54
Celebes Engineering Journal
http://journal.lldikti9.id/CEJ Vol 1, No, 1, April 2019, pp 54-61 p-ISSN:2684-8538 dan e-ISSN: 2685-0958DOI: https://doi.org/
Implementasi Metode Term Inverse Document
Frequency-Class Frequency untuk Peringkasan Berita Online
Marwa Sulehu1, Juhar2, Watty Rimalia3, Akbar Iskandar4
1Sistem Informasi, STMIK AKBA 3Teknik Informatika, Universitas Pancasakti
2,4Teknik Informatika, STMIK AKBA
Email: [email protected] Artikel info Artikel history: Received; Maret-2019 Revised; Maret-2019 Accepted; April-2019
Abstract. This study aims to improve and implement the Term Frequency Inverse Document Frequency Method with the Class Frequency method in summarizing online news to save time for news readers in understanding news through news summaries. Data (text documents) used in this study amounted to 20 Indonesian language news documents obtained from the site http://www.kompas.com. The trial document is a collection of news from the economic sports and technology categories. Data were analyzed using the Term Frequency Inverse Document Frequency Class Frequency method. The results of this study, show that Class Frequency implementation can affect the accuracy of word weighting in the Term Frequency and Inverse Document Frequency methods where the test results obtain an average accuracy of up to 75% of the 20 documents tested by comparing system testing with manual testing. Abstrak. Penelitian ini bertujuan untuk meningkatkan dan mengimplementasikan Metode Term Frequency Inverse Document Frequency dengan metode Class Frequency pada peringkasan berita online untuk menghemat waktu bagi para pembaca berita dalam memahami berita melalui ringkasan berita. Data (dokumen teks) yang digunakan dalam penelitian ini berjumlah 20 dokumen berita berbahasa Indonesia yang diperoleh dari situs http://www.kompas.com. Dokumen uji coba tersebut merupakan kumpulan berita dari kategori olahraga ekonomi dan teknologi. Data dianalisis dengan mengunakan metode Term Frequency Inverse Document Frequency Class Frequency. Hasil penelitian ini, menunjukan bahwa implementasi Class Frequency dapat mempengaruhi akurasi pembobotan kata pada metode Term Frequency dan Inverse Document Frequency dimana hasil pengujian memperoleh rata-rata akurasi sampai 75% dari 20 dokumen yang diuji dengan membandingkan pengujian sistem dengan pengujian manual.
| Celebes Engineering Journal Keywords: Peringkasan; Term Frequency; Inverse Document Frequency; Class Frequency. Coresponden author: Email: [email protected] artikel dengan akses terbuka dibawah lisensi CC BY -4.0
PENDAHULUAN
Informasi secara online semakin meningkat seiring berkembangnya media elektronik. Salah satu bentuk informasi tersebut adalah dokumen ataupun artikel berita. Kebutuhan akan informasi yang berupa dokumen atau artikel meyebabkan pengguna membutuhkan waktu yang lebih lama membaca keseluruhan dokumen atau artikel (Firmawati & Ataina, 2011). Jumlah informasi yang tersedia menyebabkan penurunan efektivitas dan efesiensi ketika individu menggunakan informasi. Pertumbuhan informasi yang tersedia membuat sulit untuk mendapatkan informasi yang diperlukan yang berkaitan dengan kebutuhan pengguna. Dengan menggunakan ringkasan pengguna dapat memutuskan jika dokumen sesuai dengan kebutuhan tanpa membaca seluruh isi dokumen atau artikel dengan berbagai macam metode(Ozsoy, M. G., Alpaslan & Cicekli, 2011). Berbagai metode untuk melakukan peringkasan dokumen telah diusulkan oleh para peneliti. Beberapa metode tersebut antara lain Term Frequency-Inverse Document Frequency (TF-IDF) (Gupta & Lehal, 2010), Dependency Based Discourse Tree (DEP-DT) (Silvia, Rukmana, Aprilia, Suhartono, Wongso, & Meiliana., 2014), Latent Semantic Analysis (LSA) (Silvia, Rukmana et al., 2014), Term-Based And Ontology-Based Methods (Qiang, Chen, Ding, Xie, & Wu, 2016). Metode-metode tersebut dapat digunakan untuk meringkas dokumen secara otomatis dengan kelebihan dan kekurangan tertentu.
Metode TF-IDF ,DEP-DT ,LSA dan Term-Based And Ontology-Based Methods masing-masing memiliki kelebihan dan kekurangan. Metode-metode tersebut telah dicoba sepuluh tahun terakhir dan terbukti keberhasilannya dalam melakukan peringkasan. Akan tetapi ringkasan yang di hasilkan tidak akurasi (Hirao et al., 2015). Metode TF-IDF memiliki banyak kelebihan seperti kecepatan dan efesien dibandingkan dengan metode DEP-DT, LSA dan Term-Based And Ontology-Based Methods (Liu & Yang, 2012)(Akbar Iskandar, Virma, & Ahmar, 2018).
Metode TF-IDF merupakan metode yang efesien dan sederhana dalam melakukan peringkasan. Namu metode TF-IDF memiliki kekurangan dalam akurasi pembobotan kata. Kekurangan tersebut membuat motode TF-IDF akurasi dalam pembobotan kata apabila dokumen yang diringkas terlalu besar (Liu & Yang, 2012)(Iskandar, Rismawati, & Rahim, 2018). Keterbatasan pada metode TF-IDF harus di atasi agar ringkasan dapat lebih akurasi.
Penelitian ini diusulkan sebuah solusi untuk mengatasi kekurangan pada metode TF-IDF dengan metode pengembangan TF-IDF untuk meningkatkan keakurasian dengan mengusulkan metode Term Frequency-Inverse Document Frequency-Class Frequency (TF-IDF-CF)(Liu & Yang, 2012). Penelitian ini bertujuan mengimplementasikan metode TF-IDF-CF untuk pembobotan kata pada peringkasan berita online.
METODE PENELITIAN
Peringkasan berita online dengan penerapan metode Term Frequency Inverse Document Frequency dengan metode Class Frequency memiliki beberapa langkah yaitu :
Pengumpulan data
Data (dokumen teks) yang digunakan dalam penelitian ini berjumlah 20 dokumen berita berbahasa Indonesia yang diperoleh dari situs http://www.kompas.com. Dokumen uji coba tersebut merupakan kumpulan berita dari kategori olahraga ekonomi dan teknologi.
Term frequency
Term frequency merupakan frekuensi dokumen berdasarkan kemunculan sebuah term (istilah)
dalam dokumen yang bersangkutan. Semakin sering sebuah kata muncul, semakin tinggi bobot dokumen untuk istilah tersebut, begitu sebaliknya (Wahib, A., Santika & Arifin, 2014). Pada Term
Frequency, terdapat beberapa jenis formula yang dapat diguanakan :
a. TF biner (binary TF), hanya memperhatikan apakah suatu kata atau term ada atau tidak dalam dokumen, jika ada diberi nilai satu, jika tidak diberi nilai nol.
b. TF murni (raw TF), nilai TF diberikan berdasarkan jumlah kemunculan suatu term di dokumen. Contohnya, jika muncul lima kali maka kata tersebut akan bernilai lima.
c. TF logaritmik, hal ini untuk menghindari dominansi dokumen yang mengandung sedikit term dalam query, namun mempunyai frekuensi yang tinggi.
(1)
d. TF normalisasi, menggunakan perbandingan antara frekuensi sebuah term dengan nilai
maksimum dari keseluruhan atau kumpulan frekuensi term yang ada pada suatu dokumen (2)
Inverse Document Frequency
Inverse Document Frequency merupakan metode pembobotan yang dipadukan dengan Ters
Frequency yang menghitung banyaknya istilah tertentu dalam keseluruhan dokumen. Metode
Inverse Document Frequency merupakan perhitungan dari bagaimana term di distribusikan
secara pada koleksi dokumen yang bersangkutan (Gupta & Lehal, 2010).
Inverse Document Frequency menunjukan hubungan ketersedian sebuah term dalam seluruh
dokumen. Semakin sedikit jumlah dokumn yang mengandung term yang dimaksud, maka nilai IDF semakin besar. Sedangkan untuk IDF dihitung dengan menggunakan formula sebagai berikut :
(3) Dimana :
D : jumlah semua dokumen
dfj : jumlah dokumen yang mengandung term
Class Frequency(CF)
Class Frequency (CF) merupakan metode yang meningkatkan pembobotan dengan menekankan
kemampuan mengkarakteristik istilah dalam kelas yang sama (Liu & Yang, 2012). Sedangkan untuk CF dihitung dengan menggunakan formula sebagai berikut :
dimana df, banyak dokumen sedangkan D, jumlah dokumen yang mengandung Term.
HASIL DAN PEMBAHASAN
Pengambilan sampel dokumen asli
Pengusaha yang tergabung dalam Kamar Dagang dan Industri (Kadin) Indonesia mempertanyakan rencana Ditjen Pajak memeriksa wajib pajak yang sudah ikut program tax amnesty. Padahal sebelumnya, Ditjen Pajak menuturkan, pemeriksaan pajak hanya akan memprioritaskan wajib pajak yang tidak ikut tax amnesty. "Pemeriksaan sebaiknya dilakukan kepada wajib pajak yang tidak ikut tax amnesty," ujar Ketua Kadin Rosan Roeslani kepada Kompas.com, Jakarta, Selasa (16/5/2017). Kebingungan yang meliputi pengusaha lantaran pemerintah sudah memberikan janji tidak akan lagi mengejar wajib pajak bila ikut program tax amnesty. Seharusnya tutur ia, perlakuan kepada wajib pajak
| Celebes Engineering Journal
yang sudah ikut dan wajib pajak yang tidak ikut tax amnesty harus berbeda. Pemeriksaan pajak seharusnya memprioritaskan wajib pajak yang tidak ikut tax amnesty."Menkeu sudah menyampaikan belum lama ini kepada kami kalau wajib pajak sudah ikut tax amnesty dan comply tidak akan di uber-uber orang pajak lagi," kata Rosan
Gambar 4.1 Dokumen Asli
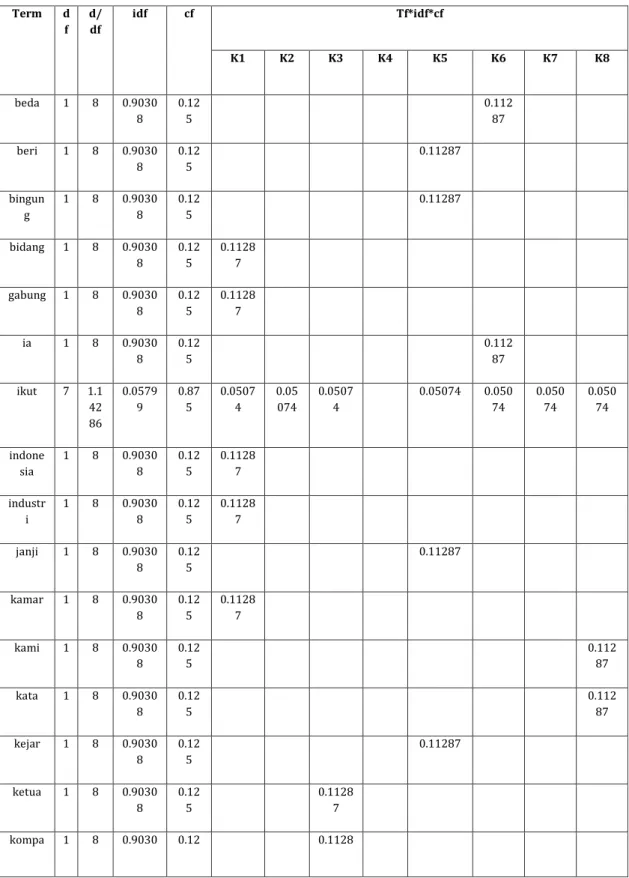
Tabel 4.1. Term Frequency, Inverce Document Frequency & Class Frequency
Term d f d/ df idf cf Tf*idf*cf K1 K2 K3 K4 K5 K6 K7 K8 beda 1 8 0.9030 8 0.12 5 0.112 87 beri 1 8 0.9030 8 0.12 5 0.11287 bingun g 1 8 0.9030 8 0.12 5 0.11287 bidang 1 8 0.9030 8 0.12 5 0.1128 7 gabung 1 8 0.9030 8 0.12 5 0.1128 7 ia 1 8 0.9030 8 0.12 5 0.112 87 ikut 7 1.1 42 86 0.0579 9 0.87 5 0.0507 4 0.05 074 0.0507 4 0.05074 0.050 74 0.050 74 0.050 74 indone sia 1 8 0.9030 8 0.12 5 0.1128 7 industr i 1 8 0.9030 8 0.12 5 0.1128 7 janji 1 8 0.9030 8 0.12 5 0.11287 kamar 1 8 0.9030 8 0.12 5 0.1128 7 kami 1 8 0.9030 8 0.12 5 0.112 87 kata 1 8 0.9030 8 0.12 5 0.112 87 kejar 1 8 0.9030 8 0.12 5 0.11287 ketua 1 8 0.9030 8 0.12 5 0.1128 7 kompa 1 8 0.9030 0.12 0.1128 57
s 8 5 7 laku 2 4 0.6020 5 0.25 0.1505 1 0.150 51 Lama 1 8 0.9030 8 0.12 5 0.112 87 Liput 1 8 0.9030 8 0.12 5 0.11287 Orang 1 8 0.9030 8 0.12 5 0.112 87 Pajak 7 1.1 42 86 0.0579 9 0.87 5 0.0507 4 0.05 074 0.0507 4 0.05074 0.050 74 0.050 74 0.050 74 Periksa 4 2 0.3010 3 0.5 0.1505 1 0.15 051 0.1505 1 0.150 51 Priorit as 2 4 0.6020 5 0.25 0.15 051 0.150 51 Progra m 2 4 0.6020 5 0.25 0.1505 1 0.15051 Rencan a 1 8 0.9030 8 0.12 5 0.1128 7 Rosan 2 4 0.6020 5 0.25 0.1505 1 0.150 51 Selasa 1 8 0.9030 8 0.12 5 0.11 287 Tanya 1 8 0.9030 8 0.12 5 0.1128 7 Tutur 2 4 0.6020 5 0.25 0.15 051 0.150 51 Uber 1 8 0.9030 8 0.12 5 0.112 87 Ujar 1 8 0.9030 8 0.12 5 0.1128 7 Usaha 2 4 0.6020 5 0.25 0.1505 1 0.15051 Wajib 7 1.1 42 86 0.0579 9 0.87 5 0.0507 4 0.05 074 0.0507 4 0.05074 0.050 74 0.050 74 0.050 74 Jumlah 1.396 70 0.60 375 0.942 39 0.11 287 1.01765 0.679 01 0.453 25 0.867 08
1)
Inverse Document Frequency (IDF)a)
Nilai 0.90308= log10
| Celebes Engineering Journal
b)
Nilai 0.05799 = log10c)
Nilai 0.60205 = log10d)
Nilai 0.30103 = log102)
Class Frequency (CF)a)
Nilai 0.125b)
Nilai 0.875c)
Nilai 0.25d)
Nilai 0.53)
W atau TF-IDF-CFHasil dari W di dapatkan dari hasil kali dari metode TF x IDF x CF untuk mendapatkan bobot dokumen.
Pembahasan
Setelah melakukan fase atau tahap dari metode TF-IDF-CF maka akan menentukan total jumlah nilai dari W atau jumlah TF-IDF-CF, dan untuk mendapatkan hasil ringkasan di mana :
Jika ringkasan yang diingikan 75% maka :
Nilai 8 diperoleh dari jumlah dokumen, dan nilai 75 di peroleh dari nilai threshold. Sehingga Hasil yang di peroleh adalah 6 Kalimat dari nilai tertinggi seperti pada Hasil ringkasan 75% data berikut.
(1.397)Pengusaha yang tergabung dalam Kamar Dagang dan Industri (Kadin) Indonesia
mempertanyakan rencana Ditjen Pajak memeriksa wajib pajak yang sudah ikut program tax amnesty.(1.02)Kebingungan yang meliputi pengusaha lantaran pemerintah sudah memberikan
janji tidak akan lagi mengejar wajib pajak bila ikut program tax amnesty.(0.945) "Pemeriksaan
sebaiknya dilakukan kepada wajib pajak yang tidak ikut tax amnesty," ujar Ketua Kadin Rosan Roeslani kepada Kompas.(0.869)"Menkeu sudah menyampaikan belum lama ini kepada kami
kalau wajib pajak sudah ikut tax amnesty dan comply tidak akan di uber-uber orang pajak lagi," kata Rosan.(0.681) Seharusnya tutur ia, perlakuan kepada wajib pajak yang sudah ikut dan
wajib pajak yang tidak ikut tax amnesty harus berbeda.(0.606) Padahal sebelumnya, Ditjen Pajak
menuturkan, pemeriksaan pajak hanya akan memprioritaskan wajib pajak yang tidak ikut tax amnesty.
Jika ringkasan yang diingikan 50% Maka : 59
Dari nilai threshold 50, akan menghasilkan ringkasan 4 kalimat dari dokumen asli dari nilai tertinggi, seperti yang tampak berikut ini.
(1.397)Pengusaha yang tergabung dalam Kamar Dagang dan Industri (Kadin) Indonesia
mempertanyakan rencana Ditjen Pajak memeriksa wajib pajak yang sudah ikut program tax amnesty.(1.02)Kebingungan yang meliputi pengusaha lantaran pemerintah sudah memberikan
janji tidak akan lagi mengejar wajib pajak bila ikut program tax amnesty.(0.945) "Pemeriksaan
sebaiknya dilakukan kepada wajib pajak yang tidak ikut tax amnesty," ujar Ketua Kadin Rosan Roeslani kepada Kompas.(0.869)"Menkeu sudah menyampaikan belum lama ini kepada
kami kalau wajib pajak sudah ikut tax amnesty dan comply tidak akan di uber-uber orang pajak lagi," kata Rosan.
Jika ringkasan yang diingikan 40% Maka :
Dari nilai 3,2 akan menghasilkan ringkasan 3 kalimat dari dokumen asli seperti:
(1.397)Pengusaha yang tergabung dalam Kamar Dagang dan Industri (Kadin) Indonesia
mempertanyakan rencana Ditjen Pajak memeriksa wajib pajak yang sudah ikut program tax amnesty.(1.02)Kebingungan yang meliputi pengusaha lantaran pemerintah sudah
memberikan janji tidak akan lagi mengejar wajib pajak bila ikut program tax amnesty.(0.945) "Pemeriksaan sebaiknya dilakukan kepada wajib pajak yang tidak ikut tax
amnesty," ujar Ketua Kadin Rosan Roeslani kepada Kompas. Jika ringkasan yang diingikan 30% Maka :
Dari nilai 2,4 akan menghasilkan ringkasan 2 kalimat dari dokumen asli seperti:
(1.397)Pengusaha yang tergabung dalam Kamar Dagang dan Industri (Kadin) Indonesia
mempertanyakan rencana Ditjen Pajak memeriksa wajib pajak yang sudah ikut program tax amnesty.(1.02)Kebingungan yang meliputi pengusaha lantaran pemerintah sudah
memberikan janji tidak akan lagi mengejar wajib pajak bila ikut program tax amnesty. Jika ringkasan yang diingikan 10% Maka :
Dari nilai 2,4 akan menghasilkan ringkasan 1 kalimat dari dokumen asli seperti:
(1.397)Pengusaha yang tergabung dalam Kamar Dagang dan Industri (Kadin) Indonesia
mempertanyakan rencana Ditjen Pajak memeriksa wajib pajak yang sudah ikut program tax amnesty.
Samakin besar nilai presentase semakin besar hasil ringkasan yang akan dihasilkan, sebaliknya semakin kecil nilai presentase semakin kecil hasil ringkasan. Batasan untuk nilai presentase
(threshold) yaitu lebih besar atau sama dengan (>=) 0,5 dari hasil penjumlahan. Mengukur
tingkat akurasi hasil ringkasan dilakukan dengan menguji 20 dokumen di mana pengujian berdasarkan pada metode TF-IDF-CF yang dilakukan manual atau oleh manusia yang berlandaskan pada hasil jumlah TF-IDF-CF atau W. Pada pengujian yang dilakukan terdapat 5 dokumen dari 20 dokumen yang berbeda dengan pengujian sistem. Berikut adalah hasil perhitungan tingkat keakurasian system hasil analisis berikut.
Akurasi = = 75%
Dari pengujian yang telah dilakukan secara manual dengan 20 dokumen, maka nilai akurasi yang dihasilkan sebesar 75%.
SIMPULAN DAN SARAN
| Celebes Engineering Journal
Kesimpulan dari penelitian ini dapat di jelaskan sebagai berikut bahwa Metode Class Frequency dapat dihitung dengan mengalikan Term Frequency-Inverse Document Frequency dengan Class Frequency untuk meningkatkan bobot dokumen, untuk mendapatkan hasil ringkasan 50%, maka jumlah dokumen dikali dengan 50 dibagi 100 sehingga nilai hasil perhitungan akan dijadikan dasar jumlah dokumen hasil ringkasan dari bobot terbesar. Selanjutnya Sistem peringkasan dokumen dapat diimplementasikan dengan menggunakan metode Term Frequncy – Inverce Document Frequncy dan menggabungkan metode Class Frequency untuk meningkatkan pembobotan kata yang mana hasil uji coba sistem yang telah dilakukan dengan pengujian manual dari 20 dokumen menunjukan bahwa nilai relevansi yang dihasilkan sampai 75% dengan nilai presentasi (threshold) 50%. Sehingga saran untuk para peneliti atau para pembaca berita dapat menggunakan sistem ini karena dapat menghemat waktu bagi para pembaca berita dalam memahami berita melalui ringkasan berita.
UCAPAN TERIMAKASIH
Ucapan terimakasih kepada teman sejawat dosen stmik akba atas sumbangsi pemikiran dan dukungan dari institusi berupa dana publikasi.
DAFTAR RUJUKAN
Akbar Iskandar, Virma, E., & Ahmar, A. S. (2018). Implementing DMZ in Improving Network Security of Web Testing in STMIK AKBA. International Journal of Engineering & Technology (UEA), 7(2.3), 99–104.
Firmawati, F. A., & Ataina, I. (2011). Automatic Text Summarization On Single-Document News Using Shortest Path Algorithm Pendahuluan.
Gupta, V., & Lehal, G. S. (2010). A Survey of Text Summarization Extractive techniques. Journal of Emerging Technologies in Web Intelligence.
Hirao, T., Nishino, M., Yoshida, Y., Suzuki, J., Yasuda, N., & Nagata, M. (2015). Summarizing a Document by Trimming the Discourse Tree. IEEE/ACM Transactions on Speech and Language Processing.
Iskandar, A., Rismawati, & Rahim, R. (2018). Designing Application for Performance Assessment to Measure Employee Profesionalism in Goverment. Joint Workshop KO2PI and The 1st
International Conference on Advance & Scientific Innovation, 154–161.
Liu, M., & Yang, J. (2012). An improvement of TFIDF weighting in text categorization.
Ozsoy, M. G., Alpaslan, F. N., & Cicekli, I. (2011). Text summarization using Latent Semantic Analysis. Proceedings of the 23rd International Conference on Computational Linguistics, 405–417.
Qiang, J.-P., Chen, P., Ding, W., Xie, F., & Wu, X. (2016). Knowle dge-Base d Systems Multi-document
summarization using closed patterns. Knowledge-Based Systems. (99), 28–38.
Silvia, Rukmana, P., Aprilia, V. R., Suhartono, D., Wongso, R., & Meiliana. (2014). Summarizing Text for Indonesian Language by Using Latent Dirichlet Allocation and Genetic Algorithm, (August),.
Wahib, A., Santika, P. P., & Arifin, A. Z. (2014). Perangkingan Dokumen Berbahasa Arab
Menggunakan Latent Semantic Indexing. 83–92.