IDENTIFIKASI
FIRE SPOT
BERDASARKAN POLA
SEKUENS TITIK PANAS DAN KLASIFIKASI AREA
TERBAKAR DI LAHAN GAMBUT
NALAR ISTIQOMAH
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Identifikasi Fire Spot
berdasarkan Pola Sekuens Titik Panas dan Klasifikasi Area Terbakar di Lahan Gambut adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Agustus 2016
Nalar Istiqomah
RINGKASAN
NALAR ISTIQOMAH. Identifikasi Fire Spot berdasarkan Pola Sekuens Titik Panas dan Klasifikasi Area Terbakar di Lahan Gambut. Dibimbing oleh IMAS SUKAESIH SITANGGANG dan LAILAN SYAUFINA.
Indonesia mempunyai lahan gambut terluas diantara negara tropika. Lahan gambut ini memiliki peranan penting yang menunjang kehidupan makhluk hidup. Sayangnya, dewasa ini banyak terjadi kebakaran di lahan gambut yang dapat mengakibatkan dampak buruk bagi lingkungan.
Hingga saat ini, kebakaran hutan ditandai dengan kemunculan titik panas. Menurut pakar dan praktisi kebakaran hutan, titik panas yang muncul berurutan dua hingga tiga hari di lokasi yang sama memiliki potensi yang tinggi menjadi kebakaran hutan. Oleh karena itu sequential pattern mining dapat diterapkan untuk mendapatkan pola sekuens titik panas. Namun, kemunculan titik panas tidak selalu menunjukkan terjadinya kebakaran hutan. Sehingga harus dilakukan pengecekan titik panas ke lapangan untuk mengetahui apakah titik panas tersebut merupakan kebakaran hutan atau bukan. Hal ini memerlukan waktu dan biaya yang tidak sedikit terutama untuk daerah yang sulit dijangkau. Oleh karena itu, diperlukan metode validasi pola sekuens kemunculan titik panas yang lebih mudah dan efisien. Metode yang dapat digunakan antara lain dengan mengklasifikasikan data citra satelit. Tujuan dari penelitian ini adalah mendapatkan pola sekuens kemunculan titik panas menggunakan algortime PrefixSpan, menerapkan aturan pohon keputusan C5.0 dan Spatial Decision Tree (SDT) dari penelitian Thariqa et.al
(2016), menerapkan metode maximum likelihood pada data citra satelit untuk mengklasifikasikan area terbakar serta mengidentifikasi fire spot berdasarkan pola sekuens titik panas dan hasil klasifikasi area terbakar.
SUMMARY
NALAR ISTIQOMAH. Fire Spot Identification based on Sequential Pattern of Hotspot and Burned Area Classification in Peatland. Supervised by IMAS SUKAESIH SITANGGANG and LAILAN SYAUFINA.
Indonesia has the world's largest tropical peatlands which play important roles that support life. Unfortunately, peatlands are threated by fires. This could effect the environment. Peat fires are also more difficult to extinguish forest fires than usual, because it is classified as ground fire.
Peatland fires are indicated by hotspot occurences. According to experts and forest fire practitioners, hotspots that appear in a sequence of two to three days at the same location has a high potential becoming a forest fire.Therefore, sequential pattern mining was applied to identify sequence of hotspot occurences. Sequential pattern mining was performed PrefixSpan algorithm. However, the emergence of hot spots do not necessary to indicate the occurrence of forest fires. So it must be verified into the field to find out if the hot spot is a fire spot or not. This requires many time and cost, especially for areas difficult to reach. Therefore, it is required hotspot sequence patterns validation method that more easy and efficient. Satellite image classification can be used to validate hotspot sequence patterns. The purpose of this study is to obtain a hotspot sequence pattern using PrefixSpan algorithm, applying the C5.0, SDT and maximum likelihood method on satellite image data to classify the burned area and identify the hotspot sequence pattern that become fire spot.
The results of this study indicate that the hotspot data from the Ministry of Environment does not produce an interesting pattern, since the length is only one item. On the other hand, hotspot data from NASA produces interesting pattern and its length up to 3 items. So that the pattern sequences derived from NASA was further analyzed. Pattern sequences generated in 2014 were found in East Kalimantan with total 21 of 2 item sequences and 2 of 3 item sequences. Meanwhile, sequence patterns in 2015, were found in West Kalimantan and Central Kalimantan. In West Kalimantan, there are 14 of 2 item sequence while in Central Kalimantan, there are 10 of 2 item sequences and 1 of 3 item sequences. Sattelite image classification have been conducted using C5.0, SDT dan maximum likelihood algorithm. The best result was found by maximum likelihood algorithm. Based on the classification of burned area result, it is known that in Pulang Pisau, there are 42.78% sequence patterns found in burned areas and 72.68% sequence patterns that are located the buffer of burned area with the radius of 1 km. As for Palangkaraya, there are 78.57% sequence patterns found in burned areas and 100% sequence patterns that are in the buffer of burned area with the radius of 1 km. In addition, for Pontianak, there are 100% sequence patterns found in burned areas and its buffer. Then it can be concluded that in Pulang Pisau, Palangkaraya and Pontianak there are respectively 72.68%, 100% and 100% fire spots as strong indicators for peatland fires.
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
IDENTIFIKASI
FIRE SPOT
BERDASARKAN POLA
SEKUENS TITIK PANAS DAN KLASIFIKASI AREA
TERBAKAR DI LAHAN GAMBUT
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
Judul Tesis : Identifikasi Fire Spot berdasarkan Pola Sekuens Titik Panas dan Klasifikasi Area Terbakar di Lahan Gambut
Nama : Nalar Istiqomah NIM : G651150451
Disetujui oleh Komisi Pembimbing
Dr Imas Sukaesih Sitanggang, SSi MKom Dr Ir Lailan Syaufina, MSc
Ketua Anggota
Diketahui oleh
Ketua Program Studi Ilmu Komputer
Dr Ir Sri Wahjuni, MT
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
Tanggal Ujian: 4 Agustus 2016
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhana wa ta'ala.Shalawat serta salam semoga senantiasa dilimpahkan kepada Nabi Muhammad, keluarganya, sahabatnya, dan kepada kita yang selalu berusaha menggapai ridha Allah.
Alhamdulillah atas bimbingan dan petunjuk dari Allah Subhana wa ta'ala serta bimbingan dari semua pihak, penyusunan tugas akhir yang berjudul
“Identifikasi Fire Spot berdasarkan Pola Sekuens Titik Panas dan Klasifikasi Area
Terbakar di Lahan Gambut” dapat diselesaikan. Tugas akhir ini tidak mungkin
dapat diselesaikan tanpa adanya bantuan dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terimakasih dan penghargaan yang setinggi-tingginya kepada:
Ayah (almarhum), Ibu dan keluarga yang selalu mendoakan, memberi nasihat, kasih sayang, semangat, dan dukungan sehingga penelitian ini bisa diselelsaikan.
Ibu Dr Imas Sukaesih Sitanggang, SSi MKom dan Ibu Dr Ir Lailan Syaufina, MSc selaku dosen pembimbing I dan II yang telah memberi saran, masukan dan ide-ide dalam penelitian ini.
Ibu Dr Nining Puspaningsih, MS sebagai penguji.
Teman-teman mahasiswa Magister Ilmu Komputer angkatan 2014 dan 2015, terutama ka Putri Thariqa yang telah bersedia berbagi ilmunya selama pelaksanaan penelitian.
Departemen Ilmu Komputer IPB, staf dan dosen yang telah banyak membantu selama masa perkuliahan hingga penelitian.
Semoga tesis ini dapat bermanfaat.
Bogor, Agustus 2016
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 3
Tujuan Penelitian 3
Manfaat Penelitian 3
Ruang Lingkup Penelitian 4
2 TINJAUAN PUSTAKA 4
Sequential Pattern Mining 4
Citra Satelit 7
Pohon Keputusan 8
Pohon Keputusan Spasial 11
Pohon Keputusan C5.0 12
Maximum Likelihood Classifier 12
Majority Filter 13
3 METODE 14
Area Studi 14
Data Penelitian 14
Tahapan Penelitian 15
4 HASIL DAN PEMBAHASAN 18
Penentuan Pola Sekuensial dengan Algoritme PrefixSpan 18
Klasifikasi Citra Satelit 21
Identifikasi Firespot 28
5 SIMPULAN DAN SARAN 31
Simpulan 31
Saran 32
DAFTAR PUSTAKA 32
LAMPIRAN 35
DAFTAR TABEL
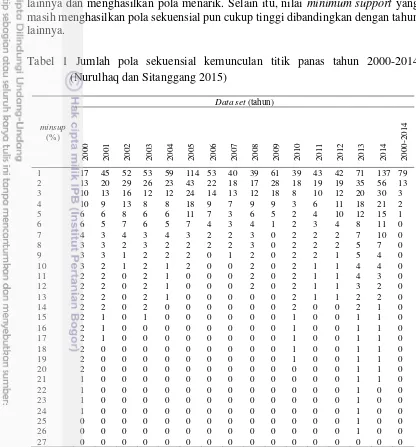
1 Jumlah pola sekuensial kemunculan titik panas tahun 2000-2014
(Nurulhaq dan Sitanggang 2015) 6
2 Perbandingan hasil algortime klasifikasi (Thariqa et.al 2016) 9 3 Hasil transformasi data titik panas Kalimantan 2014 19 4 Contoh data sekuens titik panas Kalimantan 2015 19 5 Contoh data sekuens titik panas dengan format masukan SPMF 20 6 Jumlah pola sekuens titik panas yang dihasilkan 20 7 Pola sekuens titik panas yang menarik tahun 2014 di Kalimantan
Timur 21
8 Pola sekuens titik panas yang menarik tahun 2015 di Kalimantan
Barat dan Kalimantan Tengah 21
9 Daftar tanggal pola sekuens di Kalimantan Barat dan Kalimantan
Tengah 22
10 Contoh tabel nilai piksel beserta lokasinya 25
11 Contoh lokasi sekuens titik panas dengan longitude dan latitude
dinyatakan dalam 3 angka di belakang koma 29
12 Hasil identifikasi pola sekuens di Pontianak 2015 29 13 Hasil identifikasi pola sekuens di Palangkaraya 2015 30 14 Presentase pola sekuens di area terbakar dan buffer 30
DAFTAR GAMBAR
1 Algoritme PrefixSpan (Pei et al. 2014) 5
2 Langkah penggalian pola dengan PrefixSpan (Zhao dan Bhowmick
2003) 5
3 Citra kebakaran hutan di Riau tahun 2014 (Terra Image 2014
[terra-image.com]) 7
4 Ilustrasi kerusakan SLC (USGS 2013) 7
5 Contoh pohon keputusan (Han et al. 2012) 8
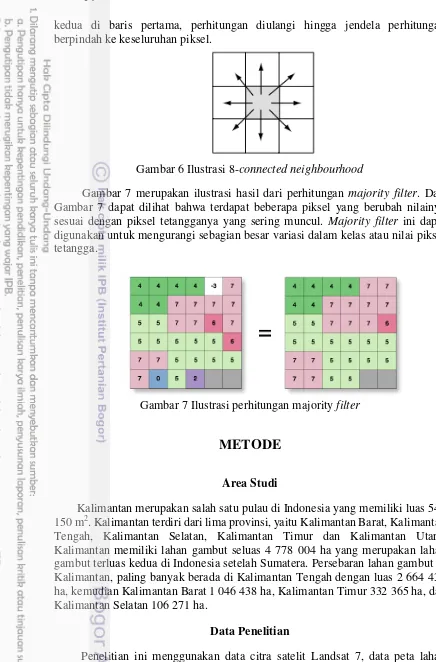
6 Ilustrasi 8-connected neighbourhood 14
7 Ilustrasi perhitungan majority filter 14
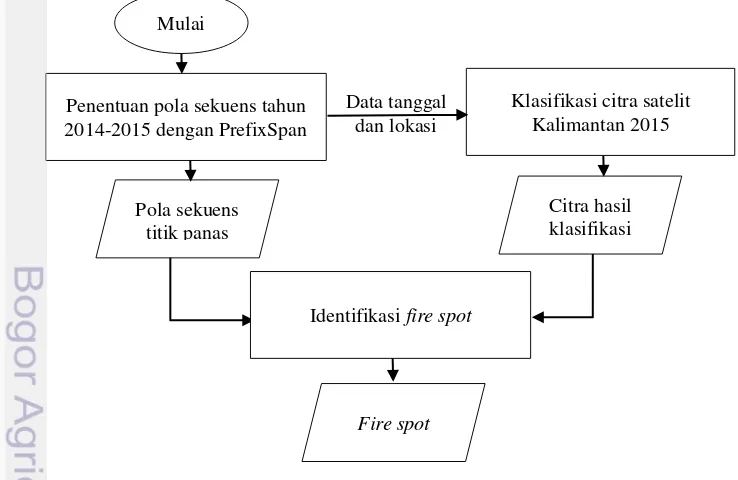
8 Tahapan penelitian 15
9 Tahapan penentuan pola sekuens titik panas tahun 2014 dan 2015
dengan algoritme PrefixSpan 16
10 Tahapan klasifikasi citra satelit 17
11 Plot data titik panas sebelum diseleksi 18
12 Hasil seleksi data titik panas 18
13 Contoh gap pada citra Landsat 7 23
14 Contoh hasil isi gap Band 7, 4, dan 2 23
15 Citra hasil composite 24
16 Proses (a) overlay Proses overlay peta lahan gambut dengan citra satelit Pulang Pisau dan (b) citra satelit hasil pemotongan 24 17 Hasil klasifikasi dengan metode C5.0 untuk citra (a) Pontianak, (b)
18 Hasil klasifikasi dengan metode SDT untuk citra (a) Pontianak, (b)
Pulang Pisau dan (c) Palangkaraya 26
19 Hasil klasifikasi dengan metode maximum likelihood untuk citra (a) Pulang Pisau, (b) Pontianak, (c) Palangkaraya 26 20 Perbandingan citra hasil filtering Pulang Pisau dengan citra asli 27 21 Perbandingan citra hasil filtering Pontianak dengan citra asli 27 22 Perbandingan citra hasil filtering Palangkaraya dengan citra asli 28 23 Hasil overlay pola sekuens dengan citra hasil klasifikasi (a) Pontianak,
(b) Pulang Pisau dan (c) Palangkaraya 28
24 Titik panas yang ditumpang-susun dengan citra hasil klasifikasi pada (a) area terbakar dan (b) area buffer sejauh 1 km dari area terbakar 29 25 Pola sekuens Pulang Pisau yang tidak berada di area terbakar dan
1
PENDAHULUAN
Latar Belakang
Indonesia mempunyai lahan gambut terluas diantara negara tropis di dunia yaitu seluas 17-27 juta hektar yang tersebar di Pulau Sumatera, Kalimantan dan Papua (Syaufina 2008). Lahan gambut memiliki peranan yang penting, diantaranya sebagai media penyimpanan air di musim hujan. Simpanan air tersebut kemudian akan dilepaskan sebagai penyedia pasokan air di musim kemarau. Air yang diserap lahan gambut di musim hujan juga dapat mencegah terjadinya banjir. Selain itu, lahan gambut juga merupakan habitat bagi hewan dan ikan.
Sayangnya, dewasa ini banyak terjadi kebakaran pada lahan gambut. Di wilayah Kalimantan pada tahun 2014, kebakaran hutan mencapai total 2327.24 ha (KLH 2015). Jumlah titik panas di lahan gambut juga meningkat dan mencapai puncaknya tahun 2005 (WWF Indonesia 2015). Hal ini dapat memberikan dampak buruk bagi lingkungan, diantaranya hilangnya biomassa dan keanekaragaman hayati, terjadinya proses subsiden, hilangnya fungsi penyerapan karbon serta timbulnya kabut asap yang menyebabkan gangguan kesehatan dan transportasi (Syaufina 2008). Kebakaran gambut merupakan ground fire yaitu api menjalar di bawah permukaan dengan pembakaran yang tidak menyala (smoldering) (Syaufina 2008). Ground fire menyebabkan pemadaman kebakaran sulit dilakukan, adanya pohon tumbang dan pohon mati yang masih berdiri tegak di atas lahan gambut juga akan mempersulit pemadaman. Selain itu, pada pembakaran
smoldering, api dapat bertahan lama dan menghasilkan asap tebal. Berdasarkan pemaparan tersebut, dapat disimpulkan bahwa kebakaran gambut lebih berbahaya dibandingkan dengan kebakaran non-gambut.
Hingga saat ini, kebakaran hutan ditandai dengan kemunculan titik panas. Data titik panas telah banyak dikumpulkan oleh berbagai institusi. Sementara itu, pakar dan praktisi kebakaran hutan menyatakan bahwa titik panas yang muncul secara berurutan dua hingga tiga hari di lokasi yang sama memiliki potensi yang tinggi menjadi kebakaran hutan. Oleh karena itu sequential pattern mining dapat diterapkan untuk mendapatkan pola sekuens dari titik panas untuk identifikasi fire spot (titik kebakaran).
Penelitian mengenai sequential pattern mining telah dilakukan oleh Nurulhaq dan Sitanggang (2015). Pada penelitian tersebut, dilakukan penggalian pola sekuens data titik panas di Provinsi Riau tahun 2000 hingga 2014 menggunakan PrefixSpan. Kemudian, diketahui bahwa pola sekuensial kemunculan titik panas yang dihasilkan setiap tahun memiliki perbedaan jumlah pola sekuens dan nilai minimum support yang masih menghasilkan pola sekuens. Kemunculan titik panas tahun 2013 dan 2014 dapat dianalisis hasil pola sekuensialnya karena jumlah kemunculan titik panasnya lebih besar dari tahun lainnya dan menghasilkan pola menarik, yaitu memiliki panjang sekuens hingga 4 item (tahun 2013) dan 3 item (tahun 2014).
2
sedikit terutama untuk daerah yang sulit dijangkau. Oleh karena itu, diperlukan metode validasi pola sekuens kemunculan titik panas yang lebih mudah dan efisien.
Untuk mengamati lokasi, luasan dan dampak dari kebakaran gambut, dapat dilakukan dengan dukungan teknologi yang dapat memberikan informasi melingkupi areal yang luas. Salah satunya adalah teknologi remote sensing. Dari satelit, data lokasi kebakaran, intensitas kebakaran dan luas area terbakar dapat diketahui dengan mudah dan efektif (Justice et al. 1993). Metode yang dapat digunakan antara lain dengan mengklasifikasikan data citra satelit. Beberapa penelitian telah dilakukan antara lain oleh Mitri dan Gitas (2002) menggunakan model klasifikasi berorientasi objek. Pada penelitian tersebut, dilakukan klasifikasi citra pesisir Mediterania Spanyol untuk mengetahui area terbakar. Dari penelitian tersebut, diketahui bahwa total area terbakar dari citra hasil klasifikasi adalah 6900 ha. Sedangkan data dari Catalan Environmental Department menyatakan bahwa luas kebakaran adalah 6000 ha. Sehingga akurasi dari penelitian tersebut mencapai 90%. Sementara itu, Li et al. (2010) melakukan klasifikasi dengan teori evidence dan pohon keputusan untuk mengklasifikasikan penggunaan lahan di Yantai Economic and Technological Development Zone.
Klasifikasi dilakukan untuk tiga kelas, yaitu lahan perumahan, lahan hijau, dan perairan. Akurasi yang didapat dari penelitian tersebut sebesar 90.23%.
Penelitian tentang klasifikasi citra satelit Indonesia juga telah dilakukan oleh Khaira et al. (2016) yang melakukan deteksi dan prediksi perubahan tutupan lahan gambut di Provinsi Riau. Penelitian tersebut menggunakan support vector machine (SVM) untuk mengklasifikasi citra dan Markov Model untuk prediksi. Dari hasil penelitian diketahui bahwa akurasi klasifikasi SVM adalah 98.2%, serta diprediksikan pada tahun 2016 lahan non-vegetasi akan berkurang hingga 53%. Selain itu, Thariqa et.al (2016) melakukan penelitian tentang perbandingan algoritme pohon keputusan untuk klasifikasi citra satelit Rokan Hilir, Riau. Algoritme yang dibandingkan adalah C4.5, CART, Spatial Decision Tree (SDT) dan C5.0. Kemudian diketahui algoritme terbaik untuk klasifikasi citra kebakaran hutan adalah C5.0 dengan akurasi 99.79% dan SDT dengan akurasi 96.39%. Adapun jumlah aturan yang dihasilkan dari C5.0 adalah sebanyak 595 sedangkan aturan yang dihasilkan SDT adalah 11.
Selain algoritme klasifikasi citra yang telah dijabarkan sebelumnya, masih terdapat banyak algoritme klasifikasi citra lainnya (Lu 2007). Salah satunya yaitu pendekatan klasifikasi per-piksel yang dapat dilakukan dengan metode maximum likelihood, minimum distance, artificial neural network, dan decision tree classifier. Metode-metode tersebut, menggunakan asumsi bahwa data menyebar normal sedangkan asumsi tersebut tidak selalu dapat dipenuhi. Terutama untuk citra yang kompleks. Namun, dari keempat metode tersebut, metode maximum likelihood merupakan metode yang paling banyak digunakan. Metode ini memiliki kelebihan antara lain robust dan banyak tersedia di hampir seluruh perangkat lunak pemrosesan citra (Lu 2007). Selain itu, metode maximum likelihood mengestimasi parameter dalam jumlah yang sedikit, sehingga metode ini dapat mengklasifikasikan citra dengan sangat cepat (Canty 2010).
3 yang menjadi kebakaran hutan dan yang tidak. Pola sekuens titik panas yang menjadi kebakaran hutan disebut dengan fire spot.
Berdasarkan pemaparan tersebut pada penelitian ini, dilakukan penggalian pola kemunculan titik panas di lahan gambut Kalimantan tahun 2014 dan 2015 menggunakan algoritme PrefixSpan. Hasil pola sekuens kemunculan titik panas akan dievaluasi menggunakan data citra satelit. Citra satelit diklasifikasikan menggunakan algoritme pohon keputusan C5.0 dan SDT serta metode maximum likelihood. Ketiga metode tersebut akan dibandingkan hasil klasifikasinya.
Perumusan Masalah
Hingga saat ini titik panas dijadikan sebagai indikator terjadinya kebakaran hutan. Data kemunculan titik panas telah banyak dikumpulkan oleh berbagai institusi. Menurut pakar, kemunculan titik panas yang muncul dua hingga tiga hari berturut-turut pada tempat yang sama merupakan indikator kuat terjadinya kebakaran hutan. Untuk mengetahui urutan kemunculan titik panas, dapat dilakukan penggalian pola sekuens titik panas. Namun, kemunculan titik panas bukan berarti pasti terjadi kebakaran. Oleh karena itu, pola sekuens kemunculan titik panas perlu dievaluasi untuk mengidentifikasi fire spot. Evaluasi pola sekuens kemunculan titik panas biasanya dilakukan dengan melakukan validasi langsung ke lapangan. Namun, cara tersebut membutuhkan biaya dan waktu yang tidak sedikit. Sehingga dibutuhkan metode identifikasi fire spot yang mudah dan efisien, yaitu melalui citra satelit. Citra satelit diklasifikasi sehingga diketahui piksel terbakar dan tidak. Kemudian hasil klasifikasi citra satelit, digunakan untuk mengevaluasi pola sekuens titik panas. Dari rumusan masalah tersebut, muncul pertanyaan penelitian bagaimana cara mengidentifikasi fire spot berdasarkan pola sekuens titik panas dan klasifikasi citra satelit untuk area yang terbakar?
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Mendapatkan pola sekuens kemunculan titik panas menggunakan algortime PrefixSpan.
2 Menerapkan model klasifikasi pohon keputusan C5.0 dan SDT pada data citra satelit dari penelitian Thariqa et.al (2016) untuk mengklasifikasikan area terbakar.
3 Menerapkan metode maximum likelihood pada data citra satelit untuk mengklasifikasikan area terbakar.
4 Identifikasi fire spot berdasarkan pola sekuens titik panas dan hasil klasifikasi area terbakar.
Manfaat Penelitian
4
Ruang Lingkup Penelitian
Ruang lingkup penelitian yang dilakukan meliputi:
1 Data kemunculan titik panas tahun 2014 dan 2015 yang diperoleh dari satelit Moderate Resolution Imaging Spectrometer National Aeronautics and Space Administration (MODIS NASA) dan Kementrian Lingkungan Hidup dan Kehutanan (KLH) untuk menentukan pola sekuens titik panas.
2 Data citra yang digunakan merupakan data citra Landsat 7 Kalimantan dari United States Geological Survey(USGS). Data citra yang diambil disesuaikan waktu dan tempatnya dengan pola sekuens yang dihasilkan. Kemudian, data citra diambil bagian lahan gambut saja.
3 Data batas wilayah yang digunakan merupakan data yang diperoleh dari Badan Pusat Statistik.
TINJAUAN PUSTAKA
Sequential Pattern Mining
Sequential pattern mining adalah penggalian pola sekuensial atau subsekuens yang sering muncul atau frekuen (Han et al. 2012). Pola sekuens yang memiliki nilai support melebihi nilai minimum support disebut pola yang frekuen.
Nilai minimum support tersebut biasanya ditetapkan oleh user. Melalui nilai
minimum support ini, pola-pola yang kurang menarik dapat diabaikan sehingga proses mining menjadi lebih efisien (Zhao dan Bhowmick 2003). Sequential pattern mining bertujuan menemukan korelasi yang menarik, pola yang sering muncul, serta asosiasi diantara set item dalam basis data (Zhao dan Bhowmick 2003). Hasil dari proses sequential pattern mining dapat mendeskripsikan suatu data atau memprediksi data berikutnya. Algoritme yang dapat digunakan untuk
sequential pattern mining diantaranya algoritme apriori, AprioriAll, AprioriSome, DynamicSome, GSP,SPADE, FreeSpan, PrefixSpan, MEMISP dan SPIRIT (Zhao dan Bhowmick 2003).
5
Gambar 2 Langkah penggalian pola dengan PrefixSpan (Zhao dan Bhowmick 2003)
PrefixSpan telah digunakan menganalisa data titik panas kebakaran hutan pada penelitian Nurulhaq dan Sitanggang (2015). Pada penelitian tersebut dilakukan penentuan pola sekuensial pada data set tahun 2000 sampai 2014 dan data semua tahun (2000 – 2014). Kemudian dihasilkan pola sekuens kemunculan titik panas dengan jumlah untuk setiap data set dan minimum support
menggunakan algoritme PrefixSpan yang dapat dilihat pada Tabel 1 (Nurulhaq dan Sitanggang 2015).
Dari Tabel 1 dapat disimpulkan bahwa data set yang masih menghasilkan pola sekuensial kemunculan titik panas dengan nilai minimum support terbesar adalah tahun 2013 saat minimum support bernilai 26%. Diikuti dengan data tahun 2000 dan 2014. Data tahun 2014 menghasilkan pola sekuensial hingga minimum support 21%. Selain itu berdasarkan penelitian Nurulhaq dan Sitanggang (2015), data tahun 2014 masih menghasilkan pola sekuensial dengan panjang 2 item saat
Algoritme 1 (PrefixSpan)
Masukan : Database sekuensial S, min_support
Luaran : Himpunan lengkap pola sekuensial
Metode : PrefixSpan(<> ,0,S)
Parameter : (1) α adalah pola sekuensial; (2) l adalah panjang dari α;(3)
S|α adalah proyeksi database α
Prosedur PrefixSpan (α, l, S|α ):
1) Pindai S|α satu kali, dapatkan semua item berulang b, sedemikian sehingga:
a)b dapat diletakkan pada elemen terakhir dari α untuk membentuk
pola sekuensial.
b)<b> dapat diletakkan di belakang α untuk membentuk pola
sekuensial.
2) Untuk setiap item berulang b, letakkan b di belakang α untuk membentuk pola sekuensial α' dan menghasilkan α'.
3) Untuk setiap α' , bangunlah proyeksi database α' S|α'. 4) PrefixSpan (α' , l+1, S|α').
6
minimum support 5%. Adapun presentase titik panas yang menjadi indikator kebakaran hutan pada tahun 2013 adalah sebesar 8.88% sedangkan pada tahun 2014 sebesar 16.95%. Dari penjelasan tersebut, didapat kesimpulan bahwa kemunculan titik panas tahun 2013 dan 2014 dapat dianalisis hasil pola sekuensialnya karena jumlah kemunculan titik panasnya lebih besar dari tahun lainnya dan menghasilkan pola menarik. Selain itu, nilai minimum support yang masih menghasilkan pola sekuensial pun cukup tinggi dibandingkan dengan tahun lainnya.
7 Citra Satelit
Citra satelit merupakan citra yang dihasilkan dari pemotretan menggunakan satelit. Gambar 3 merupakan contoh dari citra satelit, yaitu citra kebakaran hutan di Riau pada 17 Februari 2014.
Salah satu satelit yang digunakan untuk penginderaan jarak jauh adalah Land Satellite (Landsat). Landsat merupakan program tertua dalam perangkat observasi bumi (Rastermaps 2014). Satelit Landsat terdiri atas beberapa seri yaitu Landsat-1, Landsat-2 diteruskan 3, 4 hingga 8. Satelit Landsat yang paling baru adalah Landsat 7 dan 8.
Gambar 3 Citra kebakaran hutan di Riau tahun 2014 (Terra Image 2014 [terra-image.com])
Citra Landsat 7 sejak 31 Mei 2003 memiliki gap (USGS 2013). Hal ini disebabkan Scan Line Corrector (SLC) yang membuat Landsat 7 menscan
berurutan ke depan, mengalami kerusakan (USGS 2013). Usaha perbaikan SLC yang dilakukan tidak berhasil sehingga kerusakan SLC bersifat permanen. Tanpa SLC, Landsat 7 melakukan scanning secara zig-zag. Akibatnya, area yang tergambar diduplikasi dengan lebar yang meningkat ke tepi scene citra. Gambar 4 merupakan ilustrasi kerusakan SLC (USGS 2013).
Gambar 4 Ilustrasi kerusakan SLC (USGS 2013)
8
secara radiometrik maupun geometrik (USGS 2013). Oleh karena itu, citra Landsat 7 masih banyak digunakan dalam penelitian. Untuk mendapatkan 22% piksel yang hilang akibat kerusakan SLC, dapat dilakukan dengan mengisi gap (gap filling).
Pengisian gap dilakukan dengan menggunakan file SLC-off gap mask yang disertakan pada setiap data citra Landsat 7. File gap mask ini membantu pengguna mengidentifikasi lokasi piksel yang dipengaruhi oleh data asli dalam scene SLC-off (USGS 2013). Kemudian perhitungan aproksimasi nilai piksel untuk mengisi
gap dilakukan dengan menggunakan perangkat lunak, salah satunya QGIS. Pohon Keputusan
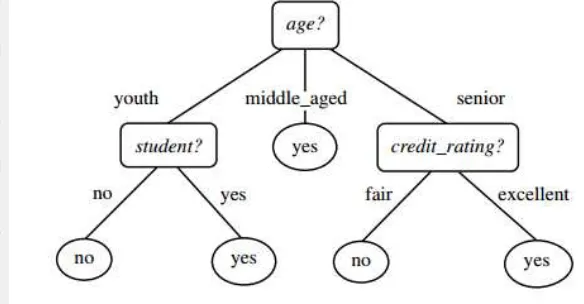
Pohon keputusan adalah sebuah struktur pohon, dimana setiap node pada pohon merepresentasikan atribut, setiap cabang merepresentasikan nilai atribut, dan node daun (leaf) merepresentasikan kelas tertentu (Han et al. 2012). Level
node teratas dari sebuah pohon keputusan adalah node akar (root) yang biasanya berupa atribut yang paling memiliki pengaruh terbesar pada suatu kelas tertentu. Pada umumnya, pohon keputusan melakukan strategi pencarian secara top-down
untuk solusinya. Pada proses mengklasifikasi data uji, nilai atribut akan diuji dengan cara membaca pohon dari node akar (root) sampai node akhir (daun) dan kemudian akan diprediksi kelas yang dimiliki oleh suatu data tersebut. Gambar 5 merupakan contoh dari pohon keputusan(Han et al. 2012).
Gambar 5 Contoh pohon keputusan (Han et al. 2012)
Klasifikasi citra satelit adalah metode pemberian label atau kelas pada setiap piksel citra berdasarkan karakteristik spektral pada berbagai bands (Sharma et al.
2013). Beberapa penelitian tentang klasifikasi citra satelit telah dilakukan diantaranya adalah penelitian Otukei dan Blaschke (2010) yang membandingkan algoritme pohon keputusan, maximum likelihood dan support vector machine
(SVM) untuk mengklasifikasikan citra Landsat TM dan ETM+. Dari penelitian tersebut diketahui algoritme klasifikasi yang paling baik adalah pohon keputusan. Punia et al. (2011) juga menggunakan C5.0 untuk mengklasifikasikan data IRS-P6 AWiFS dan mendapatkan akurasi yang tinggi. Berdasarkan penelitian tersebut, pohon keputusan merupakan metode yang baik untuk klasifikasi citra satelit.
9 penjelas adalah spectral bands atau informasi yang diturunkan dari spectral bands
(Sharma et al. 2013). Pohon keputusan diestimasi menggunakan data training
yang diolah dengan prosedur statistik. Informasi (entropi) yang didapat dari sistem dapat dihitung dengan Persamaan 1 (Han et al. 2012).
Info D = − ∑m pi
i=1 log2(pi) (1)
dengan pi adalah peluang data latih � termasuk ke kelas Ci dan diduga
dengan |Ci,D|/|D|. Log basis dua digunakan karena informasi dikodekan dalam bit,
yaitu nol dan satu. Misalkan, data latih D dipecah berdasarkan atribut A yang mempunyai v nilai berbeda {a1, a2,....,av}. Informasi yang didapat setelah
pemecahan tersebut dapat dihitung dengan Persamaan 2 (Han et al. 2012).
InfoA D = ∑vj=1||DDj||× info(Di) (2)
Informasi yang didapat dengan memecah data latih berdasarkan atribut A
dapat dihitung dengan Persamaan 3 (Han et al. 2012).
Gain(A)=info(D)−infoA(D) (3) Nilai Gain(A) menginformasikan seberapa besar informasi yang didapat setelah memecah data latih berdasarkan atribut A. Maka, atribut A dengan nilai
gain tertinggi dipilih sebagai atribut “pemecah” pada node N.
Terdapat beberapa algoritme dalam pohon keputusan antara lain pohon keputusan spasial (SDT), Classification and Regression Trees (CART), algoritme C5.0, dan algoritme C4.5. Pada penelitian Thariqa et.al (2016), dilakukan perbandingan keempat algoritme tersebut. Tabel 2 merupakan hasil perbandingan keempat algortime pohon keputusan (Thariqa et.al 2016)
Tabel 2 Perbandingan hasil algortime klasifikasi (Thariqa et.al 2016) Algoritme Akurasi
(%)
Jumlah aturan
Ukuran Pohon
C4.5 98.89 1681 3362
CART 95.67 8 15
C5.0 99.79 595 1603
SDT 96.39 11 20
Dari Tabel 2 diketahui bahwa algortime C5.0 memiliki akurasi terbaik yaitu 99.79%. Namun ukuran pohon yang dihasilkan algoritme C5.0 berukuran sangat besar, aturan yang dihasilkan pun cukup banyak yaitu sebanyak 595 aturan sehingga kurang efisien. Berikut adalah contoh aturan yang dihasilkan algoritme C5.0:
10
3 IF Band7 > 19 DAN Band7 ≤ 21 DAN Band4 > 37 DAN Band2 ≤ 42 MAKA Sebelum Terbakar
4 IF Band7 > 24 DAN Band7 ≤ 27 DAN Band4 > 37 DAN Band2 ≤ 42 MAKA Sebelum Terbakar
5 IF Band7 > 22 DAN Band7 ≤ 28 DAN Band4 > 48 DAN Band2 ≤ 42 MAKA Sebelum Terbakar
6 IF Band7 > 49 DAN Band7 ≤ 51 DAN Band4 > 35 DAN Band4 ≤ 54 DAN
Band2 ≤ 49 MAKA Setelah Terbakar
7 IF Band7 > 49 DAN Band7 ≤ 54 DAN Band4 > 37 DAN Band4 ≤ 54 DAN
Band2 ≤ 49 MAKA Setelah Terbakar
8 IF Band7 > 49 DAN Band7 ≤ 56 DAN Band4 > 40 DAN Band4 ≤ 54 DAN
Band2 ≤ 49 MAKA Setelah Terbakar
9 IF Band7 > 49 DAN Band7 ≤ 57 DAN Band4 > 41 DAN Band4 ≤ 54 DAN
Band2 ≤ 49 MAKA Setelah Terbakar
10 IF Band7 > 49 DAN Band7 ≤ 59 DAN Band4 > 43 DAN Band4 ≤ 54 DAN
Band2 ≤ 49 MAKA Setelah Terbakar
11 IF Band7 > 60 DAN Band4 > 32 DAN Band4 ≤ 33 MAKA Terbakar
12 IF Band7 > 60 DAN Band4 > 41 DAN Band4 ≤ 42 DAN Band2 ≤ 49 MAKA Terbakar
13 IF Band7 > 60 DAN Band4 ≤ 45 DAN Band2 > 14 DAN Band2 ≤ 16 MAKA Terbakar
14 IF Band7 > 62 DAN Band4 ≤ 47 DAN Band2 > 14 DAN Band2 ≤ 16 MAKA Terbakar
15 IF Band7 > 63 DAN Band4 ≤ 49 DAN Band2 > 14 DAN Band2 ≤ 16 MAKA Terbakar
16 IF Band7 ≤ 84 DAN Band4 > 42 DAN Band2 > 82 MAKA Non Gambut 17 IF Band7 ≤ 79 DAN Band4 > 42 DAN Band2 > 75 MAKA Non Gambut 18 IF Band7 ≤ 85 DAN Band2 > 84 MAKA Non Gambut
19 IF Band7 ≤ 88 DAN Band2 > 85 MAKA Non Gambut 20 IF Band7 ≤ 95 DAN Band2 > 88 MAKA Non Gambut
Sementara itu SDT memiliki akurasi yang cukup baik yaitu 96.39% dan menghasilkan aturan sebanyak 11. Berikut 11 aturan yang dihasilkan dari algoritme SDT:
1 JIKA Band4 > 54 DAN 13 < Band7 ≤ 51 MAKA Sebelum Terbakar 2 JIKA Band4 > 70 DAN Band7 > 51 MAKA Sebelum Terbakar 3 JIKA Band4 > 54 DAN Band7 ≤ 13 MAKA Sebelum Terbakar
4 JIKA Band4 ≤ 54 DAN Band7 ≤ 41 DAN Band2 ≤ 49 MAKA Sebelum Terbakar
5 JIKA 50 < Band4 ≤ 70 DAN 51 < Band7 ≤ 79 MAKA Setelah Terbakar 6 JIKA Band4 ≤ 43 DAN 41 < Band7 ≤ 66 MAKA Setelah Terbakar
11 8 JIKA 54 < Band4 ≤ 70 DAN Band7 > 79 MAKA Terbakar
9 JIKA Band4 ≤ 54 DAN Band7 > 66 MAKA Terbakar 10 JIKA Band4 ≤ 43 DAN 54 < Band7 ≤ 66 MAKA Terbakar
11 JIKA Band4 ≤ 54 DAN Band7 ≤ 41 DAN Band2 > 49 MAKA Non Gambut Aturan yang dihasilkan algoritme C5.0 dan SDT dapat mengklasifikasikan citra ke dalam kelas sebelum terbakar, terbakar, setelah terbakar dan non-gambut berdasarkan band citra. Aturan yang dihasilkan berupa kalimat jika-maka. Berikut
adalah contoh cara membaca aturan pohon keputusan “jika Band4 bernilai lebih
dari 54 dan Band7 bernilai antara 13 hingga 51 maka area tersebut termasuk
kedalam kelas sebelum terbakar”.
Aturan dari algoritme C5.0 dan SDT yang dihasilkan penelitian Thariqa et.al
(2016) inilah yang akan digunakan dalam mengklasifikasikan citra satelit lahan gambut di Kalimantan pada penelitian ini.
Pohon Keputusan Spasial
Pada SDT, klasifikasi dipandang sebagai penyusunan objek menggunakan atributnya (nilai non-spasial) dan atribut tetangganya (Zeitouni et al. 2001). Pada
dataset spasial terdapat autokorelasi, berbeda dengan pohon keputusan tradisional yang menganggap data terdistribusi secara identik. Karena itu, untuk menentukan pembagian pohon keputusan, algoritme ini menghitung spatial information gain
(SIG) yang terdiri atas information gain dan neighborhood split autocorrelation ratio (NSAR). Persamaan 4 digunakan untuk menghitung nilai NSAR dari data ke-i (Jiang et al. 2012):
NSARi= Г
' i
Гi (4)
dimana Гi dan Г’i adalah nilai gamma lokal dari data ke-i sebelum dan
sesudah split. Nilai gamma lokal dapat dihitung dengan menggunakan Persamaan 5 (Jiang et al 2012):
Гi= ∑jai,jbi,j= ∑jωi,jδi,j=ci (5)
dimana i, j adalah indeks data; ai,j, bi,j adalah kemiripan spasial dan kelas
yang kemudian direpresentasikan dengan W-matriks �i,j dan �i,j fungsi indikator.
Nilai NSAR yang digunakan pada SIG adalah nilai NSAR dari semua sampel. Persamaan 6 adalah rata-rata dari nilai NSAR (Jiang et al 2012):
NSAR
̅̅̅̅̅̅̅̅= m1 ∑mi=1NSARi (6)
dimana i adalah indeks dari sampel yang bernilai 1 sampai m (m adalah banyaknya data). Nilai SIG, dapat dihitung dengan Persamaan 7 (Jiang et al 2012):
SIG= 1−α IG+ α NSAR̅̅̅̅̅̅̅̅ (7)
12
Pohon Keputusan C5.0
Algoritme C5.0 merupakan perbaikan dari C4.5. C5.0 lebih baik dari C4.5 dalam hal kecepatan, efisiensi penggunaan memori, ukuran pohon keputusan dan kesalahan klasifikasi (Pandya 2015). Pada algoritme C5.0, data latih awal dianggap sebagai node root dari pohon keputusan, kemudian dihitung setiap gain ratio setiap atribut. Untuk menghitung entropi informasi, digunakan Persamaan 8 (Zhai et al. 2012).
E S =− ∑m pilog2(pi)
i=1 (8)
dimana S set data yang terdiri atas n data sampel. C adalah kategori atribut yang memiliki m nilai berbeda. pi adalah proporsi yang bisa dihitung dengan pi=|s|ni,
niadalah jumlah data yang termasuk kelas ke-i ke-i dan |s| adalah banyaknya data
pada data set S (maka |s|=n).
Untuk menghitung entropi bersyarat atribut A digunakan persamaan 9 (Zhai
et al. 2012).
E S|A =− ∑ pj'∑m pij
i=1 log2(pij) v
j=1 (9)
dimana pj’ adalah proporsi yang dapat dihitung dengan
p
j'=
|sj| s
=
∑mi nij n ; pij
adalah peluang bersyarat yang dapat dihitung dengan
p
ij=
nij|sj|; dan |Sj| adalah
jumlah data dengan atribut A. Maka, nilai gain dari atribut A dapat dihitung dengan Persamaan 10 (Zhai et al. 2012).
Gain A =E A −E(S|A) (10) Nilai gain ratio dari atribut A dihitung dengan Persamaan 11 (Zhai et al.
2012).
Gain Ratio A =Splitl(Gain(AA)) (11)
dimana Spiltl A =− ∑vj=1pj'log2 pj' . Algoritme C5.0 memecah data latih berdasarkan atribut yang memiliki nilai informasi gain terbesar. Prosedur split
terus dilakukan hingga tidak ada lagi subset data yang dapat di-split.
Maximum Likelihood Classifier
13 keempat metode tersebut, metode maximum likelihood merupakan metode yang paling banyak digunakan. Metode ini memiliki kelebihan antara lain robust dan banyak tersedia di hampir seluruh perangkat lunak pemrosesan citra (Lu 2007). Selain itu, metode maximum likelihood mengestimasi parameter dalam jumlah yang sedikit, sehingga metode ini dapat mengklasifikasikan citra dengan sangat cepat (Canty 2010).
Metode maximum likelihood didasarkan pada teori peluang Bayes. Persamaan teori Bayes disajikan pada Persamaan 12 (Canty 2010).
Pr
k
|
g
=
p g|p(kgPr() k) (12)dimana Pr(k), k=1,2,...,K adalah peluang prior, p(g|k) adalah fungsi densitas peluang per-kelas, dan p(g) dihitung dengan Persamaan 13 (Canty 2010).
Pr k|g =∑K p g|j Pr(j)
j=1 (13)
Karena p(g) adalah independen dari k, maka rule decision-nya adalah: klasifikasikan g ke kelas k jika p g|k Pr(k)≥p g|j Pr(j) untuk j=1,2,...,K (Canty 2010). Dengan asumsi data terdistribusi normal, didapat fungsi diskriminan pada Persamaan 14 (Canty 2010).
dk g = log Pr k −12log|Σk| −12(g−μk)TΣk-1(g−μ
k) (14)
Sehingga, maximum likelihood classifier-nya adalah sebagai berikut
klasifikasikan g ke kelas k jika dk g ≥ dj g untuk j=1,…,k (15)
Tahapan klasifikasi dengan maximum likelihood adalah, parameter diestimasi dari data latih terlebih dahulu. Kemudian tahapan berikutnya secara umum hanya mengaplikasikan Persamaan 15 ke setiap piksel citra. Dalam penelitian ini, setiap piksel citra akan dikelaskan ke dalam dua kelas, yaitu kelas terbakar dan tidak terbakar.
Majority Filter
14
kedua di baris pertama, perhitungan diulangi hingga jendela perhitungan berpindah ke keseluruhan piksel.
Gambar 6 Ilustrasi 8-connected neighbourhood
Gambar 7 merupakan ilustrasi hasil dari perhitungan majority filter. Dari Gambar 7 dapat dilihat bahwa terdapat beberapa piksel yang berubah nilainya sesuai dengan piksel tetangganya yang sering muncul. Majority filter ini dapat digunakan untuk mengurangi sebagian besar variasi dalam kelas atau nilai piksel tetangga.
Gambar 7 Ilustrasi perhitungan majority filter
METODE
Area Studi
Kalimantan merupakan salah satu pulau di Indonesia yang memiliki luas 544 150 m2. Kalimantan terdiri dari lima provinsi, yaitu Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur dan Kalimantan Utara. Kalimantan memiliki lahan gambut seluas 4 778 004 ha yang merupakan lahan gambut terluas kedua di Indonesia setelah Sumatera. Persebaran lahan gambut di Kalimantan, paling banyak berada di Kalimantan Tengah dengan luas 2 664 438 ha, kemudian Kalimantan Barat 1 046 438 ha, Kalimantan Timur 332 365 ha, dan Kalimantan Selatan 106 271 ha.
Data Penelitian
15 sekuens kemunculan titik panas, digunakan data titik panas tahun 2014 dan 2015 dari MODIS NASA dan KLH. Data titik panas tersebut dipilih yang memiliki nilai
confidence lebih dari sama dengan 70%. Data yang digunakan untuk proses klasifikasi adalah citra Landsat 7 dengan resolusi spasial 30 × 30 m. Lokasi citra yang dipilih merupakan kabupaten yang banyak terdapat pola sekuens titik panas yang muncul. Kabupaten tersebut antara lain Kabupaten Pulang Pisau dan Palangkaraya, Provinsi Kalimantan Tengah serta Pontianak, Kalimantan Barat. Tanggal akusisi citra disesuaikan dengan tanggal kemunculan sekuens dan ketersediaan citra di USGS, yaitu tanggal 14 Oktober 2015 dan 8 September 2015. Peta lahan gambut Kalimantan tahun 2002 dengan resolusi dengan skala 1:250 000 digunakan untuk mengetahui letak tutupan lahan gambut yang terdapat pada citra satelit Landsat. Peta lahan gambut berupa poligon diperoleh dari Wetlands International. Adapun peta batas wilayah Kalimantan dari BPS tahun 2013 digunakan untuk mengetahui desa, kecamatan, kabupaten dan provinsi dari sekuens yang dihasilkan.
Perangkat lunak yang digunakan pada penelitian ini meliputi:
R digunakan untuk proses klasifikasi,
Ilwis 3.8.3 digunakan untuk praproses citra satelit,
QGIS digunakan untuk pemroses citra satelit,
PostgreSQL 9.1 digunakan untuk mengelola data spasial Perangkat keras dengan spesifikasi:
Processor Intel Core i5-4200U,
RAM 4 GB, dan
HDD 500 GB
Tahapan Penelitian
Pada penelitian ini, terdapat tiga bagian besar yang dilakukan yaitu menentukan pola sekuens kemunculan titik panas tahun 2014 dan 2015 dengan PrefixSpan, klasifikasi citra satelit, kemudian mengidentifikasi fire spot. Langkah penelitian digambarkan dalam Gambar 8.
Pola sekuens titik panas
Citra hasil klasifikasi
Identifikasi fire spot Penentuan pola sekuens tahun
2014-2015 dengan PrefixSpan
Klasifikasi citra satelit Kalimantan 2015
Fire spot Data tanggal
dan lokasi Mulai
16
Penentuan Pola Sekuensial dengan Algoritme PrefixSpan
Tahap penentuan pola sekuens kemunculan titik panas tahun 2014 dan 2015 dengan PrefixSpan digambarkan pada Gambar 9.
Gambar 9 Tahapan penentuan pola sekuens titik panas tahun 2014 dan 2015 dengan algoritme PrefixSpan
1 Praproses Data
Pada tahap praproses data, dilakukan seleksi data, pembersihan data, transformasi data, dan pembuatan data sekuensial. Seleksi data bertujuan memilih atribut yang akan digunakan dalam penelitian, yaitu longitude, latitude
dan tanggal kemunculan. Selain itu, pada seleksi data, data titik panas dipilih yang berada pada lahan gambut Kalimantan dan memiliki nilai confidence lebih dari sama dengan 70%. Transformasi data bertujuan mengubah tipe atribut dan penyimpanan data dalam format Excel (.xls) atau comma separated values
(.csv). Pembuatan data sekuensial dilakukan dengan mengurutkan data berdasarkan atribut longitude, latitude, dan tanggal.
2 Penentuan Pola Sekuensial dengan Algoritme PrefixSpan
Data sekuens hasil praproses kemudian dicari pola sekuensnya dengan algoritme PrefixSpan menggunakan perangkat lunak SPMF. PrefixSpan menerapkan pendekatan divide dan conquer. Pendekatan ini secara rekursif akan memproyeksi basis data menjadi sekumpulan basis data yang lebih kecil berdasarkan pola berulang saat itu, lalu proyeksi tersebut digali untuk memperoleh polanya.PrefixSpan akan memproyeksi prefiksnya sajasehingga ukuran proyeksi database akansemakin menyusut dan redundansi pemeriksaan pada setiap posisi yang mungkin dari sebuah kandidat potensial pun akan tereduksi (Pei et al. 2004).
Klasifikasi Citra Satelit
Pada tahap ini akan dilakukan klasifikasi citra satelit menggunakan algoritme C5.0, SDT dan maximum likelihood. Tahapan klasifikasi citra digambarkan pada Gambar 10.
1 Praproses citra
Pada tahap ini dilakukan pengisian gap, proses kombinasi band, dan proses subset citra. Pengisian gap dilakukan dengan tujuan mengisi bagian citra yang nilai pikselnya tidak mempunyai nilai. Pengisian gap menggunakan gap mask untuk mengetahui lokasi piksel yang harus diisi. Sedangkan perhitungan nilai untuk mengisi pikselnya dilakukan dengan menggunakan perangkat lunak QGIS. Proses kombinasi band bertujuan mendapatkan warna RGB dari citra.
17 Warna R direpresentasikan dengan band 7, G direpresentasikan dengan band 4 dan B direpresentasikan dengan band 2. Citra satelit dipilih atau dipotong bagian yang merupakan lahan gambut serta bersih dari awan untuk melakukan pengolahan.
Gambar 10 Tahapan klasifikasi citra satelit
2 Klasifikasi menggunakan metode C5.0, SDT dan maximum likelihood
Citra yang telah dipraproses kemudian diklasifikasi dengan metode C5.0, SDT dan maximum likelihood. Klasifikasi dengan C5.0 dan SDT dilakukan dengan menggunakan rule yang dihasilkan penelitian Thariqa et.al (2016). Adapun klasifikasi dengan maximum likelihood dilakukan dengan menggunakan perangkat lunak ILWIS. Sebelum melakukan klasifikasi, perlu dilakukan pengambilan sampel untuk setiap citra. Sampel berupa contoh piksel terbakar dan contoh piksel tidak terbakar. Pada penelitian ini, sampel piksel diambil dari citra hasil kombinasi band 7, 4, dan 2. Piksel terbakar merupakan piksel yang berwarna merah, sedangkan piksel tidak terbakar, selainnya. Hasil klasifikasi dari ketiga metode tersebut kemudian dipilih yang paling baik. Citra hasil klasfikasi yang paling baik kemudian digunakan pada tahapan selanjutnya.
3 Filtering hasil klasifikasi
Pada tahap ini dilakukan pemulusan hasil klasifikasi metode maximum likelihood di ILWIS. Pada hasil klasifikasi masih terdapat kumpulan sejumlah kecil piksel terbakar yang terpisah-pisah, disebut salt-and-pepper noise. Noise
ini dapat dihilangkan dengan melakukan pemulusan menggunakan filter. Penelitian ini menggunakan majority filter dengan ukuran 3×3 untuk pemulusan citra hasil klasifikasi.
Identifikasi fire spot
Dari hasil klasifikasi citra satelit, diketahui piksel yang merupakan kebakaran dan bukan kebakaran. Sementara itu, dari hasil pencarian pola dengan PrefixSpan, diketahui pola sekuens kemunculan titik panas di Kalimantan. Kemudian pola sekuens tersebut dibandingkan dengan hasil klasifikasi citra. Citra hasil klasifikasi ditumpang-susun kemudian diidentifikasi pola sekuens yang berada pada area terbakar. Sehingga diketahui pola kemuculan titik panas yang menjadi fire spot yang merepresentasikan kebakaran lahan gambut.
Praproses citra
klasifikasi Citra hasil klasifikasi
18
HASIL DAN PEMBAHASAN
Penentuan Pola Sekuensial dengan Algoritme PrefixSpan
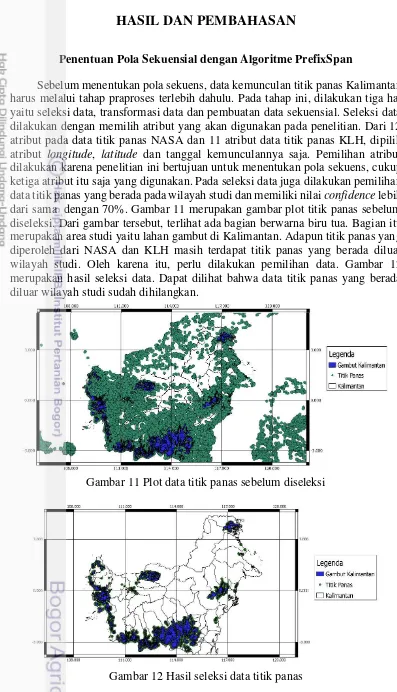
Sebelum menentukan pola sekuens, data kemunculan titik panas Kalimantan harus melalui tahap praproses terlebih dahulu. Pada tahap ini, dilakukan tiga hal yaitu seleksi data, transformasi data dan pembuatan data sekuensial. Seleksi data dilakukan dengan memilih atribut yang akan digunakan pada penelitian. Dari 12 atribut pada data titik panas NASA dan 11 atribut data titik panas KLH, dipilih atribut longitude, latitude dan tanggal kemunculannya saja. Pemilihan atribut dilakukan karena penelitian ini bertujuan untuk menentukan pola sekuens, cukup ketiga atribut itu saja yang digunakan. Pada seleksi data juga dilakukan pemilihan data titik panas yang berada pada wilayah studi dan memiliki nilai confidence lebih dari sama dengan 70%. Gambar 11 merupakan gambar plot titik panas sebelum diseleksi. Dari gambar tersebut, terlihat ada bagian berwarna biru tua. Bagian itu merupakan area studi yaitu lahan gambut di Kalimantan. Adapun titik panas yang diperoleh dari NASA dan KLH masih terdapat titik panas yang berada diluar wilayah studi. Oleh karena itu, perlu dilakukan pemilihan data. Gambar 12 merupakan hasil seleksi data. Dapat dilihat bahwa data titik panas yang berada diluar wilayah studi sudah dihilangkan.
Gambar 11 Plot data titik panas sebelum diseleksi
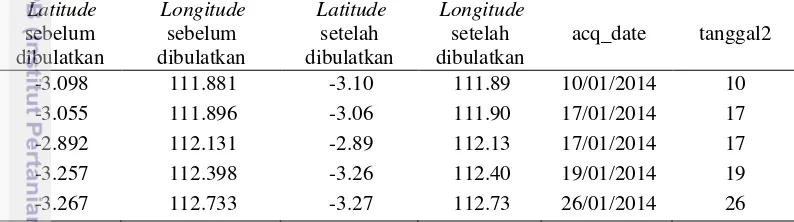
19 Pada tahap transformasi data, dilakukan penambahan atribut tanggal bertipe integer yang diberi nama tanggal2 serta pembulatan pada atribut longitude dan
latitude. Isi atribut tanggal2 merupakan konversi atribut acq_date yang bertipe
date mejadi kode tanggal bertipe integer. Hal ini dilakukan karena SPMF hanya dapat menerima input data dengan tipe integer. Pada penelitian ini, kode tanggal yang digunakan adalah nilai 1 hingga 730. Kode tanggal 1 diberikan untuk kemuculan titik panas pada tanggal 1 Januari 2014. Kode tanggal 2 diberikan untuk kemunculan titik panas pada tanggal 2 Januari 2014, begitu seterusnya hingga kode tanggal 730 untuk 31 Desember 2015. Setelah itu, dilakukan pembulatan pada atribut longitude dan latitude yang awalnya 3 angka di belakang koma, menjadi 2 angka di belakang koma. Hal ini dilakukan karena hanya sedikit lokasi dengan nilai longitude dan latitude tertentu yang memiliki jumlah kemunculan titik panas lebih dari satu. Sehingga akan sulit untuk dibuat pola sekuensnya. Data
set titik panas yang telah dibulatkan memiliki arti bahwa satu titik panas mewakili lebih dari satu kemunculan titik panas pada radius 1 km. Atribut longitude dan
latitude yang telah dibulatkan ini yang akan digunakan pada tahapan selanjutnya. Kemudian, data diurutkan berdasarkan atribut tanggal2. Tabel 3 merupakan hasil transformasi data.
Tabel 3 Hasil transformasi data titik panas Kalimantan 2014
Latitude
Tahap praproses data terakhir adalah pembuatan data sekuensial. Tahap ini dilakukan dengan pemrograman PHP dengan menggunakan atribut longitude dan
latitude sebagai id dan tanggal2 sebagai event atau item. Satu sekuens merupakan rangkaian event pada satu lokasi. Tabel 4 merupakan contoh data sekuens titik panas yang terbentuk.
Tabel 4 Contoh data sekuens titik panas Kalimantan 2015
Longitude Latitude Data sekuensial 108.94 0.80 <(728)>
109.48 -0.53 <(622)(629)>
109.12 0.32 <(618)(622)(627)(628)(630)>
Berdasarkan Tabel 4 dapat diketahui bahwa pada lokasi dengan nilai
longitude 109.48 dan latitude -0.53, terdapat kemunculan titik panas pada hari ke-622 dan hari ke-629. Dengan kata lain, pada lokasi tersebut terdapat kemunculan titik panas pada tanggal 14 September 2015 dan 21 September 2015. Dari informasi itu juga diketahui bahwa kemunculan titik panas pada lokasi tersebut mempunyai rentang waktu 8 hari.
20
karakter “-1” sedangkan akhir list item diakhiri dengan karakter “-2”. Tabel 5 merupakan contoh data sekuensial yang telah disesuaikan formatnya.
Tabel 5 Contoh data sekuens titik panas dengan format masukan SPMF
Longitude Latitude Data sekuensial 108.94 0.80 728 -1 -2
109.48 -0.53 622 -1 629 -1 -2
109.12 0.32 618 -1 622 -1 627 -1 628 -1 630 -1 -2
Setelah data sekuensial dihasilkan, pola sekuensial dapat ditentukan dengan menggunakan algoritme PrefixSpan di SPMF. Pada penelitian ini, penentuan pola sekuens dilakukan pada dataset masing-masing tahun 2014 dan 2015 untuk masing-masing provinsi di Kalimantan. Adapun nilai minimum support yang digunakan adalah 1%. Pola sekuens yang dihasilkan memiliki panjang 1 item hingga 3 item. Namun pada penelitian ini yang akan dianalisis lebih lanjut adalah pola sekuens yang panjangnya 2 hingga 3 item. Karena pola sekuens yang panjangnya 1 item tidak menarik untuk dianalisis. Tabel 6 merupakan jumlah pola sekuens titik panas untuk setiap dataset menggunakan PrefixSpan di SPMF.
Tabel 6 Jumlah pola sekuens titik panas yang dihasilkan
Tabel 6 menjelaskan bahwa data titik panas dari KLH tidak menghasilkan pola yang menarik, karena panjangnya hanya 1 item. Sedangkan data titik panas dari NASA menghasilkan pola yang panjangnya hingga 3 item. Tabel 6 juga menjelaskan bahwa pola sekuens tahun 2014, banyak terdapat di Kalimantan Timur dengan panjang item 2 sebanyak 21 dan panjang item 3 sebanyak 2 sekuens. Adapun pada tahun 2015, pola sekuens banyak terdapat di Kalimantan Barat dan Kalimantan Tengah. Pada Kalimantan Barat, terdapat 14 sekuens yang panjangnya 2 item sedangkan pada Kalimantan Tengah terdapat 10 sekuens yang panjangnya 2 item dan 1 sekuens yang panjangnya 3 item. Tabel 7 merupakan hasil sekuens tahun 2014 di Kalimantan Timur yang merupakan pola menarik (panjangnya 2 item atau lebih dan nilai supportnya besar). Tabel 8 merupakan hasil pola sekuens tahun 2015 di Kalimantan Barat dan Tengah yang merupakan pola yang menarik. Adapun daftar lengkap pola sekuens yang dihasilkan di Kalimantan Timur tahun 2014 dapat dilihat di Lampiran 1, sedangkan daftar lengkap pola sekuens yang dihasilkan di Kalimanta Barat dan Kalimantan Tengah tahun 2015 dapat dilihat di Lampiran 2.
Pada penelitian ini, pola sekuens tahun 2015 di Kalimantan Barat dan Kalimantan Tengah akan dianalisis lebih lanjut. Sehingga pola sekuens tersebut harus diketahui lokasinya. Pencarian lokasi pola sekuens dilakukan dengan melakukan scanning pada data sekuens. Lokasi pola disajikan pada Lampiran 3 untuk Kalimantan Barat dan Lampiran 4 untuk Kalimantan Tengah. Dari Sumber
Data
Tahun Kalbar Kalsel Kalteng Kaltim Kalimantan
21 Lampiran 3 dan 4, diketahui kabupaten yang paling banyak muncul adalah Kabupaten Kubu Raya dan Pontianak, Kalimantan Barat serta Kabupaten Palangkaraya dan Pulang Pisau, Kalimantan Tengah. Data titik panas kabupaten tersebut yang akan digunakan pada tahap selanjutnya.
Tabel 7 Pola sekuens titik panas yang menarik tahun 2014 di Kalimantan Timur
Provinsi 2-item 3-item
Tabel 8 Pola sekuens titik panas yang menarik tahun 2015 di Kalimantan Barat dan Kalimantan Tengah
22
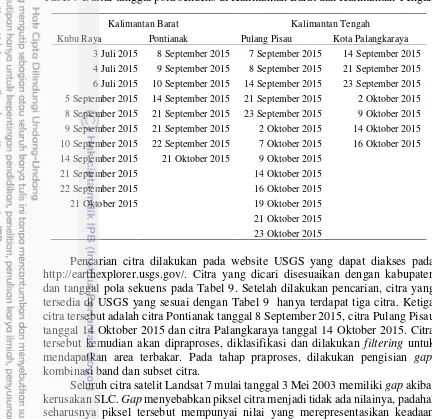
Tabel 9 Daftar tanggal pola sekuens di Kalimantan Barat dan Kalimantan Tengah
Kalimantan Barat Kalimantan Tengah
Kubu Raya Pontianak Pulang Pisau Kota Palangkaraya 3 Juli 2015 8 September 2015 7 September 2015 14 September 2015 4 Juli 2015 9 September 2015 8 September 2015 21 September 2015 6 Juli 2015 10 September 2015 14 September 2015 23 September 2015 5 September 2015 14 September 2015 21 September 2015 2 Oktober 2015 8 September 2015 21 September 2015 23 September 2015 9 Oktober 2015 9 September 2015 21 September 2015 2 Oktober 2015 14 Oktober 2015 10 September 2015 22 September 2015 7 Oktober 2015 16 Oktober 2015 14 September 2015 21 Oktober 2015 9 Oktober 2015
21 September 2015 14 Oktober 2015 22 September 2015 16 Oktober 2015 21 Oktober 2015 19 Oktober 2015 21 Oktober 2015 23 Oktober 2015
Pencarian citra dilakukan pada website USGS yang dapat diakses pada http://earthexplorer.usgs.gov/. Citra yang dicari disesuaikan dengan kabupaten dan tanggal pola sekuens pada Tabel 9. Setelah dilakukan pencarian, citra yang tersedia di USGS yang sesuai dengan Tabel 9 hanya terdapat tiga citra. Ketiga citra tersebut adalah citra Pontianak tanggal 8 September 2015, citra Pulang Pisau tanggal 14 Oktober 2015 dan citra Palangkaraya tanggal 14 Oktober 2015. Citra tersebut kemudian akan dipraproses, diklasifikasi dan dilakukan filtering untuk mendapatkan area terbakar. Pada tahap praproses, dilakukan pengisian gap, kombinasi band dan subset citra.
Seluruh citra satelit Landsat 7 mulai tanggal 3 Mei 2003 memiliki gap akibat kerusakan SLC. Gap menyebabkan piksel citra menjadi tidak ada nilainya, padahal seharusnya piksel tersebut mempunyai nilai yang merepresentasikan keadaan lanskap yang dibaca satelit. Gap ini juga akan menyebabkan hasil klasifikasi kurang baik. Gambar 13 merupakan contoh citra yang memiliki gap.
Dengan alasan tersebut, maka perlu dilakukan pengisian gap dengan mengestimasi nilai piksel yang hilang. USGS telah menyediakan gap mask untuk setiap band citra yang memungkinkan pengguna mengetahui lokasi piksel yang hilang. Perangkat lunak QGIS juga telah menyediakan metode untuk mengestimasi nilai piksel untuk mengisi gap. Jadi, pada penelitian dilakukan pengisian gap menggunakan perangkat lunak QGIS dan gap mask dari USGS. Pengisian gap dilakukan pada masing-masing band menggunakan gap mask yang disesuaikan dengan band yang dioperasikan. Gambar 14 merupakan contoh citra
23
Gambar 13 Contoh gap pada citra Landsat 7
Gambar 14 Contoh hasil isi gap Band 7, 4, dan 2
Setelah setiap band diisi gap-nya, dilakukan kombinasi band. Pada penelitian ini kombinasi band yang digunakan adalah band 7, band 4, dan band 2.
Band 7 direpresentasikan dengan warna merah, band 4 direpresentasikan dengan warna hijau, dan band 2 direpresentasikan dengan warna biru. Area terbakar direpresentasikan dengan warna merah terang karena relfektansi band 7 yang tinggi. Kombinasi band 7,4,2 membuat daerah setelah terbakar mudah terlihat dari daerah yang tidak terbakar dan valid untuk digunakan mendeteksi area kebakaran (Thariqa et.al 2016). Kombinasi band dilakukan dengan membuat citra composite
24
Gambar 15 Citra hasil composite
Gambar 15 menunjukkan keseluruhan area Kabupaten Pulang Pisau. Penelitian ini hanya menggunakan bagian citra yang merupakan lahan gambut. Untuk mendapatkan bagian lahan gambut pada citra maka perlu dilakukan proses subset citra. Proses subset citra terdiri dari overlay dan pemotongan menggunakan peta lahan gambut. Overlay dilakukan untuk mengetahui daerah tutupan lahan gambut, dan proses clipping dilakukan untuk mengambil bagian lahan gambutnya saja. Proses clipping dilakukan pada semua citra yang digunakan, yaitu citra Pulang Pisau 14 Oktober 2015, Palangkaraya 14 Oktober 2015 dan Pontianak 8 September 2015. Gambar 16 mengilustrasikan tahap proses overlay, pemotongan.
(a) (b)
Gambar 16 Proses (a) overlay Proses overlay peta lahan gambut dengan citra satelit Pulang Pisau dan (b) citra satelit hasil pemotongan
Seiring dengan selesainya proses subset citra, maka selesai pula praproses citra. Citra hasil praproses kemudian diklasifikasikan. Klasifikasi dilakukan dengan menggunakan metode C5.0, SDT dan maximum likelihood. Hasil klasifikasi dari ketiga metode tersebut kemudian dibandingkan.
1 Klasifikasi dengan metode pohon keputusan C5.0
25 mengkonversi citra composite yang telah dipotong dalam bentuk raster menjadi tabel menggunakan perangkat lunak R.
Tabel 10 Contoh tabel nilai piksel beserta lokasinya
No x y Band 7 Band 4 Band 2
1 201120 -252690 178 176 212
2 111030 -290010 179 178 141
3 262140 -327300 255 68 57
4 172050 -364620 205 162 88
5 81930 -401940 173 27 59
Setelah tabel nilai piksel dan lokasinya didapat, tahapan selanjutnya adalah memberi label pada setiap piksel. Pemberian label dilakukan dengan menggunakan aturan yang dihasilkan dari penelitian Thariqa et.al (2016). Label berupa kelas sebelum terbakar, terbakar, setelah terbakar dan non-gambut. Piksel yang telah diberi label tersebut kemudian dikonversi kembali kedalam bentuk raster. Raster hasil klasifikasi diberi warna agar mudah dibedakan kelasnya. Warna hijau untuk kelas sebelum terbakar, oranye untuk kelas setelah terbakar, merah untuk kelas terbakar dan hitam untuk kelas non-gambut. Gambar 17 merupakan hasil klasifikasi menggunakan metode C5.0.
(a) (b) (c)
Gambar 17 Hasil klasifikasi dengan metode C5.0 untuk citra (a) Pontianak, (b) Pulang Pisau dan (c) Palangkaraya
Dari Gambar 17 dapat dilihat bahwa hampir seluruh bagian piksel termasuk kelas terbakar. Padahal pada citra composite, tidak semua wilayah berwarna merah. Dengan kata lain, kebakaran tidak terjadi di semua wilayah, ada pula yang tidak terbakar (baik sebelum atau setelah terbakar).
2 Klasifikasi dengan metode SDT
26
data latih berupa citra Rokan Hilir, Riau. Sedangkan pada penelitian ini digunakan citra Pontianak, Pulang Pisau dan Palangkaraya yang berada di Kalimantan.
(a) (b) (c)
Gambar 18 Hasil klasifikasi dengan metode SDT untuk citra (a) Pontianak, (b) Pulang Pisau dan (c) Palangkaraya
3 Klasifikasi citra satelit dengan metode Maximum Likelihood
Secara umum, proses klasifikasi dengan metode ini terdiri dari dua tahap yaitu pelatihan dan pengambilan keputusan. Tahap pelatihan dilakukan dengan menentukan kelas dari beberapa piksel citra, disebut dengan piksel sampel. Sedangkan pada tahap pengambilan keputusan dilakukan penentuan kelas seluruh piksel berdasarkan karakteristik piksel sampel. Kedua tahap itu diaplikasikan pada masing-masing citra. Jadi, setiap citra memiliki piksel sampelnya sendiri-sendiri dan menentukan kelas piksel lain sendiri-sendiri. Menurut Pennington (2006), kombinasi band 742 membuat daerah setelah terbakar mudah terlihat dari daerah yang tidak terbakar.Daerah terbakar akan muncul dengan warna merah terang karena tingginya reflektansi dari band 7. Oleh karena itu, pada penelitian ini, sampel piksel kelas terbakar diambil dari bagian citra yang berwarna merah, sedangkan sampel piksel kelas tidak terbakar selainnya. Kemudian sampel tersebut digunakan untuk melakukan klasifikasi menggunakan perangkat lunak ILWIS. Gambar 19 merupakan hasil citra klasifikasi untuk citra Pulang Pisau, Pontianak dan Palangkaraya.
27 Dari Gambar 19 dapat dilihat terdapat dua warna citra yaitu hijau dan merah. Warna merah merepresentasikan area terbakar, sedangkan warna hijau merepresentasikan daerah tidak terbakar. Dari Gambar 19 juga dapat dilihat bahwa hasil klasifikasi masih terdapat piksel-piksel kecil yang terpisah, yang disebut dengan salt-and-pepper noise. Noise ini menyebabkan hasil klasifikasi kurang baik dan waktu komputasi lebih lama. Sehingga dibutuhkan filtering
untuk menghilangkan noise tersebut. Penelitian ini menggunakan majority filter
dengan ukuran 3×3 sebanyak 5 kali filtering. Gambar 20 merupakan hasil
filtering 5 kali citra Pulang Pisau dibandingkan dengan citra aslinya. Gambar 21 merupakan hasil filtering 5 kali citra Pontianak dibandingkan dengan citra aslinya. Gambar 22 merupakan hasil filtering 5 kali citra Palangkaraya dibandingkan dengan citra aslinya. Adapun hasil filtering pertama hingga kelima selengkapnya terdapat di Lampiran 5. Dari Gambar 20, 21 dan 22 dapat dilihat bahwa hasil klasifikasi yang telah dilakukan proses filtering telah mendekati citra aslinya, sehingga dapat dikatakan hasil klasifikasi sudah cukup baik.
Gambar 20 Perbandingan citra hasil filtering Pulang Pisau dengan citra asli
28
Gambar 22 Perbandingan citra hasil filtering Palangkaraya dengan citra asli Dari citra hasil klasifikasi metode C5.0, SDT dan maximum likelihood, dapat disimpulkan bahwa metode maximum likelihood yang menghasilkan citra klasifikasi yang paling baik. Oleh karena itu, citra hasil klasifikasi metode
maximum likelihood yang akan digunakan pada tahapan selanjutnya yaitu identifikasi firespot.
Identifikasi Firespot
Pada tahap ini dilakukan overlay citra hasil klasifikasi dengan pola sekuens yang dihasilkan pada tahap sebelumnya. Pada penentuan pola sekuens, dilakukan pembulatan nilai longitude dan latitude. Pembulatan ini menyebabkan pergeseran pola sejauh 1 km. Selain itu, pembulatan juga menyebabkan beberapa titik panas hanya direpresentasikan dalam satu titik lokasi. Untuk mendapatkan hasil yang akurat, maka nilai longitude dan latitude pola sekuens perlu dikembalikan lagi menjadi 3 angka di belakang koma. Hal ini dilakukan dengan membaca data titik panas awal, bukan data sekuens. Tabel 11 merupakan contoh pengembalian bentuk
longitude dan latitude menjadi 3 angka di belakang koma. Dari Tabel 11 dapat dilihat bahwa satu sekuens yang awalnya hanya mempunyai 1 nilai longitude dan
latitude, menjadi 2 atau lebih nilai longitude dan latitude. Setelah didapat nilai
longitude dan latitude 3 angka di belakang koma dari setiap sekuens, dipilih pola yang tanggalnya sama dengan tanggal citra. Kemudian pola ditumpang-susun dengan citra hasil klasifikasi. Gambar 23 merupakan contoh overlay pola sekuens dengan citra hasil klasifikasi untuk Kabupaten Pulang Pisau, Pontianak dan Palangkaraya.
(a) (b) (c)
29 Tabel 11 Contoh lokasi sekuens titik panas dengan longitude dan latitude
dinyatakan dalam 3 angka di belakang koma
Sekuens Longitude Latitude Long_spesifik Lat_spesifik Kabupaten 622 -1 629 -1 #SUP: 49 113.78 -2.85 113.782 -2.847 Pulang Pisau
113.778 -2.850
622 -1 629 -1 #SUP: 49 113.83 -2.39 113.825 -2.390 Pulang Pisau
113.834 -2.388 113.829 -2.391
622 -1 629 -1 #SUP: 49 113.83 -2.37 113.825 -2.373 Palangkaraya
113.831 -2.367
622 -1 629 -1 #SUP: 49 113.84 -2.39 113.842 -2.385 Pulang Pisau
113.837 -2.388
Jika Gambar 23 diperbesar, maka akan jelas terlihat titik panas yang berada di area terbakar dan yang tidak untuk melakukan identifikasi setiap pola pada daerah citra. Identifikasi pola sekuens juga dilakukan untuk pola yang berada di area sejauh 1 km dari area terbakar (area buffer). Gambar 24 adalah citra hasil klasifikasi Pulang Pisau yang diperbesar, beserta daerah buffernya.
(a) (b)
Gambar 24 Titik panas yang ditumpang-susun dengan citra hasil klasifikasi pada (a) area terbakar dan (b) area buffer sejauh 1 km dari area terbakar Setiap titik panas diidentifikasi dengan cara memberikan label. Jika suatu pola sekuens titik panas berada pada area terbakar, maka diberi label “ya” sedangkan jika tidak, diberi label “tidak”. Hasil identifikasi pola sekuens di Pulang Pisau dapat dilihat pada Lampiran 6. Sedangkan hasil identifikasi pola sekuens di Pontianak dapat dilihat pada Tabel 12 dan Palangkaraya pada Tabel 13.
Tabel 12 Hasil identifikasi pola sekuens di Pontianak 2015
Longitude Latitude Sekuens Di area terbakar Di dalam area buffer