripan ucapan (phonetic string matching)
merupakan pencocokan string dengan dasar kemiripan dari segi pengucapannya
meskipun ada perbedaan penulisan dua string yang dibandingkan tersebut. Contoh
step dengan steb dari tulisan berbeda tetapi dalam pengucapannya mirip sehingga dua string tersebut dianggap cocok. Contoh yang lain adalah step, dengan steppe, sttep, stepp, stepe. Exact string matching bermanfaat jika pengguna ingin mencari string
dalam dokumen yang sama persis dengan string masukan. Tetapi jika pengguna
menginginkan pencarian string yang mendekati dengan string masukan atau terjadi
kesalahan penulisan string masukan maupun dokumen objek pencarian, contoh
algoritma exact string matching antara lain: algoritma Boyer-Moore.
2.8.3 Algoritma Boyer-Moore
Algoritma Boyer-Moore dipublikasikan oleh Robert S. Boyer,dan J. Strother Moore pada
tahun 1977. Pencocokan karakter yang dilakukan menggunakan algoritma boyer-moore
Boyer Moore termasuk algoritma string matching yang paling efisien dibandingkan
algoritma-algoritma string matching lainnya. Karena sifatnya yang efisien, banyak
dikembangkan algoritma string matching dengan bertumpu pada konsep algoritma
Boyer-Moore (Efendi & Kurniadi 2013).
2.8.3.1 Ilustrasi Pencarian String Algortima Boyer-Moore Teks : OKTAVIANIPRADITA
Pattern : PRADITA
1. Mencari nilai suffix
Tabel 2.1 Suffix
Cara mencari :
Pada indeks ke – 6 pada tabel suffix beri nilai dari panjang pattern yaitu “PRADITA” mempunyai panjang karakter 7, maka tabel suffix indeks ke – 6 =7
Tabel 2.2 Proses Pencarian Suffix (a)
Lalu bandingkan dari kanan ke kiri teks, indeks ke -6 dibandingkan dengan indeks ke
–5 ( “A” banding “T”), hasil tidak sama maka beri nilai 0 pada tabel suffix
Lalu bandingkan dari kanan ke kiri teks, indeks ke -6 dibandingkan dengan indeks ke
–4 ( “A” banding “I”), hasil tidak sama maka beri nilai 0 pada tabel suffix
Lalu bandingkan dari kanan ke kiri teks, indeks ke -6 dibandingkan dengan indeks ke
– 3 ( “A” banding “D”), hasil tidak sama maka beri nilai 0 pada tabel suffix
Lalu bandingkan dari kanan ke kiri teks, indeks ke -6 dibandingkan dengan indeks ke
–2 ( “A” banding “A”), hasil sama maka beri tanda - pada tabel suffix
i 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix
I 0 1 2 3 4 5 6
X[i] P R A D I T A
Tabel 2.3 Proses Pencarian Suffix (b)
Lalu bandingkan dari kanan ke kiri teks, indeks ke -6 dibandingkan dengan indeks ke
–1 ( “A” banding “R”), hasil tidak sama maka beri nilai 0 pada tabel suffix
Lalu bandingkan dari kanan ke kiri teks, indeks ke -6 dibandingkan dengan indeks ke
– 0 ( “A” banding “P”), hasil tidak sama maka beri nilai 0 pada tabel suffix
Untuk mencari nilai indeks ke – 2 maka, masukkan rumus i – (i – s) = 2 – ( 2 – 1 ) = 2 – 1 = 1 :
Tabel 2.4 Proses Pencarian Suffix (c) i 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
S dalam rumus= jumlah berapa banyak pola yang sama pada keseluruhan teks i dalam rumus = indeks dalam pattern yang cocok yang ingin dicari nilai suffix-nya
2. Membuat tabel BmGs
Isi semua tabel BmGs dengan nilai panjang pattern yaitu 7
Tabel 2.5 Proses Pencarian BmGs
Lakukan pengecekan apakah hasil i + i hasil = suffix : Untuk indeks ke – 6 :
i + i hasil = suffix -> 6 + 1 = 7 , 7 = nilai suffix maka sama i 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 - 0 0 0 7
I 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
Tabel 2.6 Proses Pencarian BmGs (a)
Lakukan pengecekan apakah hasil i + i hasil = suffix :
Untuk indeks ke – 5 :
i + i hasil = suffix -> 5 + 1 = 6, 6 tidak sama nilai suffix maka sama
Tabel 2.7 Proses Pencarian BmGs (b)
Lakukan pengecekan apakah hasil i + i hasil = suffix : Untuk indeks ke – 4 :
i + i hasil = suffix -> 4 + 1 = 5, 5 tidak sama nilai suffix maka sama
Tabel 2.8 Proses Pencarian BmGs (c)
Lakukan pengecekan apakah hasil i + i hasil = suffix : Untuk indeks ke – 3 :
i + i hasil = suffix -> 3 + 1 = 4, 4 tidak sama nilai suffix maka sama
Tabel 2.9 Proses Pencarian BmGs (d)
Lakukan pengecekan apakah hasil i + i hasil = suffix : i 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
BmGs 7 7 7 7 7 7 7
i 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
BmGs 7 7 7 7 7 7 7
i 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
BmGs 7 7 7 7 7 7 7
i 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
i + i hasil = suffix -> 2 + 1 = 3, 3 tidak sama nilai suffix maka sama
Tabel 2.10 Proses Pencarian BmGs (e)
Lakukan pengecekan apakah hasil i + i hasil = suffix :
Untuk indeks ke – 1 :
i + i hasil = suffix -> 1 + 1 = 2, 2 tidak sama nilai suffix maka sama
Tabel 2.11 Proses Pencarian Bmgs (f)
Lakukan pengecekan apakah hasil i + i hasil = suffix : Untuk indeks ke – 0 :
i + i hasil = suffix -> 0 + 1 = 1, 1 tidak sama nilai suffix maka sama
Tabel 2.12 Proses Pencarian BmGs (g)
Masukkan rumus untuk mencari batas pencarian perhitungan nilai Bmgs :
M – 1 - i = 7 – 1 - 6 = 0 sebagai batas pertama
Karena hanya terdapat 1 saja nilai pencocokan suffix maka perhitungan di atas
selesai
Jika terdapat satu atau lebih lagi pencocokan nilai suffix yang sama maka lakukan
perhitungan dengan rumus m – 1 – i untuk batas selanjutnya. Karena tidak ada
untuk batas selanjutnya, maka :
I 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
BmGs 7 7 7 7 7 7 7
I 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
BmGs 7 7 7 7 7 7 7
i 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
Mulai menghitung untuk mengetahui batas kedua M - 2 = 7 - 2 = 5, yang artinya
menghitung nilai untuk pencarian tabel Bmgs nya dimulai dari indeks ke – 0
sampai indeks ke – 5.
Lalu masukkan rumus M - 1 – suffix-i = 0 -7 – 1 – 0 = 6 -> artinya indeks yang
ingin diisi dengan nilai Bmgs
-M – 1 – i = 7 – 1 – 0 = 6 -> niali Bmgs yang akan diisi pada indeks 6 , maka ubah nilai indeks ke – 6 menjadi 6
Tabel 2.13 Proses Pencarian BmGs (h)
i = 1
M – 1 – suffix = 7 – 1 – 0 = 6 -> artinya indeks yang ingin diisi dengan nilai Bmgs M – 1 – i = 7 – 1 – 1 = 5 -> nilai Bmgs yang akan diisi pada indeks 6 , maka ubah
nilai indeks ke – 6 menjadi 5
Tabel 2.14 Proses Pencarian BmGs (i)
i = 2
M – 1 –suffix = 7 – 1 – 1 = 5 -> artinya indeks yang ingin diisi dengan nilai Bmgs M – 1 – i = 7 – 1 – 2 = 4 -> nilai Bmgs yang akan diisi pada indeks 5 , maka ubah
nilai indeks ke – 5 menjadi 4
I 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
BmGs 7 7 7 7 7 7 6
I 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
Tabel 2.15 Proses Pencarian BmGs (j)
i = 3
M – 1 – suffix = 7 – 1 – 0 = 6 -> artinya indeks yang ingin diisi dengan nilai Bmgs M – 1 – i = 7 – 1 – 3 = 3 -> nilai Bmgs yang akan diisi pada indeks 6 , maka ubah
nilai indeks ke – 6 menjadi 3
Tabel 2.16 Proses Pencarian BmGs (k)
i = 4
M – 1 –suffix = 7 – 1 – 0 = 6 -> artinya indeks yang ingin diisi dengan nilai Bmgs M – 1 – i = 7 – 1 – 4 = 2 -> nilai Bmgs yang akan diisi pada indeks 6 , maka ubah
nilai indeks ke – 6 menjadi 2
Tabel 2.17 Proses Pencarian BmGs (l)
i = 5
M – 1 –suffix = 7 – 1 – 0 = 6 -> artinya indeks yang ingin diisi dengan nilai Bmgs M – 1 – i = 7 – 1 – 5 = 1 -> nilai Bmgs yang akan diisi pada indeks 6 , maka ubah
nilai indeks ke – 6 menjadi 1
I 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
BmGs 7 7 7 7 7 4 5
I 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7
BmGs 7 7 7 7 7 4 3
I 0 1 2 3 4 5 6
X[i] P R A D I T A
suffix 0 0 1 0 0 0 7