ANALISIS SIMULTAN ANTARA
POSITIONING
DOSEN DAN
SEGMENTASI MAHASISWA DALAM PEMILIHAN
PEMBIMBING KARYA ILMIAH
YUSMA YANTI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul “Analisis Simultan antara
Positioning Dosen dan Segmentasi Mahasiswa dalam Pemilihan Pembimbing Karya Ilmiah” adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Januari 2015
Yusma Yanti
RINGKASAN
YUSMA YANTI. Analisis Simultan antara Positioning Dosen dan Segmentasi Mahasiswa dalam Pemilihan Pembimbing Karya Ilmiah. Dibimbing oleh BAGUS SARTONO dan FARIT MOCHAMAD AFENDI.
Segmentasi, target dan positioning merupakan tiga hal penting pada proses pemasaran. Segmentasi merupakan suatu strategi memahami struktur pasar, sehingga individu mengelompok berdasarkan karakteristik tertentu. Positioning
adalah cara pandang individu terhadap suatu objek. Pendekatan klasik yang pernah dilakukan dengan analisis terpisah antara segmentasi dan positioning. Berbagai kendala yang ditemui antara lain: analisis yang memerlukan distribusi tertentu, sulit menduga matriks ragam peragam jika data menyimpang dari keluarga eksponensial, analisis sangat nonlinier yang memerlukan waktu komputasi yang lama, terdapat solusi lokal optimum dan solusinya bersifat heuristik. DeSarbo et al. (2008) mengusulkan Clusterwise Bilinear Spasial Multidimensional Scaling Model (CBSMSM) untuk analisis simultan antara segmentasi dan positioning.
Parameter CBSMSM diduga dengan menggunakan algoritma Alternating Least Square (ALS). Prosedur optimasi pada ALS dengan lima tahapan yang saling tumpang tindih. Analisis ini diaplikasikan untuk pemilihan ketua komisi pembimbing penulisan skripsi pada Program Sarjana Statistika IPB. Berdasarkan 65 responden, diperoleh matriks nilai keinginan mahasiswa untuk memilih dosen (∆ ) dan matriks nilai atribut untuk setiap dosen oleh setiap mahasiswa ( ). Pendugaan parameter dilakukan dengan menentukan sejak awal berbagai kombinasi jumlah segmen dan jumlah dimensi. Selanjutnya, ditentukan kombinasi terbaik berdasarkan nilai jumlah kuadrat galat terkecil. Hasil yang diharapkan dalam model ini secara bersamaan akan memperkirakan jumlah segmen, atribut segmen pembentuk, ruang objek.
Salah satu hasil bahwa mahasiswa terbagi menjadi empat segmen dan setiap segmen memiliki karakteristik yang berbeda. Karakteristik masing-masing segmen dapat digambarkan oleh atribut penyusunnya, dan juga dikenal posisi dosen di setiap segmen. Segmen pertama bersifat umum beranggotakan 12 orang mahasiswa. Segmen kedua dengan atribut yang menganggap sosok dosen dengan tingkat intelegensi yang lebih. Segmen ketiga merupakan kelompok mahasiswa yang menginginkan dosen yang mudah ditemui, segmen ini dapat pula dikatakan segmen perempuan. Segmen keempat terdiri dari mahasiswa yang menginginkan dosen yang mudah ditemui.
SUMMARY
YUSMA YANTI. Simultaneous Analysis of the Lecturers Positioning and Students Segmentation in the Selection of Thesis Supervisor. Supervised by BAGUS SARTONO and FARIT MOCHAMAD AFENDI.
Segmentation, targets and positioning are three important things in the marketing process. Segmentation is a strategy to understand the structure of the market, so people clustered based on certain characteristics. Positioning is the individual perspective of an object. The classical approach to the analysis ever conducted separately between segmentation and positioning. Various obstacles encountered include: analysis requires a certain distribution, variance covariance matrix is difficult to guess if the data deviates from the exponential family, highly nonlinear analysis that requires long computation time, there is a local optimum solution and the solution is heuristic. DeSarbo et al. (2008) proposed a Spatial Multidimensional Scaling Clusterwise Bilinear Model (CBSMSM) for the simultaneous analysis of segmentation and positioning.
CBSMSM parameters estimated using algorithms Alternating Least Squares (ALS). ALS optimization procedure with five overlapping phases. This analysis is apply to thesis supervisor preference undergraduate Statistics IPB. Based on 65 respondents, obtained matrix values student wishes to choose lecturers (∆ ) and attribute value matrix for each faculty by every student ( ). Parameter estimation is done by determining from the beginning of the various combinations of the number of segments and the number of dimensions. Furthermore, the best combination is determined based on the smallest value of the sum squar errors. Results are expected in this model will simultaneously estimate the number of segments, forming segment attributes, object space.
One of the results that the students are divided into four segments and each segment has different characteristics. Characteristics of each segment can be described by its constituent attributes, and also known lecturer position in each segment. The first segment of a general nature with 12 students. The second segment of the attributes that consider the figure lecturer with more intelligence level. The third segment is a group of students who wanted lecturers are easily found, this segment can also be said female segment. The fourth segment is composed of students who want lecturers are easily found.
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika
ANALISIS SIMULTAN ANTARA
POSITIONING
DOSEN DAN
SEGMENTASI MAHASISWA DALAM PEMILIHAN
PEMBIMBING KARYA ILMIAH
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2015
Judul Penelitian : Analisis Simultan antara Positioning Dosen dan Segmentasi Mahasiswa dalam Pemilihan Pembimbing Karya Ilmiah
Nama : Yusma Yanti
NRP : G151120141
Program Studi : Statistika
Disetujui Komisi Pembimbing
Dr. Bagus Sartono, S.Si M.Si. Ketua
Dr. Farit Mochamad Afendi, S.Si M.Si Anggota
Diketahui,
Ketua Program Studi Statistika
Dr. Ir. Anik Djuraidah, MS
Dekan Sekolah Pascasarjana IPB
Dr. Ir. Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur kehadirat Allah SWT yang telah memberikan rahmat dan hidayah-Nya, sehingga penulis dapat menyelesaikan tesis yang berjudul “Analisis Simultan antara Positioning Dosen dan Segmentasi Mahasiswa dalam Pemilihan Pembimbing Karya Ilmiah”.
Keberhasilan penulisan tesis ini tidak lepas dari bantuan, bimbingan, dan petunjuk dari berbagai pihak. Oleh karena itu, penulis menyampaikan terimakasih yang sebesar-besarnya kepada:
1. Bapak Dr. Bagus Sartono, S.Si, M.Si. dan Bapak Dr. Farit Mochamad Afendi, S.Si, M.Si selaku komisi pembimbing yang telah meluangkan waktu untuk memberikan bimbingan, arahan, dan masukan kepada penulis.
2. Bapak Dr. Ir. I Made Sumertajaya, M.Si selaku penguji luar komisi dan Ibu Dr. Ir. Anik Djuraidah, MS selaku Ketua Program Studi Statistika S2 yang telah turut membantu kelancaran penyelesaian tesis ini.
3. Seluruh Dosen Departemen Statistika IPB yang telah mengasuh dan mendidik penulis selama di perkuliahan hingga berhasil menyelesaikan studi, serta seluruh staf Departemen Statistika IPB atas bantuan, pelayanan, dan kerjasamanya selama ini.
4. Kedua orang tua serta seluruh keluarga atas doa, dukungan dan kasih sayangnya. 5. Septian Rahardiantoro yang selalu direpotkan ketika mengerjakan tesis ini, atas
bantuan, dukungan serta doanya.
6. Rekan-rekan mahasiswa Pascasarjana Departemen Statistika atas segala bantuan dan kebersamaannya selama menghadapi masa terindah maupun tersulit dalam menuntut ilmu, serta semua pihak yang telah banyak membantu dan tak sempat penulis sebutkan satu per satu.
Penulis menyadari sepenuhnya bahwa tesis ini masih banyak kekurangan. Kritikan yang membangun sangat penulis harapkan demi perbaikan tesis ini di masa yang akan dating. Semoga tesis ini bermanfaat.
Bogor, Januari 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
2 TINJAUAN PUSTAKA 2
Clusterwise Bilinier Spatial Multidimensional ScallingModel 2
Prosedur Optimasi 5
3 METODE 7
Data 7
Metode Analisis 7
4 HASIL DAN PEMBAHASAN 7
Deskripsi Data 7
Algoritma Alternating Least Square 10
Penentuan Banyaknya Segmen dan Dimensi 11
Hasil Analisis 15
5 SIMPULAN 17
DAFTAR PUSTAKA 17
DAFTAR TABEL
1 Struktur nilai atribut terhadap produk oleh setiap responden 3
2 Struktur nilai atribut terhadap produk ( ) 3
3 Struktur data keinginan responden untuk membeli produk (∆ ) 3 4 Hasil clusterwise bilinear spatial multidimensional scaling model 12 5 Nilai utilitas prediksi 10 atribut dengan segmen 13 6 Nilai utilitas prediksi 23 dosen dengan segmen 14 7 Analisis clusterwise bilinear spatial multidimensional scaling model
mahasiswa dan dosen 16
DAFTAR GAMBAR
1 Sebaran rata-rata nilai atribut 8
2 Sebaran nilai tingkat keinginan mahasiswa untuk memilih dosen menjadi
ketua komisi pembimbing 9
3 Bagan alir alternating least square 11
1
1
PENDAHULUAN
Latar Belakang
Segmentasi pada dasarnya adalah suatu strategi untuk memahami struktur pasar (Kotler 2008). Metode statistika yang sering digunakan antara lain: segmentasi berdasarkan regresi (Regression based segmentation), analisis latent class dan analisis Q faktor (Kasali 1998). Segmentasi berdasarkan regresi menyatakan bahwa terdapat kemungkinan terbentuk gerombol yang tidak ada hubungan dengan perilaku responden. Sehingga setiap gerombol memiliki dua atau tiga kelompok dengan nilai rataan yang berbeda. Analisis latent class merupakan pengembangan dari analisis faktor yang memiliki dua fungsi yaitu mengidentifikasi konstruk yang secara teoritis membentuk peubah dan mereduksi jumlah peubah. Metode ini membantu menduga parameter latent yang memberikan informasi seperti jumlah segmen dan peluang sebuah produk masuk ke satu segmen. Sedangkan analisis Q faktor mengidentifikasi kelompok responden (segmen).
Selain segmentasi yang tidak kalah penting harus diketahui dalam proses pemasaran yaitu positioning. Berbeda dengan segmentasi, positioning bukan hal yang kita lakukan pada produk, tetapi sesuatu yang dilakukan terhadap otak calon pelanggan. Pada proses ini diharapkan responden dapat memposisikan produk dan atribut sehingga responden memiliki penilaian tertentu dan mengidentifikasi dirinya terhadap produk tersebut. Kasali (1998) menyatakan beberapa teknik yang dapat digunakan untuk analisis positioning:pertama, teknik peta persepsi, analisis yang sering digunakan yaitu analisis diskriminan dan multidimensional scaling
(MDS). Kedua, teknik pemetaan preferensi, teknik ini menggunakan analisis faktor, analisis diskriminan dan MDS. Ketiga, teknik laddering yaitu teknik yang mengidentifikasi atribut-atribut yang membentuk preferensi.
Selama ini, kedua proses tersebut tidak dilakukan secara tumpang tindih. Dalam prakteknya, dilakukan analisis segmentasi saja atau analisis positioning saja. Sedangkan, menurut konsep pemasaran klasik yang harus diketahui dalam proses memasarkan produk yaitu segmentasi, targeting dan positioning (Lilien dan Ranggaswami 2004). Pendekatan empiris yang telah dilakukan pada segmentasi dan positioning pemasaran menurut DeSarbo (1991) dengan menggunakan MDS dan analisis gerombol secara berurutan. Kedua analisis tersebut dilakukan secara terpisah, MDS bertujuan untuk proses positioning dengan menggambarkan hubungan produk dengan atribut. Sedangkan analisis gerombol untuk proses segmentasi dengan mengelompokkan segmen pasar berdasarkan atribut yang ada. Namun DeSarbo et al. (1994) memaparkan beberapa masalah pada metode ini. Pertama, tipe analisis yang berbeda dalam mengoptimumkan fungsi juga memberikan hasil yang berbeda, sehingga pada aplikasinya sering mengabaikan aspek yang tidak saling berhubungan pada urutan prosedur tersebut. Kedua, ada banyak jenis prosedur yang tiap prosedur memberikan hasil yang berbeda.
MDS latent class. Pertama, MDS latent class merupakan model parametrik yang memerlukan asumsi distribusi tertentu. Adakalanya distribusi kontinu digunakan pada campuran terbatas yang juga berskala diskret, maka tidak mungkin asumsinya digunakan. Kedua, prosedur MDS latent class memerlukan penekanan campuran terbatas untuk diidentifikasi (McLachlan dan Krishnan 1997), jika distribusi data menyimpang dari keluarga eksponensial, ketika menggunakan distribusi multivariat normal masalah muncul saat menduga matriks kovarian. Ketiga, MDS
latent class bersifat nonlinier, sehingga memerlukan waktu komputasi yang lama saat prosedur pendugaannya. Keempat, terdapat solusi optimum lokal yang mengharuskan analisis berulang untuk masing-masing nilai dimensi dan kelompok. Kelima, solusi bersifat heuristic artinya solusi yang diperoleh bukan yang paling optimum, tetapi mendekati solusi optimum. Sifat ini dapat memberikan hasil yang berbeda untuk setiap informasi. Akhirnya MDS latent class ini dapat menyebabkan terjadinya peluang fuzzy yang sulit untuk diinterpretasikan karena merupakan solusi yang terdiri dari beberapa partisi.
Solusi untuk pemecahan masalah di atas adalah adalah dengan suatu metode reduksi data dan klasifikasi secara bersamaan yang dapat diaplikasikan pada segmentasi dan positioning. Prosedur yang digunakan juga tidak memerlukan asumsi distribusi seperti halnya MDS yang telah ada. Selain itu, juga diharapkan pendugaan parameter optimum global pada tahap pendugaan tiap iterasi relatif cepat dan lebih efisien terhadap waktu. Analisis ini dikenal dengan Clusterwise Bilinear Spatial Multidimensional Scaling Model (CBSMSM).
Analisis ini akan diaplikasikan pada bidang pendidikan, pada proses penentuan pemilihan pembimbing karya ilmiah mahasiswa program sarjana Statistika IPB. Data ini digunakan berdasarkan beberapa kriteria pemilihan dosen oleh mahasiswa, karena pada kenyataannya masih banyak mahasiswa yang mengajukan pembimbing menumpuk hanya pada beberapa orang dosen.
Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk mendapatkan secara bersamaan antara segmentasi mahasiswa dan positioning dosen dalam pemilihan pembimbing karya ilmiah, dimana segmen di representasikan oleh vektor, dosen oleh titik koordinat dan hubungan timbal balik pada ruang yang menunjukkan beberapa aspek dalam data dengan menggunakan Clusterwise Bilinear Spatial Multidimensional Scaling Model (CBSMSM).
2
TINJAUAN PUSTAKA
Clusterwise BilinearSpatial Multidimentional Scaling Model
Secara keseluruhan nilai atribut oleh semua responden akan digambarkan oleh Tabel 2. Besar nilai yang diberikan oleh masing-masing responden secara garis besar dapat memberikan gambaran preferensi/ keinginan responden untuk membeli produk tersebut. Jika besar keinginan responden ke-i untuk membeli produk ke-j dituliskan dengan ∆ dengan struktur data seperti yang tertera pada Tabel 3.
Tabel 2. Struktur nilai atribut terhadap produk ( )
Responden ke-i Produk (j) Atribut ke-1 Atribut ke-2 … Atribut ke-K
1
Menurut DeSarbo et al. (2008), banyaknya atribut akan direduksi menjadi
R dimensi. Koordinat produk ke-j pada dimensi ke-r diwakili oleh matriks yang merupakan fungsi dari atribut, koefisien pengaruh bauran pasar dan beberapa fitur yang berpengaruh lainnya. Besarnya pengaruh atribut ke-k pada dimensi ke-r untuk setiap produk diwakili oleh matriks � dengan persamaan sebagai berikut:
= ∑ = � (1)
Tabel 1. Struktur nilai atribut terhadap produk oleh setiap responden
Produk (j) Atribut ke-1 Atribut ke-2 … Atribut ke-K
1 …
2 …
… ⋱
J …
Tabel 3. Struktur data keinginan responden untuk membeli produk ∆
Responden ke-i Produk ke-1 Produk ke-2 Produk ke-J
1 ∆ ∆ … ∆
2 ∆ ∆ … ∆
⋱
Hubungan antara nilai atribut dengan keinginan membeli produk oleh setiap responden dengan memposisikan diri pada segmen tertentu dapat dituliskan sebagai berikut:
∆ = ∑ = + � (2)
Dari persamaan (1) dan persamaan (2) di atas menegaskan bahwa semakin besar nilai atribut terhadap produk yang diberikan oleh setiap responden mempengaruhi nilai dan koordinat segmen pada masing-masing dimensi secara linier juga akan mempengaruhi besar keinginan responden untuk membeli produk tersebut. Namun untuk rumus diatas hanya untuk mengetahui positioning produk, dan tidak dapat menggambarkan segmentasi dengan atribut. (DeSarbo et al.2008) mengilustrasikan rumus simultan antara segmentasi dan positioning
sebagai berikut:
∆ = ∑ = � ∑ = + + � (3)
Arabie et al. (1996) menyatakan bahwa � merupakan segmen yang keanggotaan peubah indikator biner, dengan syarat:
� = { , jika respo��e� ti�ak �ikelo�pokka� pa�a seg�e� s, jika respo��e� �ikelo�pokka� pa�a seg�e� s Sehingga:
� ∈ { , }, ∑ = � = , jika satu responden hanya masuk ke satu segmen saja < ∑ = � , jika satu responden masuk kedalam beberapa segmen
Persamaan (3) secara simultan menggambarkan posisi produk pada segmen dan segmentasi responden yang ada pada masing-masing segmen oleh matriks � . Namun persamaan ini hanya dapat digunakan jika < . Jika kondisi ini tidak terpenuhi maka dapat dilakukan beberapa pilihan sebagai berikut:
a) Reduksi data
Misalnya menggunakan AKU, skor faktor yang dihasilkan dapat digunakan untuk . Namun kelemahannya, perubahan satu atribut pada produk dalam ruang dapat hilang. Karena skor faktor merupakan kombinasi linier dari sejumlah atribut, maka sulit untuk perhitungan.
b) Pilih beberapa subset <
Subset yang terpilih dapat digunakan dalam . Solusi ini dapat menyelesaikan masalah pada solusi sebelumnya. Tetapi, masalah yang muncul adalah saat pemilihan subsetnya.
c) Setiap atribut tunggal dapat cocok ke ruang post hoc melalui prosedur regresi tanpa intercept.
Masalah yang timbul adalah lokasi produk tidak lagi menjadi fungsi yang tepat dari atribut, sehingga dimensi yang dihasilkan tidak dapat menginterpretasikan atribut dengan baik.
pada dua dimensi banyak digunakan pada aplikasi marketing sebab arah vektor menunjukkan gerakan peningkatan prediksi sebuah produk. Kadang vektor atribut diplot tanpa normalisasi, sehingga panjangnya memberikan indikasi bagaimana hubungan atribut terhadap dimensi. Atau dapat memberikan sebuah tabel korelasi antara atribut produk dan koordinat produk pada dimensi. Sehingga dapat memberikan ringkasan singkat dari struktur data yang berhubungan dengan segmentation- targeting-positioning.
Prosedur Optimasi
Menurut DeSarbo et al. (2008), prosedur pendugaan parameter untuk CBSMSM dapat dilakukan menggunakan algoritma alternatingleast square (ALS). Jika diberikan ∆ dan nilai dari S dan R, untuk menduga � = � , = ( ) atau
Algoritma Alternating Least Square (ALS) untuk Clusterwise Bilinear Spatial Multidimensional Scaling Model (CBSMSM) dilakukan dengan lima langkah pendugaan, yaitu:
Pendugaan parameter dapat dilakukan untuk (salah satu indikator identifikasi untuk partisi) menggunakan persamaan (3), untuk = � , ketika digunakan aturan turunan berantai di atas, persamaan stationer mengurangi hal-hal berikut:
′ � �′�′� − ′ ∆∗′� = (6)
�̂ = ′ − ′ ∆∗′� �′�′� ′, (7)
2. Menduga Y
dengan mengikuti properti trace dan turunan (Magnus dan Neudecker 2002), maka diperoleh nilai dugaan dari Y adalah sebagai berikut:
̂′ = ′ − ′∆∗′� �′� − (8) observasi untuk mendapatkan kondisional global yang optimal terhadap �,dengan mempertimbangkan , , Δ∗. Untuk setiap i, diminimumkan Φ = � �′ yang berhubungan dengan �. Di sini, dihitung lebih dari semua pilihan solusi (opsi S
untuk kasus ini: − pilihan solusi untuk segmen yang saling tumpang tindih) untuk setiap � (mengabaikan solusi tidak ada keanggotaan dalam setiap segmen yang diturunkan) untuk meminimalkan Φ ∀.
4. Menduga b
Langkah pertama definisikan ∆̂ = ∑ = �̂ ∑ = ̂ ̂ , dengan: =
(∆ ), = , , ′ = , , , , = (∆̂ ). Maka dapat di lakukan pendugaan kuadrat sederhana yang dihitung dengan rumus berukut:
3
METODE
Data
Data yang digunakan pada penelitian ini merupakan data survey yang dilakukan pada tanggal 01 September 2014 terhadap mahasiswa program Sarjana Statistika IPB tahun masuk 2012. Responden sebanyak 65 orang memberikan evaluasi kepada 23 dosen berdasarkan 15 atribut/ kriteria. Data ini bersifat kategorik dengan skala 1-10. Nilai tertinggi meyatakan dosen dengan kriteria yang paling disukai. Keinginan responden ke-i untuk memilih dosen ke-j diwakili oleh matriks ∆ . Sedangkan nilai atribut ke-k dari masing-masing dosen ke-j oleh seluruh responden diwakili oleh matriks .
Metode Analisis
Metode analisis pada penelitian ini adalah dengan clusterwise bilinear spatial multidimensional scaling model, tahapan pendugaan parameternya menggunakan algoritma alternating least square (ALS). Langkah-langkah dalam analisis data untuk mencapai tujuan penelitian dijabarkan sebagai berikut:
1. Pemeriksaan kelengkapan data, jika diperlukan transformasi data. 2. Deskripsi data awal.
3. Menduga parameter menggunakan algoritma alternatingleast square yang telah dijelaskan pada tinjauan pustaka.
4. Pendugaan parameter dilakukan berulang untuk berbagai kombinasi jumlah segmen dan jumlah dimensi.
5. Memilih jumlah segmen dan jumlah dimensi terbaik berdasarkan nilai jumlah kuadrat galat (JKG) terkecil.
6. Menggambarkan hasil koordinat segmen mahasiswa, atribut dan dosen secara bersamaan pada satu gambar.
7. Menyimpulkan hasil.
4
HASIL DAN PEMBAHASAN
Deskripsi Data
A1 = Kemudahan dalam hal menemui dosen yang bersangkutan.
A2 = Mahasiswa bimbingan dosen yang bersangkutan kebanyakan cepat lulus studi.
A3 = Reputasi akademik yang dimiliki oleh dosen yang bersangkutan. A4 = Reputasi non akademik yang dimiliki oleh dosen yang bersangkutan. A5 = Dosen yang bersangkutan dirasa lebih familiar oleh mahasiswa. A6 = Sering terjadi komunikasi antara dosen dengan mahasiswa. A7 = Gaya mengajar unik yang dimiliki oleh dosen yang bersangkutan. A8 = Kesan dosen yang tidak menakutkan bagi mahasiswa.
A9 = Kesesuaian bidang keahlian dosen dengan minat mahasiswa. A10 = Sifat karismatik dan berkarakter yang dimiliki oleh dosen.
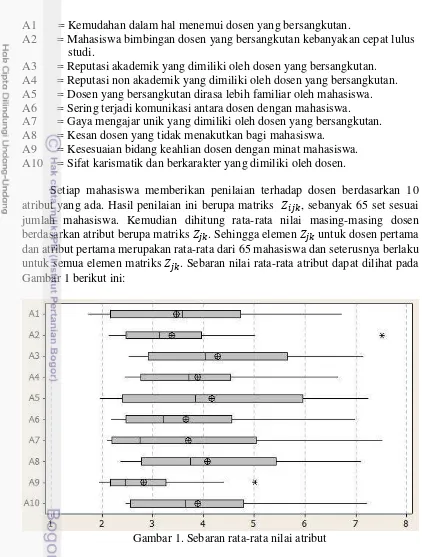
Setiap mahasiswa memberikan penilaian terhadap dosen berdasarkan 10 atribut yang ada. Hasil penilaian ini berupa matriks , sebanyak 65 set sesuai jumlah mahasiswa. Kemudian dihitung rata-rata nilai masing-masing dosen berdasarkan atribut berupa matriks . Sehingga elemen untuk dosen pertama dan atribut pertama merupakan rata-rata dari 65 mahasiswa dan seterusnya berlaku untuk semua elemen matriks . Sebaran nilai rata-rata atribut dapat dilihat pada Gambar 1 berikut ini:
Gambar 1. Sebaran rata-rata nilai atribut
skor setiap atribut berada pada kisaran nilai 3 hingga 5. Nilai ini relatif kecil jika dibandingkan dengan sebaran nilai maksimal 10.
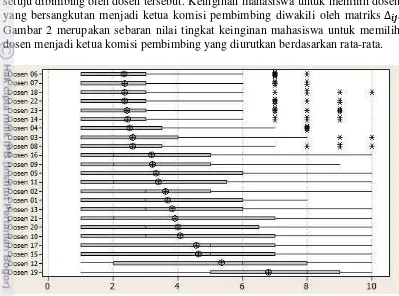
Selain memberikan penilaian terhadap setiap atribut, mahasiswa juga menyatakan tingkat minat memilih dosen sebagai ketua komisi pembimbing dengan nilai 1-10, dengan 1 menyatakan sangat tidak setuju dan 10 untuk sangat setuju dibimbing oleh dosen tersebut. Keinginan mahasiswa untuk memilih dosen yang bersangkutan menjadi ketua komisi pembimbing diwakili oleh matriks ∆ . Gambar 2 merupakan sebaran nilai tingkat keinginan mahasiswa untuk memilih dosen menjadi ketua komisi pembimbing yang diurutkan berdasarkan rata-rata.
Gambar 2. Sebaran nilai tingkat keinginan mahasiswa untuk memilih dosen menjadi ketua komisi pembimbing
Berdasarkan Gambar 2 diketahui bahwa keinginan mahasiswa untuk dibimbing oleh dosen sangat beragam. Namun secara keseluruhan, seluruh dosen memiliki nilai terkecil berupa angka 1. Dosen 06, Dosen 07, Dosen 14, Dosen 18, Dosen 22 dan Dosen 23 memiliki nilai jangkauan kuartil kecil walaupun terdapat beberapa pencilan. Dosen ini mendapatkan nilai yang kurang dari nilai rata-rata umum yakni sebesar 3.45. Persepsi tingkat keinginan mahasiswa untuk dibimbing oleh dosen 19 sangat besar. Dari Gambar 2 terlihat bahwa dosen 19 memiliki nilai kuartil dan rata-rata yang sangat berbeda secara signifikan dari yang lainnya. Dosen 19 ini memiliki nilai rata-rata tertinggi yaitu 6.78, hampir dua kali lipat dari nilai rataan umum. Terdapat beberapa dosen dengan sebaran nilai 1 hingga 10, seperti Dosen 02, Dosen 05, Dosen 10, Dosen 11, Dosen 12, Dosen 13, Dosen 16, Dosen 17, Dosen 19 dan Dosen 20. Hal ini terjadi karena beberapa mahasiswa telah mengenal dosen tersebut sedangkan sebagian lagi tidak.
Algoritma Alternating Least Square (ALS)
Y adalah koordinat segmen. Pendugaan X menggunakan persamaan (5) yang nilainya dipengaruhi oleh nilai Y, koordinat � diduga menggunakan persamaan (7) yang tergantung X. Sedangkan untuk menduga Y menggunakan persamaan (8) memerlukan nilai X yang diduga sebelumnya. Begitu pula halnya untuk pendugaan nilai P yang menggunakan persamaan (9) juga memerlukan X dan Y. Sifat ketergantungan pada ALS ini sangat mempengaruhi hasil akhir analisis. Solusi untuk hal ini diperlukan inisialisasi awal dari parameter tersebut. Pada analisis ini dilakukan inisialisasi Y dan P. Hal ini dilakukan karena pada ALS parameter yang pertama diduga adalah X, sehingga diperlukan Y dan P. Inisisalisasi Y dilakukan sedemikian rupa sehingga koordinatnya tidak bergerombol pada satu titik. Namun, pada prosesnya koordinat awal yang berpencar dapat pula menghasilkan koordinat akhir yang bergerombol.
Untuk nilai awal P, dilakukan pengacakan menggunakan sistem komputer. Jumlah baris pada matriks P sebanyak 65 baris sesuai jumlah mahasiswa, sedangkan jumlah kolom mewakili banyaknya segmen yang digunakan. Nilai P merupakan indikator biner dengan ketentuan terdapat sebuah angka 1 pada setiap baris dan selainnya 0. Nilai 1 menyatakan bahwa mahasiswa akan terkelompok pada segmen tersebut. Penentuan 1 atau 0 untuk setiap kolom pada matriks P menggunakan persamaan (9). Pada prosesnya, nilai � dihitung pada setiap segmen untuk masing-masing mahasiswa, mahasiswa dikategorikan pada segmen tersebut jika nilai � terkecil untuk detiap baris.
Namun pada prosesnya ditemui berbagai macam kendala. Seperti VAF bernilai negatif sedangkan koordinat Y dan koordinat X berpencar dengan stabil. Hal yang sering terjadi koordinat Y berdekatan antara satu segmen dengan yang lainnya dan dan begitu juga dengan koordinat X dan koordinat �. Permasalahan juga ditemui pada matriks P, mahasiswa bergerombol dalam jumlah yang banyak pada satu segmen, sehingga terdapat segmen tanpa mahasiswa.
Penentuan acak Y dan P menyebabkan hasil yang tidak selalu sama saat proses komputasi. VAF juga memegang peranan penting karena merupakan acuan untuk kebaikan model. Nilai VAF yang mendekati 1 menyatakan model telah baik. Ketelitian analisis dan inisialisasi awal yang tepat sangat dibutuhkan untuk mengatasi masalah tersebut. Hasil analisis yang diperoleh akan dikatakan baik jika Y terpencar, sedangkan X dan � pengelompokannya selalu stabil. Analisis dikatakan konsisten jika selisih nilai JKG pada iterasi selalu berdekatan dan bahkan selalu stabil. Untuk memperoleh keyakinan hasil yang didapatkan, sehingga hasil tersebut dinyatakan konsisten dilakukan ulangan sebanyak 50 hingga 60 kali untuk setiap kombinasi segmen dan dimensi.
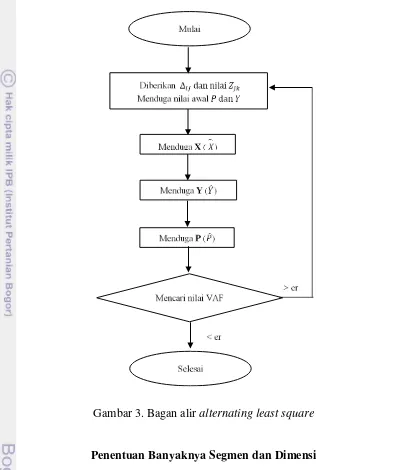
Langkah-langkah pendekatan analisis secara ringkas disajikan pada Gambar 3 berikut ini:
Gambar 3. Bagan alir alternating least square
Penentuan Banyaknya Segmen dan Dimensi
Analisis clusterwise bilinear spatial multidimensional scaling model
jika terdapat pembaca yang tertarik untuk mengkali lebih dalam dapat menghubungi penulis secara lansung pada [email protected].
Data ∆ dan yang telah diperoleh akan di import kedalam bahasa SAS. Inisialisasi P dan Y juga dilakukan dalam bahasa SAS. Berikutnya menentukan batas iterasi pendugaan parameter (er). Setelah data yang diperlukan lengkap, maka proses ALS dapat dilakukan. ALS terdiri dari 5 tahapan pendugaan yang saling berhubungan antara satu tahap dengan yang lainnya.
Tahap pertama melakukan pendugaan X, nilai ini merupakan koordinat dosen, selanjutnya pada tahapan ini juga akan dilakukan pendugaan koordinat atribut. Selanjutnya, pada tahap kedua menduga Y hasil tahap ini merupakan koordinat segmen. Tahap ketiga menduga P, yang merupakan penentuan setiap mahasiswa akan terkelompok pada salah satu segmen yang ada. Penentuannya tergantung nilai �. Setiap mahasiswa dihitung nilai � pada masing-masing kolom segmen, nilai terendah akan mengindikasikan mahasiswa dikelompokkan pada segmen dengan � terendah tersebut, dan pada segmen ini mahasiswa tersebut akan diberikan nilai 1 dan 0 untuk segmen lainnya. Selanjutnya pada tahap empat dilakukan pendugaan b dengan langkah menduga ∆∗ yang dilanjutkan dengan menduga ∆. Elemen pada matriks ∆∗ dan matriks ∆ dibentuk menjadi matriks satu kolom, sehingga dapat dilakukan perhitungan pendugaan b menggunakan persamaan (10). Tahap lima menghitung nilai VAF (Variance Accounted For), yaitu satu dikurangi dengan jumlah kuadrat selisih ∆ dengan ∆∗ dibandingkan dengan jumlah kuadrat selisih ∆ dengan ∆... Model dikatakan baik jika ��� −
���− < ��, apabila hal ini terpenuhi maka iterasi akan berhenti, jika tidak maka akan dilakukan pengulangan iterasi dari tahap pertama. Setelah model dinyatakan baik berdasarkan VAF, kemudian ditentukan jumlah kuadrat galat (JKG) dari proses iterasi ini.
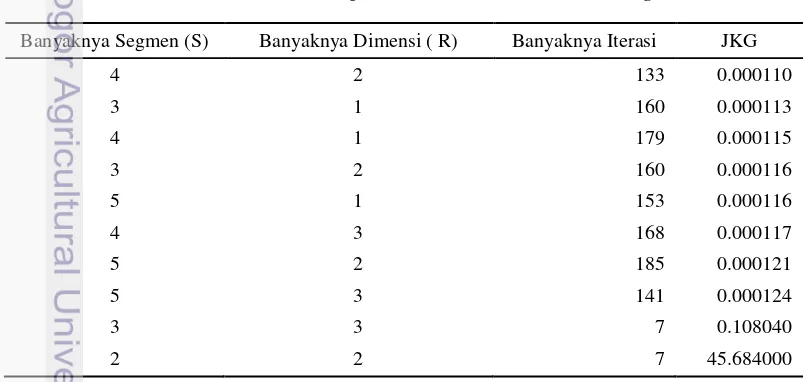
Penentuan jumlah segmen dan dimensi terbaik pada analisis diatas dapat diketahui berdasarkan nilai JKG terkecil. Tabel 4 menunjukkan hasil analisis beserta JKG yang dihasilkan. Analisis 4 segmen dan 2 dimensi menyatakan terbaik dengan JKG terkecil. Selanjutnya, hasil analisis dengan 4 segmen dan 2 dimensi tersebut diilustrasikan dalam bentuk gambar dua dimensi menggunakan program R 3.0.2, hasilnya seperti pada Gambar 4. Pada Gambar 4 dapat diketahui setiap segmen terbentuk dengan kelompok atribut beserta setiap dosen yang terkandung di dalamnya. Untuk alasan kemudahan penulisan, empat segmen tersebut dinotasikan dengan S1, S2, S3 dan S4.
Tabel 4. Hasil clusterwise bilinear spatial multidimensional scaling model
Banyaknya Segmen (S) Banyaknya Dimensi ( R) Banyaknya Iterasi JKG
Gambar 4. Solusi CBSMSMS pada 2 dimensi
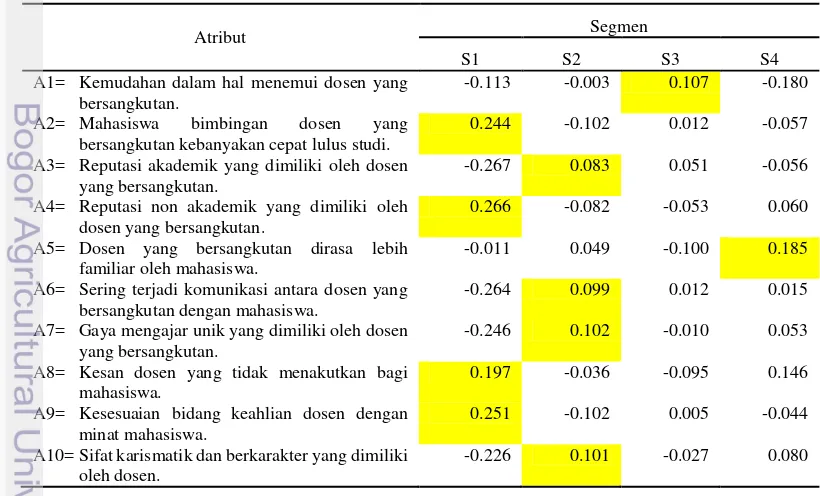
Untuk mengetahui sebuah atribut dikelompokkan pada salah satu segmen, dilakukan perhitungan proyeksi segmen terhadap atribut. Hasil perhitungan proyeksi segmen terhadap atribut secara lengkap tertera pada Tabel 5.
-0.1 0.0 0.1 0.2
Tabel 5. Nilai utilitas prediksi 10 atribut dengan segmen
Atribut Segmen
A7= Gaya mengajar unik yang dimiliki oleh dosen yang bersangkutan.
-0.246 0.102 -0.010 0.053
A8= Kesan dosen yang tidak menakutkan bagi mahasiswa.
0.197 -0.036 -0.095 0.146
A9= Kesesuaian bidang keahlian dosen dengan minat mahasiswa.
0.251 -0.102 0.005 -0.044
A10= Sifat karismatik dan berkarakter yang dimiliki oleh dosen.
Segmen S1 terbentuk oleh empat atribut, secara keseluruhan atribut pembentuk segmen ini bersifat sangat umum. Berbeda dengan S1, S2 lebih mengutamakan sosok dari setiap dosen berdasarkan tingkat intelegensi yang dimiliki oleh dosen yang bersangkutan. Segmen S3 merupakan hal yang sangat klasik, mahasiswa secara umum tentu menginginkan kemudahan dalam menemui dosen dan ini merupakan ciri khas dari S3. Dosen yang familiar menjadi ciri khas dari segmen 4. Hal ini mungkin terjadi karena dosen yang bersangkutan pernah mengajar mahasiswa atau terjadi kontak secara langsung antara dosen dengan mahasiswa.
Seluruh dosen juga tersebar pada beberapa segmen. Penentuan pengelompokan dosen ke masing-masing segmen menggunakan perhitungan proyeksi dari Dosen ke segmen. Proyeksi antara segmen dengan dosen secara lengkap tertera pada Tabel 6.
Tabel 6. Nilai utilitas prediksi 23 dosen dengan segmen
Dosen yang tergabung pada S2 seluruhnya juga memenuhi kriteria S4. Segmen S4 merupakan segmen perempuan, karena persentase mahasiswa perempuan pada segmen ini sangat tinggi. Sedangkan S2 dapat pula dikatakan segmen laki-laki karena persentase mahasiswa laki-laki pada segmen ini melebihi persentase laki-laki seluruhnya. Segmen S1 adalah segmen paling adil dengan persentase mahasiswa seimbang untuk laki-laki dan perempuan. Jika dilihat berdasarkan IPK, maka S1 memiliki mahasiswa dengan nilai median terendah. Pada S3 hanya terdapat Dosen 21. Tetapi, masih terdapat Dosen yang tidak menjadi bagian salah satu dari empat segmen yang ada, yaitu: Dosen 01, Dosen 02, Dosen 03, Dosen 14 dan Dosen 16.
Hasil Analisis
Berdasarkan Tabel 5 dan Tabel 6 diketahui setiap segmen memiliki atribut yang berbeda dan dosen yang memenuhi kriteria segmen tersebut juga berbeda. Suatu atribut dikatakan berkontribusi pada suatu segmen bila proyeksi segmen terhadap atribut tersebut besar dan bernilai positif. Karena atribut yang searah dengan segmen menghasilkan proyeksi positif dan yang berlawanan arah bernilai negatif. Sedangkan setiap Dosen dikatakan menjadi bagian segmen tertentu jika proyeksi Dosen ke segmen melebihi nilai rata-rata segmen ditambah setengah standar deviasi pada masing-masing segmen. Hasil perhitungan terhadap seorang dosen akan menjadi bagian dari satu atau beberapa segmen dan bahkan tidak tergabung dalam segmen manapun.
Gambar 4 mengilustrasikan bahwa terdapat pengelompokan karakteristik dosen secara signifikan. Namun demikian masih terdapat beberapa dosen yang terpencar dari pengelompokan besar, seperti Dosen 12, Dosen 21 dan Dosen 19 yang terlihat langsung berbeda posisi dari dosen lainnya yang menumpuk pada beberapa kelompok. Namun, hal ini tidak menutup kemungkinan dosen tersebut dapat bergabung pada suatu segmen dengan dosen yang lain. Terdapat beberapa orang dosen yang tidak memenuhi kriteria keempat segmen seperti Dosen 01, Dosen 02, Dosen 03, Dosen 14 dan Dosen 16. Hal ini terjadi karena, nilai proyeksi dosen tersebut terhadap segmen lebih kecil dibandingkan dengan nilai rata-rata yang ditambahkan dengan setengah standar deviasi seluruh dosen untuk setiap segmen.
Segmen S2 yang terdiri dari Dosen 12, Dosen 17 dan Dosen 19. Mahasiswa segmen ini terdiri dari 8 mahasiswa laki-laki dan 13 mahasiswa perempuan dengan median Indeks Prestasi Komulatif 3.47. Karakteristik segmen ini terbentuk karena mahasiswa menganggap dosen memiliki tingkat intelektual yang lebih. Atribut S2 terdiri dari: reputasi akademik yang dimiliki oleh dosen yang bersangkutan, sering terjadi komunikasi antara dosen yang bersangkutan dengan mahasiswa, cara mengajar unik yang dimiliki oleh dosen yang bersangkutan, sifat karismatik dan berkarakter yang dimiliki oleh dosen.
Segmen S3 hanya memiliki satu atribut, yakni kemudahan dalam hal menemui dosen yang bersangkutan, dan hanya terdapat Dosen 21 pada S3. Segmen S3 memiliki 19 mahasiswa dengan median Indeks Prestasi Komulati 3.58 yang terdiri dari 14 mahasiswa laki-laki dan 5 mahasiswa perempuan. Sama halnya dengan S3, segmen S4 terbentuk juga hanya oleh satu atribut yaitu dosen yang bersangkutan dirasa lebih familiar oleh mahasiswa. Dosen yang menjadi bagian S4 terdiri dari: Dosen 10, Dosen 11, Dosen 12, Dosen 13, Dosen 15, Dosen 17, Dosen 19 dan Dosen 20. Segmen ini merupakan segmen yang didominasi oleh mahasiswa perempuan yang terdiri dari 2 mahasiswa laki-laki dan 10 mahasiswa perempuan. Secara keseluruhan hasil analisis diatas dapat disimpulkan kedalam Tabel 7. Tabel 7. Analisis clusterwise bilinear spatial multidimensional scaling model
mahasiswa dan dosen
Segmen Atribut Pembangun Segmen Dosen yang Memenuhi
Kriteria segmen
Segmen 1 A2= Mahasiswa bimbingan dosen yang
bersangkutan kebanyakan cepat lulus studi
A4= Reputasi non akademik yang dimiliki oleh dosen yang bersangkutan
A8= Kesan dosen yang tidak menakutkan bagi mahasiswa
A9= Kesesuaian bidang keahlian dosen dengan minat mahasiswa
Dosen 04, Dosen 05, Dosen 06, Dosen 07, Dosen 08, Dosen 09, Dosen 22, Dosen 23
Segmen 2 A3= Reputasi akademik yang dimiliki oleh dosen yang bersangkutan.
A6= Sering terjadi komunikasi antara dosen yang bersangkutan dengan mahasiswa.
A7= Gaya mengajar unik yang dimiliki oleh dosen yang bersangkutan
A10= Sifat karismatik dan berkarakter yang dimiliki oleh dosen
Dosen 12, Dosen 17, Dosen 19
Segmen 3 A1= Kemudahan dalam hal menemui dosen
yang bersangkutan
Dosen 21
Segmen 4 A5= Dosen yang bersangkutan dirasa lebih familiar oleh mahasiswa.
5
SIMPULAN
Berdasarkan hasil analisis data secara simultan antara positioning dosen dalam pemilihan ketua komisi pembimbing karya ilmiah oleh 65 mahasiswa terhadap 23 dosen di Depertemen Statistika IPB berdasarkan 10 atribut maka dapat ditarik kesimpulan:
1. Setiap dosen memiliki kemungkinan untuk menjadi bagian setiap segmen atau tidak termasuk kedalam salah satu segmen.
2. Setiap atribut menjadi salah satu pembentuk segmen. Atribut mengenai kesesuaian keahlian dosen dengan minat mahasiswa merupakan atribut dengan sebaran nilai terkecil.
3. Terdapat 4 segmen mahasiswa dalam hal pemilihan ketua komisi pembimbing pada program sajana Statistika IPB.
4. Segmen S1 memiliki karakteristik yang bersifat umum, S2 merupakan segmen dengan dosen yang memiliki tingkat intelengensi yang lebih. S3 dengan ciri mudah untuk menemui dosen. Sedangkan S4 adalah segmen yang terdiri dari dosen yang dirasa lebih familiar oleh mahasiswa.
5. Secara keseluruhan dosen menumpuk pada suatu kelompok, namun terdapat beberapa dosen yang memiliki nilai yang cukup berbeda seperti Dosen 12, Dosen 19 dan Dosen 21, sehingga terlihat seperti pencilan.
DAFTAR PUSTAKA
Arabie P, Carroll JD, DeSarbo WS, Wind J. 1981. Overlapping Clustering: A New Method for Product Positioning. Journal of Marketing Research. 18 (August): 310-317
DeSarbo WS, Jedidi K, Cool K, Schendel D. 1991. Simultaneous Multidimensional Unfolding and Cluster Analysis: An Investigation of Strategic Groups.
Marketing Letters. 2(2): 129-146
DeSarbo WS, Manrai AK, Manrai LA. 1994. Latent Class Multimensional Scaling: A Review of Recent Developments in Marketing and Psychometric Literature. Richard PB, editor. Cambridge (US): Blackwell
DeSarbo WS, Wedel M. 1996. An Exponential Family Multidimensional Scaling Mixture Methodology. Journal of Bisuness and Economic Statistics. 14(4): 447-459
DeSarbo WS, Grewal R, Scott CJ. 2008. A Clusterwise Bilinear Multidimensional Scaling Methodology for Simultaneous Segmentation and Positioning Analysis.
Journal of Marketing Research. 45 (June): 280-292.
Johnson RA, Wichern DW. 2007. Applied Multivariate Statistical Analysis 6th ed. New Jersey (US): Pearson Prentice Hall
Kasali R. 1998. Membidik Pasar Indonesia Segmentasi Targeting Positioning. Jakarta (ID): Gramedia
Kotler P. 2008. Manajemen Pemasaran. Jakarta (ID): Erlangga
Magnus JR, Neudecker H. 2002. Matrix Differential Calculus with Applications in Statistics and Econometrics 3th ed. New York (US): John Wiley and Sons McLachlan GJ, Peel D. 2000. Finite Mixture Models. New York (US): John Wiley
and Sons
RIWAYAT HIDUP
Penulis dilahirkan di Tanjung Barulak, Sumatera Barat, pada tanggal 29 Mei
1988, sebagai anak pertama dari pasangan Fahrizal Caniago dan Nurlisma. Pendidikan
sekolah menengah ditempuh di SMA Negeri 2 Kota Padang Panjang pada Program IPA, dan lulus pada tahun 2005. Pada tahun yang sama penulis melanjutkan pendidikan sarjana pada program studi Matematika Universitas Negeri Padang (UNP), dan menyelesaikannya pada tahun 2010 dengan gelar Sarjana Sains (S.Si).