IMPLEMENTASI ALGORITMA C4.5 DALAM PEMBUATAN
APLIKASI UNTUK MENGANALISIS KEMUNGKINAN
PENGUNDURAN DIRI CALON MAHASISWA BARU
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana Program Strata Satu Jurusan Teknik Informatika
Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia
RANGGA GELAR GUNTARA
10107372
JURUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS KOMPUTER INDONESIA
BANDUNG
i
ABSTRAK
IMPLEMENTASI ALGORITMA C4.5 DALAM PEMBUATAN
APLIKASI UNTUK MENGANALISIS KEMUNGKINAN
PENGUNDURAN DIRI CALON MAHASISWA BARU
Oleh
RANGGA GELAR GUNTARA 10107372
Pada Universitas Komputer Indonesia (UNIKOM) Bandung, seringkali terjadi permasalahan mengenai calon mahasiswa baru yang telah berhasil lulus ujian saringan masuk UNIKOM, mengundurkan diri dengan cara tidak melakukan registrasi ulang. Jika kemungkinan pengunduran diri calon mahasiswa baru tersebut dapat di ketahui lebih dini, mungkin tim manajemen UNIKOM dapat melakukan tindakan-tindakan yang diperlukan untuk mempertahankan calon-calon mahasiswa tersebut agar melakukan registrasi ulang.
Aplikasi untuk menganalisis kemungkinan pengunduran diri calon mahasiswa baru telah berhasil dibangun. Analisis dilakukan dengan memanfaatkan teori penalaran berbasis kasus, yaitu membandingkan kasus calon mahasiswa baru dengan kasus-kasus yang pernah terjadi di tahun-tahun sebelumnya.
Teknik penalaran kasus yang digunakan adalah dengan membangun sebuah pohon keputusan. Pohon keputusan dibuat unuk menghasilkan daftar aturan klasifikasi. Algoritma yang digunakan untuk membentuk pohon keputusan tersebut adalah dengan mengimplementasikan Algoritma C4.5. Algoritma C4.5 merupakan pengembangan dari Algoritma ID3.
ii
OF PROSPECTIVE NEW STUDENTS
By
RANGGA GELAR GUNTARA 10107372
In UNIKOM Bandung, it often happen that a student candidate who has
been succeed in the admission test, cancel his/her application by disregarding the
next phase of admission process (re-registration). If the withdrawal possibility
arised can be detected early, then it is expected that the UNIKOM executive can
make any attempt to keep the candidate proceeds through the admission process
and subsequently, minimizes the rate of admission cancellation.
An application to detect the possibility of application withdrawal has been
built. The detection is based on the cases occurred in the past. The cases are
searched and compared with the current case.
In order to make the cases searching technically easier, an indexing is
conducted in the form of a decision tree, and it is used to build the rule bases. The
tree is built with C4.5 algorithm that is improvement from the predecessor ID3
algorithm.
iii
Dengan memanjatkan puji syukur kehadirat Allah SWT, atas rahmat dan karunianya penulis dapat menyelesaikan Tugas Akhir, yang merupakan syarat untuk menyelesaikan program studi Strata-1 Jurusan Teknik Informatika Fakultas Teknik dan Ilmu Komputer pada Universitas Komputer Indonesia dengan judul
“Implementasi Algoritma C4.5 Dalam Pembuatan Aplikasi Untuk
Menganalisis Kemungkinan Pengunduran Diri Calon Mahasiswa Baru”. Selama pelaksanaan dan penyusunan laporan Tugas Akhir ini banyak menemui hambatan dan kesulitan. Namun berkat dorongan, bantuan dan bimbingan baik secara moril ataupun materil dari berbagai pihak hingga dapat mengatasinya. Untuk itu penulis ingin mengucapkan terima kasih kepada :
1. Allah SWT yang telah melimpahkan rahmat dan karunia-Nya.
2. Kedua orang tua, keluarga serta sahabat yang telah memberikan dukungan moril maupun materil yang tak terhingga selama ini.
3. Bapak Dr. Arry Akhmad Arman, selaku Dekan Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia.
4. Ibu Mira Kania Sabariah, S.T., M.T. sebagai Ketua Jurusan Program Studi Teknik Informatika Universitas Komputer Indonesia.
5. Ibu Tati Hariyati S.T., M.T., Selaku Sekretaris Jurusan teknik Informatika di Universitas Komputer Indonesia.
iv
Indonesia yang telah membantu dan memberikan pengarahan.
9. Teman-teman kelas IF-9 angkatan 2007 yang selalu menemani penulis serta memberi dukungan dan semangat.
10.Semua pihak yang telah ikut membantu dalam penulisan laporan ini baik secara langsung maupun tidak langsung.
Semoga kebaikan yang telah diberikan kepada penulis mendapatkan berkat yang melimpah dari Allah SWT.
Penulis menyadari bahwa dalam penulisan Tugas Akhir ini masih memiliki banyak kekurangan baik dari segi materi maupun penyusunannya, mengingat terbatasnya pengetahuan dan kemampuan penulis. Untuk itu, dengan kerendahan hati penulis memohon maaf dan penulis sangat mengharapkan segala saran kritikan yang sekiranya dapat membantu penulis agar dalam penulisan selanjutnya bisa lebih baik
Wassalamu’allaikum. Wr. Wb.
Bandung, Juli 2011
1
1.1 Latar Belakang Masalah
Kehadiran data mining dilatarbelakangi dengan masalah data explosion
yang dialami akhir-akhir ini, dimana banyak perusahaan telah mengumpulkan data sekian tahun lamanya (data pembelian, data penjualan, data nasabah, data transaksi, data mahasiswa dan lain-lain). Masalah itu pula yang terjadi pada Universitas Komputer Indonesia (UNIKOM) sebagai perusahaan dalam bidang jasa pendidikan, sebagian data yang tersimpan selama ini hanya sebagai dokumentasi contohnya data calon mahasiswa baru. Pertanyaannya sekarang, apakah data tersebut akan dibiarkan menggunung, tidak berguna lalu dibuang, ataukah dapat me-“nambang”-nya untuk mencari „emas‟ dan „berlian‟ yaitu informasi yang berguna untuk perusahaan tersebut.
Pertumbuhan yang pesat dari akumulasi data itu ternyata menciptakan kondisi yang sering disebut sebagai “Rich of Data but Poor of Information”
karena data yang terkumpul itu tidak dapat digunakan untuk pengambilan keputusan. Kumpulan data itu dibiarkan begitu saja seakan-akan menjadi sebuah
“kuburan data (data tombs)”.
calon mahasiswa. Namun, ternyata jumlah keseluruhan mahasiswa baru UNIKOM untuk tahun ajaran 2010/2011 adalah sebanyak 3341, itu berarti ada sekitar 472 calon mahasiswa mengundurkan diri dengan cara tidak melakukan registrasi. 12,5 % calon mahasiswa yang mungkin potensial, tidak mampu dipertahankan oleh UNIKOM Bandung. Bayangkan bila dalam waktu 4 tahun jika jumlah calon mahasiswa baru yang mengundurkan diri rata-rata sebanyak 12,5 %, maka hampir 50% calon mahasiswa tidak dapat dipertahankan UNIKOM. Jumlah yang sangat besar mengingat persaingan di dunia pendidikan saat ini yang semakin meningkat.
Berdasarkan hal tersebut, maka jika kemungkinan pengunduran diri seorang calon mahasiswa baru dapat diketahui lebih dini mungkin pihak manajemen UNIKOM dapat melakukan tindakan-tindakan yang diperlukan untuk mempertahankan calon-calon mahasiswa tersebut. Namun, permasalahannya hingga saat ini, UNIKOM belum memiliki standar baku yang dapat dijadikan sebagai alat untuk menganalisis kemungkinan pengunduran diri calon mahasiswa baru tersebut.
penunjang keputusan berbasis komputer yang mengimplementasikan algoritma klasifikasi data mining. Dengan ketersediaan data calon mahasiswa baru yang melimpah, data mining dapat menggali informasi yang terkubur dari kumpulan data calon mahasiswa baru tersebut. Aplikasi ini dapat digunakan untuk menganalisis kemungkinan pengunduran diri calon mahasiswa baru berdasarkan data yang telah terkumpul sebelumnya.
1.2 Rumusan Masalah
Adapun masalah yang ingin diselesaikan dalam penelitian ini adalah bagaimana cara membuat aplikasi untuk membantu manajemen UNIKOM dalam melakukan analisis kemungkinan pengunduran diri seorang calon mahasiswa dengan didasarkan pada kasus-kasus yang sudah ada. Dalam penelitian ini model pohon keputusan yang akan digunakan untuk mendeteksi kemungkinan pengunduran diri seorang calon mahasiswa adalah dengan menerapkan algoritma C4.5.
1.3 Maksud dan Tujuan Penelitian
Maksud dari Penelitian ini adalah untuk mengimplementasikan algoritma pembentukan pohon keputusan C4.5 dalam sebuah aplikasi yang dapat mendeteksi kemungkinan pengunduran diri seorang calon mahasiswa di UNIKOM Bandung.
Sedangkan tujuan dari penelitian adalah:
1. Dengan adanya aplikasi ini diharapkan kemungkinan seorang calon mahasiswa akan mengundurkan diri dari UNIKOM dapat diketahui secara dini 2. Untuk membantu pihak manajemen unikom dalam melakukan proses
penjaringan calon mahasiswa baru.
3. Untuk membentuk klasifikasi data calon mahasiswa baru yang melakukan registrasi atau tidak registrasi.
1.4 Batasan Masalah
Pada tugas akhir ini, permasalahan dibatasi pada :
1. Pembentukan pohon keputusan dengan menggunakan algoritma C4.5.
2. Proses yang dilibatkan dalam aplikasi yang dibangun adalah berupa proses
data mining.
3. Aplikasi dibangun menggunakan Borland Delphi 7.
4. Keluaran yang dihasilkan aplikasi ini berupa informasi pengklasifikasian data calon mahasiswa baru dengan variabel tujuan melakukan registrasi dan tidak registrasi berdasarkan atribut-atribut dalam data mahasiswa baru berupa pohon keputusan yang dibentuk menggunakan algoritma C4.5.
5. Penyajian laporan daftar aturan yang terbentuk berdasarkan tree yang telah dibentuk disimpan ke dalam format Excel.
6. Pencocokkan kasus baru dengan kasus lama dilakukan secara manual oleh Analis.
7. Klasifikasi yang dihasilkan berdasarkan pohon keputusan adalah mengelompokkan data calon mahasiswa baru berdasarkan variabel tujuan yang terdiri dari registrasi, tidak registrasi, dan tidak terklasifikasi.
8. Data yang digunakan merupakan data sampel yang diambil secara acak dari tabel CalonMhsBaru. Tujuannya untuk membandingkan hasil pengklasifikasian yang dihitung secara manual dan secara otomatis oleh aplikasi yang dibangun.
preprocessing yang hanya menyertakan informasi-informasi yang dibutuhkan saja dengan membuang informasi yang tidak dibutuhkan.
10.Analisis pemodelan yang digunakan adalah berdasarkan aliran data terstruktur. Alat yang digunakan dalam menggambarkan model fungsional dan aliran informasi yaitu menggunakan Diagram Konteks dan Data Flow Diagram (DFD).
1.5 Metodologi Penelitian
Metodologi yang digunakan dalam penulisan tugas akhir ini adalah sebagai berikut :
1. Tahap pengumpulan data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah sebagai berikut :
a. Studi Pustaka
Pengumpulan data dengan cara mengumpulkan literatur, jurnal, paper dan bacaan-bacaan yang ada kaitannya dengan judul penelitian.
b. Observasi
Teknik pengumpulan data dengan mengadakan penelitian dan peninjauan langsung terhadap permasalahan yang diambil.
c. Wawancara
2. Tahap pembuatan perangkat lunak.
Teknik analisis data dalam pembuatan perangkat lunak menggunakan paradigma perangkat lunak secara waterfall, yang meliputi beberapa proses diantaranya:
a. System Engineering
Merupakan bagian terbesar dalam pengerjaan suatu proyek, dimulai dengan mencari dan menetapkan berbagai kebutuhan dari semua elemen yang diperlukan oleh suatu sistem.
b. Analysis
Merupakan tahap menganalisis hal-hal yang diperlukan dalam pelaksanaan proyek pembuatan perangkat lunak.
c. Design
Tahap penerjemahan dari data yang dianalisis kedalam bentuk yang mudah dimengerti oleh user.
d. Coding
Tahap penerjemahan data atau pemecahan masalah yang telah dirancang kedalam bahasa pemrograman tertentu.
e. Testing
f. Maintenance
Tahap akhir dimana suatu perangkat lunak yang sudah selesai dapat mengalami perubahan–perubahan, penambahan, atau perbaikan sesuai dengan permintaan user.
Gambar I.1 Metode Waterfall
1.6 Sistematika Penulisan
Adapun sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini menguraikan tentang latar belakang permasalahan, rumusan masalah, maksud dan tujuan, batasan masalah, metodologi penelitian, sistematika penulisan.
BAB II TINJAUAN PUSTAKA
BAB III ANALISIS DAN PERANCANGAN
Menganalisis masalah yang dihadapi dalam membuat aplikasi dan tentang perancangan dalam pembuatan sistem.
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
Berisi tahapan-tahapan yang dilakukan untuk menerapkan sistem yang telah dirancang.
BAB V KESIMPULAN DAN SARAN
1
2.1 Tinjauan Tempat Penelitian
Pada subbab ini akan membahas mengenai tempat penelitian tugas akhir ini.
2.1.1 Sejarah Perusahaan
Universitas Komputer Indonesia (UNIKOM) secara resmi berdiri pada hari Selasa, tanggal 8 Agustus 2000 berdasarkan Surat Keputusan Menteri Pendidikan Nasional nomor 126/D/0/2000.
Awalnya dimulai pada bulan Juli tahun 1994 ketika didirikan Lembaga Pendidikan Komputer Indonesia Jerman, disingkat LPKIG, bertempat di jalan Dipati Ukur 102 Bandung . Dengan 1 ruang kelas berkapasitas 50 orang dan 1 laboratorium komputer dengan 25 unit komputer, Lembaga ini membuka program pendidikan 1 tahun dengan 5 program studi yaitu Ahli Komputer Aplikasi Bisnis, Ahli Komputer Keuangan & Perbankan, Ahli Komputer Akuntansi & Perpajakan, Ahli Komputer Manajemen & Pemasaran dan Sekretaris Eksekutif. Jumlah peserta pendidikan pada tahun pertama ini sebanyak 233 siswa.
ditambah menjadi 2 buah dan laboratorium komputer menjadi 2 buah dengan jumlah siswa sebanyak 457 orang.
Pada tahun ketiga, 1996, dilakukan penambahan gedung kuliah baru bertempat di jalan Dipati Ukur 116 (gedung FISIP sekarang), sekaligus pemindahan pusat administrasi dan perkantoran. Digedung baru ini dilakukan penambahan 1(satu) Lab. Komputer, 5(lima) Ruang Kuliah, Ruang Dosen dan Ruang Kemahasiswaan. Jumlah siswa dari tahun 1996 hingga tahun 1998 bertambah dari 632 orang menjadi 1184 orang.
Pada tahun kelima, 1998, dimulai pembangunan Kampus baru (Gedung Rektorat /Kampus-1 sekarang) berlantai 6(enam) di jalan Dipati Ukur 114. Pembangunan Kampus baru ini dapat diselesaikan pada bulan Agustus 1999, sehingga pada awal perkuliahan bulan September 1999 telah dapat digunakan. Mencermati dinamika peserta didik dan pengembangan Institusi kedepan, pada tanggal 24 Desember 1998 dibentuklah Yayasan Science dan Teknologi dan dilanjutkan dengan pengajuan pendirian STIMIK IGI dan STIE IGI ke DIKTI.
Pada bulan Juli 1999 STIE IGI diresmikan dengan keluarnya SK Mendiknas no. 119/D/O/1999 dengan 5 program studi : Akuntansi S1, Manajemen S1, Manajemen Pemasaran D3, Keuangan Perbankan D3 serta Akuntansi D3.
Agar Sistem Pendidikan lebih Efisien, Efektif, Produktif dengan Struktur Organisasi yang lebih baik, enam bulan kemudian dilakukan usulan ke DIKTI untuk melakukan Merger kedua Sekolah Tinggi diatas menjadi Universitas.
Pada hari Selasa, tgl. 8 Agustus 2000 keluarlah SK MENDIKNAS no. 126/D/O/2000 atas Universitas Komputer Indonesia yang disingkat dengan nama UNIKOM. Pada SK tersebut sekaligus diijinkan dibukanya 11 program studi baru : Teknik Komputer S1, Manajemen Informatika S1, Teknik Industri S1, Teknik Arsitektur S1, Perencanaan Wilayah dan Kota S1, Ilmu Hukum S1, Ilmu Komunikasi S1, Ilmu Pemerintahan S1, Desain Interior D3, Desain Komunikasi Visual S1 dan Desain Komunikasi Visual D3.
Sejak berdirinya pada tahun 2000, setiap tahunnya UNIKOM menerima ± 2.000 mahasiswa baru. Terakhir pada tahun 2009 yang lalu diterima sebanyak 3.108 mahasiswa baru. Hingga tahun akademik 2009/2010 terdapat 6 Fakultas dan 23 Program Studi di UNIKOM dengan jumlah mahasiswa sebanyak 15.000 orang yang berasal dari berbagai pelosok tanah air dan dari luar negeri yang sedang menempuh pendidikan di UNIKOM.
2.1.2 Visi, Misi dan Target Perusahaan
2.1.2.1 Visi
2.1.2.2 Misi
Menyelenggarakan Pendidikan tinggi kearah masyarakat Industri maju dengan sistem pendidikan yang kondusif, tenaga pengajar berkualitas dan program-program studi berbasis pada teknologi informasi & komputer dengan mengoptimalkan sumber daya yang ada, kualitas dan manajemen mutu berdasarkan prinsip Quality Is Our Tradition.
2.1.2.3 Target
Menghasilkan Ilmuwan dan berpikiran tinggi maju dibidangnya masing-masing, mahir menggunakan teknologi informasi & komputer dalam bekerja serta beriman dan bertakwa kepada Tuhan Yang Maha Esa.
2.1.3 Logo Perusahaan
Berikut ini adalah logo dari Universitas Komputer Indonesia.
Gambar II.1 Logo Unikom
Penjelasan logo :
1. Bingkai Segi Lima, Melambangkan UNIKOM berlandaskan falsafah negara yakni Pancasila dan Undang-Undang Dasar 1945.
3. Bulatan Dalam Berwarna Biru, Melambangkan UNIKOM bertujuan menghasilkan ilmuwan unggul dan berpikiran maju yang Bertaqwa kepada Tuhan Yang Maha Esa.
4. Komputer, Melambangkan ciri utama UNIKOM yang memberikan pendidikan Teknologi Informasi dan Komputasi pada seluruh Jurusan yang ada dilingkungan Universitas Komputer Indonesia, menjadi Universitas Terdepan dibidang Teknologi Informasi dan Komputer serta sebagai Universitas komputer pertama di Indonesia.
5. Stasiun Relay, Melambangkan UNIKOM menyelenggarakan Pendidikan Tinggi kearah masyarakat industri maju dengan sistem pendidikan yang kondusif dan tenaga pengajar berkualitas untuk menghasilkan lulusan-lulusan terbaik.
6. Satelit, Melambangkan UNIKOM berwawasan Global dan menjadi pusat unggulan dibidang IPTEK & seni yang mendukung Pembangunan Nasional serta berorientasi pada kepentingan masyarakat, bangsa dan negara.
7. Cakrawala, Melambangkan indahnya menggapai Cita-cita dan mengejar ilmu setinggi Langit.
2.1.4 Struktur Organisasi Perusahaan
Berikut ini adalah bagan organisasi Universitas Komputer Indonesia :
2.2 Landasan Teori
2.2.1 Data
Menurut Abdul Kadir (2003: 29), data adalah deskripsi tentang benda, kejadian, aktivitas, dan transaksi, yang tidak mempunyai makna atau tidak berpengaruh secara langsung kepada pemakai. Data merupakan bentuk jamak dari
datum, berasal dari bahasa Latin yang berbarti “sesuatau yang diberikan”. Dalam penggunaan sehari-hari, data berarti suatu pernyataan yang diterima secara apa adanya. Pernyataan ini adalah suatu variabel yang bentuknya dapat berupa angka, kata-kata, atau citra. Dalam keilmuan (ilmiah), fakta dikumpulkan untuk menjadi data. Data kemudian diolah sehingga dapat diutarakan secara jelas dan tepat sehingga dapat dimengerti oleh orang lain yang tak langsung mengalaminya sendiri, hal ini dinamakan deskripsi. Pemilahan banyak data sesuai dengan persamaan atau perbedaan yang dikandungnya dinamakan klasifikasi. Secara konseptual, data adalah deskripsi tentang benda, kejadian, aktivitas, dan transaksi, yang tidak mempunyai makna atau tidak berpengaruh secara langsung kepada pemakai. Data dapat berupa nilai yang terformat, teks, citra, audio, dan video.
2.2.2 Informasi
2.2.3 Pengertian Data mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi bermanfaat dan pengetahuan yang terakit dari berbagai database besar. (Turban, dkk. 2005).
Menurut Gartner Group data mining adalah suatu proses menemukan hubungan yang berarti, pola, dan kecenderungan dengan memeriksa dalam sekumpulan besar data yang tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola seperti teknik statistik dan matematika (Larose, 2005).
Selain definisi di atas beberapa definisi juga diberikan seperti tertera di bawah ini.
“Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara
manual.” (Pramudiono, 2006)
“Data mining adalah analisis otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaannya.” (Pramudiono, 2006)
“Data mining merupakan analisis dari peninjauan kumpulan data untuk menemukan hubungan yang tidak diduga dan meringkas data dengan cara yang berbeda dengan sebelumnya, yang dapat dipahami dan bermanfaaat bagi pemilik
“Data mining merupakan bidang dari beberapa bidang keilmuan yang menyatukan teknik dari pembelajaran mesin, pengenalan pola, statistik, database, dan visualisasi untuk penanganan permasalahan pengambilan informasi dari
database yang besar.” (Larose, 2005)
Kemajuan luar biasa yang terus berlanjut dalam bidang data mining
didorong oleh beberapa faktor, antara lain (Larose, 2005): 1. Pertumbuhan yang cepat dalam kumpulan data.
2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan memiliki akses ke dalam database yang andal.
3. Adanya peningkatan akses data melalui navigasi web dan intranet.
4. Tekanan kompetisi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi.
5. Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas pengembangan media penyimpanan.
Dari definisi – definisi yang telah disampaikan, hal penting yang terkait dengan data mining adalah:
1. Data mining merupakan suatu proses otomatis terhadap data yang sudah ada. 2. Data yang akan diproses berupa data yang sangat besar.
Hubungan yang dicari dalam data mining dapat berupa hubungan antara dua atau lebih dalam satu dimensi. Misalnya dalam dimensi produk kita dapat melihat keterkaitan pembelian suatu produk dengan produk yang lain. Selain itu, hubungan juga dapat melihat antara dua atau lebih atribut dan dua atau lebih objek (Ponniah, 2001)
Sementara itu, penemuan pola merupakan keluaran lain dari data mining. Misalkan sebuah perusahaan yang akan meningkatkan fasilitas kartu kredit dari pelanggan, maka perusahaan akan mencari pola dari pelanggan-pelanggan yang ada untuk mengetahui pelanggan yang potensial dan pelanggan yang tidak potensial.
Beberapa definisi awal dari data mining menydrtakan focus pada proses otomatisasi. Berry dan Linoff dalam buku Data mining Technique for Marketing, Sales, and Customers Support mendefinisikan data mining sebagai suatu proses eksplorasi dan analisis secara otomatis maupun semiotomatis terhadap data dalam jumlah besar dengan tujuan menemukan pola atau aturan yang berarti. (Larose, 2005).
Tiga tahun kemudian, dalam buku Mastering Data mining mereka memberikan definisi ulang terhadap pengertian data mining dan memberikan definisi ulang terhadap pengertian data mining dan memberikan pernyataan
bahwa jika ada yang kami sesalkan adalah frase “secara otomatis maupun
pemahaman yang salah bahwa data mining merupakan produk yang dapat dibeli dibandingkan keilmuan yang harus dikuasai (Larose, 2005).
Pernyataan tersebut menegaskan bahwa dalam data mining otomatisasi tidak menggantikan campur tangan manusia. Manusia harus ikut aktif dalam setiap fase dalam proses data mining. Kehebatan kemampuan algoritma data mining yang terdapat dalam perangkat lunak analisis yang terdapat saat ini memungkinkan terjadinya kesalahan penggunaan yang berakibat fatal. Pengguna mungkin menerapkan analisis yang tidak tepat terhadap kumpulan data dengan menggunakan pendekatan yang berbeda. Oleh karenanya, dibutuhkan pemahaman tentang statistic dan struktur model matematika yang mendasari kerja perangkat lunak (Larose, 2005).
2.2.4 Bidang Ilmu Data mining
Data mining bukanlah ilmu yang sama sekali baru. Salah satu kesulitan untuk mendefinisikan data mining adalah kenyataan bahwa data mining mewarisi banyak aspek dan teknik dari bidang-bidang ilmu yang sudah mapan terlebih dahulu.
1. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing/Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada
dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Coding adalah proses transformasi pada tahap yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data mining
algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/Evaluation
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut Interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditentukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
2.2.5 Cross-Industry Standard Process for Data Mining (CRISP-DM)
Cross-Industry Standard Process for Data mining (CRISP-DM) yang dikembangkan tahun 1996 oleh analis dari beberapa industri seperti DaimlerChrysler, SPSS dan NCR. CRISP DM menyediakan standar proses data mining sebagai strategi pemecahan masalah secara umum dari bisnis atau unit penelitian.
Dalam CRISP-DM, sebuah proyek data mining memiliki siklus hidup yang terbagi dalam enam fase. Keseluruhan fase berurutan yang ada tersebut bersifat adaptif. Fase berikutnya dalam urutan bergantung kepada keluaran dari fase sebelumnya. Hubungan penting antarfase digambarkan dengan panah. Sebagai contoh, jika proses berada pada fase modelling. Berdasar pada perilaku dan karakteristik model, proses mungkin harus kembali kepada fase data preparation untuk perbaikan lebih lanjut terhadap data atau berpindah maju kepada fase
Enam fase CRISP-DM (Larose, 2005): 1. Fase Pemahaman Bisnis
a. Penentuan tujuan proyek dan kebutuhan detail dalam lingkup bisnis atau unit penelitian secara keseluruhan.
b. Menerjemahkan tujuan dan batasan menjadi formula dari permasalahan
data mining.
c. Menyiapkan strategi awal untuk mencapai tujuan. 2. Fase Pemahaman Data
a. Mengumpulkan data.
b. Menggunakan analisis penyelidikan data untuk mengenali lebih lanjut data dan pencarian pengetahuan awal.
c. Mengevaluasi kualitas data.
d. Jika diinginkan, pilih sebagian kecil group data yang mungkin mengandung pola dari permasalahan.
3. Fase Pengolahan Data
a. Siapkan dari data awal, kumpulan data yang akan digunakan untuk keseluruhan fase berikutnya. Fase ini merupakan pekerjaan berat yang perlu dilaksanakan secara intensif.
b. Pilih kasus dan variabel yang ingin dianalisis dan yang sesuai analisis yang akan dilakukan.
4. Fase Pemodelan
a. Pilih dan aplikasikan teknik pemodelan yang sesuai. b. Kalibrasi aturan model untuk mengoptimalkan hasil.
c. Perlu diperhatikan bahwa beberapa teknik mungkin untuk digunakan pada permasalahan data mining yang sama.
d. Jika diperlukan, proses dapat kembali ke fase pengolahan data untuk menjadikan data ke dalam bentuk yang sesuai dengan spesifikasi kebutuhan teknik data mining tertentu.
5. Fase Evaluasi
a. Mengevaluasi satu atau lebih model yang digunakan dalam fase pemodelan untuk mendapatkan kualitas dan efektivitas sebelum disebarkan untuk digunakan.
b. Menetapkan apakah terdapat model yang memenuhi tujuan pada fase awal. c. Menentukan apakah terdapat permasalahan penting dari bisnis atau
penelitian yang tidak tertangani dengan baik.
d. Mengambil keputusan berkaitan dengan penggunaan hasil dari data mining.
6. Fase Penyebaran
a. Menggunakan model yang dihasilkan. Terbentuknya model tidak menandakan telah terselesaikannya proyek.
b. Contoh sederhana penyebaran: Pembuatan laporan.
Pengelompokkan Data mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Larose, 2005):
Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik daripada ke arah kategori. Model dibangun menggunakan
record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi.
Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang. Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
Klasifikasi
Pengklusteran
Pengklusteran merupakan pengelompokkan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.
Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam cluster lain. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
Pohon Keputusan
Pohon keputusan merupakan metode klasifikasi dan prediksi yang sangat kuat dan terkenal. Metode pohon keputusan mengubah fakta yang sangat besar menjadi pohon keputusan yang merepresentasikan aturan. Aturan dapat dengan mudah dipahami dengan bahasa alami. Dan mereka juga dapat diekspresikan dalam bentuk bahasa basis data seperti Structured Query Language untuk mencari
record pada kategori tertentu.
Pohon keputusan juga berguna untuk mengeksplorasi data, menemukan hubungan tersembunyi antara sejumlah calon variabel input dengan sebuah variabel target.
Sebuah pohon keputusan adalah sebuah struktur yang dapat digunakan untuk membagi kumpulan data yang besar menjadi himpunan-himpunan record
yang lebih kecil dengan menerapkan serangkaian aturan keputusan. Dengan masing-masing rangkaian pembagian, anggota himpunan hasil menjadi mirip satu dengan yang lain (Berry & Linoff, 2004).
Sebuah model pohon keputusan terdiri dari sekumpulan aturan untuk membagi sejumlah populasi yang heterogen menjadi lebih kecil, lebih homogeny
dengan memperhatikan pada variabel tujuannya.
Sebuah pohon keputusan mungkin dibangun dengan seksama secara manual atau dapat tumbuh secara otomatis dengan menerapkan salah satu atau beberapa algoritma pohon keputusan untuk memodelkan himpunan data yang belum terklasifikasi.
Variabel tujuan biasanya dikelompokkan dengan pasti dan model pohon keputusan lebih mengarah pada perhitungan probabilitas dari tiap-tiap record terhadap kategori-kategori tersebut atau untuk mengklasifikasi record dengan mengelompokkannya dalam satu kelas.
Pohon keputusan juga dapat digunakan untuk mengestimasi nilai dari variabel continue meskipun ada beberapa teknik yang lebih sesuai untuk kasus ini. Banyak algoritma yang dapat dipakai dalam pembentukan pohon keputusan, antara lain ID3, CART, dan C4.5 (Larose, 2005). Algoritma C4.5 merupakan pengembangan dari algoritma ID3 (Larose, 2005).
sebagai kriteria dalam pembentukan pohon. Salah satu atribut merupakan atribut yang menyatakan data solusi per item data yang disebut target atribut. Atribut memiliki nilai-nilai yang dinamakan dengan instance.
Proses pada pohon keputusan adalah mengubah bentuk data (table) menjadi model pohon, mengubah model pohon menjadi rule, dan menyederhanakan rule
(Basuki & Syarif, 2003).
Algoritma C4.5
Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah sebagai berikut:
Pilih atribut sebagai akar.
Buat cabang untuk tiap-tiap nilai. Bagi kasus dalam cabang.
Ulangi proses untuk setiap cabang sampai semua kasus pada cabang memiliki kelas yang sama.
Untuk memilih atribut sebagai akar, didasarkan pada nilai Gain tertinggi dari atribut-atribut yang ada. Untuk menghitung Gain digunakan rumus seperti tertera dalam persamaan 1 berikut.
Gain(S, A) = Entropy(S) - * Entropy(Si) (1)
Keterangan:
S : himpunan kasus A : atribut
|Si| : jumlah kasus pada partisi ke-i |S| : jumlah kasus dalam S
Sementara itu, penghitungan nilai entropi dapat dilihat pada persamaan berikut.
Entropy(S) = (2)
Keterangan
S : himpunan kasus A : fitur
n : jumlah partisi S
pi : proporsi dari Si terhadap S
Basis Data (Database)
Basis data (Database) adalah sekumpulan informasi bermanfaat yang diorganisasikan kedalam tata cara yang khusus.[6]
Database adalah kumplan data yang saling berkaitan, berhubungan yang disimpan secara bersama-sama sedemikian rupa tanpa pengulangan yang tidak perlu, untuk memenuhi berbagai kebutuhan. Data-data ini harus mengandung semua informasi untuk mendukung semua kebutuhan sistem. Proses dasar yang dimiliki oleh database ada empat, yaitu:
1. Pembuatan data-data baru (create database)
2. Penambahan data (insert)
3. Mengubah data (update)
Database merupakan salah satu komponen yang penting dalam sistem informasi, karena merupakan basis dalam menyediakan informasi pada para pengguna. Basis data (database) menjadi penting karena munculnya beberapa masalah bila tidak menggunakan data yang terpusat, seperti adanya duplikasi data, hubungan antar data tidak jelas, organisasi data dan update menjadi rumit. Jadi tujuan dari pengaturan data dengan menggunakan basis data adalah :
a. Menyediakan penyimpanan data untuk dapat digunakan oleh organisasi saat sekarang dan masa yang akan datang.
b. Cara pemasukan data sehingga memudahkan tugas operator dan menyangkut pula waktu yang diperlukan oleh pemakai untuk mendapatkan data serta hak-hak yang dimiliki terhadap data yang ditangani.
c. Pengendalian data untuk setiap siklus agar data selalu up-to-date dan dapat mencerminakan perubahan spesifik yang terjadi di setiap sistem.
d. Pengamanan data terhadap kemungkinan penambahan, modifikasi, pencurian dan gangguan-gangguan lain.
Dalam basis data sistem informasi digambarkan dalam model entity relationship (E-R). Bahasa yang digunakan dalam basis data (database) yaitu : a. DDL (Data Definition Language)
Merupakan bahasa definisi data yang digunakan untuk membuat dan mengelola objek database seperti database, tabel dan view
b. DML (Data Manipulation Language)
c. DCL (Data Control Language)
Merupakan bahasa yang digunakan untuk mengendalikan pengaksesan data. Penyusunan basis data meliputi proses memasukkan data kedalam media penyimpanan data, dan diatur dengan menggunakan perangkat Sistem Manajemen Basis Data (Database Management Sistem / DBMS).
Database Management System (DBMS)
“Managemen Sistem Basis Data (Database Management System / DBMS) adalah perangkat lunak yang di desain untuk membantu dalam hal pemeliharaan
dan utilitas kumpulan data dalam jumlah besar”.
Sistem Manajemen Basis data (Database Management System) merupakan sistem pengoperasian dan sejumlah data pada komputer. Dengan sistem ini dapat merubah data, memperbaiki data yang salah dan menghapus data yang tidak dapat dipakai. Sistem manajemen database merupakan suatu perluasan software sebelumnya mengenai software pada generasi komputer yang pertama. Dalam hal ini data dan informasi merupakan kesatuan yang saling berhubungan dan berkerja sama yang terdiri dari: peralatan, tenaga pelaksana dan prosedur data. Sehingga pengolahan data ini membentuk sistem pengolahan data. Peralatan dalam hal ini berupa perangakat keras (hardware) yang digunakan, dan prosedur data yaitu berupa perangakat lunak (software) yang digunakan dan dipakai untuk mengalokasikan dalam pembuatan sistem informasi pengolahan database.
Manipulasi basis data meliputi pembuatan pernyataan (query) untuk mendapatkan informasi tertentu, melakukan pembaharuan atau penggantian
untuk menyediakan tinjauan abstrak dari data bagi user. Jadi sistem menyembunyikan informasi mengenai bagaimana data disimpan dan dirawat, tetapi data tetap dapat diambil dengan efisien. Pertimbangan efisiensi yang digunakan adalah bagaimana merancang struktur data yang kompleks, tetapi tetap dapat digunakan oleh pengguna yang masih awam, tanpa mengetahui kompleksitas stuktur data. Sistem manajemen database atau Database Management System (DBMS) adalah merupakan suatu sistem software yang memungkinkan seorang user dapat mendefinisikan, membuat, dan memelihara serta menyediakan akses terkontrol terhadap data. Database sendiri adalah sekumpulan data yang berhubungan dengan secara logika dan memiliki beberapa arti yang saling berpautan. DBMS yang utuh biasanya terdiri dari :
a. Database administrator adalah orang atau group yang bertanggungjawab mengimplementasikan sistem database di dalam suatu organisasi.
b. Enduser adalah orang yang berada di depan workstation dan berinteraksi secara langsung dengan sistem.
c. Programmer aplikasi, orang yang berinteraksi dengan database melalui cara yang berbeda.
DFD (Data Flow Diagram)
DFD sering digunakan untuk menggambarkan suatu sistem yang telah ada atau sistem baru yang akan dikembangkan secara logika tanpa mempertimbangkan lingkungan fisik dimana data tersebut mengalir atau dimana data tersebut akan disimpan.
DFD merupakan alat yang digunakan pada metodologi pengembangan sistem yang terstruktur. Kelebihan utama pendekatan aliran data, yaitu :
a. Kebebasan dari menjalankan implementasi teknis sistem.
b. Pemahaman lebih jauh mengenai keterkaitan satu sama lain dalam sistem dan subsistem.
c. Mengkomunikasikan pengetahuan sistem yang ada dengan pengguna melalui diagram aliran data.
d. Menganalisis sistem yang diajukan untuk menentukan apakah datadata dan proses yang diperlukan sudah ditetapkan.
Disamping itu terdapat kelebihan tambahan, yaitu :
1. Dapat digunakan sebagai latihan yang bermanfaat bagi penganalisis, sehingga bisa memahami dengan lebih baik keterkaitan satu sama lain dalam sistem dan subsistem.
2. Membedakan sistem dari lingkungannya dengan menempatkan batas-batasnya.
3. Dapat digunakan sebagai suatu perangkat untuk berinteraksi dengan pengguna.
DFD terdiri dari context diagram dan diagram rinci (DFD Levelled).
Context diagram berfungsi memetakan model lingkungan (menggambarkan hubungan antara entitas luar, masukan dan keluaran sistem), yang direpresentasikan dengan lingkaran tunggal yang mewakili keseluruhan sistem.
DFD levelled menggambarkan sistem sebagai jaringan kerja antara fungsi yang berhubungan satu sama lain denganaliran dan penyimpanan data, model ini hanya memodelkan sistem darisudut pandang fungsi.
Dalam DFD levelled akan terjadi penurunan level dimana dalam penurunan level yang lebih rendah harus mampu merepresentasikan proses tersebut ke dalam spesifikasi proses yang jelas. Jadi dalam DFD levelled bisa dimulai dari DFD level 0 kemudian turun ke DFD level 1 dan seterusnya. Setiap penurunan hanya dilakukan bila perlu. Aliran data yang masuk dan keluar pada suatu proses di level x harus berhubungan dengan aliran data yang masuk dan keluar pada level x+1 yang mendefinisikan proses pada level x tersebut. Proses yang tidak dapat diturunkan/dirinci lagi dikatakan primitif secara fungsional dan disebut sebagai proses primitif.
Kamus Data (Data Dictionary)
Kamus data mendefinisikan elemen data dengan fungsi sebagai berikut : 1. Menjelaskan arti aliran data dan penyimpanan dalam DFD
2. Mendeskripsikan komposisi paket data yang bergerak melalui aliran misalnya alamat diuraikan menjadi kota, negara dan kode pos
3. Mendeskripsikan komposisi penyimpanan data
4. Menspesifikasikan nilai dan satuan yang relevan bagi penyimpanan dan aliran data.
5. Mendeskripsikan hubungan detail antar penyimpanan yang akan menjadi titik perhatian dalam Diagram Keterhubungan Entitas (E-R).
Delphi
Delphi adalah suatu program berbasis bahasa Pascal yang berjalan dalam lingkungan Windows. Delphi telah memanfaatkan suatu teknik pemrograman yang disebut RAD yang telah membuat pemrograman menjadi lebih mudah. Delphi adalah suatu bahasa pemrograman yang telah memanfaatkan metode pemrograman Object Oriented Programming (OOP). Secara ringkas, object
adalah suatu komponen yang mempunyai bentuk fisik dan biasanya dapat dilihat (visual). Object biasanya dipakai untuk melakukan tugas tertentu dan mempunyai batasan-batasan tertentu. Sedangkan bahasa pemrograman secara singkat dapat disebut sebagai sekumpulan teks yang mempunyai arti tertentu dan disusun dengan aturan tertentu serta untuk menjalankan tugas tertentu.
38
BAB III
ANALISIS DAN PERANCANGAN
3.1 Analisis Sistem
Analisis sistem dapat didefinisikan sebagai penguraian dari suatu sistem informasi yang utuh ke dalam bagian-bagian komponennya dengan maksud untuk mengidentifikasikan dan mengevaluasi permasalahan-permasalahan, kesempatan-kesempatan, hambatan-hambatan yang terjadi dan kebutuhan-kebutuhan yang diharapkan sehingga dapat diusulkan perbaikan-perbaikannya.
3.1.1 Analisis Masalah
Pada tahun ajaran 2010/2011 jumlah calon mahasiswa baru UNIKOM yang dinyatakan lulus ujian saringan masuk adalah sebanyak 3813 calon mahasiswa. Namun, ternyata jumlah keseluruhan mahasiswa baru UNIKOM untuk tahun ajaran 2010/2011 adalah sebanyak 3341, itu berarti ada sekitar 472 calon mahasiswa mengundurkan diri dengan cara tidak melakukan registrasi. 12,5 % calon mahasiswa yang mungkin potensial, tidak mampu dipertahankan oleh UNIKOM Bandung.
hingga saat ini, UNIKOM belum memiliki standar baku yang dapat dijadikan sebagai alat untuk menganalisis kemungkinan pengunduran diri calon mahasiswa baru tersebut.
Kebijakan selama ini yang dilakukan oleh tim Manajemen Unikom untuk mengantisipasi pengunduran diri calon mahasiswa barunya adalah dengan cara menunggu calon mahasiswa melakukan registrasi hingga beberapa hari sebelum waktu registrasi ulang berakhir. Jika dalam waktu H-2 sebelum waktu registrasi berakhir calon mahasiswa tersebut belum melakukan registrasi, maka pihak manajemen akan mengirim surat pemberitahuan. Hal ini terasa kurang efektif karena harus menunggu dalam waktu yang lama untuk memastikan mahasiswa mana yang kemungkinan mengundurkan diri.
menganalisis kemungkinan pengunduran diri calon mahasiswa baru berdasarkan data yang telah terkumpul sebelumnya.
3.1.2 Analisis Data
Data yang akan digunakan dalam membentuk pohon keputusan untuk menganalisis kemungkinan pengunduran diri calon mahasiswa baru Universitas Komputer Indonesia (UNIKOM) adalah data calon mahasiswa baru Tahun Ajaran 2010/2011 yang tersimpan pada tabel CalonMhsBaru. Data calon mahasiswa baru tersebut selanjutnya akan dilakukan pra-proses untuk menghasilkan data kasus yang siap untuk dibentuk menjadi sebuah pohon keputusan.
Data calon mahasiswa baru Universitas Komputer Indonesia tahun ajaran 2010/2011 dengan nama tabel MhsBaru memiliki format asli seperti tampak pada Tabel 3.1 berikut ini.
Tabel III.1 Format Asli Data CalonMhsBaru
AGAMA NIM JURUSAN PROG_STUDI DISPENSASI THN_AKADEMIK NO_IDENTITAS NAMA_PROP NAMA_KAB REGISTRASI
Data yang tidak lengkap dan inkonsisten umumnya terjadi hampir pada setiap database, data yang tidak lengkap dapat disebabkan oleh berbagai macam sebab, seperti atribut dengan data yang salah atau dengan data yang kosong. Demikian pula dengan data calon mahasiswa baru Unikom, ada sebagian atribut yang tidak terlalu diperlukan sehingga proses Data Preprocessing perlu dilakukan sehingga database sesuai dengan ketentuan yang diperlukan oleh sistem.
Data preprocessing merupakan hal yang penting dalam proses data mining, hal-hal yang termasuk di dalamnya adalah:
a. Data Selection
Sebelum masuk ke proses Data Preprocessing, yang harus dilakukan lebih awal adalah pemilihan data (data selection). Data calon mahasiswa baru tersebut nantinya akan menjadi Data Kasus dalam proses operasional data mining. Dari data yang ada, kolom yang diambil sebagai atribut/variabel keputusan adalah kolom Registrasi, sedangkan kolom yang diambil sebagai variabel penentu dalam pembentukan pohon keputusan adalah kolom:
4. PROG_STUDI 5. NILAI_TEST 6. JURUSAN
Pemilihan variabel-variabel tersebut dengan pertimbangan bahwa jumlah nilai variabelnya tidak banyak sehingga diharapkan calon mahasiswa yang masuk dalam satu klasifikasi nilai variabel tersebut cukup banyak.
Berdasarkan variabel-variabel yang sudah terpilih, format data menjadi seperti tampak pada Tabel 3.2.
Tabel III.2 Format sampel data setelah pemilihan variabel
NILAI_UAN GELOMBANG CATATAN NILAI_TEST JURUSAN PROG_STUDI REGISTRASI
50,2 1 Test C MI Diploma-3 Registrasi
51.6 1 Test C MI Starata-1 Registrasi
43,7 2 Test C IF Starata-1 Tidak Registrasi
48,4 1 Test C IF Starata-1 Registrasi
b. Data Preprocessing/Data Cleaning
Data cleaning diterapkan untuk menambahkan isi atribut yang hilang atau kosong, dan merubah data yang tidak konsisten.
Tabel III.3 Contoh atribut yang tidak memiliki nilai
NILAI_UAN GELOMBANG CATATAN NILAI_TEST JURUSAN PROG_STUDI REGISTRASI
2 2 PMDK
Teknik Informatika
S1 Registrasi
Proses data cleaning yang dilakukan adalah dengan mengisi nilai dari atribut NILAI_TEST yang kosong dengan nilai T (Tidak ada nilai). Nilai T diberikan bagi calon mahasiswa baru yang tidak mengikuti ujian saringan masuk di UNIKOM yang melalui jalur PMDK.
Tabel III.4 Data atribut NILAI_TEST setelah di cleaning
NILAI_UAN GELOMBANG CATATAN NILAI_TEST JURUSAN PROG_STUDI REGISTRASI
2 2 PMDK T
Teknik Informatika
S1 Registrasi
c. Data Transformation
Dalam proses ini, data ditransformasikan ke dalam bentuk yang sesuai untuk proses data mining.
1. Mengelompokkan nilai nilai_uan
Pengelompokkan nilai nilai_uan dilakukan dengan memasukkan nilai_uan
calon mahasiswa dalam range seperti tampak pada Tabel 3.5 berikut ini.
Tabel III.5 Pengelompokkan nilai_uan
NILAI_UAN Klasifikasi 30 – 45 1
2. Menerjemahkan nilai jurusan
Penerjemahan nilai jurusan dilakukan denga mengganti nilai jurusan dengan nilai seperti Tampak pada Tabel 3.6.
Tabel III.6 Penerjemahan Jurusan
JURUSAN Nilai Baru
MI Manajemen Informatika IF Teknik Informatika
3. Menerjemahkan nilai PROG_STUDI
Penerjemahan nilai PROG_STUDI dilakukan dengan mengganti nilai PROG_STUDI dengan nilai seperti Tampak pada Tabel 3.7.
Tabel III.7 Penerjemahan Prog_Studi
PROG_STUDI Nilai Baru Diploma-3 D3
Strata-1 S1
d. Data Reduction
Reduksi data dilakukan dengan menghilangkan atribut-atribut yang tidak diperlukan sehingga ukuran dari database menjadi kecil dan hanya menyertakan atribut-atribut yang diperlukan dalam proses data mining. Hal ini dikarenakan proses data mining akan lebih efisien terhadap data yang lebih kecil.
Format tabel yang diambil dari tabel CalonMhsBaru setelah dilakukan Data Reduction adalah sebagai berikut:
3.1.3 Analisis Algoritma C4.5
Dari proses Data Preprocessing yang telah dilakukan maka dihasilkan tabel yang siap untuk proses klasifikasi, seperti pada Tabel 3.8 dibawah ini.
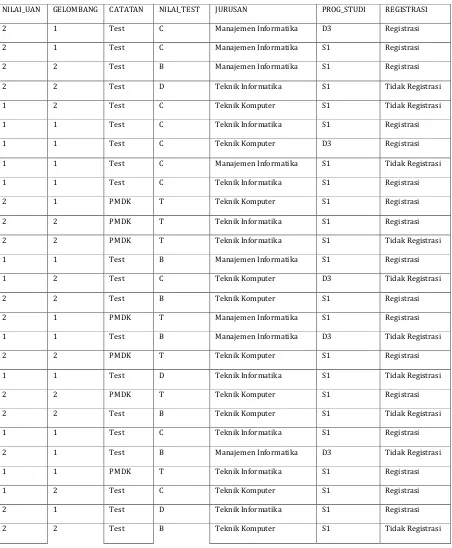
Tabel III.8 Tabel Kasus
NILAI_UAN GELOMBANG CATATAN NILAI_TEST JURUSAN PROG_STUDI REGISTRASI
2 1 Test B Teknik Informatika S1 Tidak Registrasi 2 2 Test C Teknik Informatika S1 Tidak Registrasi
1 1 Test B Teknik Komputer S1 Registrasi
1 1 Test C Teknik Informatika S1 Registrasi
1 1 Test C Teknik Informatika S1 Registrasi
1 1 Test D Teknik Informatika S1 Tidak Registrasi 1 2 Test C Manajemen Informatika S1 Registrasi 2 2 Test D Teknik Informatika S1 Tidak Registrasi
Tabel KASUS adalah kumpulan data yang akan diproses untuk membentuk sebuah pohon keputusan. Data diatas merupakan 35 data sampel yang diambil secara acak dari tabel MhsBaru. Atribut tujuannya yaitu REGISTRASI, dimana memiliki dua nilai atribut yang berbeda yaitu Registrasi dan Tidak Registrasi.
Dari Data KASUS diatas akan dibuat pohon keputusan untuk menganalisis kemungkinan pengunduran diri calon mahasiswa baru berdasarkan nilai atribut tujuannya dengan melihat nilai atribut lainnya yaitu:
1. NILAI_UAN 2. GELOMBANG 3. CATATAN 4. NILAI_TEST 5. JURUSAN 6. PROG_STUDI
Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah sebagai berikut:
1. Pilih atribut sebagai akar.
3. Bagi kasus dalam cabang.
4. Ulangi proses untuk setiap cabang sampai semua kasus pada cabang memiliki kelas yang sama.
Untuk memilih atribut sebagai akar, didasarkan pada nilai Gain tertinggi dari atribut-atribut yang ada. Untuk menghitung Gain digunakan rumus seperti tertera dalam persamaan 1 berikut.
Gain(S, A) = Entropy(S) - * Entropy(Si) (1)
Keterangan:
S : himpunan kasus A : atribut
n : jumlah partisi atribut A |Si| : jumlah kasus pada partisi ke-i |S| : jumlah kasus dalam S
Sementara itu, penghitungan nilai entropi dapat dilihat pada persamaan berikut.
Entropy(S) = (2)
Keterangan
S : himpunan kasus A : fitur
n : jumlah partisi S
Berikut ini adalah penjelasan lebih terperinci mengenai tiap-tiap langkah dalam pembentukan pohon keputusan tabel KASUS diatas dengan menggunakan algoritma C4.5.
a. Menghitung jumlah kasus, jumlah kasus untuk keputusan Registrasi, jumlah kasus untuk keputusan Tidak Registrasi, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut NILAI_UAN, GELOMBANG,
CATATAN, NILAI_TEST, JURUSAN dan PROG_STUDI. Proses
perhitungan untuk mendapatkan nilai Entropy dan Gain setiap atribut adalah sebagai berikut.
Entropy(Total) = (- )) + (- = 0.9710
a. Atribut NILAI_UAN
Entropy(1)= (- )) + (- = 0.8655
Entropy(2)= (- )) + (- = 0.9910
b. Atribut GELOMBANG
Entropy(1)= (- )) + (- = 0. 8819
Entropy(2)= (- )) + (- = 0.9965
c. Atribut CATATAN
Entropy(Test)= (- )) + (- = 0.9964
Entropy(PMDK)= (- )) + (- = 0.5914
d. Atribut NILAI_TEST
Entrop(C)= (- )) + (- = 0.8631
Entropy(D)= (- )) + (- = 0.7219
Entropy(T)= (- )) + (- = 0.5914
e. Atribut JURUSAN
Entropy(TEKNIK INFORMATIKA)= (- )) + (- =
0.9965
Entropy(MANAJEMEN INFORMATIKA)= (- )) + (- =
0.9182
Entropy(TEKNIK KOMPUTER)= (- )) + (- =
0.9450
f. Atribut PROG_STUDI
Entropy(S1)= (- )) + (- = 0.9480
Entropy(D3)= (- )) + (- = 0.9789
Menghitung nilai Gain dengan menggunakan persamaan 1.
1. Atribut NILAI_UAN
Gain(Total, NILAI_UAN) = Entropy(Total) –
Gain(Total, NILAI_UAN)
= 0.9710 – (( * 0.9910 = 0.9710 – (0.4204 + 0.5096) = 0.041
Gain(Total, GELOMBANG) = Entropy(Total) –
= 0.9710 – (( * 0.9965 = 0.9710 – (0.5039 + 0.4271) = 0.04
3. Atribut CATATAN
Gain(Total, CATATAN) = Entropy(Total) –
= 0.9710 – (( * 0.5914 = 0.9710 – (0.7971 + 0.1183) = 0.056
4. Atribut NILAI_TEST
Gain(Total, NILAI_TEST) = Entropy(Total) –
= 0.9710 – (( * 0.8631 =
0.9710 – (0.2549 + 0.3452 + 0.1031 + 0.1183) = 0.1495
5. Atribut JURUSAN
Gain(Total, JURUSAN) = Entropy(Total) –
= 0.9710 – (( * 0.9182 = 0.9710 – (0.4271
+ 0.2361 + 0.2970) = 0.0108
6. Atribut PROG_STUDI
= 0.9710 – (( * 0.9789 = 0.9710 – (0.7703 + 0.1398) = 0.061
Hasil Perhitungan nilai Entropy dan nilai Gain setiap Atribut ditunjukkan oleh Tabel 3.9 berikut ini.
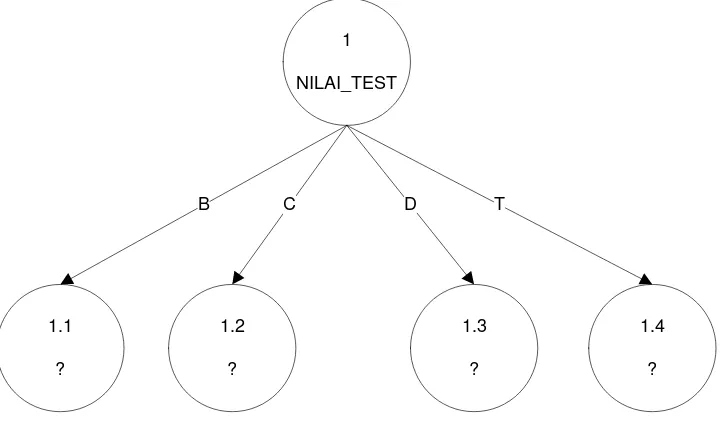
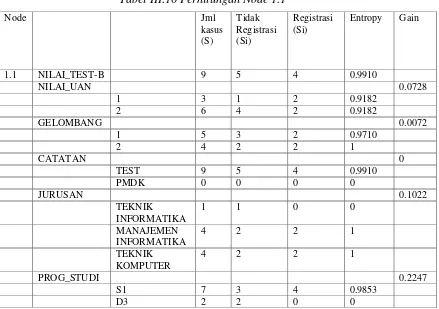
Tabel III.9 Perhitungan Node 1
Node Jml
tertinggi adalah NILAI_TEST, yaitu sebesar 0.1495. Dengan demikian
NILAI_TEST, yaitu B, C, D, dan T. Dari keempat nilai atribut tersebut masih perlu dilakukan perhitungan lagi.
Dari hasil perhitungan node 1 dapat digambarkan pohon keputusan sementaranya tampak seperti pada Gambar 3.1 berikut ini.
1 NILAI_TEST
1.1 ?
1.2 ?
1.3 ?
1.4 ?
B C D T
Gambar III.1 Pohon Keputusan Hasil Perhitungan Node 1
b. Menghitung jumlah kasus, jumlah kasus untuk keputusan Registrasi, jumlah kasus untuk keputusan Tidak Registrasi, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut NILAI_UAN, GELOMBANG,
CATATAN, JURUSAN dan PROG_STUDI. Pada pohon keputusan node 1
diatas diasumsikan yang akan menjadi node akar adalah atribut NILAI_TEST
dengan nilai atribut B.
Entropy(NILAI_TEST-B) = (- )) + (- = 0.9910 1. Atribut NILAI_UAN
Entropy(2)= (- )) + (- = 0.9182 2. Atribut GELOMBANG
Entropy(1)= (- )) + (- = 0.9710
Entropy(2)= (- )) + (- =0
3. Atribut CATATAN
Entropy(Test)= (- )) + (- = 0.9910 Entropy(PMDK)= 0
4. Atribut JURUSAN
Entropy(TEKNIK INFORMATIKA)= 0
Entropy(MANAJEMEN INFORMATIKA)= (- )) + (-= 1
Entropy(TEKNIK KOMPUTER)= (- )) + (- = 1
5. Atribut PROG_STUDI
Entropy(S1)= (- )) + (- = 0.9853
Entropy(D3)= 0 Perhitungan Gain.
1. Atribut NILAI_UAN
Gain(Total, NILAI_UAN) = Entropy(Total) –
2. Atribut GELOMBANG
Gain(Total, GELOMBANG) = Entropy(Total) –
= 0.9910 – (( * 1 = 0.9910 – (0.5394 + 0.4444) = 0.0072 3. Atribut CATATAN
Gain(Total, CATATAN) = Entropy(Total) –
= 0.9910 – (( * 0 = 0.9910 – (0.9910 + 0) = 0 4. Atribut JURUSAN
Gain(Total, JURUSAN) = Entropy(Total) –
= 0.9910 – (( * 1 = 0.9910 – (0 + 0.4444 + 0.4444) = 0.1022
5. Atribut PROG_STUDI
Gain(Total, PROG_STUDI) = Entropy(Total) –
= 0.9910 – (( * 0 = 0.9910 – (0.7663 + 0) = 0.2247
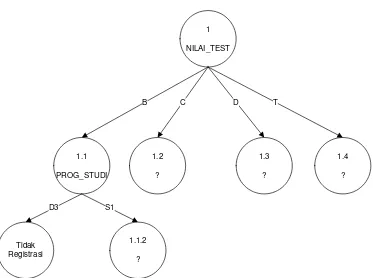
Tabel III.10 Perhitungan Node 1.1
tertinggi adalah PROG_STUDI, yaitu sebesar 0.2247. Dengan demikian
PROG_STUDI dapat menjadi node akar. Ada dua nilai atribut dari
PROG_STUDI, yaitu S1 dan D3. Dari kedua nilai atribut tersebut masih perlu dilakukan perhitungan lagi.
1
NILAI_TEST
1.1
PROG_STUDI
1.2
?
1.3
?
1.4
?
B C D T
Tidak Registrasi
1.1.2
?
D3 S1
Gambar III.2 Pohon Keputusan Hasil Perhitungan Node 1.1
c. Menghitung jumlah kasus, jumlah kasus untuk keputusan Registrasi, jumlah kasus untuk keputusan Tidak Registrasi, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut NILAI_UAN, GELOMBANG,
CATATAN, dan JURUSAN.
Entropy(NILAI_TEST-B dan PROG_STUDI-S1) = (- )) + = 0.9853
1. Atribut NILAI_UAN
Entropy(1)= (- )) + (- = 0
Entropy(2)= (- )) + (- = 0.9710
2. Atribut GELOMBANG
Entropy(2)= (- )) + (- = 0 3. Atribut CATATAN
Entropy(Test)= (- )) + (- = 0.9853 Entropy(PMDK)= 0
4. Atribut JURUSAN
Entropy(TEKNIK INFORMATIKA)= 0 Entropy(MANAJEMEN INFORMATIKA)= 0
Entropy(TEKNIK KOMPUTER)= (- )) + (- = 1
Perhitungan Gain
1. Atribut NILAI_UAN
Gain(Total, NILAI_UAN) = Entropy(Total) –
= 0.9853 – (( * 0.9710 = 0.9853 – (0 + 0.6936) = 0.2917 2. Atribut GELOMBANG
Gain(Total, GELOMBANG) = Entropy(Total) –
= 0.9853 – (( * 1 = 0.9853 – ( + 0.5714) = 0.0204 3. Atribut CATATAN
Gain(Total, CATATAN) = Entropy(Total) –
4. Atribut JURUSAN
Gain(Total, JURUSAN) = Entropy(Total) –
= 0.9853 – (( * 0 = 0.9853 – (0 + 0 + 0.5714) = 0.4139 Hasil Perhitungan nilai Entropy dan nilai Gain setiap Atribut ditunjukkan oleh Tabel 3.11 berikut ini.
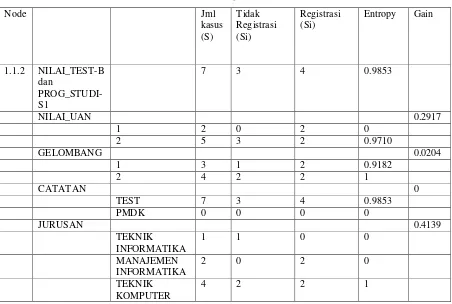
Tabel III.11 Hasil Perhitungan Node 1.1.2
Node Jml
tertinggi adalah JURUSAN, yaitu sebesar 0.4139. Dengan demikian JURUSAN
dapat menjadi node akar. Ada tiga nilai atribut dari JURUSAN, yaitu TEKNIK
KOMPUTER. Dari ketiga nilai atribut tersebut masih perlu dilakukan perhitungan lagi.
Dari hasil perhitungan node 1.1.2 dapat digambarkan pohon keputusan sementaranya tampak seperti pada Gambar 3.3 berikut ini.
1
Gambar III.3 Pohon Keputusan Hasil Perhitungan Node 1.1.2
d. Menghitung jumlah kasus, jumlah kasus untuk keputusan Registrasi, jumlah kasus untuk keputusan Tidak Registrasi, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut NILAI_UAN, GELOMBANG,
Entropy(NILAI_TEST-B dan PROG_STUDI-S1 dan JURUSAN-Teknik
Komputer) = (- )) + (- = 1
1. Atribut NILAI_UAN
Entropy(1)= (- )) + (- = 0
Entropy(2)= (- )) + (- = 0.9182 2. Atribut GELOMBANG
Entropy(1)= (- )) + (- = 0
Entropy(2)= (- )) + (- = 0.9182 3. Atribut CATATAN
Entropy(Test)= (- )) + (- = 1
Entropy(PMDK)= 0 Perhitungan Gain
1. Atribut NILAI_UAN
Gain(Total, NILAI_UAN) = Entropy(Total) –
= 1 – (( * 0.9182 = 1 – (0 + 0.6886) = 0.3114 2. Atribut GELOMBANG
Gain(Total, GELOMBANG) = Entropy(Total) –
3. Atribut CATATAN
Gain(Total, CATATAN) = Entropy(Total) –
= 1 – (( * 0 = 1 – (1 + 0) = 0
Hasil Perhitungan nilai Entropy dan nilai Gain setiap Atribut ditunjukkan oleh Tabel 3.12 berikut ini.
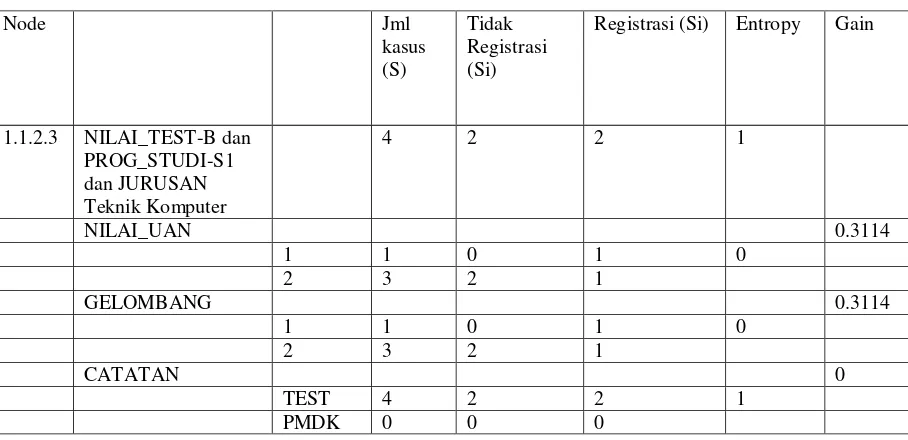
Tabel III.12 Hasil Perhitungan Node 1.1.2
Node Jml
kasus (S)
Tidak Registrasi (Si)
Registrasi (Si) Entropy Gain
1.1.2.3 NILAI_TEST-B dan PROG_STUDI-S1 dan JURUSAN Teknik Komputer
4 2 2 1
NILAI_UAN 0.3114
1 1 0 1 0
2 3 2 1
GELOMBANG 0.3114
1 1 0 1 0
2 3 2 1
CATATAN 0
TEST 4 2 2 1
1
Dengan memperhatikan pohon keputusan pada gambar 3.4, diketahui bahwa semua kasus sudah masuk dalam kelas. Dengan demikian, pohon keputusan pada Gambar 3.4 merupakan pohon keputusan terakhir yang dibentuk untuk atribut NILAI_TEST dengan nilai atribut B.
3.1.3.1Daftar Aturan
Berdasarkan pohon keputusan pada gambar 3.4, maka langkah terakhir dalam menganalisis adalah menyajikan daftar aturan yang terbentuk berdasarkan pohon keputusan.
Berikut ini merupakan daftar aturan selengkapnya yang terbentuk berdasarkan pohon keputusan menggunakan Algoritma C4.5.
1 JIKA NILAI_TEST = B DAN PROG_STUDI = D3 MAKA Tidak Registrasi 2 JIKA NILAI_TEST = B
DAN PROG_STUDI = S1
DAN JURUSAN = Manajemen Informatika MAKA Registrasi
3 JIKA NILAI_TEST = B DAN PROG_STUDI = S1
DAN JURUSAN = Teknik Informatika MAKA Tidak Registrasi
4 JIKA NILAI_TEST = B DAN PROG_STUDI = S1
DAN JURUSAN = Teknik Komputer DAN NILAI_UAN = 1
MAKA Registrasi 5 JIKA NILAI_TEST = B
DAN PROG_STUDI = S1
DAN JURUSAN = Teknik Komputer DAN NILAI_UAN = 2
DAN JURUSAN = Manajemen Informatika DAN NILAI_UAN = 1
MAKA Tidak Registrasi 7 JIKA NILAI_TEST = C DAN GELOMBANG = 1
DAN JURUSAN = Manajemen Informatika DAN NILAI_UAN = 2
MAKA Registrasi 8 JIKA NILAI_TEST = C
DAN GELOMBANG = 1
MAKA Registrasi
9 JIKA NILAI_TEST = C DAN GELOMBANG = 1
DAN JURUSAN = Teknik Komputer MAKA Registrasi
10 JIKA NILAI_TEST = C DAN GELOMBANG = 2
DAN JURUSAN = Manajemen Informatika MAKA Registrasi
11 JIKA NILAI_TEST = C DAN GELOMBANG = 2
DAN JURUSAN = Teknik Informatika MAKA Tidak Registrasi
12 JIKA NILAI_TEST = C DAN GELOMBANG = 2
DAN JURUSAN = Teknik Komputer DAN PROG_STUDI = D3
MAKA Tidak Registrasi 13 JIKA NILAI_TEST = C DAN GELOMBANG = 2
DAN JURUSAN = Teknik Komputer DAN PROG_STUDI = S1
17 JIKA NILAI_TEST = T
DAN JURUSAN = Manajemen Informatika MAKA Registrasi
18 JIKA NILAI_TEST = T
DAN JURUSAN = Teknik Informatika DAN NILAI_UAN = 1
MAKA Registrasi 19 JIKA NILAI_TEST = T
DAN JURUSAN = Teknik Informatika DAN NILAI_UAN =2
DAN GELOMBANG = 2 DAN PROG_STUDI = S1 DAN CATATAN = PMDK MAKA tidak terklasifikasi 20 JIKA NILAI_TEST = T
DAN JURUSAN = Teknik Komputer MAKA Registrasi
3.1.3.2Kategori Aturan
Dari aturan-aturan yang terbentuk diatas, ada dua kategori aturan, yaitu aturan yang menghasilkan klasifikasi tertentu (registrasi dan tidak registrasi) dan aturan yang kesimpulannya adalah tidak terklasifikasi. Contoh aturan kategori kedua adalah aturan 5 berikut.
5 JIKA NILAI_TEST = B DAN PROG_STUDI = S1
DAN JURUSAN = Teknik Komputer DAN NILAI_UAN = 2
DAN GELOMBANG = 2 DAN CATATAN = Test MAKA tidak terklasifikasi
suatu cabang, tetapi kasus belum bisa mengelompokkan dalam satu klasifikasi yaitu Registrasi atau Tidak Registrasi.
3.1.4 Analisis Kebutuhan Non Fungsioanl
Analisis non fungsional adalah sebuah langkah dimana seorang pembangun perangkat lunak menganalisis sumber daya yang akan menggunakan perangkat lunak yang dibangun.
Analisis non fungsional tidak hanya menganalisis siapa saja yang akan menggunakan aplikasi tetapi juga menganalisis perangkat keras dan perangkat lunak yang dimiliki oleh pengguna, sehingga dapat ditentukan kompabilitas aplikasi yang dibangun terhadap sumber daya yang ada. Setelah melakukan analisis non fungsional, maka dilanjutkan ke langkah berikutnya yaitu menentukan kebutuhan non fungsional sistem yang akan dibangun untuk disesuaikan dengan fakta yang ada.
Apabila terjadi ketidakcocokan antara fakta dan kebutuhan maka perlu adanya penyesuaian fakta terhadap kebutuhan yang ada. Apabila kebutuhan tidak dipenuhi maka sistem yang dibangun tidak akan berjalan baik sesuai yang diharapkan.
Analisis non fungsional dan kebutuhan non fungsional yang dilakukan dibagi dalam tiga tahap, yaitu:
1. Analisis Kebutuhan Pengguna (User)
3.1.4.1Analisis Kebutuhan Pengguna (User)
Seorang analis yang berada di lingkaran tim manajemen Unikom adalah orang yang biasa menganalisis data-data mahasiswa, salah satunya data calon mahasiswa yang tersimpan pada database perusahaan. Hal tersebut berhubungan dengan aplikasi yang akan dibangun, bahwa pengguna (user) aplikasi data mining
menggunakan Algoritma C4.5 ini adalah Seorang Analis dalam tim manajemen Unikom, dimana keterlibatannya dalam menggunakan aplikasi ini harus mengacu pada spesifikasi pengguna sebagai berikut:
1. Terbiasa menggunakan aplikasi yang ada di system operasi Windows. 2. Memiliki pengetahuan mengenai databases.
3. Mengetahui atribut yang dianggap kuat untuk dilibatkan dalam proses data mining.
Spesifikasi pengguna aplikasi dapat pula dijelaskan pada Tabel 3.11 berikut ini.
Tabel III.13 Spesifikasi pengguna aplikasi
Pengguna Hak Akses Pendidikan Tingkat Keterampilan
Pengalaman Analis Melakukan
analisis data
Minimal Strata - 1
Bisa mengikuti
petunjuk yang ada di
sistem
Pelatihan pengguna