PENDETEKSIAN KEMIRIPAN KODE PROGRAM C
DENGAN ALGORITME K-MEDOIDS
RADEN FITYAN HAKIM
DEP ARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENG ETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pendeteksian Kemiripan Kode Program C dengan Algoritme K-medoids adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
RADEN FITYAN HAKIM. Pendeteksian Kemiripan Kode Program C dengan AlgoritmeK-medoids. Dibimbing oleh IMAS SUKAESIH SITANGGANG.
Aksi penjiplakan terhadap kode program lebih sering dan lebih mudah dilakukan. Pendeteksian manual terhadap penjiplakan memakan banyak waktu maupun tenaga. Pendeteksian dapat dilakukan dengan mengelompokkan kode program yang mirip berdasarkan strukturnya. Penelitian ini bertujuan untuk menerapkan algoritme K- medoids pada 4 dataset kode program C untuk menentukan kemiripan dari kode-kode program tersebut dan menganalisis hasil pengelompokan yang diperoleh. Hasil percobaan menunjukkan clustering terbaik pada dataset1 (Kondisi If- Else dan Pengulangan While) diperoleh pada k=10 dengan rataan dissimilarity 2.655, dan sebanyak 18.9% tugas mahasiswa memiliki kelompok yang sama. Pada dataset2 (Pengulangan While), clustering terbaik diperoleh pada k=9 dengan rataan dissimilarity 2.227, dan 32.6% tugas mahasiswa memiliki kelompok yang sama. Untuk dataset3 (Pengulangan For Bersarang dan Kondisi If), tugas mahasiswa terbagi menjadi dua buah cluster dengan rataan dissimilarity 0.719, dan sebanyak 87% tugas mahasiswa berada pada cluster yang sama. Hasil clustering terbaik pada dataset4 (Kondisi If- Else dan Pengulangan For) diperoleh pada k=6 dengan rataan dissimilarity 3.199, dan sebanyak 61% tugas mahasiswa berada pada kelompok yang sama. Nilai akurasi dari hasil pengclusteran mencapai 93.28%.
Kata kunci: algoritmeK-medoids, clustering, pendeteksian kemiripan
ABSTRACT
RADEN FITYAN HAKIM. C Source Code Similarity Detection using K-Medoids Algorithm. Supervised by IMAS SUKAESIH SITANGGANG.
Practice of plagiarism on program codes is more common and easier to do. Manual detection of plagiarism takes a lot of time and effort. The detection can be done by grouping program codes that have similar structures. This study intends to apply K-medoids algorithm on 4 C code program datasets to find similarities of code program and analyze clustering results. The experimental results show that the best clustering in dataset1 (If- Else Condition and Looping While) was obtained at k=10 with an average of dissimilarity 2.655, and 18.9% of students have the same group. In dataset2 (Looping While), the best clustering was obtained at k=9 with an average of dissimilarity 2.227, and 32.6% student assignments are in the same group. For dataset3, the assignments are divided into two clusters with an average of dissimilarty 0.719, and 87% of students assignments are in the same cluster. The best c lustering result on the dataset4 was obtained at k=6 with an average of dissimalrity 3.199, and 61% of students assignments are in the same group. The accuracy rate from clustering results is 93.28%.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PENDETEKSIAN KEMIRIPAN KODE PROGRAM C
DENGAN ALGORITME K-MEDOIDS
DEP ARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENG ETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
Judul Skripsi : Pendeteksian Kemiripan Kode Program C dengan Algoritme K-Medoids
Nama : Raden Fityan Hakim NIM : G64070032
Disetujui oleh
Dr Imas Sukaesih Sitanggang, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah Subhanahu wa Ta’ala atas rahmat, hidayah, dan nikmat-Nya sehingga penulis dapat menyelesaikan penelitian ini sebagai tugas akhir untuk memperoleh gelar Sarjana Komputer.
Banyak pihak yang telah memberikan bantuan baik yang bersifat materi maupun moral kepada penulis dalam penyelesaian tugas akhir ini. Oleh karena itu, penulis ingin menyampaikan rasa terima kasih yang sebesar-besarnya kepada: 1 Ayahanda Tjatja Sudarsa dan ibunda Nenden Malihah serta Kakak penulis Elva
Munawwaroh, Vera Farohatul Mardiah, Irvaanulhakim, Maftuh Hasan Harkoni, Euis YP Harun, dan Miftah Suritho yang senantiasa mendoakan, memotivasi dan memberikan kasih sayangnya kepada penulis.
2 Ibu Dr.Imas Sukaesih Sitanggang S.Si, M.Kom selaku dosen pembimbing yang senantiasa membimbing dan mengarahkan dengan sabar serta memberi saran dan motivasi yang membangun.
3 Bapak Hari Agung Adrianto, S.Kom, M.Si dan Bapak Aziz Kustiyo S.Kom, M.Si selaku dosen penguji.
4 Seluruh staff Departemen Ilmu Komputer yang senantiasa membantu penulis. 5 Teman-teman Ilmu Komputer 44 yang selalu sabar berbagi ilmu, membantu,
dan mengajarkan penulis dalam proses menyelesaikan tugas akhir.
6 Sahabat-sahabat penulis: Rilan, Adi Gunarso, Dipta, Yanta, Abi, serta Arizal, yang selalu ada menemani, mendukung, mengingatkan, membantu, dan memberi semangat serta motivasi kepada penulis.
Akhir kata, Penulis berharap semoga tulisan ini dapat berma nfaat bagi para pembaca.
DAFTAR ISI
DAFTAR TABEL v
DAFTAR GAMBAR v
DAFTAR LAMPIRAN v
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 3
Data Penelitian 3
Tahapan Penelitian 3
Pengelompokan Data Manual 4
Praproses Data 4
Penerapan Algoritme K- medoids 6
Algoritme K-medoids 7
Analisis Hasil Cluster 8
Evaluasi Hasil Clustering 8
HASIL DAN PEMBAHASAN 9
Pengelompokan Manual 9
Praproses Data 10
Penerapan Algoritme K- medoids 12
Analisis Hasil Cluster 14
Evaluasi Hasil Clustering 19
SIMPULAN DAN SARAN 20
Simpulan 20
Saran 20
DAFTAR PUSTAKA 20
DAFTAR TABEL
1 Komposisi data penelitian 3
2 Contoh aturan konversi kode program 5
3 Dataset awal 9
4 Dataset setelah pengelompokan manual 10
5 Term frequency 12
6 Hasil clustering untuk DataSet1 13
7 Hasil clustering untuk DataSet2 13
8 Hasil clustering untuk DataSet3 13
9 Hasil clustering untuk DataSet4 14
10 Hasil cluster terbaik untuk DataSet1 14
11 Hasil cluster terbaik untuk DataSet2 16
12 Hasil cluster terbaik untuk DataSet3 17
13 Hasil cluster terbaik untuk DataSet4 18
14 Nilai akurasi setiap dataset 19
DAFTAR GAMBAR
1 Tahapan penelitian 3
2 Praproses data 4
3 Contoh penyederhanaan kode program 5
4 Algoritme K-medoid 8
5 Hasil pembuangan preprocessor directives 10
6 Hasil proses tokenisasi 11
7 Hasil Penyederhanaan token stream 11
8 N-gram dengan nilai N=4 11
DAFTAR LAMPIRAN
1 Contoh kode program dari masing- masing set data yang digunakan
dalam penelitian 22
2 Hasil pengelompokan manual 24
3 Tabel aturan konversi kode program menjadi token sederhana 25
4 Hasil clustering untuk DataSet1 26
5 Hasil clustering untuk DataSet2 27
6 Hasil clustering untuk DataSet3 28
7 Hasil clustering untuk DataSet4 29
8 Hasil evaluasi untuk DataSet1 30
9 Hasil evaluasi untuk DataSet2 31
10 Hasil evaluasi untuk DataSet3 32
PENDAHULUAN
Latar Belakang
Pada era globalisasi yang serba cepat dan instan saat ini, mahasiswa cenderung menginginkan segala sesuatunya dapat dilakukan dengan cepat, mudah, dan praktis. Kemajuan teknologi yang terjadi malah disalahgunakan oleh kebanyakan orang untuk melakukan kecurangan, salah satunya adalah tindak penjiplakan atau plagiarism. Hal itu dapat terlihat pada saat para siswa mengerjakan tugas sekolah maupun tugas matak uliah. Mereka cenderung berkeinginan untuk dapat sesegera mungkin menyelesaikan tugas mereka tanpa perlu bersusah payah, cukup dengan menjip lak dari tugas teman yang telah selesai ataupun mengambilnya dari internet. Dengan begitu tugas sekolah, kantor, maupun tugas kuliah dapat selesai dengan cepat dan mudah.
Mata kuliah Algoritme dan Pemrograman merupakan salah satu mata kuliah yang memberikan penugasan berupa kode program yang umumnya dikumpulkan dalam bentuk berkas digital. Hal ini menyebabkan tugas kode program rentan terhadap tindak penjiplakan. Saat ini pendeteksian penjiplakan semakin sulit dilakukan. Hal ini disebabkan bertambahnya jumlah mahasiswa dan semakin mudahnya mahasiswa untuk saling berbagi hasil pekerjaan baik melalui internet ataupun media lainnya. Selain itu, pendeteksian semakin sulit dengan adanya modifikasi berupa penambahan atau penghapusan baris komentar, merubah nama variabel atau fungsi, maupun merubah susunan struktur kode programnya. Sehingga, pendeteksian secara manual sangatlah memakan banyak biaya dan juga tenaga. Oleh karena itu dibutuhkan suatu cara ataupun sistem yang dapat membantu pendeteksian penjiplakan secara otomatis.
Pendeteksian kemiripan kode program secara otomatis oleh Burrows (2004) ialah dengan mengindeks semua kode program yang terkumpul, kemudian melakukan query terhadap hasil indexing tersebut untuk mendapatkan kode-kode program yang mirip. Burrows (2004) menggunakan cara pendeteksian penjiplakan structure-orientedcode-based system. Sistem ini membuat representasi sederhana dari kode program. Sistem ini sengaja mengabaikan elemen yang mudah dimodifikasi seperti komentar, whitespace, dan nama variabel. Sistem berorientasi struktur ini juga tidak rentan terhadap penambahan kode program yang bersifat redundant.
Gumilang (2013) menggunakan structure-oriented code-based system untuk pendeteksian penjiplakan kode program C dengan clustering. Proses pengelompokan pada penelitian Gumilang (2013) dilakukan dengan menggunakan algoritme means. Pada penelitian ini, Gumilang (2013) melakukan iterasi K-means secara otomatis. Iterasi K-means otomatis yaitu melakukan clustering menggunakan K- means dengan nilai K bertambah secara otomatis pada setiap iterasinya. Iterasi berhenti apabila anggota-anggota clusters hasil sudah cukup dekat dengan centroid- nya.
top-2
down, dimana seluruh dokumen dimasukkan ke dalam satu cluster awal kemudian dipisahkan berdasarkan kemiripannya dengan menggunakan K- means dengan jumlah iterasi sebanyak 5 kali.
Salah satu teknik clustering adalah K-medoids. Algoritme K-medoids merupakan penyempurnaan dari algoritme K-means yang sangat sensitif terhadap nilai outlier atau titik terjauh. K-medoids mengambil sebuah objek aktual untuk merepresentasikan sebuah cluster, dengan menggunakan sebuah objek untuk setiap clusternya (Han dan Kamber 2011).
Pendeteksian kemiripan pada penelitian ini menggunakan dataset yang berupa sejumlah N-gram dari kode program. Dataset ini kemudian diproses dengan menggunakan WEKA untuk mendapatkan tabel term frequency dari masing masing kode program dan selanjutnya dikelompokkan dengan menggunakan algoritme K-medoids.
Perumusan Masalah
Perumusan masalah dalam penelitian ini adalah
1 Bagaimana menerapkan algoritme K-medoids dalam pendeteksian kemiripan kode program.
2 Apakah algoritme K-medoids dapat menghasilkan cluster yang baik?
3 Bagaimana pola kemiripan kode program yang dihasilkan algoritme K -medoids pada setiap dataset tugas algoritme dan pemrograman.
Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan algoritme K-medoids untuk menentukan tingkat kemiripan kode program C sehingga dapat membantu pendeteksian penjiplakan pada kode program. Serta mengevaluasi dan menganalisis hasil dari pengelompokan kode program.
Manfaat Penelitian
Manfaat dari penelitian ini adalah untuk membantu mempermudah pendeteksian penjiplakan kode program C dengan mencari tingkat kemiripan dari struktur kode program, sehingga efisiensi kerja tenaga pendidik dapat meningkat dan tindak penjiplakan yang dilakukan mahasiswa dapat berkurang .
Ruang Lingkup Penelitian
3
sebelumnya yang dilakukan Notyasa (2013). Tabel 1 menunjukkan komposisi dari data yang digunakan pada penelitian ini.
Tabel 1 Komposisi data penelitian Dataset Kode
Tugas
Keterangan
dataset1 pjj0210 Kondisi If-Else dan Pengulangan While dataset2 pjj0302 Pengulangan While
dataset3 pjj0307 Pengulangan For Bersarang dan Kondisi If dataset4 pjj0309 Kondisi If-Else dan Pengulangan For
METODE
Data Penelitian
Data yang digunakan pada penelitian ini merupakan kode program yang diambil dari Bagian Komputasi Terapan Departemen Ilmu Komputer. Data penelitian ini adalah kumpulan berkas digital kode program bahasa C yang merupakan tugas mata kuliah Algoritme dan Pemrograman yang diberikan kepada mahasiswa Program S1 Ilmu Komputer. Kode program bahasa C tersebut dibagi ke dalam empat kelompok berdasarkan jenis tugas, yaitu DataSet1 untuk jenis tugas pjj0210, DataSet2 untuk pjj0302, DataSet3 untuk pjj0307 dan DataSet4 untuk jenis tugas pjj0309 dengan total data yang digunakan sebanyak 307 buah kode program tugas pemrograman bahasa C. Keempat buah jenis tugas yang dipakai untuk dataset pada penelitian ini memiliki tingkat kesulitan menengah. Hal ini dikarenakan tugas yang terlalu mudah akan memiliki variasi algoritme pemecahan yang sedikit, sedangkan tugas yang terlalu sulit cenderung memiliki jumlah kode program yang sedikit karena banyak mahasiswa yang tidak mengumpulkan tugas.
Tahapan Penelitian
Secara garis besar tahapan penelitian yang dilakukan dalam penerapan algoritme K-medoids ini memiliki 4 tahapan. Tahapan pada penelitian ini dapat dilihat pada Gambar 1.
4
Pengelompoka Data Manual
Pada tahapan ini dilakukan pemilihan sampel tugas dan pengelompokan tugas secara manual. Setiap sampel diperiksa satu persatu dan melalui 2 tahap pemeriksaaan. Tahap pertama adalah pemeriksaan nilai output kode program dan tahap kedua adalah pemeriksaan struktur dan algoritme kode program. Pada tahap pertama setiap kode program dijalankan dan diperiksa nilai output-nya, kemudian kode-kode program yang memiliki nilai output yang sama akan dikelompokkan ke dalam satu cluster yang sama. Selanjutnya pada tahap kedua, kode-kode program tiap cluster tersebut diperiksa strukturnya. Kode-kode program dengan struktur dan algoritme yang memiliki tingkat kemiripan tinggi dikelompokkan ke dalam cluster yang sama dan kode program yang berbeda dipisah ke dalam cluster yang berbeda.
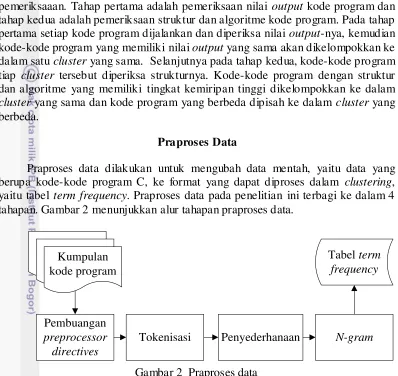
Praproses Data
Praproses data dilakukan untuk mengubah data mentah, yaitu data yang berupa kode-kode program C, ke format yang dapat diproses dalam clustering, yaitu tabel term frequency. Praproses data pada penelitian ini terbagi ke dalam 4 tahapan. Gambar 2 menunjukkan alur tahapan praproses data.
Kumpulan
Gambar 2 Praproses data Pembuangan Preprocessor Directives
Pada penelitian ini diasumsikan tidak adanya penggunaan makro pada kode program. Oleh karena itu pada tahap pertama ini dilakukan tahap pembuangan preprocessor directives. Preprocessor directives merupakan sejumlah baris pada awal program yang diawali dengan karakter “#”.
Tokenisasi
5
Penyederhanaan
Selanjutnya pada proses penyederhanaan, keywords dan special characters kode program diubah menjadi token sederhana agar lebih ringkas dan mudah dalam pembentukan term. Kode program yang telah diubah menjadi sebuah string panjang token sederhana disebut dengan token stream (Burrows 2004). Konversi kode program menjadi token sederhana dilakukan berdasarkan aturan konversi seperti pada Tabel 2.
Tabel 2 Contoh aturan konversi kode program
Keywords Token sederhana
Tabel 1 memperlihatkan contoh aturan konversi beberapa keywords dan
special characters kode program C menjadi token sederhana. ALPHANUM adalah nama fungsi, nama variabel, atau nilai variabel. STRING adalah sederetan karakter yang diapit oleh tanda "" (kutip ganda). Contoh proses penyederhanaan kode program menjadi sebuah token stream dapat dilihat pada Gambar 3.
1 #include <stdio.h>
Gambar 3 Contoh penyederhanaan kode program
N-gram
6
N-gram dibedakan berdasarkan jumlah potongan karakter sebesar N (Cavnar dan Trenkle 1994). Pengambilan potongan-potongan kata berupa karakter huruf tersebut ditambahkan dengan padding karakter blank untuk membantu pembentukan N-gram di awal dan akhir string. Sebagai contoh kata ”TEXT”
N-gram memiliki keunggulan yang lebih dalam pendeteksian penjiplakan. Hal ini dikarenakan dalam pencocokan stream, metode N-gram ini semua string dipecah menjadi beberapa substring, sehingga pada saat terjadi perubahan atau modifikasi pada kode program, kesalahan yang terjadi pada suatu string cenderung hanya berpengaruh pada N-gram yang berdekatan atau substring-nya saja. Oleh karena itu, kode program yang dimodifikasi akan tetap memiliki sebagian besar N-gram yang sama dengan kode program aslinya dan pendeteksian penjiplakan semakin mudah dilakukan (Borrows 2004). Lebih jelasnya berikut contoh 2-gram dari kata “Text” dan “Teext”:
Text : _T Te ex xt t_ Teext : _T Te ee ex xt t_
Modifikasi hanya menyebabkan munculnya kesalahan pada substring N-gram “ee” pada string“Teext”, sedangkan N-gram sisanya sama dengan N-gram pada string “Text”.
Pada penelitian ini, proses N-gram dilakukan pada token stream dengan ukuran N=4. N dipilih 4 karena merupakan nilai N yang terbaik untuk pendeteksian penjiplakan pada kode program (Chawla 2003 dalam Burrows 2004). Pada bagian akhir penelitian ini juga akan dilakukan percobaan pendeteksian dengan menggunakan nilai N yang berbeda. Hal ini dilakukan untuk melihat pengaruh nilai N yang lebih kecil dan lebih besar terhadap hasil pendeteksian pada penelitian ini.
Selanjutnya kemunculan setiap N-gram untuk setiap dokumen dihitung jumlahnya untuk memperoleh tabel term frequency. Tabel term frequency merupakan tabel yang menyimpan statistik kemunculan term atau N-gram dari masing- masing dokumen yang diperiksa, yang kemudian akan digunakan untuk memebentuk vektor-vektor dokumen pada proses clustering.
Penerapan Algoritme K-medoids
7
Algoritme K-Medoids
Algoritme K-means sangatlah sensitif terhadap keberadaan nilai outlier dari sebuah cluster karena beberapa objek memiliki posisi yang jauh dari mayoritas data, dan ketika data tersebut dimasukkan ke dalam cluster dapat menyebabkan perubahan secara dramatis terhadap nilai rata-rata dari sebuah cluster. Selain menggunakan nilai rata-rata objek dalam cluster sebagai titik acuan, kita dapat mengambil sebuah objek untuk mewakili cluster, dimana sebuah objek dari masing- masing cluster dipilih untuk menjadi objek representatif. Dengan demikian metode partisi masih bisa dilakukan berdasarkan prinsip meminimalkan jumlah ketidakmiripan antarobjek dan titik referensi yang sesuai. Konsep ini menjadi sebuah dasar dari metode K-medoids (Han & Kamber 2006).
Strategi yang mendasar dari algoritme K-medoids adalah untuk menemukan sejumlah k cluster dari n buah objek dengan terlebih dahulu menentukan objek perwakilan (medoids) untuk setiap cluster. Setiap objek yang tersisa kemudian dikelompokkan dengan medoids yang paling mirip. Algoritme K-medoids menggunakan objek representatif sebagai titik acuan, bukan menggunakan nilai rata-rata dari setiap objek dalam sebuah cluster. Algoritme ini mengambil input parameter k, yaitu jumlah cluster yang akan dipartisi antara himpunan n objek. Prinsip dari algoritme ini adalah untuk meminimalkan nilai dissimilarity antara setiap objek dengan titik representatifnya.
Algoritme K-medoids secara acak memilih k objek didalam dataset sebagai objek representatif awal yang disebut sebagai medoids. Sebuah medoid dapat didefinisikan sebagai objek di dalam cluster yang memiliki nilai rata-rata dissimilarity antarobjek dalam cluster paling minimal. Algoritme ini meminimalkan absolute error pada saat pengelompokan n buah objek ke dalam k cluster (Han dan Kamber 2011).
�
=
��
( ,
�)
∈�� �
�=1
dimana E merupakan jumlah total nilai absolute error dari semua objek p dalam dataset, oi adalah objek representative dari Ci dan dist(p,oi) merupakan ukuran
jarak kemiripan objek p terhadap objek representative oi dengan menggunakan jenis penghitungan jarak euclidean distance.
�� , � = ( �− �)2
�=1
8
Gambar 4 Algoritme K- medoids (Han dan Kamber 2011)
Analisis Hasil Cluster
Pada tahapan ini diperoleh hasil akhir berupa sejumlah cluster untuk setiap jenis dataset, jumlah anggota setiap cluster beserta daftar anggota dari masing-masing cluster, yang ditampilkan dalam bentuk NRP mahasiswa dan juga nilai huruf mutu akhir mata kuliah Algoritme dan Pemrograman dari masing anggota cluster.
Evaluasi Hasil Clustering
Pada tahapan ini dilakukan proses validasi dari hasil clustering. Tahapan ini dilakukan untuk mengukur seberapa baik hasil clustering yang didapatkan. Validasi dilakukan dengan cara membandingkan hasil cluster otomatis menggunakan metode clustering dengan hasil cluster secara manual. Evaluasi hasil clustering dilakukan dengan menggunakan perhitungan akurasi. Formula untuk mencari nilai akurasi ditunjukan sebagai berikut
Akurasi = jumlah kode program yang berada pada cluster yang sama total kode program
Jumlah kode program yang berada pada cluster yang sama adalah jumlah kode program hasil pengelompokan dengan algoritme K- medoid yang sama dengan cluster hasil pengelompokan secara manual, sedangkan total kode program merupakan jumlah total kode program dari sebuah dataset yang dievaluasi.
Algorithm : k-medoids, PAM, a k-medoids algorithm for partioning based
on medoid or central object
Input :
k: the number of cluster,
D: a data set containing n objects.
Output : A set of k cluster.
Method :
1. arbitrary choose k object in D as the initial representative object
or seeds;
2. repeat
3. Assign each remaining object to the cl uster with the nearest
representative object;
4. Randomly select a nonrepresentative object, orandom;
5. Compute the total cost, S,of swapping representative object, oj,
with orandom;
6. If S < 0 then swap oj with orandom to form the new set of k
representative object;
9
Alat
Penelitian dilakukan dengan menggunakan perangkat keras dan perangkat lunak sebagai berikut:
Perangkat keras berupa komputer personal dengan spesifikasi: Processor Intel Core i5-3210M 2.50 GHz,
Read Access Memory 4 GB, dan Hard disk 500 GB.
Perangkat lunak:
Sistem OperasiWindows 7 Professional 64-bit, Notepad ++ 6.6.8 sebagai text editor,
Microsoft Excel 2007 untuk pengolahan data,
Server control panel XAMPP 3.1.0 bitNami copyright, Web browser Mozilla Firefox 19.0.2.
Tool data mining WEKA 3.7 Tool statistika R x64 3.0.2
HASIL DAN PEMBAHASAN
Pengelompokan Manual
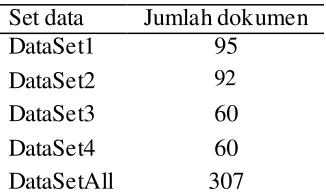
Pemilihan sampel data tugas yang digunakan berdasarkan tingkat kesulitan dari tugas tersebut. Sampel ini dipilih dengan tujuan agar mendapatkan beberapa kelompok dengan anggota yang memiliki kemiripan kode program supaya bisa dilakukan analisis. Data yang digunakan pada penelitian ini adalah kode-kode program dari tugas pemrograman berbahasa C. Jumlah data sebanyak 307 buah kode program yang dipilih dari 4 buah jenis tugas dengan kesulitan menengah. Masing- masing tugas tersebut kemudian dijadikan dataset pada penelitian ini. Tabel 3 menunjukkan komposisi dataset yang digunakan pada penelitian ini. Kode program dari masing- masing dataset penelitian ini dapat dilihat pada Lampiran 1.
Tabel 3 Dataset awal Set data Jumlah dokumen
DataSet1 95
DataSet2 92
DataSet3 60
DataSet4 60
10
Pengelompokan data secara manual dilakukan dalam dua tahap, yang pertama pemeriksaan output dari masing- masing program dan pada tahap kedua dilakukan dengan memeriksa struktur dari program tersebut. Pada DataSet1 dilakukan pengelompokan secara manual dengan membandingkan struktur kode programnya dan menghasilkan 10 buah cluster.
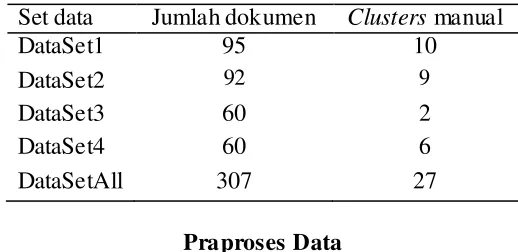
Untuk DataSet2 penelitian ini menggunakan hasil pengelompokan manual yang digunakan pada penelitian yang sudah dilakukan Gumilang (2013), dari 92 dokumen didapatkan 9 buah cluster. Untuk DataSet3 dan DataSet4 pada penelitian ini menggunakan hasil pengelompokan manual yang digunakan pada penelitian yg sudah dilakukan oleh Notiyasa (2013), yaitu 2 buah cluster untuk DataSet3 dan 6 buah cluster untuk DataSet4. Namun dari semua cluster yang dihasilkan tersebut, terdapat cluster yang hanya berisi 1 atau 2 buah kode program. Cluster yang memiliki anggota yang terlalu sedikit tersebut kemudian dihilangkan. Untuk Hasil pengelompokan manual pada DataSet1, DataSet2, DataSet3, dan juga DataSet4 dapat dilihat pada Lampiran 2. Hasil pengelompokan manual dari keempat dataset dapat dilihat pada Tabel 4.
Tabel 4 Dataset setelah pengelompokan manual Set data Jumlah dokumen Clusters manual
DataSet1 95 10
Pada bagian praproses data terbagi menjadi beberapa tahapan, yaitu: pembuangan preprocessor directives, tokenisasi, penyederhanaan dan N-gram. Tahapan pembuangan preprocessor directives dilakuakan karena pada penelitian ini diasumsikan tidak adanya makro pada kode program. Gambar 5 merupakan salah satu contoh pembuangan preprocessor directives dari salah satu kode program pada DataSet1:
9 printf("%lu\n", b); //cetak hasil 10 return 0;
11 }
11
Tahap berikutnya adalah melakukan pemilihan keyword dan special charcter pada kode program yang disebut dengan proses tokenisasi. Keyword dan special character didapatkan setelah memilah tiap term dengan membuang whitespace, baris komentar dan pembuangan karakter “;” karena merupakan karakter umum yang di gunakan di setiap akhir baris kode program C. Selanjutnya dilakukan perubahan semua huruf dari uppercase menjadi lowercase. Gambar 6 adalah contoh kode program yang telah melalui proses tokenisasi
1
Gambar 6 Hasil proses tokenisasi
Proses selanjutnya adalah tahap penyederhanaan, yaitu mengubah keyword dan special character yang didapatkan dari hasil tokenisasi menjadi deretan token sederhana yang diurutkan berdasarkan struktur kode programnya. Namun sebelumnya dilakukan pengecekan dan penambahan spasi di awal dan di akhir keyword atau special character tersebut, untuk memastikan tidak terjadinya kesalahan konversi yang diakibatkan adanya keyword dan special character yang berhimpitan satu sama lainnya. Perubahan/konversi keyword dan special character dilakukan dengan mengikuti aturan konversi yang dapat dilihat pada lampiran 3. Hasil dari proses penyederhanaan ini berupa string panjang token sederhana yang sering disebut dengan token stream. Gambar 7 adalah contoh dari token stream hasil penyederhanaan pada salah satu kode program pada Gambar 6.
NhikHFANjNoNFANoNNh5jfNiKhhNhNjNaaiimoNiNaoNNh5jNiRNl
Gambar 7 Hasil penyederhanaan token stream
Setelah token stream dari hasil penyederhanaan di dapatkan, lalu dilakukan proses N-gram pada token stream tersebut. Proses N-gram dilakukan untuk membangkitkan term dengan cara mengambil atau memotong sebuah string panjang sebanyak N buah huruf. Pada penelitian ini digunakan N=4. Gambar 8 adalah sebuah contoh N-gram dari token stream pada Gambar 7.
12
kHFA NFAN 5jfN NhNj imoN NNh5 HFAN FANo jfNi hNjN moNi Nh5j FANj AnoN fNiK NjNa oNiN h5jN ANjN NoNN NiKh jNaa NiNa 5jNi
Gambar 8 N-gram dengan nilai N=4
Selanjutnya setelah dilakukan N-gram dengan nilai N=4, frequency jumlah kemunculan setiap N-gram dari masing- masing kode program dihitung dengan menggunakan tool data mining WEKA, yaitu menggunakan fungsi filter unsupervised attribute dengan sub fungsi string to word vector yang kemudian akan diperoleh sebuah tabel term frequency, yang selanjutnya dapat digunakan untuk membentuk vektor-vektor dokumen pada proses clustering. Tabel 5 merupakan sebuah contoh term frequency dari N-gram pada Gambar 8
Tabel 5 Term frequency
Dok Term
_Nhi Nhik hikH ikHF kHFA HFAN FANj AnjN NjNo ....
dok1 1 1 1 1 1 1 1 1 1 ....
dok2 1 1 1 0 0 2 1 1 2 ....
dok3 1 1 1 1 1 3 2 1 2 ....
....
.... .... .... .... .... .... .... .... .... ....
Penerapan Algoritme K-medoids
Dari term frequency masing masing dataset yang didapatkan pada tahap praproses data, kemudian dilakukan pengclusteran. Proses clustering pada penelitian ini menggunakan algoritme K-medoids. K-medoids dapat dikatakan merupakan penyempuranaan dari algoritme K-means yang sangat sensitif terhadap nilai outlier.
13
Tabel 6 Hasil clustering untuk DataSet1
K Nilai Rata-Rata
Max.Diss Avg.Diss Diameter Separation
2 11.560 6.447 14.433 6.000
3 11.234 4.877 13.095 6.516
4 10.928 3.935 12.335 7.067
5 10.711 3.629 11.984 7.109
6 9.642 3.640 10.932 7.472
7 9.645 2.916 10.553 7.332
8 8.988 3.163 9.763 6.816
9 8.479 2.797 9.255 7.218
10 8.508 2.655 9.037 7.182
11 8.170 2.348 8.577 9.371
Tabel 7 Hasil clustering untuk DataSet2
K Nilai Rata-Rata
Max.Diss Avg.Diss Diameter Separation
2 8.215 5.516 8.489 4.123
3 7.379 4.939 7.817 5.517
4 5.966 3.926 6.803 5.374
5 5.748 4.037 6.327 5.269
6 5.890 3.381 6.747 5.207
7 5.536 2.718 6.194 5.148
8 5.395 2.446 6.366 5.130
9 5.338 2.227 6.170 4.960
10 5.338 2.060 5.971 5.012
Tabel 8 Hasil clustering untuk DataSet3
K Nilai Rata-Rata
Max.Diss Avg.Diss Diameter Separation
2 3.741 0.719 3.741 16.703
3 0.000 0.000 0.000 8.062
4 0.000 0.000 0.000 10.222
5 0.000 0.000 0.000 10.222
6 0.000 0.000 0.000 3.741
7 0.000 0.000 0.000 3.741
8 0.000 0.000 0.000 3.741
9 0.000 0.000 0.000 3.741
14
Tabel 9 Hasil clustering untuk DataSet4
K Nilai Rata-Rata
Max.Diss Avg.Diss Diameter Separation
2 19.766 4.712 19.984 13.341
Kolom K merupakan inputan yang dimasukkan untuk menentukan jumlah cluster yang diinginkan, sedangkan Max.dissimilarty merupakan nilai ketidakmiripan antar cluster, Avg.dissimilarty menunjukkan nilai ketidakmiripan antar object di dalam cluster yang sama. Semakin kecil nilai avg.dissimilarty, semakin baik cluster yang terbentuk. Kemudian kolom diameter menunjukkan panjang diameter dari masing- masing cluster.
Analisis Hasil Cluster
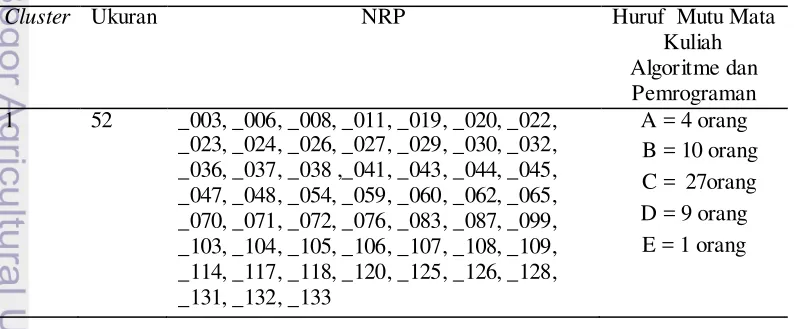
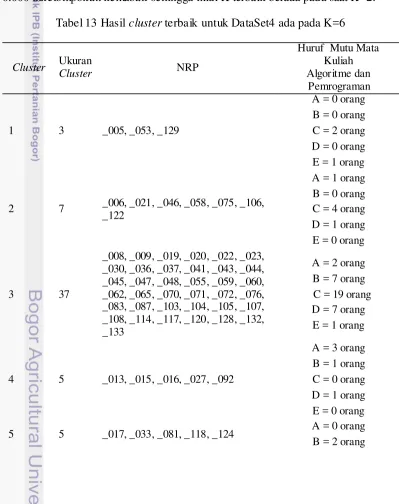
Menurut hasil percobaan yang dilakukan pada tahap penerapan algoritme K-medoids dengan menggunakan program R dapat diketahui pada saat nilai K berapa pengclusteran terbaik terjadi. Pemilihan nilai K terbaik dalam percobaan ini dapat dilihat dari nilai rata-rata keseluruhan nilai dissimilarty antar objek maupun antar cluster-nya, dan jumlah anggota dalam sebuah cluster dengan syarat jumlah anggota untuk sebuah cluster tidak kurang dari tiga anggota. Nilai K terbaik untuk masing masing dataset serta NRP mahasiswa mana saja yang memiliki kemiripan dalam struktur kode programnya untuk DataSet1, DataSet2, DataSet3, dan juga DataSet4 dapat dilihat berturut-turut pada Tabel 10, 11, 12, dan 13.
Tabel 10 Hasil cluster terbaik untuk DataSet1 ada pada K=10
Cluster Ukuran NRP
Huruf Mutu Mata Kuliah Algoritme dan
15
Cluster Ukuran NRP
Huruf Mutu Mata Kuliah Algoritme dan Pemrograman
3 18
_005,_ 006,_ 013,_ 016,_ 042,_ 045, _059,_ 075,_ 076, _079,_ 083,_ 087, _100, _107, _109, _122, _133, _8001
_012, _021, _023, _025, _026, _027, _036, _038, _047, _049, _063, _081, _088, _093, _099, _113, _118, _129
16
Pada DataSet1 yaitu dengan kode tugas pjj0210 cluster terbaik terjadi pada K=10 karena berdasarkan hasil percobaan untuk nila K=2 sampai dengan K=10 untuk DataSet1 yang dicantumkan pada Tabel 6, pada nilai K=10 memiliki rata-rata nilai dissmilarity yang paling kecil yaitu 2.65 dan rata-rata max.dissimilarity sebesar 8.508. Dan ketika K=11 terdapat salah satu anggota cluster yang hanya memiliki jumlah anggota sebanyak satu buah sehingga cluster terbaik di ambil pada saat K=10. Pada Tabel 8 dapat terlihat jumlah anggota cluster beserta NRP mahasiswa yang membuat kode program pada cluster tertentu dan juga nilai mutu mata kuliah algoritme pemrograman masing- masing mahasiswa. Dilihat dari persebaran anggota clusternya, pada jenis tugas ini penyebaran nilai mutu disetiap cluster merata antara yang nilai mutunya baik maupun yang kurang baik.
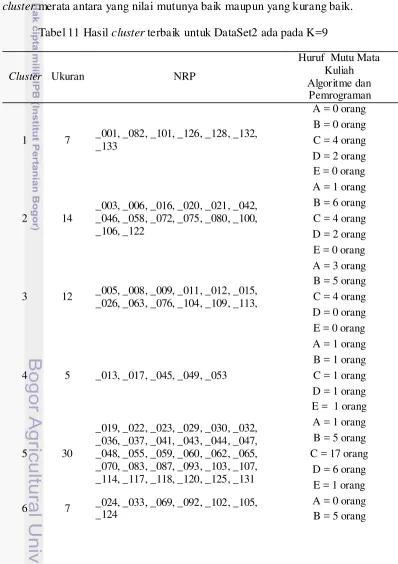
Tabel 11 Hasil cluster terbaik untuk DataSet2 ada pada K=9
Cluster Ukuran NRP
_003, _006, _016, _020, _021, _042, _046, _058, _072, _075, _080, _100, _106, _122 _026, _063, _076, _104, _109, _113,
A = 3 orang
_019, _022, _023, _029, _030, _032, _036, _037, _041, _043, _044, _047, _048, _055, _059, _060, _062, _065, _070, _083, _087, _093, _103, _107, _114, _117, _118, _120, _125, _131
17
Pada Tabel 11 diperlihatkan jumlah anggota beserta NRP anggota cluster yang saling mirip satu sama lainnya. Pemilihan nilai K terbaik untuk DataSet2 dengan kode tugas pjj0302 adalah pada saat K=9 dimana nilai rata-rata dissimilarity anggota clusternya paling kecil yaitu 2.227. Namun dari Tabel 7 terlihat bahwa nilai rata-rata dissimilarity untuk K=10 lebih kecil tetapi kenapa nilai tersebut tidak dipilih dikarenakan ada salah satu cluster-nya yang hanya beranggotakan 2 buah objek data, sehingga nilai K=9 yang dipilih sebagai cluster terbaik. Dari tabel hasil mutu terlihat persebaran huruf mutu untuk setiap cluster merata, sehingga dapat diprediksi pola kemiripannya.
Tabel 12 Hasil cluster terbaik untuk DataSet3 ada pada K=2
Cluster Ukuran NRP Huruf Mutu Mata
Kuliah Algoritme dan Pemrograman 1 52 _003, _006, _008, _011, _019, _020, _022,
18 kecil, yaitu sevesar 0.719 dan ketika niali K ditambah menjadi 3, 4 dan seterusnya ada anggota cluster yang sudah sangat mirip dengan nilai rata-rata disimilarity = 0.000 dikelompokan kemabali sehingga nilai K terbaik berada pada saat K=2.
Tabel 13 Hasil cluster terbaik untuk DataSet4 ada pada K=6
Cluster Ukuran
19 cluster terdapat mahasiswa dengan huruf mutu tinggi dan rendah.
Evaluasi Hasil Clustering
Evaluasi hasil clustering dilakukan dengan cara membandingkan hasil cluster yang dihasilkan dengan menggunakan penerapan K-medoids dengan hasil cluster yang dihasilkan pada tahap pengelompokan manual. Tabel 14 menunjukan nilai akurasi untuk masing- masing dataset serta nilai akurasi rata-rata dari semua dataset yang digunakan pada penelitian ini.
Tabel 14 Nilai akurasi setiap dataset Jenis DataSet Akuraasi DataSet1 (pjj0210) 89.4 % DataSet2 (pjj0302) 83.7 % DataSet3 (pjj0307) 100 % DataSet4 (pjj0309) 100 %
Rata-rata akurasi 93.28 %
Perbandingan hasil pengelompokan manual dengan hasil pengelompokan dengan menggunakan algoritme K- medoids untuk setiap dataset secara lengkap dapat dlihat pada Lampiran 8, 9, 10, 11
20
SIMPULAN DAN SARAN
Simpulan
Penelitian ini menerapkan algoritme K- medoid untuk mengelompokkan dataset kode program C sebagai tugas mata kuliah Algoritme dan Pemrograman. Sehingga dapat diketahui mahasiswa mana saja yang tugasnya memiliki kemiripan. Dari Hasil penelitian ini didapatkan hasil bahwa algoritme K - medoids dapat menghasilkan cluster yang baik, serta dengan membandingkan nilai huruf mutu untuk mata kuliah Algoritme dan Pemrograman dari masing- masing mahasiswa dapat dilihat atau diprediksi pola kemiripan dari kode program tersebut. Jenis tugas yang memiliki tingkat kemiripan pa ling banyak adalah pada DataSet3 yaitu tugas mengenai Pengulangan For Bersarang dan Kondisi If dengan sebanyak 87% dari total mahasiswa yang mengumpulkan kode programnya memiliki struktur kode program yang mirip. Nilai akurasi yang dihasilkan dari penerapan algoritme K-medoid mencapai 93.28%.
Saran
Untuk penelitian selanjutnya perlu ditambahkan data nilai mata kuliah lainnya yang terkait dengan pemrograman serta data diri mahasiswa untuk melihat karakteristik mahasiswa yang memiliki kemiripan pada kode program C nya dengan orang lain. Selain itu perlu ditambahkan pola jumlah cluster dalam pengerjaan tugas Algoritme Pemrograman dari tahun ke tahun dan juga memperhitungkan persentase kemiripan struktur kode program dalam setiap cluster.
DAFTAR PUSTAKA
Bowyer K, Hall L. Experience using MOSS to detect cheating on programming assignments. Di dalam: 29th ASEE/IEEE Frontiers in Education Conference: 1999 Nov 10-13; San Juan, Puerto Rico. Champaign (US): Stipes Publishing LLC. hlm 18-22.
Burrow S. 2004. Efficient and effective plagiarism detection for large code repositories [tesis]. Melbourne (AU): RMIT University.
Chawla M. 2003. An indexing technique for efficiently detecting plagiarism in large volume of source code [tesis]. Melbourne (AU): RMIT University. Gumilang AP. 2013. Pendeteksian penjiplakan kode program C dengan K-means
[skripsi]. Bogor (ID): Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Han J, Kamber M, Pei J. 2011. Data Mining : Concept and techniques, third edititon, Morgan Kaufmann, San Francisco.
Manning CD, Raghavan P, Schütze H. 2008. An Introduction to Information Retrieval. Cambridge (UK): Cambridge University Press.
21
Prechelt L, Malpohl G, Philippsen M. 2002. Finding plagiarisms among a set of programs with JPlag. Universal Computer Science. 8(11):1016–1038.
24
Lampiran 2 Hasil Pengelompokan manual
25
Lampiran 3 Tabel aturan konversi kode program menjadi token sederhana Keyword / special
character
Token sederhana
Keyword / special character
Token sederhana
+ a short E
- b long F
* c signed G
/ d unsigned H
% e if I
& f else J
| g while K
( h do L
) i for M
, j ALPHANUM N
{ k goto O
} l case P
< m break Q
> n return R
= o switch S
. p const T
! q continue U
: r sizeof W
Int A struct X
Float B enum Y
Char C typedef Z
26
Lampiran 4 Hasil Clusterng Untuk DataSet1
27
Lampiran 5 Hasil Clustering Untuk DataSet2
28
Lampiran 6 Hasil Clustering Untuk DataSet3
29
Lampiran 7 Hasil Clustering Untuk DataSet4
30
Lampiran 8 Hasil evaluasi DataSet1
31
Lampiran 9 Hasil evaluasi DataSet2
K-32
Lampiran 10 Hasil evaluasi DataSet3
K-33
Lampiran 11 Hasil evaluasi DataSet4
K-34
RIWAYAT HIDUP