CLUSTERING HASIL OPERASI OLAP UNTUK DATA
WAREHOUSE HOTSPOT MENGGUNAKAN ALGORITME
K-MEANS
TSAMRUL FUAD
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
CLUSTERING HASIL OPERASI OLAP UNTUK DATA
WAREHOUSE HOTSPOT MENGGUNAKAN ALGORITME
K-MEANS
TSAMRUL FUAD
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
TSAMRUL FUAD. Clustering of OLAP operation result for hospot datawarehouse using k-means algorithm. Under the direction of ANNISA.
Judul :Clustering hasil operasi OLAP untuk datawarehouse HOTSPOT menggunakan algoritme K-means
Nama : Tsamrul Fuad
NIM : G64052541
Menyetujui:
Pembimbing,
Annisa, S.Kom., M.Kom. NIP 197907312005012
Mengetahui,
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor
Dr. Drh. Hasim, DEA NIP 196103281986011002
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala rahmat dan hidayah-Nya sehingga tugas akhir dengan judul Clustering hasil operasi OLAP untuk datawarehouse HOTSPOT
menggunakan algoritme K-means dapat diselesaikan. Penelitian ini dilaksanakan mulai Maret 2009 sampai dengan Juli 2009, bertempat di Departemen Ilmu Komputer.
Terima kasih penulis ucapkan kepada pihak-pihak yang telah membantu dalam penyelesaian tugas akhir ini, antara lain:
1 Kepada Ibu Imas Sukesih Sitanggang, S.Si, M.Kom. selaku pembimbing pertama saya yang telah banyak memberi arahan selama penulis menjalankan penelitian
2 Kepada Ibu Annisa, S.Kom., M.Kom. selaku pembimbing yang telah banyak memberi arahan selama penulis menjalankan penelitian
3 Kepada seluruh keluarga atas doa, dukungan, dan kasih sayangnya.
4 Kepada teman seperjuangan satu bimbingan yang selama ini selalu bersama dalam mengerjakan tugas akhir ini dan saling memberikan semangat.
5 Kepada sahabat-sahabat saya atas semangat dan dukungannya.
6 Kepada Muthia Aziza yang telah membantu dan memberi semangat dalam pengerjaan tugas akhir ini.
7 Kepada teman-teman seperjuangan ilkomerz 42, serta pihak lain yang turut membantu baik secara langsung maupun tidak langsung dalam penyelesaian tugas akhir ini.
Semoga karya ilmiah ini bermanfaat.
Bogor, Agustus 2009
RIWAYAT HIDUP
Penulis dilahirkan di Blora pada tanggal 26 Agustus 1987 dari ayah Sudirman dan Ibu Ni’amah. Penulis merupakan anak kedua dari dua bersaudara.
iv
DAFTAR ISI
Halaman
DAFTAR TABEL ... v
DAFTAR GAMBAR ... v
DAFTAR LAMPIRAN ... v
PENDAHULUAN Latar Belakang... 1
Tujuan ... 1
Ruang Lingkup ... 1
Manfaat ... 1
TINJAUAN PUSTAKA Clustering ... 1
AlgoritmeK-Means ... 1
Evaluasi Cluster ... 2
Sistem Informasi Geografis (SIG) ... 2
Bentuk dan Stuktur Data pada SIG ... 3
Operasi dalam SIG ... 3
Hotspot (titik panas) ... 3
Data Warehouse ... 3
Aplikasi OLAP (On-line Analytical Processing) ... 3
METODE PENELITIAN Praproses Data ... 4
Clustering ... 4
Evaluasi Cluster ... 5
Visualisasi Clustering ... 5
Integrasi OLAP dan SIG ... 5
Lingkungan pengembangan. ... 5
HASIL DAN PEMBAHASAN Praproses Data ... 6
Clustering ... 6
Evaluasi Cluster ... 7
Visualisasi Clustering ... 8
IntegrasiOLAP dan SIG ... 8
Presentasi Persebaran Hotspot Hasil Clustering ... 11
KESIMPULAN DAN SARAN Kesimpulan... 12
Saran ... 12
DAFTAR PUSTAKA ... 13
v
DAFTAR TABEL
Halaman
1 Pusat cluster untuk k=4 dan s= 15... 7
2 Persentase dan jumlah anggota cluster untuk k=4 dan s=15 ... 7
3 Total SSE dengan k=4 dan dengan kombinasi random seed ... 7
4 Jumlah iterasi dengan k=4 ... 8
DAFTAR GAMBAR Halaman 1 Desain layout ... 5
2 Arsitektur sistem ... 5
3 Tahapan penelitian ... 5
4 Halaman web aplikasi clustering ... 8
5 Tampilan utama aplikasi OLAP... 9
6 Visualisasi grafik hasil operasi OLAP. ... 10
7 Modul filter visualisasi GIS. ... 10
8 Visualisasi GIS hasil clustering. ... 11
DAFTAR LAMPIRAN Halaman 1 Pusat cluster untuk k=4 dan s=15... 15
2 Jumlah anggota cluster untuk k=4 dan s=15. ... 16
3 Contoh visualisasi clustering untuk wilayah kabupaten dan periode waktu bulan... 17
4 Contoh visualisasi clustering untuk wilayah provinsi dan periode waktu bulan. ... 17
5 Contoh visualisasi clustering untuk wilayah pulau dan periode waktu bulan. ... 18
6 Contoh visualisasi clustering untuk wilayah kabupaten dan periode waktu quarter. ... 18
7 Contoh visualisasi clustering untuk wilayah provinsi dan periode waktu quarter ... 19
8 Contoh visualisasi clustering untuk wilayah pulau dan periode waktu quarter. ... 19
9 Contoh visualisasi clustering untuk wilayah kabupaten dan periode waktu tahun... 20
10 Contoh visualisasi clustering untuk wilayah provinsi dan periode waktu tahun. ... 20
1
PENDAHULUAN
Latar Belakang
Pada tahun 90-an di Indonesia banyak terjadi kebakaran hutan. Apabila hal ini tidak mendapat penanganan atau perhatian khusus tentu akan berdampak buruk. Salah satu penanganan yang bisa dilakukan adalah dengan melakukan pencegahan. Pencegahan
yang bisa dilakukan adalah dengan
mengetahui persebaran titik-titik panas (hotspot). Pada penelitian sebelumnya yang dilakukan oleh Hayardisi (2008) data titik-titik panas telah diolah dengan membangun data warehouse dan aplikasi OLAP mengenai persebaran hotspot yang disajikan dalam
bentuk crosstab dan grafik. Untuk
memudahkan pengguna dalam mendapatkan kelompok sebaran jumlah hotspot di setiap wilayah di Indonesia, diperlukan visualisasi hasil clustering dari data tersebut dalam bentuk peta. Visualisasi dalam bentuk peta dirasa perlu karena ketika informasi yang di tampilkan hanya dalam bentuk keterangan lokasi tanpa ada visualisasi langsung dimana lokasi itu berada, pengguna akan mengalami kesulitan karena harus mengerjakan dua tugas, yaitu melihat lokasi persebaran titik panas, kemudian melihat lagi dalam peta dimana lokasi tersebut sebenarnya berada. Pada visualisasi dalam bentuk peta, pengguna akan
langsung mengetahui lokasi geografis
persebaran titik panas, sehingga ketika seorang pengguna yang kurang familiar
mengenai informasi lokasi-lokasi di
Indonesia, dia tetap bisa mengetahui lokasi pasti persebaran titik panas.
Jumlah hotspot di Indonesia perlu di visualisasikan karena jika persebaran hotspot
diketahui, pencegahan kebakaran hutan di Indonesia dapat diatasi lebih dini. Visualisasi dalam bentuk peta juga akan mempermudah
pihak yang berwenang untuk segera
melakukan langkah pencegahan kebakaran hutan. Hasil clustering divisualisasikan dalam bentuk peta yang menggambarkan persebaran titik panas supaya pihak yang berwenang lebih mudah untuk menentukan daerah mana dulu yang menjadi prioritas untuk segera dilakukan pencegahan kebakaran hutan.
Tujuan
Tujuan dari penelitian ini adalah:
Membangun sistem informasi geografis untuk mengelola hasil operasi OLAP (
On-line Analytical Processing) untuk data warehouse persebaran Hotspot
Memvisualisasikan hasil clustering dalam bentuk peta dalam sistem informasi geografis berbasis web untuk memudahkan pengguna melihat lokasi persebaran titik panas secara langsung.
Ruang Lingkup
Clustering dilakukan untuk data persebaran hotspot sampai dengan tingkat Kabupaten dari tahun 2000 sampai dengan 2004 menggunakan metode K-means.
Manfaat
Aplikasi yang dibuat dalam penelitian ini diharapkan dapat melengkapi hasil visualisasi pada OLAP untuk persebaran hotspot yang telah dibangun dalam penelitian sebelumnya (Hayardisi 2008). Informasi yang dihasilkan dapat digunakan oleh pihak-pihak yang membutuhkan informasi mengenai persebaran
hotspot untuk keperluan pencegahan kebakaran hutan.
TINJAUAN PUSTAKA
Clustering
Pengertian umum dari clustering adalah proses pengelompokan objek-objek fisik maupun abstrak ke dalam kelas-kelas tertentu di mana objek dalam tiap kelas (cluster) memiliki kemiripan dan tiap kelas memiliki perbedaan yang membedakan dari objek dalam kelas lain (Han & Kamber 2006). Kemiripan dari objek dinilai berdasar nilai atribut dan deskripsi objek
AlgoritmeK-Means
K-means adalah algoritme clustering
yang bersifat partitional yaitu membagi data menjadi sub himpunan data (cluster ) yang tidak overlap, sehingga tiap objek data hanya memiliki tepat satu kelas. Dalam partitional-clustering yang paling sering digunakan adalah clustering berdasarkan criteria square error yang tujuannya adalah untuk memperoleh partisi dengan jumlah cluster
tetap tetapi dengan total square error yang kecil.
Sebagai contoh misalkan terdapat
himpunan N data yang dipartisi dalam k cluster {C1,C2,...,Ck}, tiap Ck mempunyai nk
2
sehingga n N
k , di mana k=1,..,K. Mean vector Mk dari cluster Ck didefinisikan
sebagai centroid dari cluster (Kantardzic 2003) atau:
adalah jumlah kuadrat jarak Euclidean antara tiap sample dalam Ck dan centroidnya.Error
ini juga disebut within-cluster variation.
k
Langkah-langkah dalam algoritme K-Means (Kantardzic 2003):
1. Menentukan initial partition dengan k cluster yang berisi sample yang dipilih secara acak, kemudian dihitung centroid
dari tiap-tiap cluster.
2. Membangkitkan partisi baru dengan
penugasan tiap sample terhadap pusat
cluster terdekat.
3. Menghitung pusat cluster baru sebagai
centroid dari cluster.
4. Mengulangi langkah 2 dan 3 sampai nilai optimum dari fungsi kriteria dipenuhi (atau sampai anggota cluster stabil)
Karakteristik algoritme K-Means (Katardzic 2003) sebagai berikut:
Kompleksitasnya O(nkl) dangan n adalah jumlah objek data, k adalah jumlah cluster
dan l adalah banyaknya iterasi. Pada
umumnya k dan l tetap sehingga
kompleksitas algoritme ini linear terhadap ukuran data.
Bisa digunakan untuk menyimpan data dalam memori utama dengan waktu akses elemen yang cepat dan efisien.
Sangat sensitif pada noise dan outline
karena mempengaruhi nilai mean.
Evaluasi Cluster
Kemampuan untuk mendeteksi ada
tidaknya struktur tidak acak pada data. Hal ini merupakan salah satu aspek penting dalam validasi cluster. Aspek lain yang juga
merupakan aspek penting dalam validasi
cluster (Tan et al.2006) yaitu:
Menentukan clusteringtendency dari data. Menentukan jumlah cluster yang tepat. Mengevaluasi seberapa baik hasil analisis
cluster tanpa diberikan informasi eksternal.
Membandingkan hasil analisis cluster
terhadap hasil eksternal yang diketahui.
Membandingkan dua himpunan cluster
untuk menentukan cluster terbaik.
Ukuran–ukuran evaluasi dapat
digolongkan menjadi 3 jenis (Tan et al. 2006) antara lain:
Unsupervised: mengukur goodness dari
struktur clustering tanpa informasi
eksternal, salah satu contohnya adalah SSE
Supervised: mengukur kecocokan stuktur
clustering dengan struktur eksternal.
Relative: membandingkan clustering yang berbeda. Besaran evaluasi cluster relatif
merupakan teknik supervised atau
unsupervised yang digunakan.
Sistem Informasi Geografis (SIG)
Sistem informasi geografis adalah suatu sistem berbasis komputer yang memiliki kemampuan untuk menangkap, menyimpan, mengkueri, menganalisis dan menyajikan data
geospatial (Chang 2008). Data geospatial
adalah data yang menjelaskan lokasi dan karakteristik dari fitur sapsial seperti jalan, bidang tanah, permekaan tanah, serta vegetasi (Chang 2008).
Secara umum komponen SIG dapat dibagi menjadi beberapa komponen utama (Chang 2008) yaitu:
Sistem komputer yang mencakup
perangkat keras dan sistem operasi yang berkaitan dengan GIS.
Perangkat lunak GIS yang mencakup program dan antarmuka pengguna untuk menjalankan perangkat keras. Tampilan untuk user yang biasanya ada dalam GIS adalah: menu area, ikon grafik, dan
command line.
Manusia yang mengacu pada ahli GIS dan pengguna yang memerlukan GIS Data yang terdiri dari banyak input yang digunakan sistem untuk menghasilkan informasi.
Infrastruktur yang mengacu pada
3
Bentuk dan Stuktur Data pada SIG
Data SIG dalam kerangka kerjanya dapat dibagi menjadi dua kategori (Chang 2008) yaitu:
Data spatial merupakan data yang
menjelaskan lokasi dari fitur spatial yang merupakan bentukan dari fitur-fitur spatial
seperti titik, garis dan bidang yang akan membentuk koordinat (data vektor), atau bisa juga diartikan sebagai data yang cara
penggunaan untuk merepresentasikan
variasi spatial nya menggunakan grid
(data raster). Data ini bisa berupa diskret (direpresentasikan dengan data vektor) atau kontinu (direpresentasikan dengan data raster).
Data atribut yang merupakan
pendeksripsian karakteristik fitur-fitur
spatial.
Operasi dalam SIG
Secara umum operasi dalam SIG dapat digolongkan ke dalam enam kelompok (Chang 2008) yaitu:
Input data spatial yang merupakan pemasukan data dan pengubahandata. Manajemen data atribut yang merupakan
pemasukan dan verifikasi selama
digitalisasi dan pengeditan. Tabel atribut dalam database harus didesain untuk memfasilitasi pemasukan, pencarian, temu kembali, manipulasi data dan hasil keluaran.
Menampilkan data dalam bentuk peta, Tabel dan grafik dari hasil query dan analisis data.
Eksplorasi data yang merupakan query dan analisis yang berpusat pada data untuk melihat trend data, subset data dan hubungan antar data.
Analisis data. Pada data vektor analisis dilakukan dengan: buffering, overlay, distance measure, dan manipulasi peta. Pada analisis raster, akan berkaitan dengan
local neighborhood, zonal dan global
Pemodelan SIG yang merupakan
penunjukan dari penggunaan SIG dalam pembuatan model analisis.
Hotspot (titik panas)
Data hotspot merupakan salah satu indikator kemungkinan terjadinya kebakaran hutan pada wilayah tertentu. Pemantauan
hotspot dilakukan dengan pengindraan jauh
(remote sensing) menggunakan satelit (Hayardisi 2008).
Satelit yang biasa digunakan adalah
satelit NOAA (national Ocean and
Atmospheric Administration) melalui sensor
AVHRR (Advanced Very High Resolution
Radiometer) karena sensor tersebut dapat membedakan suhu permukaan di darat dan laut. Satelit ini mendeteksi objek di permukaan bumi yang memiliki suhu relatif lebih tinggi dibandingkan sekitarnya. Suhu yang dideteksi berkisar antara 210 K (37°C) untuk malam hari dan 315 K (42°C) untuk saing hari.
Penginderaan satelit tersebut tentunya
akan membantu penanganan masalah
kebakaran hutan, karena jika posisi lokasi
hotspot telah diketahui maka bisa dilakukan penanganan lebih dini untuk mencegah terjadinya kebakaran hutan.
Data Warehouse
Data warehouse adalah sistem data yang mengelola operasi secara terpisah dari
database. Sistem ini menyediakan layanan pengintegrasian dengan aplikasi lain. Data warehouse juga menyediakan arsitektur yang bisa digunakan sebagai alat analisis (Han & Kamber 2006).
Karakteristik yang membedakan data
warehouse dengan sistem penyimpanan lain adalah (Han & Kamber 2006).
Berorientasi subjek: disusun berdasar pada subjek utama. Data yang tidak
berguna dihapus pada pengambilan
keputusan.
Terintegrasi: biasanya dibangun dengan mengintegrasikan berbagai sumber yang
berbeda. Teknik pembersihan dan
integrasi data dilakukan untuk
memastikan kekonsistenan data.
Time-variant: data disimpan untuk
menyediakan informasi berdasarkan
perspektif waktu.
Non-volatile:data warehouse secara fisik terpisah dari database operasional
Aplikasi OLAP (On-line Analytical Processing)
OLAP merupakan teknologi database
yang menyediakan sebuah penampilan
4
Mendefinisikan analisis persamaan
melalui dimensi-dimensi data beserta perhitungannya
Menyimpulkan dataset, agregasi dan desagregasi dari beberapa dimensi. Mengevaluasi dan menampilkan dari hasil analisis.
Operasi OLAP secara umum adalah sebagai berikut (Han & Kamber 2006):
Roll-up: operasi ini dilakukan pada kubus pusat dengan menaikkan tingkatan satu hierarki (pada saat dilakukan operasi ini jumlah dimensi akan berkurang).
Misalnya dari kubus kecamatan
dinaikkan menjadi kubus kabupaten.
Drill-down: operasi ini merepresentasi-kan kubus secara lebih detail (kebalimerepresentasi-kan dari operasi roll-up).
Slice dan dice: operasi ini melakukan pemilihan satu dimensi dari kubus sehingga dihasilkan subcube. Operasi
dice mendefinisikan subcube dari pemilihan dua dimensi atau lebih.
Pivot (rotate): operasi ini merupakan visualisasi data secara berbeda (dengan memutar koordinat) sehingga didapat presentasi data dalam bentuk lain.
METODE PENELITIAN
Pada penelitian ini akan dilakukan
pengembangan aplikasi OLAP untuk
persebaran data hotspot dengan tambahan modul visualisasi. Tahap-tahap yang akan dilakukan untuk mengembangkan aplikasi OLAP untuk hotspot adalah sebagai berikut:
Praproses Data
Pada tahap praproses dilakukan pemilihan data dan pengambilan data, transformasi data dan pembersihan data. Pada tahapan data cleaning, dilakukan pembersihan database
untuk menghilangkan atau mengurangi
kesalahan-kesalahan pada database. Pada aplikasi OLAP yang sebelumnya, telah tersedia database untuk wilayah-wilayah persebaran hotspot. Tahap data cleaning yang dilakukan yaitu dengan penyesuaian nama
wilayah dari database OLAP dengan
penamaan pada file .dbf. File dbf merupakan file yang menyimpan data wilayah. Data ini akan terhubung ke file shp yang merupakan
file yang menyimpan data spatial.
Penyesuaian dilakukan pada file .dbf, yaitu
dengan menyamakan penamaan suatu
wilayah, tujuannya yaitu agar ketika
dilakukan query, data yang terambil sesuai antara output dari aplikasi OLAP dengan data yang ada pada file .dbf.
Clustering
Tahapan ini merupakan tahapan di mana dilakukan pengambilan data dari hasil operasi OLAP sehingga data menjadi sesuatu yang lebih bermanfaat dan bermakna. Algoritme yang dipakai untuk modul ini adalah Algoritme K-Means. Data hotspot hasil
operasi OLAP pada data warehouse
persebaran hotspot dilakukan clustering.
Sebagai contoh, ketika ingin melihat
persebaran titik panas pada tahun X di wilayah Y. Data yang diambil adalah data pada tahun X di wilayah Y. Pertama dilakukan operasi OLAP untuk memilih salah satu wilayah tertentu (drill-down sampai level yang diinginkan). Dari wilayah ini ditentukan dimensi tahun (drill-down) tertentu. Setelah
didapat crosstab dengan dimensi yang
menampilkan tahun dan wilayah (sesuai
dengan level hirarki yang diinginkan,
misalnya: provinsi atau kabupaten), yang dilakukan selanjutnya adalah operasi slice dan
dice pada tahun sehingga didapatkan data persebaran titik panas dalam tahun tertentu pada suatu cakupan wilayah tertentu (provinsi /kabupaten). Atribut yang digunakan untuk tahap clustering yaitu atribut jumlah titik panas.
Setelah diperoleh data titik persebaran titik panas pada cakupan wilayah tertentu dan tahun tertentu yang dilakukan selanjutnya adalah clustering. Jumlah kelas yang dipilih adalah sejumlah 4 yakni kecil, sedang, besar, dan sangat besar. Tingkatan kelas ini didasarkan pada jumlah titik panas yang ada pada wilayah tertentu dan tahun tertentu.
Langkah-langkah clustering mengunakan
Algoritme K-means adalah sebagai berikut:
1. Menentukan initial partition dengan k cluster berisi samples yang dipilih secara acak, hitung centroid dari tiap-tiap
cluster.
2. Membangkitkan partisi baru dengan
assigning setiap sample terhadap pusat
cluster terdekat.
3. Menghitung pusat-pusat cluster baru
sebagai centroids dari cluster.
4. Mengulangi langkah 2 dan 3 sampai nilai optimum dari fungsi kriteria dipenuhi (atau sampai cluster membership stabil).
5 yang menunjukkan cluster, untuk setiap
objek/ kasus yang menjadi anggotanya
Evaluasi Cluster
Pada tahap ini dilakukan evaluasi terhadap cluster yang dihasilkan. Evaluasi
cluster dilakukan dengan menggunakan Sum of Square Error (SSE) dari kombinasi random seed.
Visualisasi Clustering
Pada tahap ini akan dibangun modul visualisasi. Modul ini menampilkan dari hasil
clustering dalam bentuk peta. Peta dibangun menggunakan MapServer sebagai web-server
dan Chameleon sebagai framework. Peta
menunjukkan pengelompokan wilayah hotspot
berdasarkan kelasnya yaitu tinggi, sedang dan rendah. Rancangan tampilan peta dapat dilihat pada Gambar 1 yang diadopsi dari penelitian
Gambar 1 Desain layout
Integrasi OLAP dan SIG
Pada tahap ini akan dilakukan
pengintegrasian dari aplikasi OLAP yang sebelumnya telah dikembangkan (Hayardisi 2008) dengan aplikasi visualisasi GIS yang telah dikembangkan oleh Harianja 2008.
Tahap pengintegrasian yaitu dengan
menambahkan modul yang merupakan link
dari aplikasi OLAP yang telah di modifikasi ke aplikasi SIG yang telah dimodifikasi.
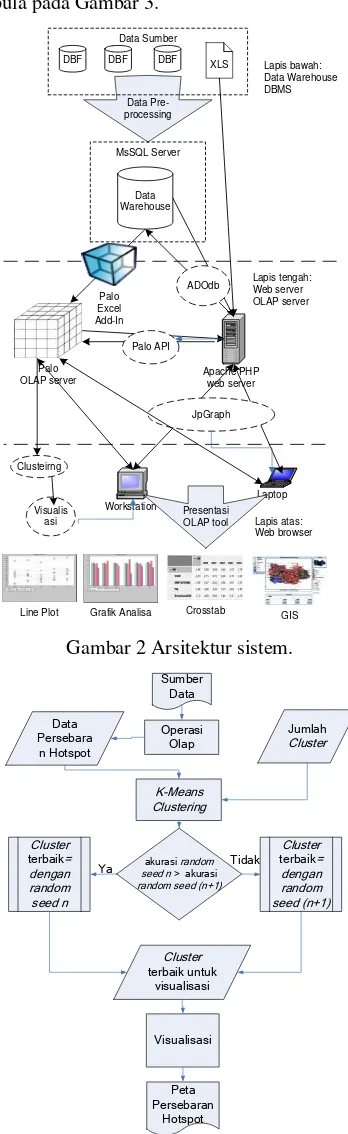
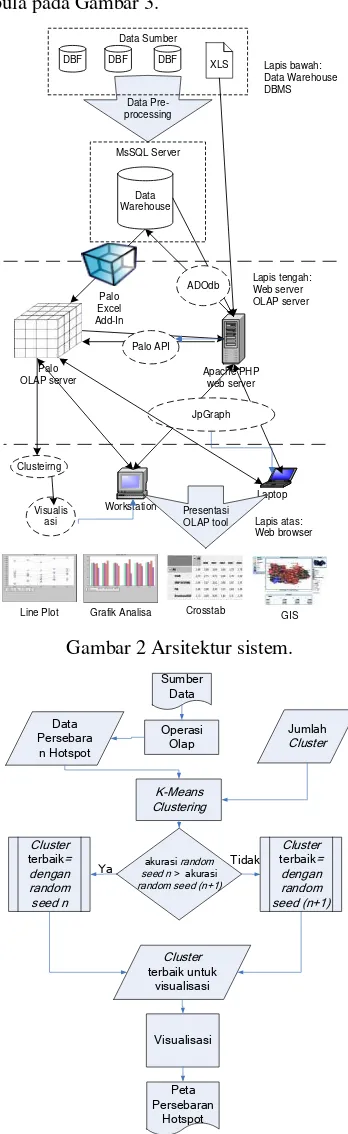
Untuk memperjelas langkah-langkah pada metode penelitian, bisa dilihat pada arsitektur sistem yang disajikan pada Gambar 2 dan disajikan pula tahapan penelitian untuk memperjelas alur penelitian. Dalam penelitian ini dilakukan pada aplikasi tambahan ini adalah pengembangan modul visualisasi yang di dalamnya mencakup modul clustering. Pada modul ini akan ditambahkah menu untuk memilih tahun, modul untuk clustering ini sendiri terpisah dari aplikasi OLAP, clustering
dilakukan di luar sistem kemudian data hasil
clustering digunakan untuk keperluan
visualisasi. Untuk tahapan penelitian disajikan pula pada Gambar 3.
Laptop
Gambar 2Arsitektur sistem.
Operasi
Gambar 3 Tahapan penelitian.
Lingkungan Pengembangan.
6 Perangkat lunak:
Sistem operasi: Windows XP Home Edition,
WEKA versi 3.5.7, ArcView GIS 3.3,
Map Server For Windows (ms4w) 2.3.1 Chameleon 2.4.1
Perangkat keras:
Prosessor intel Pentium 4 ~2GHz Memory 2 GB RAM
Monitor dengan resolusi 1024×768 Mouse dan keyboard
HASIL DAN PEMBAHASAN
Praproses Data
Data awal penelitian ini diperoleh dari hasil operasi OLAP. Data ini merupakan data titik panas untuk wilayah Indonesia pada tingkat pulau, provinsi dan kabupaten dalam tahun, quarter dan bulan periode 2000 hingga 2004. Tahap pengambilan data yaitu dengan menggunakan modul php sederhana. Data yang didapat dari operasi OLAP disimpan dalam format txt dengan ukuran 349kb. Data ini mempunyai 15895 record dan mempunyai dua atribut yaitu nama wilayah (pulau/
provinsi/ kabupaten) [spasi] waktu
(tahun/quarter/bulan) dan jumlah titik panas. Atribut yang digunakan pada tahap clustering
yaitu atribut jumlah titik panas karena atribut ini merupakan atribut numerik, karena
clutering hanya bisa dilakukan pada atribut
numerik. Atribut ini nantinya akan
dikelompokan kedalam 9 kelompok yang kemudian akan diolah untuk keperluan
clustering dengan menggunakan WEKA. Tahapan praproses yang dilakukan antara lain:
Pengelompokan data. Data yang didapat
dalam file txt tadi dikelompokan
berdasarkan jangkauan wilayah dan
waktunya. Pengelompokan dilakukan
dengan algoritme php sederhana. Hasil dari pemisahan ini menghasilkan 9 file txt. Masing-masing file mempunyai tingkatan berbeda. Hasil dari pemisahan ini yaitu:
o Tingkat Pulau dalam Tahun
o Tingkat Pulau dalam Quarter
o Tingkat Pulau dalam Bulan
o Tingkat Provinsi dalam Tahun
o Tingkat Provinsi dalam Quarter
o Tingkat Provinsi dalam Bulan
o Tingkat Kabupaten dalam Tahun
o Tingkat Kabupaten dalam Quarter
o Tingkat Kabupaten dalam Bulan.
Pembersihan data dilakukan pada file dbf, yaitu penghilangan atribut-atribut yang tidak dipergunakan dan penyesuaian nama-nama wilayah pada file dbf agar sama dengan nama wilayah pada hasil operasi OLAP.
Transformasi data. Data hasil
pengelompokan diubah menjadi format
ARFF agar dapat diproses dalam
perangkat lunak WEKA. Atribut yang dipergunakan dalam clustering adalah atribut jumlah titik panas yang bertipe numerik karena algoritme K-means bekerja secara baik pada data dengan tipe numerik, sedangkan atribut keterangan wilayah dan waktu merupakan data yang bertipe kategorik dan hanya dipergunakan sebagai keterangan.
Clustering
Tahap clustering dilakukan menggunakan
algoritme K-Means yang dilakukan
menggunakan WEKA versi 3.5.7. Data yang di-cluster-kan yaitu data jumlah titik panas. Percobaan dilakukan untuk ukuran cluster
sebanyak 4 cluster dan dilakukan percobaan dengan random seed (s) 5, 10, 15, 20.
Percobaan dilakukan pada sembilan
kombinasi clustering, sembilan kombinasi tersebut mewakili tingkatan cakupan wilayah dan tingkatan cakupan waktu. Clustering
dilakukan sebanyak jumlah kombinasi data berdasarkan cakupan wilayah dan waktu. Total percobaan clustering adalah 9 × 4 = 36
percobaan. Clustering tidak dilakukan
berdasarkan tiap hasil operasi OLAP karena jika dilakukan clustering untuk tiap hasil operasi OLAP. Sebagai contoh, misalnya data pada tahun 2000 untuk wilayah A dilakukan
clustering yang berbeda dengan data tahun 2001 untuk wilayah A, data hasil clustering
kurang sesuai karena tidak ada patokan untuk
cluster satu dan cluster lainnya, misal nilai besar untuk tahun 2000 termasuk kecil pada tahun 2001, padahal jika di lihat dari datanya, tahun 2000 memiliki jumlah titik panas yang lebih sedikit dari tahun 2001, namun karena data pembanding berbeda hasil dari clustering
akan berbeda, sehingga diperlukan standar untuk semua clustering agar terdapat patokan nilai titik panas untuk suatu wilayah tergolong
7 memantau perubahan titik panas dari waktu ke
waktu.
Hasil dari algoritme K-means adalah pusat cluster (means) untuk masing-masing
cluster sesuai dengan ukuran clusternya. Pemilihan jumlah 4 cluster disesuaikan
dengan banyaknya kelas yang di
representasikan yaitu low, medium, high, dan
very high. Pusat cluster yang dihasilkan dari
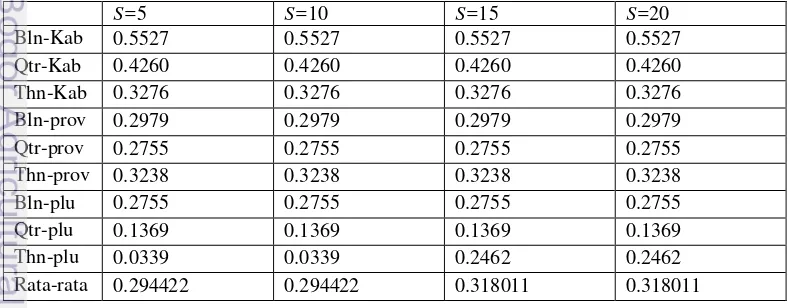
clustering dengan k=4 dan random seeds=5 pada data tingkat provinsi dengan periode waktu bulan dapat dilihat pada Tabel 1. Pusat
cluster untuk kombinasi lain dapat dilihat
Persentase dan jumlah anggota masing-masing cluster untuk ukuran cluter k=4 dan
s=5 pada tingkat provinsi dan periode waktu bulan disajikan dalam Tabel 2. Persentase dan
jumlah anggota masing-masing cluster
disajikan pada Lampiran 2.
Tabel 2 Persentase dan jumlah anggota cluster
untuk k=4 dan s=5 dan s (random seed) dievaluasi menggunakan total SSE (Sum of square error). Total SSE
sudah mencukupi untuk evaluasi cluter
menggunakan K-means karena meminimalkan SSE (cohesion) ekuivalen dengan memaksimalkan SSB (separation), (Tan P 2006).
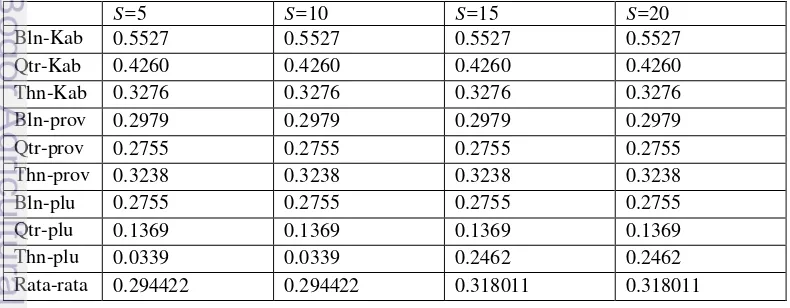
Pada nilai k yang sama dengan perbedaan nilai s, hasil clustering tidak menunjukkan perbedaan yang berarti. Pada Tabel 3 dapat dilihat bahwa nilai SSE rata-rata terbaik didapat pada saat penggunaan random seed
5.Perbedaan iterasi juga tidak terlalu berubah untuk nilai k yang sama. Hal ini dapat dilihat pada Tabel 4 yakni iterasi pada k=4.
Karena nilai K-means menghitung error
dengan mengambil jarak titik tengah dari nilai tiap anggota. Jadi ketika jumlah anggota sama dengan jumlah cluster, tiap cluster akan memiliki anggota yang nilainya sama dengan nilai titik tengah nya sehingga tidak ada nilai
error.
Semua clustering menggunakan jumlah
cluster 4 sehingga didapat standar yang sama sebagai patokan untuk semua clustering. Pembagian cluster menjadi 4 cluster terdiri dari cluster 0 yang merupakan clustering
dengan jumlah titik panas kecil, cluster 1 yang merupakan clustering dengan jumlah titik panas sedang, cluster 2 yang merupakan
clustering dengan jumlah titik panas besar,
cluster 3 yang merupakan clustering dengan jumlah titik panas sangat besar.
Tabel 3 Total SSE dengan k=4 dengan kombinasi random seed
S=5 S=10 S=15 S=20
8
Hasil clustering dari data persebaran titik panas divisualisasikan agar mempermudah analisis. Untuk keperluan tersebut maka dibuatlah aplikasi dalam bentuk sistem informasi geografis (SIG) berbasis web.
Aplikasi yang dikembangkan ini
menggunakan metode dan modul-modul yang
sebelumnya telah dikembangkan oleh
Harianja (2008). Aplikasi ini memplotkan
hasil clustering dengan melibatkan aspek
spatialya dan menampilkan nilai titik tengah tiap cluster dan detail nilai atributnya
Aplikasi visualisasi ini diintegrasikan pada aplikasi OLAP yang sebelumnya telah
dikembangkan oleh Hayardisi (2008).
Aplikasi ini dikembangkan menggunakan Mapserver sebagai web servernya, map file
sebagai konfigurasi, Chameleon sebagai
framework, modul php dan html file sebagai
template. Pada penelitian ini modul-modul dan file-file yang dipakai tersebut sebelumnya dibuat dengan modul php, namun pengaturan dan formatnya sama dengan modul dan file-file yang telah dikembangkan oleh Harianja (2008), namun karena modul visualisasi yang akan dikembangkan ingin bersifat dinamis maka beberapa file-file yang dipakai dibuat pada saat dibutuhkan.
Map file menyimpan konfigurasi dari aplikasi yang dibutuhkan oleh Mapserver. Konfigurasi ini meliputi informasi mengenai ukuran peta, warna peta, path dari file shp dan dbf, huruf yang digunakan, dan lain-lain. File html digunakan untuk menyimpan template
yang dipergunakan. Template ini berisi komponen-komponen yang akan dipakai untuk keperluan visualisasi. Komponen-komponen tersebut telah disediakan oleh
Chameleon. Komponen yang dipergunakan
antara lain mapDHTML, KeyMap, ZoomIn,
ZoomOut, PanMap, Recenter, ZoomAllLayers, Extent, Query. Modul php adalah modul untuk melihat detail data setiap ukuran cluster.
Penambahan pengaturan yang dilakukan
yaitu pada map file. Pada map file
ditambahkan class untuk menutup daerah yang tidak ingin divisualisasikan.
Data yang dipakai untuk keperluan visualisasi disimpan dalam file .dbf. Data ini berisi hasil operasi OLAP yang telah di -cluster-kan. Hasil dari data yang diolah ini adalah peta yang memplotkan suatu daerah dalam wilayah dan periode tertentu, serta label
cluster-nya. Proses pemasukan nilai cluster
pada file dbf dilakukan dengan menggunakan
spreadsheet.
Pada halaman visualisasi diplotkan
dengan warna yang berbeda untuk tiap cluster. Komponen lain yang terdapat pada halaman visualisasi antara lain legend. Komponen
legend memberi keterangan tentang warna untuk tiap cluster. Dalam halaman ini juga terdapat komponen scalebar, dan navigation tools yang terdiri dari zoom in, zoom out, recenter, pan, map unit, left extent (batas kiri),
right extent(batas kanan), top extent (batas atas), dan bottom extent (batas bawah) dari
map . Mouse x dan mouse y menyatakan letak pointer pada map. Semua komponen ini juga telah tersedia pada aplikasi yang sebelumnya (Harianja, 2008) untuk lebih jelasnya tampilan aplikasi yang telah dikembangkan (Harianja 2008) dapat dilihat pada Gambar 4.
Gambar 4 halaman web aplikasi clustering
IntegrasiOLAP dan SIG
9 index.php yaitu dengan menambahkan modul
untuk pemilihan waktu dan wilayah.
Pada modul pemilihan tahun dan wilayah, data kombinasi yang dipilih yaitu data dari semua periode waktu. Pemilihan waktu bisa dilakukan pada tingkat tahun, quarter, dan bulan. Setelah memilih tahun, kombinasi yang bisa dipilih adalah kombinasi wilayah. Batasan pemilihan wilayah yaitu dari tingkat pulau sampai pada tingkat kabupaten saja.
Modul yang dibuat selanjutnya adalah
modul untuk membuat file-file yang
diperlukan oleh aplikasi visual clustering. File tersebut adalah file dalam bentuk file map dan file phtml. Setelah diperoleh data yang ingin ditampilkan, file-file tersebut ditulis, file-file tersebut kemudian dimuat ke dalam modul visualisasi untuk keperluan visualisasi.
Pada pengintegrasian antara aplikasi OLAP dan SIG sebelumnya harus dilakukan pengaturan terlebih dahulu, yang meliputi penentuan file-file yang dibutuhkan (extension
untuk library php nya) yang perlu
ditambahkan dan dibutuhkan serta framework.
Modul visualisasi dan modul OLAP merupakan dua modul yang terpisah. Modul visualisasi mengolah data di luar aplikasi OLAP. Data yang diolah merupakan data persebaran titik panas yang telah dilakukan
clustering. Data tersebut disimpan dalam file dbf. Data ini kemudian di-load untuk keperluan visualisasi. Data yang disimpan ini berupa data titik panas dan keterangan
mengenai clusternya. Nilai cluster inilah yang digunakan sebagai pembeda pengelompokan warna antar tiap daerah. Selain nilai cluster, atribut yang diambil yaitu atribut wilayahnya.
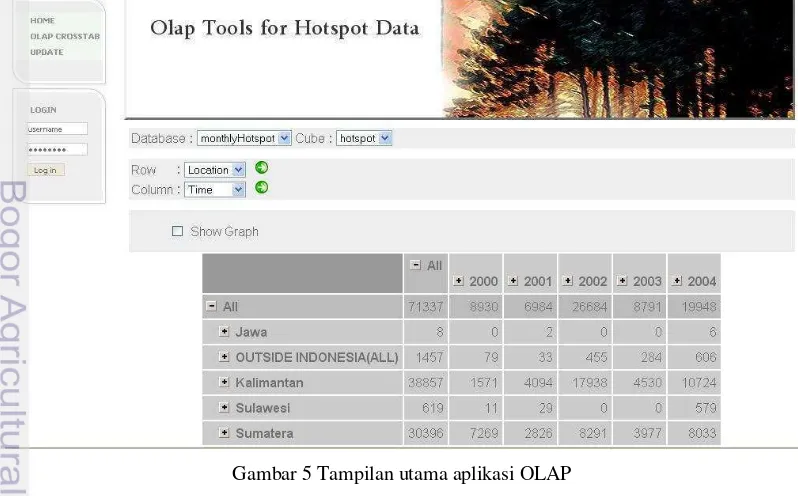
Fasilitas-fasilitas yang sebelumnya telah ada pada aplikasi OLAP (Hayardisi 2008) antara lain (dapat dilihat pada Gambar 5):
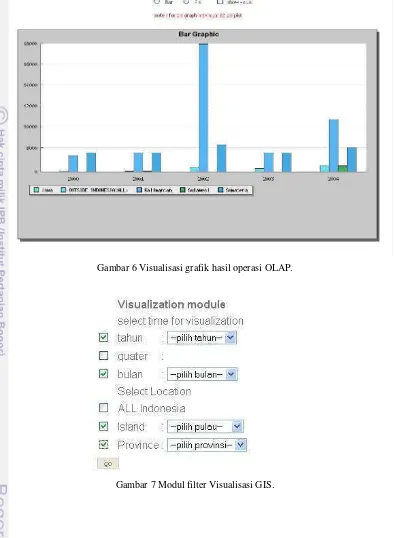
Pengguna dapat memilih database, kubus data dan dimensi yang akan ditampilkan Visualisasi dalam bentuk crosstab dan grafik yang bisa berupa bar plit dan pie plot (dapat dilihat pada Gambar 6)
Operasi OLAP seperti drill down dan
roll up
Filter dimensi untuk menyeleksi tampilan pada kolom (x-axis) dan baris (y-axis).
Filter pada dimensi waktu meliputi
quarter dan bulan
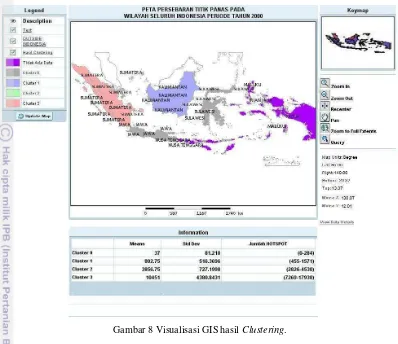
Fasilitas yang ditambahkan pada aplikasi OLAP (dapat dililhat pada Gambar 7):
Filter dimensi waktu dan wilayah untuk visualisasi.
Clustering data persebaran titik panas dari operasi OLAP dengan batasan bulan dan kabupaten.
Visualisasi dalam bentuk SIG yang
dikembangkan dari aplikasi visual
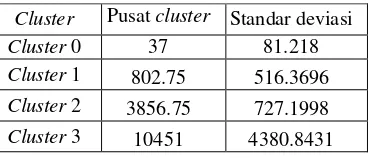
clustering (Harianja 2008), dapat dilihat pada Gambar 8.
Detail data hasil clustering yang
dikembangkan oleh Harianja (2008).
10 Gambar 6 Visualisasi grafik hasil operasi OLAP.
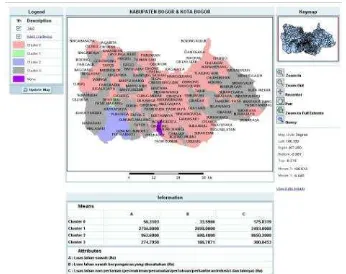
11 Gambar 8 Visualisasi GIS hasil Clustering.
Gambar 8 bagian kiri merupakan legend.
Legend disini berfungsi untuk menampilkan layer-layer yang di load pada peta. Gambar di tengah merupakan visualisasi hasil clustering
berupa peta. Bagian atas tengah merupakan judul atau keterangan mengenai lokasi dan waktu yang divisualisasikan (tampilan utama). Tampilan sebelah kanan merupakan keymap
(peta kecil untuk mempermudah navigasi),
zoom in, zoom out, recenter, pan , dan lain-lain Bagian bawah dari gambar merupakan informasi dari hasil clustering. Pada bagian ini dijelaskan tiap cluster memiliki nilai tengah berapa, standar deviasinya berapa beserta jumlah hotspot/titik panas. Jadi untuk tiap
cluster dapat dilihat berapa jumlah jangkauan titik panasnya.
Presentasi Persebaran Hotspot Hasil
Clustering
Dari aplikasi OLAP diambil 9 kombinasi
clustering pada wilayah Indonesia dari tahun 2000 sampai tahun 2004 dengan tingkat wilayah kabupaten, provinsi dan pulau.
Pada tingkat kabupaten dan bulan, diambil data titik panas untuk semua kabupaten di Indonesia pada bulan Januari 2000 sampai bulan desember 2004. Data ini kemudian di-cluster-kan. Sebagai contoh ketika ingin dilihat clustering untuk kabupaten pada provinsi Kalimantan tengah bulan Januari 2000, pertama-tama dipilih periode tahun 2000 dan bulan Januari, kemudian dipilih kabupaten-kabupaten pada provinsi Kalimantan tengah. Hasil clustering bisa dilihat pada Lampiran 3.
Pada tingkat kabupaten dan quarter, diambil data titik panas untuk semua kabupaten di Indonesia pada quarter pertama 2000 sampai quarter ke empat tahun 2004. Data ini kemudian di-cluster-kan. Sebagai contoh ketika ingin dilihat clustering untuk kabupaten pada Kalimantan tengah pada
quarter pertama tahun 2000, pertama-tama dipilih periode tahun yaitu tahun 2000 dan
quarter 1, kemudian dipilih kabupaten-kabupaten pada provinsi Kalimantan tengah. Hasil clustering bisa dilihat pada Lampiran 4.
12 sampai tahun 2004. Data ini kemudian
dilakukan clustering. Sebagai contoh ketika ingin dilihat clustering untuk kabupaten pada Kalimantan tengah pada tahun 2000, pertama-tama dipilih periode tahun yaitu tahun 2000, kemudian dipilih kabupaten-kabupaten pada provinsi Kalimantan tengah. Hasil clustering
bisa dilihat pada Lampiran 5.
Pada tingkat provinsi dan bulan, diambil data titik panas untuk semua provinsi di Indonesia pada bulan Januari 2000 sampai bulan desember 2004. Data ini kemudian
dilakukan clustering. Sebagai contoh ketika ingin dilihat clustering untuk provinsi Kalimantan pada bulan Januari 2000, pertama dipilih periode tahun 2000 dan bulan Januari, kemudian dipilih provinsi Kalimantan. Hasil
clustering bisa dilihat pada Lampiran 6.
Pada tingkat provinsi dan quarter, diambil data titik panas untuk semua provinsi di Indonesia pada quarter pertama 2000 sampai quarter ke-empat 2004. Data ini kemudian dilakukan clustering. Sebagai contoh ketika ingin dilihat clustering untuk provinsi Kalimantan pada quarter pertama 2000, pertama-tama dipilih periode tahun 2000 dan quarter 1, kemudian dipilih provinsi Kalimantan. Hasil clustering bisa dilihat pada Lampiran 7.
Pada tingkat provinsi dan tahun, diambil data titik panas untuk semua provinsi di Indonesia pada tahun 2000 sampai tahun 2004. Data ini kemudian dilakukan clustering.
Sebagai contoh ketika ingin dilihat clustering
untuk provinsi Kalimantan pada tahun 2000, pertama-tama dipilih periode tahun 2000, kemudian dipilih provinsi Kalimantan. Hasil
clustering bisa dilihat pada Lampiran 8.
Pada tingkat pulau dan bulan, diambil data titik panas untuk semua pulau di Indonesia pada bulan Januari 2000 sampai bulan desember 2004. Data ini kemudian
dilakukan clustering. Sebagai contoh ketika ingin dilihat clustering untuk pulau di Indonesia bulan Januari 2000, pertama-tama dipilih periode tahun 2000 dan bulan Januari, kemudian dipilih All Indonesia. Hasil
clustering bisa dilihat pada Lampiran 9.
Pada tingkat pulau dan quarter, diambil data titik panas untuk semua pulau di Indonesia pada quarter pertama tahun 2000 sampai quarter ke-empat 2004. Data ini kemudian dilakukan clustering. Sebagai contoh ketika ingin dilihat clustering untuk pulau di Indonesia quarter pertama tahun
2000, pertama dipilih periode tahun 2000 dan
quarter 1, kemudian dipilih All Indonesia. Hasil clustering bisa dilihat pada Lampiran 10.
Pada tingkat pulau dan tahun, diambil data titik panas untuk semua pulau di Indonesia dari tahun 2000 sampai tahun 2004. Data ini kemudian dilakukan clustering.
Sebagai contoh ketika ingin dilihat clustering
untuk pulau di Indonesia tahun 2000, pertama-tama dipilih periode tahun 2000, kemudian dipilih All Indonesia. Hasil clustering bisa dilihat pada Lampiran 11
KESIMPULAN DAN SARAN
Kesimpulan
Proses clustering yang dilakukan pada penelitian ini menggunakan algoritme K-Means data persebaran titik panas dari hasil operasi OLAP. Hasil clustering ini kemudian diplotkan dengan melibatkan aspek spatialnya untuk membantu keperluan visualisasi dalam bentuk Sistem Informasi Geografis (SIG) berbasis web. Clustering dilakukan dengan ukuran cluster 4 dan random seed 5, 10, 15, 20.
Clustering dilakukan dengan ukuran
cluster 4 dan random seed 5 karena pada ukuran ini didapat range dan nilai SSE yang cukup baik. Dari visualisasi terlihat bahwa
clustering jumlah titik panas untuk pulau Kalimantan dan Sumatera sama kecuali pada tahun 2000, di mana pulau Sumatera tergolong dalam cluster 3, sementara pulau Kalimantan pada cluster 1. Untuk pulau Jawa dan Sulawesi juga mempunyai kesamaan
clustering kecuali pada tahun 2004, di mana pulau Sulawesi tergolong cluster 1 sementara pulau jawa tergolong cluster 0. Jumlah titik panas terbesar terdapat pada tahun 2004. Dari penelitian dapat dilihat juga bahwa dari periode tahun 2000 sampai 2004, pulau Jawa tergolong pada cluster 0.
Dari visualisasi bisa diketahui bahwa pulau Sumatera dan Kalimantan memiliki jumlah titik panas yang besar, sehingga dapat dilakukan langkah-langkah pencegahan atau penanganan.
Saran
13 Pembuatan modul update data untuk
clustering, sehingga ketika data pada aplikasi OLAP di update, secara otomatis data clustering juga ter-update secara otomatis.
Merapikan tampilan dengan
menghilangkan keterangan legend layer pada daerah yang tidak di-cluster-kan. Pembuatan aplikasi dengan framework
yang lain seperti pmapper dan lain-lain, untuk aplikasi ini dikembangkan dengan Chameleon 2.4.1.
Penambahan clustering untuk dimensi
dimensi waktu lain pada aplikasi OLAP. Pada penelitian ini dimensi waktu yang digunakan adalah dimensi untuk monthly hotspot.
Visualisasi dalam bentuk titik-titik panas dan informasi lain seperti lahan hutan, pertanian, dan lain-lain.
DAFTAR PUSTAKA
Cabbibo L, Torlone R. 1997. Querying
Multidimensional Database.
http://citeseer.ist.psu.edu/cache/papers/cs /21194/http:zSzzSzwww.dia.uniroma3.itzS z~cabibbozSzpubzSzpdfzSzdbp197.pdf/ca bibbo97queriying.pdf [9 Januari 2008]
Chang kang-Tsung.2008. Introduction to
Geograpic Information System.New York : McGraw-Hills.
Han J, Kamber M.2006. Data mining:
Concept and techniques Ed ke-2. San Francisco: Morgan kaufman Publisher.
Harianja H. 2008. Visualisasi K-means
Clustering pada Data Potensi Pertanian Desa di Bogor menggunakan Mapserver
[Skripsi]. Bogor. Program Studi Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam.
Hayardisi G. 2008. Pengembangan data
warehouse dan aplikasi OLAP untuk persebaran hotspot di wilayah Indonesia
[Skripsi]. Bogor. Program Studi Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam.
Kantardzic M.2003. Data mining: Concept, model, method, and algoritme.: New York :John Wiley &sons.
Tan P, Mickael S, Vipin K. 2006. Introduction to Data mining. Pearsen education inc.
.
14
15 Lampiran 1 Pusat cluster untuk k=4 dan s=5.
Tabel Pusat cluster untuk dengan kombinasi bulan kabupaten
Cluster Pusat cluster Standar deviasi Cluster 0 2.2806 7.7012
Cluster 1 141.3506 58.7555
Cluster 2 531 163.7075
Cluster 3 1389.75 436.4132
Tabel Pusat cluster untuk dengan kombinasi bulan provinsi
Cluster Pusat cluster Standar deviasi
Cluster 0 13.1344 30.7252
Cluster 1 431.0612 148.6634
Cluster 2 1240 199.0567
Cluster 3 3060.6 1010.6927
Tabel Pusat cluster untuk dengan kombinasi bulan pulau
Cluster Pusat cluster Standar deviasi Cluster 0 35.553 73.7068
Cluster 1 708.2778 222.9151
Cluster 2 1888.9231 466.7391
Cluster 3 4929.2 1448.5476
Tabel Pusat cluster untuk dengan kombinasi
quarter kabupaten
Cluster Pusat cluster Standar deviasi
Cluster 0 5.986 14.812
Cluster 1 195.2832 80.5451
Cluster 2 701.4615 233.2877
Cluster 3 2232.4 965.4873
Tabel Pusat cluster untuk dengan kombinasi
quarter provinsi
Cluster Pusat cluster Standar deviasi Cluster 0 28.8621 52.5825
Cluster 1 517.9032 188.2148
Cluster 2 1483.8235 291.6141
Cluster 3 4639 2093.7467
Tabel Pusat cluster untuk dengan kombinasi
quarter pulau
Cluster Pusat cluster Standar deviasi Cluster 0 101.7439 186.0923
Cluster 1 1762.875 430.1974
Cluster 2 3520.25 660.1311
Cluster 3 10364.5 4123.1396
Tabel Pusat cluster untuk dengan kombinasi tahun kabupaten
Cluster Pusat cluster Standar deviasi
Cluster 0 21.602 36.6377
Cluster 1 336.8767 120.6193
Cluster 2 968.4118 327.1338
Cluster 3 3366.5 1409.7609
Tabel Pusat cluster untuk dengan kombinasi tahun provinsi
Cluster Pusat cluster Standar deviasi Cluster 0 68.5846 89.0486
Cluster 1 681.0588 265.8393
Cluster 2 2099 634.2088
Cluster 3 6114.5 3262.5652
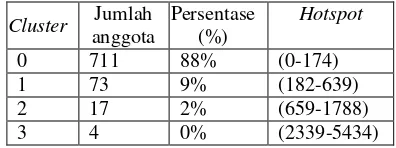
Tabel Pusat cluster untuk dengan kombinasi tahun pulau
Cluster Pusat cluster Standar deviasi
Cluster 0 37 81.218
Cluster 1 802.75 516.3696
Cluster 2 3856.75 727.1998
16 Lampiran 2 Jumlah anggota cluster untuk k=4 dan s=5.
Tabel Jumlah anggota cluster untuk dengan kombinasi bulan kabupaten
Tabel Jumlah anggota cluster untuk dengan kombinasi bulan provinsi
Tabel Jumlah anggota cluster untuk dengan kombinasi bulan pulau
Tabel Jumlah anggota cluster untuk dengan kombinasi quarter kabupaten
Cluster Jumlah
Tabel Jumlah anggota cluster untuk dengan kombinasi quarter provinsi
Cluster Jumlah
Tabel Jumlah anggota cluster untuk dengan kombinasi quarter pulau
Cluster Jumlah
Tabel Jumlah anggota cluster untuk dengan kombinasi tahun kabupaten
Tabel Jumlah anggota cluster untuk dengan kombinasi tahun provinsi
17 Lampiran 3 contoh visualisasi clustering untuk wilayah kabupaten dan periode waktu bulan
18 Lampiran 5 contoh visualisasi clustering untuk wilayah pulau dan periode waktu bulan
19 Lampiran 7 contoh visualisasi clustering untuk wilayah provinsi dan periode waktu quarter
20 Lampiran 9 contoh visualisasi clustering untuk wilayah kabupaten dan periode waktu tahun
ABSTRACT
TSAMRUL FUAD. Clustering of OLAP operation result for hospot datawarehouse using k-means algorithm. Under the direction of ANNISA.
1
PENDAHULUAN
Latar Belakang
Pada tahun 90-an di Indonesia banyak terjadi kebakaran hutan. Apabila hal ini tidak mendapat penanganan atau perhatian khusus tentu akan berdampak buruk. Salah satu penanganan yang bisa dilakukan adalah dengan melakukan pencegahan. Pencegahan
yang bisa dilakukan adalah dengan
mengetahui persebaran titik-titik panas (hotspot). Pada penelitian sebelumnya yang dilakukan oleh Hayardisi (2008) data titik-titik panas telah diolah dengan membangun data warehouse dan aplikasi OLAP mengenai persebaran hotspot yang disajikan dalam
bentuk crosstab dan grafik. Untuk
memudahkan pengguna dalam mendapatkan kelompok sebaran jumlah hotspot di setiap wilayah di Indonesia, diperlukan visualisasi hasil clustering dari data tersebut dalam bentuk peta. Visualisasi dalam bentuk peta dirasa perlu karena ketika informasi yang di tampilkan hanya dalam bentuk keterangan lokasi tanpa ada visualisasi langsung dimana lokasi itu berada, pengguna akan mengalami kesulitan karena harus mengerjakan dua tugas, yaitu melihat lokasi persebaran titik panas, kemudian melihat lagi dalam peta dimana lokasi tersebut sebenarnya berada. Pada visualisasi dalam bentuk peta, pengguna akan
langsung mengetahui lokasi geografis
persebaran titik panas, sehingga ketika seorang pengguna yang kurang familiar
mengenai informasi lokasi-lokasi di
Indonesia, dia tetap bisa mengetahui lokasi pasti persebaran titik panas.
Jumlah hotspot di Indonesia perlu di visualisasikan karena jika persebaran hotspot
diketahui, pencegahan kebakaran hutan di Indonesia dapat diatasi lebih dini. Visualisasi dalam bentuk peta juga akan mempermudah
pihak yang berwenang untuk segera
melakukan langkah pencegahan kebakaran hutan. Hasil clustering divisualisasikan dalam bentuk peta yang menggambarkan persebaran titik panas supaya pihak yang berwenang lebih mudah untuk menentukan daerah mana dulu yang menjadi prioritas untuk segera dilakukan pencegahan kebakaran hutan.
Tujuan
Tujuan dari penelitian ini adalah:
Membangun sistem informasi geografis untuk mengelola hasil operasi OLAP (
On-line Analytical Processing) untuk data warehouse persebaran Hotspot
Memvisualisasikan hasil clustering dalam bentuk peta dalam sistem informasi geografis berbasis web untuk memudahkan pengguna melihat lokasi persebaran titik panas secara langsung.
Ruang Lingkup
Clustering dilakukan untuk data persebaran hotspot sampai dengan tingkat Kabupaten dari tahun 2000 sampai dengan 2004 menggunakan metode K-means.
Manfaat
Aplikasi yang dibuat dalam penelitian ini diharapkan dapat melengkapi hasil visualisasi pada OLAP untuk persebaran hotspot yang telah dibangun dalam penelitian sebelumnya (Hayardisi 2008). Informasi yang dihasilkan dapat digunakan oleh pihak-pihak yang membutuhkan informasi mengenai persebaran
hotspot untuk keperluan pencegahan kebakaran hutan.
TINJAUAN PUSTAKA
Clustering
Pengertian umum dari clustering adalah proses pengelompokan objek-objek fisik maupun abstrak ke dalam kelas-kelas tertentu di mana objek dalam tiap kelas (cluster) memiliki kemiripan dan tiap kelas memiliki perbedaan yang membedakan dari objek dalam kelas lain (Han & Kamber 2006). Kemiripan dari objek dinilai berdasar nilai atribut dan deskripsi objek
AlgoritmeK-Means
K-means adalah algoritme clustering
yang bersifat partitional yaitu membagi data menjadi sub himpunan data (cluster ) yang tidak overlap, sehingga tiap objek data hanya memiliki tepat satu kelas. Dalam partitional-clustering yang paling sering digunakan adalah clustering berdasarkan criteria square error yang tujuannya adalah untuk memperoleh partisi dengan jumlah cluster
tetap tetapi dengan total square error yang kecil.
Sebagai contoh misalkan terdapat
himpunan N data yang dipartisi dalam k cluster {C1,C2,...,Ck}, tiap Ck mempunyai nk
1
PENDAHULUAN
Latar Belakang
Pada tahun 90-an di Indonesia banyak terjadi kebakaran hutan. Apabila hal ini tidak mendapat penanganan atau perhatian khusus tentu akan berdampak buruk. Salah satu penanganan yang bisa dilakukan adalah dengan melakukan pencegahan. Pencegahan
yang bisa dilakukan adalah dengan
mengetahui persebaran titik-titik panas (hotspot). Pada penelitian sebelumnya yang dilakukan oleh Hayardisi (2008) data titik-titik panas telah diolah dengan membangun data warehouse dan aplikasi OLAP mengenai persebaran hotspot yang disajikan dalam
bentuk crosstab dan grafik. Untuk
memudahkan pengguna dalam mendapatkan kelompok sebaran jumlah hotspot di setiap wilayah di Indonesia, diperlukan visualisasi hasil clustering dari data tersebut dalam bentuk peta. Visualisasi dalam bentuk peta dirasa perlu karena ketika informasi yang di tampilkan hanya dalam bentuk keterangan lokasi tanpa ada visualisasi langsung dimana lokasi itu berada, pengguna akan mengalami kesulitan karena harus mengerjakan dua tugas, yaitu melihat lokasi persebaran titik panas, kemudian melihat lagi dalam peta dimana lokasi tersebut sebenarnya berada. Pada visualisasi dalam bentuk peta, pengguna akan
langsung mengetahui lokasi geografis
persebaran titik panas, sehingga ketika seorang pengguna yang kurang familiar
mengenai informasi lokasi-lokasi di
Indonesia, dia tetap bisa mengetahui lokasi pasti persebaran titik panas.
Jumlah hotspot di Indonesia perlu di visualisasikan karena jika persebaran hotspot
diketahui, pencegahan kebakaran hutan di Indonesia dapat diatasi lebih dini. Visualisasi dalam bentuk peta juga akan mempermudah
pihak yang berwenang untuk segera
melakukan langkah pencegahan kebakaran hutan. Hasil clustering divisualisasikan dalam bentuk peta yang menggambarkan persebaran titik panas supaya pihak yang berwenang lebih mudah untuk menentukan daerah mana dulu yang menjadi prioritas untuk segera dilakukan pencegahan kebakaran hutan.
Tujuan
Tujuan dari penelitian ini adalah:
Membangun sistem informasi geografis untuk mengelola hasil operasi OLAP (
On-line Analytical Processing) untuk data warehouse persebaran Hotspot
Memvisualisasikan hasil clustering dalam bentuk peta dalam sistem informasi geografis berbasis web untuk memudahkan pengguna melihat lokasi persebaran titik panas secara langsung.
Ruang Lingkup
Clustering dilakukan untuk data persebaran hotspot sampai dengan tingkat Kabupaten dari tahun 2000 sampai dengan 2004 menggunakan metode K-means.
Manfaat
Aplikasi yang dibuat dalam penelitian ini diharapkan dapat melengkapi hasil visualisasi pada OLAP untuk persebaran hotspot yang telah dibangun dalam penelitian sebelumnya (Hayardisi 2008). Informasi yang dihasilkan dapat digunakan oleh pihak-pihak yang membutuhkan informasi mengenai persebaran
hotspot untuk keperluan pencegahan kebakaran hutan.
TINJAUAN PUSTAKA
Clustering
Pengertian umum dari clustering adalah proses pengelompokan objek-objek fisik maupun abstrak ke dalam kelas-kelas tertentu di mana objek dalam tiap kelas (cluster) memiliki kemiripan dan tiap kelas memiliki perbedaan yang membedakan dari objek dalam kelas lain (Han & Kamber 2006). Kemiripan dari objek dinilai berdasar nilai atribut dan deskripsi objek
AlgoritmeK-Means
K-means adalah algoritme clustering
yang bersifat partitional yaitu membagi data menjadi sub himpunan data (cluster ) yang tidak overlap, sehingga tiap objek data hanya memiliki tepat satu kelas. Dalam partitional-clustering yang paling sering digunakan adalah clustering berdasarkan criteria square error yang tujuannya adalah untuk memperoleh partisi dengan jumlah cluster
tetap tetapi dengan total square error yang kecil.
Sebagai contoh misalkan terdapat
himpunan N data yang dipartisi dalam k cluster {C1,C2,...,Ck}, tiap Ck mempunyai nk
2
sehingga n N
k , di mana k=1,..,K. Mean vector Mk dari cluster Ck didefinisikan
sebagai centroid dari cluster (Kantardzic 2003) atau:
adalah jumlah kuadrat jarak Euclidean antara tiap sample dalam Ck dan centroidnya.Error
ini juga disebut within-cluster variation.
k
Langkah-langkah dalam algoritme K-Means (Kantardzic 2003):
1. Menentukan initial partition dengan k cluster yang berisi sample yang dipilih secara acak, kemudian dihitung centroid
dari tiap-tiap cluster.
2. Membangkitkan partisi baru dengan
penugasan tiap sample terhadap pusat
cluster terdekat.
3. Menghitung pusat cluster baru sebagai
centroid dari cluster.
4. Mengulangi langkah 2 dan 3 sampai nilai optimum dari fungsi kriteria dipenuhi (atau sampai anggota cluster stabil)
Karakteristik algoritme K-Means (Katardzic 2003) sebagai berikut:
Kompleksitasnya O(nkl) dangan n adalah jumlah objek data, k adalah jumlah cluster
dan l adalah banyaknya iterasi. Pada
umumnya k dan l tetap sehingga
kompleksitas algoritme ini linear terhadap ukuran data.
Bisa digunakan untuk menyimpan data dalam memori utama dengan waktu akses elemen yang cepat dan efisien.
Sangat sensitif pada noise dan outline
karena mempengaruhi nilai mean.
Evaluasi Cluster
Kemampuan untuk mendeteksi ada
tidaknya struktur tidak acak pada data. Hal ini merupakan salah satu aspek penting dalam validasi cluster. Aspek lain yang juga
merupakan aspek penting dalam validasi
cluster (Tan et al.2006) yaitu:
Menentukan clusteringtendency dari data. Menentukan jumlah cluster yang tepat. Mengevaluasi seberapa baik hasil analisis
cluster tanpa diberikan informasi eksternal.
Membandingkan hasil analisis cluster
terhadap hasil eksternal yang diketahui.
Membandingkan dua himpunan cluster
untuk menentukan cluster terbaik.
Ukuran–ukuran evaluasi dapat
digolongkan menjadi 3 jenis (Tan et al. 2006) antara lain:
Unsupervised: mengukur goodness dari
struktur clustering tanpa informasi
eksternal, salah satu contohnya adalah SSE
Supervised: mengukur kecocokan stuktur
clustering dengan struktur eksternal.
Relative: membandingkan clustering yang berbeda. Besaran evaluasi cluster relatif
merupakan teknik supervised atau
unsupervised yang digunakan.
Sistem Informasi Geografis (SIG)
Sistem informasi geografis adalah suatu sistem berbasis komputer yang memiliki kemampuan untuk menangkap, menyimpan, mengkueri, menganalisis dan menyajikan data
geospatial (Chang 2008). Data geospatial
adalah data yang menjelaskan lokasi dan karakteristik dari fitur sapsial seperti jalan, bidang tanah, permekaan tanah, serta vegetasi (Chang 2008).
Secara umum komponen SIG dapat dibagi menjadi beberapa komponen utama (Chang 2008) yaitu:
Sistem komputer yang mencakup
perangkat keras dan sistem operasi yang berkaitan dengan GIS.
Perangkat lunak GIS yang mencakup program dan antarmuka pengguna untuk menjalankan perangkat keras. Tampilan untuk user yang biasanya ada dalam GIS adalah: menu area, ikon grafik, dan
command line.
Manusia yang mengacu pada ahli GIS dan pengguna yang memerlukan GIS Data yang terdiri dari banyak input yang digunakan sistem untuk menghasilkan informasi.
Infrastruktur yang mengacu pada
3
Bentuk dan Stuktur Data pada SIG
Data SIG dalam kerangka kerjanya dapat dibagi menjadi dua kategori (Chang 2008) yaitu:
Data spatial merupakan data yang
menjelaskan lokasi dari fitur spatial yang merupakan bentukan dari fitur-fitur spatial
seperti titik, garis dan bidang yang akan membentuk koordinat (data vektor), atau bisa juga diartikan sebagai data yang cara
penggunaan untuk merepresentasikan
variasi spatial nya menggunakan grid
(data raster). Data ini bisa berupa diskret (direpresentasikan dengan data vektor) atau kontinu (direpresentasikan dengan data raster).
Data atribut yang merupakan
pendeksripsian karakteristik fitur-fitur
spatial.
Operasi dalam SIG
Secara umum operasi dalam SIG dapat digolongkan ke dalam enam kelompok (Chang 2008) yaitu:
Input data spatial yang merupakan pemasukan data dan pengubahandata. Manajemen data atribut yang merupakan
pemasukan dan verifikasi selama
digitalisasi dan pengeditan. Tabel atribut dalam database harus didesain untuk memfasilitasi pemasukan, pencarian, temu kembali, manipulasi data dan hasil keluaran.
Menampilkan data dalam bentuk peta, Tabel dan grafik dari hasil query dan analisis data.
Eksplorasi data yang merupakan query dan analisis yang berpusat pada data untuk melihat trend data, subset data dan hubungan antar data.
Analisis data. Pada data vektor analisis dilakukan dengan: buffering, overlay, distance measure, dan manipulasi peta. Pada analisis raster, akan berkaitan dengan
local neighborhood, zonal dan global
Pemodelan SIG yang merupakan
penunjukan dari penggunaan SIG dalam pembuatan model analisis.
Hotspot (titik panas)
Data hotspot merupakan salah satu indikator kemungkinan terjadinya kebakaran hutan pada wilayah tertentu. Pemantauan
hotspot dilakukan dengan pengindraan jauh
(remote sensing) menggunakan satelit (Hayardisi 2008).
Satelit yang biasa digunakan adalah
satelit NOAA (national Ocean and
Atmospheric Administration) melalui sensor
AVHRR (Advanced Very High Resolution
Radiometer) karena sensor tersebut dapat membedakan suhu permukaan di darat dan laut. Satelit ini mendeteksi objek di permukaan bumi yang memiliki suhu relatif lebih tinggi dibandingkan sekitarnya. Suhu yang dideteksi berkisar antara 210 K (37°C) untuk malam hari dan 315 K (42°C) untuk saing hari.
Penginderaan satelit tersebut tentunya
akan membantu penanganan masalah
kebakaran hutan, karena jika posisi lokasi
hotspot telah diketahui maka bisa dilakukan penanganan lebih dini untuk mencegah terjadinya kebakaran hutan.
Data Warehouse
Data warehouse adalah sistem data yang mengelola operasi secara terpisah dari
database. Sistem ini menyediakan layanan pengintegrasian dengan aplikasi lain. Data warehouse juga menyediakan arsitektur yang bisa digunakan sebagai alat analisis (Han & Kamber 2006).
Karakteristik yang membedakan data
warehouse dengan sistem penyimpanan lain adalah (Han & Kamber 2006).
Berorientasi subjek: disusun berdasar pada subjek utama. Data yang tidak
berguna dihapus pada pengambilan
keputusan.
Terintegrasi: biasanya dibangun dengan mengintegrasikan berbagai sumber yang
berbeda. Teknik pembersihan dan
integrasi data dilakukan untuk
memastikan kekonsistenan data.
Time-variant: data disimpan untuk
menyediakan informasi berdasarkan
perspektif waktu.
Non-volatile:data warehouse secara fisik terpisah dari database operasional
Aplikasi OLAP (On-line Analytical Processing)
OLAP merupakan teknologi database
yang menyediakan sebuah penampilan