F - 1
1. DATA DIRI
Nama : Fitria Indrianti
Tempat/Tanggal Lahir : Bandung / 6 April 1995 Jenis Kelamin : Perempuan
Status Pernikahan : Belum Menikah Warga Negara : Indonesia
Agama : Islam
Alamat : Jln. Cipageran no 53 cimahi, Jawa Barat Nomor Telepon : 08155111893
Email : [email protected]
2. RIWAYAT PENDIDIKAN
a. 2001 - 2007 : SDN Bhinaharapan b. 2007 - 2009 : SMPN 2 Ngamprah c. 2009 - 2011 : SMAN 1 Cimahi
PEREKOMENDASIAN BARANG DI DISTRO FRESH WEARHOUSE
BATUJAJAR
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
Fitria Indrianti 10112246
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
KATA PENGANTAR
Assalamu Alaikum Wr.Wb
Alhamdulilah. Puji syukur kita panjatkan atas kehadirat Allah SWT, karena atas rahmat-Nyalah, penulis akhirnya dapat menyelesaikan penulisan skripsi dengan judul : Penerapan Data Mining Menggunakan Metode Association Rule Dengan Algoritma Fp-Growth Pada Perekomendasian Barang di Distro Fresh Wearhouse Batujajar.
Penulis sangat menyadari bahwa masih banyak kekurangan dalam penyusunan laporan tugas akhir sehingga masih jauh dari kata sempurna. Hal ini dikarenakan oleh pengetahuan, pengalaman, dan kemampuan penulis yang terbatas. Oleh karena itu, kritik dan saran yang membangun sangat penulis harapkan untuk menyempurnakan laporan tugas akhir ini.
Selama menulis laporan tugas akhir ini, penulis telah mendapat banyak sekali bimbingan dan bantuan dari berbagai pihak yang telah dengan segenap hati dan keikhlasan yang penuh dalam membantu dan membimbing penulis dalam menyelesaikan laporan ini. Dengan kesadaran hati, penulis ucapkan terima kasih kepada:
1. Allah SWT yang telah memberikan segala yang terbaik sehingga penulis dapat dengan lancar menyelesaikan tugas akhir ini.
2. Ayah dan Ibuku yang telah menyayangi dan mendoakanku selama ini serta telah memberikan segala dorongan moril dan materil, semangat, serta sabar yang luar biasa tanpa pamrih.
3. Ibu Dian Dharmayanti , S.T., M.Kom. selaku dosen pembimbing dan dosen penguji II laporan akhir yang dengan segala kesabaran dan keikhlasannya membimbing dan memberikan ilmunya kepada penulis dalam menulis laporan tugas akhir ini.
iv
5. Ibu Tati Harihayati Mardzuki, S.T.,M.T selaku dosen penguji yang telah memberikan masukan dan saran untuk skripsi ini.
6. Bapak Irfan Maliki, S.T., M.T. selaku dosen wali kelas IF-7 angkatan 2012
7. Bapak dan ibu dosen Fakultas Teknik Informatika yang sudah banyak memberikan ilmu baru yang sangat bermanfaat.
8. Untuk adikku Kharen yang selalu menghibur disaat kejenuhan penelitian ini berlangsung
9. Sahabatku Shativa Sonrisa dan Ahmad Sopian yang telah memberikan bantuan saat diperlukan.
10.Teman seperjuangan skripsi dari kelas Chena, Kaem, Arul yang selalu membantu dan menenangkan saya selama panik.
11.Ichsan Faizal, S.iKom yang telah membantu dalam pengerjaan skripsi ini
12.serta teman bimbingan bu Dian yang selalu menemani dan menghibur disaat bimbingan berlangsung.
13.Distro Fresh Wearhouse Batujajar yang telah mengizinkan dan memberikan data untuk penelitian tugas akhir ini.
14.Serta semua pihak yang telah turut membantu dalam penyusunan skripsi ini, yang tidak bisa disebutkan semuanya satu persatu. Penulis sangat menyadari bahwa dalam penulisan skripsi ini masih jauh dari kata sempurna, baik dalam metode penulisan, pembahas materi maupun penyajian materi, sehingga kiranya masih banyak yang perlu diperbaiki. Oleh karena itu, penulis sangat mengharapkan kritik dan saran yang bersifat membangun. Akhir kata, penulis berharap semoga skripsi ini dapat bermanfaat bagi penulis khusunya dan pembaca umumnya.
Bandung, 25 Agustus 2016
v
DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... x
DAFTAR SIMBOL ... xii
DAFTAR LAMPIRAN ... xiv
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 2
1.3 Maksud dan Tujuan ... 2
1.4 Batasan Masalah ... 3
1.5 Metodologi Penelitian ... 3
1.5.1 Metode Pengumpulan Data ... 3
1.5.2 Metode Pembangunan Perangkat Lunak ... 3
1.6 Sistematika Penulisan ... 6
BAB 2 TINJAUAN PUSTAKA ... 7
2.1 Profil Instansi ... 7
2.1.1 Sejarah Distro Fresh wearhouse ... 7
2.1.2 Logo ... 7
vi
2.1.4 Visi dan Misi ... 9
2.2 Landasan Teori ... 10
2.2.1 Data ... 10
2.2.2 Basis Data ... 10
2.2.3 Database Management system ... 12
2.2.4 Data Mining ... 13
2.2.4.1 Konsep Data Mining ... 13
2.2.5 CRISP-DM ... 17
2.2.6 Association Rule ... 18
2.2.7 Algoritma FP-Growth ... 21
2.2.8 Unified Modelling Language (UML) ... 24
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 27
3.1 Analisis Sistem ... 27
3.1.1 Analisis Masalah ... 27
3.1.2 Analisis Penerapan Metode CRISP-DM ... 27
3.1.3 Analisis Spesifikasi Kebutuhan Perangkat Lunak ... 59
3.2.1 Analisis Kebutuhan Non-Fungsional ... 59
3.2.2 Analisis Kebutuhan Fungsional ... 61
3.2.3 Activity Diagram ... 66
3.2.4 Sequense Diagram ... 72
3.2.5 Class Diagram ... 75
3.2.6 Perancangan Class ... 75
3.2.7 Skema Relasi ... 79
3.2.8 Struktur Tabel ... 79
vii
3.2.4 Perancangan Struktur Menu ... 85
3.2.5 Perancangan Pesan ... 86
3.2.6 Perancangan Jaringan Semantik ... 89
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM ... 91
4.1 Implementasi Sistem ... 91
4.1.1 Perangkat Keras yang digunakan ... 91
4.1.2 Perangkat Lunak yang digunakan ... 91
4.1.3 Implementasi Basis Data ... 92
4.1.4 Implementasi Antar Muka ... 93
4.2 Pengujian Sistem ... 94
4.2.1 Pengujian Fungsional ... 94
4.2.1 Kesimpulan Pengujian Fungsional ... 96
4.2.2 Pengujian Beta ... 96
4.2.3 Pengujian Hasil ... 97
4.2.3.1 Kesimpulan Pengujian Hasil ... 100
BAB 5 KESIMPULAN DAN SARAN ... 101
5.1 Kesimpulan ... 101
5.2 Saran ... 101
102
DAFTAR PUSTAKA
[1] I. Sommerville, Software Engineering, Edisi 6, Jakarta: Erlangga, 2003. [2] Larose D, T., 2005, Discovering knowledge in data : an introduction to data
mining, Jhon Wiley & Sons Inc.
[3] Jiawei, Han, Jian Pei, Yiwen Yin. 2004. Mining Frequent Patterns without Candidate Generation. Netherlands: Kluwer Academic Publishers.
[4] B. Liu, Sentiment Analysis and Opinion Mining, Morgan & Claypool Publisher , 2012.
[5] F. Buku Teks Komputer: Basis Data, 5th ed., Bandung: Informatika, 2004. [6] S. B. Meta, Data mining for dummies, p. 411.
[7] Jiawei, Han, Jian Pei, Yiwen Yin. 2004. Mining Frequent Patterns without Candidate Generation. Netherlands: Kluwer Academic Publishers
[8] R. W. Pate Chapman, 2000. [Online]. Available: http://the- modeling-agency.com/crisp-dm.pdf.
[10] F. Buku Teks Komputer: Basis Data, 5th ed., Bandung: Informatika, 2004. [11] H.A.Fajar, Data Mining. Andi, 2013.
1
BAB 1 PENDAHULUAN
1.1 Latar Belakang Masalah
Fresh Wearhouse merupakan sebuah distro di kawasan Jl. Raya Batujajar Timur No.148 Kab., Bandung Barat. Dalam kegiatan operasionalnya, distro ini biasa menjual produknya kepada masyarakat umum. Penjualan pada distro ini meliputi penjualan baju, tas, sepatu, topi, sandal, dan berbagai aksesoris yang biasa dijual di distro- distro lainnya. Distro ini melakukan pembaruan produk pada event tertentu. Distro ini mencatat data transaksi penjualannya secara manual.
Dari hasil wawancara di distro Fresh Wearhouse batujajar terdapat beberapa masalah yang terjadi dalam penjualan produk yang dialami oleh Fresh Wearhouse bahwa dari banyaknya produk paket yang ditawarkan hanya sedikit produk paket yang dibeli oleh pelanggan karena kombinasi produk yang dijual dalam satu paket merupakan produk yang kurang dibutuhkan dan disukai oleh pelanggan, dengan terjadinya hal tersebut maka muncul pemikiran dari pelanggan bahwa membeli produk biasa yang bukan dalam bentuk paket akan lebih berguna daripada membeli produk dalam satu paket meskipun harganya lebih murah. Pemilik distro mengira bahwa hal ini terjadi akibat tidak adanya aturan khusus dalam menentukan produk apa saja yang akan dijual dalam bentuk paket dan tidak adanya analisis yang dilakukan terhadap data yang terus bertambah untuk mendapatkan informasi. Oleh karena itu, pihak distro ingin adanya pengolahan data lebih lanjut dan lebih mendalam untuk menemukan informasi baru yang berguna sebagai bahan pertimbangan dalam proses penjualan sehingga di kemudian hari pihak distro memiliki pertimbangan dalam menentukan produk apa saja yang akan direkomendasikan dalam pemaketan produk.
adalah suatu proses menemukan hubungan yang berarti, pola dan kecenderungan dengan memeriksa dalam sekumpulan besar data yang tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola seperti statistika dan matematika [2]. Metode yang akan digunakan dalam pembangunan aplikasi ini adalah metode Association Rule dengan Algoritma FP-Growth. Metode Association Rule adalah suatu prosedur untuk mencari hubungan antara item dalam suatu kumpulan data yang ditentukan. Dalam menentukansuatu Association Rule,terdapat suatu ukuran kepercayaan yang didapatkan dari hasil pengolahan data dengan perhitungan tertentu [3]. Algoritma FP-Growth merupakan salah satu alternatif Algoritma yang dapat digunakan untuk menentukan himpunan data yang paling sering muncul (frequent itemset) dalam suatu kumpulan data [4]. Berdasarkan permasalahan yang terjadi, pada penelitian ini akan dibangun aplikasi Data Mining yang menerapkan Association Rule dan Algoritma FP-Growth yang berguna untuk perekomendasian pemaketan produk di distro Fresh Wearhouse Batujajar.
1.2 Rumusan Masalah
Berdasarkan latar belakang di atas, maka didapatkan suatu perumusan masalah yaitu bagaimana merekomendasikan pemaketan produk yang berada di distro Fresh Wearhouse dengan metode Association rule dengan menggunakan Algoritma FP- Growth.
1.3 Maksud dan Tujuan
Maksud dari penelitian ini adalah untuk menerapkan metode association rule dengan algoritma fp-growth pada perekomendasian paket produk di distro Fresh Wearhouse Batujajar.
3
1.4 Batasan Masalah
Batasan masalah pada penelitian ini adalah:
1. Data uji yang digunakan dalam penelitian ini adalah data periode November-Desember 2015
2. Tampilan Perekomendasiaan hanya berupa teks, bukan berupa gambar. 3. Aplikasi yang akan dibangun berbasis desktop.
4. Algoritma yang digunakan adalah algoritma fp-growth untuk menentukan himpunan data yang sering muncul pada suatu kumpulan data.
1.5 Metodologi Penelitian
Metodologi penelitian yang digunakan dalam pembuatan aplikasi ini adalah metode penelitian deskriptif, yaitu menggambarkan secara sistematis fakta dan karakteristik objek dan subjek yang diteliti secara tepat. Metode yang digunakan dalam penulisan laporan penelitian ini menggunakan dua metode,yaitu metode pengumpulan data dan metode pembangunan perangkat lunak.
1.5.1 Metode Pengumpulan Data
Metode yang digunakan dalam pengumpulan data pada penelitian ini adalah sebagai berikut:
a. Studi Literatur
Tahap studi literatur ini yaitu mengumpulkan serta mempelajari data-data yang berkaitan dengan laporan penelitian ini, baik dari literatur jurnal, buku, maupun situs-situs internet.
b. Observasi
Tahap observasi yaitu dengan mendatangi secara langsung lokasi yang dijadikan sebagai tempat penelitian tugas akhir ini yaitu distro Fresh Wearhouse di kawasan Jl. Raya Batujajar Timur No.148 Kab., Bandung Barat.
1.5.2 Metode Pembangunan Perangkat Lunak
tahun 1996 yang ditunjukkan untuk melakukan proses analisis dari suatu industri sebagai strategi pemecahan masalah dari bisnis satu unit penelitian [6]. Untuk data yang dapat di
proses dengan CRISP-DM ini, tidak ada ketentuan atau karakteristik tertentu, karena data tersebut akan diproses kembali pada fase-fase di dalamnya.
Berikut adalah tahapan-tahapan yang akan dilakukan dalam penelitian ini sesuai dengan CRISP-DM :
a. Business understanding
Tahap pertama adalah memahami tujuan dan kebutuhan dari sudut pandang bisnis, kemudian menterjemakan pengetahuan ini ke dalam pendefinisian masalah dalam Data Mining. Selanjutnya akan ditentukan rencana dan strategi untuk mencapai tujuan tersebut.
b. Data understanding
Tahap ini dimulai dengan pengumpulan data yang kemudian akan dilanjutkan dengan proses untuk mendapatkan pemahaman yang mendalam tentang data, mengidentifikasi masalah kualitas data, atau untuk mendeteksi adanya bagian yang menarik dari data yang dapat digunakan untuk hipotesa untuk informasi yang tersembunyi.
5
c. Data preparation
Tahap ini meliputi semua kegiatan untuk membangun dataset akhir (data yang akan diproses pada tahap pemodelan/modeling) dari data mentah. Tahap ini dapat diulang beberapa kali. Pada tahap ini juga mencakup pemilihan tabel, record, dan atribut-atribut data, termasuh proses pembersihan dan transformasi data untuk kemudian dijadikan masukan dalam tahap pemodelan (modeling).
d. Modeling
Dalam tahap ini akan dilakukan pemilihan dan penerapan berbagai teknik pemodelan dan beberapa parameternya akan disesuaikan untuk mendapatkan nilai yang optimal. Secara khusus, ada beberapa teknik berbeda yang dapat diterapkan untuk masalah Data Mining yang sama. Di pihak lain ada teknik pemodelan yang membutuhan format data khusus. Sehingga pada tahap ini masih memungkinan kembali ke tahap sebelumnya.
e. Evaluation
Pada tahap ini, model sudah terbentuk dan diharapkan memiliki kualitas baik jika dilihat dari sudut pandang analisa data. Pada tahap ini akan dilakukan evaluasi terhadap keefektifan dan kualitas model sebelum digunakan dan menentukan apakah model dapat mencapat tujuan yang ditetapkan pada fase awal (Business Understanding). Kunci dari tahap ini adalah menentukan apakah ada masalah bisnis yang belum dipertimbangkan. Di akhir dari tahap ini harus ditentukan penggunaan hasil proses Data Mining.
f. Deployment
1.6 Sistematika Penulisan
Merupakan suatu penjabaran secara deskriptif tentang hal-hal yang akan ditulis, yang secara garis besar terdiri dari beberapa Bab. Sistematika penulisan laporan tugas akhir adalah sebagai berikut :
BAB 1 PENDAHULUAN
Bab ini membahas hal-hal yang menjadi latar belakang masalah, perumusan masalah, maksud dan tujuan, batasan masalah, metode penelitian, dan sistematika penulisan.
BAB 2 TINJAUAN PUSTAKA
Bab ini membahas mengenai profile perusahaan, yang meliputi sejarah, logo, badan hukum, struktur organisasi perusahaan, dan hal-hal lain yang menjelaskan tentang perusahaan dan menjelaskan mengenai landasan teori yang berhubungan dengan aplikasi yang akan dibangun.
BAB 3 ANALISIS DAN PERANCANGAN
Bab ini membahas identifikasi masalah, analisis kebutuhan data, software, hardware, diagram pembuatan sistem dengan menggunakan UML (Unified Modeling Language).
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi penjelasan dari proses analisis dan perancangan yang telah dilakukan untuk selanjutnya diimplementasikan menjadi perangkat lunak dan dilakukan pengujian terhadap perangkat lunak tersebut.
BAB 5 KESIMPULAN DAN SARAN
7
BAB 2
TINJAUAN PUSTAKA
2.1 Profil Instansi
Berikut adalah profil dari tempat penelitian Tugas Akhir.
2.1.1 Sejarah Distro Fresh wearhouse
Distro Fresh wearhouse merupakan salah satu distro yang menyediakan berbagai produk yang memenuhi kebutuhan trend anak muda di zaman yang serba modern ini. Distro ini didirikan di kawasan Jl. Raya Batujajar Timur No.148 Kab., Bandung Barat oleh Gugi Basmalah pada tahun 2008. Selain menjual kebutuhan
trend anak muda dalam jumlah satuan, di distro ini juga menjual produk dalam
bentuk paket yang pembaruannya dilakukan dalam beberapa event yang dijual
lebih murah. Distro ini menerapkan konsep pembelian langsung yang dapat
memudahkan pembeli dapat melihat dan memilih langsung produk yang akan dibeli
sesuai dengan keinginan dan kebutuhannya. Hal inilah yang menjadikan distro ini
sangat diminati oleh para konsumen.
Seiring dengan minat konsumen terhadap produk di distro Fresh Wearhouse
ini setiap tahunnya maka pihak distro menambah beberapa produk yang
sebelumnya tidak ada di distro. Dahulu distro ini hanya mempunyai beberapa jenis
produk saja namun kini distro Fresh Wearhouse sudah memiliki beberapa jenis
produk yang dapat konsumen beli. Pihak distro berencana untuk membuka cabang
baru di daerah lainnya.
2.1.2 Logo
Gambar 2. 1 Logo Distro
Logo Fresh Wearhouse ini dibuat oleh pemilik distro dengan lambang fresh dengan maksud agar semua produk yang dihasilkan akan selalu fresh dimata konsumen seperti namanya.
2.1.3 Struktur Organisasi dan Job Description
Berikut ini adalah Struktur organisasi Distro Fresh Wearhouse Batujajar
Gambar 2. 2 Struktur Organisasi
Deskripsi Tugas :
1. Pemilik bertanggung jawab penuh terhadap distro, berikut ini adalah tugas dan tanggung jawabnya :
9
b. Melakukan kontrol secara keseluruhan terhadap operasional distro. c. Memegang kendali atas keputusan penting yang berhubungan dengan keuangan.
2. Manager berfungsi untuk membantu pemilik dalam menjalankan operasional distro berikut ini adalah tugas dan tanggung jawabnya :
a. Mengatur setiap bagian yang ada di distro agar menjalankan tugasnya dengan baik
b. Membantu pemilik dalam mengawasi operasional distro.
3. Bagian pelayan berfungsi untuk melayani setiap pelanggan yang datang atau memesan via online dan tanggung jawabnya adalah sebagai berikut :
a. Melayani semua pesanan pelanggan
b. Membantu dalam melayani pesanan pesanan pelanggan
4. Bagian Keuangan bertugas mengawasi transaksi pelanggan tugas dan tanggung jawabnya adalah sebagai berikut :
a. Menghitung pemasukan dan pengeluaran setiap bulannya
b. Bertanggung jawab terhadap hal-hal yang menyangkut keuangan di distro 5. Kasir berfungsi melayani transaksi pembelian tugas dan tanggung jawabnya
adalah sebagai berikut :
a. Melayani transaksi pembayaran langsung dengan pelanggan b. Menghitung dan mencatat pembelian setiap harinya.
2.1.4 Visi dan Misi
Visi dari distro Fresh Wearhouse ini adalah mendirikan distro dengan konsep modern dan menjadi distro yang mendistributor lokal dan berkedudukan berkepanjangan. Sedangkan misi dari distro Fresh Wearhouse ini adalah:
1. Melakukan pelayanan terbaik untuk pelanggan dan menjual kualitas produk yang akan dijual
2. Selalu melakukan inovasi terhadap produk
3. Mengembangkan usaha distro di wilayah Kab.Bandung Barat.
2.2 Landasan Teori
Dalam bab ini akan dijelaskan mengenai definisi dan teori-teori yang berkaitan dengan permasalahan yang ada. Landasan teori yang diuraikan merupakan hasil studi literatur, buku-buku, maupun internet.
2.2.1 Data
Data adalah representasi fakta dunia nyata yang mewakili suatu objek seperti manusia (pegawai, siswa, pembeli, pelanggan), barang, hewan, peristiwa, konsep, keadaan, dan sebagainya, yang direkam dalam bentuk angka, huruf, simbol, teks, gambar, bunyi, atau kombinasinya[5]. Data dapat juga digunakan sebagai input dan menghasilkan sebuah informasi. Data juga merupakan sesuatu yang belum memiliki arti dan masih membutuhkan suatu pengolahan . Dalam data terdapat himpunan data yang merupakan kumpulan dari objek dan atributnya. Atribut merupakan sifat atau karakteristik dari suatu objek yang biasanya dikenal sebagai variable, field, karakteristik atau fitur. Salah satu himpunan data adalah record data , yaitu data yang terdiri dari sekumpulan record yang masing-masing terdiri dari suatu set atribut yang tetap. Salah satu yang termasuk dalam tipe data record yaitu data transaksi. Data transaksi merupakan sebuah tipe khusus dari record data, dimana tiap record (transaksi) meliputi satu set item [6].
2.2.2 Basis Data
11
1. Himpunan kelompok data (arsip) yang saling berhubungan yang diorganisasi sedemikian rupa agar kelak dapat dimanfaatkan kembali dengan cepat dan mudah.
2. Kumpulan data yang saling berhubungan yang disimpan secara bersama sedemikian rupa dan tanpa pengulangan (redudansi) yang tidak perlu, untuk memenuhi berbagai kebutuhan.
2.2.2.1 Data pada Basis Data dan Hubungannya
Ada 3 jenis data pada sistem database, yaitu [9] :
1. Data operasional dari suatu organisasi,berupa data yang tersimpan dalam basis data.
2. Data masukan (input data), data dari luar sistem yang dimasukan melalui peralatan input (keyboard), yang dapat merubah data opersional.
3. Data keluaran (output data), berupa laporan melalui peralatan output sebagai hasil dari sistem yang mengkses data operasional.
2.2.2.2 Keuntungan dan Kerugian Pemakaian Sistem Database
Keuntungan [10] :
1. Terpeliharanya keselarasan data.
2. Data dapat dipakai secara bersama-sama.
3. Memudahkan penerapan standarisasi dan batas-batas pengaman.
4. Terpeliharanya keseimbangan atas perbedaan kebutuhan data dari setiap aplikasi.
5. Program/ data independent. Kerugian [10] :
1. Mahal dalam implementasinya. 2. Rumit.
3. Penanganan proses recovery backup sulit
4. Kerusakan pada sistem basis data dapat mempengaruhi.
2.2.3 Database Management system
13
2.2.4 Data Mining
Data mining, sering juga disebut knowledge discovery in database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian, dan historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan, sehingga istilah pattern recognition sudah tidak digunakan lagi [12].
Secara umum, definisi data mining dapat diartikan sebagai berikut [12]: 1. Proses penemuan pola yang menarik dari data yang tersimpan dalam jumlah
besar.
2. Ekstrasi dari suatu informasi yang berguna atau menarik (non-trivial, implisit, sebelumnya belum diketahui potensi kegunaannya) pola atau pengetahuan dari data yang di simpan dalam jumlah besar.
3. Eksplorasi dari analisa secara otomatis atau semiotomatis terhadap data data dalam jumlah besar untuk mencari pola dan aturan yang berarti.
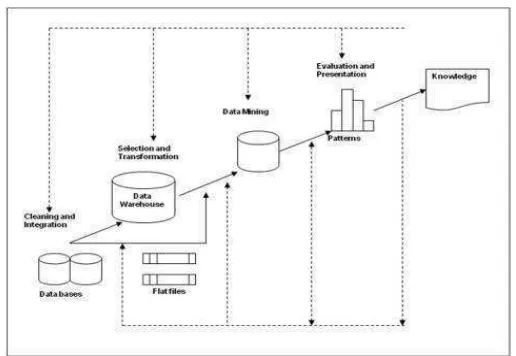
2.2.4.1 Konsep Data Mining
Gambar 2. 3 Konsep Data Mining
1. Data cleaning untuk menghilangkan noise data yang tidak konsisten.
2. Data integration untuk menggabungkan beberapa file atau database. 3. Data selection yaitu data yang relevan dengan tugas analisis yang
dikembalikan kedalam database untuk proses data mining.
4. Data transformation yaitu data berubah atau bersatu menjadi bentuk yang tepat untuk menambah ringkasan performa atau operasi agresi 5. Data mining yaitu proses esensial dimana metode intelejen
digunakan untuk mengekstrak pola data.
6. Knowledge discovery yaitu proses dimana metode intelejen digunakan untuk mengekstrak pola data.
7. Pattern evolution yaitu untuk mengidentifikasi pola yang benar-benar menarik yang mewakili pengetahuan berdasarkan beberapa tindakan yang menarik.
15
S2.2.4.2 Metode- Metode Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu [12]:
1. Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mecoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat mengumpulkan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih kearah numerik daripada kearah kategori. Model dibangun dengan record lengkap yang menyediakan nilai dari variable target sebagai nilai prediksi. Sebagai contoh,akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akhir akan ada dimasa mendatang. Contoh prediksi dalam bisnis dan penelitian adalah :
1. Prediksi harga beras dalam tiga bulan yang akan datang.
2. Prediksi persentase kenaikan kecelakaan lalu lintas tahun depan. 4. Klasifikasi
pendapatan tinggi, pendapatan sedang, dan pendapatan rendah. Contoh lain klasifikasi dalam bisnis dan penelitian adalah :
1. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau bukan
2. Mendiagnosis penyakit seorang pasien untuk mendapatkan termasuk kategori penyakit apa
5. Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan tidak memiliki kemiripan dengan record-record dalam kluster lain. Pengklusteran berbeda dengan klasifikasi yaitu dengan tidak adanya variabel target dalam pengklusteran. Pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan record dalam suatu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal. Contoh pengklusteran dalam bisnis dan penelitian adalah :
1. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produk sebuah perusahaan yang tidak memiliki dana pemasaran yang besar.
17
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang pasar. Contoh asosiasi dalam bisnis dan penelitian adalah :
1. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang diharapkan untuk memberikan respon positif terhadap penawaran upgrade layanan yang diberikan.
2. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak dibeli bersamaan.
2.2.5 CRISP-DM
Cross-Industry Standard Process for Data Mining (CRISP-DM) merupakan suatu standar yang telah dikembangkan pada tahun 1996 yang ditujukan untuk melakukan proses analisis dari suatu industri sebagai strategi pemecahan masalah dari bisnis atau unit penelitian.Untuk data yang dapat diproses dengan CRISP-DM ini, tidak ada ketentuan atau karakteristik tertentu, karena data tersebut akan diproses kembali pad fase-fse didalamnya. Terdapat enam fase dalam CRISP-DM ini yakni [6] :
1. Business Understanding
Tahap awal ini berfokus pada penentuan tujuan bisnis, menilai situasi dan penentuan sasaran data mining
2. Data understanding
Tahap pemahaman data dimualai dengan pengumpulan data awal, menjelaskan data yang memungkinkan kita untuk untuk lebih mengenal data
3. Data preparation
4. Modeling
Pada tahap ini akan dilakukan pemilihan teknik pemodelan, menghasilkan desain uji, pembangunan model, serta menilai model yang telah dibuat.
5. Evaluation
Pada tahap ini kita harus mengevaluasi hasil, review proses, dan sebelum sampai akhir pembuatan model penting untuk benar-benar mengevaluasi dan meninjau kembali langkah dan pembuatannya, untukmemastikan bahwa model benar-benar mencapai tujuan bisnis. Tujuan utama adalah untuk menentukan apakah ada beberapa masalah bisnis yang belum cukup dipertimbangkan. Pada akhir dari tahap ini, keputusan tentang penggunaan hasil data mining harus tercapai.
6. Deployment
Pada tahap ini, informasi yang diperoleh akan dipresentasikan dalam bentuk khusus sehingga dapat digunakan oleh pengguna. Tahap deployment dapat berupa pembangunan atau penginstalan software, pemantauan dan pemeliharaan, menghasilkan suatu laporan. Dalam beberapa kasus, tahap ini melibatkan konsumen, disamping analisis data karena sangat penting bagi konsumen untuk memahami tindakan apa yang harus dilakukan untuk menggunakan model yang telah dibuat.
2.2.6 Association Rule
19
Association rule adalah bentuk jika “kejadian sebelumnya” kemudian “konsekuensinya” (if antecedent, then consequent), yang diikuti dengan perhitungan aturan support dan confidence. Bentuk umum dari association rule adalah Antecedent -> Consequent. Bila kita ambil contoh dalma sebuah transaksi pembelian barang di sebuah minimarket didapat bentuk association rule roti ->selai. Yang artinya bahwa pelanggan yang membeli roti ada kemungkinan pelanggan tersebut juga membeli selai, dimana tidak ada batasan dalam jumlah item-item pada bagian antecedent atau consequent dalam sebuah rule. Dalam menentukan suatu association rule, terdapat suatu interestingness measure (ukuran kepercayaan) yang didapat dari hasil pengolahan data dengan perhitungan tertentu. Umumnya ada dua ukuran yaitu :
1. Support : Suatu ukuran yang menunjukkan seberapa besar tingkat dominasi suatu item/ itemset dari keseluruhan transaksi. Support merupakan matrik pertama yang ditetapkan dalam analisis keranjang pasar, yang merupakan probabilitas dari asosiasi ( probabilitas dari dua item yang diberi bersama- sama). Support dihasilkan dari beberapa kali jumlah item A dan B terjadi bersamaan dalam transaksi yang sama dibagi dengan jumlah total dari transaksi tersebut. Support dapat dirumuskan sebagai berikut [15] :
Support = P (A ∩ B)
= J a a a ya a a
T a a a a
2. Confidence : Confidence dihasilkan dari seberapa kuat hubungan produk yang sudah dibeli. Confidence dapat dirumuskan sebagai berikut [15]:
Confidence = P (B / A)
= � ∩
�
sebelumnya, maka pola tersebut dapat disebut sebagai interesting rule atau strong rule . metodologi dasar analisis asosiasi terbagi menjadi dua tahap yaitu [15] :
1. Analisis pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dan database. Nilai support sebuah item diperoleh dengan rumus berikut :
� = � �ℎ � � � ya � �ℎ � � � ��� � X 100 %
Persamaan (2-1)
Sementara itu, nilai support dari 2 item diperoleh dari rumus berikut :
, = � ∩ )…Persamaan (2-2)
� , =
� �ℎ � � � ya �� � �
� �ℎ � � � �
x100%.Persamaan(2-1)
2. Pembentukan aturan asosiasi
Setelah semua pola frekuensi tinggi ditemukan, kemudian mencari aturan asosiasi yang cukup kuat ketergantungan antar item. Dalam antecedent (pendahulu) dan consequent (pengikut) serta memenuhi syarat minimum untuk confidence aturan assosiatif A->B. Misalkan D adalah himpunan transaksi, dimana setiap transaksi T dalam D merepresentasikan himpunan item yang berada dalam I. I adalah himpunan item yang dijual.
Misalkan kita memilih himpunan item A dan himpunan item lain B, kemudian aturan asosiasi akan berbentuk :
Jika A, maka B (A->B)
dimana antecedent A dan consequent B merupakan subset dari I dan A dan B dimana aturan :
21
Jika B, maka A
Sebuah itemset adalah himpunan item-item yang ada dalam I, dan i itemset. Frekuensi itemset merupakan itemset yang memiliki frekuensi kemunculan lebih dari nilai minimum yang telah ditentukan.
Nilai confidence dari aturan A->B diperoleh rumus berikut :
� = � | =� � �ℎ � � � ya �ℎ � � � �� � ���� � � �
Persamaan (2-2)
2.2.7 Algoritma FP-Growth
Algoritma yang sama dengan Apriori, FP-Growth mulai dengan menghitung item tunggal sesuai dengan jumlah kemunculan item yang ada dalam dataset. Setelah proses perhitungan maka akan dibuat struktur pohon pada tahap kedua. Pohon yang dibuat mulanya kosong, yang nanti akan diisi dengan hasil dari dataset yang telah didapat sebelumnya. Kunci untuk mendapatkan struktur pohon yang bisa didapatkan denagn proses lebih cepat untuk mencari itemset yang besar menjadi sedikit dengan diurutkan secara descending dari frekuensi yang ada dataset tersebut. Masing-masing item yang tidak mencapai kebutuhan minimum dari threshold tidak dimasukkan kedalam pohon, tapi tidak dikeluarkan secara efektif dari dataset [4].
FP-Tree merupakan struktur penyimpanan data yang dimampatkan. FP-Tree dibangun dengan meletakan setiap data transaksi kedalam setiap lintasan tertentu dalam FP-Tree, karena dalam setiap transaksi yang dipetakan, mungkin ada transaksi yang memiliki item yang sama, maka lintasannya memungkinkan untuk saling menimpa. Semakin banyak data transaksi yang memiliki item sama, maka proses pemampatan dengan struktur data FP-Tree semakin efektif. Kelebihan dari FP-Tree adalah hanya memerlukan dua kali pemindaian data transaksi yang terbukti sangat efisien.
a. FP-Tree dibentuk oleh sebuah akar yang diberi label null, sekumpulan berupa pohon yang beranggotakan item-item tertentu dan sebuah tabel frequent header
b. Setiap simpul dalam FP-Tree mengandung tiga informasi penting, yaitu label item, menginformasikan jenis item yang direpesentasikan simpul tersebut, support count, merepresentasikan jumlah lintasan transaksi melalui simpul tersebut, dan pointer penghubung yang menghubungkan simpul-simpul dengan label atau item sama antar lintasan, ditandai dengan garis panah putus-putus.
2.2.4.1 Langkah-Langkah Proses Perhitungan Association Rule dengan Algoritma FP-Growth
Proses perhitungan association rule terdiri dari beberapa tahap adalah sebagai berikut
1. Membuat Header Item
Header dalam hal ini selain sebagai header suatu item ke FP-Tree juga sebagai jenis item dasar yang memenuhi minimum support. Setelah mendapatkan item dan nilai support-nya, maka item yang tidak frequent dibuang dan item diurutkan berdasarkan nilai support-nya. Header untuk item, disiapkan pada suatu array tertentu dan ditambahkan ketika membuat FP-Tree.
2. Membuat FP-Tree
23
Tiap node pada FP-Tree memiliki pointer ke parent, sehingga pencarian harus dimulai dari bawah.
3. Pattern Extraction
Pattern extraction dilakukan berdasarkan keterlibatan item pada suatu path. Di setiap path, diperiksa semua kombinasi yang mungkin dimana item tersebut terlibat. Di iterasi berikutnya dilakukan dengan melakukan item pada suatu path. Di setiap path, diperiksa semua kombinasi yang mungkin dimana item tersebut terlibat. Di iterasi berikutnya dilakukan dengan melibatkan item berikutnya, tanpa melibatkan item sebelumnya, sehingga pattern yang sama tidak akan ditemukan dua kali pada path yang sama. Bila item pertama suatu hasil kombinasi bukan item terakhir (sebelum root), maka kombinasi itemset tersebut masih bisa dikembangkan lagi.
4. Memasukkan setiap pattern yang ditemukan dalam PatternTree
Setelah mengolah FP-Tree menjadi pattern-pattern, diperlukan proses akumulasi pattern-pattern yang ditemukan mengingat pattern yang sama dapat ditemukan pada path yang berbeda. Untuk itu digunakan struktur data Pattern Tree (lihat Gambar 2.5). Setiap node di Pattern Tree merepresentasikan dan menyimpan frekuensi suatu pattern. Pattern Tree terdiri atas Pattern TreeNode yang menyimpan nilai item, nilai support dan dilengkapi dengan dua pointer yaitu untuk horizontal dan vertikal.
Misalnya pada node d:1 di atas, berarti terdapat pattern a-c-d bernilai support 1. Kemudian bila ada pattern a-c-d lagi bernilai support n yang ditemukan dari FP-Tree maka nilai support 1 tersebut menjadi n+1.
Contoh hasil lengkap dari PatternTree tersebut: 1. a:5 menggambarkan bahwa ada pattern a sebanyak 5 2. b:4 menggambarkan bahwa ada pattern a-b sebanyak 4 3. c:4 menggambarkan bahwa ada pattern a-b-c sebanyak 4 4. d:3 menggambarkan bahwa ada pattern a-b-c-d sebanyak 3 5. c:2 menggambarkan bahwa ada pattern a-c sebanyak 2 6. d:1 menggambarkan bahwa ada pattern a-c-d sebanyak 1 7. d:3 menggambarkan bahwa ada pattern a-d sebanyak 3
5. Mengurutkan dan menyeleksi Pattern.
Pattern yang tidak memenuhi minimum support, dihapus dari daftar pattern. Pattern-pattern yang tersisa kemudian diurutkan untuk memudahkan pembuatan rules.
2.2.8 Unified Modelling Language (UML)
Unified Modelling Language (UML) adalah himpunan struktur dan teknik untuk pemodelan desain program berorientasi objek serta aplikasinya.
2.2.8.1 Diagram Use Case
Diagram Use Case adalah model fungsional sebuah sistem yang menggunakan aktor dan use case. Use case adalah layanan (services) atau fungsi– fungsi yang disediakan oleh sistem untuk penggunanya.
Deskripsi dari Use Case :
1. Sebuah use case adalah dimana sistem digunakan untuk memenuhi satu atau lebih kebutuhan pemakai.
25
3. Use case menggambarkan kebutuhan sistem dari sudut pandang di luar sistem.
4. Use case menentukan nilai yang diberikan sistem kepada pemakainya. 5. Use case hanya menetapkan apa yang seharusnya dikerjakan oleh
sistem, yaitu kebutuhan fungsional sistem.
6. Use case tidak untuk menentukan kebutuhan nonfungsional, misal: sasaran kerja, bahasa pemrograman.
2.2.8.2 Diagram Kelas
Diagram kelas adalah diagram UML yang menggambarkan kelas-kelas dalam sebuah sistem dan hubungannya antara satu dengan yang lain, serta dimasukkan pula atribut dan operasi. Tahapan dari diagram kelas adalah sebagai berikut:
1. Mengidentifikasi objek dan mendapatkan kelas-kelasnya. 2. Mengidentifikasi atribut kelas-kelas.
3. Mulai mengkonstruksikan kamus data. 4. Mengidentifikasi operasi pada kelas-kelas.
5. Mengidentifikasikan hubungan antar kelas dengan menggunakan asosiasi, agregasi, dan inheritance (pewarisan).
2.2.8.3 Diagram Aktifitas
Diagram aktifitas representasi grafis dari seluruh tahapan alur kerja. Diagram ini mengandung aktivitas, pilihan tindakan, perulangan dan hasil dari aktivitas tersebut. Diagram ini dapat digunakan untuk menjelaskan proses bisnis dan alur kerja operasional secara langkah demi langkah dari komponen suatu sistem.
2.2.8.4 Diagram Sequence
diketahui objek-objek yang terlibat dalam sebuah use case beserta metode-metode yang dimiliki kelas yang diinstansiasi menjadi objek itu.
91
BAB 4
IMPLEMENTASI DAN PENGUJIAN SISTEM
Pada bab ini akan dilakukan implementasi dan pengujian pada sistem yang telah dibangun. Tahap ini dilakukan setelah perancangan dan pembangunan sistem selesai. Setelah selesai mengimplementasikan , maka tahap selanjutnya adalah pengujian pada sistem untuk mengetahui apakah sistem yang telah dibangun telah mencapai tujuannya sekaligus untuk melihat kekurangan sistem agar dapat dikembangkan selanjutnya.
4.1 Implementasi Sistem
Pada sub bab ini akan dijelaskan tahap pembuatan sistem hingga siap digunakan. Tujuannya adalah untuk memberitahukan perancangan progra pada pengguna sistem agar dapat memberi masukan pada pembuat sistem untuk pengembangannya.
Implementasi sistem terbagi menjadi dua yaitu sistem perangkat keras dan perangkat lunak.
4.1.1 Perangkat Keras yang digunakan
Perangkat keras yang digunakan dalam pembangunan sistem ini adalah:
Tabel 4. 1 Perangkat keras yang digunakan
No Perangkat Keras Spesifikasi
1 Processor Dual Core E350
2 Memory 2 GB
3 Hardisk 160 GB
4 Monitor LCD 14”
4.1.2 Perangkat Lunak yang digunakan
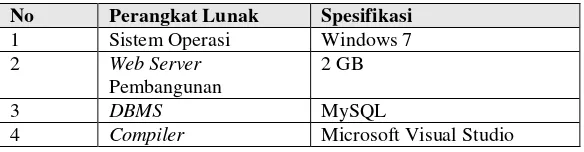
Sistem perangkat lunak yang digunakan dalam sistem ini adalah sebagai berikut:
Tabel 4. 2 Perangkat Lunak yang digunakan
No Perangkat Lunak Spesifikasi 1 Sistem Operasi Windows 7
2 Web Server
Pembangunan
2 GB
3 DBMS MySQL
4.1.3 Implementasi Basis Data
Langkah pertama dalam pembuatan aplikasi ini yaitu pembuatan database. Berikut ini adalah implementasi basis data yang dibuat:
1. Pembuatan Basis Data
1 CREATE DATABASE ‘pemaketan’
2. Pembuatan ordering
`kode_barang` varchar(10) NOT NULL, `nama_barang` varchar(100) NOT NULL, `support_count` int(11) NOT NULL, PRIMARY KEY (`kode_barang`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
3. Pembuatan preprocessing
CREATE TABLE `preprocessing` (
`id` int(10) NOT NULL AUTO_INCREMENT, `no_transaksi` varchar(50) NOT NULL, `nama_barang` text NOT NULL, `kode_barang` varchar(10) NOT NULL, `harga` int(10) NOT NULL,
`qty` int(10) NOT NULL, `jumlah` int(10) NOT NULL, PRIMARY KEY (`id`),
KEY `kode_barang` (`kode_barang`),
CONSTRAINT `preprocessing_ibfk_1` FOREIGN KEY (`kode_barang`) REFERENCES `ordering` (`kode_barang`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
4. Pembuatan transaction 1
CREATE TABLE `transaction` ( `id` int(10) NOT NULL,
`no_transaksi` varchar(50) NOT NULL, `nama_barang` text NOT NULL, `kode_barang` varchar(10) NOT NULL, `harga` int(10) NOT NULL,
`qty` int(10) NOT NULL, `jumlah` int(10) NOT NULL, PRIMARY KEY (`id`),
KEY `kode_barang` (`kode_barang`),
CONSTRAINT `transaction_ibfk_1` FOREIGN KEY (`kode_barang`) REFERENCES `ordering` (`kode_barang`)
93
5. Pembuatan rules 1
CREATE TABLE `rules` ( `id` int(11) NOT NULL, `rules` text NOT NULL,
`support_count` int(11) NOT NULL, `confidence` int(11) NOT NULL, KEY `id` (`id`),
CONSTRAINT `rules_ibfk_1` FOREIGN KEY (`id`) REFERENCES `transaction` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1;
6. Pembuatan Paket
CREATE TABLE IF NOT EXISTS `paket` ( `id` int(10) NOT NULL,
barang` varchar(150) NOT NULL, `harga` int(8) NOT NULL, FOREIGN KEY fk_paket(id) REFERENCES rules(id)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
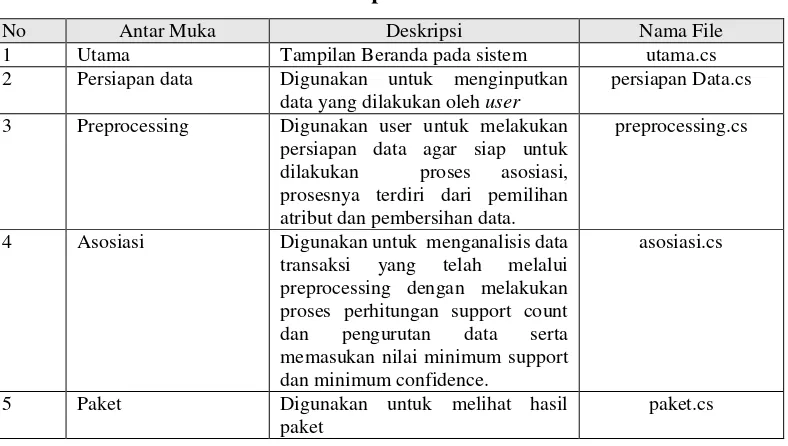
4.1.4 Implementasi Antar Muka
Implementasi antarmuka dilakukan untuk mengetahui setiap tampilan yang dibangun dalam bentuk file program. Implementasi antarmuka dijelaskan pada tabel 4.3
Tabel 4. 3 Implementasi Antar Muka
No Antar Muka Deskripsi Nama File
1 Utama Tampilan Beranda pada sistem utama.cs 2 Persiapan data Digunakan untuk menginputkan
data yang dilakukan oleh user
persiapan Data.cs
3 Preprocessing Digunakan user untuk melakukan persiapan data agar siap untuk dilakukan proses asosiasi, prosesnya terdiri dari pemilihan atribut dan pembersihan data.
preprocessing.cs
4 Asosiasi Digunakan untuk menganalisis data transaksi yang telah melalui preprocessing dengan melakukan proses perhitungan support count dan pengurutan data serta memasukan nilai minimum support dan minimum confidence.
asosiasi.cs
5 Paket Digunakan untuk melihat hasil paket
4.2 Pengujian Sistem
Pengujian sistem Pengujian sistem merupakan tahapan untuk melakukan serangkaian tes untuk mencoba sistem yang telah dibangun dengan tujuan mengetahui kualitas dari sistem yang dibangun tersebut. Pengujian bermaksud untuk mengetahui perangkat lunak yang dibuat sudah memenuhi kriteria yang sesuai dengan tujuan perancangan dan bisa memenuhi kebutuhan user. Pengujian perangkat lunak ini menggunakan pengujian black box. Pengujian black box berfokus pada persyaratan fungsional perangkat lunak.
4.2.1 Pengujian Fungsional
Pengujian alpha dilakukan mengunakan metode black box. Untuk menentukan pengujian alpha dapat dilihat dibawah ini :
1. Pemilihan fileimport data
Dibawah ini merupakan scenario pengujian yang dilakukan pada pemilihan file terdapat pada tabel 4.4
Tabel 4. 4 Tabel pengujian import data
Kasus dan hasil uji (data normal)
Data masukan Yang diharapkan Pengamatan Kesimpulan
Contoh File :
Dibawah ini merupakan scenario pengujian yang dilakukan pada terdapat pada Pengujian preprocessing tabel 4.5
Tabel 4. 5 Tabel Pengujian Preprocessing
Kasus dan hasil uji (data normal)
95
Dapat menghapus data transaksi yang hanya memiliki item tunggal dan dapat menampilkan hasil dari pembersihan data dan menampilkan info total record data transaksi sebelum dan sesudah dibersihkan
Dibawah ini merupakan scenario pengujian yang dilakukan pada perhitungan support count terdapat pada tabel 4.6
Tabel 4. 6 Tabel pengujian proses asosiasi
Kasus dan hasil uji (data normal)
Data masukan Yang diharapkan Pengamatan Kesimpulan Data transaksi
Dibawah ini merupakan scenario pengujian yang dilakukan pada proses asosiasi terdapat pada tabel 4.8
Tabel 4.7 Tabel pengujian proses asosiasi
Kasus dan hasil uji (data normal)
Data masukan Yang diharapkan Pengamatan Kesimpulan Data transaksi
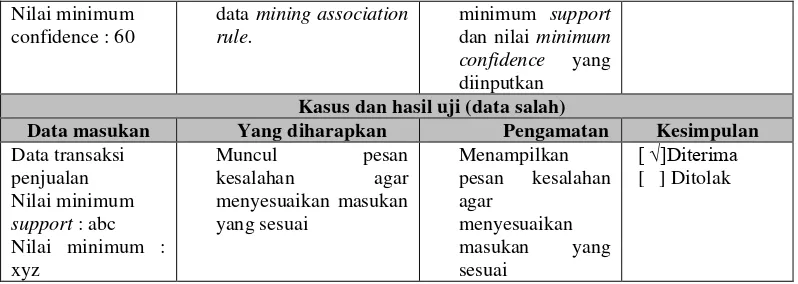
penjualan Nilai minimum support : 2
Nilai minimum confidence : 60
data mining association rule.
minimum support dan nilai minimum confidence yang diinputkan Kasus dan hasil uji (data salah)
Data masukan Yang diharapkan Pengamatan Kesimpulan Data transaksi
Dibawah ini merupakan scenario pengujian yang dilakukan pada pemaketan terdapat pada tabel 4.9
Tabel 4. 8 Tabel pengujian Pemaketan
Kasus dan hasil uji (data normal)
Data masukan Yang diharapkan Pengamatan Kesimpulan Batasan yang di
4.2.1 Kesimpulan Pengujian Fungsional
Berdasarkan hasil dari pengujian sistem yang telah dilakukan secara keseluruhan maka dapat ditarik kesimpulan bahwa beberapa proses yang terjadi dalam sistem telah mengalami perbaikan dan juga sudah memaksimalkan proses tersebut sehingga secara fungsional sistem sudah dapat digunakan.
4.2.2 Pengujian Beta
Pengujian beta dilakkan pada user yang merupakan pengguna akhir dari perangkat lunak yang akan dibangun. Pengujian ini dilakukan dengan menggunakan metode wawancara dengan pemilik distro.
97
a. Apakah sistem yang dibangun dapat membantu dalam memberikan informasi yang bermanfaat mengenai barang apa saja yang dapat dijadikan sebagai rekomendasi paket produk?
Jawaban : iya, sistem ini memberikan infomasi mengenai beberapa barang yang dapat dijadikan sebagai paket untuk distro fresh warehouse b. Apakah sistem yang telah dibangun sesuai dengan yang diharapkan? Jawaban: iya, sudah sesuai dengan yang diharapkan.
c. Apakah tampilan sistem susah untuk dimengerti dan digunakan? Jawaban: tampilan simple dan mudah dimengerti dan digunakan.
4.2.2.1 Kesimpulan Pengujian Beta
Berdasarkan hasil dari pengujian beta, dapat disimpulkan bahwa sistem yang dibuat dapat membantu distro Fresh Wearhouse dalam menentukan perekomendasian paket produk .
4.2.3 Pengujian Hasil
Pengujian hasil ini menguji perangkat lunak yang telah dibangun apakah menghasilkan data yang diinginkan dan sesuai dengan hasil contoh kasus pada BAB 3. Pengujian ini menggunakan sampel dari data transaksi penjualan dengan nilai MinimumSupport 2 dan MinimumConfidence 60%. Data hasil perhitungan manual dapat dilihat sebagai berikut:
Tabel 4. 11 Tabel hasil perhitungan manual
Hasil Perhitungan Manual
Rule Minimum Confidence
Hasil Perhitungan Manual
Rule Minimum Confidence
HAT DNM-01N (6/9)*100%=67% DNM-01N TSR-101N (5/10)*100%
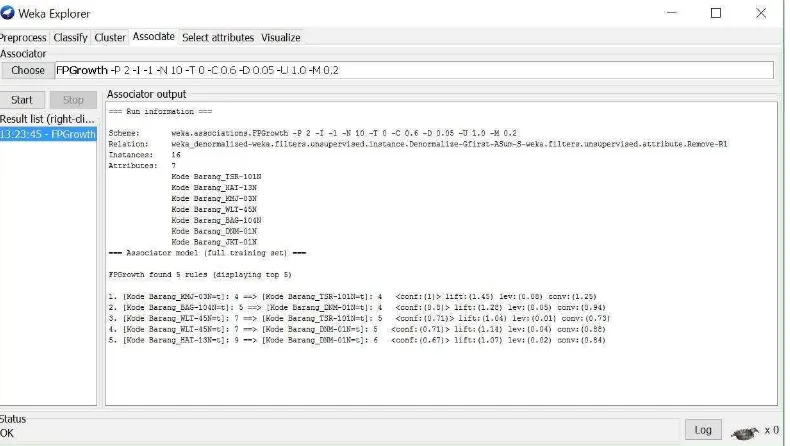
Gambar 4. 1 Hasil Perhitungan Analisis Program
Ini merupakan hasil pengujian dengan aplikasi Weka:
99
Hasil paket yang terbentuk dari analisis diatas adalah sebagai berikut :
Tabel 4. 9 Hasil Pemaketan Produk
Paket Isi Paket Harga
Paket 1 - LONG SHIRT
- TSHIRT
- HAT
Rp. 270.000
Paket 2 - SLING BAG
- LONG PANTS - TSHIRT
Rp. 285.000
Gambar 4. 3 Hasil Pemaketan Produk dari Aplikasi
Setelah dilakukan pengujian terhadap data yang dijadikan sebagai contoh kasus pada bab-3 dilakuan juga terhadap data yang sama namun dengan minimum support dan minimum confidence yang berbeda-beda.
1. Pengujian dengan data yang sama namun menggunakan minimum support 2 dan minimum confidence 80%.
Tabel 4. 10 Hasil Perhitungan manual
Hasil Perhitungan Manual
Rule Minimum Confidence
KMJ-03N TSR-101N (4/5)*100%=80% KMJ-03N HAT-13N: (4/5)*100%=80% BAG-104N DNM-01N (4/5)*100%=80%
Gambar 4. 4 Hasil Perhitungan Analisis Program
2. . Pengujian dengan data yang sama namun menggunakan minimum support 5 dan minimum confidence 70%.
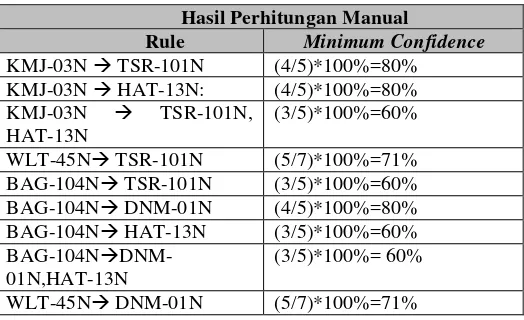
Tabel 4. 11 Hasil Perhitungan manual
Hasil Perhitungan Manual
Rule Minimum Confidence
WLT-45N TSR-101N (5/7)*100%=71%
KMJ-03N TSR-101N (4/5)*100%=80%
KMJ-03N HAT-13N: (4/5)*100%=80%
BAG-104N DNM-01N (4/5)*100%=80%
WLT-45N DNM-01N (5/7)*100%=71%
4.2.3.1 Kesimpulan Pengujian Hasil
101
BAB 5
KESIMPULAN DAN SARAN
Pada bab ini akan disimpulkan hasil penelitian yang telah dilakukan serta saran untuk pengembangan penelitian lebih lanjut
5.1 Kesimpulan
Kesimpulan yang dapat diambil dari penelitian ini adalah :
Sistem yang dibangun dapat membantu distro Fresh Wearhouse dalam menentukan produk apa saja yang akan direkomendasikan dalam satu paket produk.
5.2 Saran
Saran yang dapat diberikan oleh penulis dalam pengembangan penelitian yang telah dilakukan adalah :
![Gambar 1.1 Skema CRIP-DM[1]](https://thumb-ap.123doks.com/thumbv2/123dok/654138.79856/15.595.216.401.239.429/gambar-skema-crip-dm.webp)