KAJIAN PENGARUH PANJANG INTERVAL
KATEGORI PADA PENYEBARAN DATA
ACAK BERDISTRIBUSI SERAGAM
SKRIPSI
OKA ARIYANTO
120803066
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS
SUMATERA
UTARA
KAJIAN PENGARUH PANJANG INTERVAL
KATEGORI PADA PENYEBARAN DATA
ACAK BERDISTRIBUSI SERAGAM
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat untuk mencapai gelar
Sarjana Sains
OKA ARIYANTO
120803066
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul
: Kajian Pengaruh Panjang Interval Kategori Pada
Penyebaran Data Acak Berdistribusi Seragam
Kategori
: Skripsi
Nama
: Oka Ariyanto
Nomor Induk Mahasiswa
: 120803066
Program Studi
: Sarjana (S1) Matematika
Departemen
: Matematika
Fakultas
: Matematika Dan Ilmu Pengetahuan Alam
(FMIPA) Universitas Sumatera Utara
Disetujui di
Medan, Juni 2016
Komisi Pembimbing:
Pembimbing 2,
Pembimbing 1,
Drs. Henry Rani Sitepu, M.S
Dr. Esther SM Nababan, M.Sc
NIP.
19530303 198303 1 002
NIP. 19610318 198711 2 001
Disetujui Oleh
Departemen Matematika FMIPA USU
Ketua,
PERNYATAAN
KAJIAN PENGARUH PANJANG INTERVAL
KATEGORI PADA PENYEBARAN DATA
ACAK BERDISTRIBUSI SERAGAM
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri. Kecuali beberapa
kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Mei 2016
PENGHARGAAN
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa dan Maha
Penyayang, dengan limpahan karunia-Nya penulis dapat menyelesaikan
penyusunan skripsi ini dengan judul Kajian Pengaruh Panjang Interval Kategori
Pada Penyebaran Data Acak Berdistribusi Seragam
Terima kasih penulis sampaikan kepada Ibu Dr. Esther SM Nababan,
M.Sc. dan Bapak Drs. Henry Rani Sitepu, M.S. selaku pembimbing yang telah
memberikan bimbingan dan telah meluangkan waktunya selama penulisan skripsi
ini. Bapak Dr. Open Darniu, M.Sc. dan Bapak Dr. Suyanto, M.Kom. selaku
penguji yang telah memberikan kritik dan saran yang membangun dalam
penyempurnaan skripsi ini. Dekan dan Pembantu Dekan Fakultas Matematika dan
Ilmu Pengetahuan Alam Universitas Sumatera Utara. Ketua dan Sekretaris
Departemen Matematika Bapak Prof. Dr. Tulus, M.Si. Ph.D dan Ibu Dr.
Mardiningsih, M.Si. Seluruh staf pengajar dan staf administrasi di lingkungan
Departemen Matematika, serta seluruh sivitas akademika di lingkungan Fakultas
Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara.
Ucapan terima kasih juga ditujukan kepada kedua orang tua penulis
Ayahanda M.Safei dan Ibunda Desmul Yetri yang selalu mendoakan, memberi
semangat dan bantuan baik secara moril maupun material kepada penulis sejak
awal perkuliahan hingga selesai skripsi ini. Kepada saudara-saudara penulis yaitu
Jul Andri dan Hengki Saputra dan seluruh keluarga besar yang terus mendukung
dan mendoakan penulis.
Terima kasih kepada sahabat-sahabat penulis, Anak Jendral 2012, abang
dan kakak stambuk 2011, adik stambuk 2013, adik stambuk 2014,
adik-adik stambuk 2015, rekan-rekan di Himpunan Mahasiswa Matematika FMIPA
USU dan kepada semua pihak yang telah memberikan bantuan dan dorongan yang
tidak dapat disebutkan satu per satu. Semoga segala bentuk bantuan yang telah
diberikan kepada penulis mendapatkan balasan yang lebih baik dari Tuhan Yang
Maha Esa.
Medan, Mei 2016
Penulis
KAJIAN PENGARUH PANJANG INTERVAL
KATEGORI PADA PENYEBARAN DATA
ACAK BERDISTRIBUSI SERAGAM
ABSTRAK
Bilagan acak terdiri dari barisan bilangan rill atau barisan bilangan bulat dengan
variasi nilai yang bersifat acak dalam satu interval nilai tertentu. Bilangan acak
baku disajikan dalam bentuk bilangan rill dengan interval nilai mulai dari 0
hingga 1. Bilangan acak sering digunakan dalam simulasi. Dalam tulisan ini akan
dibahas pengaruh panjang interval kategori pada bilangan acak yang dihasilkan
dari aplikasi Ms Excel. Data acak akan dikelompokkan dalam panjang interval
yang berbeda-beda kemudian dilakukan uji frekuensi dengan menggunakan uji
Chi Square
.
STUDY OF INFLUENCE OF THE INTERVAL LENGTH
CATEGORY AT THE SPREAD UNIFORMLY
DISTRIBUTED RANDOM DATA
ABSTRACT
Consists of a random number sequence number of rill or sequence of integers with
values from random variation within a certain interval of values. Raw random
numbers is presented as a number of rill with interval values ranging from 0 to 1.
The random number is often used in the simulation. In this paper will discuss the
influence of the interval length in the category of random numbers generated from
MS Excel application. Random data will be grouped in long intervals varying
frequency and then test using Chi Square test
.
DAFTAR ISI
Halaman
Persetujuan
i
Pernyataan
ii
Penghargaan
iii
Abstrak
iv
Abstract
v
Daftar Isi
vi
Daftar Tabel
viii
Daftar Gambar
ix
Daftar Singkatan
x
Daftar Lampiran
xi
Bab 1. Pendahuluan
1.1. Latar Belakang
1
1.2. Perumusan Masalah
2
1.3. Batasan Masalah
2
1.4. Tinjauan Pustaka
3
1.5. Tujuan Penelitian
4
1.6. Kontribusi Penelitian
4
1.7. Kerangka Pemikiran
5
1.8. Metodologi Penelitian
6
Bab 2. Landasan Teori
2.1. Pembentuk Bilangan Acak
7
2.1.1. Deskripsi Bilangan Acak
8
2.1.2. Penyelesaian Generator Bilangan Acak
9
2.2. Uji Statistik
11
2.2.1. Uji
Chi Square
11
Bab 3. Pembahasan
3.1. Bilangan Acak
14
3.2. Uji Statistik
14
3.3. Langkah Penyelesaian
14
3.4. Ilustrasi Numerik
15
3.4.1 Menghasilkan Bilangan Acak
15
3.4.2 Replika Bilangan Acak
15
3.4.3 Mengelompokkan Data
15
3.4.4 Uji Statistik dengan Uji
Chi Square
16
3.4.5 Standar Deviasi
16
3.5. Pembahasan
17
3.5.1 Jumlah Bilangan Acak N=100
21
3.5.2 Jumlah Bilangan Acak N=500
27
3.6.1 Simulasi untuk Harga Jual $100 per unit
38
3.6.2 Simulasi untuk Harga jual $150 per unit
38
3.6.3 Simulasi untuk Harga Jual $200 per unit
39
Bab 4. Kesimpulan dan Saran
41
4.1. Kesimpulan
41
4.2. Saran
41
Daftar Pustaka
43
DAFTAR TABEL
Nomor
Judul
Halaman
Tabel
Tabel 3.1. Nilai
dengan L Bervariasi untuk N=100
17
Tabel 3.2. Nilai
dengan L Bervariasi untuk N=500
19
Tabel 3.3.
dan
tabel, L = 0.04
21
Tabel 3.4.
dan
tabel, L = 0.05
22
Tabel 3.5.
dan
tabel, L = 0.1
23
Tabel 3.6.
dan
tabel, L = 0.2
24
Tabel 3.7.
dan
tabel, L = 0.25
25
Tabel 3.8.
dan
tabel, L = 0.5
26
Tabel 3.9.
dan
tabel, L = 0.004
27
Tabel 3.10.
dan
tabel, L = 0.01
28
Tabel 3.11.
dan
tabel, L = 0.02
29
Tabel 3.12.
dan
tabel, L = 0.04
30
Tabel 3.13.
dan
tabel, L = 0.05
31
Tabel 3.14.
dan
tabel, L = 0.1
32
Tabel 3.15.
dan
tabel, L = 0.2
33
DAFTAR GAMBAR
Nomor Judul
Halaman
Gambar
Gambar 3.1. Perbandingan
untuk
N= 100
18
Gambar 3.2. Perbandingan
untuk
N= 100
20
Gambar 3.3. Perbandingan
dan
tabel, L = 0.04
21
Gambar 3.4. Perbandingan
dan
tabel, L= 0.05
22
Gambar 3.5. Perbandingan
dan
tabel, L= 0.1
23
Gambar 3.6. Perbandingan
dan
tabel, L= 0.2 24
Gambar 3.7. Perbandingan
dan
tabel, L= 0.25 25
Gambar 3.8. Perbandingan
dan
tabel, L= 0.5
26
Gambar 3.9. Perbandingan
dan
tabel, L= 0.004
27
Gambar 3.10. Perbandingan
dan
tabel, L= 0.01
28
Gambar 3.11. Perbandingan
dan
tabel, L= 0.02
29
Gambar 3.12. Perbandingan
dan
tabel, L= 0.04 30
Gambar 3.13. Perbandingan
dan
tabel, L= 0.05
31
Gambar 3.14. Perbandingan
dan
tabel, L= 0.1
32
Gambar 3.15. Perbandingan
dan
tabel, L= 0.2
33
Gambar 3.16. Perbandingan
dan
tabel, L= 0.5
34
DAFTAR SINGKATAN
RN
= Random Number
RNG = Random Number Generator
R0
= Data Acak Asli
DAFTAR LAMPIRAN
Nomor Judul
Halaman
Lamp
1.
Tabel Chi Square
36
2.
Tabel Bilangan acak N=100
39
3.
Tabel Bilangan Acak N=500
44
4.
Pengelompokan Data N=100
65
BAB 1
PENDAHULUAN
1.1.
Latar Belakang
Suatu permasalahan yang kompleks di dunia nyata, dapat dipandang sebagai
sebuah sistem. Sistem dapat didefinisikan sebagai gabungan atau himpunan dari
berbagai jenis objek selaku komponen-komponen dalam suatu kesatuan atau
perpaduan berdasarkan hubungan interaksi (Humala, 2009). Kinerja sebuah sistem
dapat dianalisis dan dievaluasi dengan simulasi. Pada masa yang akan datang,
simulasi akan banyak digunakan untuk menilai kinerja suatu sistem. Simulasi
merupakan suatu sistem yang digunakan untuk memecahkan atau menguraikan
persoalan-persoalan dalam kehidupan nyata yang penuh dengan ketidakpastian
dengan tidak atau menggunakan model atau metode tertentu dan lebih ditekankan
pada pemakaian komputer untuk medapatakan solusinya (Thomas, 2004).
Simulasi dapat dibedakan berdasarkan keadaan antara deterministik
dengan stokastik. Simulasi deterministik mencakup variabel dan parameter tetap
dan diketahui secara pasti. Simulasi stokastik (
probabilistic
) berkaitan dengan
distribusi peluang dari beberapa atau semua variabel dan parameter. Simulasi
probabilistik memuat keajadian-kejadian acak, distribusi peluang yang urutan
pelaksanaan simulasi berintikan percobaan statistik, membuat
kesimpulan-kesimpulan sesuai dengan statistik (Siagian, 2006).
Simulasi probabilistik atau disebut juga simulasi Monte Carlo merujuk
pada penggunaan model matematika untuk mempelajari sistem yang dicirikan
oleh munculnya kejadian diskrit dan acak. Bilangan acak dapat dihasilkan melalui
program aplikasi seperti Fortran, Basic, PL/1 dan MS Excell untuk bilangan acak
berdisribusi seragam. (Gottfried, 1992; KIM, 2003).
Keacakan suatu barisan data dapat dilihat dari berbagai sisi, antara lain
dari sisi frekuensi kemunculan data pada setiap kelas interval, variasi jarak antara
data yang satu terhadap data berikutnya dan pola maju mundur atau naik turunnya
2
frekuensi, uji baris (
serial test
), uji poker (
poker test
), uji jarak (
gap test
) dan uji
pola naik turun (
increasing and decreasing run
) (Gottfried, 1992).
Pemilihan salah satu metode untuk uji keacakan sangat bergantung pada
permasalahan yang memerlukan data acak. Misalnya, apabila diperlukan data acak
yang berdistribusi seragam maka cukup dilakukan uji frekuensi untuk menguji
keacakan. Pada umumnya uji keacakan hanya dilakukan dengan menggunakan
salah satu alat uji saja tanpa melakukan uji keacakan lainnya.
Pengertian distribusi berhubungan dengan distribusi probabilitas yang
digunakan untuk meninjau atau terlibat langsung dalam pengadaan bilangan acak
tersebut. Sedangkan, seragam (
uniform
) merupakan distribusi probabilitas yang
sama untuk semua besaran yang diambil atau dikeluarkan. Ini berarti
probabilitasnya diusahakan sama untuk setiap pengadaan bilangan acak tersebut
(Thomas, 2004).
Dalam penelitian ini akan dianalisis keacakan suatu barisan data yang
dihasilkan dari
pseudorandom generator
. Keacakan data akan diuji dari sisi uji
frekuensi setelah dikelompokkan dalam panjang interval yang berbeda-beda untuk
mendapatkan gambaran tingkat keacakan yang dihasilkan oleh alat uji keacakan
tersebut
.
1.2.
Perumusan Masalah
Perumusan masalah yang akan penulis teliti adalah bagaimana pengaruh panjang
interval kategori terhadap penyebaran data acak berdistribusi seragam.
1.3.
Batasan Masalah
Dalam penulisan skripsi ini, penulis memberikan batasan masalah yaitu:
1. Data yang digunakan adalah data bilangan acak yang di hasilkan dari
3
2. Bilangan acak yang dihasilkan Ms.Excel bernilai enam desimal.
3. Hasil perhitungan statistik bernilai dua desimal.
1.4.
Tinjauan Pustaka
Bilangan acak merupakan bilangan yang terdiri dari barisan bilangan ril atau
barisan bilangan bulat dengan variasi nilai yang bersifat acak dalam satu interval
nilai tertentu (Humala, 2009).
Konsep keacakan bilangan acak telah terabaikan dalam literatur kajian filsafat.
Jika para filsuf membicarakan mengenai keacakan, biasanya para filsuf tersebut
setuju dengan konsep dasar mengenai keacakan. Data hasil simulasi telah
mengabaikan karakter statistik dari keacakan data pada aplikasi simulasi stokastik.
50% dari seluruh publikasi mengenai studi simulasi, hanya 23 % saja dari hasil
simulasi merupakan informasi yang kredibel yang menyertakan analisis statistik
atas hasil simulasi (Palikowski dkk., 2000).
Bilangan acak dari distribusi pada komputer digital biasanya membutuhkan
satu atau lebih sampel acak yang seragam antara 0 dan 1 dan kemudian mengubah
sampel seragam menjadi sampel baru dari distribusi yang diinginkan. Sampel
independen yang seragam terdistribusi pada interval 0 sampai 1 disebut bilangan
acak (Pritsker dan alan, 1986).
Sepanjang sejarah penghasil bilangan acak, terdapat barisan bilangan acak
yang diperoleh dari beberapa sumber bilangan acak ‘
pseudorandom generator’
,
setelah diuji keacakannya menunjukkan bahwa barisan bilangan acak yang
dihasilkan ternyata sangat tidak acak, bergantung dari jenis uji keacakan tertentu
(Goldreigh, 2008).
Penyimpangan statistik (
statistical errors
) pada hasil simulasi secara umum
diukur dengan selang interval ekspektasi yang berisi nilai yang tidak diharapkan.
Probabilitas diketahui sebagai level kepercayaan. Dalam implementasinya pada
4
seiringan dengan jumlah data yang dikoleksi. Untuk mengatasi hal ini terdapat
dua skenario. Skenario pertama adalah dengan menambah panjang percobaan
simulasi sebagai parameter input pada model. Metode ini merdasarkan pada
argumentasi bahwa semakin banyak jumlah simulasi yang dilakukan maka
semakin baik hasilnya, dan error statistik yang terjadi merupakan faktor
kebetulan. Meskipun konsep metode ini digunakan secara luas, metode ini tidak
lagi merupakan metode yang dapat diterima untuk pengajaran :
.... no procedure
in which the run length is fixed before the simulation begins can be relied upon to
produce a confidence interval that covers the theoretical value with the desired
probability
.. (Law and Kelton , 2000).
(Eagle, 2005) menyarankan agar konsep keacakan dipahami sebagai kasus
khusus dari konsep epistemology dari suatu proses yang tak dapat diprediksi.
Eagle memberikan penjelasan tentang konsep keacakan secara intuitive,
sedikitnya menyarankan bahwa pemahaman akan keacakan yang telah ada selama
ini tidak lagi sepenuhnya benar, diperlukan lebih dalam pemahaman dan kajian
filosofis mengenai keacakan ini. Sepanjang sejarah penghasil bilangan acak,
terdapat barisan bilangan acak yang diperoleh dari beberapa sumber bilangan acak
‘
pseudorandom generator
’, setelah diuji keacakannya menunjukkan bahwa
barisan bilangan acak yang dihasilkan ternyata sangattidak acak, bergantung dari
jenis uji keacakan tertentu. (Goldreigh, 2008)
Hull dan Dobell mengatakan dapat menjamin kesesuaian barisan bilangan
yang terbatas secara umum, mengingat satu himpunanan tes akan selalu ada
barisan bilangan yang melewati tes ini, tetapi yang benar-benar diterima untuk
beberapa aplikasi tertentu (Pritske dan Allan, 1986).
1.5.
Tujuan Penulisan
Tujuan dari penelitian ini adalah melakukan uji statistik panjang interval data
5
1.6.
Kontribusi Penelitian
Manfaat dari penelitian ini adalah sebagai berikut:
1. Mendapatkan gambaran pengaruh dari panjang interval suatu barisan bilangan
acak terhadap hasil simulasi dan penyimpangan atau standar deviasi yang
terjadi.
2. Sebagai bahan referensi dalam menambah wawasan penulis dan pembaca
dalam bidang statistika yang berhubungan dengan pembahasan simulasi
menggunakan bilangan acak berdistribusi seragam.
3. Sebagai informasi bagi penelitian selanjutnya yang berhubungan dengan
6
1.7.
Kerangka Pemikiran
Studi literatur tentang simulasi
dan bilangan acak
pseudorandom
Membangkitkan bilangan acak
dengan Ms. Excel (sebanyak 100
dan 500 bilangan acak)
Melakukan replika bilangan acak
(10x Replika)
Penyimpangan statistik
Uji statistik (Chi square)
Analisis uji statistik dan
penyimpangan statistik
7
1.8.
Metodologi Penelitian
Penelitian yang penulis lakukan adalah penelitian literatur yang disusun dengan
langkah-langkah sebagai berikut:
1.
Mencari literatur dari beberapa buku dan jurnal yang berhubungan dengan
bilangan acak dan uji statistik .
2.
Menjelaskan definisi bilangan acak, pembangkit bilangan acak dan uji
Chi
Square.
3.
Menghasilkan bilangan acak dari aplikasi Ms Excel .
4.
Mengelompokkan bilangan acak dengan panjang interval yang berbeda-beda
dan melakukan uji statistik (U
ji Square
).
5.
Menyimpulkan hasil dan informasi dari proses uji statistik yang telah
BAB 2
LANDASAN TEORI
2.1.
Pembentuk Bilangan Acak
Pembentuk bilangan acak adalah suatu algoritma yang digunakan untuk
menghasilkan urutan-urutan dari angka-angka sebagai hasil perhitungan dengan
komputer yang diketahui distribusinya sehingga angka-angka tersebut muncul
secara acak (Thomas, 2004)
Urutan bilangan acak dapat dikembangkan dengan menggunakan cara
manual (seperti: roulette, kotak dadu dan lain sebagainya) dan dengan
menggunakan komputer. Proses pembentukan bilangan acak dengan komputer
mencakup penggunaan hubungan rekursif, yaitu aturan yang membawa satu
bilangan acak kepada yang lain di dalam urutan. Hubungan rekursif secara khusus
bekerja dengan bilangan cacah yang dibagi oleh suatu konstanta yang besar
(modulo) untuk menghasilkan bilangan acak dari 0 hingga 1. Bilangan acak yang
dihasilkan dengan hubungan rekursif disebut
pseudorandom number
(bilangan
acak yang salah atau pura-pura), sedangkan bilangan yang dihasilkan manual
disebut bilangan acak yang sebenarnya. Meskipun demikian, dalam praktek
bilangan psedorandom
sudah dapat digunakan sebagai bilangan acak (Siagian,
2006).
Pembentuk bilangan acak pada komputer terdapat dalam bentuk prosedur
yang dapat dieksekusi secara berulang-ulang dan terus-menerus. Satu putaran
pembangkit ibarat satu kali eksekusi formula pembangkit bilangan untuk
menghasilkan satu bilangan acak (Humala, 2009).
2.1.1. Deskripsi Bilangan Acak
Dalam penentuan bilangan acak pada umumnya terdapat beberapa sumber yang
digunakan, antara lain (Thomas, 2004):
9
b. Bilangan acak elektronik
c. Pembangkit bilangan acak
congruential pseudorandom
.
Pembangkit bilangan acak ini terdiri dari tiga bagian:
•
Pembangkit bilangan acak
Additive Random Number Generator
•
Pembangkit bilangan acak
Multiplicative Random Number
Generator
•
Pembangkit bilangan acak
Mixed Conruential Random Number
Generator.
Sifat-sifat pembangkit bilangan acak (Thomas, 2004):
1. Independen
Masing-masing komponen atau variabel-variabelnya harus bebas dari
ketentuan-ketentuan tersendiri.
2. Seragam
Merupakan suatu distribusi yang umum yaitu probabilitas yang sama
untuk semua besaran yang dikeluarkan.
3. Dense
Merupakan maksud dari
Density
Probabilitas, distribusi yang harus
mengikuti syarat probabilitas yaitu terletak antara 0 dan 1. Angka-angka
yang dibutuhkan dari pembangkit bilangan acak dan dibuat sedimikian
rupa sehingga
R.N
4. Efisien
Penarikan bilangan acak harus dapat menentukan angka-angka untuk
variabelnya yang sesuai sehingga dapat berjalan terus menerus.
Sifat-sifat pembangkit bilangan acak (Pritsker dan Alan, 1986) adalah :
1. Bilangan harus berdistribusi seragam pada interval (0,1).
2. Bilangan harus independen, tidak ada korelasi antara urutan dari bilangan
acak tersebut.
3. Banyak angka harus dibangkitkan sebelum bilangan yang sama diperoleh.
Ini disebut sebagai periode atau panjang siklus dari pembangkit bilangan.
10
5. Pembangkit bilangan harus cepat karena banyak bilangan yang diperlukan
dalam simulasi.
6. Persyaratan penyimpanan yang rendah lebih disukai.
Suatu metode yang digunakan untuk pembangkit bilangan acak dapat diterima
jika menghasilkan urutan bilangan yang (Bulgren dkk, 1982):
1. Berdistribusi seragam.
2. Independen secara statistik.
3. Direproduksi.
4. Tidak berulang untuk panjang yang diinginkan.
5. Mampu menghasilkan bilangan acak pada tingkat kecepatan tinggi
membutuhkan kapasistas komputer yang sedikit.
2.1.3. Penyelesaian Generator Bilangan Acak
Pada pembangkit bilangan acak
Conruential Pseudorandom
dapat dijelaskan
untuk masing-masing formula atau rumus sebagai berikut(Thomas, 2004):
1.
Additive/arithmetic
RNG
Dengan catatan:
= bilangan acak yang baru
= bilangan acak yang lama
= bilanga n konstanta yang bersyarat
= bilangan modulo
Untuk metode ini diperlukan perhatian untuk syarat-syaratnya sebagai
berikut:
a. Kontstan a harus lebih besar dari
.
11
b. Untuk konstanta c, harus berangka ganjil apabila m bernilai
pangkat dua. Tidak boleh nilai berkelipatan dari m
c. Untuk modulo m harus bilangan prima atau bilangan tidak
terbagikan, sehingga memudahkan dan memperlancar perhitungan
di dalam komputer.
d. Untuk pertama Z
0
harus merupakan bilangan bulat, ganjil dan
cukup besar.
2.
Multiplicative
RNG
Dengan catatan:
= bilangan acak semula
= bilangan acak yang baru
=
Dalam perumusan metode ini terdapat tiga variabel yang menentukan
umtuk nilai-nilai bilangan acak yang dapat diperoleh seterusnya dengan
tidak ada pengulangan pada angka-angkanya. Untuk pemilihan nilai-nilai
terbaik djiabarkan sebagai berikut:
a. Pemilihan nilai m merupakan satu bilangan bulat yang cukup
besar.
b. Pemilihan kontanta a harus bilangan prima terhadap m. Nilai a juga
harus ganjil. Pemilihan terbaik adalah dengan rumus
yang lebih mendekat pada ketepatan.
c. Untuk nilai Z
0
mengharusakan prima relatif terhadap m.
d. Bilangan c yang dipilih harus bukan merupakan kelipatan dari m
dan ganjil.
3.
Mixed Pseudo
RNG
12
Rumus ini dengan syarat utama n harus sejumlah bilangan bulat dan lebih
besar dari nol, rumus ini dikenla juga dengan
“Linier Congruential
Random Number Generator”.
a.
Apabila nilai c = 0 maka akan diperoleh rumus
Multiplicative
Congruen.
b. Beberapa syarat
Mixed Conruential Generator
menurut teorema
dari Hull dan Dobell pada tahun 1962 (Averil M Law, 1991):
1. Pembagi umum yang terbesar dari c dan m adalah satu.
2. Jika q adalah bilangan prima (dibagi oleh hanya dirinya sendiri
dan 1) yang membagi m, maka q membagi 1.
Jika 4 membagi m, maka 4 dibagi a-1.
2.2.
Uji Statistik
Terdapat beberapa alat uji statistik untuk menguji tingkat keacakan data dari
urutan bilangan acak
pseudorandom
. Dari sekian banyak uji statistik yang ada, uji
statistik yang sering digunakan adalah statistic
Chi-Square.
2.2.1 Uji
Chi Square
Uji Square
atau uji keselarasan
(goodness of fit)
pertama kali diperkenalkan oleh
Kral Pearson pada tahun 1900 (Sihono, 2001).
Chi Square
adalah teknik analisis
statistik untuk mengetahui signifikansi perbedaan antara proporsi (dan atau
probabilitas) subjek atau objek penelitian yang datanya telah dikategorikan
(Bambang Soepeno,2002).
Maksud dan tujuan dari pengujian dengan menggunakan uji
Chi Square
adalah membandingkan antara fakta yang diperoleh berdasarkan hasil observasi
dan fakta yang didasarkan secara teoritis (yang diharapkan). Hal ini sejalan
dengan konsep kenyataan yang sering terjadi, bahwa hasil observasi biasanya
13
berdasarkan konsep dari teorinya sesuai dengan aturan-aturan teori kemungkinan
atau teori probabilitasnya (Andi Supangat, 2007).
Ada beberapa persyaratan dalam penggunaan teknik analisis
Chi Square
yang harus dipenuhi, di samping berpijak pada frekuensi data kategori yang
terpisah secara
mutual excluve
, persyaratan lain adalah sebagai berikut (Bambang
Soepeno, 2002):
1. Frekuensi tidak boleh kurang dari lima. Jika ini terjadi harus dikoreksi
dengan
Yates’s correction.
2. Jumlah frekuensi observasi dan frekuensi yang diharapkan harus sama.
3. Dalam fungsinya sebagai pengujian hipotesis mengenai korelasi antara
variabel,
Chi Square
hanya dapat dipakai untuk mengetahui ada atau
tidaknnya korelasi, bukan besar kecilnya korelasi.
Prosedur uji
Chi-Square
(Ahmad Noer, 2004):
1. Pernyataan Hipotesis Nol dan Hipotesis Alternatif
Dalam uji keselarasan fungsi, hipotesis nolnya adalah populasi yang
sedang dikaji memenuhi atau selaras dengan suatu pola distribusi
probabilitas yang ditentukan. Sedangkan hipotesis alternatifnya adalah
populasi tidak memenuhi distribusi yang ditentukan tersebut.
2. Pemilihan Tingkat Kepentingan
(Level of Significance)
Biasanya digunakan tingkat kepentingan 0.01 atau 0.05.
3. Penentuan Distribusi Pengujian yang Digunakan
Dalam uji yang digunakan adalah distribusi probabilitas
Chi Square
.
Nilai-nilai dari distribusi
Chi Square
telah disajikan dalam bentuk
tabel (terlampir), yang dapat ditentukan dengan mengetahui tiga hal:
•
Tingkat kepentingan
(level of significance)
•
Derajat kebebasan fungsi : df = v = k-1, di mana k adalah
jumlah
outcome
atau observasi yang mungkin dalam sampel
4. Pendefinisian Daerah-daerah Penolakan atau Kritis
Daerah penerimaan dan penolakan dibatasi oleh nilai kritis
"
.
5. Pernyataan Aturan Keputusan
(Decision Rule)
Tolak H
0
dan terima H
1
jika
Chi Square
hitung >
Chi Square
tabel.
14
6. Perhitungan Rasio Uji
Rumus yang digunakan untuk menghitung rasio uji (nilai
"
) adalah
"
# $
$
# $
$
%
# $
$
&
# $
$
'
(
Dengan catatan:
#
= frekuensi sampel bilangan acak
$
= frekuensi harapan menurut pola distribusi seragam
7. Pengambilan Keputusan secara Statistik
Jika nilai rasio uji berada didaerah penerimaan maka hipotesisi nol
diterima, sedangkan jika berada didaerah penolakan maka hipotesis nol
ditolak.
2.3.
Distribusi Seragam
Distribusi seragam merupakan sebaran peluang yang paling sederhana
antara sebaran-sebaran lainnya. Meskipun dalam penerapananya terbatas, namun
mempunyai arti penting terutama sebagai penghampir sebaran-sebaran yang lain
yang tidak diketahui atau sebagai pembangkit sebarah lain dalam simulasi
komputer. Dalam sebaran ini setiap nilai peubah acak mempunyai peluang yang
sama untuk terjadi.
Distrubusi seragam diskrit atau sebaran seragam diskrit didefinisikan bila
peubah acak X mempunyai nilai
) * ) * + * )
'
*
dengan peluang yang sama, maka
sebaran seragam diskrit didefinisikan sebagai berikut (Sihono Dwi Waluyo,
2001):
, )
'
*
untuk
) ) * ) * + * )
'
BAB 3
HASIL DAN PEMBAHASAN
3.1.
Bilangan Acak
Bilagan acak terdiri dari barisan bilangan rill atau barisan bilangan bulat dengan
variasi nilai yang bersifat acak dalam satu interval nilai tertentu. Bilangan acak
baku biasanya disajikan dalam bentuk bilangan rill dengan interval nilai mulai
dari 0 hingga 1. Penyajian bilangan acak dalam bentuk rill dengan tingkat
ketelitian tertentu sesuai dengan jumlah digit angka pembentuk bilangan pecahan
biasanya disesuaikan dengan tujuan penggunaannya sebagai bilangan yang
menyatakan nilai peluang antara 0 sampai dengan 1. Bilangan acak yang sering
digunakan pada simulasi adalah bilangan acak rill dengan presisi 0.0001 dalam
rentang nilai mulai dari 0 hingga 1 (Humala, 2009).
3.2.
Uji Statistik
Terdapat beberapa alat uji statistik untuk menguji tingkat keacakan data dari
urutan bilangan acak pseudorandom. Dari sekian banyak uji statistik yang ada, uji
statistik yang sering digunakan adalah statistik
Chi-Square
. Dalam uji ini, yang
diuji adalah hipotesa bahwa hasil observasi dapat diwakili sebagai bilangan acak
yang benar-benar acak.
3.3.
Langkah Penyelesaian
Langkah-langkah yang dilakukan adalah:
1. Bilangan acak diperoleh dari aplikasi Ms.Excel.
3. Semua bilangan acak kemudian dikelompokkan dalam beberapa kelompok
data yang masing-masing kelompok data mempunyai panjang interval
yang berbeda-beda.
4. Dari hasil pengelompokan data pada langkah 3 kemudian dihitung nilai
Chi Square
pada setiap kelompok data.
5. Pada langkah ini, setiap kelompok data dihitung nilai standar deviasinya.
3.4.
Ilustrasi Numerik
3.4.1. Menghasilkan Bilangan Acak
Bilangan acak dimunculkan dari program aplikasi Ms.Excel sebanyak 100 buah
bilangan dan 500 buah bilangan acak. Bilangan acak yang diperoleh berjumlah
enam decimal.. Bilangan berkisar antara 0 sampai dengan 1 (lampiran 2 dan 3)
3.4.2. Replika Bilangan Acak
Bilangan acak yang telah diperoleh, direplika sebanyak 10 kali replika (lampiran 2
dan 3).
3.4.3. Mengelompokkan Data
Untuk masing-masing replika bilangan acak, akan dikelompokkan ke dalam
beberapa kelompok data yang masing-masing kelompok data mempunyai panjang
interval yang berbeda-beda. Untuk jumlah bilangan acak 100 data, terdapat enam
kelompok data dengan panjang interval masing-masing kelompok data adalah
0.04, 0.05, 0.1, 0.2, 0.25 dan 0,5 (lampiran 4). Sedangkan untuk jumlah data 500
data, dibentuk delapan buah kelompok data yang masing-masing kelompok data
mempunyai panjang interval 0.004, 0.01, 0.02, 0.04, 0.05, 0.1, 0.2 dan 0.5
3.4.4. Uji Statistik dengan Uji
Chi Square
Masing-masing kelompok data dihitung nilai
Chi Squaren
ya untuk mengetahui
apakah data yang telah dikelompokkan dalam panjang interval tertentu memenuhi
distribusi (hipotesis) yang diinginkan yaitu keacakan data. Nilai
Chi Square
yang
diperoleh akan dibandingkan dengan nilai
Chi Square
pada tabel
Chi Square
(lampiran 4) dengan tingkat kepercayaan yang digunakan adalah 0.01 dan 0.05.
Jika nilai
Chi Square
yang diperoleh lebih besar dari nilai
Chi Square
pada tabel,
maka kelompok data dengan panjang interval tersebut dapat diterima sebagai data
acak yang benar-benar acak. Jika nilai
Chi Square
yang diperoleh lebih kecil,
maka data tersebut ditolak sebagai data acak (lampiran 1).
3.4.5.
Standar Deviasi
Standar deviasi adalah simpangan baku atau penyimpangan standar yang
menggambarkan variasi nilai dalam suatu distribusi. Setiap kelompok data
dihitung standar deviasi atau penyimpangan data untuk melihat seberapa besar
penyimpangan masing-masing data yang ada dalam kelompok data tersebut.
Kelompok data dengan panjang interval tertentu di harapkan memiliki nilai
3.5.
Pembahasan
[image:31.842.111.774.199.329.2]Hasil perhitungan
.
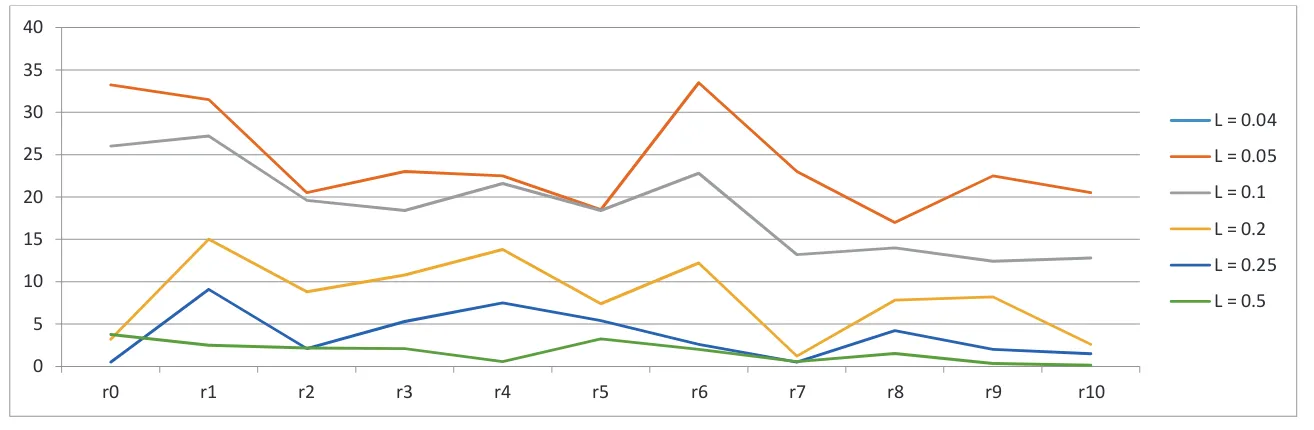
Tabel 3.1. Nilai
dengan Panjang Interval (L) Bervariasi dengan Jumlah Bilangan Acak N=100
Panjang
Interval (L)
v
Tabel
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
=0.05
=0.01
0.04
33.25 31.50 20.50
23.00 22.50 18.50 33.50
23.00 17.00 22.50 20.50
24
36.42
42.98
0.05
26.00 27.20 19.60
18.40 21.60 18.40 22.80
13.20 14.00 12.40 12.80
19
30.14
36.19
0.1
3.20
15.00
8.80
10.80 13.80
7.40
12.20
1.20
7.80
8.20
2.60
9
16.92
21.66
0.2
0.50
9.10
2.10
5.30
7.50
5.40
2.60
0.50
4.20
2.00
1.50
4
9.49
13.27
0.25
3.76
2.48
2.16
2.10
0.56
3.24
2.00
0.56
1.52
0.32
0.12
3
7.82
11.35
0.5
0.16
1.96
1.44
0.00
0.36
4.84
3.24
0.04
0.36
0.16
0.00
1
3.84
6.64
U
n
iv
e
r
s
ita
s
Su
m
a
te
r
a
Gambar 3.1. Plot Perbandingan Nilai
dengan Panjang Interval (L) Bervariasi dari Setiap Replika Dengan Jumlah Bilangan Acak
N=100
U
n
iv
e
r
s
ita
s
Su
m
a
te
r
a
U
ta
r
Hasil perhitungan
.
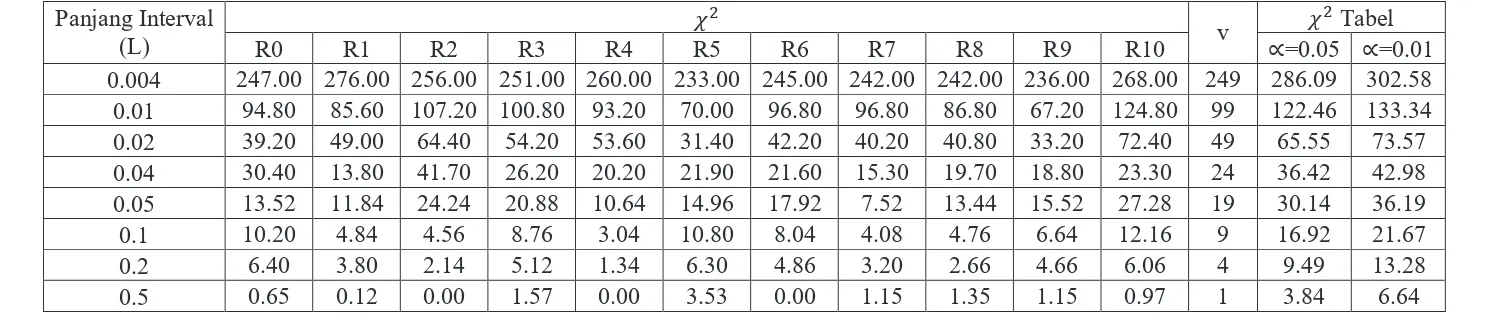
Tabel 3.2. Nilai
dengan Panjang Interval (L) Bervariasi dengan Jumlah Bilangan Acak N=500
Panjang Interval
(L)
v
Tabel
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
=0.05
=0.01
0.004
247.00 276.00 256.00 251.00 260.00 233.00 245.00 242.00 242.00 236.00 268.00
249
286.09 302.58
0.01
94.80
85.60 107.20 100.80
93.20
70.00
96.80
96.80
86.80
67.20 124.80
99
122.46 133.34
0.02
39.20
49.00
64.40
54.20
53.60
31.40
42.20
40.20
40.80
33.20
72.40
49
65.55
73.57
0.04
30.40
13.80
41.70
26.20
20.20
21.90
21.60
15.30
19.70
18.80
23.30
24
36.42
42.98
0.05
13.52
11.84
24.24
20.88
10.64
14.96
17.92
7.52
13.44
15.52
27.28
19
30.14
36.19
0.1
10.20
4.84
4.56
8.76
3.04
10.80
8.04
4.08
4.76
6.64
12.16
9
16.92
21.67
0.2
6.40
3.80
2.14
5.12
1.34
6.30
4.86
3.20
2.66
4.66
6.06
4
9.49
13.28
0.5
0.65
0.12
0.00
1.57
0.00
3.53
0.00
1.15
1.35
1.15
0.97
1
3.84
6.64
U
n
iv
e
r
s
ita
s
Su
m
a
te
r
a
Gambar 3.2. Plot Perbndingan Nilai
dengan Panjang Interval (L) Bervariasi dari Setiap Replika dengan Jumlah Bilangan Acak
N=500
U
n
iv
e
r
s
ita
s
Su
m
a
te
r
a
U
ta
r
3.5.1. Jumlah Bilangan Acak N=100
Tabel 3.3.
dan
Tabel untuk Masing-Masing Replika Bilangan Acak
pada Panjang Interval 0.04
L = 0.04
N=100
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
33.25 31.50 20.50 23.00 22.50 18.50 33.50 23.00 17.00 22.50 20.50
[image:35.595.115.539.306.516.2]0.05
36.42 36.42 36.42 36.42 36.42 36.42 36.42 36.42 36.42 36.42 36.42
0.01
42.98 42.98 42.98 42.98 42.98 42.98 42.98 42.98 42.98 42.98 42.98
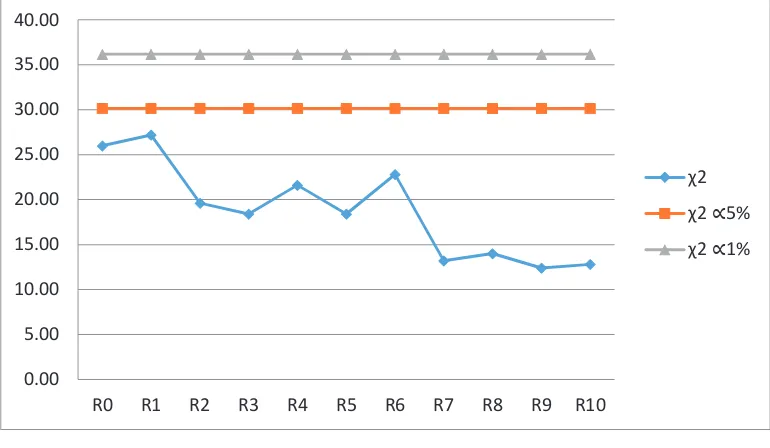
Gambar 3.3. Plot Perbandingan
Dengan
Tabelpada Panjang Interval 0.04
untuk N=100
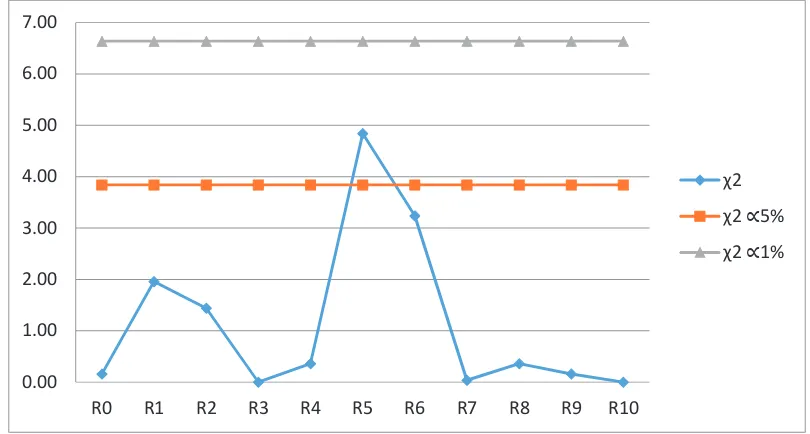
Dari gambar di atas dapat dilihat bahwa
observasi tidak melebihi
tabel
, maka
hipotesis bahwa bilangan acak yang dihasilkan adalah benar-benar acak, dapat
diterima pada tingkat kepercayaan
= 0.05. Demikian pula pada tingkat
kepercayaan
. Maka untuk panjang interval 0.04 pada jumlah data
N=100, hipotesa bahwa data acak secara signifikan dapat diterima meskipun
Distribusi data merupakan distribusi seragam yang dihasilkan dari aplikasi Ms
Excel dengan standar deviasi yang cukup kecil.
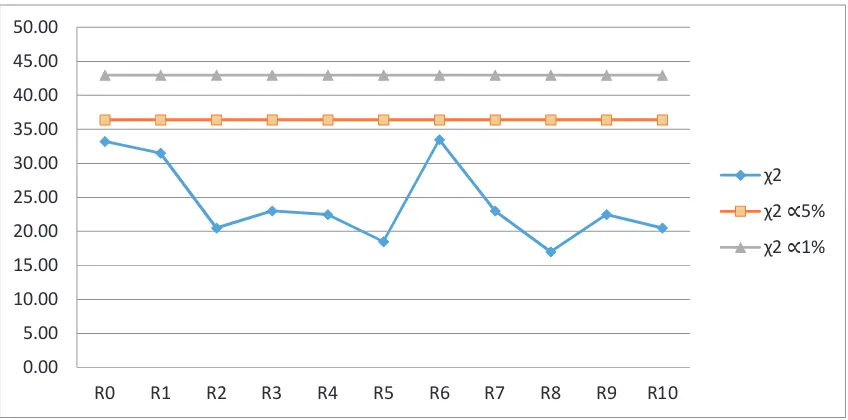
Tabel 3.4.
dan
Tabel untuk Masing-masing Replika Bilangan Acak
pada Panjang Interval 0.05
L = 0.05
N=100
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
26.00 27.20 19.60 18.40 21.60 18.40 22.80 13.20 14.00 12.40 12.80
0.05
30.14 30.14 30.14 30.14 30.14 30.14 30.14 30.14 30.14 30.14 30.14
0.01
36.19 36.19 36.19 36.19 36.19 36.19 36.19 36.19 36.19 36.19 36.19
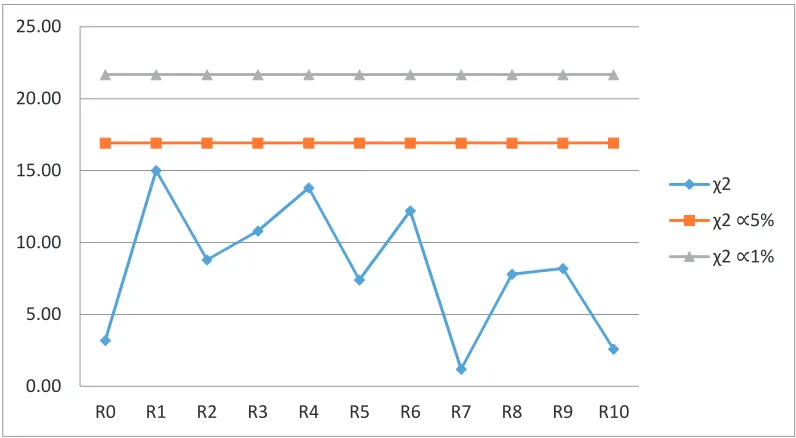
Gambar 3.4. Plot Perbandingan
dengan
Tabelpada Panjang Interval 0.05
untuk N=100
Hipotesis bahwa data acak diterima apabila
obs tabel
(
= 0.01) dan
obs tabel(
= 0.05)
[image:36.595.146.531.331.555.2]Data acak berasal dari aplikasi Ms Excel yang berdistribusi seragam dengan
standar deviasi yang cukup kecil.
Tabel 3.5.
dan
Tabel untuk Masing-masing Replika Bilangan Acak
pada Panjang Interval 0.1
L = 0.1
N=100
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
3.20 15.00
8.80 10.80 13.80
7.40 12.20
1.20
7.80
8.20
2.60
0.05
16.92 16.92 16.92 16.92 16.92 16.92 16.92 16.92 16.92 16.92 16.92
0.01
21.67 21.67 21.67 21.67 21.67 21.67 21.67 21.67 21.67 21.67 21.67
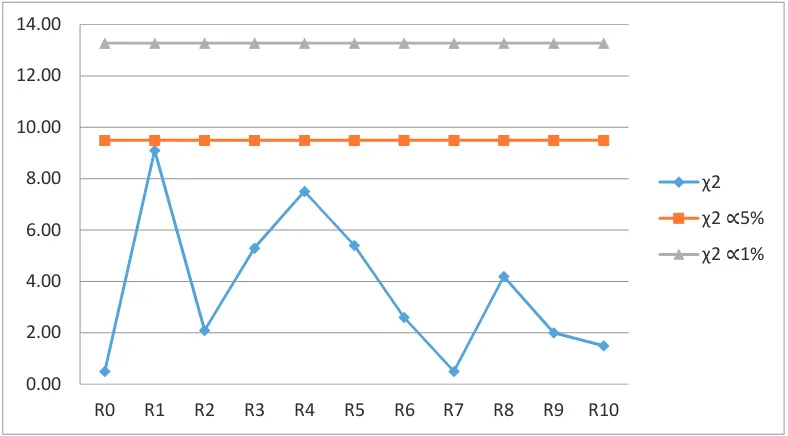
Gambar 3.5. Plot Perbandingan
dengan
Tabelpada Panjang Interval 0.1
untuk N=100
Uji
di atas menunjukkan bahwa pada tingkat kepercayaan
= 0.01 dan
= 0.05
hipotesis diterima, meskipun untuk beberapa replika hipotesis diterima tidak
secara signifikan, seperti pada replika pertama, replika ke empat dan replika ke
enam. Pada data awal, replika ketujuh dan replika kesepuluh hipotesis dapat
diterima secara signifikan dan data terdistribusi secara merata dengan standar
[image:37.595.145.543.343.562.2]Tabel 3.6.
dan
Tabel untuk Masing-masing Replika Bilangan Acak
pada Panjang Interval 0.2
L = 0.2
N=100
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
0.50
9.10
2.10
5.30
7.50
5.40
2.60
0.50
4.20
2.00
1.50
0.05
9.49
9.49
9.49
9.49
9.49
9.49
9.49
9.49
9.49
9.49
9.49
0.01
13.28 13.28 13.28 13.28 13.28 13.28 13.28 13.28 13.28 13.28 13.28
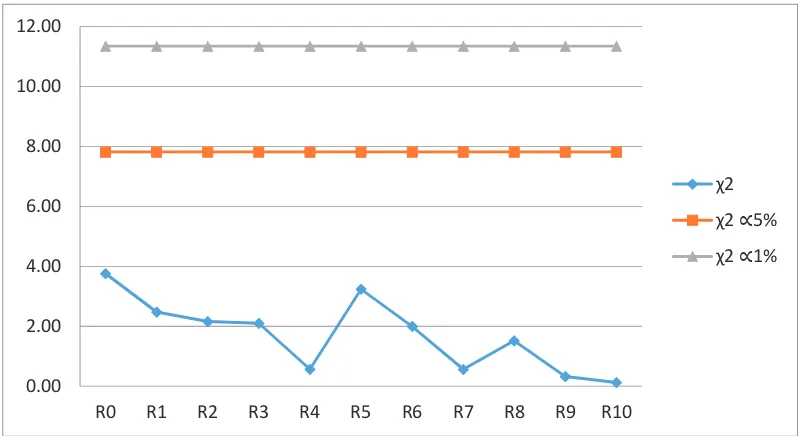
Gambar 3.6. Plot Perbandingan
dengan
tabelpada Panjang Interval 0.2
untuk N=100
[image:38.595.145.539.250.468.2]Tabel 3.7.
dan
Tabel untuk Masing-masing Replika Bilangan Acak
pada Panjang Interval 0.25
L = 0.25
N=100
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
2
3.76
2.48
2.16
2.10
0.56
3.24
2.00
0.56
1.52
0.32
0.12
2
0.05
7.82
7.82
7.82
7.82
7.82
7.82
7.82
7.82
7.82
7.82
7.82
2
0.01
11.35
11.35
11.35
11.35
11.35
11.35
11.35
11.35
11.35
11.35
11.35
Gambar 3.7. Plot Perbandingan
dengan
tabelpada Panjang Interval 0.25
untuk N=100
Pada gambar 3.7 dapat dilihat bahwa nilai
tidak melebihi
tabel, sehingga
hipotesis bahwa data acak diterima secara signifikan pada tingkat kepercayaan =
0.01 dan = 0.05. Data terdistribusi secara merata pada setiap kelas interval,
terutama pada replika keempat, ketujuh, kesembilan dan kesepuluh dengan nilai
[image:39.595.145.544.249.467.2]Tabel 3.8.
dan
Tabel untuk Masing-masing Replika Bilangan Acak
pada Panjang Interval 0.5
L = 0.5
N=100
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
0.16 1.96 1.44 0.00 0.36 4.84 3.24 0.04 0.36 0.16 0.00
0.05
3.84 3.84 3.84 3.84 3.84 3.84 3.84 3.84 3.84 3.84 3.84
0.01
6.64 6.64 6.64 6.64 6.64 6.64 6.64 6.64 6.64 6.64 6.64
Gambar 3.8. Plot Perbandingan
dengan
tabelpada Panjang Interval 0.5
untuk N=100
Uji frekuensi
pada panjang interval 0.5 dengan derajat kebebasan 1, data acak
diterima pada
= 0.01 untuk setiap replika. Tetapi pada tingkat kepercayaan =
0.05, hipotesis bahwa data acak ditolak untuk replika kelima karena nilai
obs>
tabel.
Standar deviasi untuk replika kelima cukup besar yaitu 15.55. Pada replika
ketiga dan kesepuluh standar deviasi data acak mencapai nila nol yang dapat
diartikan bahwa data pada panjang interval 0,5 untuk replika tersebut terdistribusi
secara merata. Namun secara keseluruhan data acak yang berasal dari aplikasi Ms
[image:40.595.142.547.251.468.2]3.5.2. Jumlah Bilangan Acak N=500
Tabel 3.9.
dan
Tabel untuk Masing-masing Replika Bilangan Acak pada
Panjang Interval 0.004
L = 0.004
N=500
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
247.00 276.00 256.00 251.00 260.00 233.00 245.00 242.00 242.00 236.00 268.00
[image:41.595.142.547.262.477.2]0.05
286.09 286.09 286.09 286.09 286.09 286.09 286.09 286.09 286.09 286.09 286.09
0.01
302.58 302.58 302.58 302.58 302.58 302.58 302.58 302.58 302.58 302.58 302.58
Gambar 3.9. Plot Perbandingan
dengan
tabelpada Panjang Interval 0.004
untuk N=500
Dari gambar 3.9 dapat dilihat bahwa
obslebih kecil dari
tabel, maka hipotesis
bahwa bilangan acak yang dihasilkan adalah benar-benar acak dapat diterima pada
tingkat kepercayaan = 0.01 dan = 0.05. Karena nilai
obsmendekati nilai
tabel
, maka dapat disimpulkan data acak diterima tetapi tidak secara signifikan.
Data setiap kelas interval dapat dikatakan terdistribusi cukup merata untuk semua
replika karena mempunyai standar deviasi yang cukup kecil. Dengan rata-rata
Tabel 3.10.
dan
Tabel untuk Masing-masing Replika Bilangan Acak pada
Panjang Interval 0.01
L = 0.01
N=500
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
94.80
85.60 107.20 100.80
93.20
70.00
96.80
96.80
86.80
67.20 124.80
[image:42.595.143.549.237.454.2]0.05
122.46 122.46 122.46 122.46 122.46 122.46 122.46 122.46 122.46 122.46 122.46
0.01
133.34 133.34 133.34 133.34 133.34 133.34 133.34 133.34 133.34 133.34 133.34
Gambar 3.10. Plot Perbandingan
dengan
tabelpada Panjang Interval 0.01
untuk N=500
Hasil uji frekuensi
pada gambar di atas, pada tingkat kepercayaan
= 0.01, hipotesis
bahwa data acak diterima. Sedangkan pada tingkat kepercayaan = 0.05, hipotesis
data acak ditolak untuk data pada replika kesepuluh karena nilai
obs>
tabel.
Tabel 3.11.
dan
Tabel untuk Masing-masing Replika Bilangan Acak
pada Panjang Interval 0.02
L = 0.02
N=500
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
39.20 49.00 64.40 54.20 53.60 31.40 42.20 40.20 40.80 33.20 72.40
[image:43.595.143.536.277.495.2]0.05
65.55 65.55 65.55 65.55 65.55 65.55 65.55 65.55 65.55 65.55 65.55
0.01
73.57 73.57 73.57 73.57 73.57 73.57 73.57 73.57 73.57 73.57 73.57
Gambar 3.11. Plot Perbandingan
dengan
tabelpada Panjang Interval 0.02
untuk N=500
Uji frekuensi menunjukkan bahwa pada tingkat kepercayaan = 0.01, hipotesis
data acak dapat diterima. Hipotesis diterima secara signifikan untuk data awal,
replika kelima sampai replika kesembilan. Pada replika sepuluh, nilai
obshampir
melebihi nilai
tabel,meskipun demikian hipotesis masih dapat diterima. Sedangkan
pada tingkat kepercayaan = 0.05, replika kesepuluh ditolak sebagai data acak
Tabel 3.12.
dan
Tabel untuk Masing-masing Replika Bilangan Acak pada
Panjang Interval 0.04
L = 0.04
N=500
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
30.40 13.80 41.70 26.20 20.20 21.90 21.60 15.30 19.70 18.80 23.30
0.05
36.42 36.42 36.42 36.42 36.42 36.42 36.42 36.42 36.42 36.42 36.42
0.01
42.98 42.98 42.98 42.98 42.98 42.98 42.98 42.98 42.98 42.98 42.98
[image:44.595.145.509.237.456.2]Gambar 3.12. Plot Perbandingan
dengan
tabelpada Panjang Interval 0.04
untuk N=500
Hipotesis bahwa data acak secara signifikan diterima apabila
obs tabel
(
= 0.01) dan
obs tabel(
= 0.05)
Hasil uji frekuensi
, pada tingkat kepercayaan
= 0.01, nilai
obs tabelmaka
Tabel 3.13.
dan
Tabel untuk Masing-masing Replika Bilangan Acak
pada Panjang Interval 0.05
L = 0.05
N=500
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
13.52 11.84 24.24 20.88 10.64 14.96 17.92
7.52 13.44 15.52 27.28
[image:45.595.140.548.206.463.2]0.05
30.14 30.14 30.14 30.14 30.14 30.14 30.14 30.14 30.14 30.14 30.14
0.01
36.19 36.19 36.19 36.19 36.19 36.19 36.19 36.19 36.19 36.19 36.19
Gambar 3.13. Plot Perbandingan
dengan
tabelpada Panjang Interval 0.05
untuk N=500
Tabel 3.14.
dan
Tabel untuk Masing-masing Replika Bilangan Acak pada
Panjang Interval 0.1
L = 0.1
N=500
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
10.20
4.84
4.56
8.76
3.04 10.80
8.04
4.08
4.76
6.64 12.16
0.05
16.92 16.92 16.92 16.92 16.92 16.92 16.92 16.92 16.92 16.92 16.92
0.01
21.67 21.67 21.67 21.67 21.67 21.67 21.67 21.67 21.67 21.67 21.67
Gambar 3.14. Plot Perbandingan
dengan
tabelpada Panjang Interval 0.1
untuk N=500
Dari gambar 3.14 di atas dapat dilihat bahwa untuk panjang interval 0.1 dengan derajat
kebebasan 9, untuk selang kepercayaan
= 0.05 hipotesis diterima sebagai data acak.
Begitu juga dengan tingkat kpercayaan
= 0.01, hipotesis bahwa data acak
[image:46.595.140.541.198.454.2]Tabel 3.15.
dan
Tabel untuk Masing-masing Replika Bilangan Acak
pada Panjang Interval 0.2
L = 0.2
N=500
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
6.40
3.80
2.14
5.12
1.34
6.30
4.86
3.20
2.66
4.66
6.06
0.05
9.49
9.49
9.49
9.49
9.49
9.49
9.49
9.49
9.49
9.49
9.49
0.01
13.28 13.28 13.28 13.28 13.28 13.28 13.28 13.28 13.28 13.28 13.28
Gambar 3.15. Plot Perbandingan
dengan
tabelpada Panjang Interval 0.2
untuk N=500
Gambar 3.15 di atas menunjukkan bahwa pada tingkat kepercyaan
=0.01
hipotesis diterima secara signifikan. Begitu juga dengan tingkat kepercayaan =
0.05, hipotesis bahwa data acak diterima untuk panjang interval 0.2 untuk jumlah
[image:47.595.113.500.249.465.2]Tabel 3.16.
dan
Tabel untuk Masing-masing Replika Bilangan Acak
pada Panjang Interval 0.5
L = 0.5
N=500
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
0.65 0.12 0.00 1.57 0.00 3.53 0.00 1.15 1.35 1.15 0.97
0.05
3.84 3.84 3.84 3.84 3.84 3.84 3.84 3.84 3.84 3.84 3.84
0.01
6.64 6.64 6.64 6.64 6.64 6.64 6.64 6.64 6.64 6.64 6.64
Gambar 3.16. Plot Perbandingan
dengan
tabelpada panjang Interval 0.5
untuk N=500
Uji statistik
menunjukkan bahwa pada tingkat kepercayaan
= 0.01 hipotesis
bahwa data acak diterima secara signifikan. Begitu juga dengan = 0.05, hipotesis
dapat diterima meski pada replika kelima, nilai
obshampir melebihi
tabel.Data
yang memiliki standar deviasi paling besar adalah data pada replika ke lima
dengan nilai 29.70. Sedangkan pada replika kedua, keempat dan keenam, data
[image:48.595.130.538.150.453.2]3.6.
Contoh Masalah Aplikasi Bisnis
Contoh masalah aplikasi bisnis untuk menguji keacakan data pada penilitian ini
akan diadopsi dari Gottfried (1994).
Perusahaan X akan mengembangkan suatu produk baru dan ingin
mengevaluasi keuntungan dari produk baru ini. Perusahaan memperkirakan bahwa
terdapat 35% peluang untuk menjual dengan harga antara $40.000 - $60.000, 40%
peluang untuk menjual produk sebesar antara $60.000 - $80.000 dan 25% peluang
untuk menjual dengan harga antara $80.000 - $100.000 pertahun. Berdasarkan
kondisi pasar saat ini tidak ada kecenderungan bahwa perusahaan dapat menjual
<$40.000 atau >$100.000. Biaya produksi dan distribusi juga merupakan
ketidakpastian, di mana terdapat 20% peluang bahwa biaya untuk produksi dan
distribusi $60 - $70, 35% peluang bahwa biaya untuk produksi dan distribusi $70
- $80, 30% peluang bahwa biaya untuk produksi dan distribusi $80 - $90 dan 15%
peluang bahwa biaya untuk produksi dan distribusi $90 - $100.
Terdapat kecendrungan biaya produksi dan distribusi akan <$60 atau
>$100 per unit. Perusahaan ingin menentukan ekspektasi profit tahunan pada
suatu harga jual. Di samping itu, perusahaan ingin memperkirakan (estimasi)
peluang bahwa keuntungan tahunan akan jauh lebih kecil atau jauh lebih besar
dari nilai ekspektasi. Tujuannya adalah untuk melihat indikasi derajat risiko dan
hubungannya dengan rancangan bisnis yang diusulkan.
Misalkan
S = harga per unit
C = total biaya per unit
V = volume atau jumlah unit yang terjual per tahun
P = profit atau keuntungan tahunan
Profit tahunan dapat ditulis sebagai :
P = (S – C) V
Di mana C dan V (dan dengan demikian P) merupakan variasi acak dan S
perlu dievaluasi volume penjualan tahunan (V) dan biaya per unit (C). Salah satu
cara untuk melakukan simulasi adalah dengan menghasilkan bilangan acak u
i
berdistribusi seragam dalam interval (0,1).
Jika u
1
0.35;
maka V = 50000 unit, yang merupakan nilai tengah
dari kategori
0.35 < u
1
0.75;
maka V = 70000 unit
0.75 < u
1
;
maka V = 90000 unit
Subprogram untuk masalah ini dinamakan penjualan.
Diagram alir subprogram untuk masalah ini adalah sebagai berikut :
TURN
[image:50.595.100.444.318.676.2]V=
Gambar 3. 17 Diagram Alir Subprogram
Dengan cara yang sama, komponen biaya C dihasilkan dari bilangan acak u
2
berdistribusi seragam dalam interval (0,1).
V = 90000
U
1>0.3
5
RETURN
RETURN
U
1= RAND (0)
V = 70000
V = 50000
RETURN
U
1>0.7
Jika u
2
0.2;
maka C = $65
0.2 < u
2
0.55;
maka C = $75
0.2 < u
2
0.55;
maka C = $85
0.85 < u
2
;
maka C = $95
Subprogram dari masalah ini adalah biaya.
[image:51.595.134.485.260.679.2]Diagram alir subprogram untuk masalah ini adalah sebagai berikut :
Gambar 3. 18 Diagram Alir Subprogram
BIAYA
RETURN
RETURN
RETURN
RETURN
U
2=RAND(0)
C = 95
C = 85
C = 75
C = 65
U
2>0.2
U
2>0.85
U
2>0.55
Program utama dimulai dengan menggunakan harga jual S. Dalam
penelitian ini harga jual dibuat bervariasi, yaitu $100, $150 dan $200. Selanjutnya
dilakukan pengujian statistik untuk menguji tingkat keacakan data pada
subprogram penjualan dan biaya. Pengaruh keacakan data pada hasil simulasi
akan ditinjau dari hasil simulasi untuk menentukan ekspektasi profit dan standar
deviasi.
3.6.1. Simulasi untuk Harga Jual $100 per unit
Berikut merupakan representasi distribusi profit tahunan yang mungkin
[image:52.595.205.418.343.410.2]dapat dihasilkan:
Tabel 3.17. Tabel Rata-rata Profit dan Standar Deviasi untuk $100
Sale = $100
Replika
Profit Rata-Rata
Standar Deviasi
0
1606000
757497
10
1545000
855449
Profit rata-rata merupakan ekspektasi profit tahunan yang diperoleh.
Standar deviasi berkisar antara 700 dan 800 dolar, yang merupakan angka yang
besar relatof terhadap nilai profit rata-rata. Hal ini mengindikasikan bahwa profit
tahunan mungkin berbeda secara signifikan dari ekspektasi, yang berarti terdapat
risiko tinggi untuk menjalankan bisnis ini.
3.6.2. Simulasi Untuk Harga Jual $150 per unit
Berikut merupakan representasi distribusi profit tahunan yang mungkin
dapat dihasilkan:
Tabel 3.18. Tabel Rata-rata Profit dan Standar Deviasi untuk $150
Sale = $150
[image:52.595.207.417.675.739.2]Profit rata-rata merupakan ekspektasi profit tahunan yang diperoleh. Standar
deviasi berkisar antara 1.4 juta dan 1.5 juta dollar, yang merupakan angka yang
besar. Hal ini mengindikasikan bahwa profit tahunan mungkin berbeda secara
signifikan dari ekspektasi, yang berarti terdapat risiko tinggi untuk menjalankan
bisnis ini.
3.6.3. Simulasi Untuk Harga Jual $200 per unit
Berikut merupakan representasi distribusi profit tahunan yang mungkin dapat
[image:53.595.205.416.323.388.2]dihasilkan:
Tabel 3.19. Tabel rata-rata profit dan standar deviasi untuk $200
Sale = $200
Replika
Profit Rata-Rata
Standar Deviasi
0
8536000
2126648
10
8364000
2298353
Profit rata-rata merupakan ekspektasi profit tahunan yang diperoleh.
Standar deviasi rata-rata 2 juta dolar, yang merupakan angka yang besar. Hal ini
mengindikasikan bahwa profit tahunan mungkin berbeda secara signifikan dari
ekspektasi, yang berarti terdapat risiko tinggi untuk menjalankan bisnis ini.
Secara umum simulasi dengan harga $100, $150 dan $200 menunjukkan
bahwa terfspat standar deviasi yang relatif besar terhadap ekspektasi profit
tahunan. Hal ini menggambarkan bahwa profit tahunan yang dihasilakn dapat jauh
berbeda dengan ekpektasi, yang artinya mempunyai risiko tinggi untuk
menjalankan bisnis.
Besarnya standar deviasi merupakan akibat dari penyebaran data yang
tidak merata. Hal ini akibat dari kurang acaknya data, terdapatnya penumpukan
data di dalam beberapa kelompok kelas interval, yang terlihat dari jumlah
frekuensi data yang tidak tersebar secara seragam. Padahal data yang dihasilkan
Pada program Ms Excel, subprogram yang menghasilkan variasi bilangan
BAB 4
KESIMPULAN DAN SARAN
4.1.
Kesimpulan
Hasil simulasi menunjukkan bahwa hipotesis tingkat keacakan data ditinjau dari
uji frekuensi menunjukkan bahwa data dapat diterima sebagai bilangan acak pada
taraf signifikansi 1%. Untuk tarah signifikansi 5%, terdapat beberapa data yang
tidak dapat diterima sebagai data acak. Hasil uji keacakan pada setiap selang
kelas interval yang berbeda akan menghasilkan tingkat keacakan yang berbeda
pula. Nilai keacakan suatu data ketika diuji dengan menggunakan uji
menghasilkan bahwa semakin panjang selang interval, data semakin acak dan
terdistribusi secara merata.
Pola penyebaran data yang dihasilkan oleh program aplikasi pembangkit
bilangan acak bergantung pada metode yang digunakan untuk menghasilkan
bilangan acak, misalnya pada program aplikasi Ms Excel, subprogram untuk
menghasilkan variasi bilangan acak berdistribusi seragam 0 u
i
1 berdasarkan
metode
pseudorandom.
Program aplikasi yang digunakan untuk menghasilkan
bilangan acak jelas berpengaruh untuk menghasilkan tingkat keacakan barisan
bilangan acak yang dihasilkan.
4.2.
Saran
Dapat dilakukan penelitian lebih lanjut untuk menguji keacakan dengan uji
frekuensi yaitu dengan membandingkan apakah banyaknya replika bilangan acak
mempengaruhi tingkat siginifikansi keacakan data. Dalam melakukan simulasi
yang menggunakan bilangan acak, perlu dikaji terlebih dahulu metode yang
digunakan oleh program aplikasi dalam menghasilkan bilangan acak agar periode
diperlukan harus benar-benar acak dan mengikuti distribusi yang diinginkan.
Dengan demikian dapat ditentukan berapa banyak bilangan acak yang harus
43
DAFTAR PUSTAKA
Bulgren, W.G., 1982. Contents. Library of Congress Cataloging in Publication
Data. USA
Eagle, A. (2005) “Randomness is unpredictable” .
British Journal of Philosphical
Science
56 (2005), 749–790.
Fitzek, F. H. P., E. Mota, E. Ewers, K. Pawlikowski and A. Wolisz (2000). An
Efficient Approach for Speeding Up Simulation of Wireless Networks.
Proc.
of the Western Multiconferece. on Computer Simulation, WMSC'2000
. San
Diego
Gottfried, B. 1992 .Elements of Stochastic Process Simulation. Prentice Hall, Inc.
NJ
Goldreich, O. 2008).Computational Complexity: A Conceptual Perspective.
Cambridge University Press
Kakiay. T. J. 2004. Pengantar Sistem Simulasi. Andi. Yogyakarta.
Kim, S., K. Umeno, dan A. Hasegawa. 2003. On the NIST Statistical Test Suite
for Randomnes. IEICE Technical Report, Vol. 103, No. 449, pp. 21-27.
Law, Averil M,. Kelton, David W. 1991. Simulation Modeling and Analysis.
McGraw-Hill, inc. Singapore
Law, A.M. dan W.D. Kellton (2000) “Simulation Modeling and Analysis” 5
thed.
McGraw-Hill, inc. Singapore
Napitupulu, Humala. L. 2009. Simulasi Sistem Pemodelan dan Analisis. USU
Press. Medan
Noer, Ahmad. 2004. Statistik Deskriptif dan Probabilitas. PPFE. Yogyakarta
Pritsker, A,. Alan, B. 1986. Introduction to Simulation. Library of Congress
Cataloging in Publication Data. USA
Siagian, P. 2006. Penelitian Operasional: Teori dan Praktek. Penerbit Universitas
Indonesia. Jakarta.
44
Supangat, Andi. 2007. Statistika dalam Kajian Deskriptif, Inferensi dan
Nonparamterik. Kecana Prenda Media Grup. Jakarta
<