ANALISIS SENTIMEN TERHADAP ACARA TELEVISI
INDONESIA BERDASARKAN OPINI PUBLIK
SKRIPSI
Diajukan untuk memenuhi Ujian Akhir Sarjana
ADITIA RAKHMAT SENTIAJI 10110139
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
Name : Aditia Rakhmat Sentiaji
Place/ Date of Birth : Majalengka / 10 May 1992
Address : Sekeloa Tengah No.36 RT/RW 02/04
Gender : Male
Height/Weight : 165/50
Citizenship : Indonesia
Ethnic : Sundanese
Blood Type : O
Religion : Islam
Email : [email protected]
20010 – 2014 Indonesia Computer University (UNIKOM) Majors : Informatic Engineering
2007 – 2010 SMAN I Majalengka Majors : SCIENCE
2004 – 2007 SMPN 1 Kadipaten
1997 – 1998 TK Budi Asih V, Dawuan – Majalengka
2011 – 2012 HMIF (Himpunan Mahasiswa Teknik Informatika) UNIKOM
Young Class (Angkatan Muda)
2011- 2014 CODELABS UNIKOM Member
Lead (2012-2014)
2012- 2014 MSP (Microsoft Student Partner) Regional Jawa Barat Member
2013 First Winner In Indonesia ICT Awards 2013 Interactive Digital Media for Hyjabs
Mobile Application, in Jakarta
2013 Second Winner In Motekar UNPAD Awards 2013 Technology Inovation for Game Play Me Congklak, in Bandung
2014 Winner in Digital Creative Indonesia Telkomsel 2013 Aplikasi Paling Indonesia for Game Play Me Congklak, in Jakarta
Bandung, 2014
v
DAFTAR
ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... x
DAFTAR SIMBOL ... xii
DAFTAR LAMPIRAN ... xvi
BAB I PENDAHULUAN ... 1
I.1 Latar Belakang Masalah ... 1
I.2 Perumusan Masalah ... 3
I.3 Maksud dan Tujuan ... 3
I.4 Batasan Masalah ... 3
I.5 Metodologi Penelitian ... 4
I.5.1 Metode Pengumpulan Data ... 4
I.5.2 Metode Pembangunan Perangkat Lunak ... 4
I.5.3 Metode Ekstraksi ... 5
I.6 Sistematika Penulisan ... 6
BAB II LANDASAN TEORI ... 9
II.1 Sentimen Publik Terhadap Acara Televisi ... 9
II.2 Text Mining ... 10
II.3 Analisis Sentimen ... 10
II.4 Regular Expression ... 11
II.5 Preprocessing ... 13
II.6 Naïve Bayes Classifier ... 17
II.7 Percentage Split ... 18
II.8 Pemrograman Berorientasi Objek ... 18
II.9 Unified Modeling Language ... 20
vi
III.1 Analisis Sistem ... 23
III.1.1 Analisis Masalah ... 23
III.1.2 Analisis Sistem Penilaian Berjalan ... 23
III.1.3 Analisis Karakteristik Sumber Data ... 25
III.1.4 Analisis Preprocessing ... 29
III.1.5 Analisis Penerapan Algoritma Naïve Bayes Classifier ... 39
III.1.6 Analisis Penerapan Percentage Split ... 44
III.1.7 Analisis Kebutuhan Non Fungsional ... 46
III.1.7.1 Analisis Kebutuhan Perangkat Lunak ... 47
III.1.7.2 Analisis Kebutuhan Perangkat Keras ... 47
III.1.7.3 Analisis Kebutuhan Perangkat Pikir ... 47
III.1.8 Analisis Kebutuhan Fungsional ... 48
III.1.8.1 Deskripsi Global Perangkat Lunak ... 48
III.1.8.2 Use Case Diagram ... 48
III.1.8.3 Activity Diagram ... 58
III.1.8.4 Class Diagram ... 66
III.1.8.5 Sequence Diagram ... 67
III.2 Perancangan Sistem ... 69
III.2.1 Perancangan Data ... 69
III.2.2 Perancangan Antarmuka ... 71
III.2.3 Perancangan Pesan ... 74
III.2.4 Perancangan Fungsional ... 74
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM ... 77
IV.1 Implementasi Sistem ... 77
IV.1.1 Lingkungan Implementasi ... 77
IV.1.1.1 Implementasi Perangkat Lunak ... 77
IV.1.1.2 Implementasi Perangkat Keras ... 77
IV.1.2 Implementasi Data ... 78
IV.1.3 Implementasi Antarmuka ... 79
IV.2 Pengujian Sistem ... 79
vii
IV.2.3.2 Skenario Pengujian ... 80
IV.2.3.3 Hasil Pengujian ... 83
IV.2.3.1 Evaluasi Pengujian ... 95
BAB V KESIMPULAN DAN SARAN ... 97
V.1 Kesimpulan ... 97
V.2 Saran ... 97
98
DAFTAR PUSTAKA
[1] F. Rozy, "Rakyat Medeka Online," Indonesian Online Media Syndicate, 2
November 2009. [Online]. Available:
http://www.rakyatmerdeka.co.id/news/2009/11/02/83360/Pakar:-Televisi-Cenderung-Tampilkan-Wajah-Buruk. [Accessed 19 Maret 2014].
[2] J. Bernstein, “Social Media in 2013: By the Numbers,” Social Media Today Community, 6 November 2013. [Online]. Available: http://socialmediatoday.com/jonathan-bernstein/1894441/social-media-stats-facts-2013. [Diakses 27 Januari 2014].
[3] E. Turban, R. Sharda dan D. Delen, Decision Support and Business Intelligence Systems, 2011: Pearsson, New Jersey.
[4] F. Wulandini dan A. S. Nugroho, “ext Classification Using Support Vector Machine for Webmining Based Spation Temporal Analysis of the Spread of
Tropical Diseases,” International Conference on Rural Information and
Communication Technology, Jakarta, 2009.
[5] I. Sommerville, Software Engineering vol. 8th ed, Addison-Wesley, 2007. [6] N. A. Diakopoulos and D. A. Shamma, "Characterizing Debate Performance
via," Yahoo Research, 2010.
[7] R. Atmasari, “Acara TV Terburuk 2013 Versi Twitter,” Tempo, 19 Desember
2013. [Online]. Available:
http://www.tempo.co/read/news/2013/12/19/112538664/Acara-TV-Terburuk-2013-Versi-Twitter. [Diakses 18 Maret 2014].
99
[9] L. Vogel, “Java Regex - Tutorial, Vogella,” 14 Januari 2014. [Online]. Available:
http://www.vogella.com/tutorials/JavaRegularExpressions/article.html. [Diakses 19 April 2014].
[10] W. B. Croft, D. Metzler dan T. Strohman, “Document Parsing,” dalam Search Engines Information Retrieval in Practice, Boston, Pearson, 2010, pp. 86 - 101.
[11] R. Kirkby, E. Frank and P. Reutemann, "WEKA Explorer User Guide for Version 3-5-5," University of Waikato, 2007.
iii
KATA PENGANTAR
Assalamu’alaikum Wr.Wb
Puji dan syukur dipanjatkan kehadirat Allah SWT karena berkat rahmat dan karunia-Nya, penelitian yang berjudul “ANALISIS SENTIMEN TERHADAP
ACARA INDONESIA TELEVISI BERDASARKAN OPINI PUBLIK” dapat
terselesaikan sesuai dengan waktu yang diharapkan. Penelitian ini dibuat untuk memenuhi salah satu syarat kelulusan untuk program strata I, program studi Teknik Informatika di Fakultas Teknik dan Ilmu Komputer, Universitas Komputer Indonesia.
Melalui kata pengantar ini, disampaikan rasa terima kasih yang sebesar-besarnya kepada semua pihak yang telah terlibat secara langsung ataupun tidak langsung dalam meluangkan waktu dan pemikirannya sehingga penelitian ini dapat terselesaikan. Berikut pihak-pihak yang telibat dalam penelitian ini.
1. Allah SWT atas bantuan dan izin-Nya penelitian ini bisa terselesaikan. 2. Keluarga yang telah mendukung dalam penelitian ini, khususnya mamah
(Ani Suryani), papah (Dadang Setiadi), dan wa nonoh yang selalu mendoakan untuk kelancaran penelitian ini beserta kakak (Setia Rakhmat Hidayat) dan adik-adik (Arif Setia Nurul Tauhidin dan Dani Setiadi Firman Ilahi) saya.
3. Bapak Adam Mukharil Bachtiar S.Kom.,M.T. selaku dosen pembimbing yang telah mengarahkan, memberikan masukan, dan membantu baik dalam proses bimbingan, seminar ataupun sidang dalam penelitian ini dan juga sebagai ketua codelabs yang telah membina saya menjadi seperti saat ini. 4. Ibu Dian Darmayanti S.Kom.,M.Kom. selaku dosen penguji 1 dan Ibu Rani
Susanto S.Kom.,M.Kom. selaku dosen penguji 3 yang telah memberikan masukan untuk perbaikan pada penelitian ini.
5. Bapak Irfan Maliki S.T.,M.T. yang telah menjadi dosen wali selama perkuliahan.
iv
yang terakhir juga Aldy Ginanjar yang sekaligus teman seperjuangan IF-4 2010 berjuang bersama menyelesaikan perkuliahan selama 4 tahun dan teman dan juga teman-teman codelabs lainnya.
7. Teman-teman seperjuangan bimbingan Bapak Adam Mukharil Bachtiar S.Kom,.M.T. yang setiap minggunya memperjuangkan penelitiannya masing-masing.
8. Teman-teman sepananggung sependeritaan seven magnificent Ahmad Zaelani, Rijal Fauzi Sholihin, Rida Sukmara, Sugiono, Wydianto dari kelas IF-4 2010, dan teman – teman kelas lainnya yang merasakan bersama-sama manis pahitnya dunia perkuliahan dan juga teman-teman angkatan 2010. 9. Beserta pihak-pihak lain yang tidak bisa disebutkan satu persatu yang telah
memberikan bantuan dan dukungannya.
Mohon maaf apabila untuk segala kekurangan yang ada dalam penelitian ini, baik di dalam isi, maupun dalam pengetikan, karena penelitian ini masih jauh dari kata sempurna. Akhir kata, semoga penelitian ini bisa berguna bagi mahasiswa atau pihak lain yang tertarik mengetahui lebih jauh mengenai analisis sentimen.
Wassalamualaikum Wr. Wb
Peneliti
1
BAB I
PENDAHULUAN
I.1. Latar Belakang Masalah
Dunia pertelevisian Indonesia kini sedang berkembang. Terbukti dari semakin banyaknya stasiun televisi swasta baru mengudara baik yang bersifat nasional ataupun lokal. Banyaknya jumlah stasiun televisi tentu akan berbanding lurus dengan jumlah dan keberagaman acara televisi. Namun sayangnya dengan banyaknya jumlah acara televisi tidak diimbangi dengan kualitas acara tersebut. Banyak acara televisi yang lebih mengedepankan aspek hiburan akan tetapi tidak mendidik. Banyak acara yang menonjolkan kekerasan, saling menghina, mengumbar aib seseorang, mengeksploitasi kekurangan seseorang dan lain sebagainya. Hal tersebut banyak dilakukan hanya untuk meningkatkan rating dan
share acara tersebut. Senada dengan apa yang diungkapkan oleh dosen komunikasi Universitas Indonesia dan anggota tim panel pemantau KPI Pusat, Nina Mutmainah Armando. Menurut beliau, seringkali ditampilkan acara yang melanggar norma kesopanan melecehkan orang, menggunakan bahasa kasar dan menggunakan anak dalam setting film yang tidak pantas [1].
2
Sayangnya media sosial tidak mempunyai kemampuan untuk mengagregasi
topics yang ada di twitter pun hanya menampilkan topik yang sedang banyakdiperbincangkan tanpa memberikan suatu kesimpulan. Diperlukan metode khusus agar informasi seperti acara televisi dapat menggunakan banyak sudut pandang yang bisa digunakan untuk mengambil sebuah kesimpulan tentang postif atau negatifnya suatu acara televisi.
Berdasarkan penjelasan sebelumnya, diperlukan sebuah cara agar dapat mengklasifikasikan opini publik menjadi pengetahuan baru berupa kesimpulan negatif atau positifnya mengenai acara televisi dari data yang ada di media sosial. Hal tersebut dimungkinkan dengan menggunakan text mining. Text mining yang juga dikenal dengan text data mining adalah sebuah proses yang semi otomatis melakukan klasifikasi dari pola yang ada dari database yang tidak terstruktur [3].
Sehingga, hasil dari klasifikasi tersebut bisa menjadi media alternatif bagi masyarakat untuk memilih acara televisi yang berkualitas.
Berdasarkan hasil dari beberapa penelitian mengenai pengklasifikasian informasi subjektif atau yang sering disebut analisis sentimen. Dibutuhkan suatu algoritma untuk dapat mengklasifikasikan suatu opini ke dalam kelas negatif atau positif. Adapun algoritma yang dapat digunakan dalam pengklasifikasian adalah C45, Support Vector Machine (SVM), Naïve Bayes Classifier (NBC), K-Nearest Neighbors, Information Fuzzy Networks, dan masih banyak algoritma lainnya. Melihat hasil dari penelitian Fatimah Wulandini dan Anto Satriyo Nugroho (Text Classification Using Support Machine for Webmining Based Spation Temporal
Analysis of the Spread of Tropical Disease, 2009) mendapatkan hasil bahwa algoritma SVM menunjukan akurasi paling tinggi pada kategorisasi teks Bahasa Indonesia dengan presentase 92.5%, tidak jauh berbeda dengan algoritma NBC yang memiliki presentase 90% [4].
3
lebih rendah, dan akurasi yang tidak terlalu jauh berbeda dari SVM, NBC lebih cocok untuk diimplementasikan dalam penelitian ini.
I.2. Perumusan Masalah
Berdasarkan penjelasan dari latar belakang ditemukan beberapa permasalahan yang dirumuskan ke dalam satu rumusan masalah adalah bagaimana mengklasifikasi informasi sentimen publik mengenai acara televisi dari opini publik yang ada di media sosial.
I.3. Maksud dan Tujuan
Maksud dari penelitian ini adalah mengklasifikasi informasi dari media sosial mengenai sentimen publik terhadap acara-acara televisi nasional berdasarkan opini publik di media sosial.
Adapun tujuannya dari penelitian ini adalah untuk memberikan informasi mengenai sentimen publik mengenai acara televisi sehingga bisa dijadikan referensi untuk menonton acara televisi.
I.4. Batasan Masalah
Dalam pembangunan perangkat lunak ini, pembahasan dibatasi agar tidak menyimpang dari tujuan yang ingin dicapai, adapun batasan masalahnya adalah :
1. Acara televisi yang akan dianalisis analisis sentimen publiknya dari televisi nasional.
2. Diambil maksimal 10 acara televisi unggulan dari masing-masing stasiun televisi.
3. Sistem yang akan dibangun berbentuk prototype.
4. Emoticon yang akan diproses adalah emoticon western style yang akan didefiniskan pada bahasan selanjutnya.
5. Data didapat langsung diambil dari Twitter memanfaatkan Twitter API. 6. Hasil klasifikasi disajikan dalam bentuk grafik.
4
8. Pendekatan analisis pembangunan perangkat lunak menggunakan analisis berorientasi objek.
I.5. Metodologi Penelitian
Metodologi penelitian yang digunakan dalam penelitian ini adalah penelitian kualitatif. Metode yang digunakan dalam penulisan laporan penelitian ini menggunakan dua metode, yaitu metode pengumpulan data dan metode pembangunan perangkat lunak.
I.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan dalam membantu penelitian ini menggunakan dua cara, yaitu dengan cara studi literatur dan dokumen.
1. Studi literatur
Mengumpulkan literatur, jurnal, dan bacaan-bacaan yang berhubungan dengan judul penelitian.
2. Pengumpulan Dokumen
Sumber data diambil dari sosial media twitter secara langsung.
I.5.2 Metode Pembangunan Perangkat Lunak
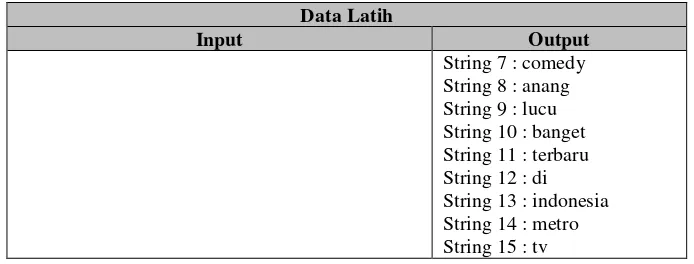
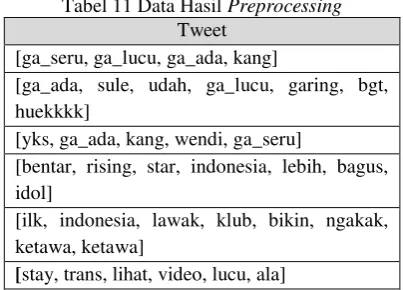
Pembangunan perangkat lunak ini menggunakan model waterfall sebagai tahapan pengembangan perangkat lunaknya.
1. Requirement analysis and definition
Tahap requirement analysis and definition merupakan tahap pengumpulan kebutuhan secara lengkap kemudian dianalisis dan didefinisikan kebutuhan yang harus dipenuhi oleh program yang akan dibangun. Fase ini harus dikerjakan secara lengkap untuk bisa menghasilkan desain yang lengkap.
2. System and Software design
Tahap system and software design merupakan tahap mendesain perangkat lunak yang dikerjakan setelah kebutuhan selesai dilakukan secara lengkap.
5
Tahap implementation and unit design merupakan tahap hasil desain program diterjemahkan ke dalam kode-kode dengan menggunakan bahasa pemrograman yang sudah ditentukan. Program yang dibangun langsung diuji baik secara unit.
4. Integration and system design
Tahap integration and system design merupakan tahap penyatuan unit-unit program kemudian diuji secara keseluruhan (system testing).
5. Operation and maintaince
Tahap operation and maintance merupakan tahap mengoperasikan program dilingkungannya dengan melakukan pemeliharaan, seperti penyesuaian atau perubahan karena adaptasi dengan situasi sebenarnya.
Gambar I-1 Model Waterfall Menurut Sommerville [5]
I.5.3 Metode Ekstraksi
6
1. Ekstraksi dan pengelompokan entitas
Mengekstraksi semua ekspresi entitas dari dokumen dan mengelompokan entitas tersebut. Karena mungkin untuk satu entitas ada dua penulisan berbeda.
2. Ekstraksi dan pengelompokan aspek
Aspek kategori merepresentasikan aspek yang unik dari entitas.sementara ekspresi aspek adalah kata atau frasa yang muncul mengindikasikan kategori aspek. Ekspresi aspek bisa berbentuk kata benda, kata kerja, kata sifat, atau keterangan.
3. Ekstraksi dan pengelompokan pemilik opini
Mengekstraksi pemilik opini dari data yang terstruktur kemudian mengkategorisasikan. Dapat dianalogikan dengan dua tugas di atas. 4. Ekstraksi dan standardisasi waktu
Mengekstraksi waktu ketika opini dikeluarkan dan melakukan standardisasi format waktu yang berbeda.
5. Klasifikasi aspek sentimen
Menentukan apakah sebuah opini apakah termasuk opini negatif ataukah opini positif.
I.6. Sistematika Penulisan
Sistematika penulisan penelitian ini disusun untuk memberikan gambaran umum mengenai penelitian yang dikerjakan. Sistematika penulisan penelitian sebgai berikut :
BAB I PENDAHULUAN
Bab ini menguraikan latar belakang permasalahan, merumuskan inti permasalahan, mencari solusi atas masalah tersebut, merumuskan masalah tersebut, menentukan maksud dan tujuan, kegunaan penelitian, pembatasan masalah, asumsi masalah, dan sistematika penulisan dari penelitian mengenai analisis sentimen ini.
BAB II LANDASAN TEORI
7
permasalahan dan hal-hal yang berguna dari penelitian-penelitian dan sintesis serupa yang pernah dikerjakan sebelumnya dan menggunakan sebagai acuan pemecah masalah pada penelitian ini.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini menganalisis masalah dari objek penelitian untuk mengetahui hal atau masalah apa yang timbul dan mencoba memecahkan permasalahan tersebut dengan memperangkat lunakan perangkat-perangkat yang digunakan. Sedangkan perancangan adalah suatau tahap pada penelitian dimana perangkat yang digunakan ditentukan, mengidentifikasi data yang diperlukan, serta menentukan cara kerja perangkat yang digunakan terhadap objek penelitian yang dirumuskan.
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini menjelaskan proses dimana analisis dan perancangan yang telah dipersiapkan untuk selanjutnya diimplementasikan menjadi perangkat lunak dan dilakukan pengujian terhadap perangkat lunak tersebut.
BAB V KESIMPULAN DAN SARAN
9
BAB II
LANDASAN TEORI
II.1. Sentimen Publik Terhadap Acara Televisi
Pada tahun 2008 stasiun televisi di Amerika Serikat melakukan suatu terobosan dengan mulai mengkombinasikan media sosial khususnya micro
-blogging seperti twitter untuk menciptakan pengalaman sosial video di sepanjang peristiwa. Saat itu acara pertama yang menggunakan terobosan ini untuk acara debat perdana pemilihan presiden Amerika Serikat. Dibuatlah sebuah metodologi analisis yang menghitung jumlah nilai dari pesan sentimen yang ada di twitter dan direpresentasikan ke dalam bentuk visual. Hal tersebut dilakukan untuk membantu para wartawan atau humas untuk memahami dinamika sementara dari sentimen sebagai reaksi perdebatan acara.
Nama dari acara televisi yang melakukan hal tersebut adalah Hack the Debate. Pada acara tersebut mereka meminta partisipasi dari publik untuk mengomentari selama acara debat berlangsung. Menggunakan layanan Twitter,
tweet yang dikirimkan oleh publik ditampilkan di TV di bawah berlangsungnya debat calon presiden antara Barack Obama dan John McCain pada saat itu. Acara tersebut menjadi pionir bagi acara lainnya untuk melakukan hal yang sama. Dengan banyaknya tweet membangun sebuah kesempatan untuk memahami sentimen publik yang diwakili oleh para pengguna twitter [6].
10
II.2. Text Mining
Text mining yang juga dikenal dengan text data mining atau pencarian pengetahuan di basis data textual adalah sebuah proses yang semi otomatis melakukan ekstraksi dari pola yang ada di database. Dari hasil ekstraksi tersebut munculah pengetahuan baru yang bisa dimanfaatkan untuk kepentingan pengambilan keputusan. Text mining mempunyai kesamaan dengan data mining. Keduanya memliki tujuan yang sama yaitu untuk memperoleh informasi dan pengetahuan dari sekumpulan data yang sangat besar. Data tersebut bisa berbentuk sebuah database. Namun keduanya memiliki perbedaan jenis data. Data mining
memiliki input data dari data yang sudah terstruktur sedangkan text mining dimulai dengan data yang tidak terstruktur.
Pemanfaatan dari text mining secara nyata sangatlah luas. Areanya seluas data tekstual yang terbentuk seperti di area hukum dengan data putusan pengadilan, penelitian dengan data artikel penelitian, keuangan dengan data laporan triwulan, teknologi dengan data arsip paten, pemasaran dengan data komentar konsumen, dan di area lainnya. Sebagi contoh sebuah perusahaan membuat formulir yang biasa diisi apabila konsumennya ingin memuji, komplain, ataupun klaim garansi. Dari kartu formulir tersebut terbentuklah data yang sangant besar dan bisa digunakan untuk mengidentifikasi secara objektif produk dan layanan dari suatu perusahaan menggunakan text mining. Selain itu proses text mining yang dilakukan secara otomatis adalah dibidang komunikasi elektronik dan email. Text mining tidak hanya mengklasifikasikan dan menyaring email sampah, tetapi bisa juga memprioritaskan
email secara otomatis berdasarkan tingkat kepentingannya [3].
II.3. Analisis Sentimen
11
mengklasifikasikan mengenai sifat yang berlawanan (antara positif dan negatif). Dari pengertian tersebut menjadi sebuah fakta yang menyebabkan beberapa penulis bahwa istilah analisis sentimen mengacu pada tugas yang sempit atau spesifik. Namun saat ini banyak yang menafsirkan istilah analisis sentiment lebih luas lagi yang berarti cara pengkomputasian pendapat, sentimen, dan subjektifitas pada teks [8].
Sistem analisis sentimen saat ini sudah banyak diterapkan di hampir setiap bisnis dan domain sosial karena opini menjadi pusat semua aktivitas manusia dan menjadi kunci yang mempengaruhi sikap seseorang. Dari keyakinan dan persepsi realita, dan pilihan yang dibuat sesorang, sebagian besar dipengaruhi oleh opini orang lain. Karena alasan itulah, keputusan sesorang yang diambil sering berdasarkan opini atau pendapat orang lain. Hal tersebut tidak hanya berlaku bagi individu tetapi juga bagi organisasi.
II.4. Regular Expression
Regular expression atau yang biasa disingkat dengan regex adalah sebuah untaian teks untuk menggambarkan pencarian sebuah pola. Regex biasa digunakan untuk pencarian atau memanipulasi teks. Pola yang dibentuk oleh regex mungkin akan cocok sekali, beberapa kali, atau tidak sama sekali untuk teks yang diberikan. Regex didukung oleh banyak bahasa pemrograman, seperti PHP, C#, Java dan banyak bahasa pemrograman lainnya. Berikut adalah aturan-aturan penulisan
regular expression dalam bahasa pemrograman Java [9]. 1. Pencocokan simbol umum
Regular expression menyediakan pola yang bisa digunakan untuk mencocokan simbol-simbol yang umum pada suatu teks. Pada Tabel II-1 akan dijelaskan regex
12
Tabel II-1 Daftar Simbol Umum Regex
Regular Expression Deskripsi
. Mencocokan dengan karakter apapun
^regex Menemukan kata regex yang ada di awal baris.
regex$ Menemukan kata regex yang ada di akhir baris.
[abc] Tanda kurung siku digunakan untuk mencocokan salah satu
huruf yang ada di dalamnya. Contoh digunakan untuk mencocokan dengan huruf a atau b atau c.
[abc][de] Mencocokan dengan huruf a atau b atau c kemudian diikuti
dengan huruf d atau e.
[^abc] Tanda sisipan yang muncul dalam tanda kurung siku
sebagai tanda negasi. Contoh digunakan untuk mencocokan dengan huruf apapun kecuali a atau b atau c.
[a-d1-7] Mencocokan dengan deretan huruf yang yang ada dari a
hingga d dan 1 sampai 7.
a|b Menemukan a atau b.
Ab Menemukan a yang kemudian diikuti dengan b.
a!b Mrnrmukan a yang kemudian diikuti bukan dengan b
2. Metacharacters
Metacharacter berikut memiliki arti yang ditentukan dan membuat pola umum yang lebih mudah digunakan. Berikut contohnya pada Tabel II-2 .
Tabel II-2 Daftar Metacharacter Regex
Regular Expression Deskripsi
\d Mencocokan dengan angka, lebih sederhana dari [0-9]
\D Mencocokan dengan bukan angka, lebih sederhana dari [^0-9]
\s Mencocokan dengan spasi, lebih sederhana dari [ \t\n\x0b\r\f]
\S Mencocokan dengan bukan spasi, lebih sederhana dari [ ^\s]
\w Mencocokan dengan alphanumerik, lebih sederhana dari
[a-zA-Z_0-9]
\W Mencocokan dengan bukan alphanumerik, lebih sederhana dari
13
3. Quantifier
Quantifier mendefinisikan seberapa sering sebuah elemen dapat terjadi. Berikut contoh dan deskripsi pada Tabel II-3.
Tabel II-3 Daftar Quantifier Regex
Regular Expression Deskripsi Contoh
* Terjadi kemunculan tidak sama
sekali atau berkali-kali. Lebih sederhana dari {0,}.
a* menemukan tidak sama
sekali atau berkali-kali
kemunculan huruf a
+ Terjadi kemunculan sekali atau
berkali-kali. Lebih sederhana dari {1,}
a+ menemukan sekali atau
berkali-kali kemunculan
huruf a
? Terjadi kemunculan tidak sama
sekali atau sekali. Lebih sederhana dari {0,1}
A? menemukan tidak sama sekali atau tepat satu kali kemunculan huruf a
{x} Terjadi kemunculan sebanyak x \d{5} mencari untuk angka
yang memiliki tiga digit.
{x,y} Terjadi kemunculan sebanyak x
hingga ke y.
\d{1-5} berarti \d harus muncul meninmal satu dan paling banyak lima kali.
4. Backslash
Backslash digunakan di dalam regular expression memiliki arti yang ditentukan dalam Java. Sebelumnya telah dibahas penggunaan secara implisit penggunaan backslah. Dalam implementasinya ketika ingin mendefiniskan \w , maka harus menggunakan \\w di regex yang dibuat. Jika ingin mendefiniskan backslahes dan tanda baca lainnya maka menggunakan double backslashes diikuti dengan tanda baca.
II.5. Preprocessing
Tahan preprocessing diperlukan untuk membersihkan data dari yang tidak diperlukan, dengan tujuan pada tahap masuk ke dalam metode Naïve Bayes Classiffier lebih optimal dalam perhitungannya. Pada tahap ini melibatkan rekognisi dari isi dan struktur teksnya. Adapun tahapan-tahapan dari preprocessing.
1. Convert Emoticon
14
yang bersesuaian. Jenis emoticon yang akan diproses oleh adalah emoticon western style, dikarenakan jenis tersebut banyak digunakan atau menjadi standar di semua platform seperti web ataupun mobile. Pada Tabel II-4 dijelaskan hasil pengklasifikasian arti dari emoticon western style secara umum.
Tabel II-4 Daftar Emoticon Yang Akan Dikonversi
Emoticon Deskripsi
Pada Tabel II-5 dijelaskan contoh penerapan dari convert emoticon menjadi kata.
Tabel II-5 Contoh Penerapan Dari Convert Emoticon
Data Latih
Input Output
Gokil,kocak,gila,seru,ngakak, ea Cuma di Indonesia Lawak Klub ;)
Gokil,kocak,gila,seru,ngakak, ea Cuma di Indonesia Lawak Klub senang
Jelek yks sekarang mah :-( Jelek yks sekarang mah kecewa
2. Cleansing
Clenasing merupakan proses membersihkan kata-kata yang tidak diperlukan untuk mengurangi noise. Kata yang dihilangkan adalah URL, hashtag (#),
username (@username), dan email. Selain itu juga tanda baca seperti titik(.), koma(,), dan tanda baca yang lainnya akan dihilangkan. Pada Tabel II-6 dijelaskan contoh penerapan dari cleansing:
Tabel II-6 Contoh Penerapan Cleansing
Data Latih
Input Output
Saya suka video @YouTube
http://youtu.be/wjLPx8J1dDs?a MATANAJWA-
Memilih Wakil Rakyat - Iwan Fals, Ahok, JK & DS (Full)
Saya suka video MATA NAJWA
Memilih Wakil Rakyat Iwan Fals Ahok JK DS Full
Stand UpComedy Anang! stand upcomedyAnang Lucu
Banget Terbaru 2014 indonesia metro tv
http://www.youtube.com/watch?v=JoSg0a4Q8vY …
Stand UpComedy Anang stand up
comedy Anang Lucu Banget
15
3. Case Folding
Case folding merupakan tahapan merubah bentuk kata-kata menjadi sama bentuknya, baik semuanya menjadi lower case ataupun menjadi upper case. Pada Tabel II-7 dijelaskan contoh dari penerapan proses case folding.
Tabel II-7 Penerapan Tahapan Case Folding
Data Latih
Input Output
Saya suka video MATA NAJWA
Memilih Wakil Rakyat Iwan Fals Ahok JK DS Full
saya suka video mata najwa memilih wakil rakyat iwan fals ahok jk ds full
Stand Up Comedy Anang stand up
comedy Anang Lucu Banget Terbaru
indonesia metrotv
stand up comedy anang stand up comedy anang lucu banget terbaru di indonesia metro tv
4. Convert Negation
Seperti halnya ilmu matematika, dalam bahasa terdapat kata yang dapat membalikan arti dari kata tersebut atau bersifat negasi. Kata-kata yang bersifat negasi adalah “kurang”, “tidak”, “enggak”, “ga”, “nggak”, “tak”, dan “gak”. Pada Tabel II-8 dijelaskan contoh penerapannya.
Tabel II-8 Contoh Penerapan Convert Negation
Sebelum Convert Negation Setelah Convert Negation
gak seru final indonesia idol tanpa virzha sabar virzha sukses pulang
ga_seru final indonesia idol tanpa virzha sabar virzha sukses pulang
5. Tokenizing
Tokenizing bekerja untuk mengidentifikasi kata-kata dalam teks menjadi beberapa urutan yang terpotong oleh spasi atau karakter spesial. Berikut contoh penerapan dari tokenizing.
Tabel II-9 Penerapan Tahapan Tokenizing
Data Latih
Input Output
stand up comedy anang stand up comedy anang lucu banget terbaru di indonesia metro tv
16
Data Latih
Input Output
String 7 : comedy String 8 : anang String 9 : lucu String 10 : banget String 11 : terbaru String 12 : di String 13 : indonesia String 14 : metro String 15 : tv
6. Stopping
Stopping berperan untuk membuang kata-kata yang sering muncul dan bersifat umum, kurang menunjukan relevansinya dengan teks. Kata-kata yang akan dibuang tersebut didefinisikan dalam stopword list. Contoh beberapa kata yang sering masuk ke dalam stopword list adalah “sebuah”, “yang”, dan “itu”. Berikut
adalah beberapa daftar stoplist yang disimpan dalam database.
Tabel II-10 Stoplist Proses Stopping
Masih Dong ke Ada Yoi
Malam Ya loe Pada Yang
Ini Dan juga Kita Saya
untuk Dari bagi Iya di mana
kapan Bisa mana Itu Sih
sudah Bikin dengan Anda Begitu
entah Lalu yuk Aku Adalah
gue Nanti tunggu Tau Kemarin
Berikut adalah contoh penerapan dari tahapan stopping:
Tabel II-11 Contoh Penerapan Stopping
Data Latih
Input Output
acara apaan tu d anteve pesbuker sih prtunjukan tp jgn kasih liat yg ngeri dong
17
7. Stemming
Stemming adalah tahapan untuk membuat kata yang berimbuhan kembali ke bentuk asalnya. Contohnya kata “memberikan” setelah melewati tahap ini maka akan menjadi “beri” [10].
Tabel II-12 Penerapan tahapan stemming
Data Latih
II.6. Naïve Bayes Classifier
Naïve bayes classifier adalah penggolong menggunakan statistik sederhana berdasarkan teorema bayes yang mengasumsikan bahwa keberadaan atau ketiadaan dari suatu fitur tertentu dari suatu kelas tidak berhubungan dengan keberadaan atau ketiadaan fitur lainnya. Sifatnya yang sebagai model probabilitas, naïve bayes classifier bisa dilatih dengan efisien sebagai supervised learning. Pada pengaplikasiannya, parameter estimasi untuk model naïve bayes menggunakan metode kemungkinan maksimum. Dengan kata lain, masih bisa bekerja dengan model naïve bayes tanpa harus mempedulikan bayesian probabilitas atau metode bayesian lainnya.
18
� �|�1, … , �� =� � � �� � 1, … , ��|� 1, … , ��
(II.1)
II.7. Percentage Split
Algoritma pengklasifikasi yang diterapkan dalam penelitian ini adalah algoritma naïve bayes classifier, akan dievaluasi tingkat keberhasilannya dalam mengklasifikasikan dokumen. Dari banyak metode yang ada, dalam penelitian ini menggunakan metode yang digunakan untuk mengevaluasi algoritma naïve bayes classifier tersebut menggunakan percentage split. Algoritma naïve bayes classifier
akan diuji dengan cara dari data latih yang digunakan akan dibagi dua untuk dijadikan sebagai data uji sebanyak n-% dan sisanya tetap sebagai data latih. Tentunya jumlah data latih harus lebih banyak dari data uji. Hasil training dari data latih yang sudah tadi akan digunakan untuk mengklasifikasikan data uji dan hasilnya menunjukan tingkat keakurasian algoritma naïve bayes classifier yang diimplementasikan [11].
II.8. Pemrograman Berorientasi Objek
Pemrograman berorientasi objek adalah sebuah pendekatan untuk pembangunan perangkat lunak di mana struktur dari perangkat lunak didasari dari objek yang saling berinteraksi satu sama lain untuk menyelesaikan suatu tugas. Sudut pandang dari pemrograman berorientasi objek menyelesaikan masalah dengan mengunakan objek, persis dengan apa yang ada di dunia nyata. Pemrograman berorientasi objek (PBO) dirancang untuk menutup kelemahan dari pemrograman berorientasi prosedural yang sulit untuk dikelola dan debug ketika kode yang dibuat telah mencapai beribu-ribu baris. Maka diperkenalkanlah struktur pemrograman untuk memecah kode ke dalam beberapa segmen atau biasa disebut prosedur atau fungsi. Dengan struktur tersebut kode mengalami perbaikan, tetapi secara program dapat melakukan fungsionalitas yang lebih kompleks. Berikut adalah konsep mendasar mengenai bahasa permrograman berorientasi objek.
1. Kelas
19
konteks PBO biasanya didasari dari pemodelan dari objek yang ada di dunia nyata dalam pemrograman untuk menyelesaikan masalah. Sebagai contoh, dilakukan pemodelan untuk sepeda untuk dijadikan sebuah kelas. Dalam sebuah sepeda misalkan terdiri dari roda, rangka, dan setir. Ketiga unsur tersebut bisa disebut sebagai atribut. Kemampuan dari sepeda itu bisa berjalan dan melompat. Kemampuan tersebut bisa disebut method yang ada di dalam kelas.
2. Objek
Objek adalah instansiasi dari sebuah class. Kemampuan yang bisa dilakukan oleh suatu objek bergantung apa dari isi yang didefinisikan dari class tersebut. 3. Abstraksi
Ketika membuat objek dalam aplikasi PBO, penting untuk menggunakan konsep dari abstraksi. Objek hanya berisi informasi yang relevan dengan konteks dari aplikasi. Contoh untuk pembangunan aplikasi pengiriman. Akan dibuat sebuah objek dengan nama produk dengan atribut ukuran dan berat. Warna akan menjadi informasi yang tidak berhubungan dan bisa diabaikan sebagi atribut dari objek produk. Di kasus lain seperti pembangunan aplikasi pencatatan pemesanan, warna menjadi informasi yang berhubungan dan bisa dijadikan atribut dari suatu objek.
4. Enkapsulasi
20
5. Polymorphism
Polymorphism adalah kemempuan untuk merespon pesan yang sama dengan cara yang berbeda. Misalkan ada dua objek yaitu sepeda dan motor. Dalam objek tersebut memiliki kemampuan method yang sama yaitu berjalan. Ketika method
berjalandari kedua objek tersebut dipanggil. Kedua objek tersebut menampilkan rekasi yang berbeda, sepeda berjalan dengan cara mengayuh pedal, sedangkan motor berjalan dengan cara menarik gas.
6. Inheritance
Inheritance dalam PBO untuk mengklasifikasikan objek di dalam program berdasarkan karakteristik umum. Dengan inheritance pemrograman lebih mudah karena bisa mengkombinasikan karakteristik umum ke dalam kelas induk kemudian bisa diturunkan ke kelas anaknya. Contoh dibuat kelas kendaraan yang berisikan method berjalan . Kemudian dibuat kelas kendaraan darat. Dalam kelas kendaraan darat tidak perlu membuat method berjalan di kelas kendaraan darat cukup dengan melakukan inheritance atau pewarisan method yang ada di kelas kendaraan ke kelas kendaraan darat [12].
II.9. Unified Modeling Language
Unified modeling language (UML) adalah bahasa pemodelan standar untuk pembangunan perangkat lunak ataupun sistem yang dibangun dengan pendekatan
object-oriented. Dalam merancang sistem, model memiliki peranan penting yaitu untuk mengelola kompleksitas. Pemodelan membantu untuk fokus menghubungkan aspek penting dari perancangan sistem. Sebuah model adalah sebuah abstraksi dari benda nyata. Model yang dibangun adalah penyederhanaan dari sistem yang dibangun. Memberikan maksud dan kelangsungan hidup sistem untuk dipahami, dievaluasi, dikritisasi bahkan lebih cepat dibandingkan harus langsung ke sistem sebenarnya.
21
hanya pemodelan perangkat lunak. Dari perubahan itulah yang membuat versi UML itu sendiri berkembang hingga kini 2.0. Secara keseluruhan ada 13 diagram yang dapat dimanfaatkan dari UML 2.0 ini. Namun dalam penelitian ini hanya akan diterapkan empat diagram. Tabel II-13 menjelasan mengenai diagram yang akan digunakan.
Tabel II-13 Diagram-Diagram Uml 2.0 yang Digunakan
Nama Diagram Deskripsi
Use Case Menggambarkan interaksi antara sistem yang akan dibangun dengan pengguna atau sistem eksternal. Juga membantu dalam pemetaan kebutuhan ke dalam sistem
Activity Menggambarkan aktivitas secara sekuensial dan pararel dalam sistem. Class Menggambarkan hubungan class, interface dalam sistem.
97
BAB V
KESIMPULAN DAN SARAN
Pada bab ini, akan diberikan kesimpulan mengenai penelitian analisis sentimen acara televisi berdasarkan opini publik, dan pembangunan peravngkat lunak yang dihubungkan dengan teori-teori mengenai segala hal yang berhubungan dengan analisis sentimen dan pembangunan perangkat lunak.
V.1. Kesimpulan
Dari hasil penelitian yang telah dilakukan terlihat bahwa algoritma naïve bayes dapat mengklasifikasikan suatu opini yang berupa tweet ke dalam dua kelas yaitu positif dan negatif dengan akurat. Tingkat keakurasian dari pengklasifikasian tersebut sangat dipengaruhi oleh proses training. Sehingga dapat disimpulkan dari hasil pengklasifikasian yang disajikan dalam bentuk grafik dapat terlihat dengan jelas informasi sentimen publik terhadap suatu acara televisi dan dapat dijadikan sebagai referensi untuk menonton acara televisi.
V.2. Saran
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
1 Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033ANALISIS SENTIMEN TERHADAP ACARA TELEVISI
BERDASARKAN OPINI PUBLIK
Aditia Rakhmat Sentiaji1,Adam Mukaharil Bachtiar2
1,2Teknik Informatika - Universitas Komputer Indonesia
Jl. Dipati Ukur No. 112-116, Bandung 40132
E-mail : [email protected] , [email protected]2
ABSTRAK
Banyak acara-acara televisi menjadi bahan perbincangan di media sosial, baik karena kualitas
acaranya yang bagus ataupun sebaliknya.Sayangnya
media sosial tidak mempunyai kemampuan untuk
mengagregasi informasi mengenai suatu
perbincangan yang ada menjadi sebuah kesimpulan. Salah satu cara untuk menarik kesimpulan dari hasil agregasi adalah menggunakan text mining. Karena salah satu fungsi dari text mining adalah untuk melakukan analisis sentiment. Naïve bayes classifier
adalah algoritma yang dimanfaatkan untuk
mengimplementasikannya. Agar mendukung
performansi yang cepat maka basis data yang digunakan adalah NoSQL.
Analisis sentimen menggunakan menggunakan algoritma naïve bayes classifier memberikan hasil
yang baik. Terbukti dengan pengujian
menggunakan algoritma percentage split
memperoleh akurasi ± 90%. Dibantu proses
preprocessing yang bertujuan untuk menghapus bagian yang tidak penting dan juga mengubah bentuk dokumen yang berbentuk tweet ke bentuk standar sehingga pengklasifikasian yang dilakukan oleh naïve bayes menjadi lebih akurat. Sehingga hasil dari analisis sentimen acara televise bisa dijadikan referensi dalam menentukan tontonan acara televisi.
Kata kunci : analisis sentiment, teks mining, NoSQL
1. PENDAHULUAN
Dunia pertelevisian Indonesia kini sedang berkembang. Terbukti dari semakin banyaknya stasiun televisi swasta baru mengudara baik yang bersifat nasional ataupun lokal. Banyaknya jumlah stasiun televisi tentu akan berbanding lurus dengan jumlah dan keberagaman acara televisi. Namun sayangnya dengan banyaknya jumlah acara televisi tidak diimbangi dengan kualitas acara tersebut. Banyak acara televisi yang lebih mengedepankan aspek hiburan akan tetapi tidak mendidik. Banyak
acara yang menonjolkan kekerasan, saling
menghina, mengumbar aib seseorang,
mengeksploitasi kekurangan seseorang dan lain
sebagainya. Hal tersebut banyak dilakukan hanya untuk meningkatkan rating dan share acara tersebut. Senada dengan apa yang diungkapkan oleh dosen komunikasi Universitas Indonesia dan anggota tim panel pemantau KPI Pusat, Nina Mutmainah Armando. Menurut beliau, seringkali ditampilkan acara yang melanggar norma kesopanan melecehkan
orang, menggunakan bahasa kasar dan
menggunakan anak dalam setting film yang tidak pantas [1].
Sentimen publik bisa dijadikan sebagai indikator untuk melihat apakah acara tersebut berkualitas atau tidak. Media sosial merupakan media yang sering digunakan untuk menuangkan sentimen atau opini publik mengenai acara televisi tersebut. Banyak acara-acara televisi menjadi bahan perbincangan di media sosial, baik karena kualitas acaranya yang bagus ataupun sebaliknya. Sebagai contoh di twitter, acara televisi yang sering di-tweet dalam suatu waktu akan menjadi trending topics. Hal tersebut bisa membuat pengguna yang melihat tertarik untuk menonton acara televisi tersebut ataupun tidak sama
sekali. Tergantung dari konteks yang
diperbincangkan. Sebagai informasi, twitter
memiliki sekitar 500 juta pengguna atau sekitar 4% dari seluruh pengguna twitter berasal dari Indonesia [2]. Angka-angka tersebut menggambarkan akan banyak sekali yang terpengaruh dari perbincangan yang lagi ramai dibahasa seperti acara televisi.
Sayangnya media sosial tidak mempunyai
kemampuan untuk mengagregasi informasi
mengenai suatu bahasan yang ada menjadi sebuah kesimpulan. Trending topics yang ada di twitter pun hanya menampilkan topik yang sedang banyak
diperbincangkan tanpa memberikan suatu
kesimpulan. Diperlukan metode khusus agar informasi seperti acara televisi dapat menggunakan banyak sudut pandang yang bisa digunakan untuk mengambil sebuah kesimpulan tentang postif atau negatifnya suatu acara televisi.
Berdasarkan penjelasan sebelumnya, diperlukan sebuah cara agar dapat mengklasifikasikan opini publik menjadi pengetahuan baru berupa kesimpulan negatif atau positifnya mengenai acara televisi dari data yang ada di media sosial. Hal tersebut
dimungkinkan dengan menggunakan text mining.
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
2 Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033mining adalah sebuah proses yang semi otomatis melakukan klasifikasi dari pola yang ada dari database yang tidak terstruktur [3]. Sehingga, hasil dari klasifikasi tersebut bisa menjadi media alternatif bagi masyarakat untuk memilih acara televisi yang berkualitas.
Berdasarkan hasil dari beberapa penelitian mengenai pengklasifikasian informasi subjektif atau yang sering disebut analisis sentimen. Dibutuhkan suatu algoritma untuk dapat mengklasifikasikan suatu opini ke dalam kelas negatif atau positif. Adapun algoritma yang dapat digunakan dalam
pengklasifikasian adalah C45, Support Vector
Machine (SVM), Naïve Bayes Classifier (NBC), K-Nearest Neighbors, Information Fuzzy Networks, dan masih banyak algoritma lainnya. Melihat hasil dari penelitian Fatimah Wulandini dan Anto Satriyo Nugroho (Text Classification Using Support Machine for Webmining Based Spation Temporal Analysis of the Spread of Tropical Disease, 2009)
mendapatkan hasil bahwa algoritma SVM
menunjukan akurasi paling tinggi pada kategorisasi teks Bahasa Indonesia dengan presentase 92.5%, tidak jauh berbeda dengan algoritma NBC yang memiliki presentase 90% [4].
Apabila dilihat kompleksitasnya, NBC jauh lebih
konvensional dan sederhana. Hal tersebut
berpengaruh terhadap waktu komputasi yang dibutuhkan. NBC memerlukan waktu komputasi lebih singkat dibanding dengan SVM yang berkembang secara kuadratik seiring dengan perkembangan jumlah data latih. Berdasarkan dari kompleksitasnya, waktu yang dibutuhkan untuk komputasi yang lebih rendah, dan akurasi yang tidak terlalu jauh berbeda dari SVM, NBC lebih cocok untuk diimplementasikan dalam penelitian ini.
1.1Text Mining
Text mining yang juga dikenal dengan text data mining atau pencarian pengetahuan di basis data textual adalah sebuah proses yang semi otomatis melakukan ekstraksi dari pola yang ada di database. Dari hasil ekstraksi tersebut munculah pengetahuan baru yang bisa dimanfaatkan untuk kepentingan
pengambilan keputusan. Text mining mempunyai
kesamaan dengan data mining. Keduanya memliki
tujuan yang sama yaitu untuk memperoleh informasi dan pengetahuan dari sekumpulan data yang sangat besar. Data tersebut bisa berbentuk sebuah database. Namun keduanya memiliki perbedaan jenis data. Data mining memiliki input data dari data yang sudah terstruktur sedangkan text mining dimulai dengan data yang tidak terstruktur.
Pemanfaatan dari text mining secara nyata
sangatlah luas. Areanya seluas data tekstual yang terbentuk seperti di area hukum dengan data putusan pengadilan, penelitian dengan data artikel penelitian, keuangan dengan data laporan triwulan, teknologi dengan data arsip paten, pemasaran dengan data
komentar konsumen, dan di area lainnya. Sebagi contoh sebuah perusahaan membuat formulir yang biasa diisi apabila konsumennya ingin memuji, komplain, ataupun klaim garansi. Dari kartu formulir tersebut terbentuklah data yang sangant besar dan bisa digunakan untuk mengidentifikasi secara objektif produk dan layanan dari suatu perusahaan menggunakan text mining. Selain itu proses text mining yang dilakukan secara otomatis adalah dibidang komunikasi elektronik dan email. Text mining tidak hanya mengklasifikasikan dan menyaring email sampah, tetapi bisa juga memprioritaskan email secara otomatis berdasarkan tingkat kepentingannya [3].
1.2Analisis Sentimen
Sejarah analisis sentimen pertama kali muncul pada sebuah jurnal karya Das, Chen, dan Tong pada tahun 2001, bahasan yang mereka angkat susuai dengan minat mereka yaitu menganalisis sentimen pasar. Analisis sentimen adalah mengekstraksi pendapat, sentimen, evaluasi, dan emosi orang
tentang suatu topik tertentu yang tertulis
menggunakan teknik pemrosesan bahasa alami. Sejumlah karya-karya besar lainnya menyebutkan analisis sentimen fokus pada aplikasi spesifik yang mengklasifikasikan mengenai sifat yang berlawanan (antara positif dan negatif). Dari pengertian tersebut menjadi sebuah fakta yang menyebabkan beberapa penulis bahwa istilah analisis sentimen mengacu pada tugas yang sempit atau spesifik. Namun saat ini banyak yang menafsirkan istilah analisis sentiment lebih luas lagi yang berarti cara pengkomputasian pendapat, sentimen, dan subjektifitas pada teks [5].
1.3Preprocessing
Tahap preprocessing diperlukan untuk
membersihkan data dari yang tidak diperlukan, dengan tujuan pada tahap masuk ke dalam metode Naïve Bayes Classiffier lebih optimal dalam perhitungannya. Pada tahap ini melibatkan rekognisi dari isi dan struktur teksnya. Adapun tahapan-tahapan dari preprocessing.
1. Convert Emoticon
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
3 Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033Tabel 1 Emoticon yang akan Dikonversi
2. Cleansing
Clenasing merupakan proses membersihkan
kata-kata yang tidak diperlukan untuk
mengurangi noise. Kata yang dihilangkan adalah URL, hashtag (#), username (@username), dan email. Selain itu juga tanda baca seperti titik(.), koma(,), dan tanda baca yang lainnya akan dihilangkan. Pada Tabel 2 dijelaskan contoh penerapan dari cleansing:
Tabel 2 Penerapan Cleansing Data Latih
Memilih Wakil Rakyat - Iwan Fals, Ahok, JK & DS
Stand UpComedyAnang!
stand up comedy Anang
Lucu Banget Terbaru 2014
indonesia metro tv
Case folding merupakan tahapan merubah bentuk kata-kata menjadi sama bentuknya, baik semuanya menjadi lower case ataupun menjadi upper case. Pada Tabel3 dijelaskan contoh dari penerapan proses case folding.
Tabel 3 Penerapan Case Folding
Data Latih
Input Output
Saya suka video
MATA NAJWA
Memilih Wakil Rakyat Iwan Fals Ahok JK DS
comedy Anang Lucu
Banget Terbaru
Seperti halnya ilmu matematika, dalam bahasa terdapat kata yang dapat membalikan arti dari kata tersebut atau bersifat negasi. Kata-kata yang bersifat negasi adalah “kurang”, “tidak”, “enggak”, “ga”, “nggak”, “tak”, dan “gak”. Pada Tabel 4 dijelaskan contoh penerapannya.
Tabel 4 Penerapan Convert Negation Sebelum Convert
Negation
Setelah Convert Negation gak seru final
indonesiaidol tanpa virzha sabar virzha
sukses pulang
ga_serufinal indonesia idol tanpa virzha sabar virzha sukses pulang
5. Tokenizing
Tokenizing bekerja untuk mengidentifikasi kata-kata dalam teks menjadi beberapa urutan yang terpotong oleh spasi atau karakter spesial. Berikut contoh penerapan dari tokenizing.
Tabel 5 Penerapan Tokenizing Data Latih
Stopping berperan untuk membuang kata-kata yang sering muncul dan bersifat umum, kurang menunjukan relevansinya dengan teks. Kata-kata yang akan dibuang tersebut didefinisikan dalam stopword list. Contoh beberapa kata yang sering masuk ke dalam stopword list adalah “sebuah”, “yang”, dan “itu”. Berikut adalah beberapa daftar stoplist yang disimpan dalam database.
Tabel 6 Stoplist yang digunakan
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
4 Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033entah Lalu Yuk Aku Adalah
gue Nanti tunggu Tau Kemarin
7. Stemming
Stemming adalah tahapan untuk membuat kata yang berimbuhan kembali ke bentuk asalnya. Contohnya kata “memberikan” setelah melewati tahap ini maka akan menjadi “beri” [6].
Tabel 8 Penerapan Stemming Data Latih
Input Output
menginspirasi insprirasi
1.4Algoritma Naïve Bayes
Naïve bayes classifier adalah penggolong
menggunakan statistik sederhana berdasarkan
teorema bayes yang mengasumsikan bahwa
keberadaan atau ketiadaan dari suatu fitur tertentu dari suatu kelas tidak berhubungan dengan keberadaan atau ketiadaan fitur lainnya. Sifatnya
yang sebagai model probabilitas, naïve bayes
classifier bisa dilatih dengan efisien sebagai supervised learning. Pada pengaplikasiannya, parameter estimasi untuk model naïve bayes menggunakan metode kemungkinan maksimum. Dengan kata lain, masih bisa bekerja dengan model naïve bayes tanpa harus mempedulikan bayesian probabilitas atau metode bayesian lainnya. Berikut
adalah model matematis untuk naïve bayes
classifier:
� �|� , … , � =� � � � , … , � |�� � , … , � (1)
2. ISI PENELITIAN
2.1Sumber Data
Data yang digunakan berberntuk tweet yang
diambil langsung memanfaatkan API twitter. Berikut contoh data yang digunakan.
Tabel 10 Contoh Data yang Digunakan Tweet
@OVJ_Trans7 gak seru, gak lucu.! Kalo gak ada kang @sule_ovj
@OVJ_Trans7 gak ada #Sule udah gak lucu , Garingg bgt sekarang .. Huekkkk
YKS ga ada kang wendi, Ga seru aah :(
@WCIndonesia
@DEV0TEES bentar lg ada Rising Star Indonesia :-) bakal lebih bagus dr Idol deh,, ILK (Indonesia lawak klub) bikin ngakak :D :D
Sebelum #jum'atan stay di trans7 lihat video2 lucu ala @CCTV_T7
2.2Implementasi Preprocessing
Sebelum masuk proses utama yaitu
pengklasifikasian tweet menggunakan algoritma naïve bayes, data akan diolah terlebih dahulu pada tahap preprocessing agar pada tahap klasifikasi hasil nya bisa jauh lebih optimal. Pada Tabel 11
menunjukan hasil preprocessing dari data pada
Tabel 10.
Tabel 11 Data Hasil Preprocessing Tweet
[ga_seru, ga_lucu, ga_ada, kang]
[ga_ada, sule, udah, ga_lucu, garing, bgt, huekkkk]
[yks, ga_ada, kang, wendi, ga_seru]
[bentar, rising, star, indonesia, lebih, bagus, idol]
[ilk, indonesia, lawak, klub, bikin, ngakak, ketawa, ketawa]
[stay, trans, lihat, video, lucu, ala]
2.3Implementasi Algoritma Naïve Bayes
Tahap ini merupakan tahap yang paling esensial dari tahap yang lainnya. Pada tahap ini proses pengklasifikasian berdasarkan sentimen yang ada di dalam dokumen dimulai. Tahap ini mempunyai dua proses, berikut prosesnya:
1. Proses learning naïve bayes classifier
Naïve bayes classifier sebagai algoritma supervised learning harus diberi pengetahuan awal terlebih dahulu, sebagai acuan untuk dapat mengklasifikasikan suatu dokumen berdasarkan sentimennya.
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
5 Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033Ada tiga langkah dalam proses learning.
Berikut ketiga tahapan pada proses learning.
a. Membentuk Fitur
Dalam penelitian ini yang dimaksud dengan fitur adalah kata kunci yang akan menjadi parameter satuan data latih, yaitu dokumen (tweet) untuk diklasifikasikan ke dalam kelas yang telah ditentukan (positif atau kelas negatif). Dalam kata lain fitur adalah kata yang memiliki nilai sentimen. Tabel 10 berisikan pembentukan fitur dari data latih yang sudah dilakukan proses preprocessing terlebih dahulu (Tabel 10).
Tabel 11 Pembentukan Fitur dari Data Latih
Data Fitur(Kemunculan) Kelas
Sentimen
D1 ga_seru(1), ga_lucu(1) Negatif
D2 ga_seru(1) Negatif
D3 ga_lucu(1) Negatif
D4 bagus(1) Positif
D5 ngakak(1),ketawa(2) Positif
D6 lucu(1) Positif
b. Menghitung probabilitas p(ci)
Setelah dibentuk fitur dengan kemunculannya dari data latih. Selanjutnya menghitung probabilitas dari setiap kelas dengan cara sebagai berikut:
p � = �
|�| (2)
Keterangan :
fd(ci) = Jumlah dokumen yang termasuk ci
|D| = Jumlah data latih / jumlah tweet
Tabel 13 Probabilitas Kelas Training Naïve Bayes Kelas
c. Menentukan probabilitas p(wk|ci)
Setelah didapat probabilitas dari setiap kelas, selanjutnya menghitung probabilitas setiap fitur pada setiap kelas dengan cara sebagi berikut:
� � |�
= � � , � + 1� � + | | (3)
Keterangan :
� � , � = Nilai kemunculan kata � pada
kelas �
� � = Jumlah keseluruhan kemunculan kata
pada kelas �
| | = Jumlah keseluruhan dari � Dari rumus 3, maka diperoleh model probabilistik untuk setiap fitur pada 12.
Tabel 14 Model Probabilitas dari Data Latih
Data � ��, �� Kelas Sentimen (c)
2. Proses klasifikasi naïve bayes classifier
Berikut alur proses dari proses klasifikasi menggunakan naïve bayes classifier.
Gambar 2 Flowchart Klasifikasi Naïve Bayes
Berikut adalah contoh satu tweet yang akan
dijadikan data uji menggunakan model
probabilitas fitur Tabel 4:
Tabel 15 Data Uji Klasifikasi Tweet ,teh siapa gitu blg
gini "guys! disini
inget studio dahsyat rctilucuga_lucu
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
6Dari alur proses klasifikasi ada dua tahapan penting. Berikut penjelasan tahapan-tahapannya:
a. Menghitung Vmap
Vmap adalah perhitungan yang digunakan naïve bayes classifier untuk menentukan probabilitas data uji dari masing-masing kelas berdasarkan dari proses learning. Nilai probabilitas yang terbesar akan dipilih. Berikut perhitungannya: Vmap = argmax p(ci) П p(wk | c) x p(c)
Berdasarkan dari hasil training, berikut hasil perhitungannya:
p("gumpreng"| ci)
1) Vmap untuk sentimen positif
Vmap(“positif”) =
P(“positif”) P("inget"|”positif”)n
P("studio"|”positif”) P("dahsyat"|”positif”) P("rcti"|”positif”) P("lucu"|”positif”) P("ga_lucu"|”positif”) P("ketawa"|”positif”) P("maksa"|”positif”) P("gumpreng"|”positif”)
= × × × × × × × × ×
= 0.00000000058
2) Vmap untuk sentimen negatif
Vmap(“negatif”) =P(“negatif”)
P("inget"|”negatif”) P("studio"|”negatif”) P("dahsyat"|”negatif”) P("rcti"|”negatif”) P("lucu"|”negatif”) P("ga_lucu"|”negatif”) P("ketawa"|”negatif”) P("maksa"|”negatif”) P("gumpreng"|”negatif”)
= × × × × × × × × ×
= 0.00000000064
b. Menentukan Vmap maksimum
Dari hasil perhitungan Vmap diatas didapatkan bahwa nilai Vmap negatif lebih besar
dibanding dengan Vmap positif. Bisa
disimpulkan bahwa tweet tersebut
diklasifikasikan ke dalam sentimen negatif.
3. PENUTUP
Dari hasil penelitian yang telah dilakukan terlihat
bahwa algoritma naïve bayes dapat
mengklasifikasikan suatu opini yang berupa tweet ke dalam dua kelas yaitu positif dan negatif dengan akurat. Tingkat keakurasian dari pengklasifikasian tersebut sangat dipengaruhi oleh proses training.
Sehingga dapat disimpulkan dari hasil
pengklasifikasian yang disajikan dalam bentuk grafik dapat terlihat dengan jelas informasi sentimen publik terhadap suatu acara televisi dan dapat dijadikan sebagai referensi untuk menonton acara televisi. Wajah-Buruk. [Diakses 19 Maret 2014].
[2] J. Bernstein, “Social Media in 2013: By the Numbers,” Social Media Today Community, 6
November 2013. [Online]. Available:
http://socialmediatoday.com/jonathan-bernstein /1894441/social-media-stats-facts-2013. [Diakses 27 Januari 2014].
[3] E. Turban, R. Sharda dan D. Delen, Decision Support and Business Intelligence Systems, 2011: Pearsson, New Jersey.
[4] F. Wulandini dan A. S. Nugroho, “ext Classification Using Support Vector Machine for Webmining Based Spation Temporal Analysis of the Spread of Tropical Diseases,” International Conference on Rural Information and Communication Technology, Jakarta, 2009. [5] B. Pang dan L. Lee, “Opinion Mining and
Sentiment Analysis,” Foundation and Trends In Information Retrieval, vol. 2, p. 10, 2008. [6] W. B. Croft, D. Metzler dan T. Strohman,
![Gambar I-1 Model Waterfall Menurut Sommerville [5]](https://thumb-ap.123doks.com/thumbv2/123dok/609504.72910/18.595.123.503.363.647/gambar-i-model-waterfall-menurut-sommerville.webp)