SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
ARIE PRIMA ANGGARA
10110038
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
KATA PENGANTAR
Puji syukur penulis panjatkan kehadirat Allah SWT yang Maha pengasih
dan juga Maha penyayang, karena atas rahmat dan hidayah-Nya penulis dapat
menyelesaikan Skripsi yang berjudul “
OTOMASI PEMBENTUKAN ABSTRAK
BAHASA INDONESIA BERDASARKAN KESELURUHAN DOKUMEN
MENGGUNAKAN TERM FREQUENCY
–
INVERSE DOCUMENT
FREQUENCY (TF-IDF)
”.
Skripsi ini dibuat sebagai salah satu syarat kelulusan program Strata 1
Fakultas Teknik dan Ilmu Komputer, Program Studi Teknik Informatika di
Universitas Komputer Indonesia. Dengan penuh rasa syukur, ucapan terima kasih
yang mendalam serta penghargaan yang setinggi-tingginya penulis sampaikan
kepada :
1.
Allah SWT yang senantiasa memberikan kekuatan, kesehatan, dan
kesempatan kepada penulis dalam proses menyelesaikan skripsi ini serta
atas semua rahmat dan hidayah-Nya yang dapat menjadikan semangat
tiada henti.
2.
Kedua orang tua yang sangat penulis cintai dan hormati, yang selalu
memberikan semangat, kekuatan moril, dan selalu mendo’akan penulis.
3.
Ayah (Alm) tercinta yang penulis banggakan, terimakasih selama ini sudah
banyak membantu dan mendukung serta mendoakan semoga tenang
disana.
4.
Ibu Nelly Indriani W, S.Si., M.T selaku pembimbing/Penguji 2 dan Wali
Dosen IF-1 2010 yang selalu memberikan yang terbaik dan selalu
meluangkan waktunya kepada penulis dalam pembuatan tugas akhir ini.
5.
Ibu Ednawati Rainarli, S.Si., M.Si. selaku reviewer/Penguji 1 atas saran
dan arahan yang sangat membantu dalam penyempurnaan tugas akhir ini.
6.
Seluruh staf dosen Teknik Informatika yang telah memberikan ilmu yang
sangat berarti untuk penulis.
7.
Kepada Reza Fahlevi, Mugiana Munggaran, Yusuf Dwikarya, Ari
iv
Irawan, dan masih banyak khususnya teman- teman IF-1 2010 terimakasih
atas kebersamaan susah senang yang telah dilalui sehingga sampai pada
penulis untuk dapat menyelesaikan skripsi ini.
8.
Kepada teman seperjuangan driver gojek warsop yang telah mendukung
penulis untuk dapat menyelesaikan skripsi ini.
9.
Teman-teman satu bimbingan yang selalu kompak dan saling membantu
untuk mencapai kelulusan bersama-sama.
Penulis sangat menyadari bahwa skripsi ini masih banyak kekurangan dan
masih jauh dari kata sempurna. Oleh karena itu, kritik dan saran yang sifatnya
membangun akan penulis terima dengan senang hati. Akhir kata penulis berharap
skripsi ini dapat bermanfaat bagi yang membutuhkan.
Bandung, Februari 2016
v
DAFTAR ISI
ABSTRAK ... i
ABSTRACT
... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... x
DAFTAR SIMBOL ... xii
DAFTAR LAMPIRAN ... xv
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 2
1.3 Maksud dan Tujuan ... 2
1.3.1 Maksud ... 2
1.3.2 Tujuan ... 2
1.4 Batasan Masalah... 2
1.5 Metodologi Penelitian ... 3
1.5.1 Metode Pengumpulan Data ... 4
1.5.2 Metode Pembangunan Perangkat Lunak ... 4
1.6 Sistematika Penulisan ... 5
BAB 2 LANDASAN TEORI ... 7
2.1 Ringkasan ... 7
2.2 Teks ... 7
vi
2.7.1
Unified Modeling Language
(UML) ... 12
2.7.2
Use case Diagram ...
13
2.7.3
Activity Diagram ...
15
2.7.4
Sequence Diagram ...
16
2.7.5
Class Diagram ...
17
2.8 Teknik Evaluasi Sistem dan Pengujian ... 19
2.9 Perangkat Lunak pendukung ... 20
2.9.1 Bahasa Program C# ... 20
2.9.2 Microsoft Visual Studio ... 21
2.9.3 DevExpress ... 24
BAB 3 ANALISIS DAN KEBUTUHAN ... 25
3.1 Analisis Masalah ... 25
3.2 Analisis Masukan ... 25
3.3 Analisis Prepocessing Data ... 25
3.4 Analisis Penerapan (TF-IDF) ... 36
3.5 Spesifikasi Kebutuhan Perangkat Lunak ... 42
3.5.1 Analisis Kebutuhan Non Fungsional
...
42
3.5.1.1 Kebutuhan Perangkat Keras ... 43
3.5.1.2 Kebutuhan Perangkat Lunak ... 43
3.6 Pemodelan Sistem ... 43
3.6.1 Use Case Diagram ... 43
vii
3.6.2 Skenario Diagram ... 46
3.6.3 Activity Diagram ... 50
3.6.4 Sequence Diagram ... 58
3.6.5 Class Diagram ... 62
3.7 Perancangan Sistem ... 62
3.7.1 Diagram Relasi ... 62
3.7.2 Rancangan Antar Muka ... 62
3.7.3 Jaringan Semantik ... 64
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM ... 65
4.1 Implementasi Sistem ... 65
4.1.1 Implementasi Perangkat Keras ... 65
4.1.2 Implementasi Perangkat Lunak ... 65
4.1.3 Implementasi Basis Data ... 66
4.1.4 Implementasi Class ... 66
4.1.5 Implementasi Antarmuka ... 67
4.2 Pengujian Sistem ... 68
4.2.1 Pengujian Akurasi ... 68
4.2.2 Skenario Pengujian ... 68
4.2.3 Kesimpulan Hasil Pengujian ... 97
BAB 5 KESIMPULAN DAN SARAN ... 95
5.1 Kesimpulan ... 95
5.2 Saran ... 95
97
pg. 117.
New York
:
Macmillan Publishers
,
ISBN 0020130856
[2] Taufiq M. Isa 1) dan Taufik Fuadi Abidin 2).,
“
Mengukur tingkat kesamaan
paragraf menggunakan vector space mod
el untuk mendeteksi plagiarisme”
Seminar Nasiaonal dan ExpoTeknik Elektro, 1) jurusan matematika.
FMIPA, Universitas Syiah Kuala, 2) Jurusan informatika, FMIPA,
Universitas Syiah Kuala, 2013.
[3]
R. S. Pressman, Software Engineering: A Practitioner’s
Approach.
[4] Raymond J. Mooney. CS, 391L: Machine Learning Text Categorization.
University of Texas at Austin, 2006.
[5]
P. P. Widodo dan Heriawati. “Menggunakan
Unified Modeling Language
(UML)”. Bandung Informatika, 2011.
[6] Wahana Komputer, Shortcourse Series: Microsoft Visual C# 2010. Andi,
2011
[7] Deny Ocr.(2014, Aug.10)
Pengenalan DevExpress
[online]. Available :
http://www.jagocoding.com/tutorial/600/Pengenalan_DevExpress_Window
s_Form
[8] Sholechul Aziz, Jurus Andalan Menguasai EYD (Ejaan yang
Disempurnakan). IV. Jakarta : Kunci Komunikasi, 2015.
[9]
Mohd. Ehmer Khan. “Different Approaches to White Box Testi
ng
Technique for Finding error”
, 2011.
[10] Many, I. and Maybury. 1999.
Advance in Automatic Text Summarization
.
The MIT Press: Cambrige.
[11]
Zaman B. dan E Winarko. 2011. Analisis Fitur Kalimat untuk Peringkas
Teks otomatis pada Bahasa Indonesia.
Indonesian Journal of Computing
1
BAB 1
PENDAHULUAN
1.1
Latar Belakang Masalah
Abstrak adalah sebuah ringkasan dari keseluruhan dokumen penelitian
agar pembaca tahu maksud dari penelitian tersebut. Abstrak digunakan sebagai
jembatan untuk memahami uraian yang akan disajikan dalam suatu karangan
biasanya laporan atau artikel ilmiah terutama untuk memahami ide-ide
permasalahannya. Dari abstrak, pembaca dapat mengetahui jalan pikiran penulis
laporan/artikel ilmiah tersebut dan mengetahui gambaran umum tulisan secara
lengkap. Untuk itulah pembuat abstrak harus dapat mewakili isi karangan ilmiah
secara keseluruhan, mulai dari latar belakang, analisis/analisa, dan hasil
penelitian/kesimpulan. [1]
Dalam membentuk paragraf abstrak pada sebuah dokumen jurnal dari
setiap sub bab tentunya membutuhkan pencarian kalimat yang singkat dan jelas.
Di
dalam
dunia
akademik,
tulisan
pendek
ini
digunakan
oleh
institusi/lembaga/organisasi pendidikan sebagai informasi awal atas sebuah
penelitian ketika dimasukkan dalam jurnal, konferensi, lokakarya, atau yang
sejenisnya. Pencarian kalimat pada setiap sub bab dalam dokumen jurnal yang
banyak akan menyulitkan penulis laporan/artikel ilmiah dalam membentuk
abstrak dengan keterbatasan pembentukan abstrak harus singkat, bagian harus
seimbang dan menghindari kalimat yang panjang. Pembuatan abstrak dapat
dilakukan secara otomatis dengan memanfaatkan metode
Term Frequency
–
Inverse Document Frequency (TF-IDF)
.
Untuk dapat membentuk kalimat abstrak secara otomatis maka akan
diterapkan metode
Term Frequency
–
Inverse Document Frequency (TF-IDF)
,
karena TF-IDF merupakan pembobotan yang mengukur seberapa penting sebuah
kata dalam dokumen bila dilihat secara global pada seluruh dokumen.[5] Pada
pembuatan abstrak penelitian akan mencari sub judul yang dibutuhkan yaitu pada
bagian pendahuluan atau latar belakang, analisis atau analisa data dan kesimpulan.
bagian kalimat yang berada dalam sub judul yang dibutuhkan
.
Dalam mengukur
sebuah kalimat dari kemiripan setiap sub bab pada sebuah dokumen akan
menggunakan teknik
text mining
.
Dari permasalahan diatas, maka penelitian ini akan menerapkan metode
Term Frequency
–
Inverse Document Frequency (TF-IDF)
pada pembentukan
sebuah paragraf abstrak secara otomatis.
1.2
Rumusan Masalah
Berdasarkan latar belakang yang sudah dijelaskan diatas, maka rumusan
dalam masalah ini adalah
bagaimana membentuk kalimat abstrak secara otomatis
berdasarkan keseluruhan dokumen jurnal penelitian dengan menggunakan
metode
Term Frequency
–
Inverse Document Frequency (TF-IDF)
yang nantinya
akan menghasilkan sebuah kalimat abstrak bahasa indonesia
.
1.3
Maksud dan Tujuan
1.3.1 Maksud
Maksud dari pada penelitian tugas akhir ini adalah membuat sistem
pembentukan abstrak secara otomatis pada keseluruhan dokumen jurnal penelitian
dengan menggunakan metode
Term Frequency
–
Inverse Document Frequency
(TF-IDF)
.
1.3.2
Tujuan
Adapun tujuan dari penelitian tugas akhir ini adalah melakukan
pembuatan kalimat abstrak yang baik secara otomatis untuk melengkapi suatu
tulisan ilmiah dengan singkat dan jelas, sehingga membantu melengkapi
laporan/artikel ilmiah dalam pembentukan kalimat abstrak secara cepat dan
akurat.
1.4
Batasan Masalah
Batasan masalah yang akan diterapkan dalam pembentukan abstrak
berdasarkan keseluruhan dokumen
yaitu:
3
2.
Dokumen yang digunakan pada penelitian ini adalah dokumen teks yang
berbahasa indonesia berformat
Microsoft Word
(*.doc).
3.
Bahasa dokumen yang digunakan yaitu bahasa indonesia baku.
4.
Dokumen yang diuji berupa jurnal dengan format umum untuk jurnal
ilmiah.
5.
Pembagian kalimat dan pengambilan teks hanya pada bagian sub bab
Pendahuluan atau Latar Belakang, Analisis atau Analisa Data, dan
Kesimpulan.
1.5
Metodologi Penelitian
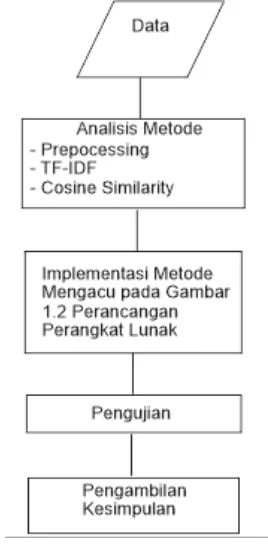
Metodologi penelitian yang digunakan adalah metode deskriptif.
Metodologi deskriptif merupakan metode yang bertujuan untuk mendapatkan
gambaran yang jelas mengenai hal-hal yang diperlukan. Metode penelitian
meliputi metode pengumpulan data dan metode pembangunan perangkat lunak.
Pada gambar 1.1 berikut ini merupakan gambaran penelitian yang dilakukan.
1.5.1
Metode Pengumpulan Data
Metode pengumpulan data yang akan digunakan adalah Studi literatur
pengumpulan data dengan cara literatur, jurnal,
paper
, dan bacaan
–
bacaan yang
berkaitan dengan judul.
1.5.2
Metode Pembangunan Perangkat Lunak
Dalam membangun aplikasi yang akan dikembangkan ini menggunakan
paradigma model prototype, yang meliputi beberapa proses diantaranya :
1.
Pengumpulan kebutuhan : pengumpulan data dengan cara mengumpulan
literature, jurnal, paper dan bacaan-bacaan yang ada kaitannya dengan
judul penelitian.
2.
Perancangan : perancangan dilakukan cepat dan rancangan mewakili
semua aspek software yang diketahui, dan rancangan ini menjadi dasar
pembuatan prototype.
3.
Evaluasi Prototype : pengujian terhadap software yang dibuat dan
digunakan untuk memperjelas kebutuhan software.
5
1.6
Sistematika Penulisan
Sistematika penulisan penelitian ini disusun untuk memberikan gambaran
umum tentang penelitian yang dijalankan. Sistematika penulisan dalam penelitian
ini adalah sebagai berikut :
BAB 1 PENDAHULUAN
Bab ini membahas tentang latar belakang masalah, perumusan masalah yang
terjadi, menentukan maksud dan tujuan penelitian, batasan masalah,
metodologi penelitian yang digunakan dan sistematika penulisan.
BAB 2 LANDASAN TEORI
Pada bab ini membahas berbagai konsep dasar dan teori-teori dalam
pembuatan abstrak dan membahas mengenai metode
Term Frequency
–
Inverse Document Frequency (TF-IDF)
serta cara penerapannya
.
BAB 3 ANALISIS DAN KEBUTUHAN
Pada bab ini membahas tentang menganalisis masalah dari penelitian serta
pemecahan masalah yang akan dilakukan dan perancangan penggunaan
metode dalam melakukan pembuatan abstrak.
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Pada bab ini berisi tentang hasil evaluasi sistem dan pengujian untuk
hasil pembentukan kalimat abstrak secara otomatis yang telah
menggunakan metode
Term Frequency
–
Inverse Document Frequency
(TF-IDF)
.
sehingga dapat ditarik suatu kesimpulan.
BAB 5 KESIMPULAN DAN SARAN
Pada bab ini membahas tentang kesimpulan dan saran yang sudah diperoleh
dari hasil penelitian yang telah dilakukan dan masukan-masukan yang dapat
digunakan untuk perbaikan hasil dari penelitian atau untuk mengembangkan
7
BAB 2
LANDASAN TEORI
2.1
Ringkasan
Ringkasan adalah suatu cara yang efektif untuk menyajikan suatu karangan
yang panjang dalam bentuk singkat. Oleh karena itu membuat ringkasan atas
sebuah karangan yang panjang dapat diumpamakan sebagai memangkas sebatang
pohon sehingga tinggal batang, cabang-cabang dan ranting-ranting yang
terpenting beserta daun-daun yang diperlukan, sehingga tampak bahwa esensi
pohon masing dipertahankan. Dalam ringkasan keindahan gaya bahasa, ilustrasi,
serta penjelasan-penjelasan yang terperinci dihilangkan, sedangkan sari
kerangaknya dibiarkan tanap hiasan. Walaupun bentuknya ringkas, namun tetap
mempertahankan pikiran pengarang dan pendekatan yang asli [11].
Dalam meringkas sebaiknya menggunakan kalimat tunggal daripada kalimat
majemuk. Kalimat majemuk menunjukan bahwa ada dua gagasan atau lebih yang
bersifat paralel. Bila memungkinkan ringkaslah kalimat menjadi frasa, selanjutnya
frasa menjadi kata. Begitu pula rangkaian gagasan yang penjang hendaknya
diganti dengan suatu gagasan sentral saja. Pada umumnya suatu ringkasan
ditentukan panjang ringkasan akhirnya, ada yang meringkas seperdua total kata,
sepertiga total kata, hingga sepersepuluh total kata. Untuk artikel yang memiliki
jumlah kata yang sangat banyak tentu saja hasil ringkasan sepersepuluh menjadi
pilihan yang tepat. Sedangkan untuk artikel yang jumlah katanya tidak terlalu
banyak maka hasil ringkasan sebanyak seperdua total kata menjadi pilihan yang
tepat sehingga hasil ringkasan nantinya masih dapat dibaca dengan struktur hasil
ringkasan yang baik.
2.2
Teks
Teks dapat diartikan kumpulan karakter yang membentuk kata yang disusun
dan memiliki suatu makna. Teks dapat berupa angka, frasa, kalimat, atau
paragraph. Dalam peringkasan teks, teks yang diinginkan dapat berbentuk
akan diproses untuk digali informasinya akan dimanfaatkan untuk menghasilkan
teks yang lebih ringan.
2.3
Abstrak
Abstrak merupakan sebuah ringkasan isi dari sebuah karya tulis ilmiah yang
ditujukan untuk membantu seorang pembaca agar dapat dengan mudah dan cepat
untuk melihat tujuan dari penulisannya. Di dalam dunia akademik, tulisan pendek
ini digunakan oleh institusi/lembaga/organisasi pendidikan sebagai informasi awal
atas sebuah penelitian ketika dimasukkan dalam jurnal, konferensi, lokakarya,
atau yang sejenisnya. Dalam dunia maya (internet), sebuah abstrak digunakan
sebagai gambaran singkat atas sebuah karya tulis ilmiah/penelitian untuk dibaca,
sebagaimana halnya sebuah “display” model pak
aian dipajang untuk dilihat atau
diuji pakai sebelum dibeli. Selanjutnya, bagian lengkap sebuah penelitian dijual
kepada mereka yang berminat untuk mendapatkannya.
Untuk membuat abstrak, hal-hal yang perlu diperhatikan adalah sebagai
berikut:
1.
Struktur paragraf
Sebuah abstrak ditulis dalam satu paragraf yang menerangkan keseluruhan
isi tulisan secara singkat dan jelas. Penulisannya tidak melakukan
indentasi pada kalimat pertama paragraf.
Single space
adalah pilihan yang
dimiliki oleh penulis untuk menyusun kalimat dalam paragrafnya. Lebih
dalam, kadang seorang pembimbing Skripsi/Tesis/Disertasi mengatur
hingga pada penggunaan jenis huruf dan ukuran tertentu.
2.
Jumlah kata
Idealnya sebuah paragraf terdiri dari 150 sampai dengan 200 kata. Namun,
pertimbangan jumlah kata yang paling tepat dalam penulisan Skripsi,
Tesis, ataupun disertasi biasanya bergantung pada pertimbangan
pandangan pembimbing (supervisor) yang mendampingi seorang
mahasiswa dalam penulisannya. Seorang supervisor harusnya tidak
mempertimbangkan jumlah kata sebagai acuan utama penulisan paragraf,
9
3.
Isi paragraf
Pertama, identifikasi fokus penelitian dijelaskan secara singkat agar
pembaca memahami apa yang diamati oleh seorang peneliti di dalam
penelitiannya. Kedua, penulis perlu menggambarkan secara jelas desain
penelitian yang dilakukan dalam proses pencarian jawaban atau solusi atas
persoalan yang diangkat di dalam penelitiannya. Desain langkah
penyelesaian masalah ini oleh mahasiswa lazim dikenal dengan istilah
Metode Penelitian. Ketiga, selanjutnya penulis akan menjelaskan hasil
temuannya kepada pembaca. Beberapa peneliti menganggap hasil temuan
yang diungkap tidak perlu mengungkap pembahasan yang dilakukan karena
hal itu justru akan membuat pengulangan isi tulisan. Jelas maksudnya
karena bagian pembahasan temuan penelitian juga diurai di dalam bagian
kesimpulan. Keempat, perlunya bagian kesimpulan di dalam sebuah tulisan
juga terlihat di dalam sebuah abstrak yang tetap mendapatkan perhatian
penting sebagai bagian akhir dari paragraf. Pada bagian ini kadangkala
sejumlah peneliti menyisipkan rekomendasi penelitian namun tanpa
pembahasan atau uraian yang panjang. Lebih lanjut, tidaklah lazim sebuah
abstrak diisi oleh nama si penulis serta para pembimbing tulisannya, apalagi
hal itu ditulis dalam huruf cetak tebal
2.4
Tahapan
Text Mining
Pada tahap
text mining
ini terdapat lima langkah yaitu:
a.
Case Folding,
yaitu mengubah semua teks ke dalam huruf kecil.
b.
Filtering,
menghapus karakter yang tidak dipakai. Adapun karakter yang
akan dihilangkan yaitu : '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ',', '"', '-', '/', '{',
'}', '+', '_', '!', '@', '#', '$', '%', '^', '&', '*', '(', ')', '?', '<', '>', '[', ']', '|', '~', '`', ';',
':', '='
dan “’s” untuk dokumen berbahasa Inggris akan dihapus kecuali
tanda titik.
d.
Synonim Checking,
yaitu mengganti kata yang ada yang memiliki arti yang
sama. Penggantian kata yang dilakukan berdasarkan
database
yang dibuat
oleh penulis.
e.
Stopwords,
yaitu Pada proses
stowords removal
ini proses yang dikerjakan
yaitu menghapus kata yang kurang relevan atau kata yang tidak memiliki
arti yang begitu penting dan berkaitan yang ada pada kalimat di dokumen
dengan mencocokan
list
kata stopword yang pada
database
yang akan
diuji.
Database
yang digunakan baik untuk Bahasa Indonesia maupun
maupun Bahasa Inggris diambil dari sebuah situs yg menyediakan
berbagain jenis
list stopword
untuk berbagai bahasa.
Pada umumnya tahap
preprocessing
terdapat 5 langkah yaitu
Case
Folding, Filtering, Tokenizing, Stemming,
dan
Stopwords.
Ada satu langkah yang
tidak penulis gunakan dalam pembuatan aplikasi peringkasan dokumen esktraktif
ini yaitu proses
stemming. Stemming
yaitu proses menghilangkan imbuhan dari
sebuah kata dan mengubahnya menjadi kata dasar. Tujuan dari penghilangan
proses
Stemming
ini yaitu karena penulis memiliki pendapat bahwa dalam sebuah
peringkasan dokumen ekstraktif imbuhan yang terdapat pada sebuah kata
memiliki arti yang berbeda. Adapun contoh kalimat yaitu : “Bapak
membuatkan
sebuah rumah untuk istrinya”, “Bapak
dibuatkan
secangkir kopi oleh ibu”,
“Bapak selalu
berbuat
baik
kepad
a tetangga”. Kata “buat” pada kalimat pertama
dan kalimat ketiga memiliki arti bapak melakukan sebuah kegiatan tapi pada
kalimat dua kata”buat” memiliki arti bapak mendapatkan sebuah perlakuan.
Apabila proses
stemming
tetap dilakukan maka tidak akan didapatkan perbedaan
antara satu kata dengan yang lainnya.
Pada tahap filtering penulis menambahkan karakter “ ’s ” yang akan
digunakan untuk menghapus tanda baca bagi dokumen yang menggunakan bahasa
11
2.5
Term Frequency
–
Inverse Document Frequency (TF-IDF)
Metode
Term Frequency-Inverse Document Frequency
(TF-IDF) adalah
cara pemberian bobot hubungan suatu kata (term) terhadap dokumen. Untuk
dokumen tunggal tiap kalimat dianggap sebagai dokumen. Metode ini
menggabungkan dua konsep untuk perhitungan bobot, yaitu
Term Frequency
(TF)
merupakan frekuensi kemunculan kata (t) pada kalimat (s).
Document frequency
(DF) adalah banyaknya kalimat dimana suatu kata (t) muncul. Frekuensi
kemunculan kata di dalam dokumen yang diberikan menunjukkan seberapa
penting kata itu di dalam dokumen tersebut. [5]
Frekuensi kalimat yang mengandung kata tersebut menunjukkan seberapa
umum kata yang ada pada dokumen uji tersebut. Bobot kata semakin besar jika
sering muncul dalam suatu kalimat dan semakin kecil jika muncul dalam banyak
kalimat. Pada Metode ini pembobotan kata dalam sebuah dokumen dilakukan
dengan mengalikan nilai TF dan IDF. Pembobotan diperoleh berdasarkan jumlah
kemunculan term dalam kalimat (TF) dan jumlah kemunculan term pada seluruh
kalimat dalam dokumen (IDF). Bobot suatu istilah semakin besar jika istilah
tersebut sering muncul dalam suatu dokumen dan semakin kecil jika istilah
tersebut muncul dalam banyak dokumen. Nilai IDF sebuah term dihitung
menggunakan persamaan (1) di bawah ini :
IDF
=
log
(
)
(1)
keterangan :
N = Jumlah keseluruhan kalimat pada dokumen
Menghitung bobot (W) masing-masing kalimat dengan persamaan (2) di bawah
ini:
W
d.t= TF
d.t* IDF
t(2)
dengan :
d
= kalimat ke-d
t
= kata (
term
) ke-t
TF =
Term Frequency
W
=
bobot kalimat ke-d terhadap kata (
term
) ke-t
IDF=
Inverse Document Frequency
Kemudian baru melakukan proses pengurutan (sorting) nilai kumulatif dari
W untuk setiap kalimat. Tiga kalimat dengan nilai W terbesar dijadikan sebagai
hasil dari ringkasan atau sebagai output dari peringkasan teks otomatis. [5]
2.7
Model Analisis Dan Perancangan
Model analisis dan perancangan yang digunakan untuk membangun aplikasi
ini adalah sebagai berikut:
2.7.1
Unified Modeling Language
(UML)
Unified Modeling Language
(UML) merupakan bahasa spesifikasi standar
untuk mendokumentasikan, menspesifikasikan, dan membangun sistem perangkat
lunak. UML tidak berdasarkan pada bahasa pemrograman tertentu. Standar
spesifikasi UML dijadikan standar
defacto
oleh OMG (
Object Management
Group
) pada tahun 1997. UML yang berorientasikan obyek mempunyai beberapa
notasi standar. Spesifikasi ini menjadi populer dan standar karena sebelum adanya
UML, telah ada berbagai macam spesifikasi yang berbeda. Hal ini menyulitkan
komunikasi antar pengembang perangkat lunak. Untuk itu beberapa pengembang
spesifikasi yang sangat berpengaruh berkumpul untuk membuat standar baru.
UML dirintis oleh Grady Booch, James Rumbaugh pada tahun 1994 dan
13
Menurut perintisnya, UML di definisikan sebagai bahasa visual untuk
menjelaskan, memberikan spesifikasi, merancang, membuat model, dan
mendokumentasikan aspek-aspek dari sebuah sistem. Karena tergolong bahasa
visual, UML lebih mendepankan penggunaan diagram untuk menggambarkan
aspek dari sistem yang sedang dimodelkan. Memahami UML itu sebagai bahasa
visual itu penting, karena penekanan tersebut membedakannya dengan bahasa
pemrograman yang lebih dekat ke mesin. Bahasa visual lebih dekat ke mental
model pikiran kita, sehingga pemodelan menggunakan bahasa visual bisa lebih
mudah dan lebih cepat dipahami dibandingkan apabila dituliskan dalam sebuah
bahasa pemrograman.
Seperti yang telah dipaparkan di atas, UML yang merupakan turunan dan
beberapa metode mempunyai kumpulan diagram
grafts
sebagai kombinasi dari
konsep pemodelan data (
Entity Relationship Diagram
), pemodelan bisnis (
work
flow
), pemodelan obyek, dan pemodelan komponen. Diagram
grafts
tersebut
merupakan tampiian dari beberapa level abstraksi yang dapat digunakan secara
bersama oleh semua proses pada seluruh
lifecycle
pengembangan perangkat lunak
serta pada implementasi kebeberapa teknologi yang berbeda. UML memiliki
berbagai jenis diagram, diantarnya adalah:
2.7.2
Use case Diagram
Use case
diagram berisi mengenai interaksi antara sekelompok proses
dengan sekelompok
actor
, menggambarkan fungsionalitas dari sebuah sistem
yang dibangun dan bagaimana sistem berinteraksi dengan dunia luar[6].
Use case
diagram
dapat digunakan selama proses analisis untuk menangkap kebutuhan
sistem dan untuk memahami bagaimana sistem seharusnya bekerja.
Use Case
diagram terdiri dari beberapa elemen pemodelan utama, yaitu
Actor, Use Case, Association, Dependency,
dan
Generalization.
a.
Actor
Pada dasarnya
actor
bukanlah bagian dari
use
case
diagram, namun untuk
dapat terciptanya suatu
use
case
diagram diperlukan beberapa
actor
.
Actor
tersebut mempresentasikan seseorang atau sesuatu (seperti perangkat, sistem lain)
tidak memiliki kontrol atas
use
case
.
Actor
digambarkan dengan stick man. Pada
gambar 2.1 menunjukan Simbol
Actor
pada
Use
Case
Diagram.
Gambar 2.1 Simbol
Actor
pada
Use
Case
diagram
b.
Use
Case
Use case
adalah gambaran fungsionalitas dari suatu sistem, sehingga
customer atau pengguna sistem paham dan mengerti mengenai kegunaan sistem
yang akan dibangun. Pada gambar 2.2 merupakan Simbol
Use Case
pada
Use
Case Diagram.
Gambar 2.2. Simbol
Use Case
c.
Association
Associaton
menghubungkan
link
antar
element,
dan
bukan
menggambarkan aliran data / informasi pada sistem.
Association
digunakan untuk
menggambarkan bagaimana
actor
terlibat dalam
use case.
Ada 4 jenis relasi yang
bisa timbul pada
use case
diagram, yaitu
Association
antara actor dan
use
case
,
Association
antara
use case
, Gene
ralization/Inheritance antara use
case, Generalization/Inheritance
antara
actors.
15
Dependency adalah sebuah
element
bergantung dalam beberapa cara ke
element
lainnya.
e.
Generalization
Generalization
disebut juga
inheritance
(pewarisan), sebuah elemen dapat
merupakan spesialisasi dari elemen lainnya.
2.7.3
Activity Diagram
Activity
diagram
menggambarkan berbagai alir aktifitas dalam sistem yang
sedang diarancang, bagaimana masing-masing alir berawal,
decision
yang
mungkin terjadi, dan bagaimana mereka berakhir[6].
Activity
diagram
juga dapat
menggambarkan proses paralel yang mungkin terjadi pada beberapa eksekusi.
Activity
diagram
merupakan
state
diagram khusus, di mana sebagian besar
state
adalah
Action
dan sebagian besar transisi di-
trigger
oleh selesainya
state
sebelumnya (
internal processing
). Oleh karena itu
activity
diagram
tidak
menggambarkan
behavior
internal sebuah sistem.
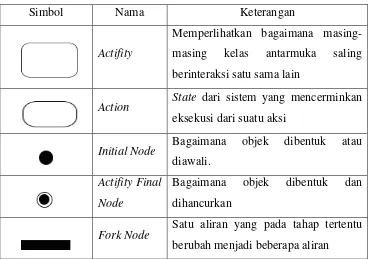
Terdapat berbagai simbol di dalam
Activity
Diagram, akan dijelaskan pada
tabel 2.1
Tabel 2.1 Simbol
Activity
Diagram
Simbol
Nama
Keterangan
Actifity
Memperlihatkan bagaimana
masing-masing
kelas
antarmuka
saling
berinteraksi satu sama lain
Action
State
dari sistem yang mencerminkan
eksekusi dari suatu aksi
Initial Node
Bagaimana
objek
dibentuk
atau
diawali.
Actifity Final
Node
Bagaimana
objek
dibentuk
dan
dihancurkan
Fork Node
Satu aliran yang pada tahap tertentu
2.7.4
Sequence Diagram
Sequence diagram
menggambarkan interaksi antar objek di dalam dan di
sekitar (termasuk pengguna,
display
, dan sebagainya) berupa
message
yang
disusun dalam suatu urutan waktu[6].
Secara khusus, diagram ini berasosiasi dengan
use case
.
Sequence
diagram
menggambarkan
behavior
internal sebuah sistem. Dan lebih menekankan pada
penyampaian
message
dengan parameter waktu.
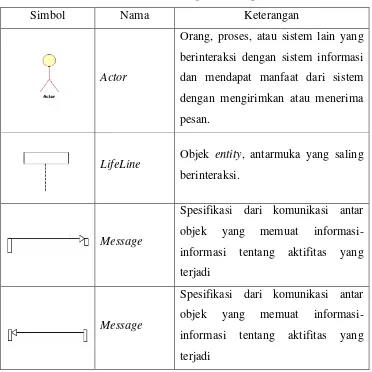
Pada Tabel 2.2 menjelaskan tentang simbol yang terdapat pada
Sequence
Diagram.
Tabel 2.2 Simbol
Sequence
Diagram
Simbol
Nama
Keterangan
Actor
Orang, proses, atau sistem lain yang
berinteraksi dengan sistem informasi
dan mendapat manfaat dari sistem
dengan mengirimkan atau menerima
pesan.
LifeLine
Objek
entity
, antarmuka yang saling
berinteraksi.
Message
Spesifikasi dari komunikasi antar
objek
yang
memuat
informasi-informasi tentang aktifitas yang
terjadi
Message
Spesifikasi dari komunikasi antar
objek
yang
memuat
informasi-informasi tentang aktifitas yang
terjadi
2.7.5
Class Diagram
17
dari sebuah sistem[6].
Class
diagram digunakan untuk menampilkan beberapa
kelas serta paket-paket yang ada dalam sistem/perangkat lunak yang sedang kita
gunakan.
Class
diagram memberi kita gambaran (diagram statis) tentang
sistem/perangkat lunak dan relas-relasi yang ada didalamnya. Sebuah
class
digambarkan seperti sebuah bujur sangkar dengan tiga bagian ruangan yaitu
bagian atas adalah bagian nama dari
class
, bagian tengah mendefinisikan
property
/
atribut
class
, bagian akhir mendefinisikan
method-method
dari sebuah
class
.
Class
sebaiknya diberi nama menggunakan kata benda sesuai dengan domain /
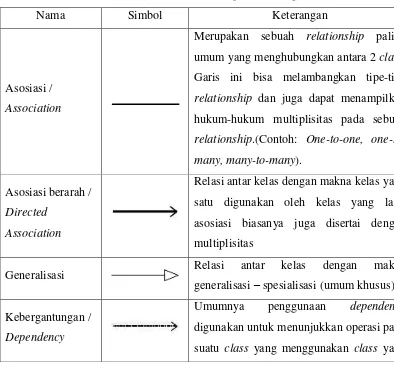
bagian / kelompoknya. Tabel 2.3 menjelaskan tentang
symbol relationship
pada
class
diagram:
Tabel 2.3
Symbol Relationship
Class
Diagram
Nama
Simbol
Keterangan
Asosiasi /
Association
Merupakan sebuah
relationship
paling
umum yang menghubungkan antara 2
class
.
Garis ini bisa melambangkan tipe-tipe
relationship
dan juga dapat menampilkan
hukum-hukum multiplisitas pada sebuah
relationship
.(Contoh:
One-to-one,
one-to-many, many-to-many
).
Asosiasi berarah /
Directed
Association
Relasi antar kelas dengan makna kelas yang
satu digunakan oleh kelas yang lain,
asosiasi biasanya juga disertai dengan
multiplisitas
Generalisasi
Relasi
antar
kelas
dengan
makna
generalisasi
–
spesialisasi (umum khusus)
Kebergantungan /
Dependency
Umumnya
penggunaan
dependency
digunakan untuk menunjukkan operasi pada
lain.
Agregasi /
Agregation
Relasi antar kelas dengan makna semua
–
bagian (
whole
part
)
2.8
Teknik Evaluasi Sistem dan Pengujian
Adapun Teknik yang digunakan untuk mengevaluasi hasil suatu
ringkasan teks merupakan topik yang cukup suilit, baik evaluasi terhadap
ringkasan yang dihasilkan dari mesin peringkas otomatis ataupun ringkasan yang
dihasilkan secara manual yang dibuat manusia, dikarenakan tidak terdapat
definisi ringkasan ideal. Menurut Zaman B. dan E Winarko [12] metode untuk
melakukan evaluasi terhadap hasil dari ringkasan secara umum dibagi 2, yaitu:
1.
Ekstrinsik
Metode evaluasi ekstrinsik adalah menghitung efektivitas dan
akseptabilitas dari hasil ringkasan untuk tugas-tugas tertentu, misalnya
assessment
terhadap hasil ringkasan.
2.
Intrinsik
Metode evaluasi intrinsik adalah evaluasi yang dilakukan oleh sistem
peringkas itu sendiri, misalnya menggunakan
F-Measures
. Evaluasi ini
difokuskan pada tingkat koheren dan informatif dari hasil ringkasan.
Dalam penelitian ini, metode evaluasi yang digunakan adalah metode
intrinsik penghitungan
F-Measure
berdasarkan perhitungan
Precision
dan
Recall
yang menurut Zaman B. dan E Winarko [12] merupakan standar evaluasi dalam
penghitungan
information retrieval
. evaluasi perhitungan
information retrieval
dengan menggunakan
Precision
dan
Recall
juga dapat digunakan dalam
evaluasi perhitungan peringkas teks otomatis.
(4)
19
Kombinasi antara nilai
recall
dan
precision menghasilkan nilai
f-measure.
(6)
Dalam metode intrinsik
, precision
dan
recall
digunakan untuk mengukur
kualitas ringkasan otomatis dengan cara membandingkan ringkasan otomatis
dengan ringkasan manual (buatan manusia). Kemudian hasil akhir akan didapatkan
dengan cara penggabungan nilai
recall
(4) dan
precision
(5) yang disebut dengan
nilai
F-measures
(5). Masalah dalam metode ini adalah dalam menentukan
kalimat relevan karena pasti terdapat perbedaan pendapat antar subyek pembuat
ringkasan dalam memilih kalimat. Misal subyek A menganggap kalimat
x
sebagai
kalimat utama tetapi bisa saja subyek B berpendapat sebaliknya bahwa kalimat
x
kurang begitu penting. Untuk mengatasi hal ini digunakan beberapa metode
seperti suara terbanyak (
majority opinion
), gabungan (
union
), atau irisan
(
intersection
)[12].
2.9
Perangkat Lunak Pendukung
Pada pembangunan aplikasi pencarian paragraf kata atau kalimat pada
dokumen menggunakan
Term Frequency-Inverse Document Frequency
(TF-IDF)
dibutuhkan perangkat lunak pendukung, diantaranya adalah:
2.9.1
Bahasa Program C#
Sebuah
bahasa
pemrograman
yang
berorientasi
objek
yang
dikempbangkan oleh Microsoft sebagai bagian dari inisiatif kerangka .NET
Framework. Bahasa pemrograman ini dibuat berbasiskan bahasa C++ yang telah
dipengaruhi oleh aspek-aspek ataupun fitur bahasa yang terdapat pada
bahasa-bahasa pemrograman lainnya seperti Java, Delphi, Visual Basic dll dengan
beberapa penyederhanaan. Menurut standar ECMA-334 C# Language
Specification, nama C# terdiri atas sebuah huruf latin C (U+0043) yang diikuti
digunakan pada C# tidak sama dengan tanda kres yang ada dalam seni musik
#(U+266F). Tanda pagar # (U+0023) tersebut digunakan karena karakter kres
dalam seni musik tidak terdapat didalam keyboard standar.
C# kadang-kadang dapat disebutkan sebagai bahasa pemrograman yang
paling mencerminkan dasar dari CLR dimana semua program-program .NET
berjalan, dan bahasa ini sangat bergantung pada kerangka tersebut sebab ia secara
spesifik di desain untuk mengambil manfaat dari fitur-fitur yang tersedia pada
CLR. [7]
2.9.2
Microsoft Visual Studio
Microsoft visual stuido merupakan sebuah perangkat lunak lengkap (suite)
yang dapat digunakan untuk melakukan pengembangan aplikasi, baik itu aplikasi
bisnis, aplikasi personal ataupun komponen aplikiasnya yang masuk ke dalam
bentuk aplikasi console, Windows dan Web. Visual studio mencakup kompiler,
SDK, Integrated Development Environment (IDE) dan dokumentsi (umumnya
berupa MSDN Library). Kompiler yang dimasukan ke dalam paket visual studio
antara lain Visual C++, Visual C#, Visual Basic, Visual Basic .NET, Visual
InterDev, Visual J++, Visual J#, Visual FoxPro dan Visual SourceSafe.
Microsoft visual studio dapat digunakan untuk mengembangkan aplikasi
dalam native code (dalam bentuk bahasa mesin yang berjalan diatas Windows)
ataupun managed code (dalam bentuk Microsoft Intermediate Language diatas
.NET Framework). Selain itu, visual studio juga dapat digunakan untuk
mengembangkan aplikasi Silverlight, aplikasi Windows Mobile (yang berjalan
diatas .NET Compact Framework). Berikut adalah tampilan halaman awal dari
21
Gambar 2.3 Halaman Utama Microsoft Visual Studio
Halaman awal tersebut merupakan tampilan utama untuk membuat suatu
project baru, mmembuka project yang akan dilanjutkan pengerjaannya dan untuk
membaca tutorial tentang bagaimana penggunaan aplikasi, cara untuk membuat
aplikasi, produk terupdate yang dibuat oleh Microsoft Visual Studio dan
pembelajaran coding.
Pada Gambar 2.4 tampilan over view yang memperlihatkan tampilan
antarmuka dari Microsof Visual Studio saat akan membuat seuah project, berikut
adalah penjelasan sederhana tentang detail dari tampilan over view Microsoft
Visual Studio :
1.
File Menu dan Toolbars Menu
Pada Gambar 2.4 nomor 1 dapat dilihat bagian ini terdiri dari
fungsi-fungsi untuk melakukan aksi save, new project, add class,
mendebug/execute program, search dan membuka project lain yang
disimpan pada sistem directory.
2.
Toolbox Bar
Pada toolbox bar terdapat semua object yang dibutuhkan oleh
pengguna yang tinggal dilakukan dengan proses drag and drop.
3.
Layout View
Layout view yaitu sebuah tempat atau wadah yang akan
menampung object-object dari toolbox bar.
4.
Solutions Explorer Bar
Pada solution explorer bar terdapat program yang akan dibuat
pengguna dan pada solution explorer juga bisa digunakan untuk
menambahkan library-library.
5.
Properties Bar
Properties bar yaitu detail dari toolbox bar yang digunakan untuk
mengedit object dari mulai penamaan object hingga warna object yang
dipakai.
6.
Error List Bar
Pada error list bar terdapat pemberitahuan jika ada source code
23
2.9.3
DevExpress
DevExpress
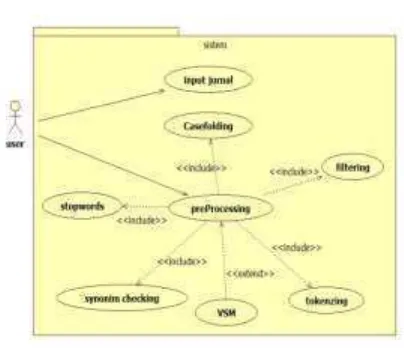
adalah
supplier
terkemuka kontrol ASP.Net yang
addins
digunakan dalam situs ASP.NET dan digunakan untuk menambah fitur,
meringankan tugas dan menghemat waktu pemakai dalam membuat suatu
program.
DevExpress
menawarkan pula seperangkat komponen presentasi dan
pelaporan serta menambahkan beberapa fungsi, karena itulah setiap situs
web
yang menggunakan ASP.Net banyak menggunakan aplikasi ini karena
kemudahannya untuk memperindah tampilan tanpa memasukkan
coding
yang
95
BAB 5
KESIMPULAN DAN SARAN
5.1
Kesimpulan
Berdasarkan hasil yang didapatkan dalam penelitian dan penyusunan
skripsi ini maka dapat disimpulkan bahwa pembentukan kalimat abstrak secara
otomatis menggunakan metode
Term Frequency
–
Inverse Document Frequency
(TF-IDF)
mampu membentuk paragraf abstrak pada sebuah dokumen jurnal
secara otomatis. Kesimpulan yang diperoleh dari hasil uji menyatakan bahwa
hasil pembentukan abstrak secara manual dengan sistem menghasilkan persentase
kalimat yang sama tidak terlalu jauh. Dimana jarak antara hasil manual dengan
sistem rata-rata hanya berbeda 2 sampai 4 kalimat saja. Akurasi dengan persentase
100% didapat oleh jurnal ke 7 dan 9 sedangkan akurasi dengan pesentase terendah
60% didapat oleh jurnal ke 1.
5.2
Saran
Berdasarkan hasil dari penelitian yang telah dilakukan, sistem
pembentukan Abstrak masih perlu dikembangkan lagi untuk meningkatkan
keakuratan dari sistem pembentukan abstrak ini. Penyempurnaan aplikasi masih
BIODATA PENULIS (RIWAYAT HIDUP)
DATA PRIBADI
Nama
Arie Prima Anggara
Jenis Kelamin
Laki-laki
Golongan Darah
A
Tempat & Tanggal Lahir
Bandung 02 Mei 1993
Alamat
Jl. Galunggung dlm 3 No.38 RT 01 / RW 03
Kecematan Lengkong Kelurahan Lingkar
Selatan, Bandung.
No. Telp
088214903833
PENDIDIKAN FORMAL
1998 - 2004
SD Negeri Babakan Priangan II Bandung
2004 - 2007
SMP Pasundan 1 Bandung
2007
–
2010
SMA Pasundan 1 Bandung
2010 - 2015
Program Studi Teknik Informatika
Fakultas Teknik dan Ilmu Komputer
Universitas Komputer Indonesia
Bandung
PENGALAMAN ORGANISASI
2011 - 2015
Anggota UKM Sadaya Unikom Bandung
TERM FREQUENCY
–
INVERSE DOCUMENT FREQUENCY (TF-IDF)
Arie Prima Anggara1
1Teknik Informatika – Universitas Komputer Indonesia
Jl. Dipatiukur 112-114 Bandung Email : [email protected]
ABSTRAK
Abstrak adalah sebuah ringkasan dari keseluruhan dokumen penelitian agar pembaca tahu maksud dari penelitian tersebut. Dari abstrak, pembaca dapat mengetahui jalan pikiran penulis laporan/artikel ilmiah tersebut dan mengetahui gambaran umum tulisan secara lengkap. Dalam membentuk paragraf abstrak pada sebuah dokumen jurnal dari setiap sub bab tentunya membutuhkan pencarian kalimat yang singkat dan jelas. Pencarian kalimat pada setiap sub bab dalam dokumen jurnal yang banyak akan membantu penulis laporan/artikel ilmiah dalam membentuk abstrak dengan keterbatasan pembentukan abstrak harus singkat, bagian harus seimbang dan menghindari kalimat yang panjang.
Dalam penelitian ini dibangun sistem pembentukan abstrak secara otomatis dengan menerapkan metode Term Frequency – Inverse Document Frequency. Metode Term Frequency – Inverse Document Frequency (TF-IDF) akan mencari kalimat pada sub judul pendahuluan, analisis, dan kesimpulan sehingga akan terbentuklah kalimat abstrak secara otomatis dengan mengutamakan isi kalimat yang berada pada sub judul tersebut. Analisis sistem pembentukan abstrak otomatis yang dibangun memiliki 3 tahapan yaitu input jurnal, praproses, pembentukan abstrak. Input jurnal yang dipilih berupa jurnal berformat doc. Praproses yang dilakukan dalam tahap ini adalah pemecahan kalimat, case folding, filtering, tokenizing, synonim checking, dan stopword. Tahap selajutnya melakukan perhitungan menggunakan tf-idf dan tahap terakhir menentukan hasil abstrak dengan metode cosine similarity.
Berdasarkan hasil pengujian, maka dilakukan tahap pengujian terhadap sistem dan secara manual. Maka diperoleh jarak antara hasil manual dengan sistem rata-rata hanya berbeda 2 sampai 4 kalimat saja. Akurasi dengan persentase 100% didapat oleh jurnal ke 7 dan 9 sedangkan akurasi dengan pesentase terendah 60% didapat oleh jurnal ke 1.
Kata Kunci: Term Frequency – Inverse Document
Frequency (TF-IDF), Kecerdasan Buatan, Pembentukan Abstrak Otomatis.
1. PENDAHULUAN
Abstrak adalah sebuah ringkasan dari keseluruhan dokumen penelitian agar pembaca tahu maksud dari penelitian tersebut. Abstrak digunakan sebagai jembatan untuk memahami uraian yang akan disajikan dalam suatu karangan biasanya laporan atau artikel ilmiah terutama untuk memahami ide-ide permasalahannya. Dari abstrak, pembaca dapat mengetahui jalan pikiran penulis laporan/artikel ilmiah tersebut dan mengetahui gambaran umum tulisan secara lengkap. Untuk itulah pembuat abstrak harus dapat mewakili isi karangan ilmiah secara keseluruhan, mulai dari latar belakang, analisis/analisa, dan hasil penelitian/kesimpulan. [1]
Dalam membentuk paragraf abstrak pada sebuah dokumen jurnal dari setiap sub bab tentunya membutuhkan pencarian kalimat yang singkat dan jelas. Di dalam dunia akademik, tulisan pendek ini digunakan oleh institusi/lembaga/organisasi pendidikan sebagai informasi awal atas sebuah penelitian ketika dimasukkan dalam jurnal, konferensi, lokakarya, atau yang sejenisnya. Pencarian kalimat pada setiap sub bab dalam dokumen jurnal yang banyak akan menyulitkan penulis laporan/artikel ilmiah dalam membentuk abstrak dengan keterbatasan pembentukan abstrak harus singkat, bagian harus seimbang dan menghindari kalimat yang panjang. Pembuatan abstrak dapat dilakukan secara otomatis dengan memanfaatkan metode Term Frequency – Inverse Document Frequency (TF-IDF).
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi.. Volume.. Bulan 20.. ISSN :2089-9033
mengukur kemiripan antara dua kalimat atau lebih pada bagian kalimat yang berada dalam sub judul yang dibutuhkan. Dalam mengukur sebuah kalimat dari kemiripan setiap sub bab pada sebuah dokumen akan menggunakan teknik text mining.
Dari permasalahan diatas, maka penelitian ini akan menerapkan metode Term Frequency – Inverse Document Frequency (TF-IDF) pada pembentukan sebuah paragraf abstrak secara otomatis.
1.1 Maksud dan Tujuan
Maksud dari pada penelitian tugas akhir ini adalah membuat sistem pembentukan abstrak secara otomatis pada keseluruhan dokumen jurnal penelitian dengan menggunakan metode Term Frequency – Inverse Document Frequency (TF-IDF). Adapun tujuan dari penelitian tugas akhir ini adalah melakukan pembuatan kalimat abstrak yang baik secara otomatis untuk melengkapi suatu tulisan ilmiah dengan singkat dan jelas, sehingga membantu melengkapi laporan/artikel ilmiah dalam pembentukan kalimat abstrak secara cepat dan akurat.
1.2Ringkasan
Ringkasan adalah suatu cara yang efektif untuk menyajikan suatu karangan yang panjang dalam bentuk singkat. Oleh karena itu membuat ringkasan atas sebuah karangan yang panjang dapat diumpamakan sebagai memangkas sebatang pohon sehingga tinggal batang, cabang-cabang dan ranting-ranting yang terpenting beserta daun-daun yang diperlukan, sehingga tampak bahwa esensi pohon masing dipertahankan. Dalam ringkasan keindahan gaya bahasa, ilustrasi, serta penjelasan-penjelasan yang terperinci dihilangkan, sedangkan sari kerangaknya dibiarkan tanap hiasan. Walaupun bentuknya ringkas, namun tetap mempertahankan pikiran pengarang dan pendekatan yang asli [11].
Dalam meringkas sebaiknya menggunakan kalimat tunggal daripada kalimat majemuk. Kalimat majemuk menunjukan bahwa ada dua gagasan atau lebih yang bersifat paralel. Bila memungkinkan ringkaslah kalimat menjadi frasa, selanjutnya frasa menjadi kata. Begitu pula rangkaian gagasan yang penjang hendaknya diganti dengan suatu gagasan sentral saja. Pada umumnya suatu ringkasan ditentukan panjang ringkasan akhirnya, ada yang meringkas seperdua total kata, sepertiga total kata, hingga sepersepuluh total kata. Untuk artikel yang memiliki jumlah kata yang sangat banyak tentu saja hasil ringkasan sepersepuluh menjadi pilihan yang tepat. Sedangkan untuk artikel yang jumlah katanya tidak terlalu banyak maka hasil ringkasan sebanyak seperdua total kata menjadi pilihan yang tepat sehingga hasil ringkasan nantinya masih dapat dibaca dengan struktur hasil ringkasan yang baik.
1.3Abstrak
Abstrak merupakan sebuah ringkasan isi dari sebuah karya tulis ilmiah yang ditujukan untuk membantu seorang pembaca agar dapat dengan mudah dan cepat untuk melihat tujuan dari penulisannya. Di dalam dunia akademik, tulisan
pendek ini digunakan oleh
institusi/lembaga/organisasi pendidikan sebagai informasi awal atas sebuah penelitian ketika dimasukkan dalam jurnal, konferensi, lokakarya, atau yang sejenisnya. Dalam dunia maya (internet), sebuah abstrak digunakan sebagai gambaran singkat atas sebuah karya tulis ilmiah/penelitian untuk dibaca, sebagaimana halnya sebuah “display” model pakaian dipajang untuk dilihat atau diuji pakai sebelum dibeli. Selanjutnya, bagian lengkap sebuah penelitian dijual kepada mereka yang berminat untuk mendapatkannya.
Untuk membuat abstrak, hal-hal yang perlu diperhatikan adalah sebagai berikut:
1. Struktur paragraf
Sebuah abstrak ditulis dalam satu paragraf yang menerangkan keseluruhan isi tulisan secara singkat dan jelas. Penulisannya tidak melakukan indentasi pada kalimat pertama paragraf. Single space adalah pilihan yang dimiliki oleh penulis untuk menyusun kalimat dalam paragrafnya. Lebih dalam, kadang seorang pembimbing Skripsi/Tesis/Disertasi mengatur hingga pada penggunaan jenis huruf dan ukuran tertentu.
2. Jumlah kata
Idealnya sebuah paragraf terdiri dari 150 sampai dengan 200 kata. Namun, pertimbangan jumlah kata yang paling tepat dalam penulisan Skripsi, Tesis, ataupun disertasi biasanya bergantung pada pertimbangan pandangan pembimbing (supervisor) yang mendampingi seorang mahasiswa dalam penulisannya. Seorang supervisor harusnya tidak mempertimbangkan jumlah kata sebagai acuan utama penulisan paragraf, karena bagian utama justru isi (content) paragraf. 3. Isi paragraf
menganggap hasil temuan yang diungkap tidak perlu mengungkap pembahasan yang dilakukan karena hal itu justru akan membuat pengulangan isi tulisan. Jelas maksudnya karena bagian pembahasan temuan penelitian juga diurai di dalam bagian kesimpulan. Keempat, perlunya bagian kesimpulan di dalam sebuah tulisan juga terlihat di dalam sebuah abstrak yang tetap mendapatkan perhatian penting sebagai bagian akhir dari paragraf. Pada bagian ini kadangkala sejumlah peneliti menyisipkan rekomendasi penelitian namun tanpa pembahasan atau uraian yang panjang. Lebih lanjut, tidaklah lazim sebuah abstrak diisi oleh nama si penulis serta para pembimbing tulisannya, apalagi hal itu ditulis dalam huruf cetak tebal.
1.4 Tahapan Text Mining
Pada tahap text mining ini terdapat lima langkah yaitu:
a. Case Folding, yaitu mengubah semua teks ke dalam huruf kecil.
b. Filtering, menghapus karakter yang tidak dipakai. Adapun karakter yang akan dihilangkan yaitu : '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ',', '"', '-', '/', '{', '}', '+', '_', '!', '@', '#', '$', '%', '^', '&', '*', '(', ')', '?', '<', '>', '[', ']', '|', '~', '`', ';', ':', '=' dan “’s” untuk dokumen berbahasa Inggris akan dihapus kecuali tanda titik.
c. Tokenizing, yaitu memecah kalimat-kalimat yang ada kedalam kata.
d. Synonim Checking, yaitu mengganti kata yang ada yang memiliki arti yang sama. Penggantian kata yang dilakukan berdasarkan database yang dibuat oleh penulis.
e. Stopwords, yaitu Pada proses stowords removal ini proses yang dikerjakan yaitu menghapus kata yang kurang relevan atau kata yang tidak memiliki arti yang begitu penting dan berkaitan yang ada pada kalimat di dokumen dengan mencocokan
list kata stopword yang pada database yang akan diuji. Database yang digunakan baik untuk Bahasa Indonesia maupun maupun Bahasa Inggris diambil dari sebuah situs yg menyediakan berbagain jenis list stopword
untuk berbagai bahasa.
Pada umumnya tahap preprocessing
terdapat 5 langkah yaitu Case Folding, Filtering, Tokenizing, Stemming, dan Stopwords. Ada satu langkah yang tidak penulis gunakan dalam pembuatan aplikasi peringkasan dokumen esktraktif ini yaitu proses stemming. Stemming yaitu proses menghilangkan imbuhan dari sebuah kata dan mengubahnya menjadi kata dasar. Tujuan dari
peringkasan dokumen ekstraktif imbuhan yang terdapat pada sebuah kata memiliki arti yang berbeda. Adapun contoh kalimat yaitu : “Bapak
membuatkan sebuah rumah untuk istrinya”, “Bapak dibuatkan secangkir kopi oleh ibu”, “Bapak selalu berbuat baik kepada tetangga”. Kata “buat” pada kalimat pertama dan kalimat ketiga memiliki arti bapak melakukan sebuah kegiatan tapi pada kalimat dua kata”buat” memiliki arti bapak mendapatkan sebuah perlakuan. Apabila proses stemming tetap dilakukan maka tidak akan didapatkan perbedaan antara satu kata dengan yang lainnya.
Pada tahap filtering penulis menambahkan karakter “ ’s ” yang akan digunakan untuk menghapus tanda baca bagi dokumen yang menggunakan bahasa Inggris. Adapun contoh kalimatnya yaitu : “that is President’s car” berubah menjadi “that is President car”.
1.5 Term Frequency – Inverse Document Frequency (TF-IDF)
Metode Term Frequency-Inverse Document Frequency (TF-IDF) adalah cara pemberian bobot hubungan suatu kata (term) terhadap dokumen. Untuk dokumen tunggal tiap kalimat dianggap sebagai dokumen. Metode ini menggabungkan dua konsep untuk perhitungan bobot, yaitu Term Frequency (TF) merupakan frekuensi kemunculan kata (t) pada kalimat (s). Document frequency (DF) adalah banyaknya kalimat dimana suatu kata (t) muncul. Frekuensi kemunculan kata di dalam dokumen yang diberikan menunjukkan seberapa penting kata itu di dalam dokumen tersebut. [5]
Frekuensi kalimat yang mengandung kata tersebut menunjukkan seberapa umum kata yang ada pada dokumen uji tersebut. Bobot kata semakin besar jika sering muncul dalam suatu kalimat dan semakin kecil jika muncul dalam banyak kalimat. Pada Metode ini pembobotan kata dalam sebuah dokumen dilakukan dengan mengalikan nilai TF dan IDF. Pembobotan diperoleh berdasarkan jumlah kemunculan term dalam kalimat (TF) dan jumlah kemunculan term pada seluruh kalimat dalam dokumen (IDF). Bobot suatu istilah semakin besar jika istilah tersebut sering muncul dalam suatu dokumen dan semakin kecil jika istilah tersebut muncul dalam banyak dokumen. Nilai IDF sebuah term dihitung menggunakan persamaan (1) di bawah ini :
IDF = log(
) (1)
keterangan :
N = Jumlah keseluruhan kalimat pada dokumen
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi.. Volume.. Bulan 20.. ISSN :2089-9033
Menghitung bobot (W) masing-masing kalimat dengan persamaan (2) di bawah ini:
Wd.t = TFd.t * IDFt (2)
dengan :
d = kalimat ke-d
t = kata (term) ke-t TF = Term Frequency
W= bobot kalimat ke-d terhadap kata (term) ke-t
IDF= Inverse Document Frequency
Kemudian baru melakukan proses pengurutan (sorting) nilai kumulatif dari W untuk setiap kalimat. Tiga kalimat dengan nilai W terbesar dijadikan sebagai hasil dari ringkasan atau sebagai output dari peringkasan teks otomatis. [5]
1.6 Pengujian Akurasi
Dalam penelitian ini, metode evaluasi yang digunakan adalah metode intrinsik penghitungan F-Measure berdasarkan perhitungan Precision dan
Recall yang menurut Zaman B. dan E Winarko [12] merupakan standar evaluasi dalam penghitungan
information retrieval. evaluasi perhitungan
information retrieval dengan menggunakan
Precision dan Recall juga dapat digunakan dalam evaluasi perhitungan peringkas teks otomatis.
(4)
dimana, recall = tingkat keberhasilan
Precision adalah tingkat ketepatan hasil ringkasan. Perhitungan precision dapat dilihat pada persamaan berikut:
(5)
dimana, precision = tingkat ketepatan
F-measure adalah gabungan antara recall dan
precision. Perhitungan f-measure dapat dilihat pada persamaan berikut:
(6)
2. ISI PENELITIAN 2.1 Analisis Masalah
Dalam membentuk paragraf abstrak pada sebuah dokumen jurnal dari setiap sub bab tentunya membutuhkan pencarian kalimat yang singkat dan jelas, pencarian kalimat pada setiap sub bab dalam dokumen jurnal yang banyak akan menyulitkan penulis dalam membentuk abstrak dengan keterbatasan pembentukan abstrak harus singkat, bagian harus seimbang dan menghindari kalimat yang panjang.
Dari permasalahan diatas, dibutuhkan metode
Term Frequency – Inverse Document Frequency (TF-IDF) yang akan mengukur kemiripan antara dua kalimat atau lebih pada bagian kalimat yang berada dalam sub judul yang dibutuhkan.
2.2 Analisis Masukan
Data masukan yang digunakan berupa file
jurnal dengan format *.doc. Dokumen tersebut dimasukan secara utuh kedalam aplikasi, yang kemudian oleh aplikasi akan dilakukan penguraian isi dari dokumen tersebut berupa beberapa kalimat yang mengacu pada aturan tertentu, seperti pengambilan kalimat hanya pada bagian pendahuluan, analisis, dan kesimpulan.
2.3 Analisis Preprocessing Data
Tahap analisis prepocessing ini digunakan untuk menganalisa data apa saja yang sebenarnya dibutuhkan dalam proses Term Frequency – Inverse Document Frequency (TF-IDF). Adapun tahapan dari analisis prepocessing data dalam penelitian ini adalah sebagai berikut :
1. Add File Data
Pertama-tama pilih dokumen terlebih dahulu.
File dokumen yang di pilih harus berupa file
berekstensi *.doc. 2. Ekstraksi Data
Setelah file jurnal yang dimaksudkan didapat, kemudian lakukan proses ekstraksi text. Pada proses ini dilakukan pengambilan text dari jurnal dengan bantuan library di .net yaitu
Microsoft.Office.Interop.Word.
3. Pengambilan Teks
Tahap pengambilan kalimat merupakan tahapan penggambilan teks yang dibutuhkan dari keseluruhan text yang ada pada jurnal tersebut. Teks yang dibutuhkan adalah teks pada bagian Pendahuluan atau Latar Belakang, Analisis atau Analisa Data dan Kesimpulan. Adapun alur proses yang dilakukan untuk mendapatkan teks yang dibutuhkan dapat dilihat pada gambar di bawah ini :
Gambar 1. Alur Seleksi Kalimat
a. Pencarian Sub judul :
Mencari judul yang dibutuhkan yaitu : pendahuluan, analisis dan kesimpulan. b. Pengambilan teks :
Pengambilan teks yang indeksnya berada setelah judul yaitu pendahuluan atau latar
c. Indexing kalimat :
Setelah didapatkan teks diatas, dilakukan pemisahan tiap-tiap kalimat yang dibatasi oleh tanda titik pada tiap-tiap teks. 4. Case Folding
Pada tahapan ini, akan dilakukan
pengecekan terhadap huruf-huruf kapital yang berada di tiap-tiap kalimat. Jika ditemukan huruf kapital tersebut, maka akan dilakukan
[image:41.595.65.275.83.637.2]lower, yaitu mengubah menjadi huruf kecil.
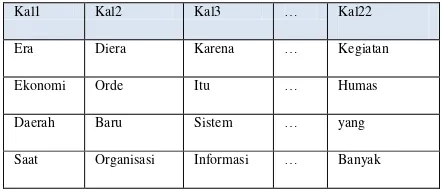
Tabel 1. Casefolding
deskripsi kalimat
kalimat 1 di era otonomi daerah saat ini, sistem pemerintahan daerah sudah berbeda dibandingkan dengan sistem pemerintah diera orde baru.
Kalimat 2 kalau diera orde baru, organisasi pemerintah dan sistem informasinya ditentukan oleh pemerintah pusat, di era otonomi daerah ini pembentukan instansi pemerintah daerah termasuk sistem informasinya ditentukan oleh pemerintah daerah setempat
Kalimat 3 oleh karena itu sistem informasi pada setiap daerah bisa berbeda sesuai dengan perkembangan yang terjadi / kebutuhan di daerah masing-masing
Kalimat 4 pada awal otonomi daerah, pemerintah di daerah bisa membentuk dinas, badan dan lembaga tehnis sesuai dengan kebutuhan daerah setempat
Kalimat 5 adanya ketentuan ini membuat berbagai daerah membentuk dinas secara berlebihan untuk menampung sebanyak mungkin pejabat struktural
Kalimat 6 ketentuan mengenai pembentukan dinas dan lembaga tehnis tersebut kemudian disusul peraturan baru yang memberikan batasan jumlah dinas yang boleh dibentuk di pemerintah daerah.
Kalimat 7 bahkan penanganan informasi di suatu daerah cukup hanya dimasukkan dalam suatu seksi/bagian dari dinas dan setiap daeah menggunakan istilah yang berbeda seperti : hubungan masyarakat (humas) informasi komunikasi (infokom), badaninformasi komunikasi telematika (bikt).
… …
Kalimat 21
3.kegiatan humas yang banyak berhubungan dengan unit kerja di pemda yang memiliki tingkat eselon yang lebih tinggi bisa menjadi hambatan bagi humas meski gengsi posisi humas cukup tinggi
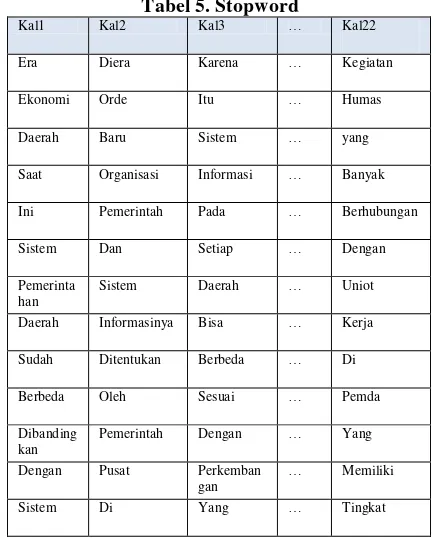
5. Filtering
Menghapus karakter khusus yang tidak dipakai. Dalam pengujian ini karakter seluruh tanda baca seperti tanda seru, tanda tanya, tanda kutip, dan lain sebagainya akan dihapus kecuali kecuali tanda titik. Langkah yang dilakukan yaitu menghilangkan beberapa karakter yang tidak diperlukan selama proses perangkuman. Adapun karakter yang akan dihilangkan yaitu : '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ',', '"', '-', '/', '{', '}', '+', '_', '!', '@', '#', '$', '%', '^', '&',
[image:41.595.305.521.179.740.2]Penghilangan karakter seperti angka akan dilakukan oleh sistem, karena sistem tidak dapat mengenali keterangan dari angka yang ada pada dokumen
Tabel 2. Filtering
deskripsi kalimat
kalimat 1 di era otonomi daerah saat ini, sistem pemerintahan daerah sudah berbeda dibandingkan dengan sistem pemerintah diera orde baru.
Kalimat 2 kalau diera orde baru, organisasi pemerintah dan sistem informasinya ditentukan oleh pemerintah pusat, di era otonomi daerah ini pembentukan instansi pemerintah daerah termasuk sistem informasinya ditentukan oleh pemerintah daerah setempat
Kalimat 3 oleh karena itu sistem informasi pada setiap daerah bisa berbeda sesuai dengan perkembangan yang terjadi / kebutuhan di daerah masing-masing
Kalimat 4 pada awal
![Gambar 1. 2 Model Prototype [4]](https://thumb-ap.123doks.com/thumbv2/123dok/415187.226079/11.595.158.471.436.662/gambar-model-prototype.webp)