PEMODELAN DATA PANEL SPASIAL MENGGUNAKAN
MODEL SUR-SAR DENGAN PENDEKATAN
BAYESIAN
HILMAN DWI ANGGANA
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Pemodelan Data Panel Spasial Menggunakan Model SUR-SAR dengan Pendekatan Bayesian adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Januari 2016
Hilman Dwi Anggana
RINGKASAN
HILMAN DWI ANGGANA. Pemodelan Data Panel Spasial Menggunakan Model SUR-SAR dengan Pendekatan Bayesian. Dibimbing oleh ASEP SAEFUDDIN dan BAGUS SARTONO.
Seemingly Unrelated Regression (SUR) adalah sebuah sistem model yang merupakan perluasan dari model regresi umum ketika terjadi permasalahan adanya hubungan antar model individu yang dibangun secara simultan. SUR merupakan hasil penelitian Zellner (1962) yang pertama mengakomodasi masalah hubungan antar model individu terhadap efisiensi pendugaan parameter dan informasi yang diperoleh. Konsep SUR telah banyak dikembangkan, salah satunya dalam kajian statistika spasial (Anselin 1988).
Pada penelitian ini dikaji model individu yang merupakan regresi otoregresif spasial (SAR) yang dibangun berdasarkan tahun yang berbeda. Adanya hubungan model-model SAR ini diakomodasi dengan model SUR sehingga menjadi model SUR-SAR berdasarkan data panel spasial. Permasalahan yang dihadapi model SUR-SAR tidak hanya terbatas pada hubungan model-model individu penyusunnya, tetapi juga terkait permasalahan metode/pendekatan pendugaan parameternya yang memberikan solusi yang tidak closed form dan sulitnya menentukan pengujian parameter secara statistik. Pendekatan Bayesian
merupakan salah satu metode pendugaan parameter yang dapat mengatasi permasalahan tersebut karena lebih praktis (Griffiths 2001) dan secara statistika memiliki banyak keuntungan (LeSage 2005).
Kajian model SUR-SAR dengan pendekatan Bayesian ini merupakan kajian empiris pada data kejadian DBD dan faktor-faktor penyertanya dari 68 kelurahan di Kota Bogor tahun 2009 - 2011. Proses pendugaan parameter dilakukan menggunakan algoritma Gibbs Sampler dan Metropolis-Hasting melalui simulasi
Markov Chain Monte Carlo (MCMC) sampai tercapainya konvergen dalam hal stasioneritas sebaran posterior parameter model. Berdasarkan analisis diperoleh hasil bahwa otokorelasi spasial lag, kontribusi peubah prediktor yang berubah setiap tahun, dan korelasi model individu (tahunan) dapat ditangkap oleh model SUR-SAR yang didukung oleh data. Model SUR-SAR merupakan model yang lebih baik daripada model-model individu SAR dalam mengepas data DBD Kota Bogor 2009-2011 karena lebih efisien dalam menduga parameter dan memiliki derajat kecocokan model yang lebih tinggi.
SUMMARY
HILMAN DWI ANGGANA. Spatial Panel Data Modeling Using SUR-SAR Model with Bayesian Approach. Supervised by ASEP SAEFUDDIN and BAGUS SARTONO.
The Seemingly Unrelated Regression (SUR) is a model system that found by Zellner (1962). The idea of using this model system is to accommodate the problems from relationship among the individual model which built simultaneously. The problems are the efficiency of parameter estimation and the obtained information. SUR concept has been developed, one of them in the study of spatial statistics (Anselin 1988).
In this study, the individual models are spatial lag regression or spatial autoregressive models (SAR) which built by different years. The relationship among SAR models is accommodated by the model so that it becomes SUR-SAR model based on spatial panel data. The problems faced by SUR-SAR models are not just limited to the relationship of individual models, but also the problem related to a method/approach on the parameter estimation that provide a closed form solution and has exact statistical test. Bayesian approach is one of the parameter estimation method that can overcome these problems due to more practical (Griffiths 2001) and statistically has many advantages (Lesage 2005).
The study of SUR-SAR model with the Bayesian approach is an empirical study on Dengue Hemorrhagic Fever (DHF) data from 68 villages in the city of Bogor during 2009 - 2011. The process of parameter estimation was performed by Markov Chain Monte Carlo (MCMC) simulation with Metropolis-Hasting and Gibbs Sampler algorithms until convergence in stationerity posterior distribution. The analysis showed that the spatial lag autocorrelation, the contributions of predictor variables which varies every year, and the correlation of individual models (yearly) could be captured by SUR-SAR models and then supported by the data. The SUR-SAR model was better than the individual SAR models in fitting DHF data of Bogor during 2009 - 2011 due to had higher level of the efficiency of parameter estimation and the goodnes of fit model.
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika
PEMODELAN DATA PANEL SPASIAL MENGGUNAKAN
MODEL SUR-SAR DENGAN PENDEKATAN
BAYESIAN
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
Judul Tesis : Pemodelan Data Panel Spasial Menggunakan Model SUR-SAR dengan Pendekatan Bayesian
Nama : Hilman Dwi Anggana NIM : G151130231
Disetujui oleh Komisi Pembimbing
Prof Dr Ir Asep Saefuddin, MSc Ketua
Dr Bagus Sartono, SSi MSi Anggota
Diketahui oleh
Ketua Program Studi Statistika
Dr Ir Kusman Sadik, MSi
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
Tanggal Ujian: 9 November 2015
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga tesis berjudul Pemodelan Data Panel Spasial Menggunakan Model SUR-SAR dengan Pendekatan Bayesian ini berhasil diselesaikan.
Terima kasih penulis ucapkan kepada Bapak Prof Dr Ir Asep Saefuddin, MSc dan Bapak Dr Bagus Sartono, SSi MSi, selaku pembimbing, atas kesediaan dan kesabaran untuk membimbing dan membagi ilmunya kepada penulis dalam penyusunan tesis ini. Terimakasih kepada Bapak Dr Ir Kusman Sadik, MSi selaku penguji luar komisi pembimbing. Ucapan terima kasih juga penulis sampaikan sebesar-besarnya kepada seluruh Dosen Departemen Statistika IPB yang telah mengasuh dan mendidik penulis selama di bangku kuliah hingga berhasil menyelesaikan studi, serta seluruh staf Departemen Statistika IPB atas bantuan, pelayanan, dan kerjasamanya selama ini.
Ucapan terima kasih yang tulus dan penghargaan yang tak terhingga juga penulis ucapkan kepada kedua orangtua penulis Bapak Tatang Sasmita dan Ibu Imas Lilis Heryani yang telah membesarkan dan mendidik penulis dengan penuh kasih sayang demi keberhasilan penulis selama menjalani proses pendidikan, juga kakak penulis Riska Liestiana serta seluruh keluarga penulis atas doa dan semangatnya.
Terakhir tak lupa penulis juga menyampaikan terima kasih kepada seluruh mahasiswa Pascasarjana Departemen Statistika atas segala bantuan dan kebersamaannya selama menghadapi masa-masa terindah maupun tersulit dalam menuntut ilmu, serta semua pihak yang telah banyak membantu dan tak sempat penulis sebutkan satu per satu.
Semoga tesis ini dapat bermanfaat bagi semua pihak yang membutuhkan.
Bogor, Januari 2016
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
2 TINJAUAN PUSTAKA 2
Seemingly Unrelated Regression 2
Seemingly Unrelated Regression-Spatial Autoregressive Model 4
BayesianModel 6
Markov Chain Monte Carlo 7
Algoritma Metropolis-Hasting 7
Algoritma Gibbs Sampler 8
Model Regresi Spasial dengan Pendekatan Bayesian 9
Bayesian Seemingly Unrelated Regression-Spatial Autoregressive Model 12
Diagnostik Konvergensi MCMC 14
Galat Baku Monte Carlo 15
Deviance Information Criterion 15
3 METODE PENELITIAN 16
Data 16
Metode Analisis Data 17
4 HASIL DAN PEMBAHASAN 19
Hubungan antar Model-model Individu 19
Penduga Model SUR-SAR dengan MCMC 19
Diagnostik Konvergensi MCMC 19
Ringkasan Statistik Posterior 21
Pengujian Keberartian Parameter Model 22
Evaluasi Model Hasil Simulasi MCMC 23
Perbandingan Model SUR-SAR dan Model Individu SAR 24 Nilai Dugaan Model SUR dan Model Individu 24 Analisis Efisiensi Pendugaan Parameter Melalui GBMC 25
5 SIMPULAN DAN SARAN 26
Simpulan 26
Saran 26
DAFTAR PUSTAKA 28
LAMPIRAN 30
DAFTAR TABEL
1 Korelasi sisaan model-model individu 19
2 Uji Geweke hasil simulasi MCMC 20
3 Statistik posterior hasil simulasi MCMC 21
4 Statistik DIC 22
5 Galat baku posterior dan galat baku Monte Carlo hasil simulasi MCMC 23 6 Penduga parameter model SUR-SAR dan model individu SAR 24
7 GBMC SUR-SAR (A) dan GBMC individu SAR 25
DAFTAR GAMBAR
1 Peta Kota Bogor 16
2 Diagram alir simulasi MCMC 18
DAFTAR LAMPIRAN
1 Penurunan Sebaran Posterior Bersyarat Model Bayesian SAR 30 2 Penurunan Sebaran Posterior Bersyarat Model Bayesian SUR-SAR 35
3 Plot diagnostik simulasi MCMC model SUR-SAR 40
1
1
PENDAHULUAN
Latar Belakang
Analisis regresi adalah sebuah analisis statistika yang digunakan untuk mengkaji pola hubungan antar peubah. Pada beberapa kasus ekonometrika, sering terjadi kasus pendugaan banyak model individu (model regresi) secara simultan. Pendugaan model regresi secara simultan ini dapat menimbulkan isu terdapatnya hubungan antar model regresi tersebut seperti halnya konsep pengukuran beberapa peubah secara simultan pada analisis peubah ganda yang mengasumsikan antar peubah saling berhubungan (Tim 2002 dan Sun et al. 2014).
Seemingly Unrelated Regression (SUR) yang diajukan oleh Zellner (1962) adalah sebuah sistem model yang merupakan perluasan dari model regresi linier yang dapat mengakomodasi hubungan antar model individu melalui struktur hubungan antar galat model individunya (Sun et al. 2014). Felmlee dan Hargens (1988) menunjukkan bahwa model SUR dapat mengatasi masalah efisiensi pendugaan parameter dan informasi dari data yang hilang pada model-model individu yang memiliki hubungan kesebayaan (contemporaneous correlation) melalui nilai galat baku penduga parameter model SUR yang nilainya lebih kecil dari galat baku penduga parameter model-model individunya. Pada kajian statistika spasial, model SUR telah banyak dikembangkan, diantaranya penelitian yang dilakukan oleh Wang dan Kockelman (2007), Zou dan Kockelman (2009), dan Kakamu et al. (2011).
Model SUR digunakan pada data panel spasial dengan membangun model-model yang terdiri dari sebuah model-model regresi spasial pada setiap periode waktu yang diduga untuk sebuah data cross section dari unit-unit spasialnya (Anselin 1988). Keuntungan penggunaan model SUR dalam model-model data panel adalah memerhatikan aspek waktu yang memiliki parameter yang nilainya berubah (time varying parameters) sehingga hal ini berguna bagi peneliti yang tertarik dengan dinamika dari parameter (Kakamu et al. 2011). Walaupun analisis data panel spasial berkembang pesat dalam beberapa area penelitian, model-model panel spasial jarang digunakan dalam ekonometrika. Salah satu alasannya adalah kesulitan mengevaluasi fungsi kemungkinan dari model (Kakamu et al. 2011)
Pendugaan parameter pada model SUR memiliki masalah yaitu solusi yang dihasilkan merupakan solusi dalam bentuk persamaan yang tidak closed form
sehingga untuk mendapatkan solusinya memerlukan pendekatan analisis numerik yang relatif rumit (Kakamu et al. 2011). Masalah lainnya terkait metode pendugaan parameter adalah solusi numerik yang diperoleh sering menghasilkan statistik yang tidak dapat diuji karena sulitnya menemukan formulasi uji statistik. Salah satu alternatif praktis pendekatan pendugaan parameter yang digunakan untuk model SUR adalah dengan menggunakan metode pendugaan Bayesian
2
galat yang konstan pada metode kemungkinan maksimum, dan fleksibel dalam perbandingan antar model.
Berdasarkan uraian di atas, menjadi hal yang menarik untuk mengkaji model berbasis SUR pada data panel spasial seperti yang diungkapkan (Anselin 1988) menggunakan pendekatan Bayesian, dalam hal ini model spasial yang digunakan adalah model otoregresif spasial /spatial autoregressive model (SAR) yang diterapkan pada data kejadian DBD Kota Bogor tahun 2009-2011.
Tujuan Penelitian
Pada umumnya tujuan utama penelitian ini adalah untuk memberikan khazanah baru pengembangan model regresi spasial (SAR) yang saling berhubungan pada data panel spasial berdasarkan masalah efisiensi pemodelan dan kepraktisan pendekatan pendugaan parameter model. Tujuan utama tersebut diperinci kedalam tujuan khusus berikut ini :
1. Mengkaji penggunaan sistem SUR untuk data panel spasial melalui model pembangun regresi SAR dengan pendekatan Bayesian yang diterapkan pada data kejadian DBD Kota Bogor 2009 -2011.
2. Mengevaluasi kelayakan model yang dihasilkan melalui proses simulasi berdasarkan konvergensi MCMC, efisiensi pendugaan model, dan kecocokan model.
2
TINJAUAN PUSTAKA
Seemingly Unrelated Regression
Andaikan sebuah sistem model regresi dibangun dari M model regresi (M
peubah respon) dengan setiap model mempunyai n unit pengamatan yang sama, vektor peubah respon dalam sistem dinotasikan dengan , matriks-matriks rancangan berisi peubah prediktor dari setiap model dalam sistem berurutan adalah X1,X2,...,Xm. Sistem model dari M model regresi ini ditulis
(Zellner 1962) :
Berdasarkan sistem model yang diberi nama Seemingly Unrelated Regression (SUR) ini maka akan terdapat M model regresi dan n unit pengamatan pada data contoh yang digunakan untuk menduga parameter model. Model SUR disajikan dalam bentuk umum untuk setiap model regresi (Zellner 1962) :
(1)
3 dengan adalah vektor peubah respon berukuran , adalah matriks rancangan yang bersifat non stokastik berukuran , menyatakan banyaknya peubah prediktor yang dimasukkan pada model ke-m, adalah vektor koefisien regresi yang sifatnya tidak diketahui berukuran dan
adalah vektor galat berukuran .
Sistem model regresi dalam bentuk vektor-matriks model regresi yang umum ditulis kesebayaan yang dinyatakan melalui struktur ragam-peragam galat model sistem SUR pada persamaan (5) dan persamaan (6) berikut definit positif yang dibangun berdasarkan nilai ragam-peragam galat model individunya. Andaikan εm adalah vektor galat model ke-m dan adalah vektor
galat model ke- , peragam keduanya dinotasikan dengan |
4
Proses pendugaan parameter model sangat bergantung kepada matriks Ω. Apabila nilai Ω diketahui, penduga generalized least square (GLS) atau metode kuadrat terkecil terampat (MKTT) dari model SUR adalah
̂
akan tetapi pada prakteknya Ω tidak diketahui dan harus diduga dari data (Baltagi 2008). Pendugaan parameter dilakukan dengan feasible generalized least square
(FGLS) melalui prosedur 3 stage least square (3SLS) atau kuadrat terkecil tiga tahap. Baltagi (2008) menjelaskan langkah-langkah pendugaan ini sebagai berikut :
1. Lakukan pendugaan parameter yaitu dengan mencari ̂ menggunakan metode kuadrat terkecil terhadap M model regresi, untuk m = 1,2,..,M. pada langkah 4 sampai diperoleh nilai yang konvergen sehingga prosedur ini kadang disebut juga prosedur pendugaan model SUR iteratif.
Seemingly Unrelated Regression – Spatial Autoregressive Model
Regresi otoregresif spasial atau spatial autoregressive model (SAR) adalah model regresi biasa dengan penambahan pengaruh spasial pada peubah responnya. Model-model regresi spasial dapat memiliki hubungan kesebayaan. Anselin (1988) mengenalkan konsep SUR spasial terhadap model-model regresi spasial yang dibangun masing-masing untuk satu periode waktu tertentu. Andaikan terdapat T periode waktu, sistem model SUR dari model regresi SAR ditulis
5 Persamaan (11) dapat ditulis ulang dalam bentuk
dengan memisalkan dan , persamaan (12) ditransformasi menjadi model regresi umum sebagai berikut
dengan y* adalah vektor peubah respon yang sudah ditransformasi berukuran , P adalah matriks diagonal dengan nilai-nilai diagonalnya ρ1, ρ2,..., ρT
berukuran T×T, W adalah matriks pembobot spasial berukuran n×n, X adalah matriks rancangan non stokastik berukuran ∑ , menyatakan banyaknya peubah prediktor yang dimasukkan pada model ke-t, β adalah vektor koefisien regresi yang tidak diketahui berukuran ∑ , dan ε adalah vektor galat berukuran .
Adanya hubungan antar model regresi SAR yang disajikan dalam sistem model SUR-SAR dinyatakan melalui matriks ragam-peragam galat model SUR yaitu
)
Jika ⁄ adalah galat model SUR-SAR yang sudah dibakukan, Anselin (1988) menyatakan fungsi kepekatan peluang vektor v dapat ditulis dalam bentuk sebaran normal ganda baku sebagai berikut
⁄ { }
Dengan demikian, fungsi kemungkinan bagi model SUR-SAR adalah (Anselin 1988)
| ⁄ | | ⁄ | | { }
| | ⁄ | | { }
dengan .
Logaritma natural dari fungsi kemungkinan model SUR-SAR yaitu | ditulis sebagai berikut
(12)
(13)
(14)
(15)
6
(18) | | | | | { }
| | | | { } | | ∑ | | { }
Penduga kemungkinan maksimum untuk parameter model SUR-SAR ini dilakukan dengan memaksimumkan fungsi | terhadap parameter yang diduga melalui optimasi secara numerik. Metode pendugaan parameter lainnya adalah dengan menggunakan instrumental variables (IV) dan metode kuadrat terkecil tiga tahap (MKTTT) atau sering disebut FGLS (Anselin, 1988). Metode kemungkinan maksimum, IV, dan FGLS semuanya memberikan solusi yang tidak
closed form sehingga diperlukan analisis numerik secara iteratif (Anselin 1988 dan Kakamu et al. 2011).
Bayesian Model
Pendekatan Bayesian berbeda dengan pendekatan statistika klasik yang mengasumsikan bahwa parameter adalah suatu nilai tidak diketahui yang sifatnya tetap. Chen et al. (2000) dan Gelman et al. (2004) menyebutkan bahwa pendekatan ini didasarkan pandangan subjektif dari peluang, ketidakpastian mengenai sesuatu yang tidak diketahui (parameter) dapat diekspresikan dengan menggunakan aturan peluang melalui optimalisasi informasi dari parameter (prior) dan informasi dari data (fungsi kemungkinan). Sebaran prior mengekspresikan informasi yang tersedia bagi peneliti sebelum data dimasukkan ke dalam analisis. Oleh karena itu, sebaran prior yang digunakan dalam model berbasis Bayesian harus ditentukan terlebih dahulu sebelum melakukan pemodelan (Hajarisman 2013).
Jika θ adalah parameter model dan D adalah data pengamatan, berdasarkan teori Bayes sebaran posterior bagi θ bersyarat D ditulis (Chen et al. 2000) :
| | |
dengan | | merupakan informasi dari data pengamatan setelah memasukan parameter model θ, informasi ini sering disebut juga sebagai fungsi kemungkinan dari parameter model, merupakan sebaran prior bagi θ.
Penentuan sebaran prior merupakan hal yang sangat penting dalam model-model berbasis Bayesian. Namun, pada umumnya sebaran prior ini tidak diketahui sehingga kita perlu menspesifikasikan sebaran prior yang tidak akan berpengaruh terhadap sebaran posterior (Hajarisman 2013). Biasanya pada kasus seperti ini sering digunakan sebaran prior noninformative. Namun, tidak pada semua kasus, penggunaan sebaran prior noninformative memberikan hasil inferensi pada sebaran posterior menjadi valid karena sebaran posterior menjadi improper (hasil integrasi menjadi tak hingga) diakibatkan sebaran prior yang improper (Ntzoufras 2009).
7 Untuk memudahkan dan menyederhanakan proses inferensi Bayes ketika tidak ada informasi yang diketahui secara pasti mengenai parameter (noninformative) digunakan sebaran prior conjugate (Gamerman & Lopes, 2006). Menurut Ntzoufras (2009), sebaran prior conjugate merupakan sebaran yang memberikan sebaran prior dan posterior yang berasal dari keluarga sebaran yang sama. Sebuah sebaran prior adalah anggota dari keluarga sebaran S dengan parameter α adalah conjugate terhadap sebaran | jika menghasilkan sebaran posterior | yang juga anggota dari keluarga sebaran yang sama. Dengan demikian jika , maka | ̃ dengan α dan ̃ adalah parameter dari sebaran prior dan posterior.
Penarikan contoh acak dilakukan dengan menggunakan sebaran posterior bersyarat bagi masing-masing parameter dan pendugaan parameter dilakukan dengan menghitung rataan posterior bersyarat dari parameter yang menjadi fokus perhatian dalam model (Carlin & Louis, 2000). Gilks et al. (1996) dan Ntzoufras (2009) mengatakan bahwa proses penarikan contoh acak dari sebaran posterior bersyarat melibatkan integrasi dan komputasi yang rumit sehingga dilakukan simulasi dengan Markov Chain Monte Carlo (MCMC).
Markov Chain Monte Carlo
Menurut Gilks et al. (1996), Markov Chain Monte Carlo (MCMC) pada model berbasis pendekatan Bayesian adalah teknik simulasi yang digunakan untuk membangkitkan contoh acak secara berurutan dari sebaran posterior bagi parameter model. Ide simulasi MCMC pada model-model Bayesian berawal dari permasalahan integrasi multidimensi yang tidak bisa diselesaikan secara analitik biasa pada pencarian momen-momen (nilai harapan dan ragam) dari sebaran posteriornya. Teknik MCMC mengkonstruksi contoh-contoh acak dari sebaran posterior sebagai rantai Markov yang konvergen pada sebaran target (stasioner) sehingga prosesnya dilakukan secara iteratif yang mana contoh yang dibangkitkan bergantung pada satu nilai sebelumnya. Dua algoritma popular yang sering digunakan dalam simulasi MCMC adalah algoritma Metropolis-Hasting dan algoritma Gibbs Sampler (Ntzoufras 2009).
Algoritma Metropolis-Hasting
8
| | | |
jika nilai kandidat diterima, nilai contoh acak pada tahap selanjutnya menjadi . Sedangkan jika nilai kandidat ditolak, nilai contoh acak pada tahap selanjutnya menjadi .
Ntzoufras (2009) meringkas algoritma Metropolis-Hasting dalam inferensi
Bayesian sebagai berikut : 1) Tentukan nilai inisiasi .
2) Untuk s=1,2,…S , ulangi langkah-langkah berikut : a. Tetapkan
b. Bangkitkan nilai kandidat parameter yang berasal dari sebuah sebaran kandidat |
c. Hitung | | | |
d. Ganti dengan peluang ; selainnya tetapkan . Salah satu kasus dari algoritma Metropolis-Hasting terjadi ketika nilai sebaran kandidat yang simetris, yang mana berlaku | | | | . Algoritma Metropolis-Hasting pada kasus ini sering disebut dengan algoritma Random-walk Metropolis dengan ciri utama peluang penerimaan hanya bergantung kepada sebaran posterior target (Gamerman & Lopes 2006).
Algoritma Gibbs Sampler
Algoritma Gibbs sampler adalah kasus khusus lainnya dari algoritma
Metropolis-Hasting yang mana peluang penerimaan selalu bernilai satu untuk setiap iterasi sehingga contoh acak yang dibangkitkan (nilai kandidat) selalu diterima sebagai contoh acak baru pada semua iterasi (Ntzoufras 2009). Pada umumnya sebaran posterior bersyarat dari parameter yang sedang diperhatikan dalam model berbasis Bayesian menggunakan algoritma ini memiliki bentuk sebaran posterior bersyarat yang pasti.
Jika sebuah vektor parameter ( dan nilai inisiasi yang diberikan , untuk iterasi s = 1, 2,…, S, maka algoritma Gibbs sampler membangkitkan dari sebagai berikut (Gamerman & Lopes 2006 dan Hoff 2009) :
1) Bangkitkan | 2) Bangkitkan | 3) Bangkitkan |
p) Bangkitkan |
9 sehingga algoritma Gibbs sampler ini akan memiliki vektor berurutan yang memiliki hubungan sebagai berikut : . Sifat ini merupakan sifat dari rantai Markov sehingga semua contoh acak berurutan pada algoritma Gibbs sampler merupakan sebuah rantai Markov.
Model Regresi Spasial dengan Pendekatan Bayesian
Menurut LeSage (1997), terdapat dua isu permasalahan pendugaan model regresi spasial menggunakan pendekatan Bayesian melalui simulasi MCMC. Kasus pertama adalah ketika semua sebaran posterior bersyarat bentuknya pasti dan diketahui, misalkan bentuk sebaran posterior bersyarat bagi parameter koefisien regresi adalah sebuah sebaran normal. Sebagai teladan, andaikan sebuah model mempunyai parameter yang sedang diperhatikan adalah β dan σ2, dengan sebaran posterior bersyarat bagi masing-masing parameter berurutan adalah sebaran normal ganda dan sebaran invers-Gamma. Memulai dengan sebuah nilai inisiasi untuk β, sebuah contoh acak dari sebaran invers-Gamma dibangkitkan, misalkan hasil bangkitannya adalah ̂ , yang digunakan untuk membangkitkan ̂ menggunakan sebaran normal ganda, nilai ̂ kemudian digunakan untuk membangkitkan contoh acak dari sebaran invers-Gamma lainnya yakni ̂ untuk mengganti ̂ , dan begitu seterusnya. Gelfand dan Smith (1990) menunjukkan bahwa algoritma Gibbs sampler pada simulasi MCMC akan memproduksi sebaran posterior bersama dari β dan σ2 yang sebarannya konvergen. Jika contoh acak yang dibangkitkan bagi β dan σ2 saling bebas, berdasarkan hukum bilangan besar nilai harapan bagi β dan σ2 nilainya diaproksimasi dari nilai rataan contoh. Kasus sederhana ini adalah kasus yang mana sebaran posterior bersyarat parameter model berasal dari sebaran posterior bersyarat yang bentuknya diketahui yang sering disebut conjugate sampling sehingga menimbulkan penggunaan sebaran prior conjugate pada model-model dengan pendekatan Bayesian.
10
parameter model regresi spasial pada penelitian ini hanya difokuskan pada penggunaan sebaran prior conjugate.
Sebaran prior bagi parameter koefisien regresi (β) umumnya sebuah sebaran normal ganda karena pada prakteknya sederhana dan secara komputasi telah banyak dikembangkan (Gelman et al. 2014). Selain itu penggunaan sebaran
conjugate berbentuk sebaran normal ganda bagi β pada model-model regresi dengan asumsi galat menyebar normal memberikan hasil pendugaan parameter yang relatif identik dengan pendugaan kemungkinan maksimum karena sebaran prior normal ganda merupakan sebaran yang datar/tidak berpengaruh (flat prior) sehingga model regresi dengan pendekatan Bayesian adalah regresi terboboti dari model regresi dengan pendekatan kemungkinan maksimum (Ntzoufras 2009 dan Gelman et al. 2014). Penggunaan sebaran normal ganda bagi parameter β dalam model-model regresi diantaranya Lindley dan Smith (1972), Ghosh dan Hoekstra (1995), dan Austin (2008). Sedangkan pada model-model regresi spasial dengan menggunakan sebaran normal ganda bagi parameter β diantaranya LeSage (1997) dan Kakamu et al. (2011).
Penentuan sebaran prior bagi parameter spasial menggunakan sebaran prior yang mudah dan sering diperlakukan sebagai sebuah konstanta, biasanya menggunakan sebaran Uniform (LeSage 1997). Hal ini dilakukan karena sebaran posterior bersyarat bagi parameter spasial yang digunakan untuk penarikan contoh memiliki bentuk sebaran yang tidak pasti sehingga diperlukan sebuah sebuah prosedur khusus untuk membangkitkan contoh acak. Prosedur khusus ini sering disebut dengan ratio of uniforms sampling (Devrove 1986 dalam LeSage 1997). Proses pembangkitan contoh acak bagi parameter spasial dengan prinsip ratio of uniforms sampling dilakukan dengan algoritma Metropolis-Hastings dengan sebaran kandidat merupakan sebaran normal baku (LeSage 1997).
11 model, β adalah vektor koefisien regresi yang sifatnya tidak diketahui berukuran
dan ε adalah vektor galat berukuran .
Informasi awal mengenai parameter, parameter β menyebar normal ganda dengan vektor rataan b0 dan matriks ragam-peragam B0, σ2 menyebar mengikuti sebaran invers-Gamma dengan parameter ⁄ dan ⁄ , dan ρ menyebar mengikuti sebaran Uniform antara kebalikan nilai maksimum dan minimum nilai ciri dari matriks pembobot spasial (W). Sebaran posterior bersama bagi parameter { } dengan mengasumsikan antar sebaran prior saling bebas adalah
| |
| | { } { }
⁄ {
}
Berdasarkan sebaran posterior bersama ini, akan ditentukan sebaran posterior bersyarat bagi masing-masing parameter yaitu sebaran posterior bersyarat bagi β, σ2, dan ρ. Sebaran posterior bersyarat bagi β adalah
| ∫ ∫ |
dengan ( dan (
Sebaran posterior bersyarat bagi σ2 adalah sebaran invers-Gamma dengan parameter a1 dan d1 yang ditulis
| ∫ ∫ |
dengan ⁄ dan { } ⁄
Sedangkan sebaran posterior bersyarat bagi ρ merupakan sebaran pendekatan yang ditulis
| ∫ ∫ |
| | { }
Penurunan sebaran posterior bersyarat bagi masing-masing parameter model
Bayesian SAR dapat dilihat pada Lampiran 1.
Bentuk sebaran posterior bersyarat bagi ρ merupakan bentuk yang tidak pasti sehingga untuk membangkitkan contoh acak bagi ρ diperlukan algoritma
Random-walk Metropolis dengan sebaran kandidatnya adalah sebaran normal baku. Nilai kandidat dibangkitkan dengan mempertimbangkan nilai saat ini dan nilai dari sebaran normal baku dengan parameter tuning (c) (21)
(22)
(23)
12
Bayesian SUR-SAR. Model Bayesian SUR-SAR ini dibangun dengan beberapa model regresi spasial SAR yang diasumsikan memiliki hubungan antar galat model regresi SAR dengan pendugaan parmeter dilakukan menggunakan pendekatan Bayesian. Berdasarkan penjelasan mengenai informasi sebaran prior yang sering digunakan pada model-model regresi spasial sebelumnya dan seperti pada model Bayesain SAR, model Bayesian SUR-SAR pada penelitian ini menggunakan asumsi sebaran prior conjugate bagi parameter koefisien regresi β dan matriks pembangun ragam-peragam galat model Σ, sedangkan parameter koefisien otokorelasi spasial ρ menggunakan sebaran Uniform. Model Bayesian SUR-SAR dapat ditulis (Kakamu et al. 2011) sebagai berikut :
⁄ ⁄
Informasi awal mengenai parameter, parameter β menyebar normal ganda dengan vektor rataan b0 dan matriks ragam-peragam B0, Σ menyebar mengikuti sebaran invers-Wishart dengan parameter skala dan derajat bebas , dan ρ menyebar mengikuti sebaran seragam antara kebalikan nilai maksimum
dan minimum nilai ciri dari matriks pembobot spasial (W) (Kakamu et al. 2011). Sebaran posterior bersama berdasarkan fungsi kemungkinan pada persamaan (16) dengan asumsi antar prior saling bebas ditulis | |
| | ⁄ | | { }
{ } | | { }
13 | ∫ ∫ |
( ̃ ̃
dengan ̃ ( ̂ ( ̂ ̂ dan ̃ ( ̂ yang diperoleh dari ̂ dan ̂
. Sebaran posterior bersyarat bagi Σ adalah sebaran invers-Wishart dengan parameter skala ̃ dan derajat bebas ̃ yang ditulis
| ∫ ∫ | ( ̃ ̃
dengan ̃ dan ̃ .Sebaran posterior bersyarat bagi ρ digunakan untuk setiap model ke-t . Sebaran yang merupakan sebaran posterior marjinal dari sebaran posterior bersama ini adalah sebuah sebaran pendekatan berbentuk
| ∫ ∫ ∫ |
| | { }
Secara lengkap penurunan sebaran posterior bersyarat bagi masing-masing parameter model Bayesian SUR-SAR dapat dilihat pada Lampiran 2.
Bentuk sebaran posterior bersyarat bagi ρt merupakan bentuk yang tidak
pasti sehingga untuk membangkitkan contoh acak bagi ρt diperlukan algoritma
Random-walk Metropolis dengan sebaran kandidatnya adalah sebaran normal baku. Nilai kandidat otokorelasi spasial lag model ke-t ( dibangkitkan dengan mempertimbangkan nilai saat ini dan nilai dari sebaran normal baku melalui persamaan
Kemudian nilai kandidat dievaluasi dengan menggunakan peluang penerimaan ( dengan formula
( ( ( |
( | )
Nilai ( tentunya bergantung kepada nilai sebaran posterior tanpa melibatkan model ke-t yang merupakan fungsi otokorelasi spasial selain model ke-t pada saat ini .
(28)
(29)
(30)
(31)
14
Diagnostik Konvergensi MCMC
Konvergensi dalam simulasi MCMC adalah isu yang sangat penting dalam menghasilkan penduga parameter yang benar dari sebaran posterior yang sedang dikaji. Sebuah masalah dalam simulasi MCMC adalah konvergensi tidak selalu didiagnosis dengan jelas seperti dalam metode optimasi. Peneliti harus menentukan banyaknya iterasi dan burn-in period dari proses simulasi MCMC yang akan dilakukan dalam menganalisis sebaran posterior model. Diagnostik konvergensi mengacu kepada tercapainya stasioneritas dari sebaran posterior model. Ada dua cara yang dapat dilakukan dalam melakukan diagnostik konvergensi MCMC yaitu melalui metode grafis dan metode formal pengujian hipotesis (Ntzoufras 2009).
Metode grafis untuk diagnostik MCMC dapat dilakukan dengan menggunakan trace plot, density plot, acf plot, dan ergodic mean plot. Trace plot
adalah plot antara nilai contoh acak/rantai Markov yang dibangkitkan dengan indeks iterasinya. Suatu rantai Markov dikatakan stasioner dalam sebaran jika nilai-nilai contoh acaknya tidak berubah sepanjang rantai Markov tersebut atau dapat dikatakan jika rantai Markov tersebut cenderung stabil tidak membentuk
trend maupun periode tertentu. Plot rataan ergodik adalah plot antara rataan kumulatif dengan indeks iterasi, jika plot rataan ergodik cenderung stabil maka rantai Markov telah mencapai konvergen dalam hal rataan sebarannya. Karena rantai Markov merupakan yang disimulasikan merupakan proses yang berhubungan dengan waktu, untuk menilai suatu proses simulasi MCMC konvergen atau belum dapat digunakan acf plot dan untuk menyatakan bentuk sebaran dapat digunakan density plot.
Uji formal konvergensi MCMC dapat dilakukan dengan statistik uji diantaranya adalah statistik Geweke, statistik Raftery-Lewis, statistik Gelman-Rubin, statistik Heidelberger-Welch, dan statistik Brooks-Gelman (Sinharay 2004). Pada penelitian ini digunakan statistik uji diagnostik konvergensi MCMC yang sederhana dan sering digunakan yaitu statistik uji Geweke. Geweke (1992) mengajukan uji diagnostik konvergensi dari rataan setiap parameter secara terpisah dari contoh acak yang dibangkitkan dari sebuah rantai tunggal. Prosedurnya adalah dengan membagi contoh acak yang telah dibangkitkan menjadi dua kelompok misalkan kelompok contoh acak A dan kelompok contoh acak B , biasanya menjadi 10% awal (A) dan 50% akhir (B) dari total contoh acak yang akan dievaluasi konvergensinya. Uji kesamaan rataan dari kedua kelompok kemudian dilakukan untuk mengetahui apakah kedua kelompok contoh acak yang dibangkitkan berasal dari sebaran yang stasioner atau belum.
15
yang secara asimtot mengikuti sebaran normal baku dengan ̅ ̅ adalah rataan contoh dari kelompok A dan kelompok B, adalah banyaknya iterasi/ukuran contoh kelompok A dan kelompok B, ⁄ ⁄ adalah ragam rataan contoh dari kelompok A dan kelompok B. Secara spesifik nilai | |yang besar, biasanya | | mengindikasikan terdapat perbedaan rataan antara contoh acak kedua kelompok sehingga rantai Markov yang disimulasikan berasal dari sebaran yang belum konvergen (Ntzoufras 2009).
Galat Baku Monte Carlo
Hasil yang diperoleh dari simulasi MCMC merupakan himpunan contoh acak yang perlu diketahui ukuran ketidakpastiannya (Ntzoufras 2009). Statistik galat baku Monte Carlo (GBMC) merupakan ukuran ketidakpastian yang menyatakan keragaman setiap nilai dugaan parameter yang diakibatkan proses simulasi. GBMC idealnya memiliki nilai yang kecil untuk memperoleh dugaan parameter yang memiliki presisi yang tinggi. Nilai GBMC merupakan fungsi dari ukuran contoh/banyaknya iterasi sehingga dapat dikontrol oleh peneliti.
Secara sederhana GBMC dapat dihitung dengan menggunakan formula [ ]√ √ ∑ [ ]
dengan merupakan himpunan contoh acak yang dibangkitkan dengan banyak iterasi S’ yang ditentukan setelah burn-in period, [ ] adalah galat baku posterior untuk S’ iterasi, dan [ ] adalah dugaan otokorelasi contoh acak dengan lag l yang berarti korelasi antara himpunan contoh acak pada iterasi ke-s yaitu [ ] dan pada iterasi ke-(s+l) yaitu [ ] . Salah satu hal penting dalam perhitungan GBMC adalah menentukan panjang lag maksimum, penentuan panjang lag maksimum menggunakan aturan nilai otokorelasi yang mendekati nol biasanya panjang lag ditentukan ketika [ ] (Carlin & Louis 2000).
Deviance Information Criterion
Deviance Information Criterion (DIC) adalah statistik ukuran kebaikan yang sering digunakan pada model-model berbasis pendekatan Bayesian (Spiegelhalter
et al. 2002). Formulasi DIC dituliskan sebagai ̅ ̂( ̂
dengan ̅ { | } adalah rataan devians dari semua parameter yang dibangkitkan untuk pendugaan parameter pada simulasi MCMC, ̂( ̂ ( { ( | ̂ } adalah devians dari rataan posterior bersyarat semua parameter. Model dikatakan memiliki derajat kebaikan yang tinggi apabila memiliki nilai DIC kecil. Statistik DIC sering digunakan dalam perbandingan model dalam hal mengepas data.
(34)
16
3
METODE PENELITIAN
Data
Data yang digunakan dalam kajian empiris ini adalah yang berasal dari penelitian sebelumnya (Rahmat 2014). Data sekunder ini diperoleh dari Profil Kesehatan dan Badan Pembangunan Daerah (Bapedda) Kota Bogor tahun 2009 – 2011. Unit pengamatannya adalah kelurahan yang berada di Kota Bogor berjumlah 68 kelurahan. Sebagai data tambahan, peta Kota Bogor yang terdiri dari 68 kelurahan digunakan untuk membuat matriks bobot spasial berdasarkan konsep berbatasan langsung (contiguity).
Gambar 1 Peta Kota Bogor
17 Metode Analisis Data
Analisis pendahuluan untuk mengeksplorasi dan mendeskripsikan karakteristik peubah-peubah penelitian tidak dilakukan dalam penelitian karena hal tersebut sudah dilakukan pada penelitian sebelumnya. Hasil eksplorasi yang dilakukan oleh Rahmat (2014) menunjukkan bahwa data dapat mendukung penggunaan regresi spasial dan antar peubah prediktor tidak memiliki kolineritas yang dapat mengakibatkan masalah serius pada model. Secara umum ada beberapa tahapan yang dilakukan dalam menganalisis data DBD Kota Bogor 2009
– 2011 menggunakan model Bayesian SUR-SAR sebagai berikut :
1. Membuat matriks bobot spasial (W) dari peta Kota Bogor menggunakan aturan queen contiguity. Matriks ini dibakukan terhadap barisnya sehingga total elemen matriks setiap baris nilainya satu. Matriks bobot spasial terdapat pada Lampiran 4 dan keterangan kode nomor kelurahan pada Lampiran 5. 2. Menduga model individu SAR untuk data tahunan menggunakan simulasi
MCMC seperti yang dilakukan Anggana (2012). Kemudian amati hubungan antar sisaan dari model-model individunya.
3. Menspesifikasikan besarnya nilai-nilai inisiasi sebaran prior dan sebaran posterior model Bayesian SUR-SAR kemudian mulai lakukan proses simulasi MCMC.
4. Membangkitan nilai kandidat koefisien otokorelasi spasial lag ( untuk model individu ke-t menggunakan algoritma Metropolis-Hastings melalui prosedur Random walk seperti pada persamaan (31). Nilai kandidat kemudian dievaluasi dengan peluang penerimaan pada persamaan (32) dan proses diulang sampai semua model individu memiliki contoh acak sebagai koefisien otokorelasi spasial lag yang dibangkitkan melalui proses simulasi.
5. Membangkitkan contoh acak vektor parameter koefisien regresi SUR-SAR menggunakan algoritma Gibbs Sampler seperti pada persamaan (28).
6. Membangkitkan contoh acak matriks parameter ragam-peragam galat SUR-SAR menggunakan algoritma Gibbs Sampler seperti pada persamaan (29). 7. Mengulangi tahap ke-4 sampai tahap ke-6 hingga diperoleh himpunan contoh
acak semua parameter untuk S iterasi. Pisahkan himpunan contoh acak semua parameter dari B iterasi pertama sebagai burn-in period .
8. Melakukan diagnostik konvergensi MCMC secara deskriptif menggunakan
trace plot, density plot, acf plot, dan ergodic plot dan melalui pengujian formal menggunakan statistik Geweke. Jika simulasi yang dilakukan belum konvergen dalam hal stasioneritas sebaran posteriornya maka burn-in period
(B) dan banyak iterasi (S) ditambah.
9. Menghitung statistik posterior model SUR-SAR diantaranya: rataan posterior, persentil 2.5 posterior, median posterior, persentil 97.5 posterior, dan galat baku posterior.
10. Melakukan uji keberartian parameter menggunakan 95% Credible Interval
(CI). Jika nilai persentil 2.5 posterior dan persentil 97.5 posterior berbeda tanda maka parameter berbeda nyata secara statistik pada taraf nyata 5%. 11. Menghitung galat baku Monte Carlo kemudian lakukan evaluasi model
menggunakan galat baku posterior (GBP) dan galat baku Monte Carlo
18
12. Membandingkan dan evaluasi model SUR-SAR dan model individu SAR dengan melihat nilai dugaan parameter model, analisis efisiensi pendugaan parameter, dan kebaikan model dalam mengepas data.
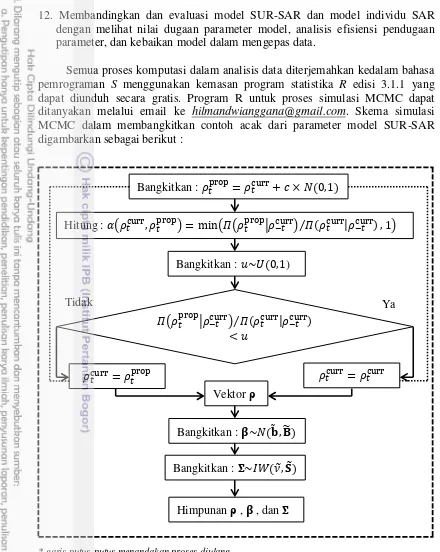
Semua proses komputasi dalam analisis data diterjemahkan kedalam bahasa pemrograman S menggunakan kemasan program statistika R edisi 3.1.1 yang dapat diunduh secara gratis. Program R untuk proses simulasi MCMC dapat ditanyakan melalui email ke [email protected]. Skema simulasi MCMC dalam membangkitkan contoh acak dari parameter model SUR-SAR digambarkan sebagai berikut :
* garis putus-putus menandakan proses diulang
Gambar 2 Diagram alir simulasi MCMC Bangkitkan :
Hitung : ( ( ( | ⁄ |
Bangkitkan : )
( | ⁄ |
Vektor ρ
Bangkitkan : ̃ ̃
Bangkitkan : ̃ ̃
Himpunan ρ , , dan
19
4
HASIL DAN PEMBAHASAN
Hubungan antar Model-model Individu
Hal pertama yang harus diselidiki ialah hubungan antar model-model individu (model yang dibangun untuk periode tahun tertentu). Adanya hubungan antar model-model individu merupakan langkah awal menduga model dengan menggunakan sistem SUR. Ukuran hubungan antar model-model individu menggunakan statistik korelasi dari sisaan model-model individunya. Model individu pada penelitian ini merupakan model otoregresif spasial (SAR). Karena model SUR yang diajukan diduga dengan menggunakan pendekatan Bayesian, pendugaan parameter terhadap model-model individu dilakukan dengan menggunakan pendekatan Bayesian melalui simulasi MCMC seperti penelitian yang dilakukan Anggana (2012).
Tabel 1 Korelasi sisaan model-model individu Tahun Korelasi Statistik t p-value
(2009;2010) 0.3692292 3.2277 0.001945 (2009;2011) 0.3343404 2.8820 0.005326 (2010;2011) 0.4623764 4.2364 0.000072
Berdasarkan Tabel 1 dapat dilihat bahwa nilai korelasi sisaan model-model individu relatif tinggi. Nilai korelasi yang relatif tinggi dapat menjadi indikasi bahwa ada hubungan model regresi SAR yang dibangun pada tahun 2009, 2010 dan 2011. Hal ini diperkuat dengan pengujian statistik pada taraf nyata 0.05, pengujian keberartian korelasi menggunakan statistik uji t memberikan nilai p-value yang lebih kecil dari 0.05 sehingga cukup bukti untuk mengatakan bahwa terdapat hubungan yang nyata antar galat model-model individu SAR. Dengan demikian penggunaan model regresi SAR dengan sistem SUR dapat dipertimbangkan untuk digunakan pada data DBD Kota Bogor tahun 2009 – 2011.
Pendugaan Model SUR-SAR dengan MCMC
Regresi SAR untuk tahun 2009, 2010, dan 2011 yang disajikan dalam satu sistem model SUR diduga dengan menggunakan simulasi MCMC. Hal yang sangat penting adalah menentukan banyak iterasi dan burn-in period yang telah menghasilkan rantai-rantai Markov yang konvergen dalam hal stasioneritas sebarannya. Simulasi MCMC dicobakan dengan menentukan banyak iterasi 104,600 dan 20,000 iterasi pertama sebagai burn-in period dan menentukan nilai-nilai inisiasi parameter.
Diagnostik Konvergensi MCMC
20
tercapainya konvergensi dari sebaran posteriornya, dalam hal ini sebaran posterior dari parameter sudah stasioner. Diagnostik konvergensi MCMC dapat dilakukan dengan metode grafik diantaranya trace plot, density plot, acf plot, dan ergodic mean plot serta pengujian hipotesis, misalnya uji Geweke.
Berdasarkan plot diagnostik untuk semua parameter model yang terdapat pada Lampiran 3 menunjukkan bahwa simulasi MCMC telah mencapai konvergen dengan banyak iterasi 104,600 dan burn-in period 20,000. Trace plot yang merupakan plot antara indeks iterasi dengan nilai contoh acak hasil simulasi MCMC tidak mengindikasikan terdapatnya kecenderungan tertentu atau periodesitas dari suatu rantai Markov, nilai-nilai yang dibangkitkan masih di sekitar rataannya sehingga dapat diasumsikan bahwa simulasi MCMC untuk membangkitkan semua parameter telah mencapai konvergen dalam hal stasioneritas sebaran posteriornya. Plot fungsi kepekatan peluang menunjukkan setiap parameter model yang dibangkitkan dengan simulasi MCMC merupakan peubah acak yang mempunyai sebaran yang simetris. Plot acf dari contoh acak yang dibangkitkan tidak menunjukkan adanya masalah otokorelasi yang serius sehingga diasumsikan contoh acak yang telah dibangkitkan merupakan rantai
Markov yang telah stasioner. Plot rataan ergodik menunjukkan rataan dari kumulatif nilai contoh acak yang dibangkitkan setelah melewati tahap iterasi tertentu adalah stabil sehingga dapat diasumsikan bahwa simulasi MCMC pada proses pembangkitan semua parameter model telah mencapai konvergen dalam hal rataan sebaran posteriornya.
Untuk memperkuat hasil diagnostik konvergensi MCMC yang telah dilakukan secara visual maka dilakukan diagnostik lanjutan secara formal melalui pengujian hipotesis dengan menggunakan uji Geweke. Uji Geweke yang dilakukan adalah dengan mengelompokkan contoh acak yang telah dibangkitkan setelah burn-in period menjadi dua kelompok yakni kelompok 1 yang merupakan 10% awal dari contoh acak setelah burn-in period dan kelompok 2 yang merupakan 50% akhir dari contoh acak setelah burn-in period.
Tabel 2 Uji Geweke hasil simulasi MCMC
Parameter z-score p-value Parameter z-score p-value
ρ2009 0.08757 0.9302184 ρ2011 -0.61787 0.5366610
β0,2009 0.22260 0.8238468 β0,2011 -0.38529 0.7000226
β1,2009 -0.15130 0.8797391 β1,2011 0.72744 0.4669565
β2,2009 -0.13321 0.8940273 β2,2011 -1.27140 0.2035864
β3,2009 -0.45852 0.6465789 β3,2011 0.54308 0.5870747
β4,2009 -0.96126 0.3364215 β4,2011 -0.79577 0.4261657
21 pengujian kesamaan rataan dari kedua kelompok contoh acak (kelompok 1 dan kelompok 2) dari contoh acak yang dibangkitkan setelah burn-in period
berdasarkan teori analisis spektral pada analisis deret waktu menggunakan statistik z (z-score) (Sinharay 2004 dan Ntzoufras 2009). Apabila nilai harga mutlak z-score lebih kecil dari dua atau p-value > taraf nyata (α) maka dapat diindikasikan bahwa kedua kelompok contoh acak memiliki rataan yang sama dan simulasi dalam membangkitkan semua contoh acak telah konvergen. Berdasarkan Tabel 2 dapat dilihat bahwa nilai p-value uji Geweke untuk semua parameter
nilainya lebih besar dari taraf nyata (α=0.05) sehingga hal ini menjadi bukti yang
kuat bahwa simulasi MCMC untuk membangkitkan semua contoh acak pada pendugaan parameter model SUR-SAR telah konvergen.
Ringkasan Statistik Posterior
Jika proses simulasi MCMC dengan banyaknya iterasi dan burn-in period
yang telah ditentukan telah mencapai konvergen (konvergen dalam hal stasioneritas sebaran posteriornya) maka contoh acak yang dibangkitkan setelah
burn-in period dapat digunakan untuk menghitung statistik dari sebaran posteriornya. Statistik yang dihitung diantaranya rataan, median, nilai persentil, dan galat baku. Nilai dugaan parameter model merupakan rataan posterior hasil simulasi MCMC dan galat baku parameter model merupakan galat baku posterior hasil simulasi MCMC.
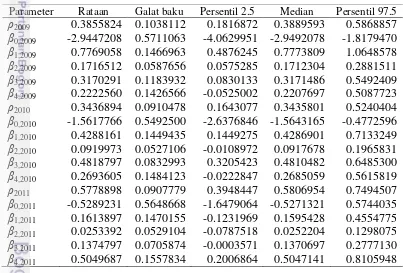
Tabel 3 Statistik posterior hasil simulasi MCMC
Parameter Rataan Galat baku Persentil 2.5 Median Persentil 97.5
ρ2009 0.3855824 0.1038112 0.1816872 0.3889593 0.5868857
β0,2009 -2.9447208 0.5711063 -4.0629951 -2.9492078 -1.8179470
β1,2009 0.7769058 0.1466963 0.4876245 0.7773809 1.0648578
β2,2009 0.1716512 0.0587656 0.0575285 0.1712304 0.2881511
β3,2009 0.3170291 0.1183932 0.0830133 0.3171486 0.5492409
β4,2009 0.2222560 0.1426566 -0.0525002 0.2207697 0.5087723
ρ2010 0.3436894 0.0910478 0.1643077 0.3435801 0.5240404
β0,2010 -1.5617766 0.5492500 -2.6376846 -1.5643165 -0.4772596
β1,2010 0.4288161 0.1449435 0.1449275 0.4286901 0.7133249
β2,2010 0.0919973 0.0527106 -0.0108972 0.0917678 0.1965831
β3,2010 0.4818797 0.0832993 0.3205423 0.4810482 0.6485300
β4,2010 0.2693605 0.1484123 -0.0222847 0.2685059 0.5615819
ρ2011 0.5778898 0.0907779 0.3948447 0.5806954 0.7494507
β0,2011 -0.5289231 0.5648668 -1.6479064 -0.5271321 0.5744035
β1,2011 0.1613897 0.1470155 -0.1231969 0.1595428 0.4554775
β2,2011 0.0253392 0.0529104 -0.0787518 0.0252204 0.1298075
β3,2011 0.1374797 0.0705874 -0.0003571 0.1370697 0.2777130
β4,2011 0.5049687 0.1557834 0.2006864 0.5047141 0.8105948
22
iterasi yang mana nilai-nilai contoh acak dari 20,000 iterasi pertama tidak digunakan dalam perhitungan statistik posterior model SUR-SAR. Nilai statistik posterior rataan dan median untuk semua parameter model SUR-SAR menunjukkan bahwa kedua statistik ini memiliki nilai yang relatif sama sehingga diindikasikan bahwa semua contoh acak setelah burn-in period tidak memiliki nilai-nilai ekstrim dan nilai-nilai pencilan dan statistik rataan posterior dapat digunakan sebagai penduga parameter model SUR-SAR. Untuk mengetahui ukuran ketidakpastian parameter model SUR-SAR sebagai peubah acak digunakan statistik posterior berupa galat baku. Sedangkan statistik posterior persentil 2.5 dan persentil 97.5 dapat digunakan dalam pengujian hipotesis parameter model SUR-SAR secara terpisah pada taraf nyata 0.05.
Tabel 4. Statistik DIC
Model DIC Model DIC
2009 2010 2011
Individu SAR 31.48183 34.25452 38.12259 SUR-SAR 72.33297 Tabel 4 menunjukkan statistik kebaikan model (statistik DIC) untuk model individu SAR dan model SUR-SAR. Berdasarkan perhitungan terhadap model individu SAR, diperoleh nilai DIC setiap tahunnya berurutan adalah 31.48183, 34.25452, dan 38.12259. Sedangkan DIC model SUR-SAR nilainya adalah 72.33297 yang secara agregat terlihat lebih kecil dari nilai DIC model individu SAR untuk ketiga tahun pengamatan. Meskipun model SUR-SAR memiliki nilai statistik DIC yang lebih kecil dibandingkan jumlah statistik DIC model individu SAR tahun 2009, 2010, dan 2011, keputusan model yang terbaik antara model individu SAR dan model SUR-SAR belum dapat ditentukan karena belum ada penelitian yang mendukung perbandingan model individu dan model dengan sistem SUR menggunakan statistik DIC.
Pengujian Keberartian Parameter Model
Pengujian parameter model SUR-SAR dengan pendekatan Bayesian pada taraf nyata 0.05 dilakukan dengan membentuk credible interval (CI) melalui nilai persentil 2.5 dan nilai persentil 97.5 seperti pada Tabel 3. Parameter dikatakan nyata secara statistik apabila nilai persentil 2.5 dan nilai persentil 97.5 tidak berbeda tanda atau antara nilai persentil 2.5 dan nilai persentil 97.5 tidak memuat nilai nol.
23 Evaluasi Model Hasil Simulasi MCMC
Hal yang penting untuk dievaluasi pada proses pendugaan parameter ialah mengenai ketidakpastian dari parameter sebagai sebuah peubah acak yang dibangkitkan melalui proses simulasi MCMC. Galat baku posterior yang telah disajikan sebelumnya pada Tabel 3 merupakan sebuah ukuran ketidakpastian parameter sebagai contoh acak yang merupakan fungsi dari ukuran contoh dengan mengasumsikan antar contoh acak saling bebas. Pada proses simulasi MCMC, sangat sulit untuk mengasumsikan contoh acak yang dibangkitkan saling bebas sehingga diperlukan sebuah ukuran ketidakpastian parameter yang merupakan fungsi dari banyaknya iterasi (ukuran contoh) dalam proses simulasi MCMC. Ukuran statistik ketidakpastian parameter hasil simulasi MCMC ini dikenal dengan galat baku Monte Carlo (Ntzoufras 2009).
Tabel 5 Galat baku posterior dan galat baku Monte Carlo hasil simulasi MCMC parameter dalam model SUR-SAR. Idealnya GBMC akan memberikan nilai yang lebih kecil dibandingkan GBP karena informasi ketidakbebasan rantai Markov
24
Perbandingan Model SUR-SAR dan Model Individu SAR
Pendugaan parameter dengan sistem SUR idealnya akan memberikan dugaan model yang efisien dibandingkan dengan model-model individunya sehingga evaluasi terkait efisiensi pendugaan parameter merupakan hal yang penting dilakukan. Efisiensi pendugaan parameter dapat dilakukan dengan membandingkan galat baku penduga parameter model. Apabila nilai galat baku dari model dengan SUR lebih kecil dibandingkan galat baku yang diperoleh dari model-model individunya maka model dengan sistem SUR memberikan nilai dugaan parameter yang lebih efisien dibandingkan dengan model-model individunya. Dengan demikian untuk keperluan ini akan disajikan statistik yang diperlukan yang diperoleh dari model-model individunya.
Nilai Dugaan Model SUR-SAR dan Model Individu SAR
Untuk membandingkan model individu SAR dan model SAR dengan sistem SUR,(SUR-SAR) dilakukan pendugaan parameter model individu SAR dengan menetapkan banyaknya iterasi dan burn-in period pada masing-masing model individu SAR sama banyaknya dengan model SUR-SAR. Kemudian, hasil pengujian keberartian parameter kedua model juga akan dibandingkan.
Tabel 6 Penduga parameter model SUR-SAR dan model individu SAR Penduga
25 tersebut. Meskipun dua parameter model pada kedua model memberikan hasil pengujian keberartian parameter yang berbeda, secara keseluruhan pengujian keberartian delapan belas parameter untuk masing-masing model memberikan hasil pengujian yang relatif sama. Adanya hasil pengujian keberartian parameter model yang berbeda menunjukkan bahwa penduga parameter yang dihasilkan model SUR-SAR boleh jadi merupakan koreksi terhadap penduga model individu SAR sehingga diperlukan penelitian lanjutan untuk mengkaji hal ini. Karena hasil dugaan parameter model SUR-SAR dan model individu SAR memberikan hasil dugaan yang tidak jauh berbeda maka hal ini cukup fair apabila kedua model ini dibandingkan untuk mencari mana model yang lebih baik dalam mengepas data.
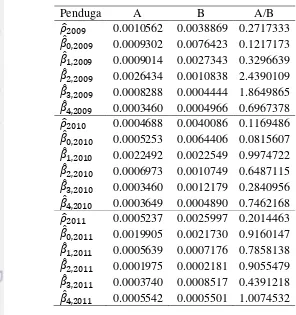
Analisis Efisiensi Pendugan Parameter Melalui GBMC
Isu efisiensi pendugaan parameter menggunakan model sistem SUR akan dievaluasi menggunakan ukuran ketidakpastian dari penduga yaitu melalui statistik galat baku. Karena penduga parameter menggunakan proses simulasi maka untuk mengakomodasi asumsi contoh acak yang tidak saling bebas digunakan galat baku Monte Carlo yang merupakan koreksi dari galat baku posterior.
Tabel 7 GBMC SUR-SAR (A) dan GBMCindividu SAR (B)
Penduga A B A/B
26
memberikan nilai GBMC lebih kecil dibandingkan model individu SAR walaupun ada tiga parameter ( , , dan ) yang memberikan model SUR-SAR nilai GBMC yang lebih besar dibandingkan model individu SUR-SAR. Hasil ini dapat mendukung klaim bahwa model dengan sistem SUR akan memberikan tingkat efisiensi pendugaan parameter yang lebih tinggi dibandingkan model individunya ketika antar model individu saling berhubungan. Adanya nilai GBMC SUR-SAR yang nilainya masih lebih besar dibandingkan GBMC model individu SAR boleh jadi karena masalah lain diluar permasalahan adanya hubungan antar model individu, misalnya masalah pada proses simulasi, ingat bahwa galat baku pada proses simulasi MCMC merupakan fungsi dari banyaknya iterasi.
5
SIMPULAN DAN SARAN
Simpulan
Model SUR-SAR dengan pendekatan Bayesian yang dikaji pada penelitian ini merupakan model yang memadukan masalah efisiensi pemodelan pada data panel spasial yang memiliki informasi hubungan antar model tahunannya dan masalah kepraktisan metode pendekatan pendugaan parameter yang tidak memiliki solusi dalam bentuk pasti (closed form) serta sulitnya menentukan statistik uji parameter model. Penggunaan model SUR-SAR pada analisis regresi spasial diantaranya adalah dapat menangkap ada atau tidak ada fenomena otokorelasi spasial, analisis kontribusi faktor-faktor non spasial model, dan analisis hubungan antar model. Proses simulasi MCMC dilakukan dengan menggunakan algoritma Gibbs Sampler dan Metropolis-Hasting sampai diperoleh simulasi yang konvergen dalam hal sebaran posterior parameter modelnya melalui bantuan plot dan uji statistik. Untuk evaluasi prioritas model SUR-SAR jika dibandngkan model individu dalam mengepas data dapat dilakukan menggunakan statistik galat baku posterior hasil simulasi.
Berdasarkan kajian empiris pada data DBD Kota Bogor tahun 2009 – 2011 diperoleh hasil bahwa data mendukung terdapatnya otokorelasi spasial pada kejadian DBD Kota Bogor, kontribusi dari faktor-faktor penyerta (pengaruh) berubah setiap tahun, dan terdapat hubungan antar model regresi SAR yang dibangun setiap tahun. Penentuan banyaknya iterasi dan burn-in period yang menghasilkan simulasi yang konvergen dilakukan dengan trial and error sehingga diperoleh banyaknya iterasi S = 104,600 dan burn-in period B = 20,000. Model SUR-SAR dapat mengepas data DBD Kota Bogor 2009 – 2011 lebih baik daripada model individu SAR karena memiliki tingkat efisiensi pendugaan parameter dan derajat kecocokan model yang lebih tinggi.
Saran
28
DAFTAR PUSTAKA
Anggana HD. 2012. Penerapan Bayesian Spatial Autoregressive Model dalam Menaksir Kontribusi Faktor-faktor yang Mempengaruhi Kejadian DBD di Kabupaten Tasikmalaya [Skripsi]. Bandung: Universitas Padjadjaran.
Anselin L. 1988. Spatial Econometrics Methods and Models. Dordrecht: Kluwer Academic Publishers.
Austin PC. 2008. Bayes Rules for Optimally Using Bayesian Hierarchical Regression Models in Provider Profiling to Identify High-mortality Hospitals.
BMC Medical Research Methodology. 8:3
Baltagi BH. 2008. Econometrics. Ed ke-4. New York: Springer-Verlag.
Carlin BP, Louis TA. 2009. Bayesian Methods for Data Analysis. Ed ke-3. Boca Raton : Chapman & Hall.
Chen MH, Shao QM, Ibrahim JG. 2000. Monte Carlo Methods in Bayesian Computation. New York: Springer-Verlag.
Felmlee DH, Hargens LL. 1988. Estimation and Hypothesis Testing for Seemingly Unrelated Regressions: A Sociological Application. Social Science
Research. 17:384-399.
Gamerman D, Lopes HF. 2006. Markov Chain Monte Carlo Stochastic Simulation for Bayesian Inference. Ed ke-2. Boca Raton: Chapman & Hall. Gelman A, Carlin JB, Stern HS, Dunson DB, Vehtari A, Rubin DB. 2014.
Bayesian Data Analysis. Ed ke-3. Boca Raton: Chapman & Hall.
Geweke J. 1992. Evaluating the Accuracy of Sampling Based Approaches to The Calculation of Posterior Moments. Bayesain Statistic. 4:169-193.
Ghosh M, Hoekstra RM. 1995. A.P.O. Rules in Hierarchical Bayes Regression Models. Sequential Analysis: Design Methods and Applications. 14(2): 99-115. Gilks WR, Richardson S, Spiegelhalter DJ. 1996. Markov Chain Monte Carlo in
Practice. Dordrecht: Springer Science+Business Media.
Griffiths W. 2001. Bayesian Inference in the Seemingly Unrelated Regressions Model. Melbourne: University of Melbourne.
Hajarisman H. 2013. Pemodelan Area Kecil untuk Menduga Angka Kematian Bayi Melalui Pendekatan Model Regresi Poisson Bayes Berhirarki Dua-Level [Disertasi]. Bogor: Institut Pertanian Bogor.
Hoff PD. 2009. A First Course in Bayesian Statistical Methods. New York: Springer-Verlag.
Kakamu K, Polasek W, Wago H. 2011. Production Technology and Agglomeration for Japanese Prefectures During 1991-2000. Papers in Regional Science. 1(1):29-42.
LeSage JP. 1997. Bayesian Estimation of Spatial Autoregressive Models.
International Regional Science Review. 1-2:113-129.
LeSage JP. 2005. Bayesian Estimation of Spatial Regression Models. Toledo: Department of Economics, University of Toledo.
Lindley DV, Smith AFM. 1972. Bayes Estimates for Linear Model. Journal of The Royal Statistical Society. 34(1):1-41.
29 Rahmat A. 2014. Analisis Spasial-Temporal untuk Mengkaji Faktor-faktor yang Mempengaruhi Sebaran Penyakit Demam Berdarah di Kota Bogor [Tesis]. Bogor: Institut Pertanian Bogor.
Sinharay S. 2004. Experiences With Markov Chain Monte Carlo Convergence Assessment in Two Psychometric Examples. Journal of Educational and Behavioral Statistics. 29(4):461-488.
Spiegelhalter DJ, Best NG, Carlin BP, van der Linde A. 2002. Bayesian Measures of Model Complexity and Fit. Journal of The Royal Statistical Society. 64:583-639.
Sun Y, Ke R, Tian Y. 2014. Some Overall Properties of Seemingly Unrelated Regression Models. AStA Advances in Statistical Analysis. 98:103-120.
Tim NH. 2002. Applied Multivariate Analysis. New York: Springer-Verlag. Wang X, Kockelman KM. 2007. Specification and Estimation of Spatially and
Temporally Autocorrelated Seemingly Unrelated Regression Model : Application to Crash Rates in China. SpringerTransportation. 34:281-300. Zellner A. 1962. An Efficient Method of Estimating Seemingly Unrelated
Regressions and Test for Aggregation Bias. Journal of American Statistical Association. 57:348-368.
30
Lampiran 1 Penurunan Sebaran Posterior Bersyarat Model Bayesian SAR
Jika , model regresi SAR +ε dibentuk ulang menjadi model regresi umum dengan asumsi ε~N(0,σ2In)
Fungsi kemungkinan model adalah | | |
⁄ {
} |
| | | ⁄ {
} | | ⁄ {
}
uraikan bentuk menjadi penjumlahan dua bentuk kuadratik :
misalkan ( ̂ ( ̂
̂ ̂ ̂
̂ ̂ ̂ ( ̂ ̂ ̂
( ̂ ̂ ̂
( ̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂
( ̂ ( ̂
sehingga
| | | ⁄ { ( ̂ ( ̂
}