BIODATA PENULIS
Data Pribadi
Nama : Taufik Ismail Effendi
NIM : 10111427
Tempat/Tanggal Lahir : Bandung, 29 Maret 1993 Jenis Kelamin : Laki-laki
Agama : Islam
Alamat : Jl. Sindang sari Kp.wareng no.81 rt.04/03 kec. Panyileukan kel. Ciapadung kulon Ujung berung Bandung
No. Telepon : 089618797392
Email : [email protected]
Riwayat Pendidikan
1999 – 2005 : SD Negeri Ciporeat Bandung 2005 – 2008 : SMP Negeri 50 Bandung 2008 – 2011 : SMA Negeri 10 Bandung
2011 – 2016 : Universitas Komputer Indonesia, S1 Program Studi Teknik Informatika
Demikian biodata ini saya buat dengan sebenar – benarnya.
Bandung, 25 Agustus 2016
IMPLEMENTASI
TERM
FREQUENCY-INVERSE DOCUMENT
FREQUENCY
(TF-IDF) DAN
VECTOR SPACE MODEL
(VSM)
UNTUK KLASIFIKASI BERITA BAHASA INDONESIA
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
TAUFIK ISMAIL EFFENDI
10111427
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
KATA PENGANTAR
Segala puji bagi Allah SWT yang maha pengasih lagi maha penyayang, dengan segala rakmatnya yang telah diberikan, penulis dapat menyelesaikan penulisan tugas akhir yang berjudul “IMPLEMENTASI TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) DAN VECTOR SPACE MODEL (VSM) UNTUK KLASIFIKASI BERITA BAHASA INDONESIA”.
Penulis menyadari dalam penulisan tugas akhir ini banyak sekali terdapat kekurangan dan keterbatasan oleh karena itu kritik, masukan serta saran yang membantu penulis akan dijadikan masukan di masa yang akan datang. Dalam penulisan laporan ini penulis banyak menerima bantuan dan dukungan dari berbagai pihak. Oleh karena itu penulis ingin mengucapkan terima kasih banyak yang setulus-tulusnya kepada :
1. Allah SWT, karena dengan izinnya tugas akhir ini dapat terselesaikan.
2. Orang tua penulis yang telah memberikan perhatian dan semangat tanpa henti kepada penulis.
3. Bapak Iskandar Ikbal S.T., M.Kom. selaku dosen pembimbing yang
senantiasa selalu sabar dan bersedia meluangkan waktunya untuk memberikan kritik, saran dan dukungannya hingga tugas akhir ini dapat
terselesakan, Terima kasih banyak atas bimbingannya.
5. Bapak Galih Hermawan, S.Kom.,M.T. selaku dosen wali IF-10 angkatan 2011 yang senantiasa selalu memberikan masukan-masukan selama penulis berkuliah dari semester 1 – 10.
6. Kepada seluruh dosen dan staf pengajar jurusan Teknik Informatika Universitas Komputer Indonesia
7. Keluarga besar Teknik Informatika 10 angkatan 2011 yang selalu mendukung dalam segala situasi.
8. Teman-teman mahasiswa teknik informatika angkatan 2011 yang telah memberikan masukan.
Semoga skripsi ini dapat bermanfaat bagi para pembaca, akhir kata Assalamualaikum wr.wb
Bandung, Agustus 2016
v
1.1. Latar Belakang Masalah ... 1
1.2. Rumusan Masalah ... 2
1.3. Maksud dan Tujuan ... 2
1.4. Batasan Masalah ... 3
1.5. Metodologi Penelitian ... 3
1.6. Sistematika Penulisan ... 5
2. BAB 2... 7
2.1. Artikel ... 7
2.2. Berita ... 7
2.3. Text mining ... 8
2.3.1. Preprocessing ... 9
2.4. Information Retrieval ... 15
2.4.1. Precision ... 16
2.4.2. Recall ... 16
2.5. Classifier ... 17
2.5.1. Algoritma TF-IDF ... 17
2.5.2. Algoritma Vector Space Model (VSM) ... 18
2.6. Analisi Tersetruktur ... 20
2.7. Bahasa pemrograman yang di gunakan ... 24
2.7.1 Bahasa Program C# ... 24
2.8. Tools Yang Digunakan ... 25
2.9.1 Microsoft Visual Studio ... 25
3. BAB 3... 27
3.1. Analisis Sistem ... 27
3.1.1.Analisis Masalah ... 27
3.1.2.Deskripsi Umum Sistem ... 28
3.1.3.Analisis Data Masukan ... 29
3.1.4 Analisis Metode ... 32
3.1.5.Analisis Kebutuhan Non Fungsional ... 58
3.1.6.Analisis Kebutuhan Fungsional ... 60
3.2. Perancangan Sistem ... 66
3.2.1 Perancangan antar muka ... 66
3.2.2 Jaringan semantik ... 68
4. BAB 4... 69
4.1. Implementasi ... 69
4.1.1 Perangkat keras (Hardware) ... 69
4.1.2 Perangkat lunak (Software) ... 69
4.1.3 Implementasi antar muka ... 70
vii
4.2.1 Skenario Pengujian Alpha ... 72
4.2.2 Uji Coba dan Hasil Pengujian ... 73
4.2.3 Pengujian Beta ... 77
BAB 5... 87
5.1. Kesimpulan ... 87
5.1. Saran ... 87
DAFTAR PUSTAKA
[1] M. Nazir, Metode Penelitian, Jakarta: Ghalia Indonesia, 1988.
[2] R. s. Pressman, Software Engineering, A Practitioner's Approach, 7th
edition, McGraw Hill Higher Education, 2012.
[3] P. Eneste, Buku Pintar Penyunting Naskah, Jakarta: Gramedia Pustaka Utama, 2005.
[4] J. Wahyudi, Dasar - Dasar Jurnalistik Radio dan Televisi, Jakarta: Pustaka Utama Grafiti, 1996.
[5] M. R. Syamsul dan A. S, Jurnalistik Praktis Untuk Pemula, Bandung: PT.
Remaja Rosdakarya, 2003.
[6] K. Budiman, Dasar - Dasar Jurnalistik, Info Jawa, 2005.
[7] R. M. S. Putra, Teknik Menulis Berita dan Feature, Jakarta, 2006.
[8] Suyanto, Artificial Intelligence, Bandung: Informatika, 2007.
[9] R. Feldman dan J. Sanger, The Text Mining Handbook, New York: Cambridge University Press, 2007.
[10] I. Amalia, B. Susanto dan A. R. C, “Sistem Klasifikasi dan Pencarian Jurnal Menggunakan Metode Naive Bayes dan Vector Space Model,” Universitas Kristen Duta, Yogyakarta, 2008.
90
[12] B. Zaman dan E. Winarko, “Analisis Fitur Kalimat untuk Peringkasan Teks
Otomatis Pada Bahasa Indonesia,” Indonesia Journal of Computing And
Cybernetics Systems, no. 5, pp. 60-68, 2011.
[13] B. Nazief dan M. Adriani, Confix-Stripping: Approach to Stemming Algorithm for Bahasa Indonesia, Jakarta: University of Indonesia, 1996.
[14] J. Han dan M. Kamber, Data Mining Concept and, San Francisco: Morgan Kaufmann, 2001.
[15] S. M. Weiss, N. Indrukhya, T. Zang dan F. Damerau, Text Mining Predictive Methods For Analyzing Unstructured Information, USA:
Springer, 2005.
[16] Y. Yiming, “ An evaluation of statistical approaches to text categorization,” Kluwer Academic Publisher, Netherlands, 1999.
[17] D. Sugono, TESAURUS BAHASA INDONESIA PUSAT BAHASA, Jakarta: PUSAT BAHASA DEPARTEMEN PENDIDIKAN NASIONAL, 2008.
[18] D. Taner dan A. Alpkocak, “Emotion Clasification of Text Using Vector,”
Proceedings of AISB 2008 Symposium on Affective Language in Human and
Machine, vol. 2, 2008.
BAB 1
PENDAHULUAN
1.1. Latar Belakang Masalah
Berita adalah cerita atau keterangan mengenai kejadian atau peristiwa
yang hangat. Berita haruslah sesuai dengan kenyataan yang ada, tidak dibuat-buat (fiktif), dan terbaru/terkini. Berita merupakan salah satu cara berkomunikasi melalui peristiwa penting, terbaru, dan menarik. Berita dapat dijumpai dimana saja seperti di koran, majalah, internet, televisi, radio, bahkan di mading sekolah. Sebuah berita harus mengandung unsur 5W+1H (What, Who, When, Where, Why,dan How) supaya pembaca dapat mengetahui lebih banyak tentang suatu kejadian.
Dalam tahun ke tahun jumlah berita semakin bertambah banyak, maka proses pencarian dan penyajian dokumen menjadi lebih sukar atau sulit sehingga minimbulkan beberapa berita yang tidak terklasifikasi kategori sesuai isi berita tersebut. Klasifikasi dokumen teks adalah permasalahan yang mendasar dan penting. Didalam dokumen teks, tulisan yang terkandung adalah bahasa alami manusia, yang merupakan bahasa dengan struktur yang kompleks dan jumlah kata yang sangat banyak. Oleh karena itu, dibutuhkan suatu sistem yang dapat mengklasifikasikan berita secara otomatis.
Berdasarkan latar belakang di atas, maka akan dibangun suatu sistem
yang berfungsi untuk mengklasifikasikan berita secara otomastis. Dimana sistem tersebut menjadi salah satu aplikasi dalam melakukan klasifikasi berita.
2
dibangun menggunakan metode TF-Idf dan VSM akan memudahkan dalam melakukan klasifikasi berita bahasa Indonesia.
1.2. Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan diatas, maka didapat rumusan masalah, yaitu : Terdapat beberapa berita yang belum adanya pengklasifikasian kategori.
1.3. Maksud dan Tujuan
Maksud dari penulisan penelitian ini adalah membangun sistem yang dapat membantu dalam menentukan kategori klasifikasi menggunakan metode TF-IDF dan Vector Space Model.
3
1.4. Batasan Masalah
Berdasarkan latar belakang yang telah diuraikan, maka dibuat batasan masalah agar ruang lingkup penelitian ini jelas batasannya.
Adapun batasan masalah yang dibuat adalah sebagai berikut :
1. Input :
Format file berita adalah .docx
Berita yang digunakan adalah berita bahasa Indonesia.
Berita yang diambil dari media online https://www.kompas.com. Kategori dibatasi 3 jenis yaitu politik, olahraga, dan teknologi.
2. Proses :
Perangkat lunak untuk membuat aplikasi ini yaitu visual studio 2010 Menggunakan bahasa pemrograman C#.
Metode TF-IDF dan Vector Space Model yang digunakan pada proses
pengklasifikasian. 3. Output :
Output yang dihasilkan adalah berupa informasi.
1.5. Metodologi Penelitian
Penelitian ini menggunakan metode penelitian deskriptif yaitu suatu metode dalam meneliti status sekelompok manusia, suatu objek, suatu set
4
Metodologi yang digunakan adalah sebagai berikut :
1. Tahap Pengumpulan Data
Metode pengumpulan data yang digunakan adalah sebagai berikut:
a. Studi literatur
Pengumpulan data dengan cara mengumpulkan literatur, jurnal, buku fisik maupun online (e-book) dan bacaan - bacaan lainnya yang berkaitan dengan
klasifikasi menggunakan metode TF-IDF dan Vector Space Model dan artikel berita bahasa Indonesia.
2. Tahap pembangunan perangkat lunak
Metode yang digunakan dalam pembuatan perangkat lunak ini menggunakan model waterfall. Waterfall adalah model klasik yang bersifat sistematis, berurutan dalam membangun software [2]. Motode waterfall
melakukan pendekatan secara sistematis dan terurut, dimana tahap demi tahap yang akan dilalui harus menunggu tahap sebelumnya selesai. Tahap dari model
waterfall adalah sebagai berikut :
1. Analisis Kebutuhan
Merupakan tahap menganalisa hal-hal apa saja yang diperlukan dalam membangun sistem. Hal yang dibutuhkan yaitu data uji berita seperti judul berita, penerbit, dan isi berita dan data training berita yang akan digunakan sebagai acuan klasifikasi.
2. Perancangan
Proses perancangan data hasil analisis kebutuhan dan studi literatur
dijadikan gambaran secara umum yang akan dibangun secara lengkap dalam bentuk diagram dan diimplementasikan pada tahap pengkodean.
3. Pengkodean
5
4. Penerapan
Tahap ini merupakan tahap pengujian sistem yang dibangun.
Gambar 1. 1Metode Waterfall [2].
1.6. Sistematika Penulisan
Sistematika penulisan penelitian ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan, sistematika penulisan penelitian ini adalah sebagai berikut:
BAB I PENDAHULUAN
Menguraikan tentang latar belakang permasalahan, rumusan masalahan, maksud dan tujuan, yang kemudian diikuti dengan batasan masalah, metodologi penelitian, serta sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini berisikan tentang konsep dasar dan teori yang mendukung dalam
pembangunan aplikasi, seperti pengertian berita, TF-IDF dan Vector Space Model dan apa saja yang digunakan pada penelitian ini.
BAB III ANALISIS DAN PERANCANGAN SISTEM
6
kebutuhan non fungsional. Pada perancangan berisi mengenai perancangan data, perancangan menu, perancangan antarmuka dari aplikasi yang akan dibuat
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini menjelaskan mengenai hasil implementasi dari hasil analisis dan perancangan sistem yang telah dibuat di sertai hasil pengujian sistem
yang diterapkan pada aplikasi yang telah dibangun.
BAB V KESIMPULAN DAN SARAN
BAB 2
LANDASAN TEORI
2.1. Artikel
Artikel merupakan sebuah karangan faktual (non fiksi), tentang suatu masalah secara lengkap yang panjangnya tidak ditentukan, untuk dimuat di surat kabar, majalah, bulletin dan sebagainya dengan tujuan untuk menyampaikan gagasan dan fakta guna meyakinkan, mendidik, menawarkan pemecahan suatu masalah, atau menghibur. Artikel termasuk termasuk tulisan kategori views (pandangan), yaitu tulisan yang berisi pandangan, ide, opini,
penilaian penulisannya tentang suatu masalah atau peristiwa.
2.2. Berita
Berita adalah cerita atau keterangan mengenai kejadian atau peristiwa yang hangat. Berita haruslah sesuai dengan kenyataan yang ada, tidak dibuat-buat (fiktif), dan terbaru/terkini. Berita merupakan salah satu cara berkomunikasi melalui peristiwa penting, terbaru, dan menarik. Kita dapat menjumpai berita dimana saja seperti di koran, majalah, internet, televisi, radio, bahkan di mading sekolah.
8
2.3. Text mining
Text mining merupakan area baru dan menarik dari penelitian ilmu komputer yang mencoba menyelesaikan krisis informasi yang berlebihan dengan menggabungkan teknik dari data mining, pembelajaran mesin, pengalahan bahasa alami, pencarian informasi, dan manajemen pengetahuan" [9]. Text mining adalah bagian dari data mining dimana Text mining mencoba
menggali pengetahuan yang terdapat pada sekumpulan teks atau sering disebut dokumen yang susunannya tidak terstruktur. Adapun tahapan utama yang
dipakai pada text mining:
1. Text Preprocessing, pada tahap awal ini dilakukan pemrosesan terhadap data teks untuk diubah kedalam bentuk token atau kata yang sering disebut dengan tokenisasi. Data dalam bentuk dokumen, paragraf ataupun kalimat dipecah menjadi token-token sebagai masukan untuk proses selanjutnya yaitu Text Transformation. Dalam tokenisasi ini, dilakukan seleksi pada tanda baca, kapitalisasi, karakter spesial dan lain sebagaianya sehingga hasil yang didapatkan berupa kumpulan token. 2. Text Transformation, pada tahap ini proses yang dilakukan adalah
melakukan stemming dan stopword. Stemming melakukan pemotongan atau penghilangan imbuhan pada token sehingga hasil yang didapat merupakan kata dasar dari kata tersebut, contoh pada kata “dipukul” dan
“memukuli” memiliki katadasar “pukul”. Stemming ini dilakukan untuk
menurunkan jumlah daftar kata pada indeks. Selain itu juga terdapat proses stopword, dimana dilakukan penghilangan pada kata sambung yang sangat umum berada pada dokumen, contoh kata “yang” dan
“pada”. Kata sambung tersebut dihilangkan karena terlalu bersifat umum
sehingga tidak dapat mencirikan sebuah dokumen tertentu.
9
4. Data Mining / Pattern Discovery, merupakan tahap terpenting dalam text mining dimana dilakukan penerapan metode data mining dengan tujuan untuk menemukan pengetahuan yang tersimpan dalam teks[10].
2.3.1.Preprocessing
Preprocessing adalah tahapan untuk mempersiapkan teks menjadi data yang akan diolah di tahapan berikutnya. Inputan awal pada proses ini adalah
berupa dokumen. Pada umumnya preprocessing memiliki beberapa tahapan yaitu case folding, tokenizing, stop word removal, stemming, dan lain-lain.
Preprocessing pada penelitian ini terdiri dari beberapa tahapan, yaitu: proses pemecahan kalimat, proses case folding, proses tokenizing kata, dan proses stop word removal
2.3.1.1Pemecahan Kalimat
Memecah dokumen menjadi kalimat-kalimat merupakan langkah awal tahapan preprocessing. Pemecahan kalimat yaitu proses memecah string teks dokumen yang panjang menjadi kumpulan kalimat-kalimat. Dalam memecah dokumen menjadi kalimat kalimat menggunakan fungsi split(), dengan tanda titik “.”, tanda tanya ”?” dan tanda tanya “!” sebagai delimiter untuk
memotong string dokumen [11].
Tabel 2.1 Contoh Pemecah Kalimat
Kalimat Hasil pemecahan kalimat
Manajemen transaksi elektronik. Pengetahuan antar individu. Dalam
manajemen pengetahuan, terdapat transfer pengetahuan elektronik
Manajemen transaksi elektronik Pengetahuan antar individu Dalam
10
2.3.1.2Case Folding
Dokumen mengandung berbagai variasi dari bentuk huruf sampai tanda baca. Variasi huruf harus diseragamkan (menjadi huruf besar saja atau huruf kecil saja) dan tanda baca dihilangkan untuk menghilangkan noise pada saat pengambilan informasi. Hal ini dapat dilakukan dengan case folding. Case folding adalah tahapan proses mengubah semua huruf dalam teks dokumen
menjadi huruf kecil, serta menghilangkan karakter selain a-z.[11].
Tabel 2.2 Contoh Case Folding
Kalimat Hasil case folding
Manajemen transaksi elektronik Pengetahuan antar individu Dalam
manajemen pengetahuan terdapat transfer pengetahuan elektronik
manajemen transaksi elektronik pengetahuan antar individu dalam
manajemen pengetahuan terdapat transfer pengetahuan elektronik
2.3.1.3Tokenizing
11
Tabel 2.3 Contoh Tokenizing
Kalimat Hasil Tokenizing
manajemen transaksi elektronik pengetahuan antar individu dalam
manajemen pengetahuan terdapat transfer pengetahuan elektronik
Manajemen transaksi elektronik pengetahuan antar individu dalam
manajemen pengetahuan terdapat transfer pengetahuan elektronik
2.3.1.4Stoplist / Stop Word Removal
Penghapusan Stopword merupakan proses penghilangan kata stopword.
Stopword adalah kata - kata yang sering kali muncul dalam dokumen namun arti dari kata kata tersebut tidak deskriptif dan tidak memiliki keterkaitan
dengan tema tertentu. Misalnya “di”, ”oleh”, “pada”, ”sebuah”, ”karena” dan lain sebagainya[11].
Tabel 2.4 Contoh Stopword
Kalimat Hasil Stop Word Removal
12
2.3.1.5Stemming
Menurut Zaman B. dan E Winarko [12] stemming adalah proses pemetaan dari penguraian berbagai bentuk kata baik itu prefix, sufix, maupun gabungan antara prefix dan sufix (confix), menjadi bentuk kata dasarnya. Algoritma stemmer yang diperkenalkan Nazief dan Adriani didefinisikan sebagai berikut (13):
1. Di awal proses stemming dan setiap langkah yang selanjutnya dilakukan, lakukan pengecekan hasil proses stemming kata yang di-input-kan pada
langkah tersebut ke kamus kata dasar. Jika kata ditemukan, berarti kata tersebut sudah berbentuk kata dasar dan proses stemming dihentikan. Jika tidak ditemukan, maka langkah selanjutnya dilakukan.
2. Hilangkan Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”). Jika berupa particles (“-lah”, “-kah”, “-tah” atau “-pun”) maka langkah ini diulangi lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu”, atau “- nya”), jika ada.
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “
-k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam
kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke
langkah 4.
4. Hilangkan derivation prefixes.
a. Langkah 4 berhenti jika :
Terjadi kombinasi awalan dan akhiran yang terlarang, awalan yang dideteksi saat ini sama dengan awalan yang dihilangkan sebelumnya, tiga awalan telah dihilangkan.
13
kata, kompleks (“me-”, “be-”, “pe”, “te-”) adalah tipe-tipe awalan yang dapat bermorfologi sesuai kata dasar yang mengikutinya.
c. Cari kata yang telah dihilangkan awalannya ini di dalam kamus kata dasar. Apabila tidak ditemukan, maka langkah 4 diulangi kembali, apabila ditemukan, maka keseluruhan proses dihentikan.
5. Apabila setelah langkah 4 kata dasar masih belum ditemukan, maka proses
recoding dilakukan dengan mengacu pada aturan pada Tabel 2.1. Recoding
dilakukan dengan menambahkan karakter recoding di awal kata yang
dipenggal. Pada Tabel 2.1, karakter recoding adalah huruf kecil setelah
tanda hubung („-‟) dan terkadang berada sebelum tanda kurung. Sebagai
contoh, kata “menangkap” (aturan 15), setelah dipenggal menjadi
“nangkap”. Karena tidak valid, maka recoding dilakukan dan menghasilkan
kata “tangkap”.
6. Jika semua langkah gagal, maka input kata yang diuji pada algoritma ini dianggap sebagai kata dasar.
Tabel 2.5 Aturan pemenggalan Awalan Stemmer Nazief dan Adriani
Aturan Format Kata Pemenggalan
1 berV... ber-V... | be-rV...
2 berCAP... ber-CAP...dimana C!=‟r‟ & P!=‟er‟ 3 berCAerV... ber-CaerV... dimana C!=‟r‟
4 Belajar bel-ajar
5 beC1erC2... be-C1erC2... dimana C1!={‟r‟|‟l‟}
14
14 men{c|d|j|z}... men-{c|d|j|z}...
15 menV... me-nV... | me-tV
16 meng{g|h|q}... meng-{g|h|q}...
17 mengV... meng-V... | meng-kV...
18 menyV... meny-sV…
19 mempV... mem-pV... dimana V!=„e‟
20 pe{w|y}V... pe-{w|y}V...
21 perV... per-V... | pe-rV...
22 perCAP per-CAP... dimana C!=‟r‟danP!=‟er‟ 23 perCAerV... per-CAerV... dimana C!=‟r‟
24 pem{b|f|V}... pem-{b|f|V}...
25 pem{rV|V}... pe-m{rV|V}... | pe-p{rV|V}...
26 pen{c|d|j|z}... pen-{c|d|j|z}... 27 penV... pe-nV... | pe-tV...
28 peng{g|h|q}... peng-{g|h|q}...
29 pengV... peng-V... | peng-kV...
30 penyV... peny-sV…
31
pelV... pe-menghasilkan “ajar”lV... kecuali “pelajar” yang 32 peCerV... per-erV... dimana C!={r|w|y|l|m|n}
33
15
2.4. Information Retrieval
Information Retrival merupakan pengorganisasian dan pencarian informasi dari sejumlah besar dokumen berbasis teks” [14]. Pencarian informasi dilakukan dengan memberikan query teks pencarian yang diinginkan untuk dicocokkan kedalam kumpulan dokumen sehingga ditemukan dokumen-dokumen yang relevan. Sesuai dengan cara kerja tersebut, Information
Retrieval sering dikaitkan dengan search engine. Konsep dasar yang digunakan pada Information Retrieval adalah mengukur kesamaan antara dua dokumen,
akan dilihar sejauh mana kemiripan yang ada pada dokumen tersebut [15].
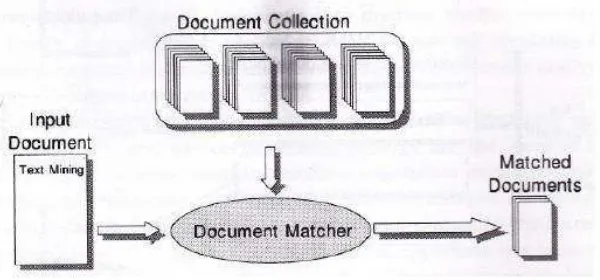
Gambar 2. 1 Pengambilan dokumen yang cocok
Pada gambar diatas, dimasukkan dokumen yang akan dicari terhadap
koleksi dokumen, dilakuakan proses pencocokan antara dokumen yang akan dicari (dokumen masukan) dengan masing-masing koleksi dokumen,
selanjutnya didapatkan dokumen yang sesuai dengan dokumen input pada koleksi dokumen. Tujuan pencarian informasi ini adalah mencari dokumen yang sesuai dengankebutuhan user.
16
2.4.1.Precision
Precision merupakan sebuah tingkat ketepatan hasil pencarian pada kumpulan dokumen (dataset)[10]. Dalam perhitungannya akan ditentukan seberapa banyak dokumen yang relevan atau sesuai dengan kebutuhan user diantara dokumen yang telah didapatkan pada hasil pencarian. Precision dapat ditentukan dengan rumus [10]:
(2.1)
Keterangan : {Relevan } = kumpulan dokumen yang relevan {Retrieved} = kumpulan dakumen yang didapat atau ditemukan
2.4.2.Recall
Recall merupakan tingkat keberhasilan dalam menemukan hasil dokumen yang relevan terhadap jumlah dokumen relevan yang sesungguhnya[10]. Recall dapat dihitung dengan rumus[10]:
(2.2)
Keterangan : {Relevan } = kumpulan dokumen yang relevan {Retrieved} = kumpulan dakumen yang didapat atau ditemukan
2.4.3.FMeasure
Adapun perhitungan yang menggabungkan nilai recall dan precision yaitu F-Measure sehingga dapat mewakili kedua nilai tersebut. F-measure
memiliki rumus [16]:
17
2.5. Classifier
klasifikasi adalah penyusunan bersistem dalam kelompok atau golongan menurut kaidah atau standar yang ditetapkan. Tahapan proses klasifikasi sendiri adalah dengan membagi data latih dan data uji adalah dengan membagi jumlah data yang akan dilakukan klasifikasi data sesuai record yang akan diinputkan.
2.5.1.Algoritma TF-IDF
Metode Term Frequency-Inverse Document Frequency (TF-IDF) adalah
cara pemberian bobot hubungan suatu kata (term) terhadap dokumen. Untuk dokumen tunggal tiap kalimat dianggap sebagai dokumen. Metode ini menggabungkan dua konsep untuk perhitungan bobot, yaitu Term frequency
(TF) merupakan frekuensi kemunculan kata (t) pada kalimat (d). Document frequency (DF) adalah banyaknya kalimat dimana suatu kata (t) muncul.
Frekuensi kemunculan kata di dalam dokumen yang diberikan menunjukkan seberapa penting kata itu di dalam dokumen tersebut. Frekuensi dokumen yang mengandung kata tersebut menunjukkan seberapa umum kata tersebut. Bobot kata semakin besar jika sering muncul dalam suatu dokumen dan semakin kecil jika muncul dalam banyak dokumen[11]. Pada aloritma TF-IDF digunakan rumus untuk menghitung bobot (W) masing masing dokumen terhadap kata kunci dengan rumus yaitu :
Wdt = tf dt * IDFt(2.4)
Dimana:
d = dokumen ke-d
t = kata ke-t dari kata kunci
W= bobot dokumen ke-d terhadap kata ke-t
tf = banyaknya kata yang dicari pada sebuah dokumen
18
IDF = log2 (D/df)
D = total dokumen
df = banyak dokumen yang mengandung kata yang dicari
Setelah bobot (W) masing-masing dokumen diketahui, maka dilakukan proses sorting/pengurutan dimana semakin besar nilai W, semakin besar tingkat similaritas dokumen tersebut terhadap kata kunci, demikian sebaliknya.
Inverse Document Frequency memperhatikan kemunculan term pada
kumpulan dokumen. Pada metode ini, term yang dianggap bernilai/berharga adalah term yang jarang muncul pada koleksi/ kumpulan dokumen[20]. Persamaan IDF adalah sebagai berikut:
�df(�) = � (�/� (�))+1 (2.5)
Dimana df(t) adalah banyak dokumen yang mengandung term t. TF*IDF
merupakan kombinasi metode TF dengan metode IDF. Sehingga persamaan TF*IDF adalah sebagai berikut:
�∗�df(�, �) = �(�, �) ∗���(�) (2.6)
Perhitungan bobot queryrelevance merupakan bobot hasil perbandingan kemiripan (similaritas) antara query yang dimasukkan oleh user terhadap keseluruhan kalimat. Sedangkan bobot similarity kalimat, merupakan bobot hasil perbandingan kemiripan antar kalimat.
2.5.2.Algoritma Vector Space Model (VSM)
19
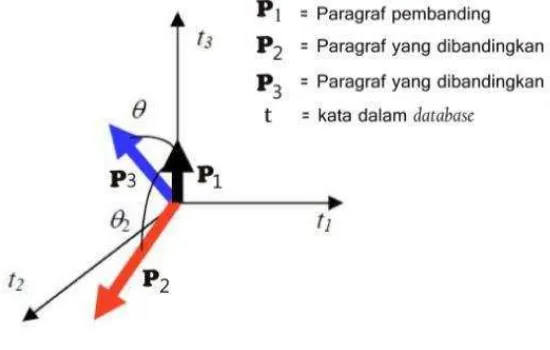
Vektor Space Model (VSM) digunakan dalam menggambarkan dokumen berbasis teks sebagai vektor dari identifier dimana model ini sering digunakan pada information retrieval [10]. Kalimat yang ada pada dokumen dibagi menjadi term-term dan dibuat vektor dimana keberadaan term dapat di nyatakan 1 bila ada dan 0 bila tidak ada.
Gambar 2. 2 Vector Space Model
Dimana : ti : Kata di database
Di : Dokumen
Q : Kata Kunci
Cara kerja dari vector space model adalah dengan menghitung nilai cosines sudut dari dua vector, yaitu vektor kata kunci terhadap vektor tiap dokumen. Perhitungan vektor space model menggunakan persamaan (2.7), (2.8) dan (2.9).
cos �� = � �, �� (2.7)
Dimana : Q : query (kata kunci)
20
J : Kata diseluruh dokumen
cos �� = |�|∗|� |�−� (2.9)
Analisis terstruktur akan dibahas tentang pengertian dan perangkat
pemodelan analisis terstruktur
a. Pengertian Analisis Tersetruktur
Analisis Terstruktur (Structured Analysis), merupakan salah satu teknik analisis yang mengunakan pendekatan berorientasi fungsi. Analisis ini terfokus pada aliran data dan proses bisnis perangkat dan perangkat lunak. Analisis ini disebut process oriented. Analisis struktur sederhana dalam konsep [19].
21
diperbaiki secara mudah (highly maintainable). Dalam bukunya itu, DeMarco mendefinisikan Analisis Terstruktur sebagai teknik untuk mendeskripsikan spesifikasi sistem baru melalui Data Flow Diagrams, Data Dictionary, Structured English, dan Data Structure Diagrams. Spesifikasi sistem tersebut dinyatakan dalam suatu dokumen yang disebut Spesifikasi Terstuktur (Structured Specification).
b. Perangkata Pemodelan Analisis Tersetruktur
Perangkat Pemodelan Analisis Terstruktur adalah alat bantu pemodelan yang digunakan untuk menggambarkan hasil pelaksanaan Analisis Terstruktur. Perangkat Analisis Terstruktur antara lain adalah:
1. Diagram Konteks
Diagram konteks adalah diagram yang terdiri dari suatu proses dan menggambarkan ruang lingkup suatu sistem. Diagram konteksmerupakan level tertinggi dari DFD yang menggambarkan seluruh input ke sistem atau output dari sistem. Ia akan memberi gambaran tentang keseluruhan sistem. Sistem dibatasi oleh boundary (dapat digambarkan dengan garis putus). Dalam diagram konteks hanya ada satu proses. Tidak boleh ada store dalam diagram konteks. Diagram konteks berisi gambaran umum (secara garis besar) sistem yang akan dibuat. Secara kalimat, dapat dikatakan bahwa diagram konteks ini berisi siapa saja yang memberi data (dan data apa saja) ke sistem, serta kepada siapa saja informasi (dan informasi apa saja) yang harus
dihasilkan sistem.
2. Diagram Aliran Data atau Data Flow Diagram (DFD)
22
memecah menjadi level yang lebih rendah.Beberapa simbol yang digunakan DFD adalah sebagai berikut :
a. Entitas luar (external entity)
Suatu yang berada diluar sistem, tetapi ia memberikan data kedalam sistem atau memberikan data dari sistem, disimbolkan dengan suatu kotak notasi. External Entity tidak termasuk bagian
dari sistem. Bila sistem informasi dirancang untuk suatu bagian lain yang masih terkait menjadi external entity.
b. Proses (Process)
Proses merupakan apa yang dikerjakan oleh sistem. Proses dapat mengolah data atau aliran data masuk menjadi aliran data keluar. Proses berfungsi mentransformasikan suatu atau beberapa data keluaran sesuai dengan spesifikasi yang diinginkan. Setiap proses memiliki satu atau beberapa masukan serta menghasilkan satu atau beberapa data kelurahan. Proses sering juga disebut bubble.
c. Arus data (Data Flow)
Arus data merupakan tempat mengalirnya informasi dan digambarkan dengan garis yang menghubungkan komponen dari sistem. Arus data ditunjukan dengan arah panah dan garis diberi nama atas arus data yang mengalir. Arus data ini mengalir diantara proses, data store dan menunjukan arus data dari data yang berupa masukan untuk sistem atau hasil proses sistem.
d. Simpanan data (Data Store)
Simpanan data merupakan tempat penyimpanaan data yang ada
23
3. Kamus Data (Data Dictionary)
Merupakan suatu tempat penyimpanan (gudang) dari data dan informasi yang dibutuhkan oleh suatu sistem informasi. Kamus data digunakan untuk mendeskripsikan rincian dari aliran data atau informasi yang mengalir dalam sistem, elemen-elemen data, file maupun basis data (tempat penyimpanan) dalam DFD.
4. Diagram Entitas-Relasi atau Entity-Relationship Diagram
(ERD)
ERD merupakan notasi grafis dalam pemodelan data konseptual yang mendeskripsikan hubungan antara penyimpanan. ERD digunangan untuk memodelkan struktur data dan hubungan antar data, karena hal ini relative kompleks. Dengan ERD kita dapat menguji model dengan mengabaikan proses yang dilakukan. ERD menggunakan sejumlah notasi dan simbol untuk menggambarkan struktur dan hubungan antar data, pada dasarnya ada 3 macam simbol yang digunakan:
a. Entity
Entity adalah suatu objek yang dapat di identifikasi dalam lingkaran pemakai, sesuatu yang penting bagi pemakai dalam konteks sistem yang akan dibuat.
b. Atribut
Entity mempunyai elemen yang disebut atribut dan berfungsi
mendeskripsikan karakter entity.
c. Relasi
24
2.7. Bahasa pemrograman yang di gunakan
Dalam pembuatan aplikasi klasifikasi berita otomatis, menggunakan bahas pemrograman C#.
2.7.1 Bahasa Program C#
C# (dibaca: C sharp) merupakan sebuah bahasa pemrograman yang berorientasi objek yang dikembangkan oleh Microsoft sebagai bagian dari inisiatif kerangka .NET Framework. Bahasa pemrograman ini dibuat berbasiskan bahasa C++ yang telah dipengaruhi oleh aspek-aspek ataupun fitur bahasa yang terdapat pada bahasa-bahasa pemrograman lainnya seperti Java, Delphi, Visual Basic, dan lain-lain) dengan beberapa penyederhanaan. Menurut standar ECMA-334 C# Language Specification, nama C# terdiri atas sebuah huruf Latin C (U+0043) yang diikuti oleh tanda pagar yang
menandakan angka # (U+0023). Tanda pagar # C# (dibaca: C sharp) merupakan sebuah bahasa pemrograman yang berorientasi objek yang
dikembangkan oleh Microsoft sebagai bagian dari inisiatif kerangka .NET Framework. Bahasa pemrograman ini dibuat berbasiskan bahasa C++ yang telah dipengaruhi oleh aspek-aspek ataupun fitur bahasa yang terdapat pada bahasa-bahasa pemrograman lainnya seperti Java, Delphi, Visual Basic, dan lain-lain) dengan beberapa penyederhanaan. Menurut standar ECMA-334 C# Language Specification, nama C# terdiri atas sebuah huruf Latin C (U+0043) yang diikuti oleh tanda pagar yang menandakan angka # (U+0023). Tanda pagar # yang digunakan memang bukan tanda kres dalam seni musik (U+266F), dan tanda pagar # (U+0023) tersebut digunakan karena karakter kres dalam seni musik tidak terdapat di dalam keyboard standar.
25
2.8. Tools Yang Digunakan
Dalam pembuatan aplikasi klasifikasi berita otomatis, menggunakan Microsoft Visual Studio 2010 sebagai pembuatan aplikasi dan menggunakan tools DevExpress Universal sebagai editor tampilan pada aplikasi yang akan dibuat.
2.9.1 Microsoft Visual Studio
Microsoft Visual Studio merupakan sebuah perangkat lunak yang dapat digunakan untuk melakukan pembuatan maupun pengembangan aplikasi, baik
itu aplikasi bisnis, aplikasi personal, ataupun komponen aplikasinya, dengan bentuk aplikasi console, aplikasi windows, ataupun aplikasi web. Visual Studio mencakup kompiler, SDK, Integrated Development Environment (IDE), dan dokumentasi (umumnya berupa MSDN Library). Kompiler yang dimasukkan ke dalam paket Visual Studio antara lain adalah : Visual C++, Visual C#, Visual Basic, Visual Basic .NET, Visual InterDev, Visual J++, Visual J#, Visual FoxPro, dan Visual SourceSafe.
BAB 5
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Berdasarkan hasil analisis,implementasi dan pengujian, kesimpulan yang diperoleh dari penelitian ini adalah :
1. Sistem dapat membantu melakukan klasifikasi terhadap berita yang belum terklasifikasi, akan tetapi masih memiliki beberapa kekurangan seperti fitur yang diberikan sistem masih kurang dan
dalam fitur kategori klasifikasi masih sedikit
2. Metode TF-IDF dan VSM dapat diterapkan untuk klasifikasi teks
berita bahasa Indonesia. Berdasarkan pengujian klasifikasi yang dihasilkan cukup maksimal dari 50 kali pengujian hanya 7 yang keliru dalam klasifikasi berita teks bahasa Indonesia
3. Hasil klasifikasi teks berita bahasa Indonesia sangat bergantung pada daftar kata kunci yang ada pada data training. Kata-kata yang tidak mewakili klasifikasi dengan baik dapat menghasilkan klasifikasi yang salah.
5.1. Saran
Berdasarkan hasil analisis, implementasi dan pengujian, saran yang dapat diberikan :
1. Perlu adanya pengembangan yang dapat mengklasifikasi banyak berita bukan hanya berita berbahas Indonesia saja.
![Gambar 1. 1 Metode Waterfall [2].](https://thumb-ap.123doks.com/thumbv2/123dok/682032.84255/17.595.174.448.163.361/gambar-metode-waterfall.webp)